Six SEAS students traveled this summer to Ghana to train university students to lead CS outreach that will impact hundreds of Ghanian students. The trip was organized by a nonprofit headed by Chelsey Roebuck (BS’10).
The paper, widely covered in the press, describes an automatic method for error-checking thousands to millions of neurons in a deep-learning neural network. Authors are Kexin Pei, Yinzhi Cao (Lehigh), Junfeng Yang, Suman Jana.
Developed by Kexin Pei, Yinzhi Cao (Lehigh), Junfeng Yang, and Suman Jana, DeepXplore error-checks thousands to millions of neurons in deep learning neural networks. In tests, DeepXplore found thousands of bugs missed by previous methods.
To uniquely identify and encode information in printed objects, Columbia researchers Dingzeyu Li, Avinash S. Nair, Shree K. Nayar, and Changxi Zheng have invented a process that embeds carefully designed air pockets, or AirCode tags, just below the surface of an object. By manipulating the size and configuration of these air pockets, the researchers cause light to scatter below the object surface in a distinctive profile they can exploit to encode information. Information encoded using this method allows 3D-fabricated objects to be tracked, linked to online content, tagged with metadata, and embedded with copyright or licensing information. Under an object’s surface, AirCode tags are invisible to human eyes but easily readable using off-the-shelf digital cameras and projectors.
The AirCode system has several advantages over existing tagging methods, including the highly visible barcodes, QR codes, and RFID circuits: AirCode tags can be generated during the 3D printing process, removing the need for post-processing steps to apply tags. Being built into a printed object, the tags cannot be removed, either inadvertently or intentionally; nor do they obscure any part of the object or detract from its visual appearance. Invisibility of the tags also means that the presence of information can remain hidden.
“With the increasing popularity of 3D printing, it’s more important than ever to personalize and identify objects,” says Changxi Zheng, who helped develop the method. “We were motivated to find an easy, unobtrusive way to link digital information to physical objects. Among their many uses, AirCode tags provide a way for artists to authenticate their work and for companies to protect their branded products.”
One additional use for AirCode tags is robotic grasping. By encoding both an object’s 3D model and its orientation into an AirCode tag, a robot would just need to read the tag rather than rely on visual or other sensors to locate the graspable part of an object (such as the handle of a mug), which might be occluded depending on the object’s orientation.
AirCode tags, which work with existing 3D printers and with almost every 3D printing material, are easy to incorporate into 3D object fabrication. A user would install the AirCode software and supply a bitstring of the information to be encoded. From this bitstring, AirCode software automatically generates air pockets of the right size and configuration to encode the supplied information, inserting the air pockets at the precise depth to be invisible but still readable using a conventional camera-projector setup.
How the AirCode system works
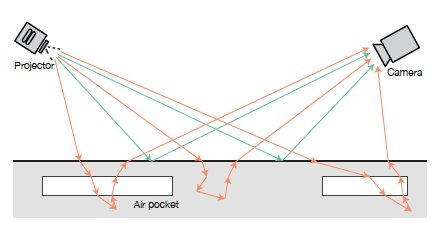
The AirCode system takes advantage of the scattering of light that occurs when light penetrates an object. Subsurface scattering in 3D materials, which is not normally noticeable to people, will be different depending on whether the light hits an air pocket or hits solid material.
Computational imaging techniques are able to differentiate reflective light from scattered light and decompose a photo into two separate components: a direct component produced by reflected light, and a global component produced from the scattered light waves that first penetrate an object. It’s this global component that AirCode tags manipulate to encode information.
Decomposing an image into direct and global components. Green vectors in this schematic represent the direct component produced from light that reflects off the surface; this component resembles the majority of light rays perceived by our eyes. Orange vectors represent the global component produced by light that first penetrates an image before reaching the camera; the global component is barely visible but can be isolated and amplified.
Other innovations are algorithmic, falling into three main steps:
Analyzing the density and optical properties of a material. Most plastic 3D printer materials exhibit strong subsurface scattering, which will be different for each printing material and will thus affect the ideal depth, size, and geometry of an AirCode structure. For each printing material, the researchers analyze the optical properties to model how light penetrates the surface and its interactions with air pockets.
“The technical difficulty here was to create a physics-based model that can predict the light scattering properties of 3D printed materials especially when air pockets are present inside of the materials,” says PhD student Dingzeyu Li, a coauthor on the paper. “It’s only by doing these analyses were we able to determine the size and depth of individual air pockets.”
Analyzing the optical properties of a material is done once with results stored in a database.
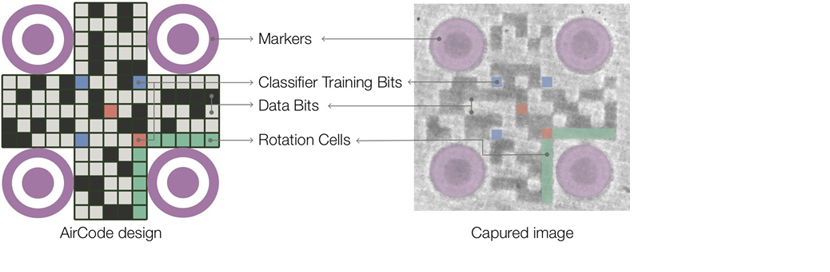
Constructing the AirCode tag for a given material. Like QR codes, AirCode tags are made up of cells arranged on a grid, with each cell representing either a 1 (air-filled) or a 0 (filled with printing material), according to the user-supplied bitstring. Circular-shaped markers, easily detected by computer vision algorithms, help orient the tag and locate different cell regions.
Unlike QR codes, which are clearly visible with sharp distinctions between white and black, AirCode tags are often noisy and blurred, with many levels of gray. To overcome these problems, the researchers insert predefined bits to serve as training data for calibrating in real time the threshold for classifying cells as 0s or 1s.
AirCode layout and its corresponding image: data bits (1s are air-filled cells, 0s are cells with solid material) for encoding user-supplied information; markers and rotation cells for orientation; classifier training bits for on-the-fly calibration. Size is variable; a 5cmx5cm tag stores about 500 bits.
Detecting and decoding the AirCode tag. To read the tag, a projector shines light on the object (multiple tags might be used to ensure the projector easily finds a tag) and a camera captures images of the object. A computer vision algorithm previously created by coauthor Shree Nayar and adapted for AirCode tags separates each image into its direct component and global component, making the AirCode tag clearly visible so it can be decoded.
While the AirCode system has certain limitations—it requires materials to be homogeneous and semitransparent (though most 3D printer materials fit this description) and the tags become unreadable when covered by opaque paint—tagging printed objects during fabrication has substantial benefits in cost, aesthetics, and function.
Interviewed by Columbia Technology Ventures (CTV), Allen discusses his recent work on surgical robots and how incorporating big data, machine learning, and computer vision is contributing to smarter robots able to cope with the unexpected.
The timing isn’t great—mid-semester with early projects coming due and midterms beginning—but still they come; 37 from Columbia and Barnard traveled to Orlando earlier this month to join 18,000 other women in tech for the Grace Hopper Celebration, an annual gathering co-produced by AnitaB.org (formerly the Anita Borg Institute) and the Association for Computing Machinery.
For three days (Oct 4-6) attendees listened to 16 keynote speakers—among them Melinda Gates, Fei-Fei Li (Professor and Director of Stanford’s AI Lab and Chief Scientist at Google Cloud), and Megan Smith (Former US Chief Technology Officer). They signed up for technical panels on AI, wearable technologies, data science, software engineering, and dozens of other innovative technologies. They networked with their peers and listened to pitches from recruiters who flock to the event.
But for many, the main draw is just being among so many other women who share their interests in computer science and engineering. In fields dominated by men, the Grace Hopper Celebration (GHC) is one of the few tech venues where women run the show. Here they are the speakers, panelists, and attendees, sharing what they love about technology and what they hope to accomplish in their careers or in their research. They share also stories of workplace discrimination, slights, and sometimes blatant sexism as well as tangible recommendations for what works to keep women in technology.
Click image to hear this year’s GHC keynote speeches. Many speakers told inspiring stories of overcoming adversity to pursue their careers in computing and technology.
Columbia CS major Tessa Hurr, attending for the fourth time, describes it this way: “GHC is a community of women who are there to support one another and lift one another up and encourage one other to pursue a career in STEM.” A senior about to embark on a career, she especially wanted to hear from women about their work experiences. “Coming from Columbia, where the engineering school and computer science department have done a lot of work to balance the ratio of males to females, you see a lot of other women and you don’t feel alone. But in industry, you see the problem of gender imbalance so glaringly. Being at GHC, I know there are support systems if I need them.”
Women at GHC may be excited about supporting other women in technology, but they’re just as enthusiastic about technology itself and the good it can do in the world. Says Hurr, “Sometimes when you’re learning different concepts in class you don’t necessarily see how they translate over to the real world; GHC tech talks help bridge that gap so you better understand how you can have an impact on the world and work towards social good through tech.”
Myra Deng, a CS student attending for the first time, appreciated the emphasis on new technologies, especially AI. A talk by keynote speaker Fei-Fei Li linking AI and diversity was especially inspiring to Deng, who is on the Intelligent Systems track. “Professor Li talked about how AI is supposed to represent the entire human experience but you can’t really model or build that with just a small section of the human population. Diversity isn’t just being nice in the workplace; it’s essential to getting the technology right.”
This mix of technology and support system is a powerful thing, and GHC has been growing by leaps and bounds. In four years, GHC has grown from 8000 to 18,000 participants.
Many attend by taking advantage of scholarships offered by some of the big tech companies. “If the concern is finances, there are lots of resources, including a Github page listing scholarships,” says Julia Di, president of WiCS, which also sponsors students. This year WiCS raised enough funding to send 16 students, though only six were able to purchase tickets in the few hours it took before tickets sold out. Next year, WiCS may follow the lead of tech companies and make a donation to pre-purchase tickets.
Some scholarships require students take the entire week off, not just the three days of the conference, making GHC even more of a time commitment as students scramble to get school work done ahead of time, and scramble again to catch up when they return to campus. That so many do shows how much importance they attach to continuing in tech and supporting others who want to do the same.
Deng encourages women to make the most of the opportunity offered by GHC. “Every now and then, it’s good to zoom out from school and see what’s going on in the world. At GHC you meet so many incredible people you might not otherwise meet. I came back a lot more motivated because I know what I’m working on is important. It’s why I’m in Tech. You can always catch up on school work later.”
For the headline Liquid Water Found on Mars, which response is the least funny? Hint: One is professionally done, and two are crowdsourced. Voting results at end.
Creativity and computation are often thought to be incompatible: one open-ended and requiring imagination, originality of thought, and perhaps even a little magic; the other logical, linear, and broken down into concrete steps. But solving the hard problems of today in medicine, environmental science, biology, and software engineering will require both.
Lydia Chilton, Assistant Professor
For Lydia Chilton, who joined the Computer Science department this fall, inventing new solutions is fundamentally about design. “When people start solving a problem, they often brainstorm over a broad range of possibilities,” says Chilton, whose research focuses on human-computer interaction and crowdsourcing. “Then there is a mysterious process by which those ideas are transformed into a solution. How can we break down this process into computational steps so that we can repeat them for new problems?” This question motivates her research into tools that are part human intelligence, part computer intelligence.
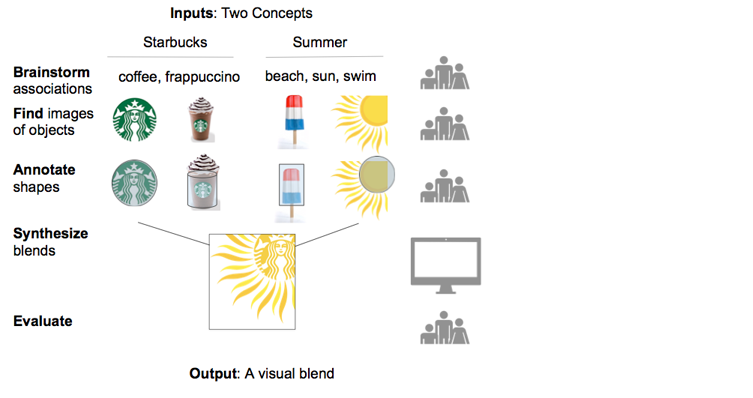
How this works in practice is illustrated by a pipeline she built to automatically generate visual metaphors, where two objects, similar in shape but having different conceptual associations, are blended to create something entirely new. It’s a juxtaposition of images and concepts intended to communicate a new idea, doing so in a way that grabs people’s attention by upending expectations.
A pipeline for creating visual metaphors by synthesizing two objects and two concepts.
Chilton decomposes the process of creating visual metaphors into a series of microtasks where people and machines collaborate by working on those microtasks they are good at. Defining the microtasks and the pipeline to make them flow together coherently is the major intellectual piece.
“The key is to identify the pieces you will need, and what relationships the pieces need to have to fit together. After you define it that way, it becomes a search problem.” Because it’s a search problem over conceptual spaces computers don’t fully understand, Chilton has people fill in the gaps and direct the search. People might examine the space of objects representing Starbucks and the space representing Summer, picking the most simple, meaningful, and iconic. The computer then searches for pairs of similarly shaped objects (as annotated by people), blending them together into an initial mockup of the visual metaphor. Humans come in at the last step to tweak the blend to be visually pleasing. At every stage in the pipeline, humans and computers work together based on their different strengths.
Crowdsourcing serves another purpose in Chilton’s research: harnessing many people’s intuitions. Foreshadowing her work on pipelines, Chilton created crowd algorithms that, more than simply aggregating uninformed opinions or intuitions, aggregate intuitions in intelligent ways to lead to correct solutions.
For example, deciphering this intentionally illegible handwriting would not be possible for any single person, but a crowd algorithm enables people to work towards a solution iteratively. People in the crowd suggest partial solutions, and then others, also in the crowd, vote on which partial solution seems like the right one to continue iterating. Those in later stages benefit from seeing contextual clues and thus build on the current solution, even if they wouldn’t have had those insights without seeing others’ partial solutions. “It’s an iterative algorithm that keeps improving on the partial solutions in every iteration until the problem is solved,” says Chilton.
Out of these scribbles, someone makes out the verb “misspelled,” providing context for others to build on. Who cares about misspellings? Maybe a teacher correcting a student; now words like “grammar” become more likely. Identifying a verb means the preceding word is likely a noun, making it easier for someone else to make out “you”. Each person starts with more information and sees something different, and a task impossible for a single person becomes 95% solved. [Iteration 6: You (misspelled) (several) (words). Please spellcheck your work next time. I also notice a few grammatical mistakes. Overall your writing style is a bit too phony. You do make some good (points), but they got lost amidst the (writing). (Signature)]
Allowing people to collaborate in productive ways is the power of crowd algorithms and interactive pipelines. Her research into crowdsourcing and computational design has already earned her a Facebook Fellowship and a Brown Institute Grant. This year, she was named to the inaugural class of the ACM Future of Computing Academy.
At Columbia, she will continue applying interactive pipelines and computational design to new domains: authoring compelling arguments for ideas, finding ways to integrate existing knowledge of health and nutrition into people’s existing habits and routines, and creating humor, a known, very hard problem for computers because of the large amount of implicit communication and emotional impact.
“Although humor is valuable as a source of entertainment and clever observations about the world, humor is also a great problem to study because it is a microcosm of the fundamental process of creating novel and useful things. If we can figure out the mechanics of humor, and orchestrate it in an interactive pipeline, we would be even further towards the grand vision of computational design that could be applied to any domain.”
Humor is also a realm where human intelligence is still necessary. Computers lack the contextual clues and real world knowledge that enable people to know intuitively that a joke insulting McDonald’s or Justin Bieber is funny but one that insults refugees or clean air is not. As she did for visual metaphors, Chilton breaks down the humor creation process into microtasks that are distributed to humans and machines. This pipeline, HumorTools, was created to compete with The Onion. It generated two of the responses to the liquid water headline. The Onion writers wrote the third.
“I pick creative problems that involve images (like visual metaphors) and text (like humor) because I think both are fundamental to the human problem-solving ability,” says Chilton. “Sometimes a picture says 1000 words, and sometimes words lay out logic in ways that might be deceiving in images. The department here is strong in graphics and in speech and language processing, and I look forward to collaborating with both groups to build tools that enhance people’s problem-solving abilities.”
One of the people she will collaborate with is Steven Feiner, who directs the Computer Graphics and User Interfaces Lab. “It’s important to extend people’s capabilities, augmenting them through computation expressed as visualization,” says Feiner. “Here, the hybrid approaches between humans and computers that Lydia is exploring are especially important because these are difficult problems that we do not yet know how to do algorithmically.”
Chilton’s first class, to be taught this spring, will be User Interface Design (W4170).
Voting results for headline Liquid Water Found on Mars.
To end his talk “Can we store all of world’s data on a pickup truck,” Erlich makes bold prediction that DNA storage could be cheaper than magnetic storage within a decade.
For major contributions to computer science education, theoretical understanding, and fostering of talent, Alfred Aho was awarded the NEC C&C Foundation C&C Prize.
A former student of Kathy McKeown and now an MIT professor, Barzilay developed novel solutions for multi-document summarization along with new algorithms for identifying paraphrases. Her work was integrated as part of Columbia’s Newsblaster system.
With the national average slightly below 20%, Columbia’s relatively high percentage of women CS majors in the 2016-2017 academic year ranks it among the top US universities in attracting women to computer science.
The Defense Advanced Research Projects Agency (DARPA) has awarded Yaniv Erlich a Young Faculty Award. The award, which identifies rising research stars in US academic institutions and introduces them to topics and issues of interest to the Department of Defense, will support Erlich’s work on DNA storage technology.
An Assistant Professor of Computer Science and Computational Biology at Columbia University and a Core Member at the New York Genome Center, Erlich does research in many facets of computational human genetics. His lab works on a wide range of topics including developing compressed sensing approach to identify rare genetic variations, devising new algorithms for personal genomics, and using Web 2.0 information for genetic studies.
The award, which is for $1M, is in response to Erlich’s proposal “Resistant and Scalable Storage Using Semi-synthetic DNA,” which describes the use of an extended genetic alphabet to create DNA storage technology that is both immune to a broad range of interception methods and also boosts the information density of DNA storage. The proposal was submitted through Columbia’s Data Science Institute, of which Erlich is also an affiliate.
Erlich’s previous research has earned him several awards, including the Burroughs Wellcome Career Award (2013), Harold M. Weintraub award (2010), and the IEEE/ACM-CS HPC award (2008). In 2010, he was selected as one of Tomorrow’s PIs team of Genome Technology.
Erlich holds B.Sc. in computational neuroscience from Tel-Aviv University and his Ph.D. in genomics and bioinformatics from Watson School of Biological Sciences, Cold Spring Harbor Laboratory in New York.
In February of this year, Erlich was named Chief Science Officer of MyHeritage Ltd.
“Travel in Large-Scale Head-Worn VR” teleports users through virtual environments by allowing them to determine orientation in advance. Another project from Feiner’s lab, “Remote Collaboration in AR and VR Using Virtual Replicas” won a third place finish.
The number of computer science majors at Columbia is expected to increase yet again this year, driven in part by the exploding interest in machine learning. Among the 10 MS tracks, machine learning is by far the most popular, selected by 60% of the department’s master’s students (vs 12% for the second most popular).
According to Nakul Verma, who joins the department this semester as lecturer in discipline, this interest in machine learning is not likely to abate any time soon. “Machine learning is growing in popularity because it has so much applicability for fields outside computer science. Every application domain is incorporating machine learning techniques, and every traditional model is being challenged by the advent of big data.”
As a PhD student at UC San Diego, Verma gravitated toward machine learning’s theory side, what he sees as fruitful territory. “I love to learn new things, and machine learning theory has this ability to borrow ideas from other fields—mathematics, statistics, and even neuroscience. Borrowing ideas will continually grow machine learning as a field and it makes the field especially dynamic.”
Verma does his borrowing from differential geometry in mathematics, a field he had not previously studied in depth. But as machine learning shifts from strictly linear models to include nonlinear ones, new methods are needed to analyze and leverage intrinsic structure in data.
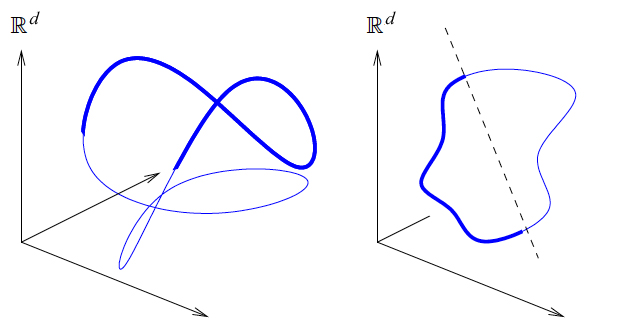
As examples of nonlinear data sets, Verma cites speech and articulations of robot motions, where data sets are high dimensional, containing many, many observations, each one associated with a potentially high number of features. However, relationships between data points may be fixed in some way so that a change in one causes a predictable change in another, giving the data an intrinsic structure. A robot might focus on key points in a gesture, analyzing how fingers move in relation to one another or to the wrist or arm. These movements are restricted along certain degrees of freedom—by joints, by the positioning of other fingers—suggesting the intrinsic structure of the data is in fact low-dimensional and that the xyz points of these joints form a manifold, or curved surface, in space.
Compressing a manifold surface into lower dimensions while retaining geospatial relationships among data points.
For a way to compress a manifold surface into lower dimensions without collapsing the underlying intrinsic structure, Verma looked to John Nash’s process for embedding manifolds, learning the math—or getting used to it—enough to understand how it could be applied to machine learning. Where Nash worked in terms of equations, Verma is working with actual data so the problem, laid out in Verma’s thesis and other papers by him, is to derive an algorithm from Nash’s technique, one that would work on today’s data sets.
While Verma’s thesis was highly theoretical, it had almost immediate practical applications. For four years at Janelia Research Campus HHMI, Verma helped geneticists and neuroscientists understand how genetics affects the brain to cause different behaviors. Working with fruit flies and other model organisms, researchers would modify certain genes thought to control aggression, social interactions, mating, and other behaviors and then record the organisms’ activity. The scale of data—from the thousands of modifications to the recorded video and audio imagery along with the neuronal recordings—was immense. Verma’s job was to tease out from the pile of data the small threads of how one change affects another, to pinpoint the relationships between the genetic modifications to the brain and the observed behavior. Verma’s work on manifolds and understanding intrinsic structure in data was crucial in developing practical yet statistically sound biological models.
Theory and application go hand in hand in machine learning, and the classes Verma will be teaching will contain a good dose of both, with the exact mix calibrated differently for grads vs undergrads. In either case, Verma sees a solid foundation on basic principles as necessary for understanding how a model is set up or why a certain framework is better than another. “The practical applications help reinforce the theory side of things. Teaching random forests should explain the basic theory but show also how it’s used in the real world. It’s not just some bookish knowledge; it’s one way Amazon and other companies reduce fraud.” Verma talks from experience, having worked at Amazon before going to Janelia.
But teaching has always been his ultimate goal. While at Janelia, Verma was awarded Teaching Fellowship, and last summer taught at Columbia as an adjunct. Says Verma, “Helping students achieve their goals and sharing their excitement for the subject is one of the most rewarding experiences of my academic career.”
In this interview, Adrian Tang describes how the CLKSCREW attack exploits the design of energy management systems to breach hardware security mechanisms.
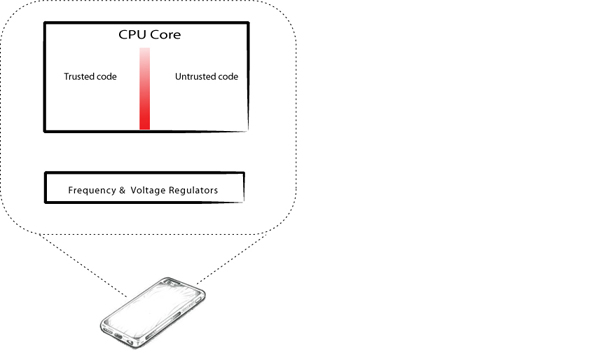
Security on smart phones is maintained by isolating sensitive data such as cryptographic keys in zones that can’t be accessed by non-authorized systems, apps, and other components running on the device. This hardware-imposed security establishes a high barrier and presumes any attacker would have to gain physical access to the device and modify the behavior of the phone using physical attacks typically involving soldering and complex equipment, all without damaging the phone.
Now three Columbia researchers have found they can bypass the hardware-imposed isolation without resorting to such hardware attacks. They do so by leveraging the energy management system, which conserves battery power on small devices loaded with systems and apps. Ubiquitous because they keep power consumption low, energy management systems work by carefully regulating voltage levels across the device, adjusting upward for an active component, adjusting downward otherwise. Knowing which components are idle and which are active requires accessing every component on the device to know its status, no matter what zone a component occupies.
The researchers exploited this design feature to create a new type of fault attack, CLKSCREW. Using this attack, they were able to infer cryptographic keys and upload their own unauthorized code to a phone without having physical access to the device. In experiments, researchers ran their attacks against the ARMv7 architecture on a Nexus 6 smartphone, but the attack would likely succeed on other similar devices since the need to conserve energy consumption is universal on devices. The paper describing the attack, “CLKSCREW: Exposing the Perils of Security-Oblivious Energy Management,” was named most distinguished paper at last month’s USENIX Security Symposium.
In this interview, lead author Adrian Tang describes the genesis of the idea for CLKSCREW and the engineering effort required to implement it.
What made you think energy management systems might have important security flaws?
We asked ourselves what technologies are ubiquitous, are so complex that any vulnerability would be hard to spot, but are nevertheless little studied from a security perspective. Energy management filled all the checkboxes. It seemed like an area ripe for exploitation, especially considering that devices are made up of many different components, all designed by different people. And in manufacturers’ relentless pursuit of smaller, faster, and more energy-efficient devices, security unfortunately is bound to be relegated to the backburner during the design of these devices.
When we looked further, we saw that the energy management features, to be effective, have their reach to almost everything running on a device. Normally, sensitive data on a device is protected through a hardware design that isolates execution environments, so if you have lower-level privileges, you can’t touch the higher-privileged stuff. It’s like a safe; non-authorized folks outside the safe can’t see or touch what’s inside.
But the hardware voltage and frequency regulators—which are part of the energy management system—do work across what’s inside and what’s outside this safe, and are thus able to affect the environment within the safe from the outside. With the right conditions, this has serious implications on the integrity of the crypto strength protecting the box.
The unfortunate kicker is that software controls these regulators. If software can affect aspects of the underlying hardware, that gives us a way into the processors without having to have physical access.
Energy management as attack vector. The regulators that adjust frequency and voltage operate across both trusted and untrusted zones.
How does the CLKSCREW attack work?
It’s a type of fault attack that pushes the regulators to operate outside the suggested operating parameters, which are published and publicly available. This destabilizes the system so it doesn’t operate correctly and doesn’t follow its normal checks, like requiring digital signatures to verify that code is trusted. So we were able to break cryptography to infer secret keys and even bypass cryptographic checks to load our own self-signed code into the trusted environment, tricking the system into thinking our code was coming from a trusted company, in this case, us.
A fault attack is a known type of attack that’s been around awhile. However, fault attacks typically require physical access to the device to bypass the hardware isolation. Our attack does not require physical access because we can use software to abuse the energy management mechanisms to control parts of the system where we are not supposed to be allowed to. The assumption is of course we need to have already gained software access to the device. To achieve that, an attacker can get the device owner to download a virus, maybe by clicking an email attachment or downloading a malware-laden app.
Why the name CLKSCREW?
This name is an oblique reference to the operating feature on the device we are exploiting – the clock. All digital circuits require a common clock signal to coordinate their functions. The faster the clock operates, the higher the operating frequency and thus the faster your device runs. When you increase the frequency, more operations need to take place over the same time period, so of course that also reduces the amount of time allowed for an operation. CLKSCREW over-stretches the frequency to the extent that operations cannot complete in time. Unexpected operations happen and the system becomes unstable, providing an avenue for an attacker to breach the security of the device.
How difficult was it to create this attack?
Quite difficult. Because energy management features do not exist in just one layer of the computing stack, we had to do a deep dive into every single stack layer to figure out the different ways software in the upper layers can influence the hardware on lower layers. We looked at the drivers, and the applications above them and the hardware below them, studying the physical aspects of the software, and the different parameters in each case. Furthermore, pulling this attack off requires knowledge from many disciplines: electrical engineering, computer science, computer engineering, and cryptography.
Were your surprised your attack worked as well as it did?
Yes. While we were somewhat surprised there were no limits on the hardware regulators, we were more flabbergasted at the fact that the regulators operate across sensitive compartments without any security controls. While these measures ensure energy management work as fast as possible—keeping users happy—security takes a back seat.
Can someone take the attack as you describe it in your paper and carry out their own attack?
Maybe with some work; however, I intentionally left out some key details of the attacks, such as the parameter values we use to time the attacks.
As part of responsible disclosure in this line of attack work, we contacted the vendors of the devices before publishing, and they were very receptive, acknowledging the seriousness of the problem, which they were able to reproduce. They are in the process of working on mitigations for existing devices, as well as future ones. It is not an easy problem to fix. Any potential fixes may involve changes to multiple layers in the stack.
We hope the paper will convince the industry as well as academia to not neglect security while designing all parts of the systems. If history is any indication, any component in the computing stack is fair game for a determined attacker. Energy management features, as we have shown in this work, are certainly no exception.
Adrian Tang is a fifth-year PhD student advised by Simha Sethumadhavan and Salvatore Stolfo. He expects to defend his thesis on rethinking security issues occurring at software-hardware interfaces later this year.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor