
A Linguist of Algorithms
Celebrated by ACL with a Lifetime Achievement Award, Kathleen McKeown continues to drive bold, cross-disciplinary research that redefines the field of natural language processing.
Celebrated by ACL with a Lifetime Achievement Award, Kathleen McKeown continues to drive bold, cross-disciplinary research that redefines the field of natural language processing.
The 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) is a premiere annual conference for natural language research. Held June 16-21, 2024, in Mexico City, Mexico, researchers from the department presented work that covers language models, summarization, social media, code-switching, and sentiment analysis.
Associate Professor Zhou Yu and her team won a Best Paper Award for their paper Teaching Language Models to Self-Improve through Interactive Demonstrations. They introduce TRIPOST, a training algorithm that endows smaller models with self-improvement ability, which shows that the interactive experience of learning from and correcting its own mistakes is crucial for small models to improve their performance.
Below are the abstracts:
Teaching Language Models to Self-Improve through Interactive Demonstrations
Xiao Yu Columbia University, Baolin Peng Microsoft Research, Michel Galley Microsoft Research, Jianfeng Gao Microsoft Research, Zhou Yu Columbia University
Abstract:
The self-improving ability of large language models (LLMs), enabled by prompting them to analyze and revise their own outputs, has garnered significant interest in recent research. However, this ability has been shown to be absent and difficult to learn for smaller models, thus widening the performance gap between state-of-the-art LLMs and more costeffective and faster ones. To reduce this gap, we introduce TRIPOST, a training algorithm that endows smaller models with such selfimprovement ability, and show that our approach can improve LLaMA-7B’s performance on math and reasoning tasks by up to 7.13%. In contrast to prior work, we achieve this by using the smaller model to interact with LLMs to collect feedback and improvements on its own generations. We then replay this experience to train the small model. Our experiments on four math and reasoning datasets show that the interactive experience of learning from and correcting its own mistakes is crucial for small models to improve their performance.
TofuEval: Evaluating Hallucinations of LLMs on Topic-Focused Dialogue Summarization
Liyan Tang The University of Texas at Austin, Igor Shalyminov AWS AI Labs, Amy Wing-mei Wong AWS AI Labs, Jon Burnsky AWS AI Labs, Jake W. Vincent AWS AI Labs, Yuan Yang AWS AI Labs, Siffi Singh AWS AI Labs, Song Feng AWS AI Labs, Hwanjun Song Korea Advanced Institute of Science & Technology, Hang Su AWS AI Labs, Lijia Sun AWS AI Labs, Yi Zhang AWS AI Labs, Saab Mansour AWS AI Labs, Kathleen McKeown Columbia University
Abstract:
Single-document news summarization has seen substantial progress in faithfulness in recent years, driven by research on the evaluation of factual consistency or hallucinations. We ask whether these advances carry over to other text summarization domains. We propose a new evaluation benchmark on topic-focused dialogue summarization, generated by LLMs of varying sizes. We provide binary sentence-level human annotations of the factual consistency of these summaries along with detailed explanations of factually inconsistent sentences. Our analysis shows that existing LLMs hallucinate significant amounts of factual errors in the dialogue domain, regardless of the model’s size. On the other hand, when LLMs, including GPT-4, serve as binary factual evaluators, they perform poorly and can be outperformed by prevailing state-of-the-art specialized factuality evaluation metrics. Finally, we conducted an analysis of hallucination types with a curated error taxonomy. We find that there are diverse errors and error distributions in modelgenerated summaries and that non-LLM-based metrics can capture all error types better than LLM-based evaluators.
Fair Abstractive Summarization of Diverse Perspectives
Yusen Zhang Penn State University, Nan Zhang Penn State University, Yixin Liu Yale University, Alexander Fabbri Salesforce Research, Junru Liu Texas A&M University, Ryo Kamoi Penn State University, Xiaoxin Lu Penn State University, Caiming Xiong Salesforce Research, Jieyu Zhao University of Southern California, Dragomir Radev Yale University, Kathleen McKeown Columbia University, Rui Zhang Penn State University
Abstract:
People from different social and demographic groups express diverse perspectives and conflicting opinions on a broad set of topics such as product reviews, healthcare, law, and politics. A fair summary should provide a comprehensive coverage of diverse perspectives without underrepresenting certain groups. However, current work in summarization metrics and Large Language Models (LLMs) evaluation has not explored fair abstractive summarization. In this paper, we systematically investigate fair abstractive summarization for user-generated data. We first formally define fairness in abstractive summarization as not underrepresenting perspectives of any groups of people, and we propose four reference-free automatic metrics by measuring the differences between target and source perspectives. We evaluate nine LLMs, including three GPT models, four LLaMA models, PaLM 2, and Claude, on six datasets collected from social media, online reviews, and recorded transcripts. Experiments show that both the model-generated and the human-written reference summaries suffer from low fairness. We conduct a comprehensive analysis of the common factors influencing fairness and propose three simple but effective methods to alleviate unfair summarization. Our dataset and code are available at https: //github.com/psunlpgroup/FairSumm.
Measuring Entrainment in Spontaneous Code-switched Speech
Debasmita Bhattacharya Columbia University, Siying Ding Columbia University, Alayna Nguyen Columbia University, Julia Hirschberg Columbia University
Abstract:
It is well-known that speakers who entrain to one another have more successful conversations than those who do not. Previous research has shown that interlocutors entrain on linguistic features in both written and spoken monolingual domains. More recent work on code-switched communication has also shown preliminary evidence of entrainment on certain aspects of code-switching (CSW). However, such studies of entrainment in codeswitched domains have been extremely few and restricted to human-machine textual interactions. Our work studies code-switched spontaneous speech between humans, finding that (1) patterns of written and spoken entrainment in monolingual settings largely generalize to code-switched settings, and (2) some patterns of entrainment on code-switching in dialogue agent-generated text generalize to spontaneous code-switched speech. Our findings give rise to important implications for the potentially “universal” nature of entrainment as a communication phenomenon, and potential applications in inclusive and interactive speech technology.
Multimodal Multi-loss Fusion Network for Sentiment Analysis
zehui wu, Ziwei Gong, Jaywon Koo, Julia Hirschberg
Abstract:
This paper investigates the optimal selection and fusion of feature encoders across multiple modalities and combines these in one neural network to improve sentiment detection. We compare different fusion methods and examine the impact of multi-loss training within the multi-modality fusion network, identifying surprisingly important findings relating to subnet performance. We have also found that integrating context significantly enhances model performance. Our best model achieves state-of-the-art performance for three datasets (CMU-MOSI, CMU-MOSEI and CH-SIMS). These results suggest a roadmap toward an optimized feature selection and fusion approach for enhancing sentiment detection in neural networks.
Identifying Self-Disclosures of Use, Misuse and Addiction in Community-based Social Media Posts
Chenghao Yang, Tuhin Chakrabarty, Karli R Hochstatter, Melissa N Slavin, Nabila El-Bassel, Smaranda Muresan
Abstract:
In the last decade, the United States has lost more than 500,000 people from an overdose involving prescription and illicit opioids, making it a national public health emergency (USDHHS, 2017). Medical practitioners require robust and timely tools that can effectively identify at-risk patients. Community-based social media platforms such as Reddit allow self-disclosure for users to discuss otherwise sensitive drug-related behaviors. We present a moderate-size corpus of 2500 opioid-related posts from various subreddits labeled with six different phases of opioid use: Medical Use, Misuse, Addiction, Recovery, Relapse, and Not Using. For every post, we annotate span-level extractive explanations and crucially study their role both in annotation quality and model development.2 We evaluate several state-of-the-art models in a supervised, few-shot, or zero-shot setting. Experimental results and error analysis show that identifying the phases of opioid use disorder is highly contextual and challenging. However, we find that using explanations during modeling leads to a significant boost in classification accuracy, demonstrating their beneficial role in a high-stakes domain such as studying the opioid use disorder continuum.
CS researchers are among the recipients of the inaugural awards from the Columbia Center of Artificial Intelligence Technology (CAIT). Amazon is providing $5 million in funding over five years to support research, education, and outreach programs.
CS researchers will be at the 2019 Annual Meeting of the Association of Computational Linguistics in Florence, Italy. Numerous papers covering the computational approaches to natural language were accepted.
Accepted papers
Summaries of the papers are below:
Pay “Attention” to Your Context when Classifying Abusive Language
Tuhin Chakrabarty Columbia University, Kilol Gupta Columbia University, and Smaranda Muresan Columbia University
The goal of any social media platform is to facilitate healthy and meaningful interactions among its users. But more often than not, it has been found that it becomes an avenue for wanton attacks.
In the paper the researchers propose an experimental study that has three aims: (1) to provide a deeper understanding of current datasets that focus on different types of abusive language, which are sometimes overlapping (racism, sexism, hate speech, offensive language and personal attacks); (2) to investigate what type of attention mechanism (contextual vs. self-attention) is better for abusive language detection using deep learning architectures; and (3) to investigate whether stacked architectures provide an advantage over simple architectures for this task.
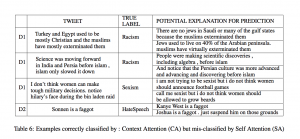
The work is about using context attention instead of self-attention for abuse detection which encapsulates the information by looking at examples globally through the training data, unlike self attention which only focuses on words for that particular tweet while trying to classify it.

The first tweet belongs to the NONE class while the second tweet belongs to RACISM class. The word “islam” may appear in the realm of racism as well as in any normal conversation. The model successfully identified the two distinct contextual usages of the word “Islam” in the two tweets, as demonstrated by a much higher attention weight in the second case and a relatively smaller one in the first case.
Neural Network Alignment for Sentential Paraphrases
Jessica Ouyang Columbia University and Kathleen McKeown Columbia University
The researchers created a system that automatically aligns paraphrases between two input sentences — that is, it detects which parts of the two sentences are paraphrases of each other. Their aligner is unique in that it is able to align phrases of arbitrary length, including full sentences, as well as relatively loose paraphrases, where the two aligned phrases mean approximately, but not necessarily exactly, the same thing.
Paraphrase alignment is the task of detecting parts of two input sentences that mean the same thing. Previous work on this task has focused on a strict definition of paraphrase, which requires that the aligned phrases mean exactly the same thing; previous systems aligned only words that exactly matched, or were close synonyms, between the sentences. In addition, previous work on paraphrase alignment was practically limited to phrases of three or fewer words, due to running time constraints. However, most people’s intuition about what counts as a paraphrase is much less strict, and paraphrases can be much longer than three words.

The phrases in bold are examples of paraphrases that the system can align, but that previous work could not. The entire phrase, “I vaguely recalled him telling me” means the same thing as “I remembered a story” in the context of these two sentences, but there is no one-to-one mapping between the words in the two phrases (eg. “vaguely” in Sentence 1 has no corresponding word in Sentence 2), which would prevent previous systems from successfully aligning these phrases.
The designed system aligns these looser and longer paraphrases by first breaking the input sentences into grammatical chunks, such as noun or verb phrases. For each chunk, it calculates a single vector that represents the meaning of that chunk by combining the vectors representing the meanings of the words within it. Then, a neural network is used to align each chunk in one of the input sentences to the chunks in the other sentence. This method allows for the alignment of all of the words within a chunk at once, regardless of the length of the chunk, and small differences in meaning or in individual words are mitigated by the meanings of the other words in the chunk. The system is the first to use a neural network to perform the alignment task, and it is able to align longer and less exactly-matching sentences than previous systems could.
Rubric Reliability and Annotation of Content and Argument in Source-Based Argument Essays
Yanjun Gao Pennsylvania State University, Alex Driban Pennsylvania State University, Brennan Xavier McManus Columbia University, Elena Musi University of Liverpool, Patricia M. Davies Prince Mohammad Bin Fahd University, Smaranda Muresan Columbia University, and Rebecca J. Passonneau Pennsylvania State University
Students with STEM majors were prompted to write short argumentative essays on topics including cryptocurrencies, cybercrime, and self-driving cars. These essays were graded on a rubric, and the essays were analyzed for content.
The argumentative structure of these essays were analyzed, which involved breaking the essays down into units of argumentation and indicating whether one argument supports, attacks, or is necessary context for another, from the main claim of the essay down to individual pieces of evidence. The results of this annotation were compared to the results of applying the rubric for each of these essays, leading to a set of argumentative features associated with essays of particular scores.
One simple finding is that essays with the highest overall score (5) tended to have a higher ratio of argumentative sentences to non-argumentative sentences, while the essays in the next highest group (4) tended to be longer. The essays with the higher scores and lower scores often had similar numbers of claims, but the latter group would tend to fail to connect these claims to the main argument of their essay.
The goal of research in this area is to assess the eventual effectiveness and usability of automated grading assistants for argumentative essays, and to what extent a rubric can be applied to fairly analyze the content and argumentative structure of essays in a similar way in which automated grading scripts are used within the CS department here at Columbia.
Researchers are using AI to decode the language of Chicago gangs. Next they’ll look for opportunities to intervene before online aggression turns deadly.