
Month: February 2017
Oscar-winning Jungle Book incorporates effects made possible by Eitan Grinspun
Animation techniques developed by Grinspun and his students rely on the geometry of physics and computer algorithms to simulate how plants and trees move in response to the wind or the swinging of monkeys.
Ilias Diakonikolas (PhD’11) receives Sloan Research Fellowship
A former student of Mihalis Yannakakis, Diakonikolas is now Assistant Professor and the Andrew and Erna Viterbi Early Career Chair in the Department of Computer Science at the University of Southern California.
Three faculty receive Google Research Awards
![]()
Suman Jana, Martha Kim, and Vishal Misra of Columbia’s Computer Science Department are each recipients of a Google Research Award, which provides funding to support research of new technologies developed by university faculty. Their three projects are among the 143 selected from 876 proposals received from over 300 universities worldwide. The funding provided by Google will cover tuition for one graduate student and allows faculty and students to work with Google engineers and researchers.
Suman Jana

For using machine learning to automatically find bugs in software, Suman Jana will receive $62K. Specifically his project Building High Coverage Fuzzers using Reinforcement Learning seeks to improve fuzzing, a software testing technique that inputs random data, called fuzz, to try to elicit error responses so the underlying code vulnerabilities can be identified before the software is released publicly and exposed to possible hacking. Current methods of fuzzing begin with seed inputs, applying mutations to produce a new generation of inputs. By evaluating which inputs generate show the most promise in leading to new bugs, fuzzers decide which inputs should be mutated further.
While fuzzing is successful at finding bugs humans might never find, especially simple bugs, the random and unsystematic nature of the evolutionary process means fuzzers might concentrate so much on certain inputs that some code gets overlooked. Jana’s project will employ reinforcement learning—a machine learning technique that reinforces successful actions by assigning reward points—to make the fuzzer more aware of how the software operates so the fuzzer can more intelligently generate input data for the specific program being tested. Rather than determining future inputs based only on the current generation of inputs (as do current fuzzers), reinforcement learning-based fuzzers will consider all previous mutations, finding program-specific patterns of mutations to ensure more complete code coverage. It’s a method that can be re-used since reinforcement learning-based fuzzers, once trained for a particular application, can be used to test other applications with similar input format and functionality.
Martha Kim

For more efficient ways of transcoding video, Martha Kim will receive $70K.
Transcoding video is the process of converting user-generated video to a size and format that views smoothly no matter the viewer being used. For video sharing sites like YouTube—currently uploading 400 hours of video each minute—more efficient transcoding translates to lower processing, storage, and other costs.
Transcoding can be done in software or hardware. While hardware accelerators operate at lower computational costs, they have serious drawbacks when it comes to video: they are slow to market (and thus slow to adapt to the release of updated codecs) and lack quality and other parameter controls that accommodate the varying requirements of a video-sharing site like YouTube, which in contrast to broadcast services such as Netflix, serve a wide-ranging and rapidly growing inventory of videos.
The ideal would be to combine the cost advantages of hardware with the flexibility, control, and upgradability of software, and that is the aim of Kim’s project, Video Transcoding Infrastructure for Video Sharing. By identifying bottlenecks in software video transcoding, Kim will design a video transcoding accelerator that avoids them. Rather than hardcoding entire algorithms into a rigid hardware design, Kim plans a modular approach, using separate building blocks for the different component stages of the transcoding. This modular approach promises to more readily support different video formats and differing quality and cost considerations.
Vishal Misra

Vishal Misra, whose research emphasizes the use of mathematical modeling to examine complex network systems, received $75K to fund Bandwidth allocation strategies for multi data center networks, which investigates strategies for estimating the right amount of bandwidth for data centers. Here the goal is to provide enough bandwidth to meet demand, even at peak times, while avoiding expensive over-provisioning.
The problem is far from simple. Global data centers provide distributed cloud computing for a host of services, all having different bandwidth and priority requirements. Communication may take place between servers within the data center or with servers at different sites.
Current methods for estimating bandwidth requirements (such as Google’s BwE) roughly work by aggregating all inputs to a data center while performing bandwidth control and priority enforcement at the application level according to the principle of max-min fair allocation (where a process with a “small” demand gets what it needs, while unused resources are evenly distributed among processes with unmet requirements).
But is this the right criteria to use? Misra who has previously investigated congestion equilibrium theory will seek to answer this and other open questions revolving around current allocation methods while also investigating other approaches (for example, separating bandwidth allocation from the traffic engineering problem and studying each independently).
This is the second Google Research Award for Misra. His first in 2009 resulted in the paper Incentivizing peer- assisted services: A fluid shapley value.
– Linda Crane
Posted 2/24/2017
What Can You Do With the World’s Largest Family Tree?
The Atlantic cites research led by Yaniv Erlich in creating a genetic tree of 13M people for studying migration, life spans, and other patterns. The work, still under peer review, was posted to bioRxiv.
Do-Not-Call list doesn’t work anymore
AI’s Factions Get Feisty. But Really, They’re All on the Same Team
Ang Cui (PhD’15) and the security vulnerabilities of office equipment
Cui’s research, which examined security risks of printers and other overlooked office devices, is the subject of a Fast Company article. Cui with his advisor, Salvatore Stolfo, founded Red Balloon Security to protect such devices.
Code-Dependent: Pros and Cons of the Algorithm Age
Dingzeyu Li awarded Adobe Research Fellowship
![]()

Dingzeyu Li has been awarded an Adobe Research Fellowship, which recognizes outstanding graduate students doing exceptional research in areas of computer science important to Adobe.
A fourth-year PhD student advised by Changxi Zheng, Li was selected for his research in a relatively new area of computer graphics: simulating sound based on the physics of actions and motions occurring within an animation. Where sound for computer-generated animations has traditionally been created separately and then later combined and synchronized with the animation, Li is working to develop algorithms and tools that automatically generate sounds from the animation itself, thereby bridging the gap between simulation and fabrication.
Extending the concept into virtual reality environments, he is developing a real-time sound engine that responds to user interactions with realistic and synchronized 3D audio. The goal is to create more realistic virtual environments where the visible and audible components are natural extensions of one another, where changes or edits to one propagate automatically and naturally to the other. Provided with a virtual scene, the sound engine will compute the spatial sounds realistically and interactively as a user interacts with the environment.
Li’s research into simulated sound is also enabling new design tools for 3D printing. In a well-received paper from last year (one funded in part by Adobe), Li and his coauthors describe a computational approach for designing acoustic filters, or voxels, that fit within an arbitrary 3D shape. At a fundamental level, voxels demonstrate the connection between shape and sound; at a practical level, they allow for uniquely identifying 3D printed objects through each object’s acoustic properties
For this same work, which pushed the boundaries of 3D printing, Li was named a recipient of the Shapeways Fall 2016 EDU Grant Contest.
Besides computer graphics, the Adobe fellowships are being awarded to students in seven other fields: computer vision, human computer interaction, machine learning, visualization, audio, natural language processing, and programming languages. Fellows are selected based on their research (creative, impactful, important, and realistic in scope); their technical skills (ability to build complex computer programs); as well as personal skills (problem-solving ability, communication, leadership, organizational skills, ability to work in teams).
The Fellowship is for one year and includes a $10,000 award, an internship this summer at Adobe, and mentorship from an Adobe Research scientist for one year. Included also are a free year-long subscription and full access to software in Adobe’s Creative Cloud.
Li entered the PhD program at Columbia’s Computer Science Department in 2013 after graduating in the top 1% of his class at Hong Kong University of Science and Technology (HKUST), where he received a Bachelors of Engineering in Computer Engineering.
– Linda Crane
Posted: 2/8/2017
Julia Hirschberg elected to the National Academy of Engineering

![]()
Professor Julia Hirschberg has been elected to the National Academy of Engineering (NAE), one of the highest professional distinctions awarded to an engineer. Hirschberg was cited by the NAE for her “contributions to the use of prosody in text-to-speech and spoken dialogue systems, and to audio browsing and retrieval.” Her research in speech analysis uses machine learning to help experts identify deceptive speech, and even to assess sentiment and emotion across languages and cultures.
“I am thrilled to be elected to such an eminent group of researchers,” said Hirschberg, who is the Percy K. and Vida L.W. Hudson Professor of Computer Science and chair of the Computer Science Department, as well as a member of the Data Science Institute. “It is such a great honor.”
Hirschberg’s main area of research is computational linguistics, with a focus on prosody, or the relationship between intonation and discourse. Her current projects include research into emotional and deceptive speech, spoken dialogue systems, entrainment in dialogue, speech synthesis, text-to-speech synthesis in low-resource languages, and hedging behaviors.
“I was very pleased to learn of Julia’s election for her pioneering work at the intersection of linguistics and computer science,” Mary C. Boyce, Dean of Engineering and Morris A. and Alma Schapiro Professor, said. “She works in an area that is central to the way we communicate, understand, and analyze our world today and is uncovering new paths that make us safer and better connected. As chair of Computer Science, she has also led the department through a period of tremendous growth and exciting changes.”
Hirschberg, who joined Columbia Engineering in 2002 as a professor in the Department of Computer Science and has served as department chair since 2012, earned her PhD in computer and information science from the University of Pennsylvania. She worked at AT&T Bell Laboratories, where in the 1980s and 1990s she pioneered techniques in text analysis for prosody assignment in text-to-speech synthesis, developing corpus-based statistical models that incorporate syntactic and discourse information, models that are in general use today.
Hirschberg serves on numerous technical boards and editorial committees, including the IEEE Speech and Language Processing Technical Committee and the board of the Computing Research Association’s Committee on the Status of Women in Computing Research (CRA-W). Previously she served as editor-in-chief of Computational Linguistics and co-editor-in-chief of Speech Communication and was on the Executive Board of the Association for Computational Linguistics (ACL), the Executive Board of the North American ACL, the CRA Board of Directors, the AAAI Council, the Permanent Council of International Conference on Spoken Language Processing (ICSLP), and the board of the International Speech Communication Association (ISCA). She also is noted for her leadership in promoting diversity, both at AT&T Bell Laboratories and Columbia, and for broadening participation in computing.
Among her many honors, Hirschberg is a fellow of the IEEE (2017), the Association for Computing Machinery (2016), the Association for Computational Linguistics (2011), the International Speech Communication Association (2008), and the Association for the Advancement of Artificial Intelligence (1994); and she is a recipient of the IEEE James L. Flanagan Speech and Audio Processing Award (2011) and the ISCA Medal for Scientific Achievement (2011). In 2007, she received an Honorary Doctorate from the Royal Institute of Technology, Stockholm, and in 2014 was elected to the American Philosophical Society.
Hirschberg joins Dean Boyce and many other Columbia Engineering colleagues who are NAE members; most recently elected were Professors David Yao (Industrial Engineering and Operations Research) in 2015, Gordana Vunjak-Novakovic (Biomedical Engineering) in 2012, and Mihalis Yannakakis (Computer Science) in 2011.
On February 8, the NAE announced 84 new members and 22 foreign members, bringing its total U.S. membership to 2,281 and foreign members to 249. NAE membership honors those who have made outstanding contributions to engineering research, practice, or education, including significant contributions to the engineering literature, and to the pioneering of new and developing fields of technology, making major advancements in traditional fields of engineering, or developing/implementing innovative approaches to engineering education.
– Holly Evarts
Posted 2/7/2017
Steven Bellovin & coauthors call for new surveillance laws to reflect internet’s complexity
Paper published in Harvard Journal of Law & Technology shows how technology blurs line between metadata and private content, eroding protections codified in pre-internet communications.
Startup cofounded by Apoorv Agarwal (PhD’16) is featured in Forbes
Text IQ uses NLP and ML techniques to streamline document review process for attorneys. Already profitable, the company saved customers $3M in legal expenses just this year, not counting what was saved by averting problems.
Daniel Bauer joins department as lecturer, adding strength in NLP and AI
![]()

Daniel Bauer, who has been teaching Data Structures for the past four semesters, is joining the Computer Science Department where he will teach two courses a semester. Bauer is the third teaching-oriented faculty hired in the past two years as the department moves to meet the surging demand for computer science classes from majors and nonmajors alike.
“I feel especially lucky to be teaching at Columbia with its diverse student body where students are super curious and super excited to learn. I hope to help them discover new areas,” says Bauer.
In addition to the honors section of Data Structures and Algorithms (COMS W3137), Bauer is teaching Introduction to Computing for Engineers and Applied Scientists (ENGI E1006) this spring; next fall he is planning to teach Natural Language Processing (NLP), his particular research focus.
A sub-area of artificial intelligence, NLP is concerned with using computers to analyze written or spoken language. NLP researchers design systems that understand and generate natural language, extract information from text or speech, and automatically translate between languages. Demand for NLP is growing as user interfaces become more language-driven and as more and more free-form written and spoken data becomes available digitally.
The inherent ambiguity and nuance of human language pose challenges, however. Says Bauer, “The old Marx Brothers line ‘I shot an elephant in my pajamas’ allows for two interpretations, but human speakers know empirically that pajamas are worn by people, not elephants. This observation or knowledge has to be conveyed somehow to language processing systems.”
One way is to collect enough sample sentences and train machine learning models that predict that pajamas is more likely to be associated with people than with elephants. This machine learning approach works extremely well to disambiguate between multiple possible syntactic structures for a sentence. Bauer, whose research focus is in computational semantics, is looking beyond syntax and tries to train models that can infer the meaning of a sentence. “Large data sets of semantic annotations for sentences have only become available in the last few years and how to best train NLP tools on this data is an open problem. While syntactic representations traditionally use trees, semantic data sets that annotate predicate-argument structure use more general graphs, so the formal machinery we have been using for trees is no longer sufficient,” says Bauer, who developed grammar formalisms and models that can translate between text and graphs in his dissertation.
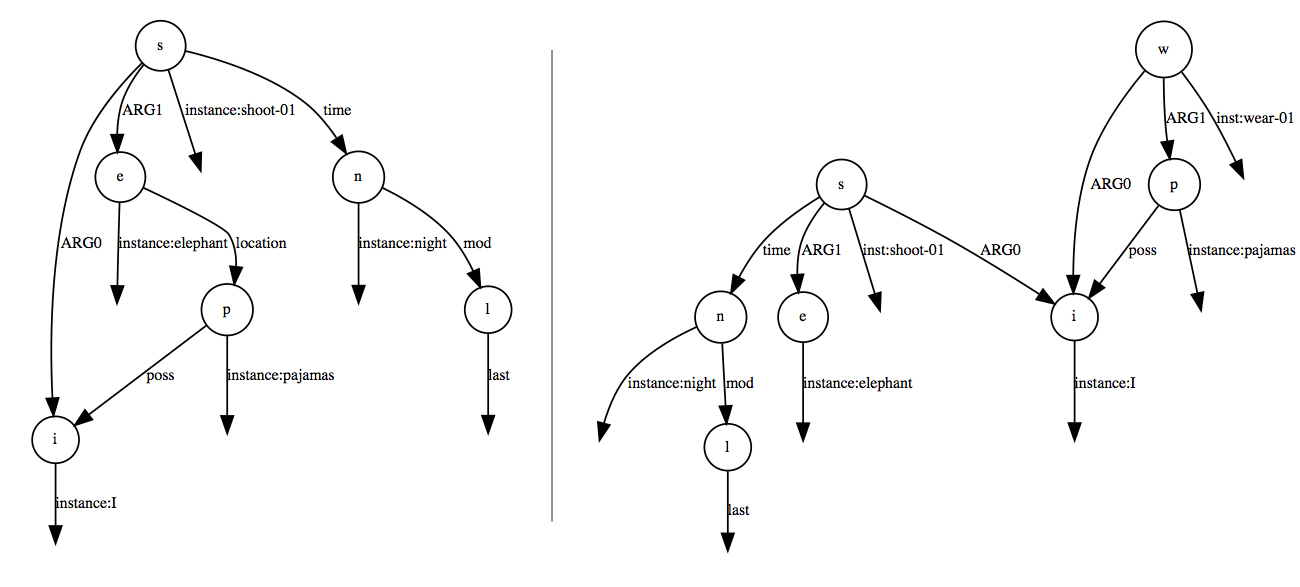
“Being able to recover the meaning of a sentence will help us build better systems for machine translation, search, text summarization, and information extraction, for example to detect emergent events, identify terror threats, or predict stock price developments.”
Bauer is also interested in incorporating outside and domain knowledge to understand a sentence in the context in which it was uttered. “In a dialog, we use language to refer to objects in our environment and events going on around us. Language processing systems, especially conversational agents, should be able to communicate using language that is grounded in this environment or in other modalities,” says Bauer.
One area of interest is trying to understand the meaning of natural language descriptions as they relate to spatial relationships of objects. As a cofounder of WordsEye, which automatically translates text into 3D scenes, Bauer is interested in extending semantic analyses to the world of objects and their properties. While WordsEye starts with a set of rules defining placement of objects according to user input text (what does “on” mean in a 3D scene?), Bauer wants to combine these rules with more machine–learning focused language processing. “Can we take the corpus of existing WordsEye scenes and automatically extract the text-to-scene generation system from that? Rather than manually engineering these rules, can we learn from how people use and place things in context?” It’s a future research subject he hopes to explore.
In his research, Bauer has always involved undergraduate and master’s students and will continue to do so as he assumes more teaching responsibility, which brings its own challenges.
“When I started out teaching programming classes, I enjoyed seeing the different expectations students bring to the classroom, but it also forces you to think hard about structuring a class that provides something to all these different students with many different backgrounds and different interests.”
This thoughtful approach to both research and educating others is an obvious asset to the department. Says Julia Hirschberg, chair of the Computer Science Department, “We are delighted that Daniel will be joining the CS faculty. Daniel has been an excellent teacher for us already as a graduate student preceptor, and we are extremely lucky to have been able to persuade him to stay on. The combination he brings of teaching expertise in the introductory classes and of deep knowledge of NLP will allow us to increase our teaching capacity in both areas.”
![]()
Bauer received an MSc in Language Science and Technology from Saarland University and a BSc in Cognitive Science from the University of Osnabrück, Germany.
This spring he will receive his PhD in Computer Science from Columbia University.
![]()
Posted 2/3/2017
– Linda Crane Photo credit: Tim Lee
Dragomir Radev joins the Yale Computer Science faculty
He received his PhD in 1999 under the supervision of Kathy McKeown. At Yale he will teach courses in Natural Language Processing and Artificial Intelligence and will lead the Language, Information, and Learning Lab.