
Suman Jana, Protecting security and privacy in an age of perceptual computing

“I like to break things. To open a thing and see its inner workings and really understand how it works . . . and then break it in some clever way that maybe no one else thought of and in the worst possible way that doesn’t seem possible, but is.”
It’s a hacker mindset, and Suman Jana is a hacker—of a sort. Though he admits enjoying the thrill of destruction and subversion, Jana wants to make systems more secure, and companies have hired him to find security flaws in their systems so those flaws can be fixed, not exploited. This semester he joins the Computer Science department to more broadly research issues related to security and privacy. It’s a wide-open field.
Two years ago, for his thesis he looked hard at the security risks inherent in perceptual computing, where devices equipped with cameras, microphones, and sensors are able to perceive the world around them so they can operate and interact more intelligently: lights that dim when a person leaves the room, games that react to a player’s throwing motion, doors that unlock when recognizing the owner.
It all comes at a cost, of course, especially in terms of privacy and security.
“Features don’t come for free; they require incredible amounts of data. And that brings risks. The same data that tells the thermostat no one is home might also be telling a would-be burglar,” says Jana.
What data is being collecting isn’t always known, even by the device manufacturers who, pursuing features, default to collecting as much data as they can. This data is handed off to gaming, health, home monitoring, and other apps: not all are trusted; all are possible hacking targets.
There is no opting out. The inexorable trend is toward more perception in devices and more data collection, with privacy and security secondary considerations. For this reason, Jana sees the need for built-in privacy protections. A paper he co-authored, A Scanner Darkly, shows how privacy protection might work in an age of perceptual computing.
“Can we disguise some data? Should a camera for detecting hand gestures also read labels on prescription medicines inadvertently left in the camera’s view? Would an app work just as well if it detected approximate contours of the hand? If so, we can pass on lower-resolution data so the prescription label isn’t readable.”
Jana’s opinion is that users should decide what data apps are able to see. His DARKLY platform—named after a dystopian novel by Philip K. Dick—inserts a privacy protection layer that intercepts the data apps receive and displays it in a console so users can see and, if they want, limit how much data is passed on to the app. The platform, which integrates with the popular computer vision library OpenCV, is designed to make it easy for companies to implement and requires no changes to apps. The DARKLY paper, called revolutionary, won the 2014 PET Award for Outstanding Research in Privacy Enhancing Technologies.
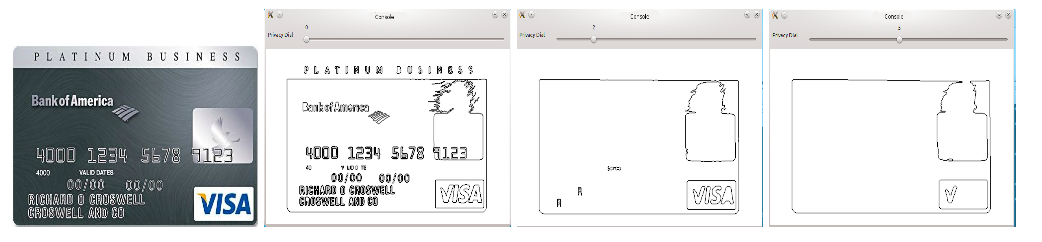 Less data for more privacy
Less data for more privacy
Making it easy to build in safety and privacy mechanisms is critical. Manufacturers have little incentive to construct privacy protections; in any case, determining what data is sensitive is not easy. A single data point by itself—a random security photo of a passerby, for instance—might seem harmless, but combined with another data point or aggregated over time—similar photos over several weeks—reveals patterns and personal behaviors. The challenge to preventing security leaks is first finding them amidst a deluge of data; a single image of a prescription label or credit card might be hidden within entire sequences of images.
Perceptual computing is rife with other such vulnerabilities made possible by devices that see, hear, and sense what goes on in their immediate environment; but the landscape of vulnerabilities is even larger than it would appear since perceptual computing, while creating new vulnerabilities, inherits all the old ones associated with any software, namely buggy code. While Jana gets a bigger space to explore, for the rest of us, it spells potential privacy disaster.
Preventing such an outcome will come from enlisting help from other technology experts. “For finding images with hidden personal information, we need classifiers. Machine learners over the years have learned how to train classifiers to recognize spam, recommend movies, and target ads. Why not train classifiers to find security risks? I’m fortunate to be working within Columbia’s Data Science Institute alongside machine learners who can build such classifiers.” For guarding against buggy code, Jana imagines adapting program analysis, an existing technology for automatically finding software bugs, so it specifically searches out those bugs that concern security and privacy.
Technology alone, however, isn’t the answer. Companies are unlikely to fix privacy problems unless pressured by the public, and Jana sees his role encompassing the policy arena, where he will work to propose and enact workable regulations and legislation to protect data and security.
At least for perceptual computing, Jana says there an opening to do something about privacy risks. “The field is still relatively new, and we have the chance to build in security from the beginning and make life better so people can trust these devices and use them.”
Jana earned his PhD in 2014 from the University of Texas,
where he was supported by the Google PhD Fellowship