 Tony Jebara
- - Research
Tony Jebara
- - Research

|
Tony Jebara
- - Research
|
|
 home
home research
papers
courses
resumé
code
press
hobbies
trips
links
research
papers
courses
resumé
code
press
hobbies
trips
links |
|||||||||
|
|
|||||||||
|
Tony directs The Columbia Machine Learning Laboratory which intersects computer science and statistics to develop new foundations and frameworks for learning from data and produces important applications in vision, spatio-temporal datasets, interfaces, bioinformatics and text. The sections below discuss three categories of our work including discriminative versus generative learning, invariance in learning and applications of machine learning. All online papers are available here. Discriminative and Generative Learning One of our main interests is providing a bridge between two competing camps in machine learning: discriminative (support vector classification) and generative (Bayesian networks and inference). Generative models seek to summarize data and are more flexible. Meanwhile discriminative models only learn from data to directly make input to output predictions. Our work has provided several computational and mathematical tools for combining these goals. This gives density estimation and complicated generative models the stronger classification performance guarantees found in (relatively more simple) support vector machines and discriminative methods. I have written a book on the topic (Machine Learning: Discriminative and Generative, Kluwer 04) as well published several papers that migrate both camps together with the following key tools: The figure below shows how full-covariance Gaussians can be estimated to give rise to a large margin classification boundary using the maximum entropy discrimination (MED) approach. The maximum likelihood estimate for two class-conditional Gaussians is shown in (a) and is used to initialized the MED optimization. An intermediate step in the MED solution is shown in (b) and the final MED solution is shown in (c). MED finds the global large-margin configuration with the same generative model. 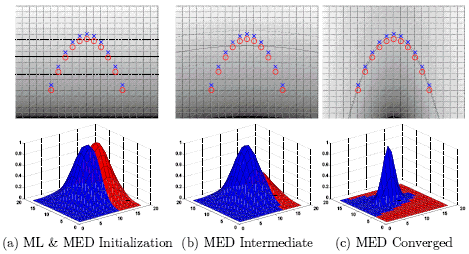 The figure below shows a probabilistic kernel (for use in support vector machines) between two hidden Markov models which can be efficiently solved using a junction tree algorithm. A hidden Markov model graph and the resulting graphical model for inferring a kernel k(p,p')= \int p(x) p'(x) between HMMs. This permits reliable SVM classification and embedding of sequences and unusual probabilistic models. 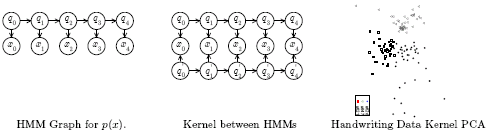 The figure below shows how large margin mixture modeling is possible using MED which recovers a large margin mixture of kernelized Gaussians (a.k.a. nonstationary kernel combination). A mixture of quadratic and linear kernels is considered. (a) shows the maximum likelihood mixture decision boundary. (b) shows the stationary kernel selection solution as a linear combination of kernels. (c) shows nonstationary kernel combination (NSKC) decision boundary as a large margin mixture model of kernels. (d) shows the NSKC kernel weight over the input space. 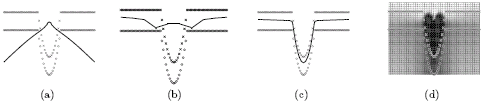
Invariance and Permutation in Learning Another key machine learning area for me is in endowing learning algorithms with invariance such that irrelevant variations in the data can be ignored. This includes permutation invariance, affine invariance, feature selection and kernel selection invariance. These allow learning algorithms to reliably capture essential variations from data instead of wasting resources modeling known a priori variations that are spurious. These tools also allow learning algorithms to apply to unusual non-vectorial inputs which typically inherit some sort of invariance. A host of papers and applied results have been produced with applications to images, text and graphs. For instance, we proposed considering images as bags-of-pixels where each pixel is a (XYI) tuple and therefore their order is permutationally irrelevant (ICCV 03, Patent Pending). We have investigated permutationally invariant representations for images that solve for the optimal correspondence between pixels in pairs of images. This was implemented by optimizing PCA over matchings (AISTAT 03, COLT 04) as well as optimizing SVM classifiers over matchings (ICML 06b). These achieved great results on image data beating standard PCA by 3 orders of magnitude as show in the Figure below. Therein, the permutation invariant PCA method's top 4 face eigenvectors are shown.  This approach also improved standard SVMs reducing classification error rate in 3D object recognition. We also explored invariance to permutation from a group-theoretic perspective by applying the fast Fourier transform on the symmetric group to perform data-association or permutation-invariant tracking (AISTAT 07a). This was a novel approach to approximate inference over distributions where group structure (permutation group) allows for a fast and space efficient Fourier approximation. We have also developed new algorithms for permutation and matching including the fastest current method which uses belief propagation. The figure below depicts loopy belief propagation for (multi) matching which is guaranteed to converge, is faster than combinatorial solvers and beats kNN for image classification with varying backgrounds. 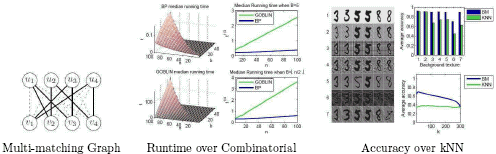 In addition, this is one of the few implementations of loopy belief propagation that is proved to converge to the global optimum (AISTAT 07b). We have also published a novel ellipsoidal version of support vector machines that is invariant to affine transformation of the data using semidefinite programming and consistently outperforms standard SVMs (AISTAT 07c) as in the Figure below. The affine invariant ellipsoidal kernel machine (EKM) maximizes the true margin.  In another paper, my group used SDP to make manifold learning and data visualization that minimizes volume and is partially invariant to graph connectivity (AISTAT 07d) as shown below. The method minimum volume embedding (MVE) improves kernel PCA and semidefinite embedding (SDE) especially for visualizing strange connectivity (such as phylogenetic trees where MVE maintains the tree relationship across species in 2D). 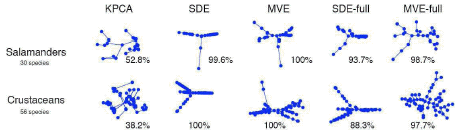 We also explored invariance with probabilistic kernels (ICML 03, COLT 03, JMLR 04) as well as kernel selection and feature selection (UAI 00 and ICML 04). Some of these invariant tools (primarily the permutation invariant kernel from ICML 03 which obtained the best paper award and the permutation and matching work in ECML 06 and AISTAT 07b) were used to obtain the top score in a double-blind entity-resolution competition administered by the CIA and KDD in 05. Application Areas We have had several applied successes using these machine learning tools in real-world problems. These include: | |||||||||
|
|