Research from the department was featured at the 66th Annual Symposium on Foundations of Computer Science (FOCS 2025). Several of our faculty and students had their papers accepted, contributing new insights to areas such as algorithms, complexity theory, and cryptography. This digest provides an overview of their work and showcases the innovative research emerging from our community.
Abstract: In 1992 Blum and Rudich [BR92] gave an algorithm that uses membership and equivalence queries to learn k-term DNF formulas over {0, 1} n in time poly(n, 2 k ), improving on the naive O(n k ) running time that can be achieved without membership queries [Val84]. Since then, many alternative algorithms [Bsh95, Kus97, Bsh97, BBB+00] have been given which also achieve runtime poly(n, 2 k ). We give an algorithm that uses membership and equivalence queries to learn k-term DNF formulas in time poly(n) · 2 O˜( √ k) . This is the first improvement for this problem since the original work of Blum and Rudich [BR92]. Our approach employs the Winnow2 algorithm for learning linear threshold functions over an enhanced feature space which is adaptively constructed using membership queries. It combines a strengthened version of a technique that effectively reduces the length of DNF terms from the original work of [BR92] with a range of additional algorithmic tools (attribute-efficient learning algorithms for low-weight linear threshold functions and techniques for finding relevant variables from junta testing) and analytic ingredients (extremal polynomials and noise operators) that are novel in the context of query-based DNF learning.
Abstract: In this note, we show that one can use average embeddings, introduced recently in [Nao20], to obtain efficient algorithms for approximate nearest neighbor search. In particular, a metric X embeds into ℓ2 on average, with distortion D, if, for any distribution µ on X, the embedding is D Lipschitz and the (square of) distance does not decrease on average (wrt µ). In particular existence of such an embedding (assuming it is efficient) implies a O(D 3 ) approximate nearest neigbor search under X. This can be seen as a strengthening of the classic (bi-Lipschitz) embedding approach to nearest neighbor search, and is another application of data-dependent hashing paradigm.
Abstract: In this paper, we consider generalized flow problems where there is an m-edge n-node directed graph G = (V, E) and each edge e ∈ E has a loss factor γe > 0 governing whether the flow is increased or decreased as it crosses edge e. We provide a randomized Oe((m+n 1.5 )·polylog( W δ )) time algorithm for solving the generalized maximum flow and generalized minimum cost flow problems in this setting where δ is the target accuracy and W is the maximum of all costs, capacities, and loss factors and their inverses. This improves upon the previous state-of-theart Oe(m √ n · log2 ( W δ )) time algorithm, obtained by combining the algorithm of [DS08] with techniques from [LS14]. To obtain this result we provide new dynamic data structures and spectral results regarding the matrices associated to generalized flows and apply them through the interior point method framework of [vdBLL+21].
Abstract: In this work, we observe a tight connection between three topics: NC0 cryptography, NC0 range avoidance, and static data structure lower bounds. Using this connection, we leverage techniques from the cryptanalysis of NC0 PRGs to prove state-of-the-art results in the latter two subjects. Our main result is an improvement to the best known static data structure lower bounds, breaking a barrier which has stood for several decades. Prior to our work, the best known lower bound for any explicit problem with M inputs and N queries was SNt1(logM)1−t1 for any setting of the word length w (where S= space and t= time) (Siegel ‘89). We prove, for the same class of explicit problems considered by Siegel, a quadratically stronger lower bound of the form SNt2(logM)1−t22−O(w) for all even t0. Second, for the restricted class of nonadaptive bit probe data structures, we improve on this lower bound polynomially: for all odd constants t1 we give an explicit problem with N queries and MNO(1) inputs and prove a lower bound S(Nt2+t) for some constant t0. Our results build off of an exciting body of work on refuting semi-random CSPs.
We then utilize our explicit cell probe lower bounds to obtain the best known unconditional algorithms for NC0 range avoidance: we can solve any instance with stretch nm in polynomial time once mnt2 when t is even; with the aid of an NP oracle we can solve any instance with mnt2−t for t0 when t is odd. Finally, using our main correspondence we establish novel barrier results for obtaining significant improvements to our cell probe lower bounds: (i) near-optimal space lower bounds for an explicit problem with t=4w=1 implies EXPNPNC1; (ii) under the widely-believed assumption that polynomial-stretch NC0 PRGs exist, there is no natural proof of a lower bound of the form SN(1) when t=(1), w=1.
Abstract: We study circuits for computing linear transforms defined by Kronecker power matrices. The best-known (unbounded-depth) circuits, including the widely-applied fast Walsh–Hadamard transform and Yates’ algorithm, can be derived from the best-known depth-2 circuits using known constructions, so we focus particularly on the depth-2 case. Recent work [JS13, Alm21, AGP23, Ser22] has improved on decades-old constructions in this area using a new rebalancing approach, but it was unclear how to apply this approach optimally, and the previous versions had complicated technical requirements.
We find that Strassen’s theory of asymptotic spectra can be applied to capture the design of these circuits. This theory was designed to generalize the known techniques behind matrix multiplication algorithms as well as a variety of other algorithms with recursive structure, and it brings a number of new tools to use for designing depth-2 circuits. In particular, in hindsight, we find that the techniques of recent work on rebalancing were proving special cases of the duality theorem which is central to Strassen’s theory. We carefully outline a collection of obstructions to designing small depth-2 circuits using a rebalancing approach, and apply Strassen’s theory to show that our obstructions are complete.
Using this connection, combined with other algorithmic techniques (including matrix rigidity upper bounds, constant-weight binary codes, and a “hole-fixing lemma” from recent matrix multiplication algorithms), we give new improved circuit constructions as well as other applications, including:
• The N ×N disjointness matrix has a depth-2 linear circuit of size O(N 1.2495) over any field. This is the first construction which surpasses exponent 1.25, and thus yields smaller circuits for many families of matrices using reductions to disjointness, including all Kronecker products of 2 × 2 matrices, without using matrix rigidity upper bounds.
• Barriers to further improvements, including that the Strong Exponential Time Hypothesis implies an N1+Ω(1) size lower bound for depth-2 linear circuits computing the Walsh– Hadamard transform (and the disjointness matrix with a technical caveat), and that proving such a N1+Ω(1) depth-2 size lower bound would imply breakthrough threshold circuit lower bounds.
• The Orthogonal Vectors (OV) problem in moderate dimension d can be solved in deterministic time O˜(n · 1.155d ), derandomizing an algorithm of Nederlof and Węgrzycki [NW21], and the counting problem can be solved in time O˜(n · 1.26d ), improving an algorithm of Williams [Wil24] which runs in time O˜(n · 1.35d ). We design these new algorithms by noticing that prior algorithms for OV can be viewed as corresponding to depth-2 circuits for the disjointness matrix, then using our framework for further improvements.
The Theory Group recently hosted a three-day workshop in honor of Professor Mihalis Yannakakis’ 70th birthday.
The workshop, dubbed Mihalis Fest, invited 18 computer science researchers and professors who gave talks about the various research areas that Yannakakis’ work has strongly influenced. Among the speakers were Professor Toniann Pitassi and Turing Award winner Jeffrey Ullman, who was Yannakakis’ PhD advisor at Princeton University.
Mihalis Yannakakis and Jeffrey Ullman
“Mihalis is universally recognized as one of the true giants of our field. He’s made major contributions all over the intellectual map of theoretical computer science, in too many areas to list. He’s also a much-beloved figure in the research community, whose wisdom and kindness have impacted countless colleagues and students,” said Professor Rocco Servedio. “The CS department was delighted to host a celebratory workshop in honor of his milestone birthday!”
Professor Christos Papadimitriou closed out the workshop and shared how he and Yannakakis first met while PhD students at Princeton. Said Papadimitriou, “I introduced computer science theory to Mihalis. I should’ve retired after that accomplishment.”
Christos Papadimitriou
Papadimitriou and Yannakakis have collaborated on many papers over the years, and their 1988 paper, “Optimization, Approximation, and Complexity Classes,” introduced a whole range of new complexity classes and notions of approximation that continue to be studied to this day. They are also good friends, and colleagues have noted that the two hardly need to talk but understand each other instantly. “At one point, we started to look alike, too,” joked Papadimitriou.
Mihalis Yannakakis with former and current PhD students: (left to right) Miranda Christ, Oliver Korten, Mihalis Yannakakis, Manolis Gkaragkounis, Dimitris Paparas, Shivam Nadimpalli, Yuhao Li
Many presenters, plus former and current PhD students, shared personal stories of their time working with Yannakakis. Their tributes showed a common theme: how Yannakakis is a brilliant computer scientist who also knows how to support and nurture those around him.
Dear Academic Father: A Thank You From The Future
Tribute From Rashida Hakim
Tribute From Miranda Christ
Tribute From Oliver Korten
Tribute From Shivam Nadimpalli
Tribute From Yuhao Li
Tribute From Dimitris Paparas
Poem For Mihalis Part 1
Poem For Mihalis Part 2
Poem For Mihalis Part 2
Dear Academic Father: Just A Thank You Will Never Be Enough
Xi Chen is one of a small number of researchers to be awarded two highly prestigious honors—the 2021 Gödel Prize and the 2021 Fulkerson Prize—in one year. He and his long-time collaborator Jin-Yi Cai, a professor at the University of Wisconsin–Madison, won the prizes for their paper, Complexity of Counting CSP with Complex Weights.
The Society for the Advancement of Economic Theory named economic theory fellows who have substantially advanced economic theory through scholarly and creative achievement.
Hamoon Mousavi is a PhD student who moved to Columbia from the University of Toronto last year with Henry Yuen, whose research group studies theoretical computer science and the differences between classical and quantum computers.
Edge-Weighted Online Bipartite Matching Matthew Fahrbach Google Research, Zhiyi Huang University of Hong Kong, Runzhou Tao Columbia University, Morteza Zadimoghaddam Google Research
The online bipartite matching problem introduced by Richard Karp, Umesh Vazirani, and Vijay Vazirani in 1990 is one of the most important problems in the field of online algorithms. In this problem, only one side of the bipartite graph (called “offline nodes”) is given. The other side of the graph (called “online nodes”) is given one by one. Each time an online node arrives, the algorithm must decide whether and how it should be matched. This decision is irrevocable. The online bipartite matching problem has a wide range of applications, e.g., online ad allocation, in which we can see advertisers as offline nodes and users as online nodes.
This paper gives a positive answer for this 30-year open problem by giving an 0.508-competitive algorithm for the edge-weighted bipartite online matching problem. The algorithm uses a new subroutine called Online Correlated Selection, which takes a sequence of pairs as input and selects one element from each pair. By negatively correlating the selections, one can produce a better online matching algorithm.
This new technique will have further applications in the field of online algorithms.
Consider the problem of maintaining a directed graph under edge addition/deletions, so that connectivity between any pair of vertices can be answered quickly. This basic problem has no efficient data structure, despite decades of research. In 2010, Patrascu proposed a communication problem (the “Multiphase Conjecture”), whose resolution would prove that problems like dynamic reachability indeed require slow (n^0.1) update or query time. We use information-theoretic tools to prove a weaker version of the Multiphase Conjecture, which implies a polynomial (~ \sqrt{n}) lower bound on “weakly-adaptive” dynamic data structures for the reachability problem. We also use this result to make progress on understanding the power of nonlinear gates in networks computing *linear* operators (x –> Ax).
This paper resolves an open question about the complexity of estimating the edit distance up to a constant factor. Edit distance is a fundamental problem, and its exact quadratic-time algorithm is one of the most classic dynamic programming problems.
It was shown that under the SETH conjecture, no exact algorithm can resolve it in sub-quadratic, so the open question remained what is the best approximation one can obtain. A breakthrough result from 2018 showed the first trust sub-quadratic algorithm for Constant factor, and the question remained if it can be done in near-linear time. This paper resolved this question positively.
Range-counting is one of the most omnipresent query spatial databases, computational geometry, and eCommerce (e.g. “Find all employees from countries X who have earned salary >X between years 2000-2018”). Fast data structures with linear space are known for various such problems, all of which use only additions and subtractions of pre-computed weighted sums (aka the “group model”). However, for general ranges (geometric shapes), no efficient data structures were known, yet proving > log(n)
Lower bounds in the group model remained a fundamental challenge since the early 1980s. The paper proves a *polynomial* (n^0.1) lower bound on the query time of linear-space data structures for an explicit range-counting problem of convex polygons in R^2.
Fundamental routing problems such as the Traveling Salesman Problem (TSP) and the Vehicle Routing Problem have been widely studied since the 1950s. Given a metric space, the goal is to find a minimum-weight collection of tours (only one for TSP) so as to meet a prescribed demand at some points of the metric space. Both problems have been the source of inspiration for many algorithmic breakthroughs and, quite frustratingly, remain good examples of the limits of the power of algorithmic methods.
The paper studies the geometry of weighted minor free graphs, which is a generalization of planar graphs, where the graph is somewhat topologically restricted. The framework is this of metric embeddings, where we create a “small-complexity” graph that approximately preserves distances between pairs of points in the original graph. We have two such structural results:
1. Light subset spanner: given a set K of terminals, we construct a subgraph of the original graph that preserves all distances between terminals up to 1+\eps factor and have total weight only slightly larger than the Steiner tree: the minimal weight subgraph connecting all terminals.
2. Stochastic metric embedding into low treewidth graphs: treewidth is a graph parameter measuring how much a graph is “treelike”. Many hard problems become tractable on bounded treewidth graphs. We create a distribution over mapping of the graph into a bounded treewidth graph, such that the distance between every pair of points increases only by a small additive constant (in expectation).
The structural results are then used to obtain an efficient polynomial approximation scheme (EPTAS) for subset TSP in minor-free graphs, and a quasi-polynomial approximation scheme (QPTAS) for the vehicle routing problem in minor-free graphs.
Nine papers from CS researchers were accepted to the ACM-SIAM Symposium on Discrete Algorithms (SODA20), held in Salt Lake City, Utah. The conference focuses on algorithm design and discrete mathematics.
A common type of problem studied in machine learning is learning an unknown classification rule from labeled data. In this problem paradigm, the learner receives a collection of data points, some of which are labeled “positive” and some of which are labeled “negative”, and the goal is to come up with a rule which will have high accuracy in classifying future data points as either “positive” or “negative”.
In a SODA 2015 paper, De, Diakonikolas, and Servedio studied the possibilities and limitations of efficient machine learning algorithms when the learner is only given access to one type of data point, namely points that are labeled “positive”. (These are also known as “satisfying assignments” of the unknown classification rule.) They showed that certain types of classification rules can be learned efficiently in this setting while others cannot. However, all of the settings considered in that earlier work were ones in which the data points themselves were defined in terms of “categorical” features also known as binary yes-no features (such as “hairy/hairless” “mammal/non-mammal” “aquatic/non-aquatic” and so on). In many natural settings, though, data points are defined in terms of continuous numerical features (such as “eight inches tall” “weighs seventeen pounds” “six years old” and so on).
This paper extended the earlier SODA 2015 paper’s results to handle classification rules defined in terms of continuous features as well. It shows that certain types of classification rules over continuous data are efficiently learnable from positive examples only while others are not.
“Most learning algorithms in the literature crucially use both positive and negative examples,” said Rocco Servedio. “So at first I thought that it is somewhat surprising that learning is possible at all in this kind of setting where you only have positive examples as opposed to both positive and negative examples.”
But learning from positive examples only is actually pretty similar to what humans do when they learn — teachers rarely show students approaches that fail to solve a problem, rarely have them carry out experiments that don’t work, etc. Continued Servedio, “So maybe we should have expected this type of learning to be possible all along.”
The researchers were interested in algorithms which are given access to a large undirected graph G on n vertices and estimate the number of edges of the graph up to a small multiplicative error. In other words, for a very small ϵ > 0 (think of this as 0.01) and a graph with m edges, they wanted to output a number m’ satisfying (1-ε) m ≤ m’ ≤ (1+ε) m with probability at least 2/3, and the goal is to perform this task without having to read the whole graph.
For a simple example, suppose that the access to a graph allowed to check whether two vertices are connected by an edge. Then, an algorithm for counting the number of edges exactly would need to ask whether all pairs of vertices are connected, resulting in an (n choose 2)-query algorithm since these are all possible pairs of vertices. However, sampling Θ((n choose 2) / (m ε2)) random pairs of vertices one can estimate the edges up to (1± ε)-error with probability 2/3, which would result in a significantly faster algorithm!
The question here is: how do different types of access to the graph result in algorithms with different complexities? Recent work by Beame, Har-Peled, Ramamoorthy, Rashtchian, and Sinha studied certain “independent set queries” and “bipartite independent set queries”: in the first (most relevant to our work), an algorithm is allowed to ask whether a set of vertices of the graph forms an independent set, and in the second, the algorithm is allowed to ask whether two sets form a bipartite independent set. The researchers give nearly matching upper and lower bounds for estimating edges with an independent set queries.
The researchers imagined situations in which the graph is extremely large and wanted to determine whether or not the graph has cycles in a computationally efficient manner (by looking at as few of the nodes in the graph as possible). As yet, there’s no known solution to this problem that does significantly better than looking at a constant fraction of the nodes, but they proved a new lower bound – that is, they found a new limit on how efficiently the problem can be solved. In particular, their proof of the lower bound uses a new technique to capture the best possible behavior of any algorithm for this problem.
Suppose there is a large directed graph that describes the connections between neurons in a portion of the brain, and the number of neurons is very large, say, several billion. If the graph has many cycles, this might indicate that the portion of the brain contains recurrences and feedback loops, while if it has no cycles, this might indicate information flows through the graph in a linear manner. Knowing this fact might help deduce the function of this part of the brain. The paper’s result is negative – it provides a lower bound on the number of neurons needed to determine this fact. (This might sound a little discouraging, but this research isn’t really targeted at specific applications – rather, it takes a step toward better understanding the types of approaches we need to use to efficiently determine the properties of large directed graphs.)
This is part of a subfield of theoretical computer science that has to do with finding things out about enormous data objects by asking just a few questions (relatively speaking). Said Tim Randolph, “Problems like these become increasingly important as we generate huge volumes of data, because without knowing how to solve them we can’t take advantage of what we know.”
The paper studies the problem of privacy-preserving (approximate) similarity search, which is the backbone of many industry-scale applications and machine learning algorithms. It obtains a quadratic improvement over the highest *unconditional* lower bound for oblivious (secure) near-neighbor search in dynamic settings. This shows that dynamic similarity search has a logarithmic price if one wishes to perform it in an (information theoretic) secure manner.
In this paper the researcher studied the case where there is a set K of terminals, and the goal is to embed only the terminals into `1 with low distortion.
Given two metric spaces $(X,d_X),(Y,d_Y)$, an embedding is a function $f:X\to Y$. We say that an embedding $f$ has distortion $t$ if for every two points $u,v\in X$, it holds that $d_X(u,v)\le d_Y(f(u),f(v))\le t\cdot d_X(u,v)$. “Given a hard problem in a space $X$, it is often useful to embed it into a simpler space $Y$, solve the problem there, and then pull the solution back to the original space $X$,” said Arnold Filtser, a postdoctoral fellow. “The quality of the received solution will usually depend on the quality of the embedding (distortion), and the simplicity of the host space. Metric embeddings have a fundamental place in the algorithmic toolbox.”
In $\ell_1$ distance, a.k.a. Manhattan distance, given two vectors $\vec{x},\vec{y}\in\mathbb{R}^d$ the distance defined as $\Vert \vec{x}-\vec{y}\Vert_1=\sum_i |x_i-y_i|$. A planar graph $G=(V,E,w)$, is a graph that can be drawn in the plane in such a way that its edges $E$ intersect only at their endpoints. This paper studies metric embeddings of planar graphs into $\ell_1$.
It was conjectured by Gupta et al. that every planar graph can be embedded into $\ell_1$ with constant distortion. However, given an $n$-vertex weighted planar graph, the best upper bound on the distortion is only $O(\sqrt{\log n})$, by Rao. The only known lower bound is $2$’ and the fundamental question of the right bound is quite eluding.
The paper studies the case where there is a set $K$ of terminals, and the goal is to embed only the terminals into $\ell_1$ with low distortion and it’s contribution is a further improvement on the upper bound to $O(\sqrt{\log\gamma})$. Since every planar graph has at most $O(n)$ faces, any further improvement on this result, will be a major breakthrough, directly improving upon Rao’s long standing upper bound.
It is well known that the flow-cut gap equals to the distortion of the best embedding into $\ell_1$. Therefore, our result provides a polynomial time $O(\sqrt{\log \gamma})$-approximation to the sparsest cut problem on planar graphs, for the case where all the demand pairs can be covered by $\gamma$ faces.
A Boolean function f : {0,1}n → {0,1} is monotone if for every two points x, y ∈ {0,1}n where xi ≤ yi for every i∈[n], f(x) ≤ f(y). There has been a long and very fruitful line of research, starting with the work of Goldreich, Goldwasser, Lehman, Ron, and Samorodnitsky, exploring algorithms which can test whether a Boolean function is monotone.
The core question studied in the first paper was: suppose a function f is ϵ-far from monotone, i.e., any monotone function must differ with f on at least an ϵ-fraction of the points, how many pairs of points x, y ∈ {0,1}n which differ in only one bit i∈[n] (an edge of the hypercube) must satisfy f(x) = 1 but f(y) = 0 but x ≤ y (a violation of monotonicity)?
The paper focuses on the question of efficient algorithms which can estimate the distance to monotonicity of a function, i.e., the smallest possible ϵ where f is ϵ-far from monotone. It gives a non-adaptive algorithm making poly(n) queries which estimates ϵ up to a factor of Õ(√n). “The above approximation is not good since it degrades very badly as the number of variables of the function increases,” said Erik Waingarten. “However, the surprising thing is that substantially better approximations require exponentially many non-adaptive queries.”
The Complexity of Contracts Paul Duetting London School of Economics, Tim Roughgarden Columbia University, Inbal Talgam-Cohen Technion, Israel Institute of Technology
Contract theory is a major topic in economics (e.g., the 2016 Nobel Prize in Economics was awarded to Oliver Hart and Bengt Holmström for their work on the topic). A canonical problem in the area is how to structure compensation to employees (e.g. as a function of sales), when the effort exerted by employees is not directly observable.
This paper provides both positive and negative results about when optimal or approximately optimal contracts can be computed efficiently by an algorithm. The researchers design such an efficient algorithm for settings with very large outcome spaces (such as all subsets of a set of products) and small agent action spaces (such as exerting low, medium, or high effort).
How to Store a Random Walk Emanuele Viola Northeastern University, Omri Weinstein Columbia University, Huacheng Yu Harvard University
Motivated by storage applications, the researchers studied the problem of “locally-decodable” data compression. For example, suppose an encoder wishes to store a collection of n *correlated* files using as little space as possible, such that each individual X_i can be recovered quickly with few (ideally constant) memory accesses.
A natural example is a collection of similar images or DNA strands on a large sever, say, Dropbox. The researchers show that for file collections with “time-decaying” correlations (i.e., Markov chains), one can get the best of both worlds. This surprising result is achieved by proving that a random walk on any graph can be stored very close to its entropy, while still enabling *constant* time decoding on a word-RAM. The data structures generalize to dynamic (online) setting.
The paper investigates for which metric spaces the performance of distance labeling and of `∞- embeddings differ, and how significant can this difference be.
A distance labeling is a distributed representation of distances in a metric space $(X,d)$, where each point $x\in X$ is assigned a succinct label, such that the distance between any two points $x,y \in X$ can be approximated given only their labels.
A highly structured special case is an embedding into $\ell_\infty$, where each point $x\in X$ is assigned a vector $f(x)$ such that $\|f(x)-f(y)\|_\infty$ is approximately $d(x,y)$. The performance of a distance labeling, or an $\ell_\infty$-embedding, is measured by its distortion and its label-size/dimension. “As $\ell_\infty$ is a norm space, it posses a natural structure that can be exploited by various algorithms,” said Arnold Filtser. “Thus it is more desirable to obtain embeddings rather than general labeling schemes.”
The researchers also studied the analogous question for the prioritized versions of these two measures. Here, a priority order $\pi=(x_1,\dots,x_n)$ of the point set $X$ is given, and higher-priority points should have shorter labels. Formally, a distance labeling has prioritized label-size $\alpha(.)$ if every $x_j$ has label size at most $\alpha(j)$. Similarly, an embedding $f: X \to \ell_\infty$ has prioritized dimension $\alpha(\cdot)$ if $f(x_j)$ is non-zero only in the first $\alpha(j)$ coordinates. In addition, they compare these prioritized measures to their classical (worst-case) versions.
They answer these questions in several scenarios, uncovering a surprisingly diverse range of behaviors. First, in some cases labelings and embeddings have very similar worst-case performance, but in other cases there is a huge disparity. However in the prioritized setting, they found a strict separation between the performance of labelings and embeddings. And finally, when comparing the classical and prioritized settings, they found that the worst-case bound for label size often “translates” to a prioritized one, but also a surprising exception to this rule.
Papers from CS researchers were accepted to the 60th Annual Symposium on Foundations of Computer Science (FOCS 2019). The papers delve into population recovery, sublinear time, auctions, and graphs.
Finding Monotone Patterns in Sublinear Time Omri Ben-Eliezer Tel-Aviv University, Clement L. Canonne Stanford University, Shoham Letzter ETH-ITS, ETH Zurich, Erik Waingarten Columbia University
The paper is about finding increasing subsequences in an array in sublinear time. Imagine an array of n numbers where at least 1% of the numbers can be arranged into increasing subsequences of length k. We want to pick random locations from the array in order to find an increasing subsequence of length k. At a high level, in an array with many increasing subsequences, the task is to find one. The key is to cleverly design the distribution over random locations to minimize the number of locations needed.
Roughly speaking, the arrays considered have a lot of increasing subsequences of length k; think of these as “evidence of existence of increasing subsequences”. However, these subsequences can be hidden throughout the array: they can be spread out, or concentrated in particular sections, or they can even have very large gaps between the starts and the ends of the subsequences.
“The surprising thing is that after a specific (and simple!) re-ordering of the “evidence”, structure emerges within the increasing subsequences of length k,” said Erik Waingarten, a PhD student. “This allows for design efficient sampling procedures which are optimal for non-adaptive algorithms.”
Consider the problem of reconstructing the DNA sequence of an extinct species, given some DNA sequences of its descendant(s) that are alive today. We know that DNA sequences get modified through random mutations, which can be substitutions, insertions and deletions.
A mathematical abstraction of this problem is to recover an unknown source string x of length n, given access to independent samples of x that have been corrupted according to a certain noise model. The goal is to determine the minimum number of samples required in order to recover x with high confidence. In the special case that the corruption occurs via a deletion channel (i.e., each character in x is deleted independently with some probability, say 0.1, and the surviving characters are concatenated and transmitted), each sample is called a trace. The corresponding recovery problem is called trace reconstruction, and it has received significant attention in recent years.
The researchers considered a generalized version of this problem (known as population recovery) where there are multiple unknown source strings, along with an unknown distribution over them specifying the relative frequency of each source string. Each sample is generated by first drawing a source string with the associated probability, and then generating a trace from it via the deletion channel. The goal is to recover the source strings, along with the distribution over them (up to small error), from the mixture of traces.
For the main sample complexity upper bound, they show that for any population size s = o(log n / log log n), a population of s strings from {0,1}^n can be learned under deletion channel noise using exp(n^{1/2 + o(1)}) samples. On the lower bound side, we show that at least n^{\Omega(s)} samples are required to perform population recovery under the deletion channel when the population size is s, for all s <= n^0.49.
“I found it interesting that our work is based on certain mathematical results in which, at first glance, seem to be completely unrelated to the computational problem we consider,” said Sandip Sinha, a PhD student. In particular, they used constructions based on Chebyshev polynomials, a certain sequence of polynomials which are extremal for many properties, and is hence ubiquitous throughout theoretical computer science. Similarly, previous work on trace reconstruction rely on certain extremal results about complex-valued polynomials. Continued Sinha, “I think it is quite intriguing that complex analytic techniques yield useful results about a problem which is fundamentally about discrete structures (binary strings).”
The paper is about the theory of combinatorial auctions. In a combinatorial auction, an auctioneer wants to allocate several items among bidders. Each bidder has a certain amount that they value each item; bidders also have values for combinations of items, and in a combinatorial auction a bidder might not value a combination of items as much as each item individually.
For instance, say that a pencil and a pen will be auctioned. The pencil is valued at 30 cents and the pen at 40 cents, but the pen and pencil together at only 50 cents (it may be that there isn’t any additional value from having both the pencil and the pen). Valuation functions with this property — that the value of a combination of items is less than or equal to the sum of the values of each item — are called subadditive.
In the paper, the researchers answered a longstanding open question about combinatorial auctions with two bidders who have subadditive valuation — roughly speaking, is it possible for an auctioneer to efficiently communicate with both bidders to figure out how to allocate the items between them to make the bidders happy?
The answer turns out to be no. In general, if the auctioneer wants to do better than just giving all of the items to one bidder or the other at random, the auctioneer needs to communicate a very large amount with the bidders.
The result itself was somewhat surprising, the researchers expected it to be possible for the auctioneer to do pretty well without having to communicate with the bidders too much. “Also, information theory was extensively used as part of proving the result,” said Eric Neyman, a PhD student. “This is unexpected, because information theory has not been used much in the study of combinatorial auctions.”
In a graph, an independent set is a set of vertices with the property that none are adjacent. For example, in the graph of Facebook friends, vertices are people and there is an edge between two people who are friends. An independent set would be a set of people, none of whom are friends with each other. A basic problem is to find a large independent set. The paper focuses on one type of large independent set known as a maximal independent set, that is, one that cannot have any more vertices added to it.
Graphs, such as the friends graph, evolve over time. As the graph evolves, the maximal independent set needs to be maintained, without recomputing one from scratch. The paper significantly decreases the time to do so, from time that is polynomial in the input size to one that is polylogarithmic.
A graph can have many maximal independent sets (e.g. in a triangle, each of the vertices is a potential maximal independent set). One might think that this freedom makes the problems easier. The researchers picked one particular kind of maximal independent set, known as a lexicographically first maximal independent set (roughly this means that in case of a tie, the vertex whose name is first in alphabetical order is always chosen) and show that this kind of set can be maintained more efficiently.
“Giving up this freedom actually makes the problems easier,” said Cliff Stein, a computer science professor. “The idea of restricting the set of possible solutions making the problem easier is a good general lesson.”
Researchers from around the country gathered at Columbia Engineering this past weekend for a three-day event honoring four decades of ground-breaking research by Prof. Christos Papadimitriou. The conference, which organizers dubbed “PapaFest,” included individual speakers, panel discussions, social events, and even a rock band.
The Symposium on Theory of Computing (STOC) covers research within theoretical computer science, such as algorithms and computation theory. This year, four papers from CS researchers and collaborators from various institutions made it into the conference.
The researchers were interested in the problem of compressing texts with local context, like texts in which there is some correlation between nearby characters. For example, the letter ‘q’ is almost always followed by ‘u’ in an English text.
It is a reasonable goal to design compression schemes that exploit local context to reduce the length of the string considerably. Indeed, the FM-Index and other such schemes, based on a transformation called the Burrows-Wheeler transform followed by Move-to-Front encoding, have been widely used in practice to compress DNA sequences etc. “I think it’s interesting that compression schemes have been known for nearly 20 years in the pattern-matching and bioinformatics community but there has not been satisfactory theoretical guarantees of the compression achieved by these algorithms,” said Sandip Sinha, a PhD student in the Theory Group.
Moreover, these schemes are inherently non-local – in order to extract a character or a short substring at a particular position of the original text, one needs to decode the entire string, which requires time proportional to the length of the original string. This is prohibitive in many applications. The team designed a data structure which matches almost exactly the space bound of such compression schemes, while also supporting highly efficient local decoding queries (alluded to above), as well as certain pattern-matching queries. In particular, they were able to design a succinct “locally-decodable” Move-to-Front (MTF) code, that reduces the decoding time per character (in the MTF encoding) from n to around log(n), where n is the length of the string. Shared Sinha, “We also show a lower bound showing that for a wide class of strings, one cannot hope to do much better using any data structure based on the above transform.”
“Hopefully our paper draws wider attention of the theoretical CS community to similar problems in these fields,” said Sinha. To that end, they have made a conscious effort to make the paper accessible across research domains. “I also think there is no significant mathematical knowledge required to understand the paper, beyond some basic notions in information theory.”
Fooling Polytopes Ryan O’Donnell Carnegie Mellon University, Rocco A. Servedio Columbia University, Li-Yang Tan Stanford University
The paper is about “getting rid of the randomness in random sampling”.
Suppose you are given a complicated shape on a blackboard and you need to estimate what fraction of the blackboard’s area is covered by the shape. One efficient way to estimate this fraction is by doing random sampling: throw darts randomly at the blackboard and count the fraction of the darts that land inside the shape. If you throw a reasonable number of darts, and they land uniformly at random inside the blackboard, the fraction of darts that land inside the shape will be a good estimate of the actual fraction of the blackboard’s area that is contained inside the shape. (This is analogous to surveying a small random sample of voters to try and predict who will win an election.)
“This kind of random sampling approach is very powerful,” said Rocco Servedio, professor and chair of the computer science department. “In fact, there is a sense in which every randomized computation can be viewed as doing this sort of random sampling.”
It is a fundamental goal in theoretical computer science to understand whether randomness is really necessary to carry out computations efficiently. The point of this paper is to show that for an important class of high-dimensional estimation problems of the sort described above, it is actually possible to come up with the desired estimates efficiently without using any randomness at all.
In this specific paper, the “blackboard” is a high-dimensional Boolean hypercube and the “shape on the blackboard” is a subset of the hypercube defined by a system of high-dimensional linear inequalities (such a subset is also known as a polytope). Previous work had tried to prove this result but could only handle certain specialized types of linear inequalities. By developing some new tools in high dimensional geometry and probability, in this paper the researchers were able to get rid of those limitations and handle all systems of linear inequalities.
The paper shows an interesting connection between the task of proving time-space lower bounds on data structure problems (with linear queries), and the long-standing open problem of constructing “stable” (rigid) matrices — a matrix M whose rank remains very high unless a lot of entries are modified. Constructing rigid matrices is one of the major open problems in theoretical computer science since the late 1970s, with far-reaching consequences on circuit complexity.
The result shows a real barrier for proving lower bounds on data structures: If one can exhibit any “hard” data structure problem with linear queries (the canonical example being Range Counting queries: given n points in d dimensions, report the number of points in a given rectangle), then this problem can be essentially used to construct “stable” (rigid) matrices.
“This is a rather surprising ‘threshold’ result, since in slightly weaker models of data structures (with small space usage), we do in fact have very strong lower bounds on the query time,” said Omri Weinstein, an assistant professor of computer science. “Perhaps surprisingly, our work shows that anything beyond that is out of reach with current techniques.”
The paper is about testing unateness of Boolean functions on the hypercube.
For this paper the researchers set out to design highly efficient algorithms which, by evaluating very few random inputs of a Boolean function, can “test” whether the function is unate (meaning that every variable is either non-increasing or non-decreasing or is pretty non-unate).
Referring to a previous paper the researchers set out to create an algorithm which is optimal (up to poly-logarithmic factors), giving a lower bound on the complexity of these testing algorithms.
An example of a Boolean function which is unate is a halfspace, i.e., for some values w1, …, wn, θ ∈ ℝ, the function f : {0,1}n → {0,1} is given by f(x) = 1 if ∑ wi xi≥ θ and 0 otherwise. Here, every variable i ∈ [n] is either non-decreasing, when wi ≥ 0, or non-increasing, when wi ≤ 0.
“One may hope that such an optimal algorithm could be non-adaptive, in the sense that all evaluations could be done at once,” said Erik Waingarten, an algorithms and computational complexity PhD student. “These algorithms tend to be easier to analyze and have the added benefit of being parallelize-able.”
However, the algorithm they developed is crucially adaptive, and a surprising thing is that non-adaptive algorithms could never achieve optimal complexity. A highlight of the paper is a new analysis of a very simple binary search procedure on the hypercube.
“This procedure is the ‘obvious’ thing one would do for these kinds of algorithms, but analyzing it has been very difficult because of its adaptive nature,” said Waingarten. “For us, this is the crucial component of the algorithm.”
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor

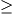 Nt1(logM)1−t1 for any setting of the word length w (where S= space and t= time) (Siegel ‘89). We prove, for the same class of explicit problems considered by Siegel, a quadratically stronger lower bound of the form S
Nt1(logM)1−t1 for any setting of the word length w (where S= space and t= time) (Siegel ‘89). We prove, for the same class of explicit problems considered by Siegel, a quadratically stronger lower bound of the form S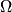

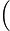 Nt2
Nt2 (logM)1−t2
(logM)1−t2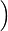 for all even t
for all even t 0. Second, for the restricted class of nonadaptive bit probe data structures, we improve on this lower bound polynomially: for all odd constants t
0. Second, for the restricted class of nonadaptive bit probe data structures, we improve on this lower bound polynomially: for all odd constants t NO(1) inputs and prove a lower bound S
NO(1) inputs and prove a lower bound S t) for some constant
t) for some constant  t
t
 m in polynomial time once m
m in polynomial time once m w=1 implies EXPNP
w=1 implies EXPNP
 NC1 ; (ii) under the widely-believed assumption that polynomial-stretch NC0 PRGs exist, there is no natural proof of a lower bound of the form S
NC1 ; (ii) under the widely-believed assumption that polynomial-stretch NC0 PRGs exist, there is no natural proof of a lower bound of the form S (1) when t=
(1) when t= (1), w=1.
(1), w=1.













