
A Linguist of Algorithms
Celebrated by ACL with a Lifetime Achievement Award, Kathleen McKeown continues to drive bold, cross-disciplinary research that redefines the field of natural language processing.
Celebrated by ACL with a Lifetime Achievement Award, Kathleen McKeown continues to drive bold, cross-disciplinary research that redefines the field of natural language processing.
CS researchers were among the experts who considered AI from every angle at the kick-off session of the Columbia AI Summit.
CS researchers presented their work at the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024).
Parallel Structures in Pre-training Data Yield In-Context Learning
Yanda Chen Columbia University, Chen Zhao New York University, Zhou Yu Columbia University, Kathleen McKeown Columbia University, He He New York University
Abstract:
Pre-trained language models (LMs) are capable of in-context learning (ICL): they can adapt to a task with only a few examples given in the prompt without any parameter update. However, it is unclear where this capability comes from as there is a stark distribution shift between pre-training text and ICL prompts. In this work, we study what patterns of the pretraining data contribute to ICL. We find that LMs’ ICL ability depends on parallel structures in the pre-training data—pairs of phrases following similar templates in the same context window. Specifically, we detect parallel structures by checking whether training on one phrase improves prediction of the other, and conduct ablation experiments to study their effect on ICL. We show that removing parallel structures in the pre-training data reduces LMs’ ICL accuracy by 51% (vs 2% from random ablation). This drop persists even when excluding common patterns such as n-gram repetitions and long-range dependency, showing the diversity and generality of parallel structures. A closer look at the detected parallel structures indicates that they cover diverse linguistic tasks and span long distances in the data.
Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
Zachary Horvitz Columbia University, Jingru Chen Columbia University, Rahul Aditya Columbia University, Harshvardhan Srivastava Columbia University, Robert West EPFL, Zhou Yu Columbia University, Kathleen McKeown Columbia University
Abstract:
Humor is a fundamental facet of human cognition and interaction. Yet, despite recent advances in natural language processing, humor detection remains a challenging task that is complicated by the scarcity of datasets that pair humorous texts with similar non-humorous counterparts. We investigate whether large language models (LLMs) can generate synthetic data for humor detection via editing texts. We benchmark LLMs on an existing human dataset and show that current LLMs display an impressive ability to “unfun” jokes, as judged by humans and as measured on the downstream task of humor detection. We extend our approach to a code-mixed English-Hindi humor dataset where we find that GPT-4’s synthetic data is highly rated by bilingual annotators and provides challenging adversarial examples for humor classifiers.
ICLEF: In-Context Learning with Expert Feedback for Explainable Style Transfer
Arkadiy Saakyan Columbia University and Smaranda Muresan Columbia University
Abstract:
While state-of-the-art large language models (LLMs) can excel at adapting text from one style to another, current work does not address the explainability of style transfer models. Recent work has explored generating textual explanations from larger teacher models and distilling them into smaller student models. One challenge with such approach is that LLM outputs may contain errors that require expertise to correct, but gathering and incorporating expert feedback is difficult due to cost and availability. To address this challenge, we propose ICLEF, a novel human-AI collaboration approach to model distillation that incorporates scarce expert human feedback by combining in-context learning and model self-critique. We show that our method leads to generation of high-quality synthetic explainable style transfer datasets for formality (E-GYAFC) and subjective bias (EWNC). Via automatic and human evaluation, we show that specialized student models finetuned on our datasets outperform generalist teacher models on the explainable style transfer task in one-shot settings, and perform competitively compared to few-shot teacher models, highlighting the quality of the data and the role of expert feedback. In an extrinsic task of authorship attribution, we show that explanations generated by smaller models fine-tuned on E-GYAFC are more predictive of authorship than explanations generated by few-shot teacher models.
ProLex: A Benchmark for Language Proficiency-oriented Lexical Substitution
Xuanming Zhang Columbia University, Zixun Chen Columbia University, and Zhou Yu Columbia University
Abstract:
Lexical Substitution discovers appropriate substitutes for a given target word in a context sentence. However, the task fails to consider substitutes that are of equal or higher proficiency than the target, an aspect that could be beneficial for language learners looking to improve their writing. To bridge this gap, we propose a new task — language proficiencyoriented lexical substitution. We also introduce ProLex, a novel benchmark designed to assess systems’ ability to generate not only appropriate substitutes but also substitutes that demonstrate better language proficiency. Besides the benchmark, we propose models that can automatically perform the new task. We show that our best model, a Llama2-13B model fine-tuned with task-specific synthetic data, outperforms ChatGPT by an average of 3.2% in F-score and achieves comparable results with GPT-4 on ProLex.
LOCALRQA: From Generating Data to Locally Training, Testing, and Deploying Retrieval-Augmented QA Systems
Xiao Yu Columbia University, Yunan Lu Columbia University, Zhou Yu Columbia University
Abstract:
Retrieval-augmented question-answering systems combine retrieval techniques with large language models to provide answers that are more accurate and informative. Many existing toolkits allow users to quickly build such systems using off-the-shelf models, but they fall short in supporting researchers and developers to customize the model training, testing, and deployment process. We propose LOCALRQA1 , an open-source toolkit that features a wide selection of model training algorithms, evaluation methods, and deployment tools curated from the latest research. As a showcase, we build QA systems using online documentation obtained from Databricks and Faire’s websites. We find 7B-models trained and deployed using LOCALRQA reach a similar performance compared to using OpenAI’s text-ada-002 and GPT-4-turbo.
Large Language Models are Few-Shot Training Example Generators: A Case Study in Fallacy Recognition
Tariq Alhindi Mohamed bin Zayed University of Artificial Intelligence, Smaranda Muresan Columbia University, Preslav Nakov Mohamed bin Zayed University of Artificial Intelligence
Abstract:
Recognizing fallacies is crucial for ensuring the quality and validity of arguments across various domains. However, computational fallacy recognition faces challenges due to the diverse genres, domains, and types of fallacies found in datasets. This leads to a highly multiclass, and even multi-label, setup with substantial class imbalance. In this study, we aim to enhance existing models for fallacy recognition by incorporating additional context and by leveraging large language models to generate synthetic data, thus increasing the representation of the infrequent classes. We experiment with GPT-3.5 to generate synthetic examples and we examine the impact of prompt settings for this. Moreover, we explore zero-shot and few-shot scenarios to evaluate the effectiveness of using the generated examples for training smaller models within a unified fallacy recognition framework. Furthermore, we analyze the overlap between the synthetic data and existing fallacy datasets. Finally, we investigate the usefulness of providing supplementary context for detecting fallacy types that need such context, e.g., diversion fallacies. Our evaluation results demonstrate consistent improvements across fallacy types, datasets, and generators. The code and the synthetic datasets are all publicly available.
Brian Smith received an NSF CAREER Award to develop a framework that will improve digital imagery so that blind and low-vision (BLV) individuals can better perceive and interact with visual content in the digital realm.
The paper “An Empirical Study of API Stability and Adoption in the Android Ecosystem”, was recognized as the Most Impactful Paper from among the published papers at ICSME ’13.
The projects will explore algorithmic fairness, unified methods for interpreting artistic images found on the internet, and the development of a differentially-private data market system.
“Revisiting Residue Codes for Modern Memories” from the Computer Engineering group is one of the Top Picks for IEEE Micro Magazine.
After growing up in Jiangsu, China, Sitong Wang studied electrical engineering at Chongqing University and the University of Cincinnati. During her co-op at the Hong Kong University of Science and Technology (HKUST), she was introduced to Human-Computer Interaction (HCI). This research area understands and enhances the interaction between humans and computers. She became interested in the field and then took her master’s at Columbia CS. Wang was intrigued by how computation can power the creative process when she worked on a design challenge that blends pop culture references with products or services and helped a group of students promote their beverage start-up.

Encouraged by the creative work she could do, Wang joined the Computational Design Lab as a PhD student to continue to work with Assistant Professor Lydia Chilton and explore ways to design AI-powered creativity support tools. She recently published her first first-author research paper at the Conference on Human Factors in Computing Systems (CHI 2023). She and colleagues designed PopBlends, a system that automatically suggests conceptual blends by connecting a user’s topic with a pop culture domain. Their user study shows that people found twice as many blend suggestions as they did without the system and with half the mental demand.
We caught up with Wang to discuss her research, her work on generative AI tools, and what it is like to be a graduate student at Columbia.

In the paper, we tackled the creative challenge of designing pop culture blends—images that use pop culture references to promote a product or service. We designed PopBlends, an automated pipeline consisting of three complementary strategies to find creative connections between a product and a pop culture domain.
Our work explores how large language models (LLMs) can provide associative knowledge and commonsense reasoning for creative tasks. We also discuss how to combine the power of traditional knowledge bases and LLMs to support creators in their divergent and convergent thinking.
It can help people, especially those without a design background, create pop culture blends more easily to advertise their brands. We want to make the design process more enjoyable and less cognitively demanding for everyone. We hope to enhance people’s creativity and productivity by scaffolding the creative process and using the power of computation to help people explore the design space more efficiently.
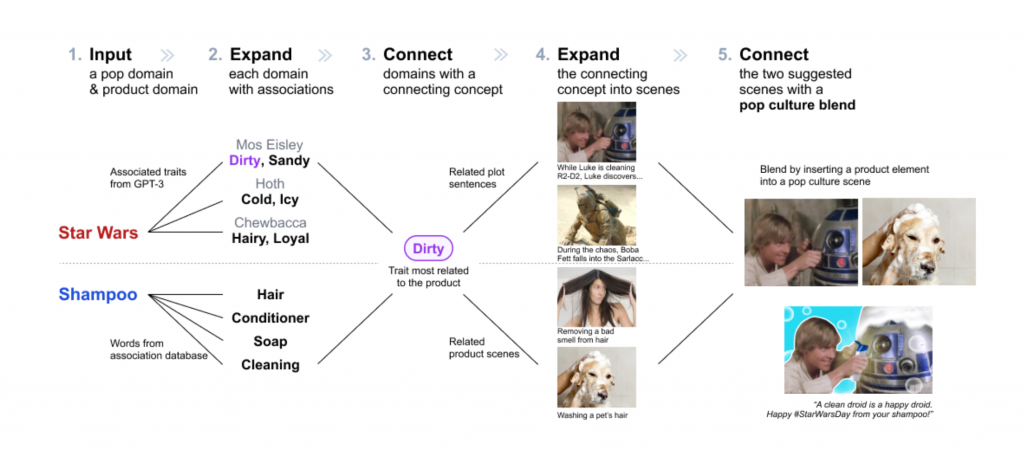
Pop culture is important in everyday communication. Pop culture blends are helpful for online campaigns because they capture attention and connect the product to something people already know and like. However, creating these images is a challenging conceptual blending task and requires finding connections between two very different domains.
So we built an automated computational pipeline that can effectively support divergent and convergent thinking in finding such creative connections. We explored how to apply generative AI to creative workflows to assist people better—generative AI is powerful, but it is not perfect—thus, it is valuable to use different strategies that combine a knowledge base (which is accurate) and LLM (which has a vast amount of data) to support creative tasks.
Conceptual blending is complex—the design space is vast and valuable connections are rare—to tackle this challenge, we need to scaffold the ideation process and combine the intelligence of humans and machines. When we started this project, GPT-3 was not yet available; we tried traditional NLP techniques to find attribute associations (e.g., Chewbacca is fluffy) but faced challenges. Then, by chance, we tried GPT-3, which worked well with the necessary prompt engineering.
I was surprised by the associative reasoning capability of LLMs—which is technically a model that predicts the most probable next word. It easily listed related concepts for different domains and could suggest possible creative connections. I was also surprised by the hallucinations the LLMs made through our experiments, and the models could say things that were not true with great confidence.
As an emerging technology, LLMs are powerful in many ways and open up new opportunities for the computational design field. However, LLMs currently have a lot of limitations; it is essential to explore how to build system architectures around them to produce valuable results for people.

I was both nervous and excited because it had been a long time since I had presented in front of a crowd (since we did everything online during COVID). It was also my first time presenting at a computing conference, and the “Large Language Models” session I attended was very popular.
I am grateful to my labmate Vivian Liu, who provided valuable advice, helped me rehearse, and took pictures of me. The presentation went well, and I am glad we had the opportunity to present our work to a large audience of researchers. I would also like to express my gratitude to the researchers I met during the conference, as they provided encouragement and helpful tips that greatly contributed to my experience.
I am working on a tool to help journalists transform their print articles into reels using generative AI by assisting them in the creative stages of producing scripts, character boards, and storyboards. In this work, in addition to LLMs, we incorporate text-to-image models and try to combine the power of both to support creators.
During the summer, I will work as a research intern at Adobe, where I will be focusing on AI and video authoring. Our work will revolve around facilitating the future of podcast video creation.
My undergraduate program offered great co-op opportunities that allowed me to explore different paths, including roles as an engineer, UI designer, and research intern across Chongqing, Charlottesville, and Hong Kong. During my final co-op, I had the opportunity to work in the HCI lab at the Hong Kong University of Science and Technology (HKUST). This experience ignited my passion for HCI research and marked the beginning of my research journey in this field.
I enjoy exploring unanswered questions, particularly those that reside at the intersection of multiple disciplines. A PhD program provides an excellent opportunity to work on the problems that interest me the most. In addition, I think the training provided at the PhD level can enhance essential skills such as leadership, collaboration, critical thinking, and effective communication.
My research interest lies in the creativity support in the HCI field. I am particularly interested in exploring the role of multimodal generative AI in creativity support tools. I enjoy developing co-creative interactive systems to support everyone in their everyday creative tasks.
I want to explore the role of generative AI models in future creativity support tools and build co-creative intelligent systems that support multimodal creativity, especially in the dimensions of audio and videos, as they are how we interact with the world. I also want to explore some theoretical questions, such as the overtrust/overreliance in AI, and see how we might understand and resolve them.

I love the vibrant environment of Columbia and NYC and how Columbia is strong in diverse disciplines, such as journalism, business, and law. It is an ideal place to do multi-disciplinary collaborative research.
Also, I got to know Professor Chilton well during my masters at Columbia. She is incredibly supportive and wonderful, and we share many common interests. That is why I chose to continue to work with her for my PhD journey.
The highlight would be when I witnessed the success of the students I mentored. It was such a rewarding process to guide and help undergraduate students interested in HCI research begin their journey.
Enjoy your time in NYC! Please don’t burn yourself out; learn how to manage your time efficiently. Don’t be afraid to try new things—start with manageable tasks, but also step out of your comfort zone. You will have fun!
If you want to do research, find research questions that genuinely interest you and be prepared to face challenges. Most importantly, preserve and trust yourself and your collaborators. Your efforts will eventually pay off!
Research from the department has been accepted to the 2023 Computer Vision and Pattern Recognition (CVPR) Conference. The annual event explores machine learning, artificial intelligence, and computer vision research and its applications.
CoWs on Pasture: Baselines and Benchmarks for Language-Driven Zero-Shot Object Navigation
Samir Yitzhak Gadre Columbia University, Mitchell Wortsman University of Washington, Gabriel Ilharco University of Washington, Ludwig Schmidt University of Washington, Shuran Song Columbia University
For robots to be generally useful, they must be able to find arbitrary objects described by people (i.e., be language-driven) even without expensive navigation training on in-domain data (i.e., perform zero-shot inference). We explore these capabilities in a unified setting: language-driven zero-shot object navigation (L-ZSON). Inspired by the recent success of open-vocabulary models for image classification, we investigate a straightforward framework, CLIP on Wheels (CoW), to adapt open-vocabulary models to this task without fine-tuning. To better evaluate L-ZSON, we introduce the Pasture benchmark, which considers finding uncommon objects, objects described by spatial and appearance attributes, and hidden objects described relative to visible objects. We conduct an in-depth empirical study by directly deploying 21 CoW baselines across Habitat, RoboTHOR, and Pasture. In total, we evaluate over 90k navigation episodes and find that (1) CoW baselines often struggle to leverage language descriptions, but are proficient at finding uncommon objects. (2) A simple CoW, with CLIP-based object localization and classical exploration — and no additional training — matches the navigation efficiency of a state-of-the-art ZSON method trained for 500M steps on Habitat MP3D data. This same CoW provides a 15.6 percentage point improvement in success over a state-of-the-art RoboTHOR ZSON model.
Towards Fast Adaptation of Pretrained Contrastive Models for Multi-Channel Video-Language Retrieval
Xudong Lin Columbia University, Simran Tiwari Columbia University, Shiyuan Huang Columbia University, Manling Li UIUC, Mike Zheng Shou National University of Singapore, Heng Ji UIUC, Shih-Fu Chang Columbia University
Multi-channel video-language retrieval require models to understand information from different channels (e.g. video+question, video+speech) to correctly link a video with a textual response or query. Fortunately, contrastive multimodal models are shown to be highly effective at aligning entities in images/videos and text, e.g., CLIP; text contrastive models are extensively studied recently for their strong ability of producing discriminative sentence embeddings, e.g., SimCSE. However, there is not a clear way to quickly adapt these two lines to multi-channel video-language retrieval with limited data and resources. In this paper, we identify a principled model design space with two axes: how to represent videos and how to fuse video and text information. Based on categorization of recent methods, we investigate the options of representing videos using continuous feature vectors or discrete text tokens; for the fusion method, we explore the use of a multimodal transformer or a pretrained contrastive text model. We extensively evaluate the four combinations on five video-language datasets. We surprisingly find that discrete text tokens coupled with a pretrained contrastive text model yields the best performance, which can even outperform state-of-the-art on the iVQA and How2QA datasets without additional training on millions of video-text data. Further analysis shows that this is because representing videos as text tokens captures the key visual information and text tokens are naturally aligned with text models that are strong retrievers after the contrastive pretraining process. All the empirical analysis establishes a solid foundation for future research on affordable and upgradable multimodal intelligence.
DiGeo: Discriminative Geometry-Aware Learning for Generalized Few-Shot Object Detection
Jiawei Ma Columbia University, Yulei Niu Columbia University, Jincheng Xu Columbia University, Shiyuan Huang Columbia University, Guangxing Han Columbia University, Shih-Fu Chang Columbia University
Generalized few-shot object detection aims to achieve precise detection on both base classes with abundant annotations and novel classes with limited training data. Existing approaches enhance few-shot generalization with the sacrifice of base-class performance, or maintain high precision in base-class detection with limited improvement in novel-class adaptation. In this paper, we point out the reason is insufficient Discriminative feature learning for all of the classes. As such, we propose a new training framework, DiGeo, to learn Geometry-aware features of inter-class separation and intra-class compactness. To guide the separation of feature clusters, we derive an offline simplex equiangular tight frame (ETF) classifier whose weights serve as class centers and are maximally and equally separated. To tighten the cluster for each class, we include adaptive class-specific margins into the classification loss and encourage the features close to the class centers. Experimental studies on two few-shot benchmark datasets (VOC, COCO) and one long-tail dataset (LVIS) demonstrate that, with a single model, our method can effectively improve generalization on novel classes without hurting the detection of base classes.
Supervised Masked Knowledge Distillation for Few-Shot Transformers
Han Lin Columbia University, Guangxing Han Columbia University, Jiawei Ma Columbia University, Shiyuan Huang Columbia University, Xudong Lin Columbia University, Shih-Fu Chang Columbia University
Vision Transformers (ViTs) emerge to achieve impressive performance on many data-abundant computer vision tasks by capturing long-range dependencies among local features. However, under few-shot learning (FSL) settings on small datasets with only a few labeled data, ViT tends to overfit and suffers from severe performance degradation due to its absence of CNN-alike inductive bias. Previous works in FSL avoid such problem either through the help of self-supervised auxiliary losses, or through the dextile uses of label information under supervised settings. But the gap between self-supervised and supervised few-shot Transformers is still unfilled. Inspired by recent advances in self-supervised knowledge distillation and masked image modeling (MIM), we propose a novel Supervised Masked Knowledge Distillation model (SMKD) for few-shot Transformers which incorporates label information into self-distillation frameworks. Compared with previous self-supervised methods, we allow intra-class knowledge distillation on both class and patch tokens, and introduce the challenging task of masked patch tokens reconstruction across intra-class images. Experimental results on four few-shot classification benchmark datasets show that our method with simple design outperforms previous methods by a large margin and achieves a new start-of-the-art. Detailed ablation studies confirm the effectiveness of each component of our model. Code for this paper is available here: this https URL.
FLEX: Full-Body Grasping Without Full-Body Grasps
Purva Tendulkar Columbia University, Dídac Surís Columbia University, Carl Vondrick Columbia University
Synthesizing 3D human avatars interacting realistically with a scene is an important problem with applications in AR/VR, video games and robotics. Towards this goal, we address the task of generating a virtual human — hands and full body — grasping everyday objects. Existing methods approach this problem by collecting a 3D dataset of humans interacting with objects and training on this data. However, 1) these methods do not generalize to different object positions and orientations, or to the presence of furniture in the scene, and 2) the diversity of their generated full-body poses is very limited. In this work, we address all the above challenges to generate realistic, diverse full-body grasps in everyday scenes without requiring any 3D full-body grasping data. Our key insight is to leverage the existence of both full-body pose and hand grasping priors, composing them using 3D geometrical constraints to obtain full-body grasps. We empirically validate that these constraints can generate a variety of feasible human grasps that are superior to baselines both quantitatively and qualitatively. See our webpage for more details: this https URL.
Humans As Light Bulbs: 3D Human Reconstruction From Thermal Reflection
Ruoshi Liu Columbia University, Carl Vondrick Columbia University
The relatively hot temperature of the human body causes people to turn into long-wave infrared light sources. Since this emitted light has a larger wavelength than visible light, many surfaces in typical scenes act as infrared mirrors with strong specular reflections. We exploit the thermal reflections of a person onto objects in order to locate their position and reconstruct their pose, even if they are not visible to a normal camera. We propose an analysis-by-synthesis framework that jointly models the objects, people, and their thermal reflections, which combines generative models with differentiable rendering of reflections. Quantitative and qualitative experiments show our approach works in highly challenging cases, such as with curved mirrors or when the person is completely unseen by a normal camera.
Tracking Through Containers and Occluders in the Wild
Basile Van Hoorick Columbia University, Pavel Tokmakov Toyota Research Institute, Simon Stent Woven Planet, Jie Li Toyota Research Institute, Carl Vondrick Columbia University
Tracking objects with persistence in cluttered and dynamic environments remains a difficult challenge for computer vision systems. In this paper, we introduce TCOW, a new benchmark and model for visual tracking through heavy occlusion and containment. We set up a task where the goal is to, given a video sequence, segment both the projected extent of the target object, as well as the surrounding container or occluder whenever one exists. To study this task, we create a mixture of synthetic and annotated real datasets to support both supervised learning and structured evaluation of model performance under various forms of task variation, such as moving or nested containment. We evaluate two recent transformer-based video models and find that while they can be surprisingly capable of tracking targets under certain settings of task variation, there remains a considerable performance gap before we can claim a tracking model to have acquired a true notion of object permanence.
Doubly Right Object Recognition: A Why Prompt for Visual Rationales
Chengzhi Mao Columbia University, Revant Teotia Columbia University, Amrutha Sundar Columbia University, Sachit Menon Columbia University, Junfeng Yang Columbia University, Xin Wang Microsoft Research, Carl Vondrick Columbia University
Many visual recognition models are evaluated only on their classification accuracy, a metric for which they obtain strong performance. In this paper, we investigate whether computer vision models can also provide correct rationales for their predictions. We propose a “doubly right” object recognition benchmark, where the metric requires the model to simultaneously produce both the right labels as well as the right rationales. We find that state-of-the-art visual models, such as CLIP, often provide incorrect rationales for their categorical predictions. However, by transferring the rationales from language models into visual representations through a tailored dataset, we show that we can learn a “why prompt,” which adapts large visual representations to produce correct rationales. Visualizations and empirical experiments show that our prompts significantly improve performance on doubly right object recognition, in addition to zero-shot transfer to unseen tasks and datasets.
What You Can Reconstruct From a Shadow
Ruoshi Liu Columbia University, Sachit Menon Columbia University, Chengzhi Mao Columbia University, Dennis Park Toyota Research Institute, Simon Stent Woven Planet, Carl Vondrick Columbia University
3D reconstruction is a fundamental problem in computer vision, and the task is especially challenging when the object to reconstruct is partially or fully occluded. We introduce a method that uses the shadows cast by an unobserved object in order to infer the possible 3D volumes under occlusion. We create a differentiable image formation model that allows us to jointly infer the 3D shape of an object, its pose, and the position of a light source. Since the approach is end-to-end differentiable, we are able to integrate learned priors of object geometry in order to generate realistic 3D shapes of different object categories. Experiments and visualizations show that the method is able to generate multiple possible solutions that are consistent with the observation of the shadow. Our approach works even when the position of the light source and object pose are both unknown. Our approach is also robust to real-world images where ground-truth shadow mask is unknown.
CLIP-Sculptor: Zero-Shot Generation of High-Fidelity and Diverse Shapes From Natural Language
Aditya Sanghi Autodesk Research, Rao Fu Brown University, Vivian Liu Columbia University, Karl D.D. Willis Autodesk Research, Hooman Shayani Autodesk Research, Amir H. Khasahmadi Autodesk Research, Srinath Sridhar Brown University, Daniel Ritchie Brown University
Recent works have demonstrated that natural language can be used to generate and edit 3D shapes. However, these methods generate shapes with limited fidelity and diversity. We introduce CLIP-Sculptor, a method to address these constraints by producing high-fidelity and diverse 3D shapes without the need for (text, shape) pairs during training. CLIP-Sculptor achieves this in a multi-resolution approach that first generates in a low-dimensional latent space and then upscales to a higher resolution for improved shape fidelity. For improved shape diversity, we use a discrete latent space which is modeled using a transformer conditioned on CLIP’s image-text embedding space. We also present a novel variant of classifier-free guidance, which improves the accuracy-diversity trade-off. Finally, we perform extensive experiments demonstrating that CLIP-Sculptor outperforms state-of-the-art baselines.
Research papers from the department were accepted to the 11th International Conference on Learning Representations (ICLR 2023). ICLR is the premier conference on deep learning where researchers gather to discuss their work in the fields of artificial intelligence, statistics, and data science.
Visual Classification via Description from Large Language Models
Sachit Menon Columbia University, Carl Vondrick Columbia University
Keywords: vision-language models, CLIP, prompting, GPT-3, large language models, zero-shot recognition, multimodal
TL;DR: We enhance zero-shot recognition with vision-language models by comparing to category descriptors from GPT-3, enabling better performance in an interpretable setting that also allows for the incorporation of new concepts and bias mitigation.
Abstract:
Vision-language models such as CLIP have shown promising performance on a variety of recognition tasks using the standard zero-shot classification procedure — computing similarity between the query image and the embedded words for each category. By only using the category name, they neglect to make use of the rich context of additional information that language affords. The procedure gives no intermediate understanding of why a category is chosen and furthermore provides no mechanism for adjusting the criteria used towards this decision. We present an alternative framework for classification with VLMs, which we call classification by description. We ask VLMs to check for descriptive features rather than broad categories: to find a tiger, look for its stripes; its claws; and more. By basing decisions on these descriptors, we can provide additional cues that encourage using the features we want to be used. In the process, we can get a clear idea of what the model “thinks” it is seeing to make its decision; it gains some level of inherent explainability. We query large language models (e.g., GPT-3) for these descriptors to obtain them in a scalable way. Extensive experiments show our framework has numerous advantages past interpretability. We show improvements in accuracy on ImageNet across distribution shifts; demonstrate the ability to adapt VLMs to recognize concepts unseen during training; and illustrate how descriptors can be edited to effectively mitigate bias compared to the baseline.
CROM: Continuous Reduced-Order Modeling of PDEs Using Implicit Neural Representations
Peter Yichen Chen Columbia University, Jinxu Xiang Columbia University, Dong Heon Cho Columbia University, Yue Chang University of Toronto, G A Pershing Columbia University, Henrique Teles Maia Columbia University, Maurizio M Chiaramonte Meta Reality Labs Research, Kevin Thomas Carlberg Meta Reality Labs Research, Eitan Grinspun University of Toronto
Keywords: PDE, implicit neural representation, neural field, latent space traversal, reduced-order modeling, numerical methods
TL;DR: We accelerate PDE solvers via rapid latent space traversal of continuous vector fields leveraging implicit neural representations.
Abstract:
The long runtime of high-fidelity partial differential equation (PDE) solvers makes them unsuitable for time-critical applications. We propose to accelerate PDE solvers using reduced-order modeling (ROM). Whereas prior ROM approaches reduce the dimensionality of discretized vector fields, our continuous reduced-order modeling (CROM) approach builds a low-dimensional embedding of the continuous vector fields themselves, not their discretization. We represent this reduced manifold using continuously differentiable neural fields, which may train on any and all available numerical solutions of the continuous system, even when they are obtained using diverse methods or discretizations. We validate our approach on an extensive range of PDEs with training data from voxel grids, meshes, and point clouds. Compared to prior discretization-dependent ROM methods, such as linear subspace proper orthogonal decomposition (POD) and nonlinear manifold neural-network-based autoencoders, CROM features higher accuracy, lower memory consumption, dynamically adaptive resolutions, and applicability to any discretization. For equal latent space dimension, CROM exhibits 79x and 49x better accuracy, and 39x and 132x smaller memory footprint, than POD and autoencoder methods, respectively. Experiments demonstrate 109x and 89x wall-clock speedups over unreduced models on CPUs and GPUs, respectively. Videos and codes are available on the project page: https://crom-pde.github.io
Quantile Risk Control: A Flexible Framework for Bounding the Probability of High-Loss Predictions
Jake Snell Princeton University, Thomas P Zollo Columbia University, Zhun Deng Columbia University, Toniann Pitassi Columbia University, Richard Zemel Columbia University
Keywords: distribution-free uncertainty quantification
TL;DR: We propose a framework to rigorously and flexible control the quantiles of the loss distribution incurred by a predictor or set of predictors.
Abstract:
Rigorous guarantees about the performance of predictive algorithms are necessary in order to ensure their responsible use. Previous work has largely focused on bounding the expected loss of a predictor, but this is not sufficient in many risk-sensitive applications where the distribution of errors is important. In this work, we propose a flexible framework to produce a family of bounds on quantiles of the loss distribution incurred by a predictor. Our method takes advantage of the order statistics of the observed loss values rather than relying on the sample mean alone. We show that a quantile is an informative way of quantifying predictive performance, and that our framework applies to a variety of quantile-based metrics, each targeting important subsets of the data distribution. We analyze the theoretical properties of our proposed method and demonstrate its ability to rigorously control loss quantiles on several real-world datasets.
Causal Imitation Learning via Inverse Reinforcement Learning
Kangrui Ruan Columbia University, Junzhe Zhang Columbia University, Xuan Di Columbia University, Elias Bareinboim Columbia University
Keywords: Causal Inference, Graphical Models
TL;DR: This paper proposes novel inverse reinforcement learning methods to learn effective imitating policies from the expert’s demonstrations when unobserved confounders are present.
Abstract:
One of the most common ways children learn when unfamiliar with the environment is by mimicking adults. Imitation learning concerns an imitator learning to behave in an unknown environment from an expert’s demonstration; reward signals remain latent to the imitator. This paper studies imitation learning through causal lenses and extends the analysis and tools developed for behavior cloning (Zhang, Kumor, Bareinboim, 2020) to inverse reinforcement learning. First, we propose novel graphical conditions that allow the imitator to learn a policy performing as well as the expert’s behavior policy, even when the imitator and the expert’s state-action space disagree, and unobserved confounders (UCs) are present. When provided with parametric knowledge about the unknown reward function, such a policy may outperform the expert’s. Also, our method is easily extensible and allows one to leverage existing IRL algorithms even when UCs are present, including the multiplicative-weights algorithm (MWAL) (Syed & Schapire, 2008) and the generative adversarial imitation learning (GAIL) (Ho & Ermon, 2016). Finally, we validate our framework by simulations using real-world and synthetic data.
Neural Causal Models for Counterfactual Identification and Estimation
Kevin Muyuan Xia Columbia University, Yushu Pan Columbia University, Elias Bareinboim Columbia University
Keywords: causal inference, deep learning, neural models, neural causal models, causal identification, causal estimation, counterfactual
TL;DR: We solve the two problems of counterfactual identification and estimation from arbitrary surrogate experiments using a Generative Adversarial Network implementation of the Neural Causal Model.
Abstract:
Evaluating hypothetical statements about how the world would be had a different course of action been taken is arguably one key capability expected from modern AI systems. Counterfactual reasoning underpins discussions in fairness, the determination of blame and responsibility, credit assignment, and regret. In this paper, we study the evaluation of counterfactual statements through neural models. Specifically, we tackle two causal problems required to make such evaluations, i.e., counterfactual identification and estimation from an arbitrary combination of observational and experimental data. First, we show that neural causal models (NCMs) are expressive enough and encode the structural constraints necessary for performing counterfactual reasoning. Second, we develop an algorithm for simultaneously identifying and estimating counterfactual distributions. We show that this algorithm is sound and complete for deciding counterfactual identification in general settings. Third, considering the practical implications of these results, we introduce a new strategy for modeling NCMs using generative adversarial networks. Simulations corroborate with the proposed methodology.
Understanding Zero-shot Adversarial Robustness for Large-Scale Models
Chengzhi Mao Columbia University, Scott Geng Columbia University, Junfeng Yang Columbia University, Xin Wang Microsoft Research, Carl Vondrick Columbia University
Keywords: Adversarial Robustness, Zero-Shot Recognition
Abstract:
Pretrained large-scale vision-language models like CLIP have exhibited strong generalization over unseen tasks. Yet imperceptible adversarial perturbations can significantly reduce CLIP’s performance on new tasks. In this work, we identify and explore the problem of adapting large-scale models for zero-shot adversarial robustness. We first identify two key factors during model adaption–training losses and adaptation methods–that affect the model’s zero-shot adversarial robustness. We then propose a text-guided contrastive adversarial training loss, which aligns the text embeddings and the adversarial visual features with contrastive learning on a small set of training data. We apply this training loss to two adaption methods, model finetuning and visual prompt tuning. We find that visual prompt tuning is more effective in the absence of texts, while finetuning wins in the existence of text guidance. Overall, our approach significantly improves the zero-shot adversarial robustness over CLIP, seeing an average improvement of 31 points over ImageNet and 15 zero-shot datasets. We hope this work can shed light on understanding the zero-shot adversarial robustness of large-scale models.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Yuncong Yang Columbia University, Jiawei Ma Columbia University, Shiyuan Huang Columbia University, Long Chen Columbia University, Xudong Lin Columbia University, Guangxing Han Columbia University, Shih-Fu Chang Columbia University
Keywords: Representation learning, Global Sequence Alignment, Zero/Few-shot Transfer
TL;DR: Global sequence matching under temporal order consistency matters in contrastive-based video-paragraph/text learning.
Abstract:
Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
The third-year PhD student is creating tools to help people with vision impairments navigate the world.
Imagine walking to your office from the subway station on a Monday morning. You notice a new café on the way, so you decide to take a detour and try a latté. That sounds like a normal way to start the week, right?
But for people with vision impairment or low vision, like those who are categorized as blind and low vision (BLV), this kind of spontaneous exploration while outside is challenging. Current navigation assistance systems (NAS) provide turn-by-turn instructions, but they do not allow visually impaired users to deviate from the shortest path to their destination or make decisions on the fly. As a result, people with vision impairment or low vision often miss out on the freedom to go out and navigate on their own terms.

In a paper published at the ACM Conference On Computer-Supported Cooperative Work And Social Computing (CSCW ‘23), computer science researchers introduced the concept of “Exploration Assistance,” which is an evolution of current NASs that can support BLV people’s exploration in unfamiliar environments. Led by Gaurav Jain, the researchers investigated how NASs should be designed by interviewing BLV people, orientation and mobility instructors, and leaders of blind-serving organizations, to understand their specific needs and challenges. Their findings highlight the types of spatial information required for exploration beyond turn-by-turn instructions and the difficulties faced by BLV people when exploring alone or with the help of others.
Jain, who is advised by Assistant Professor Brian Smith, is a PhD student in the Computer-Enabled Abilities Laboratory (CEAL Lab), where researchers develop computers that help people perceive and interact with the world around them. Their paper presents the results of interviews with BLV people and other stakeholders to identify the types of spatial information BLV people need for exploration and the challenges BLV people face when exploring unfamiliar environments. The paper offers insights into the design and development of new navigation assistance systems that can support BLV people in exploring unfamiliar environments with greater spontaneity and agency.
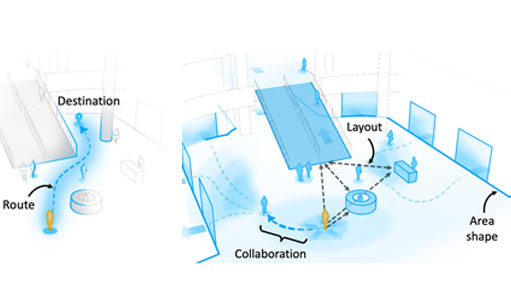
Based on their findings, they presented several instances of NASs that support the exploration assistance paradigm and identify several challenges that need to be overcome to make these systems a reality. Jain hopes that his research will ultimately enable BLV people to experience greater agency and independence as they navigate and explore their environments. We sat down with Jain to learn more about his research, doing qualitative research, and the thought processes behind writing research papers.
This research is incredibly exciting for the blind and low vision (BLV) community, as it represents a significant step towards equal access and agency in exploring unfamiliar environments. For BLV people, the ability to navigate and explore independently is essential to daily life, and current navigation assistance systems often limit their ability to do so. By introducing the concept of exploration assistance, this research opens up new possibilities for BLV people to explore and discover their surroundings with greater spontaneity and freedom. This research has the potential to significantly improve the quality of life for BLV people and is a major development in the ongoing pursuit of accessibility and inclusion for all.
This was my first project as a PhD student in the CEAL lab. The project was initiated as a camera-based wearable NAS for BLV people, and we conducted several formative studies with BLV people.
As we progressed, we realized that there was a significant research gap in the research community’s understanding of how NASs could support BLV people’s exploration in navigation. Based on these findings, we shifted our focus toward investigating this gap, and the paper I worked on was the result of this pivot. The paper is titled, “I Want to Figure Things Out”: Supporting Exploration in Navigation for People with Visual Impairments.
Over the course of approximately one year, I had the opportunity to work on this project that challenged me to step outside of my comfort zone as a human-computer interaction (HCI) researcher. Before this project, my research experience had primarily focused on computer vision and deep learning. I was more at ease with HCI systems research, which involved designing, building, and evaluating tools and techniques to solve user problems.
This project, however, was a qualitative research study that aimed to gain a deeper understanding of user needs, behaviors, challenges, and attitudes toward technology through in-depth interviews, observations, and other qualitative data collection methods. To prepare for this project, I had to immerse myself in the field of accessibility and navigation assistance for BLV people and read extensively on papers that employed qualitative research methods.
Although it took some time for me to shift my mindset towards qualitative research, this project helped me become a more well-rounded researcher, as I now feel comfortable with both qualitative and systems research. Overall, this project was a significant personal and professional growth experience, as I was able to expand my research expertise and contribute to a worthy cause.
Writing the paper was a critical stage in the research process, and I approached it by first organizing my thoughts and drafting a clear outline. I started by creating an outline of the paper with section and subsection headers, accompanied by a brief summary of what I intended to discuss in each section. This process allowed me to see the overall structure of the paper and ensure that I covered all the essential elements.
Once I had a clear structure in mind, I began to tackle each section of the paper one by one, starting with the introduction and then moving on to the methods, results, and discussion sections. I iteratively refined my writing based on feedback from my advisor, lab mates, and friends.
Throughout the writing process, I also ensured that my writing was clear, concise, and easy to follow. I paid close attention to the flow of ideas and transitions between sections, making sure that each paragraph and sentence contributed to the overall argument and was well-supported by the evidence.
Overall, the process of writing the paper was challenging but rewarding. It allowed me to synthesize the research findings and present them in a compelling way, showcasing the impact of our work on the lives of BLV people.
Throughout the research process, I encountered various challenges that both surprised and tested me. Interviewing participants, in particular, proved to be an intriguing yet difficult task. Initially, I struggled to guide conversations naturally toward my research questions without leading participants toward a certain answer. However, with each interview, I became more confident and began to enjoy the process. Hearing firsthand from BLV people that our work could make a real impact on their lives was also incredibly rewarding.
Analyzing and synthesizing the interview data was another major challenge. Unlike quantitative data, conversations are often open-ended and context-dependent, making it difficult to separate my own biases from the interviewee’s responses. I spent a considerable amount of time reviewing the interview transcripts and identifying emerging themes. To facilitate this process, I leveraged tools like NVivo to better organize the interview data, and our team held several discussions to refine these themes. To ensure the accuracy of our interpretation, we sought feedback from two BLV interns who worked with us over the summer on another project.
Overall, this research experience pushed me to become more adaptable. While it presented its own unique set of challenges, I am proud to have contributed to a project that has the potential to create meaningful change in the lives of BLV people.

Yes, my experience with this research project has certainly changed my view on how to approach research. It has taught me the importance of keeping the paper in mind from the beginning of a project.
Now, I make a conscious effort to think about how I want to present my work and what story I want to tell with the research. This helps me gain more clarity on the direction of the project and how to steer it toward producing meaningful results. As part of my workflow, I now write early drafts of paper introductions even before developing any tools or systems. This allows me to zoom out from the day-to-day technical challenges and see the big picture, which is crucial in making sure that the research is both impactful and well-presented.
Writing a research paper can be a challenging task, but here are a few tips that have helped me make the process smoother:
Finally, one resource that I would totally recommend to every PhD student at Columbia is Adjunct Professor Janet Kayfetz’s class on Technical Writing. Her class is an excellent way to deeply understand research writing.
I am currently working on two exciting projects that further my research goal of developing inclusive physical and digital environments for BLV people. The first project involves enhancing the capabilities of smart streets, streets with sensors like cameras and computing power, to help BLV people navigate street intersections safely.
This project is part of the NSF Engineering Research Center for Smart Streetscapes’ application thrust. The second project is focused on making videos accessible to BLV people by creating high-quality audio descriptions available at scale.
My exposure to research during my undergrad was invaluable, as it allowed me to work on diverse projects utilizing computer vision for various applications such as biometric security and medical imaging. These experiences instilled in me a passion for the research process. It was fulfilling to be able to identify problems that I care about, explore solutions, and disseminate new knowledge.
While I knew I enjoyed research, it was during the summer research fellowship at the Indian Institute of Sciences, where I collaborated with Professor P. K. Yalavarthy in the Medical Imaging Group, that crystallized my decision to pursue a PhD. The opportunity to work in a research lab, lead a project, and receive mentorship from an experienced advisor provided a glimpse of what a PhD program entails. I was excited by the prospect of being able to make a real-world impact by solving complex problems, and it was then that I decided to pursue a career in research.
I am interested in building Human-AI systems that embed AI technologies (e.g., computer vision) into human interactions to help BLV people better experience the world around them. My work on exploration assistance informs the design of future navigation assistance systems that enable BLV people to experience the physical world with more agency and spontaneity during navigation.
In addition to the physical world, I’ve also broadened my research focus to enhance BLV people’s experiences within the digital world. For example, I developed a system that makes it possible for BLV people to visualize the action in sports broadcasts rather than relying on other people’s descriptions of the game.
Accessibility research has traditionally focused on aiding daily-life activities and providing access to digital information for productivity and work, but there’s an increasing realization that providing access to everyday cultural experiences is equally important for inclusion and well-being.
This encompasses various forms of entertainment and recreation, such as watching TV, exploring museums, playing video games, listening to music, and engaging with social media. Ensuring that everyone has equal opportunities to enjoy these experiences is an emerging challenge. My goal is to design human-AI systems that enhance such experiences.
I was drawn to Columbia CS because of the type of problems my advisor works on. His research focused on creating systems that have a direct impact on people’s lives, where evaluating the user’s experience with the system is a key component.
This was a departure from my undergraduate research, where I focused on building systems to achieve high accuracy and efficiency. I found this user-centered approach to be extremely exciting, especially in the context of his project “RAD,” which aimed to make video games accessible to blind gamers. It was a super exciting prospect to be working on similar problems where you can firsthand see how people reacted and benefited from your solutions. This still remains one of the most fulfilling aspects of HCI research for me. In the end, this is what led me to choose Columbia and work with Brian Smith.

The first thing that comes to mind is the people that I have had the pleasure of working with and meeting. I am grateful for the opportunity to learn from my advisor and appreciate the incredible atmosphere he has created for me to thrive.
Additionally, I have been fortunate enough to make some amazing friends here at Columbia who have become a vital support system. Balancing work with passions outside of work has also been important to me, and I am grateful for the chance to engage with student clubs such as the dance team, Columbia Bhangra, and meet some amazing people there as well. Overall, the community at Columbia has been a highlight for me.
One thing that students wanting to do research should know is that research involves a lot of uncertainty and ambiguity. In fact, dealing with uncertainty can be one of the most challenging aspects of research, even more so than learning the technical skills required to complete a project.
In my own experience, staying motivated about the problem statement has been key to powering through those uncertain moments. Therefore, it is important to be true to yourself about what you are really excited about and work on those problems. Ultimately, this approach can go a long way in helping you navigate your time at Columbia and make the most of your research opportunities.
OpenAI’s ChatGPT is an artificial intelligence (AI) chatbot that is trained to follow the instruction in a prompt and give a detailed response. It is built upon GPT-3, a type of large language model (LLM) that predicts and generates text. Given a sequence of words, it will predict the word that has the highest probability of following next (kind of like autocomplete). These models are trained on huge datasets that allow them to generate answers to questions. ChatGPT works quickly and gives answers within seconds, and it also learns from every interaction and improves daily.
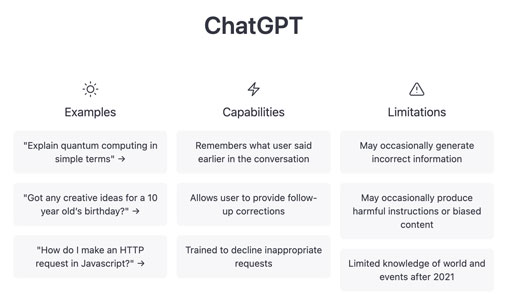
It can create a letter to your super asking for a repair to be done, write code and fix bugs, and suggest plot summaries for novels. But that does not mean that it is perfect. The problem with LLMs is that they can “hallucinate” and make things up. ChatGPT is guilty of this; some of the answers in its outputs do not even exist. It is also not trained to be truthful and it answers queries with a lot of confidence and authority, which is worrisome.
It is being compared to the last great tech disruption–the internet’s onset in the 1990s. We asked CS professors what the technology could do and how to use the tool the right way.
Vishal Misra
I have been using GPT-3 for over two years now. It is the underlying model behind my cricket search app for ESPN.
The original interface was cumbersome and needed an analyst who could use specialized programming languages to access the answer.
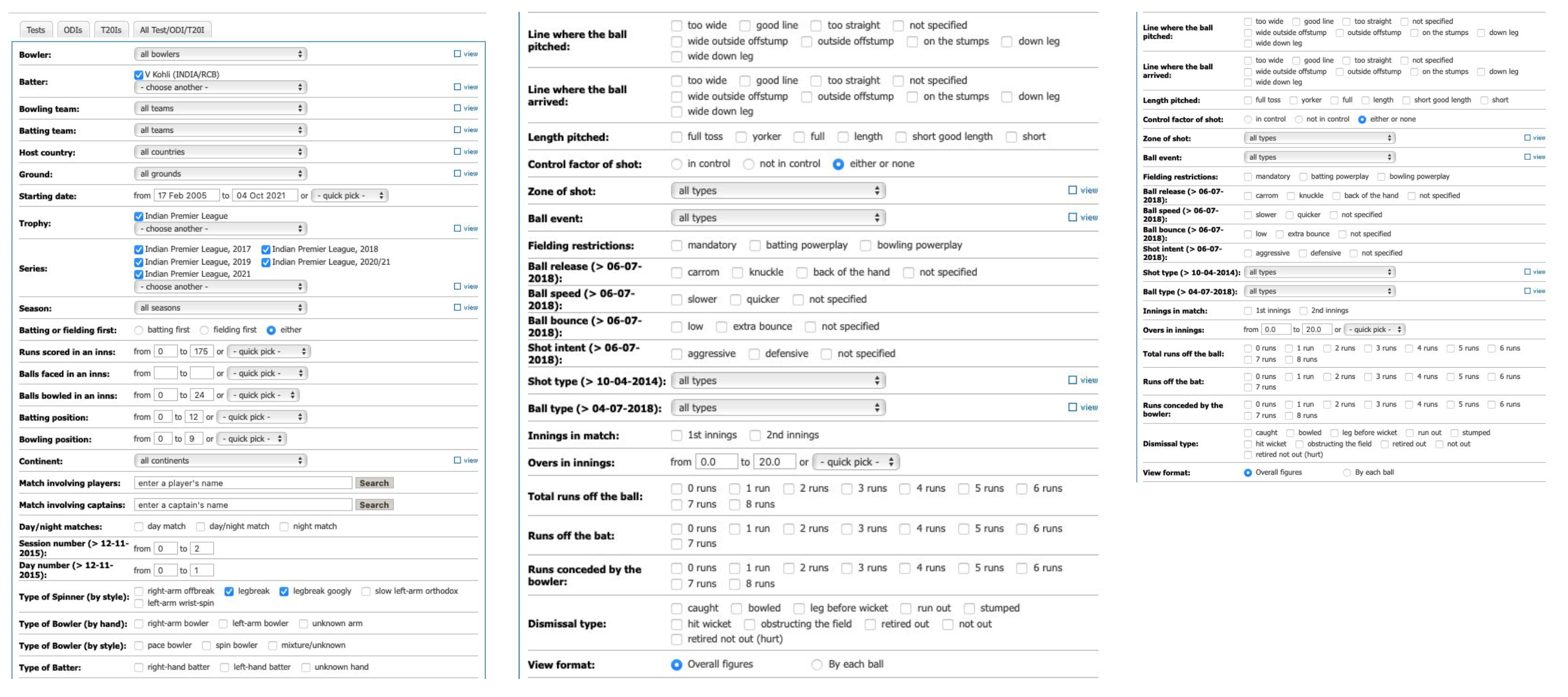
We developed AskCricInfo, which takes human input–questions or search queries–and converts the queries into a structured language like SQL that machines understand. The technology can “translate” the question into a programming language, find the answer, and quickly send it back to the user.
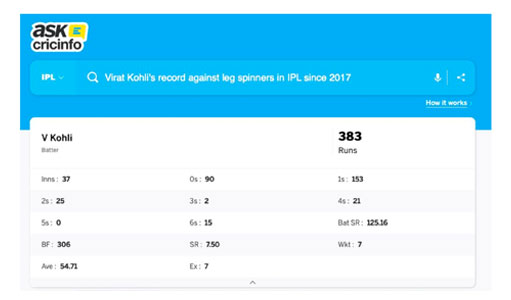
It is an excellent example of the power of underlying technology and what the tool can do. ChatGPT is very interesting. It is the first chatbot that makes “intelligent” and engaging conversations. There are definite use cases for making it a very effective teaching tool. It is up to the instructors to imagine a world where something like ChatGPT will always be available and teach students how to use it effectively. A lot can go wrong with ChatGPT- primarily because of its design that makes it bullshit confidently. But that is a problem with all LLMs, not just ChatGPT.
Kathy McKeown
ChatGPT and the technology it is built on, GPT3, are game changers. With them and the other large language models that have recently emerged, models can now produce extremely fluent text. They are also able to perform a variety of tasks in a way that was not previously possible. And there are many situations in which they can be used to help us do things that we previously found tedious. But they are not able to do as much as we might initially have imagined. They have limitations that are not always immediately obvious, and researchers are taking the time to study them so that we can accurately characterize what they can and cannot do. Nonetheless, they change how we do research in the natural language field and how we build new models to carry out other tasks.
I think we need to learn how to incorporate them into our teaching because they are here to stay. Students know about them and will know how to use them. We will need to think creatively about how to teach students what these tools do well and what they do poorly, when they can be used as a tool to aid in research, and situations in which it would be dishonest. I imagine situations where we ask ChatGPT to answer an essay question, ask the student to critique the essay and identify what it does poorly, and then ask the student to write an essay that goes beyond what ChatGPT can do.
The worst problem with ChatGPT is that it is not always truthful. In fact, it may often lie or hallucinate facts. It does this very fluently, making its lies sound very plausible. This is quite a barrier to use in a real-world situation unless it is used by someone who knows what is correct, what is not, and can sift the good from the bad. Technology constantly changes, though, and it is a problem that researchers are actively working on.
Itsik Pe’er
I asked ChatGPT about AI language models, and this is the output:
AI language models like ChatGPT, its competitors and successors represent a significant advancement in the field of Natural Language Processing (NLP). These models have the ability to generate human-like text based on a massive amount of input data, making them useful for various applications such as chatbots, question-answering systems, and content generation.
However, it is important to note that despite their sophisticated capabilities, they still have limitations and may generate outputs that are inaccurate, biased, or inappropriate. It is crucial to ensure responsible development and deployment of these models to maximize their benefits while minimizing potential harm.
The above demonstrates my thoughts more than I could otherwise express. In particular: it is already useful, but often not out-of-the-box, but I am a techno-optimist and believe even more usefulness is coming.
As a former judge in high school debate competitions, it reminds me of the most eloquent contestants, who would, if they needed to, lie through their teeth without missing a heartbeat. For instance, in response to this prompt, “What could go wrong with tools like ChatGPT?”, it writes:
There are several potential risks associated with the use of AI language models like ChatGPT:
Bias: AI models are trained on large amounts of text data, which may reflect societal biases and lead to biased outputs.
Misinformation: AI models may generate false or misleading information, which could have serious consequences if relied upon.
Privacy Concerns: AI models process large amounts of personal information, raising privacy and security concerns.
Misuse: AI models may be used for malicious purposes, such as spreading hate speech, fake news, or conducting phishing attacks.
Job Loss: AI models may automate certain tasks, leading to job loss in industries that rely on those tasks.
Therefore, it is important to carefully consider the potential risks and consequences of AI models and to develop and deploy them responsibly to minimize potential harm.
These are all valid points, but more context needs to be considered:
The field of natural language processing (NLP) has ramped up by leaps and bounds. This branch of artificial intelligence focuses on the ability of computers to understand and process language as humans do. It has been in the news these past few months because of a chatbot, ChatGPT, that can provide answers and data conversationally. The technology gives us a taste of just how powerful and useful NLP can be.
Tuhin Chakrabarty wants to see how much further he can push NLP in the field of computational creativity to see how computers can generate creative output. This is what ChatGPT had to say about computational creativity:
Computational creativity is a field that uses computational methods to simulate and enhance human-like creativity, producing valuable outputs such as art, music, stories, and scientific discoveries. It aims to understand and replicate the cognitive processes involved in human creativity, combining techniques from AI, cognitive psychology, and philosophy. Examples of computational creativity include generative art and music, game design, natural language processing, and scientific discovery. Ultimately, computational creativity seeks to leverage computers and algorithms to augment and extend human creativity, creating new possibilities for creative expression and innovation.

“Generating text beyond a few sentences was almost very difficult two years ago, but things look much better now. It is not perfect, but I am optimistic,” said Tuhin Chakrabarty, who first became interested in computational creativity in 2019. “One of the things that I am excited about is how better we can align models like ChatGPT to human expectations and different cultures.”
Instead of creating text conversationally, Chakrabarty’s research focuses on how AI can be used to create metaphors and detect sarcasm with little to no training data. The fifth-year PhD student advised by Smaranda Muresan has expanded his work to generating long narratives of 2,000-word documents and visual metaphors. We recently sat down with him to learn more about his research and the creative possibilities of NLP.
I did not have much research experience as an undergrad. I got accepted to the CS masters program and I was fortunate enough to take a class offered by my advisor Smaranda Muresan, which still happens to be one of my all-time favorite courses at Columbia. Computational models of Social Meaning was a graduate seminar course about impactful papers in NLP. Reading all the papers in that class made me think about what I want to do with NLP and how so many interesting research questions can be answered computationally by studying language. Alongside this, I was also working with my advisor and my friend Chris Hidey on extracting arguments from social media. That experience was really precious. The enthusiasm everyone shared in trying to solve the problem at hand made me sure of my decision to pursue research.
Around 2019, Nanyun Peng and He He, two very important researchers in the field of computational creativity, wrote a paper on generating puns. I happened to attend NAACL 2019 in Minneapolis, where the paper was presented. I thought the paper was beautiful in every possible way and it quantified the surprisal theory in humor algorithmically. This made me really fascinated about how we can use inductive biases to help machines generate creative output. For selfish reasons, I reached out to Nanyun Peng and told her that I wanted to work with her. She was very kind and agreed to mentor me. My PhD advisor Smaranda Muresan is one of the experts in the field of Figurative Language, which deals with creativity. So, of course, that influenced my decision to work in computational creativity too.
Computational creativity is a multidisciplinary endeavor located at the intersection of artificial intelligence, cognitive psychology, philosophy, and the arts. The goal of computational creativity is to model, simulate or replicate creativity using a computer to achieve one of several ends:
State-of-the-art models are often found to be inadequate for creative tasks. The principal reason for this is that in addition to composing grammatical and fluent sentences to articulate given content, these tasks usually require extensive world and common sense knowledge.
It should also be noted that current approaches to text generation require lots of training data for supervision. However, most existing corpus for creative forms of text is limited in size. Even if such a corpus existed, learning the distribution of existing data and sampling from it is unlikely to lead to truly novel, creative output.
So we have to rely on unsupervised or weakly supervised techniques to train an end-to-end model to interpret or generate creative text. Of course, with the advent of Large Language Models and few-shot learning, we can now prompt a model with a few examples of creative text and it can somewhat generalize (but not as well as humans). My dissertation deals with a lot of this.
Over the past several years, a key focus for NYTimes Research and Development has understood how advances in machine learning can extend the capabilities of journalists and unlock reader experiences that aren’t possible today. Questions and answers are central to how humans learn. Times journalism frequently uses FAQ and Q&A-style articles to help readers understand complex topics like the Covid-19 vaccines. To enhance this style of journalism, we experimented with large language models to match questions to answers, even if the reader asks their question in a novel way.
Last year we launched a new research effort to explore generating open-ended questions for news articles. Our hypothesis is that understanding the questions our news articles are implicitly answering may be helpful in the reporting process and may ultimately enable us to create FAQ and Q&A-style articles more efficiently.
You can find more information here: https://rd.nytimes.com/projects/generating-open-ended-questions-from-news-articles
This was fundamentally different from what I have been doing because I had to work towards upholding journalism values such as accuracy and verifiability. In creativity, your model can generate something that does not require attribution. But, when working on a project that deals with news and journalism, the focus is on factuality.
Recent work on question generation has primarily focused on factoid questions such as who, what, where, and when about basic facts. Generating open-ended why, how, what, etc., questions that require long-form answers has proven more difficult. To facilitate the generation of open-ended questions, we propose CONSISTENT, a new end-to-end system for generating open-ended questions that are answerable from and faithful to the input text. Using news articles as a trustworthy foundation for experimentation, we demonstrate our model’s strength over several baselines using both automatic and human-based evaluations. We contribute an evaluation dataset of expert-generated open-ended questions and discuss potential downstream applications for news media organizations.

Much of my recent and upcoming work is on human-AI collaboration for creativity. I recently worked on developing methods and evaluation frameworks for two creative tasks–poetry generation and visual metaphor generation–by leveraging collaboration between expert humans and state-of-the-art generative models. I further highlighted how collaboration improves the final output over either standalone models or only humans.
I have long focused on developing and evaluating machine learning models aimed at creativity in an isolated setting. This somehow limits their capacity to behave in an interactive setting with real humans. In a creative setting, it is crucial for models to understand human needs and provide assistance to augment human capabilities and improve performance based on human edits or feedback over time. So that is my focus now.
This is a difficult question. Pursuing a PhD can be a really fun experience, but at the same time, it can be daunting. There is a lot of uncertainty around research questions and whether something will work or not. I wish I had been a little easier on myself and not taken everything personally. Like, if an idea didn’t work, instead of spending months trying to make it work, it is okay to give up and move in a different direction.
One of the things I learned during my PhD is to focus on what you care about. There are hundreds of researchers who might work on slightly dense areas, while your work can feel niche. This is not a problem. When I started working on NLP and creativity, the field still felt very young, but over the past three to four years, it has grown tremendously.
Your advisor will be one of the most important people in your PhD. It is essential to have good communication and working chemistry with them. One of the reasons my PhD felt like so much fun is because my advisor and I cared about the same problems.
Form a community and foster friendships with your lab mates, talk about research, or email a colleague whose work moved you and get a coffee with them at a conference. Also, try for opportunities to work with people in your lab or your community. It helps us learn so much.
Researchers from the department presented machine learning and artificial intelligence research at the thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2022).
Finding and Listing Front-door Adjustment Sets
Hyunchai Jeong Purdue University, Jin Tian Iowa State University, Elias Bareinboim Columbia University
Abstract:
Identifying the effects of new interventions from data is a significant challenge found across a wide range of the empirical sciences. A well-known strategy for identifying such effects is Pearl’s front-door (FD) criterion. The definition of the FD criterion is declarative, only allowing one to decide whether a specific set satisfies the criterion. In this paper, we present algorithms for finding and enumerating possible sets satisfying the FD criterion in a given causal diagram. These results are useful in facilitating the practical applications of the FD criterion for causal effects estimation and helping scientists to select estimands with desired properties, e.g., based on cost, feasibility of measurement, or statistical power.
Causal Identification under Markov equivalence: Calculus, Algorithm, and Completeness
Amin Jaber Purdue University, Adele Ribeiro Columbia University, Jiji Zhang Hong Kong Baptist University, Elias Bareinboim Columbia University
Abstract:
One common task in many data sciences applications is to answer questions about the effect of new interventions, like: `what would happen to Y if we make X equal to x while observing covariates Z=z?’. Formally, this is known as conditional effect identification, where the goal is to determine whether a post-interventional distribution is computable from the combination of an observational distribution and assumptions about the underlying domain represented by a causal diagram. A plethora of methods was developed for solving this problem, including the celebrated do-calculus [Pearl, 1995]. In practice, these results are not always applicable since they require a fully specified causal diagram as input, which is usually not available. In this paper, we assume as the input of the task a less informative structure known as a partial ancestral graph (PAG), which represents a Markov equivalence class of causal diagrams, learnable from observational data. We make the following contributions under this relaxed setting. First, we introduce a new causal calculus, which subsumes the current state-of-the-art, PAG-calculus. Second, we develop an algorithm for conditional effect identification given a PAG and prove it to be both sound and complete. In words, failure of the algorithm to identify a certain effect implies that this effect is not identifiable by any method. Third, we prove the proposed calculus to be complete for the same task.
Online Reinforcement Learning for Mixed Policy Scopes
Junzhe Zhang Columbia University, Elias Bareinboim Columbia University
Abstract:
Combination therapy refers to the use of multiple treatments — such as surgery, medication, and behavioral therapy – to cure a single disease, and has become a cornerstone for treating various conditions including cancer, HIV, and depression. All possible combinations of treatments lead to a collection of treatment regimens (i.e., policies) with mixed scopes, or what physicians could observe and which actions they should take depending on the context. In this paper, we investigate the online reinforcement learning setting for optimizing the policy space with mixed scopes. In particular, we develop novel online algorithms that achieve sublinear regret compared to an optimal agent deployed in the environment. The regret bound has a dependency on the maximal cardinality of the induced state-action space associated with mixed scopes. We further introduce a canonical representation for an arbitrary subset of interventional distributions given a causal diagram, which leads to a non-trivial, minimal representation of the model parameters.
Masked Prediction: A Parameter Identifiability View
Bingbin Liu Carnegie Mellon University, Daniel Hsu Columbia University, Pradeep Ravikumar Carnegie Mellon University, Andrej Risteski Carnegie Mellon University
Abstract:
The vast majority of work in self-supervised learning have focused on assessing recovered features by a chosen set of downstream tasks. While there are several commonly used benchmark datasets, this lens of feature learning requires assumptions on the downstream tasks which are not inherent to the data distribution itself. In this paper, we present an alternative lens, one of parameter identifiability: assuming data comes from a parametric probabilistic model, we train a self-supervised learning predictor with a suitable parametric form, and ask whether the parameters of the optimal predictor can be used to extract the parameters of the ground truth generative model.Specifically, we focus on latent-variable models capturing sequential structures, namely Hidden Markov Models with both discrete and conditionally Gaussian observations. We focus on masked prediction as the self-supervised learning task and study the optimal masked predictor. We show that parameter identifiability is governed by the task difficulty, which is determined by the choice of data model and the amount of tokens to predict. Technique-wise, we uncover close connections with the uniqueness of tensor rank decompositions, a widely used tool in studying identifiability through the lens of the method of moments.
Learning single-index models with shallow neural networks
Alberto Bietti Meta AI/New York University, Joan Bruna New York University, Clayton Sanford Columbia University, Min Jae Song New York University
Abstract:
Single-index models are a class of functions given by an unknown univariate link” function applied to an unknown one-dimensional projection of the input. These models are particularly relevant in high dimension, when the data might present low-dimensional structure that learning algorithms should adapt to. While several statistical aspects of this model, such as the sample complexity of recovering the relevant (one-dimensional) subspace, are well-understood, they rely on tailored algorithms that exploit the specific structure of the target function. In this work, we introduce a natural class of shallow neural networks and study its ability to learn single-index models via gradient flow. More precisely, we consider shallow networks in which biases of the neurons are frozen at random initialization. We show that the corresponding optimization landscape is benign, which in turn leads to generalization guarantees that match the near-optimal sample complexity of dedicated semi-parametric methods.
On Scrambling Phenomena for Randomly Initialized Recurrent Networks
Evangelos Chatziafratis University of California Santa Cruz, Ioannis Panageas University of California Irvine, Clayton Sanford Columbia University, Stelios Stavroulakis University of California Irvine
Abstract:
Recurrent Neural Networks (RNNs) frequently exhibit complicated dynamics, and their sensitivity to the initialization process often renders them notoriously hard to train. Recent works have shed light on such phenomena analyzing when exploding or vanishing gradients may occur, either of which is detrimental for training dynamics. In this paper, we point to a formal connection between RNNs and chaotic dynamical systems and prove a qualitatively stronger phenomenon about RNNs than what exploding gradients seem to suggest. Our main result proves that under standard initialization (e.g., He, Xavier etc.), RNNs will exhibit \textit{Li-Yorke chaos} with \textit{constant} probability \textit{independent} of the network’s width. This explains the experimentally observed phenomenon of \textit{scrambling}, under which trajectories of nearby points may appear to be arbitrarily close during some timesteps, yet will be far away in future timesteps. In stark contrast to their feedforward counterparts, we show that chaotic behavior in RNNs is preserved under small perturbations and that their expressive power remains exponential in the number of feedback iterations. Our technical arguments rely on viewing RNNs as random walks under non-linear activations, and studying the existence of certain types of higher-order fixed points called \textit{periodic points} in order to establish phase transitions from order to chaos.
Patching open-vocabulary models by interpolating weights
Gabriel Ilharco University of Washington, Mitchell Wortsman University of Washington, Samir Yitzhak Gadre Columbia University, Shuran Song Columbia University, Hannaneh Hajishirzi University of Washington, Simon Kornblith Google Brain, Ali Farhadi University of Washington, Ludwig Schmidt University of Washington
Abstract:
Open-vocabulary models like CLIP achieve high accuracy across many image classification tasks. However, there are still settings where their zero-shot performance is far from optimal. We study model patching, where the goal is to improve accuracy on specific tasks without degrading accuracy on tasks where performance is already adequate. Towards this goal, we introduce PAINT, a patching method that uses interpolations between the weights of a model before fine-tuning and the weights after fine-tuning on a task to be patched. On nine tasks where zero-shot CLIP performs poorly, PAINT increases accuracy by 15 to 60 percentage points while preserving accuracy on ImageNet within one percentage point of the zero-shot model. PAINT also allows a single model to be patched on multiple tasks and improves with model scale. Furthermore, we identify cases of broad transfer, where patching on one task increases accuracy on other tasks even when the tasks have disjoint classes. Finally, we investigate applications beyond common benchmarks such as counting or reducing the impact of typographic attacks on CLIP. Our findings demonstrate that it is possible to expand the set of tasks on which open-vocabulary models achieve high accuracy without re-training them from scratch.
ASPiRe: Adaptive Skill Priors for Reinforcement Learning
Mengda Xu Columbia University, Manuela Veloso JP Morgan/Carnegie Mellon University, Shuran Song Columbia University
Abstract:
We introduce ASPiRe (Adaptive Skill Prior for RL), a new approach that leverages prior experience to accelerate reinforcement learning. Unlike existing methods that learn a single skill prior from a large and diverse dataset, our framework learns a library of different distinction skill priors (i.e., behavior priors) from a collection of specialized datasets, and learns how to combine them to solve a new task. This formulation allows the algorithm to acquire a set of specialized skill priors that are more reusable for downstream tasks; however, it also brings up additional challenges of how to effectively combine these unstructured sets of skill priors to form a new prior for new tasks. Specifically, it requires the agent not only to identify which skill prior(s) to use but also how to combine them (either sequentially or concurrently) to form a new prior. To achieve this goal, ASPiRe includes Adaptive Weight Module (AWM) that learns to infer an adaptive weight assignment between different skill priors and uses them to guide policy learning for downstream tasks via weighted Kullback-Leibler divergences. Our experiments demonstrate that ASPiRe can significantly accelerate the learning of new downstream tasks in the presence of multiple priors and show improvement on competitive baselines.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
Zhenhailong Wang Columbia University, Manling Li Columbia University, Ruochen Xu Microsoft, Luowei Zhou Meta, Jie Lei Meta, Xudong Lin Columbia University, Shuohang Wang Microsoft, Ziyi Yang Stanford University, Chenguang Zhu Stanford University, Derek Hoiem University of Illinois, Shih-Fu Chang Columbia University, Mohit Bansal University of North Carolina Chapel Hill, Heng Ji University of Illinois
Abstract:
The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal-aware template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets.Code and processed data are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL.
Implications of Model Indeterminacy for Explanations of Automated Decisions
Marc-Etienne Brunet University of Toronto, Ashton Anderson University of Toronto, Richard Zemel Columbia University
Abstract:
There has been a significant research effort focused on explaining predictive models, for example through post-hoc explainability and recourse methods. Most of the proposed techniques operate upon a single, fixed, predictive model. However, it is well-known that given a dataset and a predictive task, there may be a multiplicity of models that solve the problem (nearly) equally well. In this work, we investigate the implications of this kind of model indeterminacy on the post-hoc explanations of predictive models. We show how it can lead to explanatory multiplicity, and we explore the underlying drivers. We show how predictive multiplicity, and the related concept of epistemic uncertainty, are not reliable indicators of explanatory multiplicity. We further illustrate how a set of models showing very similar aggregate performance on a test dataset may show large variations in their local explanations, i.e., for a specific input. We explore these effects for Shapley value based explanations on three risk assessment datasets. Our results indicate that model indeterminacy may have a substantial impact on explanations in practice, leading to inconsistent and even contradicting explanations.
Reconsidering Deep Ensembles
Taiga Abe Columbia University, Estefany Kelly Buchanan Columbia University, Geoff Pleiss Columbia University, Richard Zemel Columbia University, John Cunningham Columbia University
Abstract:
Ensembling neural networks is an effective way to increase accuracy, and can often match the performance of individual larger models. This observation poses a natural question: given the choice between a deep ensemble and a single neural network with similar accuracy, is one preferable over the other? Recent work suggests that deep ensembles may offer distinct benefits beyond predictive power: namely, uncertainty quantification and robustness to dataset shift. In this work, we demonstrate limitations to these purported benefits, and show that a single (but larger) neural network can replicate these qualities. First, we show that ensemble diversity, by any metric, does not meaningfully contribute to an ensemble’s ability to detect out-of-distribution (OOD) data, but is instead highly correlated with the relative improvement of a single larger model. Second, we show that the OOD performance afforded by ensembles is strongly determined by their in-distribution (InD) performance, and – in this sense – is not indicative of any “effective robustness.” While deep ensembles are a practical way to achieve improvements to predictive power, uncertainty quantification, and robustness, our results show that these improvements can be replicated by a (larger) single model
The projects of the Undergraduate Computer and Data Science Research Fair fell under the themes of Data Science and Society, Interdisciplinary Data Science Applications, Data Science and Computer Science Research. Posters and demonstrations were proudly hosted by twenty-five students from SEAS, Barnard College, Columbia College, and the School of General Studies.




The fair was organized by the Data, Media and Society Center at the Data Science Institute, Columbia University; the Barnard Program in Computer Science and the Vagelos Computational Science Center; and the Department of Computer Science at Columbia Engineering led by Eugene Wu, Susan McGregor, Rebecca Wright, and Alexis Avedisian.

In the Columbia Artificial Intelligence and Robotics (CAIR) Lab, Cheng Chi stands in front of a robotic arm. At the end of the arm sits a yellow plastic cup. His goal at the moment is to use a piece of rope to hit the cup to the ground.
“I never thought I would have to do this as part of a research project,” said Chi, a second-year PhD student. He was conducting the exercise to gain a better understanding of physical movement and how it can be applied to a robotic control system.
Existing robotic systems struggle to precisely manipulate objects with complex dynamics, such as hitting a small target with a whip or swinging tablecloths to an exact location. While these tasks are quite hard even for humans, we usually have a good intuition about how to change our actions after a failed attempt, and iteratively get closer to the goal.

Chi was able to knock the cup off after five tries. Now, it’s the robot’s turn to fling the piece of rope. It takes the robot four times to hit the target during the experiment (in general less than 10 times). The algorithm/neural network was trained in a simulator using a large amount of data. The robot, called Oolong, had to hit a target and was tested on different kinds of ropes it had never seen before.
Together with Assistant Professor Shuran Song and colleagues from the CAIR Lab, Chi worked to formalize this intuition into an algorithm called Iterative Residual Policy (IRP), a general learning framework for repeatable tasks with complex dynamics where a single model was trained using inaccurate simulation data. IRP can learn from that data and hit many targets with unfamiliar ropes in real robotic experiments, reaching sub-inch accuracy, and demonstrating its strong generalization capability.
This research brings robots from factories, where everything is rigid and can be accurately modeled, closer to everyday households filled with dirty laundry, raw vegetables to be washed in the sink, and leftover food to be cleaned from the fridge. It could potentially alleviate the labor shortage in food, retail, and logistics due to the aging population in many parts of the world. This could also enable the automation of simple tasks like changing bed sheets and badges in hospitals with infectious disease patients.
The team won a Best Paper Award at the Robot Science and Systems Conference (RSS 2022). We caught up with Chi to find out more about his research and PhD life at Columbia.
This is part of a grant from the Toyota Research Institute on deformable object manipulation. For this specific project, I wanted to explore more complex and dynamic forms of robotic manipulation and control. As the primary researcher of this project, I decided on the research topic, problem, and task.
The project started in May 2021. I did a lot of research about control theory for underactuated systems, chaos, and how to work with robot hardware.
Classical robotics literature divides the operation of a robot into three stages — perception, planning, and control. In my previous research, I studied perception and the planning stage of robotics. However, I realized that my knowledge still has a noticeable hole in control theory and systems that control the function and movement of robots.
I believe that I will never become a full-fledged roboticist without understanding all parts of robotic operations. Therefore, I intentionally steered this project toward control which allows me to read more into control-related literature and classes.
For example, I went over the YouTube recording of MIT’s underactuated robotics, taught by Professor Russ Tedrake, who has been known for his contributions to the control of locomotion systems (such as Boston Dynamic’s quadruped robots).
Another interesting thing about control is that, unlike planning, the control of the human body mostly happens at a subconscious level. Therefore, understanding more about control also gave me more insight into how the human body works.
The key realization came after months of reflecting on how I achieved certain tasks and how to formulate such a problem.
Since the relatively early stage of this project (after I decided to tackle the rope whipping task), I had this lingering feeling that being able to adjust the next action based on the error of my previous action is critical for how humans accomplish this task (by observing myself doing it). But I wasn’t able to connect it with math and concrete algorithms.
The next few months were spent playing with data collected in simulations to understand the structure of this task and problem. I often spent a few afternoons a week just staring at my iPad notes, sketching potential algorithms that can solve this task efficiently. Most of them were futile. However, one afternoon in late September, I suddenly came up with the idea that connects my lingering feeling to this concrete algorithm. And the rest was mostly planning out experiments, executing, and verifying results.
I decided on the research project jointly on what is missing in the field and what I wanted to learn. For example, I wanted to get into control last summer, so I took classes online and read relevant papers to build a foundation. I noticed that the missing piece in the field is deformable manipulation with precision.
Existing robotic algorithms often assume the object being manipulated is rigid, and ignore its physics/dynamics, due to its complexity. My research thrust has been targeting this complexity (of object physics and non-rigidity) head-on, which hopefully will result in better algorithms that will improve the overall performance and robustness of robotics systems, outside of confined/structured industrial environments.
Whipping a piece of rope is one of the simplest instances of dynamic deformable object manipulation, without the additional perceptive complexity such as self-occlusion, etc. However, we believe that whipping a piece of rope and tablecloth is representative of the class of problem we are interested in and that there is no existing robotic system/algorithm that can accomplish this task. Therefore, our algorithm has expanded what is considered possible in robotics.
I thought that it would be cool to simplify it to a minimum-working task, like whipping. Whipping a piece of rope or cloth accurately requires adapting existing skills which humans are good at but it is very difficult for robots to do.
Humans can hit targets with reasonable accuracy after usually 10~20 trials. The best algorithm before IRP takes 100-1000+ trials to get there.
The project spanned 10 months and it was not easy, since solving this novel and challenging task requires going beyond the common paradigm in the field, for example, reinforcement learning or system identification.
I tried three ideas at first and none of them worked or advanced the field to a satisfying degree for me. The final idea was inspired by some studies from the biomechanics/neural science community that I came across while doing research.
While I was struggling with this project, my advisor pointed me to this recording of an RSS 2020 workshop. I was fascinated by one of the talks by Professor Dagmar Stenard and her findings from the biomechanical perspective of how humans minimize uncertainty and avoid the chaotic region of the state space when taking actions.
I read further into her publications and was pleasantly surprised that her group was studying the same rope-whipping problem. Their algorithm was crude and they only tested in simulation with many additional assumptions, but I really liked their problem formulation of the whipping task and their use of action primitive, which dramatically reduced the number of parameters needed to describe the dynamic and continuous robot action.
They also demonstrated that their action primitives (that bio literature believes humans also use) are sufficient for this task. Therefore, I took their problem formulation and tweaked their action primitive to better fit real robotic hardware, and eventually developed the IRP algorithm on top of that.

The type of rope we simulated for training is modeled after a thick cotton rope we bought on Amazon. However, due to the various complex physical properties and their effects, the rope modeled in simulation behaves significantly differently from its real-world counterpart. This is an instance of a well-known challenge in the robotics community called “sim2real gap”.
Since the deep-learning revolution (~2014), a large body of robotic algorithms emerged that have shown very promising results in simulated environments. However, they also rely on a large amount of data for training (our algorithm included), which is only feasible to collect in simulation. If the behavior of objects in simulation matches exactly their counterparts in real life, in theory, we can directly apply these data-hungry algorithms to the real world. Unfortunately, this is far from the truth, and the difference is especially big for deformable objects.
The biggest contribution of this paper is providing a solution to close this “sim2real gap” for a limited class of problems (where the actions are repeatable, and the objects can be reset to the original state), i.e. the algorithm behaves just as good in the real world as in simulation, despite the simulation it was trained on is very “wrong”.
To further demonstrate how “wrong” the simulation can be while the algorithm still works, we cut out a long strip of cloth, that behaves like a gymnastic ribbon and treated it as the rope. We also bought a very thick leather bullwhip, that has a non-uniform density (it becomes thinner and thinner as it goes toward the tip), while all ropes we trained in simulation have uniform thickness and density. The experimental results on these two “ropes” were just as good.
I like how researchers are able to try high-risk ideas that actually advance the field and also learn fundamental knowledge about the field. Working in industry usually constrains research options to low-risk ideas, while the engineering effort might be larger.
I gained my initial research experience during my undergrad at the University of Michigan, working on deformable object perception. I had multiple internships, as well as full-time jobs at autonomous vehicle companies, which taught me how to properly engineer a robotics software system.
I applied to Columbia to work with Assistant Professor Shuran Song. Just before I graduated from undergrad, Shuran did a job talk at the University of Michigan. My undergrad research advisor Professor Dmitry Berenson was at her talk and he was really impressed. Berenson strongly recommended that I apply to work with her and he thought we would be a great fit. After researching her past publications, I did find a large overlap in our research interests and I only heard good words about her after asking other people who have worked with her.
At the time, I wasn’t really sure about getting a PhD, and because of the time needed to complete the applications, I only applied to two schools. The application website could have been improved, but the overall process is surprisingly smooth. I really like the idea that students are admitted by and to individual professors, and the professors make the decision.
The highlight of my time is being able to be taught and guided by my advisor, as well as other PhD students.
I think what improved the most was to think more structurally and not be buried by the details. Due to the engineering complexity of robotic systems, there are thousands of variables and decisions, large and small, I needed to make for the project to progress. For example, on the high level, how to model the rope in the simulation, how to model the robot, how to represent the observation and actions, how the model should be architected, etc.
For an inexperienced researcher like myself, it is not obvious which one of these parameters will make or break the project, or will only yield a small change in the final performance. So, I over-analyzed, over-engineered, and over-thought the small problems. Fortunately, Shuran often called out that some of these decisions probably don’t matter that much, and choosing an arbitrary path to go forward is strictly better than spending time thinking about which one is better.
The problem is that this is mostly based on intuition. Shuran can’t always give evidence of why one thing doesn’t matter and why another does. But fortunately, I think I am getting a better grasp of these intuitions. It will become easier for me as time passes and I become an expert in robotics.
I also have found that it is really important to communicate clearly, both in meetings and when writing things down for reports or even emails. Learning by example from my advisor also helps a lot.
New students going into research should try as hard as possible to push through the first research project. It is always hard in the beginning, and it might feel impossible, but you can do it. Build up a tolerance for failure and continue to try different things, which is often critical to making a contribution to the field.
Michelle Zhou (PhD ’99) explains what no-code AI means and presents five inflection points that led to her current work, including the impact of two professors in graduate school who helped her find her direction in AI.
Influential computer scientist Kathy McKeown heads up two multi-million dollar grants—one to analyze cross-cultural norms and another to better understand grief in the Black community.
Papers from CS researchers have been accepted to the 38th International Conference on Machine Learning (ICML 2021).
Below are the abstracts and links to the accepted papers.
Simple And Near-Optimal Algorithms For Hidden Stratification And Multi-Group Learning
Christopher Tosh Memorial Sloan Kettering Cancer Center, Daniel Hsu Columbia University
Abstract
Multi-group agnostic learning is a formal learning criterion that is concerned with the conditional risks of predictors within subgroups of a population. The criterion addresses recent practical concerns such as subgroup fairness and hidden stratification. This paper studies the structure of solutions to the multi-group learning problem and provides simple and near-optimal algorithms for the learning problem.
On Measuring Causal Contributions Aia Do-Interventions
Yonghan Jung Purdue University, Shiva Kasiviswanathan Amazon, Jin Tian Iowa State University, Dominik Janzing Amazon, Patrick Bloebaum Amazon, Elias Bareinboim Columbia University
Abstract
Causal contributions measure the strengths of different causes to a target quantity. Understanding causal contributions is important in empirical sciences and data-driven disciplines since it allows to answer practical queries like “what are the contributions of each cause to the effect?” In this paper, we develop a principled method for quantifying causal contributions. First, we provide desiderata of properties (axioms) that causal contribution measures should satisfy and propose the do-Shapley values (inspired by do-interventions (Pearl, 2000)) as a unique method satisfying these properties. Next, we develop a criterion under which the do-Shapley values can be efficiently inferred from non-experimental data. Finally, we provide do-Shapley estimators exhibiting consistency, computational feasibility, and statistical robustness. Simulation results corroborate with the theory.
Partial Counterfactual Identification From Observational And Experimental Data
Junzhe Zhang Columbia University, Jin TianIowa Iowa State University, Elias Bareinboim Columbia University
Abstract
This paper investigates the problem of bounding counterfactual queries from an arbitrary collection of observational and experimental distributions and qualitative knowledge about the underlying data-generating model represented in the form of a causal diagram. We show that all counterfactual distributions in an arbitrary structural causal model (SCM) with discrete observed domains could be generated by a canonical family of SCMs with the same causal diagram where unobserved (exogenous) variables are also discrete, taking values in finite domains. Utilizing the canonical SCMs, we translate the problem of bounding counterfactuals into that of polynomial programming whose solution provides optimal bounds for the counterfactual query. Solving such polynomial programs is in general computationally expensive. We then develop effective Monte Carlo algorithms to approximate optimal bounds from a combination of observational and experimental data. Our algorithms are validated extensively on synthetic and real-world datasets.
Counterfactual Transportability: A Formal Approach
Juan D. Correa Universidad Autonoma de Manizales, Sanghack Lee Seoul National University, Elias Bareinboim Columbia University
Abstract
Generalizing causal knowledge across environments is a common challenge shared across many of the data-driven disciplines, including AI and ML. Experiments are usually performed in one environment (e.g., in a lab, on Earth, in a training ground), almost invariably, with the intent of being used elsewhere (e.g., outside the lab, on Mars, in the real world), in an environment that is related but somewhat different than the original one, where certain conditions and mechanisms are likely to change. This generalization task has been studied in the causal inference literature under the rubric of transportability (Pearl and Bareinboim, 2011). While most transportability works focused on generalizing associational and interventional distributions, the generalization of counterfactual distributions has not been formally studied. In this paper, we investigate the transportability of counterfactuals from an arbitrary combination of observational and experimental distributions coming from disparate domains. Specifically, we introduce a sufficient and necessary graphical condition and develop an efficient, sound, and complete algorithm for transporting counterfactual quantities across domains in nonparametric settings. Failure of the algorithm implies the impossibility of generalizing the target counterfactual from the available data without further assumptions.
Variational Inference for Infinitely Deep Neural Networks
Achille Nazaret Columbia University, David Blei Columbia University
Abstract
We introduce the unbounded depth neural network (UDN), an infinitely deep probabilistic model that adapts its complexity to the training data. The UDN contains an infinite sequence of hidden layers and places an unbounded prior on a truncation ℓ, the layer from which it produces its data. Given a dataset of observations, the posterior UDN provides a conditional distribution of both the parameters of the infinite neural network and its truncation. We develop a novel variational inference algorithm to approximate this posterior, optimizing a distribution of the neural network weights and of the truncation depth ℓ, and without any upper limit on ℓ. To this end, the variational family has a special structure: it models neural network weights of arbitrary depth, and it dynamically creates or removes free variational parameters as its distribution of the truncation is optimized. (Unlike heuristic approaches to model search, it is solely through gradient-based optimization that this algorithm explores the space of truncations.) We study the UDN on real and synthetic data. We find that the UDN adapts its posterior depth to the dataset complexity; it outperforms standard neural networks of similar computational complexity; and it outperforms other approaches to infinite-depth neural networks.
The award will help fund research and support the work of a graduate student.

Researchers from the Software Systems Laboratory bagged a Best Paper Award at the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 2021). OSDI is “a premier forum for discussing the design, implementation, and implications of systems software.” A total of six research papers from the department were accepted to the conference.
XRP: In-Kernel Storage Functions with eBPF
Yuhong Zhong Columbia University, Haoyu Li Columbia University, Yu Jian Wu Columbia University, Ioannis Zarkadas Columbia University, Jeffrey Tao Columbia University, Evan Mesterhazy Columbia University, Michael Makris Columbia University, Junfeng Yang Columbia University, Amy Tai Google, Ryan Stutsman University of Utah; Asaf Cidon Columbia University
Abstract:
With the emergence of microsecond-scale NVMe storage devices, the Linux kernel storage stack overhead has become significant, almost doubling access times. We present XRP, a framework that allows applications to execute user-defined storage functions, such as index lookups or aggregations, from an eBPF hook in the NVMe driver, safely bypassing most of the kernel’s storage stack. To preserve file system semantics, XRP propagates a small amount of kernel state to its NVMe driver hook where the user-registered eBPF functions are called. We show how two key-value stores, BPF-KV, a simple B+-tree key-value store, and WiredTiger, a popular log-structured merge tree storage engine, can leverage XRP to significantly improve throughput and latency.
ROLLER: Fast and Efficient Tensor Compilation for Deep Learning
Hongyu Zhu University of Toronto and Microsoft Research; Ruofan Wu Renmin University of China and Microsoft Research; Yijia Diao Shanghai Jiao Tong University and Microsoft Research, Shanbin Ke UCSD and Microsoft Research, Haoyu Li Columbia University and Microsoft Research; Chen Zhang Tsinghua University and Microsoft Research; Jilong Xue Microsoft Research, Lingxiao Ma Microsoft Research, Yuqing Xia Microsoft Research, Wei Cui Microsoft Research, Fan Yang Microsoft Research, Mao Yang Microsoft Research, Lidong Zhou Microsoft Research, Asaf Cidon Columbia University, Gennady Pekhimenko University of Toronto
Abstract:
Despite recent advances in tensor compilers, it often costs hours to generate an efficient kernel for an operator, a compute-intensive sub-task in a deep neural network (DNN), on various accelerators (e.g., GPUs). This significantly slows down DNN development cycles and incurs heavy burdens on the development of general kernel libraries and custom kernels, especially for new hardware vendors. The slow compilation process is due to the large search space formulated by existing DNN compilers, which have to use machine learning algorithms to find good solutions.
In this paper, we present ROLLER, which takes a different construction-based approach to generate kernels. At the core of ROLLER is rTile, a new tile abstraction that encapsulates tensor shapes that align with the key features of the underlying accelerator, thus achieving efficient execution by limiting the shape choices. ROLLER then adopts a recursive rTile-based construction algorithm to generate rTile-based programs (rProgram), whose performance can be evaluated efficiently with a micro-performance model without being evaluated in a real device. As a result, ROLLER can generate efficient kernels in seconds, with comparable performance to the state-of-the-art solutions on popular accelerators like GPUs, while offering better kernels on less mature accelerators like IPUs.
Design and Verification of the Arm Confidential Compute Architecture
Xupeng Li Columbia University, Xuheng Li Columbia University, Christoffer Dall Arm Ltd, Ronghui Gu Columbia University, Jason Nieh Columbia University, Yousuf Sait Arm Ltd, Gareth Stockwell Arm Ltd
Abstract:
The increasing use of sensitive private data in computing is matched by a growing concern regarding data privacy. System software such as hypervisors and operating systems are supposed to protect and isolate applications and their private data, but their large codebases contain many vulnerabilities that can risk data confidentiality and integrity. We introduce Realms, a new abstraction for confidential computing to protect the data confidentiality and integrity of virtual machines. Hardware creates and enforces Realm world, a new physical address space for Realms. Firmware controls the hardware to secure Realms and handles requests from untrusted system software to manage Realms, including creating and running them. Untrusted system software retains control of the dynamic allocation of memory to Realms, but cannot access Realm memory contents, even if run at a higher privileged level. To guarantee the security of Realms, we verified the firmware, introducing novel verification techniques that enable us to prove, for the first time, the security and correctness of concurrent software with hand-over-hand locking and dynamically allocated shared page tables, data races in kernel code running on relaxed memory hardware, integrated C and Arm assembly code calling one another, and untrusted software being in full control of allocating system resources. Realms are included in the Arm Confidential Compute Architecture.
DuoAI: Fast, Automated Inference of Inductive Invariants for Verifying Distributed Protocols
Jianan Yao Columbia University, Runzhou Tao Columbia University, Ronghui Gu Columbia University, Jason Nieh Columbia University
Abstract:
Distributed systems are complex and difficult to build correctly. Formal verification can provably rule out bugs in such systems, but finding an inductive invariant that implies the safety property of the system is often the hardest part of the proof. We present DuoAI, an automated system that quickly finds inductive invariants for verifying distributed protocols by reducing SMT query costs in checking invariants with existential quantifiers. DuoAI enumerates the strongest candidate invariants that hold on validate states from protocol simulations, then applies two methods in parallel, returning the result from the method that succeeds first. One checks all candidate invariants and weakens them as needed until it finds an inductive invariant that implies the safety property. Another checks invariants without existential quantifiers to find an inductive invariant without the safety property, then adds candidate invariants with existential quantifiers to strengthen it until the safety property holds. Both methods are guaranteed to find an inductive invariant that proves desired safety properties, if one exists, but the first reduces SMT query costs when more candidate invariants with existential quantifiers are needed, while the second reduces SMT query costs when few candidate invariants with existential quantifiers suffice. We show that DuoAI verifies more than two dozen common distributed protocols automatically, including various versions of Paxos, and outperforms alternative methods both in the number of protocols it verifies and the speed at which it does so, including solving Paxos more than two orders of magnitude faster than previous methods.
BlackBox: A Container Security Monitor for Protecting Containers on Untrusted Operating Systems
Alexander Van’t Hof Columbia University, Jason Nieh Columbia University
Abstract:
Containers are widely deployed to package, isolate, and multiplex applications on shared computing infrastructure, but rely on the operating system to enforce their security guarantees. This poses a significant security risk as large operating system codebases contain many vulnerabilities. We have created BlackBox, a new container architecture that provides fine-grain protection of application data confidentiality and integrity without trusting the operating system. BlackBox introduces a container security monitor, a small trusted computing base that creates protected physical address spaces (PPASes) for each container such that there is no direct information flow from container to operating system or other container PPASes. Indirect information flow can only happen through the monitor, which only copies data between container PPASes and the operating system as system call arguments, encrypting data as needed to protect interprocess communication through the operating system. Containerized applications do not need to be modified, can still make use of operating system services via system calls, yet their CPU and memory state are isolated and protected from other containers and the operating system. We have implemented BlackBox by leveraging Arm hardware virtualization support, using nested paging to enforce PPASes. The trusted computing base is a few thousand lines of code, many orders of magnitude less than Linux, yet supports widely-used Linux containers with only modest modifications to the Linux kernel. We show that BlackBox provides superior security guarantees over traditional hypervisor and container architectures with only modest performance overhead on real application workloads.
UPGRADVISOR: Early Adopting Dependency Updates Using Hybrid Program Analysis and Hardware Tracing
Yaniv David Columbia University, Xudong Sun Nanjing University, Raphael J. Sofaer Columbia University, Aditya Senthilnathan IIT, Delhi, Junfeng Yang Columbia University, Zhiqiang Zuo Nanjing University, Guoqing Harry Xu UCLA, Jason Nieh Columbia University, Ronghui Gu Columbia University
Abstract:
Applications often have fast-paced release schedules, but adoption of software dependency updates can lag by years, leaving applications susceptible to security risks and unexpected breakage. To address this problem, we present UPGRADVISOR, a system that reduces developer effort in evaluating dependency updates and can, in many cases, automatically determine which updates are backward-compatible versus API-breaking. UPGRADVISOR introduces a novel co-designed static analysis and dynamic tracing mechanism to gauge the scope and effect of dependency updates on an application. Static analysis prunes changes irrelevant to an application and clusters relevant ones into targets. Dynamic tracing needs to focus only on whether targets affect an application, making it fast and accurate. UPGRADVISOR handles dynamic interpreted languages and introduces call graph over-approximation to account for their lack of type information and selective hardware tracing to capture program execution while ignoring interpreter machinery.
We have implemented UPGRADVISOR for Python and evaluated it on 172 dependency updates previously blocked from being adopted in widely-used open-source software, including Django, aws-cli, tfx, and Celery. UPGRADVISOR automatically determined that 56% of dependencies were safe to update and reduced by more than an order of magnitude the number of code changes that needed to be considered by dynamic tracing. Evaluating UPGRADVISOR’s tracer in a production-like environment incurred only 3% overhead on average, making it fast enough to deploy in practice. We submitted safe updates that were previously blocked as pull requests for nine projects, and their developers have already merged most of them.
Researchers from the department presented natural language processing (NLP) papers at the 2022 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2022).
Selective Differential Privacy for Language Models
Weiyan Shi, Aiqi Cui, Evan Li, Ruoxi Jia, Zhou Yu
With the increasing applications of language models, it has become crucial to protect these models from leaking private information. Previous work has attempted to tackle this challenge by training RNN-based language models with differential privacy guarantees. However, applying classical differential privacy to language models leads to poor model performance as the underlying privacy notion is over-pessimistic and provides undifferentiated protection for all tokens in the data. Given that the private information in natural language is sparse (for example, the bulk of an email might not carry personally identifiable information), we propose a new privacy notion, selective differential privacy, to provide rigorous privacy guarantees on the sensitive portion of the data to improve model utility. To realize such a new notion, we develop a corresponding privacy mechanism, Selective-DPSGD, for RNN-based language models. Besides language modeling, we also apply the method to a more concrete application–dialog systems. Experiments on both language modeling and dialog system building show that the proposed privacy-preserving mechanism achieves better utilities while remaining safe under various privacy attacks compared to the baselines. The data and code are released at this HTTPS URL to facilitate future research.
Knowledge-Grounded Dialogue Generation with a Unified Knowledge Representation
Yu Li, Baolin Peng, Yelong Shen, Yi Mao, Lars Liden, Zhou Yu, Jianfeng Gao
Knowledge-grounded dialogue systems are challenging to build due to the lack of training data and heterogeneous knowledge sources. Existing systems perform poorly on unseen topics due to limited topics covered in the training data. In addition, heterogeneous knowledge sources make it challenging for systems to generalize to other tasks because knowledge sources in different knowledge representations require different knowledge encoders. To address these challenges, we present PLUG, a language model that homogenizes different knowledge sources to a unified knowledge representation for knowledge-grounded dialogue generation tasks. PLUG is pre-trained on a dialogue generation task conditioned on a unified essential knowledge representation. It can generalize to different downstream knowledge-grounded dialogue generation tasks with a few training examples. The empirical evaluation on two benchmarks shows that our model generalizes well across different knowledge-grounded tasks. It can achieve comparable performance with state-of-the-art methods under a fully-supervised setting and significantly outperforms other methods in zero-shot and few-shot settings.
Database Search Results Disambiguation for Task-Oriented Dialog Systems
Kun Qian, Ahmad Beirami, Satwik Kottur, Shahin Shayandeh, Paul Crook, Alborz Geramifard, Zhou Yu, Chinnadhurai Sankar
As task-oriented dialog systems are becoming increasingly popular in our lives, more realistic tasks have been proposed and explored. However, new practical challenges arise. For instance, current dialog systems cannot effectively handle multiple search results when querying a database, due to the lack of such scenarios in existing public datasets. In this paper, we propose Database Search Result (DSR) Disambiguation, a novel task that focuses on disambiguating database search results, which enhances user experience by allowing them to choose from multiple options instead of just one. To study this task, we augment the popular task-oriented dialog datasets (MultiWOZ and SGD) with turns that resolve ambiguities by (a) synthetically generating turns through a pre-defined grammar, and (b) collecting human paraphrases for a subset. We find that training on our augmented dialog data improves the model’s ability to deal with ambiguous scenarios, without sacrificing performance on unmodified turns. Furthermore, pre-fine tuning and multi-task learning help our model to improve performance on DSRdisambiguation even in the absence of indomain data, suggesting that it can be learned as a universal dialog skill. Our data and code will be made publicly available.
ErAConD: Error Annotated Conversational Dialog Dataset for Grammatical Error Correction
Xun Yuan, Sam Pham, Sam Davidson, Zhou Yu
Currently available grammatical error correction (GEC) datasets are compiled using well-formed written text, limiting the applicability of these datasets to other domains such as informal writing and dialog. In this paper, we present a novel parallel GEC dataset drawn from open-domain chatbot conversations; this dataset is, to our knowledge, the first GEC dataset targeted to a conversational setting. To demonstrate the utility of the dataset, we use our annotated data to fine-tune a state-of-the-art GEC model, resulting in a 16-point increase in model precision. This is of particular importance in a GEC model, as model precision is considered more important than recall in GEC tasks since false positives could lead to serious confusion in language learners. We also present a detailed annotation scheme which ranks errors by perceived impact on comprehensibility, making our dataset both reproducible and extensible. Experimental results show the effectiveness of our data in improving GEC model performance in conversational scenarios.
Improving Conversational Recommendation Systems’ Quality with Context-Aware Item Meta-Information
Bowen Yang, Cong Han, Yu Li, Lei Zuo, Zhou Yu
Conversational recommendation systems (CRS) engage with users by inferring user preferences from dialog history, providing accurate recommendations, and generating appropriate responses. Previous CRSs use knowledge graph (KG) based recommendation modules and integrate KG with language models for response generation. Although KG-based approaches prove effective, two issues remain to be solved. First, KG-based approaches ignore the information in the conversational context but only rely on entity relations and bag of words to recommend items. Second, it requires substantial engineering efforts to maintain KGs that model domain-specific relations, thus leading to less flexibility. In this paper, we propose a simple yet effective architecture comprising a pre-trained language model (PLM) and an item metadata encoder. The encoder learns to map item metadata to embeddings that can reflect the semantic information in the dialog context. The PLM then consumes the semantic-aligned item embeddings together with dialog context to generate high-quality recommendations and responses. Instead of modeling entity relations with KGs, our model reduces engineering complexity by directly converting each item to an embedding. Experimental results on the benchmark dataset ReDial show that our model obtains state-of-the-art results on both recommendation and response generation tasks.
Differentially private decoding in large language models
By Jimit Majmudar, Christophe Dupuy, Charith Peris, Sami Smaili, Rahul Gupta, Richard Zemel
Recent large-scale natural language processing (NLP) systems use a pre-trained Large Language Model (LLM) on massive and diverse corpora as a headstart. In practice, the pre-trained model is adapted to a wide array of tasks via fine-tuning on task-specific datasets. LLMs, while effective, have been shown to memorize instances of training data thereby potentially revealing private information processed during pre-training. The potential leakage might further propagate to the downstream tasks for which LLMs are fine-tuned. On the other hand, privacy-preserving algorithms usually involve retraining from scratch, which is prohibitively expensive for LLMs. In this work, we propose a simple, easy to interpret, and computationally lightweight perturbation mechanism to be applied to an already trained model at the decoding stage. Our perturbation mechanism is model-agnostic and can be used in conjunction with any LLM. We provide a theoretical analysis showing that the proposed mechanism is differentially private, and experimental results show a privacy-utility trade-off.
Song and her students won for their paper, Iterative Residual Policy for Goal-Conditioned Dynamic Manipulation of Deformable Objects.
The Wu Lab, led by Eugene Wu, will talk at paper presentations, workshops, and a panel on “The Dos and Don’ts of Sharing Research.”
CS researchers demonstrate that the new privacy method—using differential privacy—is more effective than the old method of swapping, and better protects the privacy of minorities.
“So, this is a rough idea for modeling trajectories and I need your feedback,” said Didac Suris to the room while his teammates looked at him over bowls of Chinese food. “I literally just thought of this two days ago.”
It is the first week that working lunch meetings can resume at Columbia. Suris, along with other members of the computer vision lab, immediately took advantage of it. As they settle down into the meeting, Suris talks about his research proposal and his audience exchanges ideas with him in between bites of food. The last time this happened was two years ago.
“We came back in the Fall and it is good to be back in the office,” said Didac Suris, a third-year PhD student advised by Carl Vondrick. “Collaborating with teammates and just being out has worked wonders for my productivity which has skyrocketed compared to when working alone, or from home.”

Suris can be found in an office in CEPSR working on research projects that study computer vision and machine learning. The projects focus on training machines to interact and observe their surroundings, including his work on predicting what will happen next in a video. This is in line with his long-term goal of creating systems that can model video more appropriately and help predict the future actions of a video, which will be useful in autonomous vehicles, human-robot interaction, broadcasting of sports events, and assistive technology.
Suris was recently named a Microsoft Research Fellow. The research he has done while at Columbia focuses on computer vision and building systems that can learn on their own, which is very different from what he studied in undergrad, telecommunications at the Polytechnic University of Catalunya in Barcelona, Spain. We caught up with Suris to ask about how his PhD is going and winning the fellowship.
Q: What was your journey to Columbia? How did you pivot from telecommunications to applying for a PhD in computer vision?
It was only during my master’s, when I started doing research on computer vision, that I started to consider doing a PhD. The main reason I’m doing a PhD is because I believe it is the best way to push myself intellectually.
I really recommend doing research in different places before starting a PhD. Before starting at Columbia, I did research at three different universities, which prepared me for my current research. These experiences helped me to 1) understand what research is about, and 2) understand that different research groups work differently, and get the best out of each one.
Q: What drew you to machine learning and artificial intelligence?
One of the characteristic aspects of this field is how fast it is evolving, and how impressive the research results have been in the last decade. I don’t think there was a specific moment where I decided to do research on this topic, I would say there was a series of circumstances that led me here, including the fact that I was originally interested in artificial intelligence in the first place, of course.
Q: Why did you decide to focus on computer vision?
There is a lot of information online because of the vast amount of videos, images, text, audio, and other forms of data. But the thing is the majority of this information is not labeled clearly. For example, we do not have information about the actions taking place in every YouTube video. But we can still use the information in the YouTube video to learn about the world.
We can teach a computer to relate the audio in a video to the visual content in a video. And then we can relate all of this to the comments on the YouTube video to learn associations between all of these different signals, and help the computer understand the world based on these associations. I want to be able to use any and all information out there to develop systems that will train computers to learn with minimal human supervision.
Q: What sort of research questions or issues do you hope to answer?
There is a lot of data about the world on the Internet – billions of videos are recorded every day across the world. My main research question is how can we make sense of all of this raw video content.
Q: What was the thesis proposal that you submitted for the Microsoft PhD?
The proposal was called “Video Hyperboles.” The idea is to model long videos (most of the literature nowadays is on very short clips, not long-format videos) by modeling their temporal hierarchy. For example, the action of “cutting an onion” is composed of the subactions “grabbing a knife”, “pressing the knife”, “gathering the pieces.” This forms a temporal hierarchy, in which the action “cutting an onion” is higher in the hierarchy, and the subactions are lower in the hierarchy. Hierarchies can be modeled in a geometric space called Hyperbolic Space, and thus the name “Video Hyperboles.”
I have not been working on the project directly, but I am building up pieces to eventually be able to achieve something like what I described in the proposal. I work on related topics, with the general direction of creating a video representation (for example, a hierarchy) that allows us to model video more appropriately, and helps us predict the future of a video. And I will work on this for the rest of my PhD.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research what should they know or do to prepare?
Research requires a combination of abilities that may take time to develop: patience, asking the right questions, etc. So experience is very important. My main advice would be to try to do research as soon as possible. Experience is very necessary to do research but is also important in order to decide whether or not research is for you. It is not for everyone, and the sooner you figure that out, the better.
Q: Is there anything else that you think people should know about getting a PhD?
Most of the time, a PhD is sold as a lot of pain and suffering, as working all day every day, and being very concerned about what your advisor will think of you. At least this is how it is in our field. It is sometimes seen as a competition to be a great and prolific researcher, too. And I don’t see it like that – you can enjoy (or hate) your PhD the same way you enjoy any other career path. It is all about finding the correct topics to work on, and the correct balance between research and personal life.
Research papers from the department were accepted to the Conference on Robot Learning 2021 (CoRL) and the Best System Paper award was given to Assistant Professor Shuran Song and PhD student Huy Ha.
Below are the abstracts and links to the papers:
Best System Paper Award
FlingBot: The Unreasonable Effectiveness of Dynamic Manipulation for Cloth Unfolding
Huy Ha Columbia University and Shuran Song Columbia University
Abstract:
High-velocity dynamic actions (e.g., fling or throw) play a crucial role in our everyday interaction with deformable objects by improving our efficiency and effectively expanding our physical reach range. Yet, most prior works have tackled cloth manipulation using exclusively single-arm quasi-static actions, which requires a large number of interactions for challenging initial cloth configurations and strictly limits the maximum cloth size by the robot’s reach range. In this work, we demonstrate the effectiveness of dynamic flinging actions for cloth unfolding with our proposed self-supervised learning framework, FlingBot. Our approach learns how to unfold a piece of fabric from arbitrary initial configurations using a pick, stretch, and fling primitive for a dual-arm setup from visual observations. The final system achieves over 80% coverage within 3 actions on novel cloths, can unfold cloths larger than the system’s reach range, and generalizes to T-shirts despite being trained on only rectangular cloths. We also finetuned FlingBot on a real-world dual-arm robot platform, where it increased the cloth coverage over 4 times more than the quasi-static baseline did. The simplicity of FlingBot combined with its superior performance over quasi-static baselines demonstrates the effectiveness of dynamic actions for deformable object manipulation.
Toward Robots That Learn To Summarize Their Actions In Natural Language: A Set Of Tasks
Chad DeChant Columbia University and Daniel Bauer Columbia University
Abstract:
Robots should be able to report in natural language what they have done. They should provide concise summaries, respond to questions about them, and be able to learn from the natural language responses they receive to their summaries. We propose that developing the capabilities for robots to summarize their actions is a new and necessary challenge that should be taken up by the robotic learning community. We propose an initial framework for robot action summarization, presented as a set of tasks that can serve as a target for research and a measure of progress.
The Boombox: Visual Reconstruction from Acoustic Vibrations
Boyuan Chen Columbia University, Mia Chiquier Columbia University, Hod Lipson Columbia University, and Carl Vondrick Columbia University
Abstract:
Interacting with bins and containers is a fundamental task in robotics, making state estimation of the objects inside the bin critical.
While robots often use cameras for state estimation, the visual modality is not always ideal due to occlusions and poor illumination. We introduce The Boombox, a container that uses sound to estimate the state of the contents inside a box. Based on the observation that the collision between objects and their containers will cause an acoustic vibration, we present a convolutional network for learning to reconstruct visual scenes. Although we use low-cost and low-power contact microphones to detect the vibrations, our results show that learning from multimodal data enables state estimation from affordable audio sensors. Due to the many ways that robots use containers, we believe the box will have a number of applications in robotics.
Giannis Karamanolakis, a natural language processing and machine learning PhD student, talks about his research projects and how he is developing machine learning techniques for natural language processing applications.

Can you talk about your background and why you decided to pursue a PhD?
I used to live in Greece and grew up in Sitia, a small town in Crete. In 2011, I left my hometown to study electrical and computer engineering at the National Technical University of Athens (NTUA).
At NTUA, taking part in machine learning (ML) research was not planned but rather a spontaneous outcome stemming from my love for music. The initial goal for my undergraduate thesis was to build an automatic music transcription system that converts polyphonic raw audio into music sheets. However, after realizing that such a system would not be possible to develop in a limited amount of time, I worked on the simpler task of automatically tagging audio clips with descriptive tags (e.g., “car horn” for audio clips where a car horn is sound). Right after submitting a new algorithm as a conference paper, I realized that I love doing ML research.
After NTUA, I spent one and a half years working as an ML engineer at a startup called Behavioral Signals, where we trained statistical models for the recognition of core emotions from speech and text data. After a few months of ML engineering, I found myself spending more time reading research papers and evaluating new research ideas on ML and natural language processing (NLP). By then, I was confident about my decision to pursue a PhD in ML/NLP.
What about NLP did you like and when did you realize that you wanted to do research on it?
I am fascinated by the ability of humans to understand complex natural language. At the moment of writing this response, I submitted the following 10-word query to Google: “when did you realize that you wanted to do research” by keeping quotation marks so that Google looks for exact matches only. Can you guess the number of the documents returned by Google that contain this exact sequence of 10 words?
The answer that I got was 0 (zero) documents, no results! In other words, Google, a company with huge collections of documents, did not detect any document that contains this specific sequence of words. Sentences rarely recur but humans easily understand the semantics of such rare sentences.
I decided to do research on NLP when I realized that current NLP algorithms are far away from human-level language understanding. As an example back from my time at Behavioral Signals, emotion classifiers were misclassifying sentences that contained sarcasm, negation, and other complex linguistic phenomena. I could not directly fix those issues (which are prevalent beyond emotion classification), which initially felt both surprising and frustrating, but then evolved into my excitement for research on NLP.
Why did you apply to Columbia and how was that process?
The computer science department at Columbia was one of my top choices for several reasons, but I will discuss the first one.
I was excited to learn about the joint collaboration between Columbia University and the New York City Department of Health and Mental Hygiene (DOHMH), on a project that aims to understand user-generated textual content in social media (e.g., Yelp reviews, tweets) for critical public health applications, such as detecting and acting on foodborne illness outbreaks in restaurants. I could see that the project would offer the unique opportunity to do research in ML and NLP and at the same time contribute to this important public application in collaboration with epidemiologists at DOHMH. Fortunately, I have been able to work on the project, advised by Professor Luis Gravano and Associate Professor Daniel Hsu.
Applying to Columbia and other American universities was quite a stressful experience. For many months, my days were filled with working for Behavioral Signals, studying hard for high scores in GRE and TOEFL exams (both of which were required at that time by all US universities), creating a short CV for the first time, and writing a distinct statement-of-purpose for each university. I am glad to observe the recent promising changes in the PhD application procedure for our department, such as waiving the GRE requirements and offering the Pre-submission Application Review (PAR) program, in which current PhD students help applicants improve their applications. (Both of which I would have liked to have been able to take advantage of.)
What sort of research questions or issues do you hope to answer?
My research in the past few years focuses on the following question: Can we effectively train ML classifiers for NLP applications with limited training data using alternative forms of human supervision?
An important limitation of current “supervised ML” techniques is that they require large amounts of training data, which is expensive and time-consuming to obtain manually. Thus, while supervised ML techniques (especially deep neural networks) thrive in standard benchmarks, it would be too expensive to apply to emerging real-world applications with limited labeled data.
Our work attempts to address the expensive requirement of manually labeled data through novel frameworks that leverage alternative, less expensive forms of human supervision. In sentiment classification, for example, we allow domain experts to provide a small set of domain-specific rules (e.g., “happy” keyword indicates positive sentiment, “diarrhea” is a symptom of food poisoning). Under low-resource settings with no labeled data, can we leverage expert-defined rules as supervision for training state-of-the-art neural networks?
For your research papers, how did you decide to do research on those topics? How long did it take you to complete the work? Was it easy?
For my first research project at Columbia, my goal was to help epidemiologists in health departments with daily inspections of restaurant reviews that discuss food poisoning events. Restaurant reviews can be quite long, with many irrelevant sentences surrounding the truly important ones that discuss food poisoning or relevant symptoms. Thus, we developed a neural network that highlights only important sentences in potentially long reviews and deployed it for inspections in health departments, where epidemiologists could quickly focus on the relevant sentences and safely ignore the rest.
The goal behind my next research projects was to develop frameworks for addressing a broader range of text-mining tasks, such as sentiment analysis and news document classification, and for supporting multiple languages without expensive labeled data for each language. To address this goal, we initially proposed a framework for leveraging just a few domain-specific keywords as supervision for aspect detection and later extended our framework for training classifiers across 18 languages using minimal resources.
Each project took about 6 months to complete. None of them were easy; each required substantial effort in reading relevant papers, discussing potential solutions with my advisors, implementing executable code, evaluating hypotheses on real data, and repeating the same process until we were all satisfied with the solutions and evaluation results. The projects also involved meeting with epidemiologists at DOHMH, re-designing our system to satisfy several (strict) data transfer protocols imposed by health departments, and overcoming several issues related to missing data for training ML classifiers.
Your advisors are not part of the NLP group, how has that worked out for you and your projects?
It has worked great in my humble opinion. For the public health project, the expertise of Professor Gravano on information extraction, combined with the expertise of Professor Hsu on machine learning, and the technical needs of the project have contributed without any doubt to the current formulation of our NLP-related frameworks. My advisors’ feedback covers a broad spectrum of research, ranging from core technical challenges to more general research practices, such as problem formulation and paper writing.
Among others, I appreciate the freedom I have been given for exploring new interesting research questions as well as the frequent and insightful feedback that helps me to reframe questions and forming solutions. At the same time, discussions with members of the NLP group, including professors and students, have been invaluable and have clearly influenced our projects.
What do you think is the most interesting thing about doing research?
I think it is the high amount of surprise it encompasses. For many research problems that I have tried to tackle, I started by shaping an initial solution in my mind but in the process discovered surprising findings that undoubtedly changed my way of thinking – such as that my initial solution did not actually work, simpler approaches worked better than more sophisticated approaches, data followed unexpected patterns, etc. These instances of surprise turned research into an interesting experience, similar to solving riddles or listening to jazz music.
Please talk about your internships – the work you did, how was it, what did you learn?
In the summer of 2019, I worked at Amazon’s headquarters in Seattle with a team of more than 15 scientists and engineers. Our goal was to automatically extract and store knowledge about billions of products in a product knowledge graph. As part of my internship, we developed TXtract, a deep neural network that efficiently extracts information from product descriptions for thousands of product categories. TXtract has been a core component of Amazon’s AutoKnow, which provides the collected knowledge for Amazon search and product detail pages.
During the summer of 2020, I worked for Microsoft Research remotely from New York City (because of the pandemic). In collaboration with researchers at the Language and Information Technologies team, we developed a weak supervision framework that enables domain experts to express their knowledge in the form of rules and further integrates rules for training deep neural networks.
These two internships equipped me with invaluable experiences. I learned new coding tools, ML techniques, and research practices. Through the collaboration with different teams, I realized that even researchers who work on the same subfield may think in incredibly different ways, so to carry out a successful collaboration within a limited time, one needs to listen carefully, pre-define expected outcomes (with everyone in the team), and adapt fast.
Do you think your skills were improved by your time at Columbia? In which ways?
Besides having improved my problem-finding and -solving skills, I have expanded my presentation capabilities. In the beginning, I was frustrated when other people (even experienced researchers) could not follow my presentations and I was worried when I could not follow other presenters’ work. Later, I realized that if (at least part of) the audience is not able to follow a presentation, then the presentation is either flawed or has been designed for the wrong audience.
Over the past four years, I have presented my work at various academic conferences and workshops, symposiums at companies, and student seminars, and after having received constructive feedback from other researchers, I can say that my presentation skills have vastly improved. Without any doubt, I feel more confident and can explain my work to a broader type of audience with diverse expertise. That said, I’m still struggling to explain my PhD topic to my family. 🙂

What has been the highlight of your time at Columbia?
The first thing that comes to mind is the “Greek Happy Hour” that I co-organized in October 2019. More than 40 PhD students joined the happy hour, listened to Greek music (mostly “rempetika”), tasted greek specialties (including spanakopita), and all toasted loudly by saying “Γειά μας” (ya mas; the greek version of “cheers”).
Was there anything that was tough to handle while taking your PhD?

It is hard to work from home during a pandemic. A core part of my PhD used to involve multi-person collaborations, drawing illustrations on the whiteboards of the Data Science Institute, random chats in hallways, happy hours, and other social events. All these have been harder or impossible to retain during the pandemic. I miss it and look forward to enjoying it again soon.
Looking back, what would you have done differently?
If I could, I would have engaged in more discussions and collaborations, taken more classes, played more music, and slept less. 🙂
What is your advice to students on how to navigate their time at Columbia? If they want to do NLP research what should they know or do to prepare?
They should register for diverse courses; Columbia offers the opportunity to attend courses from multiple departments. They should reach out to as many people as possible and do not hesitate to email graduate students and professors. I love receiving emails from people that I haven’t met before, some of which stimulated creative collaborations.
For those that want to do NLP research (which I highly recommend–subjectively speaking), you should contact me or any person in the NLP group.
What are your plans after Columbia?
I plan to continue working on research, either as a faculty member or in an industry research and development department.
Is there anything else that you think people should know?
Columbia offers free and discounted tickets to museums and performances around New York City, even virtual art events. I personally consider New York as the “state-of-the-art”.
Research from the department was accepted to the 34th Annual Conference on Learning Theory (COLT2021). The conference highlights research on the theoretical aspects of machine learning.
Below are the abstracts and links to the accepted papers.
Size and Depth Separation in Approximating Natural Functions with Neural Networks
Gal Vardi Weizmann Institute of Science, Daniel Reichman Worcester Polytechnic Institute, Toniann Pitassi Columbia University, Ohad Shamir Weizmann Institute of Science
When studying the expressive power of neural networks, a main challenge is to understand how the size and depth of the network affect its ability to approximate real functions. However, not all functions are interesting from a practical viewpoint: functions of interest usually have a polynomially bounded Lipschitz constant, and can be computed efficiently. We call functions that satisfy these conditions “benign” and explore the benefits of size and depth for approximation of benign functions with ReLU networks. As we show, this problem is more challenging than the corresponding problem for non-benign functions. We give complexity-theoretic barriers to showing depth-lower bounds: Proving existence of a benign function that cannot be approximated by polynomial-sized networks of depth 4 would settle longstanding open problems in computational complexity. It implies that beyond depth 4 there is a barrier to showing depth-separation for benign functions, even between networks of constant depth and networks of nonconstant depth. We also study size separation, namely, whether there are benign functions that can be approximated with networks of size O(s(d)), but not with networks of size O(s 0 (d)). We show a complexity-theoretic barrier to proving such results beyond size O(d log2 (d)), but also show an explicit benign function, that can be approximated with networks of size O(d) and not with networks of size o(d/ log d). For approximation in the L∞ sense we achieve such separation already between size O(d) and size o(d). Moreover, we show superpolynomial size lower bounds and barriers to such lower bounds, depending on the assumptions on the function. Our size-separation results rely on an analysis of size lower bounds for Boolean functions, which is of independent interest: We show linear size lower bounds for computing explicit Boolean functions (such as set disjointness) with neural networks and threshold circuits.
Learning sparse mixtures of permutations from noisy information
Rocco Servedio Columbia University, Anindya De University of Pennsylvania, Ryan O’Donnell Carnegie Mellon University
We study the problem of learning an unknown mixture of k permutations over n elements, given access to noisy samples drawn from the unknown mixture. We consider a range of different noise models, including natural variants of the “heat kernel” noise framework and the Mallows model. We give an algorithm which, for each of these noise models, learns the unknown mixture to high accuracy under mild assumptions and runs in n O(log k) time. Our approach is based on a new procedure that recovers an unknown mixture of permutations from noisy higher-order marginals.
Learning and testing junta distributions with subcube conditioning
Xi Chen Columbia University, Rajesh Jayaram Carnegie Mellon University, Amit Levi University of Waterloo, Erik Waingarten Stanford University
We study the problems of learning and testing junta distributions on {−1, 1} n with respect to the uniform distribution, where a distribution p is a k-junta if its probability mass function p(x) depends on a subset of at most k variables. The main contribution is an algorithm for finding relevant coordinates in a k-junta distribution with subcube conditioning Bhattacharyya and Chakraborty (2018); Canonne et al. (2019). We give two applications: • An algorithm for learning k-junta distributions with O˜(k/2 ) log n + O(2k/2 ) subcube conditioning queries, and • An algorithm for testing k-junta distributions with O˜((k + √ n)/2 ) subcube conditioning queries. All our algorithms are optimal up to poly-logarithmic factors. Our results show that subcube conditioning, as a natural model for accessing high-dimensional distributions, enables significant savings in learning and testing junta distributions compared to the standard sampling model. This addresses an open question posed by Aliakbarpour et al. (2016).
Survival of the strictest: Stable and unstable equilibria under regularized learning with partial information
Emmanouil Vasileios Vlatakis-Gkaragkounis Columbia University, Angeliki Giannou National Technical University of Athens, Panayotis Mertikopoulos Univ. Grenoble Alpes, CNRS, Inria, Grenoble INP, LIG, 38000 Grenoble, France & Criteo AI Lab
In this paper, we examine the Nash equilibrium convergence properties of no-regret learning in general N-player games. For concreteness, we focus on the archetypal “follow the regularized leader” (FTRL) family of algorithms, and we consider the full spectrum of uncertainty that the players may encounter – from noisy, oracle-based feedback, to bandit, payoff-based information. In this general context, we establish a comprehensive equivalence between the stability of a Nash equilibrium and its support: a Nash equilibrium is stable and attracting with arbitrarily high probability if and only if it is strict (i.e., each equilibrium strategy has a unique best response). This equivalence extends existing continuous-time versions of the “folk theorem” of evolutionary game theory to a bona fide algorithmic learning setting, and it provides a clear refinement criterion for the prediction of the day-to-day behavior of no-regret learning in games.
Reconstructing weighted voting schemes from partial information about their power indices
Emmanouil Vasileios Vlatakis-Gkaragkounis Columbia University, Huck Bennett Columbia University, Anindya De Columbia University, Rocco Servedio Columbia University
A number of recent works (Goldberg, 2006; O’Donnell and Servedio, 2011; De et al., 2017, 2014) have considered the problem of approximately reconstructing an unknown weighted voting scheme given information about various sorts of “power indices” that characterize the level of control that individual voters have over the final outcome. In the language of theoretical computer science, this is the problem of approximating an unknown linear threshold function (LTF) over {−1, 1} n given some numerical measure (such as the function’s n “Chow parameters,” a.k.a. its degree-1 Fourier coefficients, or the vector of its n Shapley indices) of how much each of the n individual input variables affects the outcome of the function. In this paper we consider the problem of reconstructing an LTF given only partial information about its Chow parameters or Shapley indices; i.e. we are given only the Chow parameters or the Shapley indices corresponding to a subset S ⊆ [n] of the n input variables. A natural goal in this partial information setting is to find an LTF whose Chow parameters or Shapley indices corresponding to indices in S accurately match the given Chow parameters or Shapley indices of the unknown LTF. We refer to this as the Partial Inverse Power Index Problem. Our main results are a polynomial time algorithm for the (ε-approximate) Chow Parameters Partial Inverse Power Index Problem and a quasi-polynomial time algorithm for the (ε-approximate) Shapley Indices Partial Inverse Power Index Problem.
On the Approximation Power of Two-Layer Networks of Random ReLUs
Daniel Hsu Columbia University, Clayton H Sanford Columbia University, Rocco Servedio Columbia University, Emmanouil Vasileios Vlatakis-Gkaragkounis Columbia University
This paper considers the following question: how well can depth-two ReLU networks with randomly initialized bottom-level weights represent smooth functions? We give near-matching upper and lower-bounds for L2-approximation in terms of the Lipschitz constant, the desired accuracy, and the dimension of the problem, as well as similar results in terms of Sobolev norms. Our positive results employ tools from harmonic analysis and ridgelet representation theory, while our lower-bounds are based on (robust versions of) dimensionality arguments.
Weak learning convex sets under normal distributions
Anindya De Columbia University, Rocco Servedio Columbia University
This paper addresses the following natural question: can efficient algorithms weakly learn convex sets under normal distributions? Strong learnability of convex sets under normal distributions is well understood, with near-matching upper and lower bounds given in Klivans et al. (2008), but prior to the current work nothing seems to have been known about weak learning. We essentially answer this question, giving near-matching algorithms and lower bounds. For our positive result, we give a poly(n)-time algorithm that can weakly learn the class of convex sets to advantage Ω(1/ √ n) using only random examples drawn from the background Gaussian distribution. Our algorithm and analysis are based on a new “density increment” result for convex sets, which we prove using tools from isoperimetry. We also give an information-theoretic lower bound showing that O(log(n)/ √ n) advantage is best possible even for algorithms that are allowed to make poly(n) many membership queries.
David Blei and Chong Wang were named winners of the Test of Time Award for Research at the 27th SIGKDD Conference on Knowledge Discovery and Data Mining. The duo was recognized for their 2011 paper, “Collaborative topic modeling for recommending scientific articles.”
Research from the department was presented at the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL 2021). The conference is a forum for academic and industry researchers to discuss their work on discourse and dialogue including discourse processing, dialogue systems, corpora, tools, and methodology.
Professor Julia Hirschberg was one of the invited keynote speakers and during her lecture she talked about how computer systems can encourage user trust for recommender systems, knowledge-delivery systems, and dialogue systems.
Below are the links to the accepted papers and abstracts.
What to Fact-Check: Guiding Check-Worthy Information Detection in News Articles Through Argumentative Discourse Structure
Tariq Alhindi Columbia University, Brennan McManus Columbia University, and Smaranda Muresan Columbia University
Most existing methods for automatic fact checking start with a precompiled list of claims to verify. We investigate the understudied problem of determining what statements in news articles are worthy to factcheck. We annotate the argument structure of 95 news articles in the climate change domain that are fact-checked by climate scientists at climatefeedback.org. We release the first multi-layer annotated corpus for both argumentative discourse structure (argument components and relations) and for fact checked statements in news articles. We discuss the connection between argument structure and check-worthy statements and develop several baseline models for detecting checkworthy statements in the climate change domain. Our preliminary results show that using information about argumentative discourse structure shows slight but statistically significant improvement over a baseline of local discourse structure.
Improving Named Entity Recognition in Spoken Dialog Systems By Context and Speech Pattern Modeling
Minh Nguyen University of California, Davis and Zhou Yu Columbia University
While named entity recognition (NER) from speech has been around as long as NER from written text has, the accuracy of NER from speech has generally been much lower than that of NER from text. The rise in popularity of spoken dialog systems such as Siri or Alexa highlights the need for more accurate NER from speech because NER is a core component for understanding what users said in dialogs. Deployed spoken dialog systems receive user input in the form of automatic speech recognition (ASR) transcripts, and simply applying NER model trained on written text to ASR transcripts often leads to low accuracy because compared to written text, ASR transcripts lack important cues such as punctuation and capitalization. Besides, errors in ASR transcripts also make NER from speech challenging. We propose two models that exploit dialog context and speech pattern clues to extract named entities more accurately from open-domain dialogs in spoken dialog systems. Our results show the benefit of modeling dialog context and speech patterns in two settings: a standard setting with random partition of data and a more realistic but also more difficult setting where many named entities encountered during deployment are unseen during training.
Evaluation of In-Person Counseling Strategies to Develop Physical Activity Chatbot for Women
Kai-Hui Liang Columbia University, Patrick Lange University of California, Davis, Yoo Jung Oh University of California, Davis, Jingwen Zhang University of California, Davis, Yoshimi Fukuoka University of California, San Francisco, and Zhou Yu Columbia University
Artificial intelligence chatbots are the vanguard in technology-based intervention to change people’s behavior. To develop intervention chatbots, the first step is to understand natural language conversation strategies in human conversation. This work introduces an intervention conversation dataset collected from a real-world physical activity intervention program for women. We designed comprehensive annotation schemes in four dimensions (domain, strategy, social exchange, and taskfocused exchange) and annotated a subset of dialogs. We built a strategy classifier with context information to detect strategies from both trainers and participants based on the annotation. To understand how human intervention induces effective behavior changes, we analyzed the relationships between the intervention strategies and the participants’ changes in the barrier and social support for physical activity. We also analyzed how the participant’s baseline weight correlates to the amount of occurrence of the corresponding strategy. This work lays the foundation for developing a personalized physical activity intervention bot.
DialogStitch: Synthetic Deeper and Multi-Context Task-Oriented Dialogs
Satwik Kottur Facebook AI, Chinnadhurai Sankar Facebook AI, Zhou Yu Columbia University, and Alborz Geramifard Facebook AI
Real-world conversational agents must effectively handle long conversations that span multiple contexts. Such context can be interspersed with chitchat (dialog turns not directly related to the task at hand), and potentially grounded in a multimodal setting. While prior work focused on the above aspects in isolation, there is a lack of a unified framework that studies them together. To overcome this, we propose DialogStitch, a novel framework to seamlessly ‘stitch’ multiple conversations and highlight these desirable traits in a task-oriented dialog. After stitching, our dialogs are provably deeper, contain longer-term dependencies, and span multiple contexts, when compared with the source dialogs— all by leveraging existing human annotations! Though our framework generalizes to a variety of combinations, we demonstrate its benefits in two settings: (a) multimodal, image-grounded conversations, and, (b) task-oriented dialogs fused with chit-chat conversations. We benchmark state-of-the-art dialog models on our datasets and find accuracy drops of (a) 12% and (b) 45% respectively, indicating the additional challenges in the stitched dialogs. Our code and data are publicly available.
Annotation Inconsistency and Entity Bias in MultiWOZ
Kun Qian Columbia University, Ahmad Beirami Facebook AI, Zhouhan Lin Facebook AI, Ankita De Facebook AI, Alborz Geramifard Facebook AI, Zhou Yu Columbia University, and Chinnadhurai Sankar Facebook AI
MultiWOZ (Budzianowski et al., 2018) is one of the most popular multi-domain taskoriented dialog datasets, containing 10K+ annotated dialogs covering eight domains. It has been widely accepted as a benchmark for various dialog tasks, e.g., dialog state tracking (DST), natural language generation (NLG) and end-to-end (E2E) dialog modeling. In this work, we identify an overlooked issue with dialog state annotation inconsistencies in the dataset, where a slot type is tagged inconsistently across similar dialogs leading to confusion for DST modeling. We propose an automated correction for this issue, which is present in 70% of the dialogs. Additionally, we notice that there is significant entity bias in the dataset (e.g., “cambridge” appears in 50% of the destination cities in the train domain). The entity bias can potentially lead to named entity memorization in generative models, which may go unnoticed as the test set suffers from a similar entity bias as well. We release a new test set with all entities replaced with unseen entities. Finally, we benchmark joint goal accuracy (JGA) of the state-of-the art DST baselines on these modified versions of the data. Our experiments show that the annotation inconsistency corrections lead to 7- 10% improvement in JGA. On the other hand, we observe a 29% drop in JGA when models are evaluated on the new test set with unseen entities.
Papers from CS researchers have been accepted to the 38th International Conference on Machine Learning (ICML 2021).
Associate Professor Daniel Hsu was one of the publication chairs of the conference and Assistant Professor Elham Azizi helped organize the 2021 ICML Workshop on Computational Biology. The workshop highlighted how machine learning approaches can be tailored to making both translational and basic scientific discoveries with biological data.
Below are the abstracts and links to the accepted papers.
A Proxy Variable View of Shared Confounding
Yixin Wang Columbia University, David Blei Columbia University
Causal inference from observational data can be biased by unobserved confounders. Confounders—the variables that affect both the treatments and the outcome—induce spurious non-causal correlations between the two. Without additional conditions, unobserved confounders generally make causal quantities hard to identify. In this paper, we focus on the setting where there are many treatments with shared confounding, and we study under what conditions is causal identification possible. The key observation is that we can view subsets of treatments as proxies of the unobserved confounder and identify the intervention distributions of the rest. Moreover, while existing identification formulas for proxy variables involve solving integral equations, we show that one can circumvent the need for such solutions by directly modeling the data. Finally, we extend these results to an expanded class of causal graphs, those with other confounders and selection variables.
Unsupervised Representation Learning via Neural Activation Coding
Yookoon Park Columbia University, Sangho Lee Seoul National University, Gunhee Kim Seoul National University, David Blei Columbia University
We present neural activation coding (NAC) as a novel approach for learning deep representations from unlabeled data for downstream applications. We argue that the deep encoder should maximize its nonlinear expressivity on the data for downstream predictors to take full advantage of its representation power. To this end, NAC maximizes the mutual information between activation patterns of the encoder and the data over a noisy communication channel. We show that learning for a noise-robust activation code increases the number of distinct linear regions of ReLU encoders, hence the maximum nonlinear expressivity. More interestingly, NAC learns both continuous and discrete representations of data, which we respectively evaluate on two downstream tasks: (i) linear classification on CIFAR-10 and ImageNet-1K and (ii) nearest neighbor retrieval on CIFAR-10 and FLICKR-25K. Empirical results show that NAC attains better or comparable performance on both tasks over recent baselines including SimCLR and DistillHash. In addition, NAC pretraining provides significant benefits to the training of deep generative models. Our code is available at https://github.com/yookoon/nac.
The Logical Options Framework
Brandon Araki MIT, Xiao Li MIT, Kiran Vodrahalli Columbia University, Jonathan DeCastro Toyota Research Institute, Micah Fry MIT Lincoln Laboratory, Daniela Rus MIT CSAIL
Learning composable policies for environments with complex rules and tasks is a challenging problem. We introduce a hierarchical reinforcement learning framework called the Logical Options Framework (LOF) that learns policies that are satisfying, optimal, and composable. LOF efficiently learns policies that satisfy tasks by representing the task as an automaton and integrating it into learning and planning. We provide and prove conditions under which LOF will learn satisfying, optimal policies. And lastly, we show how LOF’s learned policies can be composed to satisfy unseen tasks with only 10-50 retraining steps on our benchmarks. We evaluate LOF on four tasks in discrete and continuous domains, including a 3D pick-and-place environment.
Estimating Identifiable Causal Effects on Markov Equivalence Class through Double Machine Learning
Yonghan Jung Columbia University, Jin Tian Columbia University, Elias Bareinboim Columbia University
General methods have been developed for estimating causal effects from observational data under causal assumptions encoded in the form of a causal graph. Most of this literature assumes that the underlying causal graph is completely specified. However, only observational data is available in most practical settings, which means that one can learn at most a Markov equivalence class (MEC) of the underlying causal graph. In this paper, we study the problem of causal estimation from a MEC represented by a partial ancestral graph (PAG), which is learnable from observational data. We develop a general estimator for any identifiable causal effects in a PAG. The result fills a gap for an end-to-end solution to causal inference from observational data to effects estimation. Specifically, we develop a complete identification algorithm that derives an influence function for any identifiable causal effects from PAGs. We then construct a double/debiased machine learning (DML) estimator that is robust to model misspecification and biases in nuisance function estimation, permitting the use of modern machine learning techniques. Simulation results corroborate with the theory.
Environment Inference for Invariant Learning
Elliot Creager University of Toronto, Joern Jacobsen Apple Inc., Richard Zemel Columbia University
Learning models that gracefully handle distribution shifts is central to research on domain generalization, robust optimization, and fairness. A promising formulation is domain-invariant learning, which identifies the key issue of learning which features are domain-specific versus domain-invariant. An important assumption in this area is that the training examples are partitioned into domains'' orenvironments”. Our focus is on the more common setting where such partitions are not provided. We propose EIIL, a general framework for domain-invariant learning that incorporates Environment Inference to directly infer partitions that are maximally informative for downstream Invariant Learning. We show that EIIL outperforms invariant learning methods on the CMNIST benchmark without using environment labels, and significantly outperforms ERM on worst-group performance in the Waterbirds dataset. Finally, we establish connections between EIIL and algorithmic fairness, which enables EIIL to improve accuracy and calibration in a fair prediction problem.
SketchEmbedNet: Learning Novel Concepts by Imitating Drawings
Alex Wang University of Toronto, Mengye Ren University of Toronto, Richard Zemel Columbia University
Sketch drawings capture the salient information of visual concepts. Previous work has shown that neural networks are capable of producing sketches of natural objects drawn from a small number of classes. While earlier approaches focus on generation quality or retrieval, we explore properties of image representations learned by training a model to produce sketches of images. We show that this generative, class-agnostic model produces informative embeddings of images from novel examples, classes, and even novel datasets in a few-shot setting. Additionally, we find that these learned representations exhibit interesting structure and compositionality.
Universal Template for Few-Shot Dataset Generalization
Eleni Triantafillou University of Toronto, Hugo Larochelle Google Brain, Richard Zemel Columbia University, Vincent Dumoulin Google
Few-shot dataset generalization is a challenging variant of the well-studied few-shot classification problem where a diverse training set of several datasets is given, for the purpose of training an adaptable model that can then learn classes from \emph{new datasets} using only a few examples. To this end, we propose to utilize the diverse training set to construct a \emph{universal template}: a partial model that can define a wide array of dataset-specialized models, by plugging in appropriate components. For each new few-shot classification problem, our approach therefore only requires inferring a small number of parameters to insert into the universal template. We design a separate network that produces an initialization of those parameters for each given task, and we then fine-tune its proposed initialization via a few steps of gradient descent. Our approach is more parameter-efficient, scalable and adaptable compared to previous methods, and achieves the state-of-the-art on the challenging Meta-Dataset benchmark.
On Monotonic Linear Interpolation of Neural Network Parameters
James Lucas University of Toronto, Juhan Bae University of Toronto, Michael Zhang University of Toronto, Stanislav Fort Google AI, Richard Zemel Columbia University, Roger Grosse University of Toronto
Linear interpolation between initial neural network parameters and converged parameters after training with stochastic gradient descent (SGD) typically leads to a monotonic decrease in the training objective. This Monotonic Linear Interpolation (MLI) property, first observed by Goodfellow et al. 2014, persists in spite of the non-convex objectives and highly non-linear training dynamics of neural networks. Extending this work, we evaluate several hypotheses for this property that, to our knowledge, have not yet been explored. Using tools from differential geometry, we draw connections between the interpolated paths in function space and the monotonicity of the network — providing sufficient conditions for the MLI property under mean squared error. While the MLI property holds under various settings (e.g., network architectures and learning problems), we show in practice that networks violating the MLI property can be produced systematically, by encouraging the weights to move far from initialization. The MLI property raises important questions about the loss landscape geometry of neural networks and highlights the need to further study their global properties.
A Computational Framework For Slang Generation
Zhewei Sun University of Toronto, Richard Zemel Columbia University, Yang Xu University of Toronto
Slang is a common type of informal language, but its flexible nature and paucity of data resources present challenges for existing natural language systems. We take an initial step toward machine generation of slang by developing a framework that models the speaker’s word choice in slang context. Our framework encodes novel slang meaning by relating the conventional and slang senses of a word while incorporating syntactic and contextual knowledge in slang usage. We construct the framework using a combination of probabilistic inference and neural contrastive learning. We perform rigorous evaluations on three slang dictionaries and show that our approach not only outperforms state-of-the-art language models, but also better predicts the historical emergence of slang word usages from 1960s to 2000s. We interpret the proposed models and find that the contrastively learned semantic space is sensitive to the similarities between slang and conventional senses of words. Our work creates opportunities for the automated generation and interpretation of informal language.
Wandering Within A World: Online Contextualized Few-Shot Learning
Mengye Ren University of Toronto, Michael Iuzzolino Google Research, Michael Mozer Google Research, Richard Zemel Columbia University
We aim to bridge the gap between typical human and machine-learning environments by extending the standard framework of few-shot learning to an online, continual setting. In this setting, episodes do not have separate training and testing phases, and instead models are evaluated online while learning novel classes. As in the real world, where the presence of spatiotemporal context helps us retrieve learned skills in the past, our online few-shot learning setting also features an underlying context that changes throughout time. Object classes are correlated within a context and inferring the correct context can lead to better performance. Building upon this setting, we propose a new few-shot learning dataset based on large scale indoor imagery that mimics the visual experience of an agent wandering within a world. Furthermore, we convert popular few-shot learning approaches into online versions and we also propose a new contextual prototypical memory model that can make use of spatiotemporal contextual information from the recent past.
Bayesian Few-Shot Classification With One-Vs-Each Polya-Gamma Augmented Gaussian Processes
Jake Snell University of Toronto, Richard Zemel Columbia University
Few-shot classification (FSC), the task of adapting a classifier to unseen classes given a small labeled dataset, is an important step on the path toward human-like machine learning. Bayesian methods are well-suited to tackling the fundamental issue of overfitting in the few-shot scenario because they allow practitioners to specify prior beliefs and update those beliefs in light of observed data. Contemporary approaches to Bayesian few-shot classification maintain a posterior distribution over model parameters, which is slow and requires storage that scales with model size. Instead, we propose a Gaussian process classifier based on a novel combination of Pólya-Gamma augmentation and the one-vs-each softmax approximation that allows us to efficiently marginalize over functions rather than model parameters. We demonstrate improved accuracy and uncertainty quantification on both standard few-shot classification benchmarks and few-shot domain transfer tasks.
Theoretical Bounds On Estimation Error For Meta-Learning
James Lucas University of Toronto, Mengye Ren University of Toronto, Irene Kameni African Master for Mathematical Sciences, Toni Pitassi Columbia University, Richard Zemel Columbia University
Machine learning models have traditionally been developed under the assumption that the training and test distributions match exactly. However, recent success in few-shot learning and related problems are encouraging signs that these models can be adapted to more realistic settings where train and test distributions differ. Unfortunately, there is severely limited theoretical support for these algorithms and little is known about the difficulty of these problems. In this work, we provide novel information-theoretic lower-bounds on minimax rates of convergence for algorithms that are trained on data from multiple sources and tested on novel data. Our bounds depend intuitively on the information shared between sources of data, and characterize the difficulty of learning in this setting for arbitrary algorithms. We demonstrate these bounds on a hierarchical Bayesian model of meta-learning, computing both upper and lower bounds on parameter estimation via maximum-a-posteriori inference.
A PAC-Bayesian Approach To Generalization Bounds For Graph Neural Networks
Renjie Liao University of Toronto, Raquel Urtasun University of Toronto, Richard Zemel Columbia University
In this paper, we derive generalization bounds for the two primary classes of graph neural networks (GNNs), namely graph convolutional networks (GCNs) and message passing GNNs (MPGNNs), via a PAC-Bayesian approach. Our result reveals that the maximum node degree and spectral norm of the weights govern the generalization bounds of both models. We also show that our bound for GCNs is a natural generalization of the results developed in arXiv:1707.09564v2 [cs.LG] for fully-connected and convolutional neural networks. For message passing GNNs, our PAC-Bayes bound improves over the Rademacher complexity based bound in arXiv:2002.06157v1 [cs.LG], showing a tighter dependency on the maximum node degree and the maximum hidden dimension. The key ingredients of our proofs are a perturbation analysis of GNNs and the generalization of PAC-Bayes analysis to non-homogeneous GNNs. We perform an empirical study on several real-world graph datasets and verify that our PAC-Bayes bound is tighter than others.
Researchers from the Software Systems Laboratory bagged Best Paper Awards at the 15th USENIX Symposium on Operating Systems Design and Implementation (OSDI 2021) and the 2021 USENIX Annual Technical Conference (USENIX ATC 2021).
DistAI: Data-Driven Automated Invariant Learning for Distributed Protocols
Jianan Yao, Runzhou Tao, Ronghui Gu, Jason Nieh, Suman Jana, and Gabriel Ryan
Distributed systems are notoriously hard to implement correctly due to non-determinism. Finding the inductive invariant of the distributed protocol is a critical step in verifying the correctness of distributed systems, but takes a long time to do even for simple protocols. We present DistAI, a data-driven automated system for learning inductive invariants for distributed protocols. DistAI generates data by simulating the distributed protocol at different instance sizes and recording states as samples. Based on the observation that invariants are often concise in practice, DistAI starts with small invariant formulas and enumerates all strongest possible invariants that hold for all samples. It then feeds those invariants and the desired safety properties to an SMT solver to check if the conjunction of the invariants and the safety properties is inductive. Starting with small invariant formulas and strongest possible invariants avoids large SMT queries, improving SMT solver performance. Because DistAI starts with the strongest possible invariants, if the SMT solver fails, DistAI does not need to discard failed invariants, but knows to monotonically weaken them and try again with the solver, repeating the process until it eventually succeeds. We prove that DistAI is guaranteed to find the ∃-free inductive invariant that proves the desired safety properties in finite time, if one exists. Our evaluation shows that DistAI successfully verifies 13 common distributed protocols automatically and outperforms alternative methods both in the number of protocols it verifies and the speed at which it does so, in some cases by more than two orders of magnitude.
Argus: Debugging Performance Issues in Modern Desktop Applications with Annotated Causal Tracing
Lingmei Weng, Peng Huang, Jason Nieh, and Junfeng Yang
Modern desktop applications involve many asynchronous, concurrent interactions that make performance issues difficult to diagnose. Although prior work has used causal tracing for debugging performance issues in distributed systems, we find that these techniques suffer from high inaccuracies for desktop applications. We present Argus, a fast, effective causal tracing tool for debugging performance anomalies in desktop applications. Argus introduces a novel notion of strong and weak edges to explicitly model and annotate trace graph ambiguities, a new beam-search-based diagnosis algorithm to select the most likely causal paths in the presence of ambiguities, and a new way to compare causal paths across normal and abnormal executions. We have implemented Argus across multiple versions of macOS and evaluated it on 12 infamous spinning pinwheel issues in popular macOS applications. Argus diagnosed the root causes for all issues, 10 of which were previously unknown, some of which have been open for several years. Argus incurs less than 5% CPU overhead when its system-wide tracing is enabled, making always-on tracing feasible.
Associate Professor Simha Sethumadhavan, Mohamed Tarek, and Miguel Arroyo design new techniques to bolster memory safety; ideas are now being used by Air Force Research Lab.
Research from the department has been accepted to the 2021 Computer Vision and Pattern Recognition (CVPR) Conference. The annual event explores machine learning, artificial intelligence, and computer vision research and its applications.
Open-Vocabulary Object Detection Using Captions
Alireza Zareian Snap Inc. and Columbia University, Kevin Dela Rosa Snap Inc., Derek Hao Hu Snap Inc., Shih-Fu Chang Columbia University
Abstract
Despite the remarkable accuracy of deep neural networks in object detection, they are costly to train and scale due to supervision requirements. Particularly, learning more object categories typically requires proportionally more bounding box annotations. Weakly supervised and zero-shot learning techniques have been explored to scale object detectors to more categories with less supervision, but they have not been as successful and widely adopted as supervised models. In this paper, we put forth a novel formulation of the object detection problem, namely open-vocabulary object detection, which is more general, more practical, and more effective than weakly supervised and zero-shot approaches. We propose a new method to train object detectors using bounding box annotations for a limited set of object categories, as well as image-caption pairs that cover a larger variety of objects at a significantly lower cost. We show that the proposed method can detect and localize objects for which no bounding box annotation is provided during training, at a significantly higher accuracy than zero-shot approaches. Meanwhile, objects with bounding box annotation can be detected almost as accurately as supervised methods, which is significantly better than weakly supervised baselines. Accordingly, we establish a new state-of-the-art for scalable object detection.
Vx2Text: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs
Xudong Lin Columbia University, Gedas Bertasius Facebook AI, Jue Wang Facebook AI, Shih-Fu Chang Columbia University, Devi Parikh Facebook AI and Georgia Tech, Lorenzo Torresani Facebook AI and Dartmouth
Abstract
We present Vx2Text, a framework for text generation from multimodal inputs consisting of video plus text, speech, or audio. In order to leverage transformer networks, which have been shown to be effective at modeling language, each modality is first converted into a set of language embeddings by a learnable tokenizer. This allows our approach to perform multimodal fusion in the language space, thus eliminating the need for ad-hoc cross-modal fusion modules. To address the non-differentiability of tokenization on continuous inputs (e.g., video or audio), we utilize a relaxation scheme that enables end-to-end training. Furthermore, unlike prior encoder-only models, our network includes an autoregressive decoder to generate open-ended text from the multimodal embeddings fused by the language encoder. This renders our approach fully generative and makes it directly applicable to different “video+x to text” problems without the need to design specialized network heads for each task. The proposed framework is not only conceptually simple but also remarkably effective: experiments demonstrate that our approach based on a single architecture outperforms the state-of-the-art on three video-based text-generation tasks—captioning, question answering, and audio-visual scene-aware dialog. Our code will be made publicly available.
Co-Grounding Networks With Semantic Attention for Referring Expression Comprehension in Videos
Sijie Song Wangxuan Institute of Computer Technology, Xudong Lin Columbia University, Jiaying Liu Wangxuan Institute of Computer Technology, Zongming Guo Wangxuan Institute of Computer Technology, Shih-Fu Chang Columbia University
Abstract
In this paper, we address the problem of referring expression comprehension in videos, which is challenging due to complex expression and scene dynamics. Unlike previous methods which solve the problem in multiple stages (i.e., tracking, proposal-based matching), we tackle the problem from a novel perspective, co-grounding, with an elegant one-stage framework. We enhance the single-frame grounding accuracy by semantic attention learning and improve the cross-frame grounding consistency with co-grounding feature learning. Semantic attention learning explicitly parses referring cues in different attributes to reduce the ambiguity in the complex expression. Co-grounding feature learning boosts visual feature representations by integrating temporal correlation to reduce the ambiguity caused by scene dynamics. Experiment results demonstrate the superiority of our framework on the video grounding datasets VID and OTB in generating accurate and stable results across frames. Our model is also applicable to referring expression comprehension in images, illustrated by the improved performance on the RefCOCO dataset. Our project is available at https://sijiesong.github.io/co-grounding.
Seeing in Extra Darkness Using a Deep-Red Flash
Jinhui Xiong KAUST, Jian Wang Snap Research, Wolfgang Heidrich KAUST, Shree Nayar Snap Research and Columbia University
Abstract
We propose a new flash technique for low-light imaging, using deep-red light as an illuminating source. Our main observation is that in a dim environment, the human eye mainly uses rods for the perception of light, which are not sensitive to wavelengths longer than 620nm, yet the camera sensor still has a spectral response. We propose a novel modulation strategy when training a modern CNN model for guided image filtering, fusing a noisy RGB frame and a flash frame. This fusion network is further extended for video reconstruction. We have built a prototype with minor hardware adjustments and tested the new flash technique on a variety of static and dynamic scenes. The experimental results demonstrate that our method produces compelling reconstructions, even in extra dim conditions.
UC2: Universal Cross-Lingual Cross-Modal Vision-and-Language Pre-Training
Mingyang Zhou University of California, Davis, Luowei Zhou Microsoft Dynamics 365 AI Research, Shuohang Wang Microsoft Dynamics 365 AI Research, Yu Cheng Microsoft Dynamics 365 AI Research, Linjie Li Microsoft Dynamics 365 AI Research, Zhou Yu University of California, Davis and Columbia University, Jingjing Liu Microsoft Dynamics 365 AI Research
Abstract
Vision-and-language pre-training has achieved impressive success in learning multimodal representations between vision and language. To generalize this success to non-English languages, we introduce UC^2, the first machine translation-augmented framework for cross-lingual cross-modal representation learning. To tackle the scarcity problem of multilingual captions for image datasets, we first augment existing English-only datasets with other languages via machine translation (MT). Then we extend the standard Masked Language Modeling and Image-Text Matching training objectives to multilingual setting, where alignment between different languages is captured through shared visual context (eg. using image as pivot). To facilitate the learning of a joint embedding space of images and all languages of interest, we further propose two novel pre-training tasks, namely Maksed Region-to-Token Modeling (MRTM) and Visual Translation Language Modeling (VTLM), leveraging MT-enhanced translated data. Evaluation on multilingual image-text retrieval and multilingual visual question answering benchmarks demonstrates that our proposed framework achieves new state of the art on diverse non-English benchmarks while maintaining comparable performance to monolingual pre-trained models on English tasks.
Learning Goals From Failure
Dave Epstein Columbia University and Carl Vondrick Columbia University
Abstract
We introduce a framework that predicts the goals behind observable human action in video. Motivated by evidence in developmental psychology, we leverage video of unintentional action to learn video representations of goals without direct supervision. Our approach models videos as contextual trajectories that represent both low-level motion and high-level action features. Experiments and visualizations show our trained model is able to predict the underlying goals in video of unintentional action. We also propose a method to “automatically correct” unintentional action by leveraging gradient signals of our model to adjust latent trajectories. Although the model is trained with minimal supervision, it is competitive with or outperforms baselines trained on large (supervised) datasets of successfully executed goals, showing that observing unintentional action is crucial to learning about goals in video.
Generative Interventions for Causal Learning
Chengzhi Mao Columbia University, Augustine Cha Columbia University, Amogh Gupta Columbia University, Hao Wang Rutgers University, Junfeng Yang Columbia University, Carl Vondrick Columbia University
Abstract
We introduce a framework for learning robust visual representations that generalize to new viewpoints, backgrounds, and scene contexts. Discriminative models often learn naturally occurring spurious correlations, which cause them to fail on images outside of the training distribution. In this paper, we show that we can steer generative models to manufacture interventions on features caused by confounding factors. Experiments, visualizations, and theoretical results show this method learns robust representations more consistent with the underlying causal relationships. Our approach improves performance on multiple datasets demanding out-of-distribution generalization, and we demonstrate state-of-the-art performance generalizing from ImageNet to ObjectNet dataset.
Learning the Predictability of the Future
Didac Suris Columbia University, Ruoshi Liu Columbia University, Carl Vondrick Columbia University
Abstract
We introduce a framework for learning from unlabeled video what is predictable in the future. Instead of committing up front to features to predict, our approach learns from data which features are predictable. Based on the observation that hyperbolic geometry naturally and compactly encodes hierarchical structure, we propose a predictive model in hyperbolic space. When the model is most confident, it will predict at a concrete level of the hierarchy, but when the model is not confident, it learns to automatically select a higher level of abstraction. Experiments on two established datasets show the key role of hierarchical representations for action prediction. Although our representation is trained with unlabeled video, visualizations show that action hierarchies emerge in the representation.
Linear Semantics in Generative Adversarial Networks
Jianjin Xu Columbia University, Changxi Zheng Columbia University
Abstract
Generative Adversarial Networks (GANs) are able to generate high-quality images, but it remains difficult to explicitly specify the semantics of synthesized images. In this work, we aim to better understand the semantic representation of GANs, and thereby enable semantic control in GAN’s generation process. Interestingly, we find that a well-trained GAN encodes image semantics in its internal feature maps in a surprisingly simple way: a linear transformation of feature maps suffices to extract the generated image semantics. To verify this simplicity, we conduct extensive experiments on various GANs and datasets; and thanks to this simplicity, we are able to learn a semantic segmentation model for a trained GAN from a small number (e.g., 8) of labeled images. Last but not least, leveraging our finding, we propose two few-shot image editing approaches, namely Semantic-Conditional Sampling and Semantic Image Editing. Given a trained GAN and as few as eight semantic annotations, the user is able to generate diverse images subject to a user-provided semantic layout, and control the synthesized image semantics. We have made the code publicly available.
Faculty from the department have been named recipients of the 2020 Amazon Research Awards.
Six papers from CS researchers were accepted to the 16th conference of the European Chapter of the Association for Computational Linguistics (EACL). As the flagship European conference in the field of computational linguistics, EACL welcomes European and international researchers covering a broad spectrum of research areas that are concerned with computational approaches to natural language.
Below are brief descriptions and links to the papers.
Event-Driven News Stream Clustering using Entity-Aware Contextual Embeddings
Kailash Karthik Saravanakumar Columbia University, Miguel Ballesteros Amazon AI, Muthu Kumar Chandrasekaran Amazon AI, Kathleen McKeown Columbia University & Amazon AI
This paper presents a new clustering paradigm for news streams, where clusters have a one-to-one correspondence with real-world events (for example, the Suez canal blockage). An important aspect of this problem is that the number of clusters is unknown and varies with time (new events occur and old events cease to be of relevance). The proposed paradigm follows a pipeline approach – where representations are built for each new article, comparisons are made with existing clusters to pick the most compatible one, and finally, a clustering decision is produced.
A surprising observation from this work is that contextual embeddings (from models like BERT), in contrast to their overwhelming success in many NLP problems, achieve sub-par performance by themselves on this clustering problem. However, when combined with other representations (like TF-IDF and timestamps) and fine-tuned with task-specific augmentations, they achieve new state-of-the-art performance. Another interesting observation is that the widely reported B-Cubed metrics are biased towards large clusters and hence don’t capture cluster fragmentation on smaller clusters as well. Since clusters corresponding to emerging events are small and errors made on such clusters are highly undesirable, the authors suggest using an additional metric CEAF-e to evaluate models for this task.
Segmenting Subtitles for Correcting ASR Segmentation Errors
David Wan Columbia University, Chris Kedzie Columbia University, Faisal Ladakh Columbia University, Elsbeth Turcan Columbia University, Petra Galuszkova University of Maryland, Elena Zotkina University of Maryland, Zhengping Jiang Columbia University, Peter Bell University of Edinburgh, and Kathleen McKeown Columbia University
For the task of spoken language translation, the usual approach is to have a pipeline consisting of Automatic Speech Recognition (ASR) that transforms audio files into words and utterances in the original language and a Machine Translation (MT) that translate the utterances into the target language. However this setup may suffer from input-output mismatches: ASR segments utterances by acoustic information such as pauses, and thus may produce run-on sentences or sentence fragments, but MT is usually trained on proper sentences without such issues and may not perform well under such setting. This paper proposes the use of an intermediate model to segment utterances into sentences to improve performance in MT as well as other downstream tasks.
One crucial problem for developing such models is the lack of suitable training data for segmentation, especially when the languages involved are low-resourced. To this end, this paper also proposes a way to use subtitles dataset as proxy speech data as well as creating synthetic acoustic utterances that mimic common ASR errors for the model to learn to fix. Using a simple neural tagging model, the authors of this paper show improvement over the baseline ASR segmentation on MT for Lithuanian, Bulgarian, and Farisi. A surprising finding is that the segmentation model most improves the translation quality of more syntactically complex segments.
“Talk to me with left, right, and angles”: Lexical entrainment in spoken Hebrew dialogue
Andreas Weise CUNY Graduate Center, Vered Silber-Varod The Open University of Israel, Anat Lerner The Open University of Israel, Julia Hirschberg Columbia University, and Rivka Levitan Columbia University
It has been well-documented for several languages that human interlocutors tend to adapt their linguistic productions to become more similar to each other. This behavior, known as entrainment, affects lexical choice as well, both with regard to specific words, such as referring expressions, and overall style.
Lexical entrainment is the behavior that causes the words that speakers use in a conversation to become more similar over time. Entrainment more broadly is a human behavior causing interlocutors to adapt to each other to become more similar. Its effects are measurable but entrainment itself is not a measure.
This paper offers the first investigation of such lexical entrainment in Hebrew.
The analysis of Hebrew speakers interacting in a Map Task, a popular experimental setup, provides rich evidence of lexical entrainment. No clear pattern of differences is found between speaker pairs by the combination of their genders, nor between speakers by their individual gender. However, speakers in a position of less power are found to entrain more than those with greater power, which matches theoretical accounts.
Overall, the results mostly accord with those for American English. There is, however, a surprising lack of entrainment on a list of hedge words that were previously found to be highly entrained in English. This might be due to cultural differences between American and Israeli speakers that render adoption of a more tentative style less appropriate in the Hebrew context.
Entity-level Factual Consistency of Abstractive Text Summarization
Feng Nan Amazon Web Services, Ramesh Nallapati Amazon Web Services, Zhiguo Wang Amazon Web Services, Cicero Nogueira dos Santos Amazon Web Services, Henghui Zhu Amazon Web Services, Dejiao Zhang Amazon Web Services, Kathleen McKeown Amazon Web Services & Columbia University, Bing Xiang Amazon Web Services
A key challenge for abstractive summarization is ensuring factual consistency of the generated summary with respect to the original document. For example, state-of-the-art models trained on existing datasets exhibit entity hallucination, generating names of entities that are not present in the source document.
The paper proposes a set of new metrics to quantify the entity-level factual consistency of generated summaries and shows that the entity hallucination problem can be alleviated by simply filtering the training data. In addition, the paper introduces a summary-worthy entity classification task to the training process as well as a joint entity and summary generation approach, which yields further improvements in entity-level metrics.
“Laughing at you or with you”: The Role of Sarcasm in Shaping the Disagreement Space
Debanjan Ghosh Educational Testing Service, Ritvik Shrivastava MindMeld, Cisco Systems & Columbia University, and Smaranda Muresan Columbia University
Detecting arguments in online interactions is useful to understand how conflicts arise and get resolved. Users often use figurative language, such as sarcasm, either as persuasive devices or to attack the opponent by an ad hominem argument. To further our understanding of the role of sarcasm in shaping the disagreement space, the paper presents a thorough experimental setup using a corpus annotated with both argumentative moves (agree/disagree) and sarcasm. The research exploits joint modeling in terms of (a) applying discrete features that are useful in detecting sarcasm to the task of argumentative relation classification (agree/disagree/none), and (b) multitask learning for argumentative relation classification and sarcasm detection using deep learning architectures (e.g., dual Long ShortTerm Memory (LSTM) with hierarchical attention and Transformer-based architectures). The paper shows that modeling sarcasm improves the argumentative relation classification task (agree/disagree/none) in all setups.
A Unified Feature Representation for Lexical Connotations
Emily Allaway Columbia University and Kathleen McKeown Columbia University
Ideological attitudes and stances are often expressed through subtle meanings of words and phrases. Understanding these connotations is critical to recognize the cultural and emotional perspectives of the speaker. In this paper, the researchers use distant labeling to create a new lexical resource representing connotation aspects for nouns and adjectives. Their analysis shows that it aligns well with human judgments. Additionally, they present a method for creating lexical representations that capture connotations within the embedding space and show that using the embeddings provides a statistically significant improvement on the task of stance detection when data is limited.
Assistant Professor Carl Vondrick has won the National Science Foundation’s (NSF) Faculty Early Career Development award for his proposal program to develop machine perception systems that robustly detect and track objects even when they disappear from sight, thereby enabling machines to build spatial awareness of their surroundings.
Shuran Song and Carl Vondrick are among the awardees chosen for their artificial intelligence (AI) research. The program aims to use AI for societal good.
The award recognizes Moti Yung’s significant contributions to the field of cryptography, specifically, coinventing malicious cryptography and pioneering contributions to distributed cryptosystems.
Research from the department was accepted to the 35th AAAI Conference on Artificial Intelligence. The conference promotes research in artificial intelligence (AI) and scientific exchange among AI researchers, practitioners, scientists, and engineers in affiliated disciplines.
Automated Symbolic Law Discovery: A Computer Vision Approach
Hengrui Xing Columbia University, Ansaf Salleb-Aouissi Columbia University, Nakul Verma Columbia University
One of the most exciting applications of modern artificial intelligence is to automatically discover scientific laws from experimental data. This is not a trivial problem as it involves searching for a complex mathematical relationship over a large set of explanatory variables and operators that can be combined in an infinite number of ways. Inspired by the incredible success of deep learning in computer vision, the authors tackle this problem by adapting various successful network architectures into the symbolic law discovery pipeline. The novelty of this new approach is in (1) encoding the input data as an image with super-resolution, (2) developing an appropriate deep network pipeline, and (3) predicting the importance of each mathematical operator from the relationship image. This allowed to prior the exponentially large search with the predicted importance of the symbolic operators, which can significantly accelerate the discovery process.
The model was then applied to a variety of plausible relationships—both simulated and from physics and mathematics domains—involving different dimensions and constituents. The authors show that their model is able to identify the underlying operators from data, achieving a high accuracy and AUC (91% and 0.96 on average resp.) for systems with as many as ten independent variables. Their method significantly outperforms the current state of the art in terms of data fitting (R^2), discovery rate (recovering the true relationship), and succinctness (output formula complexity). The discovered equations can be seen as first drafts of scientific laws that can be helpful to the scientists for (1) hypothesis building, and (2) understanding the complex underlying structure of the studied phenomena. This novel approach holds a real promise to help speed up the rate of scientific discovery.
Bounding Causal Effects on Continuous Outcome
Junzhe Zhang Columbia University, Elias Bareinboim Columbia University
One of the most common methods for policy learning used throughout the empirical sciences is the use of randomization of the treatment assignment. This method is considered the gold standard within many disciplines and can be traced back, at least, to Fisher (Fisher 1935) and Neyman (Neyman 1923). Whenever human subjects are at the center of the experiment, unfortunately, issues of non-compliance arise. Namely, subjects do not necessarily follow the experimental protocol and end up doing what they want. It is well-understood that under such conditions, unobserved confounding bias will emerge. For instance, subjects who did not comply with the treatment assignment may be precisely those who would have responded adversely to the treatment. Therefore, the actual causal effects of the treatment, when it is applied uniformly to the population, might be substantially less effective than the data reveals. Moreover, since one does not observe how subjects decide/respond to the realized treatment, the actual treatment effects are not uniquely computably from the collected data, called non-identifiable.
Robins (1989) and Manski (1990) derived the first informative bounds over the causal effects from studies with imperfect compliance under a set of non-parametric assumptions called instrumental variables (IV). In their seminal work, Balke and Pearl (1994a, 1997) improved earlier results by employing an algebraic method to derive analytic expressions of the causal bounds, which are provably optimal. However, this approach assumes the primary outcome to be discrete and finite. Solving such a program could be intractable when high-dimensional context variables are present.
This paper presents novel non-parametric methods to bound causal effects on the continuous outcome from studies with imperfect compliance. These methods could be generalized to settings with a high-dimensional context. Perhaps surprisingly, this paper introduced a latent data representation that could characterize all constraints on the observational and interventional distributions implied by IV assumptions, even when the primary outcome is continuous. Such representation allows one to reduce the original bounding problem to a series of linear programs. Solve these programs, therefore, leads to tight causal bounds.
Estimating Identifiable Causal Effects through Double Machine Learning
Yonghan Jung, Jin Tian, Elias Bareinboim Columbia University
Learning causal effects from observational data is a pervasive challenge found throughout the data-intensive sciences. General methods of determining the identifiability of causal effect from a combination of observational data and causal knowledge about the underlying system have been well-understood in theory. In practice, however, there are still challenges to estimating identifiable causal functionals from finite samples. Recently, a novel approach, named double/debiased machine learning (DML) (Chernozhukov et al. 2018), has been proposed to learn parameters leveraging modern machine learning techniques, which are both robust to model misspecification (‘doubly robust’) and slow convergence (‘debiased’). Still, DML has only been used for causal estimation in settings when the back-door condition (also known as conditional ignorability) holds.
This paper aims to bridge this gap by developing a general class of estimators for any identifiable causal functionals that exhibit robustness properties of DML estimators, which the authors called ‘DML-ID.’ In particular, they provide a complete procedure for deriving an essential ingredient of the DML estimator called an influence function (IF) and construct a general class of estimators based on the IF. This means that one can estimate any causal functional and enjoy two robustness properties, doubly robustness and debiasedness.
Ref-NMS: Breaking Proposal Bottlenecks in Two-Stage Referring Expression Grounding
Long Chen Tencent AI Lab, Wenbo Ma Zhejiang University, Jun Xiao Zhejiang University, Hanwang Zhang Nanyang Technological University, Shih-Fu Chang Columbia University
The prevailing framework for solving referring expression grounding is based on a two-stage process: 1) detecting proposals with an object detector and 2) grounding the referent to one of the proposals. Existing two-stage solutions mostly focus on the grounding step, which aims to align the expressions with the proposals.
In this paper, the researchers argue that these methods overlook an obvious mismatch between the roles of proposals in the two stages: they generate proposals solely based on the detection confidence (i.e., expression-agnostic), hoping that the proposals contain all right instances in the expression (i.e., expression-aware). Due to this mismatch, current two-stage methods suffer from a severe performance drop between detected and ground-truth proposals.
The paper proposes Ref-NMS, which is the first method to yield expression-aware proposals at the first stage. Ref-NMS regards all nouns in the expression as critical objects, and introduces a lightweight module to predict a score for aligning each box with a critical object. These scores can guide the NMS operation to filter out the boxes irrelevant to the expression, increasing the recall of critical objects, resulting in a significantly improved grounding performance.
Since RefNMS is agnostic to the grounding step, it can be easily integrated into any state-of-the-art two-stage method. Extensive ablation studies on several backbones, benchmarks, and tasks consistently demonstrate the superiority of Ref-NMS. Codes are available at: https://github.com/ChopinSharp/ref-nms.
Jihye Kwon, a computer engineering PhD student, talks about her research projects and what it took to win a Best Paper award.

What drew you to computer engineering, specifically the application of machine learning to computer-aided design? What questions or issues do you hope to answer?
I was attracted to the concept of a computer: a machine that performs calculations. I found it very interesting how modern computers evolved from executing one instruction at a time to executing many instructions simultaneously by exploiting multiple levels of parallelism. Still, various challenges remained, or newly arose, so I dreamed about designing a brand-new computer system. That is what I had in mind when coming to Columbia.
At the beginning of my PhD, I experimented and learned how to design the core parts of special-purpose computers, using computer-aided design tools. I also explored machine learning from both theoretical and practical perspectives. These activities led me to work on my current research problems.
In advanced computer-aided design of computer systems, computers solve many complex optimization problems in steps to generate a final design. They do so as guided by the designers via means of the configurable ‘knobs’. My focus is on the designers’ work.
For a target system, designers run the computer-aided design tools repeatedly with the many different knob configurations until the tools output final designs with optimal or desired properties, e.g., in timing, area, and power. I wondered if machines can learn, from designers’ previous work, how to configure the knobs to optimize a new target system. Can designers virtually collaborate across time and tasks through the machine learning models? These are the main questions that I hope to answer.
Could you talk about your research and how you collaborated with other groups? Was this something you considered when applying to Columbia – that there are opportunities to do multi-disciplinary work?
When I was applying to Columbia, I wished I could have collaboration opportunities to study and work in the interdisciplinary research communities at the center of New York City. I wanted to explore applications of computer science in different areas to eventually gain insight and inspiration for my own research, which is centered at computer engineering.
Fortunately, these were realized as I worked with my advisor, Professor Luca Carloni. I was invited to join the project “Energy Efficient Computing with Chip-Based Photonics”, which is a part of a large initiative supported by the government and industry. In this project, I worked closely with Lightwave Research Laboratory in Electrical Engineering on a new optical computing system. We proposed the concept of a next-generation computing system that is co-designed with silicon photonics and electronic circuitry, in order to overcome the fundamental and physical limitations of today’s computers.
Another project on optical communication was initiated from a student project that I mentored in my advisor’s class, Embedded Scalable Platforms. This project investigated the use of photonic switches in optically-connected memory systems for deep learning applications.
Outside Columbia, I have also collaborated with researchers at IBM TJ Watson Research Center via my summer internships on the project of auto-tuning computer-aided design flows for commercial supercomputers. All these collaborations opened new horizons for me.
You won the MLCAD 2020 Best Paper award for your research, can you talk about your process – how did the research come about? How long did it take you to complete the work? What were the things you had to overcome?
In this work, I proposed a novel machine learning approach for computer-aided design optimization of hardware accelerators. I wanted to address this problem because it is computationally very expensive to explore the entire optimization space. It took me about one year to complete the work. One of the biggest difficulties I faced was the limited availability of the data for applying machine learning to the problem.
Then, I found out that transfer learning has been recently successfully applied in other areas with limited data. In transfer learning, a model trained for a related problem (e.g., natural image recognition) is transferred to aid the machine learning for the target problem (e.g., face recognition). Hence, I tried to apply transfer learning to my research problem. I trained a neural network model for a different accelerator design, and transferred the model to predict the design properties of a target accelerator.
However, the transferred model did not perform well in this case. I realized that due to the diverse characteristics of the accelerators, I needed to distinguish which piece of the source information should be transferred. Based on this intuition, I constructed a series of new models, and eventually, proposed one with promising performance. While it was a long process of building new models without knowing the answers, my advisor greatly encouraged me in our discussions to keep moving forward, and it was very rewarding in the end.
The Machine Learning for Systems session from the 2nd ACM/IEEE Workshop on Machine Learning for CAD (MLCAD) can be viewed here and the Best Paper announcement here.
Looking back, how have you grown as a researcher and a person?
Besides expanding my problem-solving capabilities and technical skills, I have grown to be a better presenter and communicator. One of the tasks of a researcher is to explain one’s work to various groups and different types of audiences. I had a number of opportunities to present my work at academic conferences, seminars at companies, lightning talks, and annual project reviews. Initially, I struggled to meet the audience’s interests whose expertise spans a diverse range of areas and levels. Through those opportunities, I have received very helpful feedback, I have tried to ask myself questions from other people’s perspectives and progressively learned to keep a good balance between abstraction and elaboration.
Also, by interacting with a lot of students with heterogeneous backgrounds in the classes I TA’ed, I have learned to understand what their questions mean and where they come from. Based on that, I tried to adjust my answers to have more relatable conversations. From those conversations, sometimes the students found the topics very interesting, and sometimes I learned something new from them. It was such a great pleasure to inspire others and to be inspired. I think those experiences have made me a better researcher and person.
There are many organizations on campus, why did you choose to join Womxn in Computer Science (WiCS)?
In Fall 2017, I received an invitation from WiCS’ president, Julia Di, and was impressed by the passionate and caring board members working on the common goal of supporting the advancement of womxn in computer science. In my second year I launched the WiCS Lightning Talks for students with research experience to share their work and stories. The goal was for young students to get to know more about research and demystify the process.
I am one of the few women at Columbia in my research area of computer engineering and would like to contribute to inspiring the next generation to join us.
What was the highlight of your time at Columbia?
Every moment was special for me. Some of the highlights were during happy hour with members of the fishbowl. The fishbowl is a large office occupied by the majority of PhD students in computer engineering. We call it the fishbowl, because it is surrounded by large windows and students inside look like small fishes. Once, my colleagues talked about their memories of old computers that I had never seen. I enjoyed imagining the machines from their descriptions, and thinking about different types and generations of computers.
What is your advice to students on how to navigate their time at Columbia?
Explore, experience, and exploit. There are recommended lists of classes, activities, and companies, depending on your track and interests, but no one is exactly like you. There is such a great variety of opportunities and resources at Columbia and in New York City. I hope you can spend enough time exploring them and get involved in many ways before determining your academic and career goals.
Is there anything else that you think people should know?
Columbia is beautiful in the snow! It gets pretty windy in the winter, so please be aware if you are coming from warmer places. There are many places where you can study but Avery Library is my favorite library on campus. If you have any questions or opinions on this Q&A story, please feel free to drop me a line!
For this year’s Outstanding Undergraduate Researcher Award, Payal Chandak, Sophia Kolak, and Yanda Chen were among students recognized by the Computing Research Association (CRA) for their work in an area of computing research.
 Payal Chandak
Payal Chandak
Finalist
Using Machine Learning to Identify Adverse Drug Effects Posing Increased Risk to Women
Payal Chandak Columbia University, Nicholas Tatonetti Columbia University
The researchers developed AwareDX – Analysing Women At Risk for Experiencing Drug toXicity – a machine learning algorithm that identifies and predicts differences in adverse drug effects between men and women by analyzing 50 years’ worth of reports in an FDA database. The algorithm automatically corrects for biases in these data that stem from an overrepresentation of male subjects in clinical research trials.
Though men and women can have different responses to medications – the sleep aid Ambien, for example, metabolizes more slowly in women, causing next-day grogginess – doctors may not know about these differences because most clinical trial data itself is biased toward men. This trickles down to impact prescribing guidelines, drug marketing, and ultimately, patients’ health. Unfortunately, pharmaceutical companies have a history of ignoring complex problems and clinical trials have singularly studied men, not even including women. As a result, there is a lot less information about how women respond to drugs compared to men. The research tries to bridge this information gap.
 Sophia Kolak
Sophia Kolak
Finalist
It Takes a Village to Build a Robot: An Empirical Study of The ROS Ecosystem
Sophia Kolak Columbia University, Afsoon Afzal Carnegie Mellon University, Claire Le Goues Carnegie Mellon University, Michael Hilton Carnegie Mellon University, Christopher Steven Timperley Carnegie Mellon University
The Robot Operating System (ROS) is the most popular framework for robotics development. In this paper, the researchers conducted the first major empirical study of ROS, with the goal of understanding how developers collaborate across the many technical disciplines that coalesce in robotics.
Building a complete robot is a difficult task that involves bridging many technical disciplines. ROS aims to simplify development by providing reusable libraries, tools, and conventions for building a robot. Still, as building a robot requires domain expertise in software, mechanical, and electrical engineering, as well as artificial intelligence and robotics, ROS faces knowledge-based barriers to collaboration. The researchers wanted to understand how the necessity of domain-specific knowledge impacts the open-source collaboration model in ROS.
Virtually no one is an expert in every subdomain of robotics: experts who create computer vision packages likely need to rely on software designed by mechanical engineers to implement motor control. As a result, the researchers found that development in ROS is centered around a few unique subgroups each devoted to a different specialty in robotics (i.e. perception, motion). This is unlike other ecosystems, where competing implementations are the norm.
Detecting Performance Patterns with Deep Learning
Sophia Kolak Columbia University
Performance has a major impact on the overall quality of a software project. Performance bugs—bugs that substantially decrease run-time—have long been studied in software engineering, and yet they remain incredibly difficult for developers to handle. In this project, the researchers leveraged contemporary methods in machine learning to create graph embeddings of Python code that can be used to automatically predict performance.
Using un-optimized programming language concepts can lead to performance bugs and the researchers hypothesized that statistical language embeddings could help reveal these patterns. By transforming code samples into graphs that captured the control and data flow of a program, the researchers studied how various unsupervised embeddings of these graphs could be used to predict performance.
Implementing “sort” by hand as opposed to using the built-in Python sort function is an example of a choice that typically slows down a program’s run-time. When the researchers embedded the AST and data flow of a code snippet in Euclidean space (using DeepWalk), patterns like this were captured in the embedding and allowed classifiers to learn which structures are correlated with various levels of performance.
“I was surprised by how often research changes directions,” said Sophia Kolak. In both projects, they started out with one set of questions but answered completely different ones by the end. “It showed me that, in addition to persistence, research requires open-mindedness.”
 Yanda Chen
Yanda Chen
Honorable Mention
Cross-language Sentence Selection Via Data Augmentation and Rationale Training
Yanda Chen Columbia University, Chris Kedzie Columbia University, Suraj Nair University of Maryland, Petra Galuscakova University of Maryland, Rui Zhang Yale University, Douglas Oard University of Maryland, and Kathleen McKeown Columbia University
In this project, the researchers proposed a new approach to cross-language sentence selection, where they used models to predict sentence-level query relevance with English queries over sentences within document collections in low-resource languages such as Somali, Swahili, and Tagalog.
The system is used as part of cross-lingual information retrieval and query-focused summarization system. For example, if a user puts in a query word “business activity” and specifies Swahili as the language of source documents, then the system will automatically retrieve the Swahili documents that are related to “business activity” and produce short summaries that are then translated from Swahili to English.
A major challenge of the project was the lack of training data for low-resource languages. To tackle this problem, the researchers proposed to generate a relevance dataset of query-sentence pairs through data augmentation based on parallel corpora collected from the web. To mitigate the spurious correlations learned by the model, they proposed the idea of rationale training where they first trained a phrase-based statistical machine translation system and used the alignment information to provide additional supervision for the models.
The approach achieved state-of-the-art results on both text and speech across three languages – Somali, Swahili, and Tagalog.
Six papers from the Speech & NLP group were accepted to the Empirical Methods in Natural Language Processing (EMNLP) conference.
Generating Similes Effortlessly Like a Pro: A Style Transfer Approach for Simile Generation
Tuhin Chakrabarty Columbia University, Smaranda Muresan Columbia University, and Nanyun Peng University of Southern California and University of California, Los Angeles
Abstract:
Literary tropes, from poetry to stories, are at the crux of human imagination and communication. Figurative language, such as a simile, goes beyond plain expressions to give readers new insights and inspirations. We tackle the problem of simile generation. Generating a simile requires proper understanding for effective mapping of properties between two concepts. To this end, we first propose a method to automatically construct a parallel corpus by transforming a large number of similes collected from Reddit to their literal counterpart using structured common sense knowledge. We then fine-tune a pre-trained sequence to sequence model, BART (Lewis et al., 2019), on the literal-simile pairs to generate novel similes given a literal sentence. Experiments show that our approach generates 88% novel similes that do not share properties with the training data. Human evaluation on an independent set of literal statements shows that our model generates similes better than two literary experts 37%1 of the times, and three baseline systems including a recent metaphor generation model 71%2 of the times when compared pairwise.3 We also show how replacing literal sentences with similes from our best model in machine-generated stories improves evocativeness and leads to better acceptance by human judges.
Content Planning for Neural Story Generation with Aristotelian Rescoring
Seraphina Goldfarb-Tarrant University of Southern California and University of Edinburgh, Tuhin Chakrabarty Columbia University, Ralph Weischedel University of Southern California and Nanyun Peng University of Southern California and University of California, Los Angeles
Abstract:
Long-form narrative text generated from large language models manages a fluent impersonation of human writing, but only at the local sentence level, and lacks structure or global cohesion. We posit that many of the problems of story generation can be addressed via high-quality content planning, and present a system that focuses on how to learn good plot structures to guide story generation. We utilize a plot-generation language model along with an ensemble of rescoring models that each implement an aspect of good story-writing as detailed in Aristotle’s Poetics. We find that stories written with our more principled plot structure are both more relevant to a given prompt and higher quality than baselines that do not content plan, or that plan in an unprincipled way.
Severing the Edge Between Before and After: Neural Architectures for Temporal Ordering of Events
Miguel Ballesteros Amazon AI, Rishita Anubhai Amazon AI, Shuai Wang Amazon AI, Nima Pourdamghani Amazon AI, Yogarshi Vyas Amazon AI, Jie Ma Amazon AI, Parminder Bhatia Amazon AI, Kathleen McKeown Columbia University and Amazon AI and Yaser Al-Onaizan Amazon AI
Abstract:
In this paper, we propose a neural architecture and a set of training methods for ordering events by predicting temporal relations. Our proposed models receive a pair of events within a span of text as input and they identify temporal relations (Before, After, Equal, Vague) between them. Given that a key challenge with this task is the scarcity of annotated data, our models rely on either pre-trained representations (i.e. RoBERTa, BERT or ELMo), transfer, and multi-task learning (by leveraging complementary datasets), and self-training techniques. Experiments on the MATRES dataset of English documents establish a new state-of-the-art on this task.
Controllable Meaning Representation to Text Generation: Linearization and Data Augmentation Strategies
Chris Kedzie Columbia University and Kathleen McKeown Columbia University
Abstract:
We study the degree to which neural sequenceto-sequence models exhibit fine-grained controllability when performing natural language generation from a meaning representation. Using two task-oriented dialogue generation benchmarks, we systematically compare the effect of four input linearization strategies on controllability and faithfulness. Additionally, we evaluate how a phrase-based data augmentation method can improve performance. We find that properly aligning input sequences during training leads to highly controllable generation, both when training from scratch or when fine-tuning a larger pre-trained model. Data augmentation further improves control on difficult, randomly generated utterance plans.
Zero-Shot Stance Detection: A Dataset and Model using Generalized Topic Representations
Emily Allaway Columbia University and Kathleen McKeown Columbia University
Abstract:
Stance detection is an important component of understanding hidden influences in everyday life. Since there are thousands of potential topics to take a stance on, most with little to no training data, we focus on zero-shot stance detection: classifying stance from no training examples. In this paper, we present a new dataset for zero-shot stance detection that captures a wider range of topics and lexical variation than in previous datasets. Additionally, we propose a new model for stance detection that implicitly captures relationships between topics using generalized topic representations and show that this model improves performance on a number of challenging linguistic phenomena.
Unsupervised Cross-Lingual Part-of-Speech Tagging for Truly Low-Resource Scenarios
Ramy Eskander Columbia University, Smaranda Muresan Columbia University, and Michael Collins Columbia University
Abstract:
We describe a fully unsupervised cross-lingual transfer approach for part-of-speech (POS) tagging under a truly low resource scenario. We assume access to parallel translations between the target language and one or more source languages for which POS taggers are available. We use the Bible as parallel data in our experiments: small size, out-of-domain, and covering many diverse languages. Our approach innovates in three ways: 1) a robust approach of selecting training instances via cross-lingual annotation projection that exploits best practices of unsupervised type and token constraints, word-alignment confidence and density of projected POS, 2) a Bi-LSTM architecture that uses contextualized word embeddings, affix embeddings and hierarchical Brown clusters, and 3) an evaluation on 12 diverse languages in terms of language family and morphological typology. In spite of the use of limited and out-of-domain parallel data, our experiments demonstrate significant improvements in accuracy over previous work. In addition, we show that using multi-source information, either via projection or output combination, improves the performance for most target languages.
Open-source CRYLOGGER is the first tool that detects cryptographic misuses by running the Android app instead of analyzing its code.
Payal Chandak (CC ’21) developed a machine learning model, AwareDX, that helps detect adverse drug effects specific to women patients. AwareDX mitigates sex biases in a drug safety dataset maintained by the FDA.
Below, Chandak talks about how her internship under the guidance of Nicholas Tatonetti, associate professor of biomedical informatics and a member of the Data Science Institute, inspired her to develop a machine learning tool to improve healthcare for women.

How did the project come about?
I initiated this project during my internship at the Tatonetti Lab (T-lab) the summer after my first year. T-lab uses data science to study the side effects of drugs. I did some background research and learned that women face a two-fold greater risk of adverse events compared to men. While knowledge of sex differences in drug response is critical to drug prescription, there currently isn’t a comprehensive understanding of these differences. Dr. Tatonetti and I felt that we could use machine learning to tackle this problem and that’s how the project was born.
How many hours did you work on the project? How long did it last?
The project lasted about two years. We refined our machine learning (ML) model, AwareDX, over many iterations to make it less susceptible to biases in the data. I probably spent a ridiculous number of hours developing it but the journey has been well worth it.
Were you prepared to work on it or did you learn as the project progressed?
As a first-year student, I definitely didn’t know much when I started. Learning on the go became the norm. I understood some things by taking relevant CS classes and through reading Medium blogs and GitHub repositories –– this ability to learn independently might be one of the most valuable skills I have gained. I am very fortunate that Dr. Tatonetti guided me through this process and invested his time in developing my knowledge.
What were the things you already knew and what were the things you had to learn while working on the project?
While I was familiar with biology and mathematics, computer science was totally new! In fact, T-Lab launched my journey to exploring computer science. This project exposed me to the great potential of artificial intelligence (AI) for revolutionizing healthcare, which in turn inspired me to explore the discipline academically. I went back and forth between taking classes relevant to my research and applying what I learned in class to my research. As I took increasingly technical classes like ML and probabilistic modelling, I was able to advance my abilities.
Looking back, what were the skills that you wished you had before the project?
Having some experience with implementing real-world machine learning projects on giant datasets with millions of observations would have been very valuable.
Was this your first project to collaborate on? How was it?
This was my first project and I worked under the guidance of Dr. Tatonetti. I thought it was a wonderful experience – not only has it been extremely rewarding to see my work come to fruition, but the journey itself has been so valuable. And Dr. Tatonetti has been the best mentor that I could have asked for!
Did working on this project make you change your research interests?
I actually started off as pre-med. I was fascinated by the idea that “intelligent machines” could be used to improve medicine, and so I joined T-Lab. Over time, I’ve realized that recent advances in machine learning could redefine how doctors interact with their patients. These technologies have an incredible potential to assist with diagnosis, identify medical errors, and even recommend treatments. My perspective on how I could contribute to healthcare shifted completely, and I decided that bioinformatics has more potential to change the practice of medicine than a single doctor will ever have. This is why I’m now hoping to pursue a PhD in Biomedical Informatics.
Do you think your skills were enhanced by working on the project?
Both my knowledge of ML and statistics and my ability to implement my ideas have grown immensely as a result of working on this project. Also, I failed about seven times over two years. We were designing the algorithm and it was an iterative process – the initial versions of the algorithm had many flaws and we started from scratch multiple times. The entire process required a lot of patience and persistence since it took over 2 years! So, I guess it has taught me immense patience and persistence.
Why did you decide to intern at the T-Lab?
I was curious to learn more about the intersection of artificial intelligence and healthcare. I’m endlessly fascinated by the idea of improving the standards of healthcare by using machine learning models to assist doctors.
Would you recommend volunteering or seeking projects out to other students?
Absolutely. I think everyone should explore research. We have incredible labs here at Columbia with the world’s best minds leading them. Research opens the doors to work closely with them. It creates an environment for students to learn about a niche discipline and to apply the knowledge they gain in class.
This summer seminar series highlights 14 computer science PhD students. The handpicked group of students hosted individual Zoom sessions to discuss their experiences and research projects.
A team led by professor Christos Papadimitriou proposes a new computational system to expand the understanding of the brain at an intermediate level, between neurons and cognitive phenomena such as language.
For this year’s Outstanding Undergraduate Researcher Award, three computer science students received honorable mentions – Lalita Devadas, Dave Epstein, and Jessy Xinyi Han. The Computing Research Association (CRA) recognized the undergraduates for their work in an area of computing research.

Secure Montgomery Multiplication and Repeated Squares for Modular Exponentiation
Lalita Devadas Columbia University and Justin Bloom Oregon State University
The researchers worked on using some recent advances in garbling of arithmetic circuits for secure exponentiation mod N, a vital operation in many cryptosystems, including in the RSA public-key cryptosystem.
A garbled circuit is a cryptographic protocol which allows for secure two-party computation, in which two parties, Alice and Bob, each with a private input, want to compute some shared function of their inputs without either party learning the other’s input.
Their novel approach implemented the Montgomery multiplication method, which uses clever arithmetic to avoid costly division by the modulus being multiplied in. The best method they found had each wire in a circuit representing one digit of a number in base p. They developed a system of base p arithmetic which is asymptotically more efficient in the given garbled circuit architecture than any existing protocols.
They measured performance for both approaches by counting the ciphertexts communicated for a single multiplication (a typical measure of efficiency for garbled circuit operations). They found that the base p Montgomery multiplication implementation vastly outperformed all other implementations for values of N with bit length greater than 500 (i.e., all N used for applications like RSA encryption).
“Unfortunately, our best implementations showed only incremental improvement over existing non-Montgomery-based implementations for values of N used in practice,” said Lalita Devadas. “We are still looking into further optimizations using Montgomery multiplication.”
Secure multiparty computation has many applications outside of computer science. For example, suppose five friends want to know their cumulative net worth without anyone learning anyone else’s individual net worth. This is actually a secure computation problem, since the friends want to perform some computation of their inputs while keeping said inputs private from other parties.

Oops! Predicting Unintentional Action in Video
Dave Epstein Columbia University, Boyuan Chen Columbia University, and Carl Vondrick Columbia University
The paper trains models to detect when human action is unintentional using self-supervised computer vision, an important step towards machines that can intelligently reason about the intentions behind complex human actions.
Despite enormous scientific progress over the last five to ten years, machines still struggle with tasks learned quickly and autonomously by young children, such as understanding human behavior or learning to speak a language. Epstein’s research tackles these types of problems by using self-supervised computer vision, a paradigm that predicts information naturally present in large amounts of input data such as images or videos. This stands in contrast with supervised learning, which relies on humans manually labelling data (e.g. “this is a picture of a dog”).
“I was surprised to learn that failure is an expected part of research and that it can take a long time to realize you’re failing,” said Dave Epstein. “Taking a failed idea, identifying the promising parts, and trying again leads to successful research.”

Seeding Network Influence in Biased Networks and the Benefits of Diversity
Ana-Andreea Stoica Columbia University, Jessy Xinyi Han Columbia University, and Augustin Chaintreau Columbia University
The paper explores the problem of social influence maximization and how information is diffused in a social network.
For example, it might be about what kind of news people read on social media, how many people know about job opportunities or who hears about the latest loan options from a bank. So given a social network, classical algorithms are focused on picking the best k early-adopters based on how central they are in a network, say, based on their number of connections, to maximize outreach.
However, since social inequalities are reflected in the uneven networks, classical algorithms which ignore demographics often amplify such inequalities in information access.
“We were wondering if we can do better than an algorithm that ignores demographics,” said Jessy Xinyi Han. “‘Better’ here means more people in total and more people from the disadvantaged group can receive the information.”
Through a network model with unequal communities, they developed new heuristics to take demographics into account, showing that including sensitive features in the input of most natural seed selection algorithms substantially improves diversity but also often leaves efficiency untouched or even provides a small gain.
Such analytical condition turned out to be a closed-form condition on the number of early adopters. They also validated this result on the real CS co-authorship network from DBLP.
The 33rd Conference on Neural Information Processing Systems (NeurIPS 2019) fosters the exchange of research on neural information processing systems in their biological, technological, mathematical, and theoretical aspects.
The annual meeting is one of the premier gatherings in artificial intelligence and machine learning that featured talks, demos from industry partners as well as tutorials. Professor Vishal Misra, with colleagues from the Massachusetts Institute of Technology (MIT), held a tutorial on synthetic control.
At this year’s NeurIPS, 21 papers from the department were accepted to the conference. Computer science professors and students worked with researchers from the statistics department and the Data Science Institute.
Noise-tolerant Fair Classification
Alex Lamy Columbia University, Ziyuan Zhong Columbia University, Aditya Menon Google, Nakul Verma Columbia University
Fairness-aware learning involves designing algorithms that do not discriminate with respect to some sensitive feature (e.g., race or gender) and is usually done under the assumption that the sensitive feature available in a training sample is perfectly reliable.
This assumption may be violated in many real-world cases: for example, respondents to a survey may choose to conceal or obfuscate their group identity out of fear of potential discrimination. In the paper, the researchers show that fair classifiers can still be used given noisy sensitive features by simply changing the desired fairness-tolerance. Their procedure is empirically effective on two relevant real-world case-studies involving sensitive feature censoring.
Poisson-randomized Gamma Dynamical Systems
Aaron Schein UMass Amherst, Scott Linderman Columbia University, Mingyuan Zhou University of Texas at Austin, David Blei Columbia University, Hanna Wallach MSR NYC
This paper presents a new class of state space models for count data. It derives new properties of the Poisson-randomized gamma distribution for efficient posterior inference.
Using Embeddings to Correct for Unobserved Confounding in Networks
Victor Veitch Columbia University, Yixin Wang Columbia University, David Blei Columbia University
This paper address causal inference in the presence of unobserved confounder when proxy is available for the confounders in the form of a network connecting the units. For example, the link structure of friendships in a social network reveals information about the latent preferences of people in that network. The researchers show how modern network embedding methods can be exploited to harness the network estimation for efficient causal adjustment.
Variational Bayes Under Model Misspecification
Yixin Wang Columbia University, David Blei Columbia University
The paper characterizes the theoretical properties of a popular machine learning algorithm, variational Bayes (VB). The researchers studied the VB under model misspecification, which is the setting that is most aligned with the practice, and show that the VB posterior is asymptotically normal and centers at the value that minimizes the Kullback-Leibler (KL) divergence to the true data-generating distribution.
As a consequence, they found that the model misspecification error dominates the variational approximation error in VB posterior predictive distributions. In other words, VB pays a negligible price in producing posterior predictive distributions. It explains the widely observed phenomenon that VB achieves comparable predictive accuracy with MCMC even though VB uses an approximating family.
Poincaré Recurrence, Cycles and Spurious Equilibria in Gradient-Descent-Ascent for Non-Convex Non-Concave Zero-Sum Games
Emmanouil-Vasileios Vlatakis-Gkaragkounis Columbia University, Lampros Flokas Columbia University, Georgios Piliouras Singapore University of Technology and Design
The paper introduces a model that captures a min-max competition over complex error landscapes and shows that even a simplified model can provably replicate some of the most commonly reported failure modes of GANs (non-convergence, deadlock in suboptimal states, etc).
Moreover, the researchers were able to understand the hidden structure in these systems — the min-max competition can lead to system behavior that is similar to that of energy preserving systems in physics (e.g. connected pendulums, many-body problems, etc). This makes it easier to understand why these systems can fail and gives new tools in the design of algorithms for training GANs.
Near-Optimal Reinforcement Learning in Dynamic Treatment Regimes
Junzhe Zhang Columbia University, Elias Bareinboim Columbia University
Dynamic Treatment Regimes (DTRs) are particularly effective for managing chronic disorders and is arguably one of the key aspects towards more personalized decision-making. The researchers developed the first adaptive algorithm that achieves near-optimal regret in DTRs in online settings, while leveraging the abundant, yet imperfect confounded observations. Applications are given to personalized medicine and treatment recommendation in clinical decision support.
Paraphrase Generation with Latent Bag of Words
Yao Fu Columbia University, Yansong Feng Peking University, John Cunningham University of Columbia
The paper proposes a latent bag of words model for differentiable content planning and surface realization in text generation. This model generates paraphrases with clear steps, adding interpretability and controllability of existing neural text generation models.
Adapting Neural Networks for the Estimation of Treatment Effects
Claudia Shi Columbia University, David Blei Columbia University, Victor Veitch Columbia University
This paper addresses how to design neural networks to get very accurate estimates of causal effects from observational data. The researchers propose two methods based on insights from the statistical literature on the estimation of treatment effects.
The first is a new architecture, the Dragonnet, that exploits the sufficiency of the propensity score for estimation adjustment. The second is a regularization procedure, targeted regularization, that induces a bias towards models that have non-parametrically optimal asymptotic properties “out-of-the-box”. Studies on benchmark datasets for causal inference show these adaptations outperform existing methods.
Efficiently Avoiding Saddle Points with Zero Order Methods: No Gradients Required
Emmanouil-Vasileios Vlatakis-Gkaragkounis Columbia University, Lampros Flokas Columbia University, Georgios Piliouras Singapore University of Technology and Design
The researchers prove that properly tailored zero-order methods are as effective as their first-order counterparts. This analysis requires a combination of tools from optimization theory, probability theory and dynamical systems to show that even without perfect knowledge of the shape of the error landscape, effective optimization is possible.
Metric Learning for Adversarial Robustness
Chengzhi Mao Columbia University, Ziyuan Zhong Columbia University, Junfeng Yang Columbia University, Carl Vondrick Columbia University, Baishakhi Ray Columbia University
Deep networks are well-known to be fragile to adversarial attacks. The paper introduces a novel Triplet Loss Adversarial (TLA) regulation that is the first method that leverages metric learning to improve the robustness of deep networks. This method is inspired by the evidence that deep networks suffer from distorted feature space under adversarial attacks. The method increases the model robustness and efficiency for the detection of adversarial attacks significantly.
Efficient Symmetric Norm Regression via Linear Sketching
Zhao Song University of Washington, Ruosong Wang Carnegie Mellon University, Lin Yang Johns Hopkins University, Hongyang Zhang TTIC, Peilin Zhong Columbia University
The paper studies linear regression problems with general symmetric norm loss and gives efficient algorithms for solving such linear regression problems via sketching techniques.
Rethinking Generative Coverage: A Pointwise Guaranteed Approach
Peilin Zhong Columbia University, Yuchen Mo Columbia University, Chang Xiao Columbia University, Pengyu Chen Columbia University, Changxi Zheng Columbia University
The paper presents a novel and formal definition of mode coverage for generative models. It also gives a boosting algorithm to achieve this mode coverage guarantee.
How Many Variables Should Be Entered in a Principal Component Regression Equation?
Ji Xu Columbia University, Daniel Hsu Columbia University
The researchers studied the least-squares linear regression over $N$ uncorrelated Gaussian features that are selected in order of decreasing variance with the number of selected features $p$ can be either smaller or greater than the sample size $n$. And give an average-case analysis of the out-of-sample prediction error as $p,n,N \to \infty$ with $p/N \to \alpha$ and $n/N \to \beta$, for some constants $\alpha \in [0,1]$ and $\beta \in (0,1)$. In this average-case setting, the prediction error exhibits a “double descent” shape as a function of $p$. This also establishes conditions under which the minimum risk is achieved in the interpolating ($p>n$) regime.
Adaptive Influence Maximization with Myopic Feedback
Binghui Peng Columbia University, Wei Chen Microsoft Research
The paper investigates the adaptive influence maximization problem and provides upper and lower bounds for the adaptivity gaps under myopic feedback model. The results confirm a long standing open conjecture by Golovin and Krause (2011).
Towards a Zero-One Law for Column Subset Selection
Zhao Song University of Washington, David Woodruff Carnegie Mellon University, Peilin Zhong Columbia University
The researchers studied low-rank matrix approximation with general loss function and showed that if the loss function has several good properties, then there is an efficient way to compute a good low-rank approximation. Otherwise, it could be hard to compute a good low-rank approximation efficiently.
Average Case Column Subset Selection for Entrywise l1-Norm Loss
Zhao Song University of Washington, David Woodruff Carnegie Mellon University, Peilin Zhong Columbia University
The researchers studied how to compute an l1-norm loss low-rank matrix approximation to a given matrix. And showed that if the given matrix can be decomposed into a low-rank matrix and a noise matrix with a mild distributional assumption, we can obtain a (1+eps) approximation to the optimal solution.
A New Distribution on the Simplex with Auto-Encoding Applications
Andrew Stirn Columbia University, Tony Jebara Spotify, David Knowles Columbia University
The researchers developed a surrogate distribution for the Dirichlet that offers explicit, tractable reparameterization, the ability to capture sparsity, and has barycentric symmetry properties (i.e. exchangeability) equivalent to the Dirichlet. Previous works have used the Kumaraswamy distribution in a stick-breaking process to create a non-exchangeable distribution on the simplex. The method was improved by restoring exchangeability and demonstrating that approximate exchangeability is efficiently achievable. Lastly, the method was showcased in a variety of VAE semi-supervised learning tasks.
Discrete Flows: Invertible Generative Models of Discrete Data
Dustin Tran Google Brain, Keyon Vafa Columbia University, Kumar Agrawal Google AI Resident, Laurent Dinh Google Brain, Ben Poole Google Brain
While normalizing flows have led to significant advances in modeling high-dimensional continuous distributions, their applicability to discrete distributions remains unknown. The researchers extend normalizing flows to discrete events, using a simple change-of-variables formula not requiring log-determinant-Jacobian computations. Empirically, they find that discrete flows obtain competitive performance with or outperform autoregressive baselines on various tasks, including addition, Potts models, and language models.
Characterization and Learning of Causal Graphs with Latent Variables from Soft Interventions
Murat Kocaoglu MIT-IBM Watson AI Lab IBM Research, Amin Jaber Purdue University, Karthikeyan Shanmugam MIT-IBM Watson AI Lab IBM Research NY, Elias Bareinboim Columbia University
This work is all about learning causal relationships – the classic aim of which is to characterize all possible sets that could produce the observed data. In the paper, the researchers provide a complete characterization of all possible causal graphs with observational and interventional data involving so-called ‘soft interventions’ on variables when the targets of soft interventions are known.
This work potentially could lead to discovery of other novel learning algorithms that are both sound and complete.
Identification of Conditional Causal Effects Under Markov Equivalence
Amin Jaber Purdue University, Jiji Zhang Lingnan University, Elias Bareinboim Columbia University
Causal identification is the problem of deciding whether a causal distribution is computable from a combination of qualitative knowledge about the underlying data-generating process, which is usually encoded in the form of a causal graph, and an observational distribution. Despite the obvious need for identifying causal effects throughout the data-driven sciences, in practice, finding the causal graph is a notoriously challenging task.
In this work, the researchers provide a relaxation of the requirement of having to specify the causal graph (based on substantive knowledge) and allow the input of the inference to be an equivalence class of causal graphs, which can be inferred from data. Specifically, they propose the first general algorithm to learn conditional causal effects entirely from data. This result is particularly useful for evaluating the impact of conditional plans and stochastic policies, which appear both in AI (in the context of reinforcement learning) and in the data-driven sciences.
Efficient Identification in Linear Structural Causal Models with Instrumental Cutsets
Daniel Kumor Purdue University, Bryant Chen Brex Inc., Elias Bareinboim Columbia University
Regression analysis is one of the most common tools used in modern data science. While there is a great understanding and powerful technology to perform regression analysis in high dimensional spaces, the output of such a method is purely associational and devoid of any causal interpretation.
The researchers studied the problem of identification of structural (causal) coefficients in linear systems (deciding whether regression coefficients are amenable to causal interpretation, etc). Building on a technique called instrumental variables, they developed a new method called Instrumental Cutset, which partitions the systems into tractable components such that identification can be decided more efficiently. The resulting algorithm was efficient and strictly more powerful than the current state-of-the-art methods.
Assistant Professor Allison Bishop takes a look at failure and how people can learn from “unsuccessful” research.
When it comes to research and getting papers into cryptography conferences, there usually has to be a “positive” result — either a new theorem must be proven, a new algorithm must be presented, or a successful attack on an existing algorithm must be obtained. If researchers try to accomplish a lofty goal and fall short, but manage to achieve a smaller goal, they typically present only the smaller goal as if it was the point on its own.

“I’ve found that not every research paper magically comes together and has a “great” result,” said Allison Bishop, who has been teaching since 2013. “Our community doesn’t really talk about the research process and I wanted to highlight research where even if it “failed” there is still something to learn from it.”
Through the years Bishop noticed the lack of a venue to talk about all kinds of research. When she and other researchers studied obfuscation it resulted in a paper “In Pursuit of Clarity In Obfuscation”. In the paper they talked about how they “failed” but managed to still learn from their mistakes. Their topic on failure was not considered a “standard” that could be published and they were not able to submit it to a conference. But Bishop, along with PhD students Luke Kowalczyk and Kevin Shi, really wanted to get their findings out and share it with other researchers.
And so, a conference dedicated to disseminating insightful failures of the cryptology research community was born. The Conference for Failed Approaches and Insightful Losses in Cryptology or CFAIL featured seven previously unpublished papers for a day of talks by computer scientists on insightful failures spanning the full range from cryptanalysis (trying to break systems) to cryptographic theory and design (constructing new systems and proving things about specific systems or about abstract systems, etc.).
“CFAIL is great for our field in that it promotes openness and accessibility for these kinds of ideas which are typically sort of intimate,” said Luke Kowalczyk, who completed his PhD in November of last year. “When approaching new problems, it’s always helpful to see the approaches of other researchers, even if they were not successful. However, it’s rare to see failed approaches explained in a public and formal setting.”
They were not alone in thinking about the lack of dialogue on research failures. At the time of the conference, a thread on Hacker News (a tech news aggregator) discussed the incentive structures of academia. Shared Kowalczyk, “I was proud to see CFAIL cited as an example of a scientific field with a formal venue to help promote this kind of openness.”
“There is a deeply ingrained human tendency to fear that being open about failure will make other people think you are dumb,” said Bishop. On the contrary, the researchers at CFAIL were some of the “most creative, bold, and deeply intelligent people.” And the atmosphere it created was energizing for the participants — the audience got pretty involved and felt comfortable asking questions, and even started thinking about some of the open research problems in real time. Continued Bishop, ”I think talking about failure is probably the best scientific communication strategy left that is severely underused.”
Bishop will continue to promote openness in scientific research with another CFAIL at Crypto 2020. This time around it will be a workshop at the conference and a call for papers will be out soon.
IBM has selected assistant professor Baishakhi Ray for an IBM Faculty Award. The highly selective award is given to professors in leading universities worldwide to foster collaboration with IBM researchers. Ray will use the funds to continue research on artificial intelligence-driven program analysis to understand software robustness.
Although much research has been done, there are still countless vulnerabilities that make system robustness brittle. Hidden vulnerabilities are discovered all the time – either through a system hack or monitoring system’s functionalities. Ray is working to automatically detect system weaknesses using artificial intelligence (AI) with her project, “Improving code representation for enhanced deep learning to detect and remediate security vulnerabilities”.
One of the major challenges in AI-based security vulnerability detection is finding the best source code representation that can distinguish between vulnerable versus benign code. Such representation can further be used as an input in supervised learning settings for automatic vulnerability detection and fixes. Ray is tackling this problem by building new machine-learning models for source code and applying machine learning techniques such as code embeddings. This approach could open new ways of encoding source code into feature vectors.
“It will provide new ways to make systems secure,” said Ray, who joined the department in 2018. “The goal is to reduce the hours of manual effort spent in automatically detecting vulnerabilities and fixing them.”
A successful outcome of this project will produce a new technique to encode source code with associated trained models that will be able to detect and remediate a software vulnerability with increased accuracy.
IBM researchers Jim Laredo and Alessandro Morari will collaborate closely with Ray and her team on opportunities around design, implementation, and evaluation of this research.
FREP awards grants to faculty members in support of research to enhance people’s lives by improving the internet. FREP was founded in 2012 to foster cutting-edge collaborations between scientists in academic settings and those at Yahoo Research.
Jana’s proposal aims to improve security, reliability and robustness of infrastructure software.

The application performance testing company NimbleDroid was recently acquired by mobile performance platform HeadSpin. Co-founded by professor Junfeng Yang and PhD student Younghoon Jeon, the tool is used to detect bugs and performance bottlenecks during the development and testing phase of mobile apps and websites.
“I’ve always liked programming but hated the manual debugging process,” said Junfeng Yang, who joined the department in 2008. “So I thought it would be good to use artificial intelligence and program analysis to automate the task of debugging.”
NimbleDroid scans apps for bugs and bottlenecks and sends a report back with a list of issues. The New York Times wrote about how they used it to identify bottleneck issues with the start up time of their android app and speed it up by four times. Pinterest also used the tool during a testing phase and was able to resolve issues within 21 hours. Previously they would hear about problems from users once the app was already released, and spent “multiple days” to identify and fix the problems.
NimbleDroid has a premier list of customers, some of which also use HeadSpin. These common customers connected Yang and HeadSpin’s CEO Manish Lachwani. They thought that NimbleDroid would be a great addition to HeadSpin’s suite of mobile testing and performance solutions. The acquisition was recently announced with Yang named as Chief Scientist of HeadSpin.
Because the initial technology for NimbleDroid started at Columbia, Yang and Jeon worked with Columbia Technology Ventures (CTV) to license the technology. They started a company, got the exclusive license for the technology, and further developed the tool. CTV is the technology transfer office that facilitates the transition of inventions from academic research labs to the market.
“We are excited that our research is widely used by unicorn and Fortune 1000 companies and helps over a billion users,” said Yang. “But our work is not done, we are developing more technologies to make it easy to launch better software faster.”
Professor Vishal Misra is an avid fan of cricket and now works on research that looks at the vast amount of data on the sport.
“I live in two worlds – one where I am a computer science professor and the other where I am ‘the cricket guy’,” said Vishal Misra, who has been with the department since 2001 and recently received the Distinguished Alumnus of IIT Bombay award.

For the most part, Misra has kept these two worlds separate until last year when he worked on research with colleagues at MIT that forecasts the evolution or progress of the score of a cricket match.
When a game is affected by rain and is cut short, there is a statistical system in place – the Duckworth-Lewis-Stern System which either resets the target or declares the winner if no more play is possible. Their analysis showed that the current method is biased and they developed a better method based on the same ideas that are used to predict the evolution of the game. Their algorithm looks at data of past games and the current game and uses the theory of robust synthetic control to come up with a prediction that is surprisingly accurate.
The first time Misra became involved in the techie side of cricket was through CricInfo, the go-to website for anything to do with the sport. (It is now owned by ESPN.)

In the early 90s, during the internet’s infancy, fans would “meet” and chat in IRC (internet relay chat) chat rooms to talk about the sport. This was a godsend for Misra who had moved to the United States from India for graduate studies at the University of Massachusetts Amherst. Cricket was (and still is) not that popular here but imagine living in 1993 and not be able to hop onto a computer or a smartphone to find out the latest scores? He would call home or go to a bookstore in Boston to buy Indian sports magazines like Sportstar and India Today.
Through the #cricket chatrooms, he met CricInfo’s founder Simon King and they developed the first website with the help of other volunteers spread across the globe. Misra shared, “It was a site by the fans for the fans, that was always the priority.” They also launched live scorecards and game coverage of the 1996 world championships. Misra wrote about the experience for CricInfo’s 20th anniversary. He stuck with his PhD studies and remained in the US when CricInfo became a proper business and opened an office in England.
“I did a lot of coding back then but my first computer science class was the one I taught here in Columbia,” said Misra, who studied electrical engineering for his undergraduate and graduate degrees and joined the department as an assistant professor.
For his PhD thesis, he developed a stochastic differential equation model for TCP, the protocol that carries almost all of the internet’s data traffic. Some of the work he did with colleagues to create a congestion control mechanism based on that model has become part of the internet standard and runs on every cable modem in the world. Cisco took the basic mechanism that they developed, adapted it, and pushed it for standardization. “That gives me a big kick,” said Misra. “That algorithm is actually running almost everywhere.”
Since then his research focus has been on networking and now includes work on internet economics. Richard Ma, a former PhD student who is now faculty at National University Singapore, introduced him to this area. They studied network neutrality issues very early on which led to his playing an active part in the net neutrality debate in India, working with the government, regulators, and citizen activists. “India now has the strongest pro-consumer regulations anywhere in the world, which mirrors the definition I proposed of network neutrality,” he said.
For now, he continues research on net neutrality and differential pricing. He is also working on data center networking research with Google, where he is a visiting scientist. Another paper that generalizes the theory of synthetic control and applies the generalized theory to cricket is in the works. The new paper makes a fundamental contribution to the theory of synthetic control and as a fun application, they used it to study cricket.
“While I continue my work in networking, I am really excited about the applications of generalized synthetic control. It is a tool that is going to become incredibly important in all aspects of society,” said Misra. “It can be used in applications from studying the impact of a legislation or policy to algorithmic changes in some system – to predicting cricket scores!”
Columbia researchers presented their work at the Empirical Methods in Natural Language Processing (EMNLP) in Brussels, Belgium.
Professor Julia Hirschberg gave a keynote talk on the work done by the Spoken Language Processing Group on how to automatically detect deception in spoken language – how to identify cues in trusted speech vs. mistrusted speech and how these features differ by speaker and by listener. Slides from the talk can be viewed here.
Five teams with computer science undergrad and PhD students from the Natural Language Processing Group (NLP) also attended the conference to showcase their work on text summarization, analysis of social media, and fact checking.
Robust Document Retrieval and Individual Evidence Modeling for Fact Extraction and Verification
Tuhin Chakrabarty Computer Science Department, Tariq Alhindi Computer Science Department, and Smaranda Muresan Computer Science Department and Data Science Institute
”Given the difficult times, we are living in, it’s extremely necessary to be perfect with our facts,” said Tuhin Chakrabarty, lead researcher of the paper. “Misinformation spreads like wildfire and has long-lasting impacts. This motivated us to delve into the area of fact extraction and verification.”
This paper presents the ColumbiaNLP submission for the FEVER Workshop Shared Task. Their system is an end-to-end pipeline that extracts factual evidence from Wikipedia and infers a decision about the truthfulness of the claim based on the extracted evidence.
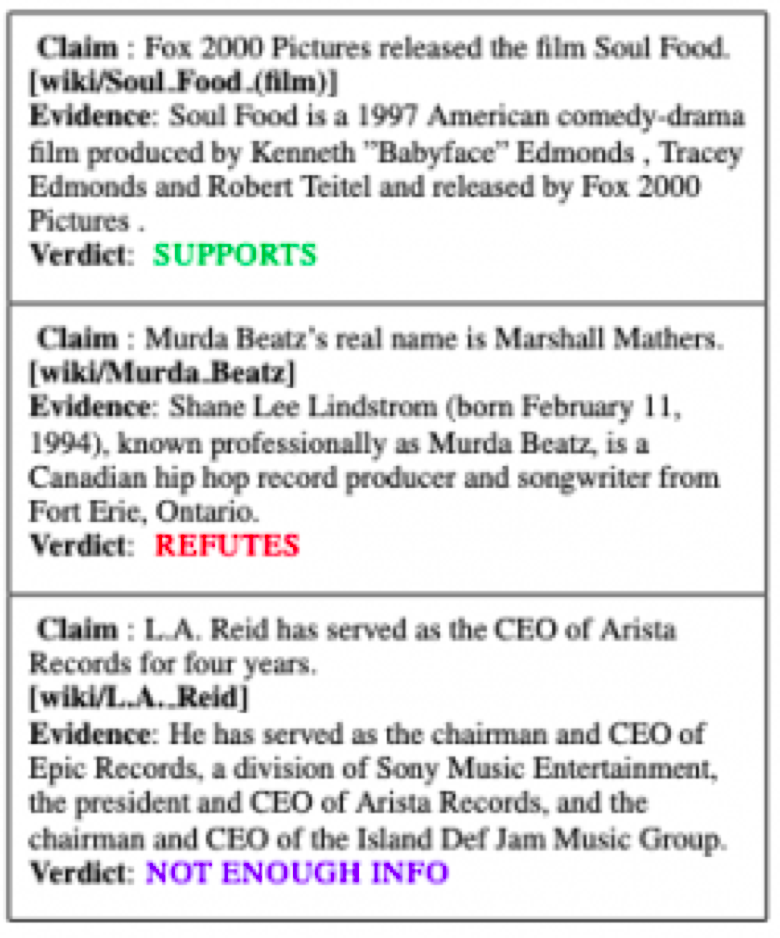
Fact checking is a type of investigative journalism where experts examine the claims published by others for their veracity. The claims can range from statements made by public figures to stories reported by other publishers. The end goal of a fact checking system is to provide a verdict on whether the claim is true, false, or mixed. Several organizations such as FactCheck.org and PolitiFact are devoted to such activities.
The FEVER Shared task aims to evaluate the ability of a system to verify information using evidence from Wikipedia. Given a claim involving one or more entities (mapping to Wikipedia pages), the system must extract textual evidence (sets of sentences from Wikipedia pages) that supports or refutes the claim and then using this evidence, it must label the claim as Supported, Refuted or NotEnoughInfo.
Detecting Gang-Involved Escalation on Social Media Using Context
Serina Chang Computer Science Department, Ruiqi Zhong Computer Science Department, Ethan Adams Computer Science Department, Fei-Tzin Lee Computer Science Department, Siddharth Varia Computer Science Department, Desmond Patton School of Social Work, William Frey School of Social Work, Chris Kedzie Computer Science Department, and Kathleen McKeown Computer Science Department
This research is a collaboration between Professor Kathy McKeown’s NLP lab and the Columbia School of Social Work. Professor Desmond Patton, from the School of Social Work and a member of the Data Science Institute, discovered that gang-involved youth in cities such as Chicago increasingly turn to social media to grieve the loss of loved ones, which may escalate into aggression toward rival gangs and plans for violence.
The team created a machine learning system that can automatically detect aggression and loss in the social media posts of gang-involved youth. They developed an approach with the hope to eventually use a system that can save critical time, scale reach, and intervene before more young lives are lost.
The system features the use of word embeddings and lexicons, automatically derived from a large domain-specific corpus which the team constructed. They also created context features that capture user’s recent posts, both in semantic and emotional content, and their interactions with other users in the dataset. Incorporating domain-specific resources and context feature in a Convolutional Neural Network (CNN) that leads to a significant improvement over the prior state-of-the-art.
The dataset used spans the public Twitter posts of nearly 300 users from a gang-involved community in Chicago. Youth volunteers and violence prevention organizations helped identify users and annotate the dataset for aggression and loss. Here are two examples of labeled tweets, both of which the system was able to classify correctly. Names are blocked out to preserve the privacy of users.

For semantics, which were represented by word embeddings, the researchers found that it was optimal to include 90 days of recent tweet history. While for emotion, where an emotion lexicon was employed, only two days of recent tweets were needed. This matched insight from prior social work research, which found that loss is significantly likely to precede aggression in a two-day window. They also found that emotions fluctuate more quickly than semantics so the tighter context window would be able to capture more fine-grained fluctuation.
“We took this context-driven approach because we believed that interpreting emotion in a given tweet requires context, including what the users had been saying recently, how they had been feeling, and their social dynamics with others,” said Serina Chang, an undergraduate computer science student. One thing that surprised them was the extent to which different types of context offered different types of information, as demonstrated by the contrasting contributions of the semantic-based user history feature and the emotion-based one. Continued Chang, “As we hypothesized, adding context did result in a significant performance improvement in our neural net model.”
Team SWEEPer: Joint Sentence
Extraction and Fact Checking with Pointer Networks
Christopher
Hidey Columbia University, Mona Diab Amazon AI Lab
Automated fact checking of textual claims is of increasing interest in today’s world. Previous research has investigated fact checking in political statements, news articles, and community forums.
“Through our model we can fact check claims and find specific statements that support the evidence,” said Christopher Hidey, a fourth year PhD student. “This is a step towards addressing the propagation of misinformation online.”
As part of the FEVER community shared task, the researchers developed models that given a statement would jointly find a Wikipedia article and a sentence related to the statement, and then predict whether the statement is supported by that sentence.
For example, given the claim “Lorelai Gilmore’s father is named Robert,” one could find the Wikipedia article on Lorelai Gilmore and extract the third sentence “Lorelai has a strained relationship with her wealthy parents, Richard and Emily, after running away as a teen to raise her daughter on her own” to show that the claim is false.
One aspect of this problem that the team observed was how poorly TF-IDF, a standard technique in information retrieval and natural language processing, performed at retrieving Wikipedia articles and sentences. Their custom model improved performance by 35 points in terms of recall over a TF-IDF baseline, achieving 90% recall for 5 articles. Overall, the model retrieved the correct sentence and predicted the veracity of the claim 50% of the time.
Where is your Evidence: Improving Fact-checking by Justification Modeling
Tariq Alhindi Computer Science Department, Savvas Petridis Computer Science Department, Smaranda Muresan Computer Science Department and Data Science Institute
The rate of which misinformation is spreading on the web is faster than the rate of manual fact-checking conducted by organizations like Politifact.com and Factchecking.org. For this paper the researchers wanted to explore how to automate parts or all of the fact-checking process. A poster with their findings was presented as part of the FEVER workshop.
“In order to come up with reliable fact-checking systems we need to understand the current manual process and identify opportunities for automation,” said Tariq Alhindi, lead author on the paper. They looked at the LIAR dataset – around 10,000 claims classified by Politifact.com to one of six degrees of truth – pants-on-fire, false, mostly-false, half-true, mostly-true, true. Continued Alhindi, we also looked at the fact-checking article for each claim and automatically extracted justification sentences of a given verdict and used them in our models, after removing all sentences that contain the verdict (e.g. true or false).

Feature-based machine learning models and neural networks were used to develop models that can predict whether a given statement is true or false. Results showed that using some sort of justification or evidence always improves the results of fake-news detection models.
“What was most surprising about the results is that adding features from the extracted justification sentences consistently improved the results no matter what classifier we used or what other features we included,” shared Alhindi, a PhD student. “However, we were surprised that the improvement was consistent even when we compare traditional feature-based linear machine learning models against state of the art deep learning models.”
Their research extends the previous work done on this data set which only looked at the linguistic cues of the claim and/or the metadata of the speaker (history, venue, party-affiliation, etc.). The researchers also released the extended dataset to the community to allow further work on this dataset with the extracted justifications.
Content Selection in Deep Learning Models of Summarization
Chris Kedzie Columbia University, Kathleen McKeown Columbia University, Hal Daume III University of Maryland, College Park
Recently, a specific type of machine learning, called deep learning, has made strides in reaching human level performance on hard to articulate problems, that is, things people do subconsciously like recognizing faces or understanding speech. And so, natural language processing researchers have turned to these models for the task of identifying the most important phrases and sentences in text documents, and have trained them to imitate the decisions a human editor might make when selecting content for a summary.
“Deep learning models have been successful in summarizing natural language texts, news articles and online comments,” said Chris Kedzie, a fifth year PhD student. “What we wanted to know is how they are doing it.”
While these deep learning models are empirically successful, it is not clear how they are performing this task. By design, they are learning to create their own representation of words and sentences, and then using them to predict whether a sentence is important – if it should go into a summary of the document. But just what kinds of information are they using to create these representations?
One hypotheses the researchers had was that certain types of words were more informative than others. For example, in a news article, nouns and verbs might be more important than adjectives and adverbs for identifying the most important information since such articles are typically written in a relatively objective manner.
To see if this was so, they trained models to predict sentence importance on redacted datasets, where either nouns, verbs, adjectives, adverbs, or function words were removed and compared them to models trained on the original data.
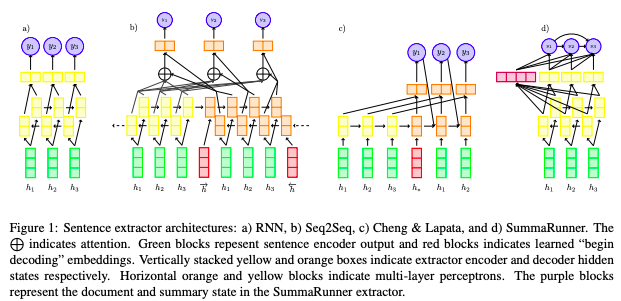
On a dataset of personal stories published on Reddit, adjectives and adverbs were the key to achieving the best performance. This made intuitive sense in that people tend to use intensifiers to highlight the most important or climactic moments in their stories with sentences like, “And those were the WORST customers I ever served.”
What surprised the researchers were the news articles – removing any one class of words did not dramatically decrease model performance. Either important content was broadly distributed across all kinds of words or there was some other signal that the model was using.
They suspected that sentence order was important because journalists are typically instructed to write according to the inverted pyramid style with the most important information at the top of the article. It was possible that the models were implicitly learning this and simply selecting sentences from the article lead.
Two pieces of evidence confirmed this. First, looking at a histogram of sentence positions selected as important, the models overwhelmingly preferred the lead of the article. Second, in a follow up experiment, the sentence ordered was shuffled to remove sentence position as a viable signal from which to learn. On news articles, model performance dropped significantly, leading to the conclusion that sentence position was most responsible for model performance on news documents.
The result concerned the researchers as they want models to be trained to truly understand human language and not use simple and brittle heuristics (like sentence position). “To connect this to broader trends in machine learning, we should be very concerned and careful about what signals are being exploited by our models, especially when making sensitive decisions,” Kedzie continued. ”The signals identified by the model as helpful may not truly capture the problem we are trying to solve, and worse yet, may be exploiting biases in the dataset that we do not wish it to learn.”
However, Kedzie sees this as an opportunity to improve the utility of word representations so that models are better able to use the article content itself. Along these lines, in the future, he hopes to show that by quantifying the surprisal or novelty of a particular word or phrase, models are able to make better sentence importance predictions. Just as people might remember the most surprising and unexpected parts of a good story.
Hwang spent the summer working for the Natural Language Text Processing Lab (NLP) and the Data Science Institute (DSI) on a joint project, doing research on gang violence in Chicago.
What was the topic/central focus of your research project?
I used the DSI’s Deep Neural Inspector to evaluate an NLP model that classified Tweets from gang-related users.
What were your findings?
Through my research, I found that the DNI reported higher correlation between hypothesis functions and neuron/layer output in trained models than random models, which confirms that the models learn how to classify the data input.
The aggression model showed interesting correlation with activation hypotheses, and the same with the loss model with imagery, which implies that aggressive speech tends to be very active (intense) and that text containing loss tend to use language that is concrete rather than abstract. If I had more time to continue this research, I would love to explore different types and sentiments in text and how that would affect how well a model learns its task.
What about the project did you find interesting?
The most interesting part of my research was seeing how interconnected all of these disciplines are. I split most of my time between the Natural Language Processing Lab and the Data Science Institute, but I also had the chance to meet some great people from the School of Social Work–their work on gang-related speech is part of an even bigger project to predict, and later prevent, violence based on social media data.
How did you get involved in/ choose this project?
I’ve been working at the NLP Lab since freshman year and decided to continue working there over the summer. In my opinion research is one of the best ways to develop your skillset and ask questions to people already established in the same field. I knew I wanted to pursue research even before I decided to major in computer science, and I feel so grateful to be included in a lab that combines so many of my interests and develops technology that matters.
How much time did it take and who did you work with?
The project was for three months and I worked with CS faculty – Professor Kathy McKeown and Professor Eugene Wu.
Which CS classes were most helpful in putting this project together?
Python, Data Structures
What were some obstacles you faced in working on this project?
I had just finished my sophomore year when I tackled this project, which means that the most advanced class I had taken at that point was Advanced Programming. I spent a lot of time just learning: figuring out how machine learning models work, reading a natural language processing textbook, and even conducting a literature review on violence, social media, and Chicago gangs just so I could familiarize myself with the dataset. I felt that I had to absorb an enormous amount of information all at once, which was intimidating, but I was surrounded by people with infinite patience for all of my questions.
What were some positives of this project?
Through this project, I really started to appreciate how accessible computer science is. Half of the answers we need are already out on the internet. The other half is exactly why we need research. I can learn an entire CS language for free in a matter of days thanks to all of these online resources, but it takes a bit more effort to answer the questions I am interested in: what makes text persuasive? What’s a fair way of summarizing emotional multi-document texts?
Can you discuss your experience presenting?
Along with the Columbia Summer Symposium, I have presented my research at the Harvard National Collegiate Research Conference and the Stanford Research Conference.
Do you plan to present this research at any other events/conferences?
Yes, but I have yet to hear if I have been accepted.
What do you plan to do with your CS undergraduate degree?
Not sure yet but definitely something in the natural language understanding/software engineering space.
Do you see yourself pursuing research after graduation?
Yes! I loved working on a project that mattered and added good to the world beyond just technology. I also loved presenting my research because it inspired me to think beyond my project: what more can we do, how can others use this research, and how can we keep thinking bigger?
In light of how easy it is to identify people based on their DNA, researchers suggest ways to protect genetic information.
Genetic information uploaded to a website is now used to help identify criminals. This technique, employed by law enforcement to solve the Golden State Killer case, took genetic material from the crime scene and compared it to publicly available genetic information on third party website GEDmatch.
Inspired by how the Golden State Killer was caught, researchers set out to see just how easy it is to identify individuals by searching databases and finding genetic matches through distant relatives. The paper out today in Science Magazine also proposes a way to protect genetic information.
“We want people to discover their genetic data,” said the paper’s lead author, Yaniv Erlich, a computer scientist at Columbia University and Chief Science Officer at MyHeritage, a genealogy and DNA testing company. “But we have to think about how to keep people safe and prevent issues.”
Commercially available genetic tests are increasingly popular and users can opt to have their information used by genetic testing companies. Companies like 23andMe have used customer’s data for research to discover therapeutics and come up with hypothesis to make medicines. People can also upload their genetic information to third party websites, such as GEDmatch and DNA.Land, to find long-lost relatives.
With these scenarios, the data is used for good but what about the opposite? The situation can easily be switched, which could prove harmful for those who work covert operations (aka spies) and need their identities to remain secret.
Erlich shared that it takes roughly a day and a half to sift through a dataset of 1.28 million individuals to identify a third cousin. This is especially true for people of European descent in the United States. Then, based on sex, age and area of residence it is easy to get down to 40 individuals. At that point, the information can be used as an investigative lead.
To alleviate the situation and protect people, the researchers propose that raw data should be cryptographically encrypted and only those with the right key can view and use the data.
“Things are complicated but with the right strategy and policy we can mitigate the risks,” said Erlich.




























