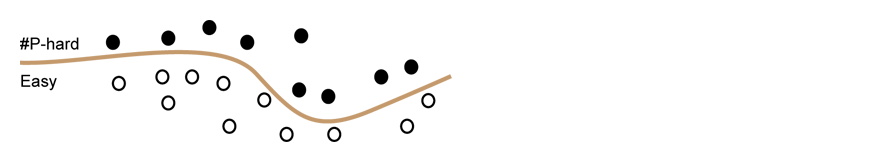PhD student Brian A. Smith developed the RAD—racing auditory display—to enable people who are visually impaired to play the same racing games sighted players play, with the same level of speed, control, and excitement.
Peter Allen and Eugene Wu of Columbia’s Computer Science Department are each recipients of a Google Faculty Research Award. This highly competitive award (15% acceptance rate) recognizes and financially supports university faculty working on research in fields of interest to Google. The award amount, given as an unrestricted gift, is designed to support the cost of one graduate student for one year. The intent is for projects funded through this award to be made openly available to the research community.
Peter Allen: Visual-Tactile Integration for Reinforcement Learning of Robotic Grasping
Peter Allen
To incorporate a visual-tactile learning component into a robotic grasping and manipulation system, Peter Allen will receive $71K. A Professor of Computer Science at Columbia, Allen heads the Columbia University Robotics Group.
In grasping objects, robots for the most part rely on visual feedback to locate an object and guide the grasping movements. But visual information by itself is not sufficient to achieve a stable grasp: it cannot measure how much force or pressure to apply and is of limited value when an object is partially occluded or hidden at the bottom of a gym bag. Humans rely as much or more on touch, easily grasping objects sight unseen and feeling an object to deduce its shape, apply the right amount of pressure and force, and detect when it begins to slip from grasp.
With funding provided by Google, Allen will add simulated rich tactile sensor data (both capacitive and piezoelectric) to robotic hand simulators, capturing and transforming low-level sensor data into high-level information useful for grasping and manipulation. This high-level information can then be used to build reinforcement learning (RL) algorithms that enable an agent to find stable grasps of complex objects using multi-fingered hands. The RL system can learn a grasping control policy and an ability to reason about 3D geometry from both raw depth and tactile sensory observations.
This project builds on previous work by Allen’s group on shape completion—also with a Google research grant—where an occluded object’s complete 3D shape is inferred by comparing it to hundreds of thousands of models contained within a data set. The shape completion work used machine learning with a convolutional neural network (CNN), with simulated 3D vision data on models of hundreds of thousands of views of everyday objects. This allowed the CNN to generalize a full 3D model from a single limited view. With this project, the CNN will now be trained on both visual and tactile information to produce more realistic simulation environments that can be used by Google and others (the project code and datasets will be open source) for more accurate robot grasping.
Eugene Wu: NeuroFlash: System to Inspect, Check, and Monitor Deep Neural Networks
Deep neural networks, consisting of many layers of interacting neurons, are famously difficult to debug. Unlike traditional software programs, which are structured into modular functions that can be separately interpreted and debugged, deep neural networks are more akin to a single, massive block of code, often described as a black box, where logic is smeared throughout the behavior of thousands of neurons with no clear way of disentangling interactions among neurons. Without an ability to reason about how neural networks make decisions, it is not possible to understand if and how they can fail, for example, when used for self-driving cars or managing critical infrastructure.
To bring modularity to deep neural networks, NeuroFlash aims to identify functional logic components within the network. Using a method similar to MRI in medical diagnosis, which looks for brain neuron activations when humans perform specific tasks, NeuroFlash observes the behavior of neural network neurons to identify which ones are mimicking a user-provided high-level function (e.g., identify sentiment, detect vertical line, parse verb). To verify that the neurons are indeed following the function’s behavior and not spurious, NeuroFlash alters the neural network in systematic ways to examine and compare its behavior with the function.
The ability to attribute high-level logic to portions of a deep neural network forms the basis for being able to introduce “modules” into neural networks; test and debug these modules in isolation in order to ensure they work when deployed; and develop monitoring tools for machine learning pipelines.
Work on the project is driven by Thibault Sellam, Kevin Lin, Ian Huang, and Carl Vondrick and complements recent work from Google on model attribution, where neuron output is attributed to specific input features. With a focus on scalability, NeuroFlash generalizes this idea by attributing logical functions.
Wu will make all code and data open source, hosting it on Github for other researchers to access.
A study published in Science describes how researchers created, from 86M genealogy profiles, population-scale family trees to reassess longevity and marriage and migration patterns. Yaniv Erlich is the study’s senior author.
A counting problem asks the question: What is the exact number of solutions that exist for a given instance of a computational problem?
Theoretical computer scientists in the last 15 years have made tremendous progress in understanding the complexity of several families of counting problems, resulting in a number of intriguing dichotomies: a problem in each family is either easy—solvable in polynomial time—or computationally hard. Complexity Dichotomies for Counting Problems, Volume 1, Boolean Domain, a new book by Jin-Yi Cai (University of Wisconsin, Madison) and Xi Chen, provides a high-level overview of the current state of dichotomies for counting problems, pulling together and summarizing the major results and key papers that have contributed to progress in the field. This is the first time much of this material is available in book form.
Structured around several families of problems—counting constraint specification problems (#CSP), Holant, counting graph homomorphisms—the book begins by introducing many common techniques that are reused in later proofs. Each subsequent chapter revolves around a family of problems, starting with easier, specific cases before moving onto more complex and more general cases.
For the first volume, the authors focus on the Boolean domain (where variables are assigned 0-1 values); a second volume, expected to be released next year, will look at problems in the general domain where variables can be assigned three, four, or any number of values.
In this interview, Chen talks more about the motivation for the book and why dichotomies for counting problems is an area deserving of more study.
Why write the book?
Currently it’s hard for PhD students and others to get started in the field. Many of the papers are long and technically very dense, and they build on work done in previous papers. To understand one paper often requires a lot of backtracking. This can be frustrating at times because different papers use different notation and sometimes prove the same result or use the same tool in different contexts.
Our aim in writing this book was to minimize the effort needed to study dichotomies for counting problems. We summarize and streamline the major results using a common notation and unified framework so it is easier to see the progression of ideas and techniques. To encourage students to start working in this area, we wrote the book so an undergraduate with some basic knowledge of complexity theory can follow the proofs.
Could you define at a high level “dichotomies for counting problems”?
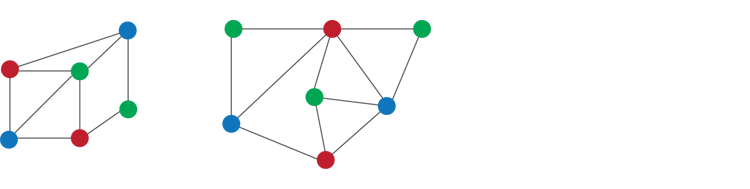
Counting problems involve determining the exact number of solutions that exist for a given input instance. Does a 3SAT instance have 10 or 11 satisfying assignments or 20 or 27? What is the exact number? In a graph, for instance, you might want to know the exact number of ways to apply three colors to vertices so that no two adjacent vertices share the same color.
The 3-coloring problem, where no two adjacent vertices can have the same color, is a classic hard (#P-hard) problem in graph theory.
A number of families of counting problems have been studied. For example, we are interested in counting homomorphisms from an input graph G to a fixed graph H (where a homomorphism from G to H is a map f from vertices of G to vertices of H that preserves edges in G). In this case, each graph H defines a counting problem; e.g., when H is the triangle, the problem it defines is exactly the problem of counting 3-colorings. The 3-coloring problem is one of the classical problems known to be #P-hard, where #P is the complexity class that contains all counting problems, just as NP is for decision problems.
Can we classify EVERY graph H according to the complexity of the counting problem it defines? Such a result is called a dichotomy, which shows that all problems of a certain family can be classified into one of two groups: those admitting efficient algorithms and those that are #P-hard. Imagining each problem in a family as a dot, a dichotomy theorem can be viewed as a curve that classifies all the dots correctly according to their complexities. This curve typically involves a number of well-defined conditions: every problem that violates one of these conditions can be shown to be #P-hard and every problem that satisfies all the conditions can be solved by a unified efficient algorithm.
A dichotomy theorem classifies the complexity of each problem within a family of problems according to whether it can be efficiently solved or is computationally hard.
How has the field matured in the past few years?
Proofs have gotten stronger and more general. In the language of counting constraint satisfaction problems, the dichotomy theorem we had fifteen years ago only applied to problems defined by a single 0-1 valued symmetric function. In contrast we now have a full dichotomy for all counting constraint satisfaction problems (i.e., all problems defined by multiple complex-valued constraint functions with arbitrary arities).
What attracts you to the problem?
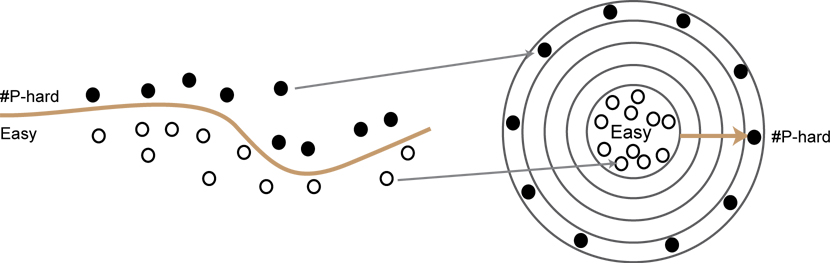
To me it is amazing that for these families of problems, a dichotomy theorem exists to once and for all classify the complexity of every problem. As it is shown by the classical Ladner’s theorem, there are infinitely many layers of problems in #P, ordered by their complexity, between P and #P-hard problems. Every time you move outside by one layer, problems become strictly harder.
If you can prove a dichotomy for a family of problems, all problem instances will be easy or hard, with nothing in between even with many intermediate layers of complexity.
Dichotomy theorems covered in the book, however, show that all (infinitely many) problems in these lie either in P (the core) or the outmost #P-hard shell, and none of them belongs to layers in between. The intuition to me is that these families consist of “natural” counting problems only and do not contain any of those strange “#P-intermediate” problems, but I am curious: how much further can we go as we move to more and more general families of counting problems? Especially with Holant problems, not much is known for the general domain case. It’s one reason we need to develop stronger techniques to prove dichotomies for more general families of counting problems.
Volume 2 of Complexity Dichotomies for Counting Problems, which covers the general domain, is expected to be published next year.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor