
Tag: Daniel Hsu
CS Professors Part of the Inaugural J.P. Morgan Faculty Research Awards
The J.P. Morgan AI Research Awards 2019 partners with research thinkers across artificial intelligence. The program is structured as a gift that funds a year of study for a graduate student.
Prediction semantics and interpretations that are
grounded in real data
Principal Investigator: Daniel Hsu Computer Science Department & Data Science Institute
The importance of transparency in predictive technologies is by now well-understood by many machine learning practitioners and researchers, especially for applications in which predictions may have serious impacts on human lives (e.g., medicine, finance, criminal justice). One common approach to providing transparency is to ensure interpretability in the models and predictions produced by an application, or to accompany predictions with explanations. Interpretations and explanations may help individuals understand predictions that affect them, and also help developers reason about failure cases of their applications.
However, there are numerous possibilities for what constitutes a suitable interpretation or explanation, and the semantics of such provided by existing systems are not always clear.
Suppose, for example, that a bank uses a linear model to predict whether or not a loan applicant will forfeit on a loan. A natural strategy is to seek a sparse linear model, which are often touted as highly interpretable. However, attributing significance to variables with non-zero regression coefficients (e.g., zip-code) and not others (e.g., race, age) is suspect when variables may be correlated. Moreover, an explanation based on pointing to individual variables or other parameters of a model ignores the source of the model itself: the training data (e.g., a biased history of borrowers and forfeiture outcomes) and the model fitting procedure. Invalid or inappropriate explanations may create a “transparency fallacy” that creates more problems than are solved.
The researchers propose a general class of mechanisms that provide explanations based on training or validation examples, rather than any specific component or parameters of a predictive model. In this way, the explanation will satisfy two key features identified in successful human explanations: the explanation will be contrastive, allowing an end-user to compare the present data to the specific examples chosen from the training or validation data, and the explanation will be pertinent to the actual causal chain that results in the prediction in question. These features are missing in previous systems that seek to explain predictions based on machine learning methods.
“We expect this research to lead to new methods for interpretable machine learning,” said Daniel Hsu, the principal investigator of the project. Because the explanations will be based on actual training examples, the methods will be widely applicable, in essentially any domain where examples can be visualized or communicated to a human. He continued, “This stands in contrast to nearly all existing methods for explanatory machine learning, which either require strong assumptions like linearity or sparsity, or do not connect to the predictive model of interest or the actual causal chain leading to a given prediction of interest.”
Efficient Formal Safety Analysis of Neural Networks
Principal Investigators: Suman Jana Computer Science Department, Jeannette M. Wing Computer Science Department & Data Science Institute, Junfeng Yang Computer Science Department
Over the last few years, artificial intelligence (AI), in particular Deep Learning (DL) and Deep Neural Networks (DNNs), has made tremendous progress, achieving or surpassing human-level performance for a diverse set of tasks including image classification, speech recognition, and playing games such as Go. These advances have led to widespread adoption and deployment of DL in critical domains including finance, healthcare, autonomous driving, and security. In particular, the financial industry has embraced AI in applications ranging from portfolio management (“Robo-Advisor”), algorithmic trading, fraud detection, loan and insurance underwriting, sentiment and news analysis, customer service, to sales.
“Machine learning models are used in more and more safety and security-critical applications such as autonomous driving and medical diagnosis,” said Suman Jana, one of the principal investigators of the project. “Yet they are known to be fragile and frequently mispredicts on edge cases.“
In many critical domains including finance and autonomous driving, such incorrect behaviors can lead to disastrous consequences such as a gigantic loss in automated financial trading or a fatal collision of a self-driving car. For example, in 2016, a Google self-driving car crashed into a bus because it expected the bus to yield under a set of rare conditions but the bus did not. Also in 2016, a Tesla car in autopilot crashed into a trailer because the autopilot system failed to recognize the trailer as an obstacle due to its ‘white color against a brightly lit sky’ and the ‘high ride height.’
Before AI can become the next technological revolution, it must be robust against such corner-case inputs and does not cause disasters. The researchers believe AI robustness is one of the biggest challenges that needs to be solved in order to fully tame AI for good.
“Our research aims to create novel tools to verify that a machine learning model will not mispredict on certain important input ranges, ensuring safety and security,” said Junfeng Yang, one of the investigators of the research.
The proposed work enables rigorous analysis of autonomous AI systems and machine learning (ML) algorithms, enabling data scientists to (1) verify that their AI models function correctly within certain input regions and violate no critical properties they specify (e.g., bidding price is never higher than a given maximum) or (2) locate all sub-regions where their models misbehave and repair their model accordingly. This capability will also enable data scientists to explain and interpret the outputs from autonomous AI systems and ML algorithms by understanding how different input regions may lead to different output predictions. Said Yang,”If successful, our work will dramatically boost the robustness, explainability, and interpretability of today’s autonomous AI systems and ML algorithms, benefiting virtually every individual, business, and government that relies on AI and ML.”
Daniel Hsu Recipient of 2019 Faculty and Research Engagement Program (FREP)
FREP awards grants to faculty members in support of research to enhance people’s lives by improving the internet. FREP was founded in 2012 to foster cutting-edge collaborations between scientists in academic settings and those at Yahoo Research.
Roxana Geambasu and Daniel Hsu Chosen for Google Faculty Research Awards Program
The award is given to faculty at top universities to support research that is relevant to Google’s products and services. The program is structured as a gift that funds a year of study for a graduate student.
Certified Robustness to Adversarial Examples with Differential Privacy
Principal Investigator: Roxana Geambasu Computer Science Department
The proposal builds on Geambasu’s recent work on providing a “guaranteed” level of robustness for machine learning models against attackers that may try to fool their predictions. PixelDP works by randomizing the prediction of a model in such a way to obtain a bound on the maximum change an attacker can make on the probability of any label with only a small change in the image (measured in some norm).
Imagine that a building rolls out a face recognition-based authorization system. People are automatically recognized as they approach the door and are let into the building if they are labeled as someone with access to that building.
The face recognition system is most likely backed by a machine learning model, such as a deep neural network. These models have been shown to be extremely vulnerable to “adversarial examples,” where an adversary finds a very small change in their appearance that causes the models to classify them incorrectly – wearing a specific kind of hat or makeup can cause a face recognition model to misclassify even if the model would have been able to correctly classify without these “distractions.”
The bound the researchers enforce is then used to assess, on each prediction on an image, whether any attack up to a given norm size could have changed the prediction on that image. If it cannot, then the prediction is deemed “certifiably robust” against attacks up to that size.
A sample PixelDP DNN: original architecture in blue; the changes introduced by PixelDP in red.
This robustness certificate for an individual prediction is the key piece of functionality that their defense provides, and it can serve two purposes. First, a building authentication system can use it to decide whether a prediction is sufficiently robust to rely on the face recognition model to make an automated decision, or whether additional authentication is required. If the face recognition model cannot certify a particular person, that person may be required to use their key to get into the building. Second, a model designer can use robustness certificates for predictions on a test set to assess a lower bound of their model on accuracy under attack. They can use this certified accuracy to compare model designs and choose one that is most robust for deployment.
“Our defense is currently the most scalable defense that provides a formal guarantee of robustness to adversarial example attacks,” said Roxana Geambasu, principal investigator of the research project.
The project is joint work with Mathias Lecuyer, Daniel Hsu, and Suman Jana. It will develop new training and prediction algorithms for PixelDP models to increase certified accuracy for both small and large attacks. The Google funds will support PhD student Mathias Lecuyer, the primary author of PixelDP, to develop these directions and evaluate them on large networks in diverse domains.
The role of over-parameterization in solving non-convex problems
Principal Investigators: Daniel Hsu Computer Science Department, Arian Maleki Department of Statistics
One of the central computational tasks in data science is that of fitting statistical models to large and complex data sets. These models allow for people to reason and draw conclusions from the data.
For example, such models have been used to discover communities in social network data and to uncover human ancestry structure from genetic data. In order to make accurate inferences, it has to be ensured that the model is well-fit to the data. This is a challenge because the predominant approach to fitting models to data requires solving complex optimization problems that are computationally intractable in the worst case.
“Our research considers a surprising way to alleviate the computational burden, which is to ‘over-parameterize’ the statistical model,” said Daniel Hsu, one of the principal investigators. “By over-parameterization, we mean introducing additional ‘parameters’ to the statistical model that are unnecessary from the statistical point-of-view.”
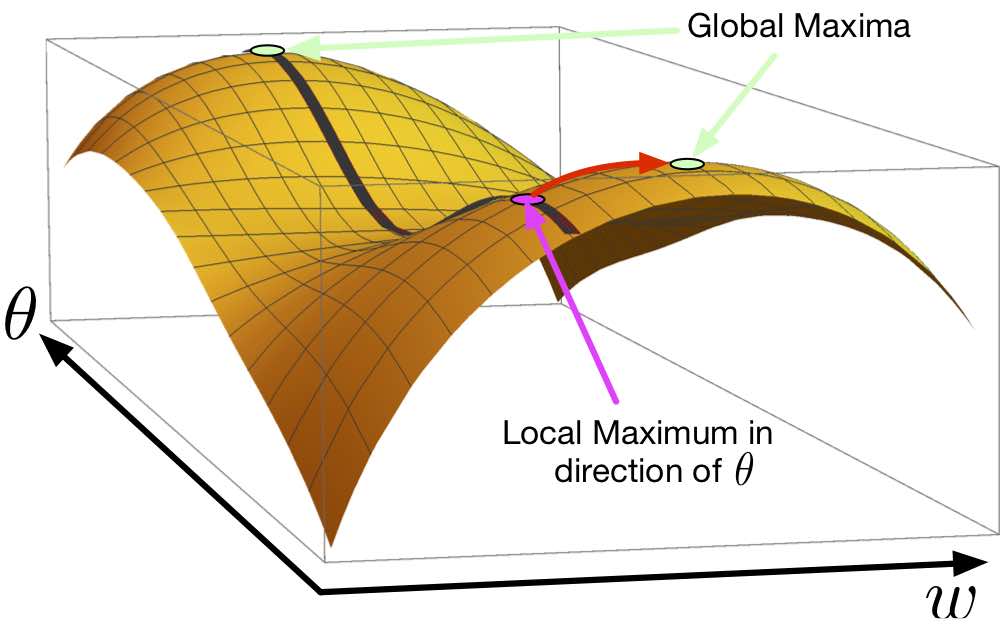
One way to over-parameterize a model is to take some some prior information about the data and now regard it as a variable parameter to fit. For instance, in the social network case, the sizes of the communities expected to discover may have been known; the model can be over-parameterized by treating the sizes as parameters to be estimated. This over-parameterization would seem to make the model fitting task more difficult. However, the researchers proved that, for a particular statistical model called a Gaussian mixture model, over-parameterization can be computationally beneficial in a very strong sense.
This result is important because it suggests a way around computational intractability that data scientists may face in their work of fitting models to data.
The aim of the proposed research project is to understand this computational benefit of over-parameterization in the context of other statistical models. The researchers have empirical evidence of this benefit for many other variants of the Gaussian mixture model beyond the one for which their theorem applies. The Google funds will support PhD student Ji Xu, who is jointly advised by Daniel Hsu and Arian Maleki.