In a paper presented this week at the ACM Conference on Computer and Communications Security, four computer scientists from Columbia University—Yossi Oren, Vasileios P. Kemerlis, Simha Sethumadhavan, and Angelos D. Keromytis—demonstrate that it’s possible to spy on activities of a computer user from a web browser, