
A Linguist of Algorithms
Celebrated by ACL with a Lifetime Achievement Award, Kathleen McKeown continues to drive bold, cross-disciplinary research that redefines the field of natural language processing.
Celebrated by ACL with a Lifetime Achievement Award, Kathleen McKeown continues to drive bold, cross-disciplinary research that redefines the field of natural language processing.
A driving force in the field of natural language processing, Kathleen McKeown will receive this year’s Faculty Mentoring Award bestowed at University Commencement.
Columbia University is the first academic institution to partner with Richtech Robotics Inc. in its Richtech Accelerator Program, an initiative to advance localized AI and robotics research at U.S. universities.

Columbia Engineering’s Zhou Yu, associate professor of computer science, will lead research on Natural Language Processing (NLP) and using localized NLP models within robotic systems, empowering robots to comprehend and perform tasks through NLP instead of relying on engineers to program each function. This integration allows robots to use AI tailored to their specific settings, improving their ability to understand and respond to human interactions or environmental factors more effectively.
The program’s primary objective is to enable manufacturing, healthcare, and the service sector industries to leverage AI-driven robotic solutions, enhancing efficiency and mitigating labor shortages. Learn more about the accelerator program here.
CS researchers presented their work at the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024), showcasing research across natural language processing. Held from November 12-16 in Miami, this event includes diverse sessions covering topics from core NLP advancements to innovative applications. The accepted papers promise insights into cutting-edge techniques, inviting academics, practitioners, and enthusiasts to explore the latest in language processing research.
STORYSUMM: Evaluating Faithfulness in Story Summarization
Melanie Subbiah Columbia University, Faisal Ladhak Answer.AI, Akankshya Mishra Columbia University, Griffin Thomas Adams Answer.AI, Lydia Chilton Columbia University, Kathleen McKeown Columbia University
Abstract:
Human evaluation has been the gold standard for checking faithfulness in abstractive summarization. However, with a challenging source domain like narrative, multiple annotators can agree a summary is faithful, while missing details that are obvious errors only once pointed out. We therefore introduce a new dataset, StorySumm, comprising LLM summaries of short stories with localized faithfulness labels and error explanations. This benchmark is for evaluation methods, testing whether a given method can detect challenging inconsistencies. Using this dataset, we first show that any one human annotation protocol is likely to miss inconsistencies, and we advocate for pursuing a range of methods when establishing ground truth for a summarization dataset. We finally test recent automatic metrics and find that none of them achieve more than 70% balanced accuracy on this task, demonstrating that it is a challenging benchmark for future work in faithfulness evaluation.
MASIVE: Open-Ended Affective State Identification in English and Spanish
Nicholas Deas Columbia University, Elsbeth Turcan Columbia University, Ivan Ernesto Perez Mejia Columbia University, Kathleen McKeown Columbia University
Abstract:
In the field of emotion analysis, much NLP research focuses on identifying a limited number of discrete emotion categories, often applied across languages. These basic sets, however, are rarely designed with textual data in mind, and culture, language, and dialect can influence how particular emotions are interpreted. In this work, we broaden our scope to a practically unbounded set of affective states, which includes any terms that humans use to describe their experiences of feeling. We collect and publish MASIVE, a dataset of Reddit posts in English and Spanish containing over 1,000 unique affective states each. We then define the new problem of affective state identification for language generation models framed as a masked span prediction task. On this task, we find that smaller finetuned multilingual models outperform much larger LLMs, even on region-specific Spanish affective states. Additionally, we show that pretraining on MASIVE improves model performance on existing emotion benchmarks. Finally, through machine translation experiments, we find that native speaker-written data is vital to good performance on this task.
EmoKnob: Enhance Voice Cloning with Fine-Grained Emotion Control
Haozhe Chen Columbia University, Run Chen Columbia University, Julia Hirschberg Columbia University
Abstract:
While recent advances in Text-to-Speech (TTS) technology produce natural and expressive speech, they lack the option for users to select emotion and control intensity. We propose EmoKnob, a framework that allows fine-grained emotion control in speech synthesis with few-shot demonstrative samples of arbitrary emotion. Our framework leverages the expressive speaker representation space made possible by recent advances in foundation voice cloning models. Based on the few-shot capability of our emotion control framework, we propose two methods to apply emotion control on emotions described by open-ended text, enabling an intuitive interface for controlling a diverse array of nuanced emotions. To facilitate a more systematic emotional speech synthesis field, we introduce a set of evaluation metrics designed to rigorously assess the faithfulness and recognizability of emotion control frameworks. Through objective and subjective evaluations, we show that our emotion control framework effectively embeds emotions into speech and surpasses emotion expressiveness of commercial TTS services.
Enhancing Pre-Trained Generative Language Models with Question Attended Span Extraction on Machine Reading Comprehension
Lin Ai Columbia University, Zheng Hui Columbia University, Zizhou Liu Columbia University, Julia Hirschberg Columbia University
Abstract:
Machine Reading Comprehension (MRC) poses a significant challenge in the field of Natural Language Processing (NLP). While mainstream MRC methods predominantly leverage extractive strategies using encoder-only models such as BERT, generative approaches face the issue of out-of-control generation – a critical problem where answers generated are often incorrect, irrelevant, or unfaithful to the source text. To address these limitations in generative models for extractive MRC, we introduce the Question-Attended Span Extraction (QASE) module. Integrated during the finetuning phase of pre-trained generative language models (PLMs), QASE significantly enhances their performance, allowing them to surpass the extractive capabilities of advanced Large Language Models (LLMs) such as GPT-4 in few-shot settings. Notably, these gains in performance do not come with an increase in computational demands. The efficacy of the QASE module has been rigorously tested across various datasets, consistently achieving or even surpassing state-of-the-art (SOTA) results, thereby bridging the gap between generative and extractive models in extractive MRC tasks. Our code is available at this GitHub repository.
Defending Against Social Engineering Attacks in the Age of LLMs
Lin Ai Columbia University, Tharindu Sandaruwan Kumarage Arizona State University, Amrita Bhattacharjee Arizona State University, Zizhou Liu Columbia University, Zheng Hui Columbia University, Michael S. Davinroy Aptima, Inc., James Cook Aptima, Inc., Laura Cassani Aptima, Inc., Kirill Trapeznikov STR, Matthias Kirchner Kitware, Inc., Arslan Basharat Kirchner Kitware, Inc., Anthony Hoogs Kirchner Kitware, Inc., Joshua Garland Arizona State University, Huan Liu Arizona State University, Julia Hirschberg Columbia University
Abstract:
The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrievalaugmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity. Our code and data are available at this GitHub repository.
LIONs: An Empirically Optimized Approach to Align Language Models
Xiao Yu Columbia University, Qingyang Wu Columbia University, Yu Li Columbia University, Zhou Yu Columbia University
Abstract:
Alignment is a crucial step to enhance the instruction-following and conversational abilities of language models. Despite many recent works proposing new algorithms, datasets, and training pipelines, there is a lack of comprehensive studies measuring the impact of various design choices throughout the whole training process. We first conduct a rigorous analysis over a three-stage training pipeline consisting of supervised fine-tuning, offline preference learning, and online preference learning. We have found that using techniques like sequence packing, loss masking in SFT, increasing the preference dataset size in DPO, and online DPO training can significantly improve the performance of language models. We then train from Gemma-2b-base and LLama-3-8b-base, and find that our best models exceed the performance of the official instruct models tuned with closed-source data and algorithms. Our code and models can be found at https://github.com/Columbia-NLP-Lab/LionAlignment.
DECOR: Improving Coherence in L2 English Writing with a Novel Benchmark for Incoherence Detection, Reasoning, and Rewriting
Xuanming Zhang Columbia University, Anthony Diaz University of California, Davis, Zixun Chen Columbia University, Qingyang Wu Columbia University, Kun Qian Columbia University, Erik Voss Columbia University, Zhou Yu Columbia University
Abstract:
Coherence in writing, an aspect that L2 English learners often struggle with, is crucial in assessing L2 English writing. Existing automated writing evaluation systems primarily use basic surface linguistic features to detect coherence in writing. However, little effort has been made to correct the detected incoherence, which could significantly benefit L2 language learners seeking to improve their writing. To bridge this gap, we introduce DECOR, a novel benchmark that includes expert annotations for detecting incoherence in L2 English writing, identifying the underlying reasons, and rewriting the incoherent sentences. To our knowledge, DECOR is the first coherence assessment dataset specifically designed for improving L2 English writing, featuring pairs of original incoherent sentences alongside their expert-rewritten counterparts. Additionally, we fine-tuned models to automatically detect and rewrite incoherence in student essays. We find that incorporating specific reasons for incoherence during fine-tuning consistently improves the quality of the rewrites, achieving a level that is favored in both automatic and human evaluations.
ACE: A LLM-based Negotiation Coaching System
Ryan Shea Columbia University, Aymen Kallala Columbia University, Xin Lucy Liu Columbia University, Michael W. Morris Columbia University, Zhou Yu Columbia University
Abstract:
The growing prominence of LLMs has led to an increase in the development of AI tutoring systems. These systems are crucial in providing underrepresented populations with improved access to valuable education. One important area of education that is unavailable to many learners is strategic bargaining related to negotiation. To address this, we develop a LLM-based Assistant for Coaching nEgotiation (ACE). ACE not only serves as a negotiation partner for users but also provides them with targeted feedback for improvement. To build our system, we collect a dataset of negotiation transcripts between MBA students. These transcripts come from trained negotiators and emulate realistic bargaining scenarios. We use the dataset, along with expert consultations, to design an annotation scheme for detecting negotiation mistakes. ACE employs this scheme to identify mistakes and provide targeted feedback to users. To test the effectiveness of ACE-generated feedback, we conducted a user experiment with two consecutive trials of negotiation and found that it improves negotiation performances significantly compared to a system that doesn’t provide feedback and one which uses an alternative method of providing feedback.
EDEN: Empathetic Dialogues for English Learning
Siyan Li Columbia University, Teresa Shao Columbia University, Zhou Yu Columbia University, Julia Hirschberg Columbia University
Abstract:
Dialogue systems have been used as conversation partners in English learning, but few have studied whether these systems improve learning outcomes. Student passion and perseverance, or grit, has been associated with language learning success. Recent work establishes that as students perceive their English teachers to be more supportive, their grit improves. Hypothesizing that the same pattern applies to English-teaching chatbots, we create EDEN, a robust open-domain chatbot for spoken conversation practice that provides empathetic feedback. To construct EDEN, we first train a specialized spoken utterance grammar correction model and a high-quality social chit-chat conversation model. We then conduct a preliminary user study with a variety of strategies for empathetic feedback. Our experiment suggests that using adaptive empathetic feedback leads to higher *perceived affective support*. Furthermore, elements of perceived affective support positively correlate with student grit.
A Fairness-Driven Method for Learning Human-Compatible Negotiation Strategies
Ryan Shea Columbia University, Zhou Yu Columbia University
Abstract:
Despite recent advancements in AI and NLP, negotiation remains a difficult domain for AI agents. Traditional game theoretic approaches that have worked well for two-player zero-sum games struggle in the context of negotiation due to their inability to learn human-compatible strategies. On the other hand, approaches that only use human data tend to be domain-specific and lack the theoretical guarantees provided by strategies grounded in game theory. Motivated by the notion of fairness as a criterion for optimality in general sum games, we propose a negotiation framework called FDHC which incorporates fairness into both the reward design and search to learn human-compatible negotiation strategies. Our method includes a novel, RL+search technique called LGM-Zero which leverages a pre-trained language model to retrieve human-compatible offers from large action spaces. Our results show that our method is able to achieve more egalitarian negotiation outcomes and improve negotiation quality.
TinyStyler: Efficient Few-Shot Text Style Transfer with Authorship Embeddings
Zachary Horvitz Columbia University, Ajay Patel University of Pennsylvania, Kanishk Singh Columbia University, Chris Callison-Burch University of Pennsylvania, Kathleen McKeown Columbia University, Zhou Yu Columbia University
Abstract
The goal of text style transfer is to transform the style of texts while preserving their original meaning, often with only a few examples of the target style. Existing style transfer methods generally rely on the few-shot capabilities of large language models or on complex controllable text generation approaches that are inefficient and underperform on fluency metrics. We introduce TinyStyler, a lightweight but effective approach, which leverages a small language model (800M params) and pre-trained authorship embeddings to perform efficient, few-shot text style transfer. We evaluate on the challenging task of authorship style transfer and find TinyStyler outperforms strong approaches such as GPT-4. We also evaluate TinyStyler’s ability to perform text attribute style transfer (formal ↔ informal) with automatic and human evaluations and find that the approach outperforms recent controllable text generation methods.
A PhD candidate who worked for OpenAI and Apple discusses natural language processing, AI hallucinations, and deep fakes.
The CS Department mourns the loss of Dragomir R. Radev, a 1999 computer science PhD graduate who unexpectedly passed away on March 29th in his home in New Haven, Connecticut. He was 54 years old and leaves behind his wife, Axinia, and children, Laura and Victoria.

Radev worked with Professor Kathleen McKeown on seminal multi-document text summarization research, the topic of his PhD dissertation. His first job after Columbia was at IBM TJ Watson Research in Hawthorne, New York, where he worked for a year as a Research Staff Member. Then he spent 16 years on the computer science faculty at the University of Michigan before joining Yale University in 2017 as the A. Bartlett Giamatti Professor of Computer Science and led the Language, Information, and Learning (LILY) Lab at Yale University.
His research and work were influential, from his widely cited paper on LexRank to his most recent papers providing datasets, benchmarks, and evaluation of metrics for text summarization. His wide-ranging research touched many areas beyond summarization. He worked on graph-based methods for natural language processing (NLP), question answering, interfaces to databases, and language generation.
Over his career, Radev received many honors, including Fellow of the Association for Computational Linguistics (2018), the American Association for the Advancement of Science (2020), the Association for Computing Machinery (2015), and the Association for the Advancement of Artificial Intelligence (2020). He served as the Secretary of ACL from 2006-2015 and was awarded the ACL Distinguished Service Award in 2022.
Radev co-founded the North American Computational Linguistics Open Competition, an annual competition in which high school students solve brain teasers about language. He organized the contest and traveled with top-ranked students to the International Linguistics Olympiad every year.
“Drago was a very special, incredible person who touched all of us with his energy, his love for NLP, and his kindness,” said Kathleen McKeown. “He touched so many people and has had a huge impact on the field and on the ACL, the primary organization for our field.”

Fundraising note: A small group of faculty members from Columbia University, Yale University, and the University of Michigan have joined forces to raise money and set up a GoFundMe to help the Radev family support Victoria, who has a disability. The fund will help Axinia and the family continue to provide Victoria with the care she needs. If you are interested in and capable of donating in any way, please consider giving to the fundraiser.
The field of natural language processing (NLP) has ramped up by leaps and bounds. This branch of artificial intelligence focuses on the ability of computers to understand and process language as humans do. It has been in the news these past few months because of a chatbot, ChatGPT, that can provide answers and data conversationally. The technology gives us a taste of just how powerful and useful NLP can be.
Tuhin Chakrabarty wants to see how much further he can push NLP in the field of computational creativity to see how computers can generate creative output. This is what ChatGPT had to say about computational creativity:
Computational creativity is a field that uses computational methods to simulate and enhance human-like creativity, producing valuable outputs such as art, music, stories, and scientific discoveries. It aims to understand and replicate the cognitive processes involved in human creativity, combining techniques from AI, cognitive psychology, and philosophy. Examples of computational creativity include generative art and music, game design, natural language processing, and scientific discovery. Ultimately, computational creativity seeks to leverage computers and algorithms to augment and extend human creativity, creating new possibilities for creative expression and innovation.

“Generating text beyond a few sentences was almost very difficult two years ago, but things look much better now. It is not perfect, but I am optimistic,” said Tuhin Chakrabarty, who first became interested in computational creativity in 2019. “One of the things that I am excited about is how better we can align models like ChatGPT to human expectations and different cultures.”
Instead of creating text conversationally, Chakrabarty’s research focuses on how AI can be used to create metaphors and detect sarcasm with little to no training data. The fifth-year PhD student advised by Smaranda Muresan has expanded his work to generating long narratives of 2,000-word documents and visual metaphors. We recently sat down with him to learn more about his research and the creative possibilities of NLP.
I did not have much research experience as an undergrad. I got accepted to the CS masters program and I was fortunate enough to take a class offered by my advisor Smaranda Muresan, which still happens to be one of my all-time favorite courses at Columbia. Computational models of Social Meaning was a graduate seminar course about impactful papers in NLP. Reading all the papers in that class made me think about what I want to do with NLP and how so many interesting research questions can be answered computationally by studying language. Alongside this, I was also working with my advisor and my friend Chris Hidey on extracting arguments from social media. That experience was really precious. The enthusiasm everyone shared in trying to solve the problem at hand made me sure of my decision to pursue research.
Around 2019, Nanyun Peng and He He, two very important researchers in the field of computational creativity, wrote a paper on generating puns. I happened to attend NAACL 2019 in Minneapolis, where the paper was presented. I thought the paper was beautiful in every possible way and it quantified the surprisal theory in humor algorithmically. This made me really fascinated about how we can use inductive biases to help machines generate creative output. For selfish reasons, I reached out to Nanyun Peng and told her that I wanted to work with her. She was very kind and agreed to mentor me. My PhD advisor Smaranda Muresan is one of the experts in the field of Figurative Language, which deals with creativity. So, of course, that influenced my decision to work in computational creativity too.
Computational creativity is a multidisciplinary endeavor located at the intersection of artificial intelligence, cognitive psychology, philosophy, and the arts. The goal of computational creativity is to model, simulate or replicate creativity using a computer to achieve one of several ends:
State-of-the-art models are often found to be inadequate for creative tasks. The principal reason for this is that in addition to composing grammatical and fluent sentences to articulate given content, these tasks usually require extensive world and common sense knowledge.
It should also be noted that current approaches to text generation require lots of training data for supervision. However, most existing corpus for creative forms of text is limited in size. Even if such a corpus existed, learning the distribution of existing data and sampling from it is unlikely to lead to truly novel, creative output.
So we have to rely on unsupervised or weakly supervised techniques to train an end-to-end model to interpret or generate creative text. Of course, with the advent of Large Language Models and few-shot learning, we can now prompt a model with a few examples of creative text and it can somewhat generalize (but not as well as humans). My dissertation deals with a lot of this.
Over the past several years, a key focus for NYTimes Research and Development has understood how advances in machine learning can extend the capabilities of journalists and unlock reader experiences that aren’t possible today. Questions and answers are central to how humans learn. Times journalism frequently uses FAQ and Q&A-style articles to help readers understand complex topics like the Covid-19 vaccines. To enhance this style of journalism, we experimented with large language models to match questions to answers, even if the reader asks their question in a novel way.
Last year we launched a new research effort to explore generating open-ended questions for news articles. Our hypothesis is that understanding the questions our news articles are implicitly answering may be helpful in the reporting process and may ultimately enable us to create FAQ and Q&A-style articles more efficiently.
You can find more information here: https://rd.nytimes.com/projects/generating-open-ended-questions-from-news-articles
This was fundamentally different from what I have been doing because I had to work towards upholding journalism values such as accuracy and verifiability. In creativity, your model can generate something that does not require attribution. But, when working on a project that deals with news and journalism, the focus is on factuality.
Recent work on question generation has primarily focused on factoid questions such as who, what, where, and when about basic facts. Generating open-ended why, how, what, etc., questions that require long-form answers has proven more difficult. To facilitate the generation of open-ended questions, we propose CONSISTENT, a new end-to-end system for generating open-ended questions that are answerable from and faithful to the input text. Using news articles as a trustworthy foundation for experimentation, we demonstrate our model’s strength over several baselines using both automatic and human-based evaluations. We contribute an evaluation dataset of expert-generated open-ended questions and discuss potential downstream applications for news media organizations.

Much of my recent and upcoming work is on human-AI collaboration for creativity. I recently worked on developing methods and evaluation frameworks for two creative tasks–poetry generation and visual metaphor generation–by leveraging collaboration between expert humans and state-of-the-art generative models. I further highlighted how collaboration improves the final output over either standalone models or only humans.
I have long focused on developing and evaluating machine learning models aimed at creativity in an isolated setting. This somehow limits their capacity to behave in an interactive setting with real humans. In a creative setting, it is crucial for models to understand human needs and provide assistance to augment human capabilities and improve performance based on human edits or feedback over time. So that is my focus now.
This is a difficult question. Pursuing a PhD can be a really fun experience, but at the same time, it can be daunting. There is a lot of uncertainty around research questions and whether something will work or not. I wish I had been a little easier on myself and not taken everything personally. Like, if an idea didn’t work, instead of spending months trying to make it work, it is okay to give up and move in a different direction.
One of the things I learned during my PhD is to focus on what you care about. There are hundreds of researchers who might work on slightly dense areas, while your work can feel niche. This is not a problem. When I started working on NLP and creativity, the field still felt very young, but over the past three to four years, it has grown tremendously.
Your advisor will be one of the most important people in your PhD. It is essential to have good communication and working chemistry with them. One of the reasons my PhD felt like so much fun is because my advisor and I cared about the same problems.
Form a community and foster friendships with your lab mates, talk about research, or email a colleague whose work moved you and get a coffee with them at a conference. Also, try for opportunities to work with people in your lab or your community. It helps us learn so much.
Influential computer scientist Kathy McKeown heads up two multi-million dollar grants—one to analyze cross-cultural norms and another to better understand grief in the Black community.
Giannis Karamanolakis, a natural language processing and machine learning PhD student, talks about his research projects and how he is developing machine learning techniques for natural language processing applications.

Can you talk about your background and why you decided to pursue a PhD?
I used to live in Greece and grew up in Sitia, a small town in Crete. In 2011, I left my hometown to study electrical and computer engineering at the National Technical University of Athens (NTUA).
At NTUA, taking part in machine learning (ML) research was not planned but rather a spontaneous outcome stemming from my love for music. The initial goal for my undergraduate thesis was to build an automatic music transcription system that converts polyphonic raw audio into music sheets. However, after realizing that such a system would not be possible to develop in a limited amount of time, I worked on the simpler task of automatically tagging audio clips with descriptive tags (e.g., “car horn” for audio clips where a car horn is sound). Right after submitting a new algorithm as a conference paper, I realized that I love doing ML research.
After NTUA, I spent one and a half years working as an ML engineer at a startup called Behavioral Signals, where we trained statistical models for the recognition of core emotions from speech and text data. After a few months of ML engineering, I found myself spending more time reading research papers and evaluating new research ideas on ML and natural language processing (NLP). By then, I was confident about my decision to pursue a PhD in ML/NLP.
What about NLP did you like and when did you realize that you wanted to do research on it?
I am fascinated by the ability of humans to understand complex natural language. At the moment of writing this response, I submitted the following 10-word query to Google: “when did you realize that you wanted to do research” by keeping quotation marks so that Google looks for exact matches only. Can you guess the number of the documents returned by Google that contain this exact sequence of 10 words?
The answer that I got was 0 (zero) documents, no results! In other words, Google, a company with huge collections of documents, did not detect any document that contains this specific sequence of words. Sentences rarely recur but humans easily understand the semantics of such rare sentences.
I decided to do research on NLP when I realized that current NLP algorithms are far away from human-level language understanding. As an example back from my time at Behavioral Signals, emotion classifiers were misclassifying sentences that contained sarcasm, negation, and other complex linguistic phenomena. I could not directly fix those issues (which are prevalent beyond emotion classification), which initially felt both surprising and frustrating, but then evolved into my excitement for research on NLP.
Why did you apply to Columbia and how was that process?
The computer science department at Columbia was one of my top choices for several reasons, but I will discuss the first one.
I was excited to learn about the joint collaboration between Columbia University and the New York City Department of Health and Mental Hygiene (DOHMH), on a project that aims to understand user-generated textual content in social media (e.g., Yelp reviews, tweets) for critical public health applications, such as detecting and acting on foodborne illness outbreaks in restaurants. I could see that the project would offer the unique opportunity to do research in ML and NLP and at the same time contribute to this important public application in collaboration with epidemiologists at DOHMH. Fortunately, I have been able to work on the project, advised by Professor Luis Gravano and Associate Professor Daniel Hsu.
Applying to Columbia and other American universities was quite a stressful experience. For many months, my days were filled with working for Behavioral Signals, studying hard for high scores in GRE and TOEFL exams (both of which were required at that time by all US universities), creating a short CV for the first time, and writing a distinct statement-of-purpose for each university. I am glad to observe the recent promising changes in the PhD application procedure for our department, such as waiving the GRE requirements and offering the Pre-submission Application Review (PAR) program, in which current PhD students help applicants improve their applications. (Both of which I would have liked to have been able to take advantage of.)
What sort of research questions or issues do you hope to answer?
My research in the past few years focuses on the following question: Can we effectively train ML classifiers for NLP applications with limited training data using alternative forms of human supervision?
An important limitation of current “supervised ML” techniques is that they require large amounts of training data, which is expensive and time-consuming to obtain manually. Thus, while supervised ML techniques (especially deep neural networks) thrive in standard benchmarks, it would be too expensive to apply to emerging real-world applications with limited labeled data.
Our work attempts to address the expensive requirement of manually labeled data through novel frameworks that leverage alternative, less expensive forms of human supervision. In sentiment classification, for example, we allow domain experts to provide a small set of domain-specific rules (e.g., “happy” keyword indicates positive sentiment, “diarrhea” is a symptom of food poisoning). Under low-resource settings with no labeled data, can we leverage expert-defined rules as supervision for training state-of-the-art neural networks?
For your research papers, how did you decide to do research on those topics? How long did it take you to complete the work? Was it easy?
For my first research project at Columbia, my goal was to help epidemiologists in health departments with daily inspections of restaurant reviews that discuss food poisoning events. Restaurant reviews can be quite long, with many irrelevant sentences surrounding the truly important ones that discuss food poisoning or relevant symptoms. Thus, we developed a neural network that highlights only important sentences in potentially long reviews and deployed it for inspections in health departments, where epidemiologists could quickly focus on the relevant sentences and safely ignore the rest.
The goal behind my next research projects was to develop frameworks for addressing a broader range of text-mining tasks, such as sentiment analysis and news document classification, and for supporting multiple languages without expensive labeled data for each language. To address this goal, we initially proposed a framework for leveraging just a few domain-specific keywords as supervision for aspect detection and later extended our framework for training classifiers across 18 languages using minimal resources.
Each project took about 6 months to complete. None of them were easy; each required substantial effort in reading relevant papers, discussing potential solutions with my advisors, implementing executable code, evaluating hypotheses on real data, and repeating the same process until we were all satisfied with the solutions and evaluation results. The projects also involved meeting with epidemiologists at DOHMH, re-designing our system to satisfy several (strict) data transfer protocols imposed by health departments, and overcoming several issues related to missing data for training ML classifiers.
Your advisors are not part of the NLP group, how has that worked out for you and your projects?
It has worked great in my humble opinion. For the public health project, the expertise of Professor Gravano on information extraction, combined with the expertise of Professor Hsu on machine learning, and the technical needs of the project have contributed without any doubt to the current formulation of our NLP-related frameworks. My advisors’ feedback covers a broad spectrum of research, ranging from core technical challenges to more general research practices, such as problem formulation and paper writing.
Among others, I appreciate the freedom I have been given for exploring new interesting research questions as well as the frequent and insightful feedback that helps me to reframe questions and forming solutions. At the same time, discussions with members of the NLP group, including professors and students, have been invaluable and have clearly influenced our projects.
What do you think is the most interesting thing about doing research?
I think it is the high amount of surprise it encompasses. For many research problems that I have tried to tackle, I started by shaping an initial solution in my mind but in the process discovered surprising findings that undoubtedly changed my way of thinking – such as that my initial solution did not actually work, simpler approaches worked better than more sophisticated approaches, data followed unexpected patterns, etc. These instances of surprise turned research into an interesting experience, similar to solving riddles or listening to jazz music.
Please talk about your internships – the work you did, how was it, what did you learn?
In the summer of 2019, I worked at Amazon’s headquarters in Seattle with a team of more than 15 scientists and engineers. Our goal was to automatically extract and store knowledge about billions of products in a product knowledge graph. As part of my internship, we developed TXtract, a deep neural network that efficiently extracts information from product descriptions for thousands of product categories. TXtract has been a core component of Amazon’s AutoKnow, which provides the collected knowledge for Amazon search and product detail pages.
During the summer of 2020, I worked for Microsoft Research remotely from New York City (because of the pandemic). In collaboration with researchers at the Language and Information Technologies team, we developed a weak supervision framework that enables domain experts to express their knowledge in the form of rules and further integrates rules for training deep neural networks.
These two internships equipped me with invaluable experiences. I learned new coding tools, ML techniques, and research practices. Through the collaboration with different teams, I realized that even researchers who work on the same subfield may think in incredibly different ways, so to carry out a successful collaboration within a limited time, one needs to listen carefully, pre-define expected outcomes (with everyone in the team), and adapt fast.
Do you think your skills were improved by your time at Columbia? In which ways?
Besides having improved my problem-finding and -solving skills, I have expanded my presentation capabilities. In the beginning, I was frustrated when other people (even experienced researchers) could not follow my presentations and I was worried when I could not follow other presenters’ work. Later, I realized that if (at least part of) the audience is not able to follow a presentation, then the presentation is either flawed or has been designed for the wrong audience.
Over the past four years, I have presented my work at various academic conferences and workshops, symposiums at companies, and student seminars, and after having received constructive feedback from other researchers, I can say that my presentation skills have vastly improved. Without any doubt, I feel more confident and can explain my work to a broader type of audience with diverse expertise. That said, I’m still struggling to explain my PhD topic to my family. 🙂

What has been the highlight of your time at Columbia?
The first thing that comes to mind is the “Greek Happy Hour” that I co-organized in October 2019. More than 40 PhD students joined the happy hour, listened to Greek music (mostly “rempetika”), tasted greek specialties (including spanakopita), and all toasted loudly by saying “Γειά μας” (ya mas; the greek version of “cheers”).
Was there anything that was tough to handle while taking your PhD?

It is hard to work from home during a pandemic. A core part of my PhD used to involve multi-person collaborations, drawing illustrations on the whiteboards of the Data Science Institute, random chats in hallways, happy hours, and other social events. All these have been harder or impossible to retain during the pandemic. I miss it and look forward to enjoying it again soon.
Looking back, what would you have done differently?
If I could, I would have engaged in more discussions and collaborations, taken more classes, played more music, and slept less. 🙂
What is your advice to students on how to navigate their time at Columbia? If they want to do NLP research what should they know or do to prepare?
They should register for diverse courses; Columbia offers the opportunity to attend courses from multiple departments. They should reach out to as many people as possible and do not hesitate to email graduate students and professors. I love receiving emails from people that I haven’t met before, some of which stimulated creative collaborations.
For those that want to do NLP research (which I highly recommend–subjectively speaking), you should contact me or any person in the NLP group.
What are your plans after Columbia?
I plan to continue working on research, either as a faculty member or in an industry research and development department.
Is there anything else that you think people should know?
Columbia offers free and discounted tickets to museums and performances around New York City, even virtual art events. I personally consider New York as the “state-of-the-art”.
Research from the department has been accepted to the Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021).
Below are the abstracts and links to the accepted papers.
COVID-Fact: Fact Extraction and Verification of Real-World Claims on COVID-19 Pandemic
Arkadiy Saakyan, Tuhin Chakrabarty, and Smaranda Muresan
We introduce a FEVER-like dataset COVID-Fact of 4,086 claims concerning the COVID-19 pandemic. The dataset contains claims, evidence for the claims, and contradictory claims refuted by the evidence. Unlike previous approaches, we automatically detect true claims and their source articles and then generate counter-claims using automatic methods rather than employing human annotators. Along with our constructed resource, we formally present the task of identifying relevant evidence for the claims and verifying whether the evidence refutes or supports a given claim. In addition to scientific claims, our data contains simplified general claims from media sources, making it better suited for detecting general misinformation regarding COVID-19. Our experiments indicate that COVID-Fact will provide a challenging testbed for the development of new systems and our approach will reduce the costs of building domain-specific datasets for detecting misinformation.
Metaphor Generation with Conceptual Mappings
Kevin Stowe, Tuhin Chakrabarty, Nanyun Peng, Smaranda Muresan, and Iryna Gurevych
Generating metaphors is a difficult task as it requires understanding nuanced relationships between abstract concepts. In this paper, we aim to generate a metaphoric sentence given a literal expression by replacing relevant verbs. Guided by conceptual metaphor theory, we propose to control the generation process by encoding conceptual mappings between cognitive domains to generate meaningful metaphoric expressions. To achieve this, we develop two methods: 1) using FrameNet-based embeddings to learn mappings between domains and applying them at the lexical level (CM-Lex), and 2) deriving source/target pairs to train a controlled seq-to-seq generation model (CM-BART). We assess our methods through automatic and human evaluation for basic metaphoricity and conceptual metaphor presence. We show that the unsupervised CM-Lex model is competitive with recent deep learning metaphor generation systems, and CM-BART outperforms all other models both in automatic and human evaluations.
Weakly-Supervised Methods for Suicide Risk Assessment: Role of Related Domains
Chenghao Yang, Yudong Zhang, and Smaranda Muresan
Social media has become a valuable resource for the study of suicidal ideation and the assessment of suicide risk. Among social media platforms, Reddit has emerged as the most promising one due to its anonymity and its focus on topic-based communities (subreddits) that can be indicative of someone’s state of mind or interest regarding mental health disorders such as r/SuicideWatch, r/Anxiety, r/depression. A challenge for previous work on suicide risk assessment has been the small amount of labeled data. We propose an empirical investigation into several classes of weakly-supervised approaches, and show that using pseudo-labeling based on related issues around mental health (e.g., anxiety, depression) helps improve model performance for suicide risk assessment.
Improving Factual Consistency of Abstractive Summarization via Question Answering
Feng Nan, Cicero Nogueira Dos Santos, Henghui Zhu, Patrick Ng, Kathleen McKeown, Ramesh Nallapati, Dejiao Zhang, Zhiguo Wang, Andrew O. Arnold, and Bing Xiang
A commonly observed problem with the state-of-the art abstractive summarization models is that the generated summaries can be factually inconsistent with the input documents. The fact that automatic summarization may produce plausible-sounding yet inaccurate summaries is a major concern that limits its wide application. In this paper we present an approach to address factual consistency in summarization. We first propose an efficient automatic evaluation metric to measure factual consistency; next, we propose a novel learning algorithm that maximizes the proposed metric during model training. Through extensive experiments, we confirm that our method is effective in improving factual consistency and even overall quality of the summaries, as judged by both automatic metrics and human evaluation.
InfoSurgeon: Cross-Media Fine-grained Information Consistency Checking for Fake News Detection
Yi Fung, Christopher Thomas, Revanth Gangi Reddy, Sandeep Polisetty, Heng Ji, Shih-Fu Chang, Kathleen McKeown, Mohit Bansal, and Avi Sil
To defend against neural system-generated fake news, an effective mechanism is urgently needed. We contribute a novel benchmark for fake news detection at the knowledge element level, as well as a solution for this task which incorporates cross-media consistency checking to detect the fine-grained knowledge elements making news articles misinformative. Due to training data scarcity, we also formulate a novel data synthesis method by manipulating knowledge elements within the knowledge graph to generate noisy training data with specific, hard to detect, known inconsistencies. Our detection approach outperforms the state-of-the-art (up to 16.8% absolute accuracy gain), and more critically, yields fine-grained explanations.
Cross-language Sentence Selection via Data Augmentation and Rationale Training
Yanda Chen, Chris Kedzie, Suraj Nair, Petra Galuscakova, Rui Zhang, Douglas Oard, and Kathleen McKeown
This paper proposes an approach to crosslanguage sentence selection in a low-resource setting. It uses data augmentation and negative sampling techniques on noisy parallel sentence data to directly learn a cross-lingual embedding-based query relevance model. Results show that this approach performs as well as or better than multiple state-of-theart machine translation + monolingual retrieval systems trained on the same parallel data. Moreover, when a rationale training secondary objective is applied to encourage the model to match word alignment hints from a phrase-based statistical machine translation model, consistent improvements are seen across three language pairs (EnglishSomali, English-Swahili and English-Tagalog) over a variety of state-of-the-art baselines.
SocAoG: Incremental Graph Parsing for Social Relation Inference in Dialogues
Liang Qiu, Yuan Liang, Yizhou Zhao, Pan Lu, Baolin Peng, Zhou Yu, Ying Nian Wu, and Song-Chun Zhu
Inferring social relations from dialogues is vital for building emotionally intelligent robots to interpret human language better and act accordingly. We model the social network as an And-or Graph, named SocAoG, for the consistency of relations among a group and leveraging attributes as inference cues. Moreover, we formulate a sequential structure prediction task, and propose an α–β–γ strategy to incrementally parse SocAoG for the dynamic inference upon any incoming utterance: (i) an α process predicting attributes and relations conditioned on the semantics of dialogues, (ii) a β process updating the social relations based on related attributes, and (iii) a γ process updating individual’s attributes based on interpersonal social relations. Empirical results on DialogRE and MovieGraph show that our model infers social relations more accurately than the state-of-the-art methods. Moreover, the ablation study shows the three processes complement each other, and the case study demonstrates the dynamic relational inference.
HERALD: An Annotation Efficient Method to Detect User Disengagement in Social Conversations
Weixin Liang, Kai-Hui Liang, and Zhou Yu
Open-domain dialog systems have a usercentric goal: to provide humans with an engaging conversation experience. User engagement is one of the most important metrics for evaluating open-domain dialog systems, and could also be used as real-time feedback to benefit dialog policy learning. Existing work on detecting user disengagement typically requires hand-labeling many dialog samples. We propose HERALD, an efficient annotation framework that reframes the training data annotation process as a denoising problem. Specifically, instead of manually labeling training samples, we first use a set of labeling heuristics to label training samples automatically. We then denoise the weakly labeled data using the Shapley algorithm. Finally, we use the denoised data to train a user engagement detector. Our experiments show that HERALD improves annotation efficiency significantly and achieves 86% user disengagement detection accuracy in two dialog corpora. Our implementation is available at https:// github.com/Weixin-Liang/HERALD/.
Towards Emotional Support Dialog Systems
Siyang Liu, Chujie Zheng, Orianna Demasi, Sahand Sabour, Yu Li, Zhou Yu, Yong Jiang, and Minlie Huang
Emotional support is a crucial ability for many conversation scenarios, including social interactions, mental health support, and customer service chats. Following reasonable procedures and using various support skills can help to effectively provide support. However, due to the lack of a well-designed task and corpora of effective emotional support conversations, research on building emotional support into dialog systems remains untouched. In this paper, we define the Emotional Support Conversation (ESC) task and propose an ESC Framework, which is grounded on the Helping Skills Theory (Hill, 2009). We construct an Emotion Support Conversation dataset (ESConv) with rich annotation (especially support strategy) in a help-seeker and supporter mode. To ensure a corpus of high-quality conversations that provide examples of effective emotional support, we take extensive effort to design training tutorials for supporters and several mechanisms for quality control during data collection. Finally, we evaluate state-of-the-art dialog models with respect to the ability to provide emotional support. Our results show the importance of support strategies in providing effective emotional support and the utility of ESConv in training more emotional support systems.
Discovering Dialogue Slots with Weak Supervision
Vojtch Hudeek, Ondej Dusek, and Zhou Yu
Task-oriented dialogue systems typically require manual annotation of dialogue slots in training data, which is costly to obtain. We propose a method that eliminates this requirement: We use weak supervision from existing linguistic annotation models to identify potential slot candidates, then automatically identify domain-relevant slots by using clustering algorithms. Furthermore, we use the resulting slot annotation to train a neural-network-based tagger that is able to perform slot tagging with no human intervention. This tagger is trained solely on the outputs of our method and thus does not rely on any labeled data. Our model demonstrates state-of-the-art performance in slot tagging without labeled training data on four different dialogue domains. Moreover, we find that slot annotations discovered by our model significantly improve the performance of an end-to-end dialogue response generation model, compared to using no slot annotation at all.
The R-U-A-Robot Dataset: Helping Avoid Chatbot Deception by Detecting User Questions About Human or Non-Human Identity
David Gros, Yu Li, and Zhou Yu
Humans are increasingly interacting with machines through language, sometimes in contexts where the user may not know they are talking to a machine (like over the phone or a text chatbot). We aim to understand how system designers and researchers might allow their systems to confirm its non-human identity. We collect over 2,500 phrasings related to the intent of “Are you a robot?”. This is paired with over 2,500 adversarially selected utterances where only confirming the system is non-human would be insufficient or disfluent. We compare classifiers to recognize the intent and discuss the precision/recall and model complexity tradeoffs. Such classifiers could be integrated into dialog systems to avoid undesired deception. We then explore how both a generative research model (Blender) as well as two deployed systems (Amazon Alexa, Google Assistant) handle this intent, finding that systems often fail to confirm their nonhuman identity. Finally, we try to understand what a good response to the intent would be, and conduct a user study to compare the important aspects when responding to this intent.
On the Generation of Medical Dialogs for COVID-19
Meng Zhou, Zechen Li, Bowen Tan, Guangtao Zeng, Wenmian Yang, Xuehai He, Zeqian Ju, Subrato Chakravorty, Shu Chen, Xingyi Yang, Yichen Zhang, Qingyang Wu, Zhou Yu, Kun Xu, Eric Xing, and Pengtao Xie
Under the pandemic of COVID-19, people experiencing COVID19-related symptoms or exposed to risk factors have a pressing need to consult doctors. Due to hospital closure, a lot of consulting services have been moved online. Because of the shortage of medical professionals, many people cannot receive online consultations timely. To address this problem, we aim to develop a medical dialogue system that can provide COVID19-related consultations. We collected two dialogue datasets – CovidDialog – (in English and Chinese respectively) containing conversations between doctors and patients about COVID-19. On these two datasets, we train several dialogue generation models based on Transformer, GPT, and BERT-GPT. Since the two COVID-19 dialogue datasets are small in size, which bear high risk of overfitting, we leverage transfer learning to mitigate data deficiency. Specifically, we take the pretrained models of Transformer, GPT, and BERT-GPT on dialog datasets and other large-scale texts, then finetune them on our CovidDialog datasets. Experiments demonstrate that these approaches are promising in generating meaningful medical dialogues about COVID-19. But more advanced approaches are needed to build a fully useful dialogue system that can offer accurate COVID-related consultations. The data and code are available at https://github.com/UCSD-AI4H/COVID-Dialogue
PRAL: A Tailored Pre-Training Model for Task-Oriented Dialog Generation
Jing Gu, Qingyang Wu, Chongruo Wu, Weiyan Shi, and Zhou Yu
The recent success of large pre-trained language models such as BERT and GPT-2 has suggested the effectiveness of incorporating language priors in down-stream dialog generation tasks. However, the performance of pre-trained models on dialog task is not as optimal as expected. In this paper, we propose a Pre-trained Role Alternating Language model (PRAL), designed specifically for taskoriented conversational systems. We adopt ARDM (Wu et al., 2019) that models two speakers separately. We also design several techniques, such as start position randomization, knowledge distillation and history discount to improve pre-training performance. We introduce a task-oriented dialog pretraining dataset by cleaning 13 existing data sets. We test PRAL on three different downstream tasks. The results show that PRAL performs better or on par with the state-of-the-art methods.
Six papers from the Speech & NLP group were accepted to the Empirical Methods in Natural Language Processing (EMNLP) conference.
Generating Similes Effortlessly Like a Pro: A Style Transfer Approach for Simile Generation
Tuhin Chakrabarty Columbia University, Smaranda Muresan Columbia University, and Nanyun Peng University of Southern California and University of California, Los Angeles
Abstract:
Literary tropes, from poetry to stories, are at the crux of human imagination and communication. Figurative language, such as a simile, goes beyond plain expressions to give readers new insights and inspirations. We tackle the problem of simile generation. Generating a simile requires proper understanding for effective mapping of properties between two concepts. To this end, we first propose a method to automatically construct a parallel corpus by transforming a large number of similes collected from Reddit to their literal counterpart using structured common sense knowledge. We then fine-tune a pre-trained sequence to sequence model, BART (Lewis et al., 2019), on the literal-simile pairs to generate novel similes given a literal sentence. Experiments show that our approach generates 88% novel similes that do not share properties with the training data. Human evaluation on an independent set of literal statements shows that our model generates similes better than two literary experts 37%1 of the times, and three baseline systems including a recent metaphor generation model 71%2 of the times when compared pairwise.3 We also show how replacing literal sentences with similes from our best model in machine-generated stories improves evocativeness and leads to better acceptance by human judges.
Content Planning for Neural Story Generation with Aristotelian Rescoring
Seraphina Goldfarb-Tarrant University of Southern California and University of Edinburgh, Tuhin Chakrabarty Columbia University, Ralph Weischedel University of Southern California and Nanyun Peng University of Southern California and University of California, Los Angeles
Abstract:
Long-form narrative text generated from large language models manages a fluent impersonation of human writing, but only at the local sentence level, and lacks structure or global cohesion. We posit that many of the problems of story generation can be addressed via high-quality content planning, and present a system that focuses on how to learn good plot structures to guide story generation. We utilize a plot-generation language model along with an ensemble of rescoring models that each implement an aspect of good story-writing as detailed in Aristotle’s Poetics. We find that stories written with our more principled plot structure are both more relevant to a given prompt and higher quality than baselines that do not content plan, or that plan in an unprincipled way.
Severing the Edge Between Before and After: Neural Architectures for Temporal Ordering of Events
Miguel Ballesteros Amazon AI, Rishita Anubhai Amazon AI, Shuai Wang Amazon AI, Nima Pourdamghani Amazon AI, Yogarshi Vyas Amazon AI, Jie Ma Amazon AI, Parminder Bhatia Amazon AI, Kathleen McKeown Columbia University and Amazon AI and Yaser Al-Onaizan Amazon AI
Abstract:
In this paper, we propose a neural architecture and a set of training methods for ordering events by predicting temporal relations. Our proposed models receive a pair of events within a span of text as input and they identify temporal relations (Before, After, Equal, Vague) between them. Given that a key challenge with this task is the scarcity of annotated data, our models rely on either pre-trained representations (i.e. RoBERTa, BERT or ELMo), transfer, and multi-task learning (by leveraging complementary datasets), and self-training techniques. Experiments on the MATRES dataset of English documents establish a new state-of-the-art on this task.
Controllable Meaning Representation to Text Generation: Linearization and Data Augmentation Strategies
Chris Kedzie Columbia University and Kathleen McKeown Columbia University
Abstract:
We study the degree to which neural sequenceto-sequence models exhibit fine-grained controllability when performing natural language generation from a meaning representation. Using two task-oriented dialogue generation benchmarks, we systematically compare the effect of four input linearization strategies on controllability and faithfulness. Additionally, we evaluate how a phrase-based data augmentation method can improve performance. We find that properly aligning input sequences during training leads to highly controllable generation, both when training from scratch or when fine-tuning a larger pre-trained model. Data augmentation further improves control on difficult, randomly generated utterance plans.
Zero-Shot Stance Detection: A Dataset and Model using Generalized Topic Representations
Emily Allaway Columbia University and Kathleen McKeown Columbia University
Abstract:
Stance detection is an important component of understanding hidden influences in everyday life. Since there are thousands of potential topics to take a stance on, most with little to no training data, we focus on zero-shot stance detection: classifying stance from no training examples. In this paper, we present a new dataset for zero-shot stance detection that captures a wider range of topics and lexical variation than in previous datasets. Additionally, we propose a new model for stance detection that implicitly captures relationships between topics using generalized topic representations and show that this model improves performance on a number of challenging linguistic phenomena.
Unsupervised Cross-Lingual Part-of-Speech Tagging for Truly Low-Resource Scenarios
Ramy Eskander Columbia University, Smaranda Muresan Columbia University, and Michael Collins Columbia University
Abstract:
We describe a fully unsupervised cross-lingual transfer approach for part-of-speech (POS) tagging under a truly low resource scenario. We assume access to parallel translations between the target language and one or more source languages for which POS taggers are available. We use the Bible as parallel data in our experiments: small size, out-of-domain, and covering many diverse languages. Our approach innovates in three ways: 1) a robust approach of selecting training instances via cross-lingual annotation projection that exploits best practices of unsupervised type and token constraints, word-alignment confidence and density of projected POS, 2) a Bi-LSTM architecture that uses contextualized word embeddings, affix embeddings and hierarchical Brown clusters, and 3) an evaluation on 12 diverse languages in terms of language family and morphological typology. In spite of the use of limited and out-of-domain parallel data, our experiments demonstrate significant improvements in accuracy over previous work. In addition, we show that using multi-source information, either via projection or output combination, improves the performance for most target languages.
Columbia researchers presented their work at the Empirical Methods in Natural Language Processing (EMNLP) in Brussels, Belgium.
Professor Julia Hirschberg gave a keynote talk on the work done by the Spoken Language Processing Group on how to automatically detect deception in spoken language – how to identify cues in trusted speech vs. mistrusted speech and how these features differ by speaker and by listener. Slides from the talk can be viewed here.
Five teams with computer science undergrad and PhD students from the Natural Language Processing Group (NLP) also attended the conference to showcase their work on text summarization, analysis of social media, and fact checking.
Robust Document Retrieval and Individual Evidence Modeling for Fact Extraction and Verification
Tuhin Chakrabarty Computer Science Department, Tariq Alhindi Computer Science Department, and Smaranda Muresan Computer Science Department and Data Science Institute
”Given the difficult times, we are living in, it’s extremely necessary to be perfect with our facts,” said Tuhin Chakrabarty, lead researcher of the paper. “Misinformation spreads like wildfire and has long-lasting impacts. This motivated us to delve into the area of fact extraction and verification.”
This paper presents the ColumbiaNLP submission for the FEVER Workshop Shared Task. Their system is an end-to-end pipeline that extracts factual evidence from Wikipedia and infers a decision about the truthfulness of the claim based on the extracted evidence.
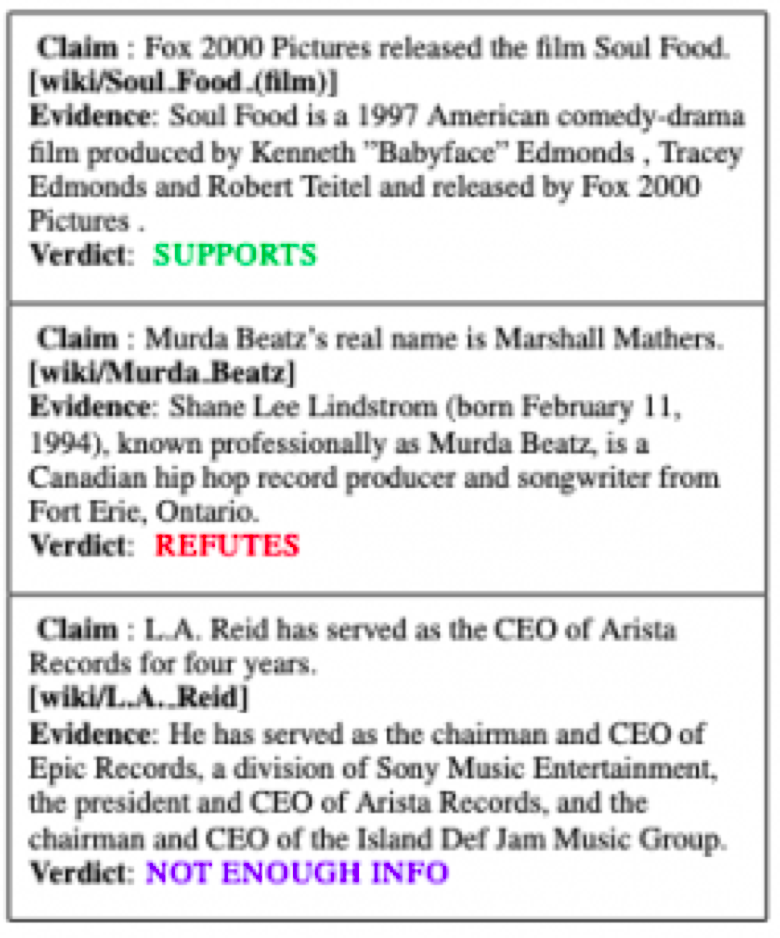
Fact checking is a type of investigative journalism where experts examine the claims published by others for their veracity. The claims can range from statements made by public figures to stories reported by other publishers. The end goal of a fact checking system is to provide a verdict on whether the claim is true, false, or mixed. Several organizations such as FactCheck.org and PolitiFact are devoted to such activities.
The FEVER Shared task aims to evaluate the ability of a system to verify information using evidence from Wikipedia. Given a claim involving one or more entities (mapping to Wikipedia pages), the system must extract textual evidence (sets of sentences from Wikipedia pages) that supports or refutes the claim and then using this evidence, it must label the claim as Supported, Refuted or NotEnoughInfo.
Detecting Gang-Involved Escalation on Social Media Using Context
Serina Chang Computer Science Department, Ruiqi Zhong Computer Science Department, Ethan Adams Computer Science Department, Fei-Tzin Lee Computer Science Department, Siddharth Varia Computer Science Department, Desmond Patton School of Social Work, William Frey School of Social Work, Chris Kedzie Computer Science Department, and Kathleen McKeown Computer Science Department
This research is a collaboration between Professor Kathy McKeown’s NLP lab and the Columbia School of Social Work. Professor Desmond Patton, from the School of Social Work and a member of the Data Science Institute, discovered that gang-involved youth in cities such as Chicago increasingly turn to social media to grieve the loss of loved ones, which may escalate into aggression toward rival gangs and plans for violence.
The team created a machine learning system that can automatically detect aggression and loss in the social media posts of gang-involved youth. They developed an approach with the hope to eventually use a system that can save critical time, scale reach, and intervene before more young lives are lost.
The system features the use of word embeddings and lexicons, automatically derived from a large domain-specific corpus which the team constructed. They also created context features that capture user’s recent posts, both in semantic and emotional content, and their interactions with other users in the dataset. Incorporating domain-specific resources and context feature in a Convolutional Neural Network (CNN) that leads to a significant improvement over the prior state-of-the-art.
The dataset used spans the public Twitter posts of nearly 300 users from a gang-involved community in Chicago. Youth volunteers and violence prevention organizations helped identify users and annotate the dataset for aggression and loss. Here are two examples of labeled tweets, both of which the system was able to classify correctly. Names are blocked out to preserve the privacy of users.

For semantics, which were represented by word embeddings, the researchers found that it was optimal to include 90 days of recent tweet history. While for emotion, where an emotion lexicon was employed, only two days of recent tweets were needed. This matched insight from prior social work research, which found that loss is significantly likely to precede aggression in a two-day window. They also found that emotions fluctuate more quickly than semantics so the tighter context window would be able to capture more fine-grained fluctuation.
“We took this context-driven approach because we believed that interpreting emotion in a given tweet requires context, including what the users had been saying recently, how they had been feeling, and their social dynamics with others,” said Serina Chang, an undergraduate computer science student. One thing that surprised them was the extent to which different types of context offered different types of information, as demonstrated by the contrasting contributions of the semantic-based user history feature and the emotion-based one. Continued Chang, “As we hypothesized, adding context did result in a significant performance improvement in our neural net model.”
Team SWEEPer: Joint Sentence
Extraction and Fact Checking with Pointer Networks
Christopher
Hidey Columbia University, Mona Diab Amazon AI Lab
Automated fact checking of textual claims is of increasing interest in today’s world. Previous research has investigated fact checking in political statements, news articles, and community forums.
“Through our model we can fact check claims and find specific statements that support the evidence,” said Christopher Hidey, a fourth year PhD student. “This is a step towards addressing the propagation of misinformation online.”
As part of the FEVER community shared task, the researchers developed models that given a statement would jointly find a Wikipedia article and a sentence related to the statement, and then predict whether the statement is supported by that sentence.
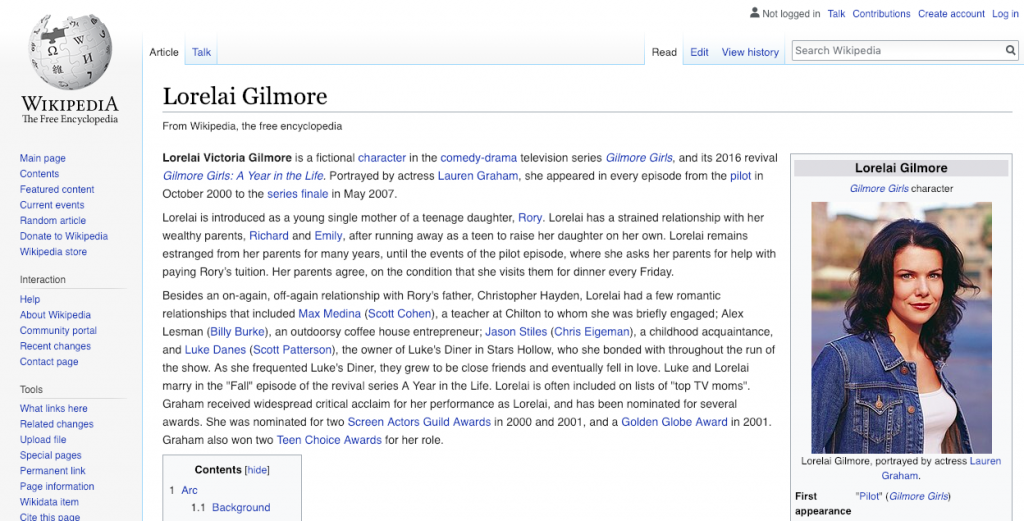
For example, given the claim “Lorelai Gilmore’s father is named Robert,” one could find the Wikipedia article on Lorelai Gilmore and extract the third sentence “Lorelai has a strained relationship with her wealthy parents, Richard and Emily, after running away as a teen to raise her daughter on her own” to show that the claim is false.
One aspect of this problem that the team observed was how poorly TF-IDF, a standard technique in information retrieval and natural language processing, performed at retrieving Wikipedia articles and sentences. Their custom model improved performance by 35 points in terms of recall over a TF-IDF baseline, achieving 90% recall for 5 articles. Overall, the model retrieved the correct sentence and predicted the veracity of the claim 50% of the time.
Where is your Evidence: Improving Fact-checking by Justification Modeling
Tariq Alhindi Computer Science Department, Savvas Petridis Computer Science Department, Smaranda Muresan Computer Science Department and Data Science Institute
The rate of which misinformation is spreading on the web is faster than the rate of manual fact-checking conducted by organizations like Politifact.com and Factchecking.org. For this paper the researchers wanted to explore how to automate parts or all of the fact-checking process. A poster with their findings was presented as part of the FEVER workshop.
“In order to come up with reliable fact-checking systems we need to understand the current manual process and identify opportunities for automation,” said Tariq Alhindi, lead author on the paper. They looked at the LIAR dataset – around 10,000 claims classified by Politifact.com to one of six degrees of truth – pants-on-fire, false, mostly-false, half-true, mostly-true, true. Continued Alhindi, we also looked at the fact-checking article for each claim and automatically extracted justification sentences of a given verdict and used them in our models, after removing all sentences that contain the verdict (e.g. true or false).

Feature-based machine learning models and neural networks were used to develop models that can predict whether a given statement is true or false. Results showed that using some sort of justification or evidence always improves the results of fake-news detection models.
“What was most surprising about the results is that adding features from the extracted justification sentences consistently improved the results no matter what classifier we used or what other features we included,” shared Alhindi, a PhD student. “However, we were surprised that the improvement was consistent even when we compare traditional feature-based linear machine learning models against state of the art deep learning models.”
Their research extends the previous work done on this data set which only looked at the linguistic cues of the claim and/or the metadata of the speaker (history, venue, party-affiliation, etc.). The researchers also released the extended dataset to the community to allow further work on this dataset with the extracted justifications.
Content Selection in Deep Learning Models of Summarization
Chris Kedzie Columbia University, Kathleen McKeown Columbia University, Hal Daume III University of Maryland, College Park
Recently, a specific type of machine learning, called deep learning, has made strides in reaching human level performance on hard to articulate problems, that is, things people do subconsciously like recognizing faces or understanding speech. And so, natural language processing researchers have turned to these models for the task of identifying the most important phrases and sentences in text documents, and have trained them to imitate the decisions a human editor might make when selecting content for a summary.
“Deep learning models have been successful in summarizing natural language texts, news articles and online comments,” said Chris Kedzie, a fifth year PhD student. “What we wanted to know is how they are doing it.”
While these deep learning models are empirically successful, it is not clear how they are performing this task. By design, they are learning to create their own representation of words and sentences, and then using them to predict whether a sentence is important – if it should go into a summary of the document. But just what kinds of information are they using to create these representations?
One hypotheses the researchers had was that certain types of words were more informative than others. For example, in a news article, nouns and verbs might be more important than adjectives and adverbs for identifying the most important information since such articles are typically written in a relatively objective manner.
To see if this was so, they trained models to predict sentence importance on redacted datasets, where either nouns, verbs, adjectives, adverbs, or function words were removed and compared them to models trained on the original data.
On a dataset of personal stories published on Reddit, adjectives and adverbs were the key to achieving the best performance. This made intuitive sense in that people tend to use intensifiers to highlight the most important or climactic moments in their stories with sentences like, “And those were the WORST customers I ever served.”
What surprised the researchers were the news articles – removing any one class of words did not dramatically decrease model performance. Either important content was broadly distributed across all kinds of words or there was some other signal that the model was using.
They suspected that sentence order was important because journalists are typically instructed to write according to the inverted pyramid style with the most important information at the top of the article. It was possible that the models were implicitly learning this and simply selecting sentences from the article lead.
Two pieces of evidence confirmed this. First, looking at a histogram of sentence positions selected as important, the models overwhelmingly preferred the lead of the article. Second, in a follow up experiment, the sentence ordered was shuffled to remove sentence position as a viable signal from which to learn. On news articles, model performance dropped significantly, leading to the conclusion that sentence position was most responsible for model performance on news documents.
The result concerned the researchers as they want models to be trained to truly understand human language and not use simple and brittle heuristics (like sentence position). “To connect this to broader trends in machine learning, we should be very concerned and careful about what signals are being exploited by our models, especially when making sensitive decisions,” Kedzie continued. ”The signals identified by the model as helpful may not truly capture the problem we are trying to solve, and worse yet, may be exploiting biases in the dataset that we do not wish it to learn.”
However, Kedzie sees this as an opportunity to improve the utility of word representations so that models are better able to use the article content itself. Along these lines, in the future, he hopes to show that by quantifying the surprisal or novelty of a particular word or phrase, models are able to make better sentence importance predictions. Just as people might remember the most surprising and unexpected parts of a good story.