
Meet Columbia Engineering’s 2022 Valedictorian and Salutatorian
Ahmet Cem Karadeniz (ME ’22) and Maya Venkatraman (CS’ 22) speak about life at Columbia Engineering.
Ahmet Cem Karadeniz (ME ’22) and Maya Venkatraman (CS’ 22) speak about life at Columbia Engineering.
Extreme weather and climate hazards negatively affect the food production and income of smallholder farmers across the world. One of the risk reduction strategies employed is index insurance for drought, which allows smallholder farmers to reduce their risk of losing money in the event of a drought. Computing the insurance claims requires data on the drought severity and timing. The problem is that these smallholder farmers do not have the infrastructure to accurately collect data, causing a “data void”. This, in turn, makes it hard for them to receive fair and timely relief.
Over the past decade, Columbia Earth Institute’s Daniel Osgood, has led the Financial Instruments Sector Team (FIST) which partners with farmers in Ethiopia, Zambia, and Senegal to develop an insurance index design process. The data was collected manually and in person but when COVID hit, the researchers realized they needed to develop scalable and easy-to-use digital tools.
In a recently funded NSF grant, Osgood collaborated with Assistant Professor Lydia Chilton and Associate Professor Eugene Wu to create systems that accurately collect data, tools that clean and visualize the data, and ultimately create an “open insurance toolkit” that any organization or government can use. One of the major tools created for the collaboration was Reptile, an easy-to-use app that helps clean and cross-verify farmer drought reports developed by third-year PhD student Zachary Huang. Reptile utilizes the predictive power of satellite data readily available at the International Research Institute’s data library as well as data collected from the farmers themselves. Farmer drought reports are critical for the FIST team to make high-stakes data-driven decisions in index insurance design. The insurance could protect hundreds of millions of farmers in face of climate hazards and extreme weather events.

Huang is a PhD student in Eugene Wu’s Wu Lab where researchers are addressing three bottlenecks in the future of data analysis: data cleaning, creating interactive data exploration and visualization interfaces, and understanding analysis results. Even though Huang’s background is in data analytics and database management systems, he shared he was not concerned about diving into the index insurance project. He learned about index insurance through a “very friendly” index insurance tutorial made by the FIST team. He also reviewed previous research papers and it was enough for him to work on the project. He likened himself to a blacksmith who builds tools for swordsmen. Said Huang, “I just need to know what swordsmen care about when using swords, but I do not have to be a swordmaster.”
We caught up with Huang to talk about his research, working on the Reptile app, and how his research focus has evolved.
Q: What was your role in the project? What did you do?
I mainly had two roles. My first role is as a software engineer, where I developed many useful data exploration tools to help FIST clean farmer drought reports and track the progress of data cleaning.
My second role is as a researcher. I studied the problem of data cleaning, data exploration, and data integration in-depth. I found there was a gap between what data cleaning research focused on and the problems the FIST team actually had. So I formalized the problem of cleaning farmer drought data and solved many hard technical problems while building Reptile. Our paper has been accepted by the ACM SIGMOD International Conference on Management of Data (SIGMOD 2022).
Q: What kinds of data did you have to work with and how did you manage it?
The main data I worked with is farmer drought data collected through questionnaires and a large volume of satellite data available from the International Research Institute’s data library. The data library compiles raw climate, geophysical, health, and agriculture data from numerous providers and formats it into a common framework that is publicly available.
These data from the data library are very predictive of drought severity. For example, the rainfall data are negatively correlated with the drought data. However, I was surprised by how laborious and frustrating it was to merge these data with the drought data from farmers and fully exploit their predictive power. This “data integration” problem is a hard problem even in industry.
The problem of data analytics across different data sources is very common across areas and challenging. To give you a sense of the difficulty, let’s take a look at the structure of public data from IMDB, the Internet Movie Database website. The information about movies, actors, companies, etc. is distributed across so many tables. Unfortunately, traditional data analytics tools are typically designed for a single table at a time. As a result, analysts have to manually “join” these tables together, which is confusing for non-experts, slow, and generally painful. FIST is facing the same problem: there are so many valuable tables, but how to take advantage of them?
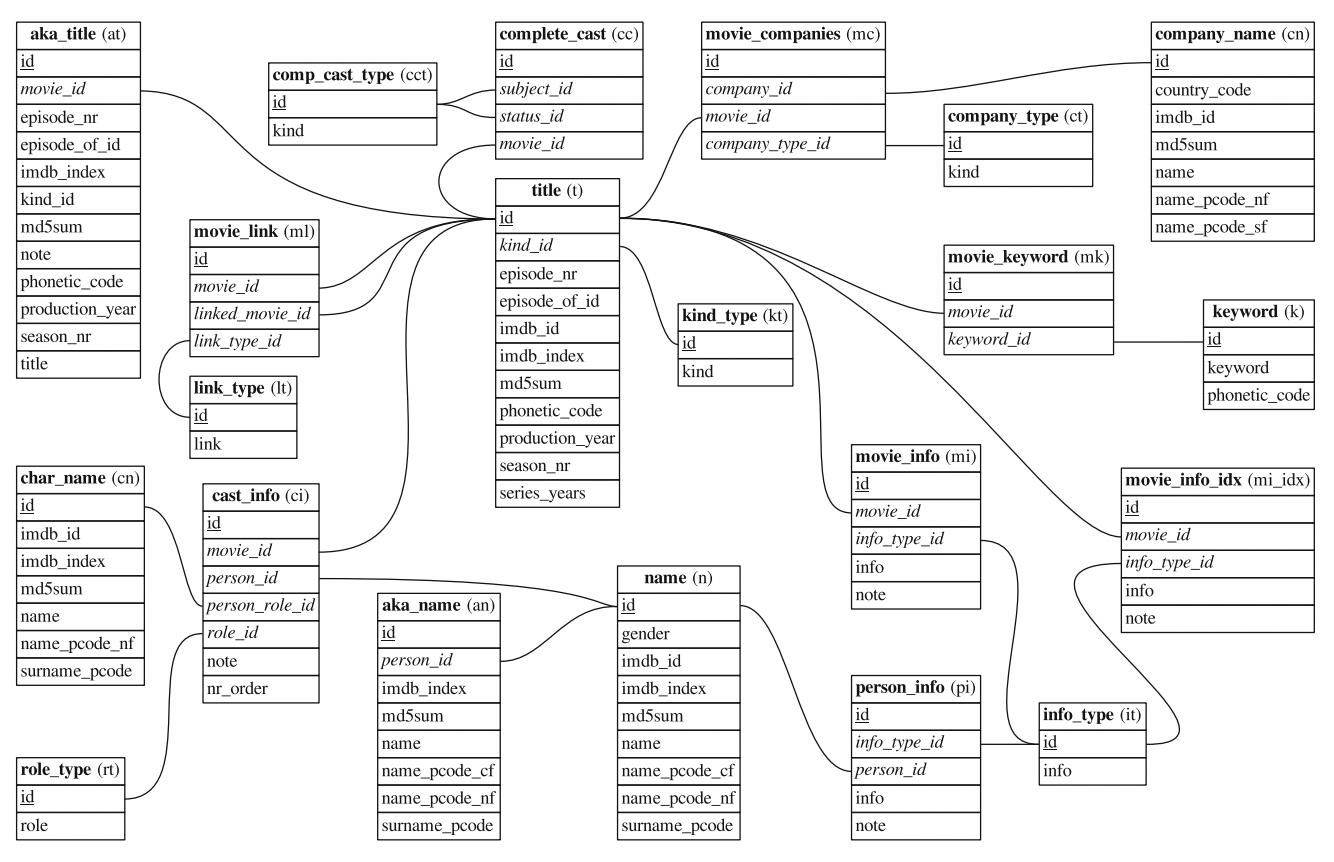
Q: What does Reptile do?
Farmer reports can often have errors from wrong data entry, misremembering historical events, and bias. It’s not realistic to examine and assess each report individually, so Reptile helps the FIST team identify abnormalities at the district or national level, cross-verify these patterns with satellite data, and quickly fix the errors. FIST and local partners then rely on these cleaned data to design the index insurance.
Q: You mentioned that you decided to make the system simple and much easier to use. Why is that?
Initially, I built many different features per the requests from FIST. The end result is a monolithic system that tries to do everything but does nothing well. Users had to go to different systems even if the tasks are similar and had huge overlaps, which caused confusion.
About why I decided to make the system simple, let me quote Steve Jobs, “Simple can be harder than complex: You have to work hard to get your thinking clean to make it simple. But it’s worth it in the end because once you get there, you can move mountains.” I invested most of my time thinking about the project and trying to think of creative ways to solve problems. I read many papers, studied the problems in abstraction, and solved research problems. As a result, I aggressively simplified the system and made it much more useful for users.
Q: Can you talk about your background and why did you decide to pursue a PhD?
In undergrad, I had a decent mathematical background and transferred to computer science during my junior year. I initially intended to apply for some software engineering jobs. However, I learned from a friend who was a software engineer in a big tech company that his job is “an endless routine of crushing monotony”, and he also wanted to apply for a PhD to do something more intellectual.
I enjoy doing projects. But if you are hired as a junior software engineer, chances are that you are assigned some tedious tasks in the beginning and you need to slowly climb the career ladder before you can become a project lead. I very much wanted to be an entrepreneur, but I was totally not ready at that time. Doing a PhD sounded like a cool option, as it is intellectual and I can take initiative with research projects.
Q: What is your research focus?
I am interested in data analytics in cloud databases. I pursue this type of research because I believe the cloud is the future. It is the most profitable service in big tech companies like Microsoft and Amazon. The momentum keeps going with a large growth rate. I believe in the near future almost all data will be stored in the cloud, people will never want to move data outside of the cloud, and all these data analytics and machine learning tasks will be done inside the cloud.
With great power comes great responsibility. However, current cloud databases only store large volumes of data, but leave it to users to figure out how to use them. People call those data in cloud databases a “data swamp” – they just dump tons of tables but no one understands them.
Before Reptile, my research interest was to automate data cleaning. Given the fact that there are so much data in the cloud, it is a huge waste not to use it. However, while designing Reptile, I realized that data cleaning is a human problem, not a system problem. There are so many errors that are domain-specific and cannot be automated. For instance, farmer reports could be wrong because they confused drought with a flood, mixed planting and harvesting seasons, misremember the year, etc. While any of these issues sound trivial, discovering and understanding all of them requires domain knowledge, experiences, and common sense. We call these types of problems “AI-complete” problems; they are the most difficult problems in AI and can’t be solved until we can make computers as intelligent as people.
After Reptile, I shifted my attention from data cleaning to algorithmic optimization of data analytics over multiple tables. I utilized theories from probabilistic graphical models to aggressively save computations and significantly accelerate the process. We have an active project that shows how this can enable practical “data markets”, which are platforms where people can trade and monetize data across and within organizations, such that people have huge incentives to clean and improve the utility of data so that they are more valuable to potential buyers.
Q: What are you working on now?
My theoretical and algorithmic work has led to many exciting applications.
For instance, I’m collaborating with the Microsoft Azure team to build an innovative in-database machine learning system. Currently, if customers want to apply machine learning to data in cloud databases, they have to move data “outside” of the database to a machine learning system, which is slow, wasteful, and not secure. We implement all the machine learning algorithms “inside” cloud databases so that customers can conduct data analytics directly in cloud databases.
Another application is to support data analytics and machine learning over hundreds of tables without the need to “join” them. For example, FIST can use this system to directly combine the predictive power of hundreds of satellite data in the data library with the drought reports from farmers. Our preliminary results show orders of magnitude performance improvement over traditional machine learning systems.
Q: How long did it take you to complete the work? How was it?
Reptile took about two years to complete. It took a lot longer than I expected! I started the initial draft in the first semester of my PhD. However, figuring out the details, conducting experiments, polishing the writing, and revising based on reviewers’ feedback…there were so many things to attend to, which made the project long. Luckily, the whole process is a cumulative learning experience and inspired many research ideas for my future projects. Plus, I think I will be able to finish any future research projects much more efficiently moving forward.
Q: How did your previous experiences prepare you for a PhD?
I did research projects when I was an undergraduate – one on data cleaning and another on database storage. These projects helped me understand the research process and what are the critical problems nowadays in databases. Ultimately, having research experience strengthened my PhD application.
Q: What are some things you wish you knew before starting your PhD?
Things take time and research projects especially take time! We all want overnight success, but success happens because we have prepared for it for a long time. It is important not to worry if your research papers are not accepted at conferences and published. There are too many factors that are out of our control. If you have good ideas and decent work, being published is just a matter of time.
Also, it is better to focus on learning. Because research projects take such a long period, it is easy for us to get lost in monotonous and repetitive routines. However, you do not improve by just working hard. Do something that is cumulative in the long term, like learning! Small things will add up and make a huge difference in the long term.
Q: What is your advice for students on how to navigate their PhD? If they want to do research what should they know?
They should definitely work on some new areas and get a competitive advantage that is unique to them. The aim of your PhD research is to innovate in a specific area and push the boundaries of human knowledge. However, if you are working in an area that has been well-studied by so many smart people for decades, chances are there is no room for further innovation. For instance, if you want to improve system performance based on your coding skills, there are so many talented people who can code, so it’s unlikely for you to beat them. Your PhD life will be much happier if you can find something that not too many people know but is quite useful, and then become an expert in it.
I invest a lot of time learning probabilistic graphical models and graph theory. These statistical techniques seem irrelevant to database systems but they solve a similar problem – how to conduct analytics over multiple tables. This competitive advantage lets me easily design algorithms that are magnitudes faster than previous work.
Q: What else do you think is important for PhD students to think about?
I think it is good to periodically check if your research direction is useful. Committing to a research project and spending huge amounts of time on it requires a certain kind of fooling yourself – you need to convince yourself that your research project is useful and it is worthwhile to work so hard on.
However, you need to periodically jump out of your comfort zone and verify if your research direction is really useful. It is disappointing to devote five years to a research direction only to later find out that no one cares. One way to verify the usefulness of a research topic is to find some users or collaborators, like the FIST team for my Reptile project.
You should also ask your advisors for help, as they have a much deeper understanding of the area. My advisor, Eugene Wu, helped me a lot in finding the real-world applications of my theoretical ideas. To find applications, we have connected with professors in different domains, research departments in different companies, and even venture capitalists.

Shayan Hooshmand grew up speaking Spanish, Persian, and English. Every time he switched between the three languages he felt like he was walking between social worlds and presenting a different version of himself. Hooshmand is also an actor and it is this same affinity for shapeshifting that underpins his theatre career. As he got older, he tried to learn more languages or at least more about as many languages as he could.
Once he got to Columbia, he was all set to study computer science (CS) and found himself gravitating toward natural language processing and speech processing because those research areas combined CS and linguistics. The prospect of teaching machines to understand language was interesting to him. Hooshmand decided to take Intro Linguistics, loved it, and added Linguistics as a double major.
When he came across Professor Julia Hirschberg’s Speech Lab and their research on emotion and charisma in speech, it caught his attention. He emailed Hirschberg every semester for three semesters until, in the spring of 2021, there was finally an opening to join one of her projects which he accepted immediately.
The research project he was assigned to focuses on automatically identifying humor in Facebook (FB) posts. The system the team created, Collecting Humor Reaction Labels, earned them a Best Paper award at a prestigious conference, Empirical Methods in Natural Language Processing (EMNLP 2021). We caught up with Hooshmand to learn more about what it takes to do research and win an award.
Q: What is CHoRAL and what were your findings?
CHoRaL stands for Collecting Humor Reaction Labels, it is a framework for automatically scoring Facebook posts on humor. It presents two formulas, one to calculate a humor score, and one to calculate a non-humor score – each is based on the reaction distribution of a Facebook post.
Our paper presents both the framework and a dataset collected using the framework. The dataset contains about 800,000 COVID-related FB posts, each post was assigned humor and non-humor scores. Our goal for this framework and dataset is to enable future humor prediction research.
We validated our framework with experiments using several different BERT-based deep learning models. BERT is a machine learning model that learns contextual relations between words (or sub-words) in a text. We also ran lexico-semantic analyses on the humorous posts and non-humorous posts in our dataset to find some interesting patterns, like words related to space and time being negatively correlated with humor.

Q: How did this project come about? What was the process of deciding what to do?
The overall project didn’t have anything to do with humor immediately. The goal of this (ongoing) project is to detect fake and manipulated media online. As part of this larger goal, we thought it would be useful to automatically predict humor; then, if some piece of false information online is clearly humorous, we can attribute it to benign “fake news” and not anything malicious.
The pleasure of being an undergrad, though, is that I wasn’t fixated on these larger goals or the meetings with outside sponsors and collaborators that Professor Hirschberg and the PhD students attended. I got to focus on humor prediction and working directly with my PhD mentor, Zixiaofan Brenda Yang. Brenda came in with the brilliant idea to use Facebook humor reactions as a proxy for humor labels. At a high level, posts with more humor reactions would be more “humorous.” From there, the work became testing different methods to formalize this intuition.
Q: How much data did you have to work with? How was it processed?
So much data! We worked with millions of Facebook posts. We downloaded posts from CrowdTangle, a social media insights tool owned by Facebook. At first, we downloaded small batches of ~20,000 posts to test some of our formulas and definitions of humor and non-humor scores. In the end, we downloaded a couple of million Facebook posts and filtered them to keep only pure-text posts in English. We wrote the cleaning scripts in Python and ran them remotely on our lab computers.

Q: Were you prepared to work on it or did you learn as the project progressed?
It was a bit of a trial by fire for me since I was unaware of the standard proceedings and expectations surrounding academic research. For example, it shocked me that most of the “framing” work is done only when it comes time for paper writing. For a lot of the research process, you do not actually have a set, detailed idea of how you are going to present your work.
I also had to study technical concepts from information theory and statistics as we went along. Luckily, I always had my mentor, Brenda, as a guide.
Q: What were the things you already knew and what were the things you had to learn while working on the project?
I knew about the state-of-the-art deep learning models for NLP (RNNs, Transformers, etc.) and some other basic machine learning concepts. Naively, I thought my work would involve working with these models all the time, playing with their architecture, and tuning their hyperparameters.
In reality, I focused much more on data collection, preprocessing, and developing those formulas on humor and non-humor scores. Data collection and preprocessing were almost completely new to me (aside from some preprocessing functions I had written in previous CS classes) –– at least for our project, this work was fairly straightforward.
Developing the formulas required a lot of experimentation and reading up on technical concepts. I spent a couple of days trying to understand KL divergence conceptually before we tried to use it for an element of our project. In the end, it did not even end up being part of the paper. The cool thing, though, is that once I read up on that I ended up using it later in the project as the basis for calculating our non-humor score.
Q: Looking back, what were the skills that you wished you had before starting the project?
I wish I had a greater understanding of reading scientific papers, writing them, and the expectations for what kind of information from your project goes into them. There were many instances throughout the semester where Brenda had to remind me that we needed to be thorough with a certain decision or read up on previous work that might have faced the same problem because we would need to justify all our processes to the scientific community.
Q: Did working on this project make you want to change your research interests or focus?
The most interesting parts of the project for me were the linguistic analyses we ran on our humor-labeled data and writing the paper. I think that is because I like to approach things from more of a linguistics perspective, not as much pure computer science, so I am trying to direct my research from that angle more now.
Q: Will you continue to work on CHoRAL? Or are you working on something else now?
I have switched to a text-to-speech project in the Speech Lab this semester, so I’m not working on CHoRaL full-time anymore.
Q: Do you want to continue doing research and pursue a graduate degree?
I am definitely going to continue research throughout my undergrad years, and a PhD is possibly in my future. I am leaning toward working outside of academia for a few years after college and then applying to PhD programs later in my 20s.
Q: Would you recommend volunteering or seeking projects out to other students?
Of course! Even if you’re not interested in pursuing higher education, there’s so much to learn from a research environment. Particularly in the AI/ML space, doing research demystifies all the jargon and far-reaching statements about computer intelligence that you hear in the media. It is also a great way to gain practical skills, like keeping a project codebase organized and communicating the work I did independently with my mentors.
Q: Is there anything else that you think people should know about the project?
Not that I can think of right now, but if any students want to talk more about the project or undergrad research in general, my UNI is sh3988.
“So, this is a rough idea for modeling trajectories and I need your feedback,” said Didac Suris to the room while his teammates looked at him over bowls of Chinese food. “I literally just thought of this two days ago.”
It is the first week that working lunch meetings can resume at Columbia. Suris, along with other members of the computer vision lab, immediately took advantage of it. As they settle down into the meeting, Suris talks about his research proposal and his audience exchanges ideas with him in between bites of food. The last time this happened was two years ago.
“We came back in the Fall and it is good to be back in the office,” said Didac Suris, a third-year PhD student advised by Carl Vondrick. “Collaborating with teammates and just being out has worked wonders for my productivity which has skyrocketed compared to when working alone, or from home.”

Suris can be found in an office in CEPSR working on research projects that study computer vision and machine learning. The projects focus on training machines to interact and observe their surroundings, including his work on predicting what will happen next in a video. This is in line with his long-term goal of creating systems that can model video more appropriately and help predict the future actions of a video, which will be useful in autonomous vehicles, human-robot interaction, broadcasting of sports events, and assistive technology.
Suris was recently named a Microsoft Research Fellow. The research he has done while at Columbia focuses on computer vision and building systems that can learn on their own, which is very different from what he studied in undergrad, telecommunications at the Polytechnic University of Catalunya in Barcelona, Spain. We caught up with Suris to ask about how his PhD is going and winning the fellowship.
Q: What was your journey to Columbia? How did you pivot from telecommunications to applying for a PhD in computer vision?
It was only during my master’s, when I started doing research on computer vision, that I started to consider doing a PhD. The main reason I’m doing a PhD is because I believe it is the best way to push myself intellectually.
I really recommend doing research in different places before starting a PhD. Before starting at Columbia, I did research at three different universities, which prepared me for my current research. These experiences helped me to 1) understand what research is about, and 2) understand that different research groups work differently, and get the best out of each one.
Q: What drew you to machine learning and artificial intelligence?
One of the characteristic aspects of this field is how fast it is evolving, and how impressive the research results have been in the last decade. I don’t think there was a specific moment where I decided to do research on this topic, I would say there was a series of circumstances that led me here, including the fact that I was originally interested in artificial intelligence in the first place, of course.
Q: Why did you decide to focus on computer vision?
There is a lot of information online because of the vast amount of videos, images, text, audio, and other forms of data. But the thing is the majority of this information is not labeled clearly. For example, we do not have information about the actions taking place in every YouTube video. But we can still use the information in the YouTube video to learn about the world.
We can teach a computer to relate the audio in a video to the visual content in a video. And then we can relate all of this to the comments on the YouTube video to learn associations between all of these different signals, and help the computer understand the world based on these associations. I want to be able to use any and all information out there to develop systems that will train computers to learn with minimal human supervision.
Q: What sort of research questions or issues do you hope to answer?
There is a lot of data about the world on the Internet – billions of videos are recorded every day across the world. My main research question is how can we make sense of all of this raw video content.
Q: What was the thesis proposal that you submitted for the Microsoft PhD?
The proposal was called “Video Hyperboles.” The idea is to model long videos (most of the literature nowadays is on very short clips, not long-format videos) by modeling their temporal hierarchy. For example, the action of “cutting an onion” is composed of the subactions “grabbing a knife”, “pressing the knife”, “gathering the pieces.” This forms a temporal hierarchy, in which the action “cutting an onion” is higher in the hierarchy, and the subactions are lower in the hierarchy. Hierarchies can be modeled in a geometric space called Hyperbolic Space, and thus the name “Video Hyperboles.”
I have not been working on the project directly, but I am building up pieces to eventually be able to achieve something like what I described in the proposal. I work on related topics, with the general direction of creating a video representation (for example, a hierarchy) that allows us to model video more appropriately, and helps us predict the future of a video. And I will work on this for the rest of my PhD.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research what should they know or do to prepare?
Research requires a combination of abilities that may take time to develop: patience, asking the right questions, etc. So experience is very important. My main advice would be to try to do research as soon as possible. Experience is very necessary to do research but is also important in order to decide whether or not research is for you. It is not for everyone, and the sooner you figure that out, the better.
Q: Is there anything else that you think people should know about getting a PhD?
Most of the time, a PhD is sold as a lot of pain and suffering, as working all day every day, and being very concerned about what your advisor will think of you. At least this is how it is in our field. It is sometimes seen as a competition to be a great and prolific researcher, too. And I don’t see it like that – you can enjoy (or hate) your PhD the same way you enjoy any other career path. It is all about finding the correct topics to work on, and the correct balance between research and personal life.
Mustafa Eyceoz (SEAS ’22) is featured in the Profile Issue of Columbia Spectator’s magazine, The Eye.
Team leader David Watkins discusses how playing computer games can give roboticists real-world insights.
Molecular biologist, pianist, and cognitive scientist/biologist will receive scholarship aid from a program that supports students from non-computational backgrounds applying computer science in a broad range of interdisciplinary areas.
Hamoon Mousavi is a PhD student who moved to Columbia from the University of Toronto last year with Henry Yuen, whose research group studies theoretical computer science and the differences between classical and quantum computers.
When it comes to deploying her computer science skills, Camille-Louise Mbayo MS’22 is already looking far beyond the halls of academia.
Two Columbia engineers behind fashion app Upcomers on creating a marketplace to showcase Black-owned brands and five new designers everyone should know.