The Symposium on Theory of Computing (STOC) covers research within theoretical computer science, such as algorithms and computation theory. This year, four papers from CS researchers and collaborators from various institutions made it into the conference.
The researchers were interested in the problem of compressing texts with local context, like texts in which there is some correlation between nearby characters. For example, the letter ‘q’ is almost always followed by ‘u’ in an English text.
It is a reasonable goal to design compression schemes that exploit local context to reduce the length of the string considerably. Indeed, the FM-Index and other such schemes, based on a transformation called the Burrows-Wheeler transform followed by Move-to-Front encoding, have been widely used in practice to compress DNA sequences etc. “I think it’s interesting that compression schemes have been known for nearly 20 years in the pattern-matching and bioinformatics community but there has not been satisfactory theoretical guarantees of the compression achieved by these algorithms,” said Sandip Sinha, a PhD student in the Theory Group.
Moreover, these schemes are inherently non-local – in order to extract a character or a short substring at a particular position of the original text, one needs to decode the entire string, which requires time proportional to the length of the original string. This is prohibitive in many applications. The team designed a data structure which matches almost exactly the space bound of such compression schemes, while also supporting highly efficient local decoding queries (alluded to above), as well as certain pattern-matching queries. In particular, they were able to design a succinct “locally-decodable” Move-to-Front (MTF) code, that reduces the decoding time per character (in the MTF encoding) from n to around log(n), where n is the length of the string. Shared Sinha, “We also show a lower bound showing that for a wide class of strings, one cannot hope to do much better using any data structure based on the above transform.”
“Hopefully our paper draws wider attention of the theoretical CS community to similar problems in these fields,” said Sinha. To that end, they have made a conscious effort to make the paper accessible across research domains. “I also think there is no significant mathematical knowledge required to understand the paper, beyond some basic notions in information theory.”
Fooling Polytopes Ryan O’Donnell Carnegie Mellon University, Rocco A. Servedio Columbia University, Li-Yang Tan Stanford University
The paper is about “getting rid of the randomness in random sampling”.
Suppose you are given a complicated shape on a blackboard and you need to estimate what fraction of the blackboard’s area is covered by the shape. One efficient way to estimate this fraction is by doing random sampling: throw darts randomly at the blackboard and count the fraction of the darts that land inside the shape. If you throw a reasonable number of darts, and they land uniformly at random inside the blackboard, the fraction of darts that land inside the shape will be a good estimate of the actual fraction of the blackboard’s area that is contained inside the shape. (This is analogous to surveying a small random sample of voters to try and predict who will win an election.)
“This kind of random sampling approach is very powerful,” said Rocco Servedio, professor and chair of the computer science department. “In fact, there is a sense in which every randomized computation can be viewed as doing this sort of random sampling.”
It is a fundamental goal in theoretical computer science to understand whether randomness is really necessary to carry out computations efficiently. The point of this paper is to show that for an important class of high-dimensional estimation problems of the sort described above, it is actually possible to come up with the desired estimates efficiently without using any randomness at all.
In this specific paper, the “blackboard” is a high-dimensional Boolean hypercube and the “shape on the blackboard” is a subset of the hypercube defined by a system of high-dimensional linear inequalities (such a subset is also known as a polytope). Previous work had tried to prove this result but could only handle certain specialized types of linear inequalities. By developing some new tools in high dimensional geometry and probability, in this paper the researchers were able to get rid of those limitations and handle all systems of linear inequalities.
The paper shows an interesting connection between the task of proving time-space lower bounds on data structure problems (with linear queries), and the long-standing open problem of constructing “stable” (rigid) matrices — a matrix M whose rank remains very high unless a lot of entries are modified. Constructing rigid matrices is one of the major open problems in theoretical computer science since the late 1970s, with far-reaching consequences on circuit complexity.
The result shows a real barrier for proving lower bounds on data structures: If one can exhibit any “hard” data structure problem with linear queries (the canonical example being Range Counting queries: given n points in d dimensions, report the number of points in a given rectangle), then this problem can be essentially used to construct “stable” (rigid) matrices.
“This is a rather surprising ‘threshold’ result, since in slightly weaker models of data structures (with small space usage), we do in fact have very strong lower bounds on the query time,” said Omri Weinstein, an assistant professor of computer science. “Perhaps surprisingly, our work shows that anything beyond that is out of reach with current techniques.”
The paper is about testing unateness of Boolean functions on the hypercube.
For this paper the researchers set out to design highly efficient algorithms which, by evaluating very few random inputs of a Boolean function, can “test” whether the function is unate (meaning that every variable is either non-increasing or non-decreasing or is pretty non-unate).
Referring to a previous paper the researchers set out to create an algorithm which is optimal (up to poly-logarithmic factors), giving a lower bound on the complexity of these testing algorithms.
An example of a Boolean function which is unate is a halfspace, i.e., for some values w1, …, wn, θ ∈ ℝ, the function f : {0,1}n → {0,1} is given by f(x) = 1 if ∑ wi xi≥ θ and 0 otherwise. Here, every variable i ∈ [n] is either non-decreasing, when wi ≥ 0, or non-increasing, when wi ≤ 0.
“One may hope that such an optimal algorithm could be non-adaptive, in the sense that all evaluations could be done at once,” said Erik Waingarten, an algorithms and computational complexity PhD student. “These algorithms tend to be easier to analyze and have the added benefit of being parallelize-able.”
However, the algorithm they developed is crucially adaptive, and a surprising thing is that non-adaptive algorithms could never achieve optimal complexity. A highlight of the paper is a new analysis of a very simple binary search procedure on the hypercube.
“This procedure is the ‘obvious’ thing one would do for these kinds of algorithms, but analyzing it has been very difficult because of its adaptive nature,” said Waingarten. “For us, this is the crucial component of the algorithm.”
Columbia’s computer science community is growing with Barnard College’s creation of a program in Computer Science (CS). Rebecca Wright has been hired as the director of Barnard’s CS program and as the director of the Vagelos Computational Science Center (Vagelos CSC), both of which are located in the Milstein Center.
Wright will lay down the groundwork to establish a computer science department to better serve the Barnard community. According to Wright, the goals of Barnard’s CS program are to bring computing education in a meaningful way to all Barnard students, to better integrate Barnard’s CS majors into the Barnard community, and to build a national presence for Barnard in computing research and education. Barnard students have already been able to take CS classes at Columbia and to major in CS by completing the Columbia CS major requirements. The Barnard program will continue to collaborate closely with the Columbia CS department, seeking to add opportunities rather than duplicating existing efforts or changing existing requirements.
“Initial course offerings are expected to focus on how CS interacts with
other disciplines, such as social science, lab science, arts, and the
humanities,” said Wright, who comes to
Columbia from Rutgers University. “We will address the different ways it can
interact with various disciplines and ways to advance those disciplines, but
with a focus on how to advance computer science to meet the needs of those
disciplines.”
Wright sees room to create more opportunities for students to see the
full spectrum of computer science – from the one end of the spectrum using the
computer as a tool, to the other end of the spectrum where there is the ability
to design new algorithms, to implement new systems, to carry out things at the
forefront of computer science. Barnard will enable students to find more places
along that spectrum to become fluent in the underlying tools and mechanisms and
be able to reason about them, create them, and combine them in new ways.
The first course will be taught by Wright and offered next year in the
fall. It is currently being developed and will most likely fall under her
research interests – security, privacy, and cryptography. She also is
working on building the faculty through both tenure-stream professors and a new
teaching and research fellows program.
For now, students can
continue to visit Barnard’s CSC and CS facilities on the fifth floor of the
Milstein Center, including making use of the Computer Science and Math Help
Room for guidance from tutors, studying or relaxing in the CSC social space,
and enrolling in CSC workshops.
Wright encourages students
to visit the Milstein Center,”I love walking through the library up to our
offices.” The space is open and a modern presentation of a library – much like
how she envisions how the computer science program will develop.
“Computing has an impact on advances in virtually every
field today,” said Wright. “I am excited to see what we develop around these
multidisciplinary interactions and interpretations of computing.”
Columbia researchers presented their work at the Empirical Methods in Natural Language Processing (EMNLP) in Brussels, Belgium.
Professor Julia Hirschberg gave a keynote talk on the work done by the Spoken Language Processing Group on how to automatically detect deception in spoken language – how to identify cues in trusted speech vs. mistrusted speech and how these features differ by speaker and by listener. Slides from the talk can be viewed here.
Five teams with computer science undergrad and PhD students from the Natural Language Processing Group (NLP) also attended the conference to showcase their work on text summarization, analysis of social media, and fact checking.
”Given the difficult times, we are living in, it’s extremely necessary to be perfect with our facts,” said Tuhin Chakrabarty, lead researcher of the paper. “Misinformation spreads like wildfire and has long-lasting impacts. This motivated us to delve into the area of fact extraction and verification.”
This paper presents the ColumbiaNLP
submission for the FEVER Workshop Shared Task. Their system is an end-to-end pipeline that
extracts factual evidence from Wikipedia and infers a decision about the
truthfulness of the claim based on the extracted evidence.
Fact checking is a type
of investigative journalism where experts examine the claims published by
others for their veracity. The claims can range from statements made by public
figures to stories reported by other publishers. The end goal of a fact
checking system is to provide a verdict on whether the claim is true, false, or
mixed. Several organizations such as FactCheck.org and PolitiFact are devoted
to such activities.
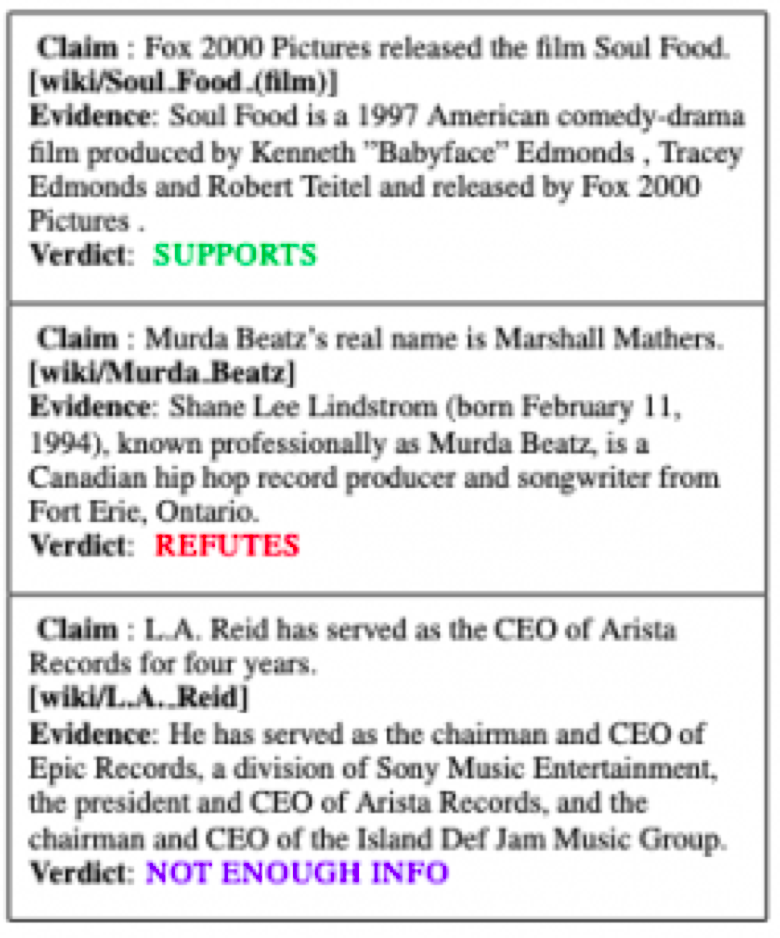
The FEVER Shared task aims to evaluate the ability of a system to verify information using evidence from Wikipedia. Given a claim involving one or more entities (mapping to Wikipedia pages), the system must extract textual evidence (sets of sentences from Wikipedia pages) that supports or refutes the claim and then using this evidence, it must label the claim as Supported, Refuted or NotEnoughInfo.
Detecting Gang-Involved Escalation on Social Media Using Context Serina Chang Computer Science Department, Ruiqi Zhong Computer Science Department, Ethan Adams Computer Science Department, Fei-Tzin Lee Computer Science Department, Siddharth Varia Computer Science Department, Desmond Patton School of Social Work, William Frey School of Social Work, Chris Kedzie Computer Science Department, and Kathleen McKeown Computer Science Department
This research is a
collaboration between Professor Kathy McKeown’s NLP lab and the
Columbia School of Social Work. Professor Desmond Patton, from the School of Social Work and a member of the Data
Science Institute, discovered that gang-involved youth in cities such as
Chicago increasingly turn to social media to grieve the loss of loved ones,
which may escalate into aggression toward rival gangs and plans for violence.
The team created a machine
learning system that can automatically detect aggression and loss in the social
media posts of gang-involved youth. They developed an approach with the hope to
eventually use a system that can save critical time, scale reach, and intervene
before more young lives are lost.
The
system features the use of word embeddings and lexicons, automatically derived
from a large domain-specific corpus which the team constructed. They also
created context features that capture user’s recent posts, both in semantic and
emotional content, and their interactions with other users in the dataset.
Incorporating domain-specific resources and context feature in a Convolutional
Neural Network (CNN) that leads to a significant improvement over the prior
state-of-the-art.
The dataset used spans the public Twitter posts of nearly 300 users from a gang-involved community in Chicago. Youth volunteers and violence prevention organizations helped identify users and annotate the dataset for aggression and loss. Here are two examples of labeled tweets, both of which the system was able to classify correctly. Names are blocked out to preserve the privacy of users.
Tweet examples
For semantics, which were represented by word embeddings, the researchers found that it was optimal to include 90 days of recent tweet history. While for emotion, where an emotion lexicon was employed, only two days of recent tweets were needed. This matched insight from prior social work research, which found that loss is significantly likely to precede aggression in a two-day window. They also found that emotions fluctuate more quickly than semantics so the tighter context window would be able to capture more fine-grained fluctuation.
“We took this context-driven approach because we believed that interpreting emotion in a given tweet requires context, including what the users had been saying recently, how they had been feeling, and their social dynamics with others,” said Serina Chang, an undergraduate computer science student. One thing that surprised them was the extent to which different types of context offered different types of information, as demonstrated by the contrasting contributions of the semantic-based user history feature and the emotion-based one. Continued Chang, “As we hypothesized, adding context did result in a significant performance improvement in our neural net model.”
Automated fact checking of textual claims is of increasing interest in today’s world. Previous research has investigated fact checking in political statements, news articles, and community forums.
“Through our model we can fact check claims
and find specific statements that support the evidence,” said Christopher Hidey,
a fourth year PhD student. “This is a step towards addressing the
propagation of misinformation online.”
As part of the FEVER community
shared task, the researchers developed models that given a statement would jointly find a Wikipedia article and a sentence related
to the statement, and then predict whether the statement is supported by that sentence.
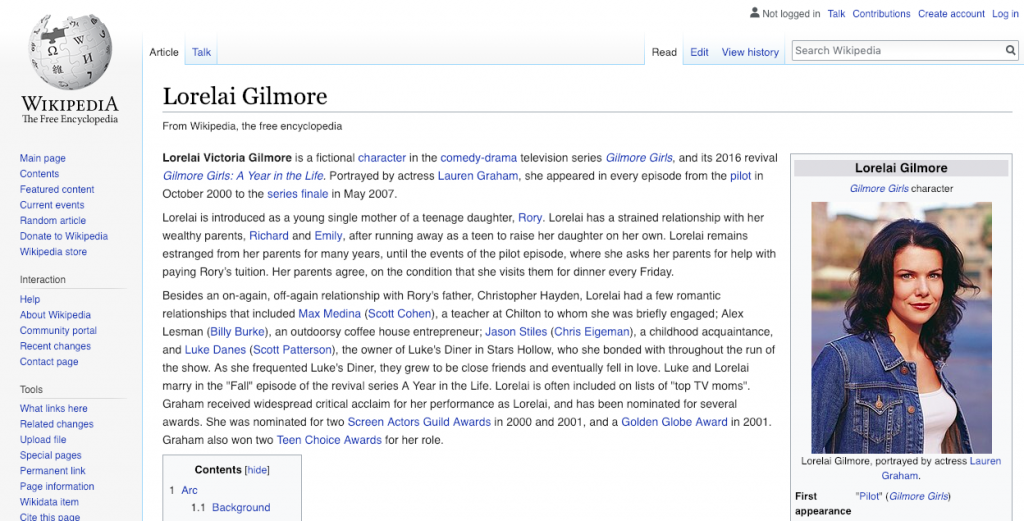
For example, given the claim “Lorelai Gilmore’s father is named Robert,” one could find the Wikipedia article on Lorelai Gilmore and extract the third sentence “Lorelai has a strained relationship with her wealthy parents, Richard and Emily, after running away as a teen to raise her daughter on her own” to show that the claim is false.
Credit : Wikipedia – https://en.wikipedia.org/wiki/Lorelai_Gilmore
One aspect of this problem that the team observed was how poorly TF-IDF, a standard technique in information retrieval and natural language processing, performed at retrieving Wikipedia articles and sentences. Their custom model improved performance by 35 points in terms of recall over a TF-IDF baseline, achieving 90% recall for 5 articles. Overall, the model retrieved the correct sentence and predicted the veracity of the claim 50% of the time.
The rate of which misinformation is spreading on
the web is faster than the rate of manual fact-checking conducted by
organizations like Politifact.com and Factchecking.org. For this paper the
researchers wanted to explore how to automate parts or all of the fact-checking
process. A poster with their findings was presented as part
of the FEVER workshop.
“In order to come up with reliable fact-checking
systems we need to understand the current manual process and identify
opportunities for automation,” said Tariq Alhindi, lead author on the paper. They looked at the LIAR dataset – around 10,000 claims classified by Politifact.com to one of six
degrees of truth – pants-on-fire, false, mostly-false, half-true, mostly-true,
true. Continued Alhindi, we also looked at the fact-checking article for each
claim and automatically extracted justification sentences of a given
verdict and used them in our models, after removing all sentences that contain
the verdict (e.g. true or false).
Excerpt from the LIAR-PLUS dataset
Feature-based machine learning models and
neural networks were used to develop models that can predict whether
a given statement is true or false. Results showed that using some sort of
justification or evidence always improves the results of fake-news detection
models.
“What was most surprising about the results is that
adding features from the extracted justification sentences consistently improved
the results no matter what classifier we used or what other features we
included,” shared Alhindi, a PhD student. “However, we were surprised that the
improvement was consistent even when we compare
traditional feature-based linear machine learning models against state of
the art deep learning models.”
Their research extends the previous work done on this data set which only looked at the linguistic cues of the claim and/or the metadata of the speaker (history, venue, party-affiliation, etc.). The researchers also released the extended dataset to the community to allow further work on this dataset with the extracted justifications.
Recently,
a specific type of machine learning, called deep learning, has made strides in
reaching human level performance on hard to articulate problems, that is,
things people do subconsciously like recognizing faces or understanding speech.
And so, natural language processing researchers have turned to these models for
the task of identifying the most important phrases and sentences in text
documents, and have trained them to imitate the decisions a human editor might
make when selecting content for a summary.
“Deep
learning models have been successful in summarizing natural language texts,
news articles and online comments,” said Chris Kedzie, a fifth
year PhD student. “What we wanted to know is how they are doing it.”
While
these deep learning models are empirically successful, it is not clear how they
are performing this task. By design, they are learning to create their own
representation of words and sentences, and then using them to predict whether a
sentence is important – if it should go into a summary of the document. But
just what kinds of information are they using to create these
representations?
One
hypotheses the researchers had was that certain types of words were more
informative than others. For example, in a news article, nouns and verbs might
be more important than adjectives and adverbs for identifying the most
important information since such articles are typically written in a relatively
objective manner.
To see if this was so, they trained models to predict sentence importance on redacted datasets, where either nouns, verbs, adjectives, adverbs, or function words were removed and compared them to models trained on the original data.
On
a dataset of personal stories published on Reddit, adjectives and adverbs were
the key to achieving the best performance. This made intuitive sense in that
people tend to use intensifiers to highlight the most important or climactic
moments in their stories with sentences like, “And those were the WORST
customers I ever served.”
What surprised the researchers were the news articles – removing any one class of words did not dramatically decrease model performance. Either important content was broadly distributed across all kinds of words or there was some other signal that the model was using.
They suspected that sentence order was important because journalists are typically instructed to write according to the inverted pyramid style with the most important information at the top of the article. It was possible that the models were implicitly learning this and simply selecting sentences from the article lead.
Two pieces of evidence confirmed this. First, looking at a histogram of sentence positions selected as important, the models overwhelmingly preferred the lead of the article. Second, in a follow up experiment, the sentence ordered was shuffled to remove sentence position as a viable signal from which to learn. On news articles, model performance dropped significantly, leading to the conclusion that sentence position was most responsible for model performance on news documents.
The
result concerned the researchers as they want models to be trained to truly
understand human language and not use simple and brittle heuristics (like
sentence position). “To connect this to broader trends in machine learning, we
should be very concerned and careful about what signals are being exploited by
our models, especially when making sensitive decisions,” Kedzie continued. ”The
signals identified by the model as helpful may not truly capture the problem we
are trying to solve, and worse yet, may be exploiting biases in the dataset
that we do not wish it to learn.”
However,
Kedzie sees this as an opportunity to improve the utility of word
representations so that models are better able to use the article content
itself. Along these lines, in the future, he hopes to show that by quantifying
the surprisal or novelty of a particular word or phrase, models are able to
make better sentence importance predictions. Just as people might remember the
most surprising and unexpected parts of a good story.
The department welcomes Baishakhi Ray, Ronghui Gu, Carl Vondrick, and Tony Dear.
Baishakhi Ray Assistant Professor, Computer Science PhD, University of Texas, Austin, 2013; MS, University of Colorado, Boulder, 2009; BTech, Calcutta University, India, 2004; BSc, Presidency College, India, 2001
Baishakhi Ray works on end-to-end software solutions and treats the entire software system – anything from debugging, patching, security, performance, developing methodology, to even the user experience of developers and users.
At the moment her research is focused on machine learning bias. For example, some models see a picture of a baby and a man and identify it as a woman and child. Her team is developing ways on how to train a system and to solve practical problems.
Ray previously taught at the University of Virginia and was a postdoctoral fellow in computer science at the University of California, Davis. In 2017, she received Best Paper Awards at the SIGSOFT Symposium on the Foundations of Software Engineering and the International Conference on Mining Software Repositories.
Ronghui Gu focuses on programming languages and operating systems, specifically language-based support for safety and security, certified system software, certified programming and compilation, formal methods, and concurrency reasoning. He seeks to build certified concurrent operating systems that can resist cyberattacks.
Gu previously worked at Google and co-founded Certik, a formal verification platform for smart contracts and blockchain ecosystems. The startup grew out of his thesis, which proposed CertiKOS, a comprehensive verification framework. CertiKOS is used in high-profile DARPA programs CRASH and HACMS, is a core component of an NSF Expeditions in Computing project DeepSpec, and has been widely considered “a real breakthrough” toward hacker-resistant systems.
Carl Vondrick Assistant Professor, Computer Science PhD, Massachusetts Institute of Technology, 2017; BS, University of California, Irvine, 2011
Carl Vondrick’s research focuses on computer vision and machine learning. His work often uses large amounts of unlabeled data to teach perception to machines. Other interests include interpretable models, high-level reasoning, and perception for robotics.
His past research developed computer systems that watch video in order to anticipate human actions, recognize ambient sounds, and visually track objects. Computer vision is enabling applications across health, security, and robotics, but they currently require large labeled datasets to work well, which is expensive to collect. Instead, Vondrick’s research develops systems that learn from unlabeled data, which will enable computer vision systems to efficiently scale up and tackle versatile tasks. His research has been featured on CNN and Wired and in a skit on the Late Show with Stephen Colbert, for training computer vision models through binge-watching TV shows.
Recently, three research papers he worked on were presented at the European Conference for Computer Vision (EECV). Vondrick comes to Columbia from Google Research, where he was a research scientist.
Tony Dear Lecturer in Discipline, Computer Science PhD, Carnegie Mellon University, 2018; MS, Carnegie Mellon University, 2015; BS, University of California, Berkeley, 2012
Tony Dear’s research and pedagogical interests lie in bringing theory into practice. In his PhD research, this idea motivated the application of analytical tools to motion planning for “real” or physical locomoting robotic systems that violate certain ideal assumptions but still exhibit some structure – how to get unconventional robots to move around with stealth of animals and biological organisms. Also, how to simplify tools and expand that to other systems, as well as how to generalize mathematical models to be used in multiple robots.
In his teaching, Dear strives to engage students with relatable examples and projects, alternative ways of learning, such as an online curriculum with lecture videos. He completed the Future Faculty Program at the Eberly Center for Teaching Excellence at Carnegie Mellon and has been the recipient of a National Defense Science and Engineering Graduate Fellowship.
At Columbia, Dear is looking forward to teaching computer science, robotics, and AI. He hopes to continue small-scale research projects in robotic locomotion and conduct outreach to teach teens STEM and robotics courses.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor