In a world fixated on ever-higher resolutions and increasingly detailed images, a revolutionary new camera takes a daring step in the opposite direction. The Minimalist Camera is an innovation designed to prioritize efficiency and privacy over unnecessary detail. By capturing only the minimal data needed for a specific task, this groundbreaking technology challenges conventional thinking about imaging—and redefines what cameras don’t need to do.
Jeremy Klotz
Developed by Jeremy Klotz, a third-year PhD student in the CAVE Lab, in collaboration with Professor Shree Nayar, the minimalist camera forgoes traditional images. Instead, it relies on a handful of custom-shaped “freeform” pixels, carefully tailored to the task at hand. The result? A device that preserves privacy by avoiding the capture of identifiable details while consuming so little power that it’s entirely self-sustaining. Whether monitoring traffic flow or analyzing crowd movements, this camera captures only the essential data—empowering practical applications without compromising individual privacy.
Jeremy Klotz and Shree Nayar at ECCV 2024
The innovation has not gone unnoticed, earning a Best Paper Award at the European Conference on Computer Vision (ECCV 2024). More than just an accolade, the minimalist camera signals a paradigm shift in how cameras can function in our increasingly interconnected world.
We caught up with Klotz to explore the story behind the minimalist camera, the ups and downs of PhD life, and what it means to push the boundaries of imaging technology in the name of privacy and efficiency.
Q: How did you develop the idea for the minimalist camera? When I started my PhD, my advisor and I began brainstorming research directions. After discussing different ideas, we landed on the high-level concept of creating a camera that captures the least information necessary to perform a vision task. In contrast to a traditional camera that uses millions of tiny square pixels, our idea was to let each pixel take on an arbitrary shape (which we call a freeform pixel). Once we evaluated this idea in simulation, we found that freeform pixels can solve vision tasks with significantly fewer pixels than traditional cameras.
I worked with my advisor on every aspect of the project, from refining the high-level idea to building a prototype camera. This involved careful thinking about how to design freeform pixels, simulating them in software, and then building a camera that uses a very small number of freeform pixels to solve real-world vision tasks. This project took about one and a half years from start to finish.
Shree Nayar and Jeremy Klotz
Q: Can you describe your research focus and what motivates your work? My research is in computational imaging, where we design new cameras using novel hardware and software. This area is particularly exciting since it merges research in computer vision (typically all software) with imaging hardware. In particular, I love building prototypes to demonstrate our research ideas. Working with hardware is definitely challenging, but seeing a prototype work at the end of the day makes it even more rewarding.
I’m interested in asking questions like, “What are the fewest measurements needed to solve a vision task?” and “How can we build a camera that captures the fewest measurements?” These questions are particularly relevant right now. Most cameras produce exceptionally high-quality images, but this comes at a cost: high-resolution images often reveal too much information about the world, and the cameras consume so much power that they can only be deployed on buildings (with a tether for power) or with a battery that needs to be recharged.
Q: Why did you decide to pursue a PhD? Before coming to Columbia, I studied electrical and computer engineering at Carnegie Mellon. While I was an undergrad, I was introduced to research in computational imaging. I didn’t plan to pursue a PhD at the time, but after this foray into research, I found that I really enjoyed the open-ended problems and decided to pursue a PhD.
My undergraduate research was the most important experience that prepared me for my PhD. Although it’s hard to completely understand what a PhD entails until you start, my undergrad research introduced me to how it feels to do research full-time and what it’s like to work with a professor rather than for a professor.
Now as a PhD student, my work’s direction is completely up to me. If I believe that an idea is worth pursuing, then I can commit all of my time to working on it. This freedom is incredible, and it allows me to choose the most interesting problems to work on.
Q: What standout moments or experiences have shaped your journey at Columbia so far? I’ve really enjoyed going to conferences—presenting research and meeting others in the field is a blast. I’ve also enjoyed attending department seminars on research outside my area. It’s helped me to ask thoughtful questions about work in other fields.
With my research, we’ve had quite a few ideas that simply don’t work out. My strategy is to try to determine if a new idea is viable as early as possible, and quickly pivot if it isn’t.
Q: What is your advice to students on how to navigate their time at Columbia? If you want to do research, keep an open mind to explore areas you may not be familiar with. A lot of research can appear intimidating at first, but the students and faculty working in the area are extremely passionate and excited to chat if you ask.
Second-year PhD student Cheng Chi talks about how his research on robotic control won a Best Paper Award at RSS 2022
In the Columbia Artificial Intelligence and Robotics (CAIR) Lab, Cheng Chi stands in front of a robotic arm. At the end of the arm sits a yellow plastic cup. His goal at the moment is to use a piece of rope to hit the cup to the ground.
“I never thought I would have to do this as part of a research project,” said Chi, a second-year PhD student. He was conducting the exercise to gain a better understanding of physical movement and how it can be applied to a robotic control system.
Existing robotic systems struggle to precisely manipulate objects with complex dynamics, such as hitting a small target with a whip or swinging tablecloths to an exact location. While these tasks are quite hard even for humans, we usually have a good intuition about how to change our actions after a failed attempt, and iteratively get closer to the goal.
Cheng Chi in the CAIR Lab
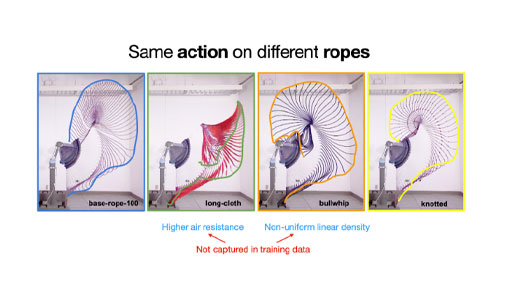
Chi was able to knock the cup off after five tries. Now, it’s the robot’s turn to fling the piece of rope. It takes the robot four times to hit the target during the experiment (in general less than 10 times). The algorithm/neural network was trained in a simulator using a large amount of data. The robot, called Oolong, had to hit a target and was tested on different kinds of ropes it had never seen before.
Together with Assistant Professor Shuran Song and colleagues from the CAIR Lab, Chi worked to formalize this intuition into an algorithm called Iterative Residual Policy (IRP), a general learning framework for repeatable tasks with complex dynamics where a single model was trained using inaccurate simulation data. IRP can learn from that data and hit many targets with unfamiliar ropes in real robotic experiments, reaching sub-inch accuracy, and demonstrating its strong generalization capability.
This research brings robots from factories, where everything is rigid and can be accurately modeled, closer to everyday households filled with dirty laundry, raw vegetables to be washed in the sink, and leftover food to be cleaned from the fridge. It could potentially alleviate the labor shortage in food, retail, and logistics due to the aging population in many parts of the world. This could also enable the automation of simple tasks like changing bed sheets and badges in hospitals with infectious disease patients.
The team won a Best Paper Award at the Robot Science and Systems Conference (RSS 2022). We caught up with Chi to find out more about his research and PhD life at Columbia.
Q: How did you become part of the research project?
This is part of a grant from the Toyota Research Institute on deformable object manipulation. For this specific project, I wanted to explore more complex and dynamic forms of robotic manipulation and control. As the primary researcher of this project, I decided on the research topic, problem, and task.
Q: How long did you work on the project? What did you have to do, or read to prepare to make the system?
The project started in May 2021. I did a lot of research about control theory for underactuated systems, chaos, and how to work with robot hardware.
Classical robotics literature divides the operation of a robot into three stages — perception, planning, and control. In my previous research, I studied perception and the planning stage of robotics. However, I realized that my knowledge still has a noticeable hole in control theory and systems that control the function and movement of robots.
I believe that I will never become a full-fledged roboticist without understanding all parts of robotic operations. Therefore, I intentionally steered this project toward control which allows me to read more into control-related literature and classes.
For example, I went over the YouTube recording of MIT’s underactuated robotics, taught by Professor Russ Tedrake, who has been known for his contributions to the control of locomotion systems (such as Boston Dynamic’s quadruped robots).
Another interesting thing about control is that, unlike planning, the control of the human body mostly happens at a subconscious level. Therefore, understanding more about control also gave me more insight into how the human body works.
The key realization came after months of reflecting on how I achieved certain tasks and how to formulate such a problem.
Since the relatively early stage of this project (after I decided to tackle the rope whipping task), I had this lingering feeling that being able to adjust the next action based on the error of my previous action is critical for how humans accomplish this task (by observing myself doing it). But I wasn’t able to connect it with math and concrete algorithms.
The next few months were spent playing with data collected in simulations to understand the structure of this task and problem. I often spent a few afternoons a week just staring at my iPad notes, sketching potential algorithms that can solve this task efficiently. Most of them were futile. However, one afternoon in late September, I suddenly came up with the idea that connects my lingering feeling to this concrete algorithm. And the rest was mostly planning out experiments, executing, and verifying results.
Q: Why did you decide to do research on robotic control?
I decided on the research project jointly on what is missing in the field and what I wanted to learn. For example, I wanted to get into control last summer, so I took classes online and read relevant papers to build a foundation. I noticed that the missing piece in the field is deformable manipulation with precision.
Existing robotic algorithms often assume the object being manipulated is rigid, and ignore its physics/dynamics, due to its complexity. My research thrust has been targeting this complexity (of object physics and non-rigidity) head-on, which hopefully will result in better algorithms that will improve the overall performance and robustness of robotics systems, outside of confined/structured industrial environments.
Whipping a piece of rope is one of the simplest instances of dynamic deformable object manipulation, without the additional perceptive complexity such as self-occlusion, etc. However, we believe that whipping a piece of rope and tablecloth is representative of the class of problem we are interested in and that there is no existing robotic system/algorithm that can accomplish this task. Therefore, our algorithm has expanded what is considered possible in robotics.
I thought that it would be cool to simplify it to a minimum-working task, like whipping. Whipping a piece of rope or cloth accurately requires adapting existing skills which humans are good at but it is very difficult for robots to do.
Humans can hit targets with reasonable accuracy after usually 10~20 trials. The best algorithm before IRP takes 100-1000+ trials to get there.
The project spanned 10 months and it was not easy, since solving this novel and challenging task requires going beyond the common paradigm in the field, for example, reinforcement learning or system identification.
I tried three ideas at first and none of them worked or advanced the field to a satisfying degree for me. The final idea was inspired by some studies from the biomechanics/neural science community that I came across while doing research.
While I was struggling with this project, my advisor pointed me to this recording of an RSS 2020 workshop. I was fascinated by one of the talks by Professor Dagmar Stenard and her findings from the biomechanical perspective of how humans minimize uncertainty and avoid the chaotic region of the state space when taking actions.
I read further into her publications and was pleasantly surprised that her group was studying the same rope-whipping problem. Their algorithm was crude and they only tested in simulation with many additional assumptions, but I really liked their problem formulation of the whipping task and their use of action primitive, which dramatically reduced the number of parameters needed to describe the dynamic and continuous robot action.
They also demonstrated that their action primitives (that bio literature believes humans also use) are sufficient for this task. Therefore, I took their problem formulation and tweaked their action primitive to better fit real robotic hardware, and eventually developed the IRP algorithm on top of that.
Q: Why did you decide to use different kinds of ropes for the project?
The type of rope we simulated for training is modeled after a thick cotton rope we bought on Amazon. However, due to the various complex physical properties and their effects, the rope modeled in simulation behaves significantly differently from its real-world counterpart. This is an instance of a well-known challenge in the robotics community called “sim2real gap”.
Since the deep-learning revolution (~2014), a large body of robotic algorithms emerged that have shown very promising results in simulated environments. However, they also rely on a large amount of data for training (our algorithm included), which is only feasible to collect in simulation. If the behavior of objects in simulation matches exactly their counterparts in real life, in theory, we can directly apply these data-hungry algorithms to the real world. Unfortunately, this is far from the truth, and the difference is especially big for deformable objects.
The biggest contribution of this paper is providing a solution to close this “sim2real gap” for a limited class of problems (where the actions are repeatable, and the objects can be reset to the original state), i.e. the algorithm behaves just as good in the real world as in simulation, despite the simulation it was trained on is very “wrong”.
To further demonstrate how “wrong” the simulation can be while the algorithm still works, we cut out a long strip of cloth, that behaves like a gymnastic ribbon and treated it as the rope. We also bought a very thick leather bullwhip, that has a non-uniform density (it becomes thinner and thinner as it goes toward the tip), while all ropes we trained in simulation have uniform thickness and density. The experimental results on these two “ropes” were just as good.
Q: What do you think is the most interesting thing about doing research?
I like how researchers are able to try high-risk ideas that actually advance the field and also learn fundamental knowledge about the field. Working in industry usually constrains research options to low-risk ideas, while the engineering effort might be larger.
Q: How did your previous experiences prepare you for a PhD?
I gained my initial research experience during my undergrad at the University of Michigan, working on deformable object perception. I had multiple internships, as well as full-time jobs at autonomous vehicle companies, which taught me how to properly engineer a robotics software system.
Q: Why did you apply to Columbia and how was that process?
I applied to Columbia to work with Assistant Professor Shuran Song. Just before I graduated from undergrad, Shuran did a job talk at the University of Michigan. My undergrad research advisor Professor Dmitry Berenson was at her talk and he was really impressed. Berenson strongly recommended that I apply to work with her and he thought we would be a great fit. After researching her past publications, I did find a large overlap in our research interests and I only heard good words about her after asking other people who have worked with her.
At the time, I wasn’t really sure about getting a PhD, and because of the time needed to complete the applications, I only applied to two schools. The application website could have been improved, but the overall process is surprisingly smooth. I really like the idea that students are admitted by and to individual professors, and the professors make the decision.
Q: What has been the highlight of your time at Columbia?
The highlight of my time is being able to be taught and guided by my advisor, as well as other PhD students.
Q: You are starting the third year of your PhD at Columbia, do you think your skills have improved? In which ways?
I think what improved the most was to think more structurally and not be buried by the details. Due to the engineering complexity of robotic systems, there are thousands of variables and decisions, large and small, I needed to make for the project to progress. For example, on the high level, how to model the rope in the simulation, how to model the robot, how to represent the observation and actions, how the model should be architected, etc.
For an inexperienced researcher like myself, it is not obvious which one of these parameters will make or break the project, or will only yield a small change in the final performance. So, I over-analyzed, over-engineered, and over-thought the small problems. Fortunately, Shuran often called out that some of these decisions probably don’t matter that much, and choosing an arbitrary path to go forward is strictly better than spending time thinking about which one is better.
The problem is that this is mostly based on intuition. Shuran can’t always give evidence of why one thing doesn’t matter and why another does. But fortunately, I think I am getting a better grasp of these intuitions. It will become easier for me as time passes and I become an expert in robotics.
I also have found that it is really important to communicate clearly, both in meetings and when writing things down for reports or even emails. Learning by example from my advisor also helps a lot.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research what should they know or do to prepare?
New students going into research should try as hard as possible to push through the first research project. It is always hard in the beginning, and it might feel impossible, but you can do it. Build up a tolerance for failure and continue to try different things, which is often critical to making a contribution to the field.
XRP: In-Kernel Storage Functions with eBPF Yuhong Zhong Columbia University, Haoyu Li Columbia University, Yu Jian Wu Columbia University, Ioannis Zarkadas Columbia University, Jeffrey Tao Columbia University, Evan Mesterhazy Columbia University, Michael Makris Columbia University, Junfeng Yang Columbia University, Amy Tai Google, Ryan Stutsman University of Utah; Asaf Cidon Columbia University
Abstract: With the emergence of microsecond-scale NVMe storage devices, the Linux kernel storage stack overhead has become significant, almost doubling access times. We present XRP, a framework that allows applications to execute user-defined storage functions, such as index lookups or aggregations, from an eBPF hook in the NVMe driver, safely bypassing most of the kernel’s storage stack. To preserve file system semantics, XRP propagates a small amount of kernel state to its NVMe driver hook where the user-registered eBPF functions are called. We show how two key-value stores, BPF-KV, a simple B+-tree key-value store, and WiredTiger, a popular log-structured merge tree storage engine, can leverage XRP to significantly improve throughput and latency.
ROLLER: Fast and Efficient Tensor Compilation for Deep Learning Hongyu Zhu University of Toronto and Microsoft Research; Ruofan Wu Renmin University of China and Microsoft Research; Yijia Diao Shanghai Jiao Tong University and Microsoft Research, Shanbin Ke UCSD and Microsoft Research, Haoyu Li Columbia University and Microsoft Research; Chen Zhang Tsinghua University and Microsoft Research; Jilong Xue Microsoft Research, Lingxiao Ma Microsoft Research, Yuqing Xia Microsoft Research, Wei Cui Microsoft Research, Fan Yang Microsoft Research, Mao Yang Microsoft Research, Lidong Zhou Microsoft Research, Asaf Cidon Columbia University, Gennady Pekhimenko University of Toronto
Abstract: Despite recent advances in tensor compilers, it often costs hours to generate an efficient kernel for an operator, a compute-intensive sub-task in a deep neural network (DNN), on various accelerators (e.g., GPUs). This significantly slows down DNN development cycles and incurs heavy burdens on the development of general kernel libraries and custom kernels, especially for new hardware vendors. The slow compilation process is due to the large search space formulated by existing DNN compilers, which have to use machine learning algorithms to find good solutions.
In this paper, we present ROLLER, which takes a different construction-based approach to generate kernels. At the core of ROLLER is rTile, a new tile abstraction that encapsulates tensor shapes that align with the key features of the underlying accelerator, thus achieving efficient execution by limiting the shape choices. ROLLER then adopts a recursive rTile-based construction algorithm to generate rTile-based programs (rProgram), whose performance can be evaluated efficiently with a micro-performance model without being evaluated in a real device. As a result, ROLLER can generate efficient kernels in seconds, with comparable performance to the state-of-the-art solutions on popular accelerators like GPUs, while offering better kernels on less mature accelerators like IPUs.
Abstract: The increasing use of sensitive private data in computing is matched by a growing concern regarding data privacy. System software such as hypervisors and operating systems are supposed to protect and isolate applications and their private data, but their large codebases contain many vulnerabilities that can risk data confidentiality and integrity. We introduce Realms, a new abstraction for confidential computing to protect the data confidentiality and integrity of virtual machines. Hardware creates and enforces Realm world, a new physical address space for Realms. Firmware controls the hardware to secure Realms and handles requests from untrusted system software to manage Realms, including creating and running them. Untrusted system software retains control of the dynamic allocation of memory to Realms, but cannot access Realm memory contents, even if run at a higher privileged level. To guarantee the security of Realms, we verified the firmware, introducing novel verification techniques that enable us to prove, for the first time, the security and correctness of concurrent software with hand-over-hand locking and dynamically allocated shared page tables, data races in kernel code running on relaxed memory hardware, integrated C and Arm assembly code calling one another, and untrusted software being in full control of allocating system resources. Realms are included in the Arm Confidential Compute Architecture.
Abstract: Distributed systems are complex and difficult to build correctly. Formal verification can provably rule out bugs in such systems, but finding an inductive invariant that implies the safety property of the system is often the hardest part of the proof. We present DuoAI, an automated system that quickly finds inductive invariants for verifying distributed protocols by reducing SMT query costs in checking invariants with existential quantifiers. DuoAI enumerates the strongest candidate invariants that hold on validate states from protocol simulations, then applies two methods in parallel, returning the result from the method that succeeds first. One checks all candidate invariants and weakens them as needed until it finds an inductive invariant that implies the safety property. Another checks invariants without existential quantifiers to find an inductive invariant without the safety property, then adds candidate invariants with existential quantifiers to strengthen it until the safety property holds. Both methods are guaranteed to find an inductive invariant that proves desired safety properties, if one exists, but the first reduces SMT query costs when more candidate invariants with existential quantifiers are needed, while the second reduces SMT query costs when few candidate invariants with existential quantifiers suffice. We show that DuoAI verifies more than two dozen common distributed protocols automatically, including various versions of Paxos, and outperforms alternative methods both in the number of protocols it verifies and the speed at which it does so, including solving Paxos more than two orders of magnitude faster than previous methods.
Abstract: Containers are widely deployed to package, isolate, and multiplex applications on shared computing infrastructure, but rely on the operating system to enforce their security guarantees. This poses a significant security risk as large operating system codebases contain many vulnerabilities. We have created BlackBox, a new container architecture that provides fine-grain protection of application data confidentiality and integrity without trusting the operating system. BlackBox introduces a container security monitor, a small trusted computing base that creates protected physical address spaces (PPASes) for each container such that there is no direct information flow from container to operating system or other container PPASes. Indirect information flow can only happen through the monitor, which only copies data between container PPASes and the operating system as system call arguments, encrypting data as needed to protect interprocess communication through the operating system. Containerized applications do not need to be modified, can still make use of operating system services via system calls, yet their CPU and memory state are isolated and protected from other containers and the operating system. We have implemented BlackBox by leveraging Arm hardware virtualization support, using nested paging to enforce PPASes. The trusted computing base is a few thousand lines of code, many orders of magnitude less than Linux, yet supports widely-used Linux containers with only modest modifications to the Linux kernel. We show that BlackBox provides superior security guarantees over traditional hypervisor and container architectures with only modest performance overhead on real application workloads.
Abstract: Applications often have fast-paced release schedules, but adoption of software dependency updates can lag by years, leaving applications susceptible to security risks and unexpected breakage. To address this problem, we present UPGRADVISOR, a system that reduces developer effort in evaluating dependency updates and can, in many cases, automatically determine which updates are backward-compatible versus API-breaking. UPGRADVISOR introduces a novel co-designed static analysis and dynamic tracing mechanism to gauge the scope and effect of dependency updates on an application. Static analysis prunes changes irrelevant to an application and clusters relevant ones into targets. Dynamic tracing needs to focus only on whether targets affect an application, making it fast and accurate. UPGRADVISOR handles dynamic interpreted languages and introduces call graph over-approximation to account for their lack of type information and selective hardware tracing to capture program execution while ignoring interpreter machinery.
We have implemented UPGRADVISOR for Python and evaluated it on 172 dependency updates previously blocked from being adopted in widely-used open-source software, including Django, aws-cli, tfx, and Celery. UPGRADVISOR automatically determined that 56% of dependencies were safe to update and reduced by more than an order of magnitude the number of code changes that needed to be considered by dynamic tracing. Evaluating UPGRADVISOR’s tracer in a production-like environment incurred only 3% overhead on average, making it fast enough to deploy in practice. We submitted safe updates that were previously blocked as pull requests for nine projects, and their developers have already merged most of them.
The CS undergrad shares how he started doing research in the Speech Lab and won a Best Paper award at EMNLP 2021
Shayan Hooshmand
Shayan Hooshmand grew up speaking Spanish, Persian, and English. Every time he switched between the three languages he felt like he was walking between social worlds and presenting a different version of himself. Hooshmand is also an actor and it is this same affinity for shapeshifting that underpins his theatre career. As he got older, he tried to learn more languages or at least more about as many languages as he could.
Once he got to Columbia, he was all set to study computer science (CS) and found himself gravitating toward natural language processing and speech processing because those research areas combined CS and linguistics. The prospect of teaching machines to understand language was interesting to him. Hooshmand decided to take Intro Linguistics, loved it, and added Linguistics as a double major.
When he came across Professor Julia Hirschberg’s Speech Lab and their research on emotion and charisma in speech, it caught his attention. He emailed Hirschberg every semester for three semesters until, in the spring of 2021, there was finally an opening to join one of her projects which he accepted immediately.
The research project he was assigned to focuses on automatically identifying humor in Facebook (FB) posts. The system the team created, Collecting Humor Reaction Labels, earned them a Best Paper award at a prestigious conference, Empirical Methods in Natural Language Processing (EMNLP 2021). We caught up with Hooshmand to learn more about what it takes to do research and win an award.
Q: What is CHoRAL and what were your findings? CHoRaL stands for Collecting Humor Reaction Labels, it is a framework for automatically scoring Facebook posts on humor. It presents two formulas, one to calculate a humor score, and one to calculate a non-humor score – each is based on the reaction distribution of a Facebook post.
Our paper presents both the framework and a dataset collected using the framework. The dataset contains about 800,000 COVID-related FB posts, each post was assigned humor and non-humor scores. Our goal for this framework and dataset is to enable future humor prediction research.
We validated our framework with experiments using several different BERT-based deep learning models. BERT is a machine learning model that learns contextual relations between words (or sub-words) in a text. We also ran lexico-semantic analyses on the humorous posts and non-humorous posts in our dataset to find some interesting patterns, like words related to space and time being negatively correlated with humor.
Facebook Reactions emojis
Q: How did this project come about? What was the process of deciding what to do? The overall project didn’t have anything to do with humor immediately. The goal of this (ongoing) project is to detect fake and manipulated media online. As part of this larger goal, we thought it would be useful to automatically predict humor; then, if some piece of false information online is clearly humorous, we can attribute it to benign “fake news” and not anything malicious.
The pleasure of being an undergrad, though, is that I wasn’t fixated on these larger goals or the meetings with outside sponsors and collaborators that Professor Hirschberg and the PhD students attended. I got to focus on humor prediction and working directly with my PhD mentor, Zixiaofan Brenda Yang. Brenda came in with the brilliant idea to use Facebook humor reactions as a proxy for humor labels. At a high level, posts with more humor reactions would be more “humorous.” From there, the work became testing different methods to formalize this intuition.
Q: How much data did you have to work with? How was it processed? So much data! We worked with millions of Facebook posts. We downloaded posts from CrowdTangle, a social media insights tool owned by Facebook. At first, we downloaded small batches of ~20,000 posts to test some of our formulas and definitions of humor and non-humor scores. In the end, we downloaded a couple of million Facebook posts and filtered them to keep only pure-text posts in English. We wrote the cleaning scripts in Python and ran them remotely on our lab computers.
User reactions to a humorous Facebook post (top) and a non-humorous post (bottom).
Q: Were you prepared to work on it or did you learn as the project progressed? It was a bit of a trial by fire for me since I was unaware of the standard proceedings and expectations surrounding academic research. For example, it shocked me that most of the “framing” work is done only when it comes time for paper writing. For a lot of the research process, you do not actually have a set, detailed idea of how you are going to present your work.
I also had to study technical concepts from information theory and statistics as we went along. Luckily, I always had my mentor, Brenda, as a guide.
Q: What were the things you already knew and what were the things you had to learn while working on the project? I knew about the state-of-the-art deep learning models for NLP (RNNs, Transformers, etc.) and some other basic machine learning concepts. Naively, I thought my work would involve working with these models all the time, playing with their architecture, and tuning their hyperparameters.
In reality, I focused much more on data collection, preprocessing, and developing those formulas on humor and non-humor scores. Data collection and preprocessing were almost completely new to me (aside from some preprocessing functions I had written in previous CS classes) –– at least for our project, this work was fairly straightforward.
Developing the formulas required a lot of experimentation and reading up on technical concepts. I spent a couple of days trying to understand KL divergence conceptually before we tried to use it for an element of our project. In the end, it did not even end up being part of the paper. The cool thing, though, is that once I read up on that I ended up using it later in the project as the basis for calculating our non-humor score.
Q: Looking back, what were the skills that you wished you had before starting the project? I wish I had a greater understanding of reading scientific papers, writing them, and the expectations for what kind of information from your project goes into them. There were many instances throughout the semester where Brenda had to remind me that we needed to be thorough with a certain decision or read up on previous work that might have faced the same problem because we would need to justify all our processes to the scientific community.
Q: Did working on this project make you want to change your research interests or focus? The most interesting parts of the project for me were the linguistic analyses we ran on our humor-labeled data and writing the paper. I think that is because I like to approach things from more of a linguistics perspective, not as much pure computer science, so I am trying to direct my research from that angle more now.
Q: Will you continue to work on CHoRAL? Or are you working on something else now? I have switched to a text-to-speech project in the Speech Lab this semester, so I’m not working on CHoRaL full-time anymore.
Q: Do you want to continue doing research and pursue a graduate degree? I am definitely going to continue research throughout my undergrad years, and a PhD is possibly in my future. I am leaning toward working outside of academia for a few years after college and then applying to PhD programs later in my 20s.
Q: Would you recommend volunteering or seeking projects out to other students? Of course! Even if you’re not interested in pursuing higher education, there’s so much to learn from a research environment. Particularly in the AI/ML space, doing research demystifies all the jargon and far-reaching statements about computer intelligence that you hear in the media. It is also a great way to gain practical skills, like keeping a project codebase organized and communicating the work I did independently with my mentors.
Q: Is there anything else that you think people should know about the project? Not that I can think of right now, but if any students want to talk more about the project or undergrad research in general, my UNI is sh3988.
Papers from CS researchers were accepted to the Empirical Methods in Natural Language Processing (EMNLP) 2021. The Best Short Paper Award was also awarded to a paper from the Spoken Language Processing Group.
Humor detection has gained attention in recent years due to the desire to understand user-generated content with figurative language. However, substantial individual and cultural differences in humor perception make it very difficult to collect a large-scale humor dataset with reliable humor labels. We propose CHoRaL, a framework to generate perceived humor labels on Facebook posts, using the naturally available user reactions to these posts with no manual annotation needed. CHoRaL provides both binary labels and continuous scores of humor and non-humor. We present the largest dataset to date with labeled humor on 785K posts related to COVID-19. Additionally, we analyze the expression of COVID-related humor in social media by extracting lexico-semantic and affective features from the posts, and build humor detection models with performance similar to humans. CHoRaL enables the development of large-scale humor detection models on any topic and opens a new path to the study of humor on social media.
Dialogue summarization comes with its own peculiar challenges as opposed to news or scientific articles summarization. In this work, we explore four different challenges of the task: handling and differentiating parts of the dialogue belonging to multiple speakers, negation understanding, reasoning about the situation, and informal language understanding. Using a pretrained sequence-to-sequence language model, we explore speaker name substitution, negation scope highlighting, multi-task learning with relevant tasks, and pretraining on in-domain data. Our experiments show that our proposed techniques indeed improve summarization performance, outperforming strong baselines.
Timeline Summarization identifies major events from a news collection and describes them following temporal order, with key dates tagged. Previous methods generally generate summaries separately for each date after they determine the key dates of events. These methods overlook the events’ intra-structures (arguments) and inter-structures (event-event connections). Following a different route, we propose to represent the news articles as an event-graph, thus the summarization task becomes compressing the whole graph to its salient sub-graph. The key hypothesis is that the events connected through shared arguments and temporal order depict the skeleton of a timeline, containing events that are semantically related, structurally salient, and temporally coherent in the global event graph. A time-aware optimal transport distance is then introduced for learning the compression model in an unsupervised manner. We show that our approach significantly improves the state of the art on three real-world datasets, including two public standard benchmarks and our newly collected Timeline100 dataset.
Despite constant improvements in machine translation quality, automatic poetry translation remains a challenging problem due to the lack of open-sourced parallel poetic corpora, and to the intrinsic complexities involved in preserving the semantics, style and figurative nature of poetry. We present an empirical investigation for poetry translation along several dimensions: 1) size and style of training data (poetic vs. non-poetic), including a zeroshot setup; 2) bilingual vs. multilingual learning; and 3) language-family-specific models vs. mixed-language-family models. To accomplish this, we contribute a parallel dataset of poetry translations for several language pairs. Our results show that multilingual fine-tuning on poetic text significantly outperforms multilingual fine-tuning on non-poetic text that is 35X larger in size, both in terms of automatic metrics (BLEU, BERTScore, COMET) and human evaluation metrics such as faithfulness (meaning and poetic style). Moreover, multilingual fine-tuning on poetic data outperforms bilingual fine-tuning on poetic data.
Enthymemes are defined as arguments where a premise or conclusion is left implicit. We tackle the task of generating the implicit premise in an enthymeme, which requires not only an understanding of the stated conclusion and premise, but also additional inferences that could depend on commonsense knowledge. The largest available dataset for enthymemes (Habernal et al., 2018) consists of 1.7k samples, which is not large enough to train a neural text generation model. To address this issue, we take advantage of a similar task and dataset: Abductive reasoning in narrative text (Bhagavatula et al., 2020). However, we show that simply using a state-of-the-art seq2seq model fine-tuned on this data might not generate meaningful implicit premises associated with the given enthymemes. We demonstrate that encoding discourse-aware commonsense during fine-tuning improves the quality of the generated implicit premises and outperforms all other baselines both in automatic and human evaluations on three different datasets.
Practical dialogue systems require robust methods of detecting out-of-scope (OOS) utterances to avoid conversational breakdowns and related failure modes. Directly training a model with labeled OOS examples yields reasonable performance, but obtaining such data is a resource-intensive process. To tackle this limited-data problem, previous methods focus on better modeling the distribution of in-scope (INS) examples. We introduce GOLD as an orthogonal technique that augments existing data to train better OOS detectors operating in low-data regimes. GOLD generates pseudo-labeled candidates using samples from an auxiliary dataset and keeps only the most beneficial candidates for training through a novel filtering mechanism. In experiments across three target benchmarks, the top GOLD model outperforms all existing methods on all key metrics, achieving relative gains of 52.4%, 48.9% and 50.3% against median baseline performance. We also analyze the unique properties of OOS data to identify key factors for optimally applying our proposed method.
Continual learning in task-oriented dialogue systems can allow us to add new domains and functionalities through time without incurring the high cost of a whole system retraining. In this paper, we propose a continual learning benchmark for task-oriented dialogue systems with 37 domains to be learned continuously in four settings, such as intent recognition, state tracking, natural language generation, and end-to-end. Moreover, we implement and compare multiple existing continual learning baselines, and we propose a simple yet effective architectural method based on residual adapters. Our experiments demonstrate that the proposed architectural method and a simple replay-based strategy perform comparably well but they both achieve inferior performance to the multi-task learning baseline, in where all the data are shown at once, showing that continual learning in task-oriented dialogue systems is a challenging task. Furthermore, we reveal several trade-off between different continual learning methods in term of parameter usage and memory size, which are important in the design of a task-oriented dialogue system. The proposed benchmark is released together with several baselines to promote more research in this direction.
Zero-shot transfer learning for dialogue state tracking (DST) enables us to handle a variety of task-oriented dialogue domains without the expense of collecting in-domain data. In this work, we propose to transfer the crosstask knowledge from general question answering (QA) corpora for the zero-shot DST task. Specifically, we propose TransferQA, a transferable generative QA model that seamlessly combines extractive QA and multichoice QA via a text-to-text transformer framework, and tracks both categorical slots and non-categorical slots in DST. In addition, we introduce two effective ways to construct unanswerable questions, namely, negative question sampling and context truncation, which enable our model to handle “none” value slots in the zero-shot DST setting. The extensive experiments show that our approaches substantially improve the existing zero-shot and few-shot results on MultiWoz. Moreover, compared to the fully trained baseline on the Schema-Guided Dialogue dataset, our approach shows better generalization ability in unseen domains.Zero-shot transfer learning for dialogue state tracking (DST) enables us to handle a variety of task-oriented dialogue domains without the expense of collecting in-domain data. In this work, we propose to transfer the crosstask knowledge from general question answering (QA) corpora for the zero-shot DST task. Specifically, we propose TransferQA, a transferable generative QA model that seamlessly combines extractive QA and multichoice QA via a text-to-text transformer framework, and tracks both categorical slots and non-categorical slots in DST. In addition, we introduce two effective ways to construct unanswerable questions, namely, negative question sampling and context truncation, which enable our model to handle “none” value slots in the zero-shot DST setting. The extensive experiments show that our approaches substantially improve the existing zero-shot and few-shot results on MultiWoz. Moreover, compared to the fully trained baseline on the Schema-Guided Dialogue dataset, our approach shows better generalization ability in unseen domains.
Despite the recent success of large-scale language models on various downstream NLP tasks, the repetition and inconsistency problems still persist in dialogue response generation. Previous approaches have attempted to avoid repetition by penalizing the language model’s undesirable behaviors in the loss function. However, these methods focus on tokenlevel information and can lead to incoherent responses and uninterpretable behaviors. To alleviate these issues, we propose to apply reinforcement learning to refine an MLE-based language model without user simulators, and distill sentence-level information about repetition, inconsistency and task relevance through rewards. In addition, to better accomplish the dialogue task, the model learns from human demonstration to imitate intellectual activities such as persuasion, and selects the most persuasive responses. Experiments show that our model outperforms previous state-of-the-art dialogue models on both automatic metrics and human evaluation results on a donation persuasion task, and generates more diverse, consistent and persuasive conversations according to the user feedback.
Large language models benefit from training with a large amount of unlabeled text, which gives them increasingly fluent and diverse generation capabilities. However, using these models for text generation that takes into account target attributes, such as sentiment polarity or specific topics, remains a challenge. We propose a simple and flexible method for controlling text generation by aligning disentangled attribute representations. In contrast to recent efforts on training a discriminator to perturb the token level distribution for an attribute, we use the same data to learn an alignment function to guide the pre-trained, non-controlled language model to generate texts with the target attribute without changing the original language model parameters. We evaluate our method on sentiment- and topiccontrolled generation, and show large performance gains over previous methods while retaining fluency and diversity.
Recommendation dialogs require the system to build a social bond with users to gain trust and develop affinity in order to increase the chance of a successful recommendation. It is beneficial to divide up, such conversations with multiple subgoals (such as social chat, question answering, recommendation, etc.), so that the system can retrieve appropriate knowledge with better accuracy under different subgoals. In this paper, we propose a unified framework for common knowledge-based multi-subgoal dialog: knowledge-enhanced multi-subgoal driven recommender system (KERS). We first predict a sequence of subgoals and use them to guide the dialog model to select knowledge from a sub-set of existing knowledge graph. We then propose three new mechanisms to filter noisy knowledge and to enhance the inclusion of cleaned knowledge in the dialog response generation process. Experiments show that our method obtains state-of-the-art results on DuRecDial dataset in both automatic and human evaluation.
Distributed systems are notoriously hard to implement correctly due to non-determinism. Finding the inductive invariant of the distributed protocol is a critical step in verifying the correctness of distributed systems, but takes a long time to do even for simple protocols. We present DistAI, a data-driven automated system for learning inductive invariants for distributed protocols. DistAI generates data by simulating the distributed protocol at different instance sizes and recording states as samples. Based on the observation that invariants are often concise in practice, DistAI starts with small invariant formulas and enumerates all strongest possible invariants that hold for all samples. It then feeds those invariants and the desired safety properties to an SMT solver to check if the conjunction of the invariants and the safety properties is inductive. Starting with small invariant formulas and strongest possible invariants avoids large SMT queries, improving SMT solver performance. Because DistAI starts with the strongest possible invariants, if the SMT solver fails, DistAI does not need to discard failed invariants, but knows to monotonically weaken them and try again with the solver, repeating the process until it eventually succeeds. We prove that DistAI is guaranteed to find the ∃-free inductive invariant that proves the desired safety properties in finite time, if one exists. Our evaluation shows that DistAI successfully verifies 13 common distributed protocols automatically and outperforms alternative methods both in the number of protocols it verifies and the speed at which it does so, in some cases by more than two orders of magnitude.
Modern desktop applications involve many asynchronous, concurrent interactions that make performance issues difficult to diagnose. Although prior work has used causal tracing for debugging performance issues in distributed systems, we find that these techniques suffer from high inaccuracies for desktop applications. We present Argus, a fast, effective causal tracing tool for debugging performance anomalies in desktop applications. Argus introduces a novel notion of strong and weak edges to explicitly model and annotate trace graph ambiguities, a new beam-search-based diagnosis algorithm to select the most likely causal paths in the presence of ambiguities, and a new way to compare causal paths across normal and abnormal executions. We have implemented Argus across multiple versions of macOS and evaluated it on 12 infamous spinning pinwheel issues in popular macOS applications. Argus diagnosed the root causes for all issues, 10 of which were previously unknown, some of which have been open for several years. Argus incurs less than 5% CPU overhead when its system-wide tracing is enabled, making always-on tracing feasible.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor