Researchers from our department showcased their work at NeurIPS 2024, a leading conference that brings together experts in machine learning and related sciences to exchange ideas, foster collaboration, and advance interdisciplinary innovation.
Abstract: As society increasingly relies on AI-based tools for decision-making in socially sensitive domains, investigating fairness and equity of such automated systems has become a critical field of inquiry. Most of the literature in fair machine learning focuses on defining and achieving fairness criteria in the context of prediction, while not explicitly focusing on how these predictions may be used later on in the pipeline. For instance, if commonly used criteria, such as independence or sufficiency, are satisfied for a prediction score S used for binary classification, they need not be satisfied after an application of a simple thresholding operation on S (as commonly used in practice). In this paper, we take an important step to address this issue in numerous statistical and causal notions of fairness. We introduce the notion of a margin complement, which measures how much a prediction score S changes due to a thresholding operation. We then demonstrate that the marginal difference in the optimal 0/1 predictor Yb between groups, written P(ˆy | x1) − P(ˆy | x0), can be causally decomposed into the influences of X on the L2-optimal prediction score S and the influences of X on the margin complement M, along different causal pathways (direct, indirect, spurious). We then show that under suitable causal assumptions, the influences of X on the prediction score S are equal to the influences of X on the true outcome Y . This yields a new decomposition of the disparity in the predictor Yb that allows us to disentangle causal differences inherited from the true outcome Y that exists in the real world vs. those coming from the optimization procedure itself. This observation highlights the need for more regulatory oversight due to the potential for bias amplification, and to address this issue we introduce new notions of weak and strong business necessity, together with an algorithm for assessing whether these notions are satisfied. We apply our method to three real-world datasets and derive new insights on bias amplification in prediction and decision-making.
Abstract: Imitation learning enables an agent to learn from expert demonstrations when the performance measure is unknown and the reward signal is not specified. Standard imitation methods do not generally apply when the learner and the expert’s sensory capabilities mismatch and demonstrations are contaminated with unobserved confounding bias. To address these challenges, recent advancements in causal imitation learning have been pursued. However, these methods often require access to underlying causal structures that might not always be available, posing practical challenges.In this paper, we investigate robust imitation learning within the framework of canonical Markov Decision Processes (MDPs) using partial identification, allowing the agent to achieve expert performance even when the system dynamics are not uniquely determined from the confounded expert demonstrations. Specifically, first, we theoretically demonstrate that when unobserved confounders (UCs) exist in an MDP, the learner is generally unable to imitate expert performance. We then explore imitation learning in partially identifiable settings — either transition distribution or reward function is non-identifiable from the available data and knowledge. Augmenting the celebrated GAIL method (Ho \& Ermon, 2016), our analysis leads to two novel causal imitation algorithms that can obtain effective policies guaranteed to achieve expert performance.
Abstract: A fundamental task in AI is providing performance guarantees for predictions made in unseen domains. In practice, there can be substantial uncertainty about the distribution of new data, and corresponding variability in the performance of existing predictors. Building on the theory of partial identification and transportability, this paper introduces new results for bounding the value of a functional of the target distribution, such as the generalization error of a classifiers, given data from source domains and assumptions about the data generating mechanisms, encoded in causal diagrams. Our contribution is to provide the first general estimation technique for transportability problems, adapting existing parameterization schemes such Neural Causal Models to encode the structural constraints necessary for cross-population inference. We demonstrate the expressiveness and consistency of this procedure and further propose a gradient-based optimization scheme for making scalable inferences in practice. Our results are corroborated with experiments.
Abstract: Causal effect identification and estimation are two crucial tasks in causal inference. Although causal effect identification has been theoretically resolved, many existing estimators only address a subset of scenarios, known as the sequential back-door adjustment (SBD) (Pearl and Robins, 1995) or g-formula (Robins, 1986). Recent efforts for developing general-purpose estimators with broader coverage, incorporating the front-door adjustment (FD) (Pearl, 2000) and more, lack scalability due to the high computational cost of summing over high-dimensional variables. In this paper, we introduce a novel approach that achieves broad coverage of causal estimands beyond the SBD, incorporating various sum-product functionals like the FD, while maintaining scalability — estimated in polynomial time relative to the number of variables and samples. Specifically, we present the class of UCA for which a scalable and doubly robust estimator is developed. In particular, we illustrate the expressiveness of UCA for a wide spectrum of causal estimands (e.g., SBD, FD, and more) in causal inference. We then develop an estimator that exhibits computational efficiency and doubly robustness. The scalability and robustness of the proposed framework are verified through simulations.
Abstract: Considering various data modalities, such as images, videos, and text, humans perform causal reasoning using high-level causal variables, as opposed to operating at the low, pixel level from which the data comes. In practice, most causal reasoning methods assume that the data is described as granular as the underlying causal generative factors, which is often violated in various AI tasks. This mismatch translates into a lack of guarantees in various tasks such as generative modeling, decision-making, fairness, and generalizability, to cite a few. In this paper, we acknowledge this issue and study the problem of causal disentangled representation learning from a combination of data gathered from various heterogeneous domains and assumptions in the form of a latent causal graph. To the best of our knowledge, the proposed work is the first to consider i) non-Markovian causal settings, where there may be unobserved confounding, ii) arbitrary distributions that arise from multiple domains, and iii) a relaxed version of disentanglement. Specifically, we introduce graphical criteria that allow for disentanglement under various conditions. Building on these results, we develop an algorithm that returns a causal disentanglement map, highlighting which latent variables can be disentangled given the combination of data and assumptions. The theory is corroborated by experiments.
The Fine-Grained Complexity of Gradient Computation for Training Large Language Models Josh Alman Columbia University, Zhao Song Adobe Research
Abstract: Large language models (LLMs) have made fundamental contributions over the last a few years. To train an LLM, one needs to alternatingly run ‘forward’ computations and ‘backward’ computations. The forward computation can be viewed as attention function evaluation, and the backward computation can be viewed as a gradient computation. In previous work by [Alman and Song, NeurIPS 2023], it was proved that the forward step can be performed in almost-linear time in certain parameter regimes, but that there is no truly sub-quadratic time algorithm in the remaining parameter regimes unless the popular hypothesis SETH is false. In this work, we show nearly identical results for the harder-seeming problem of computing the gradient of loss function of one layer attention network, and thus for the entire process of LLM training. This completely characterizes the fine-grained complexity of every step of LLM training.
Metric Transforms and Low Rank Representations of Kernels for Fast Attention Timothy Chu Independent Researcher, Josh Alman Columbia University, Gary L. Miller Carnegie Mellon University, Shyam Narayanan Citadel Securities, Mark Sellke Harvard University, Zhao Song Simons Institute for the Theory of Computing, UC Berkeley
Abstract: We introduce a new linear-algebraic tool based on group representation theory, and use it to address three key problems in machine learning.
Past researchers have proposed fast attention algorithms for LLMs by approximating or replace softmax attention with other functions, such as low-degree polynomials. The key property of these functions is that, when applied entrywise to the matrix QK>, the result is a low rank matrix when Q and K are n × d matrices and n d. This suggests a natural question: what are all functions f with this property? If other f exist and are quickly computable, they can be used in place of softmax for fast subquadratic attention algorithms. It was previously known that low-degree polynomials have this property. We prove that low-degree polynomials are the only piecewise continuous functions with this property. This suggests that the low-rank fast attention only works for functions approximable by polynomials. Our work gives a converse to the polynomial method in algorithm design.
We prove the first full classification of all positive definite kernels that are functions of Manhattan or `1 distance. Our work generalizes, and also gives a new proof for, an existing theorem at the heart of kernel methods in machine learning: the classification of all positive definite kernels that are functions of Euclidean distance.
The key problem in metric transforms, a mathematical theory used in geometry and machine learning, asks what functions transform pairwise distances in metric space M to metric space N for specified M and N. We prove the first full classification of functions that transform Manhattan distances to Manhattan distances. Our work generalizes the foundational work of Schoenberg, which fully classifies functions that transform Euclidean to Euclidean distances.
We additionally prove results about stable-rank preserving functions that are potentially useful in algorithmic design, and more. Our core tool for all our results is a new technique called the representation theory of the hyperrectangle.
Statistical-Computational Trade-offs for Density Estimation Anders Aamand University of Copenhagen, Alexandr Andoni Columbia University, Justin Chen hen MIT, Piotr Indyk hen MIT, Shyam Narayanan Citadel Securities, Sandeep Silwal UW-Madison, Haike Xu MIT
Abstract: We study the density estimation problem defined as follows: given k distributions p1, . . . , pk over a discrete domain [n], as well as a collection of samples chosen from a “query” distribution q over [n], output pi that is “close” to q. Recently [1] gave the first and only known result that achieves sublinear bounds in both the sampling complexity and the query time while preserving polynomial data structure space. However, their improvement over linear samples and time is only by subpolynomial factors. Our main result is a lower bound showing that, for a broad class of data structures, their bounds cannot be significantly improved. In particular, if an algorithm uses O(n/ logc k) samples for some constant c > 0 and polynomial space, then the query time of the data structure must be at least k 1−O(1)/ log log k , i.e., close to linear in the number of distributions k. This is a novel statistical-computational trade-off for density estimation, demonstrating that any data structure must use close to a linear number of samples or take close to linear query time. The lower bound holds even in the realizable case where q = pi for some i, and when the distributions are flat (specifically, all distributions are uniform over half of the domain [n]). We also give a simple data structure for our lower bound instance with asymptotically matching upper bounds. Experiments show that the data structure is quite efficient in practice.
Hypothesis Testing the Circuit Hypothesis in LLMs Claudia Shi Columbia University, Nicolas Beltran Velez Columbia University, Achille Nazaret Columbia University, Carolina Zheng Columbia University, Adrià Garriga-Alonso FAR AI, Andrew Jesson Columbia University, Maggie Makar University of Michigan, Ann Arbor, David Blei Columbia University
Abstract: Large language models (LLMs) demonstrate surprising capabilities, but we do not understand how they are implemented. One hypothesis suggests that these capabilities are primarily executed by small subnetworks within the LLM, known as circuits. But how can we evaluate this hypothesis?In this paper, we formalize a set of criteria that a circuit is hypothesized to meet and develop a suite of hypothesis tests to evaluate how well circuits satisfy them. The criteria focus on the extent to which the LLM’s behavior is preserved, the degree of localization of this behavior, and whether the circuit is minimal.We apply these tests to six circuits described in the research literature. We find that synthetic circuits — circuits that are hard-coded in the model — align with the idealized properties. Circuits discovered in Transformer models satisfy the criteria to varying degrees.To facilitate future empirical studies of circuits, we created the \textit{circuitry} package, a wrapper around the \textit{TransformerLens} library, which abstracts away lower-level manipulations of hooks and activations. The software is available at \url{https://github.com/blei-lab/circuitry}.
Abstract: Probabilistic prediction aims to compute predictive distributions rather than single point predictions. These distributions enable practitioners to quantify uncertainty, compute risk, and detect outliers. However, most probabilistic methods assume parametric responses, such as Gaussian or Poisson distributions. When these assumptions fail, such models lead to bad predictions and poorly calibrated uncertainty. In this paper, we propose Treeffuser, an easy-to-use method for probabilistic prediction on tabular data. The idea is to learn a conditional diffusion model where the score function is estimated using gradient-boosted trees. The conditional diffusion model makes Treeffuser flexible and non-parametric, while the gradient-boosted trees make it robust and easy to train on CPUs. Treeffuser learns well-calibrated predictive distributions and can handle a wide range of regression tasks—including those with multivariate, multimodal, and skewed responses. We study Treeffuser on synthetic and real data and show that it outperforms existing methods, providing better calibrated probabilistic predictions. We further demonstrate its versatility with an application to inventory allocation under uncertainty using sales data from Walmart. We implement Treeffuser in https://github.com/blei-lab/treeffuser.
Estimating the Hallucination Rate of Generative AI Andrew Jesson Columbia University, Nicolas Beltran Velez Columbia University, Quentin Chu Columbia University, Sweta Karlekar Columbia University, Jannik Kossen University of Oxford, Yarin Gal University of Oxford, John Cunningham Columbia University, David Blei Columbia University
Abstract: This paper presents a method for estimating the hallucination rate for in-context learning (ICL) with generative AI. In ICL, a conditional generative model (CGM) is prompted with a dataset and a prediction question and asked to generate a response. One interpretation of ICL assumes that the CGM computes the posterior predictive of an unknown Bayesian model, which implicitly defines a joint distribution over observable datasets and latent mechanisms. This joint distribution factorizes into two components: the model prior over mechanisms and the model likelihood of datasets given a mechanism. With this perspective, we define a \textit{hallucination} as a generated response to the prediction question with low model likelihood given the mechanism. We develop a new method that takes an ICL problem and estimates the probability that a CGM will generate a hallucination. Our method only requires generating prediction questions and responses from the CGM and evaluating its response log probability. We empirically evaluate our method using large language models for synthetic regression and natural language ICL tasks.
Abstract We develop EigenVI, an eigenvalue-based approach for black-box variational inference (BBVI). EigenVI constructs its variational approximations from orthogonal function expansions. For distributions over R D, the lowest order term in these expansions provides a Gaussian variational approximation, while higher-order terms provide a systematic way to model non-Gaussianity. These approximations are flexible enough to model complex distributions (multimodal, asymmetric), but they are simple enough that one can calculate their low-order moments and draw samples from them. EigenVI can also model other types of random variables (e.g., nonnegative, bounded) by constructing variational approximations from different families of orthogonal functions. Within these families, EigenVI computes the variational approximation that best matches the score function of the target distribution by minimizing a stochastic estimate of the Fisher divergence. Notably, this optimization reduces to solving a minimum eigenvalue problem, so that EigenVI effectively sidesteps the iterative gradient-based optimizations that are required for many other BBVI algorithms. (Gradient-based methods can be sensitive to learning rates, termination criteria, and other tunable hyperparameters.) We use EigenVI to approximate a variety of target distributions, including a benchmark suite of Bayesian models from posteriordb. On these distributions, we find that EigenVI is more accurate than existing methods for Gaussian BBVI.
Abstract: This paper presents a new optimization approach to causal estimation. Given data that contains covariates and an outcome, which covariates are causes of the outcome, and what is the strength of the causality? In classical machine learning (ML), the goal of optimization is to maximize predictive accuracy. However, some covariates might exhibit a non-causal association with the outcome. Such spurious associations provide predictive power for classical ML, but they prevent us from causally interpreting the result. This paper proposes CoCo, an optimization algorithm that bridges the gap between pure prediction and causal inference. CoCo leverages the recently-proposed idea of environments, datasets of covariates/response where the causal relationships remain invariant but where the distribution of the covariates changes from environment to environment. Given datasets from multiple environments—and ones that exhibit sufficient heterogeneity—CoCo maximizes an objective for which the only solution is the causal solution. We describe the theoretical foundations of this approach and demonstrate its effectiveness on simulated and real datasets. Compared to classical ML and existing methods, CoCo provides more accurate estimates of the causal model and more accurate predictions under interventions.
Understanding Transformer Reasoning Capabilities via Graph Algorithms Clayton Sanford Columbia University, Bahare Fatemi Google Research, Ethan Hall Google, Anton Tsitsulin Google Research, Mehran Kazemi Google DeepMind, Jonathan Halcrow Google Research, Bryan Perozzi Google Research, Vahab Mirrokni Google Research
Abstract: Which transformer scaling regimes are able to perfectly solve different classes of algorithmic problems? While tremendous empirical advances have been attained by transformer-based neural networks, a theoretical understanding of their algorithmic reasoning capabilities in realistic parameter regimes is lacking. We investigate this question in terms of the network’s depth, width, and number of extra tokens for algorithm execution. Our novel representational hierarchy separates 9 algorithmic reasoning problems into classes solvable by transformers in different realistic parameter scaling regimes. We prove that logarithmic depth is necessary and sufficient for tasks like graph connectivity, while single-layer transformers with small embedding dimensions can solve contextual retrieval tasks. We also support our theoretical analysis with ample empirical evidence using the GraphQA benchmark. These results show that transformers excel at many graph reasoning tasks, even outperforming specialized graph neural networks.
The fourth-year PhD student’s love of cartoons springboarded into a research career advancing realism in human-centric generative computer vision.
As kids, many of us spent countless hours watching cartoons, getting lost in the colorful worlds and playful characters. For most, these shows are simply a source of entertainment, a fun escape into magical realms. But for Purva Tendulkar, those endless hours of watching animated movies and shows became something more—a spark that ignited a lifelong curiosity about how animation works.
While other kids pressed play to enjoy the story, Tendulkar found herself drawn to the process behind the scenes. She would watch “making of” videos, fascinated by the creative techniques that brought her favorite characters to life. This early passion for animation has stayed with her, growing into a dedicated pursuit in her PhD studies, where she now works with Carl Vondrick on using computer vision and graphics techniques to make films and video games come alive. Her research, recognized with the prestigious Apple Scholars in AIML PhD fellowship, explores how to create digital humans that interact more authentically with their environments, aiming to push the boundaries of perceptive and generative tools for designers and developers.
(1) Tendulkar at CVPR, (2) Purva Tendulkar, Samir Gadre, Revant Teotia, Basile Van Hoorick, Ruoshi Liu, Sachit Menon, (3) Dídac Surís, Purva Tendulkar, Scott Geng, Arjun Mani, Sachit Menon, Ishaan Chandratreya, Basile Van Hoorick, Carl Vondrick, Sruthi Sudhakar, Mia Chiquier, Revant Teotia
In this interview, Tendulkar delves into the inspiration behind her research and her vision for the future of realistic human motion in digital environments.
Q: Can you describe your research focus and what motivates your work? My research interests lie at the intersection of Computer Vision, Machine Learning, and Computer Graphics. My vision is to emulate the varied facets of human behavior authentically. I work on understanding and synthesizing humans and how they interact with their physical surroundings. This has applications in developing cutting-edge video games, robotic simulators, and immersive AR/VR experiences – all of which cater to human needs and behaviors.
I grew up watching Disney movies and have been fascinated with the magic that could be created on-screen by bringing animated characters to life and the emotions they evoked in me. I would find myself watching hours of behind-the-scenes of these movies – how the artists hand-designed each character’s personality and refined the animations (e.g., sword fights) to be more realistic.
This directly reflected my choices when it came to selecting a topic to work on in the first year of my PhD – which was to synthesize all the realistic ways humans might interact with the world. This theme has stayed consistent throughout my PhD.
Q: What challenges and questions drive your research? Humans interact with the world, as well as each other, in a variety of physically and logically plausible ways that come very naturally to us. However, it is difficult to teach machines what is plausible and what is not – one of the biggest challenges is the data. Presently, human motion data arises from highly accurate but extremely expensive motion capture systems that are catered to a specific scene. On the other hand, there is abundant information present in internet videos (e.g., on YouTube) that cannot possibly be captured in a studio. Through my research, I aim to creatively combine the benefits of complementary data sources to build powerful generative models that wouldn’t be possible with just one source.
I have worked on generating 3D human-object interactions. Concretely, given a 3D object in a 3D environment (e.g., a mug on a kitchen countertop), my method, called FLEX, is able to generate a number of diverse human avatars, grasping the object realistically. Such a tool could serve as a template for animation artists to work with.
Earlier works that tackled this problem collected expensive full-body 3D human-object interaction data and trained models on it. However, such methods suffer from the limitations of the dataset and do not scale when the object appears in a different configuration than seen during training. For example, when an object was placed on the floor, previous methods would generate humans that were sinking into the floor rather than a kneeling/squatting pose.
Instead of creating a model that has to be trained to learn a full-body pose to grasp an object, we decided to combine two information sources – systems that can generate “hand-only” grasps and full-body data without objects. Then, we developed an algorithm that optimized a full-body pose that matched the “hand-only” grasp. We found that our approach, which does not use full-body grasping data, outperforms methods trained on it, thus challenging existing data collection paradigms for 3D humans and propagating for better utilization of existing sources.
Q: Do you play video games, and how do they influence your research? I quite enjoy playing video games in my free time. Still, I often find myself spending more time appreciating/critiquing the design rather than finishing the game. Some games that I think have great graphics are Horizon Zero Dawn, God of War, and Uncharted.
I think the visuals in current video games are truly impressive from a graphics/rendering standpoint – clothing, skin, object textures, and lighting effects are all very realistic and convincing. But there’s still a lot of room for improvement when it comes to how characters move and interact.
Most characters walk the same way, which strips away their unique personalities. Even human-object interaction feels templated and unrealistic, wherein objects sometimes appear to just “stick” to a hand instead of a realistic grasp. Sometimes, you see characters behave in an unpredictable way when interacting with the world around them. For instance, if you try to move your character into a spot that isn’t pre-programmed, like a tight space in a wall, the game just freaks out, and you might end up walking through the wall! And when it comes to how characters react to each other beyond scripted scenes, it feels a bit off. Say, if you have your character run circles around others or bump into them, the other characters barely react—they just go on about their business as if nothing’s happening.
I find all these problems very fascinating! Getting characters to behave in a truly convincing way would really prove how deeply we understand human behavior. After all, our world is built by humans, for humans, and I am excited to continue pushing the frontiers of 3D human research.
Emily Yin (SEAS’25), was selected as one of 10 national finalists out of over 15,000 applicants to participate in the national finals for Red Bull Basement, a global pitch competition for young entrepreneurs to develop and launch their ideas with the help of AI.
Several graduate students have been awarded prestigious scholarships in recognition of their academic excellence and research contributions. These highly competitive scholarships acknowledge the recipients’ dedication to advancing knowledge in their respective fields.
Apple Scholars in AI/ML PhD Fellowship
The Apple Scholars in AIML PhD fellowship recognizes the contributions of researchers in computer science and engineering at the graduate and postgraduate levels.
Purva Tendulkar Purva Tendulkar is fourth-year PhD candidate advised by Carl Vondrick. Her research vision is to authentically emulate the varied facets of human behavior in our dynamic world. She works on understanding and synthesizing humans by learning 3D representations of human-centric interactions.
Tendulkar earned a MS in Computer Science from Georgia Tech in 2020 and a BS in Computer Science from the College of Engineering, Pune (COEP) in India. She has interned at the University of Tübingen (2024), Meta Reality Labs (2023), UC San Diego (2020), and AiBee (2019).
At Columbia, she co-organizes the Vision, Interaction, Graphics & Robotics (VIGR) seminar. In her free time, she enjoys listening to and practicing Indian classical music, hiking, and playing board games.
Google PhD Fellowship
The Google PhD Fellowship Program was created to recognize outstanding graduate students doing exceptional and innovative research in areas relevant to computer science and related fields.
Natalie Parham Natalie Parham is a third-year PhD student in the theoretical computer science group advised by Henry Yuen. She is interested in quantum computation, computational complexity theory, and quantum circuit complexity.
Parham completed an MMath at the Institute for Quantum Computing at the University of Waterloo and received a BS in Electrical Engineering and Computer Science from the University of California, Berkeley. She also spent some time as a Quantum Engineer at QC Ware and at IBM Quantum as a Quantum Research Scientist Intern.
In her free time, she skateboards around New York City.
Funai Foundation Overseas Scholarship
The Funai Overseas Scholarship’s purpose is to develop young talent and thereby contribute to the development of Japan’s science and technology fields by providing scholarships to Japanese students who wish to study at graduate schools overseas and obtain a degree.
Hideaki Takahashi Hideaki Takahashi is a first-year PhD student advised by Junfeng Yang. He is interested in building practical tools to analyze and improve software security, including new technologies such as AI, smart contracts, etc. His work focuses on the cross-area of AI, security, and systems.
Takahashi graduated in 2024 with a Bachelor of Arts and Science Informatics at The University of Tokyo. He won two silver and three bronze medals at Kaggle, one of the world’s most prestigious AI competition platforms and is a professional eater of sushi.
NSF CISE Graduate Fellowship (CSGrad4US)
The CSGrad4US program aims to increase the number and diversity of domestic graduate students pursuing research and innovation careers in computer and information science and engineering fields. The program helps bachelor’s degree holders return to academia and pursue their research interests, enabling them to engage in innovative and high-impact projects without the burden of financial constraints.
Robin Linzmayer Robin Linzmayer is a first-year PhD student interested in machine learning applications in medicine with the goal of improving patient outcomes. They will be working with Noemie Elhadad in the Department of Biomedical Informatics.
Linzmayer graduated from Washington University in St. Louis in May 2019 with a BS in Computer Science and a BA in Biology. Afterward, they spent four years building models to extract structured data from unstructured clinical text sources while working as a data scientist at Flatiron Health. In the Spring of 2024, Linzmayer completed a northbound thru-hike of the Appalachian Trail.
Filipp Shelobolin Filipp Shelobolin is a first-year PhD student working with Augustin Chaintreau and Jeanette Wing on the fairness and explainability of complex machine learning systems.
After receiving a BS in Statistics and Machine Learning from Carnegie Mellon in 2021, Filipp worked as a Research Scientist at Upstart for three years. Filipp enjoys writing, performing improv comedy, playing pool, and reading almost anything.
NSF Graduate Research Fellowships Program
The NSF GRFP is a three-year fellowship that recognizes and supports outstanding graduate students in NSF-supported STEM disciplines who are pursuing research-based master’s and doctoral degrees.
David Nguyen David Nguyen is a first-year PhD student working with Brian Smith. He studies video games from the lens of human-computer interaction.
Nguyen received his first bachelor’s degree from UC Los Angeles with a design-your-own-major in “Social Science Research Methodology” and his second bachelor’s degree from UC Irvine in software engineering.
His hobbies include video games, comic books, and trying out new vegan recipes.
Riya Sahni Riya Sahni is a first-year PhD student interested in Human-Computer and Human-AI Interaction. She is advised by Lydia Chilton and will focus on improving large-scale adoption strategies for AI tools in industry and designing AI tools that enhance productivity.
Sahni graduated from the University of Chicago with a BA in Economics and a BS in Computer Science with a specialization in Human-Computer Interaction in 2023. Before joining Columbia, she worked at Microsoft as a Customer Success Account Manager in the Financial Services Industry. In her free time, she enjoys playing tennis, reading the classics, and learning how to crochet.
Leo Orshansky Leo Orshansky is a first-year PhD student in the Computer Science Theory group, co-advised by Tal Malkin and Henry Yuen. His research interests lie at the intersection of cryptography and quantum computing, along with broader interests in computational complexity, both quantum and classical.
Orshansky graduated in 2024 from the University of Texas at Austin with B.S. degrees in Computer Science (Honors) and Mathematics, as well as a minor in Chinese Language. He was named a 2024 Dean’s Honored Graduate from the College of Natural Sciences at UT Austin, with a distinction in research.
Outside of the academic realm, Orshansky is passionate about learning languages, speed-solving the New York Times crossword, playing board games, and running.
Samsung Fellow
Jihwan Kim Jihwan Kim is a first-year doctoral student in the Software Systems Lab, working with Junfeng Yang. His research interests are based on security, robustness of machine learning, and developing tools to find security vulnerability.
Kim received a BS in computer science from Sogang University in South Korea in 2015 and worked as a Software Engineer at Samsung Electronics. He also loves to travel and explore new places around the world.
SEAS Fellowships
The School of Engineering and Applied Sciences established fellowships to recruit outstanding students from around the world to pursue graduate studies at the school.
Mudd Fellow
Zechao Cai Zechao Cai is a first-year PhD student co-advised by Jason Nieh and Gail Kaiser. His research interests focus on next-generation System-on-Chip (SoC) systems, spanning Operating Systems, Computer Architecture, and Formal Methods. He earned his MS in Computer Science from Zhejiang University in 2023 and holds a BE from Guangdong University of Foreign Studies.
Outside of research, Zechao is passionate about music, particularly electronica and classical. He enjoys vinyl digging, DJing, and playing table tennis and video games in his free time.
Tang Fellow
Yi Rong Yi Rong is a first-year PhD student in the Software Systems Laboratory, advised by Ronghui Gu. She is interested in formal methods and verification.
Rong obtained a B.Eng. in Software Engineering from Tsinghua University in 2024. In her free time, she enjoys traveling and trying out new restaurants.
Greenwood Fellow
Conlan Olson Conlan Olson is a first-year PhD student advised by Rich Zemel and Toni Pitassi. Their research focuses on fairness and privacy, and they are interested in responsible computing and applications of technology to social justice.
Olson graduated from Harvard University with an AB in math and computer science in 2021 and an EdM Master’s in Education in 2023. Before Columbia, they taught math and special education at a high school. Outside of computer science, they enjoy writing and working on sewing projects.
Presidential Fellows
Hailie Mitchell Hailie Mitchell is a first-year PhD student advised by Junfeng Yang. She is interested in working on how to make the software development process easier for developers by leveraging AI and how to effectively test those AI systems and tools.
Mitchell graduated from Dickinson College in 2024 with a BS in Computer Science, and in her free time enjoys going to concerts, reading, and hiking.
Shreyas Havaldar Shreyas Havaldar is a first-year PhD student in Elias Bareinboim’s Causal Artificial Intelligence Lab. He aspires to build an impactful research career in trustworthy machine learning to create systems that are accountable, accessible, equitable, and inclusive. His goal is to fundamentally understand artificial intelligence and make it even more intelligent.
Havaldar graduated from the Indian Institute of Technology, Hyderabad (IIT) in 2022 with a Bachelor of Technology (Honors) in Computer Science. He worked at Google DeepMind for two years as a researcher before joining Columbia. His work has been recognized with the Academic Excellence Award, Best Paper Award at the Adversarial ML Workshop at CVPR ’21, KVPY Fellowship, INSPIRE Fellowship, Times Spark Scholarship, and Research Week with Google Invitation, among others.
He loves exploring new places, new activities, and learning random facts. He scrolls Wikipedia pages for fun, visits museums whenever he can, and travels as much as possible. Fun fact: he’s visited 12 countries in the last nine months.
Nikolaos Pagonas Nikos Pagonas is a first-year PhD student working with Kostis Kaffes. His research focuses on distributed systems and cloud computing. Currently, he is working on improving the performance of large language model serving.
Pagonas received his MEng and BSc degrees in Electrical and Computer Engineering from the National Technical University of Athens in 2024. Before joining Columbia, he was a research intern at Brown University, where he worked on the design and development of a serverless shell.
In his free time, he loves singing, playing guitar and piano, as well as fervently crossing off concerts from his ever-increasing bucket list.
Ziang Ren Ziang Ren is a first-year CS PhD student advised by Xia Zhou. His research focuses on improving the perception abilities of agents using various techniques in computer vision and mobile computing.
In his leisure time, Ren enjoys painting, playing the piano, and tennis. He received an MS degree from Dartmouth College in 2024 and a BS degree from Nanjing University of Posts and Telecommunications in 2022.
Styopa Zharkov Styopa Zharkov is a first-year PhD student in the theory group with an interest in algorithms. They are advised by Alex Andoni and Cliff Stein.
Zharkov graduated from Stanford University with a BS in math and an MS in computer science. Outside of research, they make clothes, dance tango, roller skate, and go backpacking.
SEAS Doctoral Fellows
Soyoon Park Soyoon Park is a first-year PhD student working with Martha Kim on computer architecture, keen on increasing computational energy efficiencies via modeling. She is also interested in algorithms found in nontraditional computational systems.
Park graduated from the University of Pennsylvania in 2024 as part of the Vagelos Integrated Program in Energy Research (VIPER), receiving a BSE in Computer Engineering and a BA in Mathematics. She enjoys listening to music, seeing Broadway shows, and traveling to new places.
Georgios Liargkovas Georgios Liargkovas is a first-year PhD student advised by Kostis Kaffes. His research focuses on operating systems (OS) scheduling, with a particular interest in leveraging machine learning to enhance scheduling decisions.
In 2023 he graduated with a BS in Management Science and Technology from Athens University of Economics and Business in Greece. During his undergraduate studies, Liargkovas was a research assistant at BALab under Diomidis Spinellis, where he focused on empirical software engineering research. He also collaborated with the Atlas Systems Group at Brown University, working on shell-script parallelization alongside Nikos Vasilakis.
His broader research interests include system design and optimization, cloud computing, and software engineering. In his free time, he is passionate about long-distance running, hiking, music, and cooking.
Professors are looking for motivated and talented PhD students to join their research teams. These opportunities are ideal for individuals who are passionate about contributing to their field and are looking for dedicated mentorship from leading experts.
CS researchers presented their work at the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024), showcasing research across natural language processing. Held from November 12-16 in Miami, this event includes diverse sessions covering topics from core NLP advancements to innovative applications. The accepted papers promise insights into cutting-edge techniques, inviting academics, practitioners, and enthusiasts to explore the latest in language processing research.
STORYSUMM: Evaluating Faithfulness in Story Summarization Melanie Subbiah Columbia University, Faisal Ladhak Answer.AI, Akankshya Mishra Columbia University, Griffin Thomas Adams Answer.AI, Lydia Chilton Columbia University, Kathleen McKeown Columbia University
Abstract: Human evaluation has been the gold standard for checking faithfulness in abstractive summarization. However, with a challenging source domain like narrative, multiple annotators can agree a summary is faithful, while missing details that are obvious errors only once pointed out. We therefore introduce a new dataset, StorySumm, comprising LLM summaries of short stories with localized faithfulness labels and error explanations. This benchmark is for evaluation methods, testing whether a given method can detect challenging inconsistencies. Using this dataset, we first show that any one human annotation protocol is likely to miss inconsistencies, and we advocate for pursuing a range of methods when establishing ground truth for a summarization dataset. We finally test recent automatic metrics and find that none of them achieve more than 70% balanced accuracy on this task, demonstrating that it is a challenging benchmark for future work in faithfulness evaluation.
Abstract: In the field of emotion analysis, much NLP research focuses on identifying a limited number of discrete emotion categories, often applied across languages. These basic sets, however, are rarely designed with textual data in mind, and culture, language, and dialect can influence how particular emotions are interpreted. In this work, we broaden our scope to a practically unbounded set of affective states, which includes any terms that humans use to describe their experiences of feeling. We collect and publish MASIVE, a dataset of Reddit posts in English and Spanish containing over 1,000 unique affective states each. We then define the new problem of affective state identification for language generation models framed as a masked span prediction task. On this task, we find that smaller finetuned multilingual models outperform much larger LLMs, even on region-specific Spanish affective states. Additionally, we show that pretraining on MASIVE improves model performance on existing emotion benchmarks. Finally, through machine translation experiments, we find that native speaker-written data is vital to good performance on this task.
Abstract: While recent advances in Text-to-Speech (TTS) technology produce natural and expressive speech, they lack the option for users to select emotion and control intensity. We propose EmoKnob, a framework that allows fine-grained emotion control in speech synthesis with few-shot demonstrative samples of arbitrary emotion. Our framework leverages the expressive speaker representation space made possible by recent advances in foundation voice cloning models. Based on the few-shot capability of our emotion control framework, we propose two methods to apply emotion control on emotions described by open-ended text, enabling an intuitive interface for controlling a diverse array of nuanced emotions. To facilitate a more systematic emotional speech synthesis field, we introduce a set of evaluation metrics designed to rigorously assess the faithfulness and recognizability of emotion control frameworks. Through objective and subjective evaluations, we show that our emotion control framework effectively embeds emotions into speech and surpasses emotion expressiveness of commercial TTS services.
Abstract: Machine Reading Comprehension (MRC) poses a significant challenge in the field of Natural Language Processing (NLP). While mainstream MRC methods predominantly leverage extractive strategies using encoder-only models such as BERT, generative approaches face the issue of out-of-control generation – a critical problem where answers generated are often incorrect, irrelevant, or unfaithful to the source text. To address these limitations in generative models for extractive MRC, we introduce the Question-Attended Span Extraction (QASE) module. Integrated during the finetuning phase of pre-trained generative language models (PLMs), QASE significantly enhances their performance, allowing them to surpass the extractive capabilities of advanced Large Language Models (LLMs) such as GPT-4 in few-shot settings. Notably, these gains in performance do not come with an increase in computational demands. The efficacy of the QASE module has been rigorously tested across various datasets, consistently achieving or even surpassing state-of-the-art (SOTA) results, thereby bridging the gap between generative and extractive models in extractive MRC tasks. Our code is available at this GitHub repository.
Defending Against Social Engineering Attacks in the Age of LLMs Lin Ai Columbia University, Tharindu Sandaruwan Kumarage Arizona State University, Amrita Bhattacharjee Arizona State University, Zizhou Liu Columbia University, Zheng Hui Columbia University, Michael S. Davinroy Aptima, Inc., James Cook Aptima, Inc., Laura Cassani Aptima, Inc., Kirill Trapeznikov STR, Matthias Kirchner Kitware, Inc., Arslan Basharat Kirchner Kitware, Inc., Anthony Hoogs Kirchner Kitware, Inc., Joshua Garland Arizona State University, Huan Liu Arizona State University, Julia Hirschberg Columbia University
Abstract: The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrievalaugmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity. Our code and data are available at this GitHub repository.
Abstract: Alignment is a crucial step to enhance the instruction-following and conversational abilities of language models. Despite many recent works proposing new algorithms, datasets, and training pipelines, there is a lack of comprehensive studies measuring the impact of various design choices throughout the whole training process. We first conduct a rigorous analysis over a three-stage training pipeline consisting of supervised fine-tuning, offline preference learning, and online preference learning. We have found that using techniques like sequence packing, loss masking in SFT, increasing the preference dataset size in DPO, and online DPO training can significantly improve the performance of language models. We then train from Gemma-2b-base and LLama-3-8b-base, and find that our best models exceed the performance of the official instruct models tuned with closed-source data and algorithms. Our code and models can be found at https://github.com/Columbia-NLP-Lab/LionAlignment.
Abstract: Coherence in writing, an aspect that L2 English learners often struggle with, is crucial in assessing L2 English writing. Existing automated writing evaluation systems primarily use basic surface linguistic features to detect coherence in writing. However, little effort has been made to correct the detected incoherence, which could significantly benefit L2 language learners seeking to improve their writing. To bridge this gap, we introduce DECOR, a novel benchmark that includes expert annotations for detecting incoherence in L2 English writing, identifying the underlying reasons, and rewriting the incoherent sentences. To our knowledge, DECOR is the first coherence assessment dataset specifically designed for improving L2 English writing, featuring pairs of original incoherent sentences alongside their expert-rewritten counterparts. Additionally, we fine-tuned models to automatically detect and rewrite incoherence in student essays. We find that incorporating specific reasons for incoherence during fine-tuning consistently improves the quality of the rewrites, achieving a level that is favored in both automatic and human evaluations.
ACE: A LLM-based Negotiation Coaching System Ryan Shea Columbia University, Aymen Kallala Columbia University, Xin Lucy Liu Columbia University, Michael W. Morris Columbia University, Zhou Yu Columbia University
Abstract: The growing prominence of LLMs has led to an increase in the development of AI tutoring systems. These systems are crucial in providing underrepresented populations with improved access to valuable education. One important area of education that is unavailable to many learners is strategic bargaining related to negotiation. To address this, we develop a LLM-based Assistant for Coaching nEgotiation (ACE). ACE not only serves as a negotiation partner for users but also provides them with targeted feedback for improvement. To build our system, we collect a dataset of negotiation transcripts between MBA students. These transcripts come from trained negotiators and emulate realistic bargaining scenarios. We use the dataset, along with expert consultations, to design an annotation scheme for detecting negotiation mistakes. ACE employs this scheme to identify mistakes and provide targeted feedback to users. To test the effectiveness of ACE-generated feedback, we conducted a user experiment with two consecutive trials of negotiation and found that it improves negotiation performances significantly compared to a system that doesn’t provide feedback and one which uses an alternative method of providing feedback.
Abstract: Dialogue systems have been used as conversation partners in English learning, but few have studied whether these systems improve learning outcomes. Student passion and perseverance, or grit, has been associated with language learning success. Recent work establishes that as students perceive their English teachers to be more supportive, their grit improves. Hypothesizing that the same pattern applies to English-teaching chatbots, we create EDEN, a robust open-domain chatbot for spoken conversation practice that provides empathetic feedback. To construct EDEN, we first train a specialized spoken utterance grammar correction model and a high-quality social chit-chat conversation model. We then conduct a preliminary user study with a variety of strategies for empathetic feedback. Our experiment suggests that using adaptive empathetic feedback leads to higher *perceived affective support*. Furthermore, elements of perceived affective support positively correlate with student grit.
Abstract: Despite recent advancements in AI and NLP, negotiation remains a difficult domain for AI agents. Traditional game theoretic approaches that have worked well for two-player zero-sum games struggle in the context of negotiation due to their inability to learn human-compatible strategies. On the other hand, approaches that only use human data tend to be domain-specific and lack the theoretical guarantees provided by strategies grounded in game theory. Motivated by the notion of fairness as a criterion for optimality in general sum games, we propose a negotiation framework called FDHC which incorporates fairness into both the reward design and search to learn human-compatible negotiation strategies. Our method includes a novel, RL+search technique called LGM-Zero which leverages a pre-trained language model to retrieve human-compatible offers from large action spaces. Our results show that our method is able to achieve more egalitarian negotiation outcomes and improve negotiation quality.
Abstract The goal of text style transfer is to transform the style of texts while preserving their original meaning, often with only a few examples of the target style. Existing style transfer methods generally rely on the few-shot capabilities of large language models or on complex controllable text generation approaches that are inefficient and underperform on fluency metrics. We introduce TinyStyler, a lightweight but effective approach, which leverages a small language model (800M params) and pre-trained authorship embeddings to perform efficient, few-shot text style transfer. We evaluate on the challenging task of authorship style transfer and find TinyStyler outperforms strong approaches such as GPT-4. We also evaluate TinyStyler’s ability to perform text attribute style transfer (formal ↔ informal) with automatic and human evaluations and find that the approach outperforms recent controllable text generation methods.
Researchers from the department presented their work at the Conference on Robot Learning (CoRL) in Munich, Germany. Since its inception in 2017, CoRL has promoted pioneering research and innovative applications at the intersection of robotics and machine learning, showcasing groundbreaking advancements in these dynamic fields.
D$^3$Fields: Dynamic 3D Descriptor Fields for Zero-Shot Generalizable Rearrangement Yixuan Wang Columbia University, Mingtong Zhang University of Illinois, Urbana-Champaign, Zhuoran Li National University of Singapore, Tarik Kelestemur Boston Dynamics AI Institute, Katherine Rose Driggs-Campbell University of Illinois, Urbana-Champaign, Jiajun Wu Stanford University, Li Fei-Fei Stanford University, Yunzhu Li Columbia University
Abstract: Scene representation is a crucial design choice in robotic manipulation systems. An ideal representation is expected to be 3D, dynamic, and semantic to meet the demands of diverse manipulation tasks. However, previous works often lack all three properties simultaneously. In this work, we introduce 3D Fields—dynamic 3D descriptor fields. These fields are implicit 3D representations that take in 3D points and output semantic features and instance masks. They can also capture the dynamics of the underlying 3D environments. Specifically, we project arbitrary 3D points in the workspace onto multi-view 2D visual observations and interpolate features derived from visual foundational models. The resulting fused descriptor fields allow for flexible goal specifications using 2D images with varied contexts, styles, and instances. To evaluate the effectiveness of these descriptor fields, we apply our representation to rearrangement tasks in a zero-shot manner. Through extensive evaluation in real worlds and simulations, we demonstrate that 3D Fields are effective for zero-shot generalizable rearrangement tasks. We also compare 3D Fields with state-of-the-art implicit 3D representations and show significant improvements in effectiveness and efficiency. Project page: https://robopil.github.io/d3fields/
Abstract: Tactile and visual perception are both crucial for humans to perform fine-grained interactions with their environment. Developing similar multi-modal sensing capabilities for robots can significantly enhance and expand their manipulation skills. This paper introduces 3D-ViTac, a multi-modal sensing and learning system designed for dexterous bimanual manipulation. Our system features tactile sensors equipped with dense sensing units, each covering an area of 3mm2. These sensors are low-cost and flexible, providing detailed and extensive coverage of physical contacts, effectively complementing visual information. To integrate tactile and visual data, we fuse them into a unified 3D representation space that preserves their 3D structures and spatial relationships. The multi-modal representation can then be coupled with diffusion policies for imitation learning. Through concrete hardware experiments, we demonstrate that even low-cost robots can perform precise manipulations and significantly outperform vision-only policies, particularly in safe interactions with fragile items and executing long-horizon tasks involving in-hand manipulation. Our project page is available at https://binghao-huang.github.io/3D-ViTac/.
RoboEXP: Action-Conditioned Scene Graph via Interactive Exploration for Robotic Manipulation Hanxiao Jiang Columbia University, Binghao Huang Columbia University, Ruihai Wu Peking University, Zhuoran Li National University of Singapore, Shubham Garg Amazon, Hooshang Nayyeri Amazon, Shenlong Wang University of Illinois, Urbana-Champaign, Yunzhu Li Columbia University
Abstract: We introduce the novel task of interactive scene exploration, wherein robots autonomously explore environments and produce an action-conditioned scene graph (ACSG) that captures the structure of the underlying environment. The ACSG accounts for both low-level information (geometry and semantics) and high-level information (action-conditioned relationships between different entities) in the scene. To this end, we present the Robotic Exploration (RoboEXP) system, which incorporates the Large Multimodal Model (LMM) and an explicit memory design to enhance our system’s capabilities. The robot reasons about what and how to explore an object, accumulating new information through the interaction process and incrementally constructing the ACSG. Leveraging the constructed ACSG, we illustrate the effectiveness and efficiency of our RoboEXP system in facilitating a wide range of real-world manipulation tasks involving rigid, articulated objects, nested objects, and deformable objects. Project Page: https://jianghanxiao.github.io/roboexp-web/
Abstract: Videos of robots interacting with objects encode rich information about the objects’ dynamics. However, existing video prediction approaches typically do not explicitly account for the 3D information from videos, such as robot actions and objects’ 3D states, limiting their use in real-world robotic applications. In this work, we introduce a framework to learn object dynamics directly from multi-view RGB videos by explicitly considering the robot’s action trajectories and their effects on scene dynamics. We utilize the 3D Gaussian representation of 3D Gaussian Splatting (3DGS) to train a particle-based dynamics model using Graph Neural Networks. This model operates on sparse control particles downsampled from the densely tracked 3D Gaussian reconstructions. By learning the neural dynamics model on offline robot interaction data, our method can predict object motions under varying initial configurations and unseen robot actions. The 3D transformations of Gaussians can be interpolated from the motions of control particles, enabling the rendering of predicted future object states and achieving action-conditioned video prediction. The dynamics model can also be applied to model-based planning frameworks for object manipulation tasks. We conduct experiments on various kinds of deformable materials, including ropes, clothes, and stuffed animals, demonstrating our framework’s ability to model complex shapes and dynamics. Our project page is available at \url{https://gaussian-gbnd.github.io/}.
Abstract: Representing robotic manipulation tasks as constraints that associate the robot and the environment is a promising way to encode desired robot behaviors. However, it remains unclear how to formulate the constraints such that they are 1) versatile to diverse tasks, 2) free of manual labeling, and 3) optimizable by off-the-shelf solvers to produce robot actions in real-time. In this work, we introduce Relational Keypoint Constraints (ReKep), a visually-grounded representation for constraints in robotic manipulation. Specifically, ReKep are expressed as Python functions mapping a set of 3D keypoints in the environment to a numerical cost. We demonstrate that by representing a manipulation task as a sequence of Relational Keypoint Constraints, we can employ a hierarchical optimization procedure to solve for robot actions (represented by a sequence of end-effector poses in SE(3)) with a perception-action loop at a real-time frequency. Furthermore, in order to circumvent the need for manual specification of ReKep for each new task, we devise an automated procedure that leverages large vision models and vision-language models to produce ReKep from free-form language instructions and RGB-D observation. We present system implementations on a mobile single-arm platform and a stationary dual-arm platform that can perform a large variety of manipulation tasks, featuring multi-stage, in-the-wild, bimanual, and reactive behaviors, all without task-specific data or environment models.
GenDP: 3D Semantic Fields for Category-Level Generalizable Diffusion Policy Yixuan Wang Columbia University, Guang Yin University of Illinois, Urbana-Champaign, Binghao Huang Columbia University, Tarik Kelestemur Boston Dynamics AI Institute, Jiuguang Wang Boston Dynamics AI Institute, Yunzhu Li Columbia University
Abstract: Diffusion-based policies have shown remarkable capability in executing complex robotic manipulation tasks but lack explicit characterization of geometry and semantics, which often limits their ability to generalize to unseen objects and layouts. To enhance the generalization capabilities of Diffusion Policy, we introduce a novel framework that incorporates explicit spatial and semantic information via 3D semantic fields. We generate 3D descriptor fields from multi-view RGBD observations with large foundational vision models, then compare these descriptor fields against reference descriptors to obtain semantic fields. The proposed method explicitly considers geometry and semantics, enabling strong generalization capabilities in tasks requiring category-level generalization, resolving geometric ambiguities, and attention to subtle geometric details. We evaluate our method across eight tasks involving articulated objects and instances with varying shapes and textures from multiple object categories. Our method demonstrates its effectiveness by increasing Diffusion Policy’s average success rate on \textit{unseen} instances from 20% to 93%. Additionally, we provide a detailed analysis and visualization to interpret the sources of performance gain and explain how our method can generalize to novel instances. Project page: https://robopil.github.io/GenDP/
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation Junbang Liang Columbia University, Ruoshi Liu Columbia University, Ege Ozguroglu Columbia University, Sruthi Sudhakar Columbia University, Achal Dave Toyota Research Institute, Pavel Tokmakov Toyota Research Institute, Shuran Song Stanford University, Carl Vondrick Columbia University
Abstract: A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models, which are pretrained on large-scale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate an example of an execution of the task conditioned on images of a novel scene, and use this synthesized execution directly to control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on 4 tasks of increasing complexity and demonstrate that capitalizing on internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches.
Differentiable Robot Rendering Ruoshi Liu Columbia University, Alper Canberk Columbia University, Shuran Song Stanford University, Carl Vondrick Columbia University
Abstract: Vision foundation models trained on massive amounts of visual data have shown unprecedented reasoning and planning skills in open-world settings. A key challenge in applying them to robotic tasks is the modality gap between visual data and action data. We introduce differentiable robot rendering, a method allowing the visual appearance of a robot body to be directly differentiable with respect to its control parameters. Our model integrates a kinematics-aware deformable model and Gaussians Splatting and is compatible with any robot form factors and degrees of freedom. We demonstrate its capability and usage in applications including reconstruction of robot poses from images and controlling robots through vision language models. Quantitative and qualitative results show that our differentiable rendering model provides effective gradients for robotic control directly from pixels, setting the foundation for the future applications of vision foundation models in robotics.
PhD student Andrea Sevilla-Clark reviewed 50 years’ worth of pregnancy data released by the Centers for Disease Control and developed an interactive web application called CDC NatView to make it easy for others to explore the large dataset.
The paper is the first study that investigates risk factors associated with preterm birth (PTB) in the United States using CDC Natality data from 1968 to 2021. The study reveals a concerning upward trend in late preterm births (PTB). It highlights significant racial disparities, particularly between African American and White populations, in PTB rates, education, body mass index, and access to prenatal care.
Preterm birth, defined as the delivery of a baby before 37 weeks of gestation, is a significant health issue that affects millions of families worldwide each year. The early arrival of a newborn not only presents immediate health challenges but also has long-term implications for both the baby and the family. Preterm infants are at an increased risk for a range of complications, from respiratory distress and infections to developmental delays and chronic health conditions. Understanding the causes, risks, and preventive measures associated with preterm birth is crucial for expectant parents, healthcare providers, and society as a whole.
The study highlighted key findings, including the rise of late PTBs, the influence of maternal age and interpregnancy intervals on PTB risk, and the persistent disparities between African American and White populations.
CDC NatView Data
Sevilla-Clark and the team also developed CDC NatView, an open-source RShiny web application that allows easy exploration and visualization of the CDC natality data, enabling further research and understanding of PTB risk factors and maternal morbidities. The web application enables users to explore birth records by showing how PTB rates and risk factors have changed over time. It also shows associations and relationships between maternal characteristics like race, age, BMI, and PTB outcomes, as well as how multiple risk factors might work together to influence PTB risk.
The findings underscore the importance of PTB prevention, particularly among high-risk groups. Key interventions include reducing health disparities that address social and economic factors, ensuring women have access to early, regular, high-quality prenatal care, and educating women about risk factors like interpregnancy intervals and body mass index.
We sat down with Sevilla-Clark to find out more about the paper and why she thinks it is important to do research on women’s health.
Q: What made you want to research women’s health?
Women’s health is as important for women themselves as it is for the entire society. In particular, women’s pregnancy health is an important part of women’s holistic health and wellness.
However, there are persisting bottleneck issues that hinder healthy pregnancies, and these include: (1) Adverse pregnancy outcomes that include premature birth, preeclampsia, and gestational diabetes contribute to maternal and fetal mortality and morbidity;
(2) A persisting disparity in pregnant women’s health needs to be addressed to ensure adequate healthcare for pregnant women across different groups in society.
Using large amounts of data and machine learning can be game-changing in tackling these issues.
Healthy pregnancies mean healthy women and children and, thus, a healthy and thriving community and society.
Q: What did you discover from the CDC Natality dataset?
We made a few key findings. Firstly, we found that the increase in preterm rate has largely comprised the late preterm category, that is, a birth between 34 and 36 weeks of gestation.
We also confirmed the racial disparities that have been reported in the literature, namely between the African American and White populations. This appears to be driven by social-economic and lifestyle factors, for example highest educational attainment and pre-pregnancy BMI. The African American population exhibited a statistically significant higher proportion of high pre-pregnancy BMI (overweight and obese BMI brackets) and lower levels of educational attainment (e.g. some college or less), as compared to the White population.
Maternal age has also been steadily increasing over time, which is consistent with higher educational attainment in women over the years. We also confirmed that shorter intervals between pregnancies are linked to higher preterm birth rates.
This study demonstrates how the CDC dataset can be used to conduct large-scale longitudinal analyses of preterm birth trends and risk factors in the U.S. The development of the CDC NatView application also provides a valuable open-source tool for other researchers to easily explore this data and generate insights to enhance our understanding of preterm birth.
PTB incidence by race (1995-2021). The figure shows the count normalized rate of PTB incidence by race, with the African American population experiencing the highest incidence by a large margin.
Q: What does the CDC NatViewapp do?
We developed the CDC NatView to make it easy for others to explore this large dataset. While this study and web app are geared more towards researchers and health professionals, the insights gained could eventually lead to better prenatal care practices and interventions to reduce preterm birth rates. This would benefit expecting mothers and families by decreasing the chances of complications and lifelong health issues associated with preterm birth.
This is exciting for researchers, clinicians, and public health professionals interested in maternal and child health. The study uncovered concerning trends in preterm births and created a valuable tool to help further understand and potentially prevent preterm births, which can lead to infant mortality and health issues.
The CDC NatView tool can be used by anyone interested in exploring trends and risk factors related to preterm birth. They could use the web application to easily interact with and visualize nearly 60 years worth of CDC pregnancy data.
They can explore how various risk factors, maternal demographics, and other aspects like prenatal care are associated with preterm birth outcomes. The insights generated could potentially inform clinical practices, public health policies, and interventions designed to reduce preterm birth rates and related racial disparities. For example, emphasizing the importance of adequate prenatal care and pregnancy spacing to patients.
Q: What’s your next step in this research?
Future work will focus on expanding the CDC NatView tool to include more maternal health factors to analyze, enable more complex queries to understand factor interactions, and automatically pull the latest CDC data as it becomes available each year.
Our P R A I S E lab is also focusing on the bias and fairness issue from the causality lens, as this goes beyond analyzing the data at the observational level, i.e. finding correlations with specific subsets of features, and aims to understand the data generating process and how this contributes to our understanding of bias in the target outcome. For example, how is the occurrence of preterm birth driven by race at a fundamental level? Simply looking at the proportions of preterm outcomes conditioned by race does not give us the full story.
Christos Papadimitriou and Michael Weinstein are being recognized for their considerable achievements in their respective fields and their dedication to teaching.
David Knowles is part of a research team focused on identifying variants and genes affecting language disorder and studying the neuronal pathways and circuits involved in sound association along with the mutations that can disrupt them.
Steven Feiner worked with Kaveri Thakoor to create a tool that combines the pattern-recognition power of AI with the domain expertise of human medical experts. The AI-powered decision support tool assists doctors in diagnosing eye disease.
CS researchers won a Best Paper Award at the European Conference on Computer Vision (ECCV) 2024, one of the premier international conferences in the fields of computer vision and machine learning. As a biennial event, ECCV attracts leading researchers, scholars, and practitioners from around the world, presenting cutting-edge advancements and breakthroughs. This year’s accepted papers from the department showcase groundbreaking innovations and high-impact research that push the boundaries of computer vision and artificial intelligence.
Abstract A minimalist vision system uses the smallest number of pixels needed to solve a vision task. While traditional cameras use a large grid of square pixels, a minimalist camera uses freeform pixels that can take on arbitrary shapes to increase their information content. We show that the hardware of a minimalist camera can be modeled as the first layer of a neural network, where the subsequent layers are used for inference. Training the network for any given task yields the shapes of the camera’s freeform pixels, each of which is implemented using a photodetector and an optical mask. We have designed minimalist cameras for monitoring indoor spaces (with 8 pixels), measuring room lighting (with 8 pixels), and estimating traffic flow (with 8 pixels). The performance demonstrated by these systems is on par with a traditional camera with orders of magnitude more pixels. Minimalist vision has two major advantages. First, it naturally tends to preserve the privacy of individuals in the scene since the captured information is inadequate for extracting visual details. Second, since the number of measurements made by a minimalist camera is very small, we show that it can be fully self-powered, i.e., function without an external power supply or a battery.
How Video Meetings Change Your Expression Sumit Sarin Columbia University, Utkarsh Mall Columbia University, Purva Tendulkar Columbia University, Carl Vondrick Columbia University
Abstract Do our facial expressions change when we speak over video calls? Given two unpaired sets of videos of people, we seek to automatically find spatio-temporal patterns that are distinctive of each set. Existing methods use discriminative approaches and perform post-hoc explainability analysis. Such methods are insufficient as they are unable to provide insights beyond obvious dataset biases, and the explanations are useful only if humans themselves are good at the task. Instead, we tackle the problem through the lens of generative domain translation: our method generates a detailed report of learned, input-dependent spatio-temporal features and the extent to which they vary between the domains. We demonstrate that our method can discover behavioral differences between conversing face-to-face (F2F) and on video-calls (VCs). We also show the applicability of our method on discovering differences in presidential communication styles. Additionally, we are able to predict temporal change-points in videos that decouple expressions in an unsupervised way, and increase the interpretability and usefulness of our model. Finally, our method, being generative, can be used to transform a video call to appear as if it were recorded in a F2F setting. Experiments and visualizations show our approach is able to discover a range of behaviors, taking a step towards deeper understanding of human behaviors.
Controlling the World by Sleight of Hand Sruthi Sudhakar Columbia University, Ruoshi Liu Columbia University, Basile Van Hoorick Columbia University, Carl Vondrick Columbia University, and Richard Zemel Columbia University
Abstract Humans naturally build mental models of object interactions and dynamics, allowing them to imagine how their surroundings will change if they take a certain action. While generative models today have shown impressive results on generating/editing images unconditionally or conditioned on text, current methods do not provide the ability to perform object manipulation conditioned on actions, an important tool for world modeling and action planning. Therefore, we propose to learn an action-conditional generative models by learning from unlabeled videos of human hands interacting with objects. The vast quantity of such data on the internet allows for efficient scaling which can enable high-performing action-conditional models. Given an image, and the shape/location of a desired hand interaction, CosHand, synthesizes an image of a future after the interaction has occurred. Experiments show that the resulting model can predict the effects of hand-object interactions well, with strong generalization particularly to translation, stretching, and squeezing interactions of unseen objects in unseen environments. Further, CosHand can be sampled many times to predict multiple possible effects, modeling the uncertainty of forces in the interaction/environment. Finally, method generalizes to different embodiments, including non-human hands, i.e. robot hands, suggesting that generative video models can be powerful models for robotics.
Generative Camera Dolly: Extreme Monocular Dynamic Novel View Synthesis Basile Van Hoorick Columbia University, Rundi Wu Columbia University, Ege Ozguroglu Columbia University, Kyle Sargent Stanford University, Ruoshi Liu Columbia University, Pavel Tokmakov Toyota Research Institute, Achal Dave Toyota Research Institute, Changxi Zheng Columbia University, Carl Vondrick Columbia University
Abstract Accurate reconstruction of complex dynamic scenes from just a single viewpoint continues to be a challenging task in computer vision. Current dynamic novel view synthesis methods typically require videos from many different camera viewpoints, necessitating careful recording setups, and significantly restricting their utility in the wild as well as in terms of embodied AI applications. In this paper, we propose GCD, a controllable monocular dynamic view synthesis pipeline that leverages large-scale diffusion priors to, given a video of any scene, generate a synchronous video from any other chosen perspective, conditioned on a set of relative camera pose parameters. Our model does not require depth as input, and does not explicitly model 3D scene geometry, instead performing end-to-end video-to-video translation in order to achieve its goal efficiently. Despite being trained on synthetic multi-view video data only, zero-shot real-world generalization experiments show promising results in multiple domains, including robotics, object permanence, and driving environments. We believe our framework can potentially unlock powerful applications in rich dynamic scene understanding, perception for robotics, and interactive 3D video viewing experiences for virtual reality.
Abstract Multimodal pre-trained models, such as CLIP, are popular for zero-shot classification due to their open-vocabulary flexibility and high performance. However, vision-language models, which compute similarity scores between images and class labels, are largely black-box, with limited interpretability, risk for bias, and inability to discover new visual concepts not written down. Moreover, in practical settings, the vocabulary for class names and attributes of specialized concepts will not be known, preventing these methods from performing well on images uncommon in large-scale vision-language datasets. To address these limitations, we present a novel method that discovers interpretable yet discriminative sets of attributes for visual recognition. We introduce an evolutionary search algorithm that uses a large language model and its in-context learning abilities to iteratively mutate a concept bottleneck of attributes for classification. Our method produces state-of-the-art, interpretable fine-grained classifiers. We outperform the latest baselines by 18 .4% on five fine-grained iNaturalist datasets and by 22 .2% on two KikiBouba datasets, despite the baselines having access to privileged information about class names.
RAP: Retrieval-Augmented Planner for Adaptive Procedure Planning in Instructional Videos Ali Zare Columbia University, Yulei Niu Columbia University, Hammad Ayyubi Columbia University, and Shih-Fu Chang Columbia University
Abstract Procedure Planning in instructional videos entails generating a sequence of action steps based on visual observations of the initial and target states. Despite the rapid progress in this task, there remain several critical challenges to be solved: (1) Adaptive procedures: Prior works hold an unrealistic assumption that the number of action steps is known and fixed, leading to non-generalizable models in real-world scenarios where the sequence length varies. (2) Temporal relation: Understanding the step temporal relation knowledge is essential in producing reasonable and executable plans. (3) Annotation cost: Annotating instructional videos with step-level labels (i.e., timestamp) or sequencelevel labels (i.e., action category) is demanding and labor-intensive, limiting its generalizability to large-scale datasets. In this work, we propose a new and practical setting, called adaptive procedure planning in instructional videos, where the procedure length is not fixed or pre-determined. To address these challenges, we introduce Retrieval-Augmented Planner (RAP) model. Specifically, for adaptive procedures, RAP adaptively determines the conclusion of actions using an auto-regressive model architecture. For temporal relation, RAP establishes an external memory module to explicitly retrieve the most relevant state-action pairs from the training videos and revises the generated procedures. To tackle high annotation cost, RAP utilizes a weakly-supervised learning manner to expand the training dataset to other task-relevant, unannotated videos by generating pseudo labels for action steps. Experiments on CrossTask and COIN benchmarks show the superiority of RAP over traditional fixedlength models, establishing it as a strong baseline solution for adaptive procedure planning.
PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation Tianyuan Zhang Massachusetts Institute of Technology, Hong-Xing Yu Stanford University, Rundi Wu Columbia University, Brandon Y. Feng Massachusetts Institute of Technology, Changxi Zheng Columbia University, Noah Snavely Cornell University, Jiajun Wu Stanford University, William T. Freeman Massachusetts Institute of Technology
Abstract Realistic object interactions are crucial for creating immersive virtual experiences, yet synthesizing realistic 3D object dynamics in response to novel interactions remains a significant challenge. Unlike unconditional or text-conditioned dynamics generation, action-conditioned dynamics requires perceiving the physical material properties of objects and grounding the 3D motion prediction on these properties, such as object stiffness. However, estimating physical material properties is an open problem due to the lack of material ground-truth data, as measuring these properties for real objects is highly difficult. We present PhysDreamer, a physics-based approach that endows static 3D objects with interactive dynamics by leveraging the object dynamics priors learned by video generation models. By distilling these priors, PhysDreamer enables the synthesis of realistic object responses to novel interactions, such as external forces or agent manipulations. We demonstrate our approach on diverse examples of elastic objects and evaluate the realism of the synthesized interactions through a user study. PhysDreamer takes a step towards more engaging and realistic virtual experiences by enabling static 3D objects to dynamically respond to interactive stimuli in a physically plausible manner. See our project page at https: //physdreamer.github.io/.
Understanding how the Core Curriculum differs for students at the School of Engineering and Applied Science can be significant for your career at Columbia.
Steven Feiner and his former PhD students, Blair MacIntyre and Sean White, were recognized for their pioneering work in virtual reality and augmented reality.
Abstract: Pre-trained language models (LMs) are capable of in-context learning (ICL): they can adapt to a task with only a few examples given in the prompt without any parameter update. However, it is unclear where this capability comes from as there is a stark distribution shift between pre-training text and ICL prompts. In this work, we study what patterns of the pretraining data contribute to ICL. We find that LMs’ ICL ability depends on parallel structures in the pre-training data—pairs of phrases following similar templates in the same context window. Specifically, we detect parallel structures by checking whether training on one phrase improves prediction of the other, and conduct ablation experiments to study their effect on ICL. We show that removing parallel structures in the pre-training data reduces LMs’ ICL accuracy by 51% (vs 2% from random ablation). This drop persists even when excluding common patterns such as n-gram repetitions and long-range dependency, showing the diversity and generality of parallel structures. A closer look at the detected parallel structures indicates that they cover diverse linguistic tasks and span long distances in the data.
Abstract: Humor is a fundamental facet of human cognition and interaction. Yet, despite recent advances in natural language processing, humor detection remains a challenging task that is complicated by the scarcity of datasets that pair humorous texts with similar non-humorous counterparts. We investigate whether large language models (LLMs) can generate synthetic data for humor detection via editing texts. We benchmark LLMs on an existing human dataset and show that current LLMs display an impressive ability to “unfun” jokes, as judged by humans and as measured on the downstream task of humor detection. We extend our approach to a code-mixed English-Hindi humor dataset where we find that GPT-4’s synthetic data is highly rated by bilingual annotators and provides challenging adversarial examples for humor classifiers.
Abstract: While state-of-the-art large language models (LLMs) can excel at adapting text from one style to another, current work does not address the explainability of style transfer models. Recent work has explored generating textual explanations from larger teacher models and distilling them into smaller student models. One challenge with such approach is that LLM outputs may contain errors that require expertise to correct, but gathering and incorporating expert feedback is difficult due to cost and availability. To address this challenge, we propose ICLEF, a novel human-AI collaboration approach to model distillation that incorporates scarce expert human feedback by combining in-context learning and model self-critique. We show that our method leads to generation of high-quality synthetic explainable style transfer datasets for formality (E-GYAFC) and subjective bias (EWNC). Via automatic and human evaluation, we show that specialized student models finetuned on our datasets outperform generalist teacher models on the explainable style transfer task in one-shot settings, and perform competitively compared to few-shot teacher models, highlighting the quality of the data and the role of expert feedback. In an extrinsic task of authorship attribution, we show that explanations generated by smaller models fine-tuned on E-GYAFC are more predictive of authorship than explanations generated by few-shot teacher models.
Abstract: Lexical Substitution discovers appropriate substitutes for a given target word in a context sentence. However, the task fails to consider substitutes that are of equal or higher proficiency than the target, an aspect that could be beneficial for language learners looking to improve their writing. To bridge this gap, we propose a new task — language proficiencyoriented lexical substitution. We also introduce ProLex, a novel benchmark designed to assess systems’ ability to generate not only appropriate substitutes but also substitutes that demonstrate better language proficiency. Besides the benchmark, we propose models that can automatically perform the new task. We show that our best model, a Llama2-13B model fine-tuned with task-specific synthetic data, outperforms ChatGPT by an average of 3.2% in F-score and achieves comparable results with GPT-4 on ProLex.
Abstract: Retrieval-augmented question-answering systems combine retrieval techniques with large language models to provide answers that are more accurate and informative. Many existing toolkits allow users to quickly build such systems using off-the-shelf models, but they fall short in supporting researchers and developers to customize the model training, testing, and deployment process. We propose LOCALRQA1 , an open-source toolkit that features a wide selection of model training algorithms, evaluation methods, and deployment tools curated from the latest research. As a showcase, we build QA systems using online documentation obtained from Databricks and Faire’s websites. We find 7B-models trained and deployed using LOCALRQA reach a similar performance compared to using OpenAI’s text-ada-002 and GPT-4-turbo.
Abstract: Recognizing fallacies is crucial for ensuring the quality and validity of arguments across various domains. However, computational fallacy recognition faces challenges due to the diverse genres, domains, and types of fallacies found in datasets. This leads to a highly multiclass, and even multi-label, setup with substantial class imbalance. In this study, we aim to enhance existing models for fallacy recognition by incorporating additional context and by leveraging large language models to generate synthetic data, thus increasing the representation of the infrequent classes. We experiment with GPT-3.5 to generate synthetic examples and we examine the impact of prompt settings for this. Moreover, we explore zero-shot and few-shot scenarios to evaluate the effectiveness of using the generated examples for training smaller models within a unified fallacy recognition framework. Furthermore, we analyze the overlap between the synthetic data and existing fallacy datasets. Finally, we investigate the usefulness of providing supplementary context for detecting fallacy types that need such context, e.g., diversion fallacies. Our evaluation results demonstrate consistent improvements across fallacy types, datasets, and generators. The code and the synthetic datasets are all publicly available.
Papers from CS researchers were accepted to the 41st International Conference on Machine Learning (ICML 2024). They join the machine learning research community in Vienna, Austria, on July 21 – 27, 2024. ICML brings together the brightest minds in the field to share their latest findings, foster collaborations, and inspire new directions in machine learning.
The links to the papers and the abstracts are below:
Abstract: How do large language models (LLMs) obtain their answers? The ability to explain and control an LLM’s reasoning process is key for reliability, transparency, and future model developments. We propose SelfIE (Self-Interpretation of Embeddings), a framework that enables LLMs to interpret their own embeddings in natural language by leveraging their ability to respond to inquiries about a given passage. Capable of interpreting open-world concepts in the hidden embeddings, SelfIE reveals LLM internal reasoning in cases such as making ethical decisions, internalizing prompt injection, and recalling harmful knowledge. SelfIE’s text descriptions on hidden embeddings open avenues to control LLM reasoning. We propose Supervised Control, which allows editing open-ended concepts while only requiring gradient computation of individual layer. We extend RLHF to hidden embeddings and propose Reinforcement Control that erases harmful knowledge in LLM without supervision targets.
Abstract: Counterfactual image editing is a challenging task within generative AI. The current literature on the topic focuses primarily on changing individual features while being silent about the causal relationships between features, which are present in the real world. In this paper, we first formalize this task through causal language, modeling the causal relationships between latent generative factors and images through a special type of causal model called augmented structural causal models (ASCMs). Second, we show two fundamental impossibility results: (1) counterfactual editing is impossible from i.i.d. image samples and their corresponding labels alone; (2) also, even when the causal relationships between latent generative factors and images are available, no guarantees regarding the output of the generative model can be provided. Third, we propose a relaxation over this hard problem aiming to approximate the non-identifiable target counterfactual distributions while still preserving features the users care about and that are causally consistent with the true generative model, which we call ctf-consistent estimators. Finally, we develop an efficient algorithm to generate counterfactual image samples leveraging neural causal models.
Exploiting Code Symmetries for Learning Program Semantics Kexin Pei Columbia University, Weichen Li Columbia University, Qirui Jin University of Michigan, Shuyang Liu Huazhong University of Science and Technology, Scott Geng Univerisity of Washington, Lorenzo Cavallaro University College London, Junfeng Yang Columbia University, Suman Jana Columbia University
Abstract: This paper tackles the challenge of teaching code semantics to Large Language Models (LLMs) for program analysis by incorporating code symmetries into the model architecture. We introduce a group-theoretic framework that defines code symmetries as semantics-preserving transformations, where forming a code symmetry group enables precise and efficient reasoning of code semantics. Our solution, SymC, develops a novel variant of self-attention that is provably equivariant to code symmetries from the permutation group defined over the program dependence graph. SymC obtains superior performance on five program analysis tasks, outperforming state-of-the-art code models, including GPT-4, without any pre-training. Our results suggest that code LLMs that encode the code structural prior via the code symmetry group generalize better and faster.
MGit: A Model Versioning and Management System Wei Hao Columbia University, Daniel Mendoza Stanford University, Rafael Mendes Microsoft Research, Deepak Narayanan NVIDIA, Amar Phanishayee Columbia University, Asaf Cidon Columbia University, Junfeng Yang Columbia University
Abstract: New ML models are often derived from existing ones (e.g., through fine-tuning, quantization or distillation), forming an ecosystem where models are *related* to each other and can share structure or even parameter values. Managing such a large and evolving ecosystem of model derivatives is challenging. For instance, the overhead of storing all such models is high, and models may inherit bugs from related models, complicating error attribution and debugging. In this paper, we propose a model versioning and management system called MGit that makes it easier to store, test, update, and collaborate on related models. MGit introduces a lineage graph that records the relationships between models, optimizations to efficiently store model parameters, and abstractions over this lineage graph that facilitate model testing, updating and collaboration. We find that MGit works well in practice: MGit is able to reduce model storage footprint by up to 7x. Additionally, in a user study with 20 ML practitioners, users complete a model updating task 3x faster on average with MGit.
Position: TrustLLM: Trustworthiness in Large Language Models Yue Huang Lehigh University, Lichao Sun Lehigh University, Haoran Wang Illinois Institute of Technology, Siyuan Wu CISPA, Qihui Zhang CISPA, Yuan Li University of Cambridge, Chujie Gao CISPA, Yixin Huang Institut Polytechnique de Paris, Wenhan Lyu William & Mary, Yixuan Zhang William & Mary, Xiner Li Texas A&M University, Hanchi Sun Lehigh University, Zhengliang Liu University of Georgia, Yixin Liu Lehigh University, Yijue Wang Samsung Research America, Zhikun Zhang Stanford University, Bertie Vidgen MLCommons, Bhavya Kailkhura Lawrence Livermore National Laboratory, Caiming Xiong Salesforce Research, Chaowei Xiao University of Wisconsin, Madison, Chunyuan Li Microsoft Research, Eric Xing Carnegie Mellon University, Furong Huang University of Maryland, Hao Liu University of California, Berkeley, Heng Ji University of Illinois Urbana-Champaign, Hongyi Wang Rutgers University, Huan Zhang University of Illinois Urbana-Champaign, Huaxiu Yao UNC Chapel Hill, Manolis Kellis Massachusetts Institute of Technology, Marinka Zitnik Harvard University, Meng Jiang University of Notre Dame, Mohit Bansal UNC Chapel Hill, James Zou Stanford University, Jian Pei Duke University, Jian Liu University of Tennessee, Knoxville, Jianfeng Gao Microsoft Research, Jiawei Han University of Illinois Urbana-Champaign, Jieyu Zhao University of Southern California, Jiliang Tang Michigan State University, Jindong Wang Microsoft Research Asia, Joaquin Vanschoren Eindhoven University of Technology, John Mitchell Drexel University, Kai Shu Illinois Institute of Technology, Kaidi Xu Drexel University, Kai-Wei Chang University of California, Los Angeles, Lifang He Lehigh University, Lifu Huang Virginia Tech, Michael Backes CISPA, Neil Gong Duke University, Philip Yu University of Illinois Chicago, Pin-Yu Chen IBM Research, Quanquan Gu University of California, Los Angeles, Ran Xu Salesforce Research, Rey Ying Yale University, Shuiwang Ji Texas A&M University, Suman Jana Columbia UniversityI, Tianlong Chen UNC Chapel Hill, Tianming Liu University of Georgia, Tianyi Zhou University of Maryland, William Wang University of California, Santa Barbara, Xiang Li Massachusetts General Hospital, Xiangliang Zhang University of Notre Dame, Xiao Wang Northwestern University, Xing Xie Microsoft Research Asia, Xun Chen Samsung Research America, Xuyu Wang Florida International University, Yan Liu University of Southern California, Yanfang Ye University of Notre Dame, Yinzhi Cao Johns Hopkins University, Yong Chen University of Pennsylvania, Yue Zhao University of Southern California
Abstract: Large language models (LLMs) have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and capability (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones, suggesting that open-source models can achieve high levels of trustworthiness without additional mechanisms like moderator, offering valuable insights for developers in this field. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Besides these observations, we’ve uncovered key insights into the multifaceted trustworthiness in LLMs. We emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. We advocate that the establishment of an AI alliance between industry, academia, the open-source community to foster collaboration is imperative to advance the trustworthiness of LLMs.
The vast majority of the massive, metallic towers the city commissioned to help low-income neighborhoods access high-speed 5G internet still lack cell signal equipment — more than two years after hundreds of the structures began sprouting across the five boroughs.
Five CS professors received Test of Time awards for research papers that have had a lasting impact on their fields. The influential papers were presented at their respective conferences in the past 25 years and have remained relevant to research and practice.
International Conference on Machine Learning (ICML ’23)
Professor Emeritus Peter K. Allen was one of the six esteemed professors who were honored for outstanding contributions and the lasting impact they have made in academia, research, and student mentorship.
Associate Professor Zhou Yu and her team won a Best Paper Award for their paper Teaching Language Models to Self-Improve through Interactive Demonstrations. They introduce TRIPOST, a training algorithm that endows smaller models with self-improvement ability, which shows that the interactive experience of learning from and correcting its own mistakes is crucial for small models to improve their performance.
Abstract: The self-improving ability of large language models (LLMs), enabled by prompting them to analyze and revise their own outputs, has garnered significant interest in recent research. However, this ability has been shown to be absent and difficult to learn for smaller models, thus widening the performance gap between state-of-the-art LLMs and more costeffective and faster ones. To reduce this gap, we introduce TRIPOST, a training algorithm that endows smaller models with such selfimprovement ability, and show that our approach can improve LLaMA-7B’s performance on math and reasoning tasks by up to 7.13%. In contrast to prior work, we achieve this by using the smaller model to interact with LLMs to collect feedback and improvements on its own generations. We then replay this experience to train the small model. Our experiments on four math and reasoning datasets show that the interactive experience of learning from and correcting its own mistakes is crucial for small models to improve their performance.
TofuEval: Evaluating Hallucinations of LLMs on Topic-Focused Dialogue Summarization Liyan Tang The University of Texas at Austin, Igor Shalyminov AWS AI Labs, Amy Wing-mei Wong AWS AI Labs, Jon Burnsky AWS AI Labs, Jake W. Vincent AWS AI Labs, Yuan Yang AWS AI Labs, Siffi Singh AWS AI Labs, Song Feng AWS AI Labs, Hwanjun Song Korea Advanced Institute of Science & Technology, Hang Su AWS AI Labs, Lijia Sun AWS AI Labs, Yi Zhang AWS AI Labs, Saab Mansour AWS AI Labs, Kathleen McKeown Columbia University
Abstract: Single-document news summarization has seen substantial progress in faithfulness in recent years, driven by research on the evaluation of factual consistency or hallucinations. We ask whether these advances carry over to other text summarization domains. We propose a new evaluation benchmark on topic-focused dialogue summarization, generated by LLMs of varying sizes. We provide binary sentence-level human annotations of the factual consistency of these summaries along with detailed explanations of factually inconsistent sentences. Our analysis shows that existing LLMs hallucinate significant amounts of factual errors in the dialogue domain, regardless of the model’s size. On the other hand, when LLMs, including GPT-4, serve as binary factual evaluators, they perform poorly and can be outperformed by prevailing state-of-the-art specialized factuality evaluation metrics. Finally, we conducted an analysis of hallucination types with a curated error taxonomy. We find that there are diverse errors and error distributions in modelgenerated summaries and that non-LLM-based metrics can capture all error types better than LLM-based evaluators.
Fair Abstractive Summarization of Diverse Perspectives Yusen Zhang Penn State University, Nan Zhang Penn State University, Yixin Liu Yale University, Alexander Fabbri Salesforce Research, Junru Liu Texas A&M University, Ryo Kamoi Penn State University, Xiaoxin Lu Penn State University, Caiming Xiong Salesforce Research, Jieyu Zhao University of Southern California, Dragomir Radev Yale University, Kathleen McKeown Columbia University, Rui Zhang Penn State University
Abstract: People from different social and demographic groups express diverse perspectives and conflicting opinions on a broad set of topics such as product reviews, healthcare, law, and politics. A fair summary should provide a comprehensive coverage of diverse perspectives without underrepresenting certain groups. However, current work in summarization metrics and Large Language Models (LLMs) evaluation has not explored fair abstractive summarization. In this paper, we systematically investigate fair abstractive summarization for user-generated data. We first formally define fairness in abstractive summarization as not underrepresenting perspectives of any groups of people, and we propose four reference-free automatic metrics by measuring the differences between target and source perspectives. We evaluate nine LLMs, including three GPT models, four LLaMA models, PaLM 2, and Claude, on six datasets collected from social media, online reviews, and recorded transcripts. Experiments show that both the model-generated and the human-written reference summaries suffer from low fairness. We conduct a comprehensive analysis of the common factors influencing fairness and propose three simple but effective methods to alleviate unfair summarization. Our dataset and code are available at https: //github.com/psunlpgroup/FairSumm.
Abstract: It is well-known that speakers who entrain to one another have more successful conversations than those who do not. Previous research has shown that interlocutors entrain on linguistic features in both written and spoken monolingual domains. More recent work on code-switched communication has also shown preliminary evidence of entrainment on certain aspects of code-switching (CSW). However, such studies of entrainment in codeswitched domains have been extremely few and restricted to human-machine textual interactions. Our work studies code-switched spontaneous speech between humans, finding that (1) patterns of written and spoken entrainment in monolingual settings largely generalize to code-switched settings, and (2) some patterns of entrainment on code-switching in dialogue agent-generated text generalize to spontaneous code-switched speech. Our findings give rise to important implications for the potentially “universal” nature of entrainment as a communication phenomenon, and potential applications in inclusive and interactive speech technology.
Abstract: This paper investigates the optimal selection and fusion of feature encoders across multiple modalities and combines these in one neural network to improve sentiment detection. We compare different fusion methods and examine the impact of multi-loss training within the multi-modality fusion network, identifying surprisingly important findings relating to subnet performance. We have also found that integrating context significantly enhances model performance. Our best model achieves state-of-the-art performance for three datasets (CMU-MOSI, CMU-MOSEI and CH-SIMS). These results suggest a roadmap toward an optimized feature selection and fusion approach for enhancing sentiment detection in neural networks.
Abstract: In the last decade, the United States has lost more than 500,000 people from an overdose involving prescription and illicit opioids, making it a national public health emergency (USDHHS, 2017). Medical practitioners require robust and timely tools that can effectively identify at-risk patients. Community-based social media platforms such as Reddit allow self-disclosure for users to discuss otherwise sensitive drug-related behaviors. We present a moderate-size corpus of 2500 opioid-related posts from various subreddits labeled with six different phases of opioid use: Medical Use, Misuse, Addiction, Recovery, Relapse, and Not Using. For every post, we annotate span-level extractive explanations and crucially study their role both in annotation quality and model development.2 We evaluate several state-of-the-art models in a supervised, few-shot, or zero-shot setting. Experimental results and error analysis show that identifying the phases of opioid use disorder is highly contextual and challenging. However, we find that using explanations during modeling leads to a significant boost in classification accuracy, demonstrating their beneficial role in a high-stakes domain such as studying the opioid use disorder continuum.
The 2024 Computer Vision and Pattern Recognition (CVPR) Conference recognizes top research in computer vision, artificial intelligence (AI), machine learning (ML), augmented, virtual, and mixed reality (AR/VR/MR), deep learning, and more.
Assistant Professor Carl Vondrick won a Young Researcher Award, which recognizes researchers within seven years of receiving their Ph.D. who have made distinguished research contributions to computer vision.
New faculty member, Aleksander Holynski, won a Best Paper Award for work done with Google Research. The paper, Generative Image Dynamics, presents a new approach for modeling natural oscillation dynamics from a single still picture. This approach produces photo-realistic animations from a single picture and significantly outperforms prior baselines. It also demonstrates the potential to enable several downstream applications, such as creating seamlessly looping or interactive image dynamics.
Below are the abstracts:
pix2gestalt: Amodal Segmentation by Synthesizing Wholes Ege Ozguroglu Columbia University, Ruoshi Liu Columbia University, Dídac Surís Columbia University, Dian Chen Toyota Research Institute, Achal Dave Toyota Research Institute, Pavel Tokmakov Toyota Research Institute, Carl Vondrick Columbia University
Abstract: We introduce pix2gestalt, a framework for zero-shot amodal segmentation, which learns to estimate the shape and appearance of whole objects that are only partially visible behind occlusions. By capitalizing on large-scale diffusion models and transferring their representations to this task, we learn a conditional diffusion model for reconstructing whole objects in challenging zero-shot cases, including examples that break natural and physical priors, such as art. As training data, we use a synthetically curated dataset containing occluded objects paired with their whole counterparts. Experiments show that our approach outperforms supervised baselines on established benchmarks. Our model can furthermore be used to significantly improve the performance of existing object recognition and 3D reconstruction methods in the presence of occlusions.
GES: Generalized Exponential Splatting for Efficient Radiance Field Rendering Abdullah J Hamdi University of Oxford, Luke Melas-Kyriazi University of Oxford, Jinjie Mai King Abdullah University of Science and Technology, Guocheng Qian King Abdullah University of Science and Technology, Ruoshi Liu Columbia University, Carl Vondrick Columbia University, Bernard Ghanem King Abdullah University of Science and Technology,Andrea Vedaldi University of Oxford
Abstract: Advancements in 3D Gaussian Splatting have significantly accelerated 3D reconstruction and generation. However, it may require a large number of Gaussians, which creates a substantial memory footprint. This paper introduces GES (Generalized Exponential Splatting), a novel representation that employs Generalized Exponential Function (GEF) to model 3D scenes, requiring far fewer particles to represent a scene and thus significantly outperforming Gaussian Splatting methods in efficiency with a plug-and-play replacement ability for Gaussian-based utilities. GES is validated theoretically and empirically in both principled 1D setup and realistic 3D scenes. It is shown to represent signals with sharp edges more accurately, which are typically challenging for Gaussians due to their inherent low-pass characteristics. Our empirical analysis demonstrates that GEF outperforms Gaussians in fitting natural-occurring signals (E.g. squares, triangles, parabolic signals), thereby reducing the need for extensive splitting operations that increase the memory footprint of Gaussian Splatting. With the aid of a frequency-modulated loss, GES achieves competitive performance in novel-view synthesis benchmarks while requiring less than half the memory storage of Gaussian Splatting and increasing the rendering speed by up to 39%. The code is available on the project website https://abdullahamdi.com/ges .
MoDE: CLIP Data Experts via Clustering Jiawei Ma Columbia University, Po-Yao Huang FAIR, Meta, Saining Xie New York University, Shang-Wen Li FAIR, Meta, Luke Zettlemoyer University of Washington, Shih-Fu Chang Columbia University, Wen-tau Yih FAIR, Meta, Hu Xu FAIR, Meta
Abstract: The success of contrastive language-image pretraining (CLIP) relies on the supervision from the pairing between images and captions, which tends to be noisy in webcrawled data. We present Mixture of Data Experts (MoDE) and learn a system of CLIP data experts via clustering. Each data expert is trained on one data cluster, being less sensitive to false negative noises in other clusters. At inference time, we ensemble their outputs by applying weights determined through the correlation between task metadata and cluster conditions. To estimate the correlation precisely, the samples in one cluster should be semantically similar, but the number of data experts should still be reasonable for training and inference. As such, we consider the ontology in human language and propose to use finegrained cluster centers to represent each data expert at a coarse-grained level. Experimental studies show that four CLIP data experts on ViT-B/16 outperform the ViT-L/14 by OpenAI CLIP and OpenCLIP on zero-shot image classification but with less (<35%) training cost. Meanwhile, MoDE can train all data expert asynchronously and can flexibly include new data experts. The code is available at https: //github.com/facebookresearch/MetaCLIP/ tree/main/mode.
Abstract: Spatio-temporal grounding describes the task of localizing events in space and time, e.g., in video data, based on verbal descriptions only. Models for this task are usually trained with human-annotated sentences and bounding box supervision. This work addresses this task from a multimodal supervision perspective, proposing a framework for spatio-temporal action grounding trained on loose video and subtitle supervision only, without human annotation. To this end, we combine local representation learning, which focuses on leveraging fine-grained spatial information, with a global representation encoding that captures higher-level representations and incorporates both in a joint approach. To evaluate this challenging task in a reallife setting, a new benchmark dataset is proposed, providing dense spatio-temporal grounding annotations in long, untrimmed, multi-action instructional videos for over 5K events. We evaluate the proposed approach and other methods on the proposed and standard downstream tasks, showing that our method improves over current baselines in various settings, including spatial, temporal, and untrimmed multi-action spatio-temporal grounding.
Abstract: Machine learning models struggle with generalization when encountering out-of-distribution (OOD) samples with unexpected distribution shifts. For vision tasks, recent studies have shown that test-time adaptation employing diffusion models can achieve state-of-the-art accuracy improvements on OOD samples by generating new samples that align with the model’s domain without the need to modify the model’s weights. Unfortunately, those studies have primarily focused on pixel-level corruptions, thereby lacking the generalization to adapt to a broader range of OOD types. We introduce Generalized Diffusion Adaptation (GDA), a novel diffusion-based test-time adaptation method robust against diverse OOD types. Specifically, GDA iteratively guides the diffusion by applying a marginal entropy loss derived from the model, in conjunction with style and content preservation losses during the reverse sampling process. In other words, GDA considers the model’s output behavior with the semantic information of the samples as a whole, which can reduce ambiguity in downstream tasks during the generation process. Evaluation across various popular model architectures and OOD benchmarks shows that GDA consistently outperforms prior work on diffusion-driven adaptation. Notably, it achieves the highest classification accuracy improvements, ranging from 4.4\% to 5.02\% on ImageNet-C and 2.5\% to 7.4\% on Rendition, Sketch, and Stylized benchmarks. This performance highlights GDA’s generalization to a broader range of OOD benchmarks.
Abstract: We introduce a new task of generating “Illustrated Instructions”, i.e. visual instructions customized to a user’s needs. We identify desiderata unique to this task, and formalize it through a suite of automatic and human evaluation metrics, designed to measure the validity, consistency, and efficacy of the generations. We combine the power of large language models (LLMs) together with strong textto-image generation diffusion models to propose a simple approach called StackedDiffusion, which generates such illustrated instructions given text as input. The resulting model strongly outperforms baseline approaches and stateof-the-art multimodal LLMs; and in 30% of cases, users even prefer it to human-generated articles. Most notably, it enables various new and exciting applications far beyond what static articles on the web can provide, such as personalized instructions complete with intermediate steps and pictures in response to a user’s individual situation.
This award recognizes one or two researchers within seven years of receiving their PhD who have made distinguished research contributions to computer vision.
Blei is recognized for significant contributions to machine learning, information retrieval, and statistics. His signature accomplishment is in the machine learning area of “topic modeling”, which he pioneered in the foundational paper “Latent Dirichlet Allocation” (LDA).
A game designer, entrepreneur, and computational biologist are set to receive scholarship aid from Columbia Engineering’s Computer Science MS Bridge Program.
Associate Professor Xia Zhou and her team developed Joey, a soft, lightweight sensing fabric necklace that can easily be worn by mothers to monitor their Kangaroo Mother Care practices with their babies.
The Columbia-Dream Sports AI Innovation Center will significantly advance research and workforce development at the intersection of artificial intelligence (AI), machine learning (ML), and sports tech.
Blei is recognized for his groundbreaking work in machine learning, in particular his field-defining contributions in the areas of topic models and stochastic variational inference.
The startup develops cybersecurity software tools based on technology from The Intrusion Detection Systems Group. The lab builds next-generation tools to detect stealthy and malicious intruders in computer systems. This includes research into anomaly detection, collaborative intrusion detection, attacker modeling, malicious code, and secure wireless networks.
Innokentiy Kaurov, Eric Yuang Shao, and Kevin Yang secured an impressive third place, earning a silver medal at the International Collegiate Programming Contest North America Championship, held on May 27, 2024, at the University of Central Florida.
The International Collegiate Programming Contest (ICPC) is the world’s oldest and most prestigious competitive programming competition for university students. It challenges teams of three students to solve complex algorithmic problems within a set timeframe. The teams that came out on top were the Massachusetts Institute of Technology for the gold medal, the University of Illinois Urbana-Champaign and Columbia University for the silver medal, and the bronze medal went to the University of British Columbia, the University of California San Diego, and the University of Maryland.
The “Columbia-CU later” team is preparing for the ICPC World Finals that will take place in Astana, Kazakhstan, in September. They meet weekly for five-hour team contests under the guidance of their coach Christian Lim, and co-coaches Josh Alman, Grace Lim, and Benjamin Rubio. In August, they will host an intensive 2-week training camp for teams from the Greater New York area to share knowledge and foster community.
In a recent retirement talk, Professor Steve Bellovin shared his journey from the early days of his career to his thoughts on the future of security and tech policy.
Proposals from Mechanical Engineering Professor Matei Ciocarlie and Computer Science Professors Tal Malkin and Carl Vondrick focus on wearable robotic devices for stroke victims, cryptography techniques for LLMs, and improvements in computer vision queries.
The department is extremely proud of all of our students!
The Columbia Engineering Class of 2024 gathered at Baker Athletics Complex to celebrate Class Day on May 12th and 13th.
The department honored this year’s graduates at a graduation celebration on May 13th. A number of students received awards from the department for their service and academic excellence. The list of CS awardees is in this year’s graduation handout.
Jonathan L. Gross Award for Academic Excellence awardee Weichen Li and CS Department Chair Luca Carloni
Jonathan L. Gross Award for Academic Excellence awardee Andrei Coman and CS Department Chair Luca Carloni
Jonathan L. Gross Award for Academic Excellence awardee Whitney Deng and CS Department Chair Luca Carloni
Jonathan L. Gross Award for Academic Excellence awardee Xuezhen Wang and CS Department Chair Luca Carloni
Computer Science Scholarship Award awardee Andrew Tsong-Bo Cheng and CS Department Chair Luca Carloni
Computer Science Scholarship Award awardee Ryan Xu and CS Department Chair Luca Carloni
Computer Science Scholarship Award awardee Eleanor Lin and CS Department Chair Luca Carloni
Russel C. Mills Award awardee Shelby Wengreen and CS Department Chair Luca Carloni
Russel C. Mills Award awardee Sahil Mahendrakar and CS Department Chair Luca Carloni
Russel C. Mills Award awardee Yucheng Wang and CS Department Chair Luca Carloni
Theodore R. Bashkow Award awardee Jeremy Carin and CS Department Chair Luca Carloni
Theodore R. Bashkow Award awardee Edward Ri and CS Department Chair Luca Carloni
Theodore R. Bashkow Award awardee Walter McKelvie and CS Department Chair Luca Carloni
Theodore R. Bashkow Award awardee Grace Li and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Kevin Grant Li and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Christopher Samuel Lee and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Phoebe Lu and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Joshua Young Hahn and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Marian Abuhazi and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Nirvaan Iyer and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Sphya Wu and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Hannah Rui Luo and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Amelia Wissink and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Gabriel Guo and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Helen Chu and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Alice Chen and CS Department Chair Luca Carloni
Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service awardee Daniel Mitroplosky and CS Department Chair Luca Carloni
Behring Foundation Award awardee Lidia Rodrigues Toledo and CS Department Chair Luca Carloni
Computer Science Service Award awardee Daniel Mitroplosky and CS Department Chair Luca Carloni
Davide Giri Memorial Prize awardee Daniel Mitroplosky and CS Department Chair Luca Carloni
Paul Charles Michelman Memorial Award for Exemplary Departmental Service awardee Roland Maio
Kathy McKeown and Emily Allaway
Barbara Tversky and Jen-Shuo Liu
William Brown and Christos Papadimitriou
Daniel Mitroplosky, Christos Papadimitriou, and Tal Malkin
Brian Smith received an NSF CAREER Award to develop a framework that will improve digital imagery so that blind and low-vision (BLV) individuals can better perceive and interact with visual content in the digital realm.
The award recognizes the excellence of faculty as teachers, scholars, and mentors within and outside the classroom, with a particular focus on teaching and mentoring undergraduate and graduate students.
Columbia Engineering researchers develop a novel approach that can detect AI-generated content without needing access to the AI’s architecture, algorithms, or training data–a first in the field.
Columbia Engineering and the Knight First Amendment Institute recently convened multidisciplinary experts to discuss the impact of artificial intelligence on public discourse, free speech, and democracy.
PhD students Charlie Carver and Hadleigh Schwartz unveiled Lasertag, a framework that integrates laser steering with optical tracking to maintain laser connectivity, at the 29th Annual International Conference On Mobile Computing And Networking (MobiCom). Lasertag stole the spotlight with a live demonstration that earned a Best Demo Award. The team also received a second-place award in the Student Research Competition for their pioneering work.
The system establishes a constant laser-based connection with high-velocity targets, opening doors to transformative applications such as VR content streaming and wireless power delivery. Lasertag offers a unique framework for building and deploying practical laser-based mobile systems. It creates a constantly connected laser-based tether between the Lasertag core unit and a mobile, remote target, enabling fully wireless, gigabit-level communication and wireless power delivery. Its potential applications span communication, sensing, and efficient wireless power delivery.
Lasers have unique physical properties, which make them appealing for many applications. Laser-based streaming of virtual reality content could enable higher quality experiences for VR headset users, or wireless power delivery via lasers could allow robots to work longer without returning to a charging station. These applications require constantly tracking and steering a directional laser beam to a moving target at shorter ranges (i.e., a few meters). However, before Lasertag, there were no systems for achieving this, which was a barrier to realizing laser-based mobile applications.
The response from the research community has been positive, with Lasertag’s ability to navigate the complexities of lasers and optics earning accolades. The journey continues as Lasertag is set to take the stage at The 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI) this April.
While currently a researcher’s tool, Lasertag lays the foundation for a future where laser-based applications seamlessly integrate into daily lives. From enhanced VR experiences to prolonged robot functionality through wireless power delivery, Lasertag is poised to revolutionize how we interact with technology. Carver and Schwartz worked with Associate Professor Xia Zhou and colleagues from the Mobile X Laboratory. The laboratory’s projects explore how to turn light into a powerful medium for data communication and object or behavioral sensing.
Zhou, Schwartz, Carver receive the Best Demo Award at the 29th Annual International Conference On Mobile Computing And Networking (MobiCom).
We caught up with Carver and Schwartz to learn more about their research and effective collaboration methods.
Q: What sparked this project? Schwartz: When I started my PhD last fall, Charlie and Xia described to me several of their past projects involving lasers for communication and sensing. At the time, they were trying to develop a system for laser-based streaming of virtual reality (VR) content, essentially to enable users to view high-resolution 3D/360° content without a wired connection between the VR headset and gaming console. A big challenge they were facing was how to continuously track and steer the narrow laser beam to a receiver on the headset. This application and problem sounded so cool, I knew that it was what I wanted to work on. Charlie had an initial version of Lasertag in development, so he gave me some tasks to help with, and ultimately, I was able to get more involved in the project.
Carver: Xia and I started working on the idea back in 2019, where we were originally interested in diffuse, room-scale, laser communication for mobile VR. The project has evolved significantly since that point, and we ultimately swapped the diffuse laser light with an efficient steerable beam.
Q: What was your role in the project? What did you do? Schwartz: I was very interested in the optical circuit (i.e., a series of lenses and optical components) that could allow Lasertag to work. I spent a lot of time using ray tracing and optics software to validate and improve our theoretical optical circuit designs. I also spent a good amount of time testing out different lasers, LEDs, and variations on the optical circuit to improve the system’s efficiency and usability.
Carver: I’ve been primarily responsible for leading the project, which has entailed designing/building the optical circuits, electronic circuits, software, experiments, and anything else involved. I absolutely could not have finished without help from all our collaborators, especially Hadleigh, who offered invaluable insights and support during the final stretch of the work.
Q: How long did you work on the project? What did you have to do, or read to prepare to make the system? Schwartz: Charlie and Xia formed the initial idea for the project back to 2019, but the current version using dedicated tracking was started in March of 2022 at Dartmouth. I joined the project in Fall of 2022, and the NSDI paper was published in May 2023. In addition to the simulations and computer programming stages, there was a significant amount of engineering work, including physically realizing our optical circuit, developing electronic circuits to power and communicate with different components of the system, and optimizing both the software and hardware to support tracking/steering to objects moving very fast.
Q: What were the things you had to overcome for this research project? Carver: Research can certainly be difficult. In addition to addressing all of the traditional research challenges, like quickly pivoting when something doesn’t work as expected or spending hours debugging code or experiments, we had to contend with some specific challenges that come with working with lasers and optics. For instance, the optical circuit needed to be precisely designed to get Lasertag to work as best as possible. This sometimes meant spending a day making micro-adjustments to the lens positions to get the laser beam in focus or get the geometry of the beam’s propagation through the optical circuit correct.
Q: What are your research interests? How did you decide to pursue this type of research? When did you decide to focus on it? Schwartz: Light-based sensing and communication. I first learned about this field and decided to focus on it when I started by PhD in Fall 2022.
Carver: Throughout my PhD, I have been studying the use of light to build next-generation wireless communication and sensing systems. Compared to radio frequencies, light boasts wavelengths that are orders of magnitude smaller and a bandwidth that is ten thousand times larger, enabling ultra-precise sensing and fast, competition-free communication. My research has focused on laser light to fully leverage these benefits. Unlike traditional luminaries, e.g., light-emitting diodes, laser diodes provide superior communication and sensing performance thanks to their GHz modulation speeds, narrow spectral wavelengths, strong linear polarization, high-power densities, and high electro-optical conversion ratios.
Q: What sort of research questions or issues do you hope to answer? Schwartz: I hope to continue building practical light-based sensing and communication systems. Right now I’m still figuring out what specific issues in this area I want to address in my PhD.
Carver: I’m broadly interested in questions pertaining to mobile systems and networking. More specifically, I’m interested in supporting next-generation wireless applications by exploring novel uses of light.
Q: What do you think is the most interesting about doing research? Schwartz: The ability to find a problem or challenge that interests you and then fully dive into tackling it. You get to test out ideas that seem crazy or unlikely, spend time learning new things, and really use every tool in your skillset.
Carver: I’ve encountered many applications that pervasive wireless technologies are ill-equipped to handle (usually due to underlying physics-based limitations). Oftentimes, approaching these challenges from a different perspective leads to unexpected breakthroughs that shift the status quo. I love discovering these opportunities — and so far throughout my research career — consider how light can solve them.
Q: Could you share some advice on ensuring the success of collaborative efforts? Schwartz: I think in addition to the obvious importance of clear communication, it’s valuable to keep an open mind about all ideas that may be pitched throughout the course of the collaboration and involve people from different fields or areas of expertise.
Carver: It’s very important to respect other people’s ideas, especially if they have outside perspectives, and to be an active listener and learner. Positive encouragement and appreciation also go a long way, as I believe everyone should feel that their contributions are valued.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research, what should they know or do to prepare? Schwartz: If you think you would enjoy research, don’t hesitate to get started. I spent a significant portion of my undergrad hesitating to reach out to professors or get involved in research because I was nervous that I was underqualified or would fail. In my opinion, as long as you like to solve problems and are motivated to pick up new skills, you can succeed. Taking classes in an area that interests you, reading existing research papers, and working on personal projects in which you quickly learn and apply new skills are all valuable ways to prepare for research. And if you start research and find that it is not for you, that is totally reasonable, and now you know!
Carver: I think Columbia has many opportunities for undergraduate research, and students shouldn’t hesitate to take advantage of these opportunities. However, too many opportunities may feel daunting, as so many options exist. In my opinion, successful research is only possible if you’re truly interested in the topic and want to see it progress, so I would encourage students to be judicious when considering new projects and aim for the ones you see yourself happy to work on. At the end of the day, that’s what matters most.
Two CS students were selected by the Computing Research Association (CRA) for the 2024 Outstanding Undergraduate Researcher Award for their exemplary dedication to research and academic excellence, earning them a well-deserved commendation. The honorees, Eleanor Lin and Walter McKelvie, have exhibited exceptional skills and commitment in their respective areas of focus within computer science.
Eleanor Lin (CC ‘24), distinguished herself through groundbreaking research with the Spoken Language Processing Group, where she is advised by Professor Julia Hirschberg. Her work as the lead researcher on the Switchboard Dialogue Act Re-alignment project has showcased innovation and contributed significantly to updating the corpus used to identify regional differences in U. S. speakers–extremely important for Automatic Speech Recognition, particularly in telephony. Eleanor made substantial contributions to multiple Speech Lab projects while concurrently serving as a teaching assistant for computer science and linguistics. She also collaborated with researchers from Rice University, the University of Southern California, and Teacher’s College.
Walter McKelvie (SEAS ‘24), earned an honorable mention for their remarkable work in theoretical computer science and cryptography. He worked with Professor Tal Malkin and the Crypto Lab on fixing a problem with proof-of-stake blockchains, making a secret leader election “accountable” so that leaders cannot anonymously refuse to publish a block. His dedication to pushing the boundaries of understanding in this field has been commendable, and he greatly contributed to the research by coming up with one of the three paradigms included in the paper and writing several of the technical parts in the paper. McKelvie additionally served as a teaching assistant and collaborated with researchers from Purdue and Harvard.
The honorable mentions serve as a testament to the vibrant research community of the department, where students are encouraged to explore and excel in their chosen fields. Julia Hirschberg, the Percy K. and Vida L. W. Hudson Professor of Computer Science, assembles a team of 15 undergrads with different skills to work on the Speech Lab’s projects. Students can work on data collection and annotation, building large language models (LLMs), or both. Professor Tal Malkin typically has one or two undergraduate students who work on cryptography research. Students need to have mathematical maturity; ideally, they should have taken Malkin’s graduate-level Introduction to Cryptography class.
These recognitions also highlight the department’s commitment to providing students with a robust academic environment that encourages curiosity, creativity, and a passion for discovery.
The Association for Computing Machinery (ACM) has elected Tim Roughgarden as an ACM fellow, recognizing his outstanding contributions to the field of computer science and algorithmic game theory.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor


 Purva Tendulkar
Purva Tendulkar Natalie Parham
Natalie Parham Hideaki Takahashi
Hideaki Takahashi Filipp Shelobolin
Filipp Shelobolin David Nguyen
David Nguyen Riya Sahni
Riya Sahni Leo Orshansky
Leo Orshansky Jihwan Kim
Jihwan Kim Zechao Cai
Zechao Cai Yi Rong
Yi Rong Conlan Olson
Conlan Olson Hailie Mitchell
Hailie Mitchell Shreyas Havaldar
Shreyas Havaldar Nikolaos Pagonas
Nikolaos Pagonas Ziang Ren
Ziang Ren Styopa Zharkov
Styopa Zharkov Soyoon Park
Soyoon Park Georgios Liargkovas
Georgios Liargkovas




















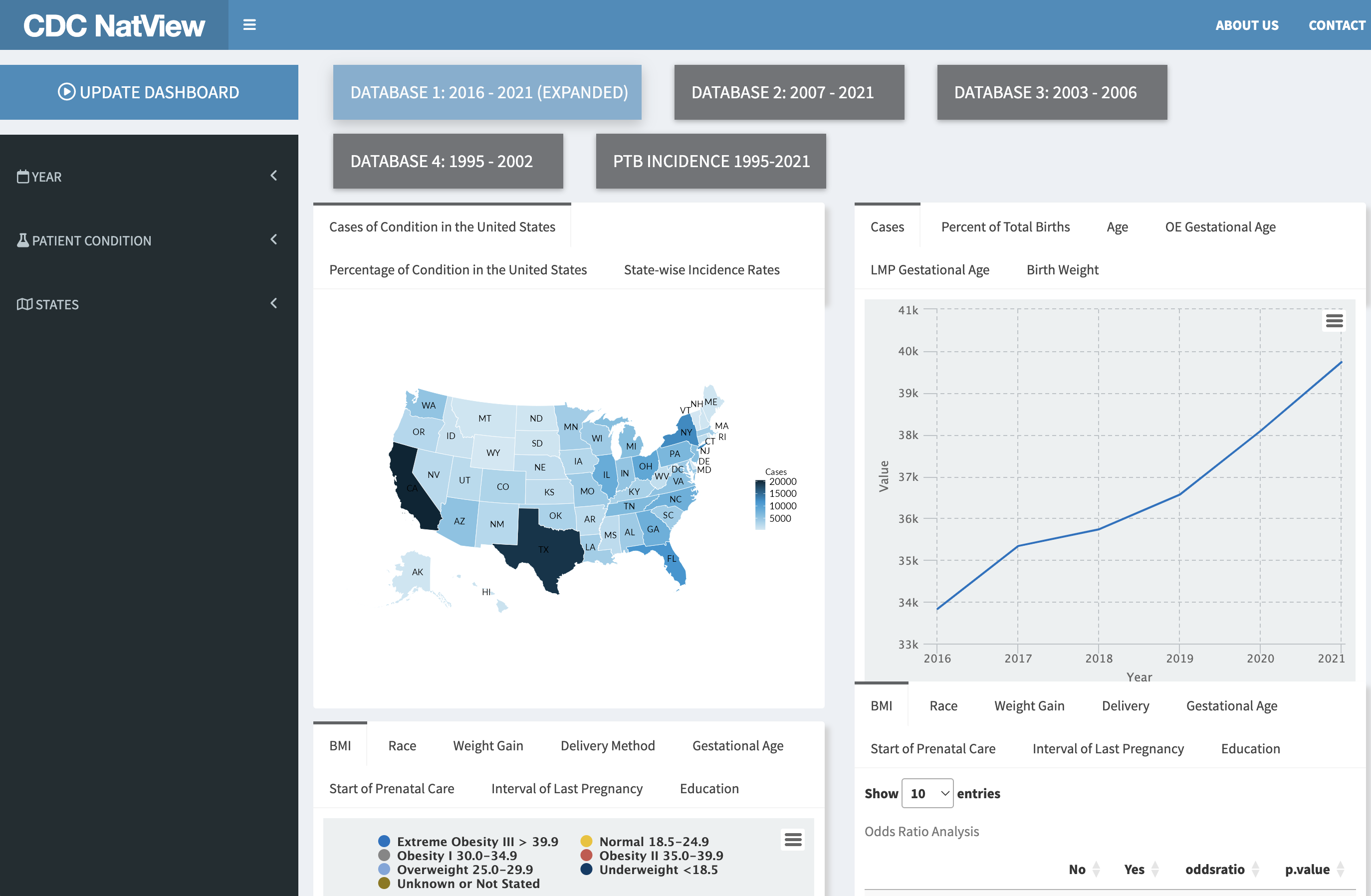
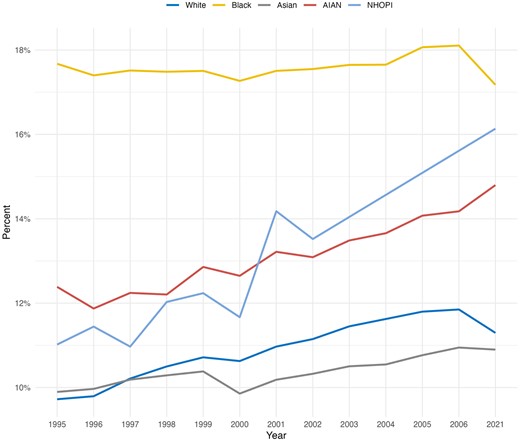
 International Conference on Machine Learning (ICML ’23)
International Conference on Machine Learning (ICML ’23) 39th IEEE International Conference on Software Maintenance and Evolution (ICSME ’23)
39th IEEE International Conference on Software Maintenance and Evolution (ICSME ’23) 43rd Annual International Conference on the Theory and Applications of Cryptographic Techniques (Eurocrypt ’24)
43rd Annual International Conference on the Theory and Applications of Cryptographic Techniques (Eurocrypt ’24) 50th ACM SIGMETRICS 2024
50th ACM SIGMETRICS 2024













































