The Data, Agents, and Processes Lab (DAPLab) will present a slate of new research at the Symposium on Operating Systems Principles (SOSP 2025) workshops, spanning agentic infrastructure and self-tuning kernels. The research highlights the future of agentic infrastructure that will enable the safe, reliable, and efficient operation of large language model agents in real-world environments.
Columbia Engineering researchers develop a novel approach that can detect AI-generated content without needing access to the AI’s architecture, algorithms, or training data–a first in the field.
The first-year PhD student is developing tools that help people create engaging images and videos.
After growing up in Jiangsu, China, Sitong Wang studied electrical engineering at Chongqing University and the University of Cincinnati. During her co-op at the Hong Kong University of Science and Technology (HKUST), she was introduced to Human-Computer Interaction (HCI). This research area understands and enhances the interaction between humans and computers. She became interested in the field and then took her master’s at Columbia CS. Wang was intrigued by how computation can power the creative process when she worked on a design challenge that blends pop culture references with products or services and helped a group of students promote their beverage start-up.
Sitong Wang
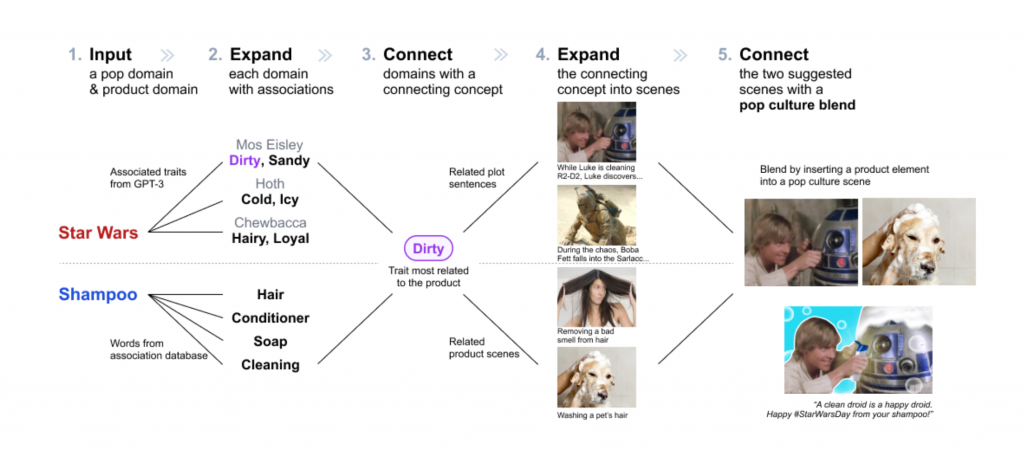
Encouraged by the creative work she could do, Wang joined the Computational Design Lab as a PhD student to continue to work with Assistant Professor Lydia Chilton and explore ways to design AI-powered creativity support tools. She recently published her first first-author research paper at the Conference on Human Factors in Computing Systems (CHI 2023). She and colleagues designed PopBlends, a system that automatically suggests conceptual blends by connecting a user’s topic with a pop culture domain. Their user study shows that people found twice as many blend suggestions as they did without the system and with half the mental demand.
We caught up with Wang to discuss her research, her work on generative AI tools, and what it is like to be a graduate student at Columbia.
Pop culture blends for Star Wars Day collected on Twitter from McDonald’s, Volkswagon, and the Girl Scouts.
Q: What is PopBlends and why did you choose to focus on the design process?
In the paper, we tackled the creative challenge of designing pop culture blends—images that use pop culture references to promote a product or service. We designed PopBlends, an automated pipeline consisting of three complementary strategies to find creative connections between a product and a pop culture domain.
Our work explores how large language models (LLMs) can provide associative knowledge and commonsense reasoning for creative tasks. We also discuss how to combine the power of traditional knowledge bases and LLMs to support creators in their divergent and convergent thinking.
It can help people, especially those without a design background, create pop culture blends more easily to advertise their brands. We want to make the design process more enjoyable and less cognitively demanding for everyone. We hope to enhance people’s creativity and productivity by scaffolding the creative process and using the power of computation to help people explore the design space more efficiently.
Q: Why did you create a tool incorporating pop culture into product ads?
Pop culture is important in everyday communication. Pop culture blends are helpful for online campaigns because they capture attention and connect the product to something people already know and like. However, creating these images is a challenging conceptual blending task and requires finding connections between two very different domains.
So we built an automated computational pipeline that can effectively support divergent and convergent thinking in finding such creative connections. We explored how to apply generative AI to creative workflows to assist people better—generative AI is powerful, but it is not perfect—thus, it is valuable to use different strategies that combine a knowledge base (which is accurate) and LLM (which has a vast amount of data) to support creative tasks.
Q: How were large language models (LLMs) helpful in your research?
Conceptual blending is complex—the design space is vast and valuable connections are rare—to tackle this challenge, we need to scaffold the ideation process and combine the intelligence of humans and machines. When we started this project, GPT-3 was not yet available; we tried traditional NLP techniques to find attribute associations (e.g., Chewbacca is fluffy) but faced challenges. Then, by chance, we tried GPT-3, which worked well with the necessary prompt engineering.
I was surprised by the associative reasoning capability of LLMs—which is technically a model that predicts the most probable next word. It easily listed related concepts for different domains and could suggest possible creative connections. I was also surprised by the hallucinations the LLMs made through our experiments, and the models could say things that were not true with great confidence.
As an emerging technology, LLMs are powerful in many ways and open up new opportunities for the computational design field. However, LLMs currently have a lot of limitations; it is essential to explore how to build system architectures around them to produce valuable results for people.
Wang presenting PopBlends at CHI’23
Q: How was it like presenting your work at CHI?
I was both nervous and excited because it had been a long time since I had presented in front of a crowd (since we did everything online during COVID). It was also my first time presenting at a computing conference, and the “Large Language Models” session I attended was very popular.
I am grateful to my labmate Vivian Liu, who provided valuable advice, helped me rehearse, and took pictures of me. The presentation went well, and I am glad we had the opportunity to present our work to a large audience of researchers. I would also like to express my gratitude to the researchers I met during the conference, as they provided encouragement and helpful tips that greatly contributed to my experience.
Q: What are you working on now?
I am working on a tool to help journalists transform their print articles into reels using generative AI by assisting them in the creative stages of producing scripts, character boards, and storyboards. In this work, in addition to LLMs, we incorporate text-to-image models and try to combine the power of both to support creators.
During the summer, I will work as a research intern at Adobe, where I will be focusing on AI and video authoring. Our work will revolve around facilitating the future of podcast video creation.
Q: Can you talk about your background and why you pursued a PhD?
My undergraduate program offered great co-op opportunities that allowed me to explore different paths, including roles as an engineer, UI designer, and research intern across Chongqing, Charlottesville, and Hong Kong. During my final co-op, I had the opportunity to work in the HCI lab at the Hong Kong University of Science and Technology (HKUST). This experience ignited my passion for HCI research and marked the beginning of my research journey in this field.
I enjoy exploring unanswered questions, particularly those that reside at the intersection of multiple disciplines. A PhD program provides an excellent opportunity to work on the problems that interest me the most. In addition, I think the training provided at the PhD level can enhance essential skills such as leadership, collaboration, critical thinking, and effective communication.
Q: What are your research interests?
My research interest lies in the creativity support in the HCI field. I am particularly interested in exploring the role of multimodal generative AI in creativity support tools. I enjoy developing co-creative interactive systems to support everyone in their everyday creative tasks.
Q: What research questions or issues do you hope to answer now?
I want to explore the role of generative AI models in future creativity support tools and build co-creative intelligent systems that support multimodal creativity, especially in the dimensions of audio and videos, as they are how we interact with the world. I also want to explore some theoretical questions, such as the overtrust/overreliance in AI, and see how we might understand and resolve them.
Sitong Wang
Q: Why did you choose to apply to Columbia CS? What attracted you to the program?
I love the vibrant environment of Columbia and NYC and how Columbia is strong in diverse disciplines, such as journalism, business, and law. It is an ideal place to do multi-disciplinary collaborative research.
Also, I got to know Professor Chilton well during my masters at Columbia. She is incredibly supportive and wonderful, and we share many common interests. That is why I chose to continue to work with her for my PhD journey.
Q: What has been the highlight of your time at Columbia?
The highlight would be when I witnessed the success of the students I mentored. It was such a rewarding process to guide and help undergraduate students interested in HCI research begin their journey.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research, what should they know or do to prepare?
Enjoy your time in NYC! Please don’t burn yourself out; learn how to manage your time efficiently. Don’t be afraid to try new things—start with manageable tasks, but also step out of your comfort zone. You will have fun!
If you want to do research, find research questions that genuinely interest you and be prepared to face challenges. Most importantly, preserve and trust yourself and your collaborators. Your efforts will eventually pay off!
CS researchers had a strong showing at the ACM CHI Conference on Human Factors in Computing Systems (CHI 2023), with seven papers and two posters accepted. The premier international conference of Human-Computer Interaction (HCI) brings together researchers and practitioners who have an overarching goal to make the world a better place with interactive digital technologies.
Capturing and reliving memories allow us to record, understand and share our past experiences. Currently, the most common approach to revisiting past moments is viewing photos and videos. These 2D media capture past events that reflect a recorder’s first-person perspective. The development of technology for accurately capturing 3D content presents an opportunity for new types of memory reliving, allowing greater immersion without perspective limitations. In this work, we adopt 2D and 3D moment-recording techniques and build a moment-reliving experience in AR that combines both display methods. Specifically, we use AR glasses to record 2D point-of-view (POV) videos, and volumetric capture to reconstruct 3D moments in AR. We allow seamless switching between AR and POV videos to enable immersive moment reliving and viewing of high-resolution details. Users can also navigate to a specific point in time using playback controls. Control is synchronized between multiple users for shared viewing.
Towards Accessible Sports Broadcasts for Blind and Low-Vision Viewers Gaurav Jain Columbia University, Basel Hindi Columbia University, Connor Courtien Hunter College, Xin Yi Therese Xu Pomona College, Conrad Wyrick University of Florida, Michael Malcolm SUNY at Albany, Brian A. Smith Columbia University
Abstract: Blind and low-vision (BLV) people watch sports through radio broadcasts that offer a play-by-play description of the game. However, recent trends show a decline in the availability and quality of radio broadcasts due to the rise of video streaming platforms on the internet and the cost of hiring professional announcers. As a result, sports broadcasts have now become even more inaccessible to BLV people. In this work, we present Immersive A/V, a technique for making sports broadcasts —in our case, tennis broadcasts— accessible and immersive to BLV viewers by automatically extracting gameplay information and conveying it through an added layer of spatialized audio cues. Immersive A/V conveys players’ positions and actions as detected by computer vision-based video analysis, allowing BLV viewers to visualize the action. We designed Immersive A/V based on results from a formative study with BLV participants. We conclude by outlining our plans for evaluating Immersive A/V and the future implications of this research.
Papers
Supporting Piggybacked Co-Located Leisure Activities via Augmented Reality Samantha Reig Carnegie Mellon University, Erica Principe Cruz Carnegie Mellon University, Melissa M. Powers New York University, Jennifer He Stanford University, Timothy Chong University of Washington, Yu Jiang Tham Snap Inc., Sven Kratz Independent, Ava Robinson Snap Inc., Brian A. Smith Columbia University, Rajan Vaish Snap Inc., Andrés Monroy-Hernández Princeton University
Abstract: Technology, especially the smartphone, is villainized for taking meaning and time away from in-person interactions and secluding people into “digital bubbles”. We believe this is not an intrinsic property of digital gadgets, but evidence of a lack of imagination in technology design. Leveraging augmented reality (AR) toward this end allows us to create experiences for multiple people, their pets, and their environments. In this work, we explore the design of AR technology that “piggybacks” on everyday leisure to foster co-located interactions among close ties (with other people and pets). We designed, developed, and deployed three such AR applications, and evaluated them through a 41-participant and 19-pet user study. We gained key insights about the ability of AR to spur and enrich interaction in new channels, the importance of customization, and the challenges of designing for the physical aspects of AR devices (e.g., holding smartphones). These insights guide design implications for the novel research space of co-located AR.
Abstract: Digital avatars are an important part of identity representation, but there is little work on understanding how to represent disability. We interviewed 18 people with disabilities and related identities about their experiences and preferences in representing their identities with avatars. Participants generally preferred to represent their disability identity if the context felt safe and platforms supported their expression, as it was important for feeling authentically represented. They also utilized avatars in strategic ways: as a means to signal and disclose current abilities, access needs, and to raise awareness. Some participants even found avatars to be a more accessible way to communicate than alternatives. We discuss how avatars can support disability identity representation because of their easily customizable format that is not strictly tied to reality. We conclude with design recommendations for creating platforms that better support people in representing their disability and other minoritized identities.
Abstract: Blind and low vision (BLV) users often rely on alt text to understand what a digital image is showing. However, recent research has investigated how touch-based image exploration on touchscreens can supplement alt text. Touchscreen-based image exploration systems allow BLV users to deeply understand images while granting a strong sense of agency. Yet, prior work has found that these systems require a lot of effort to use, and little work has been done to explore these systems’ bottlenecks on a deeper level and propose solutions to these issues. To address this, we present ImageAssist, a set of three tools that assist BLV users through the process of exploring images by touch — scaffolding the exploration process. We perform a series of studies with BLV users to design and evaluate ImageAssist, and our findings reveal several implications for image exploration tools for BLV users.
Abstract: Longform spoken dialog delivers rich streams of informative content through podcasts, interviews, debates, and meetings. While production of this medium has grown tremendously, spoken dialog remains challenging to consume as listening is slower than reading and difficult to skim or navigate relative to text. Recent systems leveraging automatic speech recognition (ASR) and automatic summarization allow users to better browse speech data and forage for information of interest. However, these systems intake disfluent speech which causes automatic summarization to yield readability, adequacy, and accuracy problems. To improve navigability and browsability of speech, we present three training agnostic post-processing techniques that address dialog concerns of readability, coherence, and adequacy. We integrate these improvements with user interfaces which communicate estimated summary metrics to aid user browsing heuristics. Quantitative evaluation metrics show a 19% improvement in summary quality. We discuss how summarization technologies can help people browse longform audio in trustworthy and readable ways.
Abstract: Recently, large language models have made huge advances in generating coherent, creative text. While much research focuses on how users can interact with language models, less work considers the social-technical gap that this technology poses. What are the social nuances that underlie receiving support from a generative AI? In this work we ask when and why a creative writer might turn to a computer versus a peer or mentor for support. We interview 20 creative writers about their writing practice and their attitudes towards both human and computer support. We discover three elements that govern a writer’s interaction with support actors: 1) what writers desire help with, 2) how writers perceive potential support actors, and 3) the values writers hold. We align our results with existing frameworks of writing cognition and creativity support, uncovering the social dynamics which modulate user responses to generative technologies.
AngleKindling: Supporting Journalistic Angle Ideation with Large Language Models Savvas Petridis Columbia University, Nicholas Diakopoulos Northwestern University, Kevin Crowston Syracuse University, Mark Hansen Columbia University, Keren Henderson Syracuse University, Stan Jastrzebski Syracuse University, Jefrey V. Nickerson Stevens Institute of Technology, Lydia B. Chilton Columbia University
Abstract: News media often leverage documents to find ideas for stories, while being critical of the frames and narratives present. Developing angles from a document such as a press release is a cognitively taxing process, in which journalists critically examine the implicit meaning of its claims. Informed by interviews with journalists, we developed AngleKindling, an interactive tool which employs the common sense reasoning of large language models to help journalists explore angles for reporting on a press release. In a study with 12 professional journalists, we show that participants found AngleKindling significantly more helpful and less mentally demanding to use for brainstorming ideas, compared to a prior journalistic angle ideation tool. AngleKindling helped journalists deeply engage with the press release and recognize angles that were useful for multiple types of stories. From our findings, we discuss how to help journalists customize and identify promising angles, and extending AngleKindling to other knowledge-work domains.
Pop culture is an important aspect of communication. On social media people often post pop culture reference images that connect an event, product, or other entity to a pop culture domain. Creating these images is a creative challenge that requires finding a conceptual connection between the users’ topic and a pop culture domain. In cognitive theory, this task is called conceptual blending. We present a system called PopBlends that automatically suggests conceptual blends. The system explores three approaches that involve both traditional knowledge extraction methods and large language models. Our annotation study shows that all three methods provide connections with similar accuracy, but with very different characteristics. Our user study shows that people found twice as many blend suggestions as they did without the system, and with half the mental demand. We discuss the advantages of combining large language models with knowledge bases for supporting divergent and convergent thinking.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor