Associate Professor Zhou Yu and her team won a Best Paper Award for their paper Teaching Language Models to Self-Improve through Interactive Demonstrations. They introduce TRIPOST, a training algorithm that endows smaller models with self-improvement ability, which shows that the interactive experience of learning from and correcting its own mistakes is crucial for small models to improve their performance.
Abstract: The self-improving ability of large language models (LLMs), enabled by prompting them to analyze and revise their own outputs, has garnered significant interest in recent research. However, this ability has been shown to be absent and difficult to learn for smaller models, thus widening the performance gap between state-of-the-art LLMs and more costeffective and faster ones. To reduce this gap, we introduce TRIPOST, a training algorithm that endows smaller models with such selfimprovement ability, and show that our approach can improve LLaMA-7B’s performance on math and reasoning tasks by up to 7.13%. In contrast to prior work, we achieve this by using the smaller model to interact with LLMs to collect feedback and improvements on its own generations. We then replay this experience to train the small model. Our experiments on four math and reasoning datasets show that the interactive experience of learning from and correcting its own mistakes is crucial for small models to improve their performance.
TofuEval: Evaluating Hallucinations of LLMs on Topic-Focused Dialogue Summarization Liyan Tang The University of Texas at Austin, Igor Shalyminov AWS AI Labs, Amy Wing-mei Wong AWS AI Labs, Jon Burnsky AWS AI Labs, Jake W. Vincent AWS AI Labs, Yuan Yang AWS AI Labs, Siffi Singh AWS AI Labs, Song Feng AWS AI Labs, Hwanjun Song Korea Advanced Institute of Science & Technology, Hang Su AWS AI Labs, Lijia Sun AWS AI Labs, Yi Zhang AWS AI Labs, Saab Mansour AWS AI Labs, Kathleen McKeown Columbia University
Abstract: Single-document news summarization has seen substantial progress in faithfulness in recent years, driven by research on the evaluation of factual consistency or hallucinations. We ask whether these advances carry over to other text summarization domains. We propose a new evaluation benchmark on topic-focused dialogue summarization, generated by LLMs of varying sizes. We provide binary sentence-level human annotations of the factual consistency of these summaries along with detailed explanations of factually inconsistent sentences. Our analysis shows that existing LLMs hallucinate significant amounts of factual errors in the dialogue domain, regardless of the model’s size. On the other hand, when LLMs, including GPT-4, serve as binary factual evaluators, they perform poorly and can be outperformed by prevailing state-of-the-art specialized factuality evaluation metrics. Finally, we conducted an analysis of hallucination types with a curated error taxonomy. We find that there are diverse errors and error distributions in modelgenerated summaries and that non-LLM-based metrics can capture all error types better than LLM-based evaluators.
Fair Abstractive Summarization of Diverse Perspectives Yusen Zhang Penn State University, Nan Zhang Penn State University, Yixin Liu Yale University, Alexander Fabbri Salesforce Research, Junru Liu Texas A&M University, Ryo Kamoi Penn State University, Xiaoxin Lu Penn State University, Caiming Xiong Salesforce Research, Jieyu Zhao University of Southern California, Dragomir Radev Yale University, Kathleen McKeown Columbia University, Rui Zhang Penn State University
Abstract: People from different social and demographic groups express diverse perspectives and conflicting opinions on a broad set of topics such as product reviews, healthcare, law, and politics. A fair summary should provide a comprehensive coverage of diverse perspectives without underrepresenting certain groups. However, current work in summarization metrics and Large Language Models (LLMs) evaluation has not explored fair abstractive summarization. In this paper, we systematically investigate fair abstractive summarization for user-generated data. We first formally define fairness in abstractive summarization as not underrepresenting perspectives of any groups of people, and we propose four reference-free automatic metrics by measuring the differences between target and source perspectives. We evaluate nine LLMs, including three GPT models, four LLaMA models, PaLM 2, and Claude, on six datasets collected from social media, online reviews, and recorded transcripts. Experiments show that both the model-generated and the human-written reference summaries suffer from low fairness. We conduct a comprehensive analysis of the common factors influencing fairness and propose three simple but effective methods to alleviate unfair summarization. Our dataset and code are available at https: //github.com/psunlpgroup/FairSumm.
Abstract: It is well-known that speakers who entrain to one another have more successful conversations than those who do not. Previous research has shown that interlocutors entrain on linguistic features in both written and spoken monolingual domains. More recent work on code-switched communication has also shown preliminary evidence of entrainment on certain aspects of code-switching (CSW). However, such studies of entrainment in codeswitched domains have been extremely few and restricted to human-machine textual interactions. Our work studies code-switched spontaneous speech between humans, finding that (1) patterns of written and spoken entrainment in monolingual settings largely generalize to code-switched settings, and (2) some patterns of entrainment on code-switching in dialogue agent-generated text generalize to spontaneous code-switched speech. Our findings give rise to important implications for the potentially “universal” nature of entrainment as a communication phenomenon, and potential applications in inclusive and interactive speech technology.
Abstract: This paper investigates the optimal selection and fusion of feature encoders across multiple modalities and combines these in one neural network to improve sentiment detection. We compare different fusion methods and examine the impact of multi-loss training within the multi-modality fusion network, identifying surprisingly important findings relating to subnet performance. We have also found that integrating context significantly enhances model performance. Our best model achieves state-of-the-art performance for three datasets (CMU-MOSI, CMU-MOSEI and CH-SIMS). These results suggest a roadmap toward an optimized feature selection and fusion approach for enhancing sentiment detection in neural networks.
Abstract: In the last decade, the United States has lost more than 500,000 people from an overdose involving prescription and illicit opioids, making it a national public health emergency (USDHHS, 2017). Medical practitioners require robust and timely tools that can effectively identify at-risk patients. Community-based social media platforms such as Reddit allow self-disclosure for users to discuss otherwise sensitive drug-related behaviors. We present a moderate-size corpus of 2500 opioid-related posts from various subreddits labeled with six different phases of opioid use: Medical Use, Misuse, Addiction, Recovery, Relapse, and Not Using. For every post, we annotate span-level extractive explanations and crucially study their role both in annotation quality and model development.2 We evaluate several state-of-the-art models in a supervised, few-shot, or zero-shot setting. Experimental results and error analysis show that identifying the phases of opioid use disorder is highly contextual and challenging. However, we find that using explanations during modeling leads to a significant boost in classification accuracy, demonstrating their beneficial role in a high-stakes domain such as studying the opioid use disorder continuum.
The first-year PhD student is developing tools that help people create engaging images and videos.
After growing up in Jiangsu, China, Sitong Wang studied electrical engineering at Chongqing University and the University of Cincinnati. During her co-op at the Hong Kong University of Science and Technology (HKUST), she was introduced to Human-Computer Interaction (HCI). This research area understands and enhances the interaction between humans and computers. She became interested in the field and then took her master’s at Columbia CS. Wang was intrigued by how computation can power the creative process when she worked on a design challenge that blends pop culture references with products or services and helped a group of students promote their beverage start-up.
Sitong Wang
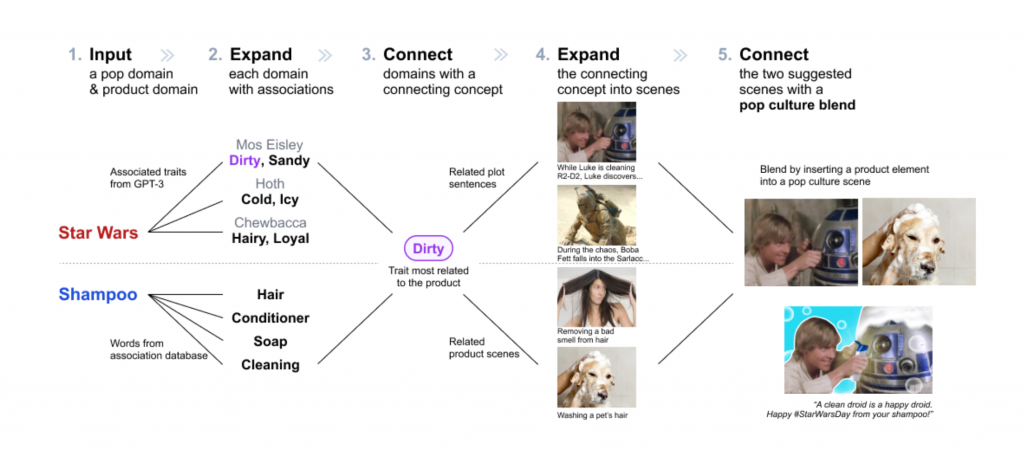
Encouraged by the creative work she could do, Wang joined the Computational Design Lab as a PhD student to continue to work with Assistant Professor Lydia Chilton and explore ways to design AI-powered creativity support tools. She recently published her first first-author research paper at the Conference on Human Factors in Computing Systems (CHI 2023). She and colleagues designed PopBlends, a system that automatically suggests conceptual blends by connecting a user’s topic with a pop culture domain. Their user study shows that people found twice as many blend suggestions as they did without the system and with half the mental demand.
We caught up with Wang to discuss her research, her work on generative AI tools, and what it is like to be a graduate student at Columbia.
Pop culture blends for Star Wars Day collected on Twitter from McDonald’s, Volkswagon, and the Girl Scouts.
Q: What is PopBlends and why did you choose to focus on the design process?
In the paper, we tackled the creative challenge of designing pop culture blends—images that use pop culture references to promote a product or service. We designed PopBlends, an automated pipeline consisting of three complementary strategies to find creative connections between a product and a pop culture domain.
Our work explores how large language models (LLMs) can provide associative knowledge and commonsense reasoning for creative tasks. We also discuss how to combine the power of traditional knowledge bases and LLMs to support creators in their divergent and convergent thinking.
It can help people, especially those without a design background, create pop culture blends more easily to advertise their brands. We want to make the design process more enjoyable and less cognitively demanding for everyone. We hope to enhance people’s creativity and productivity by scaffolding the creative process and using the power of computation to help people explore the design space more efficiently.
Q: Why did you create a tool incorporating pop culture into product ads?
Pop culture is important in everyday communication. Pop culture blends are helpful for online campaigns because they capture attention and connect the product to something people already know and like. However, creating these images is a challenging conceptual blending task and requires finding connections between two very different domains.
So we built an automated computational pipeline that can effectively support divergent and convergent thinking in finding such creative connections. We explored how to apply generative AI to creative workflows to assist people better—generative AI is powerful, but it is not perfect—thus, it is valuable to use different strategies that combine a knowledge base (which is accurate) and LLM (which has a vast amount of data) to support creative tasks.
Q: How were large language models (LLMs) helpful in your research?
Conceptual blending is complex—the design space is vast and valuable connections are rare—to tackle this challenge, we need to scaffold the ideation process and combine the intelligence of humans and machines. When we started this project, GPT-3 was not yet available; we tried traditional NLP techniques to find attribute associations (e.g., Chewbacca is fluffy) but faced challenges. Then, by chance, we tried GPT-3, which worked well with the necessary prompt engineering.
I was surprised by the associative reasoning capability of LLMs—which is technically a model that predicts the most probable next word. It easily listed related concepts for different domains and could suggest possible creative connections. I was also surprised by the hallucinations the LLMs made through our experiments, and the models could say things that were not true with great confidence.
As an emerging technology, LLMs are powerful in many ways and open up new opportunities for the computational design field. However, LLMs currently have a lot of limitations; it is essential to explore how to build system architectures around them to produce valuable results for people.
Wang presenting PopBlends at CHI’23
Q: How was it like presenting your work at CHI?
I was both nervous and excited because it had been a long time since I had presented in front of a crowd (since we did everything online during COVID). It was also my first time presenting at a computing conference, and the “Large Language Models” session I attended was very popular.
I am grateful to my labmate Vivian Liu, who provided valuable advice, helped me rehearse, and took pictures of me. The presentation went well, and I am glad we had the opportunity to present our work to a large audience of researchers. I would also like to express my gratitude to the researchers I met during the conference, as they provided encouragement and helpful tips that greatly contributed to my experience.
Q: What are you working on now?
I am working on a tool to help journalists transform their print articles into reels using generative AI by assisting them in the creative stages of producing scripts, character boards, and storyboards. In this work, in addition to LLMs, we incorporate text-to-image models and try to combine the power of both to support creators.
During the summer, I will work as a research intern at Adobe, where I will be focusing on AI and video authoring. Our work will revolve around facilitating the future of podcast video creation.
Q: Can you talk about your background and why you pursued a PhD?
My undergraduate program offered great co-op opportunities that allowed me to explore different paths, including roles as an engineer, UI designer, and research intern across Chongqing, Charlottesville, and Hong Kong. During my final co-op, I had the opportunity to work in the HCI lab at the Hong Kong University of Science and Technology (HKUST). This experience ignited my passion for HCI research and marked the beginning of my research journey in this field.
I enjoy exploring unanswered questions, particularly those that reside at the intersection of multiple disciplines. A PhD program provides an excellent opportunity to work on the problems that interest me the most. In addition, I think the training provided at the PhD level can enhance essential skills such as leadership, collaboration, critical thinking, and effective communication.
Q: What are your research interests?
My research interest lies in the creativity support in the HCI field. I am particularly interested in exploring the role of multimodal generative AI in creativity support tools. I enjoy developing co-creative interactive systems to support everyone in their everyday creative tasks.
Q: What research questions or issues do you hope to answer now?
I want to explore the role of generative AI models in future creativity support tools and build co-creative intelligent systems that support multimodal creativity, especially in the dimensions of audio and videos, as they are how we interact with the world. I also want to explore some theoretical questions, such as the overtrust/overreliance in AI, and see how we might understand and resolve them.
Sitong Wang
Q: Why did you choose to apply to Columbia CS? What attracted you to the program?
I love the vibrant environment of Columbia and NYC and how Columbia is strong in diverse disciplines, such as journalism, business, and law. It is an ideal place to do multi-disciplinary collaborative research.
Also, I got to know Professor Chilton well during my masters at Columbia. She is incredibly supportive and wonderful, and we share many common interests. That is why I chose to continue to work with her for my PhD journey.
Q: What has been the highlight of your time at Columbia?
The highlight would be when I witnessed the success of the students I mentored. It was such a rewarding process to guide and help undergraduate students interested in HCI research begin their journey.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research, what should they know or do to prepare?
Enjoy your time in NYC! Please don’t burn yourself out; learn how to manage your time efficiently. Don’t be afraid to try new things—start with manageable tasks, but also step out of your comfort zone. You will have fun!
If you want to do research, find research questions that genuinely interest you and be prepared to face challenges. Most importantly, preserve and trust yourself and your collaborators. Your efforts will eventually pay off!
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor