
CS Papers Accepted to ACL 2019
CS researchers will be at the 2019 Annual Meeting of the Association of Computational Linguistics in Florence, Italy. Numerous papers covering the computational approaches to natural language were accepted.
Accepted papers
- Pay “Attention” to Your Context when Classifying Abusive Language
Tuhin Chakrabarty Columbia University, Kilol Gupta Columbia University, and Smaranda Muresan Columbia University - Neural Network Alignment for Sentential Paraphrases
Jessica Ouyang Columbia University and Kathleen McKeown Columbia University - Rubric Reliability and Annotation of Content and Argument in Source-Based Argument Essays
Yanjun Gao Pennsylvania State University, Alex Driban Pennsylvania State University, Brennan Xavier McManus Columbia University, Elena Musi University of Liverpool, Patricia M. Davies Prince Mohammad Bin Fahd University, Smaranda Muresan Columbia University, and Rebecca J. Passonneau Pennsylvania State University - Unsupervised Morphological Segmentation for Low-Resource Polysynthetic Languages
Ramy Eskander Columbia University, Judith L. Klavans University of Maryland, Smaranda Muresan Columbia University
Summaries of the papers are below:
Pay “Attention” to Your Context when Classifying Abusive Language
Tuhin Chakrabarty Columbia University, Kilol Gupta Columbia University, and Smaranda Muresan Columbia University
The goal of any social media platform is to facilitate healthy and meaningful interactions among its users. But more often than not, it has been found that it becomes an avenue for wanton attacks.
In the paper the researchers propose an experimental study that has three aims: (1) to provide a deeper understanding of current datasets that focus on different types of abusive language, which are sometimes overlapping (racism, sexism, hate speech, offensive language and personal attacks); (2) to investigate what type of attention mechanism (contextual vs. self-attention) is better for abusive language detection using deep learning architectures; and (3) to investigate whether stacked architectures provide an advantage over simple architectures for this task.
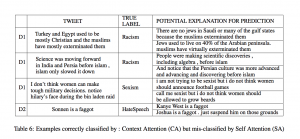
The work is about using context attention instead of self-attention for abuse detection which encapsulates the information by looking at examples globally through the training data, unlike self attention which only focuses on words for that particular tweet while trying to classify it.

The first tweet belongs to the NONE class while the second tweet belongs to RACISM class. The word “islam” may appear in the realm of racism as well as in any normal conversation. The model successfully identified the two distinct contextual usages of the word “Islam” in the two tweets, as demonstrated by a much higher attention weight in the second case and a relatively smaller one in the first case.
Neural Network Alignment for Sentential Paraphrases
Jessica Ouyang Columbia University and Kathleen McKeown Columbia University
The researchers created a system that automatically aligns paraphrases between two input sentences — that is, it detects which parts of the two sentences are paraphrases of each other. Their aligner is unique in that it is able to align phrases of arbitrary length, including full sentences, as well as relatively loose paraphrases, where the two aligned phrases mean approximately, but not necessarily exactly, the same thing.
Paraphrase alignment is the task of detecting parts of two input sentences that mean the same thing. Previous work on this task has focused on a strict definition of paraphrase, which requires that the aligned phrases mean exactly the same thing; previous systems aligned only words that exactly matched, or were close synonyms, between the sentences. In addition, previous work on paraphrase alignment was practically limited to phrases of three or fewer words, due to running time constraints. However, most people’s intuition about what counts as a paraphrase is much less strict, and paraphrases can be much longer than three words.

The phrases in bold are examples of paraphrases that the system can align, but that previous work could not. The entire phrase, “I vaguely recalled him telling me” means the same thing as “I remembered a story” in the context of these two sentences, but there is no one-to-one mapping between the words in the two phrases (eg. “vaguely” in Sentence 1 has no corresponding word in Sentence 2), which would prevent previous systems from successfully aligning these phrases.
The designed system aligns these looser and longer paraphrases by first breaking the input sentences into grammatical chunks, such as noun or verb phrases. For each chunk, it calculates a single vector that represents the meaning of that chunk by combining the vectors representing the meanings of the words within it. Then, a neural network is used to align each chunk in one of the input sentences to the chunks in the other sentence. This method allows for the alignment of all of the words within a chunk at once, regardless of the length of the chunk, and small differences in meaning or in individual words are mitigated by the meanings of the other words in the chunk. The system is the first to use a neural network to perform the alignment task, and it is able to align longer and less exactly-matching sentences than previous systems could.
Rubric Reliability and Annotation of Content and Argument in Source-Based Argument Essays
Yanjun Gao Pennsylvania State University, Alex Driban Pennsylvania State University, Brennan Xavier McManus Columbia University, Elena Musi University of Liverpool, Patricia M. Davies Prince Mohammad Bin Fahd University, Smaranda Muresan Columbia University, and Rebecca J. Passonneau Pennsylvania State University
Students with STEM majors were prompted to write short argumentative essays on topics including cryptocurrencies, cybercrime, and self-driving cars. These essays were graded on a rubric, and the essays were analyzed for content.
The argumentative structure of these essays were analyzed, which involved breaking the essays down into units of argumentation and indicating whether one argument supports, attacks, or is necessary context for another, from the main claim of the essay down to individual pieces of evidence. The results of this annotation were compared to the results of applying the rubric for each of these essays, leading to a set of argumentative features associated with essays of particular scores.
One simple finding is that essays with the highest overall score (5) tended to have a higher ratio of argumentative sentences to non-argumentative sentences, while the essays in the next highest group (4) tended to be longer. The essays with the higher scores and lower scores often had similar numbers of claims, but the latter group would tend to fail to connect these claims to the main argument of their essay.
The goal of research in this area is to assess the eventual effectiveness and usability of automated grading assistants for argumentative essays, and to what extent a rubric can be applied to fairly analyze the content and argumentative structure of essays in a similar way in which automated grading scripts are used within the CS department here at Columbia.