The renowned computer scientist and polymath Christos Papadimitriou has joined Columbia’s Computer Science Department as The Donovan Family Professor of Computer Science. He begins teaching this fall.
Christos Papadimitriou
Over four decades, Papadimitriou’s research has explored two of the most fundamental questions in Computer Science: How quickly can computers solve problems? And what kinds of obstacles come in the way of such solutions? Fast algorithms—together with Moore’s Law, the astronomical increase of computer speed over the past six decades—have powered the Computer Revolution. Equally intriguing are problems that appear to resist fast solution because of some inherent complexity: Many are known to be NP-complete, a status suggesting that (unless P = NP, an eventuality most scientists agree is unlikely) all the computers in the world wouldn’t solve it in the lifetime of the universe. As a graduate student, Papadimitriou established this for the Euclidean traveling salesperson problem, a version of the classic problem where cities are points in the two-dimensional plane. Three decades later, with Paul Goldberg and Constantinos Daskalakis, Papadimitriou proved the hardness of computing a Nash equilibrium; in doing so he helped found the field of algorithmic game theory.
“Computation is worldly. It’s about society, markets, people, brains, behaviors,
perception, emotions. Computer Science is looking outwards now. I advise my
undergrad students to take as many courses as they can: Economics, biology,
sociology, humanities, linguistics, psychology.”
– Christos Papadimitriou
Papadimitriou’s contributions extend far beyond the theoretical realm. Complexity is everywhere—in the way protein folds, in the ways database queries are processed, in the structure and activity of neurons and synapses, in how information moves on the internet in the presence of diverse economic interests; on these and other topics Papadimitriou has applied insights from the world of computation to make new discoveries. Just last year, his research made headlines in the world of biology when he connected game theory and evolution to arrive at a novel theory on the role of sex in evolution.
“Christos is one of the most original thinkers in computer science,” says Mihalis Yannakakis, a frequent collaborator and long-time friend. “He has applied the computational lens to a wide range of fields, bringing in each one of them a new perspective, and leaving his mark by founding new research areas, introducing new models and concepts, and initiating research directions that have had a tremendous impact.”
“I started writing fiction quite suddenly, and it made me very aware of how important stories are in science, in my science.” – Christos Papadimitriou
Unusual for a computer scientist, Papadimitriou engages the general public in the discussion of mathematical and computational ideas underlying science and technology. His 2003 novel Turing (A Novel about Computation) is a love story with an AI program as protagonist. His graphic novel Logicomix, coauthored with Apostolos Doxiadis, became an international best seller even though its central theme—Bertrand Russell’s attempts to establish a logical foundation for mathematics—is not an easy subject and Papadimitriou does not trivialize it. A third novel, Independence, wades into the political realm, following a family through the history of modern Greece
“There is nothing worth explaining that cannot be explained through a good story.”
– Christos Papadimitriou
He is fundamentally a teacher. His parents taught elementary and high school in Greece, and Papadimitriou himself has taught at Harvard, MIT, the National Technical University of Athens, Stanford, and the University of California at San Diego, and most recently at the University of California at Berkeley, where he found a home for 22 years. He is popular and sought after by students who rate him highly and note in particular his enthusiasm for the subjects he teaches. That Columbia students will now have the opportunity to learn algorithms and complexity theory from one of the foremost experts in the field is something the department is proud to offer. “We are absolutely delighted to have Christos joining us at Columbia,” says Julia Hirschberg, chair of the Computer Science Department. “He is a great scholar, teacher, and colleague!”
“Teaching is the only way I know to understand something.” – Christos Papadimitriou
Papadimitriou has written extensively on a wide range of topics in computer science, as well as on problems in the natural, social and life sciences that have benefited from computational approaches: Artificial intelligence and learning, databases, optimization, robotics, control theory, networks and the Internet, game theory and economics, computational biology and the theory of evolution, and recently the Brain. He is author or coauthor of five textbooks—Computational Complexity, one of the most widely used textbooks in the field; Elements of the Theory of Computation with Harry Lewis; Combinatorial Optimization: Algorithms and Complexity with Ken Steiglitz; The Theory of Database Concurrency Control, and the undergraduate textbook Algorithms with Sanjoy Dasgupta and Umesh Vazirani—and hundreds of articles and blog posts.
Amongst the recognitions and awards accorded him: the fifth Knuth Award (2002) for longstanding and seminal contributions to the foundations of computer science; the Gödel Prize (2012) for joint work with Oxford’s Elias Koutsoupias on the concept of the price of anarchy. For contributions to complexity theory, database theory, and combinatorial optimization, he was made a member of the US National Academy of Engineering in 2002. He is a member also of the National Academy of Sciences and of the American Academy of Arts and Sciences. Last year he received the John Von Neumann Medal for “providing a deeper understanding of computational complexity and its implications for approximation algorithms, artificial intelligence, economics, database theory, and biology.”
At Columbia, Papadimitriou is looking forward to continuing and expanding his recent work on an algorithmic understanding of the brain with new colleagues at the Zuckerman Institute for Mind, Brain, Behavior. But above all, he cherishes the opportunity for more collaboration with Mihalis Yannakakis.
“It’s like coming back home, to a brother.”
– Christos Papadimitriou
BS in Electrical Engineering from Athens Polytechnic (1972), an MS in Electrical Engineering and PhD in EECS at Princeton (1974, 76 respectively)
“The Role of Conversation Context for Sarcasm Detection in Online Interactions” considers the larger context of online conversations to accurately detect sarcasm while also identifying what triggered a sarcastic reply.
For decades, devicemakers, engineers, and others have been able to count on a new generation of chips coming to market, each more powerful than the previous—all courtesy of shrinking transistors that allow engineers to fit more on a chip. This is the famous Moore’s law. While a boon for technical innovation and a catalyst for entire new industries, the reliability of always having more powerful chips has had the opposite effect on chip architecture, deterring rather than spurring innovation. Why bother designing a whole new chip architecture when in two years a better chip using the traditional mold will be out? But as the expense vastly increases for each increase in transistor density, Moore’s law—more an objective than an actual law—is beginning to bump against physical limits, creating an opportunity and incentive for engineering researchers to again focus time and effort on new varieties of chips. In this interview, Luca Carloni discusses where he sees chip design to be heading, how his lab hopes to contribute to that redesign, and the changes he is making in the courses he teaches to train students for this new reality.
Jensen Huang, CEO of Nvidia, said earlier this summer that Moore’s law is dead. Is it?
Luca Carloni: You won’t ever get me to say that Moore’s law is dead—that’s something I first heard 20 years ago when still a student. Many years passed and every two years or so we have seen the arrival of a new generation of semiconductor technology. Sometime this year Intel is expected to ship advanced processors based on the company’s 10nm process technology.
What is over, however, is the economics aspect of Moore’s Law. Doubling the density of transistors can’t be done anymore without vastly increasing costs. Every jump in technology requires building a new fab [semiconductor fabrication facility], which can cost $5-10B. When there’s a ready market to buy up the newest chips—as there was when people first started buying laptops and smart phones—investing in a new fab makes sense. But it is not always easy to find a new product, or a new market, that brings billions of new chip sales. Still, I believe that these markets will continue to be discovered. There is a need for faster and better computers for autonomous cars, cloud computing, security, cognitive computing, robotics, etc.
We can’t get there just by shrinking transistors into tighter spaces and increasing their densities on chip because we can no longer dissipate the resulting power densities and heat. Now we have this fundamental tradeoff between two opposing forces: more computational performance versus higher power/energy dissipation.
How do you see this tradeoff being resolved?
By building specialized chips for different applications. One type of chip is not going to work for all applications. The system that’s best for the smart phone is going to be different than what’s best for the autonomous car, or cloud servers, or IoT [Internet-of-Things] devices. The performance-energy tradeoff is going to be different in each case.
Because of these conflicting demands, we are already seeing a migration from a homogeneous multicore architecture to heterogeneous SoCs [systems-on-chip] that contain specialized hardware. This consists of accelerators that perform a single function or algorithm much faster and more efficiently than software. Here the processor becomes just another component within a system of components. And the SoC becomes a more heterogeneous multicore architecture as it integrates many different components. Indeed, I expect that no single SoC architecture will dominate all markets. The set of heterogeneous SoCs in production in any given year will be itself heterogeneous!
We’re also seeing the rise of the field-programmable gate array, or FPGA, which can be programmed for different purposes. You’ll get better performance from an FPGA than from software and an FPGA is a much cheaper proposition that building a chip from scratch, but between an FPGA and a specialized chip there are orders of magnitude difference in energy efficiency and performance. So the demand for specialized chips will remain strong, but we need to design them faster and more cheaply while considering the target application: What algorithms or software will it run? Can it be done in parallel? How much energy-efficiency is required? There is no one right way to build a system anymore.
Heterogeneity is the emerging solution but heterogeneity increases the complexity of designing and programming chips. What you decide to put on a chip is just the beginning of a very complex engineering effort that spans both hardware and software.
What does this heterogeneity mean for computer engineering?
We need a new way of thinking about engineering chips. For too long, chip architects have been mostly on the sidelines as new faster chips based on traditional architectures continued to arrive every two years or so. But now there’s this chance to go back to design, to be creative again and come up with innovative architectures. It’s time for a renaissance in computer engineering, if you will, to think about things differently, to move, for example, from a processor-centric perspective to a system-centric perspective, where it’s necessary to think about how a change in one component affects the other components on the chip. Any change must benefit the whole system.
For handling complexity, we need to raise the level of abstraction in hardware design, similar to how it’s done in software. Instead of thinking in terms of bytes and clock cycles, we should think in terms of the behavior we’re aiming for and in terms of the corresponding data structures and tasks. As we do so, we need to reevaluate continuously the benefits and costs of doing things in hardware instead of software and vice versa. Which is the best design? It depends. Do you care more about speed? Or do you care more about power dissipation?
But it’s just not one thing. We need to think in terms of the entire infrastructure, from design and programming to fabrication. You think you have a better chip design, but can you program it and validate it—in conjunction with a system of heterogeneous components—before committing to the expensive manufacturing stage? This system-level design approach motivates the research in our lab here at Columbia.
We have developed the idea of Embedded Scalable Platforms, or ESP, that addresses the challenges of SoC design by combining a new template architecture and a companion system-level design methodology. With ESP, we are now able to realize complete prototypes of heterogeneous SoCs on FPGAs very rapidly. These prototypes have a very high degree of complexity for an academic laboratory.
To support the ESP methodology, we are developing some innovative tools. We have a new emulator for multicore architectures, which we presented at a conference last February—and we released the software as well—so we can describe a new machine and then run this emulator software on top of an existing multicore computer to see how the new architecture behaves when running complex applications. While this type of emulation has been done before—and across the different instruction sets such as Intel’s x86 and the ARM ISA—we have increased scalability so we can emulate a multicore machine on top of another multicore machine. And we made it possible to take advantage of the parallelism of the machines of today.
How have these changes affected how you teach chip architecture?
In my class on System-on-Chip Platforms, students learn to design complex hardware-software systems at a high level of abstraction. This means to design hardware with description languages that are closer to software, thus enabling faster full-system simulation and more effective optimization with high-level synthesis tools. During the first half of the semester students learn how to design accelerators with these methods. They also learn how to integrate heterogeneous components—accelerators and processors—into a given SoC, how to evaluate trade-off decisions in a multi-objective optimization space, and how to design components that are reusable across different systems and product generations.
In the second half of the semester, the students do a project that is structured as a design contest. They compete in teams to design an accelerator specialized for a certain function—one year it might be a computer vision algorithm, another year a machine learning task. They are given some vanilla code to start. They must optimize the code in different ways to design three competitive versions of the accelerator and write software to integrate them in the system and show that each runs correctly in our emulator. High-level synthesis allows each team to quickly evaluate many alternative design decisions. For example, if the algorithm requires that a multiplication is performed on two arrays of many elements, the students can decide to instance more multipliers to do many multiplications in parallel or, instead, to use fewer multipliers by performing these multiplications in time sharing. Basically, they experiment with the trade-offs of “computing in space” versus “computing in time.”
The main goal for each team is to obtain three distinct designs of the accelerator that correspond to three distinct trade-off points in terms of performance versus area occupation. The quality of each final implementation is evaluated in the context of the work done by the entire class. Throughout the one-month duration of the project, a live Pareto-efficiency plot reporting the current position of the three best design implementations for each team in the bi-objective design space is made available on the course webpage. This allows students to continuously assess their own performance with respect to the rest of the class.
Do you foresee further changes to your class?
Yes, always. Course content will never be static when the need for innovation is so great.
Last year we started complementing the competitive aspect with a collaborative aspect. We now partition the student teams in subsets. The teams in each subset compete on designing a given component but are now also asked to pair up their three designs with those designed by the teams in other subsets to get the final system. This further promotes the goal of designing components that are reusable under different scenarios and under different constraints. This is collaborative engineering, and increasingly how engineering is done in the real world today.
Every year, we change up the class by adding something new—different algorithms to implement, for example. Students love this, and in the process they learn one of the most beautiful ideas of engineering: evaluating situational complexity from multiple viewpoints and balancing multiple tradeoffs. It’s exactly what’s needed today in chip design if we are to sustain the level of innovation that we have seen over the past few decades.
Sharon Chen has already built two successful websites: ClickPA to help teenagers in Palo Alto more easily find local events and activities, and Wordcradle to motivate writers to set and meet target goals.
Last week in Stockholm, Columbia researchers presented three papers at Interspeech, the largest and most comprehensive conference on the science and technology of spoken language processing. A fourth paper was presented at the *SEM, a conference on lexical and computational semantics held August 3-4 in Vancouver, Canada. High-level descriptions of each of the four papers are given in the following summaries and interviews with lead authors.
In this work, our motivation was to see if we could use deep learning to improve our results since previous experiments were mostly based on traditional machine learning methods.
How prevalent is deep learning becoming for speech-related research? How is it changing speech research?
Deep learning is very popular these days and in fact has been for the past few years. In speech recognition, researchers originally substituted traditional machine learning models with deep learning models and gained impressive improvements. While these systems had deep learning components they were still mostly based on the traditional architecture.
Recent developments allowed researchers to design deep learning end-to-end systems that completely replace traditional methods while still obtaining state-of-the-art results. In other subfields of speech research, deep learning has not been as successful, whether it’s because simpler models suffice or the lack of big datasets.
In your view, will deep learning replace traditional machine learning approaches?
I see deep learning as just another tool in the researcher’s toolbox. The choice of algorithm requires an understanding of the underlying problem and constraints. In many cases, traditional machine learning approaches are better, faster, and easier to train. I doubt traditional methods would be completely replaced by deep learning.
You investigated four deep learning approaches to detecting deception in speech. How did you decide on these particular approaches?
We chose these methods based on previous work on deception detection, similar tasks such as emotion detection, and running thousands of experiments to develop intuition for what works.
Nonetheless there’s a lot more to be done! There are different model architectures to explore and different ways to arrange the data. I’m mostly excited about application of end-to-end models that learn to extract useful information directly from the recording without any feature engineering.
Your best performing model was a hybrid approach that combined two models. Is this what you would have expected?
Our original experiments focused on detecting deception either from lexical features (the choice of words) or acoustic features from the speaker’s voice. While both proved valuable for detecting deception we were interested to see whether they complement or overlap. By combining the two we got a better result compared to each one individually. I can’t say this was a huge surprise since humans, when trying to detect lies, utilize as many signals as possible: voice, words, body language, etc. Overall our best model achieved a score of 63.9% [F1] which is about 7.5% better than previous work on the same dataset.
Is this hybrid model adaptable to identifying other speech features other than deception?
Definitely. Now that our work is published we’re excited to see how other researchers will use it for other tasks. The hybrid model could be especially useful in tasks such as emotion detection and intent classification.
Creating a text-to-speech (TTS), or synthetic, voice—such as those used by Siri, Alexa, Microsoft’s Cortana—is a major undertaking that typically requires many hours of recorded speech, preferably made in a soundproof room by having a professional speaker reading in a prescribed fashion. It is time-consuming, labor-intensive, expensive, and almost wholly reserved for English, Spanish, German, Mandarin, Japanese, and few other languages; it is almost never used for the other 6900 or so languages in the world, leaving these languages without the resources required for building speech interfaces.
Repurposing existing, or “found,” speech from TV or radio broadcasts, audio books, or scraped from websites, may provide a less expensive alternative. In a process called parametric synthesis, many different voices are aggregated to create an entirely new one, with speaking characteristics averaged across all utterances. Columbia researchers see it as a possible way to address the lack of resources common to most languages.
Found speech utterances however have their own challenges. They contain noise, and people have varying speaking rates, pitches, and levels of articulation, some of which may hinder intelligibility. While low articulation, somewhat fast speaking rates, and low variation in pitch are known to aid naturalness, it wasn’t clear these same characteristics would aid intelligibility. More articulation and slower speaking rates might actually make voices easier to understand.
“We wanted to discover what would produce a nice, clean voice that was easy to understand,” says Erica Cooper, the paper’s lead author. “If we could identify utterances that were introducing noise or hindering intelligibility in some way, we could filter out those utterances and work only with good ones. We wanted also to understand whether a principled approach to utterance selection meant we could work with less data.”
Though the goal is to create voices for low-resource languages, the researchers focused on English initially to identify the best filtering techniques. Using the MACROPHONE corpus, an 83-hour collection of short utterances taken from telephone-based dialog systems, the researchers removed noise, including transcribed utterances labeled as noise as well as clipped utterances (where the waveform was abruptly cut off), and spelled out words.
Using the open-source HTS Toolkit, the researchers created 34 voices from utterances spoken by adult female speakers. Each voice was selected according to different acoustic and prosodic characteristics, and drawn from different subsets of the corpus; some adult female voices were from the first 10 hours of the corpus, and some from 2- and 4-hour subsets.
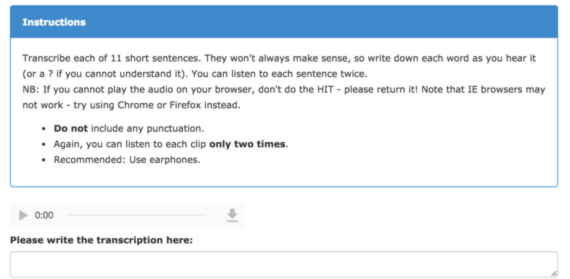
Each voice was used to synthesize the same 10 sentences, and each set of sentences was evaluated by five Mechanical Turk workers who transcribed the words as they were spoken. Word error rates associated with a voice were used to judge intelligibility.
A sample prompt for crowdsourcing transcriptions. Each worker transcribed 11 questions, ten to evaluate intelligibility and one as a check that workers were paying attention.
Workers could listen to only one question set to ensure they were not transcribing words from memory; the task thus required a relatively high number of workers. The rate at which workers signed up quickly become a bottleneck, adding weeks to the project and prompting the researchers to consider using automatic speech recognition (ASR) as a proxy for human evaluations. ASR evaluations would speed things, but would they agree with human evaluations when assessing intelligibility?
Extending the scope of the experiment, the researchers employed three off-the-shelf ASR APIs—Google Cloud Speech, wit.ai (owned by Facebook), IBM’s Watson—to study using ASR to evaluate intelligibility. ASR did in fact correlate closely with Mechanical Turk workers; for all voices humans rated better than baseline, all three ASRs did the same, showing the future promise of ASR in assessing intelligibility of spoken speech. There was one notable caveat. Sending the same audio clip multiple times to one of the APIs (wit.ai) did not necessarily return the same transcription, so variability might be expected in some ASR systems. But then again, humans were themselves even more variable in evaluating intelligibility. (Google and Watson showed no variability, always returning the same transcription.)
The most intelligible voices for both humans and the ASR methods were those with a faster speaking rate, a low level of articulation, and a middle variation in pitch. (For naturalness, the researchers had previously found the best features to be also a low-level of articulation but a low, not middle, mean pitch.) Removing transcriptions labeled as noise produced noticeable improvement, but removing clipped utterances or spelled out words did not.
More training data wasn’t necessarily better if the data was chosen in a principled way. Using the first 10-hour subset of female adult speech as a baseline with 67.7% accuracy, some two-hour subsets with carefully chosen utterances did better, validating the hypothesis that better voices can be trained by identifying the best training utterances in a noisy corpus, even with less training data.
Almost all bilingual and multilingual people code-switch, that is, they naturally switch between languages when talking and writing. People code-switch for many reasons; one language might better convey the intended meaning, a speaker might lack technical vocabulary in one language, or a speaker wants to match a listener’s speech. Worldwide, code-switchers are thought to outnumber those who speak a single language. Even in the US, famously monolingual, it is estimated that 40M people code-switch between English and Spanish.
People code-switch, but speech and natural language interfaces for the most part do not; their underlying statistical models are almost always trained for a single language, forcing people to adjust their speaking style and refrain from code-switching. To eventually enable more natural and seamless natural language interfaces so people can freely switch between languages, Columbia researchers Victor Soto and Julia Hirschberg have begun building natural language models specifically for code-switching in English and Spanish settings; the overall goal, however, is for a workable paradigm for other language pairs.
Simply combining two monolingual models was not seen as a viable solution. “Code-switching follows certain patterns and syntactic rules,” says Soto, lead author of the paper. “These rules can’t be understood from monolingual settings. Inserting code-switching intelligence into a natural language understanding system—which is our eventual aim—requires that we start with a bilingual corpus annotated with high-quality labels.”
The necessary labels include part-of-speech (POS) tags that define a word’s function within a sentence (verb, noun, adjective, and other categories). Manually annotating a corpus is time-consuming and expensive, so Soto and Hirschberg want to build an automatic POS tagger. The first step in this process is collecting training data.
The researchers start with an existing English-Spanish code-switching corpus, the Miami Bangor Corpus, compiled from 35 hours of conversational speech containing 242,475 words, two-thirds in English and one third in Spanish. While the corpus had the required size, the existing part-of-speech tags were often inaccurate or ambiguous, having been applied automatically using software that did not consider the multilingual context.
The researchers decided to redo the annotations, using tags from the Universal Part-of-Speech tag set, which would make it easier to map to tags used by other languages.
Fully half the corpus (56%) consisted of words always labeled with the same part of speech; these words were labeled automatically. Frequent words that were hard to annotate (slightly less than 2% of the corpus) were tagged by a computational linguist (Soto).
For the remaining 42% of the corpus, the researchers turned to crowdsourcing, a method used successfully in monolingual settings with untrained Mechanical Turk and Crowdflower workers. In this case, tagging tasks are structured in a way that does not require knowing grammar and linguistic rules. Workers simply answer a single question or are led through a series of prompts that converge to a single tag; in both cases, instructions and examples assist workers in choosing a tag.
Two types of prompts: a single question format used for many high-frequency words, and a decision tree structure consisting of a series of questions that progressively lead to the tag to be assigned.
To adapt this crowdsourcing approach to a bilingual setting, the Columbia researchers required workers to be bilingual, and they wrote separate prompts for the Spanish and English portions of the corpus, taking into account syntactic properties of each language (such as prompting for the infinitival verb form in Spanish, or the gerund form in English, to disambiguate between verb and nouns, among others).
Each crowdsourced word was assigned three intermediate judgments—two from crowdsourcing and one carried over from the Miami Bangor corpus—with majority vote to decide the tag. The voting considered judgments only from workers who demonstrated a tagging accuracy of at least 85% when compared to a hidden test set of tags. In 95-99% of the time, at least two votes agreed.
Over the entire corpus, Soto and Hirschberg estimate an accuracy of between 92% and 94%, close to what a trained linguist can do.
With an accurately labeled corpus, the researchers’ next step is building an automatic part-of-speech tagging model for code-switching between English and Spanish.
Why is it important to automatically identify questions?
Many applications follow a question-and-answer format where people have the flexibility to speak naturally and choose their own words but within the confines of the topic set up by the question. Often it’s often important to know how much speech goes into answering a particular question or when there is a change in topic. Our goal with this project was to develop automatic approaches to organizing and analyzing a large corpus of spontaneous speech at the topic level.
Both corpora are part of our larger effort in identifying deception in speech, something we’ve been working at here at Columbia for a number of years. The CXD corpus contains 122 hours of speech in the form of dialogs between subject pairs who played a lying game with each other. They took turns playing the role of interviewer and interviewee, and asked each other questions from a 24-item biographical questionnaire that they filled out, lying for a random half of the questions. Given this setup, we wanted to identify which question a given interviewee was answering.
With 122 hours of speech, it’s just not possible to do this manually—as we had done with the smaller CSC corpus. We needed an automatic approach, and for this we compared three different techniques for question identification to see which one was best for identifying which question a given interviewee was answering.
While we needed topic labels for the CXD corpus, the CSC corpus was chosen because it had similar topical distinctions that were hand-labeled, which we could use to test and verify that the approach that worked on CXD corpus was viable.
How do the three methods you tried—ROUGE, word embeddings, document embeddings—differ from one another?
We compared these methods because they capture similarity of language in different ways. ROUGE—which is a software package for evaluating automatic summarization, was selected to do comparison with n-grams. We selected the word embeddings and document embeddings approaches because they accounted for semantic similarity. The word embeddings approach used the Word2Vec model, which represents words as vectors, and words that were similar semantically had higher cosine similarity between the vectors, and the document embeddings approach used the Doc2Vec model, which we hoped would capture additional context.
The word embedding approach had the highest accuracy. Are these the results you expected?
It makes sense that the word embeddings approach would have higher accuracy because it also accounts for true negatives, and in any given interviewer turn, there are more true negatives than true positives.
While we weren’t surprised that word embeddings was the best method, we were nonetheless amazed at how well it worked. It matched very closely with the manually applied labels.
Your work was on labeling deceptive speech corpora. Would you expect similar results on other types of corpora?
Yes. This work applies at any type of speech that has a conversational structure. We happened to use deceptive speech corpora, but the method is unsupervised and should generalize well to other domains.
His winning presentation shows how to augment proprietary networks with public internet bandwidth to greatly enhance the user experience for wide-area communications. Kunal is a PhD student advised by Vishal Misra and Dan Rubenstein.
Interactive Robogami, an MIT CSAIL project, lets anyone design a robot in minutes, and 3D-print and assemble it in as little as four hours. A key feature is controlling a robot’s gait and geometry.
The paper, by three Columbia researchers, describes CLKSCREW, a new class of fault attacks that exploit the security-obliviousness of energy management mechanisms. The attack does not require physical access to devices or fault injection equipment.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor