With few warning signs and no screening test, pancreatic cancer is usually not diagnosed until it is well advanced; 75% of pancreatic cancer patients die within a year of a diagnosis. The prognosis improves if the disease is caught early, but the cancer’s nonspecific symptoms (bloating, abdominal or back pain) are not initially concerning. Doctors will want to rule out more likely diseases first before ordering expensive lab tests; adding to the difficulty, doctors often lack a full medical history for patients they see only intermittently or even for the first time and patients may have visited other doctors or facilities. Doctors in other words have very little data to go on.
Search engines however collect a great deal of data, and as more people turn to the web for health-related information, they are constructing a deep and broad data set of medical histories that may contain clues as to how diseases emerge.
In a study started last summer, researchers Eric Horvitz and Ryen White of Microsoft, both recognized experts in the field of information retrieval, along with Columbia PhD student John Paparizzos looked through 18 months of US Bing search data to see if they could detect patterns of symptoms in pancreatic cancer before people were diagnosed with the disease. In 5–15% of such cases, they could, and with extremely few false positives (as low as 1 in 100,000).
John Paparizzos, CS PhD student (advisor Luis Gravano)
How did you know what users had been diagnosed with pancreatic cancer?
We were very careful. We looked for people whose first-person searches indicated they had the disease: “I was just diagnosed with pancreatic cancer,” “why did I get cancer in pancreas,” and “I was told I have pancreatic cancer what to expect.” We then worked backward in time through previous searches made by these people to see if they had previously searched for symptoms associated with the disease—bloating or abdominal discomfort, unexplained weight loss, yellowing skin. From 9.2 million users with searches relevant to pancreatic cancer disease and symptoms, we focused on 3203 cases matching the diagnostic pattern.
It’s important to point out that this data was completely anonymized. Users were identified through a unique ID; we had no names or personal information about them. Just search queries.
You study computer science. How did you come to work on a medical problem?
Before starting an internship last summer at Microsoft, I talked by phone with Eric and Ryen on possible projects. They have spent several years studying how people search online, particularly how people use the web for health purposes. The idea this time was to do some type of prediction through analysis of patients’ query logs over time for a specific disease. Pancreatic cancer was a good candidate; it’s a fast-developing cancer with few overt symptoms. Search logs could conceivably provide early warning of the disease, something that doesn’t exist now.
My particular focus was to develop an approach to capture characteristics over time in the user behavior—as expressed in search query logs—that would discriminate users as early as possible to those who might experience pancreatic cancer and those who simply explore pancreatic cancer.
Since human web searches contain a lot of noise, we spent a great deal of time cleaning and annotating data before inputting it into classifiers that separate out the true signals. We excluded searches where people were looking up symptoms for general knowledge or on the behalf of someone else. We excluded idiomatic phrases that might get mistaken for real symptoms, like “I’m sick of hearing about the Kardashians.” Particular to this problem were queries generated by Steve Jobs’s death from pancreatic cancer.
Was this the first time you had worked with medical data?
Yes. It was new to me and it required learning about the disease of pancreatic cancer and its symptoms, which were all described differently also. Medical records are usually clean, formatted in templates, and reflect the precise vocabulary of doctors working in the field, but people will describe those symptoms in very different terms, even using slang. We had to do a two-level ontology of terms for symptoms and their synonyms.
The distribution of the data was different. Normally you are building classifiers where the positive and the negative cases are in balance. With this project, maybe 1 in 10,000 people will have this disease. A high misprediction rate could unnecessarily alert millions of users.
There were issues of scale. In an academic environment we might be running analysis involving 100 or 1000 users, not millions. When you’re dealing with at least 3 orders of magnitude more, there is a lot of engineering involved along with the research task.
You knew from people’s previous searches who had cancer. Could you take this model and apply to another data set where it’s not known whether people have the cancer or not?
Our KDD paper presented last month describes a similar experiment. Where our first paper describes training a model on users between October 2013 to May 2015, our KDD paper describes how we took this model and applied it on a new set of users from August 2014 to January 2016—users not used in training. We wanted to see if we could predict which searchers will later input first-person queries for the disease, which we could do at about the same accuracy as before.
The second paper also extended the methodology. In addition to looking for people with first person searches—“I have this cancer”—the second paper goes an extra step and looks for users who searched for the specific treatments for this disease—Whipple procedure, pancreaticoduodenectomy, neoadjuvant therapy—that only someone with first-hand knowledge of the disease would know.
We got slightly better results because the data was cleaner, and this raised our accuracy level from 90% to 92%.
What is the possibility that web searches will actually be used to screen for cancer?
Our goal was to demonstrate the feasibility of mining medical histories of a large population of people to successfully see symptoms at an early stage. We did this using anonymized search data, but it’s not practical in the real world. We don’t have names so we can’t contact individuals—which would raise massive privacy issues in any case.
What may be feasible is to link our method to a hospital or clinical group where patients allow their data to be shared and combined. For this, we need help from doctors working directly with patients, and it’s why we published first in a medical journal; we wanted to engage the medical community with the prospect of using nontraditional web searches in conjunction with standard practices as a way to do low-cost, passive surveillance to flag hidden problems and improve cancer screenings.
Our system won’t do the diagnosis—that is for the doctor to do—but it pulls together more clues and gives more warning that something serious might be developing, and to perhaps recommend that a specific patient gets a certain test or suggest a meeting with a physician.
We want doctors to see what’s possible when you have more data; you learn more about a single patient by having that patient’s data centralized in one spot and seeing what symptoms they had months ago, but you also learn more about the disease. For example, we found in examining the histories of many pancreatic cancers that symptoms appearing in particular order—for example, indigestion before abdominal pain—correlate positively with the experiential user cases.
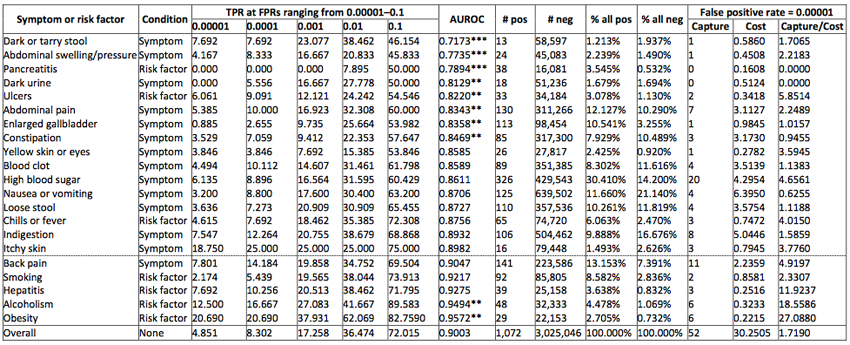
To better understand when such web-based health surveillance approach could be applied and what is the impact of the presence of particular risk factors or symptoms on the performance of the model, we have performed an analysis of the performance of our model when conditioned on users with specific symptoms or risk factors. We found that if we focus our predictions on users who search for risk factors such as alcoholism or obesity many more users would benefit from a prediction than would be mistakenly alerted.
Table describes the performance of the model when conditioned on users with particular symptoms or risk factors. The last column describes the benefit of using the researchers’ model to users with the corresponding symptom. Values > 1 indicate that more people would benefit using model than would be mistakenly alerted.
Will you continue to work with medical data sets? Did this intrigue you a lot to work in this field?
Perhaps. It’s an extremely interesting application. In our field, you don’t get to see a direct application to users. We build a new model or classier or algorithm, but often it’s not linked to such a concrete application. This is an excellent example of how we can use science and what we are learning in computer science for social good.
He previously de-anonymized participants in a large genomic study by cross-referencing their donated genetic information to DNA information in publicly available databases.
Humans are not good at detecting when someone is lying, doing little better than chance level. More reliable are computational analyses of changes in speech patterns.Julia Hirschberg with her PhD student Frank Enos, among the first to study deception in speech computationally, previously developed algorithms that canidentify deceptive speech with 70% accuracy. Further improvements may be possible by taking into account individual differences in people’s speech behaviors when they being deceptive (for instance, some may raise their voice while others lower it; some laugh more, others less). Sarah Ita Levitan, a PhD student in Hirschberg’s speech lab, is leading a series of experiments to correlate these differences with gender, culture, and personality. At the heart of these experiments is a new corpus of 122 hours of deceptive and non-deceptive speech, by far the largest such corpus ever collected. In this interview, Levitan who will be presenting results of a deceptive speech challenge at this week’s Interspeech, summarizes new findings made possible with this new corpus.
Why do people have such a difficult time detecting lies?
People rely on their intuition, but intuition is often wrong. Hesitations or saying “um” or “ah” are often interpreted as a sign of deception, but previous studies have found that these filled pauses may instead be a sign of truthful speech.
That’s why it’s important to take a quantitative approach and do in-depth statistical analyses of deceptive and nondeceptive speech.
Can you briefly describe the nature of your experiments?
We want to understand what accounts for these individual differences. Again, from previous studies we know that deceptive speech is very individualized and that gender, culture, and personality differences play a role. Our experiments are designed to more narrowly correlate individual factors with speech-related deceptive behaviors. For instance, would female, Mandarin-native speakers who are highly extroverted tend to do one thing when they lie, while male, native English-speaking, introverted speakers do something different?
Establishing strong correlations between certain deceptive speech behaviors and gender, cultural, or personality differences will help us build new classifiers to automatically detect deceptive speech.
How will your experiments differ from previous ones that also examine individual differences?
We will have more data and more specific information about individual speakers. This new corpus we’ve created contains 122 hours of deceptive and nondeceptive speech from 344 speakers, half of whom are native English speakers, and half native Mandarin speakers, though speaking in English.
This is a huge corpus; our previous work was based upon a corpus of about 15 hours of interviews. Unlike this previous one, the new corpus is gender-balanced and includes cultural information about each participant as well as personality traits gathered by administering the NEO-FFI personality test.
One thing new we did was to ask each study participant to speak truthfully for three or four minutes answering open-ended questions (“what do you like best/worst about living in NYC”). While the initial motivation was to have a baseline of truthful speech to compare with deceptive speech, these short snippets of speech actually told us a lot about an individual, both their gender and native language as well as something about their personality.
Pulling together such a large corpus was a major undertaking. It required transcribing 122 hours of speech, which we did using Amazon Mechanical Turk, and meticulously aligning the transcriptions with the speech. The effort involved a great many people, including collaborators from CUNY, interns, and undergraduates who got an early chance to participate in research.
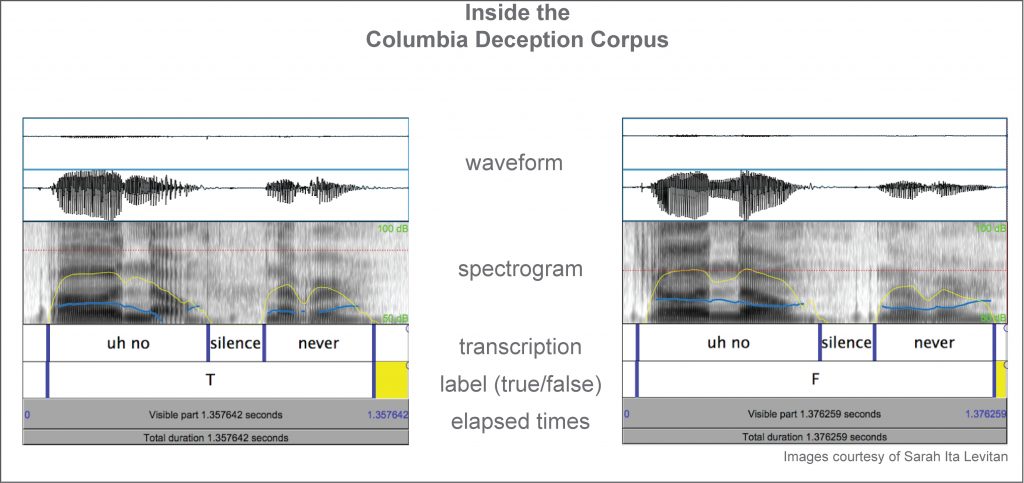
Each speech utterance can be visualized as a waveform—showing pitch, loudness, intonation, and other prosodic qualities—and a spectrogram, a visual representation of the power at each frequency. The speech utterances shown here are from the same person, showing truthful speech (left) and deceptive speech (right). The yellow line overlaid on the spectrogram shows loudness or energy (intensity), and the blue line shows pitch (f0). Variation might be subtle, but in a large corpus those differences get repeated into a pattern that can be detected.
Truthful
Deceptive
How did you collect deceptive speech?
We had participants play a lying game. After collecting the baseline speech and administering the NEO-FFI test and a biographical questionnaire, we paired off participants, who took turns interviewing one another and being interviewed. For the interviewer, the goal was to judge truth or lie for each interviewee statement whereas the goal of the interviewee was to lie convincingly. As motivation, each participant earned $1 for every lie that was believed but penalized $1 when a lie failed to convince the interviewer. When asking questions, a participant earned $1 for correctly identifying a lie and forfeited $1 when accepting a lie as truth. Participants faced each other in a sound booth but were separated by a curtain, forcing participants to rely on voice alone to decide whether a statement was true or false.
What were your results using this new corpus?
Overall we were able to detect deception with about 66% accuracy using machine-learning classifiers. This level of accuracy is achieved using acoustic-prosodic features—such as pitch and other voice characteristics like loudness—and incorporating the information about gender, native language, and personality that we have so far extracted. We are not yet using lexical features such as word choice or filled pauses, which should further improve performance.
Just as important as overall accuracy, we’re finding individual differences. We found that people who are better at detecting lies also do better at deceiving others; our gender-balanced corpus gives strong evidence that this correlation is true for women and particularly true for English-native women. People’s confidence in their ability to detect deception correlates negatively with their actual ability to detect deception, possibly because interviewers less confident in their judgments ask more follow-up questions.
Personality differences became apparent also. People who scored high on extraversion and conscientiousness were worse at deceiving. The ability to detect deception was negatively correlated with neuroticism in women but not in men.
The baseline speech, from which we automatically extracted features, was by itself enough to accurately predict gender. Using the f1 metric—which accounts both for accurately predicting gender while attaining a low number of false positives—we predicted gender with a measure of .96 on the basis of both pitch and word choice. The same features enabled us to predict whether one’s native language is English or Mandarin—here with an f measure of .78. In predicting the five personality dimensions measured by the FFI test, we achieved f measures ranging from .36 to .56. We could also use this speech baseline to predict, at 65% accuracy, who could successfully detect lies. In each case, predictions are significantly higher than the baseline.
Being able to automatically extract personality features is especially important because it points to the possibility of someday deploying a system in the real world where it’s unlikely you will have personality scores of people.
But yet the overall 66% result is less than the 70% accuracy already achieved by those within your lab in the previous deception study.
We’re just beginning to explore this new corpus and still have yet to extract all the lexical features; once we do, we can use lexical features in addition to the acoustic features our classification results now rely on.
We also plan to make better use of our personality scores and to explore additional machine learning approaches such as neural nets.
It’s a huge corpus, and it’s going to take some time to learn to use all the information it contains.
For the competition, we were given a corpus very different from our own. This challenge corpus was created by having students perform a task and then lie about it; students speak for much shorter turns, the vocabulary is more restricted, and the recording conditions are different. But still we wanted to see if we could train a model on our corpus and test on this challenge corpus. We found that we could, after first automatically selecting about 500 turns from our corpus that were similar to turns in the challenge corpus.
Using acoustic features, though not lexical ones, we achieved almost the same level of accuracy in detecting deception as we did when training and testing on the challenge corpus. Which was great because it showed that acoustic features do generalize to different domains and further points to the possibility of deception detection applications outside the laboratory.
How soon before we see speech used to detect deception in interrogations or to determine guilt?
We are certainly not at the stage of determining truth or lie in real world conditions based upon speech alone. However, information from speech analysis can be combined with other information such as facial expression, body gestures, and other behaviors to help interviewers recognize deceptive cues that they might not otherwise pay attention to. Since humans often rely upon unreliable cues to deception, speech analysis can help alert interviewers to better indicators of deception.
Of all technologies being developed to detect deception, speech is the most accurate, and it has many other benefits; it doesn’t require cumbersome equipment, it is less intrusive, and it can be used after the fact. And as our experiments show, we can continue to improve the accuracy of using speech to detect deception.
In huge data sets, it is impossible to clean everything. ActiveClean analyzes prediction models and prioritizes mistakes by how much they hurt the model.
Schulzrinne will serve in this role until December, when he returns to his former position of chief technology officer for the FCC, a position he held 2011-14.
She is one of only 200 young researchers invited to this event that brings together winners of scientific and mathematics awards (Abel, Fields, Turing, Nevanlinna).
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor