|
Right time, right place: A collaborative approach for more accurate context-awareness in mobile apps and ads
The right information delivered at the right time can make apps and ads more appealing and relevant to customers: a traffic app that auto-updates for the work or home commute as appropriate; a restaurant that offers lunch coupons for people who work in the area but dinner coupons for people who live nearby. This level of customization requires taking into account a user's immediate context, something that is not easy to do. It requires both location data and a temporal framework that gives meaning to each location, identifying it as home, work, commute, or another place frequented by a user. But location data is often surprisingly sparse for any one user. To overcome sparsity and construct reliable weekly routines for individual users, researchers integrated global temporal patterns inferred from the entire data set with user-specific spatiotemporal data. The resulting method is entirely data-driven—requiring no labeling—and flexible to accommodate variations in a user's weekly schedule.
The location data needed for context-aware ads and apps is surprisingly sparse for any single user. For privacy and to conserve energy, most smart phone apps log users' locations only when the app is active. The result is that location data sets collected from apps comprise many users but few observations per user. This sparsity makes it difficult to know how a particular GPS position is relevant to a user, whether it represents a work place, home, a point along the morning or evening commute, or some other frequently visited destination. It's this contextual information that allows companies to customize their apps and ads for their customers' immediate or near-future locations. Local businesses especially benefit when they can accurately predict who is or will soon be in their area.
(It's not just companies that want context-aware apps and ads; there is evidence users do, too. Cisco found that half of customers surveyed would use coupons sent from a nearby store.)
Location data for any single user may be too sparse to understand when a user transitions between places, but the collection of data across all users represents much more information that can help illuminate broader patterns. To exploit this collective information, four researchers—Berk Kapicioglu, David S. Rosenberg, Robert Schapire, and Tony Jebara—developed a data-driven method that learns people's important places based on global temporal patterns inferred from the entire data set. They described this method in the paper Collaborative Place Models presented in July at the International Joint Conference on Artificial Intelligence.
Collaborative place models differ from previous methods that first label locations according to time of day and day of week. By assuming, for example, a 9-to-5 workday Monday through Friday, methods that rely on labeling might average positions between 8am and 6pm and call that home while averaging positions between 9 and 5 and calling that work. It's an intuitive approach but it lacks flexibility—not everyone has the same schedule—and it ignores the commute, which can be a significant amount of time for some people and a missed opportunity for those businesses located along the commute.
Rather than imposing a static temporal framework, collaborative place models learn the quantitative relationship between week-hours by inferring similarities across all users, relying on Bayesian estimation techniques to do so. With a global temporal framework thus set, the relevance of the sparser latitude-longitude GPS coordinates from individual users can then be determined from how they fit into the global temporal pattern. In this way, the model re-constructs a particular user's home-work-commuting schedule even though a user might have been observed only at Thursday 3pm and Monday 1pm.
To prove the concept, the researchers tested the model using two real-world data sets, a sparse one collected from a mobile ad exchange, and a dense data set from a cellular carrier. In both cases, the only inputs were user IDs, latitudes, longitudes, and time stamps. (Data was anonymized by removing all personal information.)
With data aggregated across all users, a strong, global temporal pattern emerged fairly quickly, one that contained within it several temporal clusters correlated with work, morning and evening commutes, leisure times after work, and sleeping at night. With the global pattern thus established, the individual spatiotemporal patterns of individual users became apparent even with few data points associated with each user.
The spatial extent of place types associated with temporal clusters were determined by replacing multiple observations logged during the same hour with their geometric median (computed using Weiszfeld's algorithm and by clustering nearby points using a Gaussian mixture model that is a subcomponent of the collaborative place model). This contrasts with the use of averaging in other place models to handle redundant observations and the noise that occurs from GPS errors and from having multiple cell towers covering the same location; by not averaging, the collaborative place model avoids the strange results sometimes caused by deviations in the regular routine, such as a late work evening or a night or weekend away from home.
Flexibility was built into the model by allowing users to have varying numbers of places or week hours. This flexibility turned out to be key; an early, simpler prototype that constrained users to have the same week-hour distribution performed worse than a baseline model.
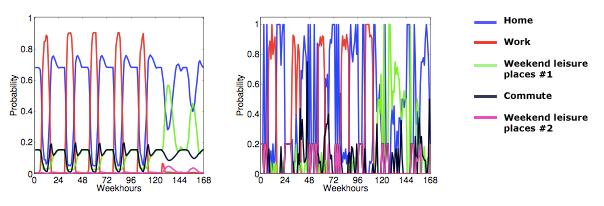
The strong, well-defined pattern on the left results from combining global weekly patterns with spatiotemporal data of an individual user arbitrarily chosen from the dense dataset. The right distribution (for the same user) represents a previous baseline model that did not infer global patterns and so as not able to correctly identify important places.
In the end, data by itself was enough to reliably assess a user's spatiotemporal schedule. Without the need to label or average location places, the collaborative approach of combining global patterns with sparse user location data reduced the median distance error by 8% from a simpler non-collaborative baseline model.
-Linda Crane
Posted 12/1/2015
|
About the researchers

Tony Jebara
Tony Jebara is Associate Professor of Computer Science at Columbia University where he directs the Columbia Machine Learning Laboratory. His research intersects computer science and statistics to develop new frameworks for learning from data with applications in vision, networks, spatiotemporal data, and text. Jebara has founded and advised several startups including Sense Networks (acquired by YP in 2014), Agolo, Ninoh and Bookt. He has published over 100 peer-reviewed papers in conferences, workshops, and journals and is the author of Machine Learning: Discriminative and Generative and co-inventor on multiple patents in vision, learning and spatiotemporal modeling. He is the recipient of the Career award from the National Science Foundation (NSF) and has received honors from the International Conference on Machine Learning and from the Pattern Recognition Society. Jebara's research has been featured on television (ABC, BBC, New York One, TechTV, etc.) as well as in the popular press (New York Times, Slash Dot, Wired, Businessweek, IEEE Spectrum, etc.). He obtained his PhD in 2002 from MIT.

Berk Kapicioglu
Berk Kapicioglu is a data scientist at Foursquare and was previously at Sense Networks, a location analytics firm where he worked on location prediction, place modeling, venue recommendation, and real-time ad targeting. He obtained his PhD and MA degrees in computer science department at Princeton University. His thesis focused on the design and analysis of machine learning algorithms for spatiotemporal datasets, and he was advised by Robert Schapire. His undergraduate degree is from the University of Pennsylvania, where he triple-majored in computer science, math, and philosophy.

David S. Rosenberg
David S. Rosenberg is a data scientist within the CTO Office at Bloomberg LP. Previously he was Chief Scientist at both YP Mobile Labs and at Sense Networks. Rosenberg specializes in machine learning, artificial intelligence, predictive analytics and statistical modeling, and earned his Bachelor of Science degree in mathematics from Yale University, his Master of Science degree in applied math (computer science focus) from Harvard University, and his PhD in statistics from the University of California, Berkeley. He holds four US patents.

Robert Schapire
Robert Schapire is a Principal Researcher at Microsoft Research in New York City. He received his PhD from MIT in 1991. After a short post-doc at Harvard, he joined the technical staff at AT&T Labs (formerly AT&T Bell Laboratories) in 1991. In 2002, he became a Professor of Computer Science at Princeton University and joined Microsoft Research in 2014. His awards include the 1991 ACM Doctoral Dissertation Award, the 2003 Gödel Prize, and the 2004 Kanelakkis Theory and Practice Award (both of the last two with Yoav Freund). He is a fellow of the AAAI, and a member of the National Academy of Engineering. His main research interest is in theoretical and applied machine learning, with particular focus on boosting, online learning, game theory, and maximum entropy.
|