Moawia Eldeeb (SEAS ’18) and Josh Augustin (SEAS ’18) created Pivot, a connected in-home gym. With seed funding, they built SmartSpot, a successful B2B forerunner of Pivot, which they sold to hundreds of gyms around the world, generating over $1 million in revenue. This past July, they closed a $17 million round of Series A funding and expect to launch a consumer version next year.
Nora Wixom (BC ’13) shares how she got to work on the visual effects of blockbuster films Jurassic World, Captain America : Civil War, Kong: Skull Island, and Star Wars Episode VIII.
Wixom at graduation, Spring 2014.
Shortly after Wixom graduated from Barnard College with a computer science degree, she found herself working at Industrial Light & Magic (ILM), the visual effects company founded by George Lucas.
On IMDB it says your role was creature technical director for Episode VIII. What did you have to do? At ILM, a creature technical director (TD) is a visual effects artist who governs the motion of a digital asset, creature or otherwise.
Having an animator control every moving piece of a movie by hand would be way too tedious and time consuming so we step in and help deform certain elements programmatically, like clothing, flesh, and hair. If you think of an animated character as a puppet, a creature artist first “rigs” the character, or puts the strings on the puppet so the animators can move it.
We then turn the character or asset over to animation, where the animators move the bones of the character in the shots throughout the movie. Those shots then come back to creature, where we use the animated primary motion to govern secondary motion, or anything that moves in response to animation. An animator might move the bones of an arm into a flexing motion, and in return we would simulate bicep muscles flexing, skin creasing and sliding, clothing wrinkling, or fur moving.
Creature technical directors at ILM also simulate non-creature assets such as crowds, leaves on trees, and major pieces of explosions or crumbling buildings. On Episode VIII in particular, I was working on hair and flesh simulations for the fathiers and the crystal foxes, as well as rigs for the Resistance ski speeder, and ship explosions for fight sequences.
Kong: Skull Island
Were you part of a team, how big or small was it? We always work as a team, but the size of the team depends heavily on the movie. For smaller or less demanding films, I’ve worked with creature crews as small as two. On large shows that are centered around digital characters, we can have 30+ creature artists in San Francisco alone with more assisting from ILM offices around the world.
Creature artists also rely heavily on many other kinds of artists to bring our characters to life: modellers to sculpt the creatures, texture artists to control their look and feel, lighters and compositors to integrate the digital character into the filmed footage. Even the smallest creature crew requires a support team in order to make our work shine.
How long did you have to work on the project? A creature TD typically spends four to six months doing “shot work” on a film, but can spend one to two years on a film if they are involved early on with rigging assets since that has to come before any animation. For Episode VIII, I was exclusively doing shot work, so I was crewed to the movie for a period of around six months. However, a movie can spend much longer inside the doors of ILM from concept art to final delivery; multiple years is not unheard of.
What was your favorite part or scene to work on? Why? My favorite part of working on Episode VIII had to be simulating TIE fighter explosions for the final fight sequence on Crait. That’s such a classic Star Wars moment, and it felt incredible to be able to contribute in a fun way to the Star Wars canon.
Wixom at the employee screening for Episode VII.
What was a major challenge that you encountered while working on visual effects? One major challenge of Episode VIII was the inclusion of the most adorable character – the Porg. Originally, the director wanted the Porg to be a puppet, and all the footage was shot with a practical, stuffed Porg. Unfortunately, once we started reviewing the footage, the director decided he no longer liked the look and feel of the puppet and wanted it replaced with a digital Porg.
Removing and replacing a character is much more difficult than just shooting without one and adding it later, and keeping the look consistent between the shots with the puppet and the shots with the digital character can be a challenge as well – not to mention this entire digital character was entirely unplanned.
In the end, it was the right choice, as the digital character was much more expressive and able to emote more fully, but it certainly would have helped to know that from the start!
You graduated in 2013, how did you get to work for ILM just two years after graduating? Landing at ILM so quickly after graduation was a combination of good timing, good connections, and being well prepared. I had a friend, Victor Frenkel, who had graduated from the 3:2 Combined Plan Program a year ahead of me and went to work for ILM as a technical assistant (an entry level job where you support render farm utilization across the studio).
Two months after my December 2013 graduation, he contacted me to share that he was getting promoted out of his role and into research and development, and knew I may be interested in filling his position. He recommended me to the team at ILM, and I proceeded to interview and be offered the job. So, although I did have a strong network, I also had the experience and the knowledge to be the right candidate for the job at the right time.
Once at ILM, I worked as a technical assistant for around eight months before transitioning into the creature department. I was able to make that transition by reaching out and working closely with the creature supervisor on Jurassic World; she would sit down with me and teach me skills, and I would have to go back on my own time and replicate what we did to prove to her that I understood.
Jurassic World
After two months of working on simple assets and shot work, she offered to bring me on to her show as a full time creature artist. My very first shot as a creature TD was the shot in Jurassic World where (spoiler alert!) the facilities worker gets eaten by the Indominous Rex after it escapes from the enclosure – I simulated the clothing on the digital double of the employee.
How did your CS degree help you prepare for work after graduation? Studying CS at Columbia made me a much better creature TD because it gave me a low-level understanding of how our software fundamentally worked.
A creature TD will run in-shot simulations by tweaking solver parameters like time steps and spring strengths. Since I had taken COMS 4167, I had first-hand experience building a physics engine and had deep knowledge of how these solvers ran their calculations. COMS 4160 taught me how raytracing worked and how images were rendered, and COMS 4170 gave me the user interface background to design effective tools for other artists to interact with my characters. The linear algebra skills I learned were also incredibly applicable as all movement in 3D space is represented with vector and matrix notation; to this day, I’m amazed by how this knowledge comes back again and again.
How did you become interested in visual effects? Believe it or not, I initially declared chemistry as my major as I intended on going to medical school. However, it turns out I was both impatient and pretty terrible at organic chemistry, so I reevaluated my options after about a year. I had realized that perhaps my interest in medicine was at its heart an interest in anatomy, and maybe there was another way to indulge that.
Motion capture shoot for the Jimmy Fallon ride at Universal Orlando resorts.
Reaching back, I did not grow up in a gaming-friendly household, but I remembered playing The Sims on my computer and thinking that the game had a sense of humor and must have been fun to work on. Working on characters for games and film seemed like it could be a good way to combine that sense of humor with STEM, art, and my anatomical interest, so I looked at character-based job listings at companies like ILM and Pixar to see what kinds of degrees and skills they required.
The shortest path between Columbia and there seemed to be through the CS department along the vision and graphics track, which taught courses in image generation, vision algorithms, and the technical aspects of animation. Although I had absolutely no CS experience, I loved the idea that computer science was a major where I could be creative and constructive and have some cool projects to show for it at the end of the day instead of a stack of papers and problems sets. I changed my major the next week, and the rest is history.
What advice would you give to students who want to get into visual effects? And how to get that first job? One important piece of advice I’d have for students pursuing visual effects (or any non-traditional career path for that matter) is to not be shy about blazing your own trail!
Jobs like this kind of fall out of the scope of what the predefined CS tracks prepare you for, so you may need to do a bit of legwork on your own to learn the skills you’ll need. In my case, I needed to have some experience using creative software packages like Autodesk Maya and Adobe Photoshop, so I took classes at the School of Visual Arts and the University of Michigan to make sure I had those bases covered. It’s safe to assume you’ll learn a ton on the job, but coming in with enough knowledge to be comfortable using the necessary tools is critical to your job application and to your ability to succeed once you’re there.
Admittedly, I struggled to find the kinds of jobs I was interested in through the Columbia employment resources. That being said, I would also highly, highly recommend that any students interested in applied computer graphics take the time to attend an industry conference like GDC or SIGGRAPH. These conferences have job fairs, portfolio reviews, and interviews on-site, and they are great places to discover hot topics in the industry, connect with like-minded individuals, and see where your skills can take you after graduation.
Although these conferences are expensive, they often offer discounted pricing for students, or have positions open for students to volunteer at the conference in exchange for free admission. SIGGRAPH typically rotates between Anaheim, Vancouver, and Los Angeles, but will make a rare visit to the East Coast (Washington DC) for the 2020 conference, so I strongly recommend going next year if it sounds interesting to any students out there.
The 33rd Conference on Neural Information Processing Systems (NeurIPS 2019) fosters the exchange of research on neural information processing systems in their biological, technological, mathematical, and theoretical aspects.
The annual meeting is one of the premier gatherings in artificial intelligence and machine learning that featured talks, demos from industry partners as well as tutorials. Professor Vishal Misra, with colleagues from the Massachusetts Institute of Technology (MIT), held a tutorial on synthetic control.
At this year’s NeurIPS, 21 papers from the department were accepted to the conference. Computer science professors and students worked with researchers from the statistics department and the Data Science Institute.
Noise-tolerant Fair Classification Alex Lamy Columbia University, Ziyuan Zhong Columbia University, Aditya Menon Google, Nakul Verma Columbia University
Fairness-aware learning involves designing algorithms that do not discriminate with respect to some sensitive feature (e.g., race or gender) and is usually done under the assumption that the sensitive feature available in a training sample is perfectly reliable.
This assumption may be violated in many real-world cases: for example, respondents to a survey may choose to conceal or obfuscate their group identity out of fear of potential discrimination. In the paper, the researchers show that fair classifiers can still be used given noisy sensitive features by simply changing the desired fairness-tolerance. Their procedure is empirically effective on two relevant real-world case-studies involving sensitive feature censoring.
Poisson-randomized Gamma Dynamical Systems Aaron Schein UMass Amherst, Scott Linderman Columbia University, Mingyuan Zhou University of Texas at Austin, David Blei Columbia University, Hanna Wallach MSR NYC
This paper presents a new class of state space models for count data. It derives new properties of the Poisson-randomized gamma distribution for efficient posterior inference.
This paper address causal inference in the presence of unobserved confounder when proxy is available for the confounders in the form of a network connecting the units. For example, the link structure of friendships in a social network reveals information about the latent preferences of people in that network. The researchers show how modern network embedding methods can be exploited to harness the network estimation for efficient causal adjustment.
The paper characterizes the theoretical properties of a popular machine learning algorithm, variational Bayes (VB). The researchers studied the VB under model misspecification, which is the setting that is most aligned with the practice, and show that the VB posterior is asymptotically normal and centers at the value that minimizes the Kullback-Leibler (KL) divergence to the true data-generating distribution.
As a consequence, they found that the model misspecification error dominates the variational approximation error in VB posterior predictive distributions. In other words, VB pays a negligible price in producing posterior predictive distributions. It explains the widely observed phenomenon that VB achieves comparable predictive accuracy with MCMC even though VB uses an approximating family.
The paper introduces a model that captures a min-max competition over complex error landscapes and shows that even a simplified model can provably replicate some of the most commonly reported failure modes of GANs (non-convergence, deadlock in suboptimal states, etc).
Moreover, the researchers were able to understand the hidden structure in these systems — the min-max competition can lead to system behavior that is similar to that of energy preserving systems in physics (e.g. connected pendulums, many-body problems, etc). This makes it easier to understand why these systems can fail and gives new tools in the design of algorithms for training GANs.
Dynamic Treatment Regimes (DTRs) are particularly effective for managing chronic disorders and is arguably one of the key aspects towards more personalized decision-making. The researchers developed the first adaptive algorithm that achieves near-optimal regret in DTRs in online settings, while leveraging the abundant, yet imperfect confounded observations. Applications are given to personalized medicine and treatment recommendation in clinical decision support.
The paper proposes a latent bag of words model for differentiable content planning and surface realization in text generation. This model generates paraphrases with clear steps, adding interpretability and controllability of existing neural text generation models.
This paper addresses how to design neural networks to get very accurate estimates of causal effects from observational data. The researchers propose two methods based on insights from the statistical literature on the estimation of treatment effects.
The first is a new architecture, the Dragonnet, that exploits the sufficiency of the propensity score for estimation adjustment. The second is a regularization procedure, targeted regularization, that induces a bias towards models that have non-parametrically optimal asymptotic properties “out-of-the-box”. Studies on benchmark datasets for causal inference show these adaptations outperform existing methods.
The researchers prove that properly tailored zero-order methods are as effective as their first-order counterparts. This analysis requires a combination of tools from optimization theory, probability theory and dynamical systems to show that even without perfect knowledge of the shape of the error landscape, effective optimization is possible.
Metric Learning for Adversarial Robustness Chengzhi Mao Columbia University, Ziyuan Zhong Columbia University, Junfeng Yang Columbia University, Carl Vondrick Columbia University, Baishakhi Ray Columbia University
Deep networks are well-known to be fragile to adversarial attacks. The paper introduces a novel Triplet Loss Adversarial (TLA) regulation that is the first method that leverages metric learning to improve the robustness of deep networks. This method is inspired by the evidence that deep networks suffer from distorted feature space under adversarial attacks. The method increases the model robustness and efficiency for the detection of adversarial attacks significantly.
The paper studies linear regression problems with general symmetric norm loss and gives efficient algorithms for solving such linear regression problems via sketching techniques.
The paper presents a novel and formal definition of mode coverage for generative models. It also gives a boosting algorithm to achieve this mode coverage guarantee.
The researchers studied the least-squares linear regression over $N$ uncorrelated Gaussian features that are selected in order of decreasing variance with the number of selected features $p$ can be either smaller or greater than the sample size $n$. And give an average-case analysis of the out-of-sample prediction error as $p,n,N \to \infty$ with $p/N \to \alpha$ and $n/N \to \beta$, for some constants $\alpha \in [0,1]$ and $\beta \in (0,1)$. In this average-case setting, the prediction error exhibits a “double descent” shape as a function of $p$. This also establishes conditions under which the minimum risk is achieved in the interpolating ($p>n$) regime.
The paper investigates the adaptive influence maximization problem and provides upper and lower bounds for the adaptivity gaps under myopic feedback model. The results confirm a long standing open conjecture by Golovin and Krause (2011).
The researchers studied low-rank matrix approximation with general loss function and showed that if the loss function has several good properties, then there is an efficient way to compute a good low-rank approximation. Otherwise, it could be hard to compute a good low-rank approximation efficiently.
The researchers studied how to compute an l1-norm loss low-rank matrix approximation to a given matrix. And showed that if the given matrix can be decomposed into a low-rank matrix and a noise matrix with a mild distributional assumption, we can obtain a (1+eps) approximation to the optimal solution.
The researchers developed a surrogate distribution for the Dirichlet that offers explicit, tractable reparameterization, the ability to capture sparsity, and has barycentric symmetry properties (i.e. exchangeability) equivalent to the Dirichlet. Previous works have used the Kumaraswamy distribution in a stick-breaking process to create a non-exchangeable distribution on the simplex. The method was improved by restoring exchangeability and demonstrating that approximate exchangeability is efficiently achievable. Lastly, the method was showcased in a variety of VAE semi-supervised learning tasks.
While normalizing flows have led to significant advances in modeling high-dimensional continuous distributions, their applicability to discrete distributions remains unknown. The researchers extend normalizing flows to discrete events, using a simple change-of-variables formula not requiring log-determinant-Jacobian computations. Empirically, they find that discrete flows obtain competitive performance with or outperform autoregressive baselines on various tasks, including addition, Potts models, and language models.
This work is all about learning causal relationships – the classic aim of which is to characterize all possible sets that could produce the observed data. In the paper, the researchers provide a complete characterization of all possible causal graphs with observational and interventional data involving so-called ‘soft interventions’ on variables when the targets of soft interventions are known.
This work potentially could lead to discovery of other novel learning algorithms that are both sound and complete.
Causal identification is the problem of deciding whether a causal distribution is computable from a combination of qualitative knowledge about the underlying data-generating process, which is usually encoded in the form of a causal graph, and an observational distribution. Despite the obvious need for identifying causal effects throughout the data-driven sciences, in practice, finding the causal graph is a notoriously challenging task.
In this work, the researchers provide a relaxation of the requirement of having to specify the causal graph (based on substantive knowledge) and allow the input of the inference to be an equivalence class of causal graphs, which can be inferred from data. Specifically, they propose the first general algorithm to learn conditional causal effects entirely from data. This result is particularly useful for evaluating the impact of conditional plans and stochastic policies, which appear both in AI (in the context of reinforcement learning) and in the data-driven sciences.
Regression analysis is one of the most common tools used in modern data science. While there is a great understanding and powerful technology to perform regression analysis in high dimensional spaces, the output of such a method is purely associational and devoid of any causal interpretation.
The researchers studied the problem of identification of structural (causal) coefficients in linear systems (deciding whether regression coefficients are amenable to causal interpretation, etc). Building on a technique called instrumental variables, they developed a new method called Instrumental Cutset, which partitions the systems into tractable components such that identification can be decided more efficiently. The resulting algorithm was efficient and strictly more powerful than the current state-of-the-art methods.
Assistant Professor Allison Bishop takes a look at failure and how people can learn from “unsuccessful” research.
When it comes to research and getting papers into cryptography conferences, there usually has to be a “positive” result — either a new theorem must be proven, a new algorithm must be presented, or a successful attack on an existing algorithm must be obtained. If researchers try to accomplish a lofty goal and fall short, but manage to achieve a smaller goal, they typically present only the smaller goal as if it was the point on its own.
Allison Bishop
“I’ve found that not every research paper magically comes together and has a “great” result,” said Allison Bishop, who has been teaching since 2013. “Our community doesn’t really talk about the research process and I wanted to highlight research where even if it “failed” there is still something to learn from it.”
Through the years Bishop noticed the lack of a venue to talk about all kinds of research. When she and other researchers studied obfuscation it resulted in a paper “In Pursuit of Clarity In Obfuscation”. In the paper they talked about how they “failed” but managed to still learn from their mistakes. Their topic on failure was not considered a “standard” that could be published and they were not able to submit it to a conference. But Bishop, along with PhD students Luke Kowalczyk and Kevin Shi, really wanted to get their findings out and share it with other researchers.
And so, a conference dedicated to disseminating insightful failures of the cryptology research community was born. The Conference for Failed Approaches and Insightful Losses in Cryptology or CFAIL featured seven previously unpublished papers for a day of talks by computer scientists on insightful failures spanning the full range from cryptanalysis (trying to break systems) to cryptographic theory and design (constructing new systems and proving things about specific systems or about abstract systems, etc.).
“CFAIL is great for our field in that it promotes openness and accessibility for these kinds of ideas which are typically sort of intimate,” said Luke Kowalczyk, who completed his PhD in November of last year. “When approaching new problems, it’s always helpful to see the approaches of other researchers, even if they were not successful. However, it’s rare to see failed approaches explained in a public and formal setting.”
They were not alone in thinking about the lack of dialogue on research failures. At the time of the conference, a thread on Hacker News (a tech news aggregator) discussed the incentive structures of academia. Shared Kowalczyk, “I was proud to see CFAIL cited as an example of a scientific field with a formal venue to help promote this kind of openness.”
“There is a deeply ingrained human tendency to fear that being open about failure will make other people think you are dumb,” said Bishop. On the contrary, the researchers at CFAIL were some of the “most creative, bold, and deeply intelligent people.” And the atmosphere it created was energizing for the participants — the audience got pretty involved and felt comfortable asking questions, and even started thinking about some of the open research problems in real time. Continued Bishop, ”I think talking about failure is probably the best scientific communication strategy left that is severely underused.”
Bishop will continue to promote openness in scientific research with another CFAIL at Crypto 2020. This time around it will be a workshop at the conference and a call for papers will be out soon.
IBM has selected assistant professor Baishakhi Ray for an IBM Faculty Award. The highly selective award is given to professors in leading universities worldwide to foster collaboration with IBM researchers. Ray will use the funds to continue research on artificial intelligence-driven program analysis to understand software robustness.
Although much research has been done, there are still countless vulnerabilities that make system robustness brittle. Hidden vulnerabilities are discovered all the time – either through a system hack or monitoring system’s functionalities. Ray is working to automatically detect system weaknesses using artificial intelligence (AI) with her project, “Improving code representation for enhanced deep learning to detect and remediate security vulnerabilities”.
One of the major challenges in AI-based security vulnerability detection is finding the best source code representation that can distinguish between vulnerable versus benign code. Such representation can further be used as an input in supervised learning settings for automatic vulnerability detection and fixes. Ray is tackling this problem by building new machine-learning models for source code and applying machine learning techniques such as code embeddings. This approach could open new ways of encoding source code into feature vectors.
“It will provide new ways to make systems secure,” said Ray, who joined the department in 2018. “The goal is to reduce the hours of manual effort spent in automatically detecting vulnerabilities and fixing them.”
A successful outcome of this project will produce a new technique to encode source code with associated trained models that will be able to detect and remediate a software vulnerability with increased accuracy.
IBM researchers Jim Laredo and Alessandro Morari will collaborate closely with Ray and her team on opportunities around design, implementation, and evaluation of this research.
With multiple grants, Professor Luca Carloni works toward developing design methodologies and system architectures for heterogeneous computing. He foresees computing systems both in the cloud and at the edge of the cloud will become more heterogeneous.
For a while, many systems in the cloud, in servers, and in computers, were based on homogeneous multi-core architectures where multiple processors are combined in a chip and multiple chips on a board. But all, in the first approximation, are copies of the same type of processor.
“Now, it is not the case,” said Carloni, who has worked on heterogeneous computing for the past 10 years. “And we have been one of the first groups to really, I think, understand this transition from a research viewpoint and change first our research focus and then our teaching efforts to address all the issues.”
Heterogeneous means that a system is made of components and each component has a different nature. Some of these components are processors that execute software – application software and system software while other components are accelerators. An accelerator is a hardware module specialized to execute a particular function. Specialization provides major benefits in terms of performance and energy efficiency.
Heterogeneous computing, however, is more difficult. Compared to its homogeneous counterpart, heterogeneous systems bring new challenges in terms of hardware-software interactions, access to shared resources, and diminished regularity of the design.
Another aspect of heterogeneity is that components often come from different sources. Let’s say that a company builds a new system-on-chip (SoC), a pervasive type of integrated circuit that is highly heterogeneous. Some parts may be designed anew inside the company, some reused from previous designs, while others may be licensed from other companies. Integrating these parts efficiently requires new design methods.
The System-Level Design Group Front row (left to right) : Luca Piccolboni, Kuan-Lin Chiu, Davide Giri, Jihye Kwon, Maico Cassel Back Row (left to right) : Paolo Mantovani, Guy Eichler, Luca Carloni, Joseph Zuckerman, Giuseppe Di Guglielmo
Carloni’s lab, the System-Level Design Group, tackles these challenges with the concept of embedded scalable platforms (ESP). A platform combines a flexible computer architecture and a companion computer-aided design methodology. The architecture defines how the computation is organized among multiple components, how the components are interconnected, and how to establish the interface between what is done in software and what is done in hardware. Because of the complexity of these systems, many important decisions must be made early, while room must be left to make adjustments later. The methodology guides software programmers and hardware engineers to design, optimize, and integrate their novel solutions.
By leveraging ESP, the SLD Group is developing many SoC prototypes, particularly with field programmable gate arrays (FPGAs). With FPGAs, the hardware in the system can be configured in the field. This allows the chance to explore several optimizations for the target heterogeneous system before committing to the fabrication of expensive silicon.
All of these topics are covered in System-on-Chip Platforms, a class Carloni teaches each fall semester. Students have to design an accelerator — not just for one particular system, but also with a good degree of reusability so that it can be leveraged across multiple systems. Earlier this year, Carloni presented a paper that describes this course at the 2019 Workshop on Computer Architecture Education.
“In developing System-on-Chip Platforms we put particular emphasis on SoC architectures for high-performance embedded applications,” he said. “But we believe that the course provides a broad foundation on the principles and practices of heterogeneous computing.”
Papers from CS researchers were accepted to the 60th Annual Symposium on Foundations of Computer Science (FOCS 2019). The papers delve into population recovery, sublinear time, auctions, and graphs.
Finding Monotone Patterns in Sublinear Time Omri Ben-Eliezer Tel-Aviv University, Clement L. Canonne Stanford University, Shoham Letzter ETH-ITS, ETH Zurich, Erik Waingarten Columbia University
The paper is about finding increasing subsequences in an array in sublinear time. Imagine an array of n numbers where at least 1% of the numbers can be arranged into increasing subsequences of length k. We want to pick random locations from the array in order to find an increasing subsequence of length k. At a high level, in an array with many increasing subsequences, the task is to find one. The key is to cleverly design the distribution over random locations to minimize the number of locations needed.
Roughly speaking, the arrays considered have a lot of increasing subsequences of length k; think of these as “evidence of existence of increasing subsequences”. However, these subsequences can be hidden throughout the array: they can be spread out, or concentrated in particular sections, or they can even have very large gaps between the starts and the ends of the subsequences.
“The surprising thing is that after a specific (and simple!) re-ordering of the “evidence”, structure emerges within the increasing subsequences of length k,” said Erik Waingarten, a PhD student. “This allows for design efficient sampling procedures which are optimal for non-adaptive algorithms.”
Consider the problem of reconstructing the DNA sequence of an extinct species, given some DNA sequences of its descendant(s) that are alive today. We know that DNA sequences get modified through random mutations, which can be substitutions, insertions and deletions.
A mathematical abstraction of this problem is to recover an unknown source string x of length n, given access to independent samples of x that have been corrupted according to a certain noise model. The goal is to determine the minimum number of samples required in order to recover x with high confidence. In the special case that the corruption occurs via a deletion channel (i.e., each character in x is deleted independently with some probability, say 0.1, and the surviving characters are concatenated and transmitted), each sample is called a trace. The corresponding recovery problem is called trace reconstruction, and it has received significant attention in recent years.
The researchers considered a generalized version of this problem (known as population recovery) where there are multiple unknown source strings, along with an unknown distribution over them specifying the relative frequency of each source string. Each sample is generated by first drawing a source string with the associated probability, and then generating a trace from it via the deletion channel. The goal is to recover the source strings, along with the distribution over them (up to small error), from the mixture of traces.
For the main sample complexity upper bound, they show that for any population size s = o(log n / log log n), a population of s strings from {0,1}^n can be learned under deletion channel noise using exp(n^{1/2 + o(1)}) samples. On the lower bound side, we show that at least n^{\Omega(s)} samples are required to perform population recovery under the deletion channel when the population size is s, for all s <= n^0.49.
“I found it interesting that our work is based on certain mathematical results in which, at first glance, seem to be completely unrelated to the computational problem we consider,” said Sandip Sinha, a PhD student. In particular, they used constructions based on Chebyshev polynomials, a certain sequence of polynomials which are extremal for many properties, and is hence ubiquitous throughout theoretical computer science. Similarly, previous work on trace reconstruction rely on certain extremal results about complex-valued polynomials. Continued Sinha, “I think it is quite intriguing that complex analytic techniques yield useful results about a problem which is fundamentally about discrete structures (binary strings).”
The paper is about the theory of combinatorial auctions. In a combinatorial auction, an auctioneer wants to allocate several items among bidders. Each bidder has a certain amount that they value each item; bidders also have values for combinations of items, and in a combinatorial auction a bidder might not value a combination of items as much as each item individually.
For instance, say that a pencil and a pen will be auctioned. The pencil is valued at 30 cents and the pen at 40 cents, but the pen and pencil together at only 50 cents (it may be that there isn’t any additional value from having both the pencil and the pen). Valuation functions with this property — that the value of a combination of items is less than or equal to the sum of the values of each item — are called subadditive.
In the paper, the researchers answered a longstanding open question about combinatorial auctions with two bidders who have subadditive valuation — roughly speaking, is it possible for an auctioneer to efficiently communicate with both bidders to figure out how to allocate the items between them to make the bidders happy?
The answer turns out to be no. In general, if the auctioneer wants to do better than just giving all of the items to one bidder or the other at random, the auctioneer needs to communicate a very large amount with the bidders.
The result itself was somewhat surprising, the researchers expected it to be possible for the auctioneer to do pretty well without having to communicate with the bidders too much. “Also, information theory was extensively used as part of proving the result,” said Eric Neyman, a PhD student. “This is unexpected, because information theory has not been used much in the study of combinatorial auctions.”
In a graph, an independent set is a set of vertices with the property that none are adjacent. For example, in the graph of Facebook friends, vertices are people and there is an edge between two people who are friends. An independent set would be a set of people, none of whom are friends with each other. A basic problem is to find a large independent set. The paper focuses on one type of large independent set known as a maximal independent set, that is, one that cannot have any more vertices added to it.
Graphs, such as the friends graph, evolve over time. As the graph evolves, the maximal independent set needs to be maintained, without recomputing one from scratch. The paper significantly decreases the time to do so, from time that is polynomial in the input size to one that is polylogarithmic.
A graph can have many maximal independent sets (e.g. in a triangle, each of the vertices is a potential maximal independent set). One might think that this freedom makes the problems easier. The researchers picked one particular kind of maximal independent set, known as a lexicographically first maximal independent set (roughly this means that in case of a tie, the vertex whose name is first in alphabetical order is always chosen) and show that this kind of set can be maintained more efficiently.
“Giving up this freedom actually makes the problems easier,” said Cliff Stein, a computer science professor. “The idea of restricting the set of possible solutions making the problem easier is a good general lesson.”
Columbia’s Womxn in Computer Science (WiCS) share their experiences from the 2019 Grace Hopper Convention in Orlando, Florida. The annual conference is the world’s largest gathering of women in computing.
Hadley Callaway Grace Hopper was a fantastic experience. I completed three interviews with companies while there, and I was able to leave the conference with an offer for a software engineering internship.
I spoke to recruiters and engineers from all sorts of different companies (big and small, offering a variety of products), and attended fun corporate events in the evening, including one at SeaWorld.
It was also very empowering to hear from womxn at the cutting edge of their field speak about their experiences and what they have learned. Attending the conference was a great opportunity for me to continue to develop professional skills such as pitching, networking, following up on connections, etc.
I am so thankful to WiCS and the Columbia CS department for making such an invaluable opportunity possible!
Michelle Mao Thanks to WiCS, I was able to go to Grace Hopper ‘19, and any womxn in STEM would be lucky to do the same. The Grace Hopper Celebration is a lot of things but the most impactful thing about the celebration, for me, was how inspiring those short few days were.
I had heard a lot about the conference from friends who have gone in the past, so I knew to expect a hectic schedule when I arrived in Orlando. In the three and a half days at Grace Hopper, I went to the career fair, got a free ticket to Harry Potter World, interviewed at a few companies, and acquired a lot of swag.
What I did not expect was spontaneously meeting other womxn while waiting in lines, running into friends I had not seen in years, or how truly friendly, open, and uplifting the atmosphere would be. I attended a researcher’s luncheon with my friend, but I was a little nervous about going because the research I was doing was not exactly related to computing. But everyone at the table was so kind and welcoming — as we ate, the conversation shifted to topics other than research, until the luncheon just felt like a chat among a group of friends.
After the first couple of days, I also noticed that in my interviews, most of my interviewers were womxn. I had not realized until then that I have grown accustomed to being interviewed by men. It was wonderful to have this representation feel so normal, and meeting and talking with these incredible womxn was just the cherry on top.
It’s difficult to put into words, but Grace Hopper really does feel like a celebration: the energy is palpable and electrifying, the conversations are genuine, and womxn in STEM are there to support each other in every way possible. Being in this space was a privilege and I felt like I belonged, in every sense of the word, and it is one hundred percent an event any womxn interested in computing should experience.
Haley So In a single word, the Grace Hopper Celebration was empowering. It was inspiring to see so many womxn pursuing and pushing the boundaries of computer science.
There were talks on everything from emerging technologies to how to promote yourself as a womxn in tech. I was also able to explore different paths and find out a little more about what direction I want to go in. I met so many lovely womxn, and I got closer to some WiCS members as we wandered around the enormous career fair and listened to talks from leaders in the field.
Going to the conference
opened my eyes to the endless possibilities, introduced me to new role models,
and made me excited about the future. I cannot wait for all those womxn to
build the future world of tech!
The goal of the competition is to develop DL driving models — predicting steering wheel angle and vehicle speed is given large-scale training data and using advanced deep learning techniques. Two teams, composed of students from the computer science (CS) department and the Data Science Institute (DSI), won the challenge in all major categories ranking first and second place.
“Winning the top three categories in this international challenge is an excellent achievement,” said adjunct associate professor Iddo Drori. “I am very proud to have mentored the teams to the finish line.”
As part of the unique DL course curriculum, students get to compete in common task framework competitions which enable them to test the waters in the real world while advancing science. This semester Drori and teaching assistants Manik Goyal and Benedikt Dietmar performed feasibility tests on the Learning-to-Drive Challenge and found it in line with the course goals.
Students used the Drive 360 dataset to design, develop and train a driving model. Over the course of three weeks, teams worked on and improved their submissions competing with groups from across the world. Students were given cloud resources to develop their models even further. The effort paid off with the CS and DSI students at the top of the competition leaderboard. In order to claim victory, they had to quickly write up and submit their findings.
CS graduate students Michael J Diodato and Yu Li won first place, while DSI graduate students Antonia Lovjer and Minsu Yeom won second place.
After 26 years in the computer science department, professor Steven Nowick is retiring. Friends, colleagues, and those dear to him recently gathered to celebrate his teaching and academic career — one that has pushed the asynchronous community to be more widely noticed and accepted. Nowick walks away with a body of work that is as diverse and nuanced as the next chapter of his life — composing music.
Left to right : Grant Chorley, Steven Nowick, David Conte (chair of composition, San Francisco Conservatory), Fred Blum, Joel Feigin (former music professor, UC Santa Barbara) at the Conservatoire Americaine, Fontainebleau, France (1975).
Many probably do not know that he has a B.A. from Yale University in music and an M.A. in music composition from Columbia University, where his master’s thesis was symphony. The better part of his 20s was spent on a music career, during which time he studied privately with composer David Diamond, and in France with the legendary music teacher Nadia Boulanger.
However, he decided to shift gears and retrain in computer science (CS) when he hit 30 years old. After two years of brushing up on CS concepts, including a class taught by Steven Feiner that first introduced him to digital hardware, he applied and was accepted to the PhD program at Stanford University in 1986.
While at Stanford, his interest in asynchronous systems was cemented when he started to work on research with professor David Dill. In 1993, he found himself back at Columbia as an assistant professor. In his first year, he recognized the need for a Computer Engineering program in the engineering school, and worked with two colleagues from computer science and electrical engineering departments to establish the degree that was later expanded to include a masters program. In his second year at Columbia, he co-founded the IEEE ASYNC symposium, the premier international forum for researchers to present their latest findings in the area of asynchronous digital design, which is still thriving after 25 years.
“Computer engineering is entirely to Steve’s credit that it grew to what it is today,” said Kathy McKeown, the Henry and Gertrude Rothschild Professor of Computer Science, who looked through her emails all the way back to the time when she was the department chair in the late 90s for her tribute to Nowick. “It is also because of his persistence and dedication as head of the strategic planning committee, that our faculty has grown.”
Also at the party, Zvi Galil, former computer science professor and dean of the School of Engineering and Applied Sciences, shared, “In the good old days we couldn’t even hire one faculty, now they can hire five in a year.” At the time in the late 90s there were less than 20 faculty, currently there are 59 faculty. Said another colleague, Shree Nayar, “Thank you for all that you’ve done for the department, we would not look the same if not for you.”
Through the years, Nowick has taught and mentored hundreds of
students. “He is an amazing academic father,” said Montek Singh, a former PhD student who is now a tenured associate professor at
the University of North Carolina at Chapel Hill. Singh shared how when they
were working on MOUSETRAP: High-Speed Transition-Signaling Asynchronous Pipelines,
they brainstormed for days working out every little detail. And then they
brainstormed even more to come up with the name, which is actually an acronym –
Minimum Overhead Ultra-high-Speed Transition-signaling Asynchronous Pipeline.
Continued Singh, “I can only hope to be half as good to my PhD students as he
is.”
Left to right : Michael Theobald (PhD student), George Faldamis (MS student), Cheoljoo Jeong (PhD student), Melinda Agyekum (PhD student), Steven Nowick, Martha Helfer (Nowick’s wife), Cheng-Hong Li (MS student), Montek Singh (PhD student)
The party was also attended by a number of his other former graduate students, post-docs, and outside colleagues, including former PhD student Michael Theobald, a research scientist in formal verification at D.E. Shaw Research, who served as “master of ceremonies.” His asynchronous colleagues Ivan Sutherland (the Turing Award winning inventor of interactive computer graphics and virtual reality) and Marly Roncken flew out from Oregon, and computer science professor Rajit Manohar came down from Yale.
“Steve is a highly ambitious person with a lot of passion, a tremendous persistence and a lot of perseverance,” said Jeannette Wing, the Avanessians Director of the Data Science Institute and computer science professor. In 2016, Nowick established a working group at the Data Science Institute, and in 2018 worked with Wing to turn it into a center – The Center for Computing Systems for Data-Driven Science. He has gathered 45 faculty from across the university to explore the design and application of large-scale computing systems for data-driven scientific discovery. It is multi-disciplinary and brings together diverse researchers at Columbia in three areas: computing systems, data science and machine learning, and large-scale computational application areas in science, engineering and medicine. Qiang Du, a professor from Applied Physics and Applied Mathematics, and associate computer science professor Martha Kim are now co-chairs of the center.
Left to right : Columbia Executive Vice President for Research Michael Purdy, Steven Nowick, and professor Sebastian Will, physics department
As chair of the working group, in 2017, he organized an on-campus inaugural symposium, attracting 150 participants, which included leading speakers from IBM, D.E. Shaw Research and NASA Goddard. In 2019, as his final major act as center chair, he co-organized the NY Scientific Data Summit jointly with nearby Brookhaven National Laboratory, to showcase regional research on data-driven science, and to forge closer bonds between the two institutions.
Of course, asynchronous research and activities to advance the field were happening simultaneously with all these other activities. Nowick has been one of the leaders in the revival of clockless, or asynchronous, digital hardware systems. While most digital systems today are synchronous, built using a central clock, increasingly the challenge of assembling large, complex and heterogeneous systems – with dozens to millions of processors and memory units – is becoming unworkable under centralized control. The vision of asynchronous systems has seen a resurgence in the last twenty years, and Nowick has been at the forefront. Such systems, assembled with “Lego-like” hardware building blocks, which are plugged together and communicate locally, promise to overcome some of the extreme barriers faced in the microelectronics industry, providing low energy, ease of assembly, high performance, and reliable operation.
Recent asynchronous advances include “brain-inspired” (i.e. neuromorphic) chips from IBM (TrueNorth) and Intel (Loihi). Nowick has collaborated closely with AMD Research, migrating his asynchronous on-chip networks into the company’s advanced technology, and experimentally demonstrating significant benefits in power, performance and area, over their synchronous commercial designs. He and his students have also introduced an influential set of computer-aided design (CAD) software tools, optimization algorithms and analysis techniques, for asynchronous circuits and systems. In addition, he has worked closely over the years with IBM Research, Boeing and NASA on asynchronous design projects.
Nowick is an IEEE Fellow (2009), a recipient of an Alfred P. Sloan Research Fellowship (1995), received NSF CAREER (1995) and RIA (1993) awards, and he is also a Senior Member of the ACM. He received Best Paper Awards at the IEEE International Conference on Computer Design (1991, 2012) and the IEEE Async Symposium (2000). He also acted as program chair at various workshops and conferences, as well as served on leading journal editorial boards, such as IEEE Design & Test Magazine, IEEE Transactions on Computer-Aided Design, IEEE Transactions on VLSI Systems, and ACM Journal on Emerging Technologies in Computer Systems, and served as a guest editor for a special issue of the Proceedings of the IEEE. He holds 13 issued US patents, and his research has been supported by over 20 grants and gifts. In recognition of his teaching, he also received the SEAS Alumni Distinguished Faculty Teaching Award in 2011.
But the pull of music has become stronger in recent years.
“In the back of my mind I always knew I would return to it and I
should do it now while I can still do it well, rather than when I’m in my 80s
or 90s,” said Nowick.
He plays the piano and his focus will be classical composition. He has written music for string quartet, orchestra, choir, piano, cello, two flutes, and for voice and piano. He is writing new compositions and looks forward to his music being performed.
“Music will be his act two,” said Montek Singh. “So in a sense
he’s come full circle.”
The J.P. Morgan AI Research Awards 2019 partners with research thinkers across artificial intelligence. The program is structured as a gift that funds a year of study for a graduate student.
Prediction semantics and interpretations that are
grounded in real data Principal Investigator: Daniel Hsu Computer Science Department & Data Science Institute
The importance of transparency in predictive technologies is by now well-understood by many machine learning practitioners and researchers, especially for applications in which predictions may have serious impacts on human lives (e.g., medicine, finance, criminal justice). One common approach to providing transparency is to ensure interpretability in the models and predictions produced by an application, or to accompany predictions with explanations. Interpretations and explanations may help individuals understand predictions that affect them, and also help developers reason about failure cases of their applications.
However, there are numerous possibilities for what constitutes a suitable interpretation or explanation, and the semantics of such provided by existing systems are not always clear.
Suppose, for example, that a bank uses a linear model to predict whether or not a loan applicant will forfeit on a loan. A natural strategy is to seek a sparse linear model, which are often touted as highly interpretable. However, attributing significance to variables with non-zero regression coefficients (e.g., zip-code) and not others (e.g., race, age) is suspect when variables may be correlated. Moreover, an explanation based on pointing to individual variables or other parameters of a model ignores the source of the model itself: the training data (e.g., a biased history of borrowers and forfeiture outcomes) and the model fitting procedure. Invalid or inappropriate explanations may create a “transparency fallacy” that creates more problems than are solved.
The researchers propose a general class of mechanisms that provide explanations based on training or validation examples, rather than any specific component or parameters of a predictive model. In this way, the explanation will satisfy two key features identified in successful human explanations: the explanation will be contrastive, allowing an end-user to compare the present data to the specific examples chosen from the training or validation data, and the explanation will be pertinent to the actual causal chain that results in the prediction in question. These features are missing in previous systems that seek to explain predictions based on machine learning methods.
“We expect this research to lead to new methods for interpretable machine learning,” said Daniel Hsu, the principal investigator of the project. Because the explanations will be based on actual training examples, the methods will be widely applicable, in essentially any domain where examples can be visualized or communicated to a human. He continued, “This stands in contrast to nearly all existing methods for explanatory machine learning, which either require strong assumptions like linearity or sparsity, or do not connect to the predictive model of interest or the actual causal chain leading to a given prediction of interest.”
Efficient Formal Safety Analysis of Neural Networks Principal Investigators: Suman Jana Computer Science Department, Jeannette M. Wing Computer Science Department & Data Science Institute, Junfeng Yang Computer Science Department
Over the last few years, artificial intelligence (AI), in particular Deep Learning (DL) and Deep Neural Networks (DNNs), has made tremendous progress, achieving or surpassing human-level performance for a diverse set of tasks including image classification, speech recognition, and playing games such as Go. These advances have led to widespread adoption and deployment of DL in critical domains including finance, healthcare, autonomous driving, and security. In particular, the financial industry has embraced AI in applications ranging from portfolio management (“Robo-Advisor”), algorithmic trading, fraud detection, loan and insurance underwriting, sentiment and news analysis, customer service, to sales.
“Machine learning models are used in more and more safety and security-critical applications such as autonomous driving and medical diagnosis,” said Suman Jana, one of the principal investigators of the project. “Yet they are known to be fragile and frequently mispredicts on edge cases.“
In many critical domains including finance and autonomous driving, such incorrect behaviors can lead to disastrous consequences such as a gigantic loss in automated financial trading or a fatal collision of a self-driving car. For example, in 2016, a Google self-driving car crashed into a bus because it expected the bus to yield under a set of rare conditions but the bus did not. Also in 2016, a Tesla car in autopilot crashed into a trailer because the autopilot system failed to recognize the trailer as an obstacle due to its ‘white color against a brightly lit sky’ and the ‘high ride height.’
Before AI can become the next technological revolution, it must be robust against such corner-case inputs and does not cause disasters. The researchers believe AI robustness is one of the biggest challenges that needs to be solved in order to fully tame AI for good.
“Our research aims to create novel tools to verify that a machine learning model will not mispredict on certain important input ranges, ensuring safety and security,” said Junfeng Yang, one of the investigators of the research.
The proposed work enables rigorous analysis of autonomous AI systems and machine learning (ML) algorithms, enabling data scientists to (1) verify that their AI models function correctly within certain input regions and violate no critical properties they specify (e.g., bidding price is never higher than a given maximum) or (2) locate all sub-regions where their models misbehave and repair their model accordingly. This capability will also enable data scientists to explain and interpret the outputs from autonomous AI systems and ML algorithms by understanding how different input regions may lead to different output predictions. Said Yang,”If successful, our work will dramatically boost the robustness, explainability, and interpretability of today’s autonomous AI systems and ML algorithms, benefiting virtually every individual, business, and government that relies on AI and ML.”
Elias Bareinboim, Brian Smith, and Shuran Song join the department.
Elias Bareinboim Associate Professor, Computer Science Director, Causal Artificial Intelligence Lab Member, Data Science Institute PhD, Computer Science, University of California, Los Angeles (UCLA), 2014 BS & MS, Computer Science, Federal University of Rio de Janeiro (UFRJ), 2007
Elias Bareinboim’s research focuses on causal and counterfactual inference and its application to data-driven fields in the health and social sciences as well as artificial intelligence and machine learning. His work was the first to propose a general solution to the problem of “causal data fusion,” providing practical methods for combining datasets generated under heterogeneous experimental conditions and plagued with various biases. This theory and methods constitute an integral part of the discipline called “causal data science,” which is a principled and systematic way of performing data analysis with the goal of inferring cause and effect relationships.
More recently, Bareinboim has been investigating how causal inference can help to improve decision-making in complex systems (including classic reinforcement learning settings), and also how to construct human-friendly explanations for large-scale societal problems, including fairness analysis in automated systems.
Bareinboim is the recipient of the NSF Faculty Early Career Development (CAREER) Award, IEEE AI’s 10 to Watch, and a number of best paper awards. Later this year, he will be teaching a causal inference class intended to train the next generation of causal inference researchers and data scientists. Bareinboim directs the Causal Artificial Intelligence Lab, which currently has open positions for Ph.D. students and Postdoctoral scholars.
Brian Smith Assistant Professor PhD, Computer Science, Columbia University, 2018 MPhil, Computer Science, Columbia University, 2015 MS, Computer Science, Columbia University, 2011 BS, Computer Science, Columbia University, 2009
Brian Smith’s interests lie in human-computer interaction (HCI) and creating computers that can help people better experience the world. His past research on video games for the visually impaired was featured in Quartz, TechCrunch, the Huffington Post, among others.
Smith has spent the last year at Snap Research (Snap is best known for Snapchat) developing new concepts in human–computer interaction (HCI), games, social computing, and augmented reality. He will continue to work on projects with Snap while at Columbia.
He comes back to the department as an assistant professor and is set to teach a class on user interface design this fall. That class had a waitlist of 235 students hoping to be part of the class. Smith shared that back when he was a student, there were only 35 students in the class he was enrolled in. “There is definitely more interest in computer science now compared to even five years ago,” he said.
Smith hopes to start a HCI group and is looking for PhD students. He encourages students from underrepresented groups to apply.
Shuran Song Assistant Professor PhD, Computer Science, Princeton University, 2018 MS, Computer Science, Princeton University, 2015 BEng, Computer Engineering, Hong Kong University of Science and Technology, 2013
Shuran Song is interested in artificial intelligence with an emphasis on computer vision and robotics. The goal of her research is to enable machines to perceive and understand their environment in a way that allows them to intelligently operate and assist people in the physical world.
Previously, Song worked at Google Brain Robotics as a researcher and developed TossingBot, a robot that learns to how to accurately throw arbitrary objects through self-supervised learning.
This fall, she is teaching a seminar class on robot learning. Song currently has one PhD student who is working on active perception — enabling robots to learn from their interactions with the physical world, and autonomously acquire the perception and manipulation skills necessary to execute complex tasks. She is looking for more students who are interested in machine learning for vision and robotics.
The ACM SIGKDD dissertation awards recognize outstanding work done by graduate students in the areas of data science, machine learning and data mining.
FREP awards grants to faculty members in support of research to enhance people’s lives by improving the internet. FREP was founded in 2012 to foster cutting-edge collaborations between scientists in academic settings and those at Yahoo Research.
Researchers from around the country gathered at Columbia Engineering this past weekend for a three-day event honoring four decades of ground-breaking research by Prof. Christos Papadimitriou. The conference, which organizers dubbed “PapaFest,” included individual speakers, panel discussions, social events, and even a rock band.
The diverse cohort come from the various groups within the department. They are a mix of those new to Columbia and students who have received fellowships for the year.
J.P. Morgan 2019 AI Research PhD Fellowship Awards The inaugural award supports researchers who have the skills and imagination to potentially transform the way we live and work.
Ana-Andreaa Stoica A third-year PhD student, Ana-Andreaa Stoica works with Augustin Chaintreau on social networks and algorithmic fairness. Her work focuses on mathematical models, data analysis, and policy implications for algorithm design in social networks. Stoica graduated from Princeton in 2016 with a bachelor’s degree in Mathematics and certificates in Computing and Applied Mathematics.
2019 Google PhD Fellowship in Algorithms, Optimizations, and Markets The program recognizes outstanding graduate students doing exceptional work in computer science and related research areas.
Peilin Zhong A member of the Theory Group, Peilin Zhong is a third-year PhD student who is particularly interested in parallel graph algorithms, generative models, and large-scale data computational models. His goal is to design new algorithms for large-scale computational models that have more impact in machine learning, data mining, and can be used in practice. Zhong was part of the Yao Class at Tsinghua University and graduated in 2016 with a bachelor’s degree in engineering.
National Defense Science and Engineering Graduate (NDSEG) Fellowship The NDSEG is a highly competitive, portable fellowship that is awarded to U.S. citizens and nationals who intend to pursue a doctoral degree in one of fifteen supported disciplines.
Gabriel Ryan Gabriel Ryan is a second-year PhD student whose current research involves using deep learning to construct logical formulas for program verification and synthesis. Prior to joining Columbia for graduate studies, he worked as a software engineer developing systems for data security, robotic 3D mapping and localization, and ballistic missile defense. Ryan graduated from Swarthmore College with a B.S. Engineering and B.A. Computer Science dual degree in 2013.
Ministry of Education of Taiwan – Government Scholarship to Study Abroad The scholarship is awarded to Taiwanese students studying abroad with exceptional academic record and potential in their research areas.
Jen-Shuo Liu Working in professor Steven Feiner’s Computer Graphics and User Interfaces Laboratory, third-year PhD student Jen-Shuo Liu’s research focus is user interface design for augmented reality and virtual reality. Liu has gained recognition for his work including an NYC Media Lab award for an augmented reality project. He graduated from National Taiwan University with an M.S. degree in Communication Engineering in 2016 .
The Belgian American Educational Foundation (BAEF) The BAEF fosters the higher education of deserving Belgians and Americans through its exchange fellowship program.
Basile Van Hoorick As an MS student, Basile Van Hoorick’s interests include computer vision, machine learning, and software engineering. While at Columbia, he hopes to work as a research and/or teaching assistant. Van Hoorick was a finalist in the Flemish Mathematics Olympiad (a national mathematics competition) in 2014 and studied electrical engineering at Ghent University in Belgium where he graduated summa cum laude in July 2019.
SEAS Fellowships Columbia School of Engineering and Applied Sciences established the Presidential and SEAS fellowships to recruit outstanding students from around the world to pursue graduate studies at the school.
Xi Chen As part of her research project, Xi Chen is trying to predict depression based on human mobility trajectory. Her interests lie in social networks and machine learning and she is a second-year PhD student working with Augustin Chaintreau. Chen graduated in 2018 with a degree in computer science and mathematics from Carleton College.
Shunhua Jiang Shunhua Jiang is a first-year PhD student with the Theory Group, under the guidance of Omri Weinstein and Alex Andoni. Her research interests range from data structures, lower bounds, to algorithms. An alum of Tsinghua University, Jiang graduated in 2015 with a degree in computer science.
Eric Neyman Eric Neyman is a first-year PhD student with the Theory Group under the supervision of professors Tim Roughgarden and Rocco Servedio. He looks forward to exploring the various disciplines of theoretical computer science. Neyman has earned three honorable mentions in the Putnam mathematical competition and graduated summa cum laude from Princeton University in 2019 with a degree in mathematics.
Chang Xiao Chang Xiao is a fourth-year PhD student in computer science who works with professor Changxi Zheng. His research focuses on building human-computer interaction systems using computational methods. He has developed methods in a range of applications and his research has attracted public interest, including media coverage from CNN, IEEE Spectrum, etc. Chang received a BS degree in computer science from Zhejiang University in 2016 and is a recipient of the Snap Fellowship in 2019.
Hengjie Zhang Hengjie Zhang’s research interests are graph theory, algorithms, and data structure. He will join the theory group as a first-year PhD student working with Alexandr Andoni and Omri Weinstein. He won a gold medal in the International Olympiad in Informatics and a Yao Award Recognition Prize from Tsinghua University where he graduated with a degree in engineering in 2019.
Joseph Zuckerman With the system-level design group, Joseph Zuckerman will work on heterogeneous system-on-chip architectures. He is a first-year PhD student interested in application-specific architectures, the integration of accelerators, and hardware design methodologies. Zuckerman completed a B.S. in Electrical Engineering from Harvard University in 2019, with a focus on hardware architectures for machine learning applications.
The AI4All 2019 class with program organizers on a field trip to Princeton University.
They could have been at the beach enjoying the summer. Instead, high school students gathered from across New York City and New Jersey for the AI4All program hosted by the Columbia community. The students came to learn about artificial intelligence (AI) but this program had a special twist – computer science (CS) and social work concepts were combined for a deeper, more meaningful look at AI.
“We created a space for young people to think critically about the social implications of artificial intelligence for the communities that they live in,” said Desmond Patton, the program co-director and associate professor of the School of Social Work. “We wanted them to understand how things like race, power, privilege and oppression can be baked into algorithms and their adverse effects on communities.”
The AI4All 2019 class with program organizers on a field trip to LinkedIn.
The program participants, composed of 9th, 10th and 11th graders, are from racial and ethnic groups underrepresented in AI: Black, Hispanic, and Asian. Girls as well as youth from lower-income backgrounds were particularly encouraged to apply. For three weeks the students attended lectures, went on field trips to visit local companies (LinkedIn and Samsung) involved in the program, and visited other AI4All programs, like at Princeton University. Their work culminated in a final project which they presented to their classmates, mentors, and industry professionals.
“I believe that it is important to bring more ethics to AI,” said Augustin Chaintreau, the program co-director and a CS assistant professor. He sees ethics integrated into technical concepts and taught at the same time. Instead of learning about the social consequences and fixing it after, to solve an issue. Shared Chaintreau, “It shouldn’t be thought about just in passing but as a central part of why this is a tool and its implications.”
An interdisciplinary approach to AI was even part of how the classes were structured. Technical CS concepts, such as machine learning and Python, were taught in the morning by professors and student volunteers. While in the afternoon, guest speakers came to talk about their perspective to the day’s lesson. So, on the same day, students learned about supervised and unsupervised learning, and in the afternoon, someone who was formerly incarcerated described how the criminal policing that survey people on social media had a role in making a case against them.
Genesis Lopez (center, in black) in class.
“We were learning college courses meant to be taught in a month but for us it was just a couple of weeks and that was really impressive,” said Genesis Lopez, who is part of the robotics team at her school. Lopez loves robotics but works more on the mechanical side. She goes back to the team knowing how to use Python and is confident she can step up and code if needed. Continued Lopez, “I learned a lot but my favorite part was the people, we became a family.”
Text IQ started as co-founder Apoorv Agarwal’s (PhD ’14) Columbia thesis project titled “Social Network Extraction From Text.” The algorithm he built was able to read a novel, like Jane Austen’s “Emma,” for example, and understand the social hierarchy and interactions between characters.
CS researchers will be at the 2019 Annual Meeting of the Association of Computational Linguistics in Florence, Italy. Numerous papers covering the computational approaches to natural language were accepted.
Rubric Reliability and Annotation of Content and Argument in Source-Based Argument Essays
Yanjun Gao Pennsylvania State University, Alex Driban Pennsylvania State University, Brennan Xavier McManus Columbia University, Elena Musi University of Liverpool, Patricia M. Davies Prince Mohammad Bin Fahd University, Smaranda Muresan Columbia University, and Rebecca J. Passonneau Pennsylvania State University
The goal of any social media platform is to facilitate healthy and meaningful interactions among its users. But more often than not, it has been found that it becomes an avenue for wanton attacks.
In the paper the researchers propose an experimental study that has three aims: (1) to provide a deeper understanding of current datasets that focus on different types of abusive language, which are sometimes overlapping (racism, sexism, hate speech, offensive language and personal attacks); (2) to investigate what type of attention mechanism (contextual vs. self-attention) is better for abusive language detection using deep learning architectures; and (3) to investigate whether stacked architectures provide an advantage over simple architectures for this task.
The work is about using context attention instead of self-attention for abuse detection which encapsulates the information by looking at examples globally through the training data, unlike self attention which only focuses on words for that particular tweet while trying to classify it.
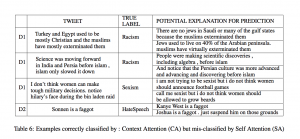
The first tweet belongs to the NONE class while the second tweet belongs to RACISM class. The word “islam” may appear in the realm of racism as well as in any normal conversation. The model successfully identified the two distinct contextual usages of the word “Islam” in the two tweets, as demonstrated by a much higher attention weight in the second case and a relatively smaller one in the first case.
The researchers created a system that automatically aligns paraphrases between two input sentences — that is, it detects which parts of the two sentences are paraphrases of each other. Their aligner is unique in that it is able to align phrases of arbitrary length, including full sentences, as well as relatively loose paraphrases, where the two aligned phrases mean approximately, but not necessarily exactly, the same thing.
Paraphrase alignment is the task of detecting parts of two input sentences that mean the same thing. Previous work on this task has focused on a strict definition of paraphrase, which requires that the aligned phrases mean exactly the same thing; previous systems aligned only words that exactly matched, or were close synonyms, between the sentences. In addition, previous work on paraphrase alignment was practically limited to phrases of three or fewer words, due to running time constraints. However, most people’s intuition about what counts as a paraphrase is much less strict, and paraphrases can be much longer than three words.
The phrases in bold are examples of paraphrases that the system can align, but that previous work could not. The entire phrase, “I vaguely recalled him telling me” means the same thing as “I remembered a story” in the context of these two sentences, but there is no one-to-one mapping between the words in the two phrases (eg. “vaguely” in Sentence 1 has no corresponding word in Sentence 2), which would prevent previous systems from successfully aligning these phrases.
The designed system aligns these looser and longer paraphrases by first breaking the input sentences into grammatical chunks, such as noun or verb phrases. For each chunk, it calculates a single vector that represents the meaning of that chunk by combining the vectors representing the meanings of the words within it. Then, a neural network is used to align each chunk in one of the input sentences to the chunks in the other sentence. This method allows for the alignment of all of the words within a chunk at once, regardless of the length of the chunk, and small differences in meaning or in individual words are mitigated by the meanings of the other words in the chunk. The system is the first to use a neural network to perform the alignment task, and it is able to align longer and less exactly-matching sentences than previous systems could.
Rubric Reliability and Annotation of Content and Argument in Source-Based Argument Essays
Yanjun Gao Pennsylvania State University, Alex Driban Pennsylvania State University, Brennan Xavier McManus Columbia University, Elena Musi University of Liverpool, Patricia M. Davies Prince Mohammad Bin Fahd University, Smaranda Muresan Columbia University, and Rebecca J. Passonneau Pennsylvania State University
Students with STEM majors were prompted to write short argumentative essays on topics including cryptocurrencies, cybercrime, and self-driving cars. These essays were graded on a rubric, and the essays were analyzed for content.
The argumentative structure of these essays were analyzed, which involved breaking the essays down into units of argumentation and indicating whether one argument supports, attacks, or is necessary context for another, from the main claim of the essay down to individual pieces of evidence. The results of this annotation were compared to the results of applying the rubric for each of these essays, leading to a set of argumentative features associated with essays of particular scores.
One simple finding is that essays with the highest overall score (5) tended to have a higher ratio of argumentative sentences to non-argumentative sentences, while the essays in the next highest group (4) tended to be longer. The essays with the higher scores and lower scores often had similar numbers of claims, but the latter group would tend to fail to connect these claims to the main argument of their essay.
The goal of research in this area is to assess the eventual effectiveness and usability of automated grading assistants for argumentative essays, and to what extent a rubric can be applied to fairly analyze the content and argumentative structure of essays in a similar way in which automated grading scripts are used within the CS department here at Columbia.
Most people take for granted that when they speak, they will be heard and understood. But for the millions who live with speech impairments caused by physical or neurological conditions, trying to communicate with others can be difficult and lead to frustration. While there have been a great number of recent advances in automatic speech recognition (ASR; a.k.a. speech-to-text) technologies, these interfaces can be inaccessible for those with speech impairments. Further, applications that rely on speech recognition as input for text-to-speech synthesis (TTS) can exhibit word substitution, deletion, and insertion errors. Critically, in today’s technological environment, limited access to speech interfaces, such as digital assistants that depend on directly understanding one’s speech, means being excluded from state-of-the-art tools and experiences, widening the gap between what those with and without speech impairments can access.
Natasha Shamis (BC ’06) talks about how her technical background has been key in the evolution of her career path to leading the design for innovative technology-powered products.
To put data science in context, we present phases of the data life cycle, from data generation to data interpretation. These phases transform raw bits into value for the end user. Data science is thus much more than data analysis, e.g., using techniques from machine learning and statistics; extracting this value takes a lot of work, before and after data analysis. Moreover, data privacy and data ethics need to be considered at each phase of the life cycle.
Assistant professor Eugene Wu also helped organize events at the ACM Special Interest Group on Management of Data (SIGMOD) annual conference held in Amsterdam.
The Symposium on Theory of Computing (STOC) covers research within theoretical computer science, such as algorithms and computation theory. This year, four papers from CS researchers and collaborators from various institutions made it into the conference.
The researchers were interested in the problem of compressing texts with local context, like texts in which there is some correlation between nearby characters. For example, the letter ‘q’ is almost always followed by ‘u’ in an English text.
It is a reasonable goal to design compression schemes that exploit local context to reduce the length of the string considerably. Indeed, the FM-Index and other such schemes, based on a transformation called the Burrows-Wheeler transform followed by Move-to-Front encoding, have been widely used in practice to compress DNA sequences etc. “I think it’s interesting that compression schemes have been known for nearly 20 years in the pattern-matching and bioinformatics community but there has not been satisfactory theoretical guarantees of the compression achieved by these algorithms,” said Sandip Sinha, a PhD student in the Theory Group.
Moreover, these schemes are inherently non-local – in order to extract a character or a short substring at a particular position of the original text, one needs to decode the entire string, which requires time proportional to the length of the original string. This is prohibitive in many applications. The team designed a data structure which matches almost exactly the space bound of such compression schemes, while also supporting highly efficient local decoding queries (alluded to above), as well as certain pattern-matching queries. In particular, they were able to design a succinct “locally-decodable” Move-to-Front (MTF) code, that reduces the decoding time per character (in the MTF encoding) from n to around log(n), where n is the length of the string. Shared Sinha, “We also show a lower bound showing that for a wide class of strings, one cannot hope to do much better using any data structure based on the above transform.”
“Hopefully our paper draws wider attention of the theoretical CS community to similar problems in these fields,” said Sinha. To that end, they have made a conscious effort to make the paper accessible across research domains. “I also think there is no significant mathematical knowledge required to understand the paper, beyond some basic notions in information theory.”
Fooling Polytopes Ryan O’Donnell Carnegie Mellon University, Rocco A. Servedio Columbia University, Li-Yang Tan Stanford University
The paper is about “getting rid of the randomness in random sampling”.
Suppose you are given a complicated shape on a blackboard and you need to estimate what fraction of the blackboard’s area is covered by the shape. One efficient way to estimate this fraction is by doing random sampling: throw darts randomly at the blackboard and count the fraction of the darts that land inside the shape. If you throw a reasonable number of darts, and they land uniformly at random inside the blackboard, the fraction of darts that land inside the shape will be a good estimate of the actual fraction of the blackboard’s area that is contained inside the shape. (This is analogous to surveying a small random sample of voters to try and predict who will win an election.)
“This kind of random sampling approach is very powerful,” said Rocco Servedio, professor and chair of the computer science department. “In fact, there is a sense in which every randomized computation can be viewed as doing this sort of random sampling.”
It is a fundamental goal in theoretical computer science to understand whether randomness is really necessary to carry out computations efficiently. The point of this paper is to show that for an important class of high-dimensional estimation problems of the sort described above, it is actually possible to come up with the desired estimates efficiently without using any randomness at all.
In this specific paper, the “blackboard” is a high-dimensional Boolean hypercube and the “shape on the blackboard” is a subset of the hypercube defined by a system of high-dimensional linear inequalities (such a subset is also known as a polytope). Previous work had tried to prove this result but could only handle certain specialized types of linear inequalities. By developing some new tools in high dimensional geometry and probability, in this paper the researchers were able to get rid of those limitations and handle all systems of linear inequalities.
The paper shows an interesting connection between the task of proving time-space lower bounds on data structure problems (with linear queries), and the long-standing open problem of constructing “stable” (rigid) matrices — a matrix M whose rank remains very high unless a lot of entries are modified. Constructing rigid matrices is one of the major open problems in theoretical computer science since the late 1970s, with far-reaching consequences on circuit complexity.
The result shows a real barrier for proving lower bounds on data structures: If one can exhibit any “hard” data structure problem with linear queries (the canonical example being Range Counting queries: given n points in d dimensions, report the number of points in a given rectangle), then this problem can be essentially used to construct “stable” (rigid) matrices.
“This is a rather surprising ‘threshold’ result, since in slightly weaker models of data structures (with small space usage), we do in fact have very strong lower bounds on the query time,” said Omri Weinstein, an assistant professor of computer science. “Perhaps surprisingly, our work shows that anything beyond that is out of reach with current techniques.”
The paper is about testing unateness of Boolean functions on the hypercube.
For this paper the researchers set out to design highly efficient algorithms which, by evaluating very few random inputs of a Boolean function, can “test” whether the function is unate (meaning that every variable is either non-increasing or non-decreasing or is pretty non-unate).
Referring to a previous paper the researchers set out to create an algorithm which is optimal (up to poly-logarithmic factors), giving a lower bound on the complexity of these testing algorithms.
An example of a Boolean function which is unate is a halfspace, i.e., for some values w1, …, wn, θ ∈ ℝ, the function f : {0,1}n → {0,1} is given by f(x) = 1 if ∑ wi xi≥ θ and 0 otherwise. Here, every variable i ∈ [n] is either non-decreasing, when wi ≥ 0, or non-increasing, when wi ≤ 0.
“One may hope that such an optimal algorithm could be non-adaptive, in the sense that all evaluations could be done at once,” said Erik Waingarten, an algorithms and computational complexity PhD student. “These algorithms tend to be easier to analyze and have the added benefit of being parallelize-able.”
However, the algorithm they developed is crucially adaptive, and a surprising thing is that non-adaptive algorithms could never achieve optimal complexity. A highlight of the paper is a new analysis of a very simple binary search procedure on the hypercube.
“This procedure is the ‘obvious’ thing one would do for these kinds of algorithms, but analyzing it has been very difficult because of its adaptive nature,” said Waingarten. “For us, this is the crucial component of the algorithm.”
The M2 system integrates cameras, displays, microphones, speakers, sensors, and GPS to improve audio conferencing, media recording, and Wii-like gaming, and allow greater access for disabled users
The annual conference of the North American Chapter of the Association for Computational Linguistics (NAACL) is the preeminent event in the field of natural language processing. CS researchers in professor Julia Hirschberg’s group won a Best Paper award for a novel resource, SpatialNet, which provides a formal representation of how a language expresses spatial relations. Other accepted papers are detailed below.
The researchers identified and analyzed unique linguistic characteristics of Reddit posts written by users who claim to have received a diagnosis for schizophrenia. The findings were interpreted in the context of established schizophrenia symptoms and compared with results from previous research that has looked at schizophrenia and language on social media platforms.
The results showed several differences in language usage between users with schizophrenia and a control group. For example, people with schizophrenia used less punctuation in their Reddit posts. Disorganized language use is a prominent and common symptom of schizophrenia.
A machine learning classifier was trained to automatically identify self-identified users with schizophrenia on Reddit, using linguistic cues.
“We hope that this work contributes toward the ultimate goal of identifying high risk individuals,” said Sara Ita Levitan, a postdoctoral research scientist with the Spoken Language Processing Group. “Early intervention and diagnosis is important to improve overall treatment outcomes for schizophrenia.”
For many people, social media is a primary source of information and it can become a key venue for opinionated discussion. In order to evaluate and analyze these discussions, it is important to understand contrast or a difference in opinions.
As a step towards a better understanding of arguments, the researchers developed a method to automatically generate responses to internet comments containing differences in stance. They created a corpus from over one million contrastive claims mined from the social media site Reddit. In order to obtain training data for the models, they extracted pairs of comments containing the acronym FTFY (“fixed that for you”).
For example, in a discussion over who should be the next President of the United States, one participant might state “Bernie Sanders for president” and another might state “Hillary Clinton for president. FTFY”
A neural network model was trained on the pairs to edit the original claim and produce a new claim with a different view.
Claim : Bernie Sanders for president New claim : Hillary Clinton for president.
“One aspect of this problem that was surprising was that the standard ‘sequence-to-sequence with attention’ baseline performed poorly, often just copying the output or selecting generic responses,” said Christopher Hidey, a fourth year PhD student. While generic response generation is a known problem in neural models, their custom model significantly outperformed this baseline in several metrics including novelty and overlap with human-generated responses.
The researchers developed an automatic summarization system that specializes in producing English summaries for documents originally written in three low-resource languages – Somali, Swahili, and Tagalog.
There is little natural language processing work done in low-resource languages and machine translation systems for those languages are of lower quality than those for high-resource languages like French or German.
As a result, the translations are often disfluent and contain errors that make them difficult for a human to understand, much less for a summarization system to process.
An example of machine-translated document originally written in Swahili : Mange Kimambi ‘I pray for the parliamentary seat for Kinondoni constituency for ticket of CCM. Not special seats’ Kinondoni without drugs is possible I pray for the parliamentary seat for Kinondoni constituency on the ticket of CCM. Yes, it’s not a special seats, Khuini Kinondoni, what will I do for Kinondoni? Tension is many I get but we must remember no good that is available easily. Kinondoni without drugs is possible. As a friend, fan or patriotism I urge you to grant your contribution to the situation and propert. You can use Western Union or money to go to Mange John Kimambi. Account of CRDB Bank is on blog. Reduce my profile in my blog understand why I have decided to vie for Kinondoni constituency. you will understand more.
A standard summarization system’s
output on the document : Mange Kimambi, who pray for parliamentary seat for Kinondoni constituency for ticket of CCM, is on blog, and not special seats’ Kinondoni without drugs.
The robust summarization system’s output
on the document : Mange Kimambi, who pray for parliamentary seat for Kinondoni constituency for ticket of CCM, comments on his plans to vie for ‘Kinondoni’ without drugs.
“We addressed this challenge by creating large collections of synthetic, errorful “translations” that mimic the output of low-quality machine translations,” said Jessica Ouyang, a seventh year PhD student. They paired the problematic text with high-quality, human-written summaries. The experiment showed that a neural network summarizer trained on this synthetic data was able to correct or elide translation errors and produce fluent English summaries. The error-correcting ability of the system extends to Arabic, a new language previously unseen by the system.
Argument mining, or argumentation mining, is a research area within the natural language processing field. Argument mining is applied in many different genres including the qualitative assessment of social media content (e.g. Twitter, Facebook) – where it provides a powerful tool for policy-makers and researchers in social and political sciences – legal documents, product reviews, scientific articles, online debates, newspaper articles, and dialogical domains. One of the main tasks of argument mining is to detect a claim.
Sentences from each dataset and their nearest neighbor in the IMHO dataset
Claims are the central component of an argument. Detecting claims across different domains or data sets can often be challenging due to their varying conceptualization. The researchers set out to alleviate this problem by fine-tuning a language model. They created a corpus mined from Reddit that is composed of 5.5 million opinionated claims. These claims are self-labeled by their authors using the internet acronyms IMO/IMHO or “In My Humble Opinion”.
By fine-tuning the language on the IMHO dataset they were able to obtain a significant improvement on claim detection of the datasets. As these data sets include diverse domains such as social media and student essays, this improvement demonstrates the robustness of fine-tuning on this novel corpus.
Community Question Answering forums such as Yahoo! Answers and Quora are popular nowadays, as they represent effective means for communities to share information around particular topics. But the information often shared on these forums may be incorrect or misleading.
The paper presents the ColumbiaNLP submission for the SemEval-2019 Task 8: Fact-Checking in Community Question Answering Forums. The researchers show how fine-tuning a language model on a large unannotated corpus of old threads from the Qatar Living forum helps to classify question types (factual, opinion, socializing) and to judge the factuality of answers on the shared task labeled data from the same forum. Their system finished 4th and 2nd on Subtask A (question type classification) and B (answer factuality prediction), respectively, based on the official metric of accuracy.
Question classification Factual : The question is asking for factual information, which can be answered by checking various information sources, and it is not ambiguous. e.g. “What is Ooredoo customer service number?” Opinion : The question asks for an opinion or advice, not for a fact. e.g. “Can anyone recommend a good Vet in Doha?” Socializing : Not a real question, but intended for socializing or for chatting. This can also mean expressing an opinion or sharing some information, without really asking anything of general interest. e.g. “What was your first car?”
Answer classification Factual – TRUE : The answer is True and can be proven with an external resource. Q : “I wanted to know if there were any specific shots and vaccinations I should get before coming over [to Doha].” A : “Yes there are; though it varies depending on which country you come from. In the UK; the doctor has a list of all countries and the vaccinations needed for each.” Factual – FALSE : The answer gives a factual response, but it is False, it is partially false or the responder is unsure about Q : “Can I bring my pitbulls to Qatar?” A : “Yes, you can bring it but be careful this kind of dog is very dangerous.” Non-Factual : When the answer does not provide factual information to the question; it can be an opinion or an advice that cannot be verified e.g. “It’s better to buy a new one.”
“We show that fine-tuning a language model on a large unsupervised corpus from the same community forum helps us achieve better accuracy for question classification,” said Tuhin Chakrabarty, lead researcher of the paper. Most community question-answering forums have such unlabeled data, which can be used in the absence of large labeled training data.
For answer classification they show how to leverage information from previously answered questions on the thread through language model fine-tuning. Their experiments also show that modeling an answer individually is not the best idea for fact-verification and results are improved when considering the context of the question.
“Determining factuality of answers requires modeling of world knowledge or external evidence – the questions asked are often very noisy and require reformulation,” shared Chakrabarty. “As a future step we would want to incorporate external evidence from the internet in the factual answer classification problem.”
The paper studied dialogue act classification in therapy transcripts. Dialogue act classification is a task in which the researchers attempt to determine the intention of the speaker at each point in a dialogue, classifying it into one of a fixed number of possible types.
This provides a layer of abstraction away from what the speaker is literally saying, giving a higher-level view of the conversation. Ultimately, they hope this work can help analyze the dynamics of text-based therapy on a large scale.
Transcripts of therapy sessions were examined, focusing on the speech of the therapist, using a classification scheme developed for this purpose. On a sentence-by-sentence basis, they found which of the labels best matches the conversational “action” the sentence takes.
For example, if a therapist makes the statement, “It almost feels like if you could do something, anything would be better than…” This would be classified into the Reflection category, as it is rephrasing or restating the experience the client just described, but in a way that makes what they are feeling more explicit.
“One of the interesting results from this research came when we analyzed the performance of our best classifier across different styles of therapy,” said Fei-Tzin Lee, a third year PhD student. Certain styles were markedly easier to classify than others; this was not simply a case where the classifier performed better on therapeutic styles for which there was more data.
Generally, it seemed that therapy styles involving more complex sentence structure were more difficult to classify, although to fully understand the differences between styles further work would be necessary. Continued Lee, “Regardless of the reason, it was interesting to note that there are marked differences that are quantitatively measurable between different styles.”
Columbia University is co-organizing and hosting the 2019 New York Scientific Data Summit, a two-and-a-half day symposium to explore data-driven discovery and innovation in science and industry. The summit is scheduled for June 12-14 in Columbia’s Davis Auditorium,
The IEEE Symposium on Security and Privacy (SP19) brings together researchers and practitioners to present and discuss developments in computer security and electronic privacy. Now in its 40th year, the conference issued Test of Time awards, one of which was bestowed to computer science professor Steven Bellovin. Also at SP19 were papers from other CS researchers, detailed below.
This paper created the subfield of cryptography now known as PAKE: Password- Authenticated Key Exchange. A Google Scholar search for cryptography password PAKE gets more than 1,300 hits, and that’s an undercount because the early papers do not use “PAKE”; the coinage is somewhat later.
The world of 1992 was moving towards networks. Rather than having a password for every computer and having to enter it constantly, a user would have to download a cryptographic credential from a server. But how was this credential protected? The answer, of course, is the user’s password.
This means that an attacker who can eavesdrop on the network connection can pick up the credential that is encrypted with the password, and see if a guess at the password yields something that looks like a valid credential. For example, a cryptographic credential often includes a username or an expiration date—if you guess at the password, do you get something that looks like a username or a reasonable expiration date? This is known as “verifiable plaintext”.
The underlying problem relates to so-called “password-guessing attacks”. That is, an attacker guesses at a user’s password and tries to verify that guess. The classic attack of this type was described in a 1979 paper by Morris and Thompson; it assumed that the attackers had somehow obtained the “hashed password file”.
Bellovin and Michael Merritt’s solution eliminated verifiable plaintext. Suppose an attacker eavesdrops on network traffic. The cryptographic credential is encrypted with the user’s password. For an incorrect guess, the attacker gets a string of random bytes. However, a correct guess yields something that “looks” like a string of random bytes, and the only way to tell that it’s not is to solve an extremely hard problem, one that may be computationally unsolvable regardless. This means that there is no way for an attacker to verify a guess by looking at network traffic.
Bellovin no longer works on PAKEs but recommends Matt Green’s post for the state of PAKEs today.
The paper proposes a new defense against adversarial examples with rigorous guarantees.
Adversarial examples are an attack against machine learning (ML) models, and especially Deep Neural Networks (DNNs). These models are used in many domains to make predictions from input data (e.g. label the contents of a picture, recognize a spoken word, etc.).
In adversarial attacks, an attacker makes a small change to the input data – such as small changes to the pixels of an image, invisible to the naked eye – that fools the ML model into make a wrong prediction chosen by the adversary. These attacks can be particularly problematic when models are used in security sensitive contexts, such as face recognition to enable access to a phone, voice recognition to operate a device, or to detect malware and credit card fraud.
PixelDP is a defense that adds specifically calibrated noise to DNNs and adapts the training and prediction procedures to make them more difficult to attack with adversarial examples. By leveraging the theory of a privacy mechanism, differential privacy, PixelDP can also prove guarantees about the maximal change an attacker can trigger with small changes to the input data, to give the operator a measure of robustness for each specific prediction.
Moreover, this approach is the first one to give both provable guarantees and scale to the large DNNs and datasets that are used in practice. As an example, this is the first defense with rigorous guarantees that supports large DNN models, such as the one called Inception released pre-trained by Google, on tasks such as large scale image classification on the ImageNet dataset.
Fuzzing is a popular and simple technique to hunt bugs by generating random test inputs and executing the target program with these inputs to trigger potential security vulnerabilities. Due to its simplicity and low performance overhead, fuzzing has been very successful at finding numerous security vulnerabilities in many real-world programs. However, existing works rely on a large number of error-trial scheme and lack sophisticated guidance to generate high-quality inputs which helps to uncover bugs.
The researchers built the first practical neural-network assisted-fuzzer which finds software vulnerabilities in real world programs. The neural network model approximates program behaviors by functioning as a differentiable program surrogate. Inspired from adversarial examples in deep learning, it computes the gradient of the neural program surrogate and performs efficient gradient-guided mutations.
Columbia University bestows the award to distinguished faculty for their teaching as recognized by the Columbia community. Tal Malkin will receive the award at this year’s commencement.
“Teaching has its own reward above any award and it is something that is very important to me,” said Malkin, an associate professor who joined Columbia in 2003. “I really enjoy teaching so I am very happy to receive this award.”
Malkin can be found in her office, where throughout the day students drop in to talk about their projects or assignments and ask questions. That is one thing that she likes – students that ask questions. She believes that it is through the process of asking questions and working through answers that students actually learn. Through this dialogue she is able to show them the “beauty of computer science theory” and how the material is interesting in its own right.
But, of course, the real joy is when she sees her students discover and understand new concepts. Computer science theory is one of the classes she teaches and it is required for all CS majors. “It isn’t an easy class so when I see that it finally clicks and a student gets it, I feel a sense of accomplishment and pride,” shared Malkin. One could say she hopes that her students “fall in love with computer science” through her class, as she once did as an undergrad in Israel.
“Tal would always explain concepts both intuitively and present material in a variety of ways to appeal to different types of students,” said Daniel Jaroslawicz (CC ’19), a former student and teaching assistant. Considering that the class had over 200 students with different levels of familiarity with computer science theory, achieving that was no simple feat. He continued, “But what really surprised me was Tal’s successful effort to learn the names of as many of her students as possible.”
Aside from teaching undergrads, PhD students are another group under her purview. In this case it is more of mentoring these researchers. Said Malkin, “My PhD students usually study other parts of cryptography so they often teach me more than I teach them.”
Dana Dachman-Soled, a former PhD student, describes Malkin as unassuming and warm but at the same time very assertive, focused, and challenging. Some of her most fond memories with Malkin took place at the Hungarian Pastry Shop where they worked on research projects along with other collaborators. “While the shop is quite dark and often crowded, we did some of our best research there,” said Dana Dachman-Soled (PhD ‘11), who is now an assistant professor at the University of Maryland, College Park. “She was never dismissive of new ideas, thereby encouraging me and her other students to bring them forward and develop them.”
This openness and yearning to impart knowledge to students is reflected in other professional activities. Malkin also heads the education track of the Columbia-IBM Center for Blockchain and Data Transparency. For that, she helps oversee curriculum development for classes on data privacy and blockchain technologies, among other topics.
“I love teaching and my door is always open for anyone that has a question,” said Malkin. “It’s very invigorating to interact with my students and I hope that I have been able to show them how cool computer science can be.”
The Jonathan Gross Prize honors students who graduate at the top of their class with a track record of promising innovative contributions to computer science. Five graduating computer science students—one senior from each of the four undergraduate schools and one student from the master’s program—were selected to receive the prize, which is named for Jonathan L. Gross, the popular professor emeritus who taught for 47 years at Columbia and cofounded the Computer Science Department. The prize is made possible by an endowment established by Yechiam (Y.Y.) Yemini, who for 31 years until his retirement in 2011, was a professor of computer science at Columbia.
Steven Shao Master of Science
I feel a deep appreciation for the potential of computers to express and realize complex ideas.
A childhood dream of building games for friends propelled Steven Shao into the world of programming and math. His interest in computer science remained with him when he first came to Columbia for undergrad and his appreciation of it has grown even more.
“Whenever I come across a technical idea in CS, like in the algorithms of ML, systems, or theory, there’s something irresistible about exploring and optimizing them further,” said Shao. “It’s like going down a rabbit hole of puzzles.”
He is inspired by how computers can be more human and how it affects society. Through classes, like computer vision, he learned how artificial intelligence powers the mechanisms underlying “this magic”. Shared Shao, “I wholly enjoyed professor Carl Vondrick’s lectures, starting from the long history of traditional vision and its relationship to optics and graphics, to its recent revolution with deep learning.”
Classes wrapped for Shao in December and he recently started as a software developer at Jane Street in downtown New York City.
Alexandre Lamy Columbia Engineering valedictorian
There are a few aspects that, in my mind, make computer science a unique and beautiful subject to study.
Alexandre Lamy loves the kind of logical thinking and problem solving approach that is needed in computer science to turn vague thoughts and ideas into precise algorithms. Each class he took showed him the beauty of the field and pushed him.
Machine learning with professor Nakul Verma was the class he liked the most. Said Lamy, “The class simultaneously gives you a deep understanding of the foundations of ML and teaches you most of the advanced mathematics you’ll need in more difficult classes – linear algebra, probability, and statistics concepts that are relevant to CS and not really covered in the corresponding required classes.” Lamy ended up working as a teacher’s assistant three times after taking the class and Verma became an important mentor for the rest of his time at Columbia.
Lamy looks forward to solving even more complex problems and formulating algorithms when he returns to Columbia in the fall for a MS in computer science.
“Looking around our world reveals an incredible number of real life problems that have been solved using computers,” he said. “But the amount of problems that are still out there and waiting to be solved seems to defy the imagination.”
Linnie Jiang Columbia College
I really appreciate how CS relies on a foundation of math so that results can be explained in a clean logical language that is familiar to us.
Computer science can be applied to so many domains and the interdisciplinarity of CS is what appeals to Jiang. While at Columbia her research with professors from the neuroscience department studied how expectation is encoded in the circuitry of the fruit fly (Drosophilamelanogaster). Her computational background contributed to a deeper understanding of how experience-dependent learning is largely a circuit phenomenon driven by the interactions of an ensemble of neurons (aka a graph!).
“I was surprised by how continuous and unending research is—if you answer one question, the next immediately pops up,” said Jiang. “It seems like there are endless implications of every discovery you make.”
Jiang will pursue a PhD in Neurosciences at Stanford University, supported by funding from the Stanford Graduate Fellowship as well as the NSF Graduate Research Fellowship. She also plans to obtain a PhD minor in computer science while at Stanford.
April Tang Barnard College
Being a computer science major allowed me to combine everything I was interested in into one degree.
April Tang came to Barnard knowing that she would study mathematics or statistics, but an intro to Java class opened her up to computer science. She quickly realized she could combine math and statistics with CS because the structural thinking in object-oriented programing and CS theory aligned perfectly with her training from mathematics.
“I was even more amazed to find that I can use my statistics knowledge in real-world applications through the use of machine learning techniques,” said Tang.
That interest in machine learning led her to a natural language processing class. It is within the context of natural language processing where questions that might seem vague in other general machine learning courses become concrete problems. Tang shared, “Having the context in mind really motivates me and allows me to think in more depth about the pros and cons of each method.”
As a Barnard student, Tang took most of her liberal arts requirements at the school. One class she particularly adored was dance in New York City – where coursework was on analyzing the choreography of different dance performances.
In July, she will join Citigroup as a quantitative analyst in their New York office. Tang hopes to study data science and go back to school for a graduate degree in the future.
Rose Orenbuch General Studies
When I took my first computer science course I realized that I would prefer an analytic and quantitative approach to biological questions.
Rose Orenbuch aspires to an academic career in the biosciences with a focus on genomics and neuroscience. She credits the skills she has gained from her CS courses as useful in conducting research – the ability to program and quickly learn new languages is particularly useful in bioinformatics, whether for statistical analysis or tool building or debugging other people’s programs.
A class that was both a favorite and the most challenging for her was computational genomics taught by professor Itsik Pe’er. Shared Orenbuch, “It was very helpful to understand the algorithms behind the tools I had been using in my research prior to the course.”
For that class, she built a tool for typing human leukocyte antigens (HLAs). HLAs are cell-surface proteins that are responsible for the regulation of the immune system. The tool has since been published and a paper describing it is currently under review at Bioinformatics.
During the summer, she will continue research to develop a tool to detect HLA expression imbalance and investigate its effect on outcomes of immunotherapy. Orenbuch is set to attend Harvard University for a PhD in systems biology in the fall.
As valedictorian of the Class of 2019, Alexandre Lamy will receive Columbia Engineering’s highest academic honor. Lamy will also be awarded the School’s Illig Medal and speak at Engineering Class Day on May 20.
CS researchers headed to the 2019 ACM CHI Conference on Human Factors in Computing Systems in Glasgow, Scotland. The conference gathers researchers and scientists to examine the ways that technology can be used to improve people and society.
This year’s papers feature women-led research – assistant professor Lydia Chilton presented three projects, including one with Katy Gero, a PhD student. While undergrad Lauren Arnett took part in a poster presentation for work that studied livestreaming.
Below are brief descriptions and links to the research.
Visual blends are an advanced graphic design technique to draw attention to a message. They combine two objects in a way that is novel and useful in conveying a message symbolically. This paper presents VisiBlends, a flexible workflow for creating visual blends that follows the iterative design process. The tool introduces a design pattern for blending symbols based on principles of human visual object recognition.
“To the average person, it seems that a visual blend requires creative inspiration—an aha! moment—and that there is no exact formula to make one,” said Chilton, in an interview. “We wanted to deconstruct the process of building visual blends and see if there was a way we could make it more accessible to people by coupling the human element with computational methods.”
An illustration of how VisiBlends creates a visual blend for “Starbucks is here for summer.” People brainstorm symbols for Starbucks and summer. The computer automatically combines them based on shape. People judge the outputs, and tell the computer how to improve the image based on color, shape, or details.
Visiblends allows users to collaboratively generate visual blends with steps involving brainstorming, synthesis, and iteration. An evaluation of the workflow shows that decentralized groups can generate blends in independent microtasks, co-located groups can collaboratively make visual blends for their own messages, and VisiBlends improves novices’ ability to make visual blends.
The paper explores how livestreamers on the platform, Twitch, may want to use other social media accounts to develop their audience.
Twitch is a social media platform owned by Amazon that focuses on livestreaming for video gamers. With opportunities for receiving donations and paid subscriptions, the most popular Twitch content creators can earn up to $500,000 per month.
Twitch users have social incentives to become popular, as passionate, tight-knit communities form in support of individual successful streamers. A common piece of advice for Twitch users looking to gain popularity is to have a social media presence and use it to promote themselves. The researchers looked into the validity of this claim to see if social media presence was in fact associated with popularity, to confirm if that is an effective way of promotion for streamers.
With data from over 17,000 streamers both directly from Twitch and scraped from social media platforms, different behaviors on social media platforms were examined to see if they correlated with popularity. For example, a Twitch user who develops a social media following before they started streaming may be able to transfer their popularity over to their Twitch profile. However, when compared with Twitch users who started a social media account after their first stream, the researchers were surprised to find that based on two measures of popularity, users who started Twitch with an existing social media presence did not experience a significant advantage over those who do not.
“Throughout this project, I’ve been amazed by the variety of people who stream and the lengths they go to for their audiences,” said Lauren Arnett, a computer science student. The livestreaming community extends all over the world and unites over particular games or streamers with a ton of enthusiasm. Streamers themselves spend the hours of an overtime work week playing for the entertainment of their viewers, creating a complex livestreaming schedule that will satisfy followers in any time zone. She continued, “although Twitch is a relatively unknown platform, the commitment and connections that exist on it run deep.”
While computation has opened a floodgate of creative tools for music and the visual arts (like synthesizers, Photoshop, ChucK, SnapChat filters, and GANS) little of that fervor has transferred to the medium of text. Word processors that detect spelling and grammatical errors are useful, but do not support the creative elements of writing.
In this work, the researchers built a metaphor generation tool to help describe abstract concepts like ‘love’ or ‘consciousness’. Metaphors convey abstract ideas by comparing them to more concrete or familiar concepts, and are used in all forms of writing from poetry to journalism.
“Metaphoria is an online tool that generates metaphorical connections between two words,” said Katy Gero, a second year PhD student. “It is designed to give you ideas for poetry, essays, or stories. It augments your abilities, rather than replacing them.”
The tool can generate suggestions that make sense to the writer, given what the writer is looking to do. It can also make suggestions that inspire writers to come up with new and different ideas. The researchers found that Metaphoria almost always produces some connections that make sense, though it’s pretty dependent on the writer as to which connections make sense.
“Metaphoria rarely resulted in people writing very similar things; instead, Metaphoria inspires people to write things they might never have thought of,” said Gero.
Rebecca Wright, the director of Barnard’s CS program, is a recipient of the 2019 Distinguished Service Award for her 11-year leadership of DIMACS, particularly in continuing and expanding the research and educational missions of DIMACS, for promoting diversity in computer science, and for using her expertise in privacy and security to help shape public policy on a national level.
Ray seeks to improve the reliability of deep-learning applications used in safety-critical systems such as autonomous cars, medical diagnosis and malware detection.
CompilHer is an educational technology podcast with the aim of encouraging high school girls to pursue computer science in college and beyond. The podcast is produced by computer science majors Surbhi Lohia (BC ’19) and Madeline Wu (BC ’19).
The interviews consist of women from various backgrounds who are involved in computer science and technology. Topics covered range from how to get started with computer science, what it’s like to be a CS major, to how to land an internship or job in the tech industry. Check out the podcast at https://anchor.fm/compilher or on Spotify.
There will be a Launch Party on Friday, April 26th from 2PM to 4PM at the CSC Student Lounge (5th floor) in the Milstein Center on Barnard’s campus. Everyone is invited to come network and mingle with the podcast’s guests and other CS and technology clubs from the Columbia community. (Event details here.)
Below is a Q&A with one of the producers, Madeline Wu:
Why produce this type of podcast on women in CS? We knew that interest in computer science drops most drastically for girls in high school and wanted to find a creative solution to target that pain point. We also noticed that most existing podcasts about women in tech are about women who are already in the tech field, and thus wouldn’t be as relatable for a high school audience with limited CS experience.
Is this a class assignment or a personal project? This project was done as a senior social action project through the Athena Scholars Program at Barnard. We’re happy to have chosen a project that is both personal and impactful!
Will you be producing more episodes? We are currently wrapping up Season 1 in New York City. After graduation, we’ll be located in Seattle and NYC so we have yet to determine the future of CompilHER but want to make it work!
How did you choose your interviewees? We wanted to choose relatable, yet aspirational role models for our target demographic of high school girls. We decided to tap into our own community of CS at Columbia and interview senior CS women about their experiences. We also tried to encompass a diverse range of backgrounds, experiences, and interests within tech.
What was the most surprising thing you’ve learned from your interviews? You are never too young or inexperienced to make an impact! By starting small and learning how to ask, our podcast guests have been able to accomplish so much and receive the support they needed along the way!
If there’s one takeaway you want people to have, what is it? We want high school girls to know that CS is for everyone, and that there is a whole community of amazing women in tech out there who want to support each other!
Learn the science behind movie magic in this talk with Nora Wixom BC’13, a visual effects director at Lucasfilm. Nora will be talking about the technology used to create the computer graphics and visual effects of movies. Nora has worked as a technical director on films such as Jurassic World, Captain America: Civil War, and Star Wars: Episode 8. Nora graduated from Barnard in 2013 with a degree in Computer Science, with a focus on Vision and Graphics.
The computer science department adds two more faculty members. With research and teaching experience in algorithmic game theory, machine learning, and computational genomics, these new CS faculty are facilitating research and learning in their respective computer science fields.
Tim Roughgarden Professor, Computer Science Postdoctoral researcher, UC Berkeley, (2004) PhD Computer Science, Cornell University, (2002) MS Mathematics, Cornell University, (2002) MS Computer Science, Stanford University (1998) BS Applied Mathematics, Stanford University (1997)
Tim Roughgarden works on algorithmic game theory and on the design, analysis, applications, and limitations of algorithms. He comes to Columbia from Stanford University, where he was a computer science professor for 15 years.
Much of his recent research explores the intersection of computer science and economics, with applications ranging from network routing to online advertising to spectrum auctions. Looking at economics through the computer science lens motivated a number of new questions that had gone unasked, shared Roughgarden. Some topics he has worked on include the price of anarchy (that is, approximation guarantees for game-theoretic equilibria), auction and mechanism design theory, and social network analysis. Other subjects that are on his radar are contract theory and blockchains.
In the fall Roughgarden will teach a randomized algorithms course, as well as an undergrad class on the intersection of computer science and economics that will cover everything from cryptocurrencies, auctions for advertising, and routing protocols. He is toying with the idea of a more advanced class on the foundations of blockchain technology with a particular emphasis on game theory.
He is in the midst of building up his research group, and has one new PhD student and one new postdoc arriving in the fall.
David Knowles Assistant Professor, Computer Science Core Faculty Member, New York Genome Center Postdoctoral researcher, Stanford University (2018) PhD Machine Learning, University of Cambridge, (2012) MSc Bioinformatics and Systems Biology, Imperial College London (2008) MEng Engineering, University of Cambridge (2007)
Knowles’ interests lie in the interface between Bayesian inference and machine learning. While at his postdoc at Stanford a lot of the work he did applied Bayesian statistical techniques in computational genomics.
Part of his research looked at questions around how genetic differences between people influence their disease risk. One study examined how chemotherapy patients could be sensitive to treatment depending on their genetic makeup, in terms of cardiac side effects. Knowles is also interested in various neurological diseases – ALS, autism, Alzheimer’s – and how to study these diseases using patients’ genetic data and patient-derived model systems such as induced neurons and organoids.
“There is some work in this area, but I think it is particularly important in biology where you want to understand how much uncertainty there is in the model and in your predictions because (like with the chemotherapy and cardiac side effects research) we want to know how certain we are that the patient will have a cardiac side effect if given a chemotherapy drug,” shared Knowles.
In the fall he will teach a class on how modern machine learning is used in genomics. The Knowles Lab opened in January and is looking for grad and postdocs. Postdocs have the option to work in the wet lab and computational side.
The Distinguished Lecture series brings computer scientists to Columbia to discuss current issues and research that is affecting their particular fields. This year, nine experts covered topics from deep learning, virtual reality, blockchains, algorithms, computing, and data science.
John Hennessy, from Stanford University, addressed the slower rate of performance growth for general processors and how he sees domain specific architectures may be the one attractive path for important classes of problems.
John Hennessy, December 03, 2018.
Below is the list of prominent faculty and industry researchers from across the country that gave talks and links to videos of their lectures.
Drinea, a lecturer in discipline of computer science, will receive this year’s Distinguished Faculty Teaching Award, an honor given annually by the Columbia Engineering Alumni Association. She’ll receive the award on Class Day, the May 20 commencement for Columbia Engineering graduates.
Looking around corners is one of the most dangerous parts of war for infantry. Ravn builds heads-up displays that let soldiers and law enforcement see around corners thanks to cameras on their gun, drones or elsewhere.
Hundreds
joined DevFest for a week of workshops that ended
with an 18-hour hackathon. In its ninth year, the event gathered technologists
from the New York City area. The hackathon had a record 26 projects from teams
across the Columbia community.
The iOs app SpineAlign took first place. The team,
composed of first-year students, wanted to help people determine if they have
scoliosis. The app hopes to be a resource that can help reduce
the cost of diagnosis and increase accessibility for patients.
Second place went to PicCode, an app that can help verify code by simply
taking a picture. Whiteboarding, coding by hand, and reading code in the form
of physical text (via textbook or otherwise) is a common practice among
programmers and CS students. PicCode enables users to take a picture of
code and receive a return text that either contains the output of the code
or any errors in the code.
The
ethos of the hackathon is you can go from zero to a working product in a very
short amount of time, shared Christopher Thomas (GS
’19), the lead organizer from the Application
Development Initiative (ADI). He continued, “I was a huge fan of EZPZ, an app that helps refugees fill out
paperwork, they knocked it out of the park.”
Thomas and the
ADI team started planning the event a year in advance to put together the four
days of workshops, panels, and talks from industry professionals. “We made sure
DevFest is a place where people can meet, learn together, and pick up coding
skills,” he said.
List of winners
First place Spine Align – Havi Nguyen, Annie Sui, Luvena Huo, James Wang
Second place PicCode – Alexander Wang, Ursula Ott, Joheen Chakraborty, Michael Jan
Third place Teach & Reach – Wu Shaun Khoo, Santoshi Ganesan
Bloomberg
Award of Excellence EZPZ – Tomer Aharoni, Alon Ezer, Jonathan Bofman, Eden Dolev
Best
Beginner Hack Delta – Kate Majidzadeh, Sofía Sánchez-Zárate, Benjamin Snyder, Carl Dobrovic
Best
Hack for Social Good WeServe – Christopher Kang, Katharyn Fatehi, Naviya Makhija
Best
Financial Hack Juvo – Rohan Macherla, Jack Shi, William Tong, Justing Won
Best
Hack for Sustainability Hungry Hippos – Samantha Figueredo, Ailene Torres, Fernando Sanchez, Kimberly Mangual
Best
Use of Facebook Mission Uberlytics – Kanishk Vashisht, Rahul Kataria, Sambhav Anand
Best
Educational Hack League of Learners – Naledi Kekana, Nelson Lai, Yvette Zhang, Kailing Chen
Best Use of Google Cloud Platform Sumy – William Zheng, Stan Liao, Sian Lee Kitt
Best
Use of Twilio API LionDine – Jake Fisher, Paul Cassoulat, Sergio Llamas, Bryce Monier
The award is given to faculty at top universities to support research that is relevant to Google’s products and services. The program is structured as a gift that funds a year of study for a graduate student.
Certified Robustness to Adversarial Examples with Differential Privacy Principal Investigator: Roxana Geambasu Computer Science Department
The proposal builds
on Geambasu’s recent work on providing a “guaranteed” level of robustness for machine
learning models against attackers that may try to fool their predictions.
PixelDP works by randomizing
the prediction of a model in such a way to obtain a bound on the maximum change
an attacker can make on the probability of any label with only a small change
in the image (measured in some norm).
Imagine that a building rolls out a face
recognition-based authorization system. People are automatically
recognized as they approach the door and are let into the building if they are
labeled as someone with access to that building.
The face recognition system is most likely backed by a
machine learning model, such as a deep neural network. These models have been
shown to be extremely vulnerable to “adversarial examples,” where an
adversary finds a very small change in their appearance that causes the models
to classify them incorrectly – wearing a specific kind of hat or makeup can
cause a face recognition model to misclassify even if the model would have been
able to correctly classify without these “distractions.”
The bound the
researchers enforce is then used to assess, on each prediction on an image,
whether any attack up to a given norm size could have changed the prediction on
that image. If it cannot, then the prediction is deemed “certifiably
robust” against attacks up to that size.
A sample PixelDP DNN: original architecture in blue; the changes introduced by PixelDP in red.
This robustness certificate for an individual prediction is the key piece of functionality that their defense provides, and it can serve two purposes. First, a building authentication system can use it to decide whether a prediction is sufficiently robust to rely on the face recognition model to make an automated decision, or whether additional authentication is required. If the face recognition model cannot certify a particular person, that person may be required to use their key to get into the building. Second, a model designer can use robustness certificates for predictions on a test set to assess a lower bound of their model on accuracy under attack. They can use this certified accuracy to compare model designs and choose one that is most robust for deployment.
“Our defense is currently the most
scalable defense that provides a formal guarantee of robustness to adversarial
example attacks,” said Roxana Geambasu, principal investigator of the research
project.
The project is joint work with Mathias Lecuyer, Daniel Hsu, and Suman Jana. It will develop new training and prediction algorithms for PixelDP models to increase certified accuracy for both small and large attacks. The Google funds will support PhD student Mathias Lecuyer, the primary author of PixelDP, to develop these directions and evaluate them on large networks in diverse domains.
The role of over-parameterization in solving non-convex problems Principal Investigators: Daniel Hsu Computer Science Department, Arian Maleki Department of Statistics
One of the central computational tasks in data science is that of fitting statistical models to large and complex data sets. These models allow for people to reason and draw conclusions from the data.
For example, such models have been used to discover communities in
social network data and to uncover human ancestry structure from genetic data.
In order to make accurate inferences, it has to be ensured that the model is
well-fit to the data. This is a challenge because the predominant approach to
fitting models to data requires solving complex optimization problems that are
computationally intractable in the worst case.
“Our research considers a surprising way to alleviate the computational
burden, which is to ‘over-parameterize’ the statistical model,” said Daniel
Hsu, one of the principal investigators. “By over-parameterization, we mean introducing
additional ‘parameters’ to the statistical model that are unnecessary from the
statistical point-of-view.”
The figure shows the landscape of the optimization problem for fitting the Gaussian mixture model.
One way to over-parameterize a model is to take some some prior information about the data and now regard it as a variable parameter to fit. For instance, in the social network case, the sizes of the communities expected to discover may have been known; the model can be over-parameterized by treating the sizes as parameters to be estimated. This over-parameterization would seem to make the model fitting task more difficult. However, the researchers proved that, for a particular statistical model called a Gaussian mixture model, over-parameterization can be computationally beneficial in a very strong sense.
This result is important because it suggests a way around computational
intractability that data scientists may face in their work of fitting models to
data.
The aim of the
proposed research project is to understand this computational benefit of
over-parameterization in the context of other statistical models. The
researchers have empirical evidence of this benefit for many other variants of
the Gaussian mixture model beyond the one for which their theorem applies. The
Google funds will support PhD student Ji Xu, who is jointly advised by
Daniel Hsu and Arian Maleki.
Columbia Engineering researchers develop Easy Email Encryption, an app that encrypts all saved emails to prevent hacks and leaks, is easy to install and use, and works with popular email services such as Gmail, Yahoo, etc.
The application performance testing company NimbleDroid was recently acquired by mobile performance platform HeadSpin. Co-founded by professor Junfeng Yang and PhD student Younghoon Jeon, the tool is used to detect bugs and performance bottlenecks during the development and testing phase of mobile apps and websites.
“I’ve always liked programming but hated the manual debugging process,” said Junfeng Yang, who joined the department in 2008. “So I thought it would be good to use artificial intelligence and program analysis to automate the task of debugging.”
NimbleDroid
scans apps for bugs and bottlenecks and sends a report back with a list of
issues. The New
York Times wrote about
how they used it to identify bottleneck issues with the start up time of their
android app and speed it up by four times. Pinterest also used
the tool during
a testing phase and was able to resolve issues within 21 hours. Previously they
would hear about problems from users once the app was already released, and spent
“multiple days” to identify and fix the problems.
NimbleDroid
has a premier list of customers, some of which also use HeadSpin. These common customers connected Yang and HeadSpin’s
CEO Manish Lachwani. They thought that NimbleDroid would be a great addition to
HeadSpin’s suite of mobile testing and performance solutions. The acquisition was recently announced with Yang
named as Chief Scientist of HeadSpin.
Because the
initial technology for NimbleDroid started at Columbia, Yang and Jeon worked
with Columbia Technology Ventures (CTV) to license the technology.
They started a company, got the exclusive license for the technology, and
further developed the tool. CTV is the technology transfer office that
facilitates the transition of inventions from academic research labs to the
market.
“We are
excited that our research is widely used by unicorn and Fortune 1000 companies
and helps over a billion users,” said Yang. “But our work is not done, we are
developing more technologies to make it easy to launch better software faster.”
Columbia’s computer science community is growing with Barnard College’s creation of a program in Computer Science (CS). Rebecca Wright has been hired as the director of Barnard’s CS program and as the director of the Vagelos Computational Science Center (Vagelos CSC), both of which are located in the Milstein Center.
Wright will lay down the groundwork to establish a computer science department to better serve the Barnard community. According to Wright, the goals of Barnard’s CS program are to bring computing education in a meaningful way to all Barnard students, to better integrate Barnard’s CS majors into the Barnard community, and to build a national presence for Barnard in computing research and education. Barnard students have already been able to take CS classes at Columbia and to major in CS by completing the Columbia CS major requirements. The Barnard program will continue to collaborate closely with the Columbia CS department, seeking to add opportunities rather than duplicating existing efforts or changing existing requirements.
“Initial course offerings are expected to focus on how CS interacts with
other disciplines, such as social science, lab science, arts, and the
humanities,” said Wright, who comes to
Columbia from Rutgers University. “We will address the different ways it can
interact with various disciplines and ways to advance those disciplines, but
with a focus on how to advance computer science to meet the needs of those
disciplines.”
Wright sees room to create more opportunities for students to see the
full spectrum of computer science – from the one end of the spectrum using the
computer as a tool, to the other end of the spectrum where there is the ability
to design new algorithms, to implement new systems, to carry out things at the
forefront of computer science. Barnard will enable students to find more places
along that spectrum to become fluent in the underlying tools and mechanisms and
be able to reason about them, create them, and combine them in new ways.
The first course will be taught by Wright and offered next year in the
fall. It is currently being developed and will most likely fall under her
research interests – security, privacy, and cryptography. She also is
working on building the faculty through both tenure-stream professors and a new
teaching and research fellows program.
For now, students can
continue to visit Barnard’s CSC and CS facilities on the fifth floor of the
Milstein Center, including making use of the Computer Science and Math Help
Room for guidance from tutors, studying or relaxing in the CSC social space,
and enrolling in CSC workshops.
Wright encourages students
to visit the Milstein Center,”I love walking through the library up to our
offices.” The space is open and a modern presentation of a library – much like
how she envisions how the computer science program will develop.
“Computing has an impact on advances in virtually every
field today,” said Wright. “I am excited to see what we develop around these
multidisciplinary interactions and interpretations of computing.”
Professor Vishal Misra is an avid fan of cricket and now works on research that looks at the vast amount of data on the sport.
“I live in two worlds – one where I am a computer science professor and the other where I am ‘the cricket guy’,” said Vishal Misra, who has been with the department since 2001 and recently received the Distinguished Alumnus of IIT Bombay award.
For the most part, Misra has kept these two worlds separate until last year when he worked on research with colleagues at MIT that forecasts the evolution or progress of the score of a cricket match.
When a game is affected by rain and is cut short, there is a statistical system in place – the Duckworth-Lewis-Stern System which either resets the target or declares the winner if no more play is possible. Their analysis showed that the current method is biased and they developed a better method based on the same ideas that are used to predict the evolution of the game. Their algorithm looks at data of past games and the current game and uses the theory of robust synthetic control to come up with a prediction that is surprisingly accurate.
The first time Misra became involved in the techie side of cricket was through CricInfo, the go-to website for anything to do with the sport. (It is now owned by ESPN.)
Misra (in the middle) on the cricket field, 2014.
In the early 90s, during the internet’s infancy, fans would “meet” and chat in IRC (internet relay chat) chat rooms to talk about the sport. This was a godsend for Misra who had moved to the United States from India for graduate studies at the University of Massachusetts Amherst. Cricket was (and still is) not that popular here but imagine living in 1993 and not be able to hop onto a computer or a smartphone to find out the latest scores? He would call home or go to a bookstore in Boston to buy Indian sports magazines like Sportstar and India Today.
Through the #cricket chatrooms, he met CricInfo’s founder Simon King and they developed the first website with the help of other volunteers spread across the globe. Misra shared, “It was a site by the fans for the fans, that was always the priority.” They also launched live scorecards and game coverage of the 1996 world championships. Misra wrote about the experience for CricInfo’s 20th anniversary. He stuck with his PhD studies and remained in the US when CricInfo became a proper business and opened an office in England.
“I did a lot of coding
back then but my first computer science class was the one I taught here in
Columbia,” said Misra, who studied electrical engineering for his undergraduate
and graduate degrees and joined the department as an assistant professor.
For his PhD thesis, he developed a stochastic differential equation model for TCP, the protocol that carries almost all of the internet’s data traffic. Some of the work he did with colleagues to create a congestion control mechanism based on that model has become part of the internet standard and runs on every cable modem in the world. Cisco took the basic mechanism that they developed, adapted it, and pushed it for standardization. “That gives me a big kick,” said Misra. “That algorithm is actually running almost everywhere.”
Since then his research focus has been on networking and now includes work on internet economics. Richard Ma, a former PhD student who is now faculty at National University Singapore, introduced him to this area. They studied network neutrality issues very early on which led to his playing an active part in the net neutrality debate in India, working with the government, regulators, and citizen activists. “India now has the strongest pro-consumer regulations anywhere in the world, which mirrors the definition I proposed of network neutrality,” he said.
For now, he continues research on net neutrality and differential pricing. He is also working on data center networking research with Google, where he is a visiting scientist. Another paper that generalizes the theory of synthetic control and applies the generalized theory to cricket is in the works. The new paper makes a fundamental contribution to the theory of synthetic control and as a fun application, they used it to study cricket.
“While I continue my work in networking, I am really
excited about the applications of generalized synthetic control. It is a tool
that is going to become incredibly important in all aspects of society,” said
Misra. “It can be used in applications from studying the impact of a
legislation or policy to algorithmic changes in some system – to predicting
cricket scores!”
Tomer Aharoni (GS ’19) will present “Nagish”, a software that helps people with hearing and speech difficulties communicate over the phone, at the Google Cloud Next ‘19 conference in April.
It
all started with a voice message and follow up text to Aharoni – his friend
needed him to reply and he was in class and could not use his phone. Curious
about what was so important, he decided to create a hack – he took the sound
output of his computer and redirected it into the input, then he opened a
Google Doc, selected the dictation option, played the voice message and the app
translated the audio into text. He was finally able to read his friend’s
message.
“I
realized that I might be onto something,” said Aharoni, a veteran of the Israeli Defense Force
who is a
general studies student majoring in computer science. “The
next week I teamed up with friends to join the DevFest hackathon and we won
second place.”
The decision to join DevFest,
Columbia’s annual hackathon, proved to be a way to open doors for Nagish. Aside
from the second place win, the team also won the Best Hack for
Social Good award and caught the eye of Google Cloud.
For the first iteration of Nagish, the team stayed up all night to create a product linked to only one phone number. They had to pre-code the number and link it to Facebook messenger. When Google showed interest and gave them a grant through the Google Cloud credits program, they focused on using Google’s APIs and added other messenger apps to reach more users.
Each call begins with a text message informing the registered user that they have an incoming call. The user can either pick up or decline the call. If the user picks up the call, the caller is informed that this is a special phone call for someone with hearing or speech difficulties so they know that they should wait on the line.
From then on the caller can speak and whatever they say will be translated into text. While the registered user will be able to reply via text that will be translated into a voice message for the caller. So one side of the call can type and read and the other side can speak and hear. The reverse is also true – registered users can place calls with the help of the software.
Video of Nagish from DevFest 2018
“The first time we built it it was like a
fraction of a second of delay,” shared Aharoni. “It sounds like nothing but the
delay is super annoying when you speak with someone over the phone.”
Since then they have worked on making the software more efficient and faster in time for beta testing set for March. Right now the team is looking for 10 people with hearing or speech difficulties to participate in a day of testing.
One of the things that is holding them back
at the moment is the cost of using Nagish. While they have a grant from Google,
not all of the APIs they use are from that suite of products. To connect the
call to Nagish they use an API called Twilio which is costly. Each incoming or
outgoing call costs 20 cents per minute. Even though they plan to release
Nagish for free, users still have to pay Twilio to be able to use Nagish.
Tomer Aharoni and Alon Ezer at DevFest 2019. Photo credit : Vivian Shen
In the beginning, Aharoni had little
experience in programming and credits the past year of working on Nagish as
invaluable. “I learned a lot from my classes but it is different to actually
work on a project and build my skills that way,” he said. Since DevFest he has continuously
worked with Alon Ezer, who also gave him a lot of guidance in the beginning. Now
he knows the whole process from project conception, implementation, to testing.
He hopes to release Nagish, which means accessible in Hebrew, for free sometime
this year.
Bloomberg also approached him after the
hackathon to apply as an intern. He spent last summer as an intern for the equities
group within the engineering department and will join the company as an employee after graduation this May.
“We’ve spent many hours working on Nagish to help others but all that
hard work has been fulfilling in more ways than one,” said Aharoni.
Composed of computer science students – Victor Lecomte, Bicheng Gao, and Aditya Shah – the team finished first place at the greater New York regional championship held last November at Manhattan College.
“The
teamwork aspect of this competition is really nice,” said Victor Lecomte, a
first year MS student who has tried for five years to get into the world
finals. “Working together as a team makes the competition even more fun.”
A
unique aspect of this programming competition is that teams have five hours to
complete ten computational problems with only one computer to use
between them. Lecomte shared that their game plan was to get the easiest
problems out of the way quickly then figure out which harder problems to
tackle. By the end of five hours they had finished eight problems.
Coaches
Chengyu Lin and Peilin Zhong helped Team Kington prepare for the regionals by holding
weekend training sessions for two months. Through that the team got to know each
other and figure out how to best work together. In preparation of the world
finals they are headed to Beijing, China for a week-long intensive training
camp at the end of February.
The
training camp serves as a boot camp with a five-hour contest in the morning, a
workshop to review the problems in the afternoon and evenings reserved for even
more practice. Participating teams are also regional winners. Teams are ranked
so it is much like a real competition. Continued Lecomte, “You can usually
figure out who the top teams are and who will likely win in the championship.”
On-campus
training sessions are open to everyone that want to sharpen their skills, shared
Chengyu Lin, one of the coaches and a third year PhD student. The sessions are
also a good way to prepare for potential interview questions as the practice
problems are often the same as what Google recruiters ask. Lecomte has been
contacted by recruiters because of his involvement in the competition.
“This
is challenging
work but if you love programming, if you love algorithms, this is definitely a
way to improve your coding skills,” said Lin.
Kara Schechtman
(CC ‘19) has been selected as one of the recipients of the Senator
George J. Mitchell Scholarship Program to pursue a
one-year postgraduate degree in Ireland. The fellowship is awarded to 12 individuals between the ages of 18
and 30 by the US-Ireland Alliance.
Schechtman is headed to Trinity College Dublin where she will study philosophy.
“Artificial
intelligence is advancing and we are at a point where ethics has to be
considered,” said Schechtman, who is majoring in English and
computer science at Columbia. “I believe studying philosophy will help me
prepare for further studies in computer science.”
A point of frustration
for her has been finding an area in computer science where both the
humanities and computing overlap in a way that fits her interests. In artificial
intelligence (AI), computing and philosophical questions can overlap, an
intersection she finds fulfilling.
The development of AI poses a whole gamut of challenges to humanity, ranging from legislation challenges, to AI bias, to ethical concerns about potential machine consciousness, and even to potential existential threat. But these challenges have remained while the technical developments of AI has grown leaps and bounds.
One thing Schechtman
hopes to answer through her studies is how society can act responsibly despite
all that is unknown. “I think it also demands technical expertise to suggest
actionable paths for responsibility now,” continued Schechtman. “Which is why
it is so important for computer scientists and philosophers to work together,
and for some people to study both.”
The
Ireland location of the fellowship is also ideal. Dublin hosts the European
Union headquarters of a number of tech giants. And having double majored in
English, she looks forward to “nerding out” over Samuel Beckett and James Joyce
in their home country.
“More broadly, the circumstances couldn’t be better — the other fellowship recipients seem amazing and I can’t wait to get to know them better, Trinity College Dublin is a wonderful school, and I am sure I will have a lot of fun exploring Ireland. I’m excited to grow from the experience in ways I don’t yet even expect,” said Schechtman.
The Computing Research Association (CRA) awarded Serina Chang as one of four awardees of the 2019 Outstanding Undergraduate Researcher Award. Three other computer science students were also nominated, including Ruiqi Zhong, Justin Whitehouse, Hamed Nilforoshan, all of whom received honorable mentions. All four undergraduates were recognized for their work in an area of computing research.
“I am always looking for innovative ways to combine computer science and social science,” said Serina Chang, a senior studying computer science and sociology. “Not only looking at research methods but to have a social impact.”
The paper on gang-involved youth in Chicago is one example of how computer science and sociology can intersect. The research continued the work of Desmond Patton, a professor at the School of Social Work and a Data Science Institute member, who found expression of loss over the death of a friend often led to tweets of aggression and real-world violence.
One of their key insights include that domain-specificity and context are extremely important. Interpreting the tweets was also context-critical, as it often depends on the emotional state of the user or what they had been tweeting prior to the current one, and may also refer to context such as the names of rival gangs or deceased friends.
The researchers hypothesized that domain-specificity and context would be important, but were surprised by the degree to which it affected convolutional neural network performance. For example, one set of experiments compared the word embeddings trained on domain-specific unlabeled corpus against word embeddings that trained on other corpora, including standard GloVE and Google News as well as an African-American vernacular English-specific corpus and a location-specific one, which they drew from the same area of Southside Chicago as their users.
The results found that their word embeddings outperformed the others by nearly 4 F1 points, which demonstrates the importance of constructing a large domain-specific corpus instead of resorting to “similar” corpora based on location or demographics. Said Chang, “Our hope is that we can eventually use our system to save critical time, scale their reach, and intervene before more young lives are lost.”
Chang’s thoughtfulness extends into other parts of her life. In her sophomore year she became a teaching assistant so she could work with students in Professor Paul Blaer’s data structures in JAVA course. She worked one-on-one with students to help them with assignments, with the additional goal of building their confidence when it comes to their abilities.
Mentoring others also came hand-in-hand with her involvement in Lean In at Columbia and Womxn in Computer Science (WiCS). In both organizations Chang held a leadership position and made it a point to foster relationships and empower women through various programs that celebrated diversity and feminism.
“I do still have time to study,” laughed Chang when asked about time management. This semester she is focused on working on her thesis. Grad school is also on the horizon and she will make her final decision in April. Part of the CRA award is financial assistance to attend a conference of their choice, she is still unsure of where she wants to go.
Looking back at all she has accomplished while at Columbia makes her feel grateful for all the opportunities she had to work with colleagues and professors, the relationships that have grown with friends and family, and the research that she hopes to continue.
“I am incredibly honored by this award and excited to be recognized for research that I am so passionate about,” said Chang.
Columbia researchers presented their work at the Empirical Methods in Natural Language Processing (EMNLP) in Brussels, Belgium.
Professor Julia Hirschberg gave a keynote talk on the work done by the Spoken Language Processing Group on how to automatically detect deception in spoken language – how to identify cues in trusted speech vs. mistrusted speech and how these features differ by speaker and by listener. Slides from the talk can be viewed here.
Five teams with computer science undergrad and PhD students from the Natural Language Processing Group (NLP) also attended the conference to showcase their work on text summarization, analysis of social media, and fact checking.
”Given the difficult times, we are living in, it’s extremely necessary to be perfect with our facts,” said Tuhin Chakrabarty, lead researcher of the paper. “Misinformation spreads like wildfire and has long-lasting impacts. This motivated us to delve into the area of fact extraction and verification.”
This paper presents the ColumbiaNLP
submission for the FEVER Workshop Shared Task. Their system is an end-to-end pipeline that
extracts factual evidence from Wikipedia and infers a decision about the
truthfulness of the claim based on the extracted evidence.
Fact checking is a type
of investigative journalism where experts examine the claims published by
others for their veracity. The claims can range from statements made by public
figures to stories reported by other publishers. The end goal of a fact
checking system is to provide a verdict on whether the claim is true, false, or
mixed. Several organizations such as FactCheck.org and PolitiFact are devoted
to such activities.
The FEVER Shared task aims to evaluate the ability of a system to verify information using evidence from Wikipedia. Given a claim involving one or more entities (mapping to Wikipedia pages), the system must extract textual evidence (sets of sentences from Wikipedia pages) that supports or refutes the claim and then using this evidence, it must label the claim as Supported, Refuted or NotEnoughInfo.
Detecting Gang-Involved Escalation on Social Media Using Context Serina Chang Computer Science Department, Ruiqi Zhong Computer Science Department, Ethan Adams Computer Science Department, Fei-Tzin Lee Computer Science Department, Siddharth Varia Computer Science Department, Desmond Patton School of Social Work, William Frey School of Social Work, Chris Kedzie Computer Science Department, and Kathleen McKeown Computer Science Department
This research is a
collaboration between Professor Kathy McKeown’s NLP lab and the
Columbia School of Social Work. Professor Desmond Patton, from the School of Social Work and a member of the Data
Science Institute, discovered that gang-involved youth in cities such as
Chicago increasingly turn to social media to grieve the loss of loved ones,
which may escalate into aggression toward rival gangs and plans for violence.
The team created a machine
learning system that can automatically detect aggression and loss in the social
media posts of gang-involved youth. They developed an approach with the hope to
eventually use a system that can save critical time, scale reach, and intervene
before more young lives are lost.
The
system features the use of word embeddings and lexicons, automatically derived
from a large domain-specific corpus which the team constructed. They also
created context features that capture user’s recent posts, both in semantic and
emotional content, and their interactions with other users in the dataset.
Incorporating domain-specific resources and context feature in a Convolutional
Neural Network (CNN) that leads to a significant improvement over the prior
state-of-the-art.
The dataset used spans the public Twitter posts of nearly 300 users from a gang-involved community in Chicago. Youth volunteers and violence prevention organizations helped identify users and annotate the dataset for aggression and loss. Here are two examples of labeled tweets, both of which the system was able to classify correctly. Names are blocked out to preserve the privacy of users.
Tweet examples
For semantics, which were represented by word embeddings, the researchers found that it was optimal to include 90 days of recent tweet history. While for emotion, where an emotion lexicon was employed, only two days of recent tweets were needed. This matched insight from prior social work research, which found that loss is significantly likely to precede aggression in a two-day window. They also found that emotions fluctuate more quickly than semantics so the tighter context window would be able to capture more fine-grained fluctuation.
“We took this context-driven approach because we believed that interpreting emotion in a given tweet requires context, including what the users had been saying recently, how they had been feeling, and their social dynamics with others,” said Serina Chang, an undergraduate computer science student. One thing that surprised them was the extent to which different types of context offered different types of information, as demonstrated by the contrasting contributions of the semantic-based user history feature and the emotion-based one. Continued Chang, “As we hypothesized, adding context did result in a significant performance improvement in our neural net model.”
Automated fact checking of textual claims is of increasing interest in today’s world. Previous research has investigated fact checking in political statements, news articles, and community forums.
“Through our model we can fact check claims
and find specific statements that support the evidence,” said Christopher Hidey,
a fourth year PhD student. “This is a step towards addressing the
propagation of misinformation online.”
As part of the FEVER community
shared task, the researchers developed models that given a statement would jointly find a Wikipedia article and a sentence related
to the statement, and then predict whether the statement is supported by that sentence.
For example, given the claim “Lorelai Gilmore’s father is named Robert,” one could find the Wikipedia article on Lorelai Gilmore and extract the third sentence “Lorelai has a strained relationship with her wealthy parents, Richard and Emily, after running away as a teen to raise her daughter on her own” to show that the claim is false.
Credit : Wikipedia – https://en.wikipedia.org/wiki/Lorelai_Gilmore
One aspect of this problem that the team observed was how poorly TF-IDF, a standard technique in information retrieval and natural language processing, performed at retrieving Wikipedia articles and sentences. Their custom model improved performance by 35 points in terms of recall over a TF-IDF baseline, achieving 90% recall for 5 articles. Overall, the model retrieved the correct sentence and predicted the veracity of the claim 50% of the time.
The rate of which misinformation is spreading on
the web is faster than the rate of manual fact-checking conducted by
organizations like Politifact.com and Factchecking.org. For this paper the
researchers wanted to explore how to automate parts or all of the fact-checking
process. A poster with their findings was presented as part
of the FEVER workshop.
“In order to come up with reliable fact-checking
systems we need to understand the current manual process and identify
opportunities for automation,” said Tariq Alhindi, lead author on the paper. They looked at the LIAR dataset – around 10,000 claims classified by Politifact.com to one of six
degrees of truth – pants-on-fire, false, mostly-false, half-true, mostly-true,
true. Continued Alhindi, we also looked at the fact-checking article for each
claim and automatically extracted justification sentences of a given
verdict and used them in our models, after removing all sentences that contain
the verdict (e.g. true or false).
Excerpt from the LIAR-PLUS dataset
Feature-based machine learning models and
neural networks were used to develop models that can predict whether
a given statement is true or false. Results showed that using some sort of
justification or evidence always improves the results of fake-news detection
models.
“What was most surprising about the results is that
adding features from the extracted justification sentences consistently improved
the results no matter what classifier we used or what other features we
included,” shared Alhindi, a PhD student. “However, we were surprised that the
improvement was consistent even when we compare
traditional feature-based linear machine learning models against state of
the art deep learning models.”
Their research extends the previous work done on this data set which only looked at the linguistic cues of the claim and/or the metadata of the speaker (history, venue, party-affiliation, etc.). The researchers also released the extended dataset to the community to allow further work on this dataset with the extracted justifications.
Recently,
a specific type of machine learning, called deep learning, has made strides in
reaching human level performance on hard to articulate problems, that is,
things people do subconsciously like recognizing faces or understanding speech.
And so, natural language processing researchers have turned to these models for
the task of identifying the most important phrases and sentences in text
documents, and have trained them to imitate the decisions a human editor might
make when selecting content for a summary.
“Deep
learning models have been successful in summarizing natural language texts,
news articles and online comments,” said Chris Kedzie, a fifth
year PhD student. “What we wanted to know is how they are doing it.”
While
these deep learning models are empirically successful, it is not clear how they
are performing this task. By design, they are learning to create their own
representation of words and sentences, and then using them to predict whether a
sentence is important – if it should go into a summary of the document. But
just what kinds of information are they using to create these
representations?
One
hypotheses the researchers had was that certain types of words were more
informative than others. For example, in a news article, nouns and verbs might
be more important than adjectives and adverbs for identifying the most
important information since such articles are typically written in a relatively
objective manner.
To see if this was so, they trained models to predict sentence importance on redacted datasets, where either nouns, verbs, adjectives, adverbs, or function words were removed and compared them to models trained on the original data.
On
a dataset of personal stories published on Reddit, adjectives and adverbs were
the key to achieving the best performance. This made intuitive sense in that
people tend to use intensifiers to highlight the most important or climactic
moments in their stories with sentences like, “And those were the WORST
customers I ever served.”
What surprised the researchers were the news articles – removing any one class of words did not dramatically decrease model performance. Either important content was broadly distributed across all kinds of words or there was some other signal that the model was using.
They suspected that sentence order was important because journalists are typically instructed to write according to the inverted pyramid style with the most important information at the top of the article. It was possible that the models were implicitly learning this and simply selecting sentences from the article lead.
Two pieces of evidence confirmed this. First, looking at a histogram of sentence positions selected as important, the models overwhelmingly preferred the lead of the article. Second, in a follow up experiment, the sentence ordered was shuffled to remove sentence position as a viable signal from which to learn. On news articles, model performance dropped significantly, leading to the conclusion that sentence position was most responsible for model performance on news documents.
The
result concerned the researchers as they want models to be trained to truly
understand human language and not use simple and brittle heuristics (like
sentence position). “To connect this to broader trends in machine learning, we
should be very concerned and careful about what signals are being exploited by
our models, especially when making sensitive decisions,” Kedzie continued. ”The
signals identified by the model as helpful may not truly capture the problem we
are trying to solve, and worse yet, may be exploiting biases in the dataset
that we do not wish it to learn.”
However,
Kedzie sees this as an opportunity to improve the utility of word
representations so that models are better able to use the article content
itself. Along these lines, in the future, he hopes to show that by quantifying
the surprisal or novelty of a particular word or phrase, models are able to
make better sentence importance predictions. Just as people might remember the
most surprising and unexpected parts of a good story.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor