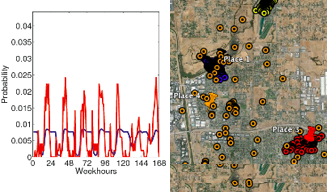
Over 10,000 have uploaded their genome data to DNA.Land, a crowd-sourcing website that taps genome info for scientific research. The site was launched
in October by CS professor Yaniv Erlich and Joe Pickrell.
in October by CS professor Yaniv Erlich and Joe Pickrell.
For “contributions to natural language processing and computational linguistics.”
The number of students seeking a computer science degree is surging. The trend is nationwide and especially strong at Columbia, which this year saw a 30% increase over last year in the number of undergraduates majoring in computer science. This year’s increase follows several years of double-digit increases, including a 50% jump three years ago.
“We’re lucky to have great student interest in computer science, but this also poses challenges. Each of our students needs to be taught the fundamental concepts underlying computer science so that they not only have a strong foundation, but also have the skills to go out and find new ways and new contexts to apply those skills. We need faculty concentrated on this important task,” says Rocco Servedio, chair of the Computer Science department. “The department is fortunate to have Paul Blaer and Ansaf Salleb-Aouissi. Both are extremely knowledgeable in their respective areas of computer science, and just as importantly, both have proven teaching abilities. They are an important addition to the department.”
Columbia this fall promoted Paul Blaer from adjunct professor to Lecturer in Discipline, a full-time faculty position that makes teaching Blaer’s primary focus, something he’s wanted for a long time.
Hiring Blaer full time is not exactly a stab in the dark for Columbia where Blaer is a well-known quantity. Since he was 3, he has been floating around campus. His father is physics professor Allan Blaer, who did both undergraduate and graduate work at Columbia and who—after teaching stints at Princeton and Swarthmore—returned to Columbia where his son would likewise attend as both undergraduate and graduate student.
Paul Blaer did his PhD research in the area of mobile robotics and 3D vision, working in Peter Allen’s lab. It was there, while a grad student leading recitations, that he got his first taste of teaching. He knew immediately that teaching was what he wanted to do. For him, it was the fun stuff, a chance to engage with students, to think on his feet to get them work through problems themselves. For three years before graduating, he was a preceptor, running classes and seeing results from the front of a class.
With teaching in mind, Blaer originally planned to seek a position at a small four-year college, but the combined draw of Columbia and New York City proved strong, and Blaer, knowing Columbia as well as he did, figured someday a teaching opportunity would open up. Until it did, there were other ways on campus for him to contribute.
In Allen’s lab Blaer had been doing systems work—his skills for controlling his own computing environments scaled up for a lab of 50 or more—which led to a full-time position at Computing Research Facilities (CRF); precepting led to part-time adjuncting. For seven years now, Blaer has been teaching introductory computer science classes part-time while working at CRF full time to help faculty design and build backend systems for all types of research projects.
With his new position, the mix gets recalibrated: teaching becomes full-time and CRF part-time.
“I’m thrilled to be working full time with students here at Columbia. It’s the best of both worlds: a large university environment with highly motivated students, yet like a college professor I have this direct interaction with the students, which is the favorite part of my job.”
Blaer knows the classes, the students and faculty, the projects, and how the computer systems are set up; in a department dependent on systems, that’s better than knowing where the bodies are buried. He’s involved also in the administrative aspects that touch on teaching; he is Director of Undergraduate Studies for BS Programs and is active in the Science Honors Program for area high-school science and math students.
Deep institutional and systems knowledge is all well and good, but a lecturer first and foremost has to be able to teach. Blaer has that angle covered especially well. As someone who genuinely cares about teaching, he pays attention to what resonates with students and what doesn’t, and strives to keep his lectures engaging, using humor and real-life stories from his own research to keep students interested. That he succeeds is clear from student comments on the Columbia Underground Listing on Teacher Abilities (CULPA) site, where Blaer has earned a silver nugget for his teaching and approachability.
“We’re thrilled to have Paul join the faculty full-time as a lecturer. The department has rock-solid confidence in his classroom skills because we have the strongest possible kind of evidence—actual results over several years,” says Rocco Servedio, chair of the Computer Science department.
Ansaf Salleb-Aouissi
Introduction to Data Science, Machine Learning for Data Science, Discrete Math, Artificial Intelligence
The increasingly data-centric approach in all aspects of science and technology means students need to learn what algorithms and methods can stand up to the immense scale of today’s data sets. Teaching computer science from the perspective of large data sets is the job of Ansaf Salleb-Aouissi. A data scientist from before the term was commonly understood, Salleb-Aouissi has worked with all types of data on projects ranging from geology and geographic information systems early in her career, to social sciences and urban design, and more recently to medical informatics and to education.
“The common denominator is data. The context may be different and the goals may be different, but at the end of the day, data is data and you try to leverage that data somehow to learn something new,” says Salleb-Aouissi.
An associate research scientist at Columbia’s Center for Computational Learning Systems (CCLS) since 2006, she has worked on both fundamental research into new machine learning and data mining algorithms and methods as well as real-world applications of those methods.
Many of her projects are predictive in nature, forecasting when power-grid failures are likely to occur in one case, and in another predicting which expectant mothers are most, or least, likely to deliver preterm. In this last example, Salleb-Aouissi, with support from the National Science Foundation Smart and Connected Health program, used advanced machine-learning methods to vastly expand the number of risk factors to be considered, including socioeconomic, psychological and behavioral factors.
Prediction is also at the heart of her most recent (and current favorite) project: a web browser optimized for self-learning. “We want to create a personalized self-learning experience by sifting through huge number of search results to identify and return those customized for student’s learning preferences—whether they be videos, books, blogs—and that also fit within the student’s short or long time constraints. The challenge here, as it was with the preterm study, is making all these different and heterogeneous resources work together in a system. It’s an ambitious project and I am very excited to work on it. More so because it is a link between my research and my teaching.”
Though research forms the bulk of her recent work, teaching has also been a component. Post-PhD, she worked as an adjunct professor at the University of Orléans and discovered how much she enjoyed interacting with students. She would have gladly accepted the position of assistant professor except for her plans to eventually move to the US. Instead she took the offer of a Postdoctoral Fellowship at the prestigious research lab INRIA (French National Institute of Computer Science and Control) at Rennes, France. There she did more fundamental investigation of new algorithms, particularly new methods for quantitative association rules, but also for frequent patterns matching, ranking, characterization, and action recommendation.
While still at INRIA, she applied to the CCLS for an open position. Though that position filled quickly, David Waltz, then director of the CCLS, took note of her INRIA fellowship and her growing publications list and contacted her when a different position came up. She and Waltz later collaborated on a number of papers and projects. “Dave smoothed my transition to the CCLS and helped make it an enriching experience where I could grow and learn. I will always be grateful to him.”
Once settled in at the CCLS, she was able to get back into teaching, adjuncting in the Computer Science department, teaching courses in data science, discrete math, and artificial intelligence. As a lecturer, teaching will now be her primary focus, but she will continue doing research, which will now serve a double purpose. “I like to deliver my lecture in an engaging and interactive way, my own way and to keep the material fresh and alive so students actively absorb it rather than just be passive recipients. My own research may serve to give students a peek into what you can do with computer science, and I hope that can motivate them and spark their interest so they learn now so they can do later.”