
Kostis Kaffes Wins 2025 Google ML and Systems Junior Faculty Award
Kaffes was selected as part of the inaugural cohort in recognition of the impact and potential of his work on tail-latency scheduling.
Kaffes was selected as part of the inaugural cohort in recognition of the impact and potential of his work on tail-latency scheduling.
Papers from CS researchers were accepted to the 41st International Conference on Machine Learning (ICML 2024). They join the machine learning research community in Vienna, Austria, on July 21 – 27, 2024. ICML brings together the brightest minds in the field to share their latest findings, foster collaborations, and inspire new directions in machine learning.
The links to the papers and the abstracts are below:
SelfIE: Self-Interpretation of Large Language Model Embeddings
Haozhe Chen Columbia University, Carl Vondrick Columbia University, Chengzhi Mao Columbia University
Abstract:
How do large language models (LLMs) obtain their answers? The ability to explain and control an LLM’s reasoning process is key for reliability, transparency, and future model developments. We propose SelfIE (Self-Interpretation of Embeddings), a framework that enables LLMs to interpret their own embeddings in natural language by leveraging their ability to respond to inquiries about a given passage. Capable of interpreting open-world concepts in the hidden embeddings, SelfIE reveals LLM internal reasoning in cases such as making ethical decisions, internalizing prompt injection, and recalling harmful knowledge. SelfIE’s text descriptions on hidden embeddings open avenues to control LLM reasoning. We propose Supervised Control, which allows editing open-ended concepts while only requiring gradient computation of individual layer. We extend RLHF to hidden embeddings and propose Reinforcement Control that erases harmful knowledge in LLM without supervision targets.
Counterfactual Image Editing
Yushu Pan Columbia University, Elias Bareinboim Columbia University
Abstract:
Counterfactual image editing is a challenging task within generative AI. The current literature on the topic focuses primarily on changing individual features while being silent about the causal relationships between features, which are present in the real world. In this paper, we first formalize this task through causal language, modeling the causal relationships between latent generative factors and images through a special type of causal model called augmented structural causal models (ASCMs). Second, we show two fundamental impossibility results: (1) counterfactual editing is impossible from i.i.d. image samples and their corresponding labels alone; (2) also, even when the causal relationships between latent generative factors and images are available, no guarantees regarding the output of the generative model can be provided. Third, we propose a relaxation over this hard problem aiming to approximate the non-identifiable target counterfactual distributions while still preserving features the users care about and that are causally consistent with the true generative model, which we call ctf-consistent estimators. Finally, we develop an efficient algorithm to generate counterfactual image samples leveraging neural causal models.
Exploiting Code Symmetries for Learning Program Semantics
Kexin Pei Columbia University, Weichen Li Columbia University, Qirui Jin University of Michigan, Shuyang Liu Huazhong University of Science and Technology, Scott Geng Univerisity of Washington, Lorenzo Cavallaro University College London, Junfeng Yang Columbia University, Suman Jana Columbia University
Abstract:
This paper tackles the challenge of teaching code semantics to Large Language Models (LLMs) for program analysis by incorporating code symmetries into the model architecture. We introduce a group-theoretic framework that defines code symmetries as semantics-preserving transformations, where forming a code symmetry group enables precise and efficient reasoning of code semantics. Our solution, SymC, develops a novel variant of self-attention that is provably equivariant to code symmetries from the permutation group defined over the program dependence graph. SymC obtains superior performance on five program analysis tasks, outperforming state-of-the-art code models, including GPT-4, without any pre-training. Our results suggest that code LLMs that encode the code structural prior via the code symmetry group generalize better and faster.
MGit: A Model Versioning and Management System
Wei Hao Columbia University, Daniel Mendoza Stanford University, Rafael Mendes Microsoft Research, Deepak Narayanan NVIDIA, Amar Phanishayee Columbia University, Asaf Cidon Columbia University, Junfeng Yang Columbia University
Abstract:
New ML models are often derived from existing ones (e.g., through fine-tuning, quantization or distillation), forming an ecosystem where models are *related* to each other and can share structure or even parameter values. Managing such a large and evolving ecosystem of model derivatives is challenging. For instance, the overhead of storing all such models is high, and models may inherit bugs from related models, complicating error attribution and debugging. In this paper, we propose a model versioning and management system called MGit that makes it easier to store, test, update, and collaborate on related models. MGit introduces a lineage graph that records the relationships between models, optimizations to efficiently store model parameters, and abstractions over this lineage graph that facilitate model testing, updating and collaboration. We find that MGit works well in practice: MGit is able to reduce model storage footprint by up to 7x. Additionally, in a user study with 20 ML practitioners, users complete a model updating task 3x faster on average with MGit.
Position: TrustLLM: Trustworthiness in Large Language Models
Yue Huang Lehigh University, Lichao Sun Lehigh University, Haoran Wang Illinois Institute of Technology, Siyuan Wu CISPA, Qihui Zhang CISPA, Yuan Li University of Cambridge, Chujie Gao CISPA, Yixin Huang Institut Polytechnique de Paris, Wenhan Lyu William & Mary, Yixuan Zhang William & Mary, Xiner Li Texas A&M University, Hanchi Sun Lehigh University, Zhengliang Liu University of Georgia, Yixin Liu Lehigh University, Yijue Wang Samsung Research America, Zhikun Zhang Stanford University, Bertie Vidgen MLCommons, Bhavya Kailkhura Lawrence Livermore National Laboratory, Caiming Xiong Salesforce Research, Chaowei Xiao University of Wisconsin, Madison, Chunyuan Li Microsoft Research, Eric Xing Carnegie Mellon University, Furong Huang University of Maryland, Hao Liu University of California, Berkeley, Heng Ji University of Illinois Urbana-Champaign, Hongyi Wang Rutgers University, Huan Zhang University of Illinois Urbana-Champaign, Huaxiu Yao UNC Chapel Hill, Manolis Kellis Massachusetts Institute of Technology, Marinka Zitnik Harvard University, Meng Jiang University of Notre Dame, Mohit Bansal UNC Chapel Hill, James Zou Stanford University, Jian Pei Duke University, Jian Liu University of Tennessee, Knoxville, Jianfeng Gao Microsoft Research, Jiawei Han University of Illinois Urbana-Champaign, Jieyu Zhao University of Southern California, Jiliang Tang Michigan State University, Jindong Wang Microsoft Research Asia, Joaquin Vanschoren Eindhoven University of Technology, John Mitchell Drexel University, Kai Shu Illinois Institute of Technology, Kaidi Xu Drexel University, Kai-Wei Chang University of California, Los Angeles, Lifang He Lehigh University, Lifu Huang Virginia Tech, Michael Backes CISPA, Neil Gong Duke University, Philip Yu University of Illinois Chicago, Pin-Yu Chen IBM Research, Quanquan Gu University of California, Los Angeles, Ran Xu Salesforce Research, Rey Ying Yale University, Shuiwang Ji Texas A&M University, Suman Jana Columbia UniversityI, Tianlong Chen UNC Chapel Hill, Tianming Liu University of Georgia, Tianyi Zhou University of Maryland, William Wang University of California, Santa Barbara, Xiang Li Massachusetts General Hospital, Xiangliang Zhang University of Notre Dame, Xiao Wang Northwestern University, Xing Xie Microsoft Research Asia, Xun Chen Samsung Research America, Xuyu Wang Florida International University, Yan Liu University of Southern California, Yanfang Ye University of Notre Dame, Yinzhi Cao Johns Hopkins University, Yong Chen University of Pennsylvania, Yue Zhao University of Southern California
Abstract:
Large language models (LLMs) have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and capability (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones, suggesting that open-source models can achieve high levels of trustworthiness without additional mechanisms like moderator, offering valuable insights for developers in this field. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Besides these observations, we’ve uncovered key insights into the multifaceted trustworthiness in LLMs. We emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. We advocate that the establishment of an AI alliance between industry, academia, the open-source community to foster collaboration is imperative to advance the trustworthiness of LLMs.
Blei is recognized for his groundbreaking work in machine learning, in particular his field-defining contributions in the areas of topic models and stochastic variational inference.
Researchers from the department presented machine learning and artificial intelligence research at the thirty-sixth Conference on Neural Information Processing Systems (NeurIPS 2023).
Outstanding Dataset Paper
ClimSim: An Open Large-Scale Dataset For Training High-Resolution Physics Emulators In Hybrid Multi-Scale Climate Models
Sungduk Yu, Walter Hannah, Liran Peng, Jerry Lin, Mohamed Aziz Bhouri, Ritwik Gupta, Björn Lütjens, Justus C. Will, Gunnar Behrens, Nora Loose, Charles Stern, Tom Beucler, Bryce Harrop, Benjamin Hillman, Andrea Jenney, Savannah L. Ferretti, Nana Liu, Animashree Anandkumar, Noah Brenowitz, Veronika Eyring, Nicholas Geneva, Pierre Gentine, Stephan Mandt, Jaideep Pathak, Akshay Subramaniam, Carl Vondrick, Rose Yu, Laure Zanna, Ryan Abernathey, Fiaz Ahmed, David Bader, Pierre Baldi, Elizabeth Barnes, Christopher Bretherton, Julius Busecke, Peter Caldwell, Wayne Chuang, Yilun Han, YU HUANG, Fernando Iglesias-Suarez, Sanket Jantre, Karthik Kashinath, Marat Khairoutdinov, Thorsten Kurth, Nicholas Lutsko, Po-Lun Ma, Griffin Mooers, J. David Neelin, David Randall, Sara Shamekh, Mark Taylor, Nathan Urban, Janni Yuval, Guang Zhang, Tian Zheng, Mike Pritchard
Abstract:
Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise predictions of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore’s Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator’s macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.
Objaverse-XL: A Colossal Universe of 3D Objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram Voleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl Vondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, Ali Farhadi
Abstract:
Natural language processing and 2D vision models have attained remarkable proficiency on many tasks primarily by escalating the scale of training data. However, 3D vision tasks have not seen the same progress, in part due to the challenges of acquiring high-quality 3D data. In this work, we present Objaverse-XL, a dataset of over 10 million 3D objects. Our dataset comprises deduplicated 3D objects from a diverse set of sources, including manually designed objects, photogrammetry scans of landmarks and everyday items, and professional scans of historic and antique artifacts. Representing the largest scale and diversity in the realm of 3D datasets, Objaverse-XL enables significant new possibilities for 3D vision. Our experiments demonstrate the improvements enabled with the scale provided by Objaverse-XL. We show that by training Zero123 on novel view synthesis, utilizing over 100 million multi-view rendered images, we achieve strong zero-shot generalization abilities. We hope that releasing Objaverse-XL will enable further innovations in the field of 3D vision at scale.
Causal discovery from observational and interventional data across multiple environments
Adam Li, Amin Jaber, Elias Bareinboim
Abstract:
A fundamental problem in many sciences is the learning of causal structure underlying a system, typically through observation and experimentation. Commonly, one even collects data across multiple domains, such as gene sequencing from different labs, or neural recordings from different species. Although there exist methods for learning the equivalence class of causal diagrams from observational and experimental data, they are meant to operate in a single domain. In this paper, we develop a fundamental approach to structure learning in non-Markovian systems (i.e. when there exist latent confounders) leveraging observational and interventional data collected from multiple domains. Specifically, we start by showing that learning from observational data in multiple domains is equivalent to learning from interventional data with unknown targets in a single domain. But there are also subtleties when considering observational and experimental data. Using causal invariances derived from do-calculus, we define a property called S-Markov that connects interventional distributions from multiple-domains to graphical criterion on a selection diagram. Leveraging the S-Markov property, we introduce a new constraint-based causal discovery algorithm, S-FCI, that can learn from observational and interventional data from different domains. We prove that the algorithm is sound and subsumes existing constraint-based causal discovery algorithms.
A Causal Framework for Decomposing Spurious Variations
Drago Plecko, Elias Bareinboim
Abstract:
One of the fundamental challenges found throughout the data sciences is to explain why things happen in specific ways, or through which mechanisms a certain variable X exerts influences over another variable Y. In statistics and machine learning, significant efforts have been put into developing machinery to estimate correlations across variables efficiently. In causal inference, a large body of literature is concerned with the decomposition of causal effects under the rubric of mediation analysis. However, many variations are spurious in nature, including different phenomena throughout the applied sciences. Despite the statistical power to estimate correlations and the identification power to decompose causal effects, there is still little understanding of the properties of spurious associations and how they can be decomposed in terms of the underlying causal mechanisms. In this manuscript, we develop formal tools for decomposing spurious variations in both Markovian and Semi-Markovian models. We prove the first results that allow a non-parametric decomposition of spurious effects and provide sufficient conditions for the identification of such decompositions. The described approach has several applications, ranging from explainable and fair AI to questions in epidemiology and medicine, and we empirically demonstrate its use on a real-world dataset.
Nonparametric Identifiability of Causal Representations from Unknown Interventions
Julius von Kügelgen, Michel Besserve, Liang Wendong, Luigi Gresele, Armin Kekić, Elias Bareinboim, David Blei, Bernhard Schölkopf
Abstract:
We study causal representation learning, the task of inferring latent causal variables and their causal relations from high-dimensional mixtures of the variables. Prior work relies on weak supervision, in the form of counterfactual pre- and post-intervention views or temporal structure; places restrictive assumptions, such as linearity, on the mixing function or latent causal model; or requires partial knowledge of the generative process, such as the causal graph or intervention targets. We instead consider the general setting in which both the causal model and the mixing function are nonparametric. The learning signal takes the form of multiple datasets, or environments, arising from unknown interventions in the underlying causal model. Our goal is to identify both the ground truth latents and their causal graph up to a set of ambiguities which we show to be irresolvable from interventional data. We study the fundamental setting of two causal variables and prove that the observational distribution and one perfect intervention per node suffice for identifiability, subject to a genericity condition. This condition rules out spurious solutions that involve fine-tuning of the intervened and observational distributions, mirroring similar conditions for nonlinear cause-effect inference. For an arbitrary number of variables, we show that at least one pair of distinct perfect interventional domains per node guarantees identifiability. Further, we demonstrate that the strengths of causal influences among the latent variables are preserved by all equivalent solutions, rendering the inferred representation appropriate for drawing causal conclusions from new data. Our study provides the first identifiability results for the general nonparametric setting with unknown interventions, and elucidates what is possible and impossible for causal representation learning without more direct supervision.
Estimating Causal Effects Identifiable from Combination of Observations and Experiments
Yonghan Jung, Ivan Diaz, Jin Tian, Elias Bareinboim
Abstract:
Learning cause and effect relations is arguably one of the central challenges found throughout the data sciences. Formally, determining whether a collection of observational and interventional distributions can be combined to learn a target causal relation is known as the problem of generalized identification (or g-identification) [Lee et al., 2019]. Although g-identification has been well understood and solved in theory, it turns out to be challenging to apply these results in practice, in particular when considering the estimation of the target distribution from finite samples. In this paper, we develop a new, general estimator that exhibits multiply robustness properties for g-identifiable causal functionals. Specifically, we show that any g-identifiable causal effect can be expressed as a function of generalized multioutcome sequential back-door adjustments that are amenable to estimation. We then construct a corresponding estimator for the g-identification expression that exhibits robustness properties to bias. We analyze the asymptotic convergence properties of the estimator. Finally, we illustrate the use of the proposed estimator in experimental studies. Simulation results corroborate the theory.
Causal Fairness for Outcome Control
Drago Plecko, Elias Bareinboim
Abstract:
As society transitions towards an AI-based decision-making infrastructure, an ever-increasing number of decisions once under control of humans are now delegated to automated systems. Even though such developments make various parts of society more efficient, a large body of evidence suggests that a great deal of care needs to be taken to make such automated decision-making systems fair and equitable, namely, taking into account sensitive attributes such as gender, race, and religion. In this paper, we study a specific decision-making task called outcome control in which an automated system aims to optimize an outcome variable Y while being fair and equitable. The interest in such a setting ranges from interventions related to criminal justice and welfare, all the way to clinical decision-making and public health. In this paper, we first analyze through causal lenses the notion of benefit, which captures how much a specific individual would benefit from a positive decision, counterfactually speaking, when contrasted with an alternative, negative one. We introduce the notion of benefit fairness, which can be seen as the minimal fairness requirement in decision-making, and develop an algorithm for satisfying it. We then note that the benefit itself may be influenced by the protected attribute, and propose causal tools which can be used to analyze this. Finally, if some of the variations of the protected attribute in the benefit are considered as discriminatory, the notion of benefit fairness may need to be strengthened, which leads us to articulating a notion of causal benefit fairness. Using this notion, we develop a new optimization procedure capable of maximizing Y while ascertaining causal fairness in the decision process.
Distribution-Free Statistical Dispersion Control for Societal Applications
Zhun Deng, Thomas Zollo, Jake Snell, Toniann Pitassi, Richard Zemel
Abstract:
Explicit finite-sample statistical guarantees on model performance are an important ingredient in responsible machine learning. Previous work has focused mainly on bounding either the expected loss of a predictor or the probability that an individual prediction will incur a loss value in a specified range. However, for many high-stakes applications, it is crucial to understand and control the dispersion of a loss distribution, or the extent to which different members of a population experience unequal effects of algorithmic decisions. We initiate the study of distribution-free control of statistical dispersion measures with societal implications and propose a simple yet flexible framework that allows us to handle a much richer class of statistical functionals beyond previous work. Our methods are verified through experiments in toxic comment detection, medical imaging, and film recommendation.
Representational Strengths and Limitations of Transformers
Clayton Sanford, Daniel Hsu, Matus Telgarsky
Abstract:
Attention layers, as commonly used in transformers, form the backbone of modern deep learning, yet there is no mathematical description of their benefits and deficiencies as compared with other architectures. In this work we establish both positive and negative results on the representation power of attention layers, with a focus on intrinsic complexity parameters such as width, depth, and embedding dimension. On the positive side, we present a sparse averaging task, where recurrent networks and feedforward networks all have complexity scaling polynomially in the input size, whereas transformers scale merely logarithmically in the input size; furthermore, we use the same construction to show the necessity and role of a large embedding dimension in a transformer. On the negative side, we present a triple detection task, where attention layers in turn have complexity scaling linearly in the input size; as this scenario seems rare in practice, we also present natural variants that can be efficiently solved by attention layers. The proof techniques emphasize the value of communication complexity in the analysis of transformers and related models, and the role of sparse averaging as a prototypical attention task, which even finds use in the analysis of triple detection.
Fast Attention Requires Bounded Entries
Josh Alman, Zhao Song
Abstract:
In modern machine learning, inner product attention computation is a fundamental task for training large language models such as Transformer, GPT-1, BERT, GPT-2, GPT-3 and ChatGPT. Formally, in this problem, one is given as input three matrices Q,K,V∈[−B,B]n×d, and the goal is to construct the matrix Att(Q,K,V):=diag(A1n)−1AV∈ℝn×d, where A=exp(QK⊤/d) is the `attention matrix’, and exp is applied entry-wise. Straightforward methods for this problem explicitly compute the n×n attention matrix A, and hence require time Ω(n2) even when d=no(1) is small.
In this paper, we investigate whether faster algorithms are possible by implicitly making use of the matrix A. We present two results, showing that there is a sharp transition at B=Θ(logn‾‾‾‾‾√).
∙ If d=O(logn) and B=o(logn‾‾‾‾‾√), there is an n1+o(1) time algorithm to approximate Att(Q,K,V) up to 1/poly(n) additive error.
∙ If d=O(logn) and B=Θ(logn‾‾‾‾‾√), assuming the Strong Exponential Time Hypothesis from fine-grained complexity theory, it is impossible to approximate Att(Q,K,V) up to 1/poly(n) additive error in truly subquadratic time n2−Ω(1).
This gives a theoretical explanation for the phenomenon observed in practice that attention computation is much more efficient when the input matrices have smaller entries.
Bypass Exponential Time Preprocessing: Fast Neural Network Training via Weight-Data Correlation Preprocessing
Josh Alman, Jiehao Liang, Zhao Song, Ruizhe Zhang, Danyang Zhuo
Abstract:
Over the last decade, deep neural networks have transformed our society, and they are already widely applied in various machine learning applications. State-of-art deep neural networks are becoming larger in size every year to deliver increasing model accuracy, and as a result, model training consumes substantial computing resources and will only consume more in the future. Using current training methods, in each iteration, to process a data point x∈ℝd in a layer, we need to spend Θ(md) time to evaluate all the m neurons in the layer. This means processing the entire layer takes Θ(nmd) time for n data points. Recent work [Song, Yang and Zhang, NeurIPS 2021] reduces this time per iteration to o(nmd), but requires exponential time to preprocess either the data or the neural network weights, making it unlikely to have practical usage.
In this work, we present a new preprocessing method that simply stores the weight-data correlation in a tree data structure in order to quickly, dynamically detect which neurons fire at each iteration. Our method requires only O(nmd) time in preprocessing and still achieves o(nmd) time per iteration. We complement our new algorithm with a lower bound, proving that assuming a popular conjecture from complexity theory, one could not substantially speed up our algorithm for dynamic detection of firing neurons.
Differentially Private Approximate Near Neighbor Counting in High Dimensions
Alexandr Andoni, Piotr Indyk, Sepideh Mahabadi, Shyam Narayanan
Abstract:
Range counting (e.g., counting the number of data points falling into a given query ball) under differential privacy has been studied extensively. However, the current algorithms for this problem are subject to the following dichotomy. One class of algorithms suffers from an additive error that is a fixed polynomial in the number of points. Another class of algorithms allows for polylogarithmic additive error, but the error grows exponentially in the dimension. To achieve the latter, the problem is relaxed to allow a “fuzzy” definition of the range boundary, e.g., a count of the points in a ball of radius r might also include points in a ball of radius cr for some c > 1.
In this paper, we present an efficient algorithm that offers a sweet spot between these two classes. The algorithm has an additive error that is an arbitrary small power of the data set size, depending on how fuzzy the range boundary is, as well as a small (1 + o(1)) multiplicative error. Crucially, the amount of noise added has no dependence on the dimension. Our algorithm introduces a variant of Locality-Sensitive Hashing, utilizing it in a novel manner.
Variational Inference with Gaussian Score Matching
Chirag Modi, Robert Gower, Charles Margossian, Yuling Yao, David Blei, Lawrence Saul
Abstract:
Variational inference (VI) is a method to approximate the computationally intractable posterior distributions that arise in Bayesian statistics. Typically, VI fits a simple parametric distribution to the target posterior by minimizing an appropriate objective such as the evidence lower bound (ELBO). In this work, we present a new approach to VI based on the principle of score matching, that if two distributions are equal then their score functions (i.e., gradients of the log density) are equal at every point on their support. With this, we develop score matching VI, an iterative algorithm that seeks to match the scores between the variational approximation and the exact posterior. At each iteration, score matching VI solves an inner optimization, one that minimally adjusts the current variational estimate to match the scores at a newly sampled value of the latent variables.
We show that when the variational family is a Gaussian, this inner optimization enjoys a closed form solution, which we call Gaussian score matching VI (GSM-VI). GSM-VI is also a “black box” variational algorithm in that it only requires a differentiable joint distribution, and as such it can be applied to a wide class of models. We compare GSM-VI to black box variational inference (BBVI), which has similar requirements but instead optimizes the ELBO. We study how GSM-VI behaves as a function of the problem dimensionality, the condition number of the target covariance matrix (when the target is Gaussian), and the degree of mismatch between the approximating and exact posterior distribution. We also study GSM-VI on a collection of real-world Bayesian inference problems from the posteriorDB database of datasets and models. In all of our studies we find that GSM-VI is faster than BBVI, but without sacrificing accuracy. It requires 10-100x fewer gradient evaluations to obtain a comparable quality of approximation.
Practical and Asymptotically Exact Conditional Sampling in Diffusion Models
Luhuan Wu, Brian Trippe, Christian Naesseth, David Blei, John Cunningham
Abstract:
Diffusion models have been successful on a range of conditional generation tasks including molecular design and text-to-image generation. However, these achievements have primarily depended on task-specific conditional training or error-prone heuristic approximations. Ideally, a conditional generation method should provide exact samples for a broad range of conditional distributions without requiring task-specific training. To this end, we introduce the Twisted Diffusion Sampler, or TDS. TDS is a sequential Monte Carlo (SMC) algorithm that targets the conditional distributions of diffusion models. The main idea is to use twisting, an SMC technique that enjoys good computational efficiency, to incorporate heuristic approximations without compromising asymptotic exactness. We first find in simulation and on MNIST image inpainting and class-conditional generation tasks that TDS provides a computational statistical trade-off, yielding more accurate approximations with many particles but with empirical improvements over heuristics with as few as two particles. We then turn to motif-scaffolding, a core task in protein design, using a TDS extension to Riemannian diffusion models. On benchmark test cases, TDS allows flexible conditioning criteria and often outperforms the state-of-the-art.
Causal-structure Driven Augmentations for Text OOD Generalization
Amir Feder, Yoav Wald, Claudia Shi, Suchi Saria, David Blei
Abstract:
The reliance of text classifiers on spurious correlations can lead to poor generalization at deployment, raising concerns about their use in safety-critical domains such as healthcare. In this work, we propose to use counterfactual data augmentation, guided by knowledge of the causal structure of the data, to simulate interventions on spurious features and to learn more robust text classifiers. We show that this strategy is appropriate in prediction problems where the label is spuriously correlated with an attribute. Under the assumptions of such problems, we discuss the favorable sample complexity of counterfactual data augmentation, compared to importance re-weighting. Pragmatically, we match examples using auxiliary data, based on diff-in-diff methodology, and use a large language model (LLM) to represent a conditional probability of text. Through extensive experimentation on learning caregiver-invariant predictors of clinical diagnoses from medical narratives and on semi-synthetic data, we demonstrate that our method for simulating interventions improves out-of-distribution (OOD) accuracy compared to baseline invariant learning algorithms.
Evaluating the Moral Beliefs Encoded in LLMs
Nino Scherrer, Claudia Shi, Amir Feder, David Blei
Abstract:
This paper presents a case study on the design, administration, post-processing, and evaluation of surveys on large language models (LLMs). It comprises two components: (1) A statistical method for eliciting beliefs encoded in LLMs. We introduce statistical measures and evaluation metrics that quantify the probability of an LLM “making a choice”, the associated uncertainty, and the consistency of that choice. (2) We apply this method to study what moral beliefs are encoded in different LLMs, especially in ambiguous cases where the right choice is not obvious. We design a large-scale survey comprising 680 high-ambiguity moral scenarios (e.g., “Should I tell a white lie?”) and 687 low-ambiguity moral scenarios (e.g., “Should I stop for a pedestrian on the road?”). Each scenario includes a description, two possible actions, and auxiliary labels indicating violated rules (e.g., “do not kill”). We administer the survey to 28 open- and closed-source LLMs. We find that (a) in unambiguous scenarios, most models “choose” actions that align with commonsense. In ambiguous cases, most models express uncertainty. (b) Some models are uncertain about choosing the commonsense action because their responses are sensitive to the question-wording. (c) Some models reflect clear preferences in ambiguous scenarios. Specifically, closed-source models tend to agree with each other.
Last August, Wei Hao stepped onto the Google Campus in Sunnyvale, California, as part of the inaugural MLCommons Rising Stars cohort.
Thirty-five recipients, out of over 100 applicants, were invited to this two-day in-person workshop. The cohort had the chance to listen to talks by researchers from Google, Intel, and Meta, and professors from Havard, UC Berkeley, and Cornell about trendy research topics, such as ML for ML systems, software-hardware codesign, and responsible machine learning. They also had the chance to do a poster presentation of their work, where they got useful feedback. The aim of the workshop was to develop community, foster research and career growth, enable collaborations, and discuss career opportunities among the rising generation of researchers at the intersection of machine learning and systems.

“It was a great experience,” said Wei, a third-year PhD student who works with Junfeng Yang and Asaf Cidon. “I always feel the fastest way of developing research ideas is to talk to people and brainstorm, and the workshop was one of the perfect occasions for that.”
His main objective was to make connections, and by the end of the workshop, he came out of it with a potential research collaboration. Along with Amber Liu, a University of Michigan PhD student, they came up with the idea of using a combination of machine learning (ML) models of various sizes to accelerate the inference process of causal language modeling.
We caught up with Wei to talk about his experience at the machine learning workshop and how his PhD life has been.
Q: How did you become part of the workshop?
I applied to the workshop months ago with my resume and a research plan. During the application process, I was not asked to talk about a specific project but an overview of the research I was doing. Looking back, I think this contributed to the diversity of the selected cohort, as people’s work covered the whole stack of ML systems from chip design to application-level ML.
The project I presented at the workshop was titled Nazar: Monitoring and Adapting ML Models on Mobile Devices. The setup is that machine learning models are more and more commonly being pushed to mobile devices due to the convenience of low latency. However, they are often undermined by unpredictable distribution shifts after deployment, such as moderate to severe weather conditions and demographic changes.
We are the first to provide a systematic solution to mitigate the performance degradation of post-deployment models by building a three-stage system that continuously monitors, analyzes, and adapts to distribution shifts without needing user feedback.

Q: Can you talk about your background and why you decided to pursue a PhD?
I engaged in doing research when I was an undergraduate student at the University of Wisconsin-Madison. At the very beginning, getting paid and sharpening my resume were two of my main objectives. However, during the process, I developed an interest in solving open problems that are intellectually challenging.
Moreover, I enjoy defining new problems, which requires a lot of logical thinking but is very rewarding. These two characteristics made me think I am a good candidate for the PhD position. I also really enjoyed the professors I worked with and was encouraged to pursue a PhD. After talking to my current advisors, Junfeng Yang and Asaf Cidon, I was impressed by their enthusiasm and finally made up my mind.
Q: What are your research interests?
My research interest is building efficient and secure systems for machine learning workloads. The reason for pursuing this type of research is my belief in realizing artificial general intelligence (AGI), which requires reliable system support. I decided to focus on it since I found satisfaction in interacting with ML workload while building practical system components while in undergrad.
Q: What sort of research questions or issues do you hope to answer?
Besides the technical questions on how to make ML deployment ubiquitous, I also hope to answer some philosophical questions: What do people expect from using artificial intelligence (AI)? Are there capacity and efficiency boundaries of AI? Which boundaries should I focus on pushing forward in the future?
Q: What are you working on now?
I am building an ML model versioning and management system called MGit.
Models derived from other models are extremely common in machine learning today. For example, transfer learning is used to create task-specific models from “pre-trained” models through finetuning. This has led to an ecosystem where models are related to each other, sharing structure and often even parameter values.
However, it is hard to manage these model derivatives: the storage overhead of storing all derived models quickly becomes onerous, prompting users to get rid of intermediate models that might be useful for further analysis. Additionally, undesired behaviors in models are hard to track down (e.g., is a bug inherited from an upstream model?).
In the current project I am working on, we propose a model versioning and management system called MGit that makes it easier to store, test, update, and collaborate on model derivatives. MGit introduces a lineage graph that records provenance and versioning information between models, optimizations to efficiently store model parameters, as well as abstractions over this lineage graph that facilitate relevant testing, updating, and collaboration functionality. MGit is able to reduce the lineage graph’s storage footprint by up to 7× and automatically update downstream models in response to updates to upstream models.”
Q: How do you decide what to work on, and what is it like doing research?
I have written four research papers during my PhD so far: Clockworks, DIVA, Nazar, and MGit. All of them are in the field of ML systems and relate to improving the efficiency and robustness of ML applications.
To decide the topics, I always start by brainstorming with my mentors and advisors to derive possible choices. Then, I read related works and define the concrete problem to tackle. The problem definition that I derive at the beginning is usually not exactly the final version before a lot of trial and error.
For example, when we started work on DIVA, we were originally attempting to tame non-determinisms during the model training process. However, I detoured when I read about quantization and found it super interesting. The research morphed into an adversarial attack that tries to enlarge the deviations between ML models and their adapted version on edge devices
Overall, I found the most time-consuming and difficult part of doing research is to define the concrete problem that is logically valid and attractive to me. It can take me up to half a year, while the solutions and corresponding implementations are relatively easy to come up with.

Q: How did your previous experiences prepare you for a PhD?
I started to do research when I was a freshman in college, and I felt well-prepared before my PhD. Since the structure of research projects is more or less the same – brainstorming, defining problems, finding and evaluating solutions, and polishing papers – I get more and more familiar after each project, which makes me confident and not stressed about temporary slow-downs.
Q: Why did you apply to Columbia, and how was that process?
Aside from the prestigious reputation of Columbia and the research interests match, I really appreciate the proactiveness of my advisors during the recruitment process. I still remember that Asaf reached out to me before the application deadline, which made me feel very welcome. Because of him and my previous advisor at Madison, my stress was hugely alleviated during the application process. Thus, I encourage reaching out to whom you are really interested in working with early on, to both students and faculty.
Q: What has been the highlight of your time at Columbia?
The highlight of my time at Columbia so far is when I get the chance to share my research with a wide audience, such as at the CAIT symposium, DSI poster session, or during this interview. I also expect my research to have some real impact, and I believe that day is coming soon.
Q: Was there anything difficult that you had to face while taking your PhD?
So far, there have been three. I think one of the hardest things is to fight the feeling of low self-worth when a paper is rejected by a conference. Then, when a field I am working on attracts too many people, it becomes competitive, and I sometimes feel stressed about this kind of speed race of everyone trying to be the first to come up with something. And some loneliness when seeing friends my age bid farewell to their student life and start a career.
But since I have chosen this road of taking my PhD, I have to bear with these and find other ways to release stress. For example, I recently started indoor cycling at the gym as it is an effective way to burn both calories and overthinking.
Q: Looking back, what would you have done differently?
I would have thought less and got my hands dirty early. Sometimes, I spend too much time reading papers before doing experiments. No one was born prepared, and the earlier one fails, the sooner one can find a way out.
Q: Do you think your skills have been enhanced by your time at Columbia? In which ways?
I think I am more and more confident in delivering my thoughts in a structural way due to the training process of defining concrete problems and writing papers. I also feel that I have gained expertise in my field through the different projects I have taken on.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research, what should they know or do to prepare?
My advice to students is to engage in what they feel passionate about as early as possible and not be afraid of failure. For those who are interested in doing research, talk to professors and PhD students proactively about your interests and how you think we can help. Do not be afraid of being an amateur and assume we know everything as the world is moving so fast, especially with the new wave of AI. I think most of us, or at least myself, value vision and passion more than the ability to solve problems, which can definitely be fostered during the PhD journey.
Q: Is there anything else that you think people should know?
My personal goal is to create start-ups that are impactful to society. If you have similar goals or related sources at Columbia that you would like to share, please reach out. Thanks!
Paparrizos is recognized for breakthroughs in time series data management, as well as contributions to adaptive methodologies for data-intensive and machine learning applications.
Researchers from the department presented machine learning and artificial intelligence research at the thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2022).
Finding and Listing Front-door Adjustment Sets
Hyunchai Jeong Purdue University, Jin Tian Iowa State University, Elias Bareinboim Columbia University
Abstract:
Identifying the effects of new interventions from data is a significant challenge found across a wide range of the empirical sciences. A well-known strategy for identifying such effects is Pearl’s front-door (FD) criterion. The definition of the FD criterion is declarative, only allowing one to decide whether a specific set satisfies the criterion. In this paper, we present algorithms for finding and enumerating possible sets satisfying the FD criterion in a given causal diagram. These results are useful in facilitating the practical applications of the FD criterion for causal effects estimation and helping scientists to select estimands with desired properties, e.g., based on cost, feasibility of measurement, or statistical power.
Causal Identification under Markov equivalence: Calculus, Algorithm, and Completeness
Amin Jaber Purdue University, Adele Ribeiro Columbia University, Jiji Zhang Hong Kong Baptist University, Elias Bareinboim Columbia University
Abstract:
One common task in many data sciences applications is to answer questions about the effect of new interventions, like: `what would happen to Y if we make X equal to x while observing covariates Z=z?’. Formally, this is known as conditional effect identification, where the goal is to determine whether a post-interventional distribution is computable from the combination of an observational distribution and assumptions about the underlying domain represented by a causal diagram. A plethora of methods was developed for solving this problem, including the celebrated do-calculus [Pearl, 1995]. In practice, these results are not always applicable since they require a fully specified causal diagram as input, which is usually not available. In this paper, we assume as the input of the task a less informative structure known as a partial ancestral graph (PAG), which represents a Markov equivalence class of causal diagrams, learnable from observational data. We make the following contributions under this relaxed setting. First, we introduce a new causal calculus, which subsumes the current state-of-the-art, PAG-calculus. Second, we develop an algorithm for conditional effect identification given a PAG and prove it to be both sound and complete. In words, failure of the algorithm to identify a certain effect implies that this effect is not identifiable by any method. Third, we prove the proposed calculus to be complete for the same task.
Online Reinforcement Learning for Mixed Policy Scopes
Junzhe Zhang Columbia University, Elias Bareinboim Columbia University
Abstract:
Combination therapy refers to the use of multiple treatments — such as surgery, medication, and behavioral therapy – to cure a single disease, and has become a cornerstone for treating various conditions including cancer, HIV, and depression. All possible combinations of treatments lead to a collection of treatment regimens (i.e., policies) with mixed scopes, or what physicians could observe and which actions they should take depending on the context. In this paper, we investigate the online reinforcement learning setting for optimizing the policy space with mixed scopes. In particular, we develop novel online algorithms that achieve sublinear regret compared to an optimal agent deployed in the environment. The regret bound has a dependency on the maximal cardinality of the induced state-action space associated with mixed scopes. We further introduce a canonical representation for an arbitrary subset of interventional distributions given a causal diagram, which leads to a non-trivial, minimal representation of the model parameters.
Masked Prediction: A Parameter Identifiability View
Bingbin Liu Carnegie Mellon University, Daniel Hsu Columbia University, Pradeep Ravikumar Carnegie Mellon University, Andrej Risteski Carnegie Mellon University
Abstract:
The vast majority of work in self-supervised learning have focused on assessing recovered features by a chosen set of downstream tasks. While there are several commonly used benchmark datasets, this lens of feature learning requires assumptions on the downstream tasks which are not inherent to the data distribution itself. In this paper, we present an alternative lens, one of parameter identifiability: assuming data comes from a parametric probabilistic model, we train a self-supervised learning predictor with a suitable parametric form, and ask whether the parameters of the optimal predictor can be used to extract the parameters of the ground truth generative model.Specifically, we focus on latent-variable models capturing sequential structures, namely Hidden Markov Models with both discrete and conditionally Gaussian observations. We focus on masked prediction as the self-supervised learning task and study the optimal masked predictor. We show that parameter identifiability is governed by the task difficulty, which is determined by the choice of data model and the amount of tokens to predict. Technique-wise, we uncover close connections with the uniqueness of tensor rank decompositions, a widely used tool in studying identifiability through the lens of the method of moments.
Learning single-index models with shallow neural networks
Alberto Bietti Meta AI/New York University, Joan Bruna New York University, Clayton Sanford Columbia University, Min Jae Song New York University
Abstract:
Single-index models are a class of functions given by an unknown univariate link” function applied to an unknown one-dimensional projection of the input. These models are particularly relevant in high dimension, when the data might present low-dimensional structure that learning algorithms should adapt to. While several statistical aspects of this model, such as the sample complexity of recovering the relevant (one-dimensional) subspace, are well-understood, they rely on tailored algorithms that exploit the specific structure of the target function. In this work, we introduce a natural class of shallow neural networks and study its ability to learn single-index models via gradient flow. More precisely, we consider shallow networks in which biases of the neurons are frozen at random initialization. We show that the corresponding optimization landscape is benign, which in turn leads to generalization guarantees that match the near-optimal sample complexity of dedicated semi-parametric methods.
On Scrambling Phenomena for Randomly Initialized Recurrent Networks
Evangelos Chatziafratis University of California Santa Cruz, Ioannis Panageas University of California Irvine, Clayton Sanford Columbia University, Stelios Stavroulakis University of California Irvine
Abstract:
Recurrent Neural Networks (RNNs) frequently exhibit complicated dynamics, and their sensitivity to the initialization process often renders them notoriously hard to train. Recent works have shed light on such phenomena analyzing when exploding or vanishing gradients may occur, either of which is detrimental for training dynamics. In this paper, we point to a formal connection between RNNs and chaotic dynamical systems and prove a qualitatively stronger phenomenon about RNNs than what exploding gradients seem to suggest. Our main result proves that under standard initialization (e.g., He, Xavier etc.), RNNs will exhibit \textit{Li-Yorke chaos} with \textit{constant} probability \textit{independent} of the network’s width. This explains the experimentally observed phenomenon of \textit{scrambling}, under which trajectories of nearby points may appear to be arbitrarily close during some timesteps, yet will be far away in future timesteps. In stark contrast to their feedforward counterparts, we show that chaotic behavior in RNNs is preserved under small perturbations and that their expressive power remains exponential in the number of feedback iterations. Our technical arguments rely on viewing RNNs as random walks under non-linear activations, and studying the existence of certain types of higher-order fixed points called \textit{periodic points} in order to establish phase transitions from order to chaos.
Patching open-vocabulary models by interpolating weights
Gabriel Ilharco University of Washington, Mitchell Wortsman University of Washington, Samir Yitzhak Gadre Columbia University, Shuran Song Columbia University, Hannaneh Hajishirzi University of Washington, Simon Kornblith Google Brain, Ali Farhadi University of Washington, Ludwig Schmidt University of Washington
Abstract:
Open-vocabulary models like CLIP achieve high accuracy across many image classification tasks. However, there are still settings where their zero-shot performance is far from optimal. We study model patching, where the goal is to improve accuracy on specific tasks without degrading accuracy on tasks where performance is already adequate. Towards this goal, we introduce PAINT, a patching method that uses interpolations between the weights of a model before fine-tuning and the weights after fine-tuning on a task to be patched. On nine tasks where zero-shot CLIP performs poorly, PAINT increases accuracy by 15 to 60 percentage points while preserving accuracy on ImageNet within one percentage point of the zero-shot model. PAINT also allows a single model to be patched on multiple tasks and improves with model scale. Furthermore, we identify cases of broad transfer, where patching on one task increases accuracy on other tasks even when the tasks have disjoint classes. Finally, we investigate applications beyond common benchmarks such as counting or reducing the impact of typographic attacks on CLIP. Our findings demonstrate that it is possible to expand the set of tasks on which open-vocabulary models achieve high accuracy without re-training them from scratch.
ASPiRe: Adaptive Skill Priors for Reinforcement Learning
Mengda Xu Columbia University, Manuela Veloso JP Morgan/Carnegie Mellon University, Shuran Song Columbia University
Abstract:
We introduce ASPiRe (Adaptive Skill Prior for RL), a new approach that leverages prior experience to accelerate reinforcement learning. Unlike existing methods that learn a single skill prior from a large and diverse dataset, our framework learns a library of different distinction skill priors (i.e., behavior priors) from a collection of specialized datasets, and learns how to combine them to solve a new task. This formulation allows the algorithm to acquire a set of specialized skill priors that are more reusable for downstream tasks; however, it also brings up additional challenges of how to effectively combine these unstructured sets of skill priors to form a new prior for new tasks. Specifically, it requires the agent not only to identify which skill prior(s) to use but also how to combine them (either sequentially or concurrently) to form a new prior. To achieve this goal, ASPiRe includes Adaptive Weight Module (AWM) that learns to infer an adaptive weight assignment between different skill priors and uses them to guide policy learning for downstream tasks via weighted Kullback-Leibler divergences. Our experiments demonstrate that ASPiRe can significantly accelerate the learning of new downstream tasks in the presence of multiple priors and show improvement on competitive baselines.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
Zhenhailong Wang Columbia University, Manling Li Columbia University, Ruochen Xu Microsoft, Luowei Zhou Meta, Jie Lei Meta, Xudong Lin Columbia University, Shuohang Wang Microsoft, Ziyi Yang Stanford University, Chenguang Zhu Stanford University, Derek Hoiem University of Illinois, Shih-Fu Chang Columbia University, Mohit Bansal University of North Carolina Chapel Hill, Heng Ji University of Illinois
Abstract:
The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal-aware template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets.Code and processed data are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL.
Implications of Model Indeterminacy for Explanations of Automated Decisions
Marc-Etienne Brunet University of Toronto, Ashton Anderson University of Toronto, Richard Zemel Columbia University
Abstract:
There has been a significant research effort focused on explaining predictive models, for example through post-hoc explainability and recourse methods. Most of the proposed techniques operate upon a single, fixed, predictive model. However, it is well-known that given a dataset and a predictive task, there may be a multiplicity of models that solve the problem (nearly) equally well. In this work, we investigate the implications of this kind of model indeterminacy on the post-hoc explanations of predictive models. We show how it can lead to explanatory multiplicity, and we explore the underlying drivers. We show how predictive multiplicity, and the related concept of epistemic uncertainty, are not reliable indicators of explanatory multiplicity. We further illustrate how a set of models showing very similar aggregate performance on a test dataset may show large variations in their local explanations, i.e., for a specific input. We explore these effects for Shapley value based explanations on three risk assessment datasets. Our results indicate that model indeterminacy may have a substantial impact on explanations in practice, leading to inconsistent and even contradicting explanations.
Reconsidering Deep Ensembles
Taiga Abe Columbia University, Estefany Kelly Buchanan Columbia University, Geoff Pleiss Columbia University, Richard Zemel Columbia University, John Cunningham Columbia University
Abstract:
Ensembling neural networks is an effective way to increase accuracy, and can often match the performance of individual larger models. This observation poses a natural question: given the choice between a deep ensemble and a single neural network with similar accuracy, is one preferable over the other? Recent work suggests that deep ensembles may offer distinct benefits beyond predictive power: namely, uncertainty quantification and robustness to dataset shift. In this work, we demonstrate limitations to these purported benefits, and show that a single (but larger) neural network can replicate these qualities. First, we show that ensemble diversity, by any metric, does not meaningfully contribute to an ensemble’s ability to detect out-of-distribution (OOD) data, but is instead highly correlated with the relative improvement of a single larger model. Second, we show that the OOD performance afforded by ensembles is strongly determined by their in-distribution (InD) performance, and – in this sense – is not indicative of any “effective robustness.” While deep ensembles are a practical way to achieve improvements to predictive power, uncertainty quantification, and robustness, our results show that these improvements can be replicated by a (larger) single model
Papers from CS researchers have been accepted to the 38th International Conference on Machine Learning (ICML 2021).
Below are the abstracts and links to the accepted papers.
Simple And Near-Optimal Algorithms For Hidden Stratification And Multi-Group Learning
Christopher Tosh Memorial Sloan Kettering Cancer Center, Daniel Hsu Columbia University
Abstract
Multi-group agnostic learning is a formal learning criterion that is concerned with the conditional risks of predictors within subgroups of a population. The criterion addresses recent practical concerns such as subgroup fairness and hidden stratification. This paper studies the structure of solutions to the multi-group learning problem and provides simple and near-optimal algorithms for the learning problem.
On Measuring Causal Contributions Aia Do-Interventions
Yonghan Jung Purdue University, Shiva Kasiviswanathan Amazon, Jin Tian Iowa State University, Dominik Janzing Amazon, Patrick Bloebaum Amazon, Elias Bareinboim Columbia University
Abstract
Causal contributions measure the strengths of different causes to a target quantity. Understanding causal contributions is important in empirical sciences and data-driven disciplines since it allows to answer practical queries like “what are the contributions of each cause to the effect?” In this paper, we develop a principled method for quantifying causal contributions. First, we provide desiderata of properties (axioms) that causal contribution measures should satisfy and propose the do-Shapley values (inspired by do-interventions (Pearl, 2000)) as a unique method satisfying these properties. Next, we develop a criterion under which the do-Shapley values can be efficiently inferred from non-experimental data. Finally, we provide do-Shapley estimators exhibiting consistency, computational feasibility, and statistical robustness. Simulation results corroborate with the theory.
Partial Counterfactual Identification From Observational And Experimental Data
Junzhe Zhang Columbia University, Jin TianIowa Iowa State University, Elias Bareinboim Columbia University
Abstract
This paper investigates the problem of bounding counterfactual queries from an arbitrary collection of observational and experimental distributions and qualitative knowledge about the underlying data-generating model represented in the form of a causal diagram. We show that all counterfactual distributions in an arbitrary structural causal model (SCM) with discrete observed domains could be generated by a canonical family of SCMs with the same causal diagram where unobserved (exogenous) variables are also discrete, taking values in finite domains. Utilizing the canonical SCMs, we translate the problem of bounding counterfactuals into that of polynomial programming whose solution provides optimal bounds for the counterfactual query. Solving such polynomial programs is in general computationally expensive. We then develop effective Monte Carlo algorithms to approximate optimal bounds from a combination of observational and experimental data. Our algorithms are validated extensively on synthetic and real-world datasets.
Counterfactual Transportability: A Formal Approach
Juan D. Correa Universidad Autonoma de Manizales, Sanghack Lee Seoul National University, Elias Bareinboim Columbia University
Abstract
Generalizing causal knowledge across environments is a common challenge shared across many of the data-driven disciplines, including AI and ML. Experiments are usually performed in one environment (e.g., in a lab, on Earth, in a training ground), almost invariably, with the intent of being used elsewhere (e.g., outside the lab, on Mars, in the real world), in an environment that is related but somewhat different than the original one, where certain conditions and mechanisms are likely to change. This generalization task has been studied in the causal inference literature under the rubric of transportability (Pearl and Bareinboim, 2011). While most transportability works focused on generalizing associational and interventional distributions, the generalization of counterfactual distributions has not been formally studied. In this paper, we investigate the transportability of counterfactuals from an arbitrary combination of observational and experimental distributions coming from disparate domains. Specifically, we introduce a sufficient and necessary graphical condition and develop an efficient, sound, and complete algorithm for transporting counterfactual quantities across domains in nonparametric settings. Failure of the algorithm implies the impossibility of generalizing the target counterfactual from the available data without further assumptions.
Variational Inference for Infinitely Deep Neural Networks
Achille Nazaret Columbia University, David Blei Columbia University
Abstract
We introduce the unbounded depth neural network (UDN), an infinitely deep probabilistic model that adapts its complexity to the training data. The UDN contains an infinite sequence of hidden layers and places an unbounded prior on a truncation ℓ, the layer from which it produces its data. Given a dataset of observations, the posterior UDN provides a conditional distribution of both the parameters of the infinite neural network and its truncation. We develop a novel variational inference algorithm to approximate this posterior, optimizing a distribution of the neural network weights and of the truncation depth ℓ, and without any upper limit on ℓ. To this end, the variational family has a special structure: it models neural network weights of arbitrary depth, and it dynamically creates or removes free variational parameters as its distribution of the truncation is optimized. (Unlike heuristic approaches to model search, it is solely through gradient-based optimization that this algorithm explores the space of truncations.) We study the UDN on real and synthetic data. We find that the UDN adapts its posterior depth to the dataset complexity; it outperforms standard neural networks of similar computational complexity; and it outperforms other approaches to infinite-depth neural networks.
“So, this is a rough idea for modeling trajectories and I need your feedback,” said Didac Suris to the room while his teammates looked at him over bowls of Chinese food. “I literally just thought of this two days ago.”
It is the first week that working lunch meetings can resume at Columbia. Suris, along with other members of the computer vision lab, immediately took advantage of it. As they settle down into the meeting, Suris talks about his research proposal and his audience exchanges ideas with him in between bites of food. The last time this happened was two years ago.
“We came back in the Fall and it is good to be back in the office,” said Didac Suris, a third-year PhD student advised by Carl Vondrick. “Collaborating with teammates and just being out has worked wonders for my productivity which has skyrocketed compared to when working alone, or from home.”

Suris can be found in an office in CEPSR working on research projects that study computer vision and machine learning. The projects focus on training machines to interact and observe their surroundings, including his work on predicting what will happen next in a video. This is in line with his long-term goal of creating systems that can model video more appropriately and help predict the future actions of a video, which will be useful in autonomous vehicles, human-robot interaction, broadcasting of sports events, and assistive technology.
Suris was recently named a Microsoft Research Fellow. The research he has done while at Columbia focuses on computer vision and building systems that can learn on their own, which is very different from what he studied in undergrad, telecommunications at the Polytechnic University of Catalunya in Barcelona, Spain. We caught up with Suris to ask about how his PhD is going and winning the fellowship.
Q: What was your journey to Columbia? How did you pivot from telecommunications to applying for a PhD in computer vision?
It was only during my master’s, when I started doing research on computer vision, that I started to consider doing a PhD. The main reason I’m doing a PhD is because I believe it is the best way to push myself intellectually.
I really recommend doing research in different places before starting a PhD. Before starting at Columbia, I did research at three different universities, which prepared me for my current research. These experiences helped me to 1) understand what research is about, and 2) understand that different research groups work differently, and get the best out of each one.
Q: What drew you to machine learning and artificial intelligence?
One of the characteristic aspects of this field is how fast it is evolving, and how impressive the research results have been in the last decade. I don’t think there was a specific moment where I decided to do research on this topic, I would say there was a series of circumstances that led me here, including the fact that I was originally interested in artificial intelligence in the first place, of course.
Q: Why did you decide to focus on computer vision?
There is a lot of information online because of the vast amount of videos, images, text, audio, and other forms of data. But the thing is the majority of this information is not labeled clearly. For example, we do not have information about the actions taking place in every YouTube video. But we can still use the information in the YouTube video to learn about the world.
We can teach a computer to relate the audio in a video to the visual content in a video. And then we can relate all of this to the comments on the YouTube video to learn associations between all of these different signals, and help the computer understand the world based on these associations. I want to be able to use any and all information out there to develop systems that will train computers to learn with minimal human supervision.
Q: What sort of research questions or issues do you hope to answer?
There is a lot of data about the world on the Internet – billions of videos are recorded every day across the world. My main research question is how can we make sense of all of this raw video content.
Q: What was the thesis proposal that you submitted for the Microsoft PhD?
The proposal was called “Video Hyperboles.” The idea is to model long videos (most of the literature nowadays is on very short clips, not long-format videos) by modeling their temporal hierarchy. For example, the action of “cutting an onion” is composed of the subactions “grabbing a knife”, “pressing the knife”, “gathering the pieces.” This forms a temporal hierarchy, in which the action “cutting an onion” is higher in the hierarchy, and the subactions are lower in the hierarchy. Hierarchies can be modeled in a geometric space called Hyperbolic Space, and thus the name “Video Hyperboles.”
I have not been working on the project directly, but I am building up pieces to eventually be able to achieve something like what I described in the proposal. I work on related topics, with the general direction of creating a video representation (for example, a hierarchy) that allows us to model video more appropriately, and helps us predict the future of a video. And I will work on this for the rest of my PhD.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research what should they know or do to prepare?
Research requires a combination of abilities that may take time to develop: patience, asking the right questions, etc. So experience is very important. My main advice would be to try to do research as soon as possible. Experience is very necessary to do research but is also important in order to decide whether or not research is for you. It is not for everyone, and the sooner you figure that out, the better.
Q: Is there anything else that you think people should know about getting a PhD?
Most of the time, a PhD is sold as a lot of pain and suffering, as working all day every day, and being very concerned about what your advisor will think of you. At least this is how it is in our field. It is sometimes seen as a competition to be a great and prolific researcher, too. And I don’t see it like that – you can enjoy (or hate) your PhD the same way you enjoy any other career path. It is all about finding the correct topics to work on, and the correct balance between research and personal life.
The Distinguished Lecture series brings computer scientists to Columbia to discuss current issues and research that are affecting their particular fields.
This year, four experts covered topics on how machine learning is used in drug discovery, software testing, RNA splicing, and surrogate loss functions:
Below are a couple of the lectures from prominent faculty from universities across the country.
Automated Test Generation: A Journey from Symbolic Execution to Smart Fuzzing and Beyond
Koushik Sen, UC Berkeley
Surrogate Loss Functions in Machine Learning: What are the Fundamental Design Principles?
Shivani Agarwal, University of Pennsylvania
Giannis Karamanolakis, a natural language processing and machine learning PhD student, talks about his research projects and how he is developing machine learning techniques for natural language processing applications.

Can you talk about your background and why you decided to pursue a PhD?
I used to live in Greece and grew up in Sitia, a small town in Crete. In 2011, I left my hometown to study electrical and computer engineering at the National Technical University of Athens (NTUA).
At NTUA, taking part in machine learning (ML) research was not planned but rather a spontaneous outcome stemming from my love for music. The initial goal for my undergraduate thesis was to build an automatic music transcription system that converts polyphonic raw audio into music sheets. However, after realizing that such a system would not be possible to develop in a limited amount of time, I worked on the simpler task of automatically tagging audio clips with descriptive tags (e.g., “car horn” for audio clips where a car horn is sound). Right after submitting a new algorithm as a conference paper, I realized that I love doing ML research.
After NTUA, I spent one and a half years working as an ML engineer at a startup called Behavioral Signals, where we trained statistical models for the recognition of core emotions from speech and text data. After a few months of ML engineering, I found myself spending more time reading research papers and evaluating new research ideas on ML and natural language processing (NLP). By then, I was confident about my decision to pursue a PhD in ML/NLP.
What about NLP did you like and when did you realize that you wanted to do research on it?
I am fascinated by the ability of humans to understand complex natural language. At the moment of writing this response, I submitted the following 10-word query to Google: “when did you realize that you wanted to do research” by keeping quotation marks so that Google looks for exact matches only. Can you guess the number of the documents returned by Google that contain this exact sequence of 10 words?
The answer that I got was 0 (zero) documents, no results! In other words, Google, a company with huge collections of documents, did not detect any document that contains this specific sequence of words. Sentences rarely recur but humans easily understand the semantics of such rare sentences.
I decided to do research on NLP when I realized that current NLP algorithms are far away from human-level language understanding. As an example back from my time at Behavioral Signals, emotion classifiers were misclassifying sentences that contained sarcasm, negation, and other complex linguistic phenomena. I could not directly fix those issues (which are prevalent beyond emotion classification), which initially felt both surprising and frustrating, but then evolved into my excitement for research on NLP.
Why did you apply to Columbia and how was that process?
The computer science department at Columbia was one of my top choices for several reasons, but I will discuss the first one.
I was excited to learn about the joint collaboration between Columbia University and the New York City Department of Health and Mental Hygiene (DOHMH), on a project that aims to understand user-generated textual content in social media (e.g., Yelp reviews, tweets) for critical public health applications, such as detecting and acting on foodborne illness outbreaks in restaurants. I could see that the project would offer the unique opportunity to do research in ML and NLP and at the same time contribute to this important public application in collaboration with epidemiologists at DOHMH. Fortunately, I have been able to work on the project, advised by Professor Luis Gravano and Associate Professor Daniel Hsu.
Applying to Columbia and other American universities was quite a stressful experience. For many months, my days were filled with working for Behavioral Signals, studying hard for high scores in GRE and TOEFL exams (both of which were required at that time by all US universities), creating a short CV for the first time, and writing a distinct statement-of-purpose for each university. I am glad to observe the recent promising changes in the PhD application procedure for our department, such as waiving the GRE requirements and offering the Pre-submission Application Review (PAR) program, in which current PhD students help applicants improve their applications. (Both of which I would have liked to have been able to take advantage of.)
What sort of research questions or issues do you hope to answer?
My research in the past few years focuses on the following question: Can we effectively train ML classifiers for NLP applications with limited training data using alternative forms of human supervision?
An important limitation of current “supervised ML” techniques is that they require large amounts of training data, which is expensive and time-consuming to obtain manually. Thus, while supervised ML techniques (especially deep neural networks) thrive in standard benchmarks, it would be too expensive to apply to emerging real-world applications with limited labeled data.
Our work attempts to address the expensive requirement of manually labeled data through novel frameworks that leverage alternative, less expensive forms of human supervision. In sentiment classification, for example, we allow domain experts to provide a small set of domain-specific rules (e.g., “happy” keyword indicates positive sentiment, “diarrhea” is a symptom of food poisoning). Under low-resource settings with no labeled data, can we leverage expert-defined rules as supervision for training state-of-the-art neural networks?
For your research papers, how did you decide to do research on those topics? How long did it take you to complete the work? Was it easy?
For my first research project at Columbia, my goal was to help epidemiologists in health departments with daily inspections of restaurant reviews that discuss food poisoning events. Restaurant reviews can be quite long, with many irrelevant sentences surrounding the truly important ones that discuss food poisoning or relevant symptoms. Thus, we developed a neural network that highlights only important sentences in potentially long reviews and deployed it for inspections in health departments, where epidemiologists could quickly focus on the relevant sentences and safely ignore the rest.
The goal behind my next research projects was to develop frameworks for addressing a broader range of text-mining tasks, such as sentiment analysis and news document classification, and for supporting multiple languages without expensive labeled data for each language. To address this goal, we initially proposed a framework for leveraging just a few domain-specific keywords as supervision for aspect detection and later extended our framework for training classifiers across 18 languages using minimal resources.
Each project took about 6 months to complete. None of them were easy; each required substantial effort in reading relevant papers, discussing potential solutions with my advisors, implementing executable code, evaluating hypotheses on real data, and repeating the same process until we were all satisfied with the solutions and evaluation results. The projects also involved meeting with epidemiologists at DOHMH, re-designing our system to satisfy several (strict) data transfer protocols imposed by health departments, and overcoming several issues related to missing data for training ML classifiers.
Your advisors are not part of the NLP group, how has that worked out for you and your projects?
It has worked great in my humble opinion. For the public health project, the expertise of Professor Gravano on information extraction, combined with the expertise of Professor Hsu on machine learning, and the technical needs of the project have contributed without any doubt to the current formulation of our NLP-related frameworks. My advisors’ feedback covers a broad spectrum of research, ranging from core technical challenges to more general research practices, such as problem formulation and paper writing.
Among others, I appreciate the freedom I have been given for exploring new interesting research questions as well as the frequent and insightful feedback that helps me to reframe questions and forming solutions. At the same time, discussions with members of the NLP group, including professors and students, have been invaluable and have clearly influenced our projects.
What do you think is the most interesting thing about doing research?
I think it is the high amount of surprise it encompasses. For many research problems that I have tried to tackle, I started by shaping an initial solution in my mind but in the process discovered surprising findings that undoubtedly changed my way of thinking – such as that my initial solution did not actually work, simpler approaches worked better than more sophisticated approaches, data followed unexpected patterns, etc. These instances of surprise turned research into an interesting experience, similar to solving riddles or listening to jazz music.
Please talk about your internships – the work you did, how was it, what did you learn?
In the summer of 2019, I worked at Amazon’s headquarters in Seattle with a team of more than 15 scientists and engineers. Our goal was to automatically extract and store knowledge about billions of products in a product knowledge graph. As part of my internship, we developed TXtract, a deep neural network that efficiently extracts information from product descriptions for thousands of product categories. TXtract has been a core component of Amazon’s AutoKnow, which provides the collected knowledge for Amazon search and product detail pages.
During the summer of 2020, I worked for Microsoft Research remotely from New York City (because of the pandemic). In collaboration with researchers at the Language and Information Technologies team, we developed a weak supervision framework that enables domain experts to express their knowledge in the form of rules and further integrates rules for training deep neural networks.
These two internships equipped me with invaluable experiences. I learned new coding tools, ML techniques, and research practices. Through the collaboration with different teams, I realized that even researchers who work on the same subfield may think in incredibly different ways, so to carry out a successful collaboration within a limited time, one needs to listen carefully, pre-define expected outcomes (with everyone in the team), and adapt fast.
Do you think your skills were improved by your time at Columbia? In which ways?
Besides having improved my problem-finding and -solving skills, I have expanded my presentation capabilities. In the beginning, I was frustrated when other people (even experienced researchers) could not follow my presentations and I was worried when I could not follow other presenters’ work. Later, I realized that if (at least part of) the audience is not able to follow a presentation, then the presentation is either flawed or has been designed for the wrong audience.
Over the past four years, I have presented my work at various academic conferences and workshops, symposiums at companies, and student seminars, and after having received constructive feedback from other researchers, I can say that my presentation skills have vastly improved. Without any doubt, I feel more confident and can explain my work to a broader type of audience with diverse expertise. That said, I’m still struggling to explain my PhD topic to my family. 🙂

What has been the highlight of your time at Columbia?
The first thing that comes to mind is the “Greek Happy Hour” that I co-organized in October 2019. More than 40 PhD students joined the happy hour, listened to Greek music (mostly “rempetika”), tasted greek specialties (including spanakopita), and all toasted loudly by saying “Γειά μας” (ya mas; the greek version of “cheers”).
Was there anything that was tough to handle while taking your PhD?

It is hard to work from home during a pandemic. A core part of my PhD used to involve multi-person collaborations, drawing illustrations on the whiteboards of the Data Science Institute, random chats in hallways, happy hours, and other social events. All these have been harder or impossible to retain during the pandemic. I miss it and look forward to enjoying it again soon.
Looking back, what would you have done differently?
If I could, I would have engaged in more discussions and collaborations, taken more classes, played more music, and slept less. 🙂
What is your advice to students on how to navigate their time at Columbia? If they want to do NLP research what should they know or do to prepare?
They should register for diverse courses; Columbia offers the opportunity to attend courses from multiple departments. They should reach out to as many people as possible and do not hesitate to email graduate students and professors. I love receiving emails from people that I haven’t met before, some of which stimulated creative collaborations.
For those that want to do NLP research (which I highly recommend–subjectively speaking), you should contact me or any person in the NLP group.
What are your plans after Columbia?
I plan to continue working on research, either as a faculty member or in an industry research and development department.
Is there anything else that you think people should know?
Columbia offers free and discounted tickets to museums and performances around New York City, even virtual art events. I personally consider New York as the “state-of-the-art”.
Papers from CS researchers have been accepted to the 38th International Conference on Machine Learning (ICML 2021).
Associate Professor Daniel Hsu was one of the publication chairs of the conference and Assistant Professor Elham Azizi helped organize the 2021 ICML Workshop on Computational Biology. The workshop highlighted how machine learning approaches can be tailored to making both translational and basic scientific discoveries with biological data.
Below are the abstracts and links to the accepted papers.
A Proxy Variable View of Shared Confounding
Yixin Wang Columbia University, David Blei Columbia University
Causal inference from observational data can be biased by unobserved confounders. Confounders—the variables that affect both the treatments and the outcome—induce spurious non-causal correlations between the two. Without additional conditions, unobserved confounders generally make causal quantities hard to identify. In this paper, we focus on the setting where there are many treatments with shared confounding, and we study under what conditions is causal identification possible. The key observation is that we can view subsets of treatments as proxies of the unobserved confounder and identify the intervention distributions of the rest. Moreover, while existing identification formulas for proxy variables involve solving integral equations, we show that one can circumvent the need for such solutions by directly modeling the data. Finally, we extend these results to an expanded class of causal graphs, those with other confounders and selection variables.
Unsupervised Representation Learning via Neural Activation Coding
Yookoon Park Columbia University, Sangho Lee Seoul National University, Gunhee Kim Seoul National University, David Blei Columbia University
We present neural activation coding (NAC) as a novel approach for learning deep representations from unlabeled data for downstream applications. We argue that the deep encoder should maximize its nonlinear expressivity on the data for downstream predictors to take full advantage of its representation power. To this end, NAC maximizes the mutual information between activation patterns of the encoder and the data over a noisy communication channel. We show that learning for a noise-robust activation code increases the number of distinct linear regions of ReLU encoders, hence the maximum nonlinear expressivity. More interestingly, NAC learns both continuous and discrete representations of data, which we respectively evaluate on two downstream tasks: (i) linear classification on CIFAR-10 and ImageNet-1K and (ii) nearest neighbor retrieval on CIFAR-10 and FLICKR-25K. Empirical results show that NAC attains better or comparable performance on both tasks over recent baselines including SimCLR and DistillHash. In addition, NAC pretraining provides significant benefits to the training of deep generative models. Our code is available at https://github.com/yookoon/nac.
The Logical Options Framework
Brandon Araki MIT, Xiao Li MIT, Kiran Vodrahalli Columbia University, Jonathan DeCastro Toyota Research Institute, Micah Fry MIT Lincoln Laboratory, Daniela Rus MIT CSAIL
Learning composable policies for environments with complex rules and tasks is a challenging problem. We introduce a hierarchical reinforcement learning framework called the Logical Options Framework (LOF) that learns policies that are satisfying, optimal, and composable. LOF efficiently learns policies that satisfy tasks by representing the task as an automaton and integrating it into learning and planning. We provide and prove conditions under which LOF will learn satisfying, optimal policies. And lastly, we show how LOF’s learned policies can be composed to satisfy unseen tasks with only 10-50 retraining steps on our benchmarks. We evaluate LOF on four tasks in discrete and continuous domains, including a 3D pick-and-place environment.
Estimating Identifiable Causal Effects on Markov Equivalence Class through Double Machine Learning
Yonghan Jung Columbia University, Jin Tian Columbia University, Elias Bareinboim Columbia University
General methods have been developed for estimating causal effects from observational data under causal assumptions encoded in the form of a causal graph. Most of this literature assumes that the underlying causal graph is completely specified. However, only observational data is available in most practical settings, which means that one can learn at most a Markov equivalence class (MEC) of the underlying causal graph. In this paper, we study the problem of causal estimation from a MEC represented by a partial ancestral graph (PAG), which is learnable from observational data. We develop a general estimator for any identifiable causal effects in a PAG. The result fills a gap for an end-to-end solution to causal inference from observational data to effects estimation. Specifically, we develop a complete identification algorithm that derives an influence function for any identifiable causal effects from PAGs. We then construct a double/debiased machine learning (DML) estimator that is robust to model misspecification and biases in nuisance function estimation, permitting the use of modern machine learning techniques. Simulation results corroborate with the theory.
Environment Inference for Invariant Learning
Elliot Creager University of Toronto, Joern Jacobsen Apple Inc., Richard Zemel Columbia University
Learning models that gracefully handle distribution shifts is central to research on domain generalization, robust optimization, and fairness. A promising formulation is domain-invariant learning, which identifies the key issue of learning which features are domain-specific versus domain-invariant. An important assumption in this area is that the training examples are partitioned into domains'' orenvironments”. Our focus is on the more common setting where such partitions are not provided. We propose EIIL, a general framework for domain-invariant learning that incorporates Environment Inference to directly infer partitions that are maximally informative for downstream Invariant Learning. We show that EIIL outperforms invariant learning methods on the CMNIST benchmark without using environment labels, and significantly outperforms ERM on worst-group performance in the Waterbirds dataset. Finally, we establish connections between EIIL and algorithmic fairness, which enables EIIL to improve accuracy and calibration in a fair prediction problem.
SketchEmbedNet: Learning Novel Concepts by Imitating Drawings
Alex Wang University of Toronto, Mengye Ren University of Toronto, Richard Zemel Columbia University
Sketch drawings capture the salient information of visual concepts. Previous work has shown that neural networks are capable of producing sketches of natural objects drawn from a small number of classes. While earlier approaches focus on generation quality or retrieval, we explore properties of image representations learned by training a model to produce sketches of images. We show that this generative, class-agnostic model produces informative embeddings of images from novel examples, classes, and even novel datasets in a few-shot setting. Additionally, we find that these learned representations exhibit interesting structure and compositionality.
Universal Template for Few-Shot Dataset Generalization
Eleni Triantafillou University of Toronto, Hugo Larochelle Google Brain, Richard Zemel Columbia University, Vincent Dumoulin Google
Few-shot dataset generalization is a challenging variant of the well-studied few-shot classification problem where a diverse training set of several datasets is given, for the purpose of training an adaptable model that can then learn classes from \emph{new datasets} using only a few examples. To this end, we propose to utilize the diverse training set to construct a \emph{universal template}: a partial model that can define a wide array of dataset-specialized models, by plugging in appropriate components. For each new few-shot classification problem, our approach therefore only requires inferring a small number of parameters to insert into the universal template. We design a separate network that produces an initialization of those parameters for each given task, and we then fine-tune its proposed initialization via a few steps of gradient descent. Our approach is more parameter-efficient, scalable and adaptable compared to previous methods, and achieves the state-of-the-art on the challenging Meta-Dataset benchmark.
On Monotonic Linear Interpolation of Neural Network Parameters
James Lucas University of Toronto, Juhan Bae University of Toronto, Michael Zhang University of Toronto, Stanislav Fort Google AI, Richard Zemel Columbia University, Roger Grosse University of Toronto
Linear interpolation between initial neural network parameters and converged parameters after training with stochastic gradient descent (SGD) typically leads to a monotonic decrease in the training objective. This Monotonic Linear Interpolation (MLI) property, first observed by Goodfellow et al. 2014, persists in spite of the non-convex objectives and highly non-linear training dynamics of neural networks. Extending this work, we evaluate several hypotheses for this property that, to our knowledge, have not yet been explored. Using tools from differential geometry, we draw connections between the interpolated paths in function space and the monotonicity of the network — providing sufficient conditions for the MLI property under mean squared error. While the MLI property holds under various settings (e.g., network architectures and learning problems), we show in practice that networks violating the MLI property can be produced systematically, by encouraging the weights to move far from initialization. The MLI property raises important questions about the loss landscape geometry of neural networks and highlights the need to further study their global properties.
A Computational Framework For Slang Generation
Zhewei Sun University of Toronto, Richard Zemel Columbia University, Yang Xu University of Toronto
Slang is a common type of informal language, but its flexible nature and paucity of data resources present challenges for existing natural language systems. We take an initial step toward machine generation of slang by developing a framework that models the speaker’s word choice in slang context. Our framework encodes novel slang meaning by relating the conventional and slang senses of a word while incorporating syntactic and contextual knowledge in slang usage. We construct the framework using a combination of probabilistic inference and neural contrastive learning. We perform rigorous evaluations on three slang dictionaries and show that our approach not only outperforms state-of-the-art language models, but also better predicts the historical emergence of slang word usages from 1960s to 2000s. We interpret the proposed models and find that the contrastively learned semantic space is sensitive to the similarities between slang and conventional senses of words. Our work creates opportunities for the automated generation and interpretation of informal language.
Wandering Within A World: Online Contextualized Few-Shot Learning
Mengye Ren University of Toronto, Michael Iuzzolino Google Research, Michael Mozer Google Research, Richard Zemel Columbia University
We aim to bridge the gap between typical human and machine-learning environments by extending the standard framework of few-shot learning to an online, continual setting. In this setting, episodes do not have separate training and testing phases, and instead models are evaluated online while learning novel classes. As in the real world, where the presence of spatiotemporal context helps us retrieve learned skills in the past, our online few-shot learning setting also features an underlying context that changes throughout time. Object classes are correlated within a context and inferring the correct context can lead to better performance. Building upon this setting, we propose a new few-shot learning dataset based on large scale indoor imagery that mimics the visual experience of an agent wandering within a world. Furthermore, we convert popular few-shot learning approaches into online versions and we also propose a new contextual prototypical memory model that can make use of spatiotemporal contextual information from the recent past.
Bayesian Few-Shot Classification With One-Vs-Each Polya-Gamma Augmented Gaussian Processes
Jake Snell University of Toronto, Richard Zemel Columbia University
Few-shot classification (FSC), the task of adapting a classifier to unseen classes given a small labeled dataset, is an important step on the path toward human-like machine learning. Bayesian methods are well-suited to tackling the fundamental issue of overfitting in the few-shot scenario because they allow practitioners to specify prior beliefs and update those beliefs in light of observed data. Contemporary approaches to Bayesian few-shot classification maintain a posterior distribution over model parameters, which is slow and requires storage that scales with model size. Instead, we propose a Gaussian process classifier based on a novel combination of Pólya-Gamma augmentation and the one-vs-each softmax approximation that allows us to efficiently marginalize over functions rather than model parameters. We demonstrate improved accuracy and uncertainty quantification on both standard few-shot classification benchmarks and few-shot domain transfer tasks.
Theoretical Bounds On Estimation Error For Meta-Learning
James Lucas University of Toronto, Mengye Ren University of Toronto, Irene Kameni African Master for Mathematical Sciences, Toni Pitassi Columbia University, Richard Zemel Columbia University
Machine learning models have traditionally been developed under the assumption that the training and test distributions match exactly. However, recent success in few-shot learning and related problems are encouraging signs that these models can be adapted to more realistic settings where train and test distributions differ. Unfortunately, there is severely limited theoretical support for these algorithms and little is known about the difficulty of these problems. In this work, we provide novel information-theoretic lower-bounds on minimax rates of convergence for algorithms that are trained on data from multiple sources and tested on novel data. Our bounds depend intuitively on the information shared between sources of data, and characterize the difficulty of learning in this setting for arbitrary algorithms. We demonstrate these bounds on a hierarchical Bayesian model of meta-learning, computing both upper and lower bounds on parameter estimation via maximum-a-posteriori inference.
A PAC-Bayesian Approach To Generalization Bounds For Graph Neural Networks
Renjie Liao University of Toronto, Raquel Urtasun University of Toronto, Richard Zemel Columbia University
In this paper, we derive generalization bounds for the two primary classes of graph neural networks (GNNs), namely graph convolutional networks (GCNs) and message passing GNNs (MPGNNs), via a PAC-Bayesian approach. Our result reveals that the maximum node degree and spectral norm of the weights govern the generalization bounds of both models. We also show that our bound for GCNs is a natural generalization of the results developed in arXiv:1707.09564v2 [cs.LG] for fully-connected and convolutional neural networks. For message passing GNNs, our PAC-Bayes bound improves over the Rademacher complexity based bound in arXiv:2002.06157v1 [cs.LG], showing a tighter dependency on the maximum node degree and the maximum hidden dimension. The key ingredients of our proofs are a perturbation analysis of GNNs and the generalization of PAC-Bayes analysis to non-homogeneous GNNs. We perform an empirical study on several real-world graph datasets and verify that our PAC-Bayes bound is tighter than others.
Assistant Professor Carl Vondrick has won the National Science Foundation’s (NSF) Faculty Early Career Development award for his proposal program to develop machine perception systems that robustly detect and track objects even when they disappear from sight, thereby enabling machines to build spatial awareness of their surroundings.
The Distinguished Lecture series brings computer scientists to Columbia to discuss current issues and research that are affecting their particular fields. This year, eight experts covered topics ranging from machine learning, human-computer interaction, neural language models, law and public policy, psychology, and computer architecture.
Below are a couple of the lectures from prominent faculty from universities across the country.
Payal Chandak (CC ’21) developed a machine learning model, AwareDX, that helps detect adverse drug effects specific to women patients. AwareDX mitigates sex biases in a drug safety dataset maintained by the FDA.
Below, Chandak talks about how her internship under the guidance of Nicholas Tatonetti, associate professor of biomedical informatics and a member of the Data Science Institute, inspired her to develop a machine learning tool to improve healthcare for women.

How did the project come about?
I initiated this project during my internship at the Tatonetti Lab (T-lab) the summer after my first year. T-lab uses data science to study the side effects of drugs. I did some background research and learned that women face a two-fold greater risk of adverse events compared to men. While knowledge of sex differences in drug response is critical to drug prescription, there currently isn’t a comprehensive understanding of these differences. Dr. Tatonetti and I felt that we could use machine learning to tackle this problem and that’s how the project was born.
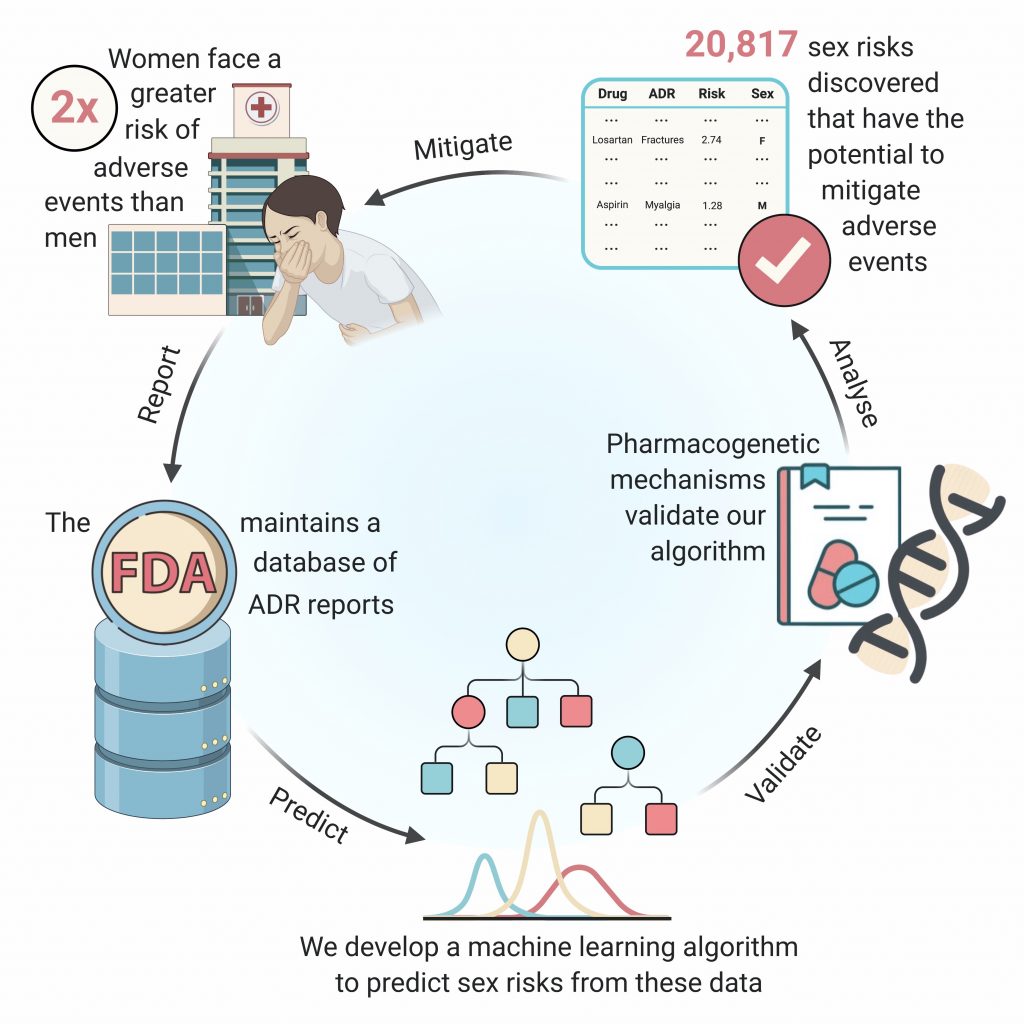
How many hours did you work on the project? How long did it last?
The project lasted about two years. We refined our machine learning (ML) model, AwareDX, over many iterations to make it less susceptible to biases in the data. I probably spent a ridiculous number of hours developing it but the journey has been well worth it.
Were you prepared to work on it or did you learn as the project progressed?
As a first-year student, I definitely didn’t know much when I started. Learning on the go became the norm. I understood some things by taking relevant CS classes and through reading Medium blogs and GitHub repositories –– this ability to learn independently might be one of the most valuable skills I have gained. I am very fortunate that Dr. Tatonetti guided me through this process and invested his time in developing my knowledge.
What were the things you already knew and what were the things you had to learn while working on the project?
While I was familiar with biology and mathematics, computer science was totally new! In fact, T-Lab launched my journey to exploring computer science. This project exposed me to the great potential of artificial intelligence (AI) for revolutionizing healthcare, which in turn inspired me to explore the discipline academically. I went back and forth between taking classes relevant to my research and applying what I learned in class to my research. As I took increasingly technical classes like ML and probabilistic modelling, I was able to advance my abilities.
Looking back, what were the skills that you wished you had before the project?
Having some experience with implementing real-world machine learning projects on giant datasets with millions of observations would have been very valuable.
Was this your first project to collaborate on? How was it?
This was my first project and I worked under the guidance of Dr. Tatonetti. I thought it was a wonderful experience – not only has it been extremely rewarding to see my work come to fruition, but the journey itself has been so valuable. And Dr. Tatonetti has been the best mentor that I could have asked for!
Did working on this project make you change your research interests?
I actually started off as pre-med. I was fascinated by the idea that “intelligent machines” could be used to improve medicine, and so I joined T-Lab. Over time, I’ve realized that recent advances in machine learning could redefine how doctors interact with their patients. These technologies have an incredible potential to assist with diagnosis, identify medical errors, and even recommend treatments. My perspective on how I could contribute to healthcare shifted completely, and I decided that bioinformatics has more potential to change the practice of medicine than a single doctor will ever have. This is why I’m now hoping to pursue a PhD in Biomedical Informatics.
Do you think your skills were enhanced by working on the project?
Both my knowledge of ML and statistics and my ability to implement my ideas have grown immensely as a result of working on this project. Also, I failed about seven times over two years. We were designing the algorithm and it was an iterative process – the initial versions of the algorithm had many flaws and we started from scratch multiple times. The entire process required a lot of patience and persistence since it took over 2 years! So, I guess it has taught me immense patience and persistence.
Why did you decide to intern at the T-Lab?
I was curious to learn more about the intersection of artificial intelligence and healthcare. I’m endlessly fascinated by the idea of improving the standards of healthcare by using machine learning models to assist doctors.
Would you recommend volunteering or seeking projects out to other students?
Absolutely. I think everyone should explore research. We have incredible labs here at Columbia with the world’s best minds leading them. Research opens the doors to work closely with them. It creates an environment for students to learn about a niche discipline and to apply the knowledge they gain in class.
CS researchers develop a new machine learning approach that shows promise in predicting necrotizing enterocolitis; could lead to improved medical decision-making in neonatal ICUs.
Almost 400,000 babies were born prematurely—before 37 weeks gestation—in 2018 in the United States. One of the leading causes of newborn deaths and long-term disabilities, preterm birth (PTB) is considered a public health problem with deep emotional and challenging financial consequences to families and society. If doctors were able to use data and artificial intelligence (AI) to predict which pregnant women might be at risk, many of these premature births might be avoided.
The 33rd Conference on Neural Information Processing Systems (NeurIPS 2019) fosters the exchange of research on neural information processing systems in their biological, technological, mathematical, and theoretical aspects.
The annual meeting is one of the premier gatherings in artificial intelligence and machine learning that featured talks, demos from industry partners as well as tutorials. Professor Vishal Misra, with colleagues from the Massachusetts Institute of Technology (MIT), held a tutorial on synthetic control.
At this year’s NeurIPS, 21 papers from the department were accepted to the conference. Computer science professors and students worked with researchers from the statistics department and the Data Science Institute.
Noise-tolerant Fair Classification
Alex Lamy Columbia University, Ziyuan Zhong Columbia University, Aditya Menon Google, Nakul Verma Columbia University
Fairness-aware learning involves designing algorithms that do not discriminate with respect to some sensitive feature (e.g., race or gender) and is usually done under the assumption that the sensitive feature available in a training sample is perfectly reliable.
This assumption may be violated in many real-world cases: for example, respondents to a survey may choose to conceal or obfuscate their group identity out of fear of potential discrimination. In the paper, the researchers show that fair classifiers can still be used given noisy sensitive features by simply changing the desired fairness-tolerance. Their procedure is empirically effective on two relevant real-world case-studies involving sensitive feature censoring.
Poisson-randomized Gamma Dynamical Systems
Aaron Schein UMass Amherst, Scott Linderman Columbia University, Mingyuan Zhou University of Texas at Austin, David Blei Columbia University, Hanna Wallach MSR NYC
This paper presents a new class of state space models for count data. It derives new properties of the Poisson-randomized gamma distribution for efficient posterior inference.
Using Embeddings to Correct for Unobserved Confounding in Networks
Victor Veitch Columbia University, Yixin Wang Columbia University, David Blei Columbia University
This paper address causal inference in the presence of unobserved confounder when proxy is available for the confounders in the form of a network connecting the units. For example, the link structure of friendships in a social network reveals information about the latent preferences of people in that network. The researchers show how modern network embedding methods can be exploited to harness the network estimation for efficient causal adjustment.
Variational Bayes Under Model Misspecification
Yixin Wang Columbia University, David Blei Columbia University
The paper characterizes the theoretical properties of a popular machine learning algorithm, variational Bayes (VB). The researchers studied the VB under model misspecification, which is the setting that is most aligned with the practice, and show that the VB posterior is asymptotically normal and centers at the value that minimizes the Kullback-Leibler (KL) divergence to the true data-generating distribution.
As a consequence, they found that the model misspecification error dominates the variational approximation error in VB posterior predictive distributions. In other words, VB pays a negligible price in producing posterior predictive distributions. It explains the widely observed phenomenon that VB achieves comparable predictive accuracy with MCMC even though VB uses an approximating family.
Poincaré Recurrence, Cycles and Spurious Equilibria in Gradient-Descent-Ascent for Non-Convex Non-Concave Zero-Sum Games
Emmanouil-Vasileios Vlatakis-Gkaragkounis Columbia University, Lampros Flokas Columbia University, Georgios Piliouras Singapore University of Technology and Design
The paper introduces a model that captures a min-max competition over complex error landscapes and shows that even a simplified model can provably replicate some of the most commonly reported failure modes of GANs (non-convergence, deadlock in suboptimal states, etc).
Moreover, the researchers were able to understand the hidden structure in these systems — the min-max competition can lead to system behavior that is similar to that of energy preserving systems in physics (e.g. connected pendulums, many-body problems, etc). This makes it easier to understand why these systems can fail and gives new tools in the design of algorithms for training GANs.
Near-Optimal Reinforcement Learning in Dynamic Treatment Regimes
Junzhe Zhang Columbia University, Elias Bareinboim Columbia University
Dynamic Treatment Regimes (DTRs) are particularly effective for managing chronic disorders and is arguably one of the key aspects towards more personalized decision-making. The researchers developed the first adaptive algorithm that achieves near-optimal regret in DTRs in online settings, while leveraging the abundant, yet imperfect confounded observations. Applications are given to personalized medicine and treatment recommendation in clinical decision support.
Paraphrase Generation with Latent Bag of Words
Yao Fu Columbia University, Yansong Feng Peking University, John Cunningham University of Columbia
The paper proposes a latent bag of words model for differentiable content planning and surface realization in text generation. This model generates paraphrases with clear steps, adding interpretability and controllability of existing neural text generation models.
Adapting Neural Networks for the Estimation of Treatment Effects
Claudia Shi Columbia University, David Blei Columbia University, Victor Veitch Columbia University
This paper addresses how to design neural networks to get very accurate estimates of causal effects from observational data. The researchers propose two methods based on insights from the statistical literature on the estimation of treatment effects.
The first is a new architecture, the Dragonnet, that exploits the sufficiency of the propensity score for estimation adjustment. The second is a regularization procedure, targeted regularization, that induces a bias towards models that have non-parametrically optimal asymptotic properties “out-of-the-box”. Studies on benchmark datasets for causal inference show these adaptations outperform existing methods.
Efficiently Avoiding Saddle Points with Zero Order Methods: No Gradients Required
Emmanouil-Vasileios Vlatakis-Gkaragkounis Columbia University, Lampros Flokas Columbia University, Georgios Piliouras Singapore University of Technology and Design
The researchers prove that properly tailored zero-order methods are as effective as their first-order counterparts. This analysis requires a combination of tools from optimization theory, probability theory and dynamical systems to show that even without perfect knowledge of the shape of the error landscape, effective optimization is possible.
Metric Learning for Adversarial Robustness
Chengzhi Mao Columbia University, Ziyuan Zhong Columbia University, Junfeng Yang Columbia University, Carl Vondrick Columbia University, Baishakhi Ray Columbia University
Deep networks are well-known to be fragile to adversarial attacks. The paper introduces a novel Triplet Loss Adversarial (TLA) regulation that is the first method that leverages metric learning to improve the robustness of deep networks. This method is inspired by the evidence that deep networks suffer from distorted feature space under adversarial attacks. The method increases the model robustness and efficiency for the detection of adversarial attacks significantly.
Efficient Symmetric Norm Regression via Linear Sketching
Zhao Song University of Washington, Ruosong Wang Carnegie Mellon University, Lin Yang Johns Hopkins University, Hongyang Zhang TTIC, Peilin Zhong Columbia University
The paper studies linear regression problems with general symmetric norm loss and gives efficient algorithms for solving such linear regression problems via sketching techniques.
Rethinking Generative Coverage: A Pointwise Guaranteed Approach
Peilin Zhong Columbia University, Yuchen Mo Columbia University, Chang Xiao Columbia University, Pengyu Chen Columbia University, Changxi Zheng Columbia University
The paper presents a novel and formal definition of mode coverage for generative models. It also gives a boosting algorithm to achieve this mode coverage guarantee.
How Many Variables Should Be Entered in a Principal Component Regression Equation?
Ji Xu Columbia University, Daniel Hsu Columbia University
The researchers studied the least-squares linear regression over $N$ uncorrelated Gaussian features that are selected in order of decreasing variance with the number of selected features $p$ can be either smaller or greater than the sample size $n$. And give an average-case analysis of the out-of-sample prediction error as $p,n,N \to \infty$ with $p/N \to \alpha$ and $n/N \to \beta$, for some constants $\alpha \in [0,1]$ and $\beta \in (0,1)$. In this average-case setting, the prediction error exhibits a “double descent” shape as a function of $p$. This also establishes conditions under which the minimum risk is achieved in the interpolating ($p>n$) regime.
Adaptive Influence Maximization with Myopic Feedback
Binghui Peng Columbia University, Wei Chen Microsoft Research
The paper investigates the adaptive influence maximization problem and provides upper and lower bounds for the adaptivity gaps under myopic feedback model. The results confirm a long standing open conjecture by Golovin and Krause (2011).
Towards a Zero-One Law for Column Subset Selection
Zhao Song University of Washington, David Woodruff Carnegie Mellon University, Peilin Zhong Columbia University
The researchers studied low-rank matrix approximation with general loss function and showed that if the loss function has several good properties, then there is an efficient way to compute a good low-rank approximation. Otherwise, it could be hard to compute a good low-rank approximation efficiently.
Average Case Column Subset Selection for Entrywise l1-Norm Loss
Zhao Song University of Washington, David Woodruff Carnegie Mellon University, Peilin Zhong Columbia University
The researchers studied how to compute an l1-norm loss low-rank matrix approximation to a given matrix. And showed that if the given matrix can be decomposed into a low-rank matrix and a noise matrix with a mild distributional assumption, we can obtain a (1+eps) approximation to the optimal solution.
A New Distribution on the Simplex with Auto-Encoding Applications
Andrew Stirn Columbia University, Tony Jebara Spotify, David Knowles Columbia University
The researchers developed a surrogate distribution for the Dirichlet that offers explicit, tractable reparameterization, the ability to capture sparsity, and has barycentric symmetry properties (i.e. exchangeability) equivalent to the Dirichlet. Previous works have used the Kumaraswamy distribution in a stick-breaking process to create a non-exchangeable distribution on the simplex. The method was improved by restoring exchangeability and demonstrating that approximate exchangeability is efficiently achievable. Lastly, the method was showcased in a variety of VAE semi-supervised learning tasks.
Discrete Flows: Invertible Generative Models of Discrete Data
Dustin Tran Google Brain, Keyon Vafa Columbia University, Kumar Agrawal Google AI Resident, Laurent Dinh Google Brain, Ben Poole Google Brain
While normalizing flows have led to significant advances in modeling high-dimensional continuous distributions, their applicability to discrete distributions remains unknown. The researchers extend normalizing flows to discrete events, using a simple change-of-variables formula not requiring log-determinant-Jacobian computations. Empirically, they find that discrete flows obtain competitive performance with or outperform autoregressive baselines on various tasks, including addition, Potts models, and language models.
Characterization and Learning of Causal Graphs with Latent Variables from Soft Interventions
Murat Kocaoglu MIT-IBM Watson AI Lab IBM Research, Amin Jaber Purdue University, Karthikeyan Shanmugam MIT-IBM Watson AI Lab IBM Research NY, Elias Bareinboim Columbia University
This work is all about learning causal relationships – the classic aim of which is to characterize all possible sets that could produce the observed data. In the paper, the researchers provide a complete characterization of all possible causal graphs with observational and interventional data involving so-called ‘soft interventions’ on variables when the targets of soft interventions are known.
This work potentially could lead to discovery of other novel learning algorithms that are both sound and complete.
Identification of Conditional Causal Effects Under Markov Equivalence
Amin Jaber Purdue University, Jiji Zhang Lingnan University, Elias Bareinboim Columbia University
Causal identification is the problem of deciding whether a causal distribution is computable from a combination of qualitative knowledge about the underlying data-generating process, which is usually encoded in the form of a causal graph, and an observational distribution. Despite the obvious need for identifying causal effects throughout the data-driven sciences, in practice, finding the causal graph is a notoriously challenging task.
In this work, the researchers provide a relaxation of the requirement of having to specify the causal graph (based on substantive knowledge) and allow the input of the inference to be an equivalence class of causal graphs, which can be inferred from data. Specifically, they propose the first general algorithm to learn conditional causal effects entirely from data. This result is particularly useful for evaluating the impact of conditional plans and stochastic policies, which appear both in AI (in the context of reinforcement learning) and in the data-driven sciences.
Efficient Identification in Linear Structural Causal Models with Instrumental Cutsets
Daniel Kumor Purdue University, Bryant Chen Brex Inc., Elias Bareinboim Columbia University
Regression analysis is one of the most common tools used in modern data science. While there is a great understanding and powerful technology to perform regression analysis in high dimensional spaces, the output of such a method is purely associational and devoid of any causal interpretation.
The researchers studied the problem of identification of structural (causal) coefficients in linear systems (deciding whether regression coefficients are amenable to causal interpretation, etc). Building on a technique called instrumental variables, they developed a new method called Instrumental Cutset, which partitions the systems into tractable components such that identification can be decided more efficiently. The resulting algorithm was efficient and strictly more powerful than the current state-of-the-art methods.