
Meet Columbia Engineering’s 2023 Valedictorian and Salutatorian
CS students Ethan Wu and Julia Zhao share what they’ll remember from Columbia as they look ahead to the future.
CS students Ethan Wu and Julia Zhao share what they’ll remember from Columbia as they look ahead to the future.
The AI Institute for Artificial and Natural Intelligence (ARNI) will be led by CS professors Richard Zemel, Kathleen McKeown, and Christos Papadimitriou, as well as Liam Paninski of the Zuckerman Institute and Xaq Pitkow of Baylor College of Medicine and Rice University.
Research papers from the department were accepted to the 11th International Conference on Learning Representations (ICLR 2023). ICLR is the premier conference on deep learning where researchers gather to discuss their work in the fields of artificial intelligence, statistics, and data science.
Visual Classification via Description from Large Language Models
Sachit Menon Columbia University, Carl Vondrick Columbia University
Keywords: vision-language models, CLIP, prompting, GPT-3, large language models, zero-shot recognition, multimodal
TL;DR: We enhance zero-shot recognition with vision-language models by comparing to category descriptors from GPT-3, enabling better performance in an interpretable setting that also allows for the incorporation of new concepts and bias mitigation.
Abstract:
Vision-language models such as CLIP have shown promising performance on a variety of recognition tasks using the standard zero-shot classification procedure — computing similarity between the query image and the embedded words for each category. By only using the category name, they neglect to make use of the rich context of additional information that language affords. The procedure gives no intermediate understanding of why a category is chosen and furthermore provides no mechanism for adjusting the criteria used towards this decision. We present an alternative framework for classification with VLMs, which we call classification by description. We ask VLMs to check for descriptive features rather than broad categories: to find a tiger, look for its stripes; its claws; and more. By basing decisions on these descriptors, we can provide additional cues that encourage using the features we want to be used. In the process, we can get a clear idea of what the model “thinks” it is seeing to make its decision; it gains some level of inherent explainability. We query large language models (e.g., GPT-3) for these descriptors to obtain them in a scalable way. Extensive experiments show our framework has numerous advantages past interpretability. We show improvements in accuracy on ImageNet across distribution shifts; demonstrate the ability to adapt VLMs to recognize concepts unseen during training; and illustrate how descriptors can be edited to effectively mitigate bias compared to the baseline.
CROM: Continuous Reduced-Order Modeling of PDEs Using Implicit Neural Representations
Peter Yichen Chen Columbia University, Jinxu Xiang Columbia University, Dong Heon Cho Columbia University, Yue Chang University of Toronto, G A Pershing Columbia University, Henrique Teles Maia Columbia University, Maurizio M Chiaramonte Meta Reality Labs Research, Kevin Thomas Carlberg Meta Reality Labs Research, Eitan Grinspun University of Toronto
Keywords: PDE, implicit neural representation, neural field, latent space traversal, reduced-order modeling, numerical methods
TL;DR: We accelerate PDE solvers via rapid latent space traversal of continuous vector fields leveraging implicit neural representations.
Abstract:
The long runtime of high-fidelity partial differential equation (PDE) solvers makes them unsuitable for time-critical applications. We propose to accelerate PDE solvers using reduced-order modeling (ROM). Whereas prior ROM approaches reduce the dimensionality of discretized vector fields, our continuous reduced-order modeling (CROM) approach builds a low-dimensional embedding of the continuous vector fields themselves, not their discretization. We represent this reduced manifold using continuously differentiable neural fields, which may train on any and all available numerical solutions of the continuous system, even when they are obtained using diverse methods or discretizations. We validate our approach on an extensive range of PDEs with training data from voxel grids, meshes, and point clouds. Compared to prior discretization-dependent ROM methods, such as linear subspace proper orthogonal decomposition (POD) and nonlinear manifold neural-network-based autoencoders, CROM features higher accuracy, lower memory consumption, dynamically adaptive resolutions, and applicability to any discretization. For equal latent space dimension, CROM exhibits 79x and 49x better accuracy, and 39x and 132x smaller memory footprint, than POD and autoencoder methods, respectively. Experiments demonstrate 109x and 89x wall-clock speedups over unreduced models on CPUs and GPUs, respectively. Videos and codes are available on the project page: https://crom-pde.github.io
Quantile Risk Control: A Flexible Framework for Bounding the Probability of High-Loss Predictions
Jake Snell Princeton University, Thomas P Zollo Columbia University, Zhun Deng Columbia University, Toniann Pitassi Columbia University, Richard Zemel Columbia University
Keywords: distribution-free uncertainty quantification
TL;DR: We propose a framework to rigorously and flexible control the quantiles of the loss distribution incurred by a predictor or set of predictors.
Abstract:
Rigorous guarantees about the performance of predictive algorithms are necessary in order to ensure their responsible use. Previous work has largely focused on bounding the expected loss of a predictor, but this is not sufficient in many risk-sensitive applications where the distribution of errors is important. In this work, we propose a flexible framework to produce a family of bounds on quantiles of the loss distribution incurred by a predictor. Our method takes advantage of the order statistics of the observed loss values rather than relying on the sample mean alone. We show that a quantile is an informative way of quantifying predictive performance, and that our framework applies to a variety of quantile-based metrics, each targeting important subsets of the data distribution. We analyze the theoretical properties of our proposed method and demonstrate its ability to rigorously control loss quantiles on several real-world datasets.
Causal Imitation Learning via Inverse Reinforcement Learning
Kangrui Ruan Columbia University, Junzhe Zhang Columbia University, Xuan Di Columbia University, Elias Bareinboim Columbia University
Keywords: Causal Inference, Graphical Models
TL;DR: This paper proposes novel inverse reinforcement learning methods to learn effective imitating policies from the expert’s demonstrations when unobserved confounders are present.
Abstract:
One of the most common ways children learn when unfamiliar with the environment is by mimicking adults. Imitation learning concerns an imitator learning to behave in an unknown environment from an expert’s demonstration; reward signals remain latent to the imitator. This paper studies imitation learning through causal lenses and extends the analysis and tools developed for behavior cloning (Zhang, Kumor, Bareinboim, 2020) to inverse reinforcement learning. First, we propose novel graphical conditions that allow the imitator to learn a policy performing as well as the expert’s behavior policy, even when the imitator and the expert’s state-action space disagree, and unobserved confounders (UCs) are present. When provided with parametric knowledge about the unknown reward function, such a policy may outperform the expert’s. Also, our method is easily extensible and allows one to leverage existing IRL algorithms even when UCs are present, including the multiplicative-weights algorithm (MWAL) (Syed & Schapire, 2008) and the generative adversarial imitation learning (GAIL) (Ho & Ermon, 2016). Finally, we validate our framework by simulations using real-world and synthetic data.
Neural Causal Models for Counterfactual Identification and Estimation
Kevin Muyuan Xia Columbia University, Yushu Pan Columbia University, Elias Bareinboim Columbia University
Keywords: causal inference, deep learning, neural models, neural causal models, causal identification, causal estimation, counterfactual
TL;DR: We solve the two problems of counterfactual identification and estimation from arbitrary surrogate experiments using a Generative Adversarial Network implementation of the Neural Causal Model.
Abstract:
Evaluating hypothetical statements about how the world would be had a different course of action been taken is arguably one key capability expected from modern AI systems. Counterfactual reasoning underpins discussions in fairness, the determination of blame and responsibility, credit assignment, and regret. In this paper, we study the evaluation of counterfactual statements through neural models. Specifically, we tackle two causal problems required to make such evaluations, i.e., counterfactual identification and estimation from an arbitrary combination of observational and experimental data. First, we show that neural causal models (NCMs) are expressive enough and encode the structural constraints necessary for performing counterfactual reasoning. Second, we develop an algorithm for simultaneously identifying and estimating counterfactual distributions. We show that this algorithm is sound and complete for deciding counterfactual identification in general settings. Third, considering the practical implications of these results, we introduce a new strategy for modeling NCMs using generative adversarial networks. Simulations corroborate with the proposed methodology.
Understanding Zero-shot Adversarial Robustness for Large-Scale Models
Chengzhi Mao Columbia University, Scott Geng Columbia University, Junfeng Yang Columbia University, Xin Wang Microsoft Research, Carl Vondrick Columbia University
Keywords: Adversarial Robustness, Zero-Shot Recognition
Abstract:
Pretrained large-scale vision-language models like CLIP have exhibited strong generalization over unseen tasks. Yet imperceptible adversarial perturbations can significantly reduce CLIP’s performance on new tasks. In this work, we identify and explore the problem of adapting large-scale models for zero-shot adversarial robustness. We first identify two key factors during model adaption–training losses and adaptation methods–that affect the model’s zero-shot adversarial robustness. We then propose a text-guided contrastive adversarial training loss, which aligns the text embeddings and the adversarial visual features with contrastive learning on a small set of training data. We apply this training loss to two adaption methods, model finetuning and visual prompt tuning. We find that visual prompt tuning is more effective in the absence of texts, while finetuning wins in the existence of text guidance. Overall, our approach significantly improves the zero-shot adversarial robustness over CLIP, seeing an average improvement of 31 points over ImageNet and 15 zero-shot datasets. We hope this work can shed light on understanding the zero-shot adversarial robustness of large-scale models.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Yuncong Yang Columbia University, Jiawei Ma Columbia University, Shiyuan Huang Columbia University, Long Chen Columbia University, Xudong Lin Columbia University, Guangxing Han Columbia University, Shih-Fu Chang Columbia University
Keywords: Representation learning, Global Sequence Alignment, Zero/Few-shot Transfer
TL;DR: Global sequence matching under temporal order consistency matters in contrastive-based video-paragraph/text learning.
Abstract:
Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
The third-year PhD student is creating tools to help people with vision impairments navigate the world.
Imagine walking to your office from the subway station on a Monday morning. You notice a new café on the way, so you decide to take a detour and try a latté. That sounds like a normal way to start the week, right?
But for people with vision impairment or low vision, like those who are categorized as blind and low vision (BLV), this kind of spontaneous exploration while outside is challenging. Current navigation assistance systems (NAS) provide turn-by-turn instructions, but they do not allow visually impaired users to deviate from the shortest path to their destination or make decisions on the fly. As a result, people with vision impairment or low vision often miss out on the freedom to go out and navigate on their own terms.

In a paper published at the ACM Conference On Computer-Supported Cooperative Work And Social Computing (CSCW ‘23), computer science researchers introduced the concept of “Exploration Assistance,” which is an evolution of current NASs that can support BLV people’s exploration in unfamiliar environments. Led by Gaurav Jain, the researchers investigated how NASs should be designed by interviewing BLV people, orientation and mobility instructors, and leaders of blind-serving organizations, to understand their specific needs and challenges. Their findings highlight the types of spatial information required for exploration beyond turn-by-turn instructions and the difficulties faced by BLV people when exploring alone or with the help of others.
Jain, who is advised by Assistant Professor Brian Smith, is a PhD student in the Computer-Enabled Abilities Laboratory (CEAL Lab), where researchers develop computers that help people perceive and interact with the world around them. Their paper presents the results of interviews with BLV people and other stakeholders to identify the types of spatial information BLV people need for exploration and the challenges BLV people face when exploring unfamiliar environments. The paper offers insights into the design and development of new navigation assistance systems that can support BLV people in exploring unfamiliar environments with greater spontaneity and agency.
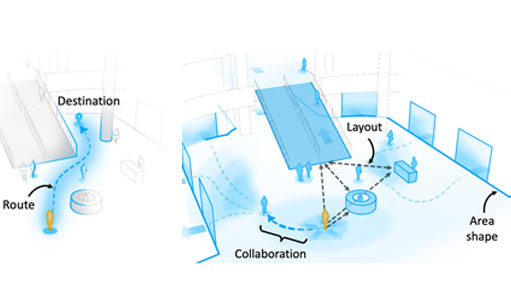
Based on their findings, they presented several instances of NASs that support the exploration assistance paradigm and identify several challenges that need to be overcome to make these systems a reality. Jain hopes that his research will ultimately enable BLV people to experience greater agency and independence as they navigate and explore their environments. We sat down with Jain to learn more about his research, doing qualitative research, and the thought processes behind writing research papers.
This research is incredibly exciting for the blind and low vision (BLV) community, as it represents a significant step towards equal access and agency in exploring unfamiliar environments. For BLV people, the ability to navigate and explore independently is essential to daily life, and current navigation assistance systems often limit their ability to do so. By introducing the concept of exploration assistance, this research opens up new possibilities for BLV people to explore and discover their surroundings with greater spontaneity and freedom. This research has the potential to significantly improve the quality of life for BLV people and is a major development in the ongoing pursuit of accessibility and inclusion for all.
This was my first project as a PhD student in the CEAL lab. The project was initiated as a camera-based wearable NAS for BLV people, and we conducted several formative studies with BLV people.
As we progressed, we realized that there was a significant research gap in the research community’s understanding of how NASs could support BLV people’s exploration in navigation. Based on these findings, we shifted our focus toward investigating this gap, and the paper I worked on was the result of this pivot. The paper is titled, “I Want to Figure Things Out”: Supporting Exploration in Navigation for People with Visual Impairments.
Over the course of approximately one year, I had the opportunity to work on this project that challenged me to step outside of my comfort zone as a human-computer interaction (HCI) researcher. Before this project, my research experience had primarily focused on computer vision and deep learning. I was more at ease with HCI systems research, which involved designing, building, and evaluating tools and techniques to solve user problems.
This project, however, was a qualitative research study that aimed to gain a deeper understanding of user needs, behaviors, challenges, and attitudes toward technology through in-depth interviews, observations, and other qualitative data collection methods. To prepare for this project, I had to immerse myself in the field of accessibility and navigation assistance for BLV people and read extensively on papers that employed qualitative research methods.
Although it took some time for me to shift my mindset towards qualitative research, this project helped me become a more well-rounded researcher, as I now feel comfortable with both qualitative and systems research. Overall, this project was a significant personal and professional growth experience, as I was able to expand my research expertise and contribute to a worthy cause.
Writing the paper was a critical stage in the research process, and I approached it by first organizing my thoughts and drafting a clear outline. I started by creating an outline of the paper with section and subsection headers, accompanied by a brief summary of what I intended to discuss in each section. This process allowed me to see the overall structure of the paper and ensure that I covered all the essential elements.
Once I had a clear structure in mind, I began to tackle each section of the paper one by one, starting with the introduction and then moving on to the methods, results, and discussion sections. I iteratively refined my writing based on feedback from my advisor, lab mates, and friends.
Throughout the writing process, I also ensured that my writing was clear, concise, and easy to follow. I paid close attention to the flow of ideas and transitions between sections, making sure that each paragraph and sentence contributed to the overall argument and was well-supported by the evidence.
Overall, the process of writing the paper was challenging but rewarding. It allowed me to synthesize the research findings and present them in a compelling way, showcasing the impact of our work on the lives of BLV people.
Throughout the research process, I encountered various challenges that both surprised and tested me. Interviewing participants, in particular, proved to be an intriguing yet difficult task. Initially, I struggled to guide conversations naturally toward my research questions without leading participants toward a certain answer. However, with each interview, I became more confident and began to enjoy the process. Hearing firsthand from BLV people that our work could make a real impact on their lives was also incredibly rewarding.
Analyzing and synthesizing the interview data was another major challenge. Unlike quantitative data, conversations are often open-ended and context-dependent, making it difficult to separate my own biases from the interviewee’s responses. I spent a considerable amount of time reviewing the interview transcripts and identifying emerging themes. To facilitate this process, I leveraged tools like NVivo to better organize the interview data, and our team held several discussions to refine these themes. To ensure the accuracy of our interpretation, we sought feedback from two BLV interns who worked with us over the summer on another project.
Overall, this research experience pushed me to become more adaptable. While it presented its own unique set of challenges, I am proud to have contributed to a project that has the potential to create meaningful change in the lives of BLV people.

Yes, my experience with this research project has certainly changed my view on how to approach research. It has taught me the importance of keeping the paper in mind from the beginning of a project.
Now, I make a conscious effort to think about how I want to present my work and what story I want to tell with the research. This helps me gain more clarity on the direction of the project and how to steer it toward producing meaningful results. As part of my workflow, I now write early drafts of paper introductions even before developing any tools or systems. This allows me to zoom out from the day-to-day technical challenges and see the big picture, which is crucial in making sure that the research is both impactful and well-presented.
Writing a research paper can be a challenging task, but here are a few tips that have helped me make the process smoother:
Finally, one resource that I would totally recommend to every PhD student at Columbia is Adjunct Professor Janet Kayfetz’s class on Technical Writing. Her class is an excellent way to deeply understand research writing.
I am currently working on two exciting projects that further my research goal of developing inclusive physical and digital environments for BLV people. The first project involves enhancing the capabilities of smart streets, streets with sensors like cameras and computing power, to help BLV people navigate street intersections safely.
This project is part of the NSF Engineering Research Center for Smart Streetscapes’ application thrust. The second project is focused on making videos accessible to BLV people by creating high-quality audio descriptions available at scale.
My exposure to research during my undergrad was invaluable, as it allowed me to work on diverse projects utilizing computer vision for various applications such as biometric security and medical imaging. These experiences instilled in me a passion for the research process. It was fulfilling to be able to identify problems that I care about, explore solutions, and disseminate new knowledge.
While I knew I enjoyed research, it was during the summer research fellowship at the Indian Institute of Sciences, where I collaborated with Professor P. K. Yalavarthy in the Medical Imaging Group, that crystallized my decision to pursue a PhD. The opportunity to work in a research lab, lead a project, and receive mentorship from an experienced advisor provided a glimpse of what a PhD program entails. I was excited by the prospect of being able to make a real-world impact by solving complex problems, and it was then that I decided to pursue a career in research.
I am interested in building Human-AI systems that embed AI technologies (e.g., computer vision) into human interactions to help BLV people better experience the world around them. My work on exploration assistance informs the design of future navigation assistance systems that enable BLV people to experience the physical world with more agency and spontaneity during navigation.
In addition to the physical world, I’ve also broadened my research focus to enhance BLV people’s experiences within the digital world. For example, I developed a system that makes it possible for BLV people to visualize the action in sports broadcasts rather than relying on other people’s descriptions of the game.
Accessibility research has traditionally focused on aiding daily-life activities and providing access to digital information for productivity and work, but there’s an increasing realization that providing access to everyday cultural experiences is equally important for inclusion and well-being.
This encompasses various forms of entertainment and recreation, such as watching TV, exploring museums, playing video games, listening to music, and engaging with social media. Ensuring that everyone has equal opportunities to enjoy these experiences is an emerging challenge. My goal is to design human-AI systems that enhance such experiences.
I was drawn to Columbia CS because of the type of problems my advisor works on. His research focused on creating systems that have a direct impact on people’s lives, where evaluating the user’s experience with the system is a key component.
This was a departure from my undergraduate research, where I focused on building systems to achieve high accuracy and efficiency. I found this user-centered approach to be extremely exciting, especially in the context of his project “RAD,” which aimed to make video games accessible to blind gamers. It was a super exciting prospect to be working on similar problems where you can firsthand see how people reacted and benefited from your solutions. This still remains one of the most fulfilling aspects of HCI research for me. In the end, this is what led me to choose Columbia and work with Brian Smith.

The first thing that comes to mind is the people that I have had the pleasure of working with and meeting. I am grateful for the opportunity to learn from my advisor and appreciate the incredible atmosphere he has created for me to thrive.
Additionally, I have been fortunate enough to make some amazing friends here at Columbia who have become a vital support system. Balancing work with passions outside of work has also been important to me, and I am grateful for the chance to engage with student clubs such as the dance team, Columbia Bhangra, and meet some amazing people there as well. Overall, the community at Columbia has been a highlight for me.
One thing that students wanting to do research should know is that research involves a lot of uncertainty and ambiguity. In fact, dealing with uncertainty can be one of the most challenging aspects of research, even more so than learning the technical skills required to complete a project.
In my own experience, staying motivated about the problem statement has been key to powering through those uncertain moments. Therefore, it is important to be true to yourself about what you are really excited about and work on those problems. Ultimately, this approach can go a long way in helping you navigate your time at Columbia and make the most of your research opportunities.
CS researchers had a strong showing at the ACM CHI Conference on Human Factors in Computing Systems (CHI 2023), with seven papers and two posters accepted. The premier international conference of Human-Computer Interaction (HCI) brings together researchers and practitioners who have an overarching goal to make the world a better place with interactive digital technologies.
Memento Player: Shared Multi-Perspective Playback of Volumetrically-Captured Moments in Augmented Reality
Yimeng Liu UC Santa Barbara, Jacob Ritchie Stanford University, Sven Kratz Snap Inc., Misha Sra UC Santa Barbara, Brian A. Smith Columbia University, Andrés Monroy-Hernández Princeton University, Rajan Vaish Snap Inc.
Capturing and reliving memories allow us to record, understand and share our past experiences. Currently, the most common approach to revisiting past moments is viewing photos and videos. These 2D media capture past events that reflect a recorder’s first-person perspective. The development of technology for accurately capturing 3D content presents an opportunity for new types of memory reliving, allowing greater immersion without perspective limitations. In this work, we adopt 2D and 3D moment-recording techniques and build a moment-reliving experience in AR that combines both display methods. Specifically, we use AR glasses to record 2D point-of-view (POV) videos, and volumetric capture to reconstruct 3D moments in AR. We allow seamless switching between AR and POV videos to enable immersive moment reliving and viewing of high-resolution details. Users can also navigate to a specific point in time using playback controls. Control is synchronized between multiple users for shared viewing.
Towards Accessible Sports Broadcasts for Blind and Low-Vision Viewers
Gaurav Jain Columbia University, Basel Hindi Columbia University, Connor Courtien Hunter College, Xin Yi Therese Xu Pomona College, Conrad Wyrick University of Florida, Michael Malcolm SUNY at Albany, Brian A. Smith Columbia University
Abstract:
Blind and low-vision (BLV) people watch sports through radio broadcasts that offer a play-by-play description of the game. However, recent trends show a decline in the availability and quality of radio broadcasts due to the rise of video streaming platforms on the internet and the cost of hiring professional announcers. As a result, sports broadcasts have now become even more inaccessible to BLV people. In this work, we present Immersive A/V, a technique for making sports broadcasts —in our case, tennis broadcasts— accessible and immersive to BLV viewers by automatically extracting gameplay information and conveying it through an added layer of spatialized audio cues. Immersive A/V conveys players’ positions and actions as detected by computer vision-based video analysis, allowing BLV viewers to visualize the action. We designed Immersive A/V based on results from a formative study with BLV participants. We conclude by outlining our plans for evaluating Immersive A/V and the future implications of this research.
Supporting Piggybacked Co-Located Leisure Activities via Augmented Reality
Samantha Reig Carnegie Mellon University, Erica Principe Cruz Carnegie Mellon University, Melissa M. Powers New York University, Jennifer He Stanford University, Timothy Chong University of Washington, Yu Jiang Tham Snap Inc., Sven Kratz Independent, Ava Robinson Snap Inc., Brian A. Smith Columbia University, Rajan Vaish Snap Inc., Andrés Monroy-Hernández Princeton University
Abstract:
Technology, especially the smartphone, is villainized for taking meaning and time away from in-person interactions and secluding people into “digital bubbles”. We believe this is not an intrinsic property of digital gadgets, but evidence of a lack of imagination in technology design. Leveraging augmented reality (AR) toward this end allows us to create experiences for multiple people, their pets, and their environments. In this work, we explore the design of AR technology that “piggybacks” on everyday leisure to foster co-located interactions among close ties (with other people and pets). We designed, developed, and deployed three such AR applications, and evaluated them through a 41-participant and 19-pet user study. We gained key insights about the ability of AR to spur and enrich interaction in new channels, the importance of customization, and the challenges of designing for the physical aspects of AR devices (e.g., holding smartphones). These insights guide design implications for the novel research space of co-located AR.
Towards Inclusive Avatars: Disability Representation in Avatar Platforms
Kelly Mack University of Washington, Rai Ching Ling Hsu Snap Inc., Andrés Monroy-Hernández Princeton University, Brian A. Smith Columbia University, Fannie Liu JPMorgan Chase
Abstract:
Digital avatars are an important part of identity representation, but there is little work on understanding how to represent disability. We interviewed 18 people with disabilities and related identities about their experiences and preferences in representing their identities with avatars. Participants generally preferred to represent their disability identity if the context felt safe and platforms supported their expression, as it was important for feeling authentically represented. They also utilized avatars in strategic ways: as a means to signal and disclose current abilities, access needs, and to raise awareness. Some participants even found avatars to be a more accessible way to communicate than alternatives. We discuss how avatars can support disability identity representation because of their easily customizable format that is not strictly tied to reality. We conclude with design recommendations for creating platforms that better support people in representing their disability and other minoritized identities.
ImageAssist: Tools for Enhancing Touchscreen-Based Image Exploration Systems for Blind and Low-Vision Users
Vishnu Nair Columbia University, Hanxiu ’Hazel’ Zhu Columbia University, Brian A. Smith Columbia University
Abstract:
Blind and low vision (BLV) users often rely on alt text to understand what a digital image is showing. However, recent research has investigated how touch-based image exploration on touchscreens can supplement alt text. Touchscreen-based image exploration systems allow BLV users to deeply understand images while granting a strong sense of agency. Yet, prior work has found that these systems require a lot of effort to use, and little work has been done to explore these systems’ bottlenecks on a deeper level and propose solutions to these issues. To address this, we present ImageAssist, a set of three tools that assist BLV users through the process of exploring images by touch — scaffolding the exploration process. We perform a series of studies with BLV users to design and evaluate ImageAssist, and our findings reveal several implications for image exploration tools for BLV users.
Improving Automatic Summarization for Browsing Longform Spoken Dialog
Daniel Li Columbia University, Thomas Chen Microsoft, Alec Zadikian Google, Albert Tung Stanford University, Lydia B. Chilton Columbia University
Abstract:
Longform spoken dialog delivers rich streams of informative content through podcasts, interviews, debates, and meetings. While production of this medium has grown tremendously, spoken dialog remains challenging to consume as listening is slower than reading and difficult to skim or navigate relative to text. Recent systems leveraging automatic speech recognition (ASR) and automatic summarization allow users to better browse speech data and forage for information of interest. However, these systems intake disfluent speech which causes automatic summarization to yield readability, adequacy, and accuracy problems. To improve navigability and browsability of speech, we present three training agnostic post-processing techniques that address dialog concerns of readability, coherence, and adequacy. We integrate these improvements with user interfaces which communicate estimated summary metrics to aid user browsing heuristics. Quantitative evaluation metrics show a 19% improvement in summary quality. We discuss how summarization technologies can help people browse longform audio in trustworthy and readable ways.
Social Dynamics of AI Support in Creative Writing
Katy Ilonka Gero Columbia University, Tao Long Columbia University, Lydia Chilton Columbia University
Abstract:
Recently, large language models have made huge advances in generating coherent, creative text. While much research focuses on how users can interact with language models, less work considers the social-technical gap that this technology poses. What are the social nuances that underlie receiving support from a generative AI? In this work we ask when and why a creative writer might turn to a computer versus a peer or mentor for support. We interview 20 creative writers about their writing practice and their attitudes towards both human and computer support. We discover three elements that govern a writer’s interaction with support actors: 1) what writers desire help with, 2) how writers perceive potential support actors, and 3) the values writers hold. We align our results with existing frameworks of writing cognition and creativity support, uncovering the social dynamics which modulate user responses to generative technologies.
AngleKindling: Supporting Journalistic Angle Ideation with Large Language Models
Savvas Petridis Columbia University, Nicholas Diakopoulos Northwestern University, Kevin Crowston Syracuse University, Mark Hansen Columbia University, Keren Henderson Syracuse University, Stan Jastrzebski Syracuse University, Jefrey V. Nickerson Stevens Institute of Technology, Lydia B. Chilton Columbia University
Abstract:
News media often leverage documents to find ideas for stories, while being critical of the frames and narratives present. Developing angles from a document such as a press release is a cognitively taxing process, in which journalists critically examine the implicit meaning of its claims. Informed by interviews with journalists, we developed AngleKindling, an interactive tool which employs the common sense reasoning of large language models to help journalists explore angles for reporting on a press release. In a study with 12 professional journalists, we show that participants found AngleKindling significantly more helpful and less mentally demanding to use for brainstorming ideas, compared to a prior journalistic angle ideation tool. AngleKindling helped journalists deeply engage with the press release and recognize angles that were useful for multiple types of stories. From our findings, we discuss how to help journalists customize and identify promising angles, and extending AngleKindling to other knowledge-work domains.
PopBlends: Strategies for Conceptual Blending with Large Language Models
Sitong Wang Columbia University, Savvas Petridis Columbia University, Taeahn Kwon Columbia University, Xiaojuan Ma Hong Kong University of Science and Technology, Lydia B. Chilton Columbia University
Pop culture is an important aspect of communication. On social media people often post pop culture reference images that connect an event, product, or other entity to a pop culture domain. Creating these images is a creative challenge that requires finding a conceptual connection between the users’ topic and a pop culture domain. In cognitive theory, this task is called conceptual blending. We present a system called PopBlends that automatically suggests conceptual blends. The system explores three approaches that involve both traditional knowledge extraction methods and large language models. Our annotation study shows that all three methods provide connections with similar accuracy, but with very different characteristics. Our user study shows that people found twice as many blend suggestions as they did without the system, and with half the mental demand. We discuss the advantages of combining large language models with knowledge bases for supporting divergent and convergent thinking.
CS students are among the grantees pursuing research-based master’s and doctoral degrees in the natural, social, and engineering sciences at US institutions.
ChatGPT and other bots have revived conversations on artificial general intelligence. Scientists say algorithms won’t surpass you any time soon.
A computer chip is hard to design and create because it requires expertise in each design flow step. This high design complexity exponentially grows the cost of making chips. Even though major semiconductor design companies can minimize such costs by leveraging design reuse, the same is not true for start-ups and academia.

PhD student Maico Cassel dos Santos aims to simultaneously minimize, if not resolve, both problems. On the one hand, he is creating a chip design flow (aka methodology) where even a designer with no major knowledge of chip-making can prototype their own architecture into a chip. On the other hand, tailoring such design flow for a heterogeneous tile-based system-on-chip (SoC) architecture will facilitate components integration and, consequently, promote design reuse.
He works with Professor Luca Carloni and colleagues from the System-Level Design Group. They have been working on Embedded Scalable Platform (ESP), an open-source framework that supports several design flows for accelerator design that has a push-button IP integration tool. For the past three years, through a collaboration with Harvard University and IBM Research, they developed the chip design methodology and a swarm-based perception chip for autonomous vehicles.
Their solution differs by having three important characteristics: flexibility, robustness, and scalability. The flexibility addresses different designs, technologies, and tool flow. The robustness covers correctness by construction in addition to the verification of correctness in each step of the design flow. Finally, their methodology enables design scaling in size and complexity while lowering human effort and computation power.
Santos hopes that their methodology will lower developing costs and shorten the time span of chip manufacturing, promoting innovation and market competition. We recently caught up with him to learn more about his research and PhD life.
The collaboration with researchers from Harvard and IBM couldn’t be better, in my opinion. Columbia alone would not have the expertise to develop the methodology and tape-out a chip of that complexity in that short time span. The tape-out process is the final result of the design process before it is sent to fabrication. It would have taken more than a year if we had done it on our own. But through the collaboration, it only took four months.
The same is true for Harvard and IBM since, back then, only the Columbia team had knowledge of the ESP architecture. Therefore, only the combination of expertise among the researchers involved from each institution could accomplish the results described in both papers. Moreover, all researchers involved in the project were fully committed to achieving the best outcome regarding chip features and design methodology.
Regarding working virtually, I would say the core part of the flow was developed during the first year of the pandemic (2020) and was improved in the second and third years (2021-2022). It was common to have daily virtual meetings among the physical design team. Since social distancing was in place, we were available from early morning to late at night to assist or discuss any issue that could arise. In this sense, communication channels such as Slack, web conference rooms, and email were crucial for the development of the project.
My initial role was to be the bridge between system-level designers, the ones who create the architecture, and physical designers, the ones that transform the architecture into a chip layout ready to send to fabrication. The role involved not only making sure the System-Level Design team, composed of Paolo Mantovani, Davide Giri, and Joseph Zuckerman, was delivering all required files and specifications to the physical design team but also reporting possible impacts of system-level design decisions on the physical design stage.
Not long after, I became one of the main physical designers with Tianyu Jia, a Harvard postdoc. Because of the considerable amount of work in a short time span, two more physical design engineers from IBM, Martin Cochet and Karthik Swaminathan, joined the team. The four of us formed the project’s core physical design team.
I have been working on the EPOCHS project for the past three years. The preparation to make the methodology can be split into two main fronts. The first was to understand the ESP architecture and what should be added or modified in the architecture to enable chip design and simultaneously facilitate the physical design workload.
The second front involved a lot of reading manuals of electronic design automation (EDA) tools. EDA tools have many parameters and several ways to reach a final chip. Not all of them, however, are clean and design-replicable. Finding the cleanest and design-independent set of parameters and commands demanded uncountable hours of reading manuals and implementation trials.
The two papers published in European Solid-State Circuits (ESSCIRC 2022) and International Conference on Computer-Aided Design (ICCAD 2022) are a preliminary result of the framework’s capabilities. The ICCAD 2022 paper details the chip design methodology tailored for ESP. The ESSCIRC 2022 paper applies the ESP framework with the new methodology to design a domain-specific SoC (DSSoC) for swarm-based perception applications (autonomous vehicle applications).
As far as I know, no other design methodology at the moment can implement a chip starting from PDK installation in four months. Moreover, no other methodology showed significant scalability between one chip and another without a time span penalty.
Finally, the complete ESP framework offers the user not only an agile, user-friendly physical design but also a methodology for accelerator design, a push button SoC integration capable of booting Linux OS, and chip testing support. In summary, ESP offers a complete agile design methodology starting from Linux software application, passing through a high-level language such as SystemC, C, Pytorch, and Tensor Flow, to mention but a few, to the final GDS file that is sent to chip fabrication.
Of course, there is space for improvement – and research – in the methodology on several fronts. Our main goal is to achieve an agile push button optimized physical design that keeps the main characteristics this methodology already has: flexibility, robustness, and scalability.

From the beginning, I was always surprised regarding the project and research deliveries from the team. I am a very conservative and cautious person with respect to chip design. The ambition and increasing complexity of the project over time always concerned me. Therefore, at every milestone we achieved, I was impressed by what an engaged small talented team could do in such a short period!
Before my PhD, I worked in chip design for 11 years. During this period, I taught how to design chips for a Brazilian government project in partnership with Cadence. This project aimed to increase the number of engineers in the country with the necessary knowledge and training to do chip design. I also designed chips and led a team to develop the RTL design flow at CEITEC, a Brazilian state-own semiconductor company.
I took my master’s while working, and at one point, I felt my career was at a plateau, and I wanted to do and learn different things. The PhD path started to sound perfect for me, especially when I could do it in the United States (US). Even though a PhD program in the US takes longer than in other countries, it is usually attached to some companies with daring projects. Therefore, it doesn’t detach you entirely from the industry, and it is easier to visualize a real-world application of your research. In addition, I would have the opportunity to use what I know, expand my knowledge, and learn important mainstream fields, such as machine learning.
I have always liked to find ways to optimize processes. When it comes to chip design, a set of NP-Hard problems, the goal is to find improvements in the final result, which indicates you are in the right direction to a near-optimal solution.
Until recently, design problems relied on analytic algorithm solvers for design automation. Nowadays, the use of machine learning to predict and find chip design solutions is showing promising results in several stages of the design process. Therefore, focusing my research on chip design methodology that leverages algorithms and machine learning allows me to learn these topics and apply this new knowledge to optimize processes in a field I am already used to–chip design.
Although we now have a flexible, robust, and scalable methodology, it is neither a push-button solution nor presents near-optimal results in terms of performance, power, and area. Therefore, my research focus now is to find ways to automate the still-required manual steps and, at the same time, produce near-global optimum solutions.
Can I say two things? The first is the feeling that you are at the leading edge of some technology–the frontier between the known and unknown. The second is that you are not alone; other researchers are trying to find similar answers and are willing to collaborate.
I am organizing the ESP ASIC design flow database to make it user-friendly and easy to maintain as we add support for new technologies, electronic design automation (EDA) tools, and ESP architecture features. Simultaneously, I am building a flow to easily port ESP RTL architecture from FPGA-ready prototyping to ASIC-ready prototyping and reading many chip design flow-related papers.

The research team I have been working with is all talented, hardworking people who do not hesitate to help each other. At the same time, whenever work allows, they are always down for having fun together as a team. This makes the PhD journey enjoyable and creates a bond that lasts beyond our time in Columbia.
First, I would say don’t start a PhD without clear reasons. You don’t need to know what specific topic you would like to research, but you need to understand why you want a PhD and why now. The reason should not be driven by the money a PhD degree can provide alone.
After you have clear reasons, try to find some fields you are interested in and which professors can best guide you in each of these fields. The researcher’s daily life involves a lot of paper reading, nights and weekends of experiments (not all will have the expected results), and, sometimes, paper rejections. Be prepared for that and keep moving forward; your work will be recognized eventually.
Finally, get to know the research team you will be working with. You will spend a lot of your time with them – the joy of your journey is strongly attached to the people surrounding you!
A PhD candidate who worked for OpenAI and Apple discusses natural language processing, AI hallucinations, and deep fakes.
Academy members are world leaders who explore societal challenges, identify solutions, and promote nonpartisan recommendations that advance the public good.