New paper by Thomas Effland, Anna Lawson, Luis Gravano, Daniel Hsu, and NYC Health Department epidemiologists describes enhancements to system that reads NYC restaurant Yelp reviews and has identified 10 food poisoning outbreaks since 2012.
Akinola was selected for his work on human-in-the-loop robot learning, and is one of ten students to receive the two-year fellowship, which covers tuition for two academic years and provides a stipend and travel allowance.
Nilforoshan was selected for his research with Eugene Wu on NLP techniques to generate automated writing feedback, and for his work with Jure Leskovec (Stanford) on the relationship between the food people eat and their environment.
The article, in this month’s Communications of the ACM, makes several recommendations, including written career goals, access to workshops and events, and dedicated institutional support to instill a sense of belonging. (Article requires login.)
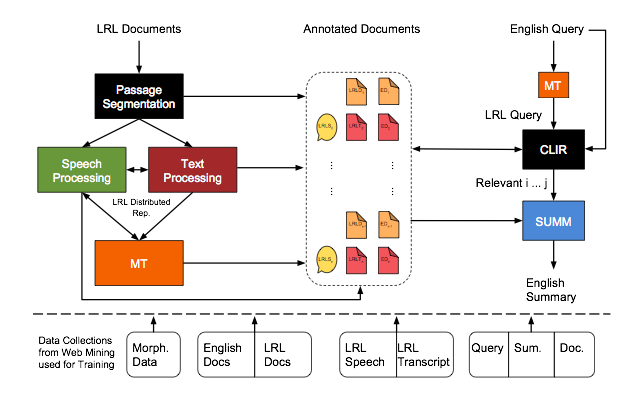
How do you search for documents, both text and speech, in a language you don’t speak or understand? Right now, there is no easy way. Google and similar search engines normally return documents in the language of the query (an English query for instance returns English documents). Translating the query first (using an automatic translator such as Google Translate) returns the documents untranslated with no indication which are most relevant and thus worth spending time, effort, and expense to translate. As for speech files, Google and similar speech engines don’t search over speech, relying instead on text tags.
But imagine entering a query in English to find resources in any foreign language—not just the 103 languages supported by Google Translate—and getting back text, audio, and video files, each accompanied by a summary in English to help identify those documents that should be translated.
That is the ambitious goal of a team of researchers led by Kathleen McKeown. Consisting of fifteen researchers from five universities, the team is now in the beginning stages of designing and building an end-to-end human language technology capable of using an English query to quickly search, retrieve, and summarize documents in any of the world’s 6000+ languages. The work is funded through the $14.5M, four-year IARPA grant from the MATERIAL program, System for CRoss-language Information Processing, Translation, and Summarization (SCRIPTS).SCRIPTS represents a large-scale project encompassing multiple underlying technologies: machine translation, cross-lingual information retrieval (similar to a regular search engine except that the query is one language, and the retrieved documents are in another), text summarization, and speech and text processing.
In this interview, McKeown discusses why such a system is needed and some of the challenges it poses.
How will the system operate in practice?
The idea is that an English-speaking user—who might be a researcher, an intelligence analyst, a journalist, or perhaps someone working with a humanitarian organization—will be able to type an English search query to locate relevant documents in another language, and get back a list of documents with summaries in English. From the summaries, the user will have enough information to evaluate which documents are most relevant and should be translated in full.
The system is geared toward what we call low-resource languages—languages that lack the large-scale data collections and automatic tools that enable automatic translators like Google Translate. Such systems work by aligning two parallel sets of translations sentence by sentence to infer statistical probabilities of how individual words and phrases are translated. It takes huge amounts of data in the form of parallel translations. Google Translate for instance was trained in part on the 30M words contained in English and French transcriptions made from Canadian parliament proceedings.
Many languages, especially in remote areas of Africa and in the South Pacific, simply don’t have large collections of translated data and for that reason also lack the basic tools—syntactic parsers, parts-of-speech taggers, or morphological analyzers—that help enable automated translation systems.
If a crisis—a coup, a natural disaster, or a terrorist attack—takes place where the only languages are low resource, automatic translation systems today will be of little use.
How will your system work without huge amounts of data?
We will have some data, including small amounts of parallel data and monolingual collections of documents. We can supplement this through webscraping or by pulling together data collected from previous projects we’ve worked on. Social media, YouTube, news reports might also be sources of data. One of the project’s innovations will be in the new ways we scrape the web.
Rather than looking at parallel translations, we will rely more on analyzing semantics and morphology, that is, what information can we derive from a word’s structure. To do so, we will build our own linguistic analysis tools to construct word embeddings, where words are represented as vectors of numbers that allow us to use computational methods to capture the semantic relationships between words and more easily discover what words have similar meanings; we’ll have tools to do this in both monolingual and cross-lingual settings. Building such tools requires deep linguistic knowledge, and we have people on the team expert in morphology and semantics.
While we will rely on morphological information, we’ll still be doing a lot statistically, but since we will have less data, we will have to do various types of bootstrapping. For example, as the system learns how to translate, for example, we can use those translations as training data in the next round. We’ll also find ways of using semi-supervised methods.
Also, we will exploit how different components in the system learn information in different ways. The way a machine translation component analyzes a query is different than how the information retrieval component analyzes a query. If we take and combine the information gained in each step, we learn a little more.
We’ll conserve computer resources by focusing on certain sentences over others. Usually there is a focus to a query. Events like the current problem of Rohingya fleeing to Bangladesh usually have several aspects: humanitarian, diplomatic, and legal. We will build a query-focused summarizer that will look at both the query and the document to summarize what in the document is relevant to the query. Previous data sets for doing this type of task are very small—maybe 30-60 documents—but with so much data on the web, we can build new data sources.
What are the difficulties?
There are many, but one in particular is error propagation. With little data, some words are bound to be mistranslated, with the risk that a mistranslation at one step is carried over to all subsequent steps, compounding the error. So rather than commit to a decision by a single component, we plan to have multiple components jointly make decisions when we have low confidence.
Summarization for example takes place multiple times: before translation—when we’re summarizing in the low-resource language and using machine translation to translate the summary in English—after translation (summarizing in English), and simultaneously with translation. At each step, we’ll let what the summarization component learns inform the translation, and also have the translation step inform summarization.
Each component will have multiple, complementary approaches also, again to create more information that we can exploit.
Information from one component is shared with others. For instance, the query serves as input to both the machine learning and the information retrieval components. The information learned in CLIR (cross-lingual information retrieval), which evaluates relevancy, will be fed to the summarization step as training data.
Why take on such a big project?
It’s a research challenge and once completed it will be the first system to combine so many language technologies in a cross-language context, pushing each of us to further advance the areas that we’ve been individually researching.
For me that area is text summarization. Several years ago, my students and I developed the NewsBlaster system to browse the news in different languages, like German and Spanish and Arabic, and return summaries of those news articles in English. It was a way for an English speaker to get different perspectives on news topics and see how the rest of the world viewed events. The students from that group have all gone onto interesting positions: several to professorships—at MIT, Penn, Cooper Union—while others are doing research in industry, a couple at Google, and one each at Amazon in Japan and IBM.
Text summarization in this new project will represent a significant advance over NewsBlaster; it will be over low-resource languages while also incorporating speech. And it will integrate into a much larger system with other components that are likewise being expanded.
We’ve got a great team, collectively representing expertise over many technologies in the field of human language technology. Many of us have worked together on other projects, so it’s always nice to again work with people whose research you respect. I think together we will produce a significant advance in the state of the art in querying over foreign language documents.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor