Giannis Karamanolakis, a natural language processing and machine learning PhD student, talks about his research projects and how he is developing machine learning techniques for natural language processing applications.
Sitia, Greece
Can you talk about your background and why you decided to pursue a PhD?
At NTUA, taking part in machine learning (ML) research was not planned but rather a spontaneous outcome stemming from my love for music. The initial goal for my undergraduate thesis was to build an automatic music transcription system that converts polyphonic raw audio into music sheets. However, after realizing that such a system would not be possible to develop in a limited amount of time, I worked on the simpler task of automatically tagging audio clips with descriptive tags (e.g., “car horn” for audio clips where a car horn is sound). Right after submitting a new algorithm as a conference paper, I realized that I love doing ML research.
After NTUA, I spent one and a half years working as an ML engineer at a startup called Behavioral Signals, where we trained statistical models for the recognition of core emotions from speech and text data. After a few months of ML engineering, I found myself spending more time reading research papers and evaluating new research ideas on ML and natural language processing (NLP). By then, I was confident about my decision to pursue a PhD in ML/NLP.
What about NLP did you like and when did you realize that you wanted to do research on it?
I am fascinated by the ability of humans to understand complex natural language. At the moment of writing this response, I submitted the following 10-word query to Google: “when did you realize that you wanted to do research” by keeping quotation marks so that Google looks for exact matches only. Can you guess the number of the documents returned by Google that contain this exact sequence of 10 words?
The answer that I got was 0 (zero) documents, no results! In other words, Google, a company with huge collections of documents, did not detect any document that contains this specific sequence of words. Sentences rarely recur but humans easily understand the semantics of such rare sentences.
I decided to do research on NLP when I realized that current NLP algorithms are far away from human-level language understanding. As an example back from my time at Behavioral Signals, emotion classifiers were misclassifying sentences that contained sarcasm, negation, and other complex linguistic phenomena. I could not directly fix those issues (which are prevalent beyond emotion classification), which initially felt both surprising and frustrating, but then evolved into my excitement for research on NLP.
Why did you apply to Columbia and how was that process?
The computer science department at Columbia was one of my top choices for several reasons, but I will discuss the first one.
I was excited to learn about the joint collaboration between Columbia University and the New York City Department of Health and Mental Hygiene (DOHMH), on a project that aims to understand user-generated textual content in social media (e.g., Yelp reviews, tweets) for critical public health applications, such as detecting and acting on foodborne illness outbreaks in restaurants. I could see that the project would offer the unique opportunity to do research in ML and NLP and at the same time contribute to this important public application in collaboration with epidemiologists at DOHMH. Fortunately, I have been able to work on the project, advised by Professor Luis Gravano and Associate Professor Daniel Hsu.
Applying to Columbia and other American universities was quite a stressful experience. For many months, my days were filled with working for Behavioral Signals, studying hard for high scores in GRE and TOEFL exams (both of which were required at that time by all US universities), creating a short CV for the first time, and writing a distinct statement-of-purpose for each university. I am glad to observe the recent promising changes in the PhD application procedure for our department, such as waiving the GRE requirements and offering the Pre-submission Application Review (PAR) program, in which current PhD students help applicants improve their applications. (Both of which I would have liked to have been able to take advantage of.)
What sort of research questions or issues do you hope to answer?
My research in the past few years focuses on the following question: Can we effectively train ML classifiers for NLP applications with limited training data using alternative forms of human supervision?
An important limitation of current “supervised ML” techniques is that they require large amounts of training data, which is expensive and time-consuming to obtain manually. Thus, while supervised ML techniques (especially deep neural networks) thrive in standard benchmarks, it would be too expensive to apply to emerging real-world applications with limited labeled data.
Our work attempts to address the expensive requirement of manually labeled data through novel frameworks that leverage alternative, less expensive forms of human supervision. In sentiment classification, for example, we allow domain experts to provide a small set of domain-specific rules (e.g., “happy” keyword indicates positive sentiment, “diarrhea” is a symptom of food poisoning). Under low-resource settings with no labeled data, can we leverage expert-defined rules as supervision for training state-of-the-art neural networks?
For your research papers, how did you decide to do research on those topics? How long did it take you to complete the work? Was it easy?
For my first research project at Columbia, my goal was to help epidemiologists in health departments with daily inspections of restaurant reviews that discuss food poisoning events. Restaurant reviews can be quite long, with many irrelevant sentences surrounding the truly important ones that discuss food poisoning or relevant symptoms. Thus, we developed a neural network that highlights only important sentences in potentially long reviews and deployed it for inspections in health departments, where epidemiologists could quickly focus on the relevant sentences and safely ignore the rest.
Each project took about 6 months to complete. None of them were easy; each required substantial effort in reading relevant papers, discussing potential solutions with my advisors, implementing executable code, evaluating hypotheses on real data, and repeating the same process until we were all satisfied with the solutions and evaluation results. The projects also involved meeting with epidemiologists at DOHMH, re-designing our system to satisfy several (strict) data transfer protocols imposed by health departments, and overcoming several issues related to missing data for training ML classifiers.
Your advisors are not part of the NLP group, how has that worked out for you and your projects?
It has worked great in my humble opinion. For the public health project, the expertise of Professor Gravano on information extraction, combined with the expertise of Professor Hsu on machine learning, and the technical needs of the project have contributed without any doubt to the current formulation of our NLP-related frameworks. My advisors’ feedback covers a broad spectrum of research, ranging from core technical challenges to more general research practices, such as problem formulation and paper writing.
Among others, I appreciate the freedom I have been given for exploring new interesting research questions as well as the frequent and insightful feedback that helps me to reframe questions and forming solutions. At the same time, discussions with members of the NLP group, including professors and students, have been invaluable and have clearly influenced our projects.
What do you think is the most interesting thing about doing research?
I think it is the high amount of surprise it encompasses. For many research problems that I have tried to tackle, I started by shaping an initial solution in my mind but in the process discovered surprising findings that undoubtedly changed my way of thinking – such as that my initial solution did not actually work, simpler approaches worked better than more sophisticated approaches, data followed unexpected patterns, etc. These instances of surprise turned research into an interesting experience, similar to solving riddles or listening to jazz music.
Please talk about your internships – the work you did, how was it, what did you learn?
In the summer of 2019, I worked at Amazon’s headquarters in Seattle with a team of more than 15 scientists and engineers. Our goal was to automatically extract and store knowledge about billions of products in a product knowledge graph. As part of my internship, we developed TXtract, a deep neural network that efficiently extracts information from product descriptions for thousands of product categories. TXtract has been a core component of Amazon’s AutoKnow, which provides the collected knowledge for Amazon search and product detail pages.
During the summer of 2020, I worked for Microsoft Research remotely from New York City (because of the pandemic). In collaboration with researchers at the Language and Information Technologies team, we developed a weak supervision framework that enables domain experts to express their knowledge in the form of rules and further integrates rules for training deep neural networks.
These two internships equipped me with invaluable experiences. I learned new coding tools, ML techniques, and research practices. Through the collaboration with different teams, I realized that even researchers who work on the same subfield may think in incredibly different ways, so to carry out a successful collaboration within a limited time, one needs to listen carefully, pre-define expected outcomes (with everyone in the team), and adapt fast.
Do you think your skills were improved by your time at Columbia? In which ways?
Besides having improved my problem-finding and -solving skills, I have expanded my presentation capabilities. In the beginning, I was frustrated when other people (even experienced researchers) could not follow my presentations and I was worried when I could not follow other presenters’ work. Later, I realized that if (at least part of) the audience is not able to follow a presentation, then the presentation is either flawed or has been designed for the wrong audience.
Over the past four years, I have presented my work at various academic conferences and workshops, symposiums at companies, and student seminars, and after having received constructive feedback from other researchers, I can say that my presentation skills have vastly improved. Without any doubt, I feel more confident and can explain my work to a broader type of audience with diverse expertise. That said, I’m still struggling to explain my PhD topic to my family. 🙂
What has been the highlight of your time at Columbia?
The first thing that comes to mind is the “Greek Happy Hour” that I co-organized in October 2019. More than 40 PhD students joined the happy hour, listened to Greek music (mostly “rempetika”), tasted greek specialties (including spanakopita), and all toasted loudly by saying “Γειά μας” (ya mas; the greek version of “cheers”).
Was there anything that was tough to handle while taking your PhD?
PhD Happy Hour in 2020
It is hard to work from home during a pandemic. A core part of my PhD used to involve multi-person collaborations, drawing illustrations on the whiteboards of the Data Science Institute, random chats in hallways, happy hours, and other social events. All these have been harder or impossible to retain during the pandemic. I miss it and look forward to enjoying it again soon.
Looking back, what would you have done differently?
If I could, I would have engaged in more discussions and collaborations, taken more classes, played more music, and slept less. 🙂
What is your advice to students on how to navigate their time at Columbia? If they want to do NLP research what should they know or do to prepare?
They should register for diverse courses; Columbia offers the opportunity to attend courses from multiple departments. They should reach out to as many people as possible and do not hesitate to email graduate students and professors. I love receiving emails from people that I haven’t met before, some of which stimulated creative collaborations.
For those that want to do NLP research (which I highly recommend–subjectively speaking), you should contact me or any person in the NLP group.
What are your plans after Columbia?
I plan to continue working on research, either as a faculty member or in an industry research and development department.
Is there anything else that you think people should know?
Columbia offers free and discounted tickets to museums and performances around New York City, even virtual art events. I personally consider New York as the “state-of-the-art”.
Papers from CS researchers have been accepted to the 38th International Conference on Machine Learning (ICML 2021).
Associate Professor Daniel Hsu was one of the publication chairs of the conference and Assistant Professor Elham Azizi helped organize the 2021 ICML Workshop on Computational Biology. The workshop highlighted how machine learning approaches can be tailored to making both translational and basic scientific discoveries with biological data.
Below are the abstracts and links to the accepted papers.
Causal inference from observational data can be biased by unobserved confounders. Confounders—the variables that affect both the treatments and the outcome—induce spurious non-causal correlations between the two. Without additional conditions, unobserved confounders generally make causal quantities hard to identify. In this paper, we focus on the setting where there are many treatments with shared confounding, and we study under what conditions is causal identification possible. The key observation is that we can view subsets of treatments as proxies of the unobserved confounder and identify the intervention distributions of the rest. Moreover, while existing identification formulas for proxy variables involve solving integral equations, we show that one can circumvent the need for such solutions by directly modeling the data. Finally, we extend these results to an expanded class of causal graphs, those with other confounders and selection variables.
We present neural activation coding (NAC) as a novel approach for learning deep representations from unlabeled data for downstream applications. We argue that the deep encoder should maximize its nonlinear expressivity on the data for downstream predictors to take full advantage of its representation power. To this end, NAC maximizes the mutual information between activation patterns of the encoder and the data over a noisy communication channel. We show that learning for a noise-robust activation code increases the number of distinct linear regions of ReLU encoders, hence the maximum nonlinear expressivity. More interestingly, NAC learns both continuous and discrete representations of data, which we respectively evaluate on two downstream tasks: (i) linear classification on CIFAR-10 and ImageNet-1K and (ii) nearest neighbor retrieval on CIFAR-10 and FLICKR-25K. Empirical results show that NAC attains better or comparable performance on both tasks over recent baselines including SimCLR and DistillHash. In addition, NAC pretraining provides significant benefits to the training of deep generative models. Our code is available at https://github.com/yookoon/nac.
The Logical Options Framework Brandon Araki MIT, Xiao Li MIT, Kiran Vodrahalli Columbia University, Jonathan DeCastro Toyota Research Institute, Micah Fry MIT Lincoln Laboratory, Daniela Rus MIT CSAIL
Learning composable policies for environments with complex rules and tasks is a challenging problem. We introduce a hierarchical reinforcement learning framework called the Logical Options Framework (LOF) that learns policies that are satisfying, optimal, and composable. LOF efficiently learns policies that satisfy tasks by representing the task as an automaton and integrating it into learning and planning. We provide and prove conditions under which LOF will learn satisfying, optimal policies. And lastly, we show how LOF’s learned policies can be composed to satisfy unseen tasks with only 10-50 retraining steps on our benchmarks. We evaluate LOF on four tasks in discrete and continuous domains, including a 3D pick-and-place environment.
General methods have been developed for estimating causal effects from observational data under causal assumptions encoded in the form of a causal graph. Most of this literature assumes that the underlying causal graph is completely specified. However, only observational data is available in most practical settings, which means that one can learn at most a Markov equivalence class (MEC) of the underlying causal graph. In this paper, we study the problem of causal estimation from a MEC represented by a partial ancestral graph (PAG), which is learnable from observational data. We develop a general estimator for any identifiable causal effects in a PAG. The result fills a gap for an end-to-end solution to causal inference from observational data to effects estimation. Specifically, we develop a complete identification algorithm that derives an influence function for any identifiable causal effects from PAGs. We then construct a double/debiased machine learning (DML) estimator that is robust to model misspecification and biases in nuisance function estimation, permitting the use of modern machine learning techniques. Simulation results corroborate with the theory.
Learning models that gracefully handle distribution shifts is central to research on domain generalization, robust optimization, and fairness. A promising formulation is domain-invariant learning, which identifies the key issue of learning which features are domain-specific versus domain-invariant. An important assumption in this area is that the training examples are partitioned into domains'' orenvironments”. Our focus is on the more common setting where such partitions are not provided. We propose EIIL, a general framework for domain-invariant learning that incorporates Environment Inference to directly infer partitions that are maximally informative for downstream Invariant Learning. We show that EIIL outperforms invariant learning methods on the CMNIST benchmark without using environment labels, and significantly outperforms ERM on worst-group performance in the Waterbirds dataset. Finally, we establish connections between EIIL and algorithmic fairness, which enables EIIL to improve accuracy and calibration in a fair prediction problem.
Sketch drawings capture the salient information of visual concepts. Previous work has shown that neural networks are capable of producing sketches of natural objects drawn from a small number of classes. While earlier approaches focus on generation quality or retrieval, we explore properties of image representations learned by training a model to produce sketches of images. We show that this generative, class-agnostic model produces informative embeddings of images from novel examples, classes, and even novel datasets in a few-shot setting. Additionally, we find that these learned representations exhibit interesting structure and compositionality.
Few-shot dataset generalization is a challenging variant of the well-studied few-shot classification problem where a diverse training set of several datasets is given, for the purpose of training an adaptable model that can then learn classes from \emph{new datasets} using only a few examples. To this end, we propose to utilize the diverse training set to construct a \emph{universal template}: a partial model that can define a wide array of dataset-specialized models, by plugging in appropriate components. For each new few-shot classification problem, our approach therefore only requires inferring a small number of parameters to insert into the universal template. We design a separate network that produces an initialization of those parameters for each given task, and we then fine-tune its proposed initialization via a few steps of gradient descent. Our approach is more parameter-efficient, scalable and adaptable compared to previous methods, and achieves the state-of-the-art on the challenging Meta-Dataset benchmark.
On Monotonic Linear Interpolation of Neural Network Parameters James Lucas University of Toronto, Juhan Bae University of Toronto, Michael Zhang University of Toronto, Stanislav Fort Google AI, Richard Zemel Columbia University, Roger Grosse University of Toronto
Linear interpolation between initial neural network parameters and converged parameters after training with stochastic gradient descent (SGD) typically leads to a monotonic decrease in the training objective. This Monotonic Linear Interpolation (MLI) property, first observed by Goodfellow et al. 2014, persists in spite of the non-convex objectives and highly non-linear training dynamics of neural networks. Extending this work, we evaluate several hypotheses for this property that, to our knowledge, have not yet been explored. Using tools from differential geometry, we draw connections between the interpolated paths in function space and the monotonicity of the network — providing sufficient conditions for the MLI property under mean squared error. While the MLI property holds under various settings (e.g., network architectures and learning problems), we show in practice that networks violating the MLI property can be produced systematically, by encouraging the weights to move far from initialization. The MLI property raises important questions about the loss landscape geometry of neural networks and highlights the need to further study their global properties.
Slang is a common type of informal language, but its flexible nature and paucity of data resources present challenges for existing natural language systems. We take an initial step toward machine generation of slang by developing a framework that models the speaker’s word choice in slang context. Our framework encodes novel slang meaning by relating the conventional and slang senses of a word while incorporating syntactic and contextual knowledge in slang usage. We construct the framework using a combination of probabilistic inference and neural contrastive learning. We perform rigorous evaluations on three slang dictionaries and show that our approach not only outperforms state-of-the-art language models, but also better predicts the historical emergence of slang word usages from 1960s to 2000s. We interpret the proposed models and find that the contrastively learned semantic space is sensitive to the similarities between slang and conventional senses of words. Our work creates opportunities for the automated generation and interpretation of informal language.
We aim to bridge the gap between typical human and machine-learning environments by extending the standard framework of few-shot learning to an online, continual setting. In this setting, episodes do not have separate training and testing phases, and instead models are evaluated online while learning novel classes. As in the real world, where the presence of spatiotemporal context helps us retrieve learned skills in the past, our online few-shot learning setting also features an underlying context that changes throughout time. Object classes are correlated within a context and inferring the correct context can lead to better performance. Building upon this setting, we propose a new few-shot learning dataset based on large scale indoor imagery that mimics the visual experience of an agent wandering within a world. Furthermore, we convert popular few-shot learning approaches into online versions and we also propose a new contextual prototypical memory model that can make use of spatiotemporal contextual information from the recent past.
Few-shot classification (FSC), the task of adapting a classifier to unseen classes given a small labeled dataset, is an important step on the path toward human-like machine learning. Bayesian methods are well-suited to tackling the fundamental issue of overfitting in the few-shot scenario because they allow practitioners to specify prior beliefs and update those beliefs in light of observed data. Contemporary approaches to Bayesian few-shot classification maintain a posterior distribution over model parameters, which is slow and requires storage that scales with model size. Instead, we propose a Gaussian process classifier based on a novel combination of Pólya-Gamma augmentation and the one-vs-each softmax approximation that allows us to efficiently marginalize over functions rather than model parameters. We demonstrate improved accuracy and uncertainty quantification on both standard few-shot classification benchmarks and few-shot domain transfer tasks.
Theoretical Bounds On Estimation Error For Meta-Learning James Lucas University of Toronto, Mengye Ren University of Toronto, Irene Kameni African Master for Mathematical Sciences, Toni Pitassi Columbia University, Richard Zemel Columbia University
Machine learning models have traditionally been developed under the assumption that the training and test distributions match exactly. However, recent success in few-shot learning and related problems are encouraging signs that these models can be adapted to more realistic settings where train and test distributions differ. Unfortunately, there is severely limited theoretical support for these algorithms and little is known about the difficulty of these problems. In this work, we provide novel information-theoretic lower-bounds on minimax rates of convergence for algorithms that are trained on data from multiple sources and tested on novel data. Our bounds depend intuitively on the information shared between sources of data, and characterize the difficulty of learning in this setting for arbitrary algorithms. We demonstrate these bounds on a hierarchical Bayesian model of meta-learning, computing both upper and lower bounds on parameter estimation via maximum-a-posteriori inference.
In this paper, we derive generalization bounds for the two primary classes of graph neural networks (GNNs), namely graph convolutional networks (GCNs) and message passing GNNs (MPGNNs), via a PAC-Bayesian approach. Our result reveals that the maximum node degree and spectral norm of the weights govern the generalization bounds of both models. We also show that our bound for GCNs is a natural generalization of the results developed in arXiv:1707.09564v2 [cs.LG] for fully-connected and convolutional neural networks. For message passing GNNs, our PAC-Bayes bound improves over the Rademacher complexity based bound in arXiv:2002.06157v1 [cs.LG], showing a tighter dependency on the maximum node degree and the maximum hidden dimension. The key ingredients of our proofs are a perturbation analysis of GNNs and the generalization of PAC-Bayes analysis to non-homogeneous GNNs. We perform an empirical study on several real-world graph datasets and verify that our PAC-Bayes bound is tighter than others.
Assistant Professor Carl Vondrick has won the National Science Foundation’s (NSF) Faculty Early Career Development award for his proposal program to develop machine perception systems that robustly detect and track objects even when they disappear from sight, thereby enabling machines to build spatial awareness of their surroundings.
The Distinguished Lecture series brings computer scientists to Columbia to discuss current issues and research that are affecting their particular fields. This year, eight experts covered topics ranging from machine learning, human-computer interaction, neural language models, law and public policy, psychology, and computer architecture.
Below are a couple of the lectures from prominent faculty from universities across the country.
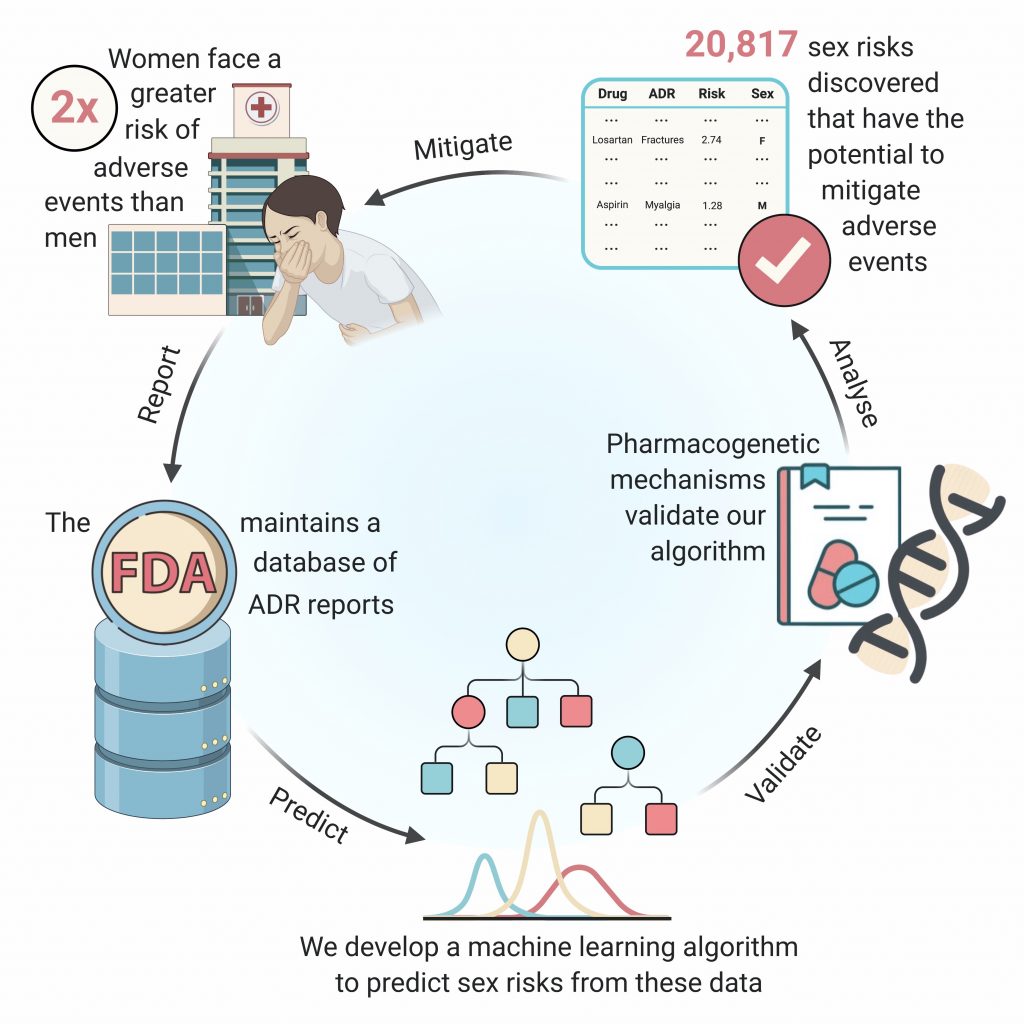
Payal Chandak (CC ’21) developed a machine learning model, AwareDX, that helps detect adverse drug effects specific to women patients. AwareDX mitigates sex biases in a drug safety dataset maintained by the FDA.
Below, Chandak talks about how her internship under the guidance of Nicholas Tatonetti, associate professor of biomedical informatics and a member of the Data Science Institute, inspired her to develop a machine learning tool to improve healthcare for women.
Payal Chandak
How did the project come about? I initiated this project during my internship at the Tatonetti Lab (T-lab) the summer after my first year. T-lab uses data science to study the side effects of drugs. I did some background research and learned that women face a two-fold greater risk of adverse events compared to men. While knowledge of sex differences in drug response is critical to drug prescription, there currently isn’t a comprehensive understanding of these differences. Dr. Tatonetti and I felt that we could use machine learning to tackle this problem and that’s how the project was born.
How many hours did you work on the project? How long did it last? The project lasted about two years. We refined our machine learning (ML) model, AwareDX, over many iterations to make it less susceptible to biases in the data. I probably spent a ridiculous number of hours developing it but the journey has been well worth it.
Were you prepared to work on it or did you learn as the project progressed? As a first-year student, I definitely didn’t know much when I started. Learning on the go became the norm. I understood some things by taking relevant CS classes and through reading Medium blogs and GitHub repositories –– this ability to learn independently might be one of the most valuable skills I have gained. I am very fortunate that Dr. Tatonetti guided me through this process and invested his time in developing my knowledge.
What were the things you already knew and what were the things you had to learn while working on the project? While I was familiar with biology and mathematics, computer science was totally new! In fact, T-Lab launched my journey to exploring computer science. This project exposed me to the great potential of artificial intelligence (AI) for revolutionizing healthcare, which in turn inspired me to explore the discipline academically. I went back and forth between taking classes relevant to my research and applying what I learned in class to my research. As I took increasingly technical classes like ML and probabilistic modelling, I was able to advance my abilities.
Looking back, what were the skills that you wished you had before the project? Having some experience with implementing real-world machine learning projects on giant datasets with millions of observations would have been very valuable.
Was this your first project to collaborate on? How was it? This was my first project and I worked under the guidance of Dr. Tatonetti. I thought it was a wonderful experience – not only has it been extremely rewarding to see my work come to fruition, but the journey itself has been so valuable. And Dr. Tatonetti has been the best mentor that I could have asked for!
Did working on this project make you change your research interests? I actually started off as pre-med. I was fascinated by the idea that “intelligent machines” could be used to improve medicine, and so I joined T-Lab. Over time, I’ve realized that recent advances in machine learning could redefine how doctors interact with their patients. These technologies have an incredible potential to assist with diagnosis, identify medical errors, and even recommend treatments. My perspective on how I could contribute to healthcare shifted completely, and I decided that bioinformatics has more potential to change the practice of medicine than a single doctor will ever have. This is why I’m now hoping to pursue a PhD in Biomedical Informatics.
Do you think your skills were enhanced by working on the project? Both my knowledge of ML and statistics and my ability to implement my ideas have grown immensely as a result of working on this project. Also, I failed about seven times over two years. We were designing the algorithm and it was an iterative process – the initial versions of the algorithm had many flaws and we started from scratch multiple times. The entire process required a lot of patience and persistence since it took over 2 years! So, I guess it has taught me immense patience and persistence.
Why did you decide to intern at the T-Lab? I was curious to learn more about the intersection of artificial intelligence and healthcare. I’m endlessly fascinated by the idea of improving the standards of healthcare by using machine learning models to assist doctors.
Would you recommend volunteering or seeking projects out to other students? Absolutely. I think everyone should explore research. We have incredible labs here at Columbia with the world’s best minds leading them. Research opens the doors to work closely with them. It creates an environment for students to learn about a niche discipline and to apply the knowledge they gain in class.
CS researchers develop a new machine learning approach that shows promise in predicting necrotizing enterocolitis; could lead to improved medical decision-making in neonatal ICUs.
Almost 400,000 babies were born prematurely—before 37 weeks gestation—in 2018 in the United States. One of the leading causes of newborn deaths and long-term disabilities, preterm birth (PTB) is considered a public health problem with deep emotional and challenging financial consequences to families and society. If doctors were able to use data and artificial intelligence (AI) to predict which pregnant women might be at risk, many of these premature births might be avoided.
The 33rd Conference on Neural Information Processing Systems (NeurIPS 2019) fosters the exchange of research on neural information processing systems in their biological, technological, mathematical, and theoretical aspects.
The annual meeting is one of the premier gatherings in artificial intelligence and machine learning that featured talks, demos from industry partners as well as tutorials. Professor Vishal Misra, with colleagues from the Massachusetts Institute of Technology (MIT), held a tutorial on synthetic control.
At this year’s NeurIPS, 21 papers from the department were accepted to the conference. Computer science professors and students worked with researchers from the statistics department and the Data Science Institute.
Noise-tolerant Fair Classification Alex Lamy Columbia University, Ziyuan Zhong Columbia University, Aditya Menon Google, Nakul Verma Columbia University
Fairness-aware learning involves designing algorithms that do not discriminate with respect to some sensitive feature (e.g., race or gender) and is usually done under the assumption that the sensitive feature available in a training sample is perfectly reliable.
This assumption may be violated in many real-world cases: for example, respondents to a survey may choose to conceal or obfuscate their group identity out of fear of potential discrimination. In the paper, the researchers show that fair classifiers can still be used given noisy sensitive features by simply changing the desired fairness-tolerance. Their procedure is empirically effective on two relevant real-world case-studies involving sensitive feature censoring.
Poisson-randomized Gamma Dynamical Systems Aaron Schein UMass Amherst, Scott Linderman Columbia University, Mingyuan Zhou University of Texas at Austin, David Blei Columbia University, Hanna Wallach MSR NYC
This paper presents a new class of state space models for count data. It derives new properties of the Poisson-randomized gamma distribution for efficient posterior inference.
This paper address causal inference in the presence of unobserved confounder when proxy is available for the confounders in the form of a network connecting the units. For example, the link structure of friendships in a social network reveals information about the latent preferences of people in that network. The researchers show how modern network embedding methods can be exploited to harness the network estimation for efficient causal adjustment.
The paper characterizes the theoretical properties of a popular machine learning algorithm, variational Bayes (VB). The researchers studied the VB under model misspecification, which is the setting that is most aligned with the practice, and show that the VB posterior is asymptotically normal and centers at the value that minimizes the Kullback-Leibler (KL) divergence to the true data-generating distribution.
As a consequence, they found that the model misspecification error dominates the variational approximation error in VB posterior predictive distributions. In other words, VB pays a negligible price in producing posterior predictive distributions. It explains the widely observed phenomenon that VB achieves comparable predictive accuracy with MCMC even though VB uses an approximating family.
The paper introduces a model that captures a min-max competition over complex error landscapes and shows that even a simplified model can provably replicate some of the most commonly reported failure modes of GANs (non-convergence, deadlock in suboptimal states, etc).
Moreover, the researchers were able to understand the hidden structure in these systems — the min-max competition can lead to system behavior that is similar to that of energy preserving systems in physics (e.g. connected pendulums, many-body problems, etc). This makes it easier to understand why these systems can fail and gives new tools in the design of algorithms for training GANs.
Dynamic Treatment Regimes (DTRs) are particularly effective for managing chronic disorders and is arguably one of the key aspects towards more personalized decision-making. The researchers developed the first adaptive algorithm that achieves near-optimal regret in DTRs in online settings, while leveraging the abundant, yet imperfect confounded observations. Applications are given to personalized medicine and treatment recommendation in clinical decision support.
The paper proposes a latent bag of words model for differentiable content planning and surface realization in text generation. This model generates paraphrases with clear steps, adding interpretability and controllability of existing neural text generation models.
This paper addresses how to design neural networks to get very accurate estimates of causal effects from observational data. The researchers propose two methods based on insights from the statistical literature on the estimation of treatment effects.
The first is a new architecture, the Dragonnet, that exploits the sufficiency of the propensity score for estimation adjustment. The second is a regularization procedure, targeted regularization, that induces a bias towards models that have non-parametrically optimal asymptotic properties “out-of-the-box”. Studies on benchmark datasets for causal inference show these adaptations outperform existing methods.
The researchers prove that properly tailored zero-order methods are as effective as their first-order counterparts. This analysis requires a combination of tools from optimization theory, probability theory and dynamical systems to show that even without perfect knowledge of the shape of the error landscape, effective optimization is possible.
Metric Learning for Adversarial Robustness Chengzhi Mao Columbia University, Ziyuan Zhong Columbia University, Junfeng Yang Columbia University, Carl Vondrick Columbia University, Baishakhi Ray Columbia University
Deep networks are well-known to be fragile to adversarial attacks. The paper introduces a novel Triplet Loss Adversarial (TLA) regulation that is the first method that leverages metric learning to improve the robustness of deep networks. This method is inspired by the evidence that deep networks suffer from distorted feature space under adversarial attacks. The method increases the model robustness and efficiency for the detection of adversarial attacks significantly.
The paper studies linear regression problems with general symmetric norm loss and gives efficient algorithms for solving such linear regression problems via sketching techniques.
The paper presents a novel and formal definition of mode coverage for generative models. It also gives a boosting algorithm to achieve this mode coverage guarantee.
The researchers studied the least-squares linear regression over $N$ uncorrelated Gaussian features that are selected in order of decreasing variance with the number of selected features $p$ can be either smaller or greater than the sample size $n$. And give an average-case analysis of the out-of-sample prediction error as $p,n,N \to \infty$ with $p/N \to \alpha$ and $n/N \to \beta$, for some constants $\alpha \in [0,1]$ and $\beta \in (0,1)$. In this average-case setting, the prediction error exhibits a “double descent” shape as a function of $p$. This also establishes conditions under which the minimum risk is achieved in the interpolating ($p>n$) regime.
The paper investigates the adaptive influence maximization problem and provides upper and lower bounds for the adaptivity gaps under myopic feedback model. The results confirm a long standing open conjecture by Golovin and Krause (2011).
The researchers studied low-rank matrix approximation with general loss function and showed that if the loss function has several good properties, then there is an efficient way to compute a good low-rank approximation. Otherwise, it could be hard to compute a good low-rank approximation efficiently.
The researchers studied how to compute an l1-norm loss low-rank matrix approximation to a given matrix. And showed that if the given matrix can be decomposed into a low-rank matrix and a noise matrix with a mild distributional assumption, we can obtain a (1+eps) approximation to the optimal solution.
The researchers developed a surrogate distribution for the Dirichlet that offers explicit, tractable reparameterization, the ability to capture sparsity, and has barycentric symmetry properties (i.e. exchangeability) equivalent to the Dirichlet. Previous works have used the Kumaraswamy distribution in a stick-breaking process to create a non-exchangeable distribution on the simplex. The method was improved by restoring exchangeability and demonstrating that approximate exchangeability is efficiently achievable. Lastly, the method was showcased in a variety of VAE semi-supervised learning tasks.
While normalizing flows have led to significant advances in modeling high-dimensional continuous distributions, their applicability to discrete distributions remains unknown. The researchers extend normalizing flows to discrete events, using a simple change-of-variables formula not requiring log-determinant-Jacobian computations. Empirically, they find that discrete flows obtain competitive performance with or outperform autoregressive baselines on various tasks, including addition, Potts models, and language models.
This work is all about learning causal relationships – the classic aim of which is to characterize all possible sets that could produce the observed data. In the paper, the researchers provide a complete characterization of all possible causal graphs with observational and interventional data involving so-called ‘soft interventions’ on variables when the targets of soft interventions are known.
This work potentially could lead to discovery of other novel learning algorithms that are both sound and complete.
Causal identification is the problem of deciding whether a causal distribution is computable from a combination of qualitative knowledge about the underlying data-generating process, which is usually encoded in the form of a causal graph, and an observational distribution. Despite the obvious need for identifying causal effects throughout the data-driven sciences, in practice, finding the causal graph is a notoriously challenging task.
In this work, the researchers provide a relaxation of the requirement of having to specify the causal graph (based on substantive knowledge) and allow the input of the inference to be an equivalence class of causal graphs, which can be inferred from data. Specifically, they propose the first general algorithm to learn conditional causal effects entirely from data. This result is particularly useful for evaluating the impact of conditional plans and stochastic policies, which appear both in AI (in the context of reinforcement learning) and in the data-driven sciences.
Regression analysis is one of the most common tools used in modern data science. While there is a great understanding and powerful technology to perform regression analysis in high dimensional spaces, the output of such a method is purely associational and devoid of any causal interpretation.
The researchers studied the problem of identification of structural (causal) coefficients in linear systems (deciding whether regression coefficients are amenable to causal interpretation, etc). Building on a technique called instrumental variables, they developed a new method called Instrumental Cutset, which partitions the systems into tractable components such that identification can be decided more efficiently. The resulting algorithm was efficient and strictly more powerful than the current state-of-the-art methods.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor