The Distinguished Lecture Series showcases pioneering thinkers whose work is driving the future of technology. From breakthroughs in theory to real-world applications that shape our daily lives, this year’s speakers will share insights at the forefront of computing. The series offers a unique opportunity to learn from leaders in the field, spark new ideas, and connect with the innovations transforming our world.
Abstract: In May 2013, Georgia Tech, together with its partners Udacity and AT&T, announced a new online master’s degree in computer science delivered through the platform popularized by massively open online courses (MOOCs). This new online MS in CS (OMSCS) costs less than $7,000 total, compared to a price tag of $40,000 for an MS CS at comparable public universities and upwards of $70,000 at private universities. The first-of-its-kind program was launched in January 2014 and has sparked a worldwide conversation about higher education in the 21st century. President Barack Obama has praised OMSCS by name twice, and hundreds of news stories have mentioned the program. It’s been described as a potential “game changer” and “ground zero of the revolution in higher education”. Harvard University researchers concluded that OMSCS is “the first rigorous evidence showing an online degree program can increase educational attainment” and predicted that OMSCS will single-handedly raise the number of annual MS CS graduates in the United States by at least 7 percent.
OMSCS started in 2014 with 5 courses and 380 students; in fall 2025 semester, it had 46 courses and almost 17,000 students. OMSCS is apparently the biggest academic program in the world in any subject, not necessarily online. So far, almost 14,500 students have graduated from OMSCS, over 7,000 in the last 3 years. The number of applications to OMSCS keeps rising. In the 2024-25 academic year, there were 9,860 applications, 31% higher than the record in the year before. The program has also paved the way for more than 50 similar programs in over 30 universities. In November 2023, a Forbes article described OMSCS as the best degree program ever. There has been a big shortage of computing professionals in the US. Therefore, OMSCS is satisfying a great national need. Starting in 2017, Georgia Tech expanded its online offerings to undergraduate computer science students. The talk will describe the OMSCS program, how it came about, its first twelve years, and what Georgia Tech has learned from the OMSCS experience. It will also discuss the speaker’s vision of the future of higher education with a much larger role for online learning.
November 5, 2025
How to Close the 100,000-Year “Data Gap” in Robotics Ken Goldberg
Abstract: Large models based on internet-scale data can now pass the Turing Test for intelligence. In this sense, data has “solved” language, and many analogously claim that data has solved speech recognition and computer vision. Will data also solve robotics and automation, allowing general-purpose humanoid robots to achieve human-level performance? Using commonly accepted metrics for converting word and image tokens into time, the amount of internet-scale data used to train contemporary large vision language models (VLMs) is on the order of 100,000 years. I’ll review 3 ways researchers are pursuing to close this gap, and a 4th approach, where data is collected as real robots operate in real commercial environments — which requires bootstrapping with AI and “good old-fashioned engineering” to create robots with real return on investment that will be adopted by industry. Such robots can create a “data flywheel” to increase performance and enable new functionality, accelerating the timeline to achieve reliable, general-purpose robots.
November 24, 2025
Quantum Networks: A Classical Perspective Don Towsley
Abstract: Quantum information processing is at the threshold of having significant impact on technology and society in the form of providing unbreakable security, ultra-high-precision distributed sensing, and polynomial/exponential speed-ups in computing. Many of these applications are enabled by high rate distributed shared entanglement between pairs and groups of users. A critical missing component that prevents crossing this threshold is a distributed infrastructure in the form of a world-wide “Quantum Internet”. This motivates the study of quantum networks, namely, to identify the right architecture and how should it operate, e.g., dynamic fair allocation of resources. Moreover, the architecture and network operation must account for operation in harsh, noisy environments.
This talk addresses the following question: what ideas can the design of a quantum network borrow from classical networks? At first glance the answer appears to be “very little”. The focus of this talk, however, is to argue that the opposite is true and that much can be borrowed from classical networks. We begin by reviewing two proposed quantum network architectures two-way and one-way architectures. A two-way network generates and distributes quantum entanglement to pairs or groups of users whereas a one-way network allows for direct transfer of quantum information from one user to another. We compare these architectures and conclude that a two-way architecture is superior. A two-way architecture appears very different from the classical Internet architecture. However, we will introduce a “connectionless” two-way quantum network architecture that allows one to easily adapt many ideas from classical networks (good and bad 🙂). We provide several examples of the adoption of good ideas and conclude with open research questions.
December 8, 2025
Towards Accountable Conversational Agents for Task Completion
Abstract: Task-oriented dialogue systems are designed to assist users in achieving specific, well-defined goals or tasks through natural language interactions. These systems act as a conversational bridge, connecting users to task-specific APIs or tools. Recent advancements have resulted in a significant paradigm shift with the integration of Large Language Models (LLMs) augmented with tool-calling into task-oriented dialogue systems and user simulators that are used for model evaluation and training. However, several issues remain that ponder the use of these systems in real applications.
In this talk, I will share our latest research towards accountability in multi-turn interactions with Large Language Models (LLMs). Our approach, called Reasoning, Acting, and Speaking (ReSpAct), has demonstrated higher task completion rates by engaging with users. To counter user over-reliance, we developed specialized accountability models for dialogue state tracking errors in task-oriented dialogue systems. We also adapted existing annotated dialogue datasets to train an LLM proficient in both interaction and tool calling, showcasing its performance on dialogue system and agentic LLM benchmarks. Our subsequent work utilized reinforcement learning for tool-based reasoning, introducing novel reward mechanisms. Finally, I will discuss user simulation for model evaluation and training. We observed that LLM-based user simulators can deviate from user goals over multi-turn interactions. To address this, we proposed a novel framework that tracks user goal progression throughout conversations, enabling the creation of user simulators that can autonomously monitor goal progression and reason to generate goal-aligned responses.
The inaugural fair gave students the opportunity to take their research from paper to presentation and showcase their hard work.
The projects of the Undergraduate Computer and Data Science Research Fair fell under the themes of Data Science and Society, Interdisciplinary Data Science Applications, Data Science and Computer Science Research. Posters and demonstrations were proudly hosted by twenty-five students from SEAS, Barnard College, Columbia College, and the School of General Studies.
CS ChairLuca CarloniandClifford Stein, Interim Director of the Data Science Institute, issued the four awards, including best overall and best in each of the three tracks.
CS & Data Science Research
Improving Model Training via Self-learned Label Representations
Xiao Yu, Senior, SEAS
Interdisciplinary Data Science
Outlier Splicing Analysis of Autism Spectrum Disorder using RNA-seq Data
Sophia Sowinski, Junior, Barnard College
Data Science & Society
Legal and Political Stance Detection of SCOTUS Language
Noah Bergam, Sophomore, Columbia College
Demonstrations
Machine Learning assisted Age-Related Macular Degeneration Detection using Indirect Fundoscopy and iOS Device
Five CS researchers received Test of Time awards for papers that have had a lasting impact on their fields. The influential papers were presented at their respective conferences in the past 25 years and have remained relevant to research and practice.
Moti Yung
IACR International Conference on Practice and Theory of Public-Key Cryptography (PKC2020) Test of Time award
Nine papers from CS researchers were accepted to the ACM-SIAM Symposium on Discrete Algorithms (SODA20), held in Salt Lake City, Utah. The conference focuses on algorithm design and discrete mathematics.
A common type of problem studied in machine learning is learning an unknown classification rule from labeled data. In this problem paradigm, the learner receives a collection of data points, some of which are labeled “positive” and some of which are labeled “negative”, and the goal is to come up with a rule which will have high accuracy in classifying future data points as either “positive” or “negative”.
In a SODA 2015 paper, De, Diakonikolas, and Servedio studied the possibilities and limitations of efficient machine learning algorithms when the learner is only given access to one type of data point, namely points that are labeled “positive”. (These are also known as “satisfying assignments” of the unknown classification rule.) They showed that certain types of classification rules can be learned efficiently in this setting while others cannot. However, all of the settings considered in that earlier work were ones in which the data points themselves were defined in terms of “categorical” features also known as binary yes-no features (such as “hairy/hairless” “mammal/non-mammal” “aquatic/non-aquatic” and so on). In many natural settings, though, data points are defined in terms of continuous numerical features (such as “eight inches tall” “weighs seventeen pounds” “six years old” and so on).
This paper extended the earlier SODA 2015 paper’s results to handle classification rules defined in terms of continuous features as well. It shows that certain types of classification rules over continuous data are efficiently learnable from positive examples only while others are not.
“Most learning algorithms in the literature crucially use both positive and negative examples,” said Rocco Servedio. “So at first I thought that it is somewhat surprising that learning is possible at all in this kind of setting where you only have positive examples as opposed to both positive and negative examples.”
But learning from positive examples only is actually pretty similar to what humans do when they learn — teachers rarely show students approaches that fail to solve a problem, rarely have them carry out experiments that don’t work, etc. Continued Servedio, “So maybe we should have expected this type of learning to be possible all along.”
The researchers were interested in algorithms which are given access to a large undirected graph G on n vertices and estimate the number of edges of the graph up to a small multiplicative error. In other words, for a very small ϵ > 0 (think of this as 0.01) and a graph with m edges, they wanted to output a number m’ satisfying (1-ε) m ≤ m’ ≤ (1+ε) m with probability at least 2/3, and the goal is to perform this task without having to read the whole graph.
For a simple example, suppose that the access to a graph allowed to check whether two vertices are connected by an edge. Then, an algorithm for counting the number of edges exactly would need to ask whether all pairs of vertices are connected, resulting in an (n choose 2)-query algorithm since these are all possible pairs of vertices. However, sampling Θ((n choose 2) / (m ε2)) random pairs of vertices one can estimate the edges up to (1± ε)-error with probability 2/3, which would result in a significantly faster algorithm!
The question here is: how do different types of access to the graph result in algorithms with different complexities? Recent work by Beame, Har-Peled, Ramamoorthy, Rashtchian, and Sinha studied certain “independent set queries” and “bipartite independent set queries”: in the first (most relevant to our work), an algorithm is allowed to ask whether a set of vertices of the graph forms an independent set, and in the second, the algorithm is allowed to ask whether two sets form a bipartite independent set. The researchers give nearly matching upper and lower bounds for estimating edges with an independent set queries.
The researchers imagined situations in which the graph is extremely large and wanted to determine whether or not the graph has cycles in a computationally efficient manner (by looking at as few of the nodes in the graph as possible). As yet, there’s no known solution to this problem that does significantly better than looking at a constant fraction of the nodes, but they proved a new lower bound – that is, they found a new limit on how efficiently the problem can be solved. In particular, their proof of the lower bound uses a new technique to capture the best possible behavior of any algorithm for this problem.
Suppose there is a large directed graph that describes the connections between neurons in a portion of the brain, and the number of neurons is very large, say, several billion. If the graph has many cycles, this might indicate that the portion of the brain contains recurrences and feedback loops, while if it has no cycles, this might indicate information flows through the graph in a linear manner. Knowing this fact might help deduce the function of this part of the brain. The paper’s result is negative – it provides a lower bound on the number of neurons needed to determine this fact. (This might sound a little discouraging, but this research isn’t really targeted at specific applications – rather, it takes a step toward better understanding the types of approaches we need to use to efficiently determine the properties of large directed graphs.)
This is part of a subfield of theoretical computer science that has to do with finding things out about enormous data objects by asking just a few questions (relatively speaking). Said Tim Randolph, “Problems like these become increasingly important as we generate huge volumes of data, because without knowing how to solve them we can’t take advantage of what we know.”
The paper studies the problem of privacy-preserving (approximate) similarity search, which is the backbone of many industry-scale applications and machine learning algorithms. It obtains a quadratic improvement over the highest *unconditional* lower bound for oblivious (secure) near-neighbor search in dynamic settings. This shows that dynamic similarity search has a logarithmic price if one wishes to perform it in an (information theoretic) secure manner.
In this paper the researcher studied the case where there is a set K of terminals, and the goal is to embed only the terminals into `1 with low distortion.
Given two metric spaces $(X,d_X),(Y,d_Y)$, an embedding is a function $f:X\to Y$. We say that an embedding $f$ has distortion $t$ if for every two points $u,v\in X$, it holds that $d_X(u,v)\le d_Y(f(u),f(v))\le t\cdot d_X(u,v)$. “Given a hard problem in a space $X$, it is often useful to embed it into a simpler space $Y$, solve the problem there, and then pull the solution back to the original space $X$,” said Arnold Filtser, a postdoctoral fellow. “The quality of the received solution will usually depend on the quality of the embedding (distortion), and the simplicity of the host space. Metric embeddings have a fundamental place in the algorithmic toolbox.”
In $\ell_1$ distance, a.k.a. Manhattan distance, given two vectors $\vec{x},\vec{y}\in\mathbb{R}^d$ the distance defined as $\Vert \vec{x}-\vec{y}\Vert_1=\sum_i |x_i-y_i|$. A planar graph $G=(V,E,w)$, is a graph that can be drawn in the plane in such a way that its edges $E$ intersect only at their endpoints. This paper studies metric embeddings of planar graphs into $\ell_1$.
It was conjectured by Gupta et al. that every planar graph can be embedded into $\ell_1$ with constant distortion. However, given an $n$-vertex weighted planar graph, the best upper bound on the distortion is only $O(\sqrt{\log n})$, by Rao. The only known lower bound is $2$’ and the fundamental question of the right bound is quite eluding.
The paper studies the case where there is a set $K$ of terminals, and the goal is to embed only the terminals into $\ell_1$ with low distortion and it’s contribution is a further improvement on the upper bound to $O(\sqrt{\log\gamma})$. Since every planar graph has at most $O(n)$ faces, any further improvement on this result, will be a major breakthrough, directly improving upon Rao’s long standing upper bound.
It is well known that the flow-cut gap equals to the distortion of the best embedding into $\ell_1$. Therefore, our result provides a polynomial time $O(\sqrt{\log \gamma})$-approximation to the sparsest cut problem on planar graphs, for the case where all the demand pairs can be covered by $\gamma$ faces.
A Boolean function f : {0,1}n → {0,1} is monotone if for every two points x, y ∈ {0,1}n where xi ≤ yi for every i∈[n], f(x) ≤ f(y). There has been a long and very fruitful line of research, starting with the work of Goldreich, Goldwasser, Lehman, Ron, and Samorodnitsky, exploring algorithms which can test whether a Boolean function is monotone.
The core question studied in the first paper was: suppose a function f is ϵ-far from monotone, i.e., any monotone function must differ with f on at least an ϵ-fraction of the points, how many pairs of points x, y ∈ {0,1}n which differ in only one bit i∈[n] (an edge of the hypercube) must satisfy f(x) = 1 but f(y) = 0 but x ≤ y (a violation of monotonicity)?
The paper focuses on the question of efficient algorithms which can estimate the distance to monotonicity of a function, i.e., the smallest possible ϵ where f is ϵ-far from monotone. It gives a non-adaptive algorithm making poly(n) queries which estimates ϵ up to a factor of Õ(√n). “The above approximation is not good since it degrades very badly as the number of variables of the function increases,” said Erik Waingarten. “However, the surprising thing is that substantially better approximations require exponentially many non-adaptive queries.”
The Complexity of Contracts Paul Duetting London School of Economics, Tim Roughgarden Columbia University, Inbal Talgam-Cohen Technion, Israel Institute of Technology
Contract theory is a major topic in economics (e.g., the 2016 Nobel Prize in Economics was awarded to Oliver Hart and Bengt Holmström for their work on the topic). A canonical problem in the area is how to structure compensation to employees (e.g. as a function of sales), when the effort exerted by employees is not directly observable.
This paper provides both positive and negative results about when optimal or approximately optimal contracts can be computed efficiently by an algorithm. The researchers design such an efficient algorithm for settings with very large outcome spaces (such as all subsets of a set of products) and small agent action spaces (such as exerting low, medium, or high effort).
How to Store a Random Walk Emanuele Viola Northeastern University, Omri Weinstein Columbia University, Huacheng Yu Harvard University
Motivated by storage applications, the researchers studied the problem of “locally-decodable” data compression. For example, suppose an encoder wishes to store a collection of n *correlated* files using as little space as possible, such that each individual X_i can be recovered quickly with few (ideally constant) memory accesses.
A natural example is a collection of similar images or DNA strands on a large sever, say, Dropbox. The researchers show that for file collections with “time-decaying” correlations (i.e., Markov chains), one can get the best of both worlds. This surprising result is achieved by proving that a random walk on any graph can be stored very close to its entropy, while still enabling *constant* time decoding on a word-RAM. The data structures generalize to dynamic (online) setting.
The paper investigates for which metric spaces the performance of distance labeling and of `∞- embeddings differ, and how significant can this difference be.
A distance labeling is a distributed representation of distances in a metric space $(X,d)$, where each point $x\in X$ is assigned a succinct label, such that the distance between any two points $x,y \in X$ can be approximated given only their labels.
A highly structured special case is an embedding into $\ell_\infty$, where each point $x\in X$ is assigned a vector $f(x)$ such that $\|f(x)-f(y)\|_\infty$ is approximately $d(x,y)$. The performance of a distance labeling, or an $\ell_\infty$-embedding, is measured by its distortion and its label-size/dimension. “As $\ell_\infty$ is a norm space, it posses a natural structure that can be exploited by various algorithms,” said Arnold Filtser. “Thus it is more desirable to obtain embeddings rather than general labeling schemes.”
The researchers also studied the analogous question for the prioritized versions of these two measures. Here, a priority order $\pi=(x_1,\dots,x_n)$ of the point set $X$ is given, and higher-priority points should have shorter labels. Formally, a distance labeling has prioritized label-size $\alpha(.)$ if every $x_j$ has label size at most $\alpha(j)$. Similarly, an embedding $f: X \to \ell_\infty$ has prioritized dimension $\alpha(\cdot)$ if $f(x_j)$ is non-zero only in the first $\alpha(j)$ coordinates. In addition, they compare these prioritized measures to their classical (worst-case) versions.
They answer these questions in several scenarios, uncovering a surprisingly diverse range of behaviors. First, in some cases labelings and embeddings have very similar worst-case performance, but in other cases there is a huge disparity. However in the prioritized setting, they found a strict separation between the performance of labelings and embeddings. And finally, when comparing the classical and prioritized settings, they found that the worst-case bound for label size often “translates” to a prioritized one, but also a surprising exception to this rule.
Papers from CS researchers were accepted to the 60th Annual Symposium on Foundations of Computer Science (FOCS 2019). The papers delve into population recovery, sublinear time, auctions, and graphs.
Finding Monotone Patterns in Sublinear Time Omri Ben-Eliezer Tel-Aviv University, Clement L. Canonne Stanford University, Shoham Letzter ETH-ITS, ETH Zurich, Erik Waingarten Columbia University
The paper is about finding increasing subsequences in an array in sublinear time. Imagine an array of n numbers where at least 1% of the numbers can be arranged into increasing subsequences of length k. We want to pick random locations from the array in order to find an increasing subsequence of length k. At a high level, in an array with many increasing subsequences, the task is to find one. The key is to cleverly design the distribution over random locations to minimize the number of locations needed.
Roughly speaking, the arrays considered have a lot of increasing subsequences of length k; think of these as “evidence of existence of increasing subsequences”. However, these subsequences can be hidden throughout the array: they can be spread out, or concentrated in particular sections, or they can even have very large gaps between the starts and the ends of the subsequences.
“The surprising thing is that after a specific (and simple!) re-ordering of the “evidence”, structure emerges within the increasing subsequences of length k,” said Erik Waingarten, a PhD student. “This allows for design efficient sampling procedures which are optimal for non-adaptive algorithms.”
Consider the problem of reconstructing the DNA sequence of an extinct species, given some DNA sequences of its descendant(s) that are alive today. We know that DNA sequences get modified through random mutations, which can be substitutions, insertions and deletions.
A mathematical abstraction of this problem is to recover an unknown source string x of length n, given access to independent samples of x that have been corrupted according to a certain noise model. The goal is to determine the minimum number of samples required in order to recover x with high confidence. In the special case that the corruption occurs via a deletion channel (i.e., each character in x is deleted independently with some probability, say 0.1, and the surviving characters are concatenated and transmitted), each sample is called a trace. The corresponding recovery problem is called trace reconstruction, and it has received significant attention in recent years.
The researchers considered a generalized version of this problem (known as population recovery) where there are multiple unknown source strings, along with an unknown distribution over them specifying the relative frequency of each source string. Each sample is generated by first drawing a source string with the associated probability, and then generating a trace from it via the deletion channel. The goal is to recover the source strings, along with the distribution over them (up to small error), from the mixture of traces.
For the main sample complexity upper bound, they show that for any population size s = o(log n / log log n), a population of s strings from {0,1}^n can be learned under deletion channel noise using exp(n^{1/2 + o(1)}) samples. On the lower bound side, we show that at least n^{\Omega(s)} samples are required to perform population recovery under the deletion channel when the population size is s, for all s <= n^0.49.
“I found it interesting that our work is based on certain mathematical results in which, at first glance, seem to be completely unrelated to the computational problem we consider,” said Sandip Sinha, a PhD student. In particular, they used constructions based on Chebyshev polynomials, a certain sequence of polynomials which are extremal for many properties, and is hence ubiquitous throughout theoretical computer science. Similarly, previous work on trace reconstruction rely on certain extremal results about complex-valued polynomials. Continued Sinha, “I think it is quite intriguing that complex analytic techniques yield useful results about a problem which is fundamentally about discrete structures (binary strings).”
The paper is about the theory of combinatorial auctions. In a combinatorial auction, an auctioneer wants to allocate several items among bidders. Each bidder has a certain amount that they value each item; bidders also have values for combinations of items, and in a combinatorial auction a bidder might not value a combination of items as much as each item individually.
For instance, say that a pencil and a pen will be auctioned. The pencil is valued at 30 cents and the pen at 40 cents, but the pen and pencil together at only 50 cents (it may be that there isn’t any additional value from having both the pencil and the pen). Valuation functions with this property — that the value of a combination of items is less than or equal to the sum of the values of each item — are called subadditive.
In the paper, the researchers answered a longstanding open question about combinatorial auctions with two bidders who have subadditive valuation — roughly speaking, is it possible for an auctioneer to efficiently communicate with both bidders to figure out how to allocate the items between them to make the bidders happy?
The answer turns out to be no. In general, if the auctioneer wants to do better than just giving all of the items to one bidder or the other at random, the auctioneer needs to communicate a very large amount with the bidders.
The result itself was somewhat surprising, the researchers expected it to be possible for the auctioneer to do pretty well without having to communicate with the bidders too much. “Also, information theory was extensively used as part of proving the result,” said Eric Neyman, a PhD student. “This is unexpected, because information theory has not been used much in the study of combinatorial auctions.”
In a graph, an independent set is a set of vertices with the property that none are adjacent. For example, in the graph of Facebook friends, vertices are people and there is an edge between two people who are friends. An independent set would be a set of people, none of whom are friends with each other. A basic problem is to find a large independent set. The paper focuses on one type of large independent set known as a maximal independent set, that is, one that cannot have any more vertices added to it.
Graphs, such as the friends graph, evolve over time. As the graph evolves, the maximal independent set needs to be maintained, without recomputing one from scratch. The paper significantly decreases the time to do so, from time that is polynomial in the input size to one that is polylogarithmic.
A graph can have many maximal independent sets (e.g. in a triangle, each of the vertices is a potential maximal independent set). One might think that this freedom makes the problems easier. The researchers picked one particular kind of maximal independent set, known as a lexicographically first maximal independent set (roughly this means that in case of a tie, the vertex whose name is first in alphabetical order is always chosen) and show that this kind of set can be maintained more efficiently.
“Giving up this freedom actually makes the problems easier,” said Cliff Stein, a computer science professor. “The idea of restricting the set of possible solutions making the problem easier is a good general lesson.”
The Symposium on Theory of Computing (STOC) covers research within theoretical computer science, such as algorithms and computation theory. This year, four papers from CS researchers and collaborators from various institutions made it into the conference.
The researchers were interested in the problem of compressing texts with local context, like texts in which there is some correlation between nearby characters. For example, the letter ‘q’ is almost always followed by ‘u’ in an English text.
It is a reasonable goal to design compression schemes that exploit local context to reduce the length of the string considerably. Indeed, the FM-Index and other such schemes, based on a transformation called the Burrows-Wheeler transform followed by Move-to-Front encoding, have been widely used in practice to compress DNA sequences etc. “I think it’s interesting that compression schemes have been known for nearly 20 years in the pattern-matching and bioinformatics community but there has not been satisfactory theoretical guarantees of the compression achieved by these algorithms,” said Sandip Sinha, a PhD student in the Theory Group.
Moreover, these schemes are inherently non-local – in order to extract a character or a short substring at a particular position of the original text, one needs to decode the entire string, which requires time proportional to the length of the original string. This is prohibitive in many applications. The team designed a data structure which matches almost exactly the space bound of such compression schemes, while also supporting highly efficient local decoding queries (alluded to above), as well as certain pattern-matching queries. In particular, they were able to design a succinct “locally-decodable” Move-to-Front (MTF) code, that reduces the decoding time per character (in the MTF encoding) from n to around log(n), where n is the length of the string. Shared Sinha, “We also show a lower bound showing that for a wide class of strings, one cannot hope to do much better using any data structure based on the above transform.”
“Hopefully our paper draws wider attention of the theoretical CS community to similar problems in these fields,” said Sinha. To that end, they have made a conscious effort to make the paper accessible across research domains. “I also think there is no significant mathematical knowledge required to understand the paper, beyond some basic notions in information theory.”
Fooling Polytopes Ryan O’Donnell Carnegie Mellon University, Rocco A. Servedio Columbia University, Li-Yang Tan Stanford University
The paper is about “getting rid of the randomness in random sampling”.
Suppose you are given a complicated shape on a blackboard and you need to estimate what fraction of the blackboard’s area is covered by the shape. One efficient way to estimate this fraction is by doing random sampling: throw darts randomly at the blackboard and count the fraction of the darts that land inside the shape. If you throw a reasonable number of darts, and they land uniformly at random inside the blackboard, the fraction of darts that land inside the shape will be a good estimate of the actual fraction of the blackboard’s area that is contained inside the shape. (This is analogous to surveying a small random sample of voters to try and predict who will win an election.)
“This kind of random sampling approach is very powerful,” said Rocco Servedio, professor and chair of the computer science department. “In fact, there is a sense in which every randomized computation can be viewed as doing this sort of random sampling.”
It is a fundamental goal in theoretical computer science to understand whether randomness is really necessary to carry out computations efficiently. The point of this paper is to show that for an important class of high-dimensional estimation problems of the sort described above, it is actually possible to come up with the desired estimates efficiently without using any randomness at all.
In this specific paper, the “blackboard” is a high-dimensional Boolean hypercube and the “shape on the blackboard” is a subset of the hypercube defined by a system of high-dimensional linear inequalities (such a subset is also known as a polytope). Previous work had tried to prove this result but could only handle certain specialized types of linear inequalities. By developing some new tools in high dimensional geometry and probability, in this paper the researchers were able to get rid of those limitations and handle all systems of linear inequalities.
The paper shows an interesting connection between the task of proving time-space lower bounds on data structure problems (with linear queries), and the long-standing open problem of constructing “stable” (rigid) matrices — a matrix M whose rank remains very high unless a lot of entries are modified. Constructing rigid matrices is one of the major open problems in theoretical computer science since the late 1970s, with far-reaching consequences on circuit complexity.
The result shows a real barrier for proving lower bounds on data structures: If one can exhibit any “hard” data structure problem with linear queries (the canonical example being Range Counting queries: given n points in d dimensions, report the number of points in a given rectangle), then this problem can be essentially used to construct “stable” (rigid) matrices.
“This is a rather surprising ‘threshold’ result, since in slightly weaker models of data structures (with small space usage), we do in fact have very strong lower bounds on the query time,” said Omri Weinstein, an assistant professor of computer science. “Perhaps surprisingly, our work shows that anything beyond that is out of reach with current techniques.”
The paper is about testing unateness of Boolean functions on the hypercube.
For this paper the researchers set out to design highly efficient algorithms which, by evaluating very few random inputs of a Boolean function, can “test” whether the function is unate (meaning that every variable is either non-increasing or non-decreasing or is pretty non-unate).
Referring to a previous paper the researchers set out to create an algorithm which is optimal (up to poly-logarithmic factors), giving a lower bound on the complexity of these testing algorithms.
An example of a Boolean function which is unate is a halfspace, i.e., for some values w1, …, wn, θ ∈ ℝ, the function f : {0,1}n → {0,1} is given by f(x) = 1 if ∑ wi xi≥ θ and 0 otherwise. Here, every variable i ∈ [n] is either non-decreasing, when wi ≥ 0, or non-increasing, when wi ≤ 0.
“One may hope that such an optimal algorithm could be non-adaptive, in the sense that all evaluations could be done at once,” said Erik Waingarten, an algorithms and computational complexity PhD student. “These algorithms tend to be easier to analyze and have the added benefit of being parallelize-able.”
However, the algorithm they developed is crucially adaptive, and a surprising thing is that non-adaptive algorithms could never achieve optimal complexity. A highlight of the paper is a new analysis of a very simple binary search procedure on the hypercube.
“This procedure is the ‘obvious’ thing one would do for these kinds of algorithms, but analyzing it has been very difficult because of its adaptive nature,” said Waingarten. “For us, this is the crucial component of the algorithm.”
Columbia’s computer science community is growing with Barnard College’s creation of a program in Computer Science (CS). Rebecca Wright has been hired as the director of Barnard’s CS program and as the director of the Vagelos Computational Science Center (Vagelos CSC), both of which are located in the Milstein Center.
Wright will lay down the groundwork to establish a computer science department to better serve the Barnard community. According to Wright, the goals of Barnard’s CS program are to bring computing education in a meaningful way to all Barnard students, to better integrate Barnard’s CS majors into the Barnard community, and to build a national presence for Barnard in computing research and education. Barnard students have already been able to take CS classes at Columbia and to major in CS by completing the Columbia CS major requirements. The Barnard program will continue to collaborate closely with the Columbia CS department, seeking to add opportunities rather than duplicating existing efforts or changing existing requirements.
“Initial course offerings are expected to focus on how CS interacts with
other disciplines, such as social science, lab science, arts, and the
humanities,” said Wright, who comes to
Columbia from Rutgers University. “We will address the different ways it can
interact with various disciplines and ways to advance those disciplines, but
with a focus on how to advance computer science to meet the needs of those
disciplines.”
Wright sees room to create more opportunities for students to see the
full spectrum of computer science – from the one end of the spectrum using the
computer as a tool, to the other end of the spectrum where there is the ability
to design new algorithms, to implement new systems, to carry out things at the
forefront of computer science. Barnard will enable students to find more places
along that spectrum to become fluent in the underlying tools and mechanisms and
be able to reason about them, create them, and combine them in new ways.
The first course will be taught by Wright and offered next year in the
fall. It is currently being developed and will most likely fall under her
research interests – security, privacy, and cryptography. She also is
working on building the faculty through both tenure-stream professors and a new
teaching and research fellows program.
For now, students can
continue to visit Barnard’s CSC and CS facilities on the fifth floor of the
Milstein Center, including making use of the Computer Science and Math Help
Room for guidance from tutors, studying or relaxing in the CSC social space,
and enrolling in CSC workshops.
Wright encourages students
to visit the Milstein Center,”I love walking through the library up to our
offices.” The space is open and a modern presentation of a library – much like
how she envisions how the computer science program will develop.
“Computing has an impact on advances in virtually every
field today,” said Wright. “I am excited to see what we develop around these
multidisciplinary interactions and interpretations of computing.”
Columbia researchers presented their work at the Empirical Methods in Natural Language Processing (EMNLP) in Brussels, Belgium.
Professor Julia Hirschberg gave a keynote talk on the work done by the Spoken Language Processing Group on how to automatically detect deception in spoken language – how to identify cues in trusted speech vs. mistrusted speech and how these features differ by speaker and by listener. Slides from the talk can be viewed here.
Five teams with computer science undergrad and PhD students from the Natural Language Processing Group (NLP) also attended the conference to showcase their work on text summarization, analysis of social media, and fact checking.
”Given the difficult times, we are living in, it’s extremely necessary to be perfect with our facts,” said Tuhin Chakrabarty, lead researcher of the paper. “Misinformation spreads like wildfire and has long-lasting impacts. This motivated us to delve into the area of fact extraction and verification.”
This paper presents the ColumbiaNLP
submission for the FEVER Workshop Shared Task. Their system is an end-to-end pipeline that
extracts factual evidence from Wikipedia and infers a decision about the
truthfulness of the claim based on the extracted evidence.
Fact checking is a type
of investigative journalism where experts examine the claims published by
others for their veracity. The claims can range from statements made by public
figures to stories reported by other publishers. The end goal of a fact
checking system is to provide a verdict on whether the claim is true, false, or
mixed. Several organizations such as FactCheck.org and PolitiFact are devoted
to such activities.
The FEVER Shared task aims to evaluate the ability of a system to verify information using evidence from Wikipedia. Given a claim involving one or more entities (mapping to Wikipedia pages), the system must extract textual evidence (sets of sentences from Wikipedia pages) that supports or refutes the claim and then using this evidence, it must label the claim as Supported, Refuted or NotEnoughInfo.
Detecting Gang-Involved Escalation on Social Media Using Context Serina Chang Computer Science Department, Ruiqi Zhong Computer Science Department, Ethan Adams Computer Science Department, Fei-Tzin Lee Computer Science Department, Siddharth Varia Computer Science Department, Desmond Patton School of Social Work, William Frey School of Social Work, Chris Kedzie Computer Science Department, and Kathleen McKeown Computer Science Department
This research is a
collaboration between Professor Kathy McKeown’s NLP lab and the
Columbia School of Social Work. Professor Desmond Patton, from the School of Social Work and a member of the Data
Science Institute, discovered that gang-involved youth in cities such as
Chicago increasingly turn to social media to grieve the loss of loved ones,
which may escalate into aggression toward rival gangs and plans for violence.
The team created a machine
learning system that can automatically detect aggression and loss in the social
media posts of gang-involved youth. They developed an approach with the hope to
eventually use a system that can save critical time, scale reach, and intervene
before more young lives are lost.
The
system features the use of word embeddings and lexicons, automatically derived
from a large domain-specific corpus which the team constructed. They also
created context features that capture user’s recent posts, both in semantic and
emotional content, and their interactions with other users in the dataset.
Incorporating domain-specific resources and context feature in a Convolutional
Neural Network (CNN) that leads to a significant improvement over the prior
state-of-the-art.
The dataset used spans the public Twitter posts of nearly 300 users from a gang-involved community in Chicago. Youth volunteers and violence prevention organizations helped identify users and annotate the dataset for aggression and loss. Here are two examples of labeled tweets, both of which the system was able to classify correctly. Names are blocked out to preserve the privacy of users.
Tweet examples
For semantics, which were represented by word embeddings, the researchers found that it was optimal to include 90 days of recent tweet history. While for emotion, where an emotion lexicon was employed, only two days of recent tweets were needed. This matched insight from prior social work research, which found that loss is significantly likely to precede aggression in a two-day window. They also found that emotions fluctuate more quickly than semantics so the tighter context window would be able to capture more fine-grained fluctuation.
“We took this context-driven approach because we believed that interpreting emotion in a given tweet requires context, including what the users had been saying recently, how they had been feeling, and their social dynamics with others,” said Serina Chang, an undergraduate computer science student. One thing that surprised them was the extent to which different types of context offered different types of information, as demonstrated by the contrasting contributions of the semantic-based user history feature and the emotion-based one. Continued Chang, “As we hypothesized, adding context did result in a significant performance improvement in our neural net model.”
Automated fact checking of textual claims is of increasing interest in today’s world. Previous research has investigated fact checking in political statements, news articles, and community forums.
“Through our model we can fact check claims
and find specific statements that support the evidence,” said Christopher Hidey,
a fourth year PhD student. “This is a step towards addressing the
propagation of misinformation online.”
As part of the FEVER community
shared task, the researchers developed models that given a statement would jointly find a Wikipedia article and a sentence related
to the statement, and then predict whether the statement is supported by that sentence.
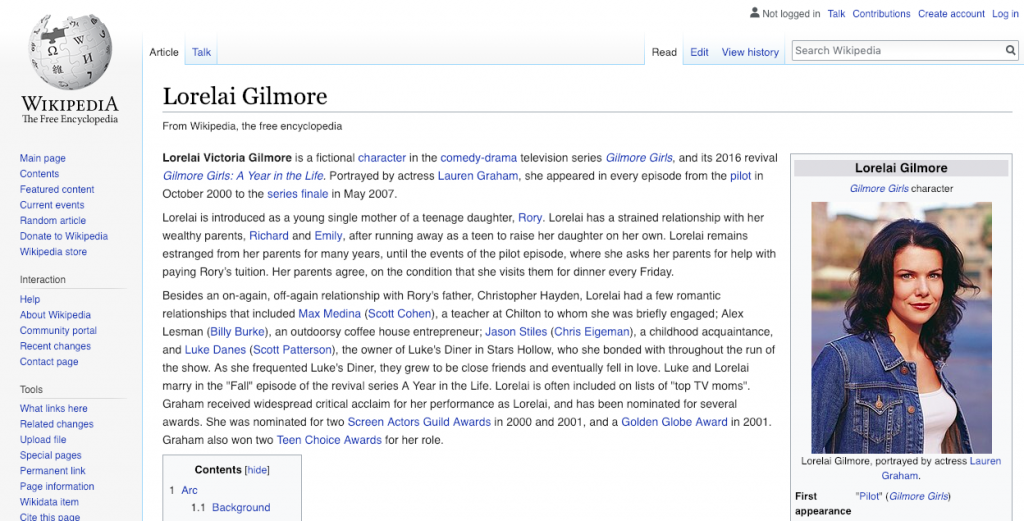
For example, given the claim “Lorelai Gilmore’s father is named Robert,” one could find the Wikipedia article on Lorelai Gilmore and extract the third sentence “Lorelai has a strained relationship with her wealthy parents, Richard and Emily, after running away as a teen to raise her daughter on her own” to show that the claim is false.
Credit : Wikipedia – https://en.wikipedia.org/wiki/Lorelai_Gilmore
One aspect of this problem that the team observed was how poorly TF-IDF, a standard technique in information retrieval and natural language processing, performed at retrieving Wikipedia articles and sentences. Their custom model improved performance by 35 points in terms of recall over a TF-IDF baseline, achieving 90% recall for 5 articles. Overall, the model retrieved the correct sentence and predicted the veracity of the claim 50% of the time.
The rate of which misinformation is spreading on
the web is faster than the rate of manual fact-checking conducted by
organizations like Politifact.com and Factchecking.org. For this paper the
researchers wanted to explore how to automate parts or all of the fact-checking
process. A poster with their findings was presented as part
of the FEVER workshop.
“In order to come up with reliable fact-checking
systems we need to understand the current manual process and identify
opportunities for automation,” said Tariq Alhindi, lead author on the paper. They looked at the LIAR dataset – around 10,000 claims classified by Politifact.com to one of six
degrees of truth – pants-on-fire, false, mostly-false, half-true, mostly-true,
true. Continued Alhindi, we also looked at the fact-checking article for each
claim and automatically extracted justification sentences of a given
verdict and used them in our models, after removing all sentences that contain
the verdict (e.g. true or false).
Excerpt from the LIAR-PLUS dataset
Feature-based machine learning models and
neural networks were used to develop models that can predict whether
a given statement is true or false. Results showed that using some sort of
justification or evidence always improves the results of fake-news detection
models.
“What was most surprising about the results is that
adding features from the extracted justification sentences consistently improved
the results no matter what classifier we used or what other features we
included,” shared Alhindi, a PhD student. “However, we were surprised that the
improvement was consistent even when we compare
traditional feature-based linear machine learning models against state of
the art deep learning models.”
Their research extends the previous work done on this data set which only looked at the linguistic cues of the claim and/or the metadata of the speaker (history, venue, party-affiliation, etc.). The researchers also released the extended dataset to the community to allow further work on this dataset with the extracted justifications.
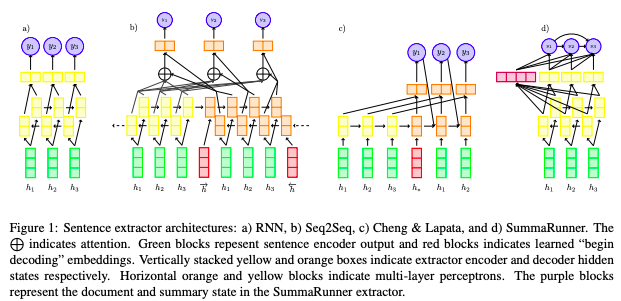
Recently,
a specific type of machine learning, called deep learning, has made strides in
reaching human level performance on hard to articulate problems, that is,
things people do subconsciously like recognizing faces or understanding speech.
And so, natural language processing researchers have turned to these models for
the task of identifying the most important phrases and sentences in text
documents, and have trained them to imitate the decisions a human editor might
make when selecting content for a summary.
“Deep
learning models have been successful in summarizing natural language texts,
news articles and online comments,” said Chris Kedzie, a fifth
year PhD student. “What we wanted to know is how they are doing it.”
While
these deep learning models are empirically successful, it is not clear how they
are performing this task. By design, they are learning to create their own
representation of words and sentences, and then using them to predict whether a
sentence is important – if it should go into a summary of the document. But
just what kinds of information are they using to create these
representations?
One
hypotheses the researchers had was that certain types of words were more
informative than others. For example, in a news article, nouns and verbs might
be more important than adjectives and adverbs for identifying the most
important information since such articles are typically written in a relatively
objective manner.
To see if this was so, they trained models to predict sentence importance on redacted datasets, where either nouns, verbs, adjectives, adverbs, or function words were removed and compared them to models trained on the original data.
On
a dataset of personal stories published on Reddit, adjectives and adverbs were
the key to achieving the best performance. This made intuitive sense in that
people tend to use intensifiers to highlight the most important or climactic
moments in their stories with sentences like, “And those were the WORST
customers I ever served.”
What surprised the researchers were the news articles – removing any one class of words did not dramatically decrease model performance. Either important content was broadly distributed across all kinds of words or there was some other signal that the model was using.
They suspected that sentence order was important because journalists are typically instructed to write according to the inverted pyramid style with the most important information at the top of the article. It was possible that the models were implicitly learning this and simply selecting sentences from the article lead.
Two pieces of evidence confirmed this. First, looking at a histogram of sentence positions selected as important, the models overwhelmingly preferred the lead of the article. Second, in a follow up experiment, the sentence ordered was shuffled to remove sentence position as a viable signal from which to learn. On news articles, model performance dropped significantly, leading to the conclusion that sentence position was most responsible for model performance on news documents.
The
result concerned the researchers as they want models to be trained to truly
understand human language and not use simple and brittle heuristics (like
sentence position). “To connect this to broader trends in machine learning, we
should be very concerned and careful about what signals are being exploited by
our models, especially when making sensitive decisions,” Kedzie continued. ”The
signals identified by the model as helpful may not truly capture the problem we
are trying to solve, and worse yet, may be exploiting biases in the dataset
that we do not wish it to learn.”
However,
Kedzie sees this as an opportunity to improve the utility of word
representations so that models are better able to use the article content
itself. Along these lines, in the future, he hopes to show that by quantifying
the surprisal or novelty of a particular word or phrase, models are able to
make better sentence importance predictions. Just as people might remember the
most surprising and unexpected parts of a good story.
The department welcomes Baishakhi Ray, Ronghui Gu, Carl Vondrick, and Tony Dear.
Baishakhi Ray Assistant Professor, Computer Science PhD, University of Texas, Austin, 2013; MS, University of Colorado, Boulder, 2009; BTech, Calcutta University, India, 2004; BSc, Presidency College, India, 2001
Baishakhi Ray works on end-to-end software solutions and treats the entire software system – anything from debugging, patching, security, performance, developing methodology, to even the user experience of developers and users.
At the moment her research is focused on machine learning bias. For example, some models see a picture of a baby and a man and identify it as a woman and child. Her team is developing ways on how to train a system and to solve practical problems.
Ray previously taught at the University of Virginia and was a postdoctoral fellow in computer science at the University of California, Davis. In 2017, she received Best Paper Awards at the SIGSOFT Symposium on the Foundations of Software Engineering and the International Conference on Mining Software Repositories.
Ronghui Gu focuses on programming languages and operating systems, specifically language-based support for safety and security, certified system software, certified programming and compilation, formal methods, and concurrency reasoning. He seeks to build certified concurrent operating systems that can resist cyberattacks.
Gu previously worked at Google and co-founded Certik, a formal verification platform for smart contracts and blockchain ecosystems. The startup grew out of his thesis, which proposed CertiKOS, a comprehensive verification framework. CertiKOS is used in high-profile DARPA programs CRASH and HACMS, is a core component of an NSF Expeditions in Computing project DeepSpec, and has been widely considered “a real breakthrough” toward hacker-resistant systems.
Carl Vondrick Assistant Professor, Computer Science PhD, Massachusetts Institute of Technology, 2017; BS, University of California, Irvine, 2011
Carl Vondrick’s research focuses on computer vision and machine learning. His work often uses large amounts of unlabeled data to teach perception to machines. Other interests include interpretable models, high-level reasoning, and perception for robotics.
His past research developed computer systems that watch video in order to anticipate human actions, recognize ambient sounds, and visually track objects. Computer vision is enabling applications across health, security, and robotics, but they currently require large labeled datasets to work well, which is expensive to collect. Instead, Vondrick’s research develops systems that learn from unlabeled data, which will enable computer vision systems to efficiently scale up and tackle versatile tasks. His research has been featured on CNN and Wired and in a skit on the Late Show with Stephen Colbert, for training computer vision models through binge-watching TV shows.
Recently, three research papers he worked on were presented at the European Conference for Computer Vision (EECV). Vondrick comes to Columbia from Google Research, where he was a research scientist.
Tony Dear Lecturer in Discipline, Computer Science PhD, Carnegie Mellon University, 2018; MS, Carnegie Mellon University, 2015; BS, University of California, Berkeley, 2012
Tony Dear’s research and pedagogical interests lie in bringing theory into practice. In his PhD research, this idea motivated the application of analytical tools to motion planning for “real” or physical locomoting robotic systems that violate certain ideal assumptions but still exhibit some structure – how to get unconventional robots to move around with stealth of animals and biological organisms. Also, how to simplify tools and expand that to other systems, as well as how to generalize mathematical models to be used in multiple robots.
In his teaching, Dear strives to engage students with relatable examples and projects, alternative ways of learning, such as an online curriculum with lecture videos. He completed the Future Faculty Program at the Eberly Center for Teaching Excellence at Carnegie Mellon and has been the recipient of a National Defense Science and Engineering Graduate Fellowship.
At Columbia, Dear is looking forward to teaching computer science, robotics, and AI. He hopes to continue small-scale research projects in robotic locomotion and conduct outreach to teach teens STEM and robotics courses.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor

 OMSCS – The Best Degree Program Ever?
OMSCS – The Best Degree Program Ever? How to Close the 100,000-Year “Data Gap” in Robotics
How to Close the 100,000-Year “Data Gap” in Robotics November 24, 2025
November 24, 2025