
Month: July 2016
Kathleen McKeown among Columbia researchers unveiling new technology Aug. 7-12
She is coauthor of three papers that incorporate natural language processing to speed and automate tasks.
Steven Nowick launches working group on massive-scale computing systems
Researchers working on extreme-scale computing systems will collaborate with those working to solve ambitious problems in the physical sciences, medicine, and engineering.
It’s a Computing Revolution in the Liberal Arts
Liberal arts majors are increasingly skipping computer science “lite” classes for the more rigorous ones meant for computer science majors. And for good reason. New methods in machine learning and text mining are turning text into data that can be analyzed computationally, giving English majors studying literary works, history majors analyzing past records, and economics majors examining financial trends powerful new ways to change how their fields are studied.
In response, Columbia’s Computer Science Department last year introduced a new class, Computing in Context, to teach computer science in a way that is both rigorous and relevant to specific liberal arts disciplines. Aimed at students who may not otherwise take computer science, it is a hybrid course taught by a team of Columbia professors and is the first of its kind to combine lectures in basic computer science with lectures and projects applying those methods to multiple disciplines within the humanities and social sciences.
The class is the brainchild of Adam Cannon, who during 15 years of teaching introductory computer science at the Engineering School has seen the number of liberal arts students in his classes climb. “These students don’t want an appreciation of computer science; they want to apply computing techniques in their own fields. And they’re going to change those fields because they can think about them differently. This is the beginning of a revolution in liberal arts,” says Cannon.
First they have to think like computer scientists. At its core, computer science is about structuring a problem into individual component parts that can be solved by computer. It entails critical and abstract thinking that is by itself a powerful method of organizing and analyzing information. Computational thinking can be learned and is part of all computer science classes, but most focus on numeric, not text, processing, and projects may not be relevant to liberal arts students.
Cannon’s class introduces context. While teaching basic concepts—functions, objects, arrays—and programming in Python, it inserts modules, or tracks, each created by a humanities or social sciences professor to show how computing concepts apply to a specific discipline.
Each track is taught live once, with the material digitized for future classes that adapt the flipped classroom approach: students digest the context-specific material online, aided by teaching assistants who lead discussions and active learning tasks.
Three tracks are offered now—digital humanities (Dennis Tenen), social science (Matthew Jones), and econ financing (Karl Sigman)—with more planned. Students all learn the same basic skills but apply them in different ways and to different projects, with social science students rating the centrality of U.S. pre-revolutionary leaders, econ students modeling the price of options, and digital humanities students constructing algorithms to automatically grade essays.
The class debuted in Spring 2015 with all 150 slots filled. The gender split was 50/50, unusual for a computer science class; 100% were liberal arts students. Reasons to enroll differed. “Even if you don’t do computer science, you will probably interact with people who are techy, so it’s important to communicate with programmers on their own level,” says student Christina Cheung.
Suzen Fylke had enrolled for computer science before but never followed through. “I didn’t feel programming was for me, so the regular class was a little intimidating. Computing in Context offered an easier entry point since half the class was analysis on topics I was familiar with. Maybe I wouldn’t be good at the computer science part, but I knew I could do the analysis part.” For her, the class has been life changing. Fylke took it spring 2015 just before graduating with a degree in American Studies and has since enrolled in Hunter College to study computational linguistics.
Demand for the class is expected to grow. Cannon hopes someday 90% of all students enroll in a computer science class. Says Cannon: “It’s exciting to think students coming out of this course are going to be faculty in 10 years. And they are going to have the computational skills to change their disciplines. That’s when I’ll feel this class is really successful.”
Limiting the undesired impact of cyber weapons
Steven Bellovin, Susan Landau, and Herbert S. Lin examine the technical requirements and policy implications of targeted cyber attacks.
Columbia researchers presenting eight papers at this year’s SIGGRAPH
Columbia University researchers are presenting eight papers at this year’s SIGGRAPH, held July 24-26 at Anaheim’s convention center. High-level descriptions are given below with links provided to the papers and companion videos.
Surface-Only Liquids
Computational Design of Reconfigurables
Acoustic Voxels: Computational Optimization of Modular Acoustic Filters
Interactive Acoustic Transfer Approximation for Modal Sound
Mesh Arrangements for Solid Geometry
DisCo: Display-Camera Communication Using Rolling Shutter Sensors
Rig Animation with a Tangible and Modular Input Device
Toward Animating Water with Complex Acoustic Bubbles
Category: Fluids simulation
Tuesday, 26 July, 3:45 pm – 5:35 pm, Ballroom D
Surface-Only Liquids
Fang Da , Columbia University
, Columbia University
David Hahn, Institute of Science and Technology, Austria
Christopher Batty, University of Waterloo
Chris Wojtan, IST Austria
Eitan Grinspun, Columbia University
, Columbia UniversityDavid Hahn, Institute of Science and Technology, Austria
Christopher Batty, University of Waterloo
Chris Wojtan, IST Austria
Eitan Grinspun, Columbia University
An interview with Eitan Grinspun.
The paper describes simulating splashes and other liquid behaviors by modeling only the surface. Where did the idea come from?
When you look at a glass of water, what is it that you see? There is a volume, and light travels through it, but the only geometry you see is the geometry of the surface. So at a philosophical level—on a minimalist level—you can ask, is it necessary to explicitly represent every point on the interior of the water if we see only the exterior surface? Our paper shows that in many cases, even complex cases, the answer is no.
It’s important to point out that while we are not representing the interior explicitly, we do so implicitly. We don’t view the surface as a membrane with just air inside. That would never work. We treat the interior as filled with solid water, though we do so in an implicit way. And we make certain assumptions about the interior that allow us to reduce away all the representation of the liquid on the interior.
This paper is the first to describe a surface-based treatment of liquids. Was such a treatment known to be a hard problem?
I think it was assumed to be impossible. Five or six years also, I asked physicist colleagues who said that a surface-only treatment would likely miss the physics of an emerging drop or crown splash, because such a method wouldn’t consider the swirling vortices that are inside the liquid, and which are just as, or more, important than anything happening on the surface.
When we started this project, we had to really think hard about what we needed to know about the interior of the water given only a surface representation. What can you say about some particular point in the interior if your only representation is on the boundary?
The outside cannot possibly summarize everything that’s happening on the inside unless you make certain assumptions. The assumption we made is that the interior is in some sense “as uninteresting as possible” given what’s happening on the boundary. It has no extra swirls. Only the swirls that can be seen or inferred from the boundary.
Were you surprised that your method worked as well as it did?
Yes, we were surprised; I think everyone was surprised.
Fortunately, there is a physical justification for it. The motion of liquids includes an effect called baroclincity, which basically means that the formation of swirls can arise only at locations having a change in density. In the interior, where the density is constant, there can be no sudden formation of a swirl. At the boundary, there is a difference in density, and there a swirl can form suddenly.
Now does a swirl formed at the boundary migrate to the interior? It depends; the migration or spreading out of swirls is caused by viscosity. Honey with high viscosity will have a lot of migration, but water, having low-viscosity, will have little migration. Effectively we assume that our water is inviscid, that it has zero viscosity. Real water does have some viscosity (the physicist Feynman would have said that we are working with “the flow of dry water”), but it’s a good enough assumption.
Would you say that you’re contributing new knowledge to the study of water dynamics?
I think we’re contributing new questions. Some previous assumptions about the complexity of what is going on inside these droplets and jets must be reexamined, otherwise our algorithm shouldn’t work. A more complex view of behavior of the inside of a volume of water apparently is not needed to explain a splash, since we can simulate that splash when we factor out that complex behavior.
No one’s been able to see exactly what the interior flow is during a crown splash; so by virtue of making the assumptions we did about what the flow can and cannot be, we’re effectively adding a data point that says the flow is actually pretty simple in the interior, and our assumptions must be sufficiently close to the truth to observe the results that we did.
Category: Deformable Surface Design
Wednesday, 27 July, 9:00 am – 10:30 am, Ballroom E
Computational Design of Reconfigurables
Akash Garg, Columbia University
Alec Jacobson, Columbia University
Eitan Grinspun, Columbia University
![]()
An interview with Eitan Grinspun
The reconfigurables paper—where you have hard, rigid surfaces and planes and the possibility of collision—seems very different from the subject of surface-only liquids. What is the connection?
The theory behind the two papers is absolutely different. The connection is geometry. For surface-only liquids, it was helpful to focus on the geometry of the surface.
What’s interesting for me when looking at reconfigurables—whether it’s a bicycle that folds up or an extremely efficient kitchen in a small space—is that your attention is focused on one configuration but then you make a geometric change to the shape that works great in some way but interferes with functionality or causes two parts to collide.
I like to look for abstractions, and one of the general areas where designing is hard is when an object can be in multiple configurations. So we wanted a CAD program where these transitions or different states were not an afterthought, but primary to the entire process.
This project seems to have more actual application for a wider range of people than simulating liquid motion.
I think you are right. We actually make a conscious effort to have different projects in the lab spanning the spectrum from more conceptual to more applied. Our idea was to create a tool that would aid designers by alerting them when and where parts might collide while also offering suggestions and edits on how to resolve collisions. Manually making adjustments through trial and error can be very tedious; our method makes the process more automatic and fluid.
How did you three authors divide up the work on this paper?
At first, Akash focused primarily on the underlying collision detection “engine” that drives the interactive collision notifications of the software, while Alec focused on the human experience, including assistive tools such as “smart” camera that automatically selected the best viewpoint for observing problem areas. But these two branches of work quickly merged, and pretty soon Alec was also working on collisions, helping to formulate the mathematics of a new “spacetime collision resolver” that automatically fixed subtle penetrations, while Akash was reciprocally contributing to the human experience, for example with a “smart picture-in-picture” that popped up automatically to highlight unintended side-effects of the present editing operation. So in the end, it’s harder to tease apart the roles. While I pitched the original project vision, the project really took shape when we as a team identified more and more domain examples where reconfigurables arise, from a folding bicycle to a kitchen or burr puzzle.
From your perspective, what most distinguishes this project from the surface-only liquids paper?
Since one project is about water and the other is about picnic benches and kitchens, I think at first glance they are completely different. So let me answer instead the question of what is the least obvious commonality among these two projects. As I said before, on a technical level, I like them both because they are both inherently geometric approaches. But I think on a scholarly level there is a birds-eye commonality that I can share. I think of both projects somewhat as “conceptual pieces” such as a “concept cars.” You build a concept car not because you think everyone should be driving one tomorrow, but because it provides inspiration and vision for where to go. Both the surface-only liquids and reconfigurables papers provide this kind of vision.
On the liquids side, we are really breaking the ice on decades of ongoing research on liquid simulation where the entire volume is discretized, and we are saying, hey, people have thought that maybe you can just simulate on the surface, but now it’s not just a pipe dream, here’s this avenue we can begin to pursue.
On the reconfigurables side, we don’t pretend to have built a computer aided design (CAD) tool that is feature-rich like commercial tools; rather, we feel that we are calling attention to a broad and practical class of design problems—reconfigurables—for which current CAD tools do not provide sufficient support. We hope that the kinds of questions (and maybe some answers) that came up in how to support the design of reconfigurables can drive the next set of features in commercial CAD packages.
Are there concrete plans to distribute your method so that designers will be able to use it?
We are definitely interested in disseminating the code. Alec has already publicly released his popular libIGL mesh processing library. Reconfigurables will be a separate code, but we hope that it will be useful for others. On a more entrepreneurial front, we are also reaching out to design and engineering firms to find out how the technologies that we have developed match up against their realities.
Category: Computational Design of Structures, Shapes, and Sound
Wednesday, 27 July, 9:00 am – 10:30 am, Ballroom D
Acoustic Voxels: Computational Optimization of Modular Acoustic Filters

Dingzeyu Li, Columbia University
David I.W. Levin, Disney Research
Wojciech Matusik, MIT CSAIL
Changxi Zheng, Columbia University
![]()
A trumpet and a muffler may seem dissimilar but inside each is an acoustic filter that modifies sound; as sound waves pass through the filter’s hollow chamber, they get reflected back and forth, which boosts or suppresses certain frequencies. Changing the chamber’s shape changes the sound, but predicting the shape-sound relationship is not intuitive; for this reason the chamber’s shape is almost always a simple tube whose acoustics are relatively simple to understand, and simple also to manufacture. But now with computational methods that accurately simulate sound wave propagation, researchers can design—and fabricate with 3D printers—more complex chambers to gain more control over the acoustics. Freed from traditional constraints, researchers re-imagined acoustic filters, building them out of small primitives called acoustic voxels. It’s a general approach that works for both wind instruments and mufflers. And, in an unexpected and propitious twist, it leads researchers in a completely new direction: acoustic tagging for uniquely identifying an object, and acoustic encoding for implanting information (think copyright) into an object’s very form.
For more information about the method, see Acoustic voxels: Manipulating sound waves makes possible acoustic tagging and encoding.
Category: Sound, Fluids, and Boundaries
Wednesday, 27 July, 10:45 am – 12:15 pm, Ballroom D
Interactive Acoustic Transfer Approximation for Modal Sound

Dingzeyu Li, Columbia University
Yun Fei, Columbia University
Changxi Zheng, Columbia University
![]()
![]()
An interview with Dingzeyu Li
What is the problem you’re solving?
Sound in animation is very important, but it’s hard to get right. Artists are usually given a mesh animation and from that they try to imagine what sounds might result from two objects colliding. But it’s hard, especially in the virtual world where anything can happen, like a cartoon car character crashing into something. There’s no real-world counterpart, and artists must rely on their imagination.
They end up recording a sound and integrating it into the animation so it aligns with the action—which takes time to get right—but often the sound is not quite what they want or they decide to change something about an object’s characteristics, and they must start all over again. It might take hours or days for a single sequence.
But you’re not using prerecorded sound?
That’s correct. Ours is a physics-based, computational approach where sound is automatically generated from vibrations produced by the collision of two rigid objects. While there are existing physics-based methods—sound from vibrations is a well-studied area—our method focuses on how that sound propagates and how it would sound at various angles and locations.
We also looked for ways to precompute many of the calculations that go into simulating a sound so that if something changes in the animation, we can quickly recompute the sound in a highly accurate, realistic way. These precomputations—which have to take into account the geometry, the sound frequency, and many other variables—can take several hours, but once they are done, they are done and stored to be immediately available if needed.
Existing methods are not as flexible. If something changes, the entire process of recomputing everything has to be redone from the beginning.
What makes your method fast?
Previous methods relied on multipole coefficients, called moments, which are much more volatile and apt to change from one sample to another, making it very hard to interpolate smoothly. It would require many samples to accurately approximate the sound propagation behavior.
We look at a very smooth function that we can interpolate easily; specifically we use the acoustic pressure value, which describes how acoustic pressure propagates in space. Because the pressure value changes smoothly in the frequency domain, we don’t have to take many samples to get a faithful approximation. It’s these pressure values that are being precomputed at a sparse set of frequencies. At runtime, the moments can be recovered from these smooth pressure values efficiently.
We look at a very smooth function that we can interpolate easily; specifically we use the acoustic pressure value, which describes how acoustic pressure propagates in space. Because the pressure value changes smoothly in the frequency domain, we don’t have to take many samples to get a faithful approximation. It’s these pressure values that are being precomputed at a sparse set of frequencies. At runtime, the moments can be recovered from these smooth pressure values efficiently.
You’re also a coauthor on the acoustic voxel paper. Was there much overlap?
One interesting link between the two projects is that the method of precomputing the pressure values can be used also to precompute size changes in the voxel primitives and so accelerate the acoustic voxel precomputation even further.
The acoustic transfer method you describe is for the modal sounds produced by rigid objects. Is it possible to apply it to deformable objects?
In the paper, we showed one extension to handle deformable body sound propagation. Currently we assume the modal shapes remain unchanged in the animation.
For animations involving large deformations, the computation is more challenging since the modal shapes are no longer constant. We are currently working on simulating sounds for deformable objects.
Category: Geometry
Monday, 25 July, 9:00 am – 10:30 am, Ballroom E
Mesh Arrangements for Solid Geometry

Qingnan Zhou, New York University
Eitan Grinspun, Columbia University
Denis Zorin, New York University
Alec Jacobson, Columbia University
Eitan Grinspun, Columbia University
Denis Zorin, New York University
Alec Jacobson, Columbia University
![]()
An interview with Alec Jacobson
Why are meshes important in computer graphics?
In mathematics we prefer to represent 3D objects in terms of continuous functions, however to work with 3D objects on the computer we need a discrete, finite representation. Memory is not infinite, so we can’t store all of the points on an object’s surface. Instead, we look to approximations. Meshes are surfaces formed out of connecting many small polygons, often triangles. This is one of the most basic ways to represent a very large class of objects. One particular advantage to traditional computer graphics is the ease at which one can display or render meshes on screen. Meshes are called an explicit representation because it is easy to march along the surface and trace out lines or areas.
This comes at a cost compared to implicit representations that can easily answer whether or how far any query point is from the surface. Implicit surfaces make Solid Geometry tasks like taking the union or difference of two objects very ease. Explicit surfaces are much trickier and these tasks require great care.
Can you describe at a high level the main innovation of your paper?
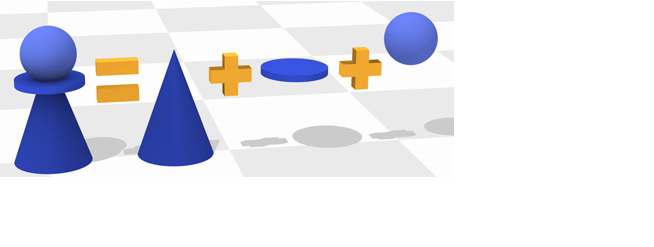
Once one or many 3D objects are represented as meshes, our method enables conducting certain operations robustly them. For example, many physical objects we use are a designed by merging multiple 3D shapes together: a chess piece pawn is a sphere merged with a cone merged with a flat disk. With out method we can achieve these type of operations on meshes—a common format for surfaces in computer graphics. Previous methods either required unrealistically high-quality inputs or produced flaws in their output.
What was your motivation in addressing this particular problem in computer graphics?
My original motivation for solving this problem was curiosity and desire for an easy to use open source implementation of these tools. Solid geometry operations are fundamental and a very powerful tool to have in one’s tool chest. I had read a recent work on peeling off layers of self-intersecting meshes to reveal their outermost layer. Initially I thought this method could be extended to more general operations on solid objects. Inevitably our method matured from that idea into its current form.
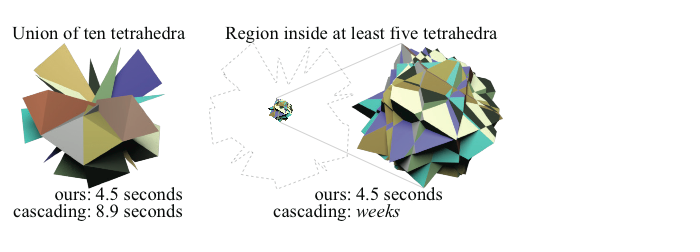
What makes your method fast? Your paper describes how a cascading operation that previously would have taken weeks to compute can be completed in only a few seconds with your method.
Our method is faster in certain scenarios because we avoid a “domino effect.” Faced with a series of operations, previous methods would resolve them one by one. In the worst case this can lead to an explosion in the number of new elements created after each operation. Our method resolves all operations simultaneously and the number of new elements is no more than what’s necessary to represent the output.
Do you plan further enhancements?
There are many directions I would like to take this work in the future. Specific to this project I would like to further improve our performance. Beyond solid operations, this work is one step toward a larger goal of making all parts of the geometry processing pipeline more robust.
Category: User Interfaces
Thursday, 28 July, 2:00 pm – 3:30 pm, Ballroom D
Thursday, 28 July, 2:00 pm – 3:30 pm, Ballroom D
Kensei Jo, Columbia University
Mohit Gupta, Columbia University
Shree Nayar, Columbia University
![]()
Abstract:
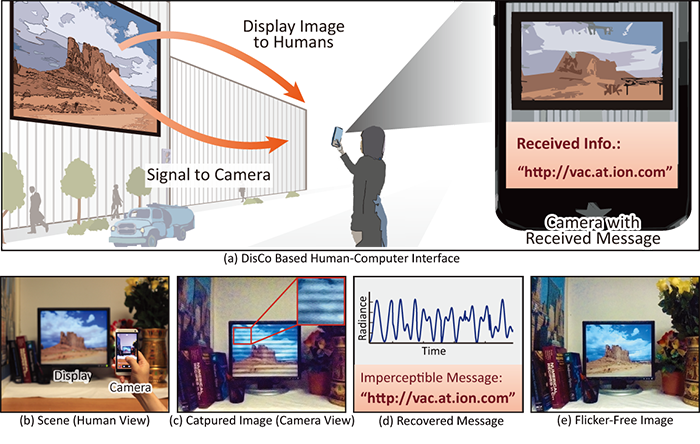
We present DisCo, a novel display-camera communication system that enables displays to send short messages to digital sensors, while simultaneously displaying images for human consumption. Existing display-camera communication methods are largely based on spatial-domain steganography, where the information is encoded as an imperceptible spatial signal (e.g., QR-code). These methods, while simple to implement, are prone to errors due to common causes of image degradations such as occlusions, display being outside the sensor’s field-of-view, defocus blur and perspective distortion. Due to these limitations, steganography-based techniques have not been widely adopted, especially in uncontrolled settings involving consumer cameras and public displays.
DisCo overcomes these limitations by embedding messages in temporal signals instead of spatial signals. We draw inspiration from the emerging field of visible light communication (VLC), where information is transmitted between a light source (transmitter) and a sensor (receiver) via high-frequency temporally modulated light. Most of these techniques require specialized high-speed cameras or photo-diodes as signal receivers [Elgala et al. 2009; Vucic et al. 2010; Sarkera et al. 2009]. Recently, a method was proposed for using low-cost rolling shutter sensors as receivers. This method, however, places strong restrictions on the transmitter; only light sources (e.g., LEDs) or surfaces with constant brightness [Danakis et al. 2012] can be used. These systems do not work with displays that need to display arbitrary images. The goal of this paper is on designing systems that can use a broad range of signal transmitters, especially displays showing arbitrary images, as well as objects that are illuminated with temporally modulated light. The objects can have arbitrary textures.
DisCo builds upon the method proposed in [Danakis et al. 2012] and uses rolling shutter cameras as signal receivers. In rolling shutter sensors, different rows of pixels are exposed in rapid succession, thereby sampling the incident light at different time instants. This converts the temporally modulated light coming from the display into a spatial flicker pattern in the captured image. The flicker encodes the transmitted signal. However, the flicker pattern is superimposed with the (unknown) display pattern. In order to extract the message, the flicker and the display pattern must be separated. Our key contribution is to show that the two components can be separated by capturing images at two different camera exposures. We also show that the flicker component is invariant to the display pattern and other common imaging degradations (e.g., defocus blur, occlusion, camera rotation and variable display size). The effect of all these degradations can be absorbed in the display pattern component. Since the display pattern is separated from the flicker component before signal recovery, the imaging degradations do not adversely affect the communication process.
Category: User Interfaces
Thursday, 28 July, 2:00 pm – 3:30 pm, Ballroom D
Thursday, 28 July, 2:00 pm – 3:30 pm, Ballroom D
Oliver Glauser, ETH Zurich
Wan-Chun, ETH Zurich
Daniele Panozzo, New York University & ETH Zurich
Alec Jacobson, Columbia University
Otmar Hilliges, ETH Zurich
Olga Sorkine-Hornung, ETH Zurich
![]()

Abstract:
We propose a novel approach to digital character animation, combining the benefits of tangible input devices and sophisticated rig animation algorithms. A symbiotic software and hardware ap- proach facilitates the animation process for novice and expert users alike. We overcome limitations inherent to all previous tangible devices by allowing users to directly control complex rigs using only a small set (5-10) of physical controls. This avoids oversimplification of the pose space and excessively bulky device configurations. Our algorithm derives a small device configuration from complex character rigs, often containing hundreds of degrees of freedom, and a set of sparse sample poses. Importantly, only the most influential degrees of freedom are controlled directly, yet detailed motion is preserved based on a pose interpolation technique. We designed a modular collection of joints and splitters, which can be assembled to represent a wide variety of skeletons. Each joint piece combines a universal joint and two twisting elements, allowing to accurately sense its configuration. The mechanical design provides a smooth inverse kinematics-like user experience and is not prone to gimbal locking. We integrate our method with the professional 3D software Autodesk Maya® and discuss a variety of results created with characters available online. Comparative user experiments show significant improvements over the closest state-of-the-art in terms of accuracy and time in a keyframe posing task.
Category: Sound, Fluids, & Boundaries
Wednesday, 27 July, 10:45 am – 12:15 pm, Ballroom D
Wednesday, 27 July, 10:45 am – 12:15 pm, Ballroom D
Toward Animating Water with Complex Acoustic Bubbles
Timothy Langlois , Cornell University
, Cornell University
Changxi Zheng, Columbia University,
Doug James, Stanford University
, Cornell UniversityChangxi Zheng, Columbia University,
Doug James, Stanford University
![]()
Abstract:
This paper explores methods for synthesizing physics-based bubble sounds directly from two-phase incompressible simulations of bubbly water flows. By tracking fluid-air interface geometry, we identify bubble geometry and topological changes due to splitting, merging and popping. A novel capacitance-based method is proposed that can estimate volume-mode bubble frequency changes due to bubble size, shape, and proximity to solid and air interfaces. Our acoustic transfer model is able to capture cavity resonance effects due to near-field geometry, and we also propose a fast precomputed bubble-plane model for cheap transfer evaluation. In addition, we consider a bubble forcing model that better accounts for bubble entrainment, splitting, and merging events, as well as a Helmholtz resonator model for bubble popping sounds. To overcome frequency bandwidth limitations associated with coarse resolution fluid grids, we simulate micro-bubbles in the audio domain using a power-law model of bubble populations. Finally, we present several detailed examples of audiovisual water simulations and physical experiments to validate our frequency model.
Posted 7/21/2016
Kathy McKeown, Vishal Misra, Junfeng Yang invited to speak at Microsoft Faculty Summit
More than 500 attendees from academia and Microsoft participated in sessions on virtual reality, optical networks, streaming analytics and big data infrastructure to the future of work and crowdsourcing.
Pokémon GO craze shows that augmented reality is hitting its stride
Acoustic voxels: Manipulating sound waves makes possible acoustic tagging and encoding

Manipulating sound waves can be a powerful tool with wide-ranging applications in medicine and surgery, materials science, pharmaceuticals, to name a few. But sound wave manipulation is not easy. Each wave contains many frequency components, and waves bounce off objects in complex ways depending on the shape or material of the obstructing object. Most recent progress in manipulating sound waves involves controlling sound waves created at specific frequencies. Manipulating sound waves in a customized way is much more challenging, but now a team led by Changxi Zheng has done exactly that. Using computational techniques, Dingzeyu Li (Columbia), Disney Researcher David Levin, and MIT professor Wojciech Matusik working with Zheng have developed a method to predict and manipulate sound waves as they pass through an air chamber such as those found in wind instruments and mufflers. The method involves building chambers out of small primitives called acoustic voxels that can be rapidly modified to change acoustic characteristics. It is a general approach that works for both musical instruments and industrial mufflers. More interestingly, it leads researchers in a completely new direction: acoustic tagging for uniquely identifying an object, and acoustic encoding for implanting information (think copyright) into an object’s very form. Much more may be possible.
Building objects with customized acoustics to both identify an object and relay information about it had not been the original goal. The project began as an extension of a previous one from last year when Changxi Zheng and his team used computational methods to design and 3D-print a zoolophone, a xylophone-type instrument with keys in the shape of zoo animals. While an original and fun musical instrument, the zoolophone represents fundamental research into vibrational sound control, leveraging the complex relationships between an object’s geometry and the vibrational sounds it produces when struck. The researchers start with a sound in mind and then computationally search over a large shape space for the exact geometry of a particular zoo animal shape that can produce the desired sound.
Zheng and his team this year turned their attention from striking instruments to wind instruments, which produce notes using a different principle: as sound waves pass through a chamber, they reflect back and forth off the sides of the chamber; this boosts certain frequencies in such a way to produce a specific note.
In theory, the sound passing through a chamber can be controlled by changing the chamber’s shape, but connecting sound characteristics with a chamber’s shape is not intuitive; for this reason, the chamber is almost always a tube or other simple shape whose acoustic properties are relatively easy to understand and easy also to manufacture. Even the simplest shape, however, often requires post-production tweaking to achieve the desired acoustic results.
Sound propagation is complex, but it can be understood and analyzed computationally, opening the door to more complex chamber shapes that can produce a broader range of sounds; and with 3D printers today, even complex shapes can be fabricated with little effort.
Freed from having to keep things simple, the researchers could re-imagine acoustic filters, concentrating on the best way of fitting a filter within an arbitrary 3D volume while achieving target characteristics. The simple but laborious process of creating and tweaking a tube-shaped chamber is formulated as a complex, computationally intensive problem of solving acoustic wave equations (or in the frequency domain, the Helmholtz equation) while searching over a huge search space for the exact chamber shape that can produce the target sound.
The solution was the acoustic voxel, a small, hollow, cube-shaped primitive through which sound enters and exits. Designed to be modular, voxels connect to form an assembly via circular insets on each side that can be opened to provide an exit or entry point, forming an infinitely adjustable graph-type structure. Changing one of several parameters—the number and size of voxels or how they connect—changes the acoustic result.
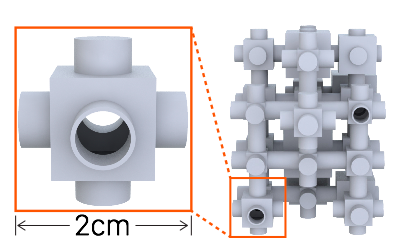
The entire assembly can be complex, but each individual voxel has a simple structure, which makes it possible, when solving equations, to separate out and precompute the transmission matrices that help to quantitatively describe a voxel’s acoustic filtering behaviors. By precomputing matrices, which are stored in a database and retrieved at runtime optimization, researchers realized a 77kx speedup over a standard method (finite-element method) that does not involve precomputations. What would normally take hours instead takes one or two seconds. (Testing done at Bruël & Kjær Laboratories showed that the computer simulations using transmission matrices closely matched results obtained using traditional, high-end lab instruments.)
The technical details of method are described fully in the paper Acoustic Voxels: Computational Optimization of Modular Acoustic Filters, but the overall method works generally as follows: Given three inputs: (1) the desired acoustic result, (2) a 3D volume in which to encapsulate the acoustic filter, and (3) the locations of the inlet and the outlet, the method specifies the size and number of voxels and how they should be assembled. The process is completely automated and optimized (via hybrid method that interleaves a stochastic optimization with a gradient-based quasi-Newton scheme). Even novices can design and fabricate objects with specified acoustics.

Because a voxel assembly can fit into any specified area, the shape of the object that contains a voxel assembly can be arbitrary. A trumpet doesn’t have to look like a traditional trumpet; it can be the shape of a cartoon hippopotamus and still produce trumpet notes.
Industrial and automotive mufflers also have an acoustic chamber, as do sound-suppressing earmuffs. It was an easy extension of the acoustic voxel method to target transmission loss in a frequency range and thus suppress, or muffle, certain frequencies.
Acoustic voxels thus expand the range of acoustic filters, providing a more generalized filtering approach that has application in both the creative realm of new music instruments and the stringent engineering requirements of automotive and industrial mufflers, two areas that previously required separate design and manufacturing.
Manipulating sound waves to embed ID and other information
Acoustic filters work by manipulating sound waves, and acoustic voxels give researchers a way to exactly control that manipulation. It soon became clear to the researchers that the potential uses of acoustic voxels extended far beyond filtering, and led them in an entirely new direction with wide-open implications: acoustic tagging to uniquely identify a 3D-printed object, and acoustic encoding to implant information in an object’s acoustics.
A unique voxel assembly produces a unique acoustic signature. Two objects may have the exact same exterior appearance but if their hollow interiors contain different voxel assemblies, each object, when struck or tapped, produces a sound unique to that object. Using an iPhone app created for the purpose, researchers recorded the sound made by objects with different voxel assemblies and used these recordings to accurately identify each object.

Acoustic tagging could complement QR codes and RFID tags, both of which entail operations entirely separate from manufacturing: printing labels (or in the case of RFID tags, attaching electric circuits in a post-process), matching them to the right object or part, and finally affixing them.
Acoustic tags instead come directly out of the 3D fabrication; ID information is “built-in,” saving the time, effort, and expense of individually labeling parts, especially helpful when building larger mechanisms or structures out of hundreds or more separate pieces.
Acoustic voxels can do still more. If a chamber can manipulate sound waves to boost or suppress frequencies, it can manipulate waves also to encode a string of binary bits and thus relay information such as copyrights or other product information. The researchers show how a “1” for instance might be encoded if frequency loss falls to a certain level at a certain location in the sound wave while a “0” might be indicated by a frequency change in a different location.
Protecting copyrights, patents, or trademarks is a growing concern for 3D printing, where it can be hard to tell an illegal counterfeit from the protected original (such as figures from Disney, Marvel, or other companies). Acoustic voxels show how information and identification can be embedded into the acoustics of an object, requiring no additional procedures or labor.
But the promise of acoustic voxels extends even further, leading Zheng and his team in still another direction.
The current acoustic voxel project is for fabricating sizable objects producing audible sounds. Zheng is already investigating how voxels might be used to control ultrasound waves, hinting at the intriguing possibilty of acoustic cloaking, where sound waves are diverted to hide objects from being detected through acoustical means. Applications range from hiding objects from sonar to disguising obstructions that block sound waves, such as in auditoriums and other spaces.

Posted 7/18/2016
– Linda Crane
Researchers embed 3D prints with acoustic meta-data that manipulates the production of sound
Modular acoustic filters simplify design of mufflers, musical instruments, audio tags
Paper coauthored by Changxi Zheng is Best Paper at Symposium on Computer Animation
Deployable 3D Linkages with Collision Avoidance describes a method for creating Hoberman-like mechanisms out of arbitrary 3D models. The method, which requires little user input, automatically avoids collisions among parts so object can expand and contract.
Flexible lens array enables wrap-around camera
Computer Science student Cecilia Reyes awarded Google Journalism Fellowship
The Google News Lab Fellowship offers students interested in journalism and technology the opportunity to spend the summer working at relevant organizations across the US.
Jingren Zhou, CS PhD’04 (advisor Ken Ross), named chief scientist for Alibaba Cloud
Zhou will lead big-data and artificial intelligence research, developing cloud-scale distributed computation platforms and data analytic products.
Columbia University computer scientists presented three papers at DAC 2016

The Columbia University Department of Computer Science contributed three papers to the technical program of the 53rd ACM/IEEE Design Automation Conference (DAC) in Austin, Texas. Founded in 1964, DAC is the most prestigious conference in the area of design and automation of electronic systems, and is also one of the oldest conferences in computer science.
Kshitij Bhardwaj, a fourth-year PhD student, presented a paper that he wrote in collaboration with his advisor Professor Steven Nowick.
Paolo Mantovani, a fifth-year PhD student, presented a paper that is the result of an interdisciplinary collaboration between researchers in the System-Level Design Group led by Professor Luca Carloni and in the Bioelectronic Systems Lab led by Ken Shepard, who is the Lau Family Professor of Electrical Engineering at Columbia.
Carloni presented an invited paper for a special session on “The Rise of Heterogeneous Architectures: From Embedded Systems to Data Centers.”
More details on each of these papers are available below.
Achieving Lightweight Multicast in Asynchronous Networks-on-Chip Using Local Speculation
K. Bhardwaj, S.M. Nowick
In today’s era of many-core parallel computers, efficient on-chip communication between dozens or hundreds of processors and memories is of critical importance. Borrowing ideas from the networking community, digital system designers and computer architects in recent years have embraced “networks-on-chip” (NoC’s) as a solution. NoC’s are structured on-chip interconnection networks to replace traditional buses, providing high performance, low power, and reliable communications.
This paper targets asynchronous, i.e. clockless, NoC’s, which offer lower power and greater ease of integration of multiple components operating at varying rates, than classic clocked, i.e. synchronous, approaches. The key contribution of this work, aiming to support the needs of advanced parallel computer architectures, is to introduce a novel and efficient approach to support multicast: the transmission of one packet to multiple destinations. This capability is essential for cache coherence and multi-threaded applications.
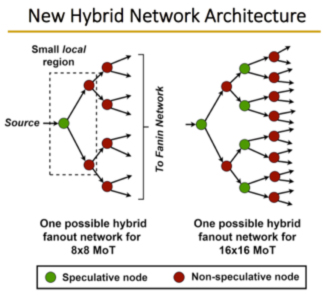
A lightweight parallel multicast approach is proposed, for use with a variant mesh-of-trees (MoT) network topology—which is the first general-purpose multicast solution for asynchronous NoC’s. A novel strategy, local speculation, is introduced, where a subset of router nodes are speculative and always broadcast. These switches are surrounded by non-speculative switches, which throttle any redundant packets, restricting these packets to small regions. Speculative switches have simplified designs, thereby improving network performance. A hybrid network architecture is proposed to mix the speculative and non-speculative nodes.
For multicast benchmarks, significant performance improvements with small power savings are obtained by the new approach over a tree-based non-speculative approach. Interestingly, similar improvements are shown for unicast benchmarks (see slide presentation).
An FPGA-Based Infrastructure for Fine-Grained DVFS Analysis in High-Performance Embedded Systems
P. Mantovani, E. Cota, K. Tien, C. Pilato, G. Di Guglielmo, K. Shepard, and L. P. Carloni
The quest for energy-efficient computing is the biggest challenge in design of all sorts of computers from the smartphones in everyone’s pocket to the servers running in data centers. The circuits empowering these computers are multi-core systems-on-chip (SoC) that integrate many heterogeneous components. The key to energy efficiency is precisely the ability to control each component independently and promptly so that it consumes power only when its operations are needed and at a rate that is proportional to the needed degree of performance. This require pervasive application of DVFS, a mechanism to dynamically scaling the power voltage and clock frequency at which the circuitry of each component operates.
At Columbia the groups of Carloni and Shepard have been working on the development and application of new technologies for DVFS to enable an unprecedented degree of fine-grained power management both in space (with multiple distinct voltage domains) and in time (with transient responses in the order of nanoseconds).
In this paper, they present the first infrastructure that allows SoC designers to evaluate the application of these technologies by emulating large-scale full-systems with real workload scenarios on field-programmable gate arrays (FPGA). The infrastructure provides the capabilities to continuously monitor and adaptively control the operations of each component.
The authors describe the application of their FPGA-based infrastructure to three different case studies of SoCs, each combining a general-purpose processor running Linux together with ten to twelve special-purpose accelerators all interconnected by a network-on-chip. They analyze the workload’s power dissipation and performance sensitivity to time-space granularity of DVFS and show that the combination of their new hardware and software solution for fine-grained power management can save up to 85% of the accelerators’ energy.
The Case for Embedded Scalable Platforms
How to simplify the design and programming of a billion-transistor system-on-chip (SoC), featuring dozens of heterogeneous components?
In this paper, Carloni addresses this question by making the case for Embedded Scalable Platforms (ESP), a novel approach that combines an architecture and a companion methodology to address the complexity of SoC design and programming. The architecture provides a flexible tile-based template that simplifies the integration of such different components as general-purpose processors and special-purpose hardware accelerators. Each component can be designed independently and plugged into the SoC through a modular socket. The socket interfaces the component with a network-on-chip that acts as the “nervous system” of the SoC as it provides inter-tile communication capabilities and per-tile adaptive control. The regularity of the tile-based organization is leveraged by the ESP companion methodology that raises the level of abstraction in the design process, thereby promoting a closer collaboration among software programmers and hardware engineers.
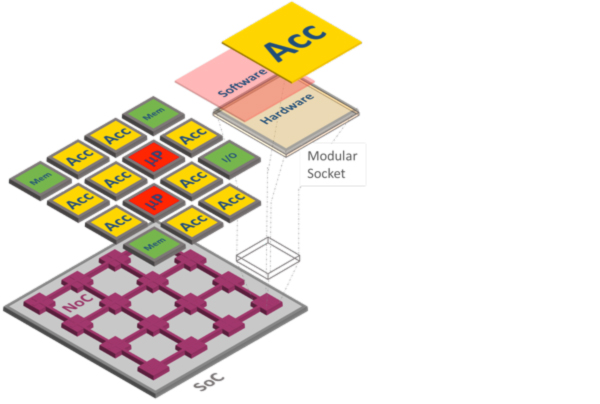
In presenting the key ideas of ESP, the paper brings together the contributions made by the members of the System-Level Design Group with various recent publications.
Furthermore, it includes a section that describes how these ideas are the foundation of System-on-Chip Platforms, a new course that Carloni has developed at Columbia University over the last five years and is now part of the upper-level undergraduate curriculum of the Computer Engineering Program.
Carloni presented this invited paper in a DAC special session on “The Rise of Heterogeneous Architectures: From Embedded Systems to Data Centers” that was chaired by Todd Austin (University of Michigan) and included talks by Mark Horowitz (Stanford) and Jason Cong (UCLA). Tech Design Forum has published a commentary on this event. All four participants of the special session are principal investigators in the Center for Future Architectures Research (C-FAR), one of six centers of STARnet, a Semiconductor Research Corporation program sponsored by MARCO and DARPA.
Posted 7/6/2016