
Year: 2018
CS professors elected 2018 ACM Fellows
CS Professors elected 2018 ACM Fellows
Rachel Wu (SEAS ’19) Chosen To Present At Google’s Annual Women Engineers Summit
Wu gave a lightning talk, “Life of a Machine Learning Dataset”, at the conference last July. She was selected out of 60 applicants to deliver a 15-minute talk to 464 attendees from over 18 North American office locations.
_________
My internship at Google came as a result of my independent research during my five month study abroad program. Two days after I returned to the United States on December 14, 2017, I delivered a 40 minute talk on bias in AI and hiring algorithms at Google headquarters for 453 attendees.
In the talk, I performed neural network experiments demonstrating bias in predictive image/video machine learning programs. A Google employee came up to me afterwards and told me to send him my resume. Taking a chance, I sent it in on the last day summer internship applications were open. Two weeks later, I had an offer.
At Google, I had three major responsibilities. First, I identified key issues across machine learning data curation process, leveraging consulting skills to scope, prioritize and identify technical solutions to major pain points. Second, I collaborated with Google’s machine learning engineers and Google’s 700+ member Operations team in Gurgaon, India to eliminate inefficiencies in training by building a training platform. Third, I created presentations with compelling messages tailored to different audience levels, including directors.
 Katie Girskis, the organizer of the Google Women Engineers conference, wanted to highlight intern projects from across Google and selected me to be one of the lightning talk speakers. On the first day of the conference, I presented “Life of a Machine Learning Dataset” at Google’s annual women engineers summit, focusing on how we’re putting a price on units of human judgements/expertise more directly than ever. For the talk, I collaborated with Google’s Business and Strategy Operations team to calculate data curation costs, resulting in new metrics to evaluate ML training costs.
Katie Girskis, the organizer of the Google Women Engineers conference, wanted to highlight intern projects from across Google and selected me to be one of the lightning talk speakers. On the first day of the conference, I presented “Life of a Machine Learning Dataset” at Google’s annual women engineers summit, focusing on how we’re putting a price on units of human judgements/expertise more directly than ever. For the talk, I collaborated with Google’s Business and Strategy Operations team to calculate data curation costs, resulting in new metrics to evaluate ML training costs.
Overall by the end fo the internship, my coworkers awarded me 1 kudos and 2 peer bonuses, as well as a return offer. At Google, I learned to write code using their internal technology stack, collaborate with departments at a larger scale, and communicate more effectively. Apart from working with highly skilled people, I enjoyed making friends with the other interns in Mountain View, and having lunch with Jeff Dean. Most importantly, I loved the fact that my code went into production and that my work is being continued even after my summer internship ended.

How taking a home genetics test could help catch a murderer
These technologies are improving video game accessibility for the blind
The promise of (practically) ‘serverless computing’
CS undergrad, Alyssa Hwang (SEAS ’20), Presented Her Research at Columbia, Harvard and Stanford Research Conferences
Hwang spent the summer working for the Natural Language Text Processing Lab (NLP) and the Data Science Institute (DSI) on a joint project, doing research on gang violence in Chicago.
What was the topic/central focus of your research project?
I used the DSI’s Deep Neural Inspector to evaluate an NLP model that classified Tweets from gang-related users.
What were your findings?
Through my research, I found that the DNI reported higher correlation between hypothesis functions and neuron/layer output in trained models than random models, which confirms that the models learn how to classify the data input.
The aggression model showed interesting correlation with activation hypotheses, and the same with the loss model with imagery, which implies that aggressive speech tends to be very active (intense) and that text containing loss tend to use language that is concrete rather than abstract. If I had more time to continue this research, I would love to explore different types and sentiments in text and how that would affect how well a model learns its task.
What about the project did you find interesting?
The most interesting part of my research was seeing how interconnected all of these disciplines are. I split most of my time between the Natural Language Processing Lab and the Data Science Institute, but I also had the chance to meet some great people from the School of Social Work–their work on gang-related speech is part of an even bigger project to predict, and later prevent, violence based on social media data.
How did you get involved in/ choose this project?
I’ve been working at the NLP Lab since freshman year and decided to continue working there over the summer. In my opinion research is one of the best ways to develop your skillset and ask questions to people already established in the same field. I knew I wanted to pursue research even before I decided to major in computer science, and I feel so grateful to be included in a lab that combines so many of my interests and develops technology that matters.
How much time did it take and who did you work with?
The project was for three months and I worked with CS faculty – Professor Kathy McKeown and Professor Eugene Wu.
Which CS classes were most helpful in putting this project together?
Python, Data Structures
What were some obstacles you faced in working on this project?
I had just finished my sophomore year when I tackled this project, which means that the most advanced class I had taken at that point was Advanced Programming. I spent a lot of time just learning: figuring out how machine learning models work, reading a natural language processing textbook, and even conducting a literature review on violence, social media, and Chicago gangs just so I could familiarize myself with the dataset. I felt that I had to absorb an enormous amount of information all at once, which was intimidating, but I was surrounded by people with infinite patience for all of my questions.
What were some positives of this project?
Through this project, I really started to appreciate how accessible computer science is. Half of the answers we need are already out on the internet. The other half is exactly why we need research. I can learn an entire CS language for free in a matter of days thanks to all of these online resources, but it takes a bit more effort to answer the questions I am interested in: what makes text persuasive? What’s a fair way of summarizing emotional multi-document texts?
Can you discuss your experience presenting?
Along with the Columbia Summer Symposium, I have presented my research at the Harvard National Collegiate Research Conference and the Stanford Research Conference.
Do you plan to present this research at any other events/conferences?
Yes, but I have yet to hear if I have been accepted.
What do you plan to do with your CS undergraduate degree?
Not sure yet but definitely something in the natural language understanding/software engineering space.
Do you see yourself pursuing research after graduation?
Yes! I loved working on a project that mattered and added good to the world beyond just technology. I also loved presenting my research because it inspired me to think beyond my project: what more can we do, how can others use this research, and how can we keep thinking bigger?
Midterm Elections: How Politicians Know Exactly How You’re Going To Vote
Here’s what happens to your information after you fill out a voter registration form.
WiCS at the 2018 Grace Hopper Celebration
Women technologists from around the world gathered in Houston, Texas to attend the Grace Hopper Celebration. Columbia’s Womxn in Computer Science (WiCS) share how it was to be part of the event that celebrates and promotes women in technology.
Xiao Lim

My favorite part about Grace Hopper was the raw experience of walking into the opening keynote and seeing over 20,000 women in tech. I think it’s easy to get bogged down by what we perceive as the status quo, but going to Grace Hopper reminded me that what is “normal” can and will always change. I can’t wait to see the future built by these women, and am proud to know that I am part of the change I want to see.
Lucille Sui
My favorite part about attending Grace Hopper was meeting so many amazing and inspirational women and also getting closer with the women I came with from Columbia! I learned a lot about the different paths in life that you can pursue with a computer science degree, from working on the Sims game to working on the tech enabled side of Home Depot. I would encourage everyone to attend this event because it’s an amazing way to meet other women in the field and understand the horizon of limitless potential you have as a woman in tech.
Kara Schechtman
Attending Grace Hopper is always such a meaningful experience as a woman in technology. It was my second time attending the conference, and both years I’ve been heartened to see the big crowds of women (and allies!) at the conference.
In addition to being in a woman-dominated space, it is really exciting to see that women are passionate about fixing many of tech’s problems; there were long lines for speakers like Joy Boulamwini who tackles bias in algorithms. For me, the most memorable experience was attending a talk given by Anita Hill the day after Christine Blasey-Ford’s hearing. Her words of advice to not give up on creating positive change were ones I really needed to hear that day. I hope I’ll be able to attend the conference for many years to come!
Madeline Wu
I had no idea what to expect from my first Grace Hopper experience, but was so glad I got to do it with fellow Barnard/Columbia seniors who also attended GHC through the WiCS sponsorship. Being at a conference with 25,000+ women in computer science is simultaneously inspiring and overwhelming, so I appreciated having other WiCS students to exchange tips with on the best giveaways, share what workshops we were attending, and to wish each other luck on interviews.
Some of my closest friends in college are fellow Barnard CS seniors who attended GHC with me, and throughout our three days in Houston we connected with women in tech from all backgrounds and interests, learned how to play poker with Palantir, enjoyed a mac and cheese themed Snapchat party, and tried all the Tex-Mex we could find. I went into this semester feeling a little burnt out, but seeing so many women in CS in one place and seeing how much companies are investing in women in tech re-motivated and inspired me to give everything my best effort senior year. Despite the giveaways and opportunities that GHC is most known for, I am most grateful that I got to experience GHC’s unparalleled sense of community with women who have been integral to my college journey!
Vivian Shen
I loved going to Grace Hopper because for once in my life, I was in an environment where womxn greatly outnumbered men at a giant, respected tech conference. As students, we try to carve out spaces for womxn in tech with our incredible clubs (Girls Who Code, Womxn in Computer Science, etc.), who hold various talks and gatherings and workshops. However, the experience is completely different when you are surrounded by thousands and thousands of womxn rather than just a handful, and these womxn come from all the corners of the globe to support each other in their technical pursuits. Not once during the week did I feel like I was talked down upon or “mansplained,” and it truly felt like every person I talked to, be it employer or peer, wanted me to succeed (and I wanted them to as well!). Sure, one of the biggest benefits of the Grace Hopper Conference is its giant career fair, where many students are able to find job offer(s).
However, I felt like the companies weren’t just there to find talented womxn engineers – they were also trying to prove that their company is inclusive and welcoming of diversity. It may seem strange to put it that way, but I believe that as these companies work to outdo each other in terms of inclusivity, they really do create better atmospheres for their workers. I’m more than happy to let companies show off all of their equity initiatives, especially when they are then receptive to feedback when we sometimes say that these initiatives aren’t doing enough.
At the conference, there were 50+ students from Columbia/Barnard, who all got sponsored in separate ways. I was lucky enough to receive a Microsoft scholarship out of the blue (I have had no prior connection with that company), so my main piece of advice to students who would like to attend GHC in the future is just to apply, apply, apply! Because it is such a renown conference, there are tons and tons of companies who offer sponsorship to those with a good enough reason to want to go, and filling out many applications increases your chances of getting funded by one of these. When it hits June, start looking for GHC scholarships on Google (I know it’s early, but trust me, you want to keep an eye on those things). Then, when you get in, I’m sure you’ll have a whole crowd of Barnumbia womxn (and peers from all over) who will be excited to attend and support you at the conference.
Four papers from Columbia at Crypto 2018
CS researchers worked with collaborators from numerous universities to explore and develop cryptographic tools. The papers were presented at the 38th Annual International Cryptology Conference.
Correcting Subverted Random Oracles
Authors: Alexander Russell University of Connecticut, Qiang Tang New Jersey Institute of Technology, Moti Yung Columbia University, Hong-Sheng Zhou Virginia Commonwealth University
Many cryptographic operations rely on cryptographic hash functions. The structure-less hash functions behave like what is called a random oracle (random looking public function). The random oracle methodology has proven to be a powerful tool for designing and reasoning about cryptographic schemes, and can often act as an effective bridge between theory and practice.
These functions are used to build blockchains for cryptocurrencies like Bitcoin, or to perform “password hashing” – where a system stores a hashed version of the user’s password to compare against the value that is presented by the user: it is hashed, and compared to the previously stored computed value in order to identify the user. These functions garble the input to look random, and it is hard from the output to find the input or any other input that maps to the same output result.
The paper is in the area of implementations of cryptographic functions that are subverted (aka implemented incorrectly or maliciously). Shared one of the researchers, Moti Yung from Columbia University,” We deal with a hash function that some entries in the function table are corrupted by the opponent – a bad guy who implemented it differently than the specification. The number of corruption is relatively small to the size of the function. What we explored is what can be done with it by the bad guys and can we protect against such bad guys.”
First, the paper shows devastating attacks are possible with this modification of a function: the bad guys can control the blockchain, or allow an impersonator to log in on behalf of a user, respectively, in the above applications.
Then, to counter the attack the researchers demonstrated how to manipulate the function (apply it a few times and combine the results in different ways) and how the new function prevents attacks.
In this paper, the focus is on the basic problem of correcting faulty—or adversarially corrupted—random oracles, so that they can be confidently applied for such cryptographic purposes.
“The construction is not too complex,” said Yung, a computer science professor. “The proof that it works, on the other hand, required the development of new techniques that show that the manipulation produces a hash function that behaves like a random oracle in spite of the manipulation by the bad guy.”
Authors: Lucas Kowalczyk Columbia University, Tal Malkin Columbia University, Jonathan Ullman Northeastern University, Daniel Wichs Northeastern University
How can one know if the way they are using data is protecting the privacy of the individuals to whom the data belongs? What does it mean to protect an individual’s privacy exactly? Differential privacy is a mathematical definition of privacy that one can objectively prove one’s usage satisfies. Informally, if data is used in a differentially private manner, then any one individual’s data cannot have significant influence on the output behavior.
For example, Apple uses differentially private data collection to collect information about its users to improve their experience, while now being able to additionally give them a mathematical guarantee about how their information is being used.
Differential privacy is a nice notion, but there is a question: is it always possible to use data in a differentially private manner? “Our paper is an impossibility result,” said Lucas Kowalczyk, a PhD student at Columbia University. “We exhibit a setting, an example of data and desired output behavior, for which we prove that differential privacy is not possible to achieve. The specific setting is constructed using tools from cryptography.”
Proofs of Work From Worst-Case Assumptions
Authors: Marshall Ball Columbia University, Alon Rosen IDC, Herzliya, Manuel Sabin UC Berkeley, Prashant Nalini Vasudevan MIT
A long standing goal in the area is constructing NP-Hard cryptography. This would involve proving a “win-win” theorem of the following form: either some cryptographic scheme is secure or the satisfiability problem can be solved efficiently. The advantage of a theorem like this, is that if the scheme is broken it will yield efficient algorithms for a huge number of interesting problems.
Unfortunately, there hasn’t been much progress beyond uncovering certain technical barriers. In the paper the researchers proved win-wins of the following form: either the cryptographic scheme is secure or there are faster (worst-case) algorithms than are currently known for satisfiability and other problems (violating certain conjectures in complexity theory).
“In particular, the cryptography we construct is something called a Proof of Work,” said Maynard Marshall Ball, a fourth year PhD student. “Roughly, a Proof of Work can be seen as a collection of puzzles such that a random one requires a certain amount of computational “work” to solve, and solutions can be checked with much less work.”
These objects appear to be inherent to cryptocurrencies, but perhaps a simpler and older application comes from spam prevention. To prevent spam, an email server can simply require a proof of work in order to receive an email. In this way, it is easy to solve a single puzzle and send a single email, but solving many puzzles to send many emails is infeasible.
A Simple Obfuscation Scheme for Pattern-Matching with Wildcards
Authors: Allison Bishop Columbia University and IEX, Lucas Kowalczyk Columbia University, Tal Malkin Columbia University, Valerio Pastro Columbia University and Yale University, Mariana Raykova Yale University, Kevin Shi Columbia University
Suppose a software patch is released which addresses a vulnerability triggered by some bad inputs. The question is how to publicly release the patch so that all users can apply it, without revealing which bad inputs trigger the vulnerability – to ensure that an attacker will not take advantage of the vulnerability on unpatched systems.
This can be addressed by what cryptographers call “program obfuscation” — producing a program that anyone can use, but no one can figure out the internal working of, or any secrets used by the program. Obfuscation has many important applications, but it is difficult to achieve, and in many cases was shown to be impossible. For cases where obfuscation is possible, existing solutions typically utilize complex and inefficient techniques and rely on cryptographic assumptions that are not well understood.
The researchers discovered a surprisingly simple and efficient construction that can obfuscate programs for pattern-matching with wildcards, motivated for example by the software patching application above. What this means is that a program can be released to check for any given input whether it matches some specific pattern (e.g., the second bit is 1, the third bit is 0, the sixth bit is 0, etc).
“Crucially, our construction allows you to publicly release such a program, while keeping the actual pattern secret,” said Tal Malkin, a computer science professor, “So people can use the program and information is kept safe.”
The Tiny Chip That Powers Up Pixel 3 Security
New Data Science Method Makes Charts Easier to Read at a Glance
“Pixel Approximate Entropy” technique quantifies visual complexity by providing a score that automatically identifies difficult charts; could help users in emergency settings to read data at a glance and make better decisions faster.
Your DNA, Identified by the DNA of Others
How Can We Keep Genetic Data Safe?
In light of how easy it is to identify people based on their DNA, researchers suggest ways to protect genetic information.
Genetic information uploaded to a website is now used to help identify criminals. This technique, employed by law enforcement to solve the Golden State Killer case, took genetic material from the crime scene and compared it to publicly available genetic information on third party website GEDmatch.
Inspired by how the Golden State Killer was caught, researchers set out to see just how easy it is to identify individuals by searching databases and finding genetic matches through distant relatives. The paper out today in Science Magazine also proposes a way to protect genetic information.
“We want people to discover their genetic data,” said the paper’s lead author, Yaniv Erlich, a computer scientist at Columbia University and Chief Science Officer at MyHeritage, a genealogy and DNA testing company. “But we have to think about how to keep people safe and prevent issues.”
Commercially available genetic tests are increasingly popular and users can opt to have their information used by genetic testing companies. Companies like 23andMe have used customer’s data for research to discover therapeutics and come up with hypothesis to make medicines. People can also upload their genetic information to third party websites, such as GEDmatch and DNA.Land, to find long-lost relatives.
With these scenarios, the data is used for good but what about the opposite? The situation can easily be switched, which could prove harmful for those who work covert operations (aka spies) and need their identities to remain secret.
Erlich shared that it takes roughly a day and a half to sift through a dataset of 1.28 million individuals to identify a third cousin. This is especially true for people of European descent in the United States. Then, based on sex, age and area of residence it is easy to get down to 40 individuals. At that point, the information can be used as an investigative lead.
To alleviate the situation and protect people, the researchers propose that raw data should be cryptographically encrypted and only those with the right key can view and use the data.
“Things are complicated but with the right strategy and policy we can mitigate the risks,” said Erlich.
A Man Of 3 Worlds: The Russian-American Billionaire Giving Millions To U.S. and U.K. Universities
Len Blavatnik (M.S. ’91) is 27th on the Forbes 400 list. Blavatnik has given $500 million to charities, including Columbia University’s Fu Foundation School of Engineering and Applied Science.
Was There a Connection Between a Russian Bank and the Trump Campaign?
New algorithms developed by CS researchers at FOCS 2018
Four papers were accepted to the Foundations of Computer Science (FOCS) symposium. CS researchers worked alongside colleagues from various organizations to develop the algorithms.
Learning Sums of Independent Random Variables with Sparse Collective Support
Authors: Anindya De Northwestern University, Philip M. Long Google, Rocco Servedio Columbia University
The paper is about a new algorithm for learning an unknown probability distribution given draws from the distribution.
A simple example of the problem that the paper considers can be illustrated with a penny tossing scenario: Suppose you have a huge jar of pennies, each of which may have a different probability of coming up heads. If you toss all the pennies in the jar, you’ll get some number of heads; how many times do you need to toss all the pennies before you can build a highly accurate model of how many pennies are likely to come up heads each time? Previous work answered this question, giving a highly efficient algorithm to learn this kind of probability distribution.
The current work studies a more difficult scenario, where there can be several different kinds of coins in the jar — for example, it may contain pennies, nickels and quarters. Each time you toss all the coins, you are told the total *value* of the coins that came up heads (but not how many of each type of coin came up heads).
“Something that surprised me is that when we go from only one kind of coin to two kinds of coins, the problem doesn’t get any harder,” said Rocco Servedio, a researcher from Columbia University. “There are algorithms which are basically just as efficient to solve the two-coin problem as the one-coin problem. But we proved that when we go from two to three kinds of coins, the problem provably gets much harder to solve.”
Holder Homeomorphisms and Approximate Nearest Neighbors
Authors: Alexandr Andoni Columbia University, Assaf Naor Princeton University, Aleksandar Nikolov University of Toronto, Ilya Razenshteyn
Microsoft Research Redmond, Erik Waingarten Columbia University
This paper gives new algorithms for the approximate near neighbor (ANN) search problem for general normed spaces. The problem is a classic problem in computational geometry, and a way to model “similarity search”.
For example, Spotify may need to preprocess their dataset of songs so that new users may find songs which are most similar to their favorite songs. While a lot of work goes into designing good algorithms for ANN, these algorithm work for specific metric spaces of interest to measure the distance between two points (such as Euclidean or Manhattan distance). This work is the first to give non-trivial algorithms for general normed spaces.
“One thing which surprised me was that even though the embedding appears weaker than established theorems that are commonly used, such as John’s theorem, the embedding is efficiently computable and gives more control over certain parameters,” said Erik Waingarten, an algorithms and computational complexity PhD student.
Parallel Graph Connectivity in Log Diameter Rounds
Authors: Alexandr Andoni Columbia University, Zhao Song Harvard University & UT-Austin, Clifford Stein Columbia University, Zhengyu Wang Harvard University, Peilin Zhong Columbia University
This paper is about designing fast algorithms for problems on graphs in parallel systems, such as MapReduce. The latter systems have been widely-successful in practice, and invite designing new algorithms for these parallel systems. While many classic “parallel algorithms” were been designed in the 1980s and 1990s (PRAM algorithms), predating the modern massive computing clusters, they had a different parallelism in mind, and hence do not take full advantage of the new systems.
The typical example is the problem of checking connectivity in a graph: given N nodes together with some connecting edges (e.g., a friendship graph or road network), check whether there’s a path between two given nodes. The classic PRAM algorithm solves this in “parallel time” that is logarithmic in N. While already much better than the sequential-time of N (or more), the researchers considered to question whether one can do even better in the new parallel systems a-la MapReduce.
While obtaining a much better runtime seems out of reach at the moment (some conjecture impossible), the researchers realized that they may be able to obtain faster algorithms when the graphs have a small diameter, for example if any two connected nodes have a path at most 10 hops. Their algorithm obtains a parallel time that is logarithmic in the diameter. (Note that the diameter of a graph is often much smaller than N.)
“Checking connectivity may be a basic problem, but its resolution is fundamental to understanding many other problems of graphs, such as shortest paths, clustering, and others,” said Alexandr Andoni, one of the authors. “We are currently exploring these extensions.”
Non-Malleable Codes for Small-Depth Circuits
Authors: Marshall Ball Columbia University, Dana Dachman-Soled University of Maryland, Siyao Guo Northeastern University, Tal Malkin Columbia University, Li-Yang Tan Stanford University
With this paper, the researchers constructed new non-malleable codes that improve efficiency over what was previously known.
“With non-malleable codes, any attempt to tamper with the encoding will do nothing and what an attacker can only hope to do is replace the information with something completely independent,” said Maynard Marshall Ball, a fourth year PhD student. “That said, non-malleable codes cannot exist for arbitrary attackers.”
The constructions were derived via a novel application of a powerful circuit lower bound technique (pseudorandom switching lemmas) to non-malleability. While non-malleability against circuit classes implies strong lower bounds for those same classes, it is not clear that the converse is true in general. This work shows that certain techniques for proving strong circuit lower bounds are indeed strong enough to yield non-malleability.
Women in Technology Initiative Addresses Gender Gap
The gender gap in technology is growing, and it’s not just for the reasons that you might expect. While access to opportunity – or rather the lack thereof – is often pointed to as the culprit for why there are so few women working in the U.S. technology sector, new research conducted by Accenture and Girls Who Code suggests it’s more complex than that – it also about holding on to their interest.
The HTC Exodus Blockchain Phone Comes Into Focus
QAnon Is Trying To Trick Facebook’s Meme-Reading AI
An AI Pioneer, And The Researcher Bringing Humanity to AI
Kai-Fu Lee (B.S. ’83) included in WIRED’s anniversary issue for his work that brings humanity to artificial intelligence.
Verizon sees 5G revolutionizing everything from surgery to education to transportation — so it’s opening high-tech labs in 4 cities by end of year
Verizon has said that 5G will revolutionize the world, enabling the latest advancements in industries from telemedicine to autonomous vehicles.
The 5G Race: China and U.S. Battle to Control World’s Fastest Wireless Internet
The early waves of mobile communications were largely driven by American and European companies. As the next era of 5G approaches, promising to again transform the way people use the internet, a battle is on to determine whether the U.S. or China will dominate.
Don’t want the police to find you through a DNA database? It may already be too late.
WASHINGTON – It’s a forensics technique that has helped crack several cold cases. Across the country, investigators are analyzing DNA and using basic genealogy to find relatives of potential suspects in the hope that these “familial searches” will lead them to the killer.
CS Welcomes New Faculty
The department welcomes Baishakhi Ray, Ronghui Gu, Carl Vondrick, and Tony Dear.

Baishakhi Ray
Assistant Professor, Computer Science
PhD, University of Texas, Austin, 2013; MS, University of Colorado, Boulder, 2009; BTech, Calcutta University, India, 2004; BSc, Presidency College, India, 2001
Baishakhi Ray works on end-to-end software solutions and treats the entire software system – anything from debugging, patching, security, performance, developing methodology, to even the user experience of developers and users.
At the moment her research is focused on machine learning bias. For example, some models see a picture of a baby and a man and identify it as a woman and child. Her team is developing ways on how to train a system and to solve practical problems.
Ray previously taught at the University of Virginia and was a postdoctoral fellow in computer science at the University of California, Davis. In 2017, she received Best Paper Awards at the SIGSOFT Symposium on the Foundations of Software Engineering and the International Conference on Mining Software Repositories.

Ronghui Gu
Assistant Professor, Computer Science
PhD, Yale University, 2017; Tsinghua University, China, 2011
Ronghui Gu focuses on programming languages and operating systems, specifically language-based support for safety and security, certified system software, certified programming and compilation, formal methods, and concurrency reasoning. He seeks to build certified concurrent operating systems that can resist cyberattacks.
Gu previously worked at Google and co-founded Certik, a formal verification platform for smart contracts and blockchain ecosystems. The startup grew out of his thesis, which proposed CertiKOS, a comprehensive verification framework. CertiKOS is used in high-profile DARPA programs CRASH and HACMS, is a core component of an NSF Expeditions in Computing project DeepSpec, and has been widely considered “a real breakthrough” toward hacker-resistant systems.

Carl Vondrick
Assistant Professor, Computer Science
PhD, Massachusetts Institute of Technology, 2017; BS, University of California, Irvine, 2011
Carl Vondrick’s research focuses on computer vision and machine learning. His work often uses large amounts of unlabeled data to teach perception to machines. Other interests include interpretable models, high-level reasoning, and perception for robotics.
His past research developed computer systems that watch video in order to anticipate human actions, recognize ambient sounds, and visually track objects. Computer vision is enabling applications across health, security, and robotics, but they currently require large labeled datasets to work well, which is expensive to collect. Instead, Vondrick’s research develops systems that learn from unlabeled data, which will enable computer vision systems to efficiently scale up and tackle versatile tasks. His research has been featured on CNN and Wired and in a skit on the Late Show with Stephen Colbert, for training computer vision models through binge-watching TV shows.
Recently, three research papers he worked on were presented at the European Conference for Computer Vision (EECV). Vondrick comes to Columbia from Google Research, where he was a research scientist.

Tony Dear
Lecturer in Discipline, Computer Science
PhD, Carnegie Mellon University, 2018; MS, Carnegie Mellon University, 2015; BS, University of California, Berkeley, 2012
Tony Dear’s research and pedagogical interests lie in bringing theory into practice. In his PhD research, this idea motivated the application of analytical tools to motion planning for “real” or physical locomoting robotic systems that violate certain ideal assumptions but still exhibit some structure – how to get unconventional robots to move around with stealth of animals and biological organisms. Also, how to simplify tools and expand that to other systems, as well as how to generalize mathematical models to be used in multiple robots.
In his teaching, Dear strives to engage students with relatable examples and projects, alternative ways of learning, such as an online curriculum with lecture videos. He completed the Future Faculty Program at the Eberly Center for Teaching Excellence at Carnegie Mellon and has been the recipient of a National Defense Science and Engineering Graduate Fellowship.
At Columbia, Dear is looking forward to teaching computer science, robotics, and AI. He hopes to continue small-scale research projects in robotic locomotion and conduct outreach to teach teens STEM and robotics courses.
A murdered teen, two million tweets and an experiment to fight gun violence
Researchers are using AI to decode the language of Chicago gangs. Next they’ll look for opportunities to intervene before online aggression turns deadly.
A Monitor’s Ultrasonic Sounds Can Reveal What’s on the Screen
AI For Humanity: Using AI To Make A Positive Impact In Developing Countries
Artificial intelligence (AI) has seeped into the daily lives of people in the developed world. From virtual assistants to recommendation engines, AI is in the news, our homes and offices. There is a lot of untapped potential in terms of AI usage, especially in humanitarian areas. The impact could have a multiplier effect in developing countries, where resources are limited. By leveraging the power of AI, businesses, nongovernmental organizations (NGOs) and governments can solve life-threatening problems and improve the livelihood of local communities in the developing world.
WuLab to present research on a query engine that supports tracking and querying lineage
Eugene Wu will also receive a Test of Time Award for WebTables: exploring the power of tables on the web at the VLDB Conference.
5G & IoT: Cousins Not Siblings
Bjarne Stroustrup Named Recipient of the John Scott Award
Universal Method to Sort Complex Information Found
The nearest neighbor problem asks where a new point fits in to an existing data set. A few researchers set out to prove that there was no universal way to solve it. Instead, they found such a way.
This tiny antenna could help future phones get ready for 5G speeds
Nine papers from CS researchers are part of SIGGRAPH 2018
Researchers from the Columbia Computer Graphics Group will present at SIGGRAPH 2018. The 45th SIGGRAPH Conference highlights the latest research on computer graphics and interactive techniques with a technical papers program.
A Multi-Scale Model for Simulating Liquid-Fabric Interactions
Authors:
Yun (Raymond) Fei Columbia University, Christopher Batty University of Waterloo, Eitan Grinspun Columbia University, Changxi Zheng Columbia University
Picture coffee splashing onto upholstery spreads, dampening a larger area or how board shorts drag along with ocean waves, often buoyant, and drip distinctively – each interaction depends on the type of liquid and fabric involved. This is the problem that researchers set out to understand by creating a computational model that captures these varied liquid-fabric interactions.
“During WWII, people developed the theory of mixture to design solid dams.” said Raymond Fei, a PhD student and the paper’s lead author. “Nowadays, we found the same theory can also be used to describe the dynamics of wet fabrics and produce compelling visual effects.”
Developability of Triangle Meshes
Authors:
Oded Stein Columbia University, Eitan Grinspun Columbia University, Keenan Crane Carnegie Mellon University
Surfaces that are smooth and that can be flattened onto a plane are known as developable surfaces. These are important because they are easy to manufacture via bending material, or with certain CNC mills. The graphic on the left is an approximation example: The first shape is an arbitrary input surface in the shape of a guitar body. The team developed an algorithm to approximate it by a piecewise developable surface (middle). The right shows how that surface would look like as a guitar.
“There is a lot of interesting math in the problem of developable surfaces,” said Oded Stein, the lead author. Many concepts from smooth mathematics don’t directly translate to the discrete world of triangle meshes. In smooth mathematics, a surface is developable if it has zero curvature. He continued, “But if we simply discretize the curvature at every point in the discrete surface, we get ugly, crumpled results unsuitable for fabrication. We had to rethink what it means to be developable, and transfer this concept to the discrete world.”
Natural Boundary Conditions for Smoothing in Geometry Processing
Authors:
Oded Stein Columbia University, Eitan Grinspun Columbia University, Max Wardetzky, Universität Göttingen, Alec Jacobson University of Toronto
In many problems in geometry processing, such as smoothing, the biharmonic equation is solved with low-order boundary conditions. This can lead to heavy bias of the solution at the boundary of the domain. By using different, higher-order boundary conditions (the natural boundary conditions of the Hessian energy), the results are unbiased by the boundary.
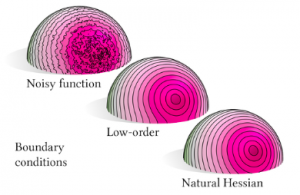
Using the Hessian as the basis for smoothness energies, this paper derives methods for animation, interpolation, data denoising, and scattered data interpolation.
“We were surprised by how many things this potentially applies to – the biharmonic equation is solved all over computer graphics whenever researchers ‘square the cotangent Laplacian,’ one of the common operators in computer graphics,” said Stein. “Many of these applications could avoid bias at the boundary by using the natural boundary conditions of the Hessian energy instead.”
Multi-Scale Simulation of Nonlinear Thin-Shell Sound with Wave Turbulence
Authors: Gabriel Cirio Inria, Université Côte d’Azur, Columbia University, Ante Qu Stanford University, George Drettakis Inria, Université Côte d’Azur, Eitan Grinspun Columbia University, Changxi Zheng Columbia University
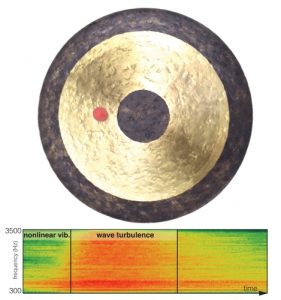
This paper is about generating the sound that virtual thin shells – such as cymbals and gongs – make when they are struck, by modeling and simulating the physics of elastic deformation and vibration using a computer.
If an animator has a sequence of a water bottle falling and hitting the ground, their model can automatically produce the corresponding sound, perfectly synchronized with the visuals and without requiring real recordings. With this technique, one can also generate the sound of virtual instruments such as a cymbal or a gong.
“It was surprising how complex something as simple as striking a cymbal can be,” said Gabriel Cirio, the lead author on the paper and post doctoral fellow at Columbia. The team turned to phenomenological models of turbulence, that capture the overall behavior instead of precisely simulating every vibration in the shell. Cirio further shared,”The resulting sounds are rich, expressive, and could easily be mistaken for a real recording.”
Scene-Aware Audio for 360° Videos
Authors:
Dingzeyu Li Columbia University, Timothy Langlois Adobe, Changxi Zheng Columbia University
“It was very challenging to make sure the synthesized audio blends in seamlessly with the recorded sound,” said Dingzeyu Li, the lead author from Columbia University. Given any input in 360° videos, the team was able to edit and manipulate the spatial audio contents that match the visual counterpart. He continued,”I am glad that we found a frequency modulation method to bridge the gap between virtually simulated and real-world audios, compensating for the room resonance effects.”

One application would be to augment existing 360° video with only a mono-channel audio. If a viewer were to watch this video, the audio would not adapt to the view direction dynamically since the mono-channel audio does not contain any spatial information. The team developed a method that can augment this video by synthesizing the spatial audio. This augmentation idea has been used before, for example to convert 2D movies shot in the early days to 3D formats. In this case, the 360° videos with only mono-channel audio are converted to ones with immersive spatial audio with a richer sound.
What Are Optimal Coding Functions for Time-of-Flight Imaging?
Authors:
Mohit Gupta University of Wisconsin-Madison, Andreas Velten University of Wisconsin-Madison, Shree Nayar Columbia University, Eric Breitbach University of Wisconsin-Madison
This paper presents a geometric theory and novel designs for time-of-flight 3D cameras that can achieve extreme depth resolution at long distances, sufficient to resolve fine details such as individual bricks in a building, even in a large, city-scale 3D model, or fine facial features needed to recognize a person’s identity from a long distance.

“Time-of-flight cameras have been around for nearly four decades now, and are fast moving towards mass adoption,” said Mohit Gupta, a former postdoc at Columbia now based at the University of Wisconsin-Madison. “We were surprised that almost all the cameras so far have been based on a particular design, which our new designs could out perform almost by an order-of-magnitude.”
 FontCode: Embedding Information in Text Documents Using Glyph Perturbation
FontCode: Embedding Information in Text Documents Using Glyph Perturbation
Authors:
Chang Xiao Columbia University, Cheng Zhang UC Irvine, Changxi Zheng Columbia University
Researches used a method based on a 1500 year old theorem called Chinese Remainder Theorem to develop an information embedding technique for text documents.
“Changing any letter, punctuation mark, or symbol into a slightly different form allows you to change the meaning of the document,” said Chang Xiao, in an interview. “This hidden information, though not visible to humans, is machine-readable just as bar and QR codes are instantly readable by computers. However, unlike bar and QR codes, FontCode won’t mar the visual aesthetics of the printed material, and its presence can remain secret.”
Interactive Exploration of Design Trade-Offs
Authors:
Adriana Schulz MIT, Harrison Wang MIT, Eitan Grinspun Columbia University, Justin Solomon MIT, Wojciech Matusik MIT
“Our method allows users to optimize designs based on a set of performance metrics,” said Adriana Schulz, a graduate student from the Massachusetts Institute of Technology. Given a design space and a set of performance evaluation functions, our method automatically extracts the Pareto set—those design points with optimal trade-offs.”
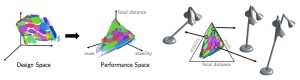
Schulz continued, we represent Pareto points in design and performance space with a set of corresponding manifolds (left). The Pareto-optimal solutions are then embedded to allow interactive exploration of performance trade-offs (right). The mapping from manifolds in performance space back to design space allows designers to explore performance trade-offs interactively while visualizing the corresponding geometry and gaining an understanding of a model’s underlying properties.
FoldSketch: Enriching Garments with Physically Reproducible Folds
Authors:
Minchen Li The University of British Columbia, Alla Sheffer The University of British Columbia, Eitan Grinspun Columbia University, Nicholas Vining The University of British Columbia
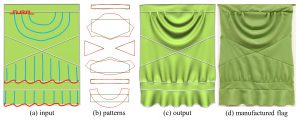
Complex physically simulated fabric folds generated using FoldSketch: (left to right) Plain input flag with user sketched schematic folds (a), original (green) and modified final (red) patterns (b); final post-simulation flag augmented with user-expected folds (c); real-life replica manufactured using the produced patterns (d).
FoldSketch allows designers to add folds to a garment via schematic annotation strokes. “We had to apply novel computational optimization and numerical simulation techniques to solve shape modeling and animation problems,” said Minchen Li, the lead author from The University of British Columbia. “The result is a new system that produces garment patterns that facilitate the formation of the desired folds on real and virtual garments.”
Internal documents show how Amazon scrambled to fix Prime Day glitches
CS students find Americans wrongly included in Twitter list linked to the Russian Internet Research Agency
Alex Calderwood, Shreya Vaidyanathan, and Erin Riglin reviewed 2,700+ Twitter accounts in a story that was published in Wired. The three are grad students under the CS and Columbia Journalism School’s dual degree program.
‘Lighter’ Can Still Be Dark by Olivia Winn and Smaranda Muresan Bags Best Short Paper at ACL 2018
The ACL organizing committee announced that Winn and the team won one of two short paper awards given at this year’s conference.
Two CS Professors Elected to Taiwan’s Academia Sinica
Two Columbia Engineering faculty have been elected to the prestigious Academia Sinica of Taiwan, founded in 1928 to promote and undertake scholarly research in science, engineering and humanities. The Academician recognition, open to scientists and scholars both domestic and overseas, represents the highest scholarly honor in Taiwan. The Academy counts seven Nobel laureates among its fellows.
Experts Disagree on Top Applications for 5G
DeepTest: automated testing of deep-neural-network-driven autonomous cars
Why Does the Internet Suck?
Eugene Agichtein (PhD ’05) wins Test of Time award at SIGIR 2018
Agichtein’s paper on incorporating user behavior signals into ranking wins the top award. The team also got an honorable mention for their research on predicting web search result preferences.
Blockchain Smart Contracts: More Trouble Than They Are Worth?
Facebook let phone makers get data trove on users and friends
What’s all the C Plus Fuss? Bjarne Stroustrup warns of dangerous future plans for his C++
How a California Banker Received Credit for His Unbreakable Cryptography 130 Years Later
‘The real horror is not knowing what to believe’: Scenes from the Fake News Horror Show
CS alum Yin Qi part of MIT’s 35 Innovators under 35 for face recognition platform
Seven years ago, Yin Qi founded a company called Megvii with two college friends in Beijing. Now people from over 220 countries and regions use Megvii’s face-recognition platform, Face++. The company has more than 1,500 employees.
Top CS graduates awarded Jonathan Gross Prize

![]() The Jonathan Gross Prize honors students who graduate at the top of their class with a track record of promising innovative contributions to computer science. Five graduating computer science students—one senior from each of the four undergraduate schools and one student from the master’s program—were selected to receive the prize, which is named for Jonathan L. Gross, the popular professor emeritus who taught for 47 years at Columbia and cofounded the Computer Science Department. The prize is made possible by an endowment established by Yechiam (Y.Y.) Yemini, who for 31 years until his retirement in 2011, was a professor of computer science at Columbia.
The Jonathan Gross Prize honors students who graduate at the top of their class with a track record of promising innovative contributions to computer science. Five graduating computer science students—one senior from each of the four undergraduate schools and one student from the master’s program—were selected to receive the prize, which is named for Jonathan L. Gross, the popular professor emeritus who taught for 47 years at Columbia and cofounded the Computer Science Department. The prize is made possible by an endowment established by Yechiam (Y.Y.) Yemini, who for 31 years until his retirement in 2011, was a professor of computer science at Columbia.
![]() Andy Arditi, Columbia College
Andy Arditi, Columbia College

“Developing computational solutions to complex problems like language processing or facial recognition is amazingly interesting and gives us insight into the nature of intelligence.”
Andy Arditi’s plan to major in a math-related field—mathematics, economics, or physics—changed in his sophomore year when he took his first CS class. Exposed to programming for the first time, he knew immediately computer science was for him. Working on programming assignments, he wouldn’t notice the hours passing. “I would be so engaged and motivated to solve whatever problem I was working on that nothing else mattered.” As he took more CS classes, he became increasingly intrigued with how mathematical and statistical modeling can solve complex problems, including those requiring human-like intelligence.
He chose Columbia for a couple of reasons. “I wanted a place where I could both be challenged academically, and at the same time keep up my jazz saxophone playing. Columbia, having an amazing jazz performance program filled with super talented musicians and being located in the jazz capital of the world, was a perfect fit.”
In August, he starts work at Microsoft in Seattle as a software engineer with the idea of one day returning to academia to pursue a master’s or PhD in a field of artificial intelligence.
![]()
Jeremy Ng

“I was drawn most immediately to the rigor of computer science—a method will typically return the same output on a given input.”
Jeremy Ng’s first two college years were spent in France studying politics, law, economics, and sociology as part of the Dual BA Program between Columbia University and Sciences Po. Not until his junior year did he take his first computer science class—Introduction to Computer Science with Professor Adam Cannon. He so enjoyed the class that he signed himself up the next semester for the 4000-level Introduction to Databases with Professor Luis Gravano.
As a self-described language nerd who reads grammar books for fun, Ng fondly remembers taking Natural Language Processing with Professor Kathy McKeown. He describes the class as “eye-opening” because it gave him a chance to see computational approaches applied to a subject he’d previously studied from a more historical and sociological perspective.
Currently Ng is interning at the United Nations Office for the Coordination of Humanitarian Affairs (OCHA). “Humanitarian actors in conflict zones or hard-to-reach areas generally lack the resources to report detailed data and statistics; at the same time, these data are used to secure billions of dollars in humanitarian financing from donors. The challenge is producing meaningful trends and insights from a set of very limited information, without sacrificing rigor or defensibility—a challenge I very much enjoy.”
In September, he will take up a macroeconomic research-related role at the investment management firm Bridgewater Associates; his long-term goal is to work in development finance, using data to evaluate the potential impact of humanitarian and development projects in under-served regions such as Central Asia, where he worked previously as a Padma Desai fellow.
![]()
![]()
Jenny Ni, Barnard College

“In my first CS class, I immediately was impressed by the logics of coding and how much a simple program could do.”
Enrolling in classes at both Barnard and Columbia, Jenny Ni took full advantage of the wide variety of resources and challenging academic curriculum offered by the two schools, and followed her curiosity. At Columbia she took her first CS class and discovered she enjoyed programming, and become curious to learn more about the field and its applications to other, especially non-STEM, fields. In particular, she enjoys thinking about the interesting and novel ways new developments in CS can be integrated with archaeology. “It’s amazing reading about how techniques like LIDAR and drone surveying are changing the ways archaeology is done.” She graduates with both a Computer Science major and an Anthropology major from Barnard’s Archaeology track.
Over the next year, she will be applying to Archaeology research positions and PhD programs. Her goal is to apply computer science technology to expand archaeological methods.
![]()
Nishant Puri
“Artificial intelligence—specifically deep learning—is poised to have a revolutionary impact on virtually every industry.”

Nishant Puri should know, having spent two years at the data analytics company Opera Solutions where he built personalized predictive models on vast streams of transactional data. The experience so spurred his interest in machine learning he decided to pursue a second post-graduate degree. (His first was in applicable mathematics from the London School of Economics, where he received distinction in all his papers.)
He chose Columbia for a master’s degree in machine learning both for its faculty and the flexibility to specialize in his area of interest. “The program aligned with my personal objective of building on my knowledge of Computer Science fundamentals acquired from my previous work experience, with a specific focus on machine learning. I was able to take various courses that linked well with one another for a comprehensive understanding of the field.”
Puri received his Master’s last fall and is now working as a Deep Learning software engineer on Nvidia’s Drive IX team. “We are using data from car sensors to build a profile of the driver and the surrounding environment. With deep learning networks, we can track head movement and gaze, and converse with the driver using advanced speech recognition, lip reading, and natural language understanding. It’s a new and really exciting area and it’s great to be part of a team that’s helping drive progress.”
![]()
Michael Tong
“I was amazed by how powerful coding could be to solve all kinds of problems.”

Michael Tong, Columbia Engineering’s valedictorian, came to Columbia intending to study mathematics. “You learn things from a very general perspective, but when you apply it to something specific these seemingly complicated definitions actually encode very simple and intuitive ideas.” But yet he declared for computer science. “When I took my first computer science class freshman year, Python with Professor Adam Cannon, it was like this whole new world opened up: I had no idea you could write code to do all these different things!”
In time, he gravitated toward theoretical computer science, which is not surprising given its close relationship to math. “It is cool when math techniques are used in computer science, to see, for instance, how basic algebraic geometry can define certain examples of error correcting codes. Studying theoretical computer science, especially complexity theory, makes me feel like I have not left the world of math.”
After graduation, Tong will work at Jane Street, a technology-focused quantitative trading firm, before applying to math doctoral programs.
Posted 05/16/18
Interview with Henning Schulzrinne on the coming COSMOS testbed
![]()

Last month, the National Science Foundation announced that it will fund COSMOS, a large-scale, outdoor testbed for a new generation of wireless technologies and applications that will eventually replace 4G. Covering one square mile in densely populated West Harlem just north of Columbia’s Morningside Heights campus, COSMOS is a high-bandwidth and low-latency network that, coupled with edge computing, gives researchers a platform to experiment with the data-intensive applications—in robotics, immersive virtual reality, and traffic safety—that future wireless networks will enable.
Columbia is one of three New York-area universities involved (with Rutgers and New York University being the other two). Columbia’s COSMOS proposal was overseen by principal investigator Gil Zussman (Electrical Engineering) who worked with a number of Columbia professors, including Henning Schulzrinne.
A researcher in applied networking who is also investigating an overall architecture for the Internet of Things (IoT), Schulzrinne has previous experience in setting up an experimental wireless network. In 2011, he oversaw the installation of WiMAX, an early 4G contender, on the roof of Mudd. WiMAX helped demonstrated the feasibility of doing wireless experiments on campus while also setting a precedent for the Computer Science Department to work with Columbia facilities, which ran the fiber, provided power, and installed the antennas.
In this interview, Schulzrinne discusses the benefits of COSMOS to researchers and students within and outside the department.
What is your role?
I have three separate roles. In the area of licensing and public policy, I did the spectrum license applications so the campus could use frequencies in the millimeter-wave radio band—not previously used for telecommunications—and I’ll work to ensure we don’t interfere with licensees who will someday be assigned those frequencies.
The way licensing is done will change under 5G. Instead of specifically requesting licenses for certain frequencies and then waiting for permission, or maybe an auction, as is done now, spectrum will be shared dynamically as needed, a more efficient way to use a limited resource. Part of COSMOS is to better understand how sharing of spectrum will work.
In the application area, I will be looking at both stationary and mobile IoT devices, putting mobile nodes on Columbia vehicles—buses and public safety and utility vehicles—to measure noise pollution, for example. I am also working with Dan Rubenstein on testing safety precautions with connected vehicles that use wireless connectivity and looking for ways to protect pedestrians and bicyclists.
And thirdly, for many years I have collaborated with researchers in Finland on a series of wireless spectrum projects, including mobile edge computing. These projects are funded by the NSF and the Academy of Finland through the WiFiUS program (Wireless Innovation between Finland and US). COSMOS gives us the chance to deploy and study mobile edge computing on a high-bandwidth, low-latency network.
Who will be able to access the test bed?
COSMOS is unique as an NSF project for building an infrastructure available to anyone, both on- and off-campus. In principle, anyone who has an email address at a US education institute can submit a proposal to use COSMOS for teaching and research.
While K-12 education plays an important role in this project—high school students, for example, might run experiments showing the propagation of radio waves—most educational interest and activity will likely be at the higher-education level, especially in networking and wireless classes, with both faculty and student researchers using the testbed to run experiments at a scale not possible in a lab.
What does COSMOS mean for Columbia researchers and students?
Columbia students, being physically close to the test bed, will have obvious advantages, like being able to easily enlist pedestrians or students for experiments on devices that are worn or carried.
I expect we’ll see many proposals coming out of the Computer Science Department in particular as we understand what becomes possible on these new networks where processing is done on edge servers rather than being sent up to cloud servers further away. Can we for instance control traffic lights to more efficiently move traffic along and increase safety of pedestrians and bicyclists? Can we use the network for augmented reality? Can public safety applications benefit from high-bandwidth video processing? Do the propagation characteristics force designers of network protocols to deal with short-lived connections with highly-variable transmission speed? The COSMOS testbed gives us a wireless infrastructure to find out.
Henning Schulzrinne is the Julian Clarence Levi Professor of Mathematical Methods and Computer Science at Columbia University. He is a researcher in applied networking and is particularly known for his contributions in developing the Session Initiation Protocol (SIP) and Real-Time Transport Protocol (RTP), the key protocols that enable Voice-over–IP (VoIP) and other multimedia applications. Active in public policy, he has twice served as Chief Technology Officer at the Federal Communications Committee (his most recent term ended October 2017). Currently he serves on the North American Numbering Council. Schulzrinne is a Fellow of the ACM and IEEE and a member of the Internet Hall of Fame. Among his awards, he has received the New York City Mayor’s Award for Excellence in Science and Technology, the VON Pioneer Award, TCCC service award, IEEE Internet Award, IEEE Region 1 William Terry Award for Lifetime Distinguished Service to IEEE, the UMass Computer Science Outstanding Alumni recognition.
Posted 05/14/2018
In discrete choice modeling, estimating parameters from two or three—not all—options
![]()
Daniel Hsu and his student Arushi Gupta show it is possible to build discrete choice models by estimating parameters from a small subset of options rather than having to analyze all possible options that may easily number in the thousands, or more. Using linear equations to estimate parameters in Hidden Markov chain choice models, the researchers were surprised to find they could estimate parameters from as few as two or three options. The results, theoretical for now, mean that in a world of choices, retailers and others can offer a small, meaningful set of well-selected items from which consumers are likely to find an acceptable choice even if their first choice is not available. For researchers, it means another tool to better model real-world behavior in ways not possible before.
 Given several choices, what option will people choose? From the 1960s this simple question—of interest to urban planners, social scientists, and naturally, retailers—has been studied by economists and statisticians using discrete choice models, which statistically model the probabilities people will choose an option among a set of alternatives. (While an individual’s choice can’t be predicted, it is possible to study groups of people and infer patterns of behavior from sales, survey, and other data.)
Given several choices, what option will people choose? From the 1960s this simple question—of interest to urban planners, social scientists, and naturally, retailers—has been studied by economists and statisticians using discrete choice models, which statistically model the probabilities people will choose an option among a set of alternatives. (While an individual’s choice can’t be predicted, it is possible to study groups of people and infer patterns of behavior from sales, survey, and other data.)
In recent years, a type of discrete choice model called multinomial logit models has been commonly used. These models, easy to fit and understand, work by associating regression coefficients to each option based on behavior observed from real-world data. If ridership data shows people choose the subway 50% of the time and the bus 50% of the time, the model’s coefficients are tweaked to assign equal probability to each option.
On the whole, multinomial logit models perform well but fail to easily accommodate the introduction of new options that substitute for existing ones. If a second bus line is added and is similar to the existing one—same route, same frequency, same cost—except that the new bus line has articulated buses, a multinomial logit model would consider all three alternatives independently, splitting the proportion equally and assigning a probability of 0.33 to all three options.
“But that is not what happens,” says Daniel Hsu, a computer science professor and a member of the Data Science Institute who explores new algorithmic approaches to statistical problems. “People don’t care whether a bus is articulated or not. People just want to get to work.” Train riders especially don’t care about a new bus option because a bus is not a substitute for a train, and for this reason, the coefficient for trainer riders should not change.
The bus-train example is small, limited to three choices. In the real world, especially in retailing, choices are so numerous as to be overwhelming. People can’t be shown all options so retailers and others must offer a small set of choices from which people will find a substitute choice they are happy with even if their most preferred choice is not included.
To better model substitution behavior, researchers in Columbia’s Industrial Engineering and Operations Research (IEOR) Department—Jose Blanchet (now at Stanford University), Guillermo Gallego, and Vineet Goyal—two years ago proposed the use of Markov Chain models, which make predictions based on previous behaviors, or states. All options have probabilities as before, but the probability changes based on preceding options. What fraction of people will choose A when the previous states are B and C, or are C and D? Removing one option, the most preferred one for example, changes the chain of probabilities, providing way for decide the next most preferred option among those remaining.
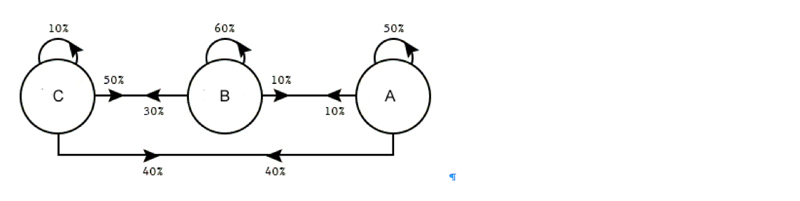
Switching from multinomial logit models to Markov chain choice models better captured substitution behavior but at the expense of much more complexity; previously, n possible options meant n parameters, but in the Markov chain models, n parameters just describes the initial probabilities; each removal of an option requires recalculating all possible combinations for a total of n squared parameters. Instead of 100 parameters, now it’s 10k parameters. Computers can handle this complexity; a consumer can’t and won’t.
The IEOR researchers showed it was possible to model substitution behavior by analyzing all possible options; left open was the possibility of doing so using less data, that is, some subset of the entire data set.
This was the starting point for Hsu and Arushi Gupta, a master’s student with an operations research background who had previously worked on estimating parameters for older discrete choice models; Gupta relished the opportunity to do the same for a more complex model.
“We looked at it as an algebraic puzzle,” says Hsu. “If you know two-thirds of people choose this option when these three are offered, how do you get there from the original Markov chain choice model? What are the parameters of the model that would give you this?”
Initially they set out to find an approximate solution but, changing tack, tried for the harder thing: getting a single exact solution. “Arushi discovered that all model parameters were related to the choice probabilities via linear equations, where the coefficients of the equations were given by yet other choice probabilities,” says Hsu. “This is great because it means choice probabilities can be estimated from data. And this gives a way to potentially indirectly estimate all of the model parameters just by solving a system of equations.”
Says Gupta, “It is also quite lucky that it turned out to be just linear equations because even very big systems of linear equations are easy to solve on a computer. If the relationship had turned out to be other polynomial equations, then it would have been much more difficult.”
The final piece of the puzzle was to prove that the linear equations uniquely determined the parameters. “We crafted a new algebraic argument using the theory of a special class of matrices called M-matrices, which naturally arise in the study of Markov chains” says Hsu. “Our proof suggested that assortments as small as two and three item sets could yield linear equations that pin down the model parameters.”
Their results, detailed in Parameter identification in Markov chain choice models, showed a small amount of data suffices to pinpoint consumer choice behavior. The paper, which was presented at last year’s Conference on Algorithmic Learning Theory, is now published in the Proceedings of Machine Learning Research.
The researchers hope their results will lead to better ways of fitting choice models to data while helping understand the strengths and weaknesses of the models used to predict consumer choice behavior.
About the Researchers
Arushi Gupta, who received her bachelors at Columbia in 2016 in computer science and operations research, will earn a master’s degree in machine learning this May. In the fall, she starts her PhD in computer science at Princeton where she will study machine learning. In addition to Parameter identification in Markov chain choice models, she is coauthor of two additional papers, Do dark matter halos explain lensing peaks? and Non-Gaussian information from weak lensing data via deep learning.
Daniel Hsu is associate professor in the Computer Science Department and a member of the Data Science Institute, both at Columbia University, with research interests in algorithmic statistics, machine learning, and privacy. His work has produced the first computationally efficient algorithms for several statistical estimation tasks (including many involving latent variable models such as mixture models, hidden Markov models, and topic models), provided new algorithmic frameworks for solving interactive machine learning problems, and led to the creation of scalable tools for machine learning applications.
Before coming to Columbia in 2013, Hsu he was a postdoc at Microsoft Research New England, and the Departments of Statistics at Rutgers University and the University of Pennsylvania. He holds a Ph.D. in Computer Science from UC San Diego, and a B.S. in Computer Science and Engineering from UC Berkeley. Hsu has been recognized with a Yahoo ACE Award (2014), selected as one of “AI’s 10 to Watch” in 2015 by IEEE Intelligent Systems, and received a 2016 Sloan Research Fellowship. Just last year, he was made a 2017 Kavli Fellow.
Posted 05/09/18
– Linda Crane
Steven Feiner featured in video showcasing early 5G use cases at Verizon’s NYC 5G incubator
Feiner’s Computer Graphics and User Interfaces Lab, among the first participating in Verizon’s 5G incubator, aims to enable therapists to work on motor rehabilitation through 5G with remote patients who simultaneously manipulate the same objects.
False starts in search for Golden State Killer reveal the pitfalls of DNA testing
Scott Pruitt’s new ‘secret science’ proposal is the wrong way to increase transparency
Mihalis Yannakakis elected to National Academy of Sciences
![]()

Mihalis Yannakakis, the Percy K. and Vida L. W. Hudson Professor of Computer Science at Columbia University, is among the 84 new members and 21 foreign associates just elected to the National Academy of Sciences (NAS) for distinguished and continuing achievements in original research. Established under President Abraham Lincoln in 1863, the NAS recognizes achievement in science, and NAS membership is considered one of the highest honors a scientist can receive.
Yannakakis is being recognized for fundamental contributions to theoretical computer science, particularly in algorithms and computational complexity, and applications to other areas. His research studies the inherent difficulty of computational problems, and the power and limitations of methods for solving them. For example, Yannakakis characterized the power of certain common approaches to optimization (based on linear programming), and proved that they cannot solve efficiently hard optimization problems like the famous traveling salesman problem. In the area of approximation algorithms, he defined with Christos Papadimitriou a complexity class that unified many important problems and helped explain why the research community had not been able to make progress in approximating a number of optimization problems.
“Complexity is the essence of computation and its most advanced research problem, the study of how hard computational problems can be,” says Papadimitriou. “Mihalis Yannakakis has changed in many ways, through his work during the past four decades, the way we think about complexity: He classified several problems whose complexity had been a mystery for decades, and he identified new forms and modes of complexity, crucial for understanding the difficulty of some very fundamental problems.”
In the area of database theory, Yannakakis contributed in the initiation of the study of acyclic databases and of non-two-phase locking. In the area of computer aided verification and testing, he laid the rigorous algorithmic and complexity-theoretic foundations of the field. His interests extend also to combinatorial optimization and algorithmic game theory.
For the significance, impact, and astonishing breadth of his contributions to theoretical computer science, Yannakakis was awarded the seventh Donald E. Knuth Prize in 2005. He is also a member of the National Academy of Engineering, of Academia Europaea, a Fellow of the ACM, and a Bell Labs Fellow.
Yannakakis received his PhD from Princeton University. Prior to joining Columbia in 2004, he was Head of the Computing Principles Research Department at Bell Labs and at Avaya Labs, and Professor of Computer Science at Stanford University. He has served on the editorial boards of several journals, including as the past editor-in-chief of the SIAM Journal on Computing, and has chaired various conferences, including the IEEE Symposium on Foundations of Computer Science, the ACM Symposium on Theory of Computing and the ACM Symposium on Principles of Database Systems.
Posted 05/02/18
Here’s How Amateur Sleuths And Police Investigators Used DNA Websites To Find The Golden State Killer
Ozzie Ozzie Ozzie, oi oi oi! Tech zillionaire Ray’s backdoor crypto for the Feds is Clipper chip v2
With $5.7M DARPA grant, Simha Sethumadhavan will lead effort to build security into hardware-software interface
In a new approach to security, Sethumadhavan will work with a team of researchers, many from the Data Science Institute, to build security mechanisms into the well-defined interface between hardware and software.
CS major Michael C. Tong named Valedictorian, Columbia Engineering Class of 2018
Tong will speak at Engineering Class Day May 14, when he will receive the Illig Medal, the highest honor awarded an engineering undergraduate. Tong is the second CS major in a row to be valedictorian.
Social media algorithms discriminating against women: Study
Steven Feiner receives 2018 SIGCHI Lifetime Research Award
For outstanding contributions to the study of human-computer interaction, Steven Feiner is the 2018 recipient of the SIGCHI Lifetime Research Award.
How social networking sites may discriminate against women
In a paper presented this week at the Web Conference, authors Ana-Andreea Stoica, Christopher Riederer, and Augustin Chaintreau identify an algorithmic glass ceiling in social networks after analyzing effects of gender, homophily, and growth dynamics.
Clever Technique Can Hide Secret Messages in the Most Unassuming Text
Helvetica Is Now An Encryption Device
Here’s Why We Need To Democratize Artificial Intelligence
With millions of AI professionals needed, we need to reach beyond elite schools, says Sameer Maskey (PhD’08, advisor Julia Hirschberg), writing in Forbes. His company Fusemachines trains AI engineers in Nepal and other developing countries.
FontCode: Hiding information in plain text, unobtrusively and across file types

By imperceptibly changing, or perturbing, the shapes of fonts, Columbia researchers have invented a way to embed hidden information in ordinary text, without the existence of the secret message being perceived. The method, called FontCode, both creates font perturbations, mapping them to a bit string, and later decodes them to recover the message. To ensure robust decoding when font perturbations are obscured, researchers introduced redundancy using the 1700-year-old Chinese Remainder Theorem, and were able to demonstrate that a messages can be fully recovered even with a recognition failure rate of 25% (and theoretically even higher). FontCode works with all fonts and, unlike other text and document methods that hide embedded information, works with all document types, even maintaining the hidden information when the document is printed on paper or converted to another file type. While having obvious advantages for spies, FontCode has perhaps more practical application for companies wanting to prevent document tampering or protect copyrights, and for retailers and artists wanting to embed QR codes and other metadata without altering the look or layout of a document.
Compare these two lines of text. Can you see the difference? One carries a hidden message.

Each character in the second line differs slightly from its counterpart in the top line. (Compare the “d” in the two “looked” instances to see how the bottom instance has slightly thicker strokes.) And in these subtle differences, or perturbations, can be hidden a secret, encoded message without its existence being detected; the secret message is retained when printing a document or photograph or converting it to another file type.
These font perturbations are created and later recognized by FontCode, a text steganographic method created by three Columbia researchers—Chang Xiao, Cheng Zhang, and Changxi Zheng. Described in FontCode: Embedding Information in Text Documents using Glyph Perturbation, the FontCode method embeds text, metadata, a URL, or a digital signature into regular text or a photograph. It works with all common font families (Times Roman, Helvetica, Calibri) and is compatible with most word processing programs (Word, FrameMaker) as well as image-editing and drawing programs (Photoshop, Illustrator). Since each letter can be perturbed, the amount of information conveyed secretly is limited only by the length of the regular text.
“Changing any letter, punctuation mark, or symbol into a slightly different form allows you to change the meaning of the document,” says Chang Xiao, the paper’s lead author. “This hidden information, though not visible to humans, is machine-readable just as bar and QR codes are instantly readable by computers. However, unlike bar and QR codes, FontCode won’t mar the visual aesthetics of the printed material, and its presence can remain secret.”
FontCode is part of a broader research effort by Changxi Zheng, the paper’s senior author, to directly link the physical and digital worlds in a way that is both unobtrusive and not external to the object itself (unlike the highly visible QR and bar codes). Working with others in Columbia’s Computer Graphics Group, which he co-directs, Zheng is instead looking to use an aspect of the physical object to uniquely tag an object and encode information for digital devices to read. Recent projects from the lab include acoustic voxels and aircodes, which use an object’s acoustic properties for tagging and information embedding.
Rather than acoustic properties, FontCode encodes information using minute font perturbations—changing the stroke width, adjusting the height of ascenders and descenders, or tightening or loosening the curves in serifs and the bowls of letters like o, p, and b. Perturbations judged visually similar to the original letter are stored in a codebook. The numbered location in the codebook can be changed, providing FontCode with its own optional built-in encryption scheme.

FontCode is not the first technology to hide a message in text—programs exist to hide messages in PDF and Word files or to resize whitespace to denote a 0 or 1—but it is the first to be document-independent and to retain the secret information even when a document or an image with text (PNG, JPG) is printed or converted to another file type. This means a FrameMaker or Word file can be converted to PDF, or a JPEG can be converted to PNG, all without losing the secret information.
The embedding process
Someone using FontCode would supply a secret message and a carrier text document. FontCode converts the secret message to a bit string (ASCII or Unicode) and then into a sequence of integers. Each integer is assigned to a five-letter block in the regular text where the numbered locations of each letter sum to the integer.

Accurately recovering the message even with recognition errors
Recovering hidden messages is the reverse process. From a digital file or from a photograph taken with a smartphone, FontCode matches each perturbed letter to the original perturbation in the codebook to reconstruct the original message.
Matching is done using convolutional neural networks (CNNs). Recognizing vector-drawn fonts (such as those stored as PDFs or created with programs like Illustrator) is straightforward since shape and path definitions are computer-readable. However, it’s a different story for PNG, IMG, and other rasterized (or pixel) fonts, where lighting changes, differing camera perspectives, or noise or blurriness may mask a part of the letter and prevent an easy recognition.
While CNNs are trained to take into account such distortions, recognition errors will still occur, and a key challenge was ensuring a message could always be recovered in the face of such errors. Redundancy is one obvious way to recover lost information, but it doesn’t work well with text since redundant letters and symbols are easy to spot.
Instead, the researchers turned to the 1700-year-old Chinese Remainder Theorem, which identifies an unknown number from its remainder after it has been divided by several different divisors. The theorem has been used to reconstruct missing information in other domains; in FontCode, researchers use it to recover the original message even when not all letters are correctly recognized.
“Imagine having three unknown variables,” says Zheng. “With three linear equations, you should be able to solve for all three. If you increase the number of equations from three to five, you can solve the three unknowns as long as you know any three out of the five equations.”
Using the Chinese Remainder theory, the researchers demonstrated they could recover messages even when 25% of the letter perturbations were not recognized. Theoretically the error rate could go higher than 25%.
Obscurity not only means of security
Data hidden using FontCode can be extremely difficult to detect. Even if an attacker detects font changes between two texts—highly unlikely given the subtlety of the perturbations—it simply isn’t practical to scan every file going and coming within a company.
Furthermore, FontCode not only embeds but also optionally encrypts messages. This encryption is based on the order in which the perturbations occur in the codebook. Two people wanting to communicate through embedded documents would agree on a private key that specifies locations of perturbations in the codebook.
Encryption however is just a backup level of protection in case an attacker was able to detect the use of font changes to convey secret information. Given how hard it is to perceive those changes, detection is very difficult to do, making FontCode a very powerful technique to get data past existing defenses.

About the Researchers

Chang Xiao is a second-year PhD student at Columbia University working in the Computer Graphics Group and advised by Changxi Zheng. His research interests focus on the principles and applications of computer graphics, with a particular emphasis on computational design. He received his bachelor degree in the College of Computer Science of Zhejiang University.

Cheng Zhang is a first-year PhD student at UC Irvine working in the Interactive Graphics and Visualization Lab advised by Shuang Zhao. His research interests focus on the principles and applications of computer graphics, with a particular emphasis on physically based rendering. He received his master degree in Computer Science in Columbia University.

Changxi Zheng is an Associate Professor in Columbia’s Computer Science Department where he co-directs Columbia’s Computer Graphics Group, working on computational fabrication, computer graphics, acoustic and optical engineering, and scientific computing. He is also a member of the Data Science Institute and collaborates with other researchers across the university to better understand and processing audiovisual information. Zheng received his Ph.D. from Cornell University with the Best Dissertation Award and his B.S. from Shanghai Jiaotong University. He currently serves as an associated editor of ACM Transactions on Graphics. He was a Conference Chair for SCA in 2017, has won a NSF CAREER Award, and was named one of Forbes’ “30 under 30” in science and healthcare in 2013.
FontCode in the News
Helvetica Is Now An Encryption Device, via FastCompany
This algorithm can hide secret messages in regular-looking text, via Digital Trends
Clever Technique Can Hide Secret Messages in the Most Unassuming Text, via Popular Mechanics
Posted 04/20/2018
– Linda Crane
Julia Hirschberg elected to the American Academy of Arts and Sciences
![]()

Julia Hirschberg has been elected to the American Academy of Arts and Sciences for her contributions to computer science. Established in 1780, the Academy is one of the oldest learned societies in the United States, and each year honors leaders from the academic, business, and government sectors who address the critical challenges facing the global society.
“Julia Hirschberg has been a pioneer and leader in the field of computational linguistics as well as the field of computer science more broadly,” says Mary Boyce, Dean of Columbia Engineering. “We are proud to see her recognition by the Academy in the Class of 2018!”
“I’m delighted and honored to receive this award,” said Hirschberg, who is the Percy K. and Vida L.W. Hudson Professor of Computer Science, chair of the Computer Science Department, as well as a member of the Data Science Institute.
Hirschberg’s area of research is computational linguistics, where she focuses on prosody, the relationship between intonation and discourse. Her current projects include research into emotional and deceptive speech, spoken dialogue systems, entrainment in dialogue, speech synthesis, text-to-speech synthesis in low-resource languages, and hedging behaviors.
Hirschberg, who joined Columbia Engineering in 2002 as a professor in the Department of Computer Science and has served as department chair since 2012, earned her PhD in computer and information science from the University of Pennsylvania. She worked at AT&T Bell Laboratories, where in the 1980s and 1990s she pioneered techniques in text analysis for prosody assignment in text-to-speech synthesis, developing corpus-based statistical models that incorporate syntactic and discourse information, models that are in general use today.
Among her many honors, Hirschberg is a member of the National Academy of Engineering (2017) and a fellow of the IEEE (2017), the Association for Computing Machinery (2016), the Association for Computational Linguistics (2011), the International Speech Communication Association (2008), and the Association for the Advancement of Artificial Intelligence (1994); she is a recipient of the IEEE James L. Flanagan Speech and Audio Processing Award (2011) and the ISCA Medal for Scientific Achievement (2011). In 2007, she received an Honorary Doctorate from the Royal Institute of Technology, Stockholm, and in 2014 was elected to the American Philosophical Society.
Hirschberg serves on numerous technical boards and editorial committees, including the IEEE Speech and Language Processing Technical Committee and the board of the Computing Research Association’s Committee on the Status of Women in Computing Research (CRA-W). Previously she served as editor-in-chief of Computational Linguistics and co-editor-in-chief of Speech Communication and was on the Executive Board of the Association for Computational Linguistics (ACL), the Executive Board of the North American ACL, the CRA Board of Directors, the AAAI Council, the Permanent Council of International Conference on Spoken Language Processing (ICSLP), and the board of the International Speech Communication Association (ISCA). She also is noted for her leadership in promoting diversity, both at AT&T Bell Laboratories and Columbia, and for broadening participation in computing.
Hirschberg is the fifth professor within the department to be elected to the Academy, joining Alfred Aho (2003), Shree Nayar (2011), Christos Papadimitriou (2001), and Jeannette Wing (2010). Across Columbia Engineering, four other faculty members were also previously elected to the Academy. They are Mary Boyce (2004), Mark Cane (2002), Aron Pinczuk (2009), and Renata Wentzcovitch (2013).
Posted 04/18/2017
Paper coauthored by Henning Schulzrinne earns Test of Time Award at IEEE INFOCOM
“An Analysis of the Skype Peer-to-Peer Internet Telephony Protocol” (2006) was first paper to use traffic analysis to reverse-engineer an intentionally obscured network application. The other coauthor, Salman Baset, was Schulzrinne’s student at the time.
Luca Carloni and Georgia Karagiorgi (Physics) are among 2018 RISE awardees
![]()

For their collaborative project “Acceleration of Deep Neural Networks via Heterogeneous Computing for Real-Time Processing of Neutrino and Particle-Trace Imagery,” Luca Carloni of the Computer Science Department and Georgia Karagiorgi of the Department of Physics were among the five teams awarded funding through the Research Initiatives in Science and Engineering (RISE) competition. Created in 2004, RISE is one of the largest internal research grant competitions within the University, and each year provides funds for interdisciplinary faculty teams from the basic sciences, engineering, and medicine to explore paradigm-shifting and high-risk ideas. This year 29 teams presented pre-proposals; of the nine teams asked to submit full proposals, five were selected to receiving funding in the amount of $80,000 per year for up to two years.

Carloni and Karagiorgi were awarded funding to develop machine learning techniques and to explore deep neural network implementations for “listening” to only the most important and rare physics signals while disregarding environmental noise and other accidental background signals. To do so, they will build a data processing system that can facilitate real-time processing and accurate classification of images streamed at rates on the order of terabytes per second. The primary target application is the future Deep Underground Neutrino Experiment (DUNE). This is a major international particle physics experiment that will be operational in the US for more than a decade, beginning in 2024, and will be continually streaming high-resolution 3D images of the active detector region at a total data rate exceeding 5 terabytes per second. The ability to process this data in real time and to efficiently identify and accurately classify interesting activity in the detector would enable the discovery of rare particle interactions that have never been observed before. This ability however requires the development of an advanced data processing system. This RISE project aims to develop a scalable heterogeneous computing system that employs machine learning for identification and classification of interesting activity in the data. The ultimate goal is to leverage recent advancements in computer science to render the DUNE experiment a powerfully sensitive instrument for fundamental particle physics discovery.
“We are in the midst of a Big Data revolution, wherein our capacity to generate data greatly exceeds our ability to analyze and make sense of everything,” says Karagiorgi. “In my own discipline of particle physics, we think that there is a great deal of information hidden in astroparticle data sets, such as those that will be recorded by the DUNE experiment. But we will need advanced methods and powerful systems to scan through those data sets and efficiently and accurately fish out the information we care about. This project requires interdisciplinary collaboration between physics and computer science, and time – afforded by RISE – to explore our early-stage ideas. If we can develop a system for only capturing the most important data, this is a project that can feasibly capture the attention of the National Science Foundation or the Department of Energy.”
The seed money provided by RISE allows teams to more fully develop high-risk, high-reward ideas to better pursue other avenues of funding. Since 2004, RISE has awarded $9.62 million to 72 projects. These 72 teams later secured more than $55.4 million from governments and private foundations: a 600% return on Columbia’s initial investment. These projects have additionally garnered more than 130 peer-reviewed publications and educated more than 130 postdoctoral scholars and graduate, undergraduate, and high school students.
Applications for the 2019 competition run from September to early-October 2018, with five to six awarded teams announced by spring 2019. Beginning in September, visit the RISE website to apply.
Posted 04/10/2018
Christos Papadimitriou and Mihalis Yannakakis receive $1.2M NSF grant
![]()
 The National Science Foundation (NSF) has awarded a $1.2M, four-year grant to computer science theorists Christos Papadimitriou and Mihalis Yannakakis for their proposal “Research in Algorithms and Complexity: Total Functions, Games, and the Brain.”
The National Science Foundation (NSF) has awarded a $1.2M, four-year grant to computer science theorists Christos Papadimitriou and Mihalis Yannakakis for their proposal “Research in Algorithms and Complexity: Total Functions, Games, and the Brain.”
The following is an abstract of the work to be done under the grant.
The ubiquitous information environment around us, which has brought to the world unprecedented connectivity and availability of information, as well as newfound opportunities for individual expression, education, work, production and commerce, entertainment, and interpersonal communication, is the result of decades of research in all fields of computer science; furthermore, our best hope for confronting the many problems this new environment has brought to humanity (privacy and fairness, to mention only two) also lies in new computer science research. Research in theoretical computer science in particular over the past half century has been instrumental in bringing the benefits of Moore’s law to bear – through fundamental clever algorithms – and has made leaps in understanding the capabilities and limitations of computers and their software; in fact, it has articulated one of the most important problems in mathematics and all of science today: is P equal to NP? – that is to say, is exponential exhaustive search for a solution always avoidable? Papadimitriou and Yannakakis have over the past four decades contributed much to this edifice of mathematical research in computer science, often in close collaboration; in addition, they have successfully applied the kind of incisive mindset known as “algorithmic thinking” to important problems in other sciences, such as economics and biology.
For this project, they will join efforts again in order to attack a new generation of problems: complexity questions in the fringe of the P vs. NP problem, a new genre of algorithms possessing a novel kind of robustness, research at the interface between computer science and economics related to income inequality and market efficiency, as well as research aiming at a better understanding of evolution, and of brain functions as basic as memory and as advanced as language. Papadimitriou and Yannakakis will train PhD and Masters students – and possibly undergraduates as well – on these research topics, and will disseminate the findings of this research to students and researchers, both in computer science and in other disciplines, as well as to the general public, through journal and conference publications, undergraduate and graduate courses, seminars, colloquia, as well as public talks and general interest articles.
In more detail, Papadimitriou and Yannakakis will work on improving our understanding of the complexity of total functions in the class TFNP and its subclasses, in view of recent research progress in that area; they will investigate the complexity of an as yet unexplored, from this point of view, Tarski-like fixed point theorem widely used in economics; they will revisit the approximability of the traveling salesperson problem; and will explore a new kind of algorithmic notion of robustness based on dense nets of algorithms. In algorithmic game theory, Papadimitriou and Yannakakis will explore a new variant of the price of anarchy inspired by wealth inequality, as well as the complexity of market equilibria in markets with production and economies of scale; they will also research a new game theoretic solution concept based on the topology of dynamical systems; finally, they will pursue the proof of an intriguing new complexity-theoretic conjecture about the inaccessibility of Nash equilibria. They will also continue their work in certain promising directions at the interface of game theory and learning theory. In the life sciences, they will explore from the algorithmic point of view the problem of the true nature of mutations, and they will work on extending recent research with collaborators aiming at the computational understanding of how long-term memory, as well as syntax and language, are achieved in the human brain.
Posted 04/06/2018
Not the usual hackathon: Five Columbia students travel to Rome for the Vatican’s VHacks competition

“How wonderful would it be if the growth of scientific and technological innovation would come along with more equality and social inclusion.” – Pope Francis
![]()
 With the Pope’s full support and encouragement, the Vatican held its first ever hackathon, VHacks, over the March 8-11 weekend. Five Columbia students were among the 120 participating from 60 universities around the world.
With the Pope’s full support and encouragement, the Vatican held its first ever hackathon, VHacks, over the March 8-11 weekend. Five Columbia students were among the 120 participating from 60 universities around the world.
Held in Rome steps from Vatican City, VHacks was a hackathon with a distinct European flavor. The hackathon itself took place in the centuries-old Palazzo della Rovere (which houses the Order of the Holy Sepulchre). Cardinals and other high-ranking curates along with secular dignitaries (the Prince of Liechtenstein) circulated among the students for demos in VR and other technologies.
In outward form, VHacks hewed closely to established hackathon outlines—a marathon coding session (in this case 36 hours interspersed with panels); corporate partners like Microsoft, Google, and Salesforce on site to hold workshops and give guidance on use of their products; prizes for the top projects; and plenty of free food, albeit of a higher quality than normally found at hackathons.
Where the VHacks diverged most noticeably was in its singular focus on social good, not market potential. Reflecting papal priorities, all projects fit one of three themes: social inclusion, interfaith dialogue, and resources to migrants and refugees. Each team before arriving in Rome was assigned one of the three themes. Diversity was another VHacks priority, with teams preselected to ensure equal representation by gender, religion, and background. Except in three or four instances, students arrived without having previously met their teammates in person.
For Myra Deng, a junior currently studying in Budapest, the chance to work toward social good was what finally convinced her to bite the bullet and enter her first hackathon. Vivian Shen, a hackathon veteran and the organizer of DevFest, signed up out of curiosity; she wanted to see how the Catholic church would embrace technology.
Being selected for a team rather than selecting your own team was another way VHacks diverged from other hackathons. Both Deng and Shen were on the same team (though they did not know one another previously), and while their team-mates quickly became close, there was an added layer of difficulty and adjustment. “You come in not knowing your team members’ strengths and weaknesses,” says Shen. “You have to both meet people and think up a new idea. It’s an additional element.”
For Nicole Valencia, not having to compete against a crowd of pre-established teams was one of the attractions. As a first-time hackathon competitor, she appreciated how VHacks leveled by the playing field by removing the advantages enjoyed by teams who come into a competition already formed, often knowing one another very well. She appreciated also the chance to interact and work with people from vastly different backgrounds.
Tomer Aharoni, fresh off two hackathons in six weeks (MakeHarvard, which his team won, and DevFest, where his team placed second) was impressed at the efforts made by organizers to ensure participation by top schools and students, and to enlist high-level executives from the corporate world. Among those serving as mentors, judges, and panelists were Google’s president of strategic relationships in Europe, the Middle East, and Africa as well as the former CEO of Ethereum Foundation, the Senior Vice President of Salesforce, the Senior Director of Microsoft, and many others.
Aharoni too chafed a bit at not being able to pick his own team or his own topic. With only three themes and 24 teams, it was harder to design a unique project that stood out from all the others. His team’s job-finding platform—which matched potential employers with migrants and refugees who advertised their skills via pictures rather than language—was one of four job-oriented projects, and though it drew outside interest (specifically by an Airbnb executive who floated the idea of doing a pilot), having a team scattered across several countries would seem to work against building a cohesive team to bring an idea to market.
VHacks organizers do hope a high percentage of participants (as high as 50%) will continue working on what they started (only 15% do in a typical hackathon). To help achieve that goal, mentors outnumbered competitors almost two to one, giving advice freely on both technical and business model aspects. Says Valencia, “I especially found it fascinating that not everyone was explicitly tech. One of our team members—not from computer science—had a brilliant mind and eye for design and was crucial is making a successful business presentation, something important not just for the judging rounds but in making pitches to potential investors.” Valencia’s team would go on to win third place in the interfaith category.
While it remains to be seen how successful VHacks will be in developing and scaling up hackathon projects for the real world, VHacks was tremendously successful in inspiring participants to think hard about how technology can be put to work for social good. Neil Chen, a veteran of over 10 hackathons, drew upon new social network analysis research done at Columbia to connect migrants in urban areas with local businesses to ease integration. “I’ve never before synthesized ideas from so many unique perspectives. After drawing from Professors Bellovin and Chaintreau’s paper on inferring ethnic migration patterns, we consulted with Maya, a Syrian refugee currently working as a web developer, and Bogomil Kohlbrenner, a social anthropologist from the University of Geneva, to figure out how to most effectively connect migrants to resources in their communities. Their experiences and Columbia research guided our application development.”
Deng and Shen’s team finished third in the social inclusion category with Xperience, a one-on-one livestreaming app intended to connect people who can’t travel—refugees and migrants, the elderly, those with disabilities—with others at a selected location who are willing to serve as guides, providing real-time, on-the-ground video. For Shen, the motivation came after attending the opening ceremonies and hearing how a Syrian refugee, separated from her family in Syria, was able through friends in France and Budapest to apply for a visa and help send money to her family. For those without such resources, Xperience serves as a virtual pen pal, providing long-distance experiences and friendships to those who may not have access to them.
And in including those otherwise excluded, Xperience perfectly fits the spirit of VHacks while showing the potential of technology and science to promote social good.

Posted 04/05/18
– Linda Crane
The Pulse interviews Brian Smith on making racing games accessible to people with vision loss
A PhD candidate advised by Shree Nayar, Smith is the creator of RAD (racing auditory display), which uses audio cues so players who are visually impaired can play existing video racing games.
Maynard Marshall Ball awarded IBM PhD Fellowship
![]()

Maynard Marshall Ball has been selected to receive a two-year IBM PhD Fellowship for the 2018-19 and 2019-2020 academic years. Highly competitive (only 50 are awarded worldwide each year), IBM PhD fellowships recognize and support PhD students researching problems important to IBM and fundamental to innovation. Special attention this year was paid to AI, security, blockchain, and quantum computing.
A third-year PhD student, Ball is particularly interested in the foundations of cryptography and complexity, two fields deeply intertwined and whose connections Ball seeks to further understand. According to his advisor Tal Malkin, Ball has made fundamental scientific contributions in three separate areas:
Fine-grained cryptography, where Ball has modeled moderately-hard cryptographic systems and crafted provably-secure proofs-of-work, with applications to blockchain technologies and spam detection.
Non-malleable codes, where Ball has designed codes with new unconditional security guarantees to protect against tampering attacks.
Topology-hiding computation, where Ball has helped maintain network privacy by constructing efficient secure protocols for peer-to-peer networks.
As well as recognizing research excellence, IBM PhD Fellowship are awarded based on a student’s publication history. Papers coauthored by Ball have been published in top cryptography, security, and theory conferences (including Eurocrypt 2016, ACM Conference on Computer and Communications Security (2016), and ACM Symposium on the Theory of Computing (2017). Two more of his papers will be presented at next month’s Eurocrypt 2018 conference.
IBM PhD fellowships, which are for two years, come with a stipend for living, travel, and conference expenses (in the US, the stipend amounts to $35,000 each academic year) as well as one-year education allowance. Fellows are matched with an IBM Mentor according to their disciplines and technical interests, and they are encouraged to participate in an onsite internship.
“I am honored and thrilled to be able to continue working on the foundations of cryptography and complexity. I am grateful to my advisor and the many other incredibly talented individuals with whom I have collaborated with thus far. I look forward to working with the outstanding cryptography group at IBM,” says Ball.
Posted 03/30/2018
Always Out of Balance
2002 paper by Michael Collins earns Test-of-Time award at NAACL
“Discriminative Training Methods for Hidden Markov Models: Theory and Experiments with Perceptron Algorithms” laid the foundation for how to use machine learning methods across a range of natural language processing tasks.
Moti Yung receives IEEE 2018 Computer Society W. Wallace McDowell Award
Award cites Yung’s innovative contributions to computer and network security. Yung (CS PhD ’88) is an adjunct and visiting faculty at Columbia and has advised several PhD students including Gödel Prize winner Matthew K. Franklin.
DevFest draws 1300 beginner, intermediate, and experienced coders

Unequal parts hackathon and learnathon—the emphasis is solidly on learning—the annual DevFest took place last month with 1300 participants attending. One of Columbia’s largest tech events and hosted annually by ADI (Application Development Initiative), DevFest is a week of classes, mini-lectures, workshops, and sponsor tech talks, topped off by an 18-hour hackathon—all interspersed with socializing, meetups, free food, and fun events.
Open to any student from Columbia College, Columbia Engineering, General Studies, and Barnard, DevFest had something for everyone.
Beginners, even those with zero coding experience, could take introductory classes in Python, HMTL, JavaScript. Those already coding had the opportunity to expand their programming knowledge through micro-lectures on iOS, data science, Civic Data and through workshops on geospatial visualization, UI/UX, web development, Chrome extensions, and more. DevFest sponsor Google gave tech talks on Tensorflow and Google Cloud Platform, with Google engineers onsite giving hands-on instruction and valuable advice.
Every evening, DevSpace offered self-paced, online tutorials to guide DevFest participants through the steps of building a fully functioning project. Four tracks were offered: Beginner Development (where participants set up a working website), Web Development, iOS Development, Data Science. On hand to provide more help were TAs, mentors, and peers.
This emphasis on learning within a supportive community made for a diverse group and not the usual hackathon mix: 60% were attending their first hackathon, 50% were women, and 25% identified as people of color.
DevFest events were kicked off on Monday, February 12, with talks by Computer Science professor Lydia Chilton (an HCI researcher) and Jenn Schiffer, a pixel design artist and tech satirist; events concluded with an 18-hour hackathon starting Saturday evening and continuing through Sunday.
Ends with a hackathon
Thirty teams competed in the DevFest hackathon. Limited to a few members only, teams either arrived ready-made or coalesced during a team-forming event where students pitched ideas to attract others with the needed skills.
The $1500 first place went to Eyes and Ears, a video service aimed at making information within video more widely accessible, both by translating it for those who don’t speak the language in a video, and by providing audio descriptions of a scene’s content for people with visual impairments. The aim was to erase barriers preventing people from accessing the increasing amounts of information resources available in video. Someone using the service simply chooses a video, selects a language, and then waits for an email delivering the translated video complete with audio scene descriptions.
Eyes and Ears is the project of four computer science MS students—Siddhant Somani, Ishan Jain, Shubham Singhal, Amit Bhat—who came to DevFest with the intent to compete as a team in the hackathon. The idea for a project came after they attended Google’s Cloud workshop, learning there about an array of Google APIs. The question then became finding a way to combine APIs to create something with an impact for good.
The initial idea was to “simply” translate a video from any language to any other language supported by Google Translate (roughly 80% of the world’s languages). However, having built a translation pipeline, the team realized the pipeline could be extended to include audio descriptions of a video’s visual scenes, both when a scene changes or per a user’s request.
That such a service is even possible—let alone buildable in 18 hours—is due to the power of APIs to perform complex technology tasks.
It’s in the spaces between the many APIs and the sequential order of those APIs that required engineering effort. The team had to shepherd the output of one API to the output of another, sync pauses to the audio (which required an algorithm for detecting the start and stop of speech), sync the pace of one language to the pace of the other language (taking into account a differing number of words). Because Google Video Intelligence API, which is designed for indexing video only, outputs sparse single words (mostly nouns like “car” or “dog”), the team had to construct full, semantically correct sentences. All in 18 hours.
The project earned praise from Google engineers for its imaginative and ambitious use of APIs. In addition to its first place prize, Eyes and Ears was named best use of Google Cloud API.
The team will look to continue work on Eyes and Ears in future hackathons.
The $1000 second-place prize went to Nagish (Hebrew for “accessible”), a platform that makes it simple for people with hearing or speaking difficulties to make and receive phone calls using their smart phone. For incoming and outgoing calls, Nagish converts text to speech and speech to text in real time so voice phone calls can be read or generated via Facebook Messenger. All conversions are done in real-time for seamless and natural phone conversations.
| The Nagish team— computer science majors Ori Aboodi, Roy Prigat, Ben Arbib, Tomer Aharoni, Alon Ezer—are five veterans who were motivated to help fellow veterans as well as others with hearing and speech impairments.
To do so required a fairly complex environment made up of several APIs (Google’s text-to-speech and speech-to-text as well as a Twilio API for generating phone numbers for each user and retrieving the mp3 files of the calls), all made to “talk” to one another over custom Python programs. Additionally, the team created a chatbot to connect Nagish to the Facebook platform. For providing a needed service to those with hearing and speech impairments, the team won the Best Hack for Social Good. Of course, potential users don’t have to be hearing- or speech-impaired to appreciate how Nagish makes it possible to unobtrusively take an important, or not so important, phone call during a meeting or perhaps even during class. |
 |
Taking the $750 third-place prize was Three a Day, a platform that matches restaurants or individuals wanting to donate food with those in need of food donations. The goal is making sure every individual gets three meals a day. The two-person team (computer science majors Kanishk Vashisht and Sambhav Anand) built Three a Day using Firebase as the database and React as the front end, with the back-end computing supplied primarily through Google Cloud functions. A Digital Ocean server runs Cron jobs to schedule the matching of restaurants and charities. The team also won for the best use of Digital Ocean products.
Posted March 22, 2018
– Linda Crane
New model reveals forgotten influencers and ‘sleeping beauties’ of science
Racing Auditory Display helps blind people play racing games as well as the sighted
For blind gamers, equal access to racing video games
PhD student Brian A. Smith developed the RAD—racing auditory display—to enable people who are visually impaired to play the same racing games sighted players play, with the same level of speed, control, and excitement.
Peter Allen and Eugene Wu selected for Google Faculty Research Awards

Peter Allen and Eugene Wu of Columbia’s Computer Science Department are each recipients of a Google Faculty Research Award. This highly competitive award (15% acceptance rate) recognizes and financially supports university faculty working on research in fields of interest to Google. The award amount, given as an unrestricted gift, is designed to support the cost of one graduate student for one year. The intent is for projects funded through this award to be made openly available to the research community.
Peter Allen: Visual-Tactile Integration for Reinforcement Learning of Robotic Grasping

To incorporate a visual-tactile learning component into a robotic grasping and manipulation system, Peter Allen will receive $71K. A Professor of Computer Science at Columbia, Allen heads the Columbia University Robotics Group.
In grasping objects, robots for the most part rely on visual feedback to locate an object and guide the grasping movements. But visual information by itself is not sufficient to achieve a stable grasp: it cannot measure how much force or pressure to apply and is of limited value when an object is partially occluded or hidden at the bottom of a gym bag. Humans rely as much or more on touch, easily grasping objects sight unseen and feeling an object to deduce its shape, apply the right amount of pressure and force, and detect when it begins to slip from grasp.
With funding provided by Google, Allen will add simulated rich tactile sensor data (both capacitive and piezoelectric) to robotic hand simulators, capturing and transforming low-level sensor data into high-level information useful for grasping and manipulation. This high-level information can then be used to build reinforcement learning (RL) algorithms that enable an agent to find stable grasps of complex objects using multi-fingered hands. The RL system can learn a grasping control policy and an ability to reason about 3D geometry from both raw depth and tactile sensory observations.
This project builds on previous work by Allen’s group on shape completion—also with a Google research grant—where an occluded object’s complete 3D shape is inferred by comparing it to hundreds of thousands of models contained within a data set. The shape completion work used machine learning with a convolutional neural network (CNN), with simulated 3D vision data on models of hundreds of thousands of views of everyday objects. This allowed the CNN to generalize a full 3D model from a single limited view. With this project, the CNN will now be trained on both visual and tactile information to produce more realistic simulation environments that can be used by Google and others (the project code and datasets will be open source) for more accurate robot grasping.
Eugene Wu: NeuroFlash: System to Inspect, Check, and Monitor Deep Neural Networks

For NeuroFlash, a system to explain, check, and monitor deep neural networks, Eugene Wu will receive $69K. An Assistant Professor of Computer Science at Columbia, Wu heads the WuLab research group and is a member of the Data Science Institute, where he co-chairs the Center for Data, Media and Society.
Deep neural networks, consisting of many layers of interacting neurons, are famously difficult to debug. Unlike traditional software programs, which are structured into modular functions that can be separately interpreted and debugged, deep neural networks are more akin to a single, massive block of code, often described as a black box, where logic is smeared throughout the behavior of thousands of neurons with no clear way of disentangling interactions among neurons. Without an ability to reason about how neural networks make decisions, it is not possible to understand if and how they can fail, for example, when used for self-driving cars or managing critical infrastructure.
To bring modularity to deep neural networks, NeuroFlash aims to identify functional logic components within the network. Using a method similar to MRI in medical diagnosis, which looks for brain neuron activations when humans perform specific tasks, NeuroFlash observes the behavior of neural network neurons to identify which ones are mimicking a user-provided high-level function (e.g., identify sentiment, detect vertical line, parse verb). To verify that the neurons are indeed following the function’s behavior and not spurious, NeuroFlash alters the neural network in systematic ways to examine and compare its behavior with the function.
The ability to attribute high-level logic to portions of a deep neural network forms the basis for being able to introduce “modules” into neural networks; test and debug these modules in isolation in order to ensure they work when deployed; and develop monitoring tools for machine learning pipelines.
Work on the project is driven by Thibault Sellam, Kevin Lin, Ian Huang, and Carl Vondrick and complements recent work from Google on model attribution, where neuron output is attributed to specific input features. With a focus on scalability, NeuroFlash generalizes this idea by attributing logical functions.
Wu will make all code and data open source, hosting it on Github for other researchers to access.
Posted 03/05/2018
– Linda Crane
When Did Americans Stop Marrying Their Cousins? Ask the World’s Largest Family Tree
The 13 Million People in Your Family Tree
Quantitative analysis of population-scale family trees with millions of relatives
Crowdsourced family tree yields new insights about humanity
A study published in Science describes how researchers created, from 86M genealogy profiles, population-scale family trees to reassess longevity and marriage and migration patterns. Yaniv Erlich is the study’s senior author.
What We Really Learned From Mueller’s Indictment Of Russian Trolls Is That Internet Providers Know Everything
Telcos may cash in on loopholes in Trai regulation, warn experts
When AI Steers Us Astray
Interview with Xi Chen, coauthor of Complexity Dichotomies for Counting Problems

![]()

A counting problem asks the question: What is the exact number of solutions that exist for a given instance of a computational problem?
Theoretical computer scientists in the last 15 years have made tremendous progress in understanding the complexity of several families of counting problems, resulting in a number of intriguing dichotomies: a problem in each family is either easy—solvable in polynomial time—or computationally hard. Complexity Dichotomies for Counting Problems, Volume 1, Boolean Domain, a new book by Jin-Yi Cai (University of Wisconsin, Madison) and Xi Chen, provides a high-level overview of the current state of dichotomies for counting problems, pulling together and summarizing the major results and key papers that have contributed to progress in the field. This is the first time much of this material is available in book form.
Structured around several families of problems—counting constraint specification problems (#CSP), Holant, counting graph homomorphisms—the book begins by introducing many common techniques that are reused in later proofs. Each subsequent chapter revolves around a family of problems, starting with easier, specific cases before moving onto more complex and more general cases.
For the first volume, the authors focus on the Boolean domain (where variables are assigned 0-1 values); a second volume, expected to be released next year, will look at problems in the general domain where variables can be assigned three, four, or any number of values.
In this interview, Chen talks more about the motivation for the book and why dichotomies for counting problems is an area deserving of more study.
Why write the book?
Currently it’s hard for PhD students and others to get started in the field. Many of the papers are long and technically very dense, and they build on work done in previous papers. To understand one paper often requires a lot of backtracking. This can be frustrating at times because different papers use different notation and sometimes prove the same result or use the same tool in different contexts.
Our aim in writing this book was to minimize the effort needed to study dichotomies for counting problems. We summarize and streamline the major results using a common notation and unified framework so it is easier to see the progression of ideas and techniques. To encourage students to start working in this area, we wrote the book so an undergraduate with some basic knowledge of complexity theory can follow the proofs.
Could you define at a high level “dichotomies for counting problems”?
Counting problems involve determining the exact number of solutions that exist for a given input instance. Does a 3SAT instance have 10 or 11 satisfying assignments or 20 or 27? What is the exact number? In a graph, for instance, you might want to know the exact number of ways to apply three colors to vertices so that no two adjacent vertices share the same color.
A number of families of counting problems have been studied. For example, we are interested in counting homomorphisms from an input graph G to a fixed graph H (where a homomorphism from G to H is a map f from vertices of G to vertices of H that preserves edges in G). In this case, each graph H defines a counting problem; e.g., when H is the triangle, the problem it defines is exactly the problem of counting 3-colorings. The 3-coloring problem is one of the classical problems known to be #P-hard, where #P is the complexity class that contains all counting problems, just as NP is for decision problems.
Can we classify EVERY graph H according to the complexity of the counting problem it defines? Such a result is called a dichotomy, which shows that all problems of a certain family can be classified into one of two groups: those admitting efficient algorithms and those that are #P-hard. Imagining each problem in a family as a dot, a dichotomy theorem can be viewed as a curve that classifies all the dots correctly according to their complexities. This curve typically involves a number of well-defined conditions: every problem that violates one of these conditions can be shown to be #P-hard and every problem that satisfies all the conditions can be solved by a unified efficient algorithm.
How has the field matured in the past few years?
Proofs have gotten stronger and more general. In the language of counting constraint satisfaction problems, the dichotomy theorem we had fifteen years ago only applied to problems defined by a single 0-1 valued symmetric function. In contrast we now have a full dichotomy for all counting constraint satisfaction problems (i.e., all problems defined by multiple complex-valued constraint functions with arbitrary arities).
What attracts you to the problem?
To me it is amazing that for these families of problems, a dichotomy theorem exists to once and for all classify the complexity of every problem. As it is shown by the classical Ladner’s theorem, there are infinitely many layers of problems in #P, ordered by their complexity, between P and #P-hard problems. Every time you move outside by one layer, problems become strictly harder.
Dichotomy theorems covered in the book, however, show that all (infinitely many) problems in these lie either in P (the core) or the outmost #P-hard shell, and none of them belongs to layers in between. The intuition to me is that these families consist of “natural” counting problems only and do not contain any of those strange “#P-intermediate” problems, but I am curious: how much further can we go as we move to more and more general families of counting problems? Especially with Holant problems, not much is known for the general domain case. It’s one reason we need to develop stronger techniques to prove dichotomies for more general families of counting problems.
Volume 2 of Complexity Dichotomies for Counting Problems, which covers the general domain, is expected to be published next year.
Posted 02/21/18
Columbia team to compete in ACM-ICPC World Finals in Beijing

 Three Columbia computer science graduate students have qualified to compete in the 2018 world finals of the Association for Computing Machinery (ACM) International Collegiate Programming Contest (ICPC) to be held April 15 – 20 in Beijing. The ACM-ICPC, sometimes called the “Olympics of Programming,” is the oldest and largest programming contest in the world and one of the most prestigious.
Three Columbia computer science graduate students have qualified to compete in the 2018 world finals of the Association for Computing Machinery (ACM) International Collegiate Programming Contest (ICPC) to be held April 15 – 20 in Beijing. The ACM-ICPC, sometimes called the “Olympics of Programming,” is the oldest and largest programming contest in the world and one of the most prestigious.
The students qualifying are Peilin Zhong, Ying Sheng, Haomin Long who, together with their coach Chengyu Lin, are all veterans of previous programming contests, including previous attempts to advance to the ICPC world finals.
The team, under the name CodeMbia, advanced this year after competing in the Greater New York Regional competition held November 19, where 52 area teams (including two other Columbia teams) were given five hours to complete 10 complex programming problems. CodeMbia solved 8 of the 10 problems, enough to tie with a Cornell team for first place, sending both onto the world finals.
With 2,948 universities competing in regional contests around the world, 128 teams earned the right to advance to the final round. Columbia last won a regional round in 2010, when the team that year traveled to Harbin, China, and finished 36th in the world.
Like in other programming contests, the ICPC regional problems consist of well-known, general computational problems that teams are asked to adapt for a specific case. Shortest path for instance might be presented as a subway map where competitors must determine the shortest path between two points. (The problems for the Greater New York Regional are given here.)
But the ICPC is a programming contest with a twist: three team members share a single computer.
“Other contests only measure how good you are in solving problems,” says Lin. “But the ICPC also tests how good you are at collaborating and at communicating with your team mates. So we have to practice collaboration, and how to divide up tasks to make the best use of the computer.”
With one person at the computer, the other two concentrate either on solving the problem or looking for errors or bugs, printing out the code to visually inspect it. Says Lin, “We have to learn to use the computer when it makes the most sense. We think a lot about how to solve the problem and how to verify that the algorithm works before we start coding. Otherwise, just coding for an hour is a waste of time.”
Hardest part for the team? “Not making mistakes. As contest veterans, we had the advantage of being able to solve the problems faster, so could spend more time double-checking our work for mistakes or for problems in the algorithm itself.”
The world finals will follow a similar format as the regionals—10 problems in five hours—but the problems themselves will be harder. So the team is stepping up its practice sessions, switching from the relatively easy regional problems to the more difficult ones from past finals.
The competition will be harder also. Facing CodeMbia will be 127 other qualifying teams. Lin makes no predictions for how well the team will do in the finals, but he stresses the fun of programming and looks forward to the challenge of competing against the world’s best collegiate programmers.
The ICPC world finals takes place at Peking University April 15 – 20.
Posted 2/20/18
– Linda Crane
3D Printing May Be the Key to Affordable Data Storage Using DNA
Donald F. Ferguson joins department as Professor of Practice
![]()
 Donald F. Ferguson, after 30 years of technical and executive leadership in the computer industry, is joining Columbia’s Computer Science Department as Professor of Practice. He will be the first in the department to have the title.
Donald F. Ferguson, after 30 years of technical and executive leadership in the computer industry, is joining Columbia’s Computer Science Department as Professor of Practice. He will be the first in the department to have the title.
For students, his appointment means a chance to learn from an industry insider the nuts and bolts of how computer science is practiced in the real world and how it differs from computer science as it is taught in a classroom.
“We learn things in industry the hard way,” says Ferguson. “I may not be able to teach it the right way, but I’ve done it all the different ways; by process of elimination, this has to be the right way because every other way I’ve done it has been wrong.”
Ferguson’s career started at IBM. For ten years he worked in IBM Research before a project of his got moved into production (becoming WebSphere), with him following to oversee architecture and technical innovation. From then on, he did less hands-on engineering and more “advise and consent,” that is, giving advice on design and then the OK to move a project forward. After being made chief architect for the Software Group at IBM, Ferguson was in charge of hundreds of products and thousands of engineers. Later at Microsoft, he managed projects exploring the future of enterprise software before moving to CA (formerly Computer Associates) where as CTO he led new product and technology development. In 2012, he moved to Dell, where as vice president and CTO for the company’s Software Group, he oversaw architecture, implementation design, technical strategy, and innovation.
Through his many positions at leading computer companies, Ferguson was directly involved in architecting numerous complex, end-to-end systems and services: hybrid cloud management, BYOD/mobility management, Internet-of-Things, and next-generation connected security. For his technical expertise and leadership, Ferguson holds the distinction of being the only person to be appointed an IBM Fellow, a Microsoft Technical Fellow, and a Dell Senior Fellow.
In his most recent role, he is an entrepreneur, having cofounded Seeka.TV, a streaming and social platform for connecting producers and consumers of video. Though nominally CTO, with only four in the company, there is no more advise and consent; he’s back to writing software.
He enjoys teaching also and for the past 10-15 years on and off, he has been an adjunct professor at Columbia, teaching advanced courses in serverless computing, cloud applications, modern as-a-service applications, and other topics directly related to his work experience. While teaching is for him an opportunity to learn, it has also given him insight into the huge gulf in how industry operates vs how software and programming are taught to students. Scale of programming is one issue—a piece of code written in a semester compared to 20M lines of code in a deployed application—but there are many others.
“The vast majority of the programming students learn is function call-return; wait a certain amount of time for a call back. But in industry, there are asynchronous applications and event-driven and queuing-based applications. Systems are big and complex, geographically distributed, and under different organizational control so it’s necessary to build and structure software that can accommodate all these different levels of complexity.”
“Don can draw from his invaluable and varied industry experience to offer great courses for our students,” says Julia Hirschberg, chair of the Computer Science Department. “We are delighted to have him returning to the department as Professor of Practice so he can teach many more students and offer more classes.”
Ferguson’s association with Columbia is of long standing. Columbia granted him a PhD in Computer Science (1989) for his thesis in applying economic models to manage system resources in distributed systems; he has taught at Columbia as an adjunct professor; and in 2013 the Columbia Engineering Alumni Association awarded him the Egleston Medal citing his contributions as a thought-leader in cloud computing, the father of WebSphere, and leader of software design.
Over his 30-year career, Ferguson has seen and been a part of tremendous technological change: from huge mainframes attended by a select coterie of engineers to computers hidden in light switches; from programming being something mysterious and little-understood to something done by high school students and others who may have little interest in a computer science degree; from all the computing power needed to send a man to the moon eclipsed by the power of an iPhone anyone can buy.
He laughs off an invitation to predict where technology will be in 10 years.
“One of the things that’s nice about being a college professor is teaching the people who will be deciding where things go in 10 years. I always tell students to stay in touch. I want to know what great things these students are going to be doing.”
This semester, Ferguson is teaching both Introduction to Databases (4111) and Introduction to Computing for Engineers and Applied Scientists (1006).
Posted 02/13/2018
– Linda Crane
Paper coauthored by Eugene Agichtein earns test-of-time award at WSDM 2018
“Finding High-Quality Content in Social Media” was originally
presented at the 2008 ACM International Conference on Web Search and Data
Mining (WSDM). Agichtein (PhD ’05, advisor: Luis Gravano) is
now Associate Professor at Emory University.
Three faculty promoted to Associate Professor
![]() Augustin Chaintreau, Yaniv Erlich, and Daniel Hsu have been promoted from Assistant to Associate Professor without tenure.
Augustin Chaintreau, Yaniv Erlich, and Daniel Hsu have been promoted from Assistant to Associate Professor without tenure.
Augustin Chaintreau
 Augustin Chaintreau is interested in personal data and what happens to it. Who is using it and for what purposes? Is personalization giving everyone a fair chance? These are not questions Facebook, Google, or other web service companies necessarily want to answer, but large-scale, unchecked data mining of people’s personal data poses multiple risks.
Augustin Chaintreau is interested in personal data and what happens to it. Who is using it and for what purposes? Is personalization giving everyone a fair chance? These are not questions Facebook, Google, or other web service companies necessarily want to answer, but large-scale, unchecked data mining of people’s personal data poses multiple risks.
To understand and mitigate these risks, Chaintreau is using mathematical analyses of networks and statistical methods to build tools and models that track how data flows, or predict how user behaviors affect them. Using those techniques, we can learn for instance why someone using online services is presented with certain ads and not others, or how a keyword (“sad”) typed in an email or an online search triggers an ad about depression or shamanic healing. Or we can prove that graph-based recommendation reinforces historical prejudice.
Connections between user actions across apps, captured and distilled over complex networks, are generally not known to people using the web. In exposing the downsides of personalization and data sharing, Chaintreau’s research often makes headlines. The New York Times, Washington Post, Economist, and Guardian have all reported on various aspects of his research, such as when he showed how geotagged data from only two apps is enough to identify someone, and that 60% of people will forward a link without reading it.
Chaintreau’s intent is not to prevent data sharing—he sees the benefits for health, energy efficiency, and public policy—but to bring transparency and accountability to the web so people can safely manage and share their personal data. Tools may inform and empower people, keep providers accountable, and sometimes present simple new ways to improve fairness.
An active member of the network and web research community, Chaintreau chaired the conference and program committees of ACM SIGMETRICS, ACM CoNEXT, and the annual meeting of the Data Transparency Lab. He served on the program committees of ACM SIGMETRICS, SIGCOMM, WWW, EC, CoNEXT, MobiCom, MobiHoc, IMC, WSDM, COSN, AAAI ICWSM, and IEEE Infocom, and is currently the founding editor in chief of the Proceedings of the ACM POMACS Series, after editing roles for IEEE TMC, ACM SIGCOMM CCR, and ACM SIGMOBILE MC2R.
For significant contributions to analyzing emerging distributed digital and social networking systems, he received the 2013 ACM SIGMETRICS Rising Star Researcher Award and he earned an NSF CAREER Award also in 2013.
Yaniv Erlich
 Working in the field of quantitative genomics, Yaniv Erlich is at the forefront of new gene sequencing techniques and the issue of genetic privacy.
Working in the field of quantitative genomics, Yaniv Erlich is at the forefront of new gene sequencing techniques and the issue of genetic privacy.
He was among the first to flag the ethical complexities of genetic privacy. A paper he spearheaded while a fellow at MIT’s Whitehead Institute showed how easy it is to take apparently anonymized genetic information donated by research participants and cross-reference it to online data sources to obtain surname information. For this, Nature Journal gave him the title Genome Hacker.
Since coming to Columbia in 2015 (through a joint appointment with the NYC Genome Center), Erlich has kept up a fast pace of new research, creating new algorithms for examining genetic information at both the molecular level and within large-scale human populations. Among his projects: software that takes only minutes to verify someone’s identity from a DNA sample; a DNA storage strategy 60% more efficient than previous methods (and approaching 90% of the theoretical maximum amount of information per nucleotide); a finding that short tandem repeats, once thought to be neutral, play an important role in regulating gene expression. In addition, he cofounded DNA.land, a crowd-sourcing site where people can donate their genome data for scientific research. Last year, he was named Chief Scientific Officer at MyHeritage, where he leads scientific development and strategy.
In his teaching too he is integrating new genetics research. His computer science class Ubiquitous Genomics was among the first courses to incorporate portable DNA sequencing devices into the curriculum, allowing students to learn DNA sequencing by doing it themselves.
Erlich’s awards include the Burroughs Wellcome Career Award (2013), the Harold M. Weintraub Award (2010), DARPA’s Young Faculty Award (2017), and the IEEE/ACM-CS HPC Award (2008). He was also recognized as one of 2010 Tomorrow’s PIs team of Genome Technology.
Daniel Hsu
 A central challenge in machine learning is to reliably and automatically discover hidden structure in data with minimal human intervention. Currently, however, machine learning relies heavily on humans to label large amounts of data, an expensive, time-consuming process that Daniel Hsu aims to streamline through new algorithmic approaches that also address the statistical difficulties of a problem. An interactive learning method he created as a PhD student selectively chooses a small set of data examples that it queries users to label. Applied to electrocardiograms, his method reduced the amount of training data by 90 percent.
A central challenge in machine learning is to reliably and automatically discover hidden structure in data with minimal human intervention. Currently, however, machine learning relies heavily on humans to label large amounts of data, an expensive, time-consuming process that Daniel Hsu aims to streamline through new algorithmic approaches that also address the statistical difficulties of a problem. An interactive learning method he created as a PhD student selectively chooses a small set of data examples that it queries users to label. Applied to electrocardiograms, his method reduced the amount of training data by 90 percent.
There are both theoretical and applied aspects to Hsu’s research. As a theoretician, he has produced the first computationally efficient algorithms for several statistical estimation tasks (including many involving latent variable models such as mixture models, hidden Markov models, and topic models), provided new algorithmic frameworks for solving interactive machine learning problems, and led in the creation of scalable tools for machine learning applications.
On the application side, Hsu has contributed to methods used in web personalization, automated natural language processing, and greater transparency to how personal data is used on the web. More recently, his research helped understand the role of gene regulation in disease, infer properties of dark energy in the universe from weak gravitational lensing, and characterize complex materials within a nanoscale structure.
At Columbia since 2013, Hsu has been recognized with a Yahoo ACE Award (2014), selected as one of “AI’s 10 to Watch” in 2015 by IEEE Intelligent Systems, and received a 2016 Sloan Research Fellowship. Just last year, he was made a 2017 Kavli Fellow.
He is a prolific author (10 papers in 2017 alone) and a member of the Data Science Institute (DSI) and the DSI’s TRIPODS Institute, where he collaborates with others to advance machine learning by tying together techniques from statistics, computer science, and applied mathematics.
Posted 02/02/2018
– Linda Crane
New cryptocurrencies offer better anonymity, new security challenges
With Amazon Research Award, Eugene Wu will add interactivity and adversarial generation to entity matching
![]()
For his proposal “Interactive Matcher Debugging via Adversarial Generation,” Eugene Wu has been awarded an Amazon Research Award. This unrestricted gift, open to institutions of higher learning in North America and Europe, is intended to support one or two graduate students or post-doc researchers doing research under the guidance of the faculty member receiving the award.
An Assistant Professor of Computer Science at Columbia, Wu heads the WuLab research group and is a member of the Data Science Institute, where he co-chairs the Center for Data, Media and Society.
Wu will use the award to fund research that will extend existing techniques for entity matching, a data cleaning task that locates duplicate data entries referencing the same real-world entity (to learn, for example, that “M. S. Smith” and “Mike S. Smith” refer to the same person).
“Finding these duplicate records is crucial for integrating different data sources, and current methods rely on machine learning,” says Wu. “The problem is that machine learning is not perfect and it is hard to even anticipate where it is matching incorrectly. We are very pleased that Amazon has selected to fund this project where we will work toward two goals: help users identify cases likely to result in matching errors, and identify realistic data examples to use to improve the machine learning model.”
Online retailers and services collect their data from a huge number of different data sources that may use different spellings or naming conventions and provide different images or descriptions for the same item. Amazon might have hundreds of vendors listing and selling iPhones or iPhone-related products. If all of this data is uploaded to Amazon without being matched, customers might see 100 product pages for “iPhone,” “iPhone 6X Large,” “IPhONE 6 Best,” or even worse, a product search might come up empty if the search string doesn’t exactly match the product name as it is assigned by the vendor. Entity matching helps prevent these types of problems but entity matching is a deeply challenging problem.
Entity matching is a classification problem, with ensemble trees often used to label entity pairs as matching or non-matching. Errors in classification are a perennial problem, but if users understand why such errors occur, they can adjust the classification process to reduce errors.
Much of Wu’s research, and the focus of WuLab, has centered on creating interactive visualizations that make it easier for users to spot anomalous patterns and other problems while also providing explanations of why certain problems occur. Wu will do the same for entity matching by developing new algorithms and software components that, once inserted into existing entity-matching pipelines, will automatically generate high-level, easy-to-understand explanations so developers can readily understand what matching errors exist.
Once errors have been identified, the second direction of the research is to address the error. Wu will do so by generating training samples to feed back into the machine learning model and ultimately improve its accuracy. As with all classification tasks, entity matching requires huge amounts of training data, and it is often necessary to synthetically create additional data to train a classification model. One such data-generation technique is adversarial generation, which creates new data by taking a supplied, real-world string of values and changing one or two values to produce a new data string similar to real-world ones.
Widely used for images, adversarial generation has drawbacks for text since perturbing a single value often produces non-semantic text samples that wouldn’t actually occur in the real world; such data, inserted into the training set, could contribute to matching errors. Here, Wu proposes constraints that will consider the entire data record (not just individual string values) when perturbing transformations, thereby ensuring synthetic data is less arbitrary, more representative of real-world cases, and in the case of text, more semantically meaningful.
As part of the award, which totals $80K with an additional $20K in Amazon Web Services (AWS) Cloud Credits, Wu and his research group will meet and collaborate with Amazon research groups. The resulting paper will be published and the code written for the project will be made open source for other research groups.
Posted 02/01/2018
– Linda Crane
Bjarne Stroustrup named recipient of 2018 IEEE-CS Computer Pioneer Award
The award recognizes Stroustrup “for bringing object-oriented programming and generic programming to the mainstream with his design and implementation of the C++ programming language.”
Ansaf Salleb-Aouissi named an EAAI 2018 New and Future AI Educator
![]()

The Eighth Symposium on Educational Advances in Artificial Intelligence 2018 (EAAI-18) has selected Ansaf Salleb-Aouissi as one of the EAAI 2018 New and Future AI Educators. Funded through a grant from the National Science Foundation, the award covers registration and travel, lodging, and participation in EAAI-18, where researchers and educators meet to discuss pedagogical issues related to teaching and using AI in education. The symposium, which is co-located with the 32st Association for the Advancement of Artificial Intelligence (AAAI-18) Conference, will be held in New Orleans February 3 and 4.
A Lecturer-in-Discipline at Columbia since 2015, Salleb-Aouissi teaches courses in the fundamentals of artificial intelligence both in front of Columbia’s classrooms and as part of the online graduate-level MicroMasters program in Artificial Intelligence, a popular edX course with over 160,000 enrollments.
Salleb-Aouissi’s research interests lie in machine learning and data science. She has done research on frequent patterns mining, rule learning, and action recommendation and has worked on data science projects including geographic information systems and machine learning for the power grid. Her current research interest includes crowd sourcing, medical informatics and educational data mining.
Salleb-Aouissi received her PhD in computer science from
University of Orleans (France) in 2003
Posted 01/31/18