CS researchers presented their work at the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024), showcasing research across natural language processing. Held from November 12-16 in Miami, this event includes diverse sessions covering topics from core NLP advancements to innovative applications. The accepted papers promise insights into cutting-edge techniques, inviting academics, practitioners, and enthusiasts to explore the latest in language processing research.
STORYSUMM: Evaluating Faithfulness in Story Summarization Melanie Subbiah Columbia University, Faisal Ladhak Answer.AI, Akankshya Mishra Columbia University, Griffin Thomas Adams Answer.AI, Lydia Chilton Columbia University, Kathleen McKeown Columbia University
Abstract: Human evaluation has been the gold standard for checking faithfulness in abstractive summarization. However, with a challenging source domain like narrative, multiple annotators can agree a summary is faithful, while missing details that are obvious errors only once pointed out. We therefore introduce a new dataset, StorySumm, comprising LLM summaries of short stories with localized faithfulness labels and error explanations. This benchmark is for evaluation methods, testing whether a given method can detect challenging inconsistencies. Using this dataset, we first show that any one human annotation protocol is likely to miss inconsistencies, and we advocate for pursuing a range of methods when establishing ground truth for a summarization dataset. We finally test recent automatic metrics and find that none of them achieve more than 70% balanced accuracy on this task, demonstrating that it is a challenging benchmark for future work in faithfulness evaluation.
Abstract: In the field of emotion analysis, much NLP research focuses on identifying a limited number of discrete emotion categories, often applied across languages. These basic sets, however, are rarely designed with textual data in mind, and culture, language, and dialect can influence how particular emotions are interpreted. In this work, we broaden our scope to a practically unbounded set of affective states, which includes any terms that humans use to describe their experiences of feeling. We collect and publish MASIVE, a dataset of Reddit posts in English and Spanish containing over 1,000 unique affective states each. We then define the new problem of affective state identification for language generation models framed as a masked span prediction task. On this task, we find that smaller finetuned multilingual models outperform much larger LLMs, even on region-specific Spanish affective states. Additionally, we show that pretraining on MASIVE improves model performance on existing emotion benchmarks. Finally, through machine translation experiments, we find that native speaker-written data is vital to good performance on this task.
Abstract: While recent advances in Text-to-Speech (TTS) technology produce natural and expressive speech, they lack the option for users to select emotion and control intensity. We propose EmoKnob, a framework that allows fine-grained emotion control in speech synthesis with few-shot demonstrative samples of arbitrary emotion. Our framework leverages the expressive speaker representation space made possible by recent advances in foundation voice cloning models. Based on the few-shot capability of our emotion control framework, we propose two methods to apply emotion control on emotions described by open-ended text, enabling an intuitive interface for controlling a diverse array of nuanced emotions. To facilitate a more systematic emotional speech synthesis field, we introduce a set of evaluation metrics designed to rigorously assess the faithfulness and recognizability of emotion control frameworks. Through objective and subjective evaluations, we show that our emotion control framework effectively embeds emotions into speech and surpasses emotion expressiveness of commercial TTS services.
Abstract: Machine Reading Comprehension (MRC) poses a significant challenge in the field of Natural Language Processing (NLP). While mainstream MRC methods predominantly leverage extractive strategies using encoder-only models such as BERT, generative approaches face the issue of out-of-control generation – a critical problem where answers generated are often incorrect, irrelevant, or unfaithful to the source text. To address these limitations in generative models for extractive MRC, we introduce the Question-Attended Span Extraction (QASE) module. Integrated during the finetuning phase of pre-trained generative language models (PLMs), QASE significantly enhances their performance, allowing them to surpass the extractive capabilities of advanced Large Language Models (LLMs) such as GPT-4 in few-shot settings. Notably, these gains in performance do not come with an increase in computational demands. The efficacy of the QASE module has been rigorously tested across various datasets, consistently achieving or even surpassing state-of-the-art (SOTA) results, thereby bridging the gap between generative and extractive models in extractive MRC tasks. Our code is available at this GitHub repository.
Defending Against Social Engineering Attacks in the Age of LLMs Lin Ai Columbia University, Tharindu Sandaruwan Kumarage Arizona State University, Amrita Bhattacharjee Arizona State University, Zizhou Liu Columbia University, Zheng Hui Columbia University, Michael S. Davinroy Aptima, Inc., James Cook Aptima, Inc., Laura Cassani Aptima, Inc., Kirill Trapeznikov STR, Matthias Kirchner Kitware, Inc., Arslan Basharat Kirchner Kitware, Inc., Anthony Hoogs Kirchner Kitware, Inc., Joshua Garland Arizona State University, Huan Liu Arizona State University, Julia Hirschberg Columbia University
Abstract: The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrievalaugmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity. Our code and data are available at this GitHub repository.
Abstract: Alignment is a crucial step to enhance the instruction-following and conversational abilities of language models. Despite many recent works proposing new algorithms, datasets, and training pipelines, there is a lack of comprehensive studies measuring the impact of various design choices throughout the whole training process. We first conduct a rigorous analysis over a three-stage training pipeline consisting of supervised fine-tuning, offline preference learning, and online preference learning. We have found that using techniques like sequence packing, loss masking in SFT, increasing the preference dataset size in DPO, and online DPO training can significantly improve the performance of language models. We then train from Gemma-2b-base and LLama-3-8b-base, and find that our best models exceed the performance of the official instruct models tuned with closed-source data and algorithms. Our code and models can be found at https://github.com/Columbia-NLP-Lab/LionAlignment.
Abstract: Coherence in writing, an aspect that L2 English learners often struggle with, is crucial in assessing L2 English writing. Existing automated writing evaluation systems primarily use basic surface linguistic features to detect coherence in writing. However, little effort has been made to correct the detected incoherence, which could significantly benefit L2 language learners seeking to improve their writing. To bridge this gap, we introduce DECOR, a novel benchmark that includes expert annotations for detecting incoherence in L2 English writing, identifying the underlying reasons, and rewriting the incoherent sentences. To our knowledge, DECOR is the first coherence assessment dataset specifically designed for improving L2 English writing, featuring pairs of original incoherent sentences alongside their expert-rewritten counterparts. Additionally, we fine-tuned models to automatically detect and rewrite incoherence in student essays. We find that incorporating specific reasons for incoherence during fine-tuning consistently improves the quality of the rewrites, achieving a level that is favored in both automatic and human evaluations.
ACE: A LLM-based Negotiation Coaching System Ryan Shea Columbia University, Aymen Kallala Columbia University, Xin Lucy Liu Columbia University, Michael W. Morris Columbia University, Zhou Yu Columbia University
Abstract: The growing prominence of LLMs has led to an increase in the development of AI tutoring systems. These systems are crucial in providing underrepresented populations with improved access to valuable education. One important area of education that is unavailable to many learners is strategic bargaining related to negotiation. To address this, we develop a LLM-based Assistant for Coaching nEgotiation (ACE). ACE not only serves as a negotiation partner for users but also provides them with targeted feedback for improvement. To build our system, we collect a dataset of negotiation transcripts between MBA students. These transcripts come from trained negotiators and emulate realistic bargaining scenarios. We use the dataset, along with expert consultations, to design an annotation scheme for detecting negotiation mistakes. ACE employs this scheme to identify mistakes and provide targeted feedback to users. To test the effectiveness of ACE-generated feedback, we conducted a user experiment with two consecutive trials of negotiation and found that it improves negotiation performances significantly compared to a system that doesn’t provide feedback and one which uses an alternative method of providing feedback.
Abstract: Dialogue systems have been used as conversation partners in English learning, but few have studied whether these systems improve learning outcomes. Student passion and perseverance, or grit, has been associated with language learning success. Recent work establishes that as students perceive their English teachers to be more supportive, their grit improves. Hypothesizing that the same pattern applies to English-teaching chatbots, we create EDEN, a robust open-domain chatbot for spoken conversation practice that provides empathetic feedback. To construct EDEN, we first train a specialized spoken utterance grammar correction model and a high-quality social chit-chat conversation model. We then conduct a preliminary user study with a variety of strategies for empathetic feedback. Our experiment suggests that using adaptive empathetic feedback leads to higher *perceived affective support*. Furthermore, elements of perceived affective support positively correlate with student grit.
Abstract: Despite recent advancements in AI and NLP, negotiation remains a difficult domain for AI agents. Traditional game theoretic approaches that have worked well for two-player zero-sum games struggle in the context of negotiation due to their inability to learn human-compatible strategies. On the other hand, approaches that only use human data tend to be domain-specific and lack the theoretical guarantees provided by strategies grounded in game theory. Motivated by the notion of fairness as a criterion for optimality in general sum games, we propose a negotiation framework called FDHC which incorporates fairness into both the reward design and search to learn human-compatible negotiation strategies. Our method includes a novel, RL+search technique called LGM-Zero which leverages a pre-trained language model to retrieve human-compatible offers from large action spaces. Our results show that our method is able to achieve more egalitarian negotiation outcomes and improve negotiation quality.
Abstract The goal of text style transfer is to transform the style of texts while preserving their original meaning, often with only a few examples of the target style. Existing style transfer methods generally rely on the few-shot capabilities of large language models or on complex controllable text generation approaches that are inefficient and underperform on fluency metrics. We introduce TinyStyler, a lightweight but effective approach, which leverages a small language model (800M params) and pre-trained authorship embeddings to perform efficient, few-shot text style transfer. We evaluate on the challenging task of authorship style transfer and find TinyStyler outperforms strong approaches such as GPT-4. We also evaluate TinyStyler’s ability to perform text attribute style transfer (formal ↔ informal) with automatic and human evaluations and find that the approach outperforms recent controllable text generation methods.
Papers from CS researchers were accepted to the Empirical Methods in Natural Language Processing (EMNLP) 2022. EMNLP is a leading conference in artificial intelligence and natural language processing. Aside from presenting their research papers, several researchers also organized workshops to gather conference attendees for discussions about current issues confronting NLP and computer science.
Workshops
Massively Multilingual Natural Language Understanding Jack FitzGerald Amazon Alexa, Kay Rottmann Amazon Alexa, Julia Hirschberg Columbia University, Mohit Bansal University of North Carolina, Anna Rumshisky University of Massachusetts Lowell, and Charith Peris Amazon Alexa
3rd Workshop on Figurative Language Processing Debanjan Ghosh Educational Testing Service, Beata Beigman Klebanov Educational Testing Service, Smaranda Muresan Columbia University, Anna Feldman Montclair State University, Soujanya Poria Singapore University of Technology and Design, and Tuhin Chakrabarty Columbia University
Sharing Stories and Lessons Learned Diyi Yang Stanford University, Pradeep Dasigi Allen Institute for AI, Sherry Tongshuang Wu Carnegie Mellon University, Tuhin Chakrabarty Columbia University, Yuval Pinter Ben-Gurion University of the Negev, and Mike Zheng Shou National University of Singapore
Abstract Recent work in training large language models (LLMs) to follow natural language instructions has opened up exciting opportunities for natural language interface design. Building on the prior success of large language models in the realm of computer assisted creativity, in this work, we present CoPoet, a collaborative poetry writing system, with the goal of to study if LLM’s actually improve the quality of the generated content. In contrast to auto-completing a user’s text, CoPoet is controlled by user instructions that specify the attributes of the desired text, such as Write a sentence about ‘love’ or Write a sentence ending in ‘fly’. The core component of our system is a language model fine-tuned on a diverse collection of instructions for poetry writing. Our model is not only competitive to publicly available LLMs trained on instructions (InstructGPT), but also capable of satisfying unseen compositional instructions. A study with 15 qualified crowdworkers shows that users successfully write poems with CoPoet on diverse topics ranging from Monarchy to Climate change, which are preferred by third-party evaluators over poems written without the system.
Abstract Figurative language understanding has been recently framed as a recognizing textual entailment (RTE) task (a.k.a. natural language inference (NLI)). However, similar to classical RTE/NLI datasets they suffer from spurious correlations and annotation artifacts. To tackle this problem, work on NLI has built explanation-based datasets such as eSNLI, allowing us to probe whether language models are right for the right reasons. Yet no such data exists for figurative language, making it harder to assess genuine understanding of such expressions. To address this issue, we release FLUTE, a dataset of 9,000 figurative NLI instances with explanations, spanning four categories: Sarcasm, Simile, Metaphor, and Idioms. We collect the data through a Human-AI collaboration framework based on GPT-3, crowd workers, and expert annotators. We show how utilizing GPT-3 in conjunction with human annotators (novices and experts) can aid in scaling up the creation of datasets even for such complex linguistic phenomena as figurative language. The baseline performance of the T5 model fine-tuned on FLUTE shows that our dataset can bring us a step closer to developing models that understand figurative language through textual explanations.
Abstract Recent work on large language models relies on the intuition that most natural language processing tasks can be described via natural language instructions and that models trained on these instructions show strong zero-shot performance on several standard datasets. However, these models even though impressive still perform poorly on a wide range of tasks outside of their respective training and evaluation sets.To address this limitation, we argue that a model should be able to keep extending its knowledge and abilities, without forgetting previous skills. In spite of the limited success of Continual Learning, we show that Fine-tuned Language Models can be continual learners.We empirically investigate the reason for this success and conclude that Continual Learning emerges from self-supervision pre-training. Our resulting model Continual-T0 (CT0) is able to learn 8 new diverse language generation tasks, while still maintaining good performance on previous tasks, spanning in total of 70 datasets. Finally, we show that CT0 is able to combine instructions in ways it was never trained for, demonstrating some level of instruction compositionality.
Abstract Fallacies are used as seemingly valid arguments to support a position and persuade the audience about its validity. Recognizing fallacies is an intrinsically difficult task both for humans and machines. Moreover, a big challenge for computational models lies in the fact that fallacies are formulated differently across the datasets with differences in the input format (e.g., question-answer pair, sentence with fallacy fragment), genre (e.g., social media, dialogue, news), as well as types and number of fallacies (from 5 to 18 types per dataset). To move towards solving the fallacy recognition task, we approach these differences across datasets as multiple tasks and show how instruction-based prompting in a multitask setup based on the T5 model improves the results against approaches built for a specific dataset such as T5, BERT or GPT-3. We show the ability of this multitask prompting approach to recognize 28 unique fallacies across domains and genres and study the effect of model size and prompt choice by analyzing the per-class (i.e., fallacy type) results. Finally, we analyze the effect of annotation quality on model performance, and the feasibility of complementing this approach with external knowledge.
Abstract Recent work on question generation has largely focused on factoid questions such as who, what, where, when about basic facts. Generating open-ended why, how, what, etc. questions that require long-form answers have proven more difficult. To facilitate the generation of open-ended questions, we propose CONSISTENT, a new end-to-end system for generating open-ended questions that are answerable from and faithful to the input text. Using news articles as a trustworthy foundation for experimentation, we demonstrate our model’s strength over several baselines using both automatic and human=based evaluations. We contribute an evaluation dataset of expert-generated open-ended questions.We discuss potential downstream applications for news media organizations.
SafeText: A Benchmark for Exploring Physical Safety in Language Models Sharon Levy University of California, Santa Barbara, Emily Allaway Columbia University, Melanie Subbiah Columbia University, Lydia Chilton Columbia University, Desmond Patton Columbia University, Kathleen McKeown Columbia University, and William Yang Wang University of California, Santa Barbara
Abstract Understanding what constitutes safe text is an important issue in natural language processing and can often prevent the deployment of models deemed harmful and unsafe. One such type of safety that has been scarcely studied is commonsense physical safety, i.e. text that is not explicitly violent and requires additional commonsense knowledge to comprehend that it leads to physical harm. We create the first benchmark dataset, SafeText, comprising real-life scenarios with paired safe and physically unsafe pieces of advice. We utilize SafeText to empirically study commonsense physical safety across various models designed for text generation and commonsense reasoning tasks. We find that state-of-the-art large language models are susceptible to the generation of unsafe text and have difficulty rejecting unsafe advice. As a result, we argue for further studies of safety and the assessment of commonsense physical safety in models before release.
Learning to Revise References for Faithful Summarization Griffin Adams Columbia University, Han-Chin Shing Amazon AWS AI, Qing Sun Amazon AWS AI, Christopher Winestock Amazon AWS AI, Kathleen McKeown Columbia University, and Noémie Elhadad Columbia University
Abstract In real-world scenarios with naturally occurring datasets, reference summaries are noisy and may contain information that cannot be inferred from the source text. On large news corpora, removing low quality samples has been shown to reduce model hallucinations. Yet, for smaller, and/or noisier corpora, filtering is detrimental to performance. To improve reference quality while retaining all data, we propose a new approach: to selectively re-write unsupported reference sentences to better reflect source data. We automatically generate a synthetic dataset of positive and negative revisions by corrupting supported sentences and learn to revise reference sentences with contrastive learning. The intensity of revisions is treated as a controllable attribute so that, at inference, diverse candidates can be over-generated-then-rescored to balance faithfulness and abstraction. To test our methods, we extract noisy references from publicly available MIMIC-III discharge summaries for the task of hospital-course summarization, and vary the data on which models are trained. According to metrics and human evaluation, models trained on revised clinical references are much more faithful, informative, and fluent than models trained on original or filtered data.
Mitigating Covertly Unsafe Text within Natural Language Systems Alex Mei University of California, Santa Barbara, Anisha Kabir University of California, Santa Barbara, Sharon Levy University of California, Santa Barbara, Melanie Subbiah Columbia University, Emily Allaway Columbia University, John N. Judge University of California, Santa Barbara, Desmond Patton University of Pennsylvania, Bruce Bimber University of California, Santa Barbara, Kathleen McKeown Columbia University, and William Yang Wang University of California, Santa Barbara
Abstract An increasingly prevalent problem for intelligent technologies is text safety, as uncontrolled systems may generate recommendations to their users that lead to injury or life-threatening consequences. However, the degree of explicitness of a generated statement that can cause physical harm varies. In this paper, we distinguish types of text that can lead to physical harm and establish one particularly underexplored category: covertly unsafe text. Then, we further break down this category with respect to the system’s information and discuss solutions to mitigate the generation of text in each of these subcategories. Ultimately, our work defines the problem of covertly unsafe language that causes physical harm and argues that this subtle yet dangerous issue needs to be prioritized by stakeholders and regulators. We highlight mitigation strategies to inspire future researchers to tackle this challenging problem and help improve safety within smart systems.
Affective Idiosyncratic Responses to Music Sky CH-Wang Columbia University, Evan Li Columbia University, Oliver Li Columbia University, Smaranda Muresan Columbia University, and Zhou Yu Columbia University
Abstract Affective responses to music are highly personal. Despite consensus that idiosyncratic factors play a key role in regulating how listeners emotionally respond to music, precisely measuring the marginal effects of these variables has proved challenging. To address this gap, we develop computational methods to measure affective responses to music from over 403M listener comments on a Chinese social music platform. Building on studies from music psychology in systematic and quasi-causal analyses, we test for musical, lyrical, contextual, demographic, and mental health effects that drive listener affective responses. Finally, motivated by the social phenomenon known as 网抑云 (wǎng-yì-yún), we identify influencing factors of platform user self-disclosures, the social support they receive, and notable differences in discloser user activity.
Abstract Dialog systems are often designed or trained to output human-like responses. However, some responses may be impossible for a machine to truthfully say (e.g. “that movie made me cry”). Highly anthropomorphic responses might make users uncomfortable or implicitly deceive them into thinking they are interacting with a human. We collect human ratings on the feasibility of approximately 900 two-turn dialogs sampled from 9 diverse data sources. Ratings are for two hypothetical machine embodiments: a futuristic humanoid robot and a digital assistant. We find that for some data-sources commonly used to train dialog systems, 20-30% of utterances are not viewed as possible for a machine. Rating is marginally affected by machine embodiment. We explore qualitative and quantitative reasons for these ratings. Finally, we build classifiers and explore how modeling configuration might affect output permissibly, and discuss implications for building less falsely anthropomorphic dialog systems.
Abstract Protecting large language models from privacy leakage is becoming increasingly crucial with their wide adoption in real-world products. Yet applying *differential privacy* (DP), a canonical notion with provable privacy guarantees for machine learning models, to those models remains challenging due to the trade-off between model utility and privacy loss. Utilizing the fact that sensitive information in language data tends to be sparse, Shi et al. (2021) formalized a DP notion extension called *Selective Differential Privacy* (SDP) to protect only the sensitive tokens defined by a policy function. However, their algorithm only works for RNN-based models. In this paper, we develop a novel framework, *Just Fine-tune Twice* (JFT), that achieves SDP for state-of-the-art large transformer-based models. Our method is easy to implement: it first fine-tunes the model with *redacted* in-domain data, and then fine-tunes it again with the *original* in-domain data using a private training mechanism. Furthermore, we study the scenario of imperfect implementation of policy functions that misses sensitive tokens and develop systematic methods to handle it. Experiments show that our method achieves strong utility compared to previous baselines. We also analyze the SDP privacy guarantee empirically with the canary insertion attack.
Abstract News Image Captioning requires describing an image by leveraging additional context from a news article. Previous works only coarsely leverage the article to extract the necessary context, which makes it challenging for models to identify relevant events and named entities. In our paper, we first demonstrate that by combining more fine-grained context that captures the key named entities (obtained via an oracle) and the global context that summarizes the news, we can dramatically improve the model’s ability to generate accurate news captions. This begs the question, how to automatically extract such key entities from an image? We propose to use the pre-trained vision and language retrieval model CLIP to localize the visually grounded entities in the news article and then capture the non-visual entities via an open relation extraction model. Our experiments demonstrate that by simply selecting a better context from the article, we can significantly improve the performance of existing models and achieve new state-of-the-art performance on multiple benchmarks.
Columbia researchers presented their work at the Empirical Methods in Natural Language Processing (EMNLP) in Brussels, Belgium.
Professor Julia Hirschberg gave a keynote talk on the work done by the Spoken Language Processing Group on how to automatically detect deception in spoken language – how to identify cues in trusted speech vs. mistrusted speech and how these features differ by speaker and by listener. Slides from the talk can be viewed here.
Five teams with computer science undergrad and PhD students from the Natural Language Processing Group (NLP) also attended the conference to showcase their work on text summarization, analysis of social media, and fact checking.
”Given the difficult times, we are living in, it’s extremely necessary to be perfect with our facts,” said Tuhin Chakrabarty, lead researcher of the paper. “Misinformation spreads like wildfire and has long-lasting impacts. This motivated us to delve into the area of fact extraction and verification.”
This paper presents the ColumbiaNLP
submission for the FEVER Workshop Shared Task. Their system is an end-to-end pipeline that
extracts factual evidence from Wikipedia and infers a decision about the
truthfulness of the claim based on the extracted evidence.
Fact checking is a type
of investigative journalism where experts examine the claims published by
others for their veracity. The claims can range from statements made by public
figures to stories reported by other publishers. The end goal of a fact
checking system is to provide a verdict on whether the claim is true, false, or
mixed. Several organizations such as FactCheck.org and PolitiFact are devoted
to such activities.
The FEVER Shared task aims to evaluate the ability of a system to verify information using evidence from Wikipedia. Given a claim involving one or more entities (mapping to Wikipedia pages), the system must extract textual evidence (sets of sentences from Wikipedia pages) that supports or refutes the claim and then using this evidence, it must label the claim as Supported, Refuted or NotEnoughInfo.
Detecting Gang-Involved Escalation on Social Media Using Context Serina Chang Computer Science Department, Ruiqi Zhong Computer Science Department, Ethan Adams Computer Science Department, Fei-Tzin Lee Computer Science Department, Siddharth Varia Computer Science Department, Desmond Patton School of Social Work, William Frey School of Social Work, Chris Kedzie Computer Science Department, and Kathleen McKeown Computer Science Department
This research is a
collaboration between Professor Kathy McKeown’s NLP lab and the
Columbia School of Social Work. Professor Desmond Patton, from the School of Social Work and a member of the Data
Science Institute, discovered that gang-involved youth in cities such as
Chicago increasingly turn to social media to grieve the loss of loved ones,
which may escalate into aggression toward rival gangs and plans for violence.
The team created a machine
learning system that can automatically detect aggression and loss in the social
media posts of gang-involved youth. They developed an approach with the hope to
eventually use a system that can save critical time, scale reach, and intervene
before more young lives are lost.
The
system features the use of word embeddings and lexicons, automatically derived
from a large domain-specific corpus which the team constructed. They also
created context features that capture user’s recent posts, both in semantic and
emotional content, and their interactions with other users in the dataset.
Incorporating domain-specific resources and context feature in a Convolutional
Neural Network (CNN) that leads to a significant improvement over the prior
state-of-the-art.
The dataset used spans the public Twitter posts of nearly 300 users from a gang-involved community in Chicago. Youth volunteers and violence prevention organizations helped identify users and annotate the dataset for aggression and loss. Here are two examples of labeled tweets, both of which the system was able to classify correctly. Names are blocked out to preserve the privacy of users.
Tweet examples
For semantics, which were represented by word embeddings, the researchers found that it was optimal to include 90 days of recent tweet history. While for emotion, where an emotion lexicon was employed, only two days of recent tweets were needed. This matched insight from prior social work research, which found that loss is significantly likely to precede aggression in a two-day window. They also found that emotions fluctuate more quickly than semantics so the tighter context window would be able to capture more fine-grained fluctuation.
“We took this context-driven approach because we believed that interpreting emotion in a given tweet requires context, including what the users had been saying recently, how they had been feeling, and their social dynamics with others,” said Serina Chang, an undergraduate computer science student. One thing that surprised them was the extent to which different types of context offered different types of information, as demonstrated by the contrasting contributions of the semantic-based user history feature and the emotion-based one. Continued Chang, “As we hypothesized, adding context did result in a significant performance improvement in our neural net model.”
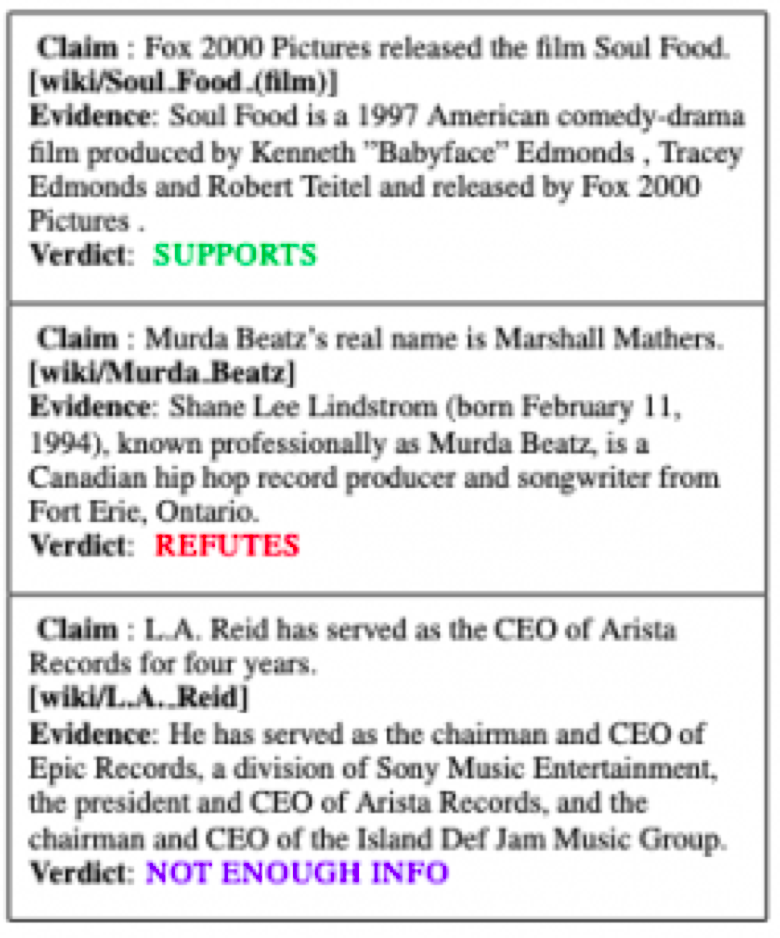
Automated fact checking of textual claims is of increasing interest in today’s world. Previous research has investigated fact checking in political statements, news articles, and community forums.
“Through our model we can fact check claims
and find specific statements that support the evidence,” said Christopher Hidey,
a fourth year PhD student. “This is a step towards addressing the
propagation of misinformation online.”
As part of the FEVER community
shared task, the researchers developed models that given a statement would jointly find a Wikipedia article and a sentence related
to the statement, and then predict whether the statement is supported by that sentence.
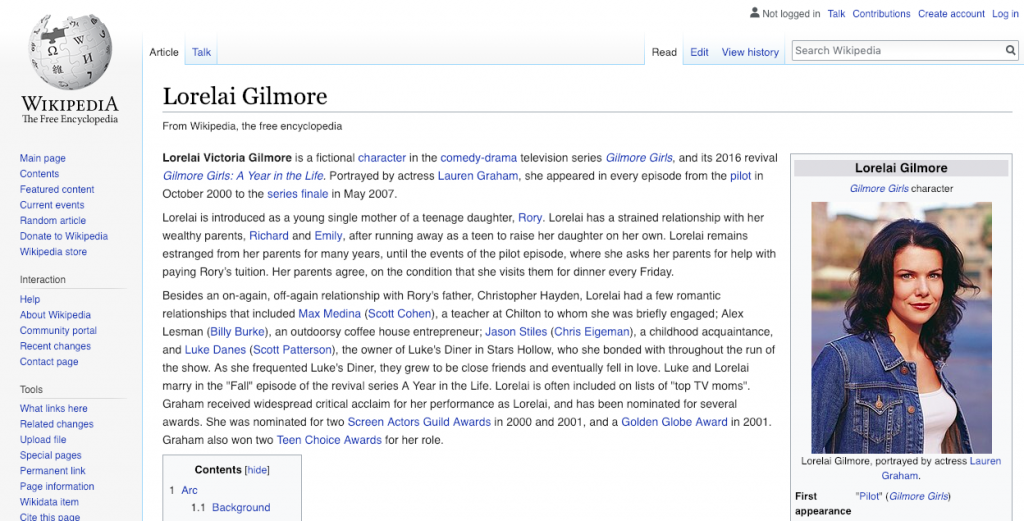
For example, given the claim “Lorelai Gilmore’s father is named Robert,” one could find the Wikipedia article on Lorelai Gilmore and extract the third sentence “Lorelai has a strained relationship with her wealthy parents, Richard and Emily, after running away as a teen to raise her daughter on her own” to show that the claim is false.
Credit : Wikipedia – https://en.wikipedia.org/wiki/Lorelai_Gilmore
One aspect of this problem that the team observed was how poorly TF-IDF, a standard technique in information retrieval and natural language processing, performed at retrieving Wikipedia articles and sentences. Their custom model improved performance by 35 points in terms of recall over a TF-IDF baseline, achieving 90% recall for 5 articles. Overall, the model retrieved the correct sentence and predicted the veracity of the claim 50% of the time.
The rate of which misinformation is spreading on
the web is faster than the rate of manual fact-checking conducted by
organizations like Politifact.com and Factchecking.org. For this paper the
researchers wanted to explore how to automate parts or all of the fact-checking
process. A poster with their findings was presented as part
of the FEVER workshop.
“In order to come up with reliable fact-checking
systems we need to understand the current manual process and identify
opportunities for automation,” said Tariq Alhindi, lead author on the paper. They looked at the LIAR dataset – around 10,000 claims classified by Politifact.com to one of six
degrees of truth – pants-on-fire, false, mostly-false, half-true, mostly-true,
true. Continued Alhindi, we also looked at the fact-checking article for each
claim and automatically extracted justification sentences of a given
verdict and used them in our models, after removing all sentences that contain
the verdict (e.g. true or false).
Excerpt from the LIAR-PLUS dataset
Feature-based machine learning models and
neural networks were used to develop models that can predict whether
a given statement is true or false. Results showed that using some sort of
justification or evidence always improves the results of fake-news detection
models.
“What was most surprising about the results is that
adding features from the extracted justification sentences consistently improved
the results no matter what classifier we used or what other features we
included,” shared Alhindi, a PhD student. “However, we were surprised that the
improvement was consistent even when we compare
traditional feature-based linear machine learning models against state of
the art deep learning models.”
Their research extends the previous work done on this data set which only looked at the linguistic cues of the claim and/or the metadata of the speaker (history, venue, party-affiliation, etc.). The researchers also released the extended dataset to the community to allow further work on this dataset with the extracted justifications.
Recently,
a specific type of machine learning, called deep learning, has made strides in
reaching human level performance on hard to articulate problems, that is,
things people do subconsciously like recognizing faces or understanding speech.
And so, natural language processing researchers have turned to these models for
the task of identifying the most important phrases and sentences in text
documents, and have trained them to imitate the decisions a human editor might
make when selecting content for a summary.
“Deep
learning models have been successful in summarizing natural language texts,
news articles and online comments,” said Chris Kedzie, a fifth
year PhD student. “What we wanted to know is how they are doing it.”
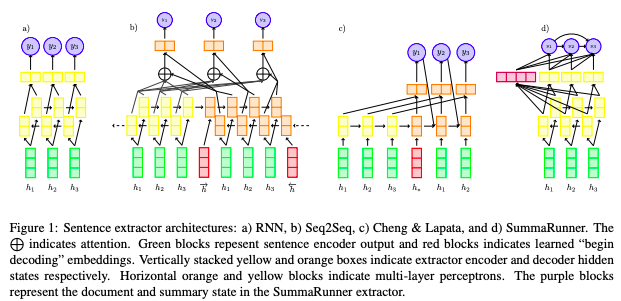
While
these deep learning models are empirically successful, it is not clear how they
are performing this task. By design, they are learning to create their own
representation of words and sentences, and then using them to predict whether a
sentence is important – if it should go into a summary of the document. But
just what kinds of information are they using to create these
representations?
One
hypotheses the researchers had was that certain types of words were more
informative than others. For example, in a news article, nouns and verbs might
be more important than adjectives and adverbs for identifying the most
important information since such articles are typically written in a relatively
objective manner.
To see if this was so, they trained models to predict sentence importance on redacted datasets, where either nouns, verbs, adjectives, adverbs, or function words were removed and compared them to models trained on the original data.
On
a dataset of personal stories published on Reddit, adjectives and adverbs were
the key to achieving the best performance. This made intuitive sense in that
people tend to use intensifiers to highlight the most important or climactic
moments in their stories with sentences like, “And those were the WORST
customers I ever served.”
What surprised the researchers were the news articles – removing any one class of words did not dramatically decrease model performance. Either important content was broadly distributed across all kinds of words or there was some other signal that the model was using.
They suspected that sentence order was important because journalists are typically instructed to write according to the inverted pyramid style with the most important information at the top of the article. It was possible that the models were implicitly learning this and simply selecting sentences from the article lead.
Two pieces of evidence confirmed this. First, looking at a histogram of sentence positions selected as important, the models overwhelmingly preferred the lead of the article. Second, in a follow up experiment, the sentence ordered was shuffled to remove sentence position as a viable signal from which to learn. On news articles, model performance dropped significantly, leading to the conclusion that sentence position was most responsible for model performance on news documents.
The
result concerned the researchers as they want models to be trained to truly
understand human language and not use simple and brittle heuristics (like
sentence position). “To connect this to broader trends in machine learning, we
should be very concerned and careful about what signals are being exploited by
our models, especially when making sensitive decisions,” Kedzie continued. ”The
signals identified by the model as helpful may not truly capture the problem we
are trying to solve, and worse yet, may be exploiting biases in the dataset
that we do not wish it to learn.”
However,
Kedzie sees this as an opportunity to improve the utility of word
representations so that models are better able to use the article content
itself. Along these lines, in the future, he hopes to show that by quantifying
the surprisal or novelty of a particular word or phrase, models are able to
make better sentence importance predictions. Just as people might remember the
most surprising and unexpected parts of a good story.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor