Abstract: Literary tropes, from poetry to stories, are at the crux of human imagination and communication. Figurative language, such as a simile, goes beyond plain expressions to give readers new insights and inspirations. We tackle the problem of simile generation. Generating a simile requires proper understanding for effective mapping of properties between two concepts. To this end, we first propose a method to automatically construct a parallel corpus by transforming a large number of similes collected from Reddit to their literal counterpart using structured common sense knowledge. We then fine-tune a pre-trained sequence to sequence model, BART (Lewis et al., 2019), on the literal-simile pairs to generate novel similes given a literal sentence. Experiments show that our approach generates 88% novel similes that do not share properties with the training data. Human evaluation on an independent set of literal statements shows that our model generates similes better than two literary experts 37%1 of the times, and three baseline systems including a recent metaphor generation model 71%2 of the times when compared pairwise.3 We also show how replacing literal sentences with similes from our best model in machine-generated stories improves evocativeness and leads to better acceptance by human judges.
Content Planning for Neural Story Generation with Aristotelian Rescoring Seraphina Goldfarb-Tarrant University of Southern California and University of Edinburgh, Tuhin Chakrabarty Columbia University, Ralph Weischedel University of Southern California and Nanyun Peng University of Southern California and University of California, Los Angeles
Abstract: Long-form narrative text generated from large language models manages a fluent impersonation of human writing, but only at the local sentence level, and lacks structure or global cohesion. We posit that many of the problems of story generation can be addressed via high-quality content planning, and present a system that focuses on how to learn good plot structures to guide story generation. We utilize a plot-generation language model along with an ensemble of rescoring models that each implement an aspect of good story-writing as detailed in Aristotle’s Poetics. We find that stories written with our more principled plot structure are both more relevant to a given prompt and higher quality than baselines that do not content plan, or that plan in an unprincipled way.
Abstract: In this paper, we propose a neural architecture and a set of training methods for ordering events by predicting temporal relations. Our proposed models receive a pair of events within a span of text as input and they identify temporal relations (Before, After, Equal, Vague) between them. Given that a key challenge with this task is the scarcity of annotated data, our models rely on either pre-trained representations (i.e. RoBERTa, BERT or ELMo), transfer, and multi-task learning (by leveraging complementary datasets), and self-training techniques. Experiments on the MATRES dataset of English documents establish a new state-of-the-art on this task.
Abstract: We study the degree to which neural sequenceto-sequence models exhibit fine-grained controllability when performing natural language generation from a meaning representation. Using two task-oriented dialogue generation benchmarks, we systematically compare the effect of four input linearization strategies on controllability and faithfulness. Additionally, we evaluate how a phrase-based data augmentation method can improve performance. We find that properly aligning input sequences during training leads to highly controllable generation, both when training from scratch or when fine-tuning a larger pre-trained model. Data augmentation further improves control on difficult, randomly generated utterance plans.
Abstract: Stance detection is an important component of understanding hidden influences in everyday life. Since there are thousands of potential topics to take a stance on, most with little to no training data, we focus on zero-shot stance detection: classifying stance from no training examples. In this paper, we present a new dataset for zero-shot stance detection that captures a wider range of topics and lexical variation than in previous datasets. Additionally, we propose a new model for stance detection that implicitly captures relationships between topics using generalized topic representations and show that this model improves performance on a number of challenging linguistic phenomena.
Abstract: We describe a fully unsupervised cross-lingual transfer approach for part-of-speech (POS) tagging under a truly low resource scenario. We assume access to parallel translations between the target language and one or more source languages for which POS taggers are available. We use the Bible as parallel data in our experiments: small size, out-of-domain, and covering many diverse languages. Our approach innovates in three ways: 1) a robust approach of selecting training instances via cross-lingual annotation projection that exploits best practices of unsupervised type and token constraints, word-alignment confidence and density of projected POS, 2) a Bi-LSTM architecture that uses contextualized word embeddings, affix embeddings and hierarchical Brown clusters, and 3) an evaluation on 12 diverse languages in terms of language family and morphological typology. In spite of the use of limited and out-of-domain parallel data, our experiments demonstrate significant improvements in accuracy over previous work. In addition, we show that using multi-source information, either via projection or output combination, improves the performance for most target languages.
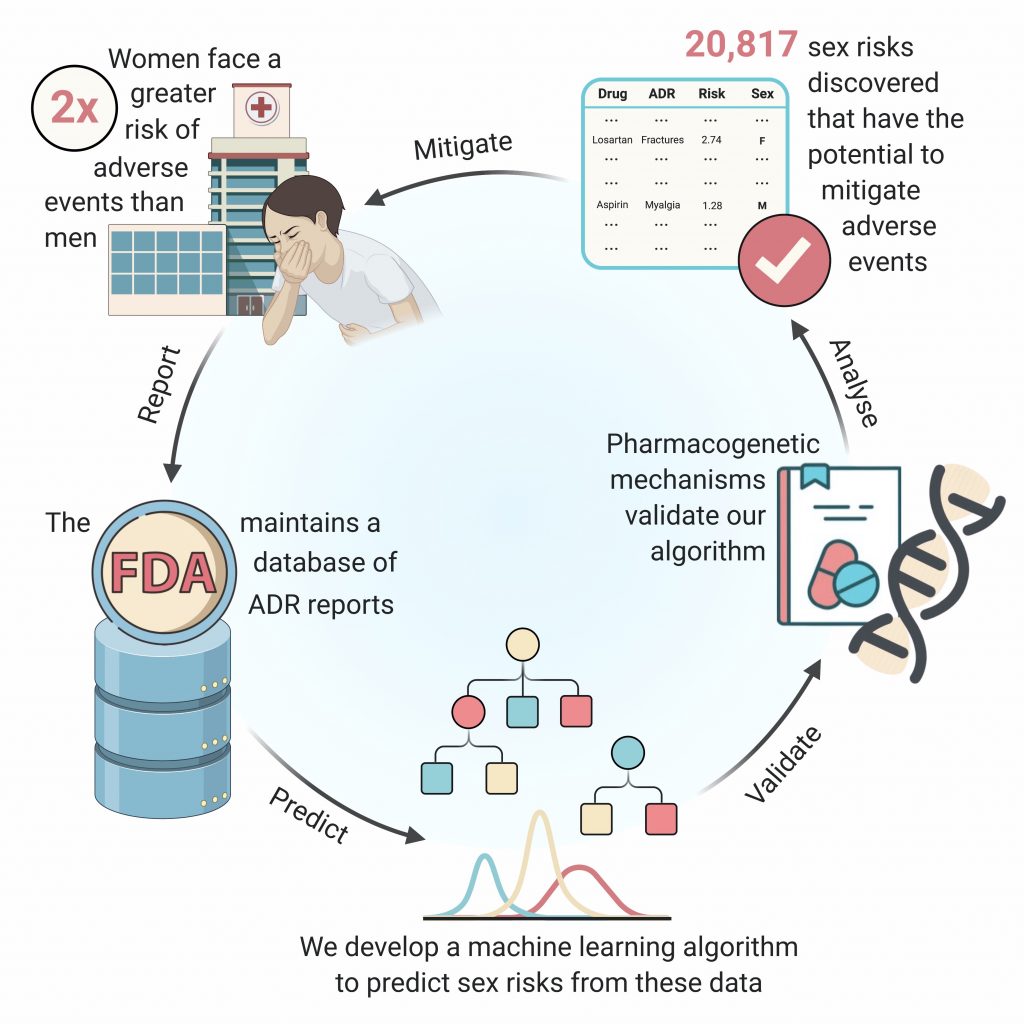
Payal Chandak (CC ’21) developed a machine learning model, AwareDX, that helps detect adverse drug effects specific to women patients. AwareDX mitigates sex biases in a drug safety dataset maintained by the FDA.
Below, Chandak talks about how her internship under the guidance of Nicholas Tatonetti, associate professor of biomedical informatics and a member of the Data Science Institute, inspired her to develop a machine learning tool to improve healthcare for women.
Payal Chandak
How did the project come about? I initiated this project during my internship at the Tatonetti Lab (T-lab) the summer after my first year. T-lab uses data science to study the side effects of drugs. I did some background research and learned that women face a two-fold greater risk of adverse events compared to men. While knowledge of sex differences in drug response is critical to drug prescription, there currently isn’t a comprehensive understanding of these differences. Dr. Tatonetti and I felt that we could use machine learning to tackle this problem and that’s how the project was born.
How many hours did you work on the project? How long did it last? The project lasted about two years. We refined our machine learning (ML) model, AwareDX, over many iterations to make it less susceptible to biases in the data. I probably spent a ridiculous number of hours developing it but the journey has been well worth it.
Were you prepared to work on it or did you learn as the project progressed? As a first-year student, I definitely didn’t know much when I started. Learning on the go became the norm. I understood some things by taking relevant CS classes and through reading Medium blogs and GitHub repositories –– this ability to learn independently might be one of the most valuable skills I have gained. I am very fortunate that Dr. Tatonetti guided me through this process and invested his time in developing my knowledge.
What were the things you already knew and what were the things you had to learn while working on the project? While I was familiar with biology and mathematics, computer science was totally new! In fact, T-Lab launched my journey to exploring computer science. This project exposed me to the great potential of artificial intelligence (AI) for revolutionizing healthcare, which in turn inspired me to explore the discipline academically. I went back and forth between taking classes relevant to my research and applying what I learned in class to my research. As I took increasingly technical classes like ML and probabilistic modelling, I was able to advance my abilities.
Looking back, what were the skills that you wished you had before the project? Having some experience with implementing real-world machine learning projects on giant datasets with millions of observations would have been very valuable.
Was this your first project to collaborate on? How was it? This was my first project and I worked under the guidance of Dr. Tatonetti. I thought it was a wonderful experience – not only has it been extremely rewarding to see my work come to fruition, but the journey itself has been so valuable. And Dr. Tatonetti has been the best mentor that I could have asked for!
Did working on this project make you change your research interests? I actually started off as pre-med. I was fascinated by the idea that “intelligent machines” could be used to improve medicine, and so I joined T-Lab. Over time, I’ve realized that recent advances in machine learning could redefine how doctors interact with their patients. These technologies have an incredible potential to assist with diagnosis, identify medical errors, and even recommend treatments. My perspective on how I could contribute to healthcare shifted completely, and I decided that bioinformatics has more potential to change the practice of medicine than a single doctor will ever have. This is why I’m now hoping to pursue a PhD in Biomedical Informatics.
Do you think your skills were enhanced by working on the project? Both my knowledge of ML and statistics and my ability to implement my ideas have grown immensely as a result of working on this project. Also, I failed about seven times over two years. We were designing the algorithm and it was an iterative process – the initial versions of the algorithm had many flaws and we started from scratch multiple times. The entire process required a lot of patience and persistence since it took over 2 years! So, I guess it has taught me immense patience and persistence.
Why did you decide to intern at the T-Lab? I was curious to learn more about the intersection of artificial intelligence and healthcare. I’m endlessly fascinated by the idea of improving the standards of healthcare by using machine learning models to assist doctors.
Would you recommend volunteering or seeking projects out to other students? Absolutely. I think everyone should explore research. We have incredible labs here at Columbia with the world’s best minds leading them. Research opens the doors to work closely with them. It creates an environment for students to learn about a niche discipline and to apply the knowledge they gain in class.
This summer seminar series highlights 14 computer science PhD students. The handpicked group of students hosted individual Zoom sessions to discuss their experiences and research projects.
A team led by professor Christos Papadimitriou proposes a new computational system to expand the understanding of the brain at an intermediate level, between neurons and cognitive phenomena such as language.
For this year’s Outstanding Undergraduate Researcher Award, three computer science students received honorable mentions – Lalita Devadas, Dave Epstein, and Jessy Xinyi Han. The Computing Research Association (CRA) recognized the undergraduates for their work in an area of computing research.
The researchers worked on using some recent advances in
garbling of arithmetic circuits for secure exponentiation mod N,
a vital operation in many cryptosystems, including in the RSA public-key
cryptosystem.
A garbled circuit is a cryptographic protocol which allows for
secure two-party computation, in which two parties, Alice and Bob, each with a
private input, want to compute some shared function of their inputs
without either party learning the other’s input.
Their novel approach implemented the Montgomery multiplication method, which uses clever arithmetic to avoid costly division by the modulus being multiplied in. The best method they found had each wire in a circuit representing one digit of a number in base p. They developed a system of base p arithmetic which is asymptotically more efficient in the given garbled circuit architecture than any existing protocols.
They measured performance for both approaches by counting
the ciphertexts communicated for a single multiplication (a typical
measure of efficiency for garbled circuit operations). They found that the
base p Montgomery multiplication implementation
vastly outperformed all other implementations for values
of N with bit length greater than 500 (i.e.,
all N used for applications like RSA encryption).
“Unfortunately, our best implementations showed only incremental improvement over existing non-Montgomery-based implementations for values of N used in practice,” said Lalita Devadas. “We are still looking into further optimizations using Montgomery multiplication.”
Secure multiparty computation has many applications outside of computer science. For example, suppose five friends want to know their cumulative net worth without anyone learning anyone else’s individual net worth. This is actually a secure computation problem, since the friends want to perform some computation of their inputs while keeping said inputs private from other parties.
The paper trains models to detect when human action is unintentional using self-supervised computer vision, an important step towards machines that can intelligently reason about the intentions behind complex human actions.
Despite enormous scientific progress over the last five to ten years, machines still struggle with tasks learned quickly and autonomously by young children, such as understanding human behavior or learning to speak a language. Epstein’s research tackles these types of problems by using self-supervised computer vision, a paradigm that predicts information naturally present in large amounts of input data such as images or videos. This stands in contrast with supervised learning, which relies on humans manually labelling data (e.g. “this is a picture of a dog”).
“I was surprised to learn that failure is an expected part of research and that it can take a long time to realize you’re failing,” said Dave Epstein. “Taking a failed idea, identifying the promising parts, and trying again leads to successful research.”
The paper explores the problem of social influence maximization
and how information is diffused in a social network.
For example, it might be about what kind of news people read on social media, how many people know about job opportunities or who hears about the latest loan options from a bank. So given a social network, classical algorithms are focused on picking the best k early-adopters based on how central they are in a network, say, based on their number of connections, to maximize outreach.
However, since social inequalities are reflected in
the uneven networks, classical algorithms which ignore demographics often
amplify such inequalities in information access.
“We were wondering if we can do better than an algorithm that ignores demographics,” said Jessy Xinyi Han. “‘Better’ here means more people in total and more people from the disadvantaged group can receive the information.”
Through a network model with unequal communities, they developed
new heuristics to take demographics into account, showing that
including sensitive features in the input of most natural seed selection
algorithms substantially improves diversity but also often leaves efficiency
untouched or even provides a small gain.
Such analytical condition turned out to be a closed-form
condition on the number of early adopters. They also validated this result on
the real CS co-authorship network from DBLP.
The 33rd Conference on Neural Information Processing Systems (NeurIPS 2019) fosters the exchange of research on neural information processing systems in their biological, technological, mathematical, and theoretical aspects.
The annual meeting is one of the premier gatherings in artificial intelligence and machine learning that featured talks, demos from industry partners as well as tutorials. Professor Vishal Misra, with colleagues from the Massachusetts Institute of Technology (MIT), held a tutorial on synthetic control.
At this year’s NeurIPS, 21 papers from the department were accepted to the conference. Computer science professors and students worked with researchers from the statistics department and the Data Science Institute.
Noise-tolerant Fair Classification Alex Lamy Columbia University, Ziyuan Zhong Columbia University, Aditya Menon Google, Nakul Verma Columbia University
Fairness-aware learning involves designing algorithms that do not discriminate with respect to some sensitive feature (e.g., race or gender) and is usually done under the assumption that the sensitive feature available in a training sample is perfectly reliable.
This assumption may be violated in many real-world cases: for example, respondents to a survey may choose to conceal or obfuscate their group identity out of fear of potential discrimination. In the paper, the researchers show that fair classifiers can still be used given noisy sensitive features by simply changing the desired fairness-tolerance. Their procedure is empirically effective on two relevant real-world case-studies involving sensitive feature censoring.
Poisson-randomized Gamma Dynamical Systems Aaron Schein UMass Amherst, Scott Linderman Columbia University, Mingyuan Zhou University of Texas at Austin, David Blei Columbia University, Hanna Wallach MSR NYC
This paper presents a new class of state space models for count data. It derives new properties of the Poisson-randomized gamma distribution for efficient posterior inference.
This paper address causal inference in the presence of unobserved confounder when proxy is available for the confounders in the form of a network connecting the units. For example, the link structure of friendships in a social network reveals information about the latent preferences of people in that network. The researchers show how modern network embedding methods can be exploited to harness the network estimation for efficient causal adjustment.
The paper characterizes the theoretical properties of a popular machine learning algorithm, variational Bayes (VB). The researchers studied the VB under model misspecification, which is the setting that is most aligned with the practice, and show that the VB posterior is asymptotically normal and centers at the value that minimizes the Kullback-Leibler (KL) divergence to the true data-generating distribution.
As a consequence, they found that the model misspecification error dominates the variational approximation error in VB posterior predictive distributions. In other words, VB pays a negligible price in producing posterior predictive distributions. It explains the widely observed phenomenon that VB achieves comparable predictive accuracy with MCMC even though VB uses an approximating family.
The paper introduces a model that captures a min-max competition over complex error landscapes and shows that even a simplified model can provably replicate some of the most commonly reported failure modes of GANs (non-convergence, deadlock in suboptimal states, etc).
Moreover, the researchers were able to understand the hidden structure in these systems — the min-max competition can lead to system behavior that is similar to that of energy preserving systems in physics (e.g. connected pendulums, many-body problems, etc). This makes it easier to understand why these systems can fail and gives new tools in the design of algorithms for training GANs.
Dynamic Treatment Regimes (DTRs) are particularly effective for managing chronic disorders and is arguably one of the key aspects towards more personalized decision-making. The researchers developed the first adaptive algorithm that achieves near-optimal regret in DTRs in online settings, while leveraging the abundant, yet imperfect confounded observations. Applications are given to personalized medicine and treatment recommendation in clinical decision support.
The paper proposes a latent bag of words model for differentiable content planning and surface realization in text generation. This model generates paraphrases with clear steps, adding interpretability and controllability of existing neural text generation models.
This paper addresses how to design neural networks to get very accurate estimates of causal effects from observational data. The researchers propose two methods based on insights from the statistical literature on the estimation of treatment effects.
The first is a new architecture, the Dragonnet, that exploits the sufficiency of the propensity score for estimation adjustment. The second is a regularization procedure, targeted regularization, that induces a bias towards models that have non-parametrically optimal asymptotic properties “out-of-the-box”. Studies on benchmark datasets for causal inference show these adaptations outperform existing methods.
The researchers prove that properly tailored zero-order methods are as effective as their first-order counterparts. This analysis requires a combination of tools from optimization theory, probability theory and dynamical systems to show that even without perfect knowledge of the shape of the error landscape, effective optimization is possible.
Metric Learning for Adversarial Robustness Chengzhi Mao Columbia University, Ziyuan Zhong Columbia University, Junfeng Yang Columbia University, Carl Vondrick Columbia University, Baishakhi Ray Columbia University
Deep networks are well-known to be fragile to adversarial attacks. The paper introduces a novel Triplet Loss Adversarial (TLA) regulation that is the first method that leverages metric learning to improve the robustness of deep networks. This method is inspired by the evidence that deep networks suffer from distorted feature space under adversarial attacks. The method increases the model robustness and efficiency for the detection of adversarial attacks significantly.
The paper studies linear regression problems with general symmetric norm loss and gives efficient algorithms for solving such linear regression problems via sketching techniques.
The paper presents a novel and formal definition of mode coverage for generative models. It also gives a boosting algorithm to achieve this mode coverage guarantee.
The researchers studied the least-squares linear regression over $N$ uncorrelated Gaussian features that are selected in order of decreasing variance with the number of selected features $p$ can be either smaller or greater than the sample size $n$. And give an average-case analysis of the out-of-sample prediction error as $p,n,N \to \infty$ with $p/N \to \alpha$ and $n/N \to \beta$, for some constants $\alpha \in [0,1]$ and $\beta \in (0,1)$. In this average-case setting, the prediction error exhibits a “double descent” shape as a function of $p$. This also establishes conditions under which the minimum risk is achieved in the interpolating ($p>n$) regime.
The paper investigates the adaptive influence maximization problem and provides upper and lower bounds for the adaptivity gaps under myopic feedback model. The results confirm a long standing open conjecture by Golovin and Krause (2011).
The researchers studied low-rank matrix approximation with general loss function and showed that if the loss function has several good properties, then there is an efficient way to compute a good low-rank approximation. Otherwise, it could be hard to compute a good low-rank approximation efficiently.
The researchers studied how to compute an l1-norm loss low-rank matrix approximation to a given matrix. And showed that if the given matrix can be decomposed into a low-rank matrix and a noise matrix with a mild distributional assumption, we can obtain a (1+eps) approximation to the optimal solution.
The researchers developed a surrogate distribution for the Dirichlet that offers explicit, tractable reparameterization, the ability to capture sparsity, and has barycentric symmetry properties (i.e. exchangeability) equivalent to the Dirichlet. Previous works have used the Kumaraswamy distribution in a stick-breaking process to create a non-exchangeable distribution on the simplex. The method was improved by restoring exchangeability and demonstrating that approximate exchangeability is efficiently achievable. Lastly, the method was showcased in a variety of VAE semi-supervised learning tasks.
While normalizing flows have led to significant advances in modeling high-dimensional continuous distributions, their applicability to discrete distributions remains unknown. The researchers extend normalizing flows to discrete events, using a simple change-of-variables formula not requiring log-determinant-Jacobian computations. Empirically, they find that discrete flows obtain competitive performance with or outperform autoregressive baselines on various tasks, including addition, Potts models, and language models.
This work is all about learning causal relationships – the classic aim of which is to characterize all possible sets that could produce the observed data. In the paper, the researchers provide a complete characterization of all possible causal graphs with observational and interventional data involving so-called ‘soft interventions’ on variables when the targets of soft interventions are known.
This work potentially could lead to discovery of other novel learning algorithms that are both sound and complete.
Causal identification is the problem of deciding whether a causal distribution is computable from a combination of qualitative knowledge about the underlying data-generating process, which is usually encoded in the form of a causal graph, and an observational distribution. Despite the obvious need for identifying causal effects throughout the data-driven sciences, in practice, finding the causal graph is a notoriously challenging task.
In this work, the researchers provide a relaxation of the requirement of having to specify the causal graph (based on substantive knowledge) and allow the input of the inference to be an equivalence class of causal graphs, which can be inferred from data. Specifically, they propose the first general algorithm to learn conditional causal effects entirely from data. This result is particularly useful for evaluating the impact of conditional plans and stochastic policies, which appear both in AI (in the context of reinforcement learning) and in the data-driven sciences.
Regression analysis is one of the most common tools used in modern data science. While there is a great understanding and powerful technology to perform regression analysis in high dimensional spaces, the output of such a method is purely associational and devoid of any causal interpretation.
The researchers studied the problem of identification of structural (causal) coefficients in linear systems (deciding whether regression coefficients are amenable to causal interpretation, etc). Building on a technique called instrumental variables, they developed a new method called Instrumental Cutset, which partitions the systems into tractable components such that identification can be decided more efficiently. The resulting algorithm was efficient and strictly more powerful than the current state-of-the-art methods.
Assistant Professor Allison Bishop takes a look at failure and how people can learn from “unsuccessful” research.
When it comes to research and getting papers into cryptography conferences, there usually has to be a “positive” result — either a new theorem must be proven, a new algorithm must be presented, or a successful attack on an existing algorithm must be obtained. If researchers try to accomplish a lofty goal and fall short, but manage to achieve a smaller goal, they typically present only the smaller goal as if it was the point on its own.
Allison Bishop
“I’ve found that not every research paper magically comes together and has a “great” result,” said Allison Bishop, who has been teaching since 2013. “Our community doesn’t really talk about the research process and I wanted to highlight research where even if it “failed” there is still something to learn from it.”
Through the years Bishop noticed the lack of a venue to talk about all kinds of research. When she and other researchers studied obfuscation it resulted in a paper “In Pursuit of Clarity In Obfuscation”. In the paper they talked about how they “failed” but managed to still learn from their mistakes. Their topic on failure was not considered a “standard” that could be published and they were not able to submit it to a conference. But Bishop, along with PhD students Luke Kowalczyk and Kevin Shi, really wanted to get their findings out and share it with other researchers.
And so, a conference dedicated to disseminating insightful failures of the cryptology research community was born. The Conference for Failed Approaches and Insightful Losses in Cryptology or CFAIL featured seven previously unpublished papers for a day of talks by computer scientists on insightful failures spanning the full range from cryptanalysis (trying to break systems) to cryptographic theory and design (constructing new systems and proving things about specific systems or about abstract systems, etc.).
“CFAIL is great for our field in that it promotes openness and accessibility for these kinds of ideas which are typically sort of intimate,” said Luke Kowalczyk, who completed his PhD in November of last year. “When approaching new problems, it’s always helpful to see the approaches of other researchers, even if they were not successful. However, it’s rare to see failed approaches explained in a public and formal setting.”
They were not alone in thinking about the lack of dialogue on research failures. At the time of the conference, a thread on Hacker News (a tech news aggregator) discussed the incentive structures of academia. Shared Kowalczyk, “I was proud to see CFAIL cited as an example of a scientific field with a formal venue to help promote this kind of openness.”
“There is a deeply ingrained human tendency to fear that being open about failure will make other people think you are dumb,” said Bishop. On the contrary, the researchers at CFAIL were some of the “most creative, bold, and deeply intelligent people.” And the atmosphere it created was energizing for the participants — the audience got pretty involved and felt comfortable asking questions, and even started thinking about some of the open research problems in real time. Continued Bishop, ”I think talking about failure is probably the best scientific communication strategy left that is severely underused.”
Bishop will continue to promote openness in scientific research with another CFAIL at Crypto 2020. This time around it will be a workshop at the conference and a call for papers will be out soon.
IBM has selected assistant professor Baishakhi Ray for an IBM Faculty Award. The highly selective award is given to professors in leading universities worldwide to foster collaboration with IBM researchers. Ray will use the funds to continue research on artificial intelligence-driven program analysis to understand software robustness.
Although much research has been done, there are still countless vulnerabilities that make system robustness brittle. Hidden vulnerabilities are discovered all the time – either through a system hack or monitoring system’s functionalities. Ray is working to automatically detect system weaknesses using artificial intelligence (AI) with her project, “Improving code representation for enhanced deep learning to detect and remediate security vulnerabilities”.
One of the major challenges in AI-based security vulnerability detection is finding the best source code representation that can distinguish between vulnerable versus benign code. Such representation can further be used as an input in supervised learning settings for automatic vulnerability detection and fixes. Ray is tackling this problem by building new machine-learning models for source code and applying machine learning techniques such as code embeddings. This approach could open new ways of encoding source code into feature vectors.
“It will provide new ways to make systems secure,” said Ray, who joined the department in 2018. “The goal is to reduce the hours of manual effort spent in automatically detecting vulnerabilities and fixing them.”
A successful outcome of this project will produce a new technique to encode source code with associated trained models that will be able to detect and remediate a software vulnerability with increased accuracy.
IBM researchers Jim Laredo and Alessandro Morari will collaborate closely with Ray and her team on opportunities around design, implementation, and evaluation of this research.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor