
Columbia researchers presenting eight papers at this year’s SIGGRAPH
Columbia University researchers are presenting eight papers at this year’s SIGGRAPH, held July 24-26 at Anaheim’s convention center. High-level descriptions are given below with links provided to the papers and companion videos.
Surface-Only Liquids
Computational Design of Reconfigurables
Acoustic Voxels: Computational Optimization of Modular Acoustic Filters
Interactive Acoustic Transfer Approximation for Modal Sound
Mesh Arrangements for Solid Geometry
DisCo: Display-Camera Communication Using Rolling Shutter Sensors
Rig Animation with a Tangible and Modular Input Device
Toward Animating Water with Complex Acoustic Bubbles
Category: Fluids simulation
Tuesday, 26 July, 3:45 pm – 5:35 pm, Ballroom D
Surface-Only Liquids
 , Columbia University
, Columbia UniversityDavid Hahn, Institute of Science and Technology, Austria
Christopher Batty, University of Waterloo
Chris Wojtan, IST Austria
Eitan Grinspun, Columbia University
It’s important to point out that while we are not representing the interior explicitly, we do so implicitly. We don’t view the surface as a membrane with just air inside. That would never work. We treat the interior as filled with solid water, though we do so in an implicit way. And we make certain assumptions about the interior that allow us to reduce away all the representation of the liquid on the interior.
The outside cannot possibly summarize everything that’s happening on the inside unless you make certain assumptions. The assumption we made is that the interior is in some sense “as uninteresting as possible” given what’s happening on the boundary. It has no extra swirls. Only the swirls that can be seen or inferred from the boundary.
Now does a swirl formed at the boundary migrate to the interior? It depends; the migration or spreading out of swirls is caused by viscosity. Honey with high viscosity will have a lot of migration, but water, having low-viscosity, will have little migration. Effectively we assume that our water is inviscid, that it has zero viscosity. Real water does have some viscosity (the physicist Feynman would have said that we are working with “the flow of dry water”), but it’s a good enough assumption.
No one’s been able to see exactly what the interior flow is during a crown splash; so by virtue of making the assumptions we did about what the flow can and cannot be, we’re effectively adding a data point that says the flow is actually pretty simple in the interior, and our assumptions must be sufficiently close to the truth to observe the results that we did.
Category: Deformable Surface Design
Wednesday, 27 July, 9:00 am – 10:30 am, Ballroom E
Computational Design of Reconfigurables
Akash Garg, Columbia University
Alec Jacobson, Columbia University
Eitan Grinspun, Columbia University
![]()
An interview with Eitan Grinspun
The theory behind the two papers is absolutely different. The connection is geometry. For surface-only liquids, it was helpful to focus on the geometry of the surface.
What’s interesting for me when looking at reconfigurables—whether it’s a bicycle that folds up or an extremely efficient kitchen in a small space—is that your attention is focused on one configuration but then you make a geometric change to the shape that works great in some way but interferes with functionality or causes two parts to collide.
I like to look for abstractions, and one of the general areas where designing is hard is when an object can be in multiple configurations. So we wanted a CAD program where these transitions or different states were not an afterthought, but primary to the entire process.
I think you are right. We actually make a conscious effort to have different projects in the lab spanning the spectrum from more conceptual to more applied. Our idea was to create a tool that would aid designers by alerting them when and where parts might collide while also offering suggestions and edits on how to resolve collisions. Manually making adjustments through trial and error can be very tedious; our method makes the process more automatic and fluid.
At first, Akash focused primarily on the underlying collision detection “engine” that drives the interactive collision notifications of the software, while Alec focused on the human experience, including assistive tools such as “smart” camera that automatically selected the best viewpoint for observing problem areas. But these two branches of work quickly merged, and pretty soon Alec was also working on collisions, helping to formulate the mathematics of a new “spacetime collision resolver” that automatically fixed subtle penetrations, while Akash was reciprocally contributing to the human experience, for example with a “smart picture-in-picture” that popped up automatically to highlight unintended side-effects of the present editing operation. So in the end, it’s harder to tease apart the roles. While I pitched the original project vision, the project really took shape when we as a team identified more and more domain examples where reconfigurables arise, from a folding bicycle to a kitchen or burr puzzle.
On the reconfigurables side, we don’t pretend to have built a computer aided design (CAD) tool that is feature-rich like commercial tools; rather, we feel that we are calling attention to a broad and practical class of design problems—reconfigurables—for which current CAD tools do not provide sufficient support. We hope that the kinds of questions (and maybe some answers) that came up in how to support the design of reconfigurables can drive the next set of features in commercial CAD packages.
We are definitely interested in disseminating the code. Alec has already publicly released his popular libIGL mesh processing library. Reconfigurables will be a separate code, but we hope that it will be useful for others. On a more entrepreneurial front, we are also reaching out to design and engineering firms to find out how the technologies that we have developed match up against their realities.
Category: Computational Design of Structures, Shapes, and Sound
Wednesday, 27 July, 9:00 am – 10:30 am, Ballroom D
Acoustic Voxels: Computational Optimization of Modular Acoustic Filters

Dingzeyu Li, Columbia University
David I.W. Levin, Disney Research
Wojciech Matusik, MIT CSAIL
Changxi Zheng, Columbia University
![]()
For more information about the method, see Acoustic voxels: Manipulating sound waves makes possible acoustic tagging and encoding.
Category: Sound, Fluids, and Boundaries
Wednesday, 27 July, 10:45 am – 12:15 pm, Ballroom D
Interactive Acoustic Transfer Approximation for Modal Sound

Dingzeyu Li, Columbia University
Yun Fei, Columbia University
Changxi Zheng, Columbia University
![]()
![]()
They end up recording a sound and integrating it into the animation so it aligns with the action—which takes time to get right—but often the sound is not quite what they want or they decide to change something about an object’s characteristics, and they must start all over again. It might take hours or days for a single sequence.
Existing methods are not as flexible. If something changes, the entire process of recomputing everything has to be redone from the beginning.
We look at a very smooth function that we can interpolate easily; specifically we use the acoustic pressure value, which describes how acoustic pressure propagates in space. Because the pressure value changes smoothly in the frequency domain, we don’t have to take many samples to get a faithful approximation. It’s these pressure values that are being precomputed at a sparse set of frequencies. At runtime, the moments can be recovered from these smooth pressure values efficiently.
For animations involving large deformations, the computation is more challenging since the modal shapes are no longer constant. We are currently working on simulating sounds for deformable objects.
Category: Geometry
Monday, 25 July, 9:00 am – 10:30 am, Ballroom E
Mesh Arrangements for Solid Geometry

Eitan Grinspun, Columbia University
Denis Zorin, New York University
Alec Jacobson, Columbia University
![]()
This comes at a cost compared to implicit representations that can easily answer whether or how far any query point is from the surface. Implicit surfaces make Solid Geometry tasks like taking the union or difference of two objects very ease. Explicit surfaces are much trickier and these tasks require great care.
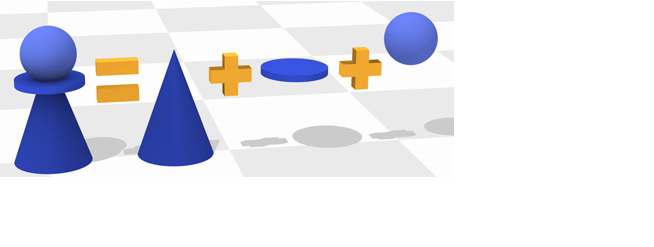
Once one or many 3D objects are represented as meshes, our method enables conducting certain operations robustly them. For example, many physical objects we use are a designed by merging multiple 3D shapes together: a chess piece pawn is a sphere merged with a cone merged with a flat disk. With out method we can achieve these type of operations on meshes—a common format for surfaces in computer graphics. Previous methods either required unrealistically high-quality inputs or produced flaws in their output.
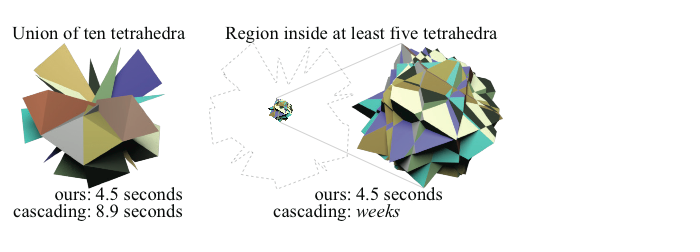
Our method is faster in certain scenarios because we avoid a “domino effect.” Faced with a series of operations, previous methods would resolve them one by one. In the worst case this can lead to an explosion in the number of new elements created after each operation. Our method resolves all operations simultaneously and the number of new elements is no more than what’s necessary to represent the output.
There are many directions I would like to take this work in the future. Specific to this project I would like to further improve our performance. Beyond solid operations, this work is one step toward a larger goal of making all parts of the geometry processing pipeline more robust.
Thursday, 28 July, 2:00 pm – 3:30 pm, Ballroom D
Kensei Jo, Columbia University
Mohit Gupta, Columbia University
Shree Nayar, Columbia University
![]()
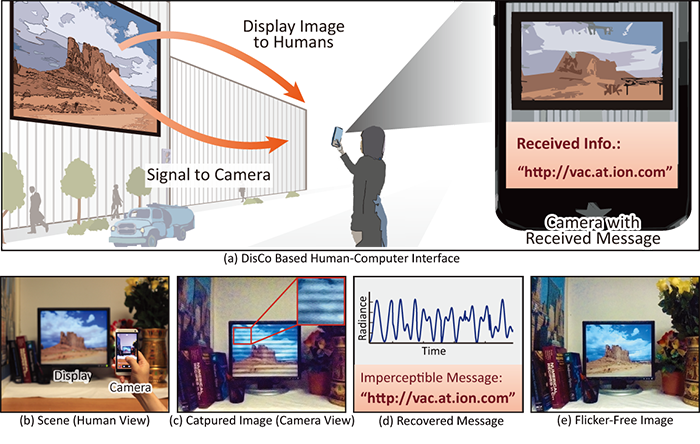
We present DisCo, a novel display-camera communication system that enables displays to send short messages to digital sensors, while simultaneously displaying images for human consumption. Existing display-camera communication methods are largely based on spatial-domain steganography, where the information is encoded as an imperceptible spatial signal (e.g., QR-code). These methods, while simple to implement, are prone to errors due to common causes of image degradations such as occlusions, display being outside the sensor’s field-of-view, defocus blur and perspective distortion. Due to these limitations, steganography-based techniques have not been widely adopted, especially in uncontrolled settings involving consumer cameras and public displays.
DisCo overcomes these limitations by embedding messages in temporal signals instead of spatial signals. We draw inspiration from the emerging field of visible light communication (VLC), where information is transmitted between a light source (transmitter) and a sensor (receiver) via high-frequency temporally modulated light. Most of these techniques require specialized high-speed cameras or photo-diodes as signal receivers [Elgala et al. 2009; Vucic et al. 2010; Sarkera et al. 2009]. Recently, a method was proposed for using low-cost rolling shutter sensors as receivers. This method, however, places strong restrictions on the transmitter; only light sources (e.g., LEDs) or surfaces with constant brightness [Danakis et al. 2012] can be used. These systems do not work with displays that need to display arbitrary images. The goal of this paper is on designing systems that can use a broad range of signal transmitters, especially displays showing arbitrary images, as well as objects that are illuminated with temporally modulated light. The objects can have arbitrary textures.
DisCo builds upon the method proposed in [Danakis et al. 2012] and uses rolling shutter cameras as signal receivers. In rolling shutter sensors, different rows of pixels are exposed in rapid succession, thereby sampling the incident light at different time instants. This converts the temporally modulated light coming from the display into a spatial flicker pattern in the captured image. The flicker encodes the transmitted signal. However, the flicker pattern is superimposed with the (unknown) display pattern. In order to extract the message, the flicker and the display pattern must be separated. Our key contribution is to show that the two components can be separated by capturing images at two different camera exposures. We also show that the flicker component is invariant to the display pattern and other common imaging degradations (e.g., defocus blur, occlusion, camera rotation and variable display size). The effect of all these degradations can be absorbed in the display pattern component. Since the display pattern is separated from the flicker component before signal recovery, the imaging degradations do not adversely affect the communication process.
Thursday, 28 July, 2:00 pm – 3:30 pm, Ballroom D
Oliver Glauser, ETH Zurich
Wan-Chun, ETH Zurich
Daniele Panozzo, New York University & ETH Zurich
Alec Jacobson, Columbia University
Otmar Hilliges, ETH Zurich
Olga Sorkine-Hornung, ETH Zurich
![]()

We propose a novel approach to digital character animation, combining the benefits of tangible input devices and sophisticated rig animation algorithms. A symbiotic software and hardware ap- proach facilitates the animation process for novice and expert users alike. We overcome limitations inherent to all previous tangible devices by allowing users to directly control complex rigs using only a small set (5-10) of physical controls. This avoids oversimplification of the pose space and excessively bulky device configurations. Our algorithm derives a small device configuration from complex character rigs, often containing hundreds of degrees of freedom, and a set of sparse sample poses. Importantly, only the most influential degrees of freedom are controlled directly, yet detailed motion is preserved based on a pose interpolation technique. We designed a modular collection of joints and splitters, which can be assembled to represent a wide variety of skeletons. Each joint piece combines a universal joint and two twisting elements, allowing to accurately sense its configuration. The mechanical design provides a smooth inverse kinematics-like user experience and is not prone to gimbal locking. We integrate our method with the professional 3D software Autodesk Maya® and discuss a variety of results created with characters available online. Comparative user experiments show significant improvements over the closest state-of-the-art in terms of accuracy and time in a keyframe posing task.
Wednesday, 27 July, 10:45 am – 12:15 pm, Ballroom D
Toward Animating Water with Complex Acoustic Bubbles
 , Cornell University
, Cornell UniversityChangxi Zheng, Columbia University,
Doug James, Stanford University
![]()