
Year: 2017
Jonathan Gross Prize recognizes top CS graduates

![]()
The Jonathan Gross Prize is being awarded this year for the first time to honor students who graduate at the top of their class with a track record of promising innovative contributions to computer science. Five graduating computer science students—one senior from each of the four undergraduate schools and one student from the master’s program—were selected to receive the prize, which is named for Jonathan L. Gross, the popular professor emeritus who taught for 47 years at Columbia and cofounded the Computer Science Department. The prize is made possible by an endowment established by Yechiam (Y.Y.) Yemini, who for 31 years until his retirement in 2011, was a professor of computer science at Columbia.

Filipe de Avila Belbute Peres, Columbia College
“We are fortunate to live in a time when machines are powerful enough to let us study intelligence by trying to reproduce it.”
Fascinated by computers and computer science from a young age, Filipe de Avila Belbute Peres started building his own PCs and swapping out parts while still a kid; he was programming by his teens. Yet when it came time for college, he applied, and was accepted, to medical school in his native Brazil. The choice reflected his developing interest in studying the biological aspects of intelligence. Upon realizing that he could tackle the problems of neuroscience through a computational/algorithmic approach rather than a biological one, he applied to study computer science in the US. “I found a way to join my different interests, and study the relationships between machine intelligence and human intelligence. That’s where my interest in artificial intelligence comes from.”
This summer he will work at Facebook AI Research, applying neural networks to natural language problems. In the fall, he begins his PhD program in Computer Science at Carnegie Mellon, where he will continue studying artificial intelligence and machine learning with an emphasis in neural nets and deep learning.

Mitchell Gouzenko, School of Engineering and Applied Science
“My first criteria when picking a major was to choose something that I could do for hours on end without getting tired of it.”
Majoring in computer science wasn’t Mitchell Gouzenko’s first choice, or even second. He came to Columbia fully intending to pursue Financial Engineering before becoming convinced that he wanted to study physics; he declared, however, for Applied Math. “I was all over the place,” he says now. In his sophomore year, his computer science classes started growing on him. “While taking Operating Systems with professor Jae Woo Lee, I finally realized how much I enjoy programming and knew it would be a huge mistake not to major in computer science.” Because programming was fun—employability concerns were secondary—he changed his major to computer science. He hasn’t looked back. His main interests are in operating systems and more generally, software architecture. “I love reasoning about large codebases and analyzing how the various components interface with each other, with attention to security, performance, and clarity of design.”
This September he starts work at Google where he easily sees himself working for the next five years. A PhD may someday also be in store, but it will first require narrowing his interests.

Rudra Gopinath, General Studies
“The advantage of a computer science education is in seeing patterns the human eye can’t see because there is too much data.”
For Rudra Gopinath, that data will be financial in nature as he prepares to take a position at Citigroup in New York City. By his own admission, it is an interesting choice for someone most excited by theoretical computer science. Taking classes with professors Mihalis Yannakakis and Xi Chen, he was “that student always asking questions in class and always showing up for office hours.” He gravitated particularly to computational complexity—and not because it offered answers. “We don’t know anything about anything in this field. We don’t even know what we know, as opposed to knowing what we don’t know. If I eventually come back to school, this is the field I still study.” But for now there is a major diversion as he moves to apply the hard skill of computer science to business and the financial markets, two fields that have also long interested him. “All the banks I interviewed said the same thing: we can teach you the finance part. What we need from you is what Columbia teaches—the algorithms, the tools to work with data.” Getting to Columbia was not a straight path. He did his freshman and sophomore years in Hong Kong before enrolling in a dual-degree program that allowed him to transfer to Columbia. “Columbia is one of the few Ivy Leagues where you can come in with that sort of flexibility and plug in seamlessly. The professors, the administration, individual people, were highly supportive. I came in and started taking computer science. It was almost as if I had been here all along.”
Lanting He, Barnard College

“A wisely designed algorithm can be succinct but unbelievably powerful and quick.”
Lanting He arrived on campus expecting to major in business or economics. Shut out of an economics class in the second semester of her first year, she opted instead for Intro to Computer Science. Never having previously done any coding, she was amazed she could quickly write a simple program to do something practical in real life. It was after taking Data Structures, where she learned to love the logic behind the design of data structures, that she decided to major in computer science. “I find algorithms and data structures to be the most fascinating things to learn, and brainstorming algorithms is the thing I enjoy most.”
This summer, she will do an internship as a strategist analyst at Goldman Sachs. In the fall, she returns to Columbia to pursue a master’s degree at Columbia in Operations Research, exploring in depth how computer science connects with other interdisciplinary studies.

Gaurav Gite, Master’s student, School of Engineering and Applied Science
“I wish to develop computer systems to process, analyze and generate natural languages.”
Gaurav Gite’s interests lie in areas of natural language processing. After graduating from the Indian Institute of Technology (IIT), his desire to conduct research in the domain of artificial intelligence led him to pursue his master’s at Columbia University. He previously interned at Google, working with a research team to optimize the performance of neural networks. This helped in predicting the next words on keyboard inputs for Android devices. For his thesis, he worked with Kathleen McKeown in the Natural Language Processing (NLP) lab on the summarization of news articles, proposing new techniques based on the clustering of topics presented in the news article and salience of sentences. He also performed research at Columbia’s Center for Computational Learning System (CCLS) where he worked on automated methods to assess the content of written text and to grade student writing. Wise Crowd Content Assessment and Educational Rubrics, a research paper he coauthored while at the CCLS was published in the International Journal of Artificial Intelligence in Education in 2016.
After graduation, Gite will start working at Google, where he will continue working in the field of natural language processing.
Posted 5/17/2017
Lauren Wilcox (PhD’13) named to inaugural class of the ACM Future of Computing Academy
A former student of Steven Feiner, Wilcox is now assistant professor in the School of Interactive Computing at Georgia Tech.
Query logs put to new uses in data analysis: democratizing interfaces and tracking sources of errors
![]()

![]()
Researchers led by Eugene Wu are presenting two papers next week in Chicago at SIGMOD, a leading international forum for database research. “Precision Interfaces” proposes a semi-automatic method for generating customized interfaces for real user tasks by analyzing logs of programs that are actually used for analysis. “QFix: Diagnosing Errors through Query Histories” is a data cleaning method that determines how errors entered a database, making it possible to diagnosis the reasons for the errors, uncover other possible errors, and help prevent their reoccurrence. Though very different applications, both papers rely on a unique and underutilized source of information: program and query logs.
An interface for every task

Data analysis is critical today to an increasing number of tasks. Modern data exploration and analysis tools (think visualization systems like Tableau, or form-based querying) make data analysis easier by providing interactive interfaces complete with buttons, sliders, checkboxes, and other widgets, rather than typing programs manually. Existing interfaces are designed for general tasks performed by many, but they often ignore the long tail of tasks and analyses that are less common but important for small number of people; for these long tail tasks, users either learn how to build interfaces for themselves, rely on existing tools ill-suited for the task, or make do without.
“Precision Interfaces,” which is being presented at the Human In the Loop Data Analysis (HILDA) workshop, is intended to address this long tail by automatically generating data analysis interfaces that are “precise” to user tasks. The aim, according to Eugene Wu and his coauthors Haoci Zhang and Thibault Sellam, is to make data analysis accessible to more users so they can do exactly the data operations they want, and on the data they want.
The question of course is figuring out what people want to do when they themselves may have trouble articulating what they want. Operations on data constitute a potentially huge space, but query and program logs serve to constrain the possibilities by capturing what subsets of data that users are most interested in, what tasks they perform most often, and the sequence of those tasks.
In most cases, these logs show that people use data in fairly predictable and limited ways. Says Wu, “If you look at what people are doing it is not totally fancy new things. Any given task is usually associated with a small set of operations. The hard part identifying these task by perusing the history of what everyone has done, and providing interface that matches these tasks.”
Whether users are entering a range of numeric values (where a slider is appropriate), or simply toggling an option (when a checkbox suffices), can be gleaned from analyzing the program logs. By modeling each program (an SQL query or Python code that performs a task) as a node in an interaction graph, and drawing edges between nodes that differ in simple structural changes, researchers can detect similar changes and generate interfaces to express them.

Aesthetics and ease of use are considerations also. Says Sellam, “An interface with only a text box (a console) is visually simple but requires users to basically program. Oppositely, an interface with one button for each program is too complicated for any non-trivial program log. How easily users can interact with the widgets matters too. Ultimately, the optimal design depends on the use case.”
Information in program logs helps constrain otherwise ill-defined, open ended problems. A similar observation is applied by Wu and coauthors Xiaolan Wang and Assistant Professor Alexandra Meliou (University of Massachusetts, Amherst) in analyzing database query logs to identify and repair errors in databases and data-driven applications.
Tracking the source of data errors
Data errors pose a huge cost to business and other entities, especially local governments. Transposing two digits in a numeric value—an income level, a gas meter reading, a phone number—can set in motion a slew of problems as customers or clients get taxed or billed for the wrong amount. One error—an incorrect tax rate, for example—begets others as later queries retrieve the erroneous rate to calculate taxes for perhaps thousands of people, thus propagating the original error throughout records in the database while obscuring the source of the original error.
The usual fix—manually intervening to change individual errors after (and if) they are discovered—is ad hoc and superficial, and it fails to address the root cause.
QFix is designed to understand how an error entered and impacted the database so it can suggest repairs (e.g., fix the incorrect tax rate). Once a problem is reported, QFix examines the query log to analyze past queries that modified the database and then isolates the query that most likely introduced the initial error. The naive approach would be roll back to a given query, change it, and re-run the rest of the queries and see if it fixed the errors. This approach will not likely to finish within a lifetime for any realistic database.
The researchers’ approach is to think of each query as a set of linear equations that compute the database’s new values from the current values. By turning the queries in the query log into a large set of equations, they can be solved using modern linear constraint solvers. Says Wu, “If your database is a single value, say 10, and you know the incorrect linear equation (query) changed its value to 100 instead of 200, then we know how the linear equation (query) should be changed to fix the error.” QFix simply does this for millions of intertwined equations.
To generate the repairs quickly, the paper describes a set of optimizations to filter out queries, database records, and attributes that are unrelated to the data errors. This lets QFix identify erroneous queries in less than a second on standard industry database benchmark applications. QFix then suggests these queries and possible repairs to an administrator, who repair those queries and propagate the repairs to erase downstream errors—errors that might otherwise go unnoticed.
In using the information contained in query logs, QFix offers a fundamentally different method of data cleaning than anomaly/outlier detection, dimensionality reduction, and other traditional methods.
Both QFix and Precision Interfaces demonstrate how program and query logs are a rich resource for critical data science applications such as data cleaning, creating customized interfaces, and understanding in general what users want and need in their data analysis applications.
Posted 5/11/2017
Top students in computer science receive awards
In addition to awards given in previous years, the Jonathan Gross Prize for Student Excellence will for the first time honor students who graduate at the top of their class with the highest overall GPA and a track record of promising innovative contributions to computer science.
The awards for 2017 are as follows:
The Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service goes to both graduate students and undergraduates for outstanding contributions to teaching in the Department and exemplary service to the Department and its mission. Candidates are nominated by faculty and have typically have been selected for the SEAS Teaching Award. Criteria include evaluations by their supervising faculty and feedback from students in Courseworks or other forms.
Undergraduate level: Kevin Chen, Zeynep Ejder
Graduate level: Julie Chien, Clement Canonne
The Certificate of Distinction for Academic Excellence is awarded at graduation to computer science and computer engineering majors who have an overall cumulative grade point average in the top 10% among graduating seniors in CS and CE. The certificates are also awarded to graduating seniors who have completed an undergraduate thesis. Generally recipients have a GPA of 3.9 or higher.
The Computer Science Department Award is a cash prize awarded to a degree candidate for scholastic achievements as a computer science major and as acknowledgement of contributions to the Department of Computer Science and to the University as a whole. Academic staff prepares a list of students with the best GPAs in the graduating class. Other factors include general scholastic excellence demonstrated through projects or class contributions. (Historically the award is given to B.A. students.) The recipients for 2017 are:
Weston Jackson (GPA 4.13, 2nd overall, 1st among BA)
Yubo Han (GPA 4.12, 3rd overall, 2nd among BA)
The Computer Science Scholarship Award, Excellence in Computer Science. Academic staff prepares a list of students with the best GPAs in the graduating class, while factoring in also general scholastic excellence demonstrated through projects or class contributions. (Historically given to BS students.) The recipients for 2017 are:
Noah Zweben (GPA 4.19, 1st overall)
David Hao (GPA 4.09, 4th overall, 2nd among BS)
The Russell C. Mills Award, established by the computer science department in 1992 in memory of Russell C. Mills, is a cash prize given to a computer science major who has exhibited excellence in the area of computer science. The recipients for 2017 are:
Ruoxin Jiang (GPA 4.09, 5th overall)
Miranda Li (GPA 4.08, 6th overall)
The Theodore R. Bashkow Award, is a cash prize presented to a computer science senior who has excelled in independent projects. It is awarded in honor of Professor Theodore R. Bashkow, whose contributions as a researcher, teacher, and consultant have significantly advanced the state of the art of computer science. The recipients for 2017 are:
Tera Blevins
Ruoxin Jiang
The Jonathan L. Gross Prize for Academic Excellence was established in 2017 in honor of Jonathan Gross, the much loved professor emeritus who taught within the Department from its establishment. Each year a cash gift is awarded to one graduating masters student and to one graduating senior from each of the four undergraduate schools served by the Computer Science Department. The recipients for 2017 are:
Lanting He, Barnard
Rudra Gopinath, General Studies
Filipe de Avila Belbute Peres, Columbia College
Mitchell Gouzenko, SEAS
Gaurav Gite, master’s student, SEAS
The Paul Charles Michelman Memorial Award for Exemplary Service is given to a PhD student in Computer Science who has devoted time and effort beyond what is expected to further the department’s goals. It is given in memory of Dr. Paul Michelman, ’93, who devoted himself to improving the department through service while excelling as a researcher. This year’s recipient is:
Clement Canonne
The following graduate-level students will receive a CS Service Award for their outstanding performance and exemplary service to the CS@CU community:
Marshall Ball
Clement Canonne
Robert Colgan
Stuart Hadfield
Luke Kowalczyk
Dingzeyu Li
Andrea Lottarini
Kevin Shi
Ana Stoica
Olivia Winn
Posted 5/10/2017
Jeannette Wing joins Department, will lead Data Science Institute
A longtime advocate of interdisciplinary and collaborative research, Wing will continue to expand the Data Science Institute’s impact on research and education.
CS major Noah Jacob Zweben is valedictorian for SEAS Class of 2017
Zweben will speak at SEAS Class Day on May 15, when he will also be awarded the Illig Medal, the highest honor awarded an engineering undergraduate.
Lessons that 5G should learn from other technologies
Dustin Tran selected for Google PhD Fellowship
![]()

For work in Bayesian deep learning, Dustin Tran has been awarded a Google PhD Fellowship in Machine Learning. This two-year fellowship recognizes and supports outstanding graduate students doing exceptional research in computer science and related disciplines. It covers tuition and provides a $34K yearly stipend and an internship opportunity. Tran is one of 33 PhD students announced this month to receive the fellowship.
As a third-year computer science PhD student, Tran does research in the fields of Bayesian statistics, machine learning, and deep learning, with a particular focus on probabilistic modeling. He is advised by David Blei (of both the Computer Science Department and the Department of Statistics) and Andrew Gelman (of both the Department of Statistics and the Department of Political Science).
Like his advisors, Tran works at the intersection of two fields. After starting in Statistics at Harvard, he switched his PhD to Computer Science, at the same time transferring to Columbia. The decision was purely strategic; he chose the program with the fewest logistical constraints so he could maximize the time spent on research and learning. So far, he’s lived up to his side of the bargain, coauthoring seven published works in the 2016-2017 academic year, with another seven currently in review. Tran also regularly blogs on aspects of statistical modeling.
Learning is equally a focus. Machine learning is highly interdisciplinary—one reason his research is “literally the same” whether within statistics or within computer science—and liberally borrows techniques from other disciplines. Says Tran, “It’s hard to understand how to apply all these different techniques, how to discover what’s most useful about them, and how to advance them. I want to be able to distill these collections of techniques into their essential components and then apply them more broadly to tasks beyond image recognition and speech translation.”
One promising approach in his view is Bayesian deep learning, which incorporates complex models (neural networks) within a probabilistic paradigm. This enables one to incorporate parameter uncertainty, generalize the models for other tasks, and to criticize the model’s fit. “Rather than just connect components of neural nets together to make predictions, Bayesian deep learning encompasses neural nets within this richer, more scientific framework to reveal hidden structure,” says Tran. “It’s about the generative process. You’re building a model of the world and continually, iteratively refining it with new data; it’s the very definition of the scientific process.”
Merging Bayesian statistics and deep learning, which come from different traditions, is not straightforward. The first relies on mathematical principles investigated over a long history dating from Laplace in the 18th century, and it adheres to simple, small models to understand every component. The second uses many heuristics to train huge and highly complex models; though their inner workings cannot be known, they have achieved unprecedented success in large-scale experiments.
While new computing power and new techniques are making it easier to combine Bayesian statistics and machine learning, Tran is still within the minority doing so. A wider, more general acceptance will require software and tools to democratize the approach, better bridging the two disciplines. To that end, Tran leads the effort to develop Edward, a Python library for probabilistic modeling, inference, and criticism. He is also a contributor to both the open-source Stan, a probabilistic programming language featuring fast, highly optimized inference algorithms, and sgd, a suite of large-scale estimation tools in R via stochastic gradient descent.
For Tran, the fellowship’s most welcome benefit will be the expanded opportunity for collaboration, which is particularly important in machine learning, a highly interdisciplinary field that has benefited from many approaches. “Collaborating with others has opened my perspective to understand the key open problems and what solutions exist to solve them. The funding provided by the fellowship will afford me additional opportunities to travel and collaborate directly with prominent researchers in the field, including Kevin Murphy and Matt Hoffman from Google Research, developers in OpenAI, Aki Vehtari from Aalto University, and Susan Athey from Stanford University. And for this I am deeply appreciative.”
– Linda Crane
Posted: April 21, 2017
Allison Bishop delivers the talk “In Pursuit of Obfuscation”
Given at Princeton’s Institute for Advanced Study, Bishop’s talk surveys recent advances in program obfuscation, an area of theoretical cryptography that has seen unprecedented levels of activity over the past four years.
Engineering Icons: David E. Shaw is uncovering secrets of human biology
Legendary quantitative investment manager (and former Columbia computer scientist) David E. Shaw spoke to a packed auditorium about his research into high-speed simulations to understand molecular biology.
David Blei awarded Guggenheim Fellowship
David Blei tailors machine learning and topic modeling for a wide variety of research areas, including image analysis and patient monitoring.
Eitan Grinspun teaches the online course Animation and CGI Motion
Part of edX’s graduate-level MicroMasters series, the course gives instruction in the technical aspects of physics-based animation. Grinspun’s research has been incorporated into films by Disney, Pixar, LucasFilm, Weta Digital, and other studios.
Airbnb fans and critics both correct in home sharing debate
Augustin Chaintreau and grad students Mathias Lecuyer and Max Tucker scrapped Manhattan Airbnb listings, finding that most listings are rarely used but a small share of listings generates most of the revenue.
Researcher Says 9 in 10 Smart TVs Vulnerable to Broadcast-based Attacks
Visiting Random Sites to Confuse Trackers Won’t Protect Your Privacy
DSI’s Frontiers in Computing Systems, chaired by Steven Nowick, holds inaugural symposium
Over 150 researchers attended the March 24 event on applying extreme-scale parallel computing systems to solve diverse problems. Ruchir Puri, chief architect of IBM Watson, was keynote speaker.
No, We Can’t Say Whether Cancer Is Mostly Bad Luck
Undergrads Millie Yang and Spencer Yen earn engineering fellowships from KPCB

Two Columbia computer science undergrads, Millie Yang and Spencer Yen, have been selected to participate in the Kleiner Perkins Caufield & Byers (KPCB) Fellows Program, a summer program that gives US college students the chance to intern inside Silicon Valley tech companies while being mentored by executives within those companies. The program also entails KPCB-arranged events that include talks by leading individuals from the tech industry and opportunities to meet and network with other fellows and KPCB partners.
Yang and Yen, among 54 students selected from 2000 applicants, will intern at DoorDash, a restaurant delivery service recently in the news for testing delivery robots.
Yang is a junior currently pursuing the computer science Applications Track. She came late to computer science, taking her first class in the subject her first year at Columbia. “I had thought that I would be disadvantaged, but the computer science community at Columbia welcomed me with open arms, and strongly encouraged me to try out computer science classes.” For her part, she embraces technology, and sees it as a way to empower underprivileged communities; it’s a lesson learned first hand after spending a summer volunteering in Peru. “I was astonished to find WiFi at a broadband greater than I had previously used. Watching the local Peruvians use their phones and second-hand tablets to check market prices and communicate in businesses, I realized technology is making a revolutionary impact and leveling the playing field in developing countries.”
For her, DoorDash stood out because it is a start-up facing rapid growth and is striving to revolutionize the delivery industry. The company’s mission statement of “streamlining the world’s cities” echoes her personal experiences. “Born in New York, and raised in Hong Kong and London, I embrace my multicultural background as a crucial part of my identity. My interviewers and recruiters at DoorDash have demonstrated their strong support of the company’s goals, and it made me feel very much at home.”
Yen is the rare first-year student to be selected as a KPCB fellow. Coming from the Silicon Valley (where he was a user of DoorDash), he is imbued with the self-starter ethos endemic to the area. He taught himself—with an assist from YouTube—how to code, and since early high school has been creating iPhone games and apps. “I love that I can come up with an idea and just make it, and seeing people enjoy using something I created makes it all the more rewarding.” Gaining confidence over time in his coding skills, he took the initiative, reaching out to companies in the area for summer work. Two summers ago, he finagled—via cold-emailing—an opportunity to work alongside Mark Pincus at Pincus’s Superlabs incubator where the other hires were all recent grads from MIT. “I learned a lot about how some of the best entrepreneurs and engineers in the industry operate. It was a great experience to see how they thought about design and product, and how they approached writing code.”
While he hesitates to call himself an entrepreneur—he is still in his first year at college after all—the early signs are all there, and he cops to “working on projects.” A startup last year made it into the Almaworks Startup Accelerator program before he and the others involved decided to go in another direction. While not actively looking to start a company, Yen is of course open to the possibility if the right idea comes along.
Neither Yang nor Yen lacked options for this summer, but both were looking for something more than just a job and work experience. The KPCB program came highly recommended; a former fellow from Columbia described the program to Yen as phenomenal. “It’s all about the other fellows in the program and the incredible people you meet through the program,” says Yen. “You learn a lot just by being around ambitious and talented people.”
Yang, who is studying economics in addition to computer science, would agree with that assessment. “KPCB’s Fellowship Program will allow me to be exposed to the venture capital network and educate myself on how startups succeed in the Silicon Valley.”
– Linda Crane
Posted 3/27/2017
Startup cofounded by undergrad Mathew Pregasen renders math script from plain English
His startup Parsegon also has an education focus, explains Pregasen in this Q&A by The Columbia Lion, helping students learn the language of math while enabling interactive math in the classroom and online.
Universities dive into VR research
Computer Science Department establishes Jonathan Gross Prizes to recognize top CS graduates
![]()
 Beginning this spring, five graduating computer science students—one senior from each of the four undergraduate schools and one student from the master’s program—will be selected to receive the Jonathan Gross Prize. The prize honors students who graduate at the top of their class with the highest overall GPA and a track record of promising innovative contributions to computer science. Students will be recommended for the prize by the department chair, with final recipients selected by a majority vote of the faculty.
Beginning this spring, five graduating computer science students—one senior from each of the four undergraduate schools and one student from the master’s program—will be selected to receive the Jonathan Gross Prize. The prize honors students who graduate at the top of their class with the highest overall GPA and a track record of promising innovative contributions to computer science. Students will be recommended for the prize by the department chair, with final recipients selected by a majority vote of the faculty.
The prize is being made possible by an endowment set up by Yechiam (Y.Y.) Yemini, who for 31 years until his retirement in 2011 was a professor of computer science at Columbia. “This university has amazing students, and they deserve to have their academic accomplishments recognized by faculty and their fellow students; in recognizing them, we inspire a culture of excellence.”
The prize recognizes students while honoring Jonathan L. Gross for his 47 years teaching at Columbia, first in the Mathematical Statistics Department and then as a cofounder of the Computer Science Department.
“Jonathan Gross built and led the CS department education program for several decades,” says Yemini. “His continuing contributions to developing CS education over several decades defined his role as the ‘father’ of CS education at Columbia.”
Though primarily a mathematician, Gross had an early interest in computers and believed computing was for everybody. He was Acting Chair of Mathematical Statistics when SEAS committed funds in 1978-1979 to found the Computer Science Department. Gross’s role in starting the new department was fundamental; among his first initiatives, Gross merged the computer science courses that were concurrently being offered by both the Mathematical Statistics and the Electrical Engineering departments. As the new Computer Science Department grew from just a few professors in its first year—it now numbers almost 50 professors and five teaching-oriented faculty—Gross organized department-wide efforts to keep the academic curriculum at the educational forefront.
“I am deeply appreciative that my dear friend YY has honored me by associating my name with this wonderful award he has endowed,” says Gross, now professor emeritus. “It is a wonderful way to recognize the academic excellence of our students.”
For his part, Yemini says he feels fortunate to have the opportunity to help ensure that the legacy of excellence begun by Gross continues. Yemini’s Columbia research lab pioneered a range of seminal network technologies, from autonomic self-managing networks, to microeconomic network control, to high-speed switches and (what became two decades later) software-defined networks. The coauthor of over 100 refereed publications and a holder of 30 patents, Yemini is also a serial entrepreneur who cofounded five high-tech startups. Three of those startups grew out of technologies developed in his Columbia Lab and employ Columbia graduates. His most recent startup, Turbonomic.com (2009), just celebrated its 24th continuous quarter of record revenues growth, raising $50M investment to value the company at over $800M. Turbonomic’s R&D team includes scores of Columbia graduates in its NYC and Westchester offices.
Now professor emeritus and officially retired, Yemini continues to develop Turbonomic technologies while also teaching the popular Columbia Course “Principles of Innovation and Entrepreneurship (PIE)” and supporting philanthropic projects.
Julia Hirschberg, chair of the Computer Science Department, will announce and distribute the first Jonathan Gross Prizes this May at the graduation reception for computer science students. “This is a wonderful gift by a great emeritus faculty, YY Yemini, to honor another great emeritus, Jonathan Gross. The Department could not be more pleased.”
– Linda Crane
Posted 3/20/2017
Lights! Camera! Algorithms? Columbia Magazine features research of Eitan Grinspun
In creating Moana and other animated movies, artists at Walt Disney Animation Studios use techniques developed by Grinspun and his students to give characters lifelike hair that flows, bounces, and twists.
Awesome people: Kathy McKeown profiled in natural language processing blog
“Whenever a new topic becomes popular in NLP, we find out that Kathy worked on it ten years ago.”
What if Quantum Computers Used Hard Drives Made of DNA?
5 ways deep learning improves your daily life
What the CIA WikiLeaks dump tells us: Encryption works
IBM inches toward human-like accuracy for speech recognition
WikiLeaks’s CIA hacking trove doesn’t live up to the hype
WikiLeaks’s statement that CIA can bypass encryption in apps is misleading, says Steven Bellovin
Encryption is strong in WhatsApp, Signal, and other apps, Bellovin explains in a blog post, forcing the CIA to hack the endpoints (phones) and collect data before it is encrypted.
Yaniv Erlich and Dina Zielinski answer questions in Reddit AMA
Their paper, published last week in Science, describes a DNA storage method capable of encoding 215 petabytes in a single gram of DNA. It is believed to be the highest-density data-storage device ever created.
Minnesota government computer systems: Old, at risk and pricey to fix
Omri Weinstein on information, communication, and computation
![]()

What is the minimum amount of resources—time, space, energy, layers in a neural net—required to solve a given computational problem? This fundamental question is the essence of complexity theory and the main driving force behind the research of Omri Weinstein, a theoretical computer scientist who joins Columbia’s Computer Science Department this semester as assistant professor.
While practitioners might be content to use empirical trial and error in the search for increasingly improved heuristics, Weinstein and other theorists aim to answer the above question in a rigorous mathematical manner. Inherent to this research endeavor is proving lower bounds, that is, showing that no algorithm—out of the infinitely many that exist for a given problem—can solve it with fewer than X resources. In this way, theorists begin to unravel the limitations of what can and cannot be done with respect to a given problem. Reasoning simultaneously about all possible algorithms for a problem requires developing “universal” tools and techniques that are independent of any particular algorithm; otherwise researchers are left with the hopeless task of ruling out each individual algorithm of the uncountable number that exists.
The new toolbox Weinstein is developing comes from the field of communication
and information theory. “Communication over a channel is one of the few models of computation that we actually understand and for which we have simple and powerful analytical tools,” says Weinstein. “Computation on the other hand, is a beast which we are still very far from understanding. It is conceivable that there is some unimaginably clever algorithm for solving the Traveling Salesman problem that we are not yet aware of, since we have few tools to reason about processing of information. However, we can capture some of the hardness of the problem by splitting the input between two (or more) parties and asking them to solve the resulting distributed problem over a communication channel. At this point, we can use tools from information theory, combinatorics, and algebra to reason about the problem, bringing it to our home court.”
The machinery Weinstein cites is mostly drawn from information theory, which was established by Claude Shannon some sixty years ago in the context of the data compression problem. In the simplest setup, Alice wishes to transmit to Bob a random message, say a huge database of high-resolution pictures, using minimum communication bits. However, most real-life (as well as theoretical) distributed scenarios are inherently interactive, with processors exchanging small chunks of data over multiple rounds (one natural example is adaptive trading in economic markets such as stock exchanges). Classic information theory does not readily lend itself to the interactive setup; in particular, compressing conversations turns out to be notoriously challenging. Much of Weinstein’s work can be viewed as an interactive extension of Shannon’s classic information theory (aka “information complexity”), where the goal is to understand how information behaves in interactive scenarios, and to develop new information-theoretic methods in communication complexity, tailored for computer science applications: “Many computational models, such as data streaming, circuit design, and economic markets, have no apparent relation to communication problems,” says Weinstein. “Using clever reductions, though, it turns out that many of these models have some intrinsic communication problem implicitly ‘embedded’ within them.”
A prototypical example of this implicit connection are data structures, which enable efficient storage and retrieval of queries in a database. Data structures may not seem to have anything to do with communication, but can in fact be viewed, in some sense, as a communication protocol between the memory (which stores the database) and the processor (which holds a query). Indeed, consider the distributed communication problem in which Alice holds the database and Bob holds a query, and the goal of the players is to answer Bob’s query with respect to Alice’s database. Clearly, neither party can solve the problem on its own; hence communication must take place. Weinstein illustrates a surprisingly simple and beautiful connection to communication complexity: “If there was a too-good-to-be-true data structure that uses too little memory and has fast access time when retrieving an answer to a query, Alice and Bob could use this hypothetical data structure to construct a very efficient communication protocol for the aforementioned distributed problem, by jointly simulating the data structure: in each communication round, Bob asks Alice for the next memory-address his query prescribes, and Alice responds with the content of this memory cell in the data structure. If the data structure has ‘fast’ retrieval time, this would imply a low-communication protocol; hence time-space lower bounds for data-structures can be obtained via lower bounds for the underlying communication problem. Again, this is typically much easier, since the communication model has much more structure.”
Information complexity has gained popularity in recent years and led to some breakthrough results on several long-standing computational problems, some by Weinstein and his colleagues, some by other scientists. His paper Direct Products in Communication Complexity, which investigated the fundamental problem of “whether solving k copies of a single problem is k times harder than solving a single copy,” led to a breakthrough in understanding the limits of parallel computing, showing that solving multiple copies of any two-party distributed problem cannot be remedied much by parallelism (i.e., parallelizing cannot reduce communication significantly). Says Weinstein, “It is hard for me to imagine a proof that does not use information theory here, as this language is much more expressive than previous analytical tools and captures the exact properties needed to solve the problem; to me this paper provides further evidence that information theory is the ‘right’ language to study communication problems.”
A tangent line of research in Weinstein’s work is studying computational aspects of economics. A 2015 paper looked to find the minimum running time required to find an approximate Nash equilibrium in two-player games, one of the most important problems in algorithmic game theory. His papers on this subject played a role in the recent breakthrough results, showing that finding Nash equilibria is some games requires a huge amount of time and communication, thereby undermining the consensus over the basic definition of equilibrium as a practical economic solution concept.
While much of his work is theoretical and abstract, Weinstein is also looking into applied problems, especially in an era where rapid evolution in technology is constantly posing new challenges that require new techniques. With Columbia colleagues, Weinstein is studying an asymmetric compression problem that naturally arises from the Internet of Things (IoT) model. Here, millions of weak tags—low resource, low memory, low power devices—are required to convey messages to a central (powerful) gateway in an extremely efficient manner, both in terms of bandwidth and processing power. Compression obviously plays a key role in this model. Alas, standard compression schemes rely on the assumption that both the encoder and the decoder know the underlying prior distribution of the message to be sent, an assumption that is not realistic on the tag side (as they do not have the space nor the energy to store expensive statistics). Says Weinstein, “Can we nevertheless exploit the fact that the gateway knows the prior distribution, even if the tags don’t?” Perhaps surprisingly, the answer is “yes.” Weinstein and his co-authors developed a low-communication encoding scheme, which further admits efficient decoding time of the message on the gateway side. Once again, information theory and communication complexity are lurking beneath this fascinating problem.
“Omri’s research strengths and interests, especially his expertise in the nascent field of information complexity, complement and enhance the scope of our existing efforts in theoretical computer science. We are thrilled he has decided to join the Computer Science Department at Columbia, and we welcome him and look forward to working together!” said Rocco Servedio, Professor of Computer Science and a member of the department’s theory group.
Weinstein received his PhD from Princeton University in 2015 under the supervision of Mark Braverman, and holds a BSc in mathematics and computer science from Tel-Aviv University. He was named a 2016 Simons Society Junior Fellow and a Siebel Scholar in 2015; in 2013, he was awarded a Simons Graduate Fellowship.
Posted 3/7/2017
Study describing efficient method for storing information in DNA garners wide press coverage
![]()

In a new study in Science, Yaniv Erlich and coauthor Dina Zielinski describe a DNA storage technique capable of encoding 215 petabytes in a single gram of DNA. Robust, scalable, and resistant to errors, the method is 60 percent more efficient than previous DNA storage strategies and approaches 90 percent of the theoretical maximum amount of information per nucleotide. News of the method, which has potential for solving the world’s data storage requirements, was widely covered in prominent news outlets.
 |
This Speck of DNA Contains a Movie, a Computer Virus, and an Amazon Gift Card |
 |
DNA could store all of the world’s data in one room |
| Researchers store computer operating system and short movie on DNA |
 |
Suduko Hints at New Encoding Strategy for DNA Data Storage |
 |
Pushing the Theoretical Limits of DNA Data Storage |
| To make better computers, researchers look to microbiology |
 |
(Subscription) What’s Stored in DNA? An Old French Movie and a $50 Gift Card |
 |
Q&A: Encoding Classic Films, Computer Operating Systems in DNA |
 |
Hard drives of the future could be made of DNA |
Study coauthored by Yaniv Erlich describes maximizing data-storage capacity of DNA molecules
The approach—scalable, highly robust, and resistant to errors—is 60% more efficient than previous DNA storage strategies and approaches 90% of the theoretical maximum amount of information per nucleotide.
EyeStyle, a PhD side project, is accepted into two accelerator programs

![]()

EyeStyle—a visual platform for connecting shoppers with retailers—was recently accepted into both the NYC Media Lab Combine program and the Verizon Connected Futures Research and Prototyping Challenge. The two accelerator programs provide funding and mentoring to New York City university teams for help in developing, prototyping, and commercializing media-focused technologies. EyeStyle, which will receive $25K from the Combine and $15K from the Verizon Challenge, was the only Columbia team to advance to the final Combine round and is among three teams from Columbia to win the Verizon Challenge.

Formed by two computer vision researchers, Jie Feng and Svebor Karaman, EyeStyle employs computer vision and machine learning technology to analyze images and automatically identify and extract visual characteristics—color, shape, texture, pattern—from objects within the image. Among the possible applications are image search and automatic metadata generation.
An immediate commercial niche is online clothes shopping. Says Feng, “It’s very natural to get inspiration from seeing what other people are wearing. But finding an item of clothing is not easy. A Google search requires text, which works well when you know precisely what you’re looking for or the product is uniquely specified in some way. But using text to describe clothing, which is about style and visual impression, is hard. It’s much simpler take a photo or click on an image, and get back a list of similar products. Fashion by nature is communicated visually, why not discover it in the way it’s meant to be.”
With online shopping a major Internet activity, the demand for image search is growing (“LIKEtoKNOW.it” currently has 2M followers on Instagram). Feng and Karaman—one a computer science PhD student advised by Shih-Fu Chang and the other a postdoc in Columbia’s Digital Video | Multimedia Lab—are looking to technology to both streamline the image search workflow (having EyeStyle automatically select the search category, for instance) and to improve search capabilities, perhaps by using 3D models to more realistically represent how clothing is worn or to better train the models by taking advantage of the huge corpus of user-generated images on social media.

Image search, for which Feng and Karaman have created an app, is on the consumer side. On the retail or B2B end, Feng and Karaman are investigating how EyeStyle can best help retailers and media companies, both to draw customers to their stores or sites and to better organize their data and inventories.
Says Feng, “The combination of computer vision and machine learning will help shape the next generation of retail technology. With the funding and mentoring provided through the Combine and the Verizon Challenge, we’ll be able to explore and validate different business-use cases. We feel very excited.”
– Linda Crane
Posted 3/2/17![]()
Game theory says publicly shaming cyberattackers could backfire
Congress May Lack Technical Expertise to Properly Investigate Russian Hacking
Oscar-winning Jungle Book incorporates effects made possible by Eitan Grinspun
Animation techniques developed by Grinspun and his students rely on the geometry of physics and computer algorithms to simulate how plants and trees move in response to the wind or the swinging of monkeys.
Ilias Diakonikolas (PhD’11) receives Sloan Research Fellowship
A former student of Mihalis Yannakakis, Diakonikolas is now Assistant Professor and the Andrew and Erna Viterbi Early Career Chair in the Department of Computer Science at the University of Southern California.
Three faculty receive Google Research Awards
![]()
Suman Jana, Martha Kim, and Vishal Misra of Columbia’s Computer Science Department are each recipients of a Google Research Award, which provides funding to support research of new technologies developed by university faculty. Their three projects are among the 143 selected from 876 proposals received from over 300 universities worldwide. The funding provided by Google will cover tuition for one graduate student and allows faculty and students to work with Google engineers and researchers.
Suman Jana

For using machine learning to automatically find bugs in software, Suman Jana will receive $62K. Specifically his project Building High Coverage Fuzzers using Reinforcement Learning seeks to improve fuzzing, a software testing technique that inputs random data, called fuzz, to try to elicit error responses so the underlying code vulnerabilities can be identified before the software is released publicly and exposed to possible hacking. Current methods of fuzzing begin with seed inputs, applying mutations to produce a new generation of inputs. By evaluating which inputs generate show the most promise in leading to new bugs, fuzzers decide which inputs should be mutated further.
While fuzzing is successful at finding bugs humans might never find, especially simple bugs, the random and unsystematic nature of the evolutionary process means fuzzers might concentrate so much on certain inputs that some code gets overlooked. Jana’s project will employ reinforcement learning—a machine learning technique that reinforces successful actions by assigning reward points—to make the fuzzer more aware of how the software operates so the fuzzer can more intelligently generate input data for the specific program being tested. Rather than determining future inputs based only on the current generation of inputs (as do current fuzzers), reinforcement learning-based fuzzers will consider all previous mutations, finding program-specific patterns of mutations to ensure more complete code coverage. It’s a method that can be re-used since reinforcement learning-based fuzzers, once trained for a particular application, can be used to test other applications with similar input format and functionality.
Martha Kim

For more efficient ways of transcoding video, Martha Kim will receive $70K.
Transcoding video is the process of converting user-generated video to a size and format that views smoothly no matter the viewer being used. For video sharing sites like YouTube—currently uploading 400 hours of video each minute—more efficient transcoding translates to lower processing, storage, and other costs.
Transcoding can be done in software or hardware. While hardware accelerators operate at lower computational costs, they have serious drawbacks when it comes to video: they are slow to market (and thus slow to adapt to the release of updated codecs) and lack quality and other parameter controls that accommodate the varying requirements of a video-sharing site like YouTube, which in contrast to broadcast services such as Netflix, serve a wide-ranging and rapidly growing inventory of videos.
The ideal would be to combine the cost advantages of hardware with the flexibility, control, and upgradability of software, and that is the aim of Kim’s project, Video Transcoding Infrastructure for Video Sharing. By identifying bottlenecks in software video transcoding, Kim will design a video transcoding accelerator that avoids them. Rather than hardcoding entire algorithms into a rigid hardware design, Kim plans a modular approach, using separate building blocks for the different component stages of the transcoding. This modular approach promises to more readily support different video formats and differing quality and cost considerations.
Vishal Misra

Vishal Misra, whose research emphasizes the use of mathematical modeling to examine complex network systems, received $75K to fund Bandwidth allocation strategies for multi data center networks, which investigates strategies for estimating the right amount of bandwidth for data centers. Here the goal is to provide enough bandwidth to meet demand, even at peak times, while avoiding expensive over-provisioning.
The problem is far from simple. Global data centers provide distributed cloud computing for a host of services, all having different bandwidth and priority requirements. Communication may take place between servers within the data center or with servers at different sites.
Current methods for estimating bandwidth requirements (such as Google’s BwE) roughly work by aggregating all inputs to a data center while performing bandwidth control and priority enforcement at the application level according to the principle of max-min fair allocation (where a process with a “small” demand gets what it needs, while unused resources are evenly distributed among processes with unmet requirements).
But is this the right criteria to use? Misra who has previously investigated congestion equilibrium theory will seek to answer this and other open questions revolving around current allocation methods while also investigating other approaches (for example, separating bandwidth allocation from the traffic engineering problem and studying each independently).
This is the second Google Research Award for Misra. His first in 2009 resulted in the paper Incentivizing peer- assisted services: A fluid shapley value.
– Linda Crane
Posted 2/24/2017
What Can You Do With the World’s Largest Family Tree?
The Atlantic cites research led by Yaniv Erlich in creating a genetic tree of 13M people for studying migration, life spans, and other patterns. The work, still under peer review, was posted to bioRxiv.
Do-Not-Call list doesn’t work anymore
AI’s Factions Get Feisty. But Really, They’re All on the Same Team
Ang Cui (PhD’15) and the security vulnerabilities of office equipment
Cui’s research, which examined security risks of printers and other overlooked office devices, is the subject of a Fast Company article. Cui with his advisor, Salvatore Stolfo, founded Red Balloon Security to protect such devices.
Code-Dependent: Pros and Cons of the Algorithm Age
Dingzeyu Li awarded Adobe Research Fellowship
![]()

Dingzeyu Li has been awarded an Adobe Research Fellowship, which recognizes outstanding graduate students doing exceptional research in areas of computer science important to Adobe.
A fourth-year PhD student advised by Changxi Zheng, Li was selected for his research in a relatively new area of computer graphics: simulating sound based on the physics of actions and motions occurring within an animation. Where sound for computer-generated animations has traditionally been created separately and then later combined and synchronized with the animation, Li is working to develop algorithms and tools that automatically generate sounds from the animation itself, thereby bridging the gap between simulation and fabrication.
Extending the concept into virtual reality environments, he is developing a real-time sound engine that responds to user interactions with realistic and synchronized 3D audio. The goal is to create more realistic virtual environments where the visible and audible components are natural extensions of one another, where changes or edits to one propagate automatically and naturally to the other. Provided with a virtual scene, the sound engine will compute the spatial sounds realistically and interactively as a user interacts with the environment.
Li’s research into simulated sound is also enabling new design tools for 3D printing. In a well-received paper from last year (one funded in part by Adobe), Li and his coauthors describe a computational approach for designing acoustic filters, or voxels, that fit within an arbitrary 3D shape. At a fundamental level, voxels demonstrate the connection between shape and sound; at a practical level, they allow for uniquely identifying 3D printed objects through each object’s acoustic properties
For this same work, which pushed the boundaries of 3D printing, Li was named a recipient of the Shapeways Fall 2016 EDU Grant Contest.
Besides computer graphics, the Adobe fellowships are being awarded to students in seven other fields: computer vision, human computer interaction, machine learning, visualization, audio, natural language processing, and programming languages. Fellows are selected based on their research (creative, impactful, important, and realistic in scope); their technical skills (ability to build complex computer programs); as well as personal skills (problem-solving ability, communication, leadership, organizational skills, ability to work in teams).
The Fellowship is for one year and includes a $10,000 award, an internship this summer at Adobe, and mentorship from an Adobe Research scientist for one year. Included also are a free year-long subscription and full access to software in Adobe’s Creative Cloud.
Li entered the PhD program at Columbia’s Computer Science Department in 2013 after graduating in the top 1% of his class at Hong Kong University of Science and Technology (HKUST), where he received a Bachelors of Engineering in Computer Engineering.
– Linda Crane
Posted: 2/8/2017
Julia Hirschberg elected to the National Academy of Engineering

![]()
Professor Julia Hirschberg has been elected to the National Academy of Engineering (NAE), one of the highest professional distinctions awarded to an engineer. Hirschberg was cited by the NAE for her “contributions to the use of prosody in text-to-speech and spoken dialogue systems, and to audio browsing and retrieval.” Her research in speech analysis uses machine learning to help experts identify deceptive speech, and even to assess sentiment and emotion across languages and cultures.
“I am thrilled to be elected to such an eminent group of researchers,” said Hirschberg, who is the Percy K. and Vida L.W. Hudson Professor of Computer Science and chair of the Computer Science Department, as well as a member of the Data Science Institute. “It is such a great honor.”
Hirschberg’s main area of research is computational linguistics, with a focus on prosody, or the relationship between intonation and discourse. Her current projects include research into emotional and deceptive speech, spoken dialogue systems, entrainment in dialogue, speech synthesis, text-to-speech synthesis in low-resource languages, and hedging behaviors.
“I was very pleased to learn of Julia’s election for her pioneering work at the intersection of linguistics and computer science,” Mary C. Boyce, Dean of Engineering and Morris A. and Alma Schapiro Professor, said. “She works in an area that is central to the way we communicate, understand, and analyze our world today and is uncovering new paths that make us safer and better connected. As chair of Computer Science, she has also led the department through a period of tremendous growth and exciting changes.”
Hirschberg, who joined Columbia Engineering in 2002 as a professor in the Department of Computer Science and has served as department chair since 2012, earned her PhD in computer and information science from the University of Pennsylvania. She worked at AT&T Bell Laboratories, where in the 1980s and 1990s she pioneered techniques in text analysis for prosody assignment in text-to-speech synthesis, developing corpus-based statistical models that incorporate syntactic and discourse information, models that are in general use today.
Hirschberg serves on numerous technical boards and editorial committees, including the IEEE Speech and Language Processing Technical Committee and the board of the Computing Research Association’s Committee on the Status of Women in Computing Research (CRA-W). Previously she served as editor-in-chief of Computational Linguistics and co-editor-in-chief of Speech Communication and was on the Executive Board of the Association for Computational Linguistics (ACL), the Executive Board of the North American ACL, the CRA Board of Directors, the AAAI Council, the Permanent Council of International Conference on Spoken Language Processing (ICSLP), and the board of the International Speech Communication Association (ISCA). She also is noted for her leadership in promoting diversity, both at AT&T Bell Laboratories and Columbia, and for broadening participation in computing.
Among her many honors, Hirschberg is a fellow of the IEEE (2017), the Association for Computing Machinery (2016), the Association for Computational Linguistics (2011), the International Speech Communication Association (2008), and the Association for the Advancement of Artificial Intelligence (1994); and she is a recipient of the IEEE James L. Flanagan Speech and Audio Processing Award (2011) and the ISCA Medal for Scientific Achievement (2011). In 2007, she received an Honorary Doctorate from the Royal Institute of Technology, Stockholm, and in 2014 was elected to the American Philosophical Society.
Hirschberg joins Dean Boyce and many other Columbia Engineering colleagues who are NAE members; most recently elected were Professors David Yao (Industrial Engineering and Operations Research) in 2015, Gordana Vunjak-Novakovic (Biomedical Engineering) in 2012, and Mihalis Yannakakis (Computer Science) in 2011.
On February 8, the NAE announced 84 new members and 22 foreign members, bringing its total U.S. membership to 2,281 and foreign members to 249. NAE membership honors those who have made outstanding contributions to engineering research, practice, or education, including significant contributions to the engineering literature, and to the pioneering of new and developing fields of technology, making major advancements in traditional fields of engineering, or developing/implementing innovative approaches to engineering education.
– Holly Evarts
Posted 2/7/2017
Steven Bellovin & coauthors call for new surveillance laws to reflect internet’s complexity
Paper published in Harvard Journal of Law & Technology shows how technology blurs line between metadata and private content, eroding protections codified in pre-internet communications.
Startup cofounded by Apoorv Agarwal (PhD’16) is featured in Forbes
Text IQ uses NLP and ML techniques to streamline document review process for attorneys. Already profitable, the company saved customers $3M in legal expenses just this year, not counting what was saved by averting problems.
Daniel Bauer joins department as lecturer, adding strength in NLP and AI
![]()

Daniel Bauer, who has been teaching Data Structures for the past four semesters, is joining the Computer Science Department where he will teach two courses a semester. Bauer is the third teaching-oriented faculty hired in the past two years as the department moves to meet the surging demand for computer science classes from majors and nonmajors alike.
“I feel especially lucky to be teaching at Columbia with its diverse student body where students are super curious and super excited to learn. I hope to help them discover new areas,” says Bauer.
In addition to the honors section of Data Structures and Algorithms (COMS W3137), Bauer is teaching Introduction to Computing for Engineers and Applied Scientists (ENGI E1006) this spring; next fall he is planning to teach Natural Language Processing (NLP), his particular research focus.
A sub-area of artificial intelligence, NLP is concerned with using computers to analyze written or spoken language. NLP researchers design systems that understand and generate natural language, extract information from text or speech, and automatically translate between languages. Demand for NLP is growing as user interfaces become more language-driven and as more and more free-form written and spoken data becomes available digitally.
The inherent ambiguity and nuance of human language pose challenges, however. Says Bauer, “The old Marx Brothers line ‘I shot an elephant in my pajamas’ allows for two interpretations, but human speakers know empirically that pajamas are worn by people, not elephants. This observation or knowledge has to be conveyed somehow to language processing systems.”
One way is to collect enough sample sentences and train machine learning models that predict that pajamas is more likely to be associated with people than with elephants. This machine learning approach works extremely well to disambiguate between multiple possible syntactic structures for a sentence. Bauer, whose research focus is in computational semantics, is looking beyond syntax and tries to train models that can infer the meaning of a sentence. “Large data sets of semantic annotations for sentences have only become available in the last few years and how to best train NLP tools on this data is an open problem. While syntactic representations traditionally use trees, semantic data sets that annotate predicate-argument structure use more general graphs, so the formal machinery we have been using for trees is no longer sufficient,” says Bauer, who developed grammar formalisms and models that can translate between text and graphs in his dissertation.
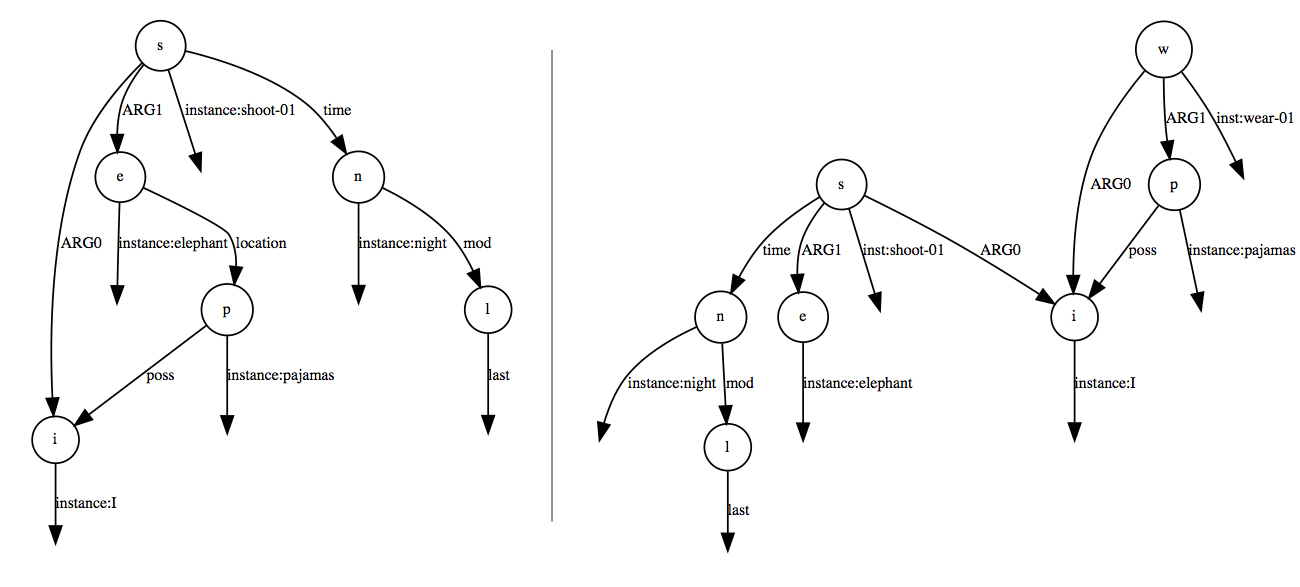
“Being able to recover the meaning of a sentence will help us build better systems for machine translation, search, text summarization, and information extraction, for example to detect emergent events, identify terror threats, or predict stock price developments.”
Bauer is also interested in incorporating outside and domain knowledge to understand a sentence in the context in which it was uttered. “In a dialog, we use language to refer to objects in our environment and events going on around us. Language processing systems, especially conversational agents, should be able to communicate using language that is grounded in this environment or in other modalities,” says Bauer.
One area of interest is trying to understand the meaning of natural language descriptions as they relate to spatial relationships of objects. As a cofounder of WordsEye, which automatically translates text into 3D scenes, Bauer is interested in extending semantic analyses to the world of objects and their properties. While WordsEye starts with a set of rules defining placement of objects according to user input text (what does “on” mean in a 3D scene?), Bauer wants to combine these rules with more machine–learning focused language processing. “Can we take the corpus of existing WordsEye scenes and automatically extract the text-to-scene generation system from that? Rather than manually engineering these rules, can we learn from how people use and place things in context?” It’s a future research subject he hopes to explore.
In his research, Bauer has always involved undergraduate and master’s students and will continue to do so as he assumes more teaching responsibility, which brings its own challenges.
“When I started out teaching programming classes, I enjoyed seeing the different expectations students bring to the classroom, but it also forces you to think hard about structuring a class that provides something to all these different students with many different backgrounds and different interests.”
This thoughtful approach to both research and educating others is an obvious asset to the department. Says Julia Hirschberg, chair of the Computer Science Department, “We are delighted that Daniel will be joining the CS faculty. Daniel has been an excellent teacher for us already as a graduate student preceptor, and we are extremely lucky to have been able to persuade him to stay on. The combination he brings of teaching expertise in the introductory classes and of deep knowledge of NLP will allow us to increase our teaching capacity in both areas.”
![]()
Bauer received an MSc in Language Science and Technology from Saarland University and a BSc in Cognitive Science from the University of Osnabrück, Germany.
This spring he will receive his PhD in Computer Science from Columbia University.
![]()
Posted 2/3/2017
– Linda Crane Photo credit: Tim Lee
Dragomir Radev joins the Yale Computer Science faculty
He received his PhD in 1999 under the supervision of Kathy McKeown. At Yale he will teach courses in Natural Language Processing and Artificial Intelligence and will lead the Language, Information, and Learning Lab.
Study coauthored by Yaniv Erlich uses DNA from family members to map risk factors
In a Nature Genetics article, researchers describe genotyping family members (rather than a patient), making it easier to collect DNA samples to carry out large-scale disease studies previously considered impossible.
Fast Company article references paper coauthored by John Paparrizos
The paper, The Social Dynamics of Language Change in Online Networks, used a data set of several million Twitter users to track language changes in progress.
Popular Photography profiles Shree Nayar
A look at an impressive 30-year career and the work that’s helping to shape the camera of the future.
Ansaf Salleb-Aouissi is teaching an online course in artificial intelligence
Part of edX’s graduate-level MicroMasters series, the course gives everyone access to the same high level of AI instruction that Columbia’s on-campus students receive.
CNN Money profiles former CS student Moawia Eldeeb (BS’15)
His is the classic immigrant’s American success story. Once living a shelter, he made his way to Columbia to study computer science, and went on to found SmartSpot, a startup that last year raised $1.5M.
Shree Nayar’s sheet camera is one of GE Reports’ “16 Coolest Things On Earth In 2016”
Fabricated in Columbia’s Computer Vision Lab, the camera—a sheet of adaptive lenses—bends to change the field of view. Thin and deformable, it can wrap around objects and still produce high-quality images.