ClimSim: An Open Large-Scale Dataset For Training High-Resolution Physics Emulators In Hybrid Multi-Scale Climate Models Sungduk Yu, Walter Hannah, Liran Peng, Jerry Lin, Mohamed Aziz Bhouri, Ritwik Gupta, Björn Lütjens, Justus C. Will, Gunnar Behrens, Nora Loose, Charles Stern, Tom Beucler, Bryce Harrop, Benjamin Hillman, Andrea Jenney, Savannah L. Ferretti, Nana Liu, Animashree Anandkumar, Noah Brenowitz, Veronika Eyring, Nicholas Geneva, Pierre Gentine, Stephan Mandt, Jaideep Pathak, Akshay Subramaniam, Carl Vondrick, Rose Yu, Laure Zanna, Ryan Abernathey, Fiaz Ahmed, David Bader, Pierre Baldi, Elizabeth Barnes, Christopher Bretherton, Julius Busecke, Peter Caldwell, Wayne Chuang, Yilun Han, YU HUANG, Fernando Iglesias-Suarez, Sanket Jantre, Karthik Kashinath, Marat Khairoutdinov, Thorsten Kurth, Nicholas Lutsko, Po-Lun Ma, Griffin Mooers, J. David Neelin, David Randall, Sara Shamekh, Mark Taylor, Nathan Urban, Janni Yuval, Guang Zhang, Tian Zheng, Mike Pritchard
Abstract: Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise predictions of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore’s Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator’s macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.
Objaverse-XL: A Colossal Universe of 3D Objects Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram Voleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl Vondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, Ali Farhadi
Abstract: Natural language processing and 2D vision models have attained remarkable proficiency on many tasks primarily by escalating the scale of training data. However, 3D vision tasks have not seen the same progress, in part due to the challenges of acquiring high-quality 3D data. In this work, we present Objaverse-XL, a dataset of over 10 million 3D objects. Our dataset comprises deduplicated 3D objects from a diverse set of sources, including manually designed objects, photogrammetry scans of landmarks and everyday items, and professional scans of historic and antique artifacts. Representing the largest scale and diversity in the realm of 3D datasets, Objaverse-XL enables significant new possibilities for 3D vision. Our experiments demonstrate the improvements enabled with the scale provided by Objaverse-XL. We show that by training Zero123 on novel view synthesis, utilizing over 100 million multi-view rendered images, we achieve strong zero-shot generalization abilities. We hope that releasing Objaverse-XL will enable further innovations in the field of 3D vision at scale.
Abstract: A fundamental problem in many sciences is the learning of causal structure underlying a system, typically through observation and experimentation. Commonly, one even collects data across multiple domains, such as gene sequencing from different labs, or neural recordings from different species. Although there exist methods for learning the equivalence class of causal diagrams from observational and experimental data, they are meant to operate in a single domain. In this paper, we develop a fundamental approach to structure learning in non-Markovian systems (i.e. when there exist latent confounders) leveraging observational and interventional data collected from multiple domains. Specifically, we start by showing that learning from observational data in multiple domains is equivalent to learning from interventional data with unknown targets in a single domain. But there are also subtleties when considering observational and experimental data. Using causal invariances derived from do-calculus, we define a property called S-Markov that connects interventional distributions from multiple-domains to graphical criterion on a selection diagram. Leveraging the S-Markov property, we introduce a new constraint-based causal discovery algorithm, S-FCI, that can learn from observational and interventional data from different domains. We prove that the algorithm is sound and subsumes existing constraint-based causal discovery algorithms.
Abstract: One of the fundamental challenges found throughout the data sciences is to explain why things happen in specific ways, or through which mechanisms a certain variable X exerts influences over another variable Y. In statistics and machine learning, significant efforts have been put into developing machinery to estimate correlations across variables efficiently. In causal inference, a large body of literature is concerned with the decomposition of causal effects under the rubric of mediation analysis. However, many variations are spurious in nature, including different phenomena throughout the applied sciences. Despite the statistical power to estimate correlations and the identification power to decompose causal effects, there is still little understanding of the properties of spurious associations and how they can be decomposed in terms of the underlying causal mechanisms. In this manuscript, we develop formal tools for decomposing spurious variations in both Markovian and Semi-Markovian models. We prove the first results that allow a non-parametric decomposition of spurious effects and provide sufficient conditions for the identification of such decompositions. The described approach has several applications, ranging from explainable and fair AI to questions in epidemiology and medicine, and we empirically demonstrate its use on a real-world dataset.
Abstract: We study causal representation learning, the task of inferring latent causal variables and their causal relations from high-dimensional mixtures of the variables. Prior work relies on weak supervision, in the form of counterfactual pre- and post-intervention views or temporal structure; places restrictive assumptions, such as linearity, on the mixing function or latent causal model; or requires partial knowledge of the generative process, such as the causal graph or intervention targets. We instead consider the general setting in which both the causal model and the mixing function are nonparametric. The learning signal takes the form of multiple datasets, or environments, arising from unknown interventions in the underlying causal model. Our goal is to identify both the ground truth latents and their causal graph up to a set of ambiguities which we show to be irresolvable from interventional data. We study the fundamental setting of two causal variables and prove that the observational distribution and one perfect intervention per node suffice for identifiability, subject to a genericity condition. This condition rules out spurious solutions that involve fine-tuning of the intervened and observational distributions, mirroring similar conditions for nonlinear cause-effect inference. For an arbitrary number of variables, we show that at least one pair of distinct perfect interventional domains per node guarantees identifiability. Further, we demonstrate that the strengths of causal influences among the latent variables are preserved by all equivalent solutions, rendering the inferred representation appropriate for drawing causal conclusions from new data. Our study provides the first identifiability results for the general nonparametric setting with unknown interventions, and elucidates what is possible and impossible for causal representation learning without more direct supervision.
Abstract: Learning cause and effect relations is arguably one of the central challenges found throughout the data sciences. Formally, determining whether a collection of observational and interventional distributions can be combined to learn a target causal relation is known as the problem of generalized identification (or g-identification) [Lee et al., 2019]. Although g-identification has been well understood and solved in theory, it turns out to be challenging to apply these results in practice, in particular when considering the estimation of the target distribution from finite samples. In this paper, we develop a new, general estimator that exhibits multiply robustness properties for g-identifiable causal functionals. Specifically, we show that any g-identifiable causal effect can be expressed as a function of generalized multioutcome sequential back-door adjustments that are amenable to estimation. We then construct a corresponding estimator for the g-identification expression that exhibits robustness properties to bias. We analyze the asymptotic convergence properties of the estimator. Finally, we illustrate the use of the proposed estimator in experimental studies. Simulation results corroborate the theory.
Abstract: As society transitions towards an AI-based decision-making infrastructure, an ever-increasing number of decisions once under control of humans are now delegated to automated systems. Even though such developments make various parts of society more efficient, a large body of evidence suggests that a great deal of care needs to be taken to make such automated decision-making systems fair and equitable, namely, taking into account sensitive attributes such as gender, race, and religion. In this paper, we study a specific decision-making task called outcome control in which an automated system aims to optimize an outcome variable Y while being fair and equitable. The interest in such a setting ranges from interventions related to criminal justice and welfare, all the way to clinical decision-making and public health. In this paper, we first analyze through causal lenses the notion of benefit, which captures how much a specific individual would benefit from a positive decision, counterfactually speaking, when contrasted with an alternative, negative one. We introduce the notion of benefit fairness, which can be seen as the minimal fairness requirement in decision-making, and develop an algorithm for satisfying it. We then note that the benefit itself may be influenced by the protected attribute, and propose causal tools which can be used to analyze this. Finally, if some of the variations of the protected attribute in the benefit are considered as discriminatory, the notion of benefit fairness may need to be strengthened, which leads us to articulating a notion of causal benefit fairness. Using this notion, we develop a new optimization procedure capable of maximizing Y while ascertaining causal fairness in the decision process.
Abstract: Explicit finite-sample statistical guarantees on model performance are an important ingredient in responsible machine learning. Previous work has focused mainly on bounding either the expected loss of a predictor or the probability that an individual prediction will incur a loss value in a specified range. However, for many high-stakes applications, it is crucial to understand and control the dispersion of a loss distribution, or the extent to which different members of a population experience unequal effects of algorithmic decisions. We initiate the study of distribution-free control of statistical dispersion measures with societal implications and propose a simple yet flexible framework that allows us to handle a much richer class of statistical functionals beyond previous work. Our methods are verified through experiments in toxic comment detection, medical imaging, and film recommendation.
Abstract: Attention layers, as commonly used in transformers, form the backbone of modern deep learning, yet there is no mathematical description of their benefits and deficiencies as compared with other architectures. In this work we establish both positive and negative results on the representation power of attention layers, with a focus on intrinsic complexity parameters such as width, depth, and embedding dimension. On the positive side, we present a sparse averaging task, where recurrent networks and feedforward networks all have complexity scaling polynomially in the input size, whereas transformers scale merely logarithmically in the input size; furthermore, we use the same construction to show the necessity and role of a large embedding dimension in a transformer. On the negative side, we present a triple detection task, where attention layers in turn have complexity scaling linearly in the input size; as this scenario seems rare in practice, we also present natural variants that can be efficiently solved by attention layers. The proof techniques emphasize the value of communication complexity in the analysis of transformers and related models, and the role of sparse averaging as a prototypical attention task, which even finds use in the analysis of triple detection.
Abstract: In modern machine learning, inner product attention computation is a fundamental task for training large language models such as Transformer, GPT-1, BERT, GPT-2, GPT-3 and ChatGPT. Formally, in this problem, one is given as input three matrices Q,K,V∈[−B,B]n×d, and the goal is to construct the matrix Att(Q,K,V):=diag(A1n)−1AV∈ℝn×d, where A=exp(QK⊤/d) is the `attention matrix’, and exp is applied entry-wise. Straightforward methods for this problem explicitly compute the n×n attention matrix A, and hence require time Ω(n2) even when d=no(1) is small. In this paper, we investigate whether faster algorithms are possible by implicitly making use of the matrix A. We present two results, showing that there is a sharp transition at B=Θ(logn‾‾‾‾‾√). ∙ If d=O(logn) and B=o(logn‾‾‾‾‾√), there is an n1+o(1) time algorithm to approximate Att(Q,K,V) up to 1/poly(n) additive error. ∙ If d=O(logn) and B=Θ(logn‾‾‾‾‾√), assuming the Strong Exponential Time Hypothesis from fine-grained complexity theory, it is impossible to approximate Att(Q,K,V) up to 1/poly(n) additive error in truly subquadratic time n2−Ω(1). This gives a theoretical explanation for the phenomenon observed in practice that attention computation is much more efficient when the input matrices have smaller entries.
Abstract: Over the last decade, deep neural networks have transformed our society, and they are already widely applied in various machine learning applications. State-of-art deep neural networks are becoming larger in size every year to deliver increasing model accuracy, and as a result, model training consumes substantial computing resources and will only consume more in the future. Using current training methods, in each iteration, to process a data point x∈ℝd in a layer, we need to spend Θ(md) time to evaluate all the m neurons in the layer. This means processing the entire layer takes Θ(nmd) time for n data points. Recent work [Song, Yang and Zhang, NeurIPS 2021] reduces this time per iteration to o(nmd), but requires exponential time to preprocess either the data or the neural network weights, making it unlikely to have practical usage.
In this work, we present a new preprocessing method that simply stores the weight-data correlation in a tree data structure in order to quickly, dynamically detect which neurons fire at each iteration. Our method requires only O(nmd) time in preprocessing and still achieves o(nmd) time per iteration. We complement our new algorithm with a lower bound, proving that assuming a popular conjecture from complexity theory, one could not substantially speed up our algorithm for dynamic detection of firing neurons.
Abstract: Range counting (e.g., counting the number of data points falling into a given query ball) under differential privacy has been studied extensively. However, the current algorithms for this problem are subject to the following dichotomy. One class of algorithms suffers from an additive error that is a fixed polynomial in the number of points. Another class of algorithms allows for polylogarithmic additive error, but the error grows exponentially in the dimension. To achieve the latter, the problem is relaxed to allow a “fuzzy” definition of the range boundary, e.g., a count of the points in a ball of radius r might also include points in a ball of radius cr for some c > 1.
In this paper, we present an efficient algorithm that offers a sweet spot between these two classes. The algorithm has an additive error that is an arbitrary small power of the data set size, depending on how fuzzy the range boundary is, as well as a small (1 + o(1)) multiplicative error. Crucially, the amount of noise added has no dependence on the dimension. Our algorithm introduces a variant of Locality-Sensitive Hashing, utilizing it in a novel manner.
Abstract: Variational inference (VI) is a method to approximate the computationally intractable posterior distributions that arise in Bayesian statistics. Typically, VI fits a simple parametric distribution to the target posterior by minimizing an appropriate objective such as the evidence lower bound (ELBO). In this work, we present a new approach to VI based on the principle of score matching, that if two distributions are equal then their score functions (i.e., gradients of the log density) are equal at every point on their support. With this, we develop score matching VI, an iterative algorithm that seeks to match the scores between the variational approximation and the exact posterior. At each iteration, score matching VI solves an inner optimization, one that minimally adjusts the current variational estimate to match the scores at a newly sampled value of the latent variables.
We show that when the variational family is a Gaussian, this inner optimization enjoys a closed form solution, which we call Gaussian score matching VI (GSM-VI). GSM-VI is also a “black box” variational algorithm in that it only requires a differentiable joint distribution, and as such it can be applied to a wide class of models. We compare GSM-VI to black box variational inference (BBVI), which has similar requirements but instead optimizes the ELBO. We study how GSM-VI behaves as a function of the problem dimensionality, the condition number of the target covariance matrix (when the target is Gaussian), and the degree of mismatch between the approximating and exact posterior distribution. We also study GSM-VI on a collection of real-world Bayesian inference problems from the posteriorDB database of datasets and models. In all of our studies we find that GSM-VI is faster than BBVI, but without sacrificing accuracy. It requires 10-100x fewer gradient evaluations to obtain a comparable quality of approximation.
Abstract: Diffusion models have been successful on a range of conditional generation tasks including molecular design and text-to-image generation. However, these achievements have primarily depended on task-specific conditional training or error-prone heuristic approximations. Ideally, a conditional generation method should provide exact samples for a broad range of conditional distributions without requiring task-specific training. To this end, we introduce the Twisted Diffusion Sampler, or TDS. TDS is a sequential Monte Carlo (SMC) algorithm that targets the conditional distributions of diffusion models. The main idea is to use twisting, an SMC technique that enjoys good computational efficiency, to incorporate heuristic approximations without compromising asymptotic exactness. We first find in simulation and on MNIST image inpainting and class-conditional generation tasks that TDS provides a computational statistical trade-off, yielding more accurate approximations with many particles but with empirical improvements over heuristics with as few as two particles. We then turn to motif-scaffolding, a core task in protein design, using a TDS extension to Riemannian diffusion models. On benchmark test cases, TDS allows flexible conditioning criteria and often outperforms the state-of-the-art.
Abstract: The reliance of text classifiers on spurious correlations can lead to poor generalization at deployment, raising concerns about their use in safety-critical domains such as healthcare. In this work, we propose to use counterfactual data augmentation, guided by knowledge of the causal structure of the data, to simulate interventions on spurious features and to learn more robust text classifiers. We show that this strategy is appropriate in prediction problems where the label is spuriously correlated with an attribute. Under the assumptions of such problems, we discuss the favorable sample complexity of counterfactual data augmentation, compared to importance re-weighting. Pragmatically, we match examples using auxiliary data, based on diff-in-diff methodology, and use a large language model (LLM) to represent a conditional probability of text. Through extensive experimentation on learning caregiver-invariant predictors of clinical diagnoses from medical narratives and on semi-synthetic data, we demonstrate that our method for simulating interventions improves out-of-distribution (OOD) accuracy compared to baseline invariant learning algorithms.
Abstract: This paper presents a case study on the design, administration, post-processing, and evaluation of surveys on large language models (LLMs). It comprises two components: (1) A statistical method for eliciting beliefs encoded in LLMs. We introduce statistical measures and evaluation metrics that quantify the probability of an LLM “making a choice”, the associated uncertainty, and the consistency of that choice. (2) We apply this method to study what moral beliefs are encoded in different LLMs, especially in ambiguous cases where the right choice is not obvious. We design a large-scale survey comprising 680 high-ambiguity moral scenarios (e.g., “Should I tell a white lie?”) and 687 low-ambiguity moral scenarios (e.g., “Should I stop for a pedestrian on the road?”). Each scenario includes a description, two possible actions, and auxiliary labels indicating violated rules (e.g., “do not kill”). We administer the survey to 28 open- and closed-source LLMs. We find that (a) in unambiguous scenarios, most models “choose” actions that align with commonsense. In ambiguous cases, most models express uncertainty. (b) Some models are uncertain about choosing the commonsense action because their responses are sensitive to the question-wording. (c) Some models reflect clear preferences in ambiguous scenarios. Specifically, closed-source models tend to agree with each other.
The multi-institutional team will use causal modeling techniques to build AI systems that better communicate with people and react to unforeseen circumstances.
Last August, Wei Hao stepped onto the Google Campus in Sunnyvale, California, as part of the inaugural MLCommons Rising Stars cohort.
Thirty-five recipients, out of over 100 applicants, were invited to this two-day in-person workshop. The cohort had the chance to listen to talks by researchers from Google, Intel, and Meta, and professors from Havard, UC Berkeley, and Cornell about trendy research topics, such as ML for ML systems, software-hardware codesign, and responsible machine learning. They also had the chance to do a poster presentation of their work, where they got useful feedback. The aim of the workshop was to develop community, foster research and career growth, enable collaborations, and discuss career opportunities among the rising generation of researchers at the intersection of machine learning and systems.
The first cohort of the MLCommons Rising Stars
“It was a great experience,” said Wei, a third-year PhD student who works with Junfeng Yang and Asaf Cidon. “I always feel the fastest way of developing research ideas is to talk to people and brainstorm, and the workshop was one of the perfect occasions for that.”
His main objective was to make connections, and by the end of the workshop, he came out of it with a potential research collaboration. Along with Amber Liu, a University of Michigan PhD student, they came up with the idea of using a combination of machine learning (ML) models of various sizes to accelerate the inference process of causal language modeling.
We caught up with Wei to talk about his experience at the machine learning workshop and how his PhD life has been.
Q: How did you become part of the workshop? I applied to the workshop months ago with my resume and a research plan. During the application process, I was not asked to talk about a specific project but an overview of the research I was doing. Looking back, I think this contributed to the diversity of the selected cohort, as people’s work covered the whole stack of ML systems from chip design to application-level ML.
The project I presented at the workshop was titled Nazar: Monitoring and Adapting ML Models on Mobile Devices. The setup is that machine learning models are more and more commonly being pushed to mobile devices due to the convenience of low latency. However, they are often undermined by unpredictable distribution shifts after deployment, such as moderate to severe weather conditions and demographic changes.
We are the first to provide a systematic solution to mitigate the performance degradation of post-deployment models by building a three-stage system that continuously monitors, analyzes, and adapts to distribution shifts without needing user feedback.
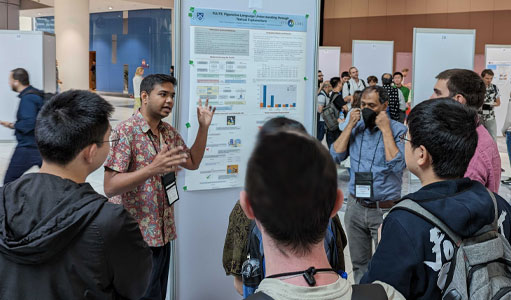
Wei Hao (in the middle back) at the poster presentation
Q: Can you talk about your background and why you decided to pursue a PhD? I engaged in doing research when I was an undergraduate student at the University of Wisconsin-Madison. At the very beginning, getting paid and sharpening my resume were two of my main objectives. However, during the process, I developed an interest in solving open problems that are intellectually challenging.
Moreover, I enjoy defining new problems, which requires a lot of logical thinking but is very rewarding. These two characteristics made me think I am a good candidate for the PhD position. I also really enjoyed the professors I worked with and was encouraged to pursue a PhD. After talking to my current advisors, Junfeng Yang and Asaf Cidon, I was impressed by their enthusiasm and finally made up my mind.
Q: What are your research interests? My research interest is building efficient and secure systems for machine learning workloads. The reason for pursuing this type of research is my belief in realizing artificial general intelligence (AGI), which requires reliable system support. I decided to focus on it since I found satisfaction in interacting with ML workload while building practical system components while in undergrad.
Q: What sort of research questions or issues do you hope to answer? Besides the technical questions on how to make ML deployment ubiquitous, I also hope to answer some philosophical questions: What do people expect from using artificial intelligence (AI)? Are there capacity and efficiency boundaries of AI? Which boundaries should I focus on pushing forward in the future?
Q: What are you working on now? I am building an ML model versioning and management system called MGit.
Models derived from other models are extremely common in machine learning today. For example, transfer learning is used to create task-specific models from “pre-trained” models through finetuning. This has led to an ecosystem where models are related to each other, sharing structure and often even parameter values.
However, it is hard to manage these model derivatives: the storage overhead of storing all derived models quickly becomes onerous, prompting users to get rid of intermediate models that might be useful for further analysis. Additionally, undesired behaviors in models are hard to track down (e.g., is a bug inherited from an upstream model?).
In the current project I am working on, we propose a model versioning and management system called MGit that makes it easier to store, test, update, and collaborate on model derivatives. MGit introduces a lineage graph that records provenance and versioning information between models, optimizations to efficiently store model parameters, as well as abstractions over this lineage graph that facilitate relevant testing, updating, and collaboration functionality. MGit is able to reduce the lineage graph’s storage footprint by up to 7× and automatically update downstream models in response to updates to upstream models.”
Q: How do you decide what to work on, and what is it like doing research? I have written four research papers during my PhD so far: Clockworks, DIVA, Nazar, and MGit. All of them are in the field of ML systems and relate to improving the efficiency and robustness of ML applications.
To decide the topics, I always start by brainstorming with my mentors and advisors to derive possible choices. Then, I read related works and define the concrete problem to tackle. The problem definition that I derive at the beginning is usually not exactly the final version before a lot of trial and error.
For example, when we started work on DIVA, we were originally attempting to tame non-determinisms during the model training process. However, I detoured when I read about quantization and found it super interesting. The research morphed into an adversarial attack that tries to enlarge the deviations between ML models and their adapted version on edge devices
Overall, I found the most time-consuming and difficult part of doing research is to define the concrete problem that is logically valid and attractive to me. It can take me up to half a year, while the solutions and corresponding implementations are relatively easy to come up with.
Left to right: Amber Liu (University of Michigan), Han Guo (Carnegie Mellon Univeristy), Hanrui Wang(MIT), Wei Hao (Columbia University), Di Wu (University of Wisconsin-Madison)
Q: How did your previous experiences prepare you for a PhD? I started to do research when I was a freshman in college, and I felt well-prepared before my PhD. Since the structure of research projects is more or less the same – brainstorming, defining problems, finding and evaluating solutions, and polishing papers – I get more and more familiar after each project, which makes me confident and not stressed about temporary slow-downs.
Q: Why did you apply to Columbia, and how was that process? Aside from the prestigious reputation of Columbia and the research interests match, I really appreciate the proactiveness of my advisors during the recruitment process. I still remember that Asaf reached out to me before the application deadline, which made me feel very welcome. Because of him and my previous advisor at Madison, my stress was hugely alleviated during the application process. Thus, I encourage reaching out to whom you are really interested in working with early on, to both students and faculty.
Q: What has been the highlight of your time at Columbia? The highlight of my time at Columbia so far is when I get the chance to share my research with a wide audience, such as at the CAIT symposium, DSI poster session, or during this interview. I also expect my research to have some real impact, and I believe that day is coming soon.
Q: Was there anything difficult that you had to face while taking your PhD? So far, there have been three. I think one of the hardest things is to fight the feeling of low self-worth when a paper is rejected by a conference. Then, when a field I am working on attracts too many people, it becomes competitive, and I sometimes feel stressed about this kind of speed race of everyone trying to be the first to come up with something. And some loneliness when seeing friends my age bid farewell to their student life and start a career.
But since I have chosen this road of taking my PhD, I have to bear with these and find other ways to release stress. For example, I recently started indoor cycling at the gym as it is an effective way to burn both calories and overthinking.
Q: Looking back, what would you have done differently? I would have thought less and got my hands dirty early. Sometimes, I spend too much time reading papers before doing experiments. No one was born prepared, and the earlier one fails, the sooner one can find a way out.
Q: Do you think your skills have been enhanced by your time at Columbia? In which ways? I think I am more and more confident in delivering my thoughts in a structural way due to the training process of defining concrete problems and writing papers. I also feel that I have gained expertise in my field through the different projects I have taken on.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research, what should they know or do to prepare? My advice to students is to engage in what they feel passionate about as early as possible and not be afraid of failure. For those who are interested in doing research, talk to professors and PhD students proactively about your interests and how you think we can help. Do not be afraid of being an amateur and assume we know everything as the world is moving so fast, especially with the new wave of AI. I think most of us, or at least myself, value vision and passion more than the ability to solve problems, which can definitely be fostered during the PhD journey.
Q: Is there anything else that you think people should know? My personal goal is to create start-ups that are impactful to society. If you have similar goals or related sources at Columbia that you would like to share, please reach out. Thanks!
Graduate students from the department have been selected to receive scholarships. The diverse group is a mix of those new to Columbia and students who have received fellowships for the year.
IBM has recognized and rewarded outstanding PhD students around the world through its highly competitive IBM PhD Fellowship Award program. The award recipients demonstrated academic excellence as well as provided innovative and exceptional research proposals.
Yangruibo Ding Yangruibo Ding is a fourth-year PhD student working with Baishakhi Ray and Gail Kaiser. His research focuses on source code modeling, specifically learning the semantic perspective of software programs to automate software engineering tasks, such as automatic code generation and program analysis. His research has been awarded the IBM PhD Fellowship and the ACM SIGSOFT Distinguished Paper Award.
Ding received an MS in Computer Science from Columbia University in 2019 and a BE in Software Engineering from the University of Electronic Science and Technology of China in 2018. In his free time, he enjoys various sports, regularly playing basketball and table tennis, but he is always looking for new sports to try.
The Google PhD Fellowship Program was created to recognize outstanding graduate students doing exceptional and innovative research in areas relevant to computer science and related fields.
Zachary Huang Zachary Huang is a fifth-year PhD student working on database management systems, advised by Eugene Wu. His previous projects involved building interactive dashboards, machine learning systems, and data search tools on top of join graphs. Currently, he is also exploring solutions to data problems with large language models and accelerating query processing with GPUs.
Zachary Huang graduated with a BS degree in Computer Science from the University of Wisconsin-Madison in 2019. Besides the Google Ph.D. Fellowship, he also received the Columbia Data Science Institute’s Avanessian PhD Fellowship. In his leisure time, he develops video games.
The Department of Defense National Defense Science and Engineering Graduate Fellowship is awarded annually to U.S. citizens pursuing doctoral degrees in science and engineering disciplines.
Jeremy Klotz Jeremy Klotz is a second-year PhD student who works with Shree Nayar on computational imaging. His research combines the design of cameras and software to solve computer vision tasks.
Klotz graduated with a BS and MS in electrical and computer engineering from Carnegie Mellon University in 2022.
Rafael Sofaer Raphael Sofaer is a third-year PhD student in the Software Systems Lab. The focus of his research is software system reliability, dependency management, and reducing the cost of building dependable software. He is co-advised by Junfeng Yang, Jason Nieh, and Ronghui Gu.
Sofaer graduated from New York University with a B.A. in Math and Computer Science in 2015. He bakes bread every week and loves to try new recipes.
The GRFP is a three-year fellowship that recognizes and supports outstanding graduate students in NSF-supported STEM disciplines who are pursuing research-based master’s and doctoral degrees.
Jacob Blindenbach Jacob Blindenbach is a first-year PhD student interested in applied cryptography and designing practical and deployable secure solutions. He will be working with Gamze Gürsoy to design new privacy-preserving protocols for biomedical data, focusing on genomic data.
In May 2022, Blindenbach received a BS with Highest Distinction in Math and Computer Science from the University of Virginia. He is an avid swimmer who placed 19th at Dutch Nationals in the 100m butterfly and enjoys playing ragtime piano.
Charlie Carver Charlie Carver is a sixth-year PhD student working with Zia Zhou on laser-based light communication and sensing in mobile systems and networking.
Carver received an MS in Computer Science from Dartmouth College in 2022 and a BS in Physics from Fordham University in 2018. Charlie won a Best Paper Award at NSDI’20, Best Demo at HotMobile’20, and the Grand Prize at the 2022 Dartmouth Innovation and Technology Festival. While at Fordham, he received the Victor F. Hess Award for the best record of achievement and service in Physics. He loves skiing, sailing, playing guitar, and caring for his two awesome cats.
Gabriel Chuang Gabriel Chuang is a first-year PhD student co-advised by Augustin Chaintreau and Cliff Stein. He is generally interested in fairness-oriented algorithm design, especially in the context of social networks and in fairness in redistricting, i.e., identifying and preventing gerrymandering.
Chuang graduated from Carnegie Mellon University with a BS in Computer Science in 2022. In his free time, he likes to draw and play board games.
Samir Gadre Samir Gadre is interested in large-scale dataset construction and model training with an emphasis on understanding how model performance improves predictably with better datasets and bigger models. Nowadays, he investigates these interests in the context of multimodal models and language models. He is a fourth-year PhD student advised by Shuran Song.
Gadre graduated from Brown University with a ScB Computer Science in 2018. Before joining Columbia, he worked as a Software Engineer at Microsoft HoloLens.
Toma Itagaki Toma Itagaki is a first-year PhD student interested in human-computer interaction and mobile computing. He will work with Zia Xhou to develop mobile computing systems and wearable tech that will enable personalized health, wellness, and productivity.
Itagaki graduated in 2023 from the University of Washington with a BS in Neuroscience.
Tal Zussman Tal Zussman is a first-year PhD student working on operating systems and storage systems for cloud computing. He is advised by Asaf Cidon.
Zussman graduated from Columbia University in May 2023 with a BS in Computer Science with Minors in Applied Mathematics and Political Science. He was a C.P. Davis Scholar and received the Department of Computer Science’s Andrew P. Kosoresow Memorial Award for Excellence in Teaching and Service, the Data Science Institute’s Outstanding Course Assistant Award, and the Columbia University Leadership and Excellence Award for Principled Action.
The CSGrad4US program aims to increase the number and diversity of domestic graduate students pursuing research and innovation careers in computer and information science and engineering fields. The program helps bachelor’s degree holders return to academia and pursue their research interests, enabling them to engage in innovative and high-impact projects without the burden of financial constraints.
Daniel Meyer Daniel Mayer is a first-year PhD student advised by David Knowles. His research interests are machine learning and gene regulation, with a focus on understanding polygenic disease.
After receiving a BS in Computer Science from Tufts University in 2018, Meyer worked as a Computational Associate at the Broad Institute for five years. Meyer is a proud dog parent, enjoys talking about Linux, and plays the bassoon.
Sarah Mundy Sarah is a first-year PhD student advised by Salvatore Stolfo. Her research interests are cybersecurity applied to quantum computing, specifically looking at potential malware attack vectors. Previously, Sarah worked with NASA’s Office of the Chief Human Capital Officer in the workforce planning group, the Pentagon’s Office of the Undersecretary of Defense Research & Engineering under the Principal Director of AI, on DARPA’s Media Forensic program, and with various military and intelligence research groups focused in the AI and ML spaces.
She graduated from the University of Nevada, Reno, with a BS in Electrical Engineering in 2013. She has received the Echostar Spot Award for outstanding performance on a satellite networking project, NAVAIR’s Flight Test Excellence Award for her work planning Tomahawk missile software test flights, the UNR Outstanding Student Service Awards for both the College of Engineering and the Department of Electrical Engineering, 1st and 2nd place in the IEEE Region 6 paper and design competition, respectively, and is a Tau Beta Pi engineering honors society lifetime member.
Her hobbies include running, lifting, hiking, reading science fiction and non-fiction, and caring for her orchids and potted fruit tree.
Argha Talukder Argha Talukder is interested in machine learning in computational biology, specifically modeling the impact of evolutionary genomics on diseases. She is a first-year PhD student advised by Itsik Pe’er and David Knowles.
In 2021, she earned a BS in Electrical Engineering from Texas A&M University, College Station. In her spare time, she learns new languages by watching foreign films.
The GFSD was founded in 1989 “to increase the number of American citizens with graduate degrees in STEM fields, emphasizing recruitment of a diverse applicant pool.”
Max Chen Max Chen is a third-year PhD student interested in dialogue systems, conversation modeling, and human-centric artificial intelligence. He works with Zhou Yu to develop better models and systems for multi-party conversations and mixed-initiative contexts.
Chen graduated cum laude in 2021 from Cornell University with a BA in Computer Science and BA in Statistical Science. He also received an NSF Graduate Research Fellowship in 2021. He likes to keep active by going for runs and playing various sports like basketball and ultimate frisbee, enjoys listening to all sorts of music, and plays the violin, piano, and ukulele.
SEAS Fellowships
The School of Engineering and Applied Sciences established the Presidential and SEAS fellowships to recruit outstanding students from around the world to pursue graduate studies at the school.
Mudd Fellows
Siyan “Sylvia” Li Siyan “Sylvia” Li is a first-year PhD student working on empathetic dialogues in both speech and text modalities and their applications. She is co-advised by Julia Hirschberg and Zhou Yu.
Li completed her BS in Computer Science at Georgia Institute of Technology in 2020 and an MS in Computer Science at Stanford University in 2023. Li enjoys arts and crafts, movies, musicals, and comedy. She is a comedic improviser and is a frequent visitor to Broadway shows.
Jingwen Liu Jingwen Liu is a first-year PhD student interested in understanding the theoretical properties of current machine learning models and developing algorithms with theoretical guarantees. She is co-advised by Daniel Hsu and Alex Andoni.
Liu graduated summa cum laude with a BS in Mathematics and Computer Science from UC San Diego in 2023. She loves skiing, playing ping pong, and reading fiction in her spare time.
Greenwood Fellow
Matthew Beveridge Matthew Beveridge is a first-year doctoral student in the CAVE Lab working with Shree Nayar. His research focuses on computer vision, computational imaging, and machine learning for robust perception of the physical environment. Beyond research, Matthew has been involved with startups in the field of autonomy, organized community events around energy and climate, and worked on human spaceflight at NASA. In addition to the Greenwoods Fellowship, he is also a recipient of the LEAP Momentum Fellowship to study the optical properties of atmospheric aerosols.
In 2021, Matthew completed an MEng and BS in Electrical Engineering and Computer Science at the Massachusetts Institute of Technology (MIT) with a double major in Mathematics and a minor in Theater Arts.
Tang Fellow
Cyrus Illick Cyrus Illickis a first-year PhD student co-advised by Vishal Misra and Dan Rubenstein. He is interested in network systems and will do research on fairness and reliability in congestion control protocols.
In 2023, Illick graduated with a BA in Computer Science from Columbia University. He enjoys playing squash and gardening.
SEAS Fellow
Xiaofeng Yan Xiaofeng Yan is a first-year PhD student in the MobileX Lab, advised by Xia Zhou. Her research interests are in human-computer interaction and the Internet of Things, with the aim to design and build mobile sensing systems with better usability.
Xiaofeng earned an MS in Information Networking in 2023 from Carnegie Mellon University. In 2021, she graduated from Tsinghua University with a BS in Automation and a second degree in Philosophy.
The Distinguished Lecture series brings computer scientists to Columbia to discuss current issues and research that are affecting their particular research fields.
Cognitive Workforce Revolution with Trustworthy and Self-Learning Generative AI
Monica Lam, Stanford University CS Auditorium (CSB 451) November 15, 2023 11:40 AM to 12:40 PM
Generative AI, and in particular Large Language Models (LLMs), have already changed how we work and study. To truly transform the cognitive workforce however, LLMs need to be trustworthy so they can operate autonomously without human oversight. Unfortunately, language models are not grounded and have a tendency to hallucinate.
Our research hypothesis is that we can turn LLM into useful workers across different domains if we (1) teach them how to acquire and apply knowledge in external corpora such as written documents, knowledge bases, and APIs; (2) have them self-learn through model distillation of simulated conversations. We showed that by supplying different external corpora to our Genie assistant framework, we can readily create trustworthy agents that can converse about topics in open domains from Wikidata, Wikipedia, or StackExchange; help navigate services and products such as restaurants or online stores; persuade users to donate to charities; and improve the social skills of people with autism spectrum disorder.
Causal Representation Learning and Optimal Intervention Design
Caroline Uhler, MIT CS Auditorium (CSB 451) November 8, 2023 11:40 AM to 12:40 PM
Massive data collection holds the promise of a better understanding of complex phenomena and, ultimately, of better decisions. Representation learning has become a key driver of deep learning applications since it allows learning latent spaces that capture important properties of the data without requiring any supervised annotations. While representation learning has been hugely successful in predictive tasks, it can fail miserably in causal tasks, including predicting the effect of an intervention. This calls for a marriage between representation learning and causal inference. An exciting opportunity in this regard stems from the growing availability of interventional data (in medicine, advertisement, education, etc.). However, these datasets are still minuscule compared to the action spaces of interest in these applications (e.g. interventions can take on continuous values like the dose of a drug or can be combinatorial as in combinatorial drug therapies). In this talk, we will present initial ideas towards building a statistical and computational framework for causal representation learning and discuss its applications to optimal intervention design in the context of drug design and single-cell biology.
SmartBook: an AI Prophetess for Disaster Reporting and Forecasting
Heng Ji, University of Illinois at Urbana-Champaign CS Auditorium (CSB 451) November 1, 2023 11:40 AM to 12:40 PM
Abstract: We propose SmartBook, a novel framework that cannot be solved by ChatGPT, targeting situation report generation which consumes large volumes of news data to produce a structured situation report with multiple hypotheses (claims) summarized and grounded with rich links to factual evidence by claim detection, fact checking, misinformation detection and factual error correction. Furthermore, SmartBook can also serve as a novel news event simulator, or an intelligent prophetess. Given “What-if” conditions and dimensions elicited from a domain expert user concerning a disaster scenario, SmartBook will induce schemas from historical events, and automatically generate a complex event graph along with a timeline of news articles that describe new simulated events based on a new Λ-shaped attention mask that can generate text with infinite length. By effectively simulating disaster scenarios in both event graph and natural language format, we expect SmartBook will greatly assist humanitarian workers and policymakers to exercise reality checks (what would the next disaster look like under these given conditions?), and thus better prevent and respond to future disasters.
Sarita Adve, University of Illinois at Urbana-Champaign CS Auditorium (CSB 451) October 25, 2023 11:40 AM to 12:40 PM
Computing is on the brink of a new immersive era. Recent innovations in virtual/augmented/mixed reality (extended reality or XR) show the potential for a new immersive modality of computing that will transform most human activities and change how we design, program, and use computers.There is, however, an orders of magnitude gap between the power/performance/quality-of-experience attributes of current and desirable immersive systems. Bridging this gap requires an inter-disciplinary research agenda that spans end-user devices, edge, and cloud, is based on hardware-software-algorithm co-design, and is driven by end-to-end human-perceived quality of experience.
The ILLIXR (Illinois Extended Reality) project has developed an open source end-to-end XR system to enable such a research agenda. ILLIXR is being used in academia and industry to quantify the research challenges for desirable immersive experiences and provide solutions to address these challenges. To further push the interdisciplinary frontier for immersive computing, we recently established the IMMERSE center at Illinois to bring together research, education, and infrastructure activities in immersive technologies, applications, and human experience. This talk will give an overview of IMMERSE and a deeper dive into the ILLIXR project, including the ILLIXR infrastructure, its use to identify XR systems research challenges, and cross-system solutions to address several of these challenges.
Ben Zhao, University of Chicago CS Auditorium (CSB 451) October 9, 2023 11:40 AM to 12:40 PM
Abstract: Recent developments in machine learning and artificial intelligence have taken nearly everyone by surprise. The arrival of arguably the most transformative wave of AI did not bring us smart cities full of self-driving cars, or robots that do our laundry and mow our lawns. Instead, it brought us over-confident token predictors that hallucinate, deepfake generators that produce realistic images and video, and ubiquitous surveillance. In this talk, I’ll describe some of our recent efforts to warn, and later defend against some of the darker side of AI.
In particular, I will tell the story of how our efforts to disrupt unauthorized facial recognition models led unexpectedly to Glaze, a tool to defend human artists against art mimicry by generative image models. I will share some of the ups and downs of implementing and deploying an adversarial ML tool to a global user base, and reflect on mistakes and lessons learned.
Christos Papadimitriou and Mihalis Yannakakis were honored by INFORMS for their significant contributions to the field of operations research and analytics.
Christos H. Papadimitriou and Mihalis Yannakakis Honored by INFORMS for their Significant Contributions to the Field of Operations Research and Analytics.
The paper “I Want to Figure Things Out”: Supporting Exploration in Navigation for People with Visual Impairments” and three other papers from the Graphics & User Interfaces group will be presented at the 26th ACM Conference On Computer-Supported Cooperative Work And Social Computing (CSCW 2023).
Navigation assistance systems (NASs) aim to help visually impaired people (VIPs) navigate unfamiliar environments. Most of today’s NASs support VIPs via turn-by-turn navigation, but a growing body of work highlights the importance of exploration as well. It is unclear, however, how NASs should be designed to help VIPs explore unfamiliar environments. In this paper, we perform a qualitative study to understand VIPs’ information needs and challenges with respect to exploring unfamiliar environments to inform the design of NASs that support exploration. Our findings reveal the types of spatial information that VIPs need as well as factors that affect VIPs’ information preferences. We also discover specific challenges that VIPs face that future NASs can address, such as orientation and mobility education and collaborating effectively with others. We present design implications for NASs that support exploration, and we identify specific research opportunities and discuss open socio-technical challenges for making such NASs possible. We conclude by reflecting on our study procedure to inform future approaches in research on ethical considerations that may be adopted while interacting with the broader VIP community.
Ubiquitous computing encapsulates the idea for technology to be interwoven into the fabric of everyday life. As computing blends into everyday physical artifacts, powerful opportunities open up for social connection. Prior connected media objects span a broad spectrum of design combinations. Such diversity suggests that people have varying needs and preferences for staying connected to one another. However, since these designs have largely been studied in isolation, we do not have a holistic understanding around how people would configure and behave within a ubiquitous social ecosystem of physically-grounded artifacts. In this paper, we create a technology probe called Social Wormholes, that lets people configure their own home ecosystem of connected artifacts. Through a field study with 24 participants, we report on patterns of behaviors that emerged naturally in the context of their daily lives and shine a light on how ubiquitous computing could be leveraged for social computing.
Exploring Immersive Interpersonal Communication via AR Kyungjun Lee University of Maryland, College Park, Hong Li Snap, Inc., Muhammad Rizky Wellytanto University of Illinois at Urbana-Champaign, Yu Jiang Tham Snap, Inc., Andrés Monroy-Hernández Snap, Inc. and Princeton University, Fannie Liu Snap, Inc. and JPMorgan Chase, Brian A. Smith Snap, Inc. and Columbia University, Rajan Vaish Snap, Inc.
A central challenge of social computing research is to enable people to communicate expressively with each other remotely. Augmented reality has great promise for expressive communication since it enables communication beyond texts and photos and towards immersive experiences rendered in recipients’ physical environments. Little research, however, has explored AR’s potential for everyday interpersonal communication. In this work, we prototype an AR messaging system, ARwand, to understand people’s behaviors and perceptions around communicating with friends via AR messaging. We present our findings under four themes observed from a user study with 24 participants, including the types of immersive messages people choose to send to each other, which factors contribute to a sense of immersiveness, and what concerns arise over this new form of messaging. We discuss important implications of our findings on the design of future immersive communication systems.
We describe the design of an immersive virtual Cyberball task that included avatar customization, and user feedback on this design. We first created a prototype of an avatar customization template and added it to a Cyberball prototype built in the Unity3D game engine. Then, we conducted in-depth user testing and feedback sessions with 15 Cyberball stakeholders: five naive participants with no prior knowledge of Cyberball and ten experienced researchers with extensive experience using the Cyberball paradigm. We report the divergent perspectives of the two groups on the following design insights; designing for intuitive use, inclusivity, and realistic experiences versus minimalism. Participant responses shed light on how system design problems may contribute to or perpetuate negative experiences when customizing avatars. They also demonstrate the value of considering multiple stakeholders’ feedback in the design process for virtual reality, presenting a more comprehensive view in designing future Cyberball prototypes and interactive systems for social science research.
Research papers from the Computer Vision Group were accepted to the International Conference on Computer Vision (ICCV ’23), the premiere international conference that includes computer vision workshops and tutorials.
Answering visual queries is a complex task that requires both visual processing and reasoning. End-to-end models, the dominant approach for this task, do not explicitly differentiate between the two, limiting interpretability and generalization. Learning modular programs presents a promising alternative, but has proven challenging due to the difficulty of learning both the programs and modules simultaneously. We introduce ViperGPT, a framework that leverages code-generation models to compose vision-and-language models into subroutines to produce a result for any query. ViperGPT utilizes a provided API to access the available modules, and composes them by generating Python code that is later executed. This simple approach requires no further training, and achieves state-of-the-art results across various complex visual tasks.
Zero-1-to-3: Zero-shot One Image to 3D Object Ruoshi Liu Columbia University, Rundi Wu Columbia University, Basile Van Hoorick Columbia University, Pavel Tokmakov Toyota Research Institute, Sergey Zakharov Toyota Research Institute, Carl Vondrick Columbia University
We introduce Zero-1-to-3, a framework for changing the camera viewpoint of an object given just a single RGB image. To perform novel view synthesis in this under-constrained setting, we capitalize on the geometric priors that large-scale diffusion models learn about natural images. Our conditional diffusion model uses a synthetic dataset to learn controls of the relative camera viewpoint, which allow new images to be generated of the same object under a specified camera transformation. Even though it is trained on a synthetic dataset, our model retains a strong zero-shot generalization ability to out-of-distribution datasets as well as in-the-wild images, including impressionist paintings. Our viewpoint-conditioned diffusion approach can further be used for the task of 3D reconstruction from a single image. Qualitative and quantitative experiments show that our method significantly outperforms state-of-the-art single-view 3D reconstruction and novel view synthesis models by leveraging Internet-scale pre-training.
Muscles in Action Mia Chiquier Columbia University, Carl Vondrick Columbia University
Human motion is created by, and constrained by, our muscles. We take a first step at building computer vision methods that represent the internal muscle activity that causes motion. We present a new dataset, Muscles in Action (MIA), to learn to incorporate muscle activity into human motion representations. The dataset consists of 12.5 hours of synchronized video and surface electromyography (sEMG) data of 10 subjects performing various exercises. Using this dataset, we learn a bidirectional representation that predicts muscle activation from video, and conversely, reconstructs motion from muscle activation. We evaluate our model on in-distribution subjects and exercises, as well as on out-of-distribution subjects and exercises. We demonstrate how advances in modeling both modalities jointly can serve as conditioning for muscularly consistent motion generation. Putting muscles into computer vision systems will enable richer models of virtual humans, with applications in sports, fitness, and AR/VR.
SurfsUp: Learning Fluid Simulation for Novel Surfaces Arjun Mani Columbia University, Ishaan Preetam Chandratreya Columbia University, Elliot Creager University of Toronto, Carl Vondrick Columbia University, Richard Zemel Columbia University
Modeling the mechanics of fluid in complex scenes is vital to applications in design, graphics, and robotics. Learning-based methods provide fast and differentiable fluid simulators, however most prior work is unable to accurately model how fluids interact with genuinely novel surfaces not seen during training. We introduce SURFSUP, a framework that represents objects implicitly using signed distance functions (SDFs), rather than an explicit representation of meshes or particles. This continuous representation of geometry enables more accurate simulation of fluid-object interactions over long time periods while simultaneously making computation more efficient. Moreover, SURFSUP trained on simple shape primitives generalizes considerably out-of-distribution, even to complex real-world scenes and objects. Finally, we show we can invert our model to design simple objects to manipulate fluid flow.
Landscape Learning for Neural Network Inversion Ruoshi Liu Columbia University, Chengzhi Mao Columbia University, Purva Tendulkar Columbia University, Hao Wang Rutgers University, Carl Vondrick Columbia University
Many machine learning methods operate by inverting a neural network at inference time, which has become a popular technique for solving inverse problems in computer vision, robotics, and graphics. However, these methods often involve gradient descent through a highly non-convex loss landscape, causing the optimization process to be unstable and slow. We introduce a method that learns a loss landscape where gradient descent is efficient, bringing massive improvement and acceleration to the inversion process. We demonstrate this advantage on a number of methods for both generative and discriminative tasks, including GAN inversion, adversarial defense, and 3D human pose reconstruction.
The paper “An Empirical Study of API Stability and Adoption in the Android Ecosystem”, was recognized as the Most Impactful Paper from among the published papers at ICSME ’13.
ARNI Director Zemel goes to Washington to explain to Congress how Columbia’s new AI institute will connect major progress made in AI systems to our understanding of the brain.
Alum Raghav Poddar created Superorder, a tool for businesses to set up their restaurant’s online presence, create digital storefronts, and receive more online sales.
The Theory Group recently hosted a three-day workshop in honor of Professor Mihalis Yannakakis’ 70th birthday.
The workshop, dubbed Mihalis Fest, invited 18 computer science researchers and professors who gave talks about the various research areas that Yannakakis’ work has strongly influenced. Among the speakers were Professor Toniann Pitassi and Turing Award winner Jeffrey Ullman, who was Yannakakis’ PhD advisor at Princeton University.
Mihalis Yannakakis and Jeffrey Ullman
“Mihalis is universally recognized as one of the true giants of our field. He’s made major contributions all over the intellectual map of theoretical computer science, in too many areas to list. He’s also a much-beloved figure in the research community, whose wisdom and kindness have impacted countless colleagues and students,” said Professor Rocco Servedio. “The CS department was delighted to host a celebratory workshop in honor of his milestone birthday!”
Professor Christos Papadimitriou closed out the workshop and shared how he and Yannakakis first met while PhD students at Princeton. Said Papadimitriou, “I introduced computer science theory to Mihalis. I should’ve retired after that accomplishment.”
Christos Papadimitriou
Papadimitriou and Yannakakis have collaborated on many papers over the years, and their 1988 paper, “Optimization, Approximation, and Complexity Classes,” introduced a whole range of new complexity classes and notions of approximation that continue to be studied to this day. They are also good friends, and colleagues have noted that the two hardly need to talk but understand each other instantly. “At one point, we started to look alike, too,” joked Papadimitriou.
Mihalis Yannakakis with former and current PhD students: (left to right) Miranda Christ, Oliver Korten, Mihalis Yannakakis, Manolis Gkaragkounis, Dimitris Paparas, Shivam Nadimpalli, Yuhao Li
Many presenters, plus former and current PhD students, shared personal stories of their time working with Yannakakis. Their tributes showed a common theme: how Yannakakis is a brilliant computer scientist who also knows how to support and nurture those around him.
Dear Academic Father: A Thank You From The Future
Tribute From Rashida Hakim
Tribute From Miranda Christ
Tribute From Oliver Korten
Tribute From Shivam Nadimpalli
Tribute From Yuhao Li
Tribute From Dimitris Paparas
Poem For Mihalis Part 1
Poem For Mihalis Part 2
Poem For Mihalis Part 2
Dear Academic Father: Just A Thank You Will Never Be Enough
Although dominant for tabular data, ML libraries that train tree models over normalized databases (e.g., LightGBM, XGBoost) require the data to be denormalized as a single table, materialized, and exported. This process is not scalable, slow, and poses security risks. In-DB ML aims to train models within DBMSes to avoid data movement and provide data governance. Rather than modify a DBMS to support In-DB ML, is it possible to offer competitive tree training performance to specialized ML libraries…with only SQL?
We present JoinBoost, a Python library that rewrites tree training algorithms over normalized databases into pure SQL. It is portable to any DBMS, offers performance competitive with specialized ML libraries, and scales with the underlying DBMS capabilities. JoinBoost extends prior work from both algorithmic and systems perspectives. Algorithmically, we support factorized gradient boosting, by updating theYvariable to the residual in the non-materialized join result. Although this view update problem is generally ambiguous, we identify addition-to-multiplication preserving, the key property of variance semi-ring to support rmse, the most widely used criterion. System-wise, we identify residual updates as a performance bottleneck. Such overhead can be natively minimized on columnar DBMSes by creating a new column of residual values and adding it as a projection. We validate this with two implementations on DuckDB, with no or minimal modifications to its internals for portability. Our experiment shows that JoinBoost is 3x (1.1x) faster for random forests (gradient boosting) compared to LightGBM, and over an order magnitude faster than state-of-the-art In-DB ML systems. Further, JoinBoost scales well beyond LightGBM in terms of the # features, DB size (TPC-DS SF=1000), and join graph complexity (galaxy schemas).
Recent data search platforms use ML task-based utility measures rather than metadata-based keywords, to search large dataset corpora. Requesters submit a training dataset and these platforms search for augmentations (join or union compatible datasets) that, when used to augment the requester’s dataset, most improve model (e.g., linear regression) performance. Although effective, providers that manage personally identifiable data demand differential privacy (DP) guarantees before granting these platforms data access. Unfortunately, making data search differentially private is nontrivial, as a single search can involve training and evaluating datasets hundreds or thousands of times, quickly depleting privacy budgets.
We present Saibot, a differentially private data search platform that employs Factorized Privacy Mechanism (FPM), a novel DP mechanism, to calculate sufficient semi-ring statistics for ML over different combinations of datasets. These statistics are privatized once, and can be freely reused for the search. This allows Saibot to scale to arbitrary numbers of datasets and requests, while minimizing the amount that DP noise affects search results. We optimize the sensitivity of FPM for common augmentation operations, and analyze its properties with respect to linear regression. Specifically, we develop an unbiased estimator for many-to-many joins, prove its bounds, and develop an optimization to redistribute DP noise to minimize the impact on the model. Our evaluation on a real-world dataset corpus of 329 datasets demonstrates that Saibot can return augmentations that achieve model accuracy within 50 to 90% of non-private search, while the leading alternative DP mechanisms (TPM, APM, shuffling) are several orders of magnitude worse.
Any system at play in a data-driven project has a fundamental requirement: the ability to load data. The de-facto standard format to distribute and consume raw data is csv. Yet, the plain text and flexible nature of this format make such files often difficult to parse and correctly load their content, requiring cumbersome data preparation steps.
We propose a benchmark to assess the robustness of systems in loading data from non-standard csv formats and with structural inconsistencies. First, we formalize a model to describe the issues that affect real-world files and use it to derive a systematic “pollution” process to generate dialects for any given grammar. Our benchmark leverages the pollution framework for the csv format. To guide pollution, we have surveyed thousands of real-world, publicly available csv files, recording the problems we encountered. We demonstrate the applicability of our benchmark by testing and scoring 16 different systems: popular csv parsing frameworks, relational database tools, spreadsheet systems, and a data visualization tool.
Data is often stored in a database management system (DBMS) but dataframe libraries are widely used among data scientists. An important but challenging problem is how to bridge the gap between databases and dataframes. To solve this problem, we present ConnectorX, a client library that enables fast and memory-efficient data loading from various databases to different dataframes.
We first investigate why the loading process is slow and consumes large memory. We surprisingly find that the main overhead comes from the client-side rather than query execution or data transfer. We integrate several existing and new techniques to reduce the overhead and carefully design the system architecture and interface to make ConnectorX easy to extend to various databases and dataframes. Moreover, we propose server-side result partitioning that can be adopted by DBMSs in order to better support exporting data to data science tools. We conduct extensive experiments to evaluate ConnectorX and compare it with popular libraries. The results show that ConnectorX significantly outperforms existing solutions. ConnectorX is open sourced at: https://github.com/sfu-db/connector-x.
Bellovin shares his second lifetime award with Tufts’ Susan Landau and Georgetown’s Matt Blaze for their work on computer science, computer security, law, and public policy.
Columbia Engineering mourns the passing of Stephen H. Unger, Professor Emeritus of Computer Science and Electrical Engineering at Columbia University. He passed away on July 4, 2023. Unger was 92 years old.
A pioneer in the fields of logic circuit design, software engineering, and technology policy, Unger worked at Bell Telephone Laboratories, where he developed software tools for the first electronic telephone switching system.
In 1961, he left Bell Labs to teach courses on technology and society at the Electrical Engineering Department at Columbia Engineering until his retirement in 2008. He was one of three tenured professors who joined the newly formed Computer Science Department in 1979, along with Theodore Bashkow from Electrical Engineering and Jonathan Gross from the Mathematical Statistics Department.
HPIM0082.JPG
Together with Professor Emeritus Steven Nowick and Professor Charles A. Zukowski of Electrical Engineering, they founded the Computer Engineering program in 1993. The program is joint between CS and EE departments and offers undergraduate and MS degrees. Unger also served as Department Chair of the program for several years.
A prolific researcher and writer, he is credited as one of the founders of the theory of asynchronous circuits. He authored the definitive early textbook Asynchronous Sequential Switching Circuits (1969) and The Essence of Logic Circuits (1989), which covers logic circuits’ fundamentals and applications.
In joint work with M.C. Paull, their paper “Minimizing the Number of States in Incompletely Specified Sequential Switching Functions”addressed one of the most challenging early digital design optimization problems, and produced a novel solution framework. This work was influential, opening the way to research on a host of advanced digital CAD (computer-aided design) problems.
Unger’s 1958 paper “A Computer Oriented Toward Spatial Problems”is one of the seminal early contributions to parallel computers. This foundational work first introduced the idea of using a spatial array of processors, all operating under the same instructions but on different data items. Such a SIMD (single-instruction multiple-data) style architecture is now a foundation of a large segment of the parallel computing industry.
Unger was a Fellow of the IEEE and the AAAS and received several awards for his contributions to the profession and society. In 1969, he helped found and later became president of the IEEE Society on Social Implications of Technology, which deals with the ethical and social issues related to technology. He also played a principal role in the development of the original IEEE Ethics Code and its 1990 revision, which provides guidelines for engineers to act responsibly and ethically in their profession.
Throughout his career, he was a respected and influential figure in the field of computer science and engineering ethics. Unger received many awards and honors for his work, such as the IEEE Centennial Medal, the IEEE USAB Distinguished Contributions to Engineering Professionalism Award, the IEEE Millennium Medal, and the Guggenheim Fellowship. Even in retirement, he continued to share his opinions on ethics and a variety of topics on his Ends and Means blog.
Unger earned a master’s degree and PhD in electrical engineering from the Massachusetts Institute of Technology. He received his electrical engineering degree from the Polytechnic Institute of Brooklyn (now the New York University Tandon School of Engineering) and graduated from the Brooklyn Technical High School.
Tributes From CS Faculty
Steven Nowick Steve Unger taught me in his Computer Organization course at Columbia in 1986, when I was a non-degree special student, before going off for my PhD at Stanford. He was instrumental in hiring me as an assistant professor in the Columbia CS department in 1993.
At Columbia, we ran a joint research seminar for many years, engaging closely with each other’s students and exploring new research directions. I greatly enjoyed our interactions and his insights and creativity in approaching new problems. Even in areas he hadn’t worked on, he “cut to the core” quickly, with provocative questions and suggestions on new directions.
Steve was an inspiring mentor, colleague, and friend to me over many years. He made major contributions to research and education at Columbia. I valued our many years working together and was deeply influenced by his approach to research, teaching, and life. He will be missed.
John Kender Steve had strongly held and often flamboyantly defended opinions. A few of them that I remember:
For many years, he was in charge of CS MS admissions, back when it could be done by one person unassisted. He was a zealous enforcer of the checklist of eight prerequisite CS courses, more than half of which were 4000-level courses required for the BS (for example, AI and PLT). He would admit students in deficit, but they would have to take those courses without MS credit. He also demanded that the MS degree require four 6000-level courses, as in the EE MS program. But because of CS manpower issues in those early days, it was cut back to three, then later two. Throughout, he insisted on defending a clear distinction between the BS and MS, until he was eventually assigned a different service responsibility.
He was a fierce opponent of the Columbia Video Network, concerned that it denied the importance of faculty-student contact and that it enabled students to cheat their way to an MS. This is back when CVN had only students from two industrial affiliates, IBM and Bell Labs, and when courses were literally taped and copies on VHS cassettes were priority-mailed offsite. I do not recall any vote of his in favor of any CVN enhancement, ever.
He gave a series of talks in the early to mid-1980s against the Reagan “Star Wars” Strategic Defense Initiative for a nationwide missile-defense system. He filled the largest CS classroom then, 535 Mudd (before it was split in half). I recall the intensity of his talks, audiences, and colorful examples. One in particular: “People say, if we can put a man on the moon, why can’t we build this? Well, the moon isn’t surrounded by decoys! The moon did not take evasive action!” The eventual defeat of the program was perhaps his clearest win.
More personally speaking, he lived in New Jersey in Englewood, the borough next to mine. I remember asking him why he hadn’t chosen Leonia instead, which at one point was home to five CS profs. He said he chose Englewood because it was the most racially integrated nearby borough and that he felt he should practice equality as much as preach it.
And the incident I remember that most clearly captured his style in a single sentence. He announced to the then-traditional “Hello Meeting,” where the entire department assembled together in one room in early Fall to introduce each other: “Despite the total absence of rumors to the contrary, I have now remarried!”
Even if you disagreed with him–and often many did, some reflexively–he was informed and articulate enough to leave you thinking. He enjoyed his tenure and wasn’t shy about using it for what he perceived to be the public good of students and of society at large.
Donald Ferguson I remember Professor Unger from my time in the PhD program at Columbia. Professor Unger was one of the foundation stones of the department. I always admired and appreciated his focus on technology’s social, political, and economic impacts. I vividly remember Professor Unger thoughtfully leading a department colloquium to discuss President Regan’s Strategic Defense Initiative. His leadership nudged the world in a thoughtful direction.
Vishal Misra Steve was a great guy – the first course I taught at Columbia was digital systems, and he was very generous to me with all his notes and time to help a nervous young assistant professor get by.
Salvatore Stolfo He was a wonderful man with quirks that are embedded in my memories of him. Besides being a principled and honorable man, he was amazingly adept at peeling an apple at faculty meetings that sometimes seemed longer than a 2-foot-long peeling in one piece. He smiled when he completed his task before eating the skinned apple. Little pleasures appealed to him.
Simha Sethumadhavan He retired the year I started. But his ethics articles, which he continued to share with the faculty on the mailing list even after retirement, were original and insightful.
He also made foundational contributions to Computer Architecture. I recall that his 1958 paper was cited in the first or second edition of the standard graduate computer architecture textbook “Computer Architecture: A Quantitative Approach” by John Hennessy and David Patterson as the beginning of the “single instruction multiple data” execution paradigm.
The paradigm he proposed was used in supercomputers (CRAY) in the late 60s/early 70s, found its way into Intel processors in the mid-90s (Multimedia extensions – MMX) and then into image processing systems on phones in the early 2000s, and informed the “Single Instruction Multiple *Thread*” paradigm” that powers all GPUs today.
I was unable to find the old edition to confirm the citation in the textbook, but a survey from 1999 “Managing Control Asynchrony on SIMD Machines-a Survey” by Nael Abu-Ghazaleh and Philip Wilsey says the following:
As a historical aside, SIMD machines were first suggested by Unger (Unger, 1958). The first machines to be designed were the SOLOMON (Slotnick et al., 1962) at Westinghouse and the Illiac at the University of Illinois, which also was the first SIMD machine to be built (Barnes et al., 1968).
Richard Zemel and Toniann Pitassi were recognized for their paper, “Learning Fair Representations,” which established the subfield of machine learning–machine learning and fairness.
The projects will explore algorithmic fairness, unified methods for interpreting artistic images found on the internet, and the development of a differentially-private data market system.
The group received the ISSTA 2023 Distinguished Paper Award for their paper, CONCORD: Clone-Aware Contrastive Learning for Source Code, a self-supervised pre-training strategy.
Bellovin shares his second lifetime award with Tufts’ Susan Landau and Georgetown’s Matt Blaze for their work on computer science, computer security, law, and public policy.
Gu received the OSDI 2023 Early-Career VMware Systems Research Award for developing fundamental system verification theory and bug-free, and hacker-resistant systems software.
The first-year PhD student is developing tools that help people create engaging images and videos.
After growing up in Jiangsu, China, Sitong Wang studied electrical engineering at Chongqing University and the University of Cincinnati. During her co-op at the Hong Kong University of Science and Technology (HKUST), she was introduced to Human-Computer Interaction (HCI). This research area understands and enhances the interaction between humans and computers. She became interested in the field and then took her master’s at Columbia CS. Wang was intrigued by how computation can power the creative process when she worked on a design challenge that blends pop culture references with products or services and helped a group of students promote their beverage start-up.
Sitong Wang
Encouraged by the creative work she could do, Wang joined the Computational Design Lab as a PhD student to continue to work with Assistant Professor Lydia Chilton and explore ways to design AI-powered creativity support tools. She recently published her first first-author research paper at the Conference on Human Factors in Computing Systems (CHI 2023). She and colleagues designed PopBlends, a system that automatically suggests conceptual blends by connecting a user’s topic with a pop culture domain. Their user study shows that people found twice as many blend suggestions as they did without the system and with half the mental demand.
We caught up with Wang to discuss her research, her work on generative AI tools, and what it is like to be a graduate student at Columbia.
Pop culture blends for Star Wars Day collected on Twitter from McDonald’s, Volkswagon, and the Girl Scouts.
Q: What is PopBlends and why did you choose to focus on the design process?
In the paper, we tackled the creative challenge of designing pop culture blends—images that use pop culture references to promote a product or service. We designed PopBlends, an automated pipeline consisting of three complementary strategies to find creative connections between a product and a pop culture domain.
Our work explores how large language models (LLMs) can provide associative knowledge and commonsense reasoning for creative tasks. We also discuss how to combine the power of traditional knowledge bases and LLMs to support creators in their divergent and convergent thinking.
It can help people, especially those without a design background, create pop culture blends more easily to advertise their brands. We want to make the design process more enjoyable and less cognitively demanding for everyone. We hope to enhance people’s creativity and productivity by scaffolding the creative process and using the power of computation to help people explore the design space more efficiently.
Q: Why did you create a tool incorporating pop culture into product ads?
Pop culture is important in everyday communication. Pop culture blends are helpful for online campaigns because they capture attention and connect the product to something people already know and like. However, creating these images is a challenging conceptual blending task and requires finding connections between two very different domains.
So we built an automated computational pipeline that can effectively support divergent and convergent thinking in finding such creative connections. We explored how to apply generative AI to creative workflows to assist people better—generative AI is powerful, but it is not perfect—thus, it is valuable to use different strategies that combine a knowledge base (which is accurate) and LLM (which has a vast amount of data) to support creative tasks.
Q: How were large language models (LLMs) helpful in your research?
Conceptual blending is complex—the design space is vast and valuable connections are rare—to tackle this challenge, we need to scaffold the ideation process and combine the intelligence of humans and machines. When we started this project, GPT-3 was not yet available; we tried traditional NLP techniques to find attribute associations (e.g., Chewbacca is fluffy) but faced challenges. Then, by chance, we tried GPT-3, which worked well with the necessary prompt engineering.
I was surprised by the associative reasoning capability of LLMs—which is technically a model that predicts the most probable next word. It easily listed related concepts for different domains and could suggest possible creative connections. I was also surprised by the hallucinations the LLMs made through our experiments, and the models could say things that were not true with great confidence.
As an emerging technology, LLMs are powerful in many ways and open up new opportunities for the computational design field. However, LLMs currently have a lot of limitations; it is essential to explore how to build system architectures around them to produce valuable results for people.
Wang presenting PopBlends at CHI’23
Q: How was it like presenting your work at CHI?
I was both nervous and excited because it had been a long time since I had presented in front of a crowd (since we did everything online during COVID). It was also my first time presenting at a computing conference, and the “Large Language Models” session I attended was very popular.
I am grateful to my labmate Vivian Liu, who provided valuable advice, helped me rehearse, and took pictures of me. The presentation went well, and I am glad we had the opportunity to present our work to a large audience of researchers. I would also like to express my gratitude to the researchers I met during the conference, as they provided encouragement and helpful tips that greatly contributed to my experience.
Q: What are you working on now?
I am working on a tool to help journalists transform their print articles into reels using generative AI by assisting them in the creative stages of producing scripts, character boards, and storyboards. In this work, in addition to LLMs, we incorporate text-to-image models and try to combine the power of both to support creators.
During the summer, I will work as a research intern at Adobe, where I will be focusing on AI and video authoring. Our work will revolve around facilitating the future of podcast video creation.
Q: Can you talk about your background and why you pursued a PhD?
My undergraduate program offered great co-op opportunities that allowed me to explore different paths, including roles as an engineer, UI designer, and research intern across Chongqing, Charlottesville, and Hong Kong. During my final co-op, I had the opportunity to work in the HCI lab at the Hong Kong University of Science and Technology (HKUST). This experience ignited my passion for HCI research and marked the beginning of my research journey in this field.
I enjoy exploring unanswered questions, particularly those that reside at the intersection of multiple disciplines. A PhD program provides an excellent opportunity to work on the problems that interest me the most. In addition, I think the training provided at the PhD level can enhance essential skills such as leadership, collaboration, critical thinking, and effective communication.
Q: What are your research interests?
My research interest lies in the creativity support in the HCI field. I am particularly interested in exploring the role of multimodal generative AI in creativity support tools. I enjoy developing co-creative interactive systems to support everyone in their everyday creative tasks.
Q: What research questions or issues do you hope to answer now?
I want to explore the role of generative AI models in future creativity support tools and build co-creative intelligent systems that support multimodal creativity, especially in the dimensions of audio and videos, as they are how we interact with the world. I also want to explore some theoretical questions, such as the overtrust/overreliance in AI, and see how we might understand and resolve them.
Sitong Wang
Q: Why did you choose to apply to Columbia CS? What attracted you to the program?
I love the vibrant environment of Columbia and NYC and how Columbia is strong in diverse disciplines, such as journalism, business, and law. It is an ideal place to do multi-disciplinary collaborative research.
Also, I got to know Professor Chilton well during my masters at Columbia. She is incredibly supportive and wonderful, and we share many common interests. That is why I chose to continue to work with her for my PhD journey.
Q: What has been the highlight of your time at Columbia?
The highlight would be when I witnessed the success of the students I mentored. It was such a rewarding process to guide and help undergraduate students interested in HCI research begin their journey.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research, what should they know or do to prepare?
Enjoy your time in NYC! Please don’t burn yourself out; learn how to manage your time efficiently. Don’t be afraid to try new things—start with manageable tasks, but also step out of your comfort zone. You will have fun!
If you want to do research, find research questions that genuinely interest you and be prepared to face challenges. Most importantly, preserve and trust yourself and your collaborators. Your efforts will eventually pay off!
For robots to be generally useful, they must be able to find arbitrary objects described by people (i.e., be language-driven) even without expensive navigation training on in-domain data (i.e., perform zero-shot inference). We explore these capabilities in a unified setting: language-driven zero-shot object navigation (L-ZSON). Inspired by the recent success of open-vocabulary models for image classification, we investigate a straightforward framework, CLIP on Wheels (CoW), to adapt open-vocabulary models to this task without fine-tuning. To better evaluate L-ZSON, we introduce the Pasture benchmark, which considers finding uncommon objects, objects described by spatial and appearance attributes, and hidden objects described relative to visible objects. We conduct an in-depth empirical study by directly deploying 21 CoW baselines across Habitat, RoboTHOR, and Pasture. In total, we evaluate over 90k navigation episodes and find that (1) CoW baselines often struggle to leverage language descriptions, but are proficient at finding uncommon objects. (2) A simple CoW, with CLIP-based object localization and classical exploration — and no additional training — matches the navigation efficiency of a state-of-the-art ZSON method trained for 500M steps on Habitat MP3D data. This same CoW provides a 15.6 percentage point improvement in success over a state-of-the-art RoboTHOR ZSON model.
Multi-channel video-language retrieval require models to understand information from different channels (e.g. video+question, video+speech) to correctly link a video with a textual response or query. Fortunately, contrastive multimodal models are shown to be highly effective at aligning entities in images/videos and text, e.g., CLIP; text contrastive models are extensively studied recently for their strong ability of producing discriminative sentence embeddings, e.g., SimCSE. However, there is not a clear way to quickly adapt these two lines to multi-channel video-language retrieval with limited data and resources. In this paper, we identify a principled model design space with two axes: how to represent videos and how to fuse video and text information. Based on categorization of recent methods, we investigate the options of representing videos using continuous feature vectors or discrete text tokens; for the fusion method, we explore the use of a multimodal transformer or a pretrained contrastive text model. We extensively evaluate the four combinations on five video-language datasets. We surprisingly find that discrete text tokens coupled with a pretrained contrastive text model yields the best performance, which can even outperform state-of-the-art on the iVQA and How2QA datasets without additional training on millions of video-text data. Further analysis shows that this is because representing videos as text tokens captures the key visual information and text tokens are naturally aligned with text models that are strong retrievers after the contrastive pretraining process. All the empirical analysis establishes a solid foundation for future research on affordable and upgradable multimodal intelligence.
Generalized few-shot object detection aims to achieve precise detection on both base classes with abundant annotations and novel classes with limited training data. Existing approaches enhance few-shot generalization with the sacrifice of base-class performance, or maintain high precision in base-class detection with limited improvement in novel-class adaptation. In this paper, we point out the reason is insufficient Discriminative feature learning for all of the classes. As such, we propose a new training framework, DiGeo, to learn Geometry-aware features of inter-class separation and intra-class compactness. To guide the separation of feature clusters, we derive an offline simplex equiangular tight frame (ETF) classifier whose weights serve as class centers and are maximally and equally separated. To tighten the cluster for each class, we include adaptive class-specific margins into the classification loss and encourage the features close to the class centers. Experimental studies on two few-shot benchmark datasets (VOC, COCO) and one long-tail dataset (LVIS) demonstrate that, with a single model, our method can effectively improve generalization on novel classes without hurting the detection of base classes.
Vision Transformers (ViTs) emerge to achieve impressive performance on many data-abundant computer vision tasks by capturing long-range dependencies among local features. However, under few-shot learning (FSL) settings on small datasets with only a few labeled data, ViT tends to overfit and suffers from severe performance degradation due to its absence of CNN-alike inductive bias. Previous works in FSL avoid such problem either through the help of self-supervised auxiliary losses, or through the dextile uses of label information under supervised settings. But the gap between self-supervised and supervised few-shot Transformers is still unfilled. Inspired by recent advances in self-supervised knowledge distillation and masked image modeling (MIM), we propose a novel Supervised Masked Knowledge Distillation model (SMKD) for few-shot Transformers which incorporates label information into self-distillation frameworks. Compared with previous self-supervised methods, we allow intra-class knowledge distillation on both class and patch tokens, and introduce the challenging task of masked patch tokens reconstruction across intra-class images. Experimental results on four few-shot classification benchmark datasets show that our method with simple design outperforms previous methods by a large margin and achieves a new start-of-the-art. Detailed ablation studies confirm the effectiveness of each component of our model. Code for this paper is available here: this https URL.
Synthesizing 3D human avatars interacting realistically with a scene is an important problem with applications in AR/VR, video games and robotics. Towards this goal, we address the task of generating a virtual human — hands and full body — grasping everyday objects. Existing methods approach this problem by collecting a 3D dataset of humans interacting with objects and training on this data. However, 1) these methods do not generalize to different object positions and orientations, or to the presence of furniture in the scene, and 2) the diversity of their generated full-body poses is very limited. In this work, we address all the above challenges to generate realistic, diverse full-body grasps in everyday scenes without requiring any 3D full-body grasping data. Our key insight is to leverage the existence of both full-body pose and hand grasping priors, composing them using 3D geometrical constraints to obtain full-body grasps. We empirically validate that these constraints can generate a variety of feasible human grasps that are superior to baselines both quantitatively and qualitatively. See our webpage for more details: this https URL.
The relatively hot temperature of the human body causes people to turn into long-wave infrared light sources. Since this emitted light has a larger wavelength than visible light, many surfaces in typical scenes act as infrared mirrors with strong specular reflections. We exploit the thermal reflections of a person onto objects in order to locate their position and reconstruct their pose, even if they are not visible to a normal camera. We propose an analysis-by-synthesis framework that jointly models the objects, people, and their thermal reflections, which combines generative models with differentiable rendering of reflections. Quantitative and qualitative experiments show our approach works in highly challenging cases, such as with curved mirrors or when the person is completely unseen by a normal camera.
Tracking Through Containers and Occluders in the Wild Basile Van Hoorick Columbia University, Pavel Tokmakov Toyota Research Institute, Simon Stent Woven Planet, Jie Li Toyota Research Institute, Carl Vondrick Columbia University
Tracking objects with persistence in cluttered and dynamic environments remains a difficult challenge for computer vision systems. In this paper, we introduce TCOW, a new benchmark and model for visual tracking through heavy occlusion and containment. We set up a task where the goal is to, given a video sequence, segment both the projected extent of the target object, as well as the surrounding container or occluder whenever one exists. To study this task, we create a mixture of synthetic and annotated real datasets to support both supervised learning and structured evaluation of model performance under various forms of task variation, such as moving or nested containment. We evaluate two recent transformer-based video models and find that while they can be surprisingly capable of tracking targets under certain settings of task variation, there remains a considerable performance gap before we can claim a tracking model to have acquired a true notion of object permanence.
Doubly Right Object Recognition: A Why Prompt for Visual Rationales Chengzhi Mao Columbia University, Revant Teotia Columbia University, Amrutha Sundar Columbia University, Sachit Menon Columbia University, Junfeng Yang Columbia University, Xin Wang Microsoft Research, Carl Vondrick Columbia University
Many visual recognition models are evaluated only on their classification accuracy, a metric for which they obtain strong performance. In this paper, we investigate whether computer vision models can also provide correct rationales for their predictions. We propose a “doubly right” object recognition benchmark, where the metric requires the model to simultaneously produce both the right labels as well as the right rationales. We find that state-of-the-art visual models, such as CLIP, often provide incorrect rationales for their categorical predictions. However, by transferring the rationales from language models into visual representations through a tailored dataset, we show that we can learn a “why prompt,” which adapts large visual representations to produce correct rationales. Visualizations and empirical experiments show that our prompts significantly improve performance on doubly right object recognition, in addition to zero-shot transfer to unseen tasks and datasets.
What You Can Reconstruct From a Shadow Ruoshi Liu Columbia University, Sachit Menon Columbia University, Chengzhi Mao Columbia University, Dennis Park Toyota Research Institute, Simon Stent Woven Planet, Carl Vondrick Columbia University
3D reconstruction is a fundamental problem in computer vision, and the task is especially challenging when the object to reconstruct is partially or fully occluded. We introduce a method that uses the shadows cast by an unobserved object in order to infer the possible 3D volumes under occlusion. We create a differentiable image formation model that allows us to jointly infer the 3D shape of an object, its pose, and the position of a light source. Since the approach is end-to-end differentiable, we are able to integrate learned priors of object geometry in order to generate realistic 3D shapes of different object categories. Experiments and visualizations show that the method is able to generate multiple possible solutions that are consistent with the observation of the shadow. Our approach works even when the position of the light source and object pose are both unknown. Our approach is also robust to real-world images where ground-truth shadow mask is unknown.
Recent works have demonstrated that natural language can be used to generate and edit 3D shapes. However, these methods generate shapes with limited fidelity and diversity. We introduce CLIP-Sculptor, a method to address these constraints by producing high-fidelity and diverse 3D shapes without the need for (text, shape) pairs during training. CLIP-Sculptor achieves this in a multi-resolution approach that first generates in a low-dimensional latent space and then upscales to a higher resolution for improved shape fidelity. For improved shape diversity, we use a discrete latent space which is modeled using a transformer conditioned on CLIP’s image-text embedding space. We also present a novel variant of classifier-free guidance, which improves the accuracy-diversity trade-off. Finally, we perform extensive experiments demonstrating that CLIP-Sculptor outperforms state-of-the-art baselines.
The department is extremely proud of all of our students! We honored this year’s graduates at a post-commencement event on May 17.
A number of students received awards from the department for their service and academic excellence. The list of CS awardees is in this year’s graduation handout.
University commencement was on May 17 and on May 15, the Columbia Engineering Class of 2023 gathered on the South Lawn of Columbia’s campus to celebrate Class Day.
Jonathan L. Gross Award for Academic Excellence Awardee Madison Fong
Jonathan L. Gross Award for Academic Excellence Awardee Anthony Ozerov
Jonathan L. Gross Award for Academic Excellence Awardee Ethan Wu
Jonathan L. Gross Award for Academic Excellence Awardee Tom Zollo
Descriptions will be added as they become available.
COMS W4995: TOPICS: Algorithmic Thinking to Development
Course Overview: From Algorithmic Thinking to Development focuses on refining problem-solving and coding skills so that students can devise solutions to problems that are frequently used in interviews for software engineering positions. The selected problems fall under the domains of brute-force, hashing, sorting, transform-and-conquer, greedy, and dynamic programming and are found on various online judges including HackerRank, LeetCode, and SPOJ. Python, Java, C, and C++ are used to implement solutions. While the instructor will provide short lectures and code walk-throughs to help the class, students will learn primarily through experimentation, working in small teams and sharing ideas. At the end of the semester, each team will select and solve a problem from an online judge and present their solutions to the class.
Prerequisite: (COMS W3134 or COMS W3137), COMS W3157 recommended
Course Outcomes: To assess student progress, we focus on key skills that can be demonstrated. Below is the list of course outcomes to be achieved by the end of the semester: 1. Translate a wide variety of algorithmic techniques into efficient programs. 2. Choose among algorithmic techniques, selecting the one that best fits a given problem. 3. Implement efficient solutions to problems using various high-level languages. 4. Create good test cases. 5. Publicly present algorithm and program design. 6. Work effectively in a team.
Manhattan Borough President Mark Levine assembled a group of New York legislators, academics, advocates, and tech policymakers — including a representative from Google — a week ago to discuss how people use artificial intelligence, and whether government regulation is keeping up with the explosive new technology.
Research papers from the department were accepted to the 11th International Conference on Learning Representations (ICLR 2023). ICLR is the premier conference on deep learning where researchers gather to discuss their work in the fields of artificial intelligence, statistics, and data science.
Keywords: vision-language models, CLIP, prompting, GPT-3, large language models, zero-shot recognition, multimodal
TL;DR: We enhance zero-shot recognition with vision-language models by comparing to category descriptors from GPT-3, enabling better performance in an interpretable setting that also allows for the incorporation of new concepts and bias mitigation.
Abstract: Vision-language models such as CLIP have shown promising performance on a variety of recognition tasks using the standard zero-shot classification procedure — computing similarity between the query image and the embedded words for each category. By only using the category name, they neglect to make use of the rich context of additional information that language affords. The procedure gives no intermediate understanding of why a category is chosen and furthermore provides no mechanism for adjusting the criteria used towards this decision. We present an alternative framework for classification with VLMs, which we call classification by description. We ask VLMs to check for descriptive features rather than broad categories: to find a tiger, look for its stripes; its claws; and more. By basing decisions on these descriptors, we can provide additional cues that encourage using the features we want to be used. In the process, we can get a clear idea of what the model “thinks” it is seeing to make its decision; it gains some level of inherent explainability. We query large language models (e.g., GPT-3) for these descriptors to obtain them in a scalable way. Extensive experiments show our framework has numerous advantages past interpretability. We show improvements in accuracy on ImageNet across distribution shifts; demonstrate the ability to adapt VLMs to recognize concepts unseen during training; and illustrate how descriptors can be edited to effectively mitigate bias compared to the baseline.
Notable, top 25%
CROM: Continuous Reduced-Order Modeling of PDEs Using Implicit Neural Representations Peter Yichen Chen Columbia University, Jinxu Xiang Columbia University, Dong Heon Cho Columbia University, Yue Chang University of Toronto, G A Pershing Columbia University, Henrique Teles Maia Columbia University, Maurizio M Chiaramonte Meta Reality Labs Research, Kevin Thomas Carlberg Meta Reality Labs Research, Eitan Grinspun University of Toronto
TL;DR: We accelerate PDE solvers via rapid latent space traversal of continuous vector fields leveraging implicit neural representations.
Abstract: The long runtime of high-fidelity partial differential equation (PDE) solvers makes them unsuitable for time-critical applications. We propose to accelerate PDE solvers using reduced-order modeling (ROM). Whereas prior ROM approaches reduce the dimensionality of discretized vector fields, our continuous reduced-order modeling (CROM) approach builds a low-dimensional embedding of the continuous vector fields themselves, not their discretization. We represent this reduced manifold using continuously differentiable neural fields, which may train on any and all available numerical solutions of the continuous system, even when they are obtained using diverse methods or discretizations. We validate our approach on an extensive range of PDEs with training data from voxel grids, meshes, and point clouds. Compared to prior discretization-dependent ROM methods, such as linear subspace proper orthogonal decomposition (POD) and nonlinear manifold neural-network-based autoencoders, CROM features higher accuracy, lower memory consumption, dynamically adaptive resolutions, and applicability to any discretization. For equal latent space dimension, CROM exhibits 79x and 49x better accuracy, and 39x and 132x smaller memory footprint, than POD and autoencoder methods, respectively. Experiments demonstrate 109x and 89x wall-clock speedups over unreduced models on CPUs and GPUs, respectively. Videos and codes are available on the project page: https://crom-pde.github.io
TL;DR: We propose a framework to rigorously and flexible control the quantiles of the loss distribution incurred by a predictor or set of predictors.
Abstract: Rigorous guarantees about the performance of predictive algorithms are necessary in order to ensure their responsible use. Previous work has largely focused on bounding the expected loss of a predictor, but this is not sufficient in many risk-sensitive applications where the distribution of errors is important. In this work, we propose a flexible framework to produce a family of bounds on quantiles of the loss distribution incurred by a predictor. Our method takes advantage of the order statistics of the observed loss values rather than relying on the sample mean alone. We show that a quantile is an informative way of quantifying predictive performance, and that our framework applies to a variety of quantile-based metrics, each targeting important subsets of the data distribution. We analyze the theoretical properties of our proposed method and demonstrate its ability to rigorously control loss quantiles on several real-world datasets.
TL;DR: This paper proposes novel inverse reinforcement learning methods to learn effective imitating policies from the expert’s demonstrations when unobserved confounders are present.
Abstract: One of the most common ways children learn when unfamiliar with the environment is by mimicking adults. Imitation learning concerns an imitator learning to behave in an unknown environment from an expert’s demonstration; reward signals remain latent to the imitator. This paper studies imitation learning through causal lenses and extends the analysis and tools developed for behavior cloning (Zhang, Kumor, Bareinboim, 2020) to inverse reinforcement learning. First, we propose novel graphical conditions that allow the imitator to learn a policy performing as well as the expert’s behavior policy, even when the imitator and the expert’s state-action space disagree, and unobserved confounders (UCs) are present. When provided with parametric knowledge about the unknown reward function, such a policy may outperform the expert’s. Also, our method is easily extensible and allows one to leverage existing IRL algorithms even when UCs are present, including the multiplicative-weights algorithm (MWAL) (Syed & Schapire, 2008) and the generative adversarial imitation learning (GAIL) (Ho & Ermon, 2016). Finally, we validate our framework by simulations using real-world and synthetic data.
TL;DR: We solve the two problems of counterfactual identification and estimation from arbitrary surrogate experiments using a Generative Adversarial Network implementation of the Neural Causal Model.
Abstract: Evaluating hypothetical statements about how the world would be had a different course of action been taken is arguably one key capability expected from modern AI systems. Counterfactual reasoning underpins discussions in fairness, the determination of blame and responsibility, credit assignment, and regret. In this paper, we study the evaluation of counterfactual statements through neural models. Specifically, we tackle two causal problems required to make such evaluations, i.e., counterfactual identification and estimation from an arbitrary combination of observational and experimental data. First, we show that neural causal models (NCMs) are expressive enough and encode the structural constraints necessary for performing counterfactual reasoning. Second, we develop an algorithm for simultaneously identifying and estimating counterfactual distributions. We show that this algorithm is sound and complete for deciding counterfactual identification in general settings. Third, considering the practical implications of these results, we introduce a new strategy for modeling NCMs using generative adversarial networks. Simulations corroborate with the proposed methodology.
Abstract: Pretrained large-scale vision-language models like CLIP have exhibited strong generalization over unseen tasks. Yet imperceptible adversarial perturbations can significantly reduce CLIP’s performance on new tasks. In this work, we identify and explore the problem of adapting large-scale models for zero-shot adversarial robustness. We first identify two key factors during model adaption–training losses and adaptation methods–that affect the model’s zero-shot adversarial robustness. We then propose a text-guided contrastive adversarial training loss, which aligns the text embeddings and the adversarial visual features with contrastive learning on a small set of training data. We apply this training loss to two adaption methods, model finetuning and visual prompt tuning. We find that visual prompt tuning is more effective in the absence of texts, while finetuning wins in the existence of text guidance. Overall, our approach significantly improves the zero-shot adversarial robustness over CLIP, seeing an average improvement of 31 points over ImageNet and 15 zero-shot datasets. We hope this work can shed light on understanding the zero-shot adversarial robustness of large-scale models.
TempCLR: Temporal Alignment Representation with Contrastive Learning Yuncong Yang Columbia University, Jiawei Ma Columbia University, Shiyuan Huang Columbia University, Long Chen Columbia University, Xudong Lin Columbia University, Guangxing Han Columbia University, Shih-Fu Chang Columbia University
Keywords: Representation learning, Global Sequence Alignment, Zero/Few-shot Transfer
TL;DR: Global sequence matching under temporal order consistency matters in contrastive-based video-paragraph/text learning.
Abstract: Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
The third-year PhD student is creating tools to help people with vision impairments navigate the world.
Imagine walking to your office from the subway station on a Monday morning. You notice a new café on the way, so you decide to take a detour and try a latté. That sounds like a normal way to start the week, right?
But for people with vision impairment or low vision, like those who are categorized as blind and low vision (BLV), this kind of spontaneous exploration while outside is challenging. Current navigation assistance systems (NAS) provide turn-by-turn instructions, but they do not allow visually impaired users to deviate from the shortest path to their destination or make decisions on the fly. As a result, people with vision impairment or low vision often miss out on the freedom to go out and navigate on their own terms.
Gaurav Jain
In a paper published at the ACM Conference On Computer-Supported Cooperative Work And Social Computing (CSCW ‘23), computer science researchers introduced the concept of “Exploration Assistance,” which is an evolution of current NASs that can support BLV people’s exploration in unfamiliar environments. Led by Gaurav Jain, the researchers investigated how NASs should be designed by interviewing BLV people, orientation and mobility instructors, and leaders of blind-serving organizations, to understand their specific needs and challenges. Their findings highlight the types of spatial information required for exploration beyond turn-by-turn instructions and the difficulties faced by BLV people when exploring alone or with the help of others.
Jain, who is advised by Assistant Professor Brian Smith, is a PhD student in the Computer-Enabled Abilities Laboratory (CEAL Lab), where researchers develop computers that help people perceive and interact with the world around them. Their paper presents the results of interviews with BLV people and other stakeholders to identify the types of spatial information BLV people need for exploration and the challenges BLV people face when exploring unfamiliar environments. The paper offers insights into the design and development of new navigation assistance systems that can support BLV people in exploring unfamiliar environments with greater spontaneity and agency.
The study investigates how navigation assistance should evolve to support blind people in exploring unfamiliar environments. Traditional approaches, as shown on the left, focus solely on guiding users to their destination. The group’s findings, as shown on the right, reveal that navigation systems can support exploration in three ways: by conveying area shapes, by conveying the layout of objects, and by facilitating effective collaboration with other people (both blind and sighted), who can “unlock” additional avenues of exploration for the user.
Based on their findings, they presented several instances of NASs that support the exploration assistance paradigm and identify several challenges that need to be overcome to make these systems a reality. Jain hopes that his research will ultimately enable BLV people to experience greater agency and independence as they navigate and explore their environments. We sat down with Jain to learn more about his research, doing qualitative research, and the thought processes behind writing research papers.
Q: What is exploration assistance and why is it important to do research on it?
This research is incredibly exciting for the blind and low vision (BLV) community, as it represents a significant step towards equal access and agency in exploring unfamiliar environments. For BLV people, the ability to navigate and explore independently is essential to daily life, and current navigation assistance systems often limit their ability to do so. By introducing the concept of exploration assistance, this research opens up new possibilities for BLV people to explore and discover their surroundings with greater spontaneity and freedom. This research has the potential to significantly improve the quality of life for BLV people and is a major development in the ongoing pursuit of accessibility and inclusion for all.
Q: How did you become part of the research project?
This was my first project as a PhD student in the CEAL lab. The project was initiated as a camera-based wearable NAS for BLV people, and we conducted several formative studies with BLV people.
As we progressed, we realized that there was a significant research gap in the research community’s understanding of how NASs could support BLV people’s exploration in navigation. Based on these findings, we shifted our focus toward investigating this gap, and the paper I worked on was the result of this pivot. The paper is titled, “I Want to Figure Things Out”: Supporting Exploration in Navigation for People with Visual Impairments.
Q: The research was more qualitative, right? How did you find working on it?
Over the course of approximately one year, I had the opportunity to work on this project that challenged me to step outside of my comfort zone as a human-computer interaction (HCI) researcher. Before this project, my research experience had primarily focused on computer vision and deep learning. I was more at ease with HCI systems research, which involved designing, building, and evaluating tools and techniques to solve user problems.
This project, however, was a qualitative research study that aimed to gain a deeper understanding of user needs, behaviors, challenges, and attitudes toward technology through in-depth interviews, observations, and other qualitative data collection methods. To prepare for this project, I had to immerse myself in the field of accessibility and navigation assistance for BLV people and read extensively on papers that employed qualitative research methods.
Although it took some time for me to shift my mindset towards qualitative research, this project helped me become a more well-rounded researcher, as I now feel comfortable with both qualitative and systems research. Overall, this project was a significant personal and professional growth experience, as I was able to expand my research expertise and contribute to a worthy cause.
Q: Can you talk about the process of writing the paper? When it came time to start writing, how did you organize your thoughts and the data?
Writing the paper was a critical stage in the research process, and I approached it by first organizing my thoughts and drafting a clear outline. I started by creating an outline of the paper with section and subsection headers, accompanied by a brief summary of what I intended to discuss in each section. This process allowed me to see the overall structure of the paper and ensure that I covered all the essential elements.
Once I had a clear structure in mind, I began to tackle each section of the paper one by one, starting with the introduction and then moving on to the methods, results, and discussion sections. I iteratively refined my writing based on feedback from my advisor, lab mates, and friends.
Throughout the writing process, I also ensured that my writing was clear, concise, and easy to follow. I paid close attention to the flow of ideas and transitions between sections, making sure that each paragraph and sentence contributed to the overall argument and was well-supported by the evidence.
Overall, the process of writing the paper was challenging but rewarding. It allowed me to synthesize the research findings and present them in a compelling way, showcasing the impact of our work on the lives of BLV people.
Q: What did you find surprising or challenging about the process?
Throughout the research process, I encountered various challenges that both surprised and tested me. Interviewing participants, in particular, proved to be an intriguing yet difficult task. Initially, I struggled to guide conversations naturally toward my research questions without leading participants toward a certain answer. However, with each interview, I became more confident and began to enjoy the process. Hearing firsthand from BLV people that our work could make a real impact on their lives was also incredibly rewarding.
Analyzing and synthesizing the interview data was another major challenge. Unlike quantitative data, conversations are often open-ended and context-dependent, making it difficult to separate my own biases from the interviewee’s responses. I spent a considerable amount of time reviewing the interview transcripts and identifying emerging themes. To facilitate this process, I leveraged tools like NVivo to better organize the interview data, and our team held several discussions to refine these themes. To ensure the accuracy of our interpretation, we sought feedback from two BLV interns who worked with us over the summer on another project.
Overall, this research experience pushed me to become more adaptable. While it presented its own unique set of challenges, I am proud to have contributed to a project that has the potential to create meaningful change in the lives of BLV people.
Jain working with a summer intern in the CEAL Lab.
Q: Did it change your view on how you should do research?
Yes, my experience with this research project has certainly changed my view on how to approach research. It has taught me the importance of keeping the paper in mind from the beginning of a project.
Now, I make a conscious effort to think about how I want to present my work and what story I want to tell with the research. This helps me gain more clarity on the direction of the project and how to steer it toward producing meaningful results. As part of my workflow, I now write early drafts of paper introductions even before developing any tools or systems. This allows me to zoom out from the day-to-day technical challenges and see the big picture, which is crucial in making sure that the research is both impactful and well-presented.
Q: What are your tips for writing a research paper?
Writing a research paper can be a challenging task, but here are a few tips that have helped me make the process smoother:
Start with a rough draft: Don’t expect your first draft to be perfect. It’s important to just start writing and get your ideas on paper. You can always revise and edit later. Use a tool like Microsoft Word or Google Docs to get started instead of working directly with Overleaf. I found this to take the pressure off me.
Observe your advisor’s edits: Your advisor can be a valuable resource when it comes to writing. Observing your advisor edit your drafts can help you learn from their feedback. I usually ask my advisor, Brian Smith, to describe why he made a certain edit and that helps me understand his process and also identify specific issues where I need to work more on.
Get feedback and revise: It’s important to get feedback on your paper from others. Share your draft with colleagues, friends, and family, and ask for their honest feedback. Use their feedback to revise and improve your paper. Whenever I’m writing, I socialize my writing with others, including my advisor, my lab mates, my friends, and my family. Interestingly, I get the most useful feedback from my friends and family, who have no idea what my research is about. I ask them to describe what they understood from the text I shared and try to match their description with my intended purpose. Writing is an iterative process; it takes several drafts before you have a polished paper.
Finally, one resource that I would totally recommend to every PhD student at Columbia is Adjunct Professor Janet Kayfetz’s class on Technical Writing. Her class is an excellent way to deeply understand research writing.
Q: What are you working on now?
I am currently working on two exciting projects that further my research goal of developing inclusive physical and digital environments for BLV people. The first project involves enhancing the capabilities of smart streets, streets with sensors like cameras and computing power, to help BLV people navigate street intersections safely.
This project is part of the NSF Engineering Research Center for Smart Streetscapes’ application thrust. The second project is focused on making videos accessible to BLV people by creating high-quality audio descriptions available at scale.
Q: Can you talk about your background and why you decided to pursue a PhD?
My exposure to research during my undergrad was invaluable, as it allowed me to work on diverse projects utilizing computer vision for various applications such as biometric security and medical imaging. These experiences instilled in me a passion for the research process. It was fulfilling to be able to identify problems that I care about, explore solutions, and disseminate new knowledge.
While I knew I enjoyed research, it was during the summer research fellowship at the Indian Institute of Sciences, where I collaborated with Professor P. K. Yalavarthy in the Medical Imaging Group, that crystallized my decision to pursue a PhD. The opportunity to work in a research lab, lead a project, and receive mentorship from an experienced advisor provided a glimpse of what a PhD program entails. I was excited by the prospect of being able to make a real-world impact by solving complex problems, and it was then that I decided to pursue a career in research.
Q: How has your research interest changed since you started your PhD?
I am interested in building Human-AI systems that embed AI technologies (e.g., computer vision) into human interactions to help BLV people better experience the world around them. My work on exploration assistance informs the design of future navigation assistance systems that enable BLV people to experience the physical world with more agency and spontaneity during navigation.
In addition to the physical world, I’ve also broadened my research focus to enhance BLV people’s experiences within the digital world. For example, I developed a system that makes it possible for BLV people to visualize the action in sports broadcasts rather than relying on other people’s descriptions of the game.
Q: What sort of research questions do you hope to answer now?
Accessibility research has traditionally focused on aiding daily-life activities and providing access to digital information for productivity and work, but there’s an increasing realization that providing access to everyday cultural experiences is equally important for inclusion and well-being.
This encompasses various forms of entertainment and recreation, such as watching TV, exploring museums, playing video games, listening to music, and engaging with social media. Ensuring that everyone has equal opportunities to enjoy these experiences is an emerging challenge. My goal is to design human-AI systems that enhance such experiences.
Q: Why did you choose to apply to Columbia CS? What attracted you to the program?
I was drawn to Columbia CS because of the type of problems my advisor works on. His research focused on creating systems that have a direct impact on people’s lives, where evaluating the user’s experience with the system is a key component.
This was a departure from my undergraduate research, where I focused on building systems to achieve high accuracy and efficiency. I found this user-centered approach to be extremely exciting, especially in the context of his project “RAD,” which aimed to make video games accessible to blind gamers. It was a super exciting prospect to be working on similar problems where you can firsthand see how people reacted and benefited from your solutions. This still remains one of the most fulfilling aspects of HCI research for me. In the end, this is what led me to choose Columbia and work with Brian Smith.
Jain at the ASSETS 2022 conference in Athens, Greece.
Q: What has been the highlight of your time at Columbia?
The first thing that comes to mind is the people that I have had the pleasure of working with and meeting. I am grateful for the opportunity to learn from my advisor and appreciate the incredible atmosphere he has created for me to thrive.
Additionally, I have been fortunate enough to make some amazing friends here at Columbia who have become a vital support system. Balancing work with passions outside of work has also been important to me, and I am grateful for the chance to engage with student clubs such as the dance team, Columbia Bhangra, and meet some amazing people there as well. Overall, the community at Columbia has been a highlight for me.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research, what should they know or do to prepare?
One thing that students wanting to do research should know is that research involves a lot of uncertainty and ambiguity. In fact, dealing with uncertainty can be one of the most challenging aspects of research, even more so than learning the technical skills required to complete a project.
In my own experience, staying motivated about the problem statement has been key to powering through those uncertain moments. Therefore, it is important to be true to yourself about what you are really excited about and work on those problems. Ultimately, this approach can go a long way in helping you navigate your time at Columbia and make the most of your research opportunities.
CS researchers had a strong showing at the ACM CHI Conference on Human Factors in Computing Systems (CHI 2023), with seven papers and two posters accepted. The premier international conference of Human-Computer Interaction (HCI) brings together researchers and practitioners who have an overarching goal to make the world a better place with interactive digital technologies.
Capturing and reliving memories allow us to record, understand and share our past experiences. Currently, the most common approach to revisiting past moments is viewing photos and videos. These 2D media capture past events that reflect a recorder’s first-person perspective. The development of technology for accurately capturing 3D content presents an opportunity for new types of memory reliving, allowing greater immersion without perspective limitations. In this work, we adopt 2D and 3D moment-recording techniques and build a moment-reliving experience in AR that combines both display methods. Specifically, we use AR glasses to record 2D point-of-view (POV) videos, and volumetric capture to reconstruct 3D moments in AR. We allow seamless switching between AR and POV videos to enable immersive moment reliving and viewing of high-resolution details. Users can also navigate to a specific point in time using playback controls. Control is synchronized between multiple users for shared viewing.
Towards Accessible Sports Broadcasts for Blind and Low-Vision Viewers Gaurav Jain Columbia University, Basel Hindi Columbia University, Connor Courtien Hunter College, Xin Yi Therese Xu Pomona College, Conrad Wyrick University of Florida, Michael Malcolm SUNY at Albany, Brian A. Smith Columbia University
Abstract: Blind and low-vision (BLV) people watch sports through radio broadcasts that offer a play-by-play description of the game. However, recent trends show a decline in the availability and quality of radio broadcasts due to the rise of video streaming platforms on the internet and the cost of hiring professional announcers. As a result, sports broadcasts have now become even more inaccessible to BLV people. In this work, we present Immersive A/V, a technique for making sports broadcasts —in our case, tennis broadcasts— accessible and immersive to BLV viewers by automatically extracting gameplay information and conveying it through an added layer of spatialized audio cues. Immersive A/V conveys players’ positions and actions as detected by computer vision-based video analysis, allowing BLV viewers to visualize the action. We designed Immersive A/V based on results from a formative study with BLV participants. We conclude by outlining our plans for evaluating Immersive A/V and the future implications of this research.
Papers
Supporting Piggybacked Co-Located Leisure Activities via Augmented Reality Samantha Reig Carnegie Mellon University, Erica Principe Cruz Carnegie Mellon University, Melissa M. Powers New York University, Jennifer He Stanford University, Timothy Chong University of Washington, Yu Jiang Tham Snap Inc., Sven Kratz Independent, Ava Robinson Snap Inc., Brian A. Smith Columbia University, Rajan Vaish Snap Inc., Andrés Monroy-Hernández Princeton University
Abstract: Technology, especially the smartphone, is villainized for taking meaning and time away from in-person interactions and secluding people into “digital bubbles”. We believe this is not an intrinsic property of digital gadgets, but evidence of a lack of imagination in technology design. Leveraging augmented reality (AR) toward this end allows us to create experiences for multiple people, their pets, and their environments. In this work, we explore the design of AR technology that “piggybacks” on everyday leisure to foster co-located interactions among close ties (with other people and pets). We designed, developed, and deployed three such AR applications, and evaluated them through a 41-participant and 19-pet user study. We gained key insights about the ability of AR to spur and enrich interaction in new channels, the importance of customization, and the challenges of designing for the physical aspects of AR devices (e.g., holding smartphones). These insights guide design implications for the novel research space of co-located AR.
Abstract: Digital avatars are an important part of identity representation, but there is little work on understanding how to represent disability. We interviewed 18 people with disabilities and related identities about their experiences and preferences in representing their identities with avatars. Participants generally preferred to represent their disability identity if the context felt safe and platforms supported their expression, as it was important for feeling authentically represented. They also utilized avatars in strategic ways: as a means to signal and disclose current abilities, access needs, and to raise awareness. Some participants even found avatars to be a more accessible way to communicate than alternatives. We discuss how avatars can support disability identity representation because of their easily customizable format that is not strictly tied to reality. We conclude with design recommendations for creating platforms that better support people in representing their disability and other minoritized identities.
Abstract: Blind and low vision (BLV) users often rely on alt text to understand what a digital image is showing. However, recent research has investigated how touch-based image exploration on touchscreens can supplement alt text. Touchscreen-based image exploration systems allow BLV users to deeply understand images while granting a strong sense of agency. Yet, prior work has found that these systems require a lot of effort to use, and little work has been done to explore these systems’ bottlenecks on a deeper level and propose solutions to these issues. To address this, we present ImageAssist, a set of three tools that assist BLV users through the process of exploring images by touch — scaffolding the exploration process. We perform a series of studies with BLV users to design and evaluate ImageAssist, and our findings reveal several implications for image exploration tools for BLV users.
Abstract: Longform spoken dialog delivers rich streams of informative content through podcasts, interviews, debates, and meetings. While production of this medium has grown tremendously, spoken dialog remains challenging to consume as listening is slower than reading and difficult to skim or navigate relative to text. Recent systems leveraging automatic speech recognition (ASR) and automatic summarization allow users to better browse speech data and forage for information of interest. However, these systems intake disfluent speech which causes automatic summarization to yield readability, adequacy, and accuracy problems. To improve navigability and browsability of speech, we present three training agnostic post-processing techniques that address dialog concerns of readability, coherence, and adequacy. We integrate these improvements with user interfaces which communicate estimated summary metrics to aid user browsing heuristics. Quantitative evaluation metrics show a 19% improvement in summary quality. We discuss how summarization technologies can help people browse longform audio in trustworthy and readable ways.
Abstract: Recently, large language models have made huge advances in generating coherent, creative text. While much research focuses on how users can interact with language models, less work considers the social-technical gap that this technology poses. What are the social nuances that underlie receiving support from a generative AI? In this work we ask when and why a creative writer might turn to a computer versus a peer or mentor for support. We interview 20 creative writers about their writing practice and their attitudes towards both human and computer support. We discover three elements that govern a writer’s interaction with support actors: 1) what writers desire help with, 2) how writers perceive potential support actors, and 3) the values writers hold. We align our results with existing frameworks of writing cognition and creativity support, uncovering the social dynamics which modulate user responses to generative technologies.
AngleKindling: Supporting Journalistic Angle Ideation with Large Language Models Savvas Petridis Columbia University, Nicholas Diakopoulos Northwestern University, Kevin Crowston Syracuse University, Mark Hansen Columbia University, Keren Henderson Syracuse University, Stan Jastrzebski Syracuse University, Jefrey V. Nickerson Stevens Institute of Technology, Lydia B. Chilton Columbia University
Abstract: News media often leverage documents to find ideas for stories, while being critical of the frames and narratives present. Developing angles from a document such as a press release is a cognitively taxing process, in which journalists critically examine the implicit meaning of its claims. Informed by interviews with journalists, we developed AngleKindling, an interactive tool which employs the common sense reasoning of large language models to help journalists explore angles for reporting on a press release. In a study with 12 professional journalists, we show that participants found AngleKindling significantly more helpful and less mentally demanding to use for brainstorming ideas, compared to a prior journalistic angle ideation tool. AngleKindling helped journalists deeply engage with the press release and recognize angles that were useful for multiple types of stories. From our findings, we discuss how to help journalists customize and identify promising angles, and extending AngleKindling to other knowledge-work domains.
Pop culture is an important aspect of communication. On social media people often post pop culture reference images that connect an event, product, or other entity to a pop culture domain. Creating these images is a creative challenge that requires finding a conceptual connection between the users’ topic and a pop culture domain. In cognitive theory, this task is called conceptual blending. We present a system called PopBlends that automatically suggests conceptual blends. The system explores three approaches that involve both traditional knowledge extraction methods and large language models. Our annotation study shows that all three methods provide connections with similar accuracy, but with very different characteristics. Our user study shows that people found twice as many blend suggestions as they did without the system, and with half the mental demand. We discuss the advantages of combining large language models with knowledge bases for supporting divergent and convergent thinking.
CS students are among the grantees pursuing research-based master’s and doctoral degrees in the natural, social, and engineering sciences at US institutions.
The fourth-year PhD student is trying to democratize chip manufacturing with a system that even non-experts can use.
A computer chip is hard to design and create because it requires expertise in each design flow step. This high design complexity exponentially grows the cost of making chips. Even though major semiconductor design companies can minimize such costs by leveraging design reuse, the same is not true for start-ups and academia.
Maico Cassel dos Santos presenting at a conference.
PhD student Maico Cassel dos Santos aims to simultaneously minimize, if not resolve, both problems. On the one hand, he is creating a chip design flow (aka methodology) where even a designer with no major knowledge of chip-making can prototype their own architecture into a chip. On the other hand, tailoring such design flow for a heterogeneous tile-based system-on-chip (SoC) architecture will facilitate components integration and, consequently, promote design reuse.
He works with Professor Luca Carloni and colleagues from the System-Level Design Group. They have been working on Embedded Scalable Platform (ESP), an open-source framework that supports several design flows for accelerator design that has a push-button IP integration tool. For the past three years, through a collaboration with Harvard University and IBM Research, they developed the chip design methodology and a swarm-based perception chip for autonomous vehicles.
Their solution differs by having three important characteristics: flexibility, robustness, and scalability. The flexibility addresses different designs, technologies, and tool flow. The robustness covers correctness by construction in addition to the verification of correctness in each step of the design flow. Finally, their methodology enables design scaling in size and complexity while lowering human effort and computation power.
Santos hopes that their methodology will lower developing costs and shorten the time span of chip manufacturing, promoting innovation and market competition. We recently caught up with him to learn more about his research and PhD life.
Q: How was it collaborating with the different groups considering you were not all physically in the same office?
The collaboration with researchers from Harvard and IBM couldn’t be better, in my opinion. Columbia alone would not have the expertise to develop the methodology and tape-out a chip of that complexity in that short time span. The tape-out process is the final result of the design process before it is sent to fabrication. It would have taken more than a year if we had done it on our own. But through the collaboration, it only took four months.
The same is true for Harvard and IBM since, back then, only the Columbia team had knowledge of the ESP architecture. Therefore, only the combination of expertise among the researchers involved from each institution could accomplish the results described in both papers. Moreover, all researchers involved in the project were fully committed to achieving the best outcome regarding chip features and design methodology.
Regarding working virtually, I would say the core part of the flow was developed during the first year of the pandemic (2020) and was improved in the second and third years (2021-2022). It was common to have daily virtual meetings among the physical design team. Since social distancing was in place, we were available from early morning to late at night to assist or discuss any issue that could arise. In this sense, communication channels such as Slack, web conference rooms, and email were crucial for the development of the project.
Q: What was your role in the project?
My initial role was to be the bridge between system-level designers, the ones who create the architecture, and physical designers, the ones that transform the architecture into a chip layout ready to send to fabrication. The role involved not only making sure the System-Level Design team, composed of Paolo Mantovani, Davide Giri, and Joseph Zuckerman, was delivering all required files and specifications to the physical design team but also reporting possible impacts of system-level design decisions on the physical design stage.
Not long after, I became one of the main physical designers with Tianyu Jia, a Harvard postdoc. Because of the considerable amount of work in a short time span, two more physical design engineers from IBM, Martin Cochet and Karthik Swaminathan, joined the team. The four of us formed the project’s core physical design team.
Q: How long did you work on the project? What did you have to do or read to prepare to make the methodology and the chip?
I have been working on the EPOCHS project for the past three years. The preparation to make the methodology can be split into two main fronts. The first was to understand the ESP architecture and what should be added or modified in the architecture to enable chip design and simultaneously facilitate the physical design workload.
The second front involved a lot of reading manuals of electronic design automation (EDA) tools. EDA tools have many parameters and several ways to reach a final chip. Not all of them, however, are clean and design-replicable. Finding the cleanest and design-independent set of parameters and commands demanded uncountable hours of reading manuals and implementation trials.
Q: What is the main contribution of your published papers?
The two papers published in European Solid-State Circuits (ESSCIRC 2022) and International Conference on Computer-Aided Design (ICCAD 2022) are a preliminary result of the framework’s capabilities. The ICCAD 2022 paper details the chip design methodology tailored for ESP. The ESSCIRC 2022 paper applies the ESP framework with the new methodology to design a domain-specific SoC (DSSoC) for swarm-based perception applications (autonomous vehicle applications).
As far as I know, no other design methodology at the moment can implement a chip starting from PDK installation in four months. Moreover, no other methodology showed significant scalability between one chip and another without a time span penalty.
Finally, the complete ESP framework offers the user not only an agile, user-friendly physical design but also a methodology for accelerator design, a push button SoC integration capable of booting Linux OS, and chip testing support. In summary, ESP offers a complete agile design methodology starting from Linux software application, passing through a high-level language such as SystemC, C, Pytorch, and Tensor Flow, to mention but a few, to the final GDS file that is sent to chip fabrication.
Of course, there is space for improvement – and research – in the methodology on several fronts. Our main goal is to achieve an agile push button optimized physical design that keeps the main characteristics this methodology already has: flexibility, robustness, and scalability.
Joseph Zuckerman, Luca Carloni, and Maico Cassel dos Santos
Q: Did anything surprise you about the research or the project?
From the beginning, I was always surprised regarding the project and research deliveries from the team. I am a very conservative and cautious person with respect to chip design. The ambition and increasing complexity of the project over time always concerned me. Therefore, at every milestone we achieved, I was impressed by what an engaged small talented team could do in such a short period!
Q: Can you talk about your background and why you pursued a PhD?
Before my PhD, I worked in chip design for 11 years. During this period, I taught how to design chips for a Brazilian government project in partnership with Cadence. This project aimed to increase the number of engineers in the country with the necessary knowledge and training to do chip design. I also designed chips and led a team to develop the RTL design flow at CEITEC, a Brazilian state-own semiconductor company.
I took my master’s while working, and at one point, I felt my career was at a plateau, and I wanted to do and learn different things. The PhD path started to sound perfect for me, especially when I could do it in the United States (US). Even though a PhD program in the US takes longer than in other countries, it is usually attached to some companies with daring projects. Therefore, it doesn’t detach you entirely from the industry, and it is easier to visualize a real-world application of your research. In addition, I would have the opportunity to use what I know, expand my knowledge, and learn important mainstream fields, such as machine learning.
Q: What are your research interests? How did you decide to pursue this type of research?
I have always liked to find ways to optimize processes. When it comes to chip design, a set of NP-Hard problems, the goal is to find improvements in the final result, which indicates you are in the right direction to a near-optimal solution.
Until recently, design problems relied on analytic algorithm solvers for design automation. Nowadays, the use of machine learning to predict and find chip design solutions is showing promising results in several stages of the design process. Therefore, focusing my research on chip design methodology that leverages algorithms and machine learning allows me to learn these topics and apply this new knowledge to optimize processes in a field I am already used to–chip design.
Q: What sort of research questions do you hope to answer?
Although we now have a flexible, robust, and scalable methodology, it is neither a push-button solution nor presents near-optimal results in terms of performance, power, and area. Therefore, my research focus now is to find ways to automate the still-required manual steps and, at the same time, produce near-global optimum solutions.
Q: What do you think is the most interesting thing about doing research?
Can I say two things? The first is the feeling that you are at the leading edge of some technology–the frontier between the known and unknown. The second is that you are not alone; other researchers are trying to find similar answers and are willing to collaborate.
Q: What are you working on now?
I am organizing the ESP ASIC design flow database to make it user-friendly and easy to maintain as we add support for new technologies, electronic design automation (EDA) tools, and ESP architecture features. Simultaneously, I am building a flow to easily port ESP RTL architecture from FPGA-ready prototyping to ASIC-ready prototyping and reading many chip design flow-related papers.
The System-Level Design Group left to right: Guy Eichler, Joseph Zuckerman, Gabriele Tombesi, Maico Cassel dos Santos, Kuan-Lin Chiu, Luca Carloni, and Biruk Seyoum.
Q: What has been the highlight of your time at Columbia?
The research team I have been working with is all talented, hardworking people who do not hesitate to help each other. At the same time, whenever work allows, they are always down for having fun together as a team. This makes the PhD journey enjoyable and creates a bond that lasts beyond our time in Columbia.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research, what should they know or do to prepare?
First, I would say don’t start a PhD without clear reasons. You don’t need to know what specific topic you would like to research, but you need to understand why you want a PhD and why now. The reason should not be driven by the money a PhD degree can provide alone.
After you have clear reasons, try to find some fields you are interested in and which professors can best guide you in each of these fields. The researcher’s daily life involves a lot of paper reading, nights and weekends of experiments (not all will have the expected results), and, sometimes, paper rejections. Be prepared for that and keep moving forward; your work will be recognized eventually.
Finally, get to know the research team you will be working with. You will spend a lot of your time with them – the joy of your journey is strongly attached to the people surrounding you!
Academy members are world leaders who explore societal challenges, identify solutions, and promote nonpartisan recommendations that advance the public good.
The CS Department mourns the loss of Dragomir R. Radev, a 1999 computer science PhD graduate who unexpectedly passed away on March 29th in his home in New Haven, Connecticut. He was 54 years old and leaves behind his wife, Axinia, and children, Laura and Victoria.
Dragomir R. Radev
Radev worked with Professor Kathleen McKeown on seminal multi-document text summarization research, the topic of his PhD dissertation. His first job after Columbia was at IBM TJ Watson Research in Hawthorne, New York, where he worked for a year as a Research Staff Member. Then he spent 16 years on the computer science faculty at the University of Michigan before joining Yale University in 2017 as the A. Bartlett Giamatti Professor of Computer Science and led the Language, Information, and Learning (LILY) Lab at Yale University.
His research and work were influential, from his widely cited paper on LexRank to his most recent papers providing datasets, benchmarks, and evaluation of metrics for text summarization. His wide-ranging research touched many areas beyond summarization. He worked on graph-based methods for natural language processing (NLP), question answering, interfaces to databases, and language generation.
Over his career, Radev received many honors, including Fellow of the Association for Computational Linguistics (2018), the American Association for the Advancement of Science (2020), the Association for Computing Machinery (2015), and the Association for the Advancement of Artificial Intelligence (2020). He served as the Secretary of ACL from 2006-2015 and was awarded the ACL Distinguished Service Award in 2022.
Radev co-founded the North American Computational Linguistics Open Competition, an annual competition in which high school students solve brain teasers about language. He organized the contest and traveled with top-ranked students to the International Linguistics Olympiad every year.
“Drago was a very special, incredible person who touched all of us with his energy, his love for NLP, and his kindness,” said Kathleen McKeown. “He touched so many people and has had a huge impact on the field and on the ACL, the primary organization for our field.”
Dragomir R. Radev and family. Left to right: Laura, Dragomir, Axinia, and Victoria.
Fundraising note: A small group of faculty members from Columbia University, Yale University, and the University of Michigan have joined forces to raise money and set up a GoFundMe to help the Radev family support Victoria, who has a disability. The fund will help Axinia and the family continue to provide Victoria with the care she needs. If you are interested in and capable of donating in any way, please consider giving to the fundraiser.
The Distinguished Lecture series brings computer scientists to Columbia to discuss current issues and research that are affecting their particular fields.
An architect, a former Communications Officer for the United States Marine Corps, and a linguist will receive scholarship aid from a program that supports students from non-computational backgrounds to gain the knowledge and skills necessary to build careers in technology.
As one of the highest honors for young faculty, the NSF CAREER award recognizes outstanding research. Meet the Columbia Engineering professors who earned the award.
The chatbot has made waves over the past couple of months for being able to answer queries in a conversational tone. CS professors discuss what it can and cannot do correctly.
OpenAI’s ChatGPT is an artificial intelligence (AI) chatbot that is trained to follow the instruction in a prompt and give a detailed response. It is built upon GPT-3, a type of large language model (LLM) that predicts and generates text. Given a sequence of words, it will predict the word that has the highest probability of following next (kind of like autocomplete). These models are trained on huge datasets that allow them to generate answers to questions. ChatGPT works quickly and gives answers within seconds, and it also learns from every interaction and improves daily.
It can create a letter to your super asking for a repair to be done, write code and fix bugs, and suggest plot summaries for novels. But that does not mean that it is perfect. The problem with LLMs is that they can “hallucinate” and make things up. ChatGPT is guilty of this; some of the answers in its outputs do not even exist. It is also not trained to be truthful and it answers queries with a lot of confidence and authority, which is worrisome.
It is being compared to the last great tech disruption–the internet’s onset in the 1990s. We asked CS professors what the technology could do and how to use the tool the right way.
The original interface was cumbersome and needed an analyst who could use specialized programming languages to access the answer.
We developed AskCricInfo, which takes human input–questions or search queries–and converts the queries into a structured language like SQL that machines understand. The technology can “translate” the question into a programming language, find the answer, and quickly send it back to the user.
It is an excellent example of the power of underlying technology and what the tool can do. ChatGPT is very interesting. It is the first chatbot that makes “intelligent” and engaging conversations. There are definite use cases for making it a very effective teaching tool. It is up to the instructors to imagine a world where something like ChatGPT will always be available and teach students how to use it effectively. A lot can go wrong with ChatGPT- primarily because of its design that makes it bullshit confidently. But that is a problem with all LLMs, not just ChatGPT.
Kathy McKeown ChatGPT and the technology it is built on, GPT3, are game changers. With them and the other large language models that have recently emerged, models can now produce extremely fluent text. They are also able to perform a variety of tasks in a way that was not previously possible. And there are many situations in which they can be used to help us do things that we previously found tedious. But they are not able to do as much as we might initially have imagined. They have limitations that are not always immediately obvious, and researchers are taking the time to study them so that we can accurately characterize what they can and cannot do. Nonetheless, they change how we do research in the natural language field and how we build new models to carry out other tasks.
I think we need to learn how to incorporate them into our teaching because they are here to stay. Students know about them and will know how to use them. We will need to think creatively about how to teach students what these tools do well and what they do poorly, when they can be used as a tool to aid in research, and situations in which it would be dishonest. I imagine situations where we ask ChatGPT to answer an essay question, ask the student to critique the essay and identify what it does poorly, and then ask the student to write an essay that goes beyond what ChatGPT can do.
The worst problem with ChatGPT is that it is not always truthful. In fact, it may often lie or hallucinate facts. It does this very fluently, making its lies sound very plausible. This is quite a barrier to use in a real-world situation unless it is used by someone who knows what is correct, what is not, and can sift the good from the bad. Technology constantly changes, though, and it is a problem that researchers are actively working on.
Itsik Pe’er I asked ChatGPT about AI language models, and this is the output:
AI language models like ChatGPT, its competitors and successors represent a significant advancement in the field of Natural Language Processing (NLP). These models have the ability to generate human-like text based on a massive amount of input data, making them useful for various applications such as chatbots, question-answering systems, and content generation.
However, it is important to note that despite their sophisticated capabilities, they still have limitations and may generate outputs that are inaccurate, biased, or inappropriate. It is crucial to ensure responsible development and deployment of these models to maximize their benefits while minimizing potential harm.
The above demonstrates my thoughts more than I could otherwise express. In particular: it is already useful, but often not out-of-the-box, but I am a techno-optimist and believe even more usefulness is coming.
As a former judge in high school debate competitions, it reminds me of the most eloquent contestants, who would, if they needed to, lie through their teeth without missing a heartbeat. For instance, in response to this prompt, “What could go wrong with tools like ChatGPT?”, it writes:
There are several potential risks associated with the use of AI language models like ChatGPT: Bias: AI models are trained on large amounts of text data, which may reflect societal biases and lead to biased outputs. Misinformation: AI models may generate false or misleading information, which could have serious consequences if relied upon. Privacy Concerns: AI models process large amounts of personal information, raising privacy and security concerns. Misuse: AI models may be used for malicious purposes, such as spreading hate speech, fake news, or conducting phishing attacks. Job Loss: AI models may automate certain tasks, leading to job loss in industries that rely on those tasks. Therefore, it is important to carefully consider the potential risks and consequences of AI models and to develop and deploy them responsibly to minimize potential harm.
These are all valid points, but more context needs to be considered:
When it comes to bias, chatbots are worse than the best other (human?) alternatives but much better than the median ones.
Misinformation is a big problem when compounded by misuse, and we can see that happening now with stories posted online.
Privacy concerns depend on who has access to the data in ChatGPT and what can be done with it. But given that we all carry powerful tracking and sensing devices 24/7, our privacy is already weakly protected against powerful actors.
Some attention-seeking blogs and websites overstate the job loss point. Many jobs will become more efficient; many jobs will change; many jobs will be created, and, yes, many will be lost. People will adapt, and we will all be better for it.
Empathy is one of the most important leadership traits for managers. It helps build trust and connection among teams and demonstrates a leader’s ability to understand the needs of employees.
She represents just one of the many female talents at Columbia Engineering. Meet computer science undergrad Kennedy Salamat, who shares her experience & achievements as a woman in STEM in celebration of Women’s History Month.
Paparrizos is recognized for breakthroughs in time series data management, as well as contributions to adaptive methodologies for data-intensive and machine learning applications.
The award supports early-career faculty who have the potential to serve as academic role models in research and education and to lead advances in the mission of their department or organization.
PhD student Tuhin Chakrabarty talks about how his research is tapping into the creative side of computer science.
The field of natural language processing (NLP) has ramped up by leaps and bounds. This branch of artificial intelligence focuses on the ability of computers to understand and process language as humans do. It has been in the news these past few months because of a chatbot, ChatGPT, that can provide answers and data conversationally. The technology gives us a taste of just how powerful and useful NLP can be.
Tuhin Chakrabarty wants to see how much further he can push NLP in the field of computational creativity to see how computers can generate creative output. This is what ChatGPT had to say about computational creativity:
Computational creativity is a field that uses computational methods to simulate and enhance human-like creativity, producing valuable outputs such as art, music, stories, and scientific discoveries. It aims to understand and replicate the cognitive processes involved in human creativity, combining techniques from AI, cognitive psychology, and philosophy. Examples of computational creativity include generative art and music, game design, natural language processing, and scientific discovery. Ultimately, computational creativity seeks to leverage computers and algorithms to augment and extend human creativity, creating new possibilities for creative expression and innovation.
Tuhin Chakrabarty
“Generating text beyond a few sentences was almost very difficult two years ago, but things look much better now. It is not perfect, but I am optimistic,” said Tuhin Chakrabarty, who first became interested in computational creativity in 2019. “One of the things that I am excited about is how better we can align models like ChatGPT to human expectations and different cultures.”
Instead of creating text conversationally, Chakrabarty’s research focuses on how AI can be used to create metaphors and detect sarcasm with little to no training data. The fifth-year PhD student advised by Smaranda Muresan has expanded his work to generating long narratives of 2,000-word documents and visual metaphors. We recently sat down with him to learn more about his research and the creative possibilities of NLP.
Q: You mentioned that you became interested in doing research during your MS. What happened that made you interested in doing research?
I did not have much research experience as an undergrad. I got accepted to the CS masters program and I was fortunate enough to take a class offered by my advisor Smaranda Muresan, which still happens to be one of my all-time favorite courses at Columbia. Computational models of Social Meaning was a graduate seminar course about impactful papers in NLP. Reading all the papers in that class made me think about what I want to do with NLP and how so many interesting research questions can be answered computationally by studying language. Alongside this, I was also working with my advisor and my friend Chris Hidey on extracting arguments from social media. That experience was really precious. The enthusiasm everyone shared in trying to solve the problem at hand made me sure of my decision to pursue research.
Q: How did you become interested in computational creativity? And what is it?
Around 2019, Nanyun Peng and He He, two very important researchers in the field of computational creativity, wrote a paper on generating puns. I happened to attend NAACL 2019 in Minneapolis, where the paper was presented. I thought the paper was beautiful in every possible way and it quantified the surprisal theory in humor algorithmically. This made me really fascinated about how we can use inductive biases to help machines generate creative output. For selfish reasons, I reached out to Nanyun Peng and told her that I wanted to work with her. She was very kind and agreed to mentor me. My PhD advisor Smaranda Muresan is one of the experts in the field of Figurative Language, which deals with creativity. So, of course, that influenced my decision to work in computational creativity too. Computational creativity is a multidisciplinary endeavor located at the intersection of artificial intelligence, cognitive psychology, philosophy, and the arts. The goal of computational creativity is to model, simulate or replicate creativity using a computer to achieve one of several ends:
To construct a program or computer capable of human-level creativity.
To better understand human creativity and formulate an algorithmic perspective on human creative behavior.
To design programs that can enhance human creativity without necessarily being creative themselves.
Q: How can you train a model or algorithm to interpret creativity or language?
State-of-the-art models are often found to be inadequate for creative tasks. The principal reason for this is that in addition to composing grammatical and fluent sentences to articulate given content, these tasks usually require extensive world and common sense knowledge.
It should also be noted that current approaches to text generation require lots of training data for supervision. However, most existing corpus for creative forms of text is limited in size. Even if such a corpus existed, learning the distribution of existing data and sampling from it is unlikely to lead to truly novel, creative output.
So we have to rely on unsupervised or weakly supervised techniques to train an end-to-end model to interpret or generate creative text. Of course, with the advent of Large Language Models and few-shot learning, we can now prompt a model with a few examples of creative text and it can somewhat generalize (but not as well as humans). My dissertation deals with a lot of this.
Q: Let’s talk about your work with the New York Times. What type of research questions did you have to answer while there? How was it different from what you have been doing?
Over the past several years, a key focus for NYTimes Research and Development has understood how advances in machine learning can extend the capabilities of journalists and unlock reader experiences that aren’t possible today. Questions and answers are central to how humans learn. Times journalism frequently uses FAQ and Q&A-style articles to help readers understand complex topics like the Covid-19 vaccines. To enhance this style of journalism, we experimented with large language models to match questions to answers, even if the reader asks their question in a novel way.
Last year we launched a new research effort to explore generating open-ended questions for news articles. Our hypothesis is that understanding the questions our news articles are implicitly answering may be helpful in the reporting process and may ultimately enable us to create FAQ and Q&A-style articles more efficiently.
This was fundamentally different from what I have been doing because I had to work towards upholding journalism values such as accuracy and verifiability. In creativity, your model can generate something that does not require attribution. But, when working on a project that deals with news and journalism, the focus is on factuality.
Q: One of your five research papers at EMNLP was from your time at the NY Times, right?
Recent work on question generation has primarily focused on factoid questions such as who, what, where, and when about basic facts. Generating open-ended why, how, what, etc., questions that require long-form answers has proven more difficult. To facilitate the generation of open-ended questions, we propose CONSISTENT, a new end-to-end system for generating open-ended questions that are answerable from and faithful to the input text. Using news articles as a trustworthy foundation for experimentation, we demonstrate our model’s strength over several baselines using both automatic and human-based evaluations. We contribute an evaluation dataset of expert-generated open-ended questions and discuss potential downstream applications for news media organizations.
Q: What are you working on now? What are the kinds of research questions that you hope to answer?
Much of my recent and upcoming work is on human-AI collaboration for creativity. I recently worked on developing methods and evaluation frameworks for two creative tasks–poetry generation and visual metaphor generation–by leveraging collaboration between expert humans and state-of-the-art generative models. I further highlighted how collaboration improves the final output over either standalone models or only humans.
I have long focused on developing and evaluating machine learning models aimed at creativity in an isolated setting. This somehow limits their capacity to behave in an interactive setting with real humans. In a creative setting, it is crucial for models to understand human needs and provide assistance to augment human capabilities and improve performance based on human edits or feedback over time. So that is my focus now.
Q: About doing a PhD, what are the things you wished you knew before starting it?
This is a difficult question. Pursuing a PhD can be a really fun experience, but at the same time, it can be daunting. There is a lot of uncertainty around research questions and whether something will work or not. I wish I had been a little easier on myself and not taken everything personally. Like, if an idea didn’t work, instead of spending months trying to make it work, it is okay to give up and move in a different direction.
Q: What are your tips for people who want to pursue a PhD?
One of the things I learned during my PhD is to focus on what you care about. There are hundreds of researchers who might work on slightly dense areas, while your work can feel niche. This is not a problem. When I started working on NLP and creativity, the field still felt very young, but over the past three to four years, it has grown tremendously.
Your advisor will be one of the most important people in your PhD. It is essential to have good communication and working chemistry with them. One of the reasons my PhD felt like so much fun is because my advisor and I cared about the same problems.
Form a community and foster friendships with your lab mates, talk about research, or email a colleague whose work moved you and get a coffee with them at a conference. Also, try for opportunities to work with people in your lab or your community. It helps us learn so much.
Dan Rubenstein explains how Netflix’s plan to curb password sharing will work.
Just a couple of years ago, Netflix declared, “Love is sharing a password,” on Twitter. But now the streaming service is putting into motion a plan to identify password sharers and limit access to the account owner and people in their household. Password sharers are apprehensive about what will happen next, if they can continue to binge-watch shows for free, and if other streaming services will clamp down on password sharing too.
Under the new terms, a Netflix subscription can be shared by a household. So, anyone living at the same physical address as the account owner can access Netflix. Those who stream while traveling must use a temporary code for access while away. And if they are away from home for long periods, they can log into Netflix from their household once every 31 days to confirm that they are an authorized user. People deemed outside the household will have to get their own subscription.
We asked Professor Dan Rubenstein, an expert in computer networks, how the tech behind password crackdown works.
Q: How easy is it for Netflix to limit password sharing?
Netflix can track users through the internet service and the IP addresses of devices connected to a household’s network. Most homes are associated with a single IP address. Netflix can use the IP address to get a rough sense of where someone is located or if it’s where they usually access from. There may be ways to redirect the IP address by using a proxy. But this is probably hard in most instances and not something most people would know how to do.
Q: How could Netflix limit its service?
Currently, they limit the number of simultaneous online devices. They can also use various means in their own app or cookies in a browser to limit the total number of devices that can use a particular account.
So, they can specify things like “at most five devices can use the account,” and maybe they could limit the number of hours you can use it “outside the home.” I just think they need to be careful about cutting someone off with legitimate use, e.g., we traveled to Montreal and logged into our Netflix account there. This could also be an issue for students who are using accounts while away from home. They would not be able to log in from their house every month to verify their access.
Since Netflix never knows whether a device “outside the home” is yours or somebody else’s, they use verification checks as a means to make it inconvenient for someone else to use the account. For instance, if I let you use my account, they will periodically send an email to my address with a code you will have to enter at your location (from your device) to verify your use.
Q: Are these newtechniques that they developed or something they could have been doing all along?
They could have always done this. The information they use was always available – it’s more about the rules they put in place. By limiting how and when an account is used, they risk making the service less convenient.
Ronghui Gu is recognized for fundamental theory underlying systems verification and for synthesizing the results into realistic bug-free and hacker-resistant systems software.
Brian Jiang CC’23 and Karen Copeland SEAS’23 have been named 2023-24 Churchill Scholars, the first time that Columbia has seen two Scholars named in the same year. Brian and Karen are among 18 Churchill Scholars who were selected: 16 Scholars were selected in science, math and engineering fields; two Kanders Churchill Scholars were selected in science policy for the 2023-2024 academic year. Established in 1963 at the request of Sir Winston Churchill, the Churchill Scholarship was inspired by Churchill’s vision for a US-UK partnership that would support the advancement of science and technology in both countries. The Churchill Scholarship provides funding for one year of postgraduate study at Churchill College, Cambridge.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor




 Yangruibo Ding
Yangruibo Ding Zachary Huang
Zachary Huang Jeremy Klotz
Jeremy Klotz  Rafael Sofaer
Rafael Sofaer Jacob Blindenbach
Jacob Blindenbach  Charlie Carver
Charlie Carver Gabriel Chuang
Gabriel Chuang Samir Gadre
Samir Gadre Toma Itagaki
Toma Itagaki Tal Zussman
Tal Zussman Daniel Meyer
Daniel Meyer Sarah Mundy
Sarah Mundy Argha Talukder
Argha Talukder Max Chen
Max Chen Siyan “Sylvia” Li
Siyan “Sylvia” Li  Jingwen Liu
Jingwen Liu Matthew Beveridge
Matthew Beveridge Cyrus Illick
Cyrus Illick Xiaofeng Yan
Xiaofeng Yan Cognitive Workforce Revolution with Trustworthy and Self-Learning Generative AI
Cognitive Workforce Revolution with Trustworthy and Self-Learning Generative AI Causal Representation Learning and Optimal Intervention Design
Causal Representation Learning and Optimal Intervention Design