Using skills learned in class, SIPA students set up early-stage startups—BTM Solutions, Cybersecurity Chatbot, Saloo—to build AI and chatbot services. All students were enrolled in the Collaboratory-funded Computing in Context – Policy.
As curiosity and enthusiasm grow around both augmented reality and virtual reality, Feiner and other panelists discuss what is new in these rapidly maturing fields and what most excites them.
In this PRI interview, Vishal Misra, who helped shape India’s strong net neutrality regulations, uses analogies to explain net neutrality while discussing how the diverging paths taken by the US and India will affect innovation.
Computer Graphics and User Interfaces Lab is one of two academic labs selected to participate in Verizon’s newly-opened Open Innovation lab, which co-locates startups and academics to promote new concepts and use cases for pre-commercial 5G.
Monday she took questions on how she overcame hating math to being a CS professor at Columbia, a children’s book author, and a quantitative researcher at IEX. Her students got into the act also.
AI talent is expensive, scarce, and hard to retain, making it tough for startups and small companies to compete with the big established tech giants that can afford the high-flying salaries and expensive perks AI engineers regularly command. But rather than compete for already trained AI engineers, NYC-based Fusemachines is pursuing a different strategy. An AI business intelligence software company founded in 2013, Fusemachines is developing its own homegrown AI talent, and doing so far from the Silicon Valley, New York City, and other major tech hubs. Having already trained 80 engineers in Nepal, Fusemachines has immediate plans to train students in the Dominican Republic, Rwanda, and a number of small colleges in New York City, providing students with the resources and opportunity to study artificial intelligence and machine learning.
Sameer Maskey
“We at Fusemachines want to find and cultivate this talent, and give them access to proper education and the opportunity to learn the concepts and methods of AI and machine learning,” says Sameer Maskey, founder and CEO of Fusemachines and a Columbia alumni who received his PhD in computer science in 2008 (advised by Julia Hirschberg). “We believe that with adequate training, these students will thrive as well as any engineering students at the elite universities in the US and Europe. There is talent around the world, and we neglect it to our detriment.”
Amidst an expansion of artificial intelligence initiatives, concerns are growing that the top pool of AI talent is going only to larger tech giants. Even though many traditional industries like healthcare and energy are primed for disruption, companies in these fields are struggling to attract engineers with a sophisticated understanding in machine learning and deep learning. By making training in AI accessible to engineers far removed from the Silicon Valley, Fusemachines hopes more companies aiming to experiment with AI will have access to the talent needed to build innovative solutions. “We are breaking down barriers by making the power of AI and machine learning available to students who can build new AI solutions across all industries,” Maskey said.
For Maskey, who is also Adjunct Assistant Professor at Columbia University, it’s about democratizing AI—making artificial intelligence technology accessible to people and companies that do not have it in the current environment. It’s also about changing assumptions about who can be trained to do cutting-edge technology.
While there is an undeniably uplifting aspect to the Fusemachines mission, making AI more widely accessible is also about ensuring a young company has the skilled engineers to differentiate its services through the use of AI.
But can Nepali computer scientists and engineers do the type of complex systems development needed for building leading-edge AI services that are usually considered the reserve of those who graduate from elite Western universities? Maskey says, yes, absolutely. They already are. Fusemachines has 80 engineers spread between its New York and Kathmandu offices; more than 85% of those engineers are working in the Nepal office, where they are creating new machine learning algorithms and designing the software systems that are core to Fusemachines’ current and future businesses.
Fusemachines started out by building customer service chatbots to automatically answer questions that come through a helpline, with New York City’s Small Business Services as one of its first clients. Bringing the same expertise to sales processes, the company next expanded into building AI sales assistants that interact with humans through emails, mobile apps, and sales software to learn what sales tasks could be automated. An AI sales assistant now does the repetitive, menial tasks of filtering through millions of sales leads to rank them according to likelihood of success, freeing salespeople to concentrate on more productive tasks.
The company’s rapid expansion was the result of an AI fellowship program that Fusemachines instituted early this year to ensure the necessary number of engineers.
AI Fellowships to find and develop raw talent
In the beginning when Fusemachines was getting off the ground, Maskey did the training himself, occasionally spending up to 80% of his time instructing either onsite in Kathmandu or over Skype, often getting up before dawn to teach students in a time zone 11 hours ahead of New York. Gradually, the engineers he trained began training newly hired engineers, freeing up more of Maskey’s time. Still, the training was not scalable to the degree needed.
With Fusemachines growing rapidly—Maskey expects to place 2,000 engineers in the next 3-5 years—and the need for many more trained engineers escalating also, Fusemachines early this year started offering 25 AI fellowships in Kathmandu. With over 400 applications, selection of the 25 fellows was based on an exam and interviews (ultimately 27 were selected). Applicants did not have to be employees of Fusemachines—in fact 14 current fellows are employed by other companies, including some that directly compete with Fusemachines—but obviously there is interest on both sides for employment. Fusemachines has already hired some of the fellows as full-time engineers.
The training of the fellows has been greatly accelerated thanks to the availability of Columbia University’s Online MicroMasters in Artificial Intelligence in partnership with edX, one of the largest online learning platforms and MOOC providers in the world. MicroMasters gives participants a rigorous, graduate-level foundation in AI through four key courses taught by Columbia Engineering faculty: Artificial Intelligence, Machine Learning, Robotics, and Computer Animation. Launched in 2016, the MicroMasters represents 25 percent of the coursework toward a Master’s degree in Computer Science at Columbia University and is intended for individuals who hold a Bachelor’s degree in Computer Science or Mathematics and are comfortable with programming languages.
Soulaymane Kachani, Vice Provost for Teaching and Learning of Columbia University and Senior Vice Dean for Columbia Engineering, says the program was designed to provide students a solid foundation in AI that will give learners an important edge in one of the fastest growing industries in the world. “Advanced technology is transforming the way we learn as much as it’s transforming the way we work,” said Kachani. “Columbia prepares students to be innovators and leaders, so it’s fitting that we are offering cutting-edge content taught by outstanding research faculty, marrying advanced technology with sound pedagogy, and opening it up to learners around the world.”
The MicroMasters has helped Fusemachines redefine its fellowship program as students from far-flung parts of the world get to learn from some of the best professors at Columbia who are teaching the subject. The first Fusemachines fellows are now halfway through the program. None have dropped out, though a few, especially those currently employed, struggle to keep pace with others who have more time to devote to the lessons. Along with the online teaching, Fellows also receive mentoring from Fusemachines engineers and scientists.
So successful is the program, Fusemachines is moving up the start of the next training round for 25 more fellows in Nepal by six months. Originally, the company planned to wait until the current fellows finished the program before beginning the next iteration. Instead the company is already taking applications and plans to start the second edition of the fellowship program in Nepal early next year.
And not just in Nepal. The company is now taking its AI fellowship program worldwide in an effort to democratize AI. Fellowships are being expanded to the Dominican Republic and to smaller New York City colleges (among them, Baruch College, Pace University, Hunter College, NYIT) where students often don’t have the opportunity to pursue Master’s degree at Ivy League schools or don’t have the means to pay for expensive boot camps. Soon the company will launch fellowships in Rwanda. Each location—Dominican Republic, NYC, and Rwanda—will offer 25 fellowships.
Apply here for Fusemachines’ AI fellowships in NYC and Dominican Republic.
Importance of research
To help run and expand the AI fellowship program, Fusemachines recently hired Stephen J. Rennie, a former team lead for the IBM Watson Multimodal Group and a veteran in speech recognition research. Rennie has one other responsibility: to oversee research projects in cutting-edge technology.
Maskey sees research as an essential component to the company’s success and necessary to improving the AI products and services that Fusemachines offers. “Doing research helps students understand the fundamentals of machine and deep learning,” Maskey said. “A lot of people can use TensorFlow to run something quick but building something new from scratch is important if you want to have deep understanding of AI mathematics and want to invent new mathematical frameworks or new equations that can win AI challenges. It’s practicing science, it’s fun, and it raises the spirit of the entire company.”
Currently machine learning engineers and fellows are building speech recognizers, image captioning programs, and chatbots from scratch, and even a unibody drone capable of flying long distances in mountainous terrain. These efforts are not small-scale. AI fellows are competing in MS COCO and SQuAD, going against competitors from Microsoft, Salesforce, MIT, CMU, and other tech powerhouses.
While drones are not part of any business plan, Maskey greenlighted the project after one of the AI fellows, now also a Fusemachines engineer, expressed interest in using AI to program drones that can fly medicine to remote areas of Nepal where an overland delivery might take two days. “Part of democratizing AI means giving engineers the means to solve the problems they see in their own country,” says Maskey. “We are able to give students the opportunity to experiment with AI, while benefiting their own countries that could never afford engineers from the US or Europe.”
A Fusemachines video featuring some current AI fellows.
Fusemachines’ program to train talented engineers is working for employees and for the company. The AI Fellowship combined with individual mentoring from the company’s engineers and scientists is providing advanced machine learning and AI training to people who would not otherwise receive it, either because they lack the needed resources or live far from technology centers. As trained engineers able to command a higher salary, Nepali engineers can achieve a better standard of living, which often benefits the entire family.
For Fusemachines, training talent means a steady and guaranteed supply of AI engineers in a time when such resources are scarce. And while the company pays market rates and above, they are market rates in Kathmandu, one third the rates in New York City or the Silicon Valley.
Perhaps the best evidence of how well Fusemachines’s strategy is working is the company’s astonishing 100% retention rate for engineers.
Maskey is betting that AI talent can be found anywhere; the company depends on it. And so far, Fusemachines is winning the bet.
Henning Schulzrinne, former CTO of the FCC, answers questions about the likely repeal of the Open Internet Report and Order, and how it removes essentially all regulatory oversight from broadband Internet access.
Last Friday, with less than a week remaining before the FCC’s expected repeal of the Open Internet Rules, a panel of four experts convened before an audience in Davis Auditorium to discuss what such a repeal is likely to mean for the Internet. Though all four spoke from different perspectives—three were technology experts and one an Internet consumer advocate and lawyer—all expressed concerns about the repeal. (Though proponents of the repeal had been invited, none were able to attend.)
The panel was moderated by Ethan Katz-Bassett, a professor of electrical engineering at Columbia, who is an expert on Internet services and content delivery, and by Brittney Gallagher, Digital Culture Correspondent for Digital Village, the oldest running radio program in Los Angeles that covers the Internet.
The discussion started with a rundown of the three bright lines that cannot be crossed under current rules—no throttling, no blocking, no paid prioritization. It is these rules (as well as other general-conduct rules) that, according to Sarah Morris ensure that Comcast doesn’t prioritize its streaming platform over Netflix or that a company can’t pay AT&T to favor its traffic over the traffic of a competitor.
While much attention has been focused on how the order will remove protections that prevent internet service providers (ISPs) like Comcast and Verizon from restricting or prioritizing traffic, Henning Schulzrinne, whose second term as CTO at the FCC just ended in October, pointed out the order also removes the FCC’s power to regulate Internet service, handing over this responsibility to the FTC. Given that the FTC has no authority to issue blanket rules to ban blocking or prevent other discriminatory practices, the US will effectively have no Internet regulation at all, a situation Schulzrinne calls unprecedented.
Another topic discussed was the lack of competition among the last-mile providers, that is, the ISPs that control the cables that run from the Internet’s main transit cables to smaller, neighborhood-scale cables that go to each individual house. Expensive as it is to lay these cables, no one was advocating for replicating last-mile cables, but under current conditions, the company that builds the last-mile cable controls access to customers.
Without competition and soon without any regulation, there is nothing to prevent AT&T, Verizon, or Comcast from monetizing their access to customers. In fact, in a market economy, there is every incentive to exploit one’s stranglehold on consumer eyeballs to extract access fees from content providers. While large rich companies like Amazon, Apple, Facebook, Microsoft, and Alphabet (Google)—the “frightful five”—can afford to pay for access to customers, many other companies cannot. It’s especially difficult for fledging startups and for not-for-profit sites and services.
For Vishal Misra, the solution is to switch from the “infrastructure-based competition” the US has currently to a model where service is based on competition between ISPs, with all ISPs having access to a common last mile everywhere and competing for customers by providing better services. It is a solution, however, that requires telecommunications oversight.
The potential downsides for innovation and new services of the FCC’s expected action was another of the topics covered. While FCC chairman Ajit Pai has argued that repeal of net neutrality is necessary for investments and to make the internet better through faster internet speeds, Peter Boothe said his analysis of M-Lab measurements over time suggests that Internet performance in the US improved at least as fast—and probably faster—since February 2015 (when the current regulations went into effect) than it was improving before the regulations.
The panel discussion in its entirety can be seen here.
Panelists Peter Boothe, Vishal Misra, Sarah Morris, and Henning Schulzrinne
Two professors in the Computer Science Department at Columbia University have been named Fellows of the Institute of Electrical and Electronics Engineers (IEEE): Steven Feiner for “contributions to augmented reality and computer graphics,” and Salvatore Stolfo for “contributions to machine learning-based computer security.” IEEE is the world’s leading professional association for advancing technology for humanity, and the IEEE Fellow is the highest grade of IEEE membership, limited every year to one-tenth of one-percent of the total voting membership.
Steven Feiner
Steven Feiner is one of the earliest researchers to investigate and publish scholarly papers on augmented reality (AR), in which computer-generated media—text, graphics, video, sound—are integrated and geometrically aligned with a user’s experience of the real world, one example being by overlaying 3D virtual objects on what the user sees. Feiner joined the Columbia faculty in 1985 and started the Computer Graphics and User Interfaces Lab, addressing a broad range of topics in designing and interacting with synthesized pictures. Several years later, Feiner extended that work to virtual reality, in which virtual objects are viewed on their own, independent of the real world, and since 1990, he and his students have been investigating AR interaction and visualization techniques, and applications of AR to tasks such as equipment maintenance.
The lab’s first AR systems used a “see-through” head-worn display that Feiner and his students assembled to optically combine the real and virtual worlds, connected to desktop and deskside computers. Their earliest project augmented the user’s view of a small flat-panel display running a desktop window system by immersing it in a larger virtual environment, viewed through the head-worn display. The user could see the windows on the flat-panel display surrounded by the outlines of windows above, below, and to the sides of the flat panel. Feiner called this a “hybrid user interface” because it combined different display technologies in a way that benefited from their respective advantages.
The lab’s next project tracked in 3D selected parts of a laser printer, overlaying maintenance instructions directly on relevant parts as the user manipulated them. This posed questions central to the effective design of many kinds of AR experiences: What virtual content should be presented to help the user and what should be suppressed to avoid confusion? How should virtual content be positioned and sized relative to physical objects? How should rendering style be controlled to make content easy to understand? How should the user’s attention be directed toward content that was outside the field of view (e.g., to make the user move or turn to see it)? Feiner’s team developed rules that automatically designed and generated virtual content based on the task to be performed, the positions and orientations of the physical objects being manipulated, and the position and orientation of the user’s head.
The Touring Machine: A prototype 3D mobile augmented reality systems for exploring the urban environment
Feiner soon decided that it was essential to explore how the lab’s AR systems could be made mobile and be taken outdoors. In 1996, Feiner and his students created the “Touring Machine,” which included a head-tracked, see-through, head-worn display, a hand-held tablet, and a backpack containing a computer and a very accurate kind of GPS. Both the backpack computer and tablet had digital radio modems for wireless access to the internet.
Before the era of smartphones, ubiquitous GPS, and Wi-Fi, and sixteen years before Google Glass in 2012, the Touring Machine allowed a user to walk around campus, be directed to a building or academic department of interest, view a building’s name and its department names overlaid on that building, and call up a department’s web page on the tablet.
Over time, the systems that Feiner and his lab built have become smaller and lighter weight, often being replaced with or built on top of purely commercial hardware and software. With support from NSF, ONR, and industry, the lab has had productive collaborations with colleagues in cognitive science, architecture, journalism, archaeology, and medicine from rehabilitation to surgery, investigating how to use augmented reality to assist users in performing many kinds of skilled tasks. Approaches designed for one person are complemented by ones that address multiple people, whether co-located or remote, and extended to asymmetric scenarios in which a remote expert working entirely in virtual reality can assist a local user performing a task in the real world guided by augmented reality. In most of the lab’s research, members create and refine new techniques, and evaluate them by designing, running, and analyzing user studies to compare those techniques with existing ones.
Being named an IEEE Fellow is his latest award. Just this fall, the paper introducing the Touring Machine received the Early Innovator Award from the International Symposium on Wearable Computers (ISWC), celebrating the paper from the first ISWC conference in 1997 that has had the most impact, and this year also Feiner received the Career Impact Award from the IEEE International Symposium on Mixed and Augmented Reality (ISMAR). Three years ago, Feiner received the IEEE VGTC 2014 Virtual Reality Career Award, and he was elected to the CHI Academy in 2011. Together with his students, he has won the ACM UIST 2010 Lasting Impact Award for early work on supporting 2D windows and hypermedia in augmented reality, and best paper awards at ACM UIST, ACM CHI, ACM VRST, IEEE ISMAR, and IEEE 3DUI.
“It is a great honor to be elevated to IEEE Fellow, and one that I owe in large part to the incredible students and colleagues with whom I have had the pleasure to work,” says Feiner. “It is fun to be in a field in which we must continually remind ourselves that the technologies we use now will, in just a few years, be eclipsed in power by ones that are a tiny fraction of the size and price. Our job is to understand how to use these ever more powerful tools to make the future a better place than the present for all of us.”
Steven Feiner did his undergraduate degree at Brown in 1973 and received his
PhD in Computer Science also from Brown in 1987
Salvatore Stolfo
Computer security is not just about technology and systems. It is also about the people who use those systems and how their vulnerable behaviors can be exploited. That premise informs much of Salvatore Stolfo’s research into computer and network security. A Columbia professor since 1979, Stolfo starts with the assumption that data will always be a target. The only unknown is the specific path hackers will take to breach security.
One previously unforeseen path, exposed by Stolfo working with his student Ang Cui, is through embedded devices such as printers, routers, drones, webcams, medical devices, and the growing legions of IoT devices, very few of which come with built-in security. Stolfo and Cui made headlines by demonstrating that certain HP LaserJet printers would accept firmware updates without verifying their authenticity, allowing hackers to upload their own software to take over control of the printer. Later Stolfo and Ang would find serious vulnerabilities in Cisco’s VolP phones that could turn the phones into listening devices.
Stolfo did not start out concentrating in security. An early proponent of artificial intelligence and machine learning, Stolfo in the early 1980s developed a large-scale expert data analysis system, called ACE (Automated Cable Expertise) that was likely the first system to combine rule-based inference (an AI expert system) with a relational database management system; ACE was widely distributed to a telephone wire centers across the US. Stolfo also created machine learning algorithms to detect patterns of fraudulent credit card transactions, research that was adopted throughout the financial industry. Stolfo also co-developed the DADO computer system, a “fifth generation computer” sponsored by DARPA’s high performance parallel computing initiative. It was a fully functional 1023-processor for performing acoustic analyses and keyword spotting capabilities, and the parallel broadcast and resolve/report function that it introduced apparently influenced part of the design of the IBM Blue Gene parallel computer, is the basis of the Apache Hadoop MapReduce functionality for processing very large datasets.
DADO had one other distinction: it was the first invention claimed by Columbia University for ownership of a faculty member’s intellectual property under the Baye Dole Act. With outside investors, the technology was later commercialized and adapted for large-scale speech recognition services.
Combining research with entrepreneurship is a hallmark of Stolfo’s career. It’s a way of being able to experiment with new technology in a lab with students while being guided at the same time by practical, real-world concerns.
With funding from DARPA’s Cyber Panel program in the early 90s, Stolfo and his students began work on detecting network attacks and e-commerce fraud; it was the challenge of detecting the activities of creative but malicious fraudsters that Stolfo became hooked on security. In 1996 he established the Intrusion Detection System (IDS) lab at Columbia, which has received many millions of dollars in research funds. The lab would pioneer the use of data analysis and machine learning techniques for computer security and created the field of Adversarial Machine Learning. With support from DARPA and other federal agencies, Stolfo launched two start-ups to commercialize his research in the areas of active user authentication, deception security, and embedded systems security. Red Balloon Security commercialized the Symbiote technology for embedded systems and was named one of Popular Science’s Best of What’s New for 2016. Allure Security Technology has received millions of dollars in funding from the US government and private investors to innovate technology to stop data breaches.
To date, Stolfo has been granted over 73 patents and has published several books and well over 250 scientific papers on many diverse topics in computer science: parallel computing, AI knowledge-based systems, data mining, computer security and intrusion detection systems. Two of his security papers are among the top 20 most-cited security papers; several others have earned best paper awards, including the RAID Most Influential Paper and Usenix Security Distinguished Paper awards. His research has been supported by DARPA, NSF, ONR, and numerous companies and state and federal agencies.
“I’m truly honored to be elevated to IEEE Fellow,” says Stolfo. “My science has been driven by making an impact both inside and outside the academy, and I’ve had the good fortune to work alongside my colleagues and students towards that goal. I believe the internet should be secure for enterprises, and for everyday people in their everyday lives. I look forward to continuing my work to making the internet safe.”
Salvatore Stolfo received his Ph.D. from The Courant Institute of Mathematical Sciences,
New York University, in 1979.
Amir Baradaran, an art-based researcher in Steven Feiner’s Computer Graphics and User Interfaces Lab (CGUI), has been awarded two grants totaling $220K to create two augmented reality installations, Facing the Cloud + (RE)storing Po{AI}try. Both will be created at Columbia within the CGUI lab.
Amir Baradaran
A winner of the Canada Council for the Arts’ New Chapter Grant (for $120K) and a recipient of the Knight Arts Challenge (for $100K) from the prestigious John S. and James L. Knight Foundation, Baradaran has long been incorporating augmented reality (AR), artificial intelligence (AI), and other technologies into performance art pieces. Even while these technologies were in their early stages, Baradaran saw the potential in AR as a platform for creating immersive, participatory art, where audiences can augment or change an artist’s work.
AR’s implications for storytelling are explored in Facing the Cloud, where audience participants will don headsets to enter into a large-scale immersive installation. Through movements and gestures, they can interact and change the content of what the artist initially created.
A headset with camera and lights captures video of Baradaran’s face to drive the performance of multiple AI-enabled avatars in an augmented environment. His body and hands are also tracked to create more expressive avatars.
“For over 100 years, cinema has conditioned audiences to passively observe a story told in linear time, with every scene tightly scripted and framed by the director and sometimes with input from the actors and other collaborators,” says Baradaran. “AR and AI fundamentally change this equation by allowing the audience to become a co-creator with the artist.”
How AR changes the relationship between art and artist doesn’t necessarily enter into the thinking of the computer scientists and programmers focused on technical aspects of AR. Says Feiner, a pioneer in developing AR technology, “Having Amir here in the lab provides a chance for cross-pollination with artists and others who bring different perspectives. We become better engineers when we’re more cognizant of how these technologies will change the way people interact with the world.”
Facing the Cloud was funded in part by the Knight Arts Challenge matching grant, which according to Victoria Rogers, VP of Arts at the Knight Foundation, “funds the best ideas for engaging and enriching Miami through the arts.” Facing the Cloud will be exhibited in late Spring 2018 in collaboration with the City of Miami’s Little Haiti Cultural Center and with the support of the Smithsonian Affiliate History Miami Museum and the Perez Art Museum Miami (PAMM).
The second project, (RE)storing Po{AI}try, is a large-scale public art project that examines the creative process of code-writing while critically exposing the notion of the presumptive neutrality of code. “Like poetry, code has syntax, symbols, punctuation, spacing, and words,” says Baradaran. “By conceptualizing the language of the machine—that is, code—as Po{AI}try, we can unsettle the disciplinary boundaries between the technologists and artists. Additionally, it helps us question the objective nature of programming as a neutral language. Like poets writing verse, engineers bring their own assumptions, value systems, and lived experiences when they write code.”
(RE)storing Po{AI}try is being funded by the Canada Council for the Arts’ New Chapter project, which was chosen for Canada’s 150th Anniversary Celebrations. Honoring the tradition of oral storytelling and its role in preserving diverse histories of Canada’s First Nations, Baradaran will collaborate with the Awkasasne Mohawk Community in Cornwall, Ontario. Canada Po{AI}try will be installed at Montreal’s Place des Arts Complex in Fall 2018.
Both Facing the Cloud and (RE)storing Po{AI}try a critical story about the evolving role of augmented reality and artificial intelligence technology. “If AR is to become a new medium for artistic creation, it will require a set of visual and conceptual vocabularies along with technical toolsets for artists to design and implement within this new field,” says Baradaran. “Just as painters have tools like brushes and pigments to express ideas, artists working in AR/AI need theirs.” As the art-based researcher within Feiner’s lab, Baradaran is working directly with engineers and others to provide a common frame of reference and set of functionalities that artists and engineers can use to communicate and co-create.
“It’s really exciting to see the creativity of the arts in collaboration with the creativity of computer science here at Columbia,” says David K Park, Dean of Strategic Initiatives at Columbia University. “The excitement isn’t just about how these fields are working together to push, inform and illuminate the boundaries of virtual reality, AR, and AI as well as other technologies, but how the collaboration creates a richer conversation about how technology is shaping society and just as importantly how society is shaping technologies that we use. I know Amir’s project will engage a broad range of disciplines beyond just the arts and computer science and am excited to see what additional collaborations his work will spark here at Columbia.”
Baradaran is seeking further faculty and student collaborations in 2018. “We are looking for folks interested in mobile application development, Unity/game development, robotics, machine learning and natural language processing,” says Baradaran. He is reaching across campus to form partnerships with faculty members and their students in 2D-3D design, storytelling, journalism, architecture, film, animation, theater performance, acting, and sound production, as well as more theoretical fields such as (art) history, policy, law, and communications.
Modeled on the Aviation Safety Reporting System, such an agency would investigate major cyberattacks and “near misses,” publishing results so others could better understand—and avoid—the threats. Reporting would be voluntary, anonymous, and nonpunitive.
Columbia Spectator gives Adam Cannon high marks for his humor, direct interaction with students, easygoing demeanor, and, most importantly, for making computer science make sense.
Peter Allen and Matei Ciocarlie were among the robotics researchers making presentations. Held October 19, the event was attended by academics and executives from venture capital firms and technology companies.
Paper published in eLife describes a method for using $1000 DNA sequencers to quickly and accurately identify cells lines from DNA. Lead author Yaniv Erlich sees a huge potential to improve cell-authentication in cancer research.
This year’s IEEE International Symposium on Mixed and Augmented Reality (ISMAR) recognized Steven Feiner with the Career Impact Award for “significant impact over his career to the ISMAR community.” ISMAR is the premier international conference for research in mixed and augmented reality.
A Professor of Computer Science at Columbia University, Feiner has been working in the field of augmented reality for more than 25 years and published some of the earliest scholarly papers on the subject.
At Columbia he directs the Computer Graphics and User Interfaces Lab, which in 1996 created the first outdoor mobile augmented reality system using a see-through display, paving the way for current smartphone outdoor augmented reality applications; the paper describing the system received the Early Innovator Award from the International Symposium on Wearable Computers(ISWC) just this year. His lab also pioneered experimental applications of augmented reality in tourism, journalism, maintenance, construction, and other fields.
A touring machine: Prototyping 3D mobile augmented reality systems for exploring the urban environment
Beyond augmented reality, Feiner’s research interests extend to human-computer interaction, 3D user interfaces, virtual environments, knowledge-based design of graphics and multimedia, mobile and wearable computing, computer games, healthcare, information visualization, and he co-directs the Columbia Vision and Graphics Center.
Among his awards, Feiner is a recipient of the IEEE VGTC 2014 Virtual Reality Career Award, and he was elected to the SIGCHI Academy (2011). Together with his students, he has won the ACM UIST 2010 Lasting Impact Award for early work on supporting 2D windows in augmented reality, and best paper awards at ACM UIST, ACM CHI, ACM VRST, IEEE ISMAR, and IEEE 3DUI.
Throughout the years, he has served as general chair (or cochair) and program chair (or cochair) for the premier research conferences in augmented reality and virtual reality: both ISMR and IEEE ISAR (the forerunners of IEEE ISMAR), IEEE VR, and ACM VRST, along with the leading research conference on innovations in human-computer interfaces, ACM UIST.
Feiner did his undergraduate degree at Brown in 1973 and received his PhD in Computer Science also from Brown in 1987
Writing to the Department of Homeland Security, 54 computer scientists and academic researchers criticized a proposed plan to use AI methods to screen immigrants and visa applicants. In this interview, Bellovin specifies some technology concerns.
Henning Schulzrinne, the Julian Clarence Levi Professor of Mathematical Methods and Computer Science at Columbia University, has been appointed to the North American Numbering Council (NANC), a federal committee advising the Federal Communications Committee (FCC) on the efficient and impartial administration of telephone numbering resources in North America. Among other responsibilities, the NANC recommends the creation of new area codes when the supply of numbers diminishes due to demand, and it advises on policy and technical issues involving numbering resources. On the Committee, he hopes to accelerate the transition to a more Internet-based and capable system for assigning and managing telephone numbers, adding the ability to prevent the spoofing of caller ID and to port numbers nationwide.
Schulzrinne, who last month completed his second term as Chief Technology Officer at the FCC, has worked with the FCC in a number of positions over the past seven years, helping shape public policy and providing guidance on technology and engineering issues. Schulzrinne played a major role in the FCC’s decision to require mobile carriers to enable customers to contact 911 using text messages. He is active also in technology solutions to limit phone spam (“robocalls”) and enable relay services for people who are deaf or hard of hearing.
As a researcher in applied networking, Schulzrinne is particularly known for his contributions in developing the Session Initiation Protocol (SIP) and Real-Time Transport Protocol (RTP), the key protocols that enable Voice-over-IP (VoIP) and other multimedia applications. Each is now an Internet standard and together VoIP and SIP have had an immense impact on telecommunications, both by greatly reducing consumer costs and by providing a flexible alternative to the traditional and expensive public-switched telephone network.
Last year Schulzrinne received the 2016 IEEE Internet Award for “formative contributions to the design and standardization of Internet multimedia protocols and applications.” Previously he was named an ACM Fellow (2015), receiving also in 2015 an Outstanding Service Award by the Internet Technical Committee (ITC), of which he was the founding chair. In 2013, Schulzrinne was inducted into the Internet Hall of Fame. Other notable awards include the New York City Mayor’s Award for Excellence in Science and Technology and the VON Pioneer Award. Active in serving the broader technology community, Schulzrinne is a past member of the Board of Governors of the IEEE Communications Society and a former vice chair of ACM SIGCOMM. He has served on the editorial board of several key publications, chaired important conferences, and published more than 250 journal and conference papers and more than 86 Internet Requests for Comment. He was recently appointed to the Intelligent Infrastructure Task Force of the Computing Community Consortium.
Schulzrinne continues to work on VoIP and other multimedia and networking applications and is currently investigating an overall architecture for the Internet of Things, including new user-friendly means of authentication, and how to protect the electric grid against cyberattacks.
Schulzrinne received his undergraduate degree in economics and electrical engineering from the Darmstadt University of Technology, Germany, his MSEE degree as a Fulbright scholar from the University of Cincinnati, Ohio, and his PhD from the University of Massachusetts in Amherst, Massachusetts.
Interdisciplinary collaborations are needed today because the hard problems—in medicine, environmental science, biology, security and privacy, and software engineering—are interdisciplinary. Too complex to fit within one or even two disciplines, they require the collective efforts of those with different types of expertise and different perspectives.
Computer scientists are in high demand as collaborators, and not just because the computer is indispensable in virtually all fields today. The computational, or algorithmic, approach—where a task is systematically decomposed into its component parts—is itself a powerful problem-solving technique that transfers across disciplines. New techniques in machine learning, natural language processing, robotics, computer graphics, visualization, and augmented reality make it possible to present and think about information in ways not possible before.
The benefits flow both ways. Collaborations offer computer scientists the chance to work on new problems they might not otherwise consider. In some cases, collaborations can change the direction of their own research.
“The most successful collaborations revolve around problems that interest everyone involved,” says Julia Hirschberg, chair of Columbia’s Computer Science Department. She adds that collaborations often require time and negotiating. “It might take a while to find out what’s interesting to you, what’s interesting to them, but in the end you figure out how to make the collaboration relevant to both of you.”
In higher education, more efforts are being put into promoting faculty-faculty collaborations across departments while also preparing students to reach across disciplinary boundaries. At Columbia, the Data Science Institute (DSI) brings together researchers from 11 of Columbia’s 20 schools—including the School of International and Public Affairs, the Columbia Medical Center, the Columbia Law School—to work on problems in smart cities, new media, health analytics, financial analytics, and cybersecurity. Fully 80% of Columbia’s computer science faculty are DSI members.
Other interdisciplinary efforts are supported by provost awards intended to encourage collaborations among schools and departments.
The Computer Science Department plays its role also, whether it’s individuals informally connecting people together or through more structured programs like the NSF-funded IGERT Data to Solutions program, which trains PhD students on taking a multi-disciplinary approach for integrating data collections. As part of its mission, IGERT sponsors talks where researchers outside the department present interesting problems from their own fields.
In spring 2015, one of those speakers was Pamela Smith, a professor specializing in the history of science and early modern European history, with particular attention to historical crafts and techniques. Her talk was on the Making and Knowing Project, which seeks to replicate 16th-century methods for constructing pigments, colored metals, coins, jewelry, guns, and decorative objects.
For the Making and Knowing Project, Smith and her students recreate historical techniques by following recipes contained in a one-of-a-kind, 340-page, 16th-century French manuscript. (The original, BnF Ms. Fr. 640, is housed in the Bibliothèque Nationale in Paris. Selected entries of the present, ongoing English translation are here.) It’s trial and error; the recipes have no precise measurements and often skip certain details so it can take several iterations to get a recipe right. Since even early attempts that “fail” can be highly informative, Smith has her students document and record every step and any objects that are produced.
Detail from BnF Ms. Fr. 640 manuscript
The result is a substantial collection of artifacts, including photos, videos, texts, translations, and objects recreated using 16th century technology. The challenge for Smith is making this content easily available to others.
Steven Feiner
Steven Feiner works in the decidedly 21st century areas of augmented reality, virtual reality, and 3D user interfaces. Together he and Smith are collaborating on how to use the technologies from Feiner’s lab to effectively present historical content in a way that is dynamic and convincing to people without access to the original manuscript.
Their joint solution is to make virtual representations of the content viewable in 3D space and, when available, in context of physical copies of artifacts from Smith’s lab, all seen through a smart device with the appropriate software. The content—texts, images, videos, and 3D simulations of objects—is naturally organized around the recipes.
The devices used by Feiner’s lab range from ordinary smartphones and tablets through devices specifically designed to support augmented reality, in which virtual content can be experienced as if it were physically present in the real world. These higher-end devices include smartphones with Google’s Tango technology and the Microsoft HoloLens stereoscopic headworn computer, both of which have sensors that are used to model the surrounding world. To view the combination of virtual and physical content, a user looks through a smart device, viewing the physical world through the device camera in the case of a smartphone or tablet. Software installed on the device blends the virtual content with the user’s physical environment, taking into account the current position and the orientation of the device’s location in space, giving the impression that the virtual content actually exists in the real environment. If the virtual content includes a 3D object, the user can move relative to the object to see it from any perspective. Virtual content can be attached to physical objects, such as a printed photo or even to Smith’s lab—either the physical room or a virtual model that the researchers are creating.
The two labs are working together to convert Smith’s artifacts into digital content that can be linked together and arranged in 3D in ways that elucidate their interrelationships. Both sides benefit as learning occurs in the two labs: Smith and her students gain new tools and the digital proficiency to use them in a way to better study their own field; Feiner and his students get the chance to work on a problem they might never have previously considered and to better understand how to present and interact with information effectively in 3D—one of their lab’s themes. As the project progresses, Feiner and his students will take what they are learning from working with Smith’s students to further improve the tools and make them more general-purpose so others can adapt them for completely different projects.
A paper copy of a board on which Smith’s lab has tested a recipe, viewed in augmented reality through a tablet that shows a virtual annotation linked to one of the tests.
It’s just one collaboration in Feiner’s lab; in another, the new media artist Amir Baradaran is incorporating augmented reality technology into two art pieces, one exploring the parallels between code and poetry, and the other looking at the implications to authorship when audience members are able to immerse themselves into an artwork and affect the content. Such issues don’t necessarily enter into the thinking of the computer scientists focused on technical aspects of augmented reality. Says Feiner, “Having Baradaran here in the lab is a chance for us to work with others who bring different perspectives. It makes us better engineers if we’re more cognizant of how these technologies will change the way people interact with the world.”
This project in particular points to another reason for computer scientists to seek collaborations: With technology so ingrained in modern life, others from outside computer science, especially those focused on aesthetic, ethical, and communication issues, can contribute to making technology more human-oriented and easier to use in everyday life.
A robotic grasping system to assist people with severe upper extremity disabilities
Peter Allen
Robotics by nature is interdisciplinary, requiring expertise in computer science and electrical and mechanical engineering. Peter Allen, director of Columbia’s Robotics Group, is often approached for collaborations by people who come to him for technical solutions; over the years, he has worked on a broad range of projects in different disciplines, from art and archaeology—where he helped construct 3D models of archeological sites from 2D images—to biology and medicine, where he works with colleagues at the medical school to develop surgical robots.
One particularly fruitful collaboration came after a colleague encouraged Allen to attend a talk in which Sanjay Joshi (Professor of Mechanical and Aerospace Engineering at UC, Davis) spoke about a noninvasive brain-muscle-computer interface he could use to control two dimensions of space.
That struck a bell for Allen. In robotic grasping, one difficulty is constraining choices. Jointed digits can fold and bend in almost unlimited number of positions to grasp an object, meaning an almost unfathomable number of micro decisions: Which fingers to use, how to bend and position each one, where on an object should digits grasp? After much research into simplifying robotic motions, Allen was eventually able to break the task down into two motions—two parameters—that could be combined to achieve 80% of grasps.
Joshi could also control two parameters—two dimensions of space. Out of this overlap, and working also with Joel Stein of Columbia’s Medical Center, who specializes in physical medicine and rehabilitation, the three are now developing a robotic grasping system to assist people with severe upper extremity disabilities to pick up and manipulate objects. (A video of the system is here.)
The system interprets and acts on an intent to grasp. Intent is signaled by the user activating a small muscle (posterior auricular) behind the ear. (This muscle, which most people can be trained to control, responds to nerves that come directly from the brain stem, not from spine nerves; even individuals with the most severe spinal cord paralysis can still access the posterior auricular.)
A noninvasive sensor (for sEMG, or surface electromyography) placed behind a patient’s ear detects activation of the posterior auricular, and from there the robotic system carries out a series of automated tasks, culminating in selecting the most appropriate grasp from a collection of preplanned grasps to pick up the desired object.
EMG activity on the surface of a single muscle site (posterior auricular) is recorded with a standard electrode.
The whole purpose of the project is to restore the ability to carry out simple daily tasks to people with the most limited motor control function, including those with tetraplegia, multiple sclerosis, stroke, amyotrophic lateral sclerosis (ALS).
“Interdisciplinary work is so important for the future of robotics, especially for human-robot interfaces,” says Allen. “If robots are capable and ubiquitous, humans have to figure out how to interact with them, whether through voice or gestures or brain interfaces—it’s an extremely complex issue. But the rewards can be very high. It’s exciting to see your technology in real clinical use where it can impact and help others.”
In this case, the complexity requires the collective efforts of researchers with expertise in signal processing, robotic grasping, and rehabilitative medicine.
Each collaboration is different, of course, but common to all successful collaborations is a shared purpose in solving a problem while at the same time having the challenge of extending knowledge in one’s own field. In the best cases, the benefits extend far beyond those working in the collaboration.
“NEZHA: Efficient Domain-Independent Differential Testing” won a 2nd place prize at the 14th Cyber Security Awareness Week (CSAW). Put on by NYU, CSAW is world’s largest student-run cybersecurity event, featuring competitions, workshops, and industry events.
Researchers create an algorithm that computes a reflector shape that boosts signals for desired indoor areas while weakening them elsewhere. The reflector can be 3D-printed for $35. Limiting signal coverage also helps prevent nearby cyberattacks.
The symposium, to be held in Rio de Janeiro, November 8-10, examines the enormous promise of AI technologies as well as the risk that uneven access to AI may amplify digital inequalities across the world.
The daylong symposium brought together eight doctoral candidates who presented their ongoing work in front of their peers and also before a panel of faculty who provided feedback on the presented material and manner of presentation. An informal setting allowed students to meet one another and get to know about one another’s research. Students selected for the symposium received a grant for travel, hotel, and registration.
“Preparing for this symposium gave me an opportunity to rethink my past research projects and connect the dots together,” says Li. “I had a lot of inspiring conversations with the diverse faculty panel and students. It is also a great honor to present and share my research to the HCI (human computer interaction) community.”
Li presented his thesis work on incorporating physics-based simulation into two relatively new research areas: computer-generated acoustics and computational fabrication. The work has particular implications for animation, immersive environments, and fabricating and tagging 3D objects.
For project page on Interactive Acoustic Transfer Approximation for Modal Sound, click here.
In projects involving sound simulation, Li has worked to closely integrate visual and audible components, so one is a natural extension of the other. Algorithms and tools he developed automatically generate sounds from the animation itself, rather than relying on pre-recorded sounds created apart from the animation. For virtual reality environments, he has developed a real-time sound engine that responds to user interactions with realistic and synchronized 3D audio to create a more realistic virtual environment.
Li’s research into simulated sound is also enabling new design tools for 3D printing. In a well-received paper from last year, Li and his coauthors describe a computational approach for designing acoustic filters, or voxels, that fit within an arbitrary 3D shape. At a fundamental level, acoustic voxels demonstrate the connection between shape and sound; at a practical level, they allow for uniquely identifying 3D-printed objects through each object’s acoustic properties. For this same work, which pushed the boundaries of 3D printing, Li was named a recipient of the Shapeways Fall 2016 Educational Grant.
In his work on computational fabrication research, Li utilized physics-based simulation on light scattering to enable the AirCode system, which uniquely identifies printed objects through carefully designed air pockets embedded just below the surface of an object. Manipulating the size and configuration of these air pockets causes light to scatter below the object surface in a distinctive manner that can be exploited to encode information. Information encoded using this method allows fabricated objects to be tracked, linked to online content, tagged with metadata, and embedded with copyright or licensing information. Under an object’s surface, AirCode tags are invisible to human eyes but easily readable using off-the-shelf digital cameras and projectors.
Li expects to graduate in 2018 and looks forward to future exciting research challenges in audio/visual computing and computational design tools. He is also interested in integrating his research into real-world products and applications.
Dingzeyu Li entered the PhD program at Columbia’s Computer Science Department in 2013 after graduating in the top 1% of his class at Hong Kong University of Science and Technology (HKUST), where he received a Bachelor’s of Engineering in Computer Engineering.
The paper presented the first outdoor augmented reality system using GPS position
tracking with a see-through head-worn display. Before the era of smartphones,
ubiquitous GPS, and Wi-Fi, the Touring Machine, which included a backpack stuffed
with electronics, let users navigate Columbia’s campus, overlaying names of buildings
and academic departments on buildings viewed through the user’s head-worn display,
and allowing users to select a department to explore its website on a hand-held display
wirelessly connected to the internet.
Cited 1257 times as of November 2017, the paper was authored by Professor Steven Feiner, Blair MacIntyre (PhD ’99, and now Professor in the School of Interactive Computing, Georgia Tech), Tobias Höllerer (PhD ’04 and now Professor of CS, UC Santa Barbara), and Tony Webster (now Lecturer in Finance, SEAS and Clinical Associate Professor of Real Estate, NYU). Both MacIntyre and Höllerer were Feiner’s PhD students at the time of the paper.
Six SEAS students traveled this summer to Ghana to train university students to lead CS outreach that will impact hundreds of Ghanian students. The trip was organized by a nonprofit headed by Chelsey Roebuck (BS’10).
The paper, widely covered in the press, describes an automatic method for error-checking thousands to millions of neurons in a deep-learning neural network. Authors are Kexin Pei, Yinzhi Cao (Lehigh), Junfeng Yang, Suman Jana.
Developed by Kexin Pei, Yinzhi Cao (Lehigh), Junfeng Yang, and Suman Jana, DeepXplore error-checks thousands to millions of neurons in deep learning neural networks. In tests, DeepXplore found thousands of bugs missed by previous methods.
To uniquely identify and encode information in printed objects, Columbia researchers Dingzeyu Li, Avinash S. Nair, Shree K. Nayar, and Changxi Zheng have invented a process that embeds carefully designed air pockets, or AirCode tags, just below the surface of an object. By manipulating the size and configuration of these air pockets, the researchers cause light to scatter below the object surface in a distinctive profile they can exploit to encode information. Information encoded using this method allows 3D-fabricated objects to be tracked, linked to online content, tagged with metadata, and embedded with copyright or licensing information. Under an object’s surface, AirCode tags are invisible to human eyes but easily readable using off-the-shelf digital cameras and projectors.
The AirCode system has several advantages over existing tagging methods, including the highly visible barcodes, QR codes, and RFID circuits: AirCode tags can be generated during the 3D printing process, removing the need for post-processing steps to apply tags. Being built into a printed object, the tags cannot be removed, either inadvertently or intentionally; nor do they obscure any part of the object or detract from its visual appearance. Invisibility of the tags also means that the presence of information can remain hidden.
“With the increasing popularity of 3D printing, it’s more important than ever to personalize and identify objects,” says Changxi Zheng, who helped develop the method. “We were motivated to find an easy, unobtrusive way to link digital information to physical objects. Among their many uses, AirCode tags provide a way for artists to authenticate their work and for companies to protect their branded products.”
One additional use for AirCode tags is robotic grasping. By encoding both an object’s 3D model and its orientation into an AirCode tag, a robot would just need to read the tag rather than rely on visual or other sensors to locate the graspable part of an object (such as the handle of a mug), which might be occluded depending on the object’s orientation.
AirCode tags, which work with existing 3D printers and with almost every 3D printing material, are easy to incorporate into 3D object fabrication. A user would install the AirCode software and supply a bitstring of the information to be encoded. From this bitstring, AirCode software automatically generates air pockets of the right size and configuration to encode the supplied information, inserting the air pockets at the precise depth to be invisible but still readable using a conventional camera-projector setup.
How the AirCode system works
The AirCode system takes advantage of the scattering of light that occurs when light penetrates an object. Subsurface scattering in 3D materials, which is not normally noticeable to people, will be different depending on whether the light hits an air pocket or hits solid material.
Computational imaging techniques are able to differentiate reflective light from scattered light and decompose a photo into two separate components: a direct component produced by reflected light, and a global component produced from the scattered light waves that first penetrate an object. It’s this global component that AirCode tags manipulate to encode information.
Decomposing an image into direct and global components. Green vectors in this schematic represent the direct component produced from light that reflects off the surface; this component resembles the majority of light rays perceived by our eyes. Orange vectors represent the global component produced by light that first penetrates an image before reaching the camera; the global component is barely visible but can be isolated and amplified.
Other innovations are algorithmic, falling into three main steps:
Analyzing the density and optical properties of a material. Most plastic 3D printer materials exhibit strong subsurface scattering, which will be different for each printing material and will thus affect the ideal depth, size, and geometry of an AirCode structure. For each printing material, the researchers analyze the optical properties to model how light penetrates the surface and its interactions with air pockets.
“The technical difficulty here was to create a physics-based model that can predict the light scattering properties of 3D printed materials especially when air pockets are present inside of the materials,” says PhD student Dingzeyu Li, a coauthor on the paper. “It’s only by doing these analyses were we able to determine the size and depth of individual air pockets.”
Analyzing the optical properties of a material is done once with results stored in a database.
Constructing the AirCode tag for a given material. Like QR codes, AirCode tags are made up of cells arranged on a grid, with each cell representing either a 1 (air-filled) or a 0 (filled with printing material), according to the user-supplied bitstring. Circular-shaped markers, easily detected by computer vision algorithms, help orient the tag and locate different cell regions.
Unlike QR codes, which are clearly visible with sharp distinctions between white and black, AirCode tags are often noisy and blurred, with many levels of gray. To overcome these problems, the researchers insert predefined bits to serve as training data for calibrating in real time the threshold for classifying cells as 0s or 1s.
AirCode layout and its corresponding image: data bits (1s are air-filled cells, 0s are cells with solid material) for encoding user-supplied information; markers and rotation cells for orientation; classifier training bits for on-the-fly calibration. Size is variable; a 5cmx5cm tag stores about 500 bits.
Detecting and decoding the AirCode tag. To read the tag, a projector shines light on the object (multiple tags might be used to ensure the projector easily finds a tag) and a camera captures images of the object. A computer vision algorithm previously created by coauthor Shree Nayar and adapted for AirCode tags separates each image into its direct component and global component, making the AirCode tag clearly visible so it can be decoded.
While the AirCode system has certain limitations—it requires materials to be homogeneous and semitransparent (though most 3D printer materials fit this description) and the tags become unreadable when covered by opaque paint—tagging printed objects during fabrication has substantial benefits in cost, aesthetics, and function.
Interviewed by Columbia Technology Ventures (CTV), Allen discusses his recent work on surgical robots and how incorporating big data, machine learning, and computer vision is contributing to smarter robots able to cope with the unexpected.
The timing isn’t great—mid-semester with early projects coming due and midterms beginning—but still they come; 37 from Columbia and Barnard traveled to Orlando earlier this month to join 18,000 other women in tech for the Grace Hopper Celebration, an annual gathering co-produced by AnitaB.org (formerly the Anita Borg Institute) and the Association for Computing Machinery.
For three days (Oct 4-6) attendees listened to 16 keynote speakers—among them Melinda Gates, Fei-Fei Li (Professor and Director of Stanford’s AI Lab and Chief Scientist at Google Cloud), and Megan Smith (Former US Chief Technology Officer). They signed up for technical panels on AI, wearable technologies, data science, software engineering, and dozens of other innovative technologies. They networked with their peers and listened to pitches from recruiters who flock to the event.
But for many, the main draw is just being among so many other women who share their interests in computer science and engineering. In fields dominated by men, the Grace Hopper Celebration (GHC) is one of the few tech venues where women run the show. Here they are the speakers, panelists, and attendees, sharing what they love about technology and what they hope to accomplish in their careers or in their research. They share also stories of workplace discrimination, slights, and sometimes blatant sexism as well as tangible recommendations for what works to keep women in technology.
Click image to hear this year’s GHC keynote speeches. Many speakers told inspiring stories of overcoming adversity to pursue their careers in computing and technology.
Columbia CS major Tessa Hurr, attending for the fourth time, describes it this way: “GHC is a community of women who are there to support one another and lift one another up and encourage one other to pursue a career in STEM.” A senior about to embark on a career, she especially wanted to hear from women about their work experiences. “Coming from Columbia, where the engineering school and computer science department have done a lot of work to balance the ratio of males to females, you see a lot of other women and you don’t feel alone. But in industry, you see the problem of gender imbalance so glaringly. Being at GHC, I know there are support systems if I need them.”
Women at GHC may be excited about supporting other women in technology, but they’re just as enthusiastic about technology itself and the good it can do in the world. Says Hurr, “Sometimes when you’re learning different concepts in class you don’t necessarily see how they translate over to the real world; GHC tech talks help bridge that gap so you better understand how you can have an impact on the world and work towards social good through tech.”
Myra Deng, a CS student attending for the first time, appreciated the emphasis on new technologies, especially AI. A talk by keynote speaker Fei-Fei Li linking AI and diversity was especially inspiring to Deng, who is on the Intelligent Systems track. “Professor Li talked about how AI is supposed to represent the entire human experience but you can’t really model or build that with just a small section of the human population. Diversity isn’t just being nice in the workplace; it’s essential to getting the technology right.”
This mix of technology and support system is a powerful thing, and GHC has been growing by leaps and bounds. In four years, GHC has grown from 8000 to 18,000 participants.
Many attend by taking advantage of scholarships offered by some of the big tech companies. “If the concern is finances, there are lots of resources, including a Github page listing scholarships,” says Julia Di, president of WiCS, which also sponsors students. This year WiCS raised enough funding to send 16 students, though only six were able to purchase tickets in the few hours it took before tickets sold out. Next year, WiCS may follow the lead of tech companies and make a donation to pre-purchase tickets.
Some scholarships require students take the entire week off, not just the three days of the conference, making GHC even more of a time commitment as students scramble to get school work done ahead of time, and scramble again to catch up when they return to campus. That so many do shows how much importance they attach to continuing in tech and supporting others who want to do the same.
Deng encourages women to make the most of the opportunity offered by GHC. “Every now and then, it’s good to zoom out from school and see what’s going on in the world. At GHC you meet so many incredible people you might not otherwise meet. I came back a lot more motivated because I know what I’m working on is important. It’s why I’m in Tech. You can always catch up on school work later.”
For the headline Liquid Water Found on Mars, which response is the least funny? Hint: One is professionally done, and two are crowdsourced. Voting results at end.
Creativity and computation are often thought to be incompatible: one open-ended and requiring imagination, originality of thought, and perhaps even a little magic; the other logical, linear, and broken down into concrete steps. But solving the hard problems of today in medicine, environmental science, biology, and software engineering will require both.
Lydia Chilton, Assistant Professor
For Lydia Chilton, who joined the Computer Science department this fall, inventing new solutions is fundamentally about design. “When people start solving a problem, they often brainstorm over a broad range of possibilities,” says Chilton, whose research focuses on human-computer interaction and crowdsourcing. “Then there is a mysterious process by which those ideas are transformed into a solution. How can we break down this process into computational steps so that we can repeat them for new problems?” This question motivates her research into tools that are part human intelligence, part computer intelligence.
How this works in practice is illustrated by a pipeline she built to automatically generate visual metaphors, where two objects, similar in shape but having different conceptual associations, are blended to create something entirely new. It’s a juxtaposition of images and concepts intended to communicate a new idea, doing so in a way that grabs people’s attention by upending expectations.
A pipeline for creating visual metaphors by synthesizing two objects and two concepts.
Chilton decomposes the process of creating visual metaphors into a series of microtasks where people and machines collaborate by working on those microtasks they are good at. Defining the microtasks and the pipeline to make them flow together coherently is the major intellectual piece.
“The key is to identify the pieces you will need, and what relationships the pieces need to have to fit together. After you define it that way, it becomes a search problem.” Because it’s a search problem over conceptual spaces computers don’t fully understand, Chilton has people fill in the gaps and direct the search. People might examine the space of objects representing Starbucks and the space representing Summer, picking the most simple, meaningful, and iconic. The computer then searches for pairs of similarly shaped objects (as annotated by people), blending them together into an initial mockup of the visual metaphor. Humans come in at the last step to tweak the blend to be visually pleasing. At every stage in the pipeline, humans and computers work together based on their different strengths.
Crowdsourcing serves another purpose in Chilton’s research: harnessing many people’s intuitions. Foreshadowing her work on pipelines, Chilton created crowd algorithms that, more than simply aggregating uninformed opinions or intuitions, aggregate intuitions in intelligent ways to lead to correct solutions.
For example, deciphering this intentionally illegible handwriting would not be possible for any single person, but a crowd algorithm enables people to work towards a solution iteratively. People in the crowd suggest partial solutions, and then others, also in the crowd, vote on which partial solution seems like the right one to continue iterating. Those in later stages benefit from seeing contextual clues and thus build on the current solution, even if they wouldn’t have had those insights without seeing others’ partial solutions. “It’s an iterative algorithm that keeps improving on the partial solutions in every iteration until the problem is solved,” says Chilton.
Out of these scribbles, someone makes out the verb “misspelled,” providing context for others to build on. Who cares about misspellings? Maybe a teacher correcting a student; now words like “grammar” become more likely. Identifying a verb means the preceding word is likely a noun, making it easier for someone else to make out “you”. Each person starts with more information and sees something different, and a task impossible for a single person becomes 95% solved. [Iteration 6: You (misspelled) (several) (words). Please spellcheck your work next time. I also notice a few grammatical mistakes. Overall your writing style is a bit too phony. You do make some good (points), but they got lost amidst the (writing). (Signature)]
Allowing people to collaborate in productive ways is the power of crowd algorithms and interactive pipelines. Her research into crowdsourcing and computational design has already earned her a Facebook Fellowship and a Brown Institute Grant. This year, she was named to the inaugural class of the ACM Future of Computing Academy.
At Columbia, she will continue applying interactive pipelines and computational design to new domains: authoring compelling arguments for ideas, finding ways to integrate existing knowledge of health and nutrition into people’s existing habits and routines, and creating humor, a known, very hard problem for computers because of the large amount of implicit communication and emotional impact.
“Although humor is valuable as a source of entertainment and clever observations about the world, humor is also a great problem to study because it is a microcosm of the fundamental process of creating novel and useful things. If we can figure out the mechanics of humor, and orchestrate it in an interactive pipeline, we would be even further towards the grand vision of computational design that could be applied to any domain.”
Humor is also a realm where human intelligence is still necessary. Computers lack the contextual clues and real world knowledge that enable people to know intuitively that a joke insulting McDonald’s or Justin Bieber is funny but one that insults refugees or clean air is not. As she did for visual metaphors, Chilton breaks down the humor creation process into microtasks that are distributed to humans and machines. This pipeline, HumorTools, was created to compete with The Onion. It generated two of the responses to the liquid water headline. The Onion writers wrote the third.
“I pick creative problems that involve images (like visual metaphors) and text (like humor) because I think both are fundamental to the human problem-solving ability,” says Chilton. “Sometimes a picture says 1000 words, and sometimes words lay out logic in ways that might be deceiving in images. The department here is strong in graphics and in speech and language processing, and I look forward to collaborating with both groups to build tools that enhance people’s problem-solving abilities.”
One of the people she will collaborate with is Steven Feiner, who directs the Computer Graphics and User Interfaces Lab. “It’s important to extend people’s capabilities, augmenting them through computation expressed as visualization,” says Feiner. “Here, the hybrid approaches between humans and computers that Lydia is exploring are especially important because these are difficult problems that we do not yet know how to do algorithmically.”
Chilton’s first class, to be taught this spring, will be User Interface Design (W4170).
Voting results for headline Liquid Water Found on Mars.
To end his talk “Can we store all of world’s data on a pickup truck,” Erlich makes bold prediction that DNA storage could be cheaper than magnetic storage within a decade.
For major contributions to computer science education, theoretical understanding, and fostering of talent, Alfred Aho was awarded the NEC C&C Foundation C&C Prize.
A former student of Kathy McKeown and now an MIT professor, Barzilay developed novel solutions for multi-document summarization along with new algorithms for identifying paraphrases. Her work was integrated as part of Columbia’s Newsblaster system.
With the national average slightly below 20%, Columbia’s relatively high percentage of women CS majors in the 2016-2017 academic year ranks it among the top US universities in attracting women to computer science.
The Defense Advanced Research Projects Agency (DARPA) has awarded Yaniv Erlich a Young Faculty Award. The award, which identifies rising research stars in US academic institutions and introduces them to topics and issues of interest to the Department of Defense, will support Erlich’s work on DNA storage technology.
An Assistant Professor of Computer Science and Computational Biology at Columbia University and a Core Member at the New York Genome Center, Erlich does research in many facets of computational human genetics. His lab works on a wide range of topics including developing compressed sensing approach to identify rare genetic variations, devising new algorithms for personal genomics, and using Web 2.0 information for genetic studies.
The award, which is for $1M, is in response to Erlich’s proposal “Resistant and Scalable Storage Using Semi-synthetic DNA,” which describes the use of an extended genetic alphabet to create DNA storage technology that is both immune to a broad range of interception methods and also boosts the information density of DNA storage. The proposal was submitted through Columbia’s Data Science Institute, of which Erlich is also an affiliate.
Erlich’s previous research has earned him several awards, including the Burroughs Wellcome Career Award (2013), Harold M. Weintraub award (2010), and the IEEE/ACM-CS HPC award (2008). In 2010, he was selected as one of Tomorrow’s PIs team of Genome Technology.
Erlich holds B.Sc. in computational neuroscience from Tel-Aviv University and his Ph.D. in genomics and bioinformatics from Watson School of Biological Sciences, Cold Spring Harbor Laboratory in New York.
In February of this year, Erlich was named Chief Science Officer of MyHeritage Ltd.
“Travel in Large-Scale Head-Worn VR” teleports users through virtual environments by allowing them to determine orientation in advance. Another project from Feiner’s lab, “Remote Collaboration in AR and VR Using Virtual Replicas” won a third place finish.
The number of computer science majors at Columbia is expected to increase yet again this year, driven in part by the exploding interest in machine learning. Among the 10 MS tracks, machine learning is by far the most popular, selected by 60% of the department’s master’s students (vs 12% for the second most popular).
According to Nakul Verma, who joins the department this semester as lecturer in discipline, this interest in machine learning is not likely to abate any time soon. “Machine learning is growing in popularity because it has so much applicability for fields outside computer science. Every application domain is incorporating machine learning techniques, and every traditional model is being challenged by the advent of big data.”
As a PhD student at UC San Diego, Verma gravitated toward machine learning’s theory side, what he sees as fruitful territory. “I love to learn new things, and machine learning theory has this ability to borrow ideas from other fields—mathematics, statistics, and even neuroscience. Borrowing ideas will continually grow machine learning as a field and it makes the field especially dynamic.”
Verma does his borrowing from differential geometry in mathematics, a field he had not previously studied in depth. But as machine learning shifts from strictly linear models to include nonlinear ones, new methods are needed to analyze and leverage intrinsic structure in data.
As examples of nonlinear data sets, Verma cites speech and articulations of robot motions, where data sets are high dimensional, containing many, many observations, each one associated with a potentially high number of features. However, relationships between data points may be fixed in some way so that a change in one causes a predictable change in another, giving the data an intrinsic structure. A robot might focus on key points in a gesture, analyzing how fingers move in relation to one another or to the wrist or arm. These movements are restricted along certain degrees of freedom—by joints, by the positioning of other fingers—suggesting the intrinsic structure of the data is in fact low-dimensional and that the xyz points of these joints form a manifold, or curved surface, in space.
Compressing a manifold surface into lower dimensions while retaining geospatial relationships among data points.
For a way to compress a manifold surface into lower dimensions without collapsing the underlying intrinsic structure, Verma looked to John Nash’s process for embedding manifolds, learning the math—or getting used to it—enough to understand how it could be applied to machine learning. Where Nash worked in terms of equations, Verma is working with actual data so the problem, laid out in Verma’s thesis and other papers by him, is to derive an algorithm from Nash’s technique, one that would work on today’s data sets.
While Verma’s thesis was highly theoretical, it had almost immediate practical applications. For four years at Janelia Research Campus HHMI, Verma helped geneticists and neuroscientists understand how genetics affects the brain to cause different behaviors. Working with fruit flies and other model organisms, researchers would modify certain genes thought to control aggression, social interactions, mating, and other behaviors and then record the organisms’ activity. The scale of data—from the thousands of modifications to the recorded video and audio imagery along with the neuronal recordings—was immense. Verma’s job was to tease out from the pile of data the small threads of how one change affects another, to pinpoint the relationships between the genetic modifications to the brain and the observed behavior. Verma’s work on manifolds and understanding intrinsic structure in data was crucial in developing practical yet statistically sound biological models.
Theory and application go hand in hand in machine learning, and the classes Verma will be teaching will contain a good dose of both, with the exact mix calibrated differently for grads vs undergrads. In either case, Verma sees a solid foundation on basic principles as necessary for understanding how a model is set up or why a certain framework is better than another. “The practical applications help reinforce the theory side of things. Teaching random forests should explain the basic theory but show also how it’s used in the real world. It’s not just some bookish knowledge; it’s one way Amazon and other companies reduce fraud.” Verma talks from experience, having worked at Amazon before going to Janelia.
But teaching has always been his ultimate goal. While at Janelia, Verma was awarded Teaching Fellowship, and last summer taught at Columbia as an adjunct. Says Verma, “Helping students achieve their goals and sharing their excitement for the subject is one of the most rewarding experiences of my academic career.”
In this interview, Adrian Tang describes how the CLKSCREW attack exploits the design of energy management systems to breach hardware security mechanisms.
Security on smart phones is maintained by isolating sensitive data such as cryptographic keys in zones that can’t be accessed by non-authorized systems, apps, and other components running on the device. This hardware-imposed security establishes a high barrier and presumes any attacker would have to gain physical access to the device and modify the behavior of the phone using physical attacks typically involving soldering and complex equipment, all without damaging the phone.
Now three Columbia researchers have found they can bypass the hardware-imposed isolation without resorting to such hardware attacks. They do so by leveraging the energy management system, which conserves battery power on small devices loaded with systems and apps. Ubiquitous because they keep power consumption low, energy management systems work by carefully regulating voltage levels across the device, adjusting upward for an active component, adjusting downward otherwise. Knowing which components are idle and which are active requires accessing every component on the device to know its status, no matter what zone a component occupies.
The researchers exploited this design feature to create a new type of fault attack, CLKSCREW. Using this attack, they were able to infer cryptographic keys and upload their own unauthorized code to a phone without having physical access to the device. In experiments, researchers ran their attacks against the ARMv7 architecture on a Nexus 6 smartphone, but the attack would likely succeed on other similar devices since the need to conserve energy consumption is universal on devices. The paper describing the attack, “CLKSCREW: Exposing the Perils of Security-Oblivious Energy Management,” was named most distinguished paper at last month’s USENIX Security Symposium.
In this interview, lead author Adrian Tang describes the genesis of the idea for CLKSCREW and the engineering effort required to implement it.
What made you think energy management systems might have important security flaws?
We asked ourselves what technologies are ubiquitous, are so complex that any vulnerability would be hard to spot, but are nevertheless little studied from a security perspective. Energy management filled all the checkboxes. It seemed like an area ripe for exploitation, especially considering that devices are made up of many different components, all designed by different people. And in manufacturers’ relentless pursuit of smaller, faster, and more energy-efficient devices, security unfortunately is bound to be relegated to the backburner during the design of these devices.
When we looked further, we saw that the energy management features, to be effective, have their reach to almost everything running on a device. Normally, sensitive data on a device is protected through a hardware design that isolates execution environments, so if you have lower-level privileges, you can’t touch the higher-privileged stuff. It’s like a safe; non-authorized folks outside the safe can’t see or touch what’s inside.
But the hardware voltage and frequency regulators—which are part of the energy management system—do work across what’s inside and what’s outside this safe, and are thus able to affect the environment within the safe from the outside. With the right conditions, this has serious implications on the integrity of the crypto strength protecting the box.
The unfortunate kicker is that software controls these regulators. If software can affect aspects of the underlying hardware, that gives us a way into the processors without having to have physical access.
Energy management as attack vector. The regulators that adjust frequency and voltage operate across both trusted and untrusted zones.
How does the CLKSCREW attack work?
It’s a type of fault attack that pushes the regulators to operate outside the suggested operating parameters, which are published and publicly available. This destabilizes the system so it doesn’t operate correctly and doesn’t follow its normal checks, like requiring digital signatures to verify that code is trusted. So we were able to break cryptography to infer secret keys and even bypass cryptographic checks to load our own self-signed code into the trusted environment, tricking the system into thinking our code was coming from a trusted company, in this case, us.
A fault attack is a known type of attack that’s been around awhile. However, fault attacks typically require physical access to the device to bypass the hardware isolation. Our attack does not require physical access because we can use software to abuse the energy management mechanisms to control parts of the system where we are not supposed to be allowed to. The assumption is of course we need to have already gained software access to the device. To achieve that, an attacker can get the device owner to download a virus, maybe by clicking an email attachment or downloading a malware-laden app.
Why the name CLKSCREW?
This name is an oblique reference to the operating feature on the device we are exploiting – the clock. All digital circuits require a common clock signal to coordinate their functions. The faster the clock operates, the higher the operating frequency and thus the faster your device runs. When you increase the frequency, more operations need to take place over the same time period, so of course that also reduces the amount of time allowed for an operation. CLKSCREW over-stretches the frequency to the extent that operations cannot complete in time. Unexpected operations happen and the system becomes unstable, providing an avenue for an attacker to breach the security of the device.
How difficult was it to create this attack?
Quite difficult. Because energy management features do not exist in just one layer of the computing stack, we had to do a deep dive into every single stack layer to figure out the different ways software in the upper layers can influence the hardware on lower layers. We looked at the drivers, and the applications above them and the hardware below them, studying the physical aspects of the software, and the different parameters in each case. Furthermore, pulling this attack off requires knowledge from many disciplines: electrical engineering, computer science, computer engineering, and cryptography.
Were your surprised your attack worked as well as it did?
Yes. While we were somewhat surprised there were no limits on the hardware regulators, we were more flabbergasted at the fact that the regulators operate across sensitive compartments without any security controls. While these measures ensure energy management work as fast as possible—keeping users happy—security takes a back seat.
Can someone take the attack as you describe it in your paper and carry out their own attack?
Maybe with some work; however, I intentionally left out some key details of the attacks, such as the parameter values we use to time the attacks.
As part of responsible disclosure in this line of attack work, we contacted the vendors of the devices before publishing, and they were very receptive, acknowledging the seriousness of the problem, which they were able to reproduce. They are in the process of working on mitigations for existing devices, as well as future ones. It is not an easy problem to fix. Any potential fixes may involve changes to multiple layers in the stack.
We hope the paper will convince the industry as well as academia to not neglect security while designing all parts of the systems. If history is any indication, any component in the computing stack is fair game for a determined attacker. Energy management features, as we have shown in this work, are certainly no exception.
Adrian Tang is a fifth-year PhD student advised by Simha Sethumadhavan and Salvatore Stolfo. He expects to defend his thesis on rethinking security issues occurring at software-hardware interfaces later this year.
For significant contributions to the history of computing, in particular pioneering the C++ programming language, Bjarne Stroustrup has been named the recipient of the 2017 Faraday Medal, the most prestigious award to an individual made by the Institution of Engineering and Technology.
Since 1922, this bronze medal, named after Michael Faraday, has recognized those who have made notable scientific or industrial achievements in engineering or rendered conspicuous service to the advancement of science, engineering, and technology. Previous recipients include Donald Knuth (2011), Roger Needham (1998), Sir Maurice Wilkes (1981), J A Ratcliffe (1966), Sir Edward Victor Appleton (1946), and Sir Ernest Rutherford (1930).
“I am honored and humbled to see my name among so many illustrious previous winners of the prize,” said Stroustrup. “This privilege is only possible through the superb work of the C++ community.”
Stroustrup began developing C++ in 1978 while working at Bell Labs. Strongly influenced by the object-oriented model of the SIMULA language (created by Ole-Johan Dahl and Kristen Nygaard), he extended the traditional C language by adding object-oriented programming and other capabilities. In 1985, C++ was commercially released and spread rapidly, becoming the dominant object-oriented programming language in the 1990s and one of the most popular languages, significantly impacting computing practices and pushing object-oriented technology into the mainstream of computing.
Currently Stroustrup is a Visiting Professor in Computer Science at Columbia University and a Managing Director in the technology division of Morgan Stanley in New York City. His publications include several books—The C++ Programming Language (Fourth Edition, 2013), A Tour of C++ (2013), Programming: Principles and Practice using C++ (2014)—as well as a long list of academic and general-interest publications that Stroustrup maintains here.
Recently elected an Honorary Fellow of Churchill College, Cambridge, Stroustrup is a member of the National Academy of Engineering and a Fellow of both the IEEE and the ACM. He is also a Fellow of the Computer History Museum.
Stroustrup continues to update and add functionality to C++. Even as new languages have been created for the rapidly shifting programming landscape, C++ is more widely used than ever, particularly in large-scale and infrastructure applications such telecommunications, banking, and embedded systems.
Stroustrup will receive the award in a ceremony to be held in London November 15.
The paper describes the aircode technique to physically tag 3D-printed objects with information using carefully designed air pockets inserted beneath an object’s surface. UIST, a top venue for HCI, will be held October 22-25.
Of 200 applicants, Pai was one of sixteen to receive this $3K scholarship to increase STEM diversity. Selection was based on academic achievement and an essay on an inspiring female leader. Pai’s subject: Ansaf Salleb-Aouissi.
The claim aroused concerns about genomic privacy. But in a paper posted to BioRxiv, Erlich matched people to their genomes using easily accessible demographic data, showing Venter’s warning about serious privacy risks to be overstated.
A faculty affiliate of the CS Department, Venkatasubramanian synthesizes concepts from economics, political philosophy, game theory, statistical mechanics, and systems engineering into a quantitative theory for maximizing fairness in free-market capitalism.
The renowned computer scientist and polymath Christos Papadimitriou has joined Columbia’s Computer Science Department as The Donovan Family Professor of Computer Science. He begins teaching this fall.
Christos Papadimitriou
Over four decades, Papadimitriou’s research has explored two of the most fundamental questions in Computer Science: How quickly can computers solve problems? And what kinds of obstacles come in the way of such solutions? Fast algorithms—together with Moore’s Law, the astronomical increase of computer speed over the past six decades—have powered the Computer Revolution. Equally intriguing are problems that appear to resist fast solution because of some inherent complexity: Many are known to be NP-complete, a status suggesting that (unless P = NP, an eventuality most scientists agree is unlikely) all the computers in the world wouldn’t solve it in the lifetime of the universe. As a graduate student, Papadimitriou established this for the Euclidean traveling salesperson problem, a version of the classic problem where cities are points in the two-dimensional plane. Three decades later, with Paul Goldberg and Constantinos Daskalakis, Papadimitriou proved the hardness of computing a Nash equilibrium; in doing so he helped found the field of algorithmic game theory.
“Computation is worldly. It’s about society, markets, people, brains, behaviors,
perception, emotions. Computer Science is looking outwards now. I advise my
undergrad students to take as many courses as they can: Economics, biology,
sociology, humanities, linguistics, psychology.”
– Christos Papadimitriou
Papadimitriou’s contributions extend far beyond the theoretical realm. Complexity is everywhere—in the way protein folds, in the ways database queries are processed, in the structure and activity of neurons and synapses, in how information moves on the internet in the presence of diverse economic interests; on these and other topics Papadimitriou has applied insights from the world of computation to make new discoveries. Just last year, his research made headlines in the world of biology when he connected game theory and evolution to arrive at a novel theory on the role of sex in evolution.
“Christos is one of the most original thinkers in computer science,” says Mihalis Yannakakis, a frequent collaborator and long-time friend. “He has applied the computational lens to a wide range of fields, bringing in each one of them a new perspective, and leaving his mark by founding new research areas, introducing new models and concepts, and initiating research directions that have had a tremendous impact.”
“I started writing fiction quite suddenly, and it made me very aware of how important stories are in science, in my science.” – Christos Papadimitriou
Unusual for a computer scientist, Papadimitriou engages the general public in the discussion of mathematical and computational ideas underlying science and technology. His 2003 novel Turing (A Novel about Computation) is a love story with an AI program as protagonist. His graphic novel Logicomix, coauthored with Apostolos Doxiadis, became an international best seller even though its central theme—Bertrand Russell’s attempts to establish a logical foundation for mathematics—is not an easy subject and Papadimitriou does not trivialize it. A third novel, Independence, wades into the political realm, following a family through the history of modern Greece
“There is nothing worth explaining that cannot be explained through a good story.”
– Christos Papadimitriou
He is fundamentally a teacher. His parents taught elementary and high school in Greece, and Papadimitriou himself has taught at Harvard, MIT, the National Technical University of Athens, Stanford, and the University of California at San Diego, and most recently at the University of California at Berkeley, where he found a home for 22 years. He is popular and sought after by students who rate him highly and note in particular his enthusiasm for the subjects he teaches. That Columbia students will now have the opportunity to learn algorithms and complexity theory from one of the foremost experts in the field is something the department is proud to offer. “We are absolutely delighted to have Christos joining us at Columbia,” says Julia Hirschberg, chair of the Computer Science Department. “He is a great scholar, teacher, and colleague!”
“Teaching is the only way I know to understand something.” – Christos Papadimitriou
Papadimitriou has written extensively on a wide range of topics in computer science, as well as on problems in the natural, social and life sciences that have benefited from computational approaches: Artificial intelligence and learning, databases, optimization, robotics, control theory, networks and the Internet, game theory and economics, computational biology and the theory of evolution, and recently the Brain. He is author or coauthor of five textbooks—Computational Complexity, one of the most widely used textbooks in the field; Elements of the Theory of Computation with Harry Lewis; Combinatorial Optimization: Algorithms and Complexity with Ken Steiglitz; The Theory of Database Concurrency Control, and the undergraduate textbook Algorithms with Sanjoy Dasgupta and Umesh Vazirani—and hundreds of articles and blog posts.
Amongst the recognitions and awards accorded him: the fifth Knuth Award (2002) for longstanding and seminal contributions to the foundations of computer science; the Gödel Prize (2012) for joint work with Oxford’s Elias Koutsoupias on the concept of the price of anarchy. For contributions to complexity theory, database theory, and combinatorial optimization, he was made a member of the US National Academy of Engineering in 2002. He is a member also of the National Academy of Sciences and of the American Academy of Arts and Sciences. Last year he received the John Von Neumann Medal for “providing a deeper understanding of computational complexity and its implications for approximation algorithms, artificial intelligence, economics, database theory, and biology.”
At Columbia, Papadimitriou is looking forward to continuing and expanding his recent work on an algorithmic understanding of the brain with new colleagues at the Zuckerman Institute for Mind, Brain, Behavior. But above all, he cherishes the opportunity for more collaboration with Mihalis Yannakakis.
“It’s like coming back home, to a brother.”
– Christos Papadimitriou
BS in Electrical Engineering from Athens Polytechnic (1972), an MS in Electrical Engineering and PhD in EECS at Princeton (1974, 76 respectively)
“The Role of Conversation Context for Sarcasm Detection in Online Interactions” considers the larger context of online conversations to accurately detect sarcasm while also identifying what triggered a sarcastic reply.
For decades, devicemakers, engineers, and others have been able to count on a new generation of chips coming to market, each more powerful than the previous—all courtesy of shrinking transistors that allow engineers to fit more on a chip. This is the famous Moore’s law. While a boon for technical innovation and a catalyst for entire new industries, the reliability of always having more powerful chips has had the opposite effect on chip architecture, deterring rather than spurring innovation. Why bother designing a whole new chip architecture when in two years a better chip using the traditional mold will be out? But as the expense vastly increases for each increase in transistor density, Moore’s law—more an objective than an actual law—is beginning to bump against physical limits, creating an opportunity and incentive for engineering researchers to again focus time and effort on new varieties of chips. In this interview, Luca Carloni discusses where he sees chip design to be heading, how his lab hopes to contribute to that redesign, and the changes he is making in the courses he teaches to train students for this new reality.
Jensen Huang, CEO of Nvidia, said earlier this summer that Moore’s law is dead. Is it?
Luca Carloni: You won’t ever get me to say that Moore’s law is dead—that’s something I first heard 20 years ago when still a student. Many years passed and every two years or so we have seen the arrival of a new generation of semiconductor technology. Sometime this year Intel is expected to ship advanced processors based on the company’s 10nm process technology.
What is over, however, is the economics aspect of Moore’s Law. Doubling the density of transistors can’t be done anymore without vastly increasing costs. Every jump in technology requires building a new fab [semiconductor fabrication facility], which can cost $5-10B. When there’s a ready market to buy up the newest chips—as there was when people first started buying laptops and smart phones—investing in a new fab makes sense. But it is not always easy to find a new product, or a new market, that brings billions of new chip sales. Still, I believe that these markets will continue to be discovered. There is a need for faster and better computers for autonomous cars, cloud computing, security, cognitive computing, robotics, etc.
We can’t get there just by shrinking transistors into tighter spaces and increasing their densities on chip because we can no longer dissipate the resulting power densities and heat. Now we have this fundamental tradeoff between two opposing forces: more computational performance versus higher power/energy dissipation.
How do you see this tradeoff being resolved?
By building specialized chips for different applications. One type of chip is not going to work for all applications. The system that’s best for the smart phone is going to be different than what’s best for the autonomous car, or cloud servers, or IoT [Internet-of-Things] devices. The performance-energy tradeoff is going to be different in each case.
Because of these conflicting demands, we are already seeing a migration from a homogeneous multicore architecture to heterogeneous SoCs [systems-on-chip] that contain specialized hardware. This consists of accelerators that perform a single function or algorithm much faster and more efficiently than software. Here the processor becomes just another component within a system of components. And the SoC becomes a more heterogeneous multicore architecture as it integrates many different components. Indeed, I expect that no single SoC architecture will dominate all markets. The set of heterogeneous SoCs in production in any given year will be itself heterogeneous!
We’re also seeing the rise of the field-programmable gate array, or FPGA, which can be programmed for different purposes. You’ll get better performance from an FPGA than from software and an FPGA is a much cheaper proposition that building a chip from scratch, but between an FPGA and a specialized chip there are orders of magnitude difference in energy efficiency and performance. So the demand for specialized chips will remain strong, but we need to design them faster and more cheaply while considering the target application: What algorithms or software will it run? Can it be done in parallel? How much energy-efficiency is required? There is no one right way to build a system anymore.
Heterogeneity is the emerging solution but heterogeneity increases the complexity of designing and programming chips. What you decide to put on a chip is just the beginning of a very complex engineering effort that spans both hardware and software.
What does this heterogeneity mean for computer engineering?
We need a new way of thinking about engineering chips. For too long, chip architects have been mostly on the sidelines as new faster chips based on traditional architectures continued to arrive every two years or so. But now there’s this chance to go back to design, to be creative again and come up with innovative architectures. It’s time for a renaissance in computer engineering, if you will, to think about things differently, to move, for example, from a processor-centric perspective to a system-centric perspective, where it’s necessary to think about how a change in one component affects the other components on the chip. Any change must benefit the whole system.
For handling complexity, we need to raise the level of abstraction in hardware design, similar to how it’s done in software. Instead of thinking in terms of bytes and clock cycles, we should think in terms of the behavior we’re aiming for and in terms of the corresponding data structures and tasks. As we do so, we need to reevaluate continuously the benefits and costs of doing things in hardware instead of software and vice versa. Which is the best design? It depends. Do you care more about speed? Or do you care more about power dissipation?
But it’s just not one thing. We need to think in terms of the entire infrastructure, from design and programming to fabrication. You think you have a better chip design, but can you program it and validate it—in conjunction with a system of heterogeneous components—before committing to the expensive manufacturing stage? This system-level design approach motivates the research in our lab here at Columbia.
We have developed the idea of Embedded Scalable Platforms, or ESP, that addresses the challenges of SoC design by combining a new template architecture and a companion system-level design methodology. With ESP, we are now able to realize complete prototypes of heterogeneous SoCs on FPGAs very rapidly. These prototypes have a very high degree of complexity for an academic laboratory.
To support the ESP methodology, we are developing some innovative tools. We have a new emulator for multicore architectures, which we presented at a conference last February—and we released the software as well—so we can describe a new machine and then run this emulator software on top of an existing multicore computer to see how the new architecture behaves when running complex applications. While this type of emulation has been done before—and across the different instruction sets such as Intel’s x86 and the ARM ISA—we have increased scalability so we can emulate a multicore machine on top of another multicore machine. And we made it possible to take advantage of the parallelism of the machines of today.
How have these changes affected how you teach chip architecture?
In my class on System-on-Chip Platforms, students learn to design complex hardware-software systems at a high level of abstraction. This means to design hardware with description languages that are closer to software, thus enabling faster full-system simulation and more effective optimization with high-level synthesis tools. During the first half of the semester students learn how to design accelerators with these methods. They also learn how to integrate heterogeneous components—accelerators and processors—into a given SoC, how to evaluate trade-off decisions in a multi-objective optimization space, and how to design components that are reusable across different systems and product generations.
In the second half of the semester, the students do a project that is structured as a design contest. They compete in teams to design an accelerator specialized for a certain function—one year it might be a computer vision algorithm, another year a machine learning task. They are given some vanilla code to start. They must optimize the code in different ways to design three competitive versions of the accelerator and write software to integrate them in the system and show that each runs correctly in our emulator. High-level synthesis allows each team to quickly evaluate many alternative design decisions. For example, if the algorithm requires that a multiplication is performed on two arrays of many elements, the students can decide to instance more multipliers to do many multiplications in parallel or, instead, to use fewer multipliers by performing these multiplications in time sharing. Basically, they experiment with the trade-offs of “computing in space” versus “computing in time.”
The main goal for each team is to obtain three distinct designs of the accelerator that correspond to three distinct trade-off points in terms of performance versus area occupation. The quality of each final implementation is evaluated in the context of the work done by the entire class. Throughout the one-month duration of the project, a live Pareto-efficiency plot reporting the current position of the three best design implementations for each team in the bi-objective design space is made available on the course webpage. This allows students to continuously assess their own performance with respect to the rest of the class.
Do you foresee further changes to your class?
Yes, always. Course content will never be static when the need for innovation is so great.
Last year we started complementing the competitive aspect with a collaborative aspect. We now partition the student teams in subsets. The teams in each subset compete on designing a given component but are now also asked to pair up their three designs with those designed by the teams in other subsets to get the final system. This further promotes the goal of designing components that are reusable under different scenarios and under different constraints. This is collaborative engineering, and increasingly how engineering is done in the real world today.
Every year, we change up the class by adding something new—different algorithms to implement, for example. Students love this, and in the process they learn one of the most beautiful ideas of engineering: evaluating situational complexity from multiple viewpoints and balancing multiple tradeoffs. It’s exactly what’s needed today in chip design if we are to sustain the level of innovation that we have seen over the past few decades.
Sharon Chen has already built two successful websites: ClickPA to help teenagers in Palo Alto more easily find local events and activities, and Wordcradle to motivate writers to set and meet target goals.
Last week in Stockholm, Columbia researchers presented three papers at Interspeech, the largest and most comprehensive conference on the science and technology of spoken language processing. A fourth paper was presented at the *SEM, a conference on lexical and computational semantics held August 3-4 in Vancouver, Canada. High-level descriptions of each of the four papers are given in the following summaries and interviews with lead authors.
In this work, our motivation was to see if we could use deep learning to improve our results since previous experiments were mostly based on traditional machine learning methods.
How prevalent is deep learning becoming for speech-related research? How is it changing speech research?
Deep learning is very popular these days and in fact has been for the past few years. In speech recognition, researchers originally substituted traditional machine learning models with deep learning models and gained impressive improvements. While these systems had deep learning components they were still mostly based on the traditional architecture.
Recent developments allowed researchers to design deep learning end-to-end systems that completely replace traditional methods while still obtaining state-of-the-art results. In other subfields of speech research, deep learning has not been as successful, whether it’s because simpler models suffice or the lack of big datasets.
In your view, will deep learning replace traditional machine learning approaches?
I see deep learning as just another tool in the researcher’s toolbox. The choice of algorithm requires an understanding of the underlying problem and constraints. In many cases, traditional machine learning approaches are better, faster, and easier to train. I doubt traditional methods would be completely replaced by deep learning.
You investigated four deep learning approaches to detecting deception in speech. How did you decide on these particular approaches?
We chose these methods based on previous work on deception detection, similar tasks such as emotion detection, and running thousands of experiments to develop intuition for what works.
Nonetheless there’s a lot more to be done! There are different model architectures to explore and different ways to arrange the data. I’m mostly excited about application of end-to-end models that learn to extract useful information directly from the recording without any feature engineering.
Your best performing model was a hybrid approach that combined two models. Is this what you would have expected?
Our original experiments focused on detecting deception either from lexical features (the choice of words) or acoustic features from the speaker’s voice. While both proved valuable for detecting deception we were interested to see whether they complement or overlap. By combining the two we got a better result compared to each one individually. I can’t say this was a huge surprise since humans, when trying to detect lies, utilize as many signals as possible: voice, words, body language, etc. Overall our best model achieved a score of 63.9% [F1] which is about 7.5% better than previous work on the same dataset.
Is this hybrid model adaptable to identifying other speech features other than deception?
Definitely. Now that our work is published we’re excited to see how other researchers will use it for other tasks. The hybrid model could be especially useful in tasks such as emotion detection and intent classification.
Creating a text-to-speech (TTS), or synthetic, voice—such as those used by Siri, Alexa, Microsoft’s Cortana—is a major undertaking that typically requires many hours of recorded speech, preferably made in a soundproof room by having a professional speaker reading in a prescribed fashion. It is time-consuming, labor-intensive, expensive, and almost wholly reserved for English, Spanish, German, Mandarin, Japanese, and few other languages; it is almost never used for the other 6900 or so languages in the world, leaving these languages without the resources required for building speech interfaces.
Repurposing existing, or “found,” speech from TV or radio broadcasts, audio books, or scraped from websites, may provide a less expensive alternative. In a process called parametric synthesis, many different voices are aggregated to create an entirely new one, with speaking characteristics averaged across all utterances. Columbia researchers see it as a possible way to address the lack of resources common to most languages.
Found speech utterances however have their own challenges. They contain noise, and people have varying speaking rates, pitches, and levels of articulation, some of which may hinder intelligibility. While low articulation, somewhat fast speaking rates, and low variation in pitch are known to aid naturalness, it wasn’t clear these same characteristics would aid intelligibility. More articulation and slower speaking rates might actually make voices easier to understand.
“We wanted to discover what would produce a nice, clean voice that was easy to understand,” says Erica Cooper, the paper’s lead author. “If we could identify utterances that were introducing noise or hindering intelligibility in some way, we could filter out those utterances and work only with good ones. We wanted also to understand whether a principled approach to utterance selection meant we could work with less data.”
Though the goal is to create voices for low-resource languages, the researchers focused on English initially to identify the best filtering techniques. Using the MACROPHONE corpus, an 83-hour collection of short utterances taken from telephone-based dialog systems, the researchers removed noise, including transcribed utterances labeled as noise as well as clipped utterances (where the waveform was abruptly cut off), and spelled out words.
Using the open-source HTS Toolkit, the researchers created 34 voices from utterances spoken by adult female speakers. Each voice was selected according to different acoustic and prosodic characteristics, and drawn from different subsets of the corpus; some adult female voices were from the first 10 hours of the corpus, and some from 2- and 4-hour subsets.
Each voice was used to synthesize the same 10 sentences, and each set of sentences was evaluated by five Mechanical Turk workers who transcribed the words as they were spoken. Word error rates associated with a voice were used to judge intelligibility.
A sample prompt for crowdsourcing transcriptions. Each worker transcribed 11 questions, ten to evaluate intelligibility and one as a check that workers were paying attention.
Workers could listen to only one question set to ensure they were not transcribing words from memory; the task thus required a relatively high number of workers. The rate at which workers signed up quickly become a bottleneck, adding weeks to the project and prompting the researchers to consider using automatic speech recognition (ASR) as a proxy for human evaluations. ASR evaluations would speed things, but would they agree with human evaluations when assessing intelligibility?
Extending the scope of the experiment, the researchers employed three off-the-shelf ASR APIs—Google Cloud Speech, wit.ai (owned by Facebook), IBM’s Watson—to study using ASR to evaluate intelligibility. ASR did in fact correlate closely with Mechanical Turk workers; for all voices humans rated better than baseline, all three ASRs did the same, showing the future promise of ASR in assessing intelligibility of spoken speech. There was one notable caveat. Sending the same audio clip multiple times to one of the APIs (wit.ai) did not necessarily return the same transcription, so variability might be expected in some ASR systems. But then again, humans were themselves even more variable in evaluating intelligibility. (Google and Watson showed no variability, always returning the same transcription.)
The most intelligible voices for both humans and the ASR methods were those with a faster speaking rate, a low level of articulation, and a middle variation in pitch. (For naturalness, the researchers had previously found the best features to be also a low-level of articulation but a low, not middle, mean pitch.) Removing transcriptions labeled as noise produced noticeable improvement, but removing clipped utterances or spelled out words did not.
More training data wasn’t necessarily better if the data was chosen in a principled way. Using the first 10-hour subset of female adult speech as a baseline with 67.7% accuracy, some two-hour subsets with carefully chosen utterances did better, validating the hypothesis that better voices can be trained by identifying the best training utterances in a noisy corpus, even with less training data.
Almost all bilingual and multilingual people code-switch, that is, they naturally switch between languages when talking and writing. People code-switch for many reasons; one language might better convey the intended meaning, a speaker might lack technical vocabulary in one language, or a speaker wants to match a listener’s speech. Worldwide, code-switchers are thought to outnumber those who speak a single language. Even in the US, famously monolingual, it is estimated that 40M people code-switch between English and Spanish.
People code-switch, but speech and natural language interfaces for the most part do not; their underlying statistical models are almost always trained for a single language, forcing people to adjust their speaking style and refrain from code-switching. To eventually enable more natural and seamless natural language interfaces so people can freely switch between languages, Columbia researchers Victor Soto and Julia Hirschberg have begun building natural language models specifically for code-switching in English and Spanish settings; the overall goal, however, is for a workable paradigm for other language pairs.
Simply combining two monolingual models was not seen as a viable solution. “Code-switching follows certain patterns and syntactic rules,” says Soto, lead author of the paper. “These rules can’t be understood from monolingual settings. Inserting code-switching intelligence into a natural language understanding system—which is our eventual aim—requires that we start with a bilingual corpus annotated with high-quality labels.”
The necessary labels include part-of-speech (POS) tags that define a word’s function within a sentence (verb, noun, adjective, and other categories). Manually annotating a corpus is time-consuming and expensive, so Soto and Hirschberg want to build an automatic POS tagger. The first step in this process is collecting training data.
The researchers start with an existing English-Spanish code-switching corpus, the Miami Bangor Corpus, compiled from 35 hours of conversational speech containing 242,475 words, two-thirds in English and one third in Spanish. While the corpus had the required size, the existing part-of-speech tags were often inaccurate or ambiguous, having been applied automatically using software that did not consider the multilingual context.
The researchers decided to redo the annotations, using tags from the Universal Part-of-Speech tag set, which would make it easier to map to tags used by other languages.
Fully half the corpus (56%) consisted of words always labeled with the same part of speech; these words were labeled automatically. Frequent words that were hard to annotate (slightly less than 2% of the corpus) were tagged by a computational linguist (Soto).
For the remaining 42% of the corpus, the researchers turned to crowdsourcing, a method used successfully in monolingual settings with untrained Mechanical Turk and Crowdflower workers. In this case, tagging tasks are structured in a way that does not require knowing grammar and linguistic rules. Workers simply answer a single question or are led through a series of prompts that converge to a single tag; in both cases, instructions and examples assist workers in choosing a tag.
Two types of prompts: a single question format used for many high-frequency words, and a decision tree structure consisting of a series of questions that progressively lead to the tag to be assigned.
To adapt this crowdsourcing approach to a bilingual setting, the Columbia researchers required workers to be bilingual, and they wrote separate prompts for the Spanish and English portions of the corpus, taking into account syntactic properties of each language (such as prompting for the infinitival verb form in Spanish, or the gerund form in English, to disambiguate between verb and nouns, among others).
Each crowdsourced word was assigned three intermediate judgments—two from crowdsourcing and one carried over from the Miami Bangor corpus—with majority vote to decide the tag. The voting considered judgments only from workers who demonstrated a tagging accuracy of at least 85% when compared to a hidden test set of tags. In 95-99% of the time, at least two votes agreed.
Over the entire corpus, Soto and Hirschberg estimate an accuracy of between 92% and 94%, close to what a trained linguist can do.
With an accurately labeled corpus, the researchers’ next step is building an automatic part-of-speech tagging model for code-switching between English and Spanish.
Why is it important to automatically identify questions?
Many applications follow a question-and-answer format where people have the flexibility to speak naturally and choose their own words but within the confines of the topic set up by the question. Often it’s often important to know how much speech goes into answering a particular question or when there is a change in topic. Our goal with this project was to develop automatic approaches to organizing and analyzing a large corpus of spontaneous speech at the topic level.
Both corpora are part of our larger effort in identifying deception in speech, something we’ve been working at here at Columbia for a number of years. The CXD corpus contains 122 hours of speech in the form of dialogs between subject pairs who played a lying game with each other. They took turns playing the role of interviewer and interviewee, and asked each other questions from a 24-item biographical questionnaire that they filled out, lying for a random half of the questions. Given this setup, we wanted to identify which question a given interviewee was answering.
With 122 hours of speech, it’s just not possible to do this manually—as we had done with the smaller CSC corpus. We needed an automatic approach, and for this we compared three different techniques for question identification to see which one was best for identifying which question a given interviewee was answering.
While we needed topic labels for the CXD corpus, the CSC corpus was chosen because it had similar topical distinctions that were hand-labeled, which we could use to test and verify that the approach that worked on CXD corpus was viable.
How do the three methods you tried—ROUGE, word embeddings, document embeddings—differ from one another?
We compared these methods because they capture similarity of language in different ways. ROUGE—which is a software package for evaluating automatic summarization, was selected to do comparison with n-grams. We selected the word embeddings and document embeddings approaches because they accounted for semantic similarity. The word embeddings approach used the Word2Vec model, which represents words as vectors, and words that were similar semantically had higher cosine similarity between the vectors, and the document embeddings approach used the Doc2Vec model, which we hoped would capture additional context.
The word embedding approach had the highest accuracy. Are these the results you expected?
It makes sense that the word embeddings approach would have higher accuracy because it also accounts for true negatives, and in any given interviewer turn, there are more true negatives than true positives.
While we weren’t surprised that word embeddings was the best method, we were nonetheless amazed at how well it worked. It matched very closely with the manually applied labels.
Your work was on labeling deceptive speech corpora. Would you expect similar results on other types of corpora?
Yes. This work applies at any type of speech that has a conversational structure. We happened to use deceptive speech corpora, but the method is unsupervised and should generalize well to other domains.
His winning presentation shows how to augment proprietary networks with public internet bandwidth to greatly enhance the user experience for wide-area communications. Kunal is a PhD student advised by Vishal Misra and Dan Rubenstein.
Interactive Robogami, an MIT CSAIL project, lets anyone design a robot in minutes, and 3D-print and assemble it in as little as four hours. A key feature is controlling a robot’s gait and geometry.
The paper, by three Columbia researchers, describes CLKSCREW, a new class of fault attacks that exploit the security-obliviousness of energy management mechanisms. The attack does not require physical access to devices or fault injection equipment.
Bjarne Stroustrup is the designer and original implementer of C++. His research interests include distributed systems, design, programming techniques, software development tools, and programming languages.
In a paper published in PNAS, they call for a holistic approach to data science, one that weaves statistics and computer science into a larger framework while considering context and responsibilities when using data. Subscription.
The Winner’s Curse—where newly discovered genetic effects are consistently overestimated and fail consistently to replicate in subsequent studies—afflicts every genome-wide association study (GWAS). This failure to replicate calls into doubt the credibility of these studies that otherwise show promise in establishing the genetic basis for both quantitative (height, obesity) and disease traits. But how much of the failure to replicate is due to the Winner’s Curse? Are other factors involved? To find out, two Columbia University researchers analyzed 332 GWAS quantitative papers to de-bias the effects of the Winner’s Curse across a broad set of traits. Their first finding? Fully 70% of GWAS did not report enough information to independently verify replication rates. Digging deeper into papers that did fully report, the researchers identified two main issues preventing replication—use of populations with different ancestry, and not reporting a cohort size for each variant. Papers without these problems did in fact replicate at expected rates. Reporting deficiencies, not the paradigm of GWAS, are to blame for the failure to replicate. The researchers’ method and the code to implement the method are made available to other researchers in the field.
Large-scale genome-wide association studies (GWAS) scan the genomes of hundreds of thousands of individuals for genetic variations common to an entire population, allowing scientists to associate traits (height, risk of diabetes) to specific genetic variations, specifically single nucleotide polymorphisms, or SNPs (pronounced “snips”).
It’s a statistical approach that looks across a very large sampling of human genomes to discover what SNPs occur more frequently in individuals exhibiting the same traits, to see for instance, what SNPs are common in tall people or in those who are obese. That GWAS cost a fraction of full DNA sequencing have made GWAS especially attractive.
But are GWAS reliable? Associations found in a GWAS often do not replicate in subsequent studies assembled to corroborate such findings. GWAS are susceptible to the Winner’s Curse, where initial discoveries are too optimistic and fail to replicate more than expected. High failure rates in GWAS call into question the credibility of the GWAS paradigm.
Itsik Pe’er
Itsik Pe’er, a computational geneticist and computer scientist at Columbia University, explains the term Winner’s Curse this way: “The millions of variants in the genome are all going through a statistical test. This is analogous to athletes competing in a time trial. The winner is very likely to be better than the average participant, but also likely to have been lucky, having had a particularly good day at the race. The time set by the winner therefore overestimates how good the winner is. Similarly, the statistical score of the winning variants overestimates the effect a winner has on the examined trait.”
A single GWAS can uncover thousands of SNPs; without the resources to investigate them all, scientists select the most promising SNPs based on how they perform against a threshold. Causal SNPs may exceed the threshold, but due to noise, so will a number of noncausal SNPs. The lower the threshold, the more SNPs of both types.
The effect of thresholding. Along an axis of SNPs contributing to a complex trait, the effect of each individual SNP is associated with a normal distribution. A threshold draws a line through otherwise symmetrical error distributions, excluding values that give a true picture of performance and often exaggerating those instances that happen to overperform.Cameron Palmer
The problems surrounding GWAS have long been known, and individual GWAS papers have attempted to correct for the Winner’s Curse to achieve the true rate of replication—but only for the studied traits. To look broadly across GWAS to de-bias the effect of the Winner’s Curse no matter the trait, Pe’er and graduate student Cameron Palmer, who is part of The Integrated Program in Cellular, Molecular and Biomedical Studies, manually examined the 332 quantitative GWAS papers within the NHGRI-EBI GWAS Catalog (a collection of peer-reviewed GWAS papers published in scientific journals) that (1) found a significant SNP-trait association and (2) where there was an attempt to replicate it. (A quantitative trait is one measured on a scale. Height and BMI are quantitative traits; disease-risk traits studied in case controls are not. The researchers did not at this time look at case-control studies, which have previously been evaluated in terms of the Winner’s Curse.)
De-biasing the effect of the Winner’s Curse across GWAS required going through all 332 papers and obtaining certain information, including the sample size (the number of individual genomes studied), along with the replication threshold and SNP frequency needed to calculate bias in effect sizes.
In 70% of the papers, Pe’er and Palmer did not find this information. The omissions for the most part were inadvertent—Palmer was surprised to find seven papers he previously worked on to be missing needed information—nor was reporting this information required by peer-reviewed publication venues.
This left 100 papers. By applying a Winner’s Curse correction previously used in disease studies, Pe’er and Palmer came fifteen-fold closer to the true rate of replication, a vast improvement but still a statistically significant failure to replicate.
Digging deeper into each these 100 papers, they identified two main issues: replication studies sometimes used populations with a different ancestry from the original, and they failed to report sample sizes on the basis of the individual variant.
Ancestry is especially important in a GWAS because, for populations in different continents, variation in correlation between SNPs makes a study in one population less relevant to the other.
Not reporting a sample size for each variant was often a function of the way replication studies are pulled together from several existing studies, each one focused on one or more of the variants of the original GWAS. The sample sizes of these studies may all be different, perhaps 50,000 in one, 20,000 in another; rather than reporting separate sample sizes, the studies often reported only a single sample size, which was usually the total number of individuals across all studies (in this case, 70,000).
Binning papers by problem, the two researchers ended up with one bin of 39 papers that did use populations with the same ancestry and did report sample sizes for each variant. And in this bin, replication rates matched expectation.
“When we looked at papers with correct ancestries and that reported cohort sizes per variant, the replication rate improved substantially,” says Palmer, “and this improvement was seen in all 39 papers, so the effect is strong and it is broad. The deviation we saw before in the 100 papers is being fixed by filtering out papers that exhibit problems. So we can say that if a replicated study uses the same ancestry of the original study, and if it reports individual cohort sizes for each variant, no matter the trait, GWAS do replicate at expected rates.”
The fault for failing to replicate lies with reporting deficiencies, not with the paradigm of GWAS.
While this news should be reassuring to those who see in GWAS a promising, low-cost way to link genetic variation to traits, especially those associated with complex diseases, the study does point to community-wide deficiencies in reporting, something that is not easily resolved without a central standards board. One concrete suggestion is for the NHGRI-EBI GWAS Catalog to upload only papers meeting certain minimum reporting criteria. Individual journals could also require minimum reporting standards.
Individual authors may have the most incentive to report all pertinent information, for it is only by doing so is it possible to claim replication does occur.
Augmented reality headsets made by Meta overlay 3D holograms on real world so people can do tasks—send emails, write code—from virtual screens. Meta’s founder is Meron Gribetz, a former student of Steven Feiner.
Eitan Grinspun and Changxi Zheng worked with MIT researchers to create InstantCAD, a plugin providing real-time feedback on how design changes affect performance. A paper describing InstantCAD will be presented at SIGGRAPH in August.
A Columbia computer science master’s student has qualified to compete in the Cambridge 2 Cambridge (C2C) Cybersecurity Challenge to be held July 24-26 in Cambridge, UK. Now in its second year, C2C has students compete in individual and team cyber challenges that include a “capture-the-flag” hackathon and exercises in binary exploitation, web security, reverse engineering, cryptography, and forensics.
The competition, which takes place over three days of social events and networking, is meant to be fun for all participants, with medals and cash prizes for the winners; but the purpose is serious: to foment US-UK cooperation in combating global cyberattacks while helping develop the cybersecurity talent of the future.
Photos from C2C 2016, where side events included lock-picking, cryptography, password cracking. and social engineering (getting people to reveal information they shouldn’t).
Last year’s inaugural C2C was a joint venture between MIT (in Cambridge, MA) and the University of Cambridge in the UK; this year, C2C was opened to US and UK college students who made it past a qualifying round held earlier this year.
The Columbia student who qualified will be identified by his alias Derrick. The use of aliases and avatars, especially in the fields of computer security and privacy, is gaining ground as people become more aware of what can happen to personal information on the web.
“Some people think using avatars or aliases is paranoia,” says Derrick. “But in the field of security, paranoia can be to your benefit.” Just starting his master’s program in computer science—it will be his second master’s—Derrick has worked as an industry researcher for the past several years, mostly on advanced hardware. But over time and after being exposed to different fields, his interest shifted to security and privacy. “I feel passionate about protecting people, especially those who are less aware of security risks.”
To make it to C2C, Derrick had to beat out other C2C hopefuls in an online Jeopardy-style qualifier made up of tasks with varying levels of difficulty in five categories: web security, binary exploit, forensics, cryptography, reverse engineering. The goal in each case was to find the security vulnerability.
Next week he will be one of 110 students competing at the live C2C event; 30 students are from the US and 80 are from the UK. Competitors will be assembled into teams carefully balanced according to their strengths and skillsets. While there will be a variety of exercises and side events, the highlight is the capture-the-flag hackathon, where twenty-two teams compete on a CyberNEXS platform.
Derrick would like to see other students consider competing in cyber competitions.
“A lot of what you learn in class is theory; a competition like C2C gives you the chance to take what you’ve learned and apply it in a real-world scenario. In class you might do something one or twice but to reinforce the lessons requires performing it many times, preferably under time constraints. And that’s one reason these hackathons and other activities are so important.”
When 108,000 students enrolled in her inaugural online edX artificial intelligence course, Ansaf Salleb-Aouissi and two assistants divided up among them the task of handling student questions. There was frustration on both sides; students sometimes had to wait up to 48 hours for a reply, and Salleb-Aouissi and her small team found themselves answering the same questions multiple times, many of them logistical in nature (“what materials can I use for the final”), leaving less time for those related directly to course content.
Even after putting together a FAQ, the volume of questions remained high.
With $20K in funding provided through a Provost Award for Hybrid Learning, enough to fund at least two graduate students, Salleb-Aouissi will now begin investigating building a chatbot to automatically answer student questions. Collaborating closely with Columbia Video Network (CVN), which produces Columbia Engineering edX courses, the goal will be a chatbot intelligent enough to “converse” with students in real time.
“We will first look at the state-of-the-art chatbots that are out there now,” says Salleb-Aouissi. “If there is open-source software that can work on our data, it makes sense to begin there.”
Though chatbots are currently in use—including by some MOOCs—machine question and answering is far from solved; it is in fact a hard problem and an active area of research. Many speech interfaces, including Siri and Alexa, involve relatively simple tasks—scheduling meetings, setting alarms, searching the web—with little back-and-forth conversation. These systems work by transcribing speech to text and then attempting to understand and classify the meaning. The answer, once retrieved, is transcribed back to speech. Some of the more difficult questions may be handled through hand-coding or automated to some extent using AI.
But true conversation, where an answer begets another question, will require much more intelligence and more automation, which Salleb-Aouissi hopes to achieve using methods borrowed from AI and machine learning.
“There is research now into using deep-learning models for text, and while we know they work well with images, text is a much, much harder problem than images. Text has many layers—lexical, semantic, contextual, metaphorical. There is ambiguity and intentional double-meaning in words, and understanding what is meant often requires considering the specific context or employing real-world knowledge. Conversation with all its stops and starts and disfluencies adds to the complexity. We will be looking to put together an interdisciplinary team with expertise in machine learning, in psychology, and of course natural language processing, which is necessary to build a language model for predicting, in the context of our class, the next word in a sentence.”
Predicting the probability of the next word will require data, the more the better. In Salleb-Aouissi’s case, the data will consist of questions taken from her MOOC supplemented with others from discussion forums (e.g., Piazza) of her on-campus AI courses, as well as from text-mining the course material. One requirement is for the chatbot to be trainable on new data so it can be used in other MOOCs (such as the three other Columbia classes that are part of the edX AI series).
The chatbot represents an ambitious project; still she hopes to have a proof of concept in a year. “You can accomplish a lot working with two or three students, especially when they are excited about artificial intelligence, and always willing to try new ideas, new avenues. It’s an inspiration to work with them.”
In a DARPA project, researchers are looking to build a less invasive implant device at the scale of 1M channels. Such a device would dramatically expand ways artificial systems can support brain functions.
The paper gives the final answer to a well-studied question in property testing, an area of theoretical computer science: given an unknown Boolean function, how many nonadaptive queries are required to determine whether it is a k-junta versus far from every k-junta?
A k-junta is a function whose value is determined by a subset of at most k relevant variables, out of a potentially huge number of input variables. For example, a decision rule for determining whether a movie is a box office bomb or not (as a Boolean function) would ignore most input attributes—title, director, leading actor, genre, release date, running length, rating, etc.—to consider maybe only two: budget and box office receipts. A simple function such as this, depending on only two variables, is a 2-junta function; a function that looked at 100 attributes would be a 100-junta function.
A function that is a k-junta is relatively simple because it relies on only a small number (k) of variables; in such cases, dimension reduction techniques could potentially be used to remove extraneous variables. A function that is far from every k-junta, on the other hand, is determined by more than k variables and is in fact different from any k-junta on a large fraction of inputs; dimension reduction will not do much to simplify such a problem because the output depends on many variables.
Testing for the k-junta property, which is a helpful first step in exploratory data analysis, works by querying values of the function on inputs chosen by the testing algorithm. The smallest number of such queries required for nonadaptive algorithms—where queries are sent all in one simultaneous batch (as opposed to being sent one after the other, as occurs in adaptive algorithms where subsequent queries can depend on the answers obtained in response to earlier queries)—had been an open question until this paper, which now establishes that at least k1.5 nonadaptive queries are required. This result represents a dramatic improvement over previous lower bounds, and matches the upper bound of k1.5 given by Eric Blais in his 2008 paper Improved bounds for testing juntas.
The new lower bound was achieved by constructing a pair of hard-to-distinguish probability distributions supported on k-juntas and functions that are far from k-juntas, respectively. It is based on an idea of random indexing that the Columbia researchers have started exploring for a range of problems, applying it in particular to make progress in monotonicity testing (see Beyond Talagrand functions: new lower bounds for testing monotonicity and unateness). For k-juntas, the functions used in the paper are illustrated in the following figure:
This figure shows how an input x in {0,1}n is evaluated by a function f used in the paper. Two disjoint subsets of randomly sampled variables, M and A, determine f(x) in the following way. Given x, one first interprets the variables in M as the index i of a function hifrom a sequence of random functions, each of which depends only on a small subset of variables in A. Then f(x) is set to the value of hi evaluated on the relevant variables in the small subset of A (depicted by the four narrow shaded bands). By adjusting the size of A, f becomes either a k-junta or far from every k-junta, for some appropriate parameter k.
“Once we had the initial idea, the work went quickly; in less than a month, we had the result,” says Chen. “The surprise is that we could push it all the way to get the lower bound to match the upper bound, which has been known since 2008. This result has two implications. We know the exact number of queries needed for nonadaptive junta testing. And we know that adaptive algorithms not only do better than nonadaptive ones, they do a lot better, with k queries instead of k1.5.”
Adds Servedio, “Junta testing is one of the best-known problems in property testing of Boolean functions. It’s nice to have a thorough understanding of what is and isn’t possible for this basic problem. Hopefully the techniques we used for this result will find further applications for other problems in property testing and query complexity.”
In this video talk, Erik Waingarten gives more technical detail about the method used in the paper.
Hirschberg’s subject was entrainment, the tendency of speakers to align their speaking style with that of a conversation partner. Joint work with Štefan Beňuš, Nishmar Cestero, Agustín Gravano, Rivka Levitan, Sarah Ita Levitan, Zhihua Xia.
Kai-Fu Lee (BS’83) cofounded Sinovation Ventures and was formerly President of Google China; he gave SEAS’ 2017 commencement speech. Jingren Zhou (PhD’04, advisor Ken Ross) is Chief Scientist and Vice President of Alibaba Cloud, Alibaba.
Two Columbia Engineering PhD students, João P. Cerqueira (Electrical Engineering) and Thomas J. Repetti (Computer Science), have been named recipients of the highly competitive $100,000 Qualcomm Innovation Fellowship (QInF) for their proposal to build a general-purpose chip that is fast, programmable, and energy-efficient. Advised by Mingoo Seok and Martha Kim, respectively, Cerqueira and Repetti are one of eight two-member teams to be awarded funding (out of 116 initial applications). This is the fifth year in a row that a Columbia team has earned the coveted fellowship.
Cerqueira and Repetti’s winning proposal, “A Programmable Spatial Architecture with Temporally/Spatially Fine-Grained Active Leakage Management for Energy-Efficient Near-Threshold-Voltage Computing,” aims to design a single chip combining programmability, energy efficiency, and high performance. It’s an ambitious undertaking considering that most chips are designed for one of these goals at a time.
For chip manufacturers like Qualcomm, the cost of designing and fabricating a variety of chips becomes costly. An architecture general enough for several types of workload that still attains the speed and efficiency of more specialized designs presents obvious cost efficiencies.
To design such a chip, Cerqueira and Repetti will employ a spatial architecture, where an array of discrete processing elements cooperate to speed the completion of a variety of workloads. Such processors take advantage the spatial structure of algorithms and can be reprogrammed to execute different tasks. To build an efficient design while maintaining this flexibility, Cerqueira and Repetti must tackle several problems. Among them:
Giving each processing element—of which there can be hundreds—its own local, independent control logic, thus extracting higher performance from individual processing elements while allowing for each to receive different voltages depending on an element’s busy or idle status.
Operating the chip at ultra-low voltage, near the minimum gate-source voltage required for a transistor to create a channel.
Maximizing energy efficiency through a variety of architectural and circuit techniques.
That Cerqueira and Repetti propose to design and complete a “tapeout” (a photomask used as the basis for fabrication) within a year reveals the true extent of their ambitions. That they are still PhD students (Cerqueira is in his third year and Repetti in his second) does not concern their advisors.
“João and Tom are uniquely positioned to see this innovative—and important—research through to completion,” says Kim. “They already have extensive experience and accomplishments directly relevant to this new project.”
Cerqueira works with energy-efficient integrated circuits and systems. He proposed novel circuit techniques on leakage current suppression to maximize the energy efficiency of parallel architectures (this work was published in the IEEE Transactions on VLSI Systems). He also collaborated on two chip-design projects for brain computer interface systems, both of which were fabricated and described in two papers accepted to IEEE Symposium on VLSI Circuits. Last year, Cerqueira led and completed a chip design to demonstrate innovative techniques on leakage energy reduction (this work was accepted for publication in September’s European Solid-State Circuits Conference).
Repetti’s studies in digital design, systems programming, and computer architecture and his previous work experience in the industry (including interning at Intel where he worked on post-silicon validation and driver debugging) have allowed him to design his own ISA (instruction set architecture), implement a functional simulator, an assembler, an FPGA prototype, and a driver to program the prototype and dispatch jobs. The infrastructure and techniques he has developed for this project so far are currently under review for publication.
Together Cerqueira and Repetti have explored a range of logic- and circuit-level designs, honing in on one as the basis of their Qualcomm prototype. Their individual strengths and previous experience as a team no doubt played a role in their being selected for the fellowship.
“This work can potentially have a ground-breaking impact on the mobile and embedded systems, which look for a pathway to design a flexible yet energy-efficient computing platform for various digital signal processing and machine learning,” says Seok, advisor to Cerqueira. “Those two things, flexibility and energy-efficiency, are not easy to come by together, and we probably need holistic approaches like what João and Tom will pursue in this project. It was my pleasure to support this project and I very much look forward to monitoring their progress over the next year. “
In addition to the $100K funding, the fellowship provides mentoring from Qualcomm researchers who will also facilitate contacts between them and Qualcomm’s R&D department.
When data can be anywhere, what country has jurisdiction? In a case involving an Outlook user—whose data was stored in Ireland by a US company (Microsoft)—a US court will rule on what country’s laws apply.
How best to efficiently search for similar items in a large dataset? In this Simons Foundation talk, Alexandr Andoni describes using the tools and perspectives of high-dimensional geometry to benefit search algorithms.
Funville Adventures tells the story of 9-year old Emmy and her 5-year old brother Leo who find themselves transported to Funville, a magical land whose ordinary-looking inhabitants have unique powers to transform objects and people. It’s an adventure book that has children anticipating the action as characters apply their powers to shrink or double the size of objects, replicate things, and turn things into elephants, lots of elephants. That these powers derive from mathematical functions is beside the point and in no way interferes with the telling of a good story. (For those wanting to dive more deeply into the explicit character-function connection, an addendum is provided for the purpose.) The authors, Allison Bishop and Sasha Fradkin, who met at Princeton when both were undergrad math students, are using story-telling to introduce mathematical concepts to children, and in so doing are pioneering a new genre: math-based fantasy.
How is math incorporated into the story?
The math is the characters. Each character personifies a mathematical function, and the power each character has derives from a different function: one can double an object’s size (f(x) = 2x), another can make copies (f(x) = (x,x)), and another can rotate (f(x) = π x) objects. Other characters have other powers. Some powers—but not all—are reversible, and part of the action is driven by Emmy and Leo having to figure out how to counteract the powers of one character with the powers of another.
At one point, a character accidentally applies his power an unknown number of times to shrink Leo, and Emmy has to find someone whose power is to double the size of something so Leo can be restored to normal.
How explicit is the math?
It’s not explicit at all, or very little, and that was in keeping with our goal of writing math-based fiction that could stand on its own merits as a story that kids would want to read; we didn’t want the math to take the reader out of the moment. Math drives the action, but it’s under the hood. For those who want an explicit explanation of the function embodied by a character, we provide an addendum, but we don’t want parents or others feeling obligated to lead a math exercise.
The whole point is for kids to pick up the math organically, not through exercises, but by applying their natural problem-solving and pattern-detecting skills and having fun doing so, similar to someone reading Sherlock Holmes and trying to think ahead to solve the crime. We have this scene with characters preparing for a party. They have to take one balloon and make many. Someone is blowing up balloons and someone else can make copies of things. We go through the thought process: if you copy the balloon not blown up, then you have to blow up all the 100 balloons whereas if you copy it after it’s blown up, you don’t have to go through this step all those times.
Why write for 5- and 10-year olds?
This age group has a great capacity to learn more mathematical concepts than they are learning in school, and to learn them in a more abstract and generalizable way.
Most kids don’t formally encounter a function until pre-algebra which is usually around 8th grade; so all of the sudden they are presented with f(x). That x is such a struggle when all you’ve ever seen is arithmetic where there is no x. We think functions belong so much earlier in the curriculum. And really, 5-10 is old enough. Children of this age love patterns; they love organizing their thinking that way.
Why did you turn to storytelling to help teach math?
The initial idea was my coauthor’s. She is a curriculum developer and teaches math for kids, so she’s around kids in the classroom and she sees first hand what motivates kids, what gets them excited. She also has two kids of her own, including a daughter who loves stories, just as I did when I was young. In fact, I hated math all through high school; I found formulas boring.
Mathematicians and scientists need to think about storytelling as a way to get broader scientific literacy across to others.
What really got me interested in math as an adult was the creative side of science research, and the human stories of how different people make different discoveries. Why them? Why that idea? What was it about that context and that time that sparked an insight?
Storytelling is fundamental to everything. Mathematicians and scientists need to think about storytelling as a way to get broader scientific literacy across to others. We as scientists don’t optimize the communication part; we spend so much time on the research. But we need to be able to explain science to someone who hasn’t spent years delving into scientific questions. People should be able to more easily see the creativity and beauty in science. So many people don’t get there.
But storytelling can provide a jumping-off point by breaking things down into pieces that people can individually follow and then fit into a larger framework. It’s how stories are told. Take Game of Thrones, an immense world with so many interweaving relationships. We as an audience are never told that there is a world and there are five houses and there are a hundred people in each house; we don’t see in the beginning the huge, overwhelming thing. We start with a single character and by observing what that character is doing, we begin to care about what happens next. As this character interacts with others, we learn about these new characters and piece by piece we begin to understand the larger world they inhabit. We could explain science in that way; we should explain science in that way.
What was the hard part in putting together the book?
Trying to get an agent and a publisher. Funville Adventures is not a typical kids book, it’s not a typical activity book so it doesn’t fit existing categories. It didn’t help that we are new authors trying to pioneer this new genre of math-based fantasy.
While everyone said that a math-based fantasy book sounded interesting, no one knew if there was a market for it. Our publisher, Natural Math, focuses more on activity books but was willing to take a leap of faith with us and try this direct-to-kids fiction format. The publisher—we never did get an agent—worked with us on a Kickstarter campaign to both validate the model and to connect with others seeking innovative approaches to math education. Money raised will help cover the costs of producing the book, which will come out in August.
What has been the response so far to the book?
It’s been good. In beta-testing the book, we’ve seen kids carry forward ideas taken from the book by inventing their own function characters. It gives support to this idea of using storytelling to convey mathematical concepts.
Ideally we want to pioneer not just this one book, but a whole genre of math-based fantasy. We’re thinking of doing a follow-up with coded messages and using encryption to keep secrets. Kids love secrets. We’re even thinking of eventually doing a book with modular arithmetic, like rhythm and periodicity; the mathematical concepts will be different, but the use of storytelling to make the concepts compelling and understandable will the same. It’s a formula we think will work for young and older children, too. Maybe even adults.
Schulzrinne, who co-developed key VoIP and other multimedia protocols, takes a look back at what was learned from deploying the land line, 2G, 3G, and 4G.
“A Multi-Scale Model for Simulating Liquid-Hair Interactions,” a paper being presented this summer at SIGGRAPH, describes innovations for capturing liquid onto hairs, modeling the flow along hairs, inducing cohesion, and enabling dripping.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor

 AI talent is expensive, scarce, and hard to retain, making it tough for startups and small companies to compete with the big established tech giants that can afford the high-flying salaries and expensive perks AI engineers regularly command. But rather than compete for already trained AI engineers, NYC-based
AI talent is expensive, scarce, and hard to retain, making it tough for startups and small companies to compete with the big established tech giants that can afford the high-flying salaries and expensive perks AI engineers regularly command. But rather than compete for already trained AI engineers, NYC-based 

 Last Friday, with less than a week remaining before the FCC’s expected repeal of the Open Internet Rules, a panel of four experts convened before an audience in Davis Auditorium to discuss what such a repeal is likely to mean for the Internet. Though all four spoke from different perspectives—three were technology experts and one an Internet consumer advocate and lawyer—all expressed concerns about the repeal. (Though proponents of the repeal had been invited, none were able to attend.)
Last Friday, with less than a week remaining before the FCC’s expected repeal of the Open Internet Rules, a panel of four experts convened before an audience in Davis Auditorium to discuss what such a repeal is likely to mean for the Internet. Though all four spoke from different perspectives—three were technology experts and one an Internet consumer advocate and lawyer—all expressed concerns about the repeal. (Though proponents of the repeal had been invited, none were able to attend.)











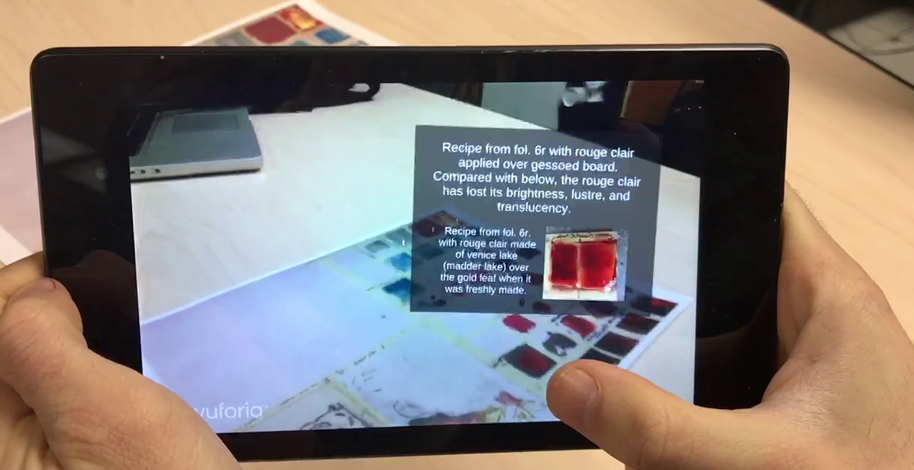







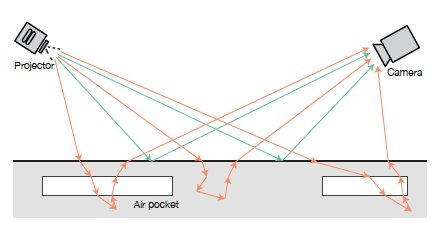
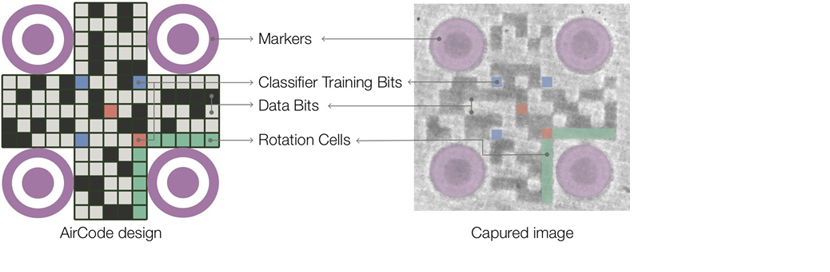





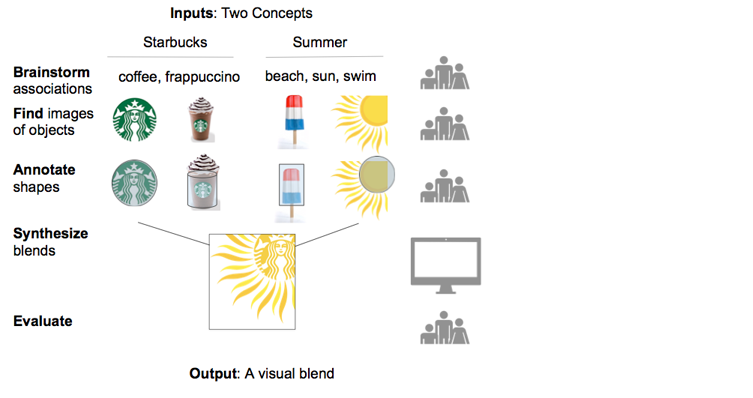






















 “
“

 Two Columbia Engineering PhD students, João P. Cerqueira (Electrical Engineering) and Thomas J. Repetti (Computer Science), have been named recipients of the highly competitive $100,000
Two Columbia Engineering PhD students, João P. Cerqueira (Electrical Engineering) and Thomas J. Repetti (Computer Science), have been named recipients of the highly competitive $100,000 


