
Year: 2018
Finding food poisoning cases via Yelp reviews
In direct comparison, an asynchronous network-on-chip design outperforms a leading-edge commercial synchronous chip
![]()

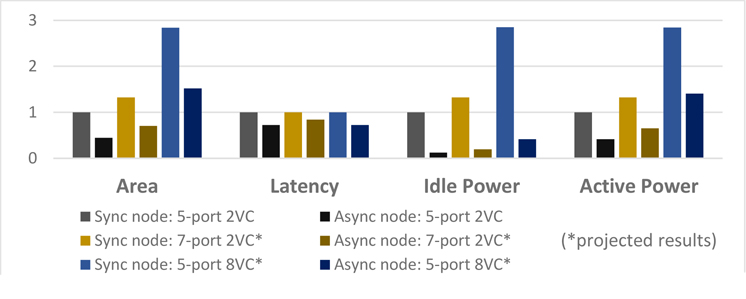
Working with colleagues in academia and industry, Steven Nowick and his group have conducted the first direct experimental comparison between an asynchronous network-on-chip (NoC) design and a leading industrial synchronous NoC chip implemented in advanced technology (14 nm FinFET). The synchronous chip was manufactured by Advanced Micro Devices (AMD) and is currently used in several commercial products. Results from the experiments, which were carried out on a single network node on the asynchronous NoC design, show the NoC design performed significantly better when compared to a synchronous chip—55% less area with 28% lower latency—along with a 58% reduction in active power and an 88% reduction in idle power.
 “While these results were mostly in line with our expectations, they are exciting as validation of our research. In particular, a major achievement was attaining significantly smaller circuit area,” says Nowick, who with his PhD student Weiwei Jiang designed the asynchronous on-chip network along with colleagues at the University of Ferrara in Italy (Professor Davide Bertozzi, PhD student Gabriele Miorandi). “People think of asynchronous chips as often being larger than their synchronous counterparts, but these results show that asynchronous designs can be much smaller than state-of-the-art NoCs in commercial products today. And they can be both faster and more energy-efficient.”
“While these results were mostly in line with our expectations, they are exciting as validation of our research. In particular, a major achievement was attaining significantly smaller circuit area,” says Nowick, who with his PhD student Weiwei Jiang designed the asynchronous on-chip network along with colleagues at the University of Ferrara in Italy (Professor Davide Bertozzi, PhD student Gabriele Miorandi). “People think of asynchronous chips as often being larger than their synchronous counterparts, but these results show that asynchronous designs can be much smaller than state-of-the-art NoCs in commercial products today. And they can be both faster and more energy-efficient.”
The experiments themselves were conducted at AMD in collaboration with AMD Fellows Greg Sadowski and Wayne Burleson. “This was a highly-productive and effective collaboration between Steve Nowick’s group and AMD,” says Sadowski. “His group’s asynchronous network-on-chip has great potential for our future systems, once the automated tool flow is developed.”
A member of Columbia’s Data Science Institute (DSI), Nowick is the founder and chair of the new working group, Frontiers in Computing Systems, which has over 35 faculty members working at the intersection of computing systems, massive-scale application areas (science/medicine/engineering), and data science. The group is in the process of approval as new DSI center, to be called “Computing Systems for Data-Driven Science.”
The collaboration with AMD is part of Nowick’s long-term research into asynchronous digital design, which contrasts to the almost universally used synchronous systems, where operations and the flow of data are all synchronized to a fixed-rate global clock. Synchronizing operations ensures things happen in an orderly fashion but because all operations—fast or slow—begin and end according to the clock’s timing signals, there is built-in inefficiency since faster operations must wait on slower ones to complete. In addition, the central organizing clock is a poor match for heterogeneous distributed systems and scalability requirements: synchronizing the hundreds and even thousands of processor and memory components on some chips today is simply unmanageable at low cost using a monolithic synchronous paradigm.
Asynchronous systems, in contrast, have no clock, allowing components to operate independently of one another and at their own optimal speed, thus reducing the latencies that occur when idle components must wait for the next clock cycle to perform an operation. Dispensing with the clock is also more energy efficient. Asynchronous components are idle until needed, i.e., naturally operate “on demand.” The clock itself can consume 20-30% of the power on a chip. Aggressive synchronous techniques for turning off idle units—called “clock-gating”—are only partly effective, and have their own not-insignificant overheads. In addition, the asynchronous design style allows simpler and more streamlined design of storage components (i.e., registers and circular buffers) and pipeline control structures.
The question of course is, how does an asynchronous design compare to actual commodity asynchronous chips being manufactured today? To provide an answer, Jiang carried out the synchronous-asynchronous evaluation at AMD using standard industry simulation in varied traffic using a pre-layout asynchronous design originally developed at Columbia by Nowick working with Davide Bertozzi’s group at the University of Ferrara. (A detailed physical layout was eventually created from the design as proof of concept and to validate correctness, but was not used in the evaluation.) The original asynchronous NoC design was modified by Jiang during his six-month internship at AMD in Boxborough, Massachusetts, with the addition of his own new techniques for efficient virtual channels (VCs) to mitigate congestion.
