Last month, the National Science Foundation announced that it will fund COSMOS, a large-scale, outdoor testbed for a new generation of wireless technologies and applications that will eventually replace 4G. Covering one square mile in densely populated West Harlem just north of Columbia’s Morningside Heights campus, COSMOS is a high-bandwidth and low-latency network that, coupled with edge computing, gives researchers a platform to experiment with the data-intensive applications—in robotics, immersive virtual reality, and traffic safety—that future wireless networks will enable.
Columbia is one of three New York-area universities involved (with Rutgers and New York University being the other two). Columbia’s COSMOS proposal was overseen by principal investigator Gil Zussman (Electrical Engineering) who worked with a number of Columbia professors, including Henning Schulzrinne.
A researcher in applied networking who is also investigating an overall architecture for the Internet of Things (IoT), Schulzrinne has previous experience in setting up an experimental wireless network. In 2011, he oversaw the installation of WiMAX, an early 4G contender, on the roof of Mudd. WiMAX helped demonstrated the feasibility of doing wireless experiments on campus while also setting a precedent for the Computer Science Department to work with Columbia facilities, which ran the fiber, provided power, and installed the antennas.
In this interview, Schulzrinne discusses the benefits of COSMOS to researchers and students within and outside the department.
What is your role?
I have three separate roles. In the area of licensing and public policy, I did the spectrum license applications so the campus could use frequencies in the millimeter-wave radio band—not previously used for telecommunications—and I’ll work to ensure we don’t interfere with licensees who will someday be assigned those frequencies.
The way licensing is done will change under 5G. Instead of specifically requesting licenses for certain frequencies and then waiting for permission, or maybe an auction, as is done now, spectrum will be shared dynamically as needed, a more efficient way to use a limited resource. Part of COSMOS is to better understand how sharing of spectrum will work.
In the application area, I will be looking at both stationary and mobile IoT devices, putting mobile nodes on Columbia vehicles—buses and public safety and utility vehicles—to measure noise pollution, for example. I am also working with Dan Rubenstein on testing safety precautions with connected vehicles that use wireless connectivity and looking for ways to protect pedestrians and bicyclists.
And thirdly, for many years I have collaborated with researchers in Finland on a series of wireless spectrum projects, including mobile edge computing. These projects are funded by the NSF and the Academy of Finland through the WiFiUS program (Wireless Innovation between Finland and US). COSMOS gives us the chance to deploy and study mobile edge computing on a high-bandwidth, low-latency network.
Who will be able to access the test bed?
COSMOS is unique as an NSF project for building an infrastructure available to anyone, both on- and off-campus. In principle, anyone who has an email address at a US education institute can submit a proposal to use COSMOS for teaching and research.
While K-12 education plays an important role in this project—high school students, for example, might run experiments showing the propagation of radio waves—most educational interest and activity will likely be at the higher-education level, especially in networking and wireless classes, with both faculty and student researchers using the testbed to run experiments at a scale not possible in a lab.
What does COSMOS mean for Columbia researchers and students?
Columbia students, being physically close to the test bed, will have obvious advantages, like being able to easily enlist pedestrians or students for experiments on devices that are worn or carried.
I expect we’ll see many proposals coming out of the Computer Science Department in particular as we understand what becomes possible on these new networks where processing is done on edge servers rather than being sent up to cloud servers further away. Can we for instance control traffic lights to more efficiently move traffic along and increase safety of pedestrians and bicyclists? Can we use the network for augmented reality? Can public safety applications benefit from high-bandwidth video processing? Do the propagation characteristics force designers of network protocols to deal with short-lived connections with highly-variable transmission speed? The COSMOS testbed gives us a wireless infrastructure to find out.
Henning Schulzrinne is the Julian Clarence Levi Professor of Mathematical Methods and Computer Science at Columbia University. He is a researcher in applied networking and is particularly known for his contributions in developing the Session Initiation Protocol (SIP) and Real-Time Transport Protocol (RTP), the key protocols that enable Voice-over–IP(VoIP) and other multimedia applications. Active in public policy, he has twice served as Chief Technology Officer at the Federal Communications Committee (his most recent term ended October 2017). Currently he serves on the North American Numbering Council. Schulzrinne is a Fellow of the ACM and IEEE and a member of the Internet Hall of Fame. Among his awards, he has received the New York City Mayor’s Award for Excellence in Science and Technology, the VON Pioneer Award, TCCC service award, IEEE Internet Award, IEEE Region 1 William Terry Award for Lifetime Distinguished Service to IEEE, the UMass Computer Science Outstanding Alumni recognition.
Daniel Hsu and his student Arushi Gupta show it is possible to build discrete choice models by estimating parameters from a small subset of options rather than having to analyze all possible options that may easily number in the thousands, or more. Using linear equations to estimate parameters in Hidden Markov chain choice models, the researchers were surprised to find they could estimate parameters from as few as two or three options. The results, theoretical for now, mean that in a world of choices, retailers and others can offer a small, meaningful set of well-selected items from which consumers are likely to find an acceptable choice even if their first choice is not available. For researchers, it means another tool to better model real-world behavior in ways not possible before.
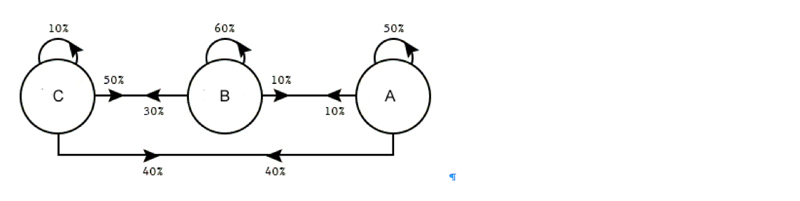
Given several choices, what option will people choose? From the 1960s this simple question—of interest to urban planners, social scientists, and naturally, retailers—has been studied by economists and statisticians using discrete choice models, which statistically model the probabilities people will choose an option among a set of alternatives. (While an individual’s choice can’t be predicted, it is possible to study groups of people and infer patterns of behavior from sales, survey, and other data.)
In recent years, a type of discrete choice model called multinomial logit models has been commonly used. These models, easy to fit and understand, work by associating regression coefficients to each option based on behavior observed from real-world data. If ridership data shows people choose the subway 50% of the time and the bus 50% of the time, the model’s coefficients are tweaked to assign equal probability to each option.
On the whole, multinomial logit models perform well but fail to easily accommodate the introduction of new options that substitute for existing ones. If a second bus line is added and is similar to the existing one—same route, same frequency, same cost—except that the new bus line has articulated buses, a multinomial logit model would consider all three alternatives independently, splitting the proportion equally and assigning a probability of 0.33 to all three options.
“But that is not what happens,” says Daniel Hsu, a computer science professor and a member of the Data Science Institute who explores new algorithmic approaches to statistical problems. “People don’t care whether a bus is articulated or not. People just want to get to work.” Train riders especially don’t care about a new bus option because a bus is not a substitute for a train, and for this reason, the coefficient for trainer riders should not change.
The bus-train example is small, limited to three choices. In the real world, especially in retailing, choices are so numerous as to be overwhelming. People can’t be shown all options so retailers and others must offer a small set of choices from which people will find a substitute choice they are happy with even if their most preferred choice is not included.
To better model substitution behavior, researchers in Columbia’s Industrial Engineering and Operations Research (IEOR) Department—Jose Blanchet (now at Stanford University), Guillermo Gallego, and Vineet Goyal—two years ago proposed the use of Markov Chain models, which make predictions based on previous behaviors, or states. All options have probabilities as before, but the probability changes based on preceding options. What fraction of people will choose A when the previous states are B and C, or are C and D? Removing one option, the most preferred one for example, changes the chain of probabilities, providing way for decide the next most preferred option among those remaining.
In a Markov chain choice mode, the current state—here the item currently desired—determines the probabilities to assign to the next state (i.e., the next desired product).
Switching from multinomial logit models to Markov chain choice models better captured substitution behavior but at the expense of much more complexity; previously, n possible options meant n parameters, but in the Markov chain models, n parameters just describes the initial probabilities; each removal of an option requires recalculating all possible combinations for a total of n squared parameters. Instead of 100 parameters, now it’s 10k parameters. Computers can handle this complexity; a consumer can’t and won’t.
The IEOR researchers showed it was possible to model substitution behavior by analyzing all possible options; left open was the possibility of doing so using less data, that is, some subset of the entire data set.
This was the starting point for Hsu and Arushi Gupta, a master’s student with an operations research background who had previously worked on estimating parameters for older discrete choice models; Gupta relished the opportunity to do the same for a more complex model.
“We looked at it as an algebraic puzzle,” says Hsu. “If you know two-thirds of people choose this option when these three are offered, how do you get there from the original Markov chain choice model? What are the parameters of the model that would give you this?”
Initially they set out to find an approximate solution but, changing tack, tried for the harder thing: getting a single exact solution. “Arushi discovered that all model parameters were related to the choice probabilities via linear equations, where the coefficients of the equations were given by yet other choice probabilities,” says Hsu. “This is great because it means choice probabilities can be estimated from data. And this gives a way to potentially indirectly estimate all of the model parameters just by solving a system of equations.”
Says Gupta, “It is also quite lucky that it turned out to be just linear equations because even very big systems of linear equations are easy to solve on a computer. If the relationship had turned out to be other polynomial equations, then it would have been much more difficult.”
The final piece of the puzzle was to prove that the linear equations uniquely determined the parameters. “We crafted a new algebraic argument using the theory of a special class of matrices called M-matrices, which naturally arise in the study of Markov chains” says Hsu. “Our proof suggested that assortments as small as two and three item sets could yield linear equations that pin down the model parameters.”
The researchers hope their results will lead to better ways of fitting choice models to data while helping understand the strengths and weaknesses of the models used to predict consumer choice behavior.
About the Researchers
Arushi Gupta, who received her bachelors at Columbia in 2016 in computer science and operations research, will earn a master’s degree in machine learning this May. In the fall, she starts her PhD in computer science at Princeton where she will study machine learning. In addition to Parameter identification in Markov chain choice models, she is coauthor of two additional papers, Do dark matter halos explain lensing peaks? and Non-Gaussian information from weak lensing data via deep learning.
Daniel Hsu is associate professor in the Computer Science Department and a member of the Data Science Institute, both at Columbia University, with research interests in algorithmic statistics, machine learning, and privacy. His work has produced the first computationally efficient algorithms for several statistical estimation tasks (including many involving latent variable models such as mixture models, hidden Markov models, and topic models), provided new algorithmic frameworks for solving interactive machine learning problems, and led to the creation of scalable tools for machine learning applications.
Before coming to Columbia in 2013, Hsu he was a postdoc at Microsoft Research New England, and the Departments of Statistics at Rutgers University and the University of Pennsylvania. He holds a Ph.D. in Computer Science from UC San Diego, and a B.S. in Computer Science and Engineering from UC Berkeley. Hsu has been recognized with a Yahoo ACE Award (2014), selected as one of “AI’s 10 to Watch” in 2015 by IEEE Intelligent Systems, and received a 2016 Sloan Research Fellowship. Just last year, he was made a 2017 Kavli Fellow.
Feiner’s Computer Graphics and User Interfaces Lab, among the first participating in Verizon’s 5G incubator, aims to enable therapists to work on motor rehabilitation through 5G with remote patients who simultaneously manipulate the same objects.
Mihalis Yannakakis, the Percy K. and Vida L. W. Hudson Professor of Computer Science at Columbia University, is among the 84 new members and 21 foreign associates just elected to the National Academy of Sciences (NAS) for distinguished and continuing achievements in original research. Established under President Abraham Lincoln in 1863, the NAS recognizes achievement in science, and NAS membership is considered one of the highest honors a scientist can receive.
Yannakakis is being recognized for fundamental contributions to theoretical computer science, particularly in algorithms and computational complexity, and applications to other areas. His research studies the inherent difficulty of computational problems, and the power and limitations of methods for solving them. For example, Yannakakis characterized the power of certain common approaches to optimization (based on linear programming), and proved that they cannot solve efficiently hard optimization problems like the famous traveling salesman problem. In the area of approximation algorithms, he defined with Christos Papadimitriou a complexity class that unified many important problems and helped explain why the research community had not been able to make progress in approximating a number of optimization problems.
“Complexity is the essence of computation and its most advanced research problem, the study of how hard computational problems can be,” says Papadimitriou. “Mihalis Yannakakis has changed in many ways, through his work during the past four decades, the way we think about complexity: He classified several problems whose complexity had been a mystery for decades, and he identified new forms and modes of complexity, crucial for understanding the difficulty of some very fundamental problems.”
In the area of database theory, Yannakakis contributed in the initiation of the study of acyclic databases and of non-two-phase locking. In the area of computer aided verification and testing, he laid the rigorous algorithmic and complexity-theoretic foundations of the field. His interests extend also to combinatorial optimization and algorithmic game theory.
For the significance, impact, and astonishing breadth of his contributions to theoretical computer science, Yannakakis was awarded the seventh Donald E. Knuth Prize in 2005. He is also a member of the National Academy of Engineering, of Academia Europaea, a Fellow of the ACM, and a Bell Labs Fellow.
Yannakakis received his PhD from Princeton University. Prior to joining Columbia in 2004, he was Head of the Computing Principles Research Department at Bell Labs and at Avaya Labs, and Professor of Computer Science at Stanford University. He has served on the editorial boards of several journals, including as the past editor-in-chief of the SIAM Journal on Computing, and has chaired various conferences, including the IEEE Symposium on Foundations of Computer Science, the ACM Symposium on Theory of Computing and the ACM Symposium on Principles of Database Systems.
In a new approach to security, Sethumadhavan will work with a team of researchers, many from the Data Science Institute, to build security mechanisms into the well-defined interface between hardware and software.
Tong will speak at Engineering Class Day May 14, when he will receive the Illig Medal, the highest honor awarded an engineering undergraduate. Tong is the second CS major in a row to be valedictorian.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor


 Given several choices, what option will people choose? From the 1960s this simple question—of interest to urban planners, social scientists, and naturally, retailers—has been studied by economists and statisticians using discrete choice models, which statistically model the probabilities people will choose an option among a set of alternatives. (While an individual’s choice can’t be predicted, it is possible to study groups of people and infer patterns of behavior from sales, survey, and other data.)
Given several choices, what option will people choose? From the 1960s this simple question—of interest to urban planners, social scientists, and naturally, retailers—has been studied by economists and statisticians using discrete choice models, which statistically model the probabilities people will choose an option among a set of alternatives. (While an individual’s choice can’t be predicted, it is possible to study groups of people and infer patterns of behavior from sales, survey, and other data.)