
Jim Kurose Explains the Internet in 5 Levels of Difficulty
Jim Kurose (PhD ’84) chats with PhD student Casper Lant about networks and IoTS for Wired magazine.
Jim Kurose (PhD ’84) chats with PhD student Casper Lant about networks and IoTS for Wired magazine.
Computer scientist honored for his pioneering research in imaging.
Computer Scientist honored for his pioneering research in imaging.
Julia Zhao, SEAS’23, has been named a 2023 Rhodes Scholar for China. China awards four Rhodes Scholars each year, and this is the second time that Columbia has had a Rhodes China Scholar named.
Papers from CS researchers were accepted to the Empirical Methods in Natural Language Processing (EMNLP) 2022. EMNLP is a leading conference in artificial intelligence and natural language processing. Aside from presenting their research papers, several researchers also organized workshops to gather conference attendees for discussions about current issues confronting NLP and computer science.
Massively Multilingual Natural Language Understanding
Jack FitzGerald Amazon Alexa, Kay Rottmann Amazon Alexa, Julia Hirschberg Columbia University, Mohit Bansal University of North Carolina, Anna Rumshisky University of Massachusetts Lowell, and Charith Peris Amazon Alexa
3rd Workshop on Figurative Language Processing
Debanjan Ghosh Educational Testing Service, Beata Beigman Klebanov Educational Testing Service, Smaranda Muresan Columbia University, Anna Feldman Montclair State University, Soujanya Poria Singapore University of Technology and Design, and Tuhin Chakrabarty Columbia University
Sharing Stories and Lessons Learned
Diyi Yang Stanford University, Pradeep Dasigi Allen Institute for AI, Sherry Tongshuang Wu Carnegie Mellon University, Tuhin Chakrabarty Columbia University, Yuval Pinter Ben-Gurion University of the Negev, and Mike Zheng Shou National University of Singapore
Help me write a Poem – Instruction Tuning as a Vehicle for Collaborative Poetry Writing
Tuhin Chakrabarty Columbia University, Vishakh Padmakumar New York University, He He New York University
Abstract
Recent work in training large language models (LLMs) to follow natural language instructions has opened up exciting opportunities for natural language interface design. Building on the prior success of large language models in the realm of computer assisted creativity, in this work, we present CoPoet, a collaborative poetry writing system, with the goal of to study if LLM’s actually improve the quality of the generated content. In contrast to auto-completing a user’s text, CoPoet is controlled by user instructions that specify the attributes of the desired text, such as Write a sentence about ‘love’ or Write a sentence ending in ‘fly’. The core component of our system is a language model fine-tuned on a diverse collection of instructions for poetry writing. Our model is not only competitive to publicly available LLMs trained on instructions (InstructGPT), but also capable of satisfying unseen compositional instructions. A study with 15 qualified crowdworkers shows that users successfully write poems with CoPoet on diverse topics ranging from Monarchy to Climate change, which are preferred by third-party evaluators over poems written without the system.
FLUTE: Figurative Language Understanding through Textual Explanations
Tuhin Chakrabarty Columbia University, Arkadiy Saakyan Columbia University, Debanjan Ghosh Educational Testing Service, and Smaranda Muresan Columbia University
Abstract
Figurative language understanding has been recently framed as a recognizing textual entailment (RTE) task (a.k.a. natural language inference (NLI)). However, similar to classical RTE/NLI datasets they suffer from spurious correlations and annotation artifacts. To tackle this problem, work on NLI has built explanation-based datasets such as eSNLI, allowing us to probe whether language models are right for the right reasons. Yet no such data exists for figurative language, making it harder to assess genuine understanding of such expressions. To address this issue, we release FLUTE, a dataset of 9,000 figurative NLI instances with explanations, spanning four categories: Sarcasm, Simile, Metaphor, and Idioms. We collect the data through a Human-AI collaboration framework based on GPT-3, crowd workers, and expert annotators. We show how utilizing GPT-3 in conjunction with human annotators (novices and experts) can aid in scaling up the creation of datasets even for such complex linguistic phenomena as figurative language. The baseline performance of the T5 model fine-tuned on FLUTE shows that our dataset can bring us a step closer to developing models that understand figurative language through textual explanations.
Fine-tuned Language Models are Continual Learners
Thomas Scialom Columbia University, Tuhin Chakrabarty Columbia University, and Smaranda Muresan Columbia University
Abstract
Recent work on large language models relies on the intuition that most natural language processing tasks can be described via natural language instructions and that models trained on these instructions show strong zero-shot performance on several standard datasets. However, these models even though impressive still perform poorly on a wide range of tasks outside of their respective training and evaluation sets.To address this limitation, we argue that a model should be able to keep extending its knowledge and abilities, without forgetting previous skills. In spite of the limited success of Continual Learning, we show that Fine-tuned Language Models can be continual learners.We empirically investigate the reason for this success and conclude that Continual Learning emerges from self-supervision pre-training. Our resulting model Continual-T0 (CT0) is able to learn 8 new diverse language generation tasks, while still maintaining good performance on previous tasks, spanning in total of 70 datasets. Finally, we show that CT0 is able to combine instructions in ways it was never trained for, demonstrating some level of instruction compositionality.
Multitask Instruction-based Prompting for Fallacy Recognition
Tariq Alhindi Columbia University, Tuhin Chakrabarty Columbia University, Elena Musi University of Liverpool, and Smaranda Muresan Columbia University
Abstract
Fallacies are used as seemingly valid arguments to support a position and persuade the audience about its validity. Recognizing fallacies is an intrinsically difficult task both for humans and machines. Moreover, a big challenge for computational models lies in the fact that fallacies are formulated differently across the datasets with differences in the input format (e.g., question-answer pair, sentence with fallacy fragment), genre (e.g., social media, dialogue, news), as well as types and number of fallacies (from 5 to 18 types per dataset). To move towards solving the fallacy recognition task, we approach these differences across datasets as multiple tasks and show how instruction-based prompting in a multitask setup based on the T5 model improves the results against approaches built for a specific dataset such as T5, BERT or GPT-3. We show the ability of this multitask prompting approach to recognize 28 unique fallacies across domains and genres and study the effect of model size and prompt choice by analyzing the per-class (i.e., fallacy type) results. Finally, we analyze the effect of annotation quality on model performance, and the feasibility of complementing this approach with external knowledge.
CONSISTENT: Open-Ended Question Generation From News Articles
Tuhin Chakrabarty Columbia University, Justin Lewis The New York Times R&D, and Smaranda Muresan Columbia University
Abstract
Recent work on question generation has largely focused on factoid questions such as who, what, where, when about basic facts. Generating open-ended why, how, what, etc. questions that require long-form answers have proven more difficult. To facilitate the generation of open-ended questions, we propose CONSISTENT, a new end-to-end system for generating open-ended questions that are answerable from and faithful to the input text. Using news articles as a trustworthy foundation for experimentation, we demonstrate our model’s strength over several baselines using both automatic and human=based evaluations. We contribute an evaluation dataset of expert-generated open-ended questions.We discuss potential downstream applications for news media organizations.
SafeText: A Benchmark for Exploring Physical Safety in Language Models
Sharon Levy University of California, Santa Barbara, Emily Allaway Columbia University, Melanie Subbiah Columbia University, Lydia Chilton Columbia University, Desmond Patton Columbia University, Kathleen McKeown Columbia University, and William Yang Wang University of California, Santa Barbara
Abstract
Understanding what constitutes safe text is an important issue in natural language processing and can often prevent the deployment of models deemed harmful and unsafe. One such type of safety that has been scarcely studied is commonsense physical safety, i.e. text that is not explicitly violent and requires additional commonsense knowledge to comprehend that it leads to physical harm. We create the first benchmark dataset, SafeText, comprising real-life scenarios with paired safe and physically unsafe pieces of advice. We utilize SafeText to empirically study commonsense physical safety across various models designed for text generation and commonsense reasoning tasks. We find that state-of-the-art large language models are susceptible to the generation of unsafe text and have difficulty rejecting unsafe advice. As a result, we argue for further studies of safety and the assessment of commonsense physical safety in models before release.
Learning to Revise References for Faithful Summarization
Griffin Adams Columbia University, Han-Chin Shing Amazon AWS AI, Qing Sun Amazon AWS AI, Christopher Winestock Amazon AWS AI, Kathleen McKeown Columbia University, and Noémie Elhadad Columbia University
Abstract
In real-world scenarios with naturally occurring datasets, reference summaries are noisy and may contain information that cannot be inferred from the source text. On large news corpora, removing low quality samples has been shown to reduce model hallucinations. Yet, for smaller, and/or noisier corpora, filtering is detrimental to performance. To improve reference quality while retaining all data, we propose a new approach: to selectively re-write unsupported reference sentences to better reflect source data. We automatically generate a synthetic dataset of positive and negative revisions by corrupting supported sentences and learn to revise reference sentences with contrastive learning. The intensity of revisions is treated as a controllable attribute so that, at inference, diverse candidates can be over-generated-then-rescored to balance faithfulness and abstraction. To test our methods, we extract noisy references from publicly available MIMIC-III discharge summaries for the task of hospital-course summarization, and vary the data on which models are trained. According to metrics and human evaluation, models trained on revised clinical references are much more faithful, informative, and fluent than models trained on original or filtered data.
Mitigating Covertly Unsafe Text within Natural Language Systems
Alex Mei University of California, Santa Barbara, Anisha Kabir University of California, Santa Barbara, Sharon Levy University of California, Santa Barbara, Melanie Subbiah Columbia University, Emily Allaway Columbia University, John N. Judge University of California, Santa Barbara, Desmond Patton University of Pennsylvania, Bruce Bimber University of California, Santa Barbara, Kathleen McKeown Columbia University, and William Yang Wang University of California, Santa Barbara
Abstract
An increasingly prevalent problem for intelligent technologies is text safety, as uncontrolled systems may generate recommendations to their users that lead to injury or life-threatening consequences. However, the degree of explicitness of a generated statement that can cause physical harm varies. In this paper, we distinguish types of text that can lead to physical harm and establish one particularly underexplored category: covertly unsafe text. Then, we further break down this category with respect to the system’s information and discuss solutions to mitigate the generation of text in each of these subcategories. Ultimately, our work defines the problem of covertly unsafe language that causes physical harm and argues that this subtle yet dangerous issue needs to be prioritized by stakeholders and regulators. We highlight mitigation strategies to inspire future researchers to tackle this challenging problem and help improve safety within smart systems.
Affective Idiosyncratic Responses to Music
Sky CH-Wang Columbia University, Evan Li Columbia University, Oliver Li Columbia University, Smaranda Muresan Columbia University, and Zhou Yu Columbia University
Abstract
Affective responses to music are highly personal. Despite consensus that idiosyncratic factors play a key role in regulating how listeners emotionally respond to music, precisely measuring the marginal effects of these variables has proved challenging. To address this gap, we develop computational methods to measure affective responses to music from over 403M listener comments on a Chinese social music platform. Building on studies from music psychology in systematic and quasi-causal analyses, we test for musical, lyrical, contextual, demographic, and mental health effects that drive listener affective responses. Finally, motivated by the social phenomenon known as 网抑云 (wǎng-yì-yún), we identify influencing factors of platform user self-disclosures, the social support they receive, and notable differences in discloser user activity.
Robots-Dont-Cry: Understanding Falsely Anthropomorphic Utterances in Dialog Systems
David Gros University of California, Davis, Yu Li Columbia University, and Zhou Yu Columbia University
Abstract
Dialog systems are often designed or trained to output human-like responses. However, some responses may be impossible for a machine to truthfully say (e.g. “that movie made me cry”). Highly anthropomorphic responses might make users uncomfortable or implicitly deceive them into thinking they are interacting with a human. We collect human ratings on the feasibility of approximately 900 two-turn dialogs sampled from 9 diverse data sources. Ratings are for two hypothetical machine embodiments: a futuristic humanoid robot and a digital assistant. We find that for some data-sources commonly used to train dialog systems, 20-30% of utterances are not viewed as possible for a machine. Rating is marginally affected by machine embodiment. We explore qualitative and quantitative reasons for these ratings. Finally, we build classifiers and explore how modeling configuration might affect output permissibly, and discuss implications for building less falsely anthropomorphic dialog systems.
Just Fine-tune Twice: Selective Differential Privacy for Large Language Models
Weiyan Shi Columbia University, Ryan Patrick Shea Columbia University, Si Chen Columbia University, Chiyuan Zhang Google Research, Ruoxi Jia Virginia Tech, and Zhou Yu Columbia University
Abstract
Protecting large language models from privacy leakage is becoming increasingly crucial with their wide adoption in real-world products. Yet applying *differential privacy* (DP), a canonical notion with provable privacy guarantees for machine learning models, to those models remains challenging due to the trade-off between model utility and privacy loss. Utilizing the fact that sensitive information in language data tends to be sparse, Shi et al. (2021) formalized a DP notion extension called *Selective Differential Privacy* (SDP) to protect only the sensitive tokens defined by a policy function. However, their algorithm only works for RNN-based models. In this paper, we develop a novel framework, *Just Fine-tune Twice* (JFT), that achieves SDP for state-of-the-art large transformer-based models. Our method is easy to implement: it first fine-tunes the model with *redacted* in-domain data, and then fine-tunes it again with the *original* in-domain data using a private training mechanism. Furthermore, we study the scenario of imperfect implementation of policy functions that misses sensitive tokens and develop systematic methods to handle it. Experiments show that our method achieves strong utility compared to previous baselines. We also analyze the SDP privacy guarantee empirically with the canary insertion attack.
Focus! Relevant and Sufficient Context Selection for News Image Captioning
Mingyang Zhou University of California, Davis, Grace Luo University of California, Berkeley, Anna Rohrbach University of California, Berkeley, and Zhou Yu Columbia University
Abstract
News Image Captioning requires describing an image by leveraging additional context from a news article. Previous works only coarsely leverage the article to extract the necessary context, which makes it challenging for models to identify relevant events and named entities. In our paper, we first demonstrate that by combining more fine-grained context that captures the key named entities (obtained via an oracle) and the global context that summarizes the news, we can dramatically improve the model’s ability to generate accurate news captions. This begs the question, how to automatically extract such key entities from an image? We propose to use the pre-trained vision and language retrieval model CLIP to localize the visually grounded entities in the news article and then capture the non-visual entities via an open relation extraction model. Our experiments demonstrate that by simply selecting a better context from the article, we can significantly improve the performance of existing models and achieve new state-of-the-art performance on multiple benchmarks.
National Academy of Inventors Selects Columbia Engineering Researchers for their “highly prolific spirit of innovation.”
The National Academy of Inventors fellows are recognized for their work that benefits society.
Axl Chen is the founder and CEO of Surplex, a new full-body tracking technology company aiming to change the gaming industry and professional sports.
Researchers from the department presented machine learning and artificial intelligence research at the thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2022).
Finding and Listing Front-door Adjustment Sets
Hyunchai Jeong Purdue University, Jin Tian Iowa State University, Elias Bareinboim Columbia University
Abstract:
Identifying the effects of new interventions from data is a significant challenge found across a wide range of the empirical sciences. A well-known strategy for identifying such effects is Pearl’s front-door (FD) criterion. The definition of the FD criterion is declarative, only allowing one to decide whether a specific set satisfies the criterion. In this paper, we present algorithms for finding and enumerating possible sets satisfying the FD criterion in a given causal diagram. These results are useful in facilitating the practical applications of the FD criterion for causal effects estimation and helping scientists to select estimands with desired properties, e.g., based on cost, feasibility of measurement, or statistical power.
Causal Identification under Markov equivalence: Calculus, Algorithm, and Completeness
Amin Jaber Purdue University, Adele Ribeiro Columbia University, Jiji Zhang Hong Kong Baptist University, Elias Bareinboim Columbia University
Abstract:
One common task in many data sciences applications is to answer questions about the effect of new interventions, like: `what would happen to Y if we make X equal to x while observing covariates Z=z?’. Formally, this is known as conditional effect identification, where the goal is to determine whether a post-interventional distribution is computable from the combination of an observational distribution and assumptions about the underlying domain represented by a causal diagram. A plethora of methods was developed for solving this problem, including the celebrated do-calculus [Pearl, 1995]. In practice, these results are not always applicable since they require a fully specified causal diagram as input, which is usually not available. In this paper, we assume as the input of the task a less informative structure known as a partial ancestral graph (PAG), which represents a Markov equivalence class of causal diagrams, learnable from observational data. We make the following contributions under this relaxed setting. First, we introduce a new causal calculus, which subsumes the current state-of-the-art, PAG-calculus. Second, we develop an algorithm for conditional effect identification given a PAG and prove it to be both sound and complete. In words, failure of the algorithm to identify a certain effect implies that this effect is not identifiable by any method. Third, we prove the proposed calculus to be complete for the same task.
Online Reinforcement Learning for Mixed Policy Scopes
Junzhe Zhang Columbia University, Elias Bareinboim Columbia University
Abstract:
Combination therapy refers to the use of multiple treatments — such as surgery, medication, and behavioral therapy – to cure a single disease, and has become a cornerstone for treating various conditions including cancer, HIV, and depression. All possible combinations of treatments lead to a collection of treatment regimens (i.e., policies) with mixed scopes, or what physicians could observe and which actions they should take depending on the context. In this paper, we investigate the online reinforcement learning setting for optimizing the policy space with mixed scopes. In particular, we develop novel online algorithms that achieve sublinear regret compared to an optimal agent deployed in the environment. The regret bound has a dependency on the maximal cardinality of the induced state-action space associated with mixed scopes. We further introduce a canonical representation for an arbitrary subset of interventional distributions given a causal diagram, which leads to a non-trivial, minimal representation of the model parameters.
Masked Prediction: A Parameter Identifiability View
Bingbin Liu Carnegie Mellon University, Daniel Hsu Columbia University, Pradeep Ravikumar Carnegie Mellon University, Andrej Risteski Carnegie Mellon University
Abstract:
The vast majority of work in self-supervised learning have focused on assessing recovered features by a chosen set of downstream tasks. While there are several commonly used benchmark datasets, this lens of feature learning requires assumptions on the downstream tasks which are not inherent to the data distribution itself. In this paper, we present an alternative lens, one of parameter identifiability: assuming data comes from a parametric probabilistic model, we train a self-supervised learning predictor with a suitable parametric form, and ask whether the parameters of the optimal predictor can be used to extract the parameters of the ground truth generative model.Specifically, we focus on latent-variable models capturing sequential structures, namely Hidden Markov Models with both discrete and conditionally Gaussian observations. We focus on masked prediction as the self-supervised learning task and study the optimal masked predictor. We show that parameter identifiability is governed by the task difficulty, which is determined by the choice of data model and the amount of tokens to predict. Technique-wise, we uncover close connections with the uniqueness of tensor rank decompositions, a widely used tool in studying identifiability through the lens of the method of moments.
Learning single-index models with shallow neural networks
Alberto Bietti Meta AI/New York University, Joan Bruna New York University, Clayton Sanford Columbia University, Min Jae Song New York University
Abstract:
Single-index models are a class of functions given by an unknown univariate link” function applied to an unknown one-dimensional projection of the input. These models are particularly relevant in high dimension, when the data might present low-dimensional structure that learning algorithms should adapt to. While several statistical aspects of this model, such as the sample complexity of recovering the relevant (one-dimensional) subspace, are well-understood, they rely on tailored algorithms that exploit the specific structure of the target function. In this work, we introduce a natural class of shallow neural networks and study its ability to learn single-index models via gradient flow. More precisely, we consider shallow networks in which biases of the neurons are frozen at random initialization. We show that the corresponding optimization landscape is benign, which in turn leads to generalization guarantees that match the near-optimal sample complexity of dedicated semi-parametric methods.
On Scrambling Phenomena for Randomly Initialized Recurrent Networks
Evangelos Chatziafratis University of California Santa Cruz, Ioannis Panageas University of California Irvine, Clayton Sanford Columbia University, Stelios Stavroulakis University of California Irvine
Abstract:
Recurrent Neural Networks (RNNs) frequently exhibit complicated dynamics, and their sensitivity to the initialization process often renders them notoriously hard to train. Recent works have shed light on such phenomena analyzing when exploding or vanishing gradients may occur, either of which is detrimental for training dynamics. In this paper, we point to a formal connection between RNNs and chaotic dynamical systems and prove a qualitatively stronger phenomenon about RNNs than what exploding gradients seem to suggest. Our main result proves that under standard initialization (e.g., He, Xavier etc.), RNNs will exhibit \textit{Li-Yorke chaos} with \textit{constant} probability \textit{independent} of the network’s width. This explains the experimentally observed phenomenon of \textit{scrambling}, under which trajectories of nearby points may appear to be arbitrarily close during some timesteps, yet will be far away in future timesteps. In stark contrast to their feedforward counterparts, we show that chaotic behavior in RNNs is preserved under small perturbations and that their expressive power remains exponential in the number of feedback iterations. Our technical arguments rely on viewing RNNs as random walks under non-linear activations, and studying the existence of certain types of higher-order fixed points called \textit{periodic points} in order to establish phase transitions from order to chaos.
Patching open-vocabulary models by interpolating weights
Gabriel Ilharco University of Washington, Mitchell Wortsman University of Washington, Samir Yitzhak Gadre Columbia University, Shuran Song Columbia University, Hannaneh Hajishirzi University of Washington, Simon Kornblith Google Brain, Ali Farhadi University of Washington, Ludwig Schmidt University of Washington
Abstract:
Open-vocabulary models like CLIP achieve high accuracy across many image classification tasks. However, there are still settings where their zero-shot performance is far from optimal. We study model patching, where the goal is to improve accuracy on specific tasks without degrading accuracy on tasks where performance is already adequate. Towards this goal, we introduce PAINT, a patching method that uses interpolations between the weights of a model before fine-tuning and the weights after fine-tuning on a task to be patched. On nine tasks where zero-shot CLIP performs poorly, PAINT increases accuracy by 15 to 60 percentage points while preserving accuracy on ImageNet within one percentage point of the zero-shot model. PAINT also allows a single model to be patched on multiple tasks and improves with model scale. Furthermore, we identify cases of broad transfer, where patching on one task increases accuracy on other tasks even when the tasks have disjoint classes. Finally, we investigate applications beyond common benchmarks such as counting or reducing the impact of typographic attacks on CLIP. Our findings demonstrate that it is possible to expand the set of tasks on which open-vocabulary models achieve high accuracy without re-training them from scratch.
ASPiRe: Adaptive Skill Priors for Reinforcement Learning
Mengda Xu Columbia University, Manuela Veloso JP Morgan/Carnegie Mellon University, Shuran Song Columbia University
Abstract:
We introduce ASPiRe (Adaptive Skill Prior for RL), a new approach that leverages prior experience to accelerate reinforcement learning. Unlike existing methods that learn a single skill prior from a large and diverse dataset, our framework learns a library of different distinction skill priors (i.e., behavior priors) from a collection of specialized datasets, and learns how to combine them to solve a new task. This formulation allows the algorithm to acquire a set of specialized skill priors that are more reusable for downstream tasks; however, it also brings up additional challenges of how to effectively combine these unstructured sets of skill priors to form a new prior for new tasks. Specifically, it requires the agent not only to identify which skill prior(s) to use but also how to combine them (either sequentially or concurrently) to form a new prior. To achieve this goal, ASPiRe includes Adaptive Weight Module (AWM) that learns to infer an adaptive weight assignment between different skill priors and uses them to guide policy learning for downstream tasks via weighted Kullback-Leibler divergences. Our experiments demonstrate that ASPiRe can significantly accelerate the learning of new downstream tasks in the presence of multiple priors and show improvement on competitive baselines.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
Zhenhailong Wang Columbia University, Manling Li Columbia University, Ruochen Xu Microsoft, Luowei Zhou Meta, Jie Lei Meta, Xudong Lin Columbia University, Shuohang Wang Microsoft, Ziyi Yang Stanford University, Chenguang Zhu Stanford University, Derek Hoiem University of Illinois, Shih-Fu Chang Columbia University, Mohit Bansal University of North Carolina Chapel Hill, Heng Ji University of Illinois
Abstract:
The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal-aware template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets.Code and processed data are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL.
Implications of Model Indeterminacy for Explanations of Automated Decisions
Marc-Etienne Brunet University of Toronto, Ashton Anderson University of Toronto, Richard Zemel Columbia University
Abstract:
There has been a significant research effort focused on explaining predictive models, for example through post-hoc explainability and recourse methods. Most of the proposed techniques operate upon a single, fixed, predictive model. However, it is well-known that given a dataset and a predictive task, there may be a multiplicity of models that solve the problem (nearly) equally well. In this work, we investigate the implications of this kind of model indeterminacy on the post-hoc explanations of predictive models. We show how it can lead to explanatory multiplicity, and we explore the underlying drivers. We show how predictive multiplicity, and the related concept of epistemic uncertainty, are not reliable indicators of explanatory multiplicity. We further illustrate how a set of models showing very similar aggregate performance on a test dataset may show large variations in their local explanations, i.e., for a specific input. We explore these effects for Shapley value based explanations on three risk assessment datasets. Our results indicate that model indeterminacy may have a substantial impact on explanations in practice, leading to inconsistent and even contradicting explanations.
Reconsidering Deep Ensembles
Taiga Abe Columbia University, Estefany Kelly Buchanan Columbia University, Geoff Pleiss Columbia University, Richard Zemel Columbia University, John Cunningham Columbia University
Abstract:
Ensembling neural networks is an effective way to increase accuracy, and can often match the performance of individual larger models. This observation poses a natural question: given the choice between a deep ensemble and a single neural network with similar accuracy, is one preferable over the other? Recent work suggests that deep ensembles may offer distinct benefits beyond predictive power: namely, uncertainty quantification and robustness to dataset shift. In this work, we demonstrate limitations to these purported benefits, and show that a single (but larger) neural network can replicate these qualities. First, we show that ensemble diversity, by any metric, does not meaningfully contribute to an ensemble’s ability to detect out-of-distribution (OOD) data, but is instead highly correlated with the relative improvement of a single larger model. Second, we show that the OOD performance afforded by ensembles is strongly determined by their in-distribution (InD) performance, and – in this sense – is not indicative of any “effective robustness.” While deep ensembles are a practical way to achieve improvements to predictive power, uncertainty quantification, and robustness, our results show that these improvements can be replicated by a (larger) single model
Professor Steven Bellovin remembers his mentor Frederick P. Brooks, Jr., in a blog post about the computer scientist and author of The Mythical Man-Month.
The projects of the Undergraduate Computer and Data Science Research Fair fell under the themes of Data Science and Society, Interdisciplinary Data Science Applications, Data Science and Computer Science Research. Posters and demonstrations were proudly hosted by twenty-five students from SEAS, Barnard College, Columbia College, and the School of General Studies.




The fair was organized by the Data, Media and Society Center at the Data Science Institute, Columbia University; the Barnard Program in Computer Science and the Vagelos Computational Science Center; and the Department of Computer Science at Columbia Engineering led by Eugene Wu, Susan McGregor, Rebecca Wright, and Alexis Avedisian.

The claim: Mail-in ballots show bad actors ‘how many fraudulent ballots they need to produce’
Computer scientist honored for his pioneering research in imaging and vision.
In a blog post for Trail of Bits, PhD student Andreas Kellas shares how he discovered a 22-year-old vulnerability in SQLite.
One of the hardest things to do is prepare application materials for a PhD program. It is hard to gather your thoughts and try to distill them in a way that makes sense and will impress the admission committee. Plus, the pressure is on for you to get into a program and a lab that matches your research interests.

These were some of the thoughts running through Tao Long’s mind this time last year when he was figuring out which PhD programs to apply to. He started doing human-computer interaction (HCI) research as an undergraduate at Cornell University and knew that he wanted to continue on the academic research track. When he saw that Columbia’s computer science PhD program had an application review program, he knew that he should apply to it and take the opportunity to get feedback on his application materials.
The Pre-submission Application Review (PAR) program is a student-led initiative where current PhD students give a one-time review of an applicant’s statement of purpose and CV. Now in its third year, the aim is to promote a diverse and welcoming intellectual environment for all. Not many PhD applicants have access to a network that can give advice and guide them through the application process; the student volunteers of the PAR program hope to address these inequities.
Long shares his experience applying to PhD programs, taking part in review programs, and how he is paying it forward by helping other students with their applications to PhD programs.
Q: Why did you decide to go into a PhD program directly after undergrad?
During my undergrad at Cornell, I worked on a few projects in several different labs, all focusing on HCI. I am really proud of a digital technology project that I contributed to – collaborating with Weill Cornell Medicine and Cornell Law; we are trying to understand the existing barriers for asylum seekers to adopt technologies and how to design ones for them.
My passion for socially impactful technology makes me want to continue doing human-computer interaction (HCI) research. HCI researchers study how people interact with technology and how to better design and develop technology according to people’s needs. Thus, both technical and social science knowledge is essential in this interdisciplinary field. With a background in information science and communication, I believe technology has a communicative capacity and responsibility: we speak, design, and build for those who can’t.
Q: How was your experience applying to PhD programs?
I finalized my school list, started reaching out to faculty members I was interested in working with, and prepared my application materials around September and October. In November, I focused on polishing my statement with some current graduate students and pre-submission application review programs held by universities.
December was the time when the long wait began. After the holidays, some applicants will begin receiving interview inquiries. Around late February and March, most applicants will receive their concluded application decisions back. Lastly, they need to decide whether they accept the offer by April 15 (see April 15 Resolution).
The whole half-year-long application process was too long for me. There are many online platforms, like the r/gradadmissions subreddit and the GradCafe, where people share their admission updates. These information sources made the waiting process more exciting but also made me feel a bit anxious. I think I really enjoyed the post-submission period, where I felt relieved after all my application materials were in. Thus, I started working at an on-campus cafe, learned knitting, and watched YouTube and TikTok all day.
Q: Why did you choose to apply to Columbia CS? What attracted you to the program?
Columbia is well-known for its strong academic and research resources. I am now taking a class on how to build a successful startup in CS. The instructor of that class is a Columbia CS PhD graduate with several well-established startups. In addition to courses, countless fascinating research projects from the department widely collaborate with different schools on campus and large tech companies in the city. Specifically, I find the research conducted by my advisor, Lydia Chilton, really cutting-edge in helping users understand and interact with artificial intelligence tools. Many of her recent publications on large language models and text-to-image generative models are fascinating and impactful to the HCI community.
Q: You were part of the PAR program last year; how was it?
I found the PAR program on the department website during my school search period. During that month, I looked through many university websites and found several schools that provided similar programs to give feedback to PhD applicants. I chose to apply for the PAR program because I wanted more feedback on my application materials. Sometimes people say you have enough experience, but it isn’t addressed well on the application. I wanted to make sure that I presented myself well and painted a full picture of myself.
Q: Was it helpful to get feedback?
I submitted my Statement of Purpose, Personal Statement, and academic CV in early November. Then, the PAR team paired me with a reviewer and provided me with valuable and insightful written comments on my application materials by November 21, which is around 20 days before Columbia’s application deadline.
The feedback contained a general evaluation of the pros and cons of my application materials. They pointed out problems in the statement structure – mention more about my experience, stress more about the technical or the non-technical skill sets, shrink the length of the statement, and move one section forward. Feedback was also given on the format and language usage like what tense to use, easy-to-read font style and size, and header or page breaks to help the user flow between sections. Thus, containing feedback from both high-level and low-level perspectives, this PAR review program was beneficial for me to navigate and make future changes.
Q: You are part of the PAR team now, right? Why did you join the group?
I became active in the subreddit r/gradadmissions last year while I was waiting for the admission results to come out. I found it helpful to check posts there to learn more about the general admission process from other people’s cases. I also found a few HCI PhD applicants there, thus establishing some prior connections before entering the field. My friend and I started helping applicants from low-resource countries or regions by reviewing their application materials and providing feedback.
When I decided to go to Columbia, I knew I wanted to continue helping PhD applicants. I am part of other review programs offered by affinity groups outside Columbia to help those interested in pursuing a PhD. I joined the department’s PAR program committee in September. We are getting ready for the upcoming November 15th deadline and recruiting current CS PhD students to become reviewers. I highly recommend that applicants join the PAR program! I am sure that you could receive a lot of insightful feedback from the current CS PhD student community to help polish your materials! Good luck!
——
Related Content
PAR Program Offers Peer Support to PhD Applicants
Student-led Initiative Aims to Help Applicants of the PhD Program
Interested applicants have to apply to the PAR program and submit their personal statement and CV by November 7th at 11:59 pm EST. Because the program is student-run and dependent on volunteers, there is no guarantee that every applicant can be accommodated. Those who are accepted will be notified by November 14th, then paired with a PhD student in the same research area who will review their materials and provide feedback to them by November 21st – well ahead of the December 15th deadline to apply to the PhD program.
Computer scientist honored for his pioneering research in imaging and vision.
This fall, Columbia University and Barnard College will host the inaugural Undergraduate Computer and Data Science Research Fair to showcase undergraduate student work in data science and related fields. Applications will be accepted along three thematic tracks and in a variety of formats to highlight the diversity of opportunities that data science affords researchers.
Get ready to roar for these Lions — including two CS majors— competing in the Capital One College Bowl, the NBC quiz show hosted by Hall of Fame quarterback Peyton Manning. The 10-episode series will feature undergraduates from 16 schools vying for a share of $1 million in scholarship money.
Xia Zhou, Brian Borowski, and Kostis Kaffes join the department. They will facilitate research and learning in mobile computing, software systems, and networks.

Xia Zhou
Associate Professor
PhD Computer Science, University of California Santa Barbara
MS Computer Science, Peking University
BS Computer Science and Technology, Wuhan University
Xia Zhou is an expert in mobile computing and networks whose research is focused on wireless systems and mobile health. Zhou joins Columbia after nine years at Dartmouth where she was the co-director of the Dartmouth Networking and Ubiquitous Systems and the Dartmouth Reality and Robotics Lab. At Columbia, she will direct the Mobile X Laboratory.

Brian Borowski
Lecturer in Discipline
PhD Computer Science, Stevens Institute of Technology
MS Computer Science, Stevens Institute of Technology
BS Computer Science, Seton Hall University
Brian Borowski is an expert in software systems who aims to present a blend of theoretical and practical instruction so his students can be successful after graduation, regardless of the path they choose. He studied underwater acoustic communication and won several awards for his teaching at Stevens Institute of Technology.
 Kostis Kaffes
Kostis Kaffes
Assistant Professor
PhD Electrical Engineering, Stanford University
MS Electrical Engineering, Stanford University
BS Electrical and Computer Engineering, National Technical University of Athens
Kostis Kaffes is interested in computer systems, cloud computing, and scheduling across the stack. He arrives in Fall 2023 and will spend the next year doing research at Google Cloud with the Systems Research Group.
Professor Kathleen R. McKeown is the recipient of the 2023 IEEE Innovation in Societal Infrastructure Award—the highest award recognizing significant technological achievements and contributions to the establishment, development, and proliferation of innovative societal infrastructure systems through the application of information technology with an emphasis on distributed computing systems.
Graduate students from the department have been selected to receive scholarships. The diverse group is a mix of those new to Columbia and students who have received fellowships for the year.
 Shunhua Jiang
Shunhua Jiang
Shunhua Jiang is a fourth-year PhD student who is advised by Professor Alexandr Andoni and Assistant Professor Omri Weinstein. Her research interests are in optimization and data structures, with a focus on using dynamic data structures to accelerate the algorithms for conic programming.
Jiang graduated from Tsinghua University with a B.Eng. in computer science. In her free time, she enjoys running and playing the Chinese flute.
 Andreas Kellas
Andreas Kellas
Andreas Kellas is a second-year PhD student working in software system security, with interests in mitigating exploits, finding vulnerabilities, and verifying the correctness of software patches. He is co-advised by Professor Simha Sethumadhavan and Professor Junfeng Yang.
Kellas graduated from the United States Military Academy in 2015 with a BS in computer science and Arabic.
 Harry Wang
Harry Wang
Harry Wang is a first-year PhD student interested in the intersection of systems, networks, and security. He joins the Software Systems Laboratory under the guidance of Professor Junfeng Yang and Assistant Professor Asaf Cidon.
Wang graduated this year from the University of Southern California with a BSc in computer engineering and computer science. He was a 2021 Goldwater Scholar and received the USC Computer Science Award for Outstanding Research for his work on binary analysis and network security.
 Sei Chang
Sei Chang
Sei Chang is a first-year PhD student interested in computational genomics and machine learning. He is advised by Assistant Professor David Knowles at the New York Genome Center. His research aims to apply machine learning techniques to analyze transcriptomic dysregulation in genetic diseases.
Chang graduated magna cum laude from the University of California, Los Angeles in 2022 with a BS in computer science and a minor in bioinformatics. He is a National Merit Scholar and recipient of the Muriel K. and Robert B. Allan Award from UCLA Engineering.
 Nick Deas
Nick Deas
Nick Deas’ interests lie in the application of natural language processing to the social sciences, particularly psychology, and developing natural language processing methods for social media and other unstructured data sources. His undergraduate research similarly involved using natural language processing techniques to analyze political tweets and detect psychological constructs from Reddit posts, but also ranged to speech transcript correction and topic modeling. He will be joining the Natural Language Processing Group under the guidance of Professor Kathleen McKeown.
Deas graduated from Clemson University in May 2022 with a BS in computer science and a BS in Psychology. He was awarded a full-tuition scholarship as part of the National Scholars Program. While there, he received the Outstanding Senior Award in the Computer Science department in 2020, the Phi Kappa Phi Certificate of Merit Award in the Computer Science department in 2022, and the Award for Academic Excellence in Psychology in 2022. The Midwest Political Science Association (MPSA) awarded him a Best Paper by an Undergraduate Student for work on natural language processing and political tweets. In addition to the NSF GRFP, his graduate studies will be funded by the SEAS Presidential Fellowship and a Provost Diversity Fellowship.
 Sruthi Sudhakar
Sruthi Sudhakar
Sruthi Sudhakar is interested in computer vision with a focus on studying stronger representations using multimodal inputs to improve robustness and generalization. She is a first-year PhD student who will work with Professor Richard Zemel and Assistant Professor Carl Vondrick.
Sudhakar graduated from the Georgia Institute of Technology with a BS in computer science and received Georgia Tech’s 2021 Outstanding Undergraduate Research Award.
 Matthew Toles
Matthew Toles
Matthew Toles is a first-year PhD student interested in generating goal-oriented questions for better human-computer collaboration. He will work with Professor Luis Gravano and Assistant Professor Zhou Yu.
Toles graduated in 2016 from the University of Washington with a BS in materials science and engineering. He was a recipient of the Mary Gates Research Fellowship, NASA SURP scholarship, and an Amazon Catalyst Fellowship.
Ira Ceka
Ira Ceka is a first-year PhD student who will be advised by Baishkakhi Ray. Her research interests are in software engineering.
Prior to Columbia, Ceka worked in industry as a software engineer. She was also a research intern at IBM Thomas J. Watson Research Center, MIT, and Harvard University. She graduated in 2019 with a BS in computer science from the University of Massachusetts Boston.
 Yusuf Efe
Yusuf Efe
Yusuf Efe is a PhD student set to work with Associate Professor Elias Bareinboim. His work will focus on designing robust causal reinforcement learning algorithms. He is particularly interested in defining dynamic and context-dependent value functions in reinforcement learning settings to render possible human-like learning processes for intelligent agents. In addition, he is interested in blockchain and decentralized finance.
Efe graduated with a BS degree in electrical engineering and physics from Bogazici University, Turkey. During his research internships at Stanford and UIUC, he analyzed multi-agent settings utilizing machine learning and game theory principles. He is an alumnus of the Turkish National Physics Olympiad team and won a gold, two silver, and bronze medals, and the Best Theory Paper award at the International Physics Olympiad.
 Rashida Hakim
Rashida Hakim
Rashida Hakim studies the design and analysis of algorithms for networked applications. These applications include the Internet, distributed computing, and the brain. She joins the Theory Group and will be advised by Professor Christos Papadimitriou and Professor Mihalis Yannakakis.
Hakim graduated from the California Institute of Technology with a BS in computer science. When she has free time, she likes to crochet, hike, and read science fiction.
 Zeyi Liu
Zeyi Liu
Zeyi Liu is a first-year PhD student working with Assistant Professor Shuran Song on robotics and computer vision. Her work focuses on developing methods for embodied agents to better understand the environment and plan for complex tasks. She is particularly interested in developing robots that are able to assist humans in household environments.
Liu graduated from Columbia University in 2022 with a BS in computer science. She recently picked up sailing as a hobby and really enjoys it.
 Hadleigh Schwartz
Hadleigh Schwartz
Hadleigh Schwartz is interested in building and analyzing interdisciplinary mobile systems. Her Master’s thesis focused on understanding the visual privacy risks posed by IoT video analytics systems. She is also interested in techniques for improving network security and reliability. She is an incoming first-year PhD student advised by Associate Professor Xia Zhou, Professor Dan Rubenstein, and Professor Vishal Misra.
Schwartz graduated summa cum laude and Phi Beta Kappa from the University of Chicago in 2022 with both a BA and MS in computer science. She likes cooking, baking, playing guitar, and hiking whenever she has free time.
 Josephine Passananti
Josephine Passananti
Josephine Passananti’s research focus is security and adversarial machine learning. While at Columbia, she hopes to further the robustness of AI applications and systems. She will be co-advised by Associate Professor Baishakhi Ray and Associate Professor Suman Jana.
Passananti recently graduated from the University of Chicago with a BS in computer science and a minor in visual arts. She loves cooking and exploring the city, and when she has the time, she goes hiking, plays tennis, and makes pottery.
 William Pires
William Pires
William Pires is a first-year PhD student who is broadly interested in computational complexity and the role of randomness in computation. While at Columbia, he hopes to continue working on problems related to the TFNP classes. He will be advised by Professor Toniann Pitassi, Professor Rocco Servedio, and Professor Xi Chen and he is a member of the Theory Group.
Pires graduated from McGill University this May where he received a BS in computer science. While there, he worked with Robert Robere on TFNP classes and Hamed Hatami on communication complexity.
He enjoys being outdoors and looks forward to hiking in New York.
 Kele Huang
Kele Huang
Kele Huang is a first-year PhD student working with Professor Ronghui Gu and Professor Jason Nieh at the Software Systems Laboratory. He is interested in systems research, with a focus on operating systems, virtualization, and formal verification.
Huang completed his BE in microelectronics science and engineering from Central South University. His undergrad studies were funded by the China National Scholarship. He was recommended to the Institute of Computing Technology, CAS, and graduated with an MS in computer science in 2021.
 Natalie Parham
Natalie Parham
Natalie Parham studies theoretical computer science with a focus on quantum complexity theory and quantum algorithms. She is particularly interested in understanding the power and limitations of near-term quantum computers. She is a first-year PhD student in the Theory group who will work with Assistant Professor Henry Yuen.
Parham graduated in 2020 from the University of California, Berkeley with a BS in electrical engineering and computer science and from the University of Waterloo with an MMath in combinatorics and optimization – quantum information in 2022.
She balances her time with strength training, skateboarding, and yoga.
 Mandi Zhao
Mandi Zhao
Mandi Zhao is a first-year PhD student working with Assistant Professor Shuran Song. She is interested in data-driven approaches for robotics, such as imitation learning and reinforcement learning, and works on developing algorithms that enable robot learning in highly complex, real-world environments.
Prior to Columbia, she obtained her BA and MS degrees from UC Berkeley, where she was affiliated with Berkeley AI Research (BAIR) advised by Professor Pieter Abbeel. In the summer of 2022, she interned at Meta AI research and worked on scaling up robot imitation learning in the Pittsburgh office.
In her free time, she likes to paint, go hiking, and watch soccer games.
 Jerry Liu
Jerry Liu
Jerry Liu is an incoming first-year PhD student advised by Associate Professor
Eugene Wu. His research interests lie in database systems and differential privacy. Particularly, he is interested in privacy-preserving data systems with high usability. During his free time, he likes hiking and playing board games.
Liu graduated from the University of Waterloo with a BS in computer science, statistics, and combinatorics and optimization in 2022.
 Sitong Wang
Sitong Wang
Sitong Wang is an incoming first-year PhD student whose work focuses on creativity support in the field of Human-Computer Interaction (HCI). She is broadly interested in research at the intersection of human creativity and technologies and will work with Assistant Professor Lydia Chilton.
Wang earned an MS in computer science in 2021 from Columbia. In 2020 she graduated with a BS in electrical engineering from the University of Cincinnati and a BE in electrical engineering and automation from Chongqing University.
Computer science is one of the most popular degrees at Columbia and each year more and more students are interested in taking a CS course or shifting majors. As the number of students enrolling in computer science classes increases, the department is expanding the number of teaching faculty to ensure a solid grounding in computer science skills and methods for all students.

Some of the largest classes, with 300 students or more, are taught by the teaching faculty. Their classes cover everything from Intro to Computer Science to graduate-level Analysis of Algorithms. Aside from teaching, some of them draw from their research backgrounds to mentor student projects, improve CS education, and advance the computer science field.
We caught up with them to get to know them a little better and to find out how students can do well in their classes!
 Daniel Bauer
Daniel Bauer
Classes this semester/year:
ENGI E1006 Introduction to Computing for Engineers Applied Scientists
COMS W4705 Natural Language Processing
What are your research projects at the moment?
I work on a variety of small projects related to natural language semantics. I also work on applications of NLP, such as knowledge graph extraction for human rights research. In addition, I am interested in CS education research, focusing on how to make CS courses more accessible and effective.
What type of student should apply to work on your research projects?
Students interested in NLP research who have taken at least COMS W4705 Natural Language Processing, or an equivalent course. They should be very comfortable programming in Python. Ideally, they’d have first-hand experience with machine learning, including using TensorFlow or PyTorch. For CS education research, students should have a strong interest in education and some prior experience working with students, for example, as a TA. They should also have some experience collecting and analyzing data. In general, I enjoy working with students who can work independently, are enthusiastic about the research topic, and are interested in how the specific work relates to the broader field.
Why did you decide to become a professor?
Some of my undergraduate professors were great role models, who engaged in cutting-edge research but also really cared about their students. I thought being a professor, as opposed to working in industry, would give you the freedom to work on any topic you are interested in, without having to worry about applicability and external demands (that turned out to be an incorrect assumption). When I started working as a TA and later as a Ph.D. student, when I started teaching courses by myself, I discovered that I really enjoyed teaching. So I decided to become teaching faculty.
What do you like about teaching?
I like getting people interested in new areas of CS and hopefully sharing some of my enthusiasm with them. Sometimes, when explaining a tricky (but beautiful) concept to someone, you can watch them have an “aha” moment when all the pieces fall into place. These are the most rewarding situations for me as a teacher. Because I teach courses at all different levels, I get to follow students through the CS program and it’s fun to watch them succeed and grow academically.
What are your tips for students so they can pass your classes?
It’s normal to get stuck, especially if you are new to CS. When students fail classes, there was usually a lack of communication. Be proactive in reaching out to the teaching staff for help, even in large classes. Talk to other students in the class. Make use of all the resources the course provides to you.

Brian Borowski
Classes this semester/year:
COMS W3134 In Data Structures in Java in the Fall
COMS W3175 Advanced Programming in the Spring
Why did you decide to become a professor?
To me, a professor is both an instructor and a mentor. I endeavor to be an effective educator, combining the finest attributes of my high school teachers and college professors while completely disregarding the approach of those who merely went through the motions.
When I was in high school, I wrote a Pascal program to multiply polynomials and combine like terms. It was challenging for me at the time, and I couldn’t wait to show my AP Computer Science teacher. My enthusiasm was met with the response, “Why don’t you go outside and play like a normal boy?”
Fortunately, I wasn’t discouraged and remained committed to computer science all throughout college, graduate school, and my career. Over the years, I’ve taken courses with professors whose enthusiasm for the material shone through as soon as they stepped into the classroom. They would explain WHY something is important as well as how it works and would work tirelessly to get everyone to understand the material. I want to share my knowledge with my students, galvanizing their enthusiasm in the classroom, so they can be inspired to always continue learning and go out into the world and make a difference.
What do you like about teaching?
Every lecture is different, even if you’ve taught the same course for years. Someone will inevitably ask a question for which you don’t know the answer or solve a problem in a way you never considered. It’s exhilarating when a typical class meeting turns into a profound discussion.
Do you have a favorite story about your students that you tell people about?
I don’t have, per se, a favorite story. I delight in my students’ accomplishments whether it be getting a good grade in a course, passing a round of technical interviews, landing an internship or full-time job, being accepted into graduate school, winning a programming competition, or completing a research or software development project. Over the years, my students have shared with me so many success stories that I don’t know where to begin recounting them!
What are your tips for students so they can pass your classes?
For years I have been saying that computer science is not a spectator sport. Students will learn better by trying to solve problems and code solutions on their own rather than by watching someone else do it. Learning takes place while making attempts, and often a small amount of coaching will get a student back on track.

Adam Cannon
Classes this semester/year:
COMS W1002 Computing in Context in the Fall
COMS W1004 Intro to CS in the Spring
Why did you decide to become a professor?
I love teaching good students and working in a university environment. I have worked in industry as an engineer and I’ve been a full-time researcher at a national lab, but I’ve always felt most at home on a university campus.
How did you end up teaching CS?
When I was getting out of grad school, I applied mostly to math departments but the work I was doing was on the interface of discrete math, statistics, and CS, so I also applied for a couple of CS positions. I didn’t think I would be teaching for long but wanted to try it and Columbia CS seemed like a good place to do that.
What do you like about teaching?
There’s a feeling you get when your students understand something new for the first time. I’ve heard some teachers call it a “teacher’s high.” It’s a thing and I like it. Then there’s something specific to STEM and that’s bringing people in that never really considered a career in STEM before. Broadening participation in CS and more generally in STEM is something that resonates with me.
What are your tips for students so they can pass your classes?
1. Go to class
2. Do the homework.
3. Do the reading
That’s it.

Tony Dear
Classes this semester/year:
COMS W3203 Discrete Math
ORCS 4200 Data-Driven Decision Modeling
About research, are you working on anything now?
I am investigating using deep reinforcement learning for robot locomotion.
What types of projects have you worked on with your students?
In an ongoing project, students have investigated wheeled and swimming snake robots in simulation to endow them with the ability to learn how to locomote. Other projects have covered using a combination of reinforcement learning with genetic algorithms to enable humanoid robot locomotion and using real-time replanning algorithms to coordinate motion planning for multiple robots.
Why did you decide to become a professor?
I am driven by the pursuit and dissemination of knowledge. My job allows me to be colleagues with experts who are authorities in their field. And I get to interact regularly with bright students who teach me new things all the time and have the potential to do great work.
What do you like about teaching?
Guiding students from the very beginning of the course to the end and seeing them make all the little connections. Continuing to interact with talented students when they work with me as TAs and seeing them solidify their knowledge. Learning about students’ diverse backgrounds and experiences, and how they’ve applied their knowledge outside the classroom.
Do you have a favorite story about your students that you tell people about?
I’ve taught a wide array of students, some of whom are older than myself. One such student had a couple of decades of industry experience before coming back to school for his graduate degree. He was an extremely talented student in my classes and ended up TAing with me in a later semester. After graduating, he took up an adjunct professor position to teach computer science at an even broader level, partially attributing this decision to his experiences working with me.
What are your tips for students so they can pass your classes?
Different strategies work for different students. But the most successful students in my classes tend to manage their time well, can focus without getting easily distracted, and ask questions as soon as they need help.

Eleni Drinea
Classes this semester/year:
CSOR W4246 Algorithms for Data Science in the Fall
CSOR W4231 Analysis of Algorithms in the Spring
What do you like about teaching?
What I mostly enjoy about teaching are the materials I teach and my students’ enthusiasm and brilliance. I love teaching courses on algorithms where we solve a wide range of interesting problems as efficiently as possible. I am fortunate to have hard-working students, often with diverse academic backgrounds (ranging from Computer Science, and Engineering more generally, to Statistics and Physics), who ask challenging questions and can offer insights and connections with other fields.
Do you have a favorite story about your students that you tell people about?
When I was teaching the Data Science Capstone & Ethics course (ENGI 4800) in Fall 2017, a student team I was supervising worked so diligently that they finished their semester-long project on Deep Learning in just two weeks. Their industry project mentor was very impressed: He extended the scope of the project to include a heavier research component and recruited two out of the five students in the team to their company (MediaMath).
What are your tips for students so they can pass your classes?
Students should always ask questions in class (or during office hours or on EdStem) if there is anything unclear from the lectures. I encourage students to pursue and test extensively their own ideas when solving homework problems to develop confidence in their own algorithmic thinking. I also recommend working through the optional exercises I provide in every homework. Finally, I encourage students to form study groups, which offer an effective and enjoyable way to learn.

Jae Woo Lee
Classes this semester/year:
On sabbatical this year
COMS 3157 Advanced Programming
COMS 4118 Operating Systems
Why did you decide to become a professor?
I’ll answer a slightly narrower question: why I became a teaching-focused professor, rather than a research-focused one. Midway into my PhD years, the department needed an instructor for AP at the last minute, due to an unexpected departure of the instructor who was assigned to teach it. I volunteered, thinking not much more than that it wouldn’t hurt to have an actual instructor experience on my resume. This turned out to be a life-changing experience for me. I spent all my time that semester creating my version of the course and teaching it (and did zero research…). After that, I knew that teaching was what I wanted to do.
What do you like about teaching?
I don’t really have one magical part of teaching that I love the most. I like all the normal things about teaching, especially when I try my best and end up doing them well. Some of the things that make me happy: preparing a well-developed lecture and delivering it exactly as I planned it, anticipating difficult questions and being ready to answer them, developing cool assignments with crystal-clear and well-thought-out instructions, writing sample code as carefully and beautifully as I can, coming up with sharp exam questions that are not unexpected yet challenging, and of course, hearing from students that they appreciate the efforts.
Do you have a favorite story about your students that you tell people about?
I get this question from time to time, but I never have an answer ready. I do have some stories about former students and TAs, but I don’t usually share them with others. I haven’t found a good story for which I am also certain that everyone involved would be OK with it being shared…
What are your tips for students so they can pass your classes?
It’s usually pretty easy to pass AP: Keep trying until the end and don’t cheat. A related question would be: How can one do well in AP? There are many tips, and my TAs and I share them at every chance we get. I’ll say one of them that some people find surprising: Get as little help as you can manage. Don’t run to a TA office hour at the first sign of trouble. Try to fix things yourself as much as possible. Even if you end up not going anywhere and needing some TA help eventually, the time you spent thinking and debugging is never wasted.
 Ansaf Salleb-Aouissi
Ansaf Salleb-Aouissi
Classes this semester/year:
COMS 4701 Artificial Intelligence
COMS 3202 Discrete Mathematics
What are your research projects at the moment?
My current research focuses on predicting and preventing adverse pregnancy outcomes like premature birth and preeclampsia.
I am also working on predicting the consequences of spine surgery like PJK (Proximal Junctional Kyphosis). On a more fundamental aspect, I study counterfactual explanations and physics law discovery from data. I strongly believe that machine learning will be a game changer in advancing science and medicine, in the next decade or so.
My overall focus is research and applications of AI for the benefit of science and education.
What type of student should apply to work on your research projects?
In general, my projects require students with backgrounds in machine learning/artificial intelligence. Whenever possible, I also involve students without experience to work on real-world problems, do data cleaning, and just learn how research goes. I am fully staffed this Fall though!
Why did you decide to become a professor?
I loved teaching ever since I was a kid. I recall mimicking my teachers, solving problems with chalk and board at home, and explaining the solution steps to an imaginary audience.
Later in high school and college, I volunteered to tutor my little neighbors and siblings. For me, teaching is a duty, a way to give back to society. It is one of the most demanding yet satisfying activities that teaches, in return, compassion and selflessness, and pushes the frontier of one’s own knowledge.
What do you like about teaching?
I like breaking up concepts to make them accessible to all students. It is for me a way to be creative about how to present things. I also genuinely care about how students perceive a new concept; I care about their self-esteem and happiness in my class.
I believe in a stress-free and inclusive teaching environment that can reach every student in class despite their difference in backgrounds and preparation.
Do you have a favorite story about your students that you tell people about?
I have many stories of students who came to class not on good terms with mathematics but ended up doing very well. Discrete math for me is the reconciliation of many young students with math that they perceived in high school as an inaccessible subject but then they discover the beauty of proofs and critical thinking, and how math is not boring but an engaging subject that sparks creativity.
What are your tips for students so they can pass your classes?
Just sit, relax, and enjoy learning the material. Make sure you do your own homework all by yourself and get the most out of it. Feel free to reach out to me anytime if you have any questions, and I will be more than happy to help. Then, not only will you pass my class, you will excel and thrive.
 Nakul Verma
Nakul Verma
Classes this semester/year:
COMS 4771 Machine Learning
COMS 4774 Unsupervised Learning
What are your research projects at the moment?
I like working on various aspects of machine learning problems and high-dimensional statistics. I am especially interested in analyzing how data geometry affects the learning problem. My theoretical projects include studying how to design effective machine learning algorithms in non-Euclidean spaces. My practical projects include developing algorithms and systems to do data analysis on domain-specific structured data, such as clustering mathematical documents or discovering patterns in neuroscience data.
What type of student should apply to work on your research projects?
Students with a strong mathematical background, who are interested in unsupervised learning or topological data analysis.
Why did you decide to become a professor?
Being a professor not only provides me the freedom to study a topic in greater depth but also gives me the opportunity to learn from and interact with world-class students and faculty. I find getting to know students and helping them achieve their goals extremely rewarding.
What do you like about teaching?
Teaching lets me share my passion for the subject with my students. It is very fulfilling to see students apply what they learned in class to their ML-related projects outside of class in creative ways.
Do you have a favorite story about your students that you tell people about?
I occasionally get students who are very stressed about taking my class because of “all the math” that is involved. I once had a student who was very underprepared to take my class. They let me know their concerns at the beginning of the semester, so we developed a plan to strengthen their math skills alongside doing their regular assignments. It was a struggle, and at times I really thought that the student would not be able to succeed. But to my pleasant surprise, this student ended up doing very well in class. I was truly impressed by what they were able to accomplish over the semester. I like to share this story to remind everyone, including myself, that planning ahead, communicating, and devoting time can and does make a remarkable difference.
What are your tips for students so they can pass your classes?
I think “passing” my class is easy, but to excel I recommend getting a solid understanding of the basics and doing consistent work throughout the semester.
In the Columbia Artificial Intelligence and Robotics (CAIR) Lab, Cheng Chi stands in front of a robotic arm. At the end of the arm sits a yellow plastic cup. His goal at the moment is to use a piece of rope to hit the cup to the ground.
“I never thought I would have to do this as part of a research project,” said Chi, a second-year PhD student. He was conducting the exercise to gain a better understanding of physical movement and how it can be applied to a robotic control system.
Existing robotic systems struggle to precisely manipulate objects with complex dynamics, such as hitting a small target with a whip or swinging tablecloths to an exact location. While these tasks are quite hard even for humans, we usually have a good intuition about how to change our actions after a failed attempt, and iteratively get closer to the goal.

Chi was able to knock the cup off after five tries. Now, it’s the robot’s turn to fling the piece of rope. It takes the robot four times to hit the target during the experiment (in general less than 10 times). The algorithm/neural network was trained in a simulator using a large amount of data. The robot, called Oolong, had to hit a target and was tested on different kinds of ropes it had never seen before.
Together with Assistant Professor Shuran Song and colleagues from the CAIR Lab, Chi worked to formalize this intuition into an algorithm called Iterative Residual Policy (IRP), a general learning framework for repeatable tasks with complex dynamics where a single model was trained using inaccurate simulation data. IRP can learn from that data and hit many targets with unfamiliar ropes in real robotic experiments, reaching sub-inch accuracy, and demonstrating its strong generalization capability.
This research brings robots from factories, where everything is rigid and can be accurately modeled, closer to everyday households filled with dirty laundry, raw vegetables to be washed in the sink, and leftover food to be cleaned from the fridge. It could potentially alleviate the labor shortage in food, retail, and logistics due to the aging population in many parts of the world. This could also enable the automation of simple tasks like changing bed sheets and badges in hospitals with infectious disease patients.
The team won a Best Paper Award at the Robot Science and Systems Conference (RSS 2022). We caught up with Chi to find out more about his research and PhD life at Columbia.
This is part of a grant from the Toyota Research Institute on deformable object manipulation. For this specific project, I wanted to explore more complex and dynamic forms of robotic manipulation and control. As the primary researcher of this project, I decided on the research topic, problem, and task.
The project started in May 2021. I did a lot of research about control theory for underactuated systems, chaos, and how to work with robot hardware.
Classical robotics literature divides the operation of a robot into three stages — perception, planning, and control. In my previous research, I studied perception and the planning stage of robotics. However, I realized that my knowledge still has a noticeable hole in control theory and systems that control the function and movement of robots.
I believe that I will never become a full-fledged roboticist without understanding all parts of robotic operations. Therefore, I intentionally steered this project toward control which allows me to read more into control-related literature and classes.
For example, I went over the YouTube recording of MIT’s underactuated robotics, taught by Professor Russ Tedrake, who has been known for his contributions to the control of locomotion systems (such as Boston Dynamic’s quadruped robots).
Another interesting thing about control is that, unlike planning, the control of the human body mostly happens at a subconscious level. Therefore, understanding more about control also gave me more insight into how the human body works.
The key realization came after months of reflecting on how I achieved certain tasks and how to formulate such a problem.
Since the relatively early stage of this project (after I decided to tackle the rope whipping task), I had this lingering feeling that being able to adjust the next action based on the error of my previous action is critical for how humans accomplish this task (by observing myself doing it). But I wasn’t able to connect it with math and concrete algorithms.
The next few months were spent playing with data collected in simulations to understand the structure of this task and problem. I often spent a few afternoons a week just staring at my iPad notes, sketching potential algorithms that can solve this task efficiently. Most of them were futile. However, one afternoon in late September, I suddenly came up with the idea that connects my lingering feeling to this concrete algorithm. And the rest was mostly planning out experiments, executing, and verifying results.
I decided on the research project jointly on what is missing in the field and what I wanted to learn. For example, I wanted to get into control last summer, so I took classes online and read relevant papers to build a foundation. I noticed that the missing piece in the field is deformable manipulation with precision.
Existing robotic algorithms often assume the object being manipulated is rigid, and ignore its physics/dynamics, due to its complexity. My research thrust has been targeting this complexity (of object physics and non-rigidity) head-on, which hopefully will result in better algorithms that will improve the overall performance and robustness of robotics systems, outside of confined/structured industrial environments.
Whipping a piece of rope is one of the simplest instances of dynamic deformable object manipulation, without the additional perceptive complexity such as self-occlusion, etc. However, we believe that whipping a piece of rope and tablecloth is representative of the class of problem we are interested in and that there is no existing robotic system/algorithm that can accomplish this task. Therefore, our algorithm has expanded what is considered possible in robotics.
I thought that it would be cool to simplify it to a minimum-working task, like whipping. Whipping a piece of rope or cloth accurately requires adapting existing skills which humans are good at but it is very difficult for robots to do.
Humans can hit targets with reasonable accuracy after usually 10~20 trials. The best algorithm before IRP takes 100-1000+ trials to get there.
The project spanned 10 months and it was not easy, since solving this novel and challenging task requires going beyond the common paradigm in the field, for example, reinforcement learning or system identification.
I tried three ideas at first and none of them worked or advanced the field to a satisfying degree for me. The final idea was inspired by some studies from the biomechanics/neural science community that I came across while doing research.
While I was struggling with this project, my advisor pointed me to this recording of an RSS 2020 workshop. I was fascinated by one of the talks by Professor Dagmar Stenard and her findings from the biomechanical perspective of how humans minimize uncertainty and avoid the chaotic region of the state space when taking actions.
I read further into her publications and was pleasantly surprised that her group was studying the same rope-whipping problem. Their algorithm was crude and they only tested in simulation with many additional assumptions, but I really liked their problem formulation of the whipping task and their use of action primitive, which dramatically reduced the number of parameters needed to describe the dynamic and continuous robot action.
They also demonstrated that their action primitives (that bio literature believes humans also use) are sufficient for this task. Therefore, I took their problem formulation and tweaked their action primitive to better fit real robotic hardware, and eventually developed the IRP algorithm on top of that.

The type of rope we simulated for training is modeled after a thick cotton rope we bought on Amazon. However, due to the various complex physical properties and their effects, the rope modeled in simulation behaves significantly differently from its real-world counterpart. This is an instance of a well-known challenge in the robotics community called “sim2real gap”.
Since the deep-learning revolution (~2014), a large body of robotic algorithms emerged that have shown very promising results in simulated environments. However, they also rely on a large amount of data for training (our algorithm included), which is only feasible to collect in simulation. If the behavior of objects in simulation matches exactly their counterparts in real life, in theory, we can directly apply these data-hungry algorithms to the real world. Unfortunately, this is far from the truth, and the difference is especially big for deformable objects.
The biggest contribution of this paper is providing a solution to close this “sim2real gap” for a limited class of problems (where the actions are repeatable, and the objects can be reset to the original state), i.e. the algorithm behaves just as good in the real world as in simulation, despite the simulation it was trained on is very “wrong”.
To further demonstrate how “wrong” the simulation can be while the algorithm still works, we cut out a long strip of cloth, that behaves like a gymnastic ribbon and treated it as the rope. We also bought a very thick leather bullwhip, that has a non-uniform density (it becomes thinner and thinner as it goes toward the tip), while all ropes we trained in simulation have uniform thickness and density. The experimental results on these two “ropes” were just as good.
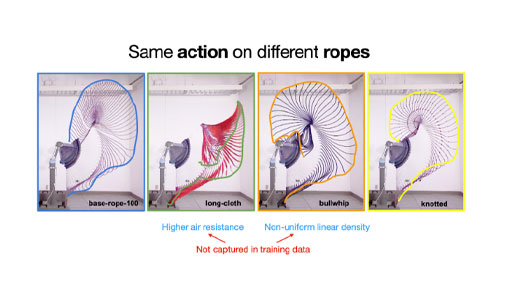
I like how researchers are able to try high-risk ideas that actually advance the field and also learn fundamental knowledge about the field. Working in industry usually constrains research options to low-risk ideas, while the engineering effort might be larger.
I gained my initial research experience during my undergrad at the University of Michigan, working on deformable object perception. I had multiple internships, as well as full-time jobs at autonomous vehicle companies, which taught me how to properly engineer a robotics software system.
I applied to Columbia to work with Assistant Professor Shuran Song. Just before I graduated from undergrad, Shuran did a job talk at the University of Michigan. My undergrad research advisor Professor Dmitry Berenson was at her talk and he was really impressed. Berenson strongly recommended that I apply to work with her and he thought we would be a great fit. After researching her past publications, I did find a large overlap in our research interests and I only heard good words about her after asking other people who have worked with her.
At the time, I wasn’t really sure about getting a PhD, and because of the time needed to complete the applications, I only applied to two schools. The application website could have been improved, but the overall process is surprisingly smooth. I really like the idea that students are admitted by and to individual professors, and the professors make the decision.
The highlight of my time is being able to be taught and guided by my advisor, as well as other PhD students.
I think what improved the most was to think more structurally and not be buried by the details. Due to the engineering complexity of robotic systems, there are thousands of variables and decisions, large and small, I needed to make for the project to progress. For example, on the high level, how to model the rope in the simulation, how to model the robot, how to represent the observation and actions, how the model should be architected, etc.
For an inexperienced researcher like myself, it is not obvious which one of these parameters will make or break the project, or will only yield a small change in the final performance. So, I over-analyzed, over-engineered, and over-thought the small problems. Fortunately, Shuran often called out that some of these decisions probably don’t matter that much, and choosing an arbitrary path to go forward is strictly better than spending time thinking about which one is better.
The problem is that this is mostly based on intuition. Shuran can’t always give evidence of why one thing doesn’t matter and why another does. But fortunately, I think I am getting a better grasp of these intuitions. It will become easier for me as time passes and I become an expert in robotics.
I also have found that it is really important to communicate clearly, both in meetings and when writing things down for reports or even emails. Learning by example from my advisor also helps a lot.
New students going into research should try as hard as possible to push through the first research project. It is always hard in the beginning, and it might feel impossible, but you can do it. Build up a tolerance for failure and continue to try different things, which is often critical to making a contribution to the field.
Michelle Zhou (PhD ’99) explains what no-code AI means and presents five inflection points that led to her current work, including the impact of two professors in graduate school who helped her find her direction in AI.
Eugene Wu and Zachary Huang created an easy-to-use app that helps fill “data voids” by cleaning and cross-verifying farmer drought reports.
Influential computer scientist Kathy McKeown heads up two multi-million dollar grants—one to analyze cross-cultural norms and another to better understand grief in the Black community.
Papers from CS researchers have been accepted to the 38th International Conference on Machine Learning (ICML 2021).
Below are the abstracts and links to the accepted papers.
Simple And Near-Optimal Algorithms For Hidden Stratification And Multi-Group Learning
Christopher Tosh Memorial Sloan Kettering Cancer Center, Daniel Hsu Columbia University
Abstract
Multi-group agnostic learning is a formal learning criterion that is concerned with the conditional risks of predictors within subgroups of a population. The criterion addresses recent practical concerns such as subgroup fairness and hidden stratification. This paper studies the structure of solutions to the multi-group learning problem and provides simple and near-optimal algorithms for the learning problem.
On Measuring Causal Contributions Aia Do-Interventions
Yonghan Jung Purdue University, Shiva Kasiviswanathan Amazon, Jin Tian Iowa State University, Dominik Janzing Amazon, Patrick Bloebaum Amazon, Elias Bareinboim Columbia University
Abstract
Causal contributions measure the strengths of different causes to a target quantity. Understanding causal contributions is important in empirical sciences and data-driven disciplines since it allows to answer practical queries like “what are the contributions of each cause to the effect?” In this paper, we develop a principled method for quantifying causal contributions. First, we provide desiderata of properties (axioms) that causal contribution measures should satisfy and propose the do-Shapley values (inspired by do-interventions (Pearl, 2000)) as a unique method satisfying these properties. Next, we develop a criterion under which the do-Shapley values can be efficiently inferred from non-experimental data. Finally, we provide do-Shapley estimators exhibiting consistency, computational feasibility, and statistical robustness. Simulation results corroborate with the theory.
Partial Counterfactual Identification From Observational And Experimental Data
Junzhe Zhang Columbia University, Jin TianIowa Iowa State University, Elias Bareinboim Columbia University
Abstract
This paper investigates the problem of bounding counterfactual queries from an arbitrary collection of observational and experimental distributions and qualitative knowledge about the underlying data-generating model represented in the form of a causal diagram. We show that all counterfactual distributions in an arbitrary structural causal model (SCM) with discrete observed domains could be generated by a canonical family of SCMs with the same causal diagram where unobserved (exogenous) variables are also discrete, taking values in finite domains. Utilizing the canonical SCMs, we translate the problem of bounding counterfactuals into that of polynomial programming whose solution provides optimal bounds for the counterfactual query. Solving such polynomial programs is in general computationally expensive. We then develop effective Monte Carlo algorithms to approximate optimal bounds from a combination of observational and experimental data. Our algorithms are validated extensively on synthetic and real-world datasets.
Counterfactual Transportability: A Formal Approach
Juan D. Correa Universidad Autonoma de Manizales, Sanghack Lee Seoul National University, Elias Bareinboim Columbia University
Abstract
Generalizing causal knowledge across environments is a common challenge shared across many of the data-driven disciplines, including AI and ML. Experiments are usually performed in one environment (e.g., in a lab, on Earth, in a training ground), almost invariably, with the intent of being used elsewhere (e.g., outside the lab, on Mars, in the real world), in an environment that is related but somewhat different than the original one, where certain conditions and mechanisms are likely to change. This generalization task has been studied in the causal inference literature under the rubric of transportability (Pearl and Bareinboim, 2011). While most transportability works focused on generalizing associational and interventional distributions, the generalization of counterfactual distributions has not been formally studied. In this paper, we investigate the transportability of counterfactuals from an arbitrary combination of observational and experimental distributions coming from disparate domains. Specifically, we introduce a sufficient and necessary graphical condition and develop an efficient, sound, and complete algorithm for transporting counterfactual quantities across domains in nonparametric settings. Failure of the algorithm implies the impossibility of generalizing the target counterfactual from the available data without further assumptions.
Variational Inference for Infinitely Deep Neural Networks
Achille Nazaret Columbia University, David Blei Columbia University
Abstract
We introduce the unbounded depth neural network (UDN), an infinitely deep probabilistic model that adapts its complexity to the training data. The UDN contains an infinite sequence of hidden layers and places an unbounded prior on a truncation ℓ, the layer from which it produces its data. Given a dataset of observations, the posterior UDN provides a conditional distribution of both the parameters of the infinite neural network and its truncation. We develop a novel variational inference algorithm to approximate this posterior, optimizing a distribution of the neural network weights and of the truncation depth ℓ, and without any upper limit on ℓ. To this end, the variational family has a special structure: it models neural network weights of arbitrary depth, and it dynamically creates or removes free variational parameters as its distribution of the truncation is optimized. (Unlike heuristic approaches to model search, it is solely through gradient-based optimization that this algorithm explores the space of truncations.) We study the UDN on real and synthetic data. We find that the UDN adapts its posterior depth to the dataset complexity; it outperforms standard neural networks of similar computational complexity; and it outperforms other approaches to infinite-depth neural networks.
The award will help fund research and support the work of a graduate student.
CS researchers demonstrate the first formally verified Arm Confidential Compute Architecture prototype

Researchers from the Software Systems Laboratory bagged a Best Paper Award at the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 2021). OSDI is “a premier forum for discussing the design, implementation, and implications of systems software.” A total of six research papers from the department were accepted to the conference.
XRP: In-Kernel Storage Functions with eBPF
Yuhong Zhong Columbia University, Haoyu Li Columbia University, Yu Jian Wu Columbia University, Ioannis Zarkadas Columbia University, Jeffrey Tao Columbia University, Evan Mesterhazy Columbia University, Michael Makris Columbia University, Junfeng Yang Columbia University, Amy Tai Google, Ryan Stutsman University of Utah; Asaf Cidon Columbia University
Abstract:
With the emergence of microsecond-scale NVMe storage devices, the Linux kernel storage stack overhead has become significant, almost doubling access times. We present XRP, a framework that allows applications to execute user-defined storage functions, such as index lookups or aggregations, from an eBPF hook in the NVMe driver, safely bypassing most of the kernel’s storage stack. To preserve file system semantics, XRP propagates a small amount of kernel state to its NVMe driver hook where the user-registered eBPF functions are called. We show how two key-value stores, BPF-KV, a simple B+-tree key-value store, and WiredTiger, a popular log-structured merge tree storage engine, can leverage XRP to significantly improve throughput and latency.
ROLLER: Fast and Efficient Tensor Compilation for Deep Learning
Hongyu Zhu University of Toronto and Microsoft Research; Ruofan Wu Renmin University of China and Microsoft Research; Yijia Diao Shanghai Jiao Tong University and Microsoft Research, Shanbin Ke UCSD and Microsoft Research, Haoyu Li Columbia University and Microsoft Research; Chen Zhang Tsinghua University and Microsoft Research; Jilong Xue Microsoft Research, Lingxiao Ma Microsoft Research, Yuqing Xia Microsoft Research, Wei Cui Microsoft Research, Fan Yang Microsoft Research, Mao Yang Microsoft Research, Lidong Zhou Microsoft Research, Asaf Cidon Columbia University, Gennady Pekhimenko University of Toronto
Abstract:
Despite recent advances in tensor compilers, it often costs hours to generate an efficient kernel for an operator, a compute-intensive sub-task in a deep neural network (DNN), on various accelerators (e.g., GPUs). This significantly slows down DNN development cycles and incurs heavy burdens on the development of general kernel libraries and custom kernels, especially for new hardware vendors. The slow compilation process is due to the large search space formulated by existing DNN compilers, which have to use machine learning algorithms to find good solutions.
In this paper, we present ROLLER, which takes a different construction-based approach to generate kernels. At the core of ROLLER is rTile, a new tile abstraction that encapsulates tensor shapes that align with the key features of the underlying accelerator, thus achieving efficient execution by limiting the shape choices. ROLLER then adopts a recursive rTile-based construction algorithm to generate rTile-based programs (rProgram), whose performance can be evaluated efficiently with a micro-performance model without being evaluated in a real device. As a result, ROLLER can generate efficient kernels in seconds, with comparable performance to the state-of-the-art solutions on popular accelerators like GPUs, while offering better kernels on less mature accelerators like IPUs.
Design and Verification of the Arm Confidential Compute Architecture
Xupeng Li Columbia University, Xuheng Li Columbia University, Christoffer Dall Arm Ltd, Ronghui Gu Columbia University, Jason Nieh Columbia University, Yousuf Sait Arm Ltd, Gareth Stockwell Arm Ltd
Abstract:
The increasing use of sensitive private data in computing is matched by a growing concern regarding data privacy. System software such as hypervisors and operating systems are supposed to protect and isolate applications and their private data, but their large codebases contain many vulnerabilities that can risk data confidentiality and integrity. We introduce Realms, a new abstraction for confidential computing to protect the data confidentiality and integrity of virtual machines. Hardware creates and enforces Realm world, a new physical address space for Realms. Firmware controls the hardware to secure Realms and handles requests from untrusted system software to manage Realms, including creating and running them. Untrusted system software retains control of the dynamic allocation of memory to Realms, but cannot access Realm memory contents, even if run at a higher privileged level. To guarantee the security of Realms, we verified the firmware, introducing novel verification techniques that enable us to prove, for the first time, the security and correctness of concurrent software with hand-over-hand locking and dynamically allocated shared page tables, data races in kernel code running on relaxed memory hardware, integrated C and Arm assembly code calling one another, and untrusted software being in full control of allocating system resources. Realms are included in the Arm Confidential Compute Architecture.
DuoAI: Fast, Automated Inference of Inductive Invariants for Verifying Distributed Protocols
Jianan Yao Columbia University, Runzhou Tao Columbia University, Ronghui Gu Columbia University, Jason Nieh Columbia University
Abstract:
Distributed systems are complex and difficult to build correctly. Formal verification can provably rule out bugs in such systems, but finding an inductive invariant that implies the safety property of the system is often the hardest part of the proof. We present DuoAI, an automated system that quickly finds inductive invariants for verifying distributed protocols by reducing SMT query costs in checking invariants with existential quantifiers. DuoAI enumerates the strongest candidate invariants that hold on validate states from protocol simulations, then applies two methods in parallel, returning the result from the method that succeeds first. One checks all candidate invariants and weakens them as needed until it finds an inductive invariant that implies the safety property. Another checks invariants without existential quantifiers to find an inductive invariant without the safety property, then adds candidate invariants with existential quantifiers to strengthen it until the safety property holds. Both methods are guaranteed to find an inductive invariant that proves desired safety properties, if one exists, but the first reduces SMT query costs when more candidate invariants with existential quantifiers are needed, while the second reduces SMT query costs when few candidate invariants with existential quantifiers suffice. We show that DuoAI verifies more than two dozen common distributed protocols automatically, including various versions of Paxos, and outperforms alternative methods both in the number of protocols it verifies and the speed at which it does so, including solving Paxos more than two orders of magnitude faster than previous methods.
BlackBox: A Container Security Monitor for Protecting Containers on Untrusted Operating Systems
Alexander Van’t Hof Columbia University, Jason Nieh Columbia University
Abstract:
Containers are widely deployed to package, isolate, and multiplex applications on shared computing infrastructure, but rely on the operating system to enforce their security guarantees. This poses a significant security risk as large operating system codebases contain many vulnerabilities. We have created BlackBox, a new container architecture that provides fine-grain protection of application data confidentiality and integrity without trusting the operating system. BlackBox introduces a container security monitor, a small trusted computing base that creates protected physical address spaces (PPASes) for each container such that there is no direct information flow from container to operating system or other container PPASes. Indirect information flow can only happen through the monitor, which only copies data between container PPASes and the operating system as system call arguments, encrypting data as needed to protect interprocess communication through the operating system. Containerized applications do not need to be modified, can still make use of operating system services via system calls, yet their CPU and memory state are isolated and protected from other containers and the operating system. We have implemented BlackBox by leveraging Arm hardware virtualization support, using nested paging to enforce PPASes. The trusted computing base is a few thousand lines of code, many orders of magnitude less than Linux, yet supports widely-used Linux containers with only modest modifications to the Linux kernel. We show that BlackBox provides superior security guarantees over traditional hypervisor and container architectures with only modest performance overhead on real application workloads.
UPGRADVISOR: Early Adopting Dependency Updates Using Hybrid Program Analysis and Hardware Tracing
Yaniv David Columbia University, Xudong Sun Nanjing University, Raphael J. Sofaer Columbia University, Aditya Senthilnathan IIT, Delhi, Junfeng Yang Columbia University, Zhiqiang Zuo Nanjing University, Guoqing Harry Xu UCLA, Jason Nieh Columbia University, Ronghui Gu Columbia University
Abstract:
Applications often have fast-paced release schedules, but adoption of software dependency updates can lag by years, leaving applications susceptible to security risks and unexpected breakage. To address this problem, we present UPGRADVISOR, a system that reduces developer effort in evaluating dependency updates and can, in many cases, automatically determine which updates are backward-compatible versus API-breaking. UPGRADVISOR introduces a novel co-designed static analysis and dynamic tracing mechanism to gauge the scope and effect of dependency updates on an application. Static analysis prunes changes irrelevant to an application and clusters relevant ones into targets. Dynamic tracing needs to focus only on whether targets affect an application, making it fast and accurate. UPGRADVISOR handles dynamic interpreted languages and introduces call graph over-approximation to account for their lack of type information and selective hardware tracing to capture program execution while ignoring interpreter machinery.
We have implemented UPGRADVISOR for Python and evaluated it on 172 dependency updates previously blocked from being adopted in widely-used open-source software, including Django, aws-cli, tfx, and Celery. UPGRADVISOR automatically determined that 56% of dependencies were safe to update and reduced by more than an order of magnitude the number of code changes that needed to be considered by dynamic tracing. Evaluating UPGRADVISOR’s tracer in a production-like environment incurred only 3% overhead on average, making it fast enough to deploy in practice. We submitted safe updates that were previously blocked as pull requests for nine projects, and their developers have already merged most of them.
Researchers from the department presented natural language processing (NLP) papers at the 2022 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2022).
Selective Differential Privacy for Language Models
Weiyan Shi, Aiqi Cui, Evan Li, Ruoxi Jia, Zhou Yu
With the increasing applications of language models, it has become crucial to protect these models from leaking private information. Previous work has attempted to tackle this challenge by training RNN-based language models with differential privacy guarantees. However, applying classical differential privacy to language models leads to poor model performance as the underlying privacy notion is over-pessimistic and provides undifferentiated protection for all tokens in the data. Given that the private information in natural language is sparse (for example, the bulk of an email might not carry personally identifiable information), we propose a new privacy notion, selective differential privacy, to provide rigorous privacy guarantees on the sensitive portion of the data to improve model utility. To realize such a new notion, we develop a corresponding privacy mechanism, Selective-DPSGD, for RNN-based language models. Besides language modeling, we also apply the method to a more concrete application–dialog systems. Experiments on both language modeling and dialog system building show that the proposed privacy-preserving mechanism achieves better utilities while remaining safe under various privacy attacks compared to the baselines. The data and code are released at this HTTPS URL to facilitate future research.
Knowledge-Grounded Dialogue Generation with a Unified Knowledge Representation
Yu Li, Baolin Peng, Yelong Shen, Yi Mao, Lars Liden, Zhou Yu, Jianfeng Gao
Knowledge-grounded dialogue systems are challenging to build due to the lack of training data and heterogeneous knowledge sources. Existing systems perform poorly on unseen topics due to limited topics covered in the training data. In addition, heterogeneous knowledge sources make it challenging for systems to generalize to other tasks because knowledge sources in different knowledge representations require different knowledge encoders. To address these challenges, we present PLUG, a language model that homogenizes different knowledge sources to a unified knowledge representation for knowledge-grounded dialogue generation tasks. PLUG is pre-trained on a dialogue generation task conditioned on a unified essential knowledge representation. It can generalize to different downstream knowledge-grounded dialogue generation tasks with a few training examples. The empirical evaluation on two benchmarks shows that our model generalizes well across different knowledge-grounded tasks. It can achieve comparable performance with state-of-the-art methods under a fully-supervised setting and significantly outperforms other methods in zero-shot and few-shot settings.
Database Search Results Disambiguation for Task-Oriented Dialog Systems
Kun Qian, Ahmad Beirami, Satwik Kottur, Shahin Shayandeh, Paul Crook, Alborz Geramifard, Zhou Yu, Chinnadhurai Sankar
As task-oriented dialog systems are becoming increasingly popular in our lives, more realistic tasks have been proposed and explored. However, new practical challenges arise. For instance, current dialog systems cannot effectively handle multiple search results when querying a database, due to the lack of such scenarios in existing public datasets. In this paper, we propose Database Search Result (DSR) Disambiguation, a novel task that focuses on disambiguating database search results, which enhances user experience by allowing them to choose from multiple options instead of just one. To study this task, we augment the popular task-oriented dialog datasets (MultiWOZ and SGD) with turns that resolve ambiguities by (a) synthetically generating turns through a pre-defined grammar, and (b) collecting human paraphrases for a subset. We find that training on our augmented dialog data improves the model’s ability to deal with ambiguous scenarios, without sacrificing performance on unmodified turns. Furthermore, pre-fine tuning and multi-task learning help our model to improve performance on DSRdisambiguation even in the absence of indomain data, suggesting that it can be learned as a universal dialog skill. Our data and code will be made publicly available.
ErAConD: Error Annotated Conversational Dialog Dataset for Grammatical Error Correction
Xun Yuan, Sam Pham, Sam Davidson, Zhou Yu
Currently available grammatical error correction (GEC) datasets are compiled using well-formed written text, limiting the applicability of these datasets to other domains such as informal writing and dialog. In this paper, we present a novel parallel GEC dataset drawn from open-domain chatbot conversations; this dataset is, to our knowledge, the first GEC dataset targeted to a conversational setting. To demonstrate the utility of the dataset, we use our annotated data to fine-tune a state-of-the-art GEC model, resulting in a 16-point increase in model precision. This is of particular importance in a GEC model, as model precision is considered more important than recall in GEC tasks since false positives could lead to serious confusion in language learners. We also present a detailed annotation scheme which ranks errors by perceived impact on comprehensibility, making our dataset both reproducible and extensible. Experimental results show the effectiveness of our data in improving GEC model performance in conversational scenarios.
Improving Conversational Recommendation Systems’ Quality with Context-Aware Item Meta-Information
Bowen Yang, Cong Han, Yu Li, Lei Zuo, Zhou Yu
Conversational recommendation systems (CRS) engage with users by inferring user preferences from dialog history, providing accurate recommendations, and generating appropriate responses. Previous CRSs use knowledge graph (KG) based recommendation modules and integrate KG with language models for response generation. Although KG-based approaches prove effective, two issues remain to be solved. First, KG-based approaches ignore the information in the conversational context but only rely on entity relations and bag of words to recommend items. Second, it requires substantial engineering efforts to maintain KGs that model domain-specific relations, thus leading to less flexibility. In this paper, we propose a simple yet effective architecture comprising a pre-trained language model (PLM) and an item metadata encoder. The encoder learns to map item metadata to embeddings that can reflect the semantic information in the dialog context. The PLM then consumes the semantic-aligned item embeddings together with dialog context to generate high-quality recommendations and responses. Instead of modeling entity relations with KGs, our model reduces engineering complexity by directly converting each item to an embedding. Experimental results on the benchmark dataset ReDial show that our model obtains state-of-the-art results on both recommendation and response generation tasks.
Differentially private decoding in large language models
By Jimit Majmudar, Christophe Dupuy, Charith Peris, Sami Smaili, Rahul Gupta, Richard Zemel
Recent large-scale natural language processing (NLP) systems use a pre-trained Large Language Model (LLM) on massive and diverse corpora as a headstart. In practice, the pre-trained model is adapted to a wide array of tasks via fine-tuning on task-specific datasets. LLMs, while effective, have been shown to memorize instances of training data thereby potentially revealing private information processed during pre-training. The potential leakage might further propagate to the downstream tasks for which LLMs are fine-tuned. On the other hand, privacy-preserving algorithms usually involve retraining from scratch, which is prohibitively expensive for LLMs. In this work, we propose a simple, easy to interpret, and computationally lightweight perturbation mechanism to be applied to an already trained model at the decoding stage. Our perturbation mechanism is model-agnostic and can be used in conjunction with any LLM. We provide a theoretical analysis showing that the proposed mechanism is differentially private, and experimental results show a privacy-utility trade-off.
Song and her students won for their paper, Iterative Residual Policy for Goal-Conditioned Dynamic Manipulation of Deformable Objects.
The Wu Lab, led by Eugene Wu, will talk at paper presentations, workshops, and a panel on “The Dos and Don’ts of Sharing Research.”
CS researchers presented their work at the 60th Annual Meeting of the Association for Computational Linguistics (ACL 2022).
Faithful or Extractive? On Mitigating the Faithfulness-Abstractiveness Trade-off in Abstractive Summarization
Faisal Ladhak Columbia University, Esin Durmus Stanford University, He He New York University, Claire Cardie Cornell University, Kathleen McKeown Columbia University
Abstract
Despite recent progress in abstractive summarization, systems still suffer from faithfulness errors. While prior work has proposed models that improve faithfulness, it is unclear whether the improvement comes from an increased level of extractiveness of the model outputs as one naive way to improve faithfulness is to make summarization models more extractive. In this work, we present a framework for evaluating the effective faithfulness of summarization systems, by generating a faithfulness-abstractiveness trade-off curve that serves as a control at different operating points on the abstractiveness spectrum. We then show that the baseline system as well as recently proposed methods for improving faithfulness, fail to consistently improve over the control at the same level of abstractiveness.
Finally, we learn a selector to identify the most faithful and abstractive summary for a given document, and show that this system can attain higher faithfulness scores in human evaluations while being more abstractive than the baseline system on two datasets. Moreover, we show that our system is able to achieve a better faithfulness-abstractiveness trade-off than the control at the same level of abstractiveness.
Towards Learning (Dis)-Similarity of Source Code from Program Contrasts
Yangruibo Ding Columbia University, Luca Buratti IBM Research, Saurabh Pujar IBM Research, Alessandro Morari IBM Research, Baishakhi Ray Columbia University, and Saikat Chakraborty Columbia University
Understanding the functional (dis)-similarity of source code is significant for code modeling tasks such as software vulnerability and code clone detection. We present DISCO (DISsimilarity of COde), a novel self-supervised model focusing on identifying (dis)similar functionalities of source code. Different from existing works, our approach does not require a huge amount of randomly collected datasets. Rather, we design structure-guided code transformation algorithms to generate synthetic code clones and inject real-world security bugs, augmenting the collected datasets in a targeted way.
Abstract
We propose to pre-train the Transformer model with such automatically generated program contrasts to better identify similar code in the wild and differentiate vulnerable programs from benign ones. To better capture the structural features of source code, we propose a new cloze objective to encode the local tree-based context (e.g., parents or sibling nodes). We pre-train our model with a much smaller dataset, the size of which is only 5% of the state-of-the-art models’ training datasets, to illustrate the effectiveness of our data augmentation and the pre-training approach. The evaluation shows that, even with much less data, DISCO can still outperform the state-of-the-art models in vulnerability and code clone detection tasks.
Fantastic Questions and Where to Find Them: FairytaleQA — An Authentic Dataset for Narrative Comprehension
Ying Xu University of California Irvine, Dakuo Wang IBM Research, Mo Yu WeChat AI/Tencent, Daniel Ritchie University of California Irvine, Bingsheng Yao Rensselaer Polytechnic Institute, Tongshuang Wu University of Washington, Zheng Zhang University of Notre Dame, Toby Jia-Jun Li University of Notre Dame, Nora Bradford University of California Irvine, Branda Sun University of California Irvine, Tran Bao Hoang University of California Irvine, Yisi Sang Syracuse University, Yufang Hou IBM Research Ireland, Xiaojuan Ma Hong Kong University of Science and Technology, Diyi Yang Georgia Institute of Technology, Nanyun Peng University of California Los Angeles, Zhou Yu Columbia University, Mark Warschauer University of California Irvine
Abstract
Question answering (QA) is a fundamental means to facilitate the assessment and training of narrative comprehension skills for both machines and young children, yet there is scarcity of high-quality QA datasets carefully designed to serve this purpose. In particular, existing datasets rarely distinguish fine-grained reading skills, such as the understanding of varying narrative elements. Drawing on the reading education research, we introduce FairytaleQA1, a dataset focusing on the narrative comprehension of kindergarten to eighth-grade students.
Generated by educational experts based on an evidence-based theoretical framework, FairytaleQA consists of 10,580 explicit and implicit questions derived from 278 children-friendly stories, covering seven types of narrative elements or relations. Our dataset is valuable in two folds: First, we ran existing QA models on our dataset and confirmed that this annotation helps assess models’ fine-grained learning skills. Second, the dataset supports question generation (QG) task in the education domain. Through benchmarking with QG models, we show that the QG model trained on FairytaleQA is capable of asking high-quality and more diverse questions.
Effective Unsupervised Constrained Text Generation based on Perturbed Masking
Yingwen Fu Guangdong University of Foreign Studies/NetEase Games AI Lab, Wenjie Ou NetEase Games AI Lab, Zhou Yu Columbia University, Yue Lin NetEase Games AI Lab
Abstract
Unsupervised constrained text generation aims to generate text under a given set of constraints without any supervised data. Current state-of-the-art methods stochastically sample edit positions and actions, which may cause unnecessary search steps.
In this paper, we propose PMCTG to improve effectiveness by searching for the best edit position and action in each step. Specifically, PMCTG extends perturbed masking technique to effectively search for the most incongruent token to edit. Then it introduces four multi-aspect scoring functions to select edit action to further reduce search difficulty. Since PMCTG does not require supervised data, it could be applied to different generation tasks. We show that under the unsupervised setting, PMCTG achieves new state-of-the-art results in two representative tasks, namely keywords-to-sentence generation and paraphrasing.
CS researchers demonstrate that the new privacy method—using differential privacy—is more effective than the old method of swapping, and better protects the privacy of minorities.
Roboticist’s proposed framework to enable robots to learn on their own and adapt to new environments could revolutionize everything from home service robots to emergency response systems.
Steven Feiner is one of 49 scholars and innovators who have been inducted into the inaugural class of the IEEE Virtual Reality Academy. Established in 2022 by the IEEE Visualization and Graphics Technical Community (VGTC), the IEEE Virtual Reality Academy recognizes significant contributions and highlights the accomplishments of the leaders in the fast-growing virtual reality field.
The jury found that CS professors Salvatore Stolfo and Angelos Keromytis of the Intrusion Detection Systems Laboratory were co-inventors of the groundbreaking cybersecurity safeguards used by NortonLifeLock Inc.
Professor Emeritus Alfred Aho and Professor Toniann Pitassi are among the Columbians recognized for their distinguished and continuing achievements in original research.
Xi Chen is one of a small number of researchers to be awarded two highly prestigious honors—the 2021 Gödel Prize and the 2021 Fulkerson Prize—in one year. He and his long-time collaborator Jin-Yi Cai, a professor at the University of Wisconsin–Madison, won the prizes for their paper, Complexity of Counting CSP with Complex Weights.
While continuing to teach at Columbia Engineering, Tim Roughgarden will serve as head of research at a16z Crypto Research
Another high-profile hack has raised more questions about the vulnerabilities of the blockchain.
The SIGecom Test of Time Award recognizes papers published between ten and twenty-five years ago that have significantly impacted research or applications exemplifying the interplay of economics and computation. Papadimitriou and Chen’s influential papers settled the complexity of computing a Nash equilibrium.
CS researchers have built an algorithm that blocks a rogue microphone from correctly hearing your words—in English so far—80% of the time.
Assistant Professor Ronghui Gu’s blockchain security firm CertiK is considered a unicorn company.
Baishakhi Ray is recognized for innovative and high-quality research on software engineering and artificial intelligence, which has impacted both the academic and industrial communities.
Bareinboim will develop a new framework that will lead to more efficient and robust decision-making; Kroer will develop new algorithms based on game theory to solve real-world problems with multiple actors.
Award supports computer scientist’s work to develop bioinformatics tools and methods to better understand RNA splicing’s role in ALS, cancer, and neuron development.
The theoretical computer scientist will use the award to push the boundaries of quantum information science.
How the 5G rollout grounded hundreds of flights—and how to fix it
Professor David Blei, with co-authors Matthew Hoffman and Francis Bach, is recognized with a Test of Time Award at NeurIPS, the world’s top machine learning conference, for scaling his topic modeling algorithm to billions of documents.
Teaching AI to distinguish between causation and correlation would be a game changer— well, the game may be about to change.
The Society for the Advancement of Economic Theory named economic theory fellows who have substantially advanced economic theory through scholarly and creative achievement.
It is one thing to study and learn about artificial intelligence in class and it is another to experience it and learn from doing it.
Girls’ Science Day was recently held and the day-long event introduced middle school girls to experiments and activities to show them how interesting and fun science can be for young women.
Ansaf Salleb-Aouissi knows how important it is to include women’s voices in science and research. She first became interested in computer science and coding when she was 14 after she joined an after-school program, near her house, and quickly realized that she would like to become a computer scientist. She achieved her dream when earned an engineering degree in computer science at the University Of Science And Technology Houari Boumediene (USTHB) in Algiers, Algeria, her home country.
Salleb-Aouissi was the only girl in the after-school computer science class, and later only a small number of women (less than 10 percent) of the class were women at her university.

As a mother of two middle-school-age daughters, she immediately volunteered to host two sessions to introduce artificial intelligence to students. Her projects in AI and education for pre-college students helped her prepare for the class. But this time around she tailored the lesson and broke down the concepts so that it would be easier for the teens to understand.
Nowadays, teens are immersed in AI, whether they know it or not, so showing them examples to explain the concepts was the perfect way of sparking interest and connecting science to their everyday lives.

Aside from gamifying the lesson with help of the online Kahoot platform, the students experienced training a model to identify objects. This is where the fun began, the students were tasked to teach the model how to identify the human body. To do this, they posed for the camera and had to think of different poses to help the model learn. A second experiment taught the model how to identify a purple pen and a green toy car. The students had to take pictures from various angles to be able to generalize and predict future images.
Once the model analyzed the photos it could easily identify the purple pen and could even identify a red and blue pen. The students were impressed by how the model worked well in identifying different objects from just a small set of sample photos.

Salleb-Aouissi joined the department in 2015 as a Senior Lecturer and does research in machine learning and medical informatics (e.g., prediction of premature birth), as well as building tools to help her students write proofs using propositional logic. This semester she is teaching discrete mathematics (COMS W3203) and is advising graduate and undergraduate students working on research projects.
Introduction to Artificial Intelligence and Kahoot materials by Ansaf Salleb-Aouissi, Uzay Macar, and Noah Mauchly (animator).
PhD student Mia Chiquier’s research is featured in Science. The new technology, called Neural Voice Camouflage, disguises words with custom noise.
The department is extremely proud of all of our students and would like to honor this year’s graduates! We were happy to have graduation celebrations in-person this year. Nothing beats the energy and excitement of commencement day!

During Class Day, awards were given to students who excelled in academics, students with independent research projects, and to those with outstanding performance in teaching and services to the department. The list of CS awardees is in this year’s graduation handout.
This year two new department awards were introduced, the Behring Foundation Award and the Davide Giri Memorial Prize. The Behring Foundation Award is given to excellent CS students who have lived, worked, or studied in Brazil or other Latin American countries.
The Davide Giri Memorial Prize will be awarded annually to a graduate student in Computer Science who has combined excellence in research results with continued outstanding efforts to promote research collaboration. The prize was established in memory of Davide Giri (PhD ’22), who promoted research collaboration in an exemplary way as part of his doctoral studies while excelling as a researcher.
The CS department gave out the awards to graduates after the University’s commencement ceremony. Below are photos from the department’s graduation celebration.


Jakob Gabriel Deutsch
Salutatorian, BS Finance and Business Analytics, Sy Syms School of Business of Yeshiva University 2020
For me, the MS Bridge program has been a great experience. Coming from a finance background with minimal experience with programming, the bridge portion of the program really gave me the necessary skills and experience to succeed in the MS portion of the program. Not only did the program bring me up to speed with other students, but the MS portion really exposed me to the various areas within the field of computer science and enabled me to explore those different disciplines.
When I started the program I wasn’t sure which track I wanted to pursue. After taking a couple of courses and seeing which ones matched best with my interest and strengths, I decided to pursue the Software Systems track. My favorite part of the program was probably a course that I took in my final semester, Advanced Database Systems with Professor Luis Gravano. It was a great class in which we learned about a variety of information extraction techniques and had the opportunity to implement a number of them ourselves as assigned projects. Professor Gravano was great and the course really bridged the gap between theory and application which is something you do not always get to see in the context of a single course.
During the summer I had the opportunity to intern for Prudential Financial as a Software Engineering Intern. There, I was able to continue building my programming skills in a more hands-on setting.
Having completed the MS program, I am confident that I have the skills necessary to be successful in any computer science related position. At the end of the summer, I will start full-time work at American Express as a Software Engineer in their New York office.

Matthew Maximino Duran
BA Economics and Mathematics, School of General Studies of Columbia University 2020
Former 3B with the New York Yankees
The program has been wonderful and it met all of my expectations. I was able to move through it at my own pace and was fully prepared for all of the master’s level coursework that I encountered. It was really important to me to not just become fluent in coding but to learn the fundamentals that underpin all of computer science. Through the Bridge classes and the master’s core, I have set the foundation for future learning as technologies change.
The MS Bridge program allowed me to get up to speed and prepare myself to thrive in the challenging master’s classes. That mission definitely succeeded, I never not once felt unprepared in any of the classes that I took in the MS portion of the program.
My favorite course was Advanced Databases with Professor Luis Gravano. In that class, we learned how the modern internet works, from web search and data mining to information retrieval and extraction. Overall, he was one of the most engaging and prepared professors that I had.
I started the program wanting to study Software Systems and I followed through on that goal. I felt that the Systems track afforded me the greatest flexibility in future career options, and for me personally, it was a “need to have.” Had I studied computer science in undergrad, then I could have potentially done Machine Learning or a different track. The systems track was very well planned and allowed me to touch all facets of modern computing from low-level hardware to the cloud. Overall, I am very thrilled with how everything turned out.
I did not do an internship during the program, one of my biggest regrets. I took summer classes with the hopes of accelerating my progress through the program. Maybe as this program takes off, there will be companies willing to partner with MS Bridge students, who have much less practical work experience than their peers.
After the program, I begin my software engineering career with American Express in New York City. I am really excited to see the types of projects that I will be working on, and how all of my foundational knowledge can be applied to real-world projects.

Ethan P Garry
BA Mathematics and Statistics, University of Rochester 2016
Associate of the Society of Actuaries in 2019
I loved the MS Bridge program! The program absolutely exceeded expectations. I might be lucky, but I 100% fell in love with coding, technology, and building systems. Now I am very confident in my tech skills, to the point where project partners are frequently impressed with my practical knowledge.
I started with software systems, then graphics, and ultimately made a personalized track (that I highly recommend for anyone looking for practical experience). Compared with friends who went with systems, they learned excellent skills and have great knowledge of systems, but lack certain high-level, real-world project building expertise.
Intro to Databases/Cloud Computing with Professor Donald Ferguson and User Interface Design/Advanced Web Design with Assistant Professor Lydia Chilton were my favorite classes. Both professors are incredibly passionate about teaching in their own unique way. These two professors were the best I have had in my entire educational career.
I was also able to do an internship where I worked with the Columbia Build Lab. This is another experience I highly recommend – it was very much like being thrown into the sea, but it forces you to learn so many practical concepts. You will be incredibly prepared for anything that comes next.
After graduation, I’ll be working as a Software Development Engineer at Amazon in their Physical Stores office in Seattle.
It’s a Friday night at International House and the graduate student residents of the dormitory are gathered to watch Central do Brasil. Andrea Clark-Sevilla is among them and looks forward to immersing herself in the touching story about friendship and finding one’s greater purpose. It is a much-needed break from the busy last semester of her master’s degree.
 The past two years have been non-stop for Clark even though she started her graduate career in 2020 at the height of the pandemic. Although she was fully remote, living in Querétaro, Mexico during her first year, she managed to pack in a research project with Senior Lecturer Ansaf Salleb-Aouissi and win a National Institutes of Health contest for it.
The past two years have been non-stop for Clark even though she started her graduate career in 2020 at the height of the pandemic. Although she was fully remote, living in Querétaro, Mexico during her first year, she managed to pack in a research project with Senior Lecturer Ansaf Salleb-Aouissi and win a National Institutes of Health contest for it.
The Decoding Maternal Morbidity Data Challenge aims to promote and advance research on pregnancy and maternal health. For the challenge, the team looked at data from the Nulliparous Pregnancy Outcomes Study: Monitoring Mothers-to-be (nuMoM2b) and decided to focus on preeclampsia, a pregnancy complication tied to high blood pressure that could lead to maternal and infant death if left untreated. Together with colleagues from Hunter College, their research, On Predicting and Understanding Preeclampsia: A Machine Learning Approach, developed a machine learning model that can predict women at risk of developing preeclampsia.
This was Clark’s first research project and being part of it helped her decide to pursue a PhD. Clark shared that she looked at the opportunity to use the two-year master’s program to explore and see if a research career is for her. “There are so many different ways to do research and chances to do other interesting things at Columbia, that I was hooked!” said Clark, she will begin her PhD in the fall and continue working with Salleb-Aouissi. “I now know for sure that I want to become a researcher and I am looking forward to starting my PhD.”
While many think that having to do meetings over Zoom and not being able to work and collaborate in person is a hindrance to good work, the opposite is true for Clark. Over the summer, she was able to do an internship with the Johns Hopkins University Applied Physics Laboratory (APL) and volunteered as a student instructor at Columbia’s AI4All summer program for high school students, where she was invited by Professor Augustin Chaintreau to lead a class on machine learning. So while doing research remotely from El Paso, Texas she would jump onto Zoom sessions with the AI4All students who were in New York City. Clark admitted she would not have been able to do both if things were in person.
When she isn’t brushing up on her French and German skills or watching a foreign film or two, Clark is working on her final projects and schoolwork and attending meetings to write the research paper for the preeclampsia project. We sat down with Clark to find out more about how she decided to pursue a PhD and her new love of research.
Q: Did you always want to do research and how did you start working with Professor Ansaf Salleb-Aouissi?
I studied math as an undergrad at Cornell, and it was not until rather late in my program that I found out what application field really interested me research-wise. I took a course in dynamical systems and biology, and it was after this that I found that I was passionate about combining biology and computing.
I actually found Professor Salleb-Aouissi through her wonderful and engaging edX course on Artificial Intelligence. After looking into her research areas, I was absolutely convinced that I wanted to work with her and applied to Columbia hoping to get a chance to collaborate with her in some capacity. It was so incredibly fortunate that it happened to work out that she was looking for students to work on a project during my second semester in the program!
Q: What did you work on and what did you like about the research?
I have mostly worked with evaluating different existing methods for interpreting traditional black-box machine learning models. For the NIH challenge, I leveraged a method called Partial Dependence Plots (PDPs) to determine which feature(s) had the greatest marginal contribution to a model we trained for predicting the incidence of preeclampsia in pregnant women. Using this method, we were able to narrow the cut-off points for high-risk factors, such as body mass index (BMI), blood pressure, and some notable placental analytes (proteins and/or hormones generated by the placenta) and show their influence on the model’s ability to predict the incidence of preeclampsia.
This can be useful information to clinicians who wish to monitor their patients based on a more curated set of risk factors and critical ranges for these, as well as organizations such as the American College of Obstetricians and Gynecologists (ACOG) who largely set the guidelines for this medical evaluation. Drafting appropriate guiding criteria for such a potentially dangerous condition has the potential to save many women.
Q: What are you working on now?
We are currently preparing the paper related to the NIH challenge for publication. Our team that worked on this challenge had so many great ideas, and the paper is slowly but surely evolving to its final form. The challenge itself felt rather short-lived, given how rich the data is and the different angles to approach the problem, depending on how one defines preeclampsia, for instance. All these details need to be properly addressed and defended, which takes much time. I am also finishing up my course requirements to graduate.
Q: Why did you decide to get a master’s degree instead of applying for a PhD?
For me, it was very important to figure out if I was suited to doing research before committing to a five-year program in which I would be doing this exclusively. I have heard stories about students dropping out of their PhD programs because it was not what they were thinking they signed up for. I don’t think the traditional undergraduate curriculum adequately prepares one for research, or at least it was not the case for me.
Q: What do you think people should know about doing a master’s degree? If you didn’t go through the program would you have applied for a PhD program?
A master’s degree is a great option if your undergraduate degree is not well-aligned with your career objectives, as it can give you the opportunity to pivot your skillset accordingly. I would say my experience is not the normal use-case for it, as I purely pursued the master’s degree to decide if I enjoyed doing research and could see myself continuing in a PhD program. If I did not enjoy it at all, two years is not a lot of sacrifice career-wise, and it is certainly a good learning experience.
The same cannot be said for a PhD program. I personally would not have had the confidence to commit to a PhD program not having the research experience I had with Professor Salleb-Aouissi. It is a bit of a double risk with a PhD program. First, you need to be reasonably committed to your research topic, and second, and I think most importantly, you need to be confident that you can work well with your advisor.
I feel that many students go into a PhD blindly, straight after undergrad. I am extremely fortunate to be able to say that I am very confident about both thanks to my experience in the master’s program.
I was also lucky enough to win a National GEM Consortium Fellowship for the master’s program. The fellowship allowed me to focus primarily on my research and not have to worry about the financial aspects of being in the program. I was also awarded this fellowship to continue funding my PhD studies.
Q: Why did you decide to apply for a PhD?
I feel that I am very driven when I have control over the questions that I want to answer and I have the freedom to explore them in the ways I see fit. I think that the most suited profession for someone with these characteristics is research.
Doing a PhD gives you the freedom to live in your own little world for five years and come out an expert in what you are passionate about. It’s really a dream situation!
Q: What will be your research focus?
I will continue my research on explainable artificial intelligence, likely in the precision medicine field. I also hope to be able to dig more into the theoretical underpinnings of more statistics-driven approaches and develop my own approaches for interpreting machine learning models.
Q: What sort of research questions or issues do you hope to answer?
I would like to bring the issue of creating explainable AI more to the forefront in the machine learning community. I feel that there is a lot more focus on developing the most state-of-the-art models in terms of predictive performance, but there is not enough research being done to make the results of such models understandable to the end-user, which might very well have serious social impacts.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research what should they know or do to prepare?
I think students should take classes that truly interest them, and if possible, also explore courses in other related departments. I have a friend who is taking a project-based course combining data science and climate change, and he is learning so much from it and enjoying it greatly!
I personally think that the best incarnation of learning comes from working on a tangible project like that and having the space to try ideas and explore. That is how it started with me and Professor Salleb-Aouissi.
Q: Is there anything else that you think people should know?
Don’t be afraid to fail at something at first! I always felt pressured to get something right on the first attempt, and I quickly realized that this mentality is not sustainable in the long run if you do research.
You learn so much more from your mistakes than from your successes. Your critical thinking skills are actively engaged when you have to analyze why something failed as compared to when it happily worked on the first try. I would hazard to say that researchers are skilled puzzlers because they always manage to pick up the pieces when something breaks.
Ahmet Cem Karadeniz (ME ’22) and Maya Venkatraman (CS’ 22) speak about life at Columbia Engineering.
Extreme weather and climate hazards negatively affect the food production and income of smallholder farmers across the world. One of the risk reduction strategies employed is index insurance for drought, which allows smallholder farmers to reduce their risk of losing money in the event of a drought. Computing the insurance claims requires data on the drought severity and timing. The problem is that these smallholder farmers do not have the infrastructure to accurately collect data, causing a “data void”. This, in turn, makes it hard for them to receive fair and timely relief.
Over the past decade, Columbia Earth Institute’s Daniel Osgood, has led the Financial Instruments Sector Team (FIST) which partners with farmers in Ethiopia, Zambia, and Senegal to develop an insurance index design process. The data was collected manually and in person but when COVID hit, the researchers realized they needed to develop scalable and easy-to-use digital tools.
In a recently funded NSF grant, Osgood collaborated with Assistant Professor Lydia Chilton and Associate Professor Eugene Wu to create systems that accurately collect data, tools that clean and visualize the data, and ultimately create an “open insurance toolkit” that any organization or government can use. One of the major tools created for the collaboration was Reptile, an easy-to-use app that helps clean and cross-verify farmer drought reports developed by third-year PhD student Zachary Huang. Reptile utilizes the predictive power of satellite data readily available at the International Research Institute’s data library as well as data collected from the farmers themselves. Farmer drought reports are critical for the FIST team to make high-stakes data-driven decisions in index insurance design. The insurance could protect hundreds of millions of farmers in face of climate hazards and extreme weather events.

Huang is a PhD student in Eugene Wu’s Wu Lab where researchers are addressing three bottlenecks in the future of data analysis: data cleaning, creating interactive data exploration and visualization interfaces, and understanding analysis results. Even though Huang’s background is in data analytics and database management systems, he shared he was not concerned about diving into the index insurance project. He learned about index insurance through a “very friendly” index insurance tutorial made by the FIST team. He also reviewed previous research papers and it was enough for him to work on the project. He likened himself to a blacksmith who builds tools for swordsmen. Said Huang, “I just need to know what swordsmen care about when using swords, but I do not have to be a swordmaster.”
We caught up with Huang to talk about his research, working on the Reptile app, and how his research focus has evolved.
Q: What was your role in the project? What did you do?
I mainly had two roles. My first role is as a software engineer, where I developed many useful data exploration tools to help FIST clean farmer drought reports and track the progress of data cleaning.
My second role is as a researcher. I studied the problem of data cleaning, data exploration, and data integration in-depth. I found there was a gap between what data cleaning research focused on and the problems the FIST team actually had. So I formalized the problem of cleaning farmer drought data and solved many hard technical problems while building Reptile. Our paper has been accepted by the ACM SIGMOD International Conference on Management of Data (SIGMOD 2022).
Q: What kinds of data did you have to work with and how did you manage it?
The main data I worked with is farmer drought data collected through questionnaires and a large volume of satellite data available from the International Research Institute’s data library. The data library compiles raw climate, geophysical, health, and agriculture data from numerous providers and formats it into a common framework that is publicly available.
These data from the data library are very predictive of drought severity. For example, the rainfall data are negatively correlated with the drought data. However, I was surprised by how laborious and frustrating it was to merge these data with the drought data from farmers and fully exploit their predictive power. This “data integration” problem is a hard problem even in industry.
The problem of data analytics across different data sources is very common across areas and challenging. To give you a sense of the difficulty, let’s take a look at the structure of public data from IMDB, the Internet Movie Database website. The information about movies, actors, companies, etc. is distributed across so many tables. Unfortunately, traditional data analytics tools are typically designed for a single table at a time. As a result, analysts have to manually “join” these tables together, which is confusing for non-experts, slow, and generally painful. FIST is facing the same problem: there are so many valuable tables, but how to take advantage of them?
Q: What does Reptile do?
Farmer reports can often have errors from wrong data entry, misremembering historical events, and bias. It’s not realistic to examine and assess each report individually, so Reptile helps the FIST team identify abnormalities at the district or national level, cross-verify these patterns with satellite data, and quickly fix the errors. FIST and local partners then rely on these cleaned data to design the index insurance.
Q: You mentioned that you decided to make the system simple and much easier to use. Why is that?
Initially, I built many different features per the requests from FIST. The end result is a monolithic system that tries to do everything but does nothing well. Users had to go to different systems even if the tasks are similar and had huge overlaps, which caused confusion.
About why I decided to make the system simple, let me quote Steve Jobs, “Simple can be harder than complex: You have to work hard to get your thinking clean to make it simple. But it’s worth it in the end because once you get there, you can move mountains.” I invested most of my time thinking about the project and trying to think of creative ways to solve problems. I read many papers, studied the problems in abstraction, and solved research problems. As a result, I aggressively simplified the system and made it much more useful for users.
Q: Can you talk about your background and why did you decide to pursue a PhD?
In undergrad, I had a decent mathematical background and transferred to computer science during my junior year. I initially intended to apply for some software engineering jobs. However, I learned from a friend who was a software engineer in a big tech company that his job is “an endless routine of crushing monotony”, and he also wanted to apply for a PhD to do something more intellectual.
I enjoy doing projects. But if you are hired as a junior software engineer, chances are that you are assigned some tedious tasks in the beginning and you need to slowly climb the career ladder before you can become a project lead. I very much wanted to be an entrepreneur, but I was totally not ready at that time. Doing a PhD sounded like a cool option, as it is intellectual and I can take initiative with research projects.
Q: What is your research focus?
I am interested in data analytics in cloud databases. I pursue this type of research because I believe the cloud is the future. It is the most profitable service in big tech companies like Microsoft and Amazon. The momentum keeps going with a large growth rate. I believe in the near future almost all data will be stored in the cloud, people will never want to move data outside of the cloud, and all these data analytics and machine learning tasks will be done inside the cloud.
With great power comes great responsibility. However, current cloud databases only store large volumes of data, but leave it to users to figure out how to use them. People call those data in cloud databases a “data swamp” – they just dump tons of tables but no one understands them.
Before Reptile, my research interest was to automate data cleaning. Given the fact that there are so much data in the cloud, it is a huge waste not to use it. However, while designing Reptile, I realized that data cleaning is a human problem, not a system problem. There are so many errors that are domain-specific and cannot be automated. For instance, farmer reports could be wrong because they confused drought with a flood, mixed planting and harvesting seasons, misremember the year, etc. While any of these issues sound trivial, discovering and understanding all of them requires domain knowledge, experiences, and common sense. We call these types of problems “AI-complete” problems; they are the most difficult problems in AI and can’t be solved until we can make computers as intelligent as people.
After Reptile, I shifted my attention from data cleaning to algorithmic optimization of data analytics over multiple tables. I utilized theories from probabilistic graphical models to aggressively save computations and significantly accelerate the process. We have an active project that shows how this can enable practical “data markets”, which are platforms where people can trade and monetize data across and within organizations, such that people have huge incentives to clean and improve the utility of data so that they are more valuable to potential buyers.
Q: What are you working on now?
My theoretical and algorithmic work has led to many exciting applications.
For instance, I’m collaborating with the Microsoft Azure team to build an innovative in-database machine learning system. Currently, if customers want to apply machine learning to data in cloud databases, they have to move data “outside” of the database to a machine learning system, which is slow, wasteful, and not secure. We implement all the machine learning algorithms “inside” cloud databases so that customers can conduct data analytics directly in cloud databases.
Another application is to support data analytics and machine learning over hundreds of tables without the need to “join” them. For example, FIST can use this system to directly combine the predictive power of hundreds of satellite data in the data library with the drought reports from farmers. Our preliminary results show orders of magnitude performance improvement over traditional machine learning systems.
Q: How long did it take you to complete the work? How was it?
Reptile took about two years to complete. It took a lot longer than I expected! I started the initial draft in the first semester of my PhD. However, figuring out the details, conducting experiments, polishing the writing, and revising based on reviewers’ feedback…there were so many things to attend to, which made the project long. Luckily, the whole process is a cumulative learning experience and inspired many research ideas for my future projects. Plus, I think I will be able to finish any future research projects much more efficiently moving forward.
Q: How did your previous experiences prepare you for a PhD?
I did research projects when I was an undergraduate – one on data cleaning and another on database storage. These projects helped me understand the research process and what are the critical problems nowadays in databases. Ultimately, having research experience strengthened my PhD application.
Q: What are some things you wish you knew before starting your PhD?
Things take time and research projects especially take time! We all want overnight success, but success happens because we have prepared for it for a long time. It is important not to worry if your research papers are not accepted at conferences and published. There are too many factors that are out of our control. If you have good ideas and decent work, being published is just a matter of time.
Also, it is better to focus on learning. Because research projects take such a long period, it is easy for us to get lost in monotonous and repetitive routines. However, you do not improve by just working hard. Do something that is cumulative in the long term, like learning! Small things will add up and make a huge difference in the long term.
Q: What is your advice for students on how to navigate their PhD? If they want to do research what should they know?
They should definitely work on some new areas and get a competitive advantage that is unique to them. The aim of your PhD research is to innovate in a specific area and push the boundaries of human knowledge. However, if you are working in an area that has been well-studied by so many smart people for decades, chances are there is no room for further innovation. For instance, if you want to improve system performance based on your coding skills, there are so many talented people who can code, so it’s unlikely for you to beat them. Your PhD life will be much happier if you can find something that not too many people know but is quite useful, and then become an expert in it.
I invest a lot of time learning probabilistic graphical models and graph theory. These statistical techniques seem irrelevant to database systems but they solve a similar problem – how to conduct analytics over multiple tables. This competitive advantage lets me easily design algorithms that are magnitudes faster than previous work.
Q: What else do you think is important for PhD students to think about?
I think it is good to periodically check if your research direction is useful. Committing to a research project and spending huge amounts of time on it requires a certain kind of fooling yourself – you need to convince yourself that your research project is useful and it is worthwhile to work so hard on.
However, you need to periodically jump out of your comfort zone and verify if your research direction is really useful. It is disappointing to devote five years to a research direction only to later find out that no one cares. One way to verify the usefulness of a research topic is to find some users or collaborators, like the FIST team for my Reptile project.
You should also ask your advisors for help, as they have a much deeper understanding of the area. My advisor, Eugene Wu, helped me a lot in finding the real-world applications of my theoretical ideas. To find applications, we have connected with professors in different domains, research departments in different companies, and even venture capitalists.

Shayan Hooshmand grew up speaking Spanish, Persian, and English. Every time he switched between the three languages he felt like he was walking between social worlds and presenting a different version of himself. Hooshmand is also an actor and it is this same affinity for shapeshifting that underpins his theatre career. As he got older, he tried to learn more languages or at least more about as many languages as he could.
Once he got to Columbia, he was all set to study computer science (CS) and found himself gravitating toward natural language processing and speech processing because those research areas combined CS and linguistics. The prospect of teaching machines to understand language was interesting to him. Hooshmand decided to take Intro Linguistics, loved it, and added Linguistics as a double major.
When he came across Professor Julia Hirschberg’s Speech Lab and their research on emotion and charisma in speech, it caught his attention. He emailed Hirschberg every semester for three semesters until, in the spring of 2021, there was finally an opening to join one of her projects which he accepted immediately.
The research project he was assigned to focuses on automatically identifying humor in Facebook (FB) posts. The system the team created, Collecting Humor Reaction Labels, earned them a Best Paper award at a prestigious conference, Empirical Methods in Natural Language Processing (EMNLP 2021). We caught up with Hooshmand to learn more about what it takes to do research and win an award.
Q: What is CHoRAL and what were your findings?
CHoRaL stands for Collecting Humor Reaction Labels, it is a framework for automatically scoring Facebook posts on humor. It presents two formulas, one to calculate a humor score, and one to calculate a non-humor score – each is based on the reaction distribution of a Facebook post.
Our paper presents both the framework and a dataset collected using the framework. The dataset contains about 800,000 COVID-related FB posts, each post was assigned humor and non-humor scores. Our goal for this framework and dataset is to enable future humor prediction research.
We validated our framework with experiments using several different BERT-based deep learning models. BERT is a machine learning model that learns contextual relations between words (or sub-words) in a text. We also ran lexico-semantic analyses on the humorous posts and non-humorous posts in our dataset to find some interesting patterns, like words related to space and time being negatively correlated with humor.

Q: How did this project come about? What was the process of deciding what to do?
The overall project didn’t have anything to do with humor immediately. The goal of this (ongoing) project is to detect fake and manipulated media online. As part of this larger goal, we thought it would be useful to automatically predict humor; then, if some piece of false information online is clearly humorous, we can attribute it to benign “fake news” and not anything malicious.
The pleasure of being an undergrad, though, is that I wasn’t fixated on these larger goals or the meetings with outside sponsors and collaborators that Professor Hirschberg and the PhD students attended. I got to focus on humor prediction and working directly with my PhD mentor, Zixiaofan Brenda Yang. Brenda came in with the brilliant idea to use Facebook humor reactions as a proxy for humor labels. At a high level, posts with more humor reactions would be more “humorous.” From there, the work became testing different methods to formalize this intuition.
Q: How much data did you have to work with? How was it processed?
So much data! We worked with millions of Facebook posts. We downloaded posts from CrowdTangle, a social media insights tool owned by Facebook. At first, we downloaded small batches of ~20,000 posts to test some of our formulas and definitions of humor and non-humor scores. In the end, we downloaded a couple of million Facebook posts and filtered them to keep only pure-text posts in English. We wrote the cleaning scripts in Python and ran them remotely on our lab computers.

Q: Were you prepared to work on it or did you learn as the project progressed?
It was a bit of a trial by fire for me since I was unaware of the standard proceedings and expectations surrounding academic research. For example, it shocked me that most of the “framing” work is done only when it comes time for paper writing. For a lot of the research process, you do not actually have a set, detailed idea of how you are going to present your work.
I also had to study technical concepts from information theory and statistics as we went along. Luckily, I always had my mentor, Brenda, as a guide.
Q: What were the things you already knew and what were the things you had to learn while working on the project?
I knew about the state-of-the-art deep learning models for NLP (RNNs, Transformers, etc.) and some other basic machine learning concepts. Naively, I thought my work would involve working with these models all the time, playing with their architecture, and tuning their hyperparameters.
In reality, I focused much more on data collection, preprocessing, and developing those formulas on humor and non-humor scores. Data collection and preprocessing were almost completely new to me (aside from some preprocessing functions I had written in previous CS classes) –– at least for our project, this work was fairly straightforward.
Developing the formulas required a lot of experimentation and reading up on technical concepts. I spent a couple of days trying to understand KL divergence conceptually before we tried to use it for an element of our project. In the end, it did not even end up being part of the paper. The cool thing, though, is that once I read up on that I ended up using it later in the project as the basis for calculating our non-humor score.
Q: Looking back, what were the skills that you wished you had before starting the project?
I wish I had a greater understanding of reading scientific papers, writing them, and the expectations for what kind of information from your project goes into them. There were many instances throughout the semester where Brenda had to remind me that we needed to be thorough with a certain decision or read up on previous work that might have faced the same problem because we would need to justify all our processes to the scientific community.
Q: Did working on this project make you want to change your research interests or focus?
The most interesting parts of the project for me were the linguistic analyses we ran on our humor-labeled data and writing the paper. I think that is because I like to approach things from more of a linguistics perspective, not as much pure computer science, so I am trying to direct my research from that angle more now.
Q: Will you continue to work on CHoRAL? Or are you working on something else now?
I have switched to a text-to-speech project in the Speech Lab this semester, so I’m not working on CHoRaL full-time anymore.
Q: Do you want to continue doing research and pursue a graduate degree?
I am definitely going to continue research throughout my undergrad years, and a PhD is possibly in my future. I am leaning toward working outside of academia for a few years after college and then applying to PhD programs later in my 20s.
Q: Would you recommend volunteering or seeking projects out to other students?
Of course! Even if you’re not interested in pursuing higher education, there’s so much to learn from a research environment. Particularly in the AI/ML space, doing research demystifies all the jargon and far-reaching statements about computer intelligence that you hear in the media. It is also a great way to gain practical skills, like keeping a project codebase organized and communicating the work I did independently with my mentors.
Q: Is there anything else that you think people should know about the project?
Not that I can think of right now, but if any students want to talk more about the project or undergrad research in general, my UNI is sh3988.
“So, this is a rough idea for modeling trajectories and I need your feedback,” said Didac Suris to the room while his teammates looked at him over bowls of Chinese food. “I literally just thought of this two days ago.”
It is the first week that working lunch meetings can resume at Columbia. Suris, along with other members of the computer vision lab, immediately took advantage of it. As they settle down into the meeting, Suris talks about his research proposal and his audience exchanges ideas with him in between bites of food. The last time this happened was two years ago.
“We came back in the Fall and it is good to be back in the office,” said Didac Suris, a third-year PhD student advised by Carl Vondrick. “Collaborating with teammates and just being out has worked wonders for my productivity which has skyrocketed compared to when working alone, or from home.”

Suris can be found in an office in CEPSR working on research projects that study computer vision and machine learning. The projects focus on training machines to interact and observe their surroundings, including his work on predicting what will happen next in a video. This is in line with his long-term goal of creating systems that can model video more appropriately and help predict the future actions of a video, which will be useful in autonomous vehicles, human-robot interaction, broadcasting of sports events, and assistive technology.
Suris was recently named a Microsoft Research Fellow. The research he has done while at Columbia focuses on computer vision and building systems that can learn on their own, which is very different from what he studied in undergrad, telecommunications at the Polytechnic University of Catalunya in Barcelona, Spain. We caught up with Suris to ask about how his PhD is going and winning the fellowship.
Q: What was your journey to Columbia? How did you pivot from telecommunications to applying for a PhD in computer vision?
It was only during my master’s, when I started doing research on computer vision, that I started to consider doing a PhD. The main reason I’m doing a PhD is because I believe it is the best way to push myself intellectually.
I really recommend doing research in different places before starting a PhD. Before starting at Columbia, I did research at three different universities, which prepared me for my current research. These experiences helped me to 1) understand what research is about, and 2) understand that different research groups work differently, and get the best out of each one.
Q: What drew you to machine learning and artificial intelligence?
One of the characteristic aspects of this field is how fast it is evolving, and how impressive the research results have been in the last decade. I don’t think there was a specific moment where I decided to do research on this topic, I would say there was a series of circumstances that led me here, including the fact that I was originally interested in artificial intelligence in the first place, of course.
Q: Why did you decide to focus on computer vision?
There is a lot of information online because of the vast amount of videos, images, text, audio, and other forms of data. But the thing is the majority of this information is not labeled clearly. For example, we do not have information about the actions taking place in every YouTube video. But we can still use the information in the YouTube video to learn about the world.
We can teach a computer to relate the audio in a video to the visual content in a video. And then we can relate all of this to the comments on the YouTube video to learn associations between all of these different signals, and help the computer understand the world based on these associations. I want to be able to use any and all information out there to develop systems that will train computers to learn with minimal human supervision.
Q: What sort of research questions or issues do you hope to answer?
There is a lot of data about the world on the Internet – billions of videos are recorded every day across the world. My main research question is how can we make sense of all of this raw video content.
Q: What was the thesis proposal that you submitted for the Microsoft PhD?
The proposal was called “Video Hyperboles.” The idea is to model long videos (most of the literature nowadays is on very short clips, not long-format videos) by modeling their temporal hierarchy. For example, the action of “cutting an onion” is composed of the subactions “grabbing a knife”, “pressing the knife”, “gathering the pieces.” This forms a temporal hierarchy, in which the action “cutting an onion” is higher in the hierarchy, and the subactions are lower in the hierarchy. Hierarchies can be modeled in a geometric space called Hyperbolic Space, and thus the name “Video Hyperboles.”
I have not been working on the project directly, but I am building up pieces to eventually be able to achieve something like what I described in the proposal. I work on related topics, with the general direction of creating a video representation (for example, a hierarchy) that allows us to model video more appropriately, and helps us predict the future of a video. And I will work on this for the rest of my PhD.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research what should they know or do to prepare?
Research requires a combination of abilities that may take time to develop: patience, asking the right questions, etc. So experience is very important. My main advice would be to try to do research as soon as possible. Experience is very necessary to do research but is also important in order to decide whether or not research is for you. It is not for everyone, and the sooner you figure that out, the better.
Q: Is there anything else that you think people should know about getting a PhD?
Most of the time, a PhD is sold as a lot of pain and suffering, as working all day every day, and being very concerned about what your advisor will think of you. At least this is how it is in our field. It is sometimes seen as a competition to be a great and prolific researcher, too. And I don’t see it like that – you can enjoy (or hate) your PhD the same way you enjoy any other career path. It is all about finding the correct topics to work on, and the correct balance between research and personal life.
Mustafa Eyceoz (SEAS ’22) is featured in the Profile Issue of Columbia Spectator’s magazine, The Eye.
Team leader David Watkins discusses how playing computer games can give roboticists real-world insights.
Molecular biologist, pianist, and cognitive scientist/biologist will receive scholarship aid from a program that supports students from non-computational backgrounds applying computer science in a broad range of interdisciplinary areas.
Hamoon Mousavi is a PhD student who moved to Columbia from the University of Toronto last year with Henry Yuen, whose research group studies theoretical computer science and the differences between classical and quantum computers.
When it comes to deploying her computer science skills, Camille-Louise Mbayo MS’22 is already looking far beyond the halls of academia.
Two Columbia engineers behind fashion app Upcomers on creating a marketplace to showcase Black-owned brands and five new designers everyone should know.
The CS@CU MS Bridge Program in Computer Science equips students from non-computer science backgrounds with the skills and knowledge necessary to build careers in technology.
The program is designed as a year of rigorous “bridge” coursework composed of introductory CS courses. This transition prepares students for a seamless entrance into Columbia Engineering’s MS program in Computer Science after the bridge year.
The program was launched in 2020 and the second cohort is currently in their bridge year. We asked these new students what their favorite class is so far.

Aneeza Asif
BA Cell and Molecular Biology, Barnard College (’21)
Through the few classes I have taken so far, COMS W1004, Intro to Computer Science has been my favorite. Professor Paul Blaer is such an amazing instructor, he truly takes time out to ensure students understand the material with the way he structures his lectures as well as his teaching style where he will pause to take questions in between different concepts. Professor Blaer offered Java Labs, which was a supplemental option to the main course, run by TA’s to help students better understand concepts taught in class. I am so appreciative of Java Labs and all the TA’s that helped me throughout the semester, as this was my first encounter with coding and it made for a great first experience.

Ryan Soeyadi
BM Piano Performance, The Juilliard School (’21)
My favorite class so far is Data Structures, mainly because I’ve reached a point where I’m comfortable programming in Java and I felt like I was able to translate my thoughts to code more easily in that class. I learned numerous ways to organize and manipulate data. I also learned how useful it is to draw diagrams with a pen and paper rather than jump to code from the beginning, a mistake beginners like me often make.

Madison Thantu
BS Cognitive Science, and Human Biology and Society, University of California, Los Angeles (’21)
Although only a few weeks into the spring semester, I am currently taking my first course in the master’s program, Artificial Intelligence, which, although challenging, I am very excited about and interested in. This course is synthesizing the information that I have learned in previous computer science and math courses and, for me, it has confirmed that I want to pursue the Machine Learning track once I officially enter the master’s program.

Jacky Wong
BA Economics, New York University (’17)
I enrolled in the MS Bridge program so that I can become a software engineer and build software to solve day-to-day problems. And it has been going well! I really like my Artificial Intelligence class. I have learned how to think computationally – how to model a question into a coding problem and how to turn an algorithm into code.

Jordan Jolley
BBA Management Information Systems, University of Texas, Austin (’18)
So far, my favorite course has been Artificial Intelligence. We not only learn general AI theories and history but also how to develop different algorithms in order to create a rational agent. Although I am not currently planning on pursuing a career in AI, I have found the class both challenging and enjoy broadening my scope of CS experiences.

Basel Hindi
BS Mechanical Engineering, Texas A&M University (’18)
I am currently enrolled in COMS 4701- Artificial Intelligence, and it is quickly proving to be my favorite class thus far. We are learning about rational agents and the axioms that govern them. I feel that the CS@CU MS Bridge program offers a tailor-made and well-structured transition into the world of graduate-level Computer Science. I believe this transition is critical in order to first hone my knowledge of CS and then apply those skill sets to solve interdisciplinary problems, which are increasingly present within the complexity of the real world.

Sean Jung
BA Nutrition Science, Georgia State University (’19)
MS Business Analytics, Emory University (’21)
I think Data Structures is one of the most important classes in the whole CS undergraduate curriculum. We are learning about different data structures such as ArrayList, LinkedList, Stacks, Queues, Hash Tables, etc, and then combining them with a set of algorithms to solve the problem in a creative and efficient way. This class has been my favorite since it is like a puzzle where I get a sense of achievement when I finally get to solve it.
Amey Pasarkar has been selected as a Finalist for his work on computational models that examine the microbiome and its role in health and disease.
Directional Gaussian Mixture Models of the Gut Microbiome Elucidate Microbial Spatial Structure
Amey P. Pasarkar, Tyler A. Joseph, Itsik Pe’er
The human gut microbiome contains trillions of bacteria that play a key role in preventing and fighting disease. However, the behaviors of these bacteria are still not well understood. One of these behaviors is the spatial arrangement of microbes in the gut. Numerous experimental studies have hinted that the various unique environments along the gut lead to certain bacterial spatial patterns. The research team created a consolidated computational model of the microbiome’s spatial arrangement. Their model can identify many of the previously discovered patterns and propose new ones as well. For example, the models found that the pH levels in the small intestine are likely promoting the growth of a specific family of bacteria.
The results demonstrate that the gut microbiome, while exceptionally large, has predictable and quantifiable spatial patterns that can be used to help us understand its role in health and disease.
The computer science community lost Davide Giri on December 2, 2021. For the past seven years, he worked in the Systems-Level Design Group under the guidance of Professor Luca Carloni. Friends and colleagues share their thoughts and memories of Davide.






















































 Wang")

 Xue")






