To help quantify how much better an asynchronous design could do against the best industry chips, the two designs—one synchronous and the other asynchronous—were as similar in architecture as possible.
 Both incorporate state-of-the-art NoC designs where components—processors, accelerators, memories—communicate over a network rather than over a simple shared bus or other simple channel that is controlled by a single master component at any time. To enable increasing numbers of components to operate in parallel—a growing necessity as chips began to incorporate hundreds or thousands of components—chip designers have looked to the networking community for ideas; the resulting “on-chip networks” ensure better congestion management, higher performance, and improved utilization of shared channel resources when compared to previous bus-based approaches.
Both incorporate state-of-the-art NoC designs where components—processors, accelerators, memories—communicate over a network rather than over a simple shared bus or other simple channel that is controlled by a single master component at any time. To enable increasing numbers of components to operate in parallel—a growing necessity as chips began to incorporate hundreds or thousands of components—chip designers have looked to the networking community for ideas; the resulting “on-chip networks” ensure better congestion management, higher performance, and improved utilization of shared channel resources when compared to previous bus-based approaches.
Both designs are also energy-efficient: the asynchronous NoC design because its components, when not busy, are always in idle mode; and the synchronous NoC through fine-grained clock-gating.
What’s different, and what accounts for the better performance and energy efficiency, is the use of asynchronous communication in Nowick’s NoC as well as highly efficient asynchronous designs that largely use standard synchronous components. Details of this first direct comparison between an asynchronous design with actual leading-edge commodity hardware, supported by National Science Foundation funding, are described in the paper. An asynchronous NoC router in a 14nm FinFET library: Comparison to an industrial synchronous counterpart presented in March 2017 at the ACM/IEEE Design, Automation and Test in Europe (DATE) Conference, one of the top two international design conferences.
For its better performance and energy efficiency, as well as scalability and ease of assembly, asynchronous NoCs have been attracting attention for the past 10 years. Intel, IBM, STMicroelectronics, and other companies have all explored and published on their development of asynchronous chips. Especially ambitious is IBM’s 4,096-core, 5-billion-transistor “TrueNorth” chip (cover story, Science magazine [August 2014]), a neuromorphic design modeled on the brain, where the goal is to recreate millions of brain neurons and synapses in silicon, something clearly not possible to do efficiently using a synchronous communication network where everything is timed to a clock cycle.
Where TrueNorth is optimized for pattern recognition, Nowick and his students are designing general-purpose multicore NoCs with an eye to ease of manufacturing and time to market, as well as extremely low energy and high performance—all concerns that weigh heavily on an industry that has invested billions of dollars in synchronous designs and workflows. With a paradigm shift to asynchronous promising to be costly, Nowick and his students are pursuing a mixed synchronous/asynchronous approach called globally asynchronous, locally synchronous systems, or GALS, where components are synchronous, enabling the use of standard off-the-shelf commodity hardware, but the communication fabric is an asynchronous network able to accommodate varying operating speeds of chip components.
“The goal is to accommodate current architectural requirements and the use of existing synchronous components—processors, caches, accelerators—but entirely replace the synchronous communication structure with a “drop-in” asynchronous one,” says Nowick.
Still, new automated computer-aided design (CAD) tools will be needed before the industry can shift away from synchronous systems. To this end, Nowick is collaborating closely with University of Ferrara colleagues (Davide Bertozzi’s group) to modify commercial synchronous CAD tools to work effectively for asynchronous designs, and to develop a portable and high-quality automated design flow. (More information on developing an automated tool flow for designing and optimizing asynchronous NoCs can be found in their paper Accurate Assessment of Bundled-Data Asynchronous NoCs Enabled by a Predictable and Efficient Hierarchical Synthesis Flow, which appeared recently at the 2017 IEEE “Async” Symposium.)
After over 25 years researching asynchronous chip design, Nowick is seeing increasing interest with a flurry of projects starting up, especially as asynchronous design shows itself to be flexible in different contexts and applications, including neural networks. Nowick’s PhD student Kshitij Bhardwaj recently interned at Intel Labs, collaborating with researchers there to design an asynchronous NoC to support the multicast communication requirements of spiking neural networks.
In a new research project, Bhardwaj and Nowick, working with Prof. Luca Carloni and associate research scientist Paolo Montavani, will implement an asynchronous NoC in a GALS form in field-programmable gate arrays (FPGAs) for a large-scale accelerator-based multicore system, and apply it for both convolutional neural network (CNN) and wide area motion imagery (WAMI) applications (such as long-term monitoring of images for security and surveillance).
Other promising directions for asynchronous design include its use with emerging technologies, such as flexible electronics and carbon nanotubes, as well as in energy harvesting circuits, where large timing deviations and tight power constraints are extremely difficult to satisfy using fixed-rate clocking. Likewise, asynchronous designs have been explored to handle extreme environments (e.g., space missions) where circuits must be robust and operate correctly over a 400° C temperature range.
“I am very encouraged by our successful collaboration with AMD and the University of Ferrara in finally demonstrating the potential of asynchronous networks-on-chip for advanced commercial computing systems,” says Nowick. “In the next year or two, we hope to develop more complete and automated design tool flows, as well enable exciting new opportunities for FPGA-based parallel computing systems for energy-efficient neural network and vision applications.”
Posted 01/19/2018
– Linda Crane
Shih-Fu Chang, professor of electrical engineering and computer science, named ACM Fellow
One of 54 new fellows recognized for their transformative roles in advancing technology in the digital age, Chang was cited for “contributions to large-scale multimedia content recognition and multimedia information retrieval.”
DNA makes an appearance
Is Yelp the next diagnostic tool for foodborne illness?
Sick Yelpers Lead Inspectors To Tainted NYC Restaurants
Blockchain or Blockheads? Bitcoin Mania Mints Believers and Skeptics
Researchers create system to track foodborne illnesses from online restaurant reviews
New paper by Thomas Effland, Anna Lawson, Luis Gravano, Daniel Hsu, and NYC Health Department epidemiologists describes enhancements to system that reads NYC restaurant Yelp reviews and has identified 10 food poisoning outbreaks since 2012.
How augmented reality can have its thrills
Iretiayo Akinola (advisor Peter Allen) named a 2018 Microsoft Research PhD fellow
Akinola was selected for his work on human-in-the-loop robot learning, and is one of ten students to receive the two-year fellowship, which covers tuition for two academic years and provides a stipend and travel allowance.
Undergrad Hamed Nilforoshan earns inaugural Snap Inc. Research Scholarship
Nilforoshan was selected for his research with Eugene Wu on NLP techniques to generate automated writing feedback, and for his work with Jure Leskovec (Stanford) on the relationship between the food people eat and their environment.
Chip flaws will be with us for a while
5G’s Olympic Debut
Julia Hirschberg and Shih-Fu Chang coauthor article on best practices to support postdocs
The article, in this month’s Communications of the ACM, makes several recommendations, including written career goals, access to workshops and events, and dedicated institutional support to instill a sense of belonging. (Article requires login.)
10 ways AI will impact the enterprise in 2018
Bjarne Stroustrup to receive the 2018 Charles Draper Prize for Engineeering
Stroustrup was honored for his creation of the C++ programming language, which has had “a monumental, singular influence on the field of computing.”
Searching for documents when you don’t know the language: Kathy McKeown to lead effort with $14M IARPA grant
![]()

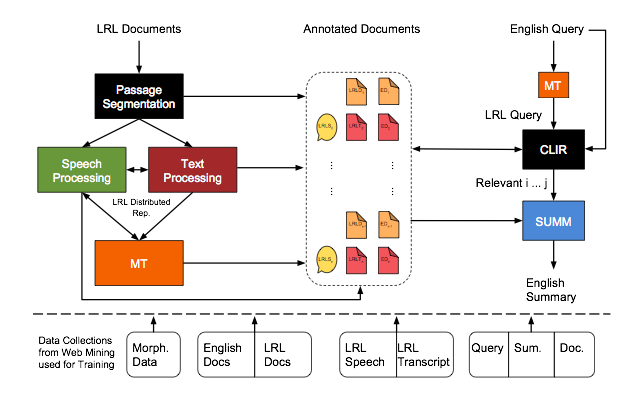
How do you search for documents, both text and speech, in a language you don’t speak or understand? Right now, there is no easy way. Google and similar search engines normally return documents in the language of the query (an English query for instance returns English documents). Translating the query first (using an automatic translator such as Google Translate) returns the documents untranslated with no indication which are most relevant and thus worth spending time, effort, and expense to translate. As for speech files, Google and similar speech engines don’t search over speech, relying instead on text tags.
But imagine entering a query in English to find resources in any foreign language—not just the 103 languages supported by Google Translate—and getting back text, audio, and video files, each accompanied by a summary in English to help identify those documents that should be translated.
| That is the ambitious goal of a team of researchers led by Kathleen McKeown. Consisting of fifteen researchers from five universities, the team is now in the beginning stages of designing and building an end-to-end human language technology capable of using an English query to quickly search, retrieve, and summarize documents in any of the world’s 6000+ languages. The work is funded through the $14.5M, four-year IARPA grant from the MATERIAL program, System for CRoss-language Information Processing, Translation, and Summarization (SCRIPTS).SCRIPTS represents a large-scale project encompassing multiple underlying technologies: machine translation, cross-lingual information retrieval (similar to a regular search engine except that the query is one language, and the retrieved documents are in another), text summarization, and speech and text processing.
In this interview, McKeown discusses why such a system is needed and some of the challenges it poses. How will the system operate in practice? The idea is that an English-speaking user—who might be a researcher, an intelligence analyst, a journalist, or perhaps someone working with a humanitarian organization—will be able to type an English search query to locate relevant documents in another language, and get back a list of documents with summaries in English. From the summaries, the user will have enough information to evaluate which documents are most relevant and should be translated in full. The system is geared toward what we call low-resource languages—languages that lack the large-scale data collections and automatic tools that enable automatic translators like Google Translate. Such systems work by aligning two parallel sets of translations sentence by sentence to infer statistical probabilities of how individual words and phrases are translated. It takes huge amounts of data in the form of parallel translations. Google Translate for instance was trained in part on the 30M words contained in English and French transcriptions made from Canadian parliament proceedings. |
Columbia University University of Maryland Yale University University of Edinburgh Cambridge University |
Many languages, especially in remote areas of Africa and in the South Pacific, simply don’t have large collections of translated data and for that reason also lack the basic tools—syntactic parsers, parts-of-speech taggers, or morphological analyzers—that help enable automated translation systems.
If a crisis—a coup, a natural disaster, or a terrorist attack—takes place where the only languages are low resource, automatic translation systems today will be of little use.
How will your system work without huge amounts of data?
We will have some data, including small amounts of parallel data and monolingual collections of documents. We can supplement this through webscraping or by pulling together data collected from previous projects we’ve worked on. Social media, YouTube, news reports might also be sources of data. One of the project’s innovations will be in the new ways we scrape the web.
Rather than looking at parallel translations, we will rely more on analyzing semantics and morphology, that is, what information can we derive from a word’s structure. To do so, we will build our own linguistic analysis tools to construct word embeddings, where words are represented as vectors of numbers that allow us to use computational methods to capture the semantic relationships between words and more easily discover what words have similar meanings; we’ll have tools to do this in both monolingual and cross-lingual settings. Building such tools requires deep linguistic knowledge, and we have people on the team expert in morphology and semantics.
While we will rely on morphological information, we’ll still be doing a lot statistically, but since we will have less data, we will have to do various types of bootstrapping. For example, as the system learns how to translate, for example, we can use those translations as training data in the next round. We’ll also find ways of using semi-supervised methods.
Also, we will exploit how different components in the system learn information in different ways. The way a machine translation component analyzes a query is different than how the information retrieval component analyzes a query. If we take and combine the information gained in each step, we learn a little more.
We’ll conserve computer resources by focusing on certain sentences over others. Usually there is a focus to a query. Events like the current problem of Rohingya fleeing to Bangladesh usually have several aspects: humanitarian, diplomatic, and legal. We will build a query-focused summarizer that will look at both the query and the document to summarize what in the document is relevant to the query. Previous data sets for doing this type of task are very small—maybe 30-60 documents—but with so much data on the web, we can build new data sources.
What are the difficulties?
There are many, but one in particular is error propagation. With little data, some words are bound to be mistranslated, with the risk that a mistranslation at one step is carried over to all subsequent steps, compounding the error. So rather than commit to a decision by a single component, we plan to have multiple components jointly make decisions when we have low confidence.
Summarization for example takes place multiple times: before translation—when we’re summarizing in the low-resource language and using machine translation to translate the summary in English—after translation (summarizing in English), and simultaneously with translation. At each step, we’ll let what the summarization component learns inform the translation, and also have the translation step inform summarization.
Each component will have multiple, complementary approaches also, again to create more information that we can exploit.
Why take on such a big project?
It’s a research challenge and once completed it will be the first system to combine so many language technologies in a cross-language context, pushing each of us to further advance the areas that we’ve been individually researching.
For me that area is text summarization. Several years ago, my students and I developed the NewsBlaster system to browse the news in different languages, like German and Spanish and Arabic, and return summaries of those news articles in English. It was a way for an English speaker to get different perspectives on news topics and see how the rest of the world viewed events. The students from that group have all gone onto interesting positions: several to professorships—at MIT, Penn, Cooper Union—while others are doing research in industry, a couple at Google, and one each at Amazon in Japan and IBM.
Text summarization in this new project will represent a significant advance over NewsBlaster; it will be over low-resource languages while also incorporating speech. And it will integrate into a much larger system with other components that are likewise being expanded.
We’ve got a great team, collectively representing expertise over many technologies in the field of human language technology. Many of us have worked together on other projects, so it’s always nice to again work with people whose research you respect. I think together we will produce a significant advance in the state of the art in querying over foreign language documents.
Posted 1/3/2017
– Linda Crane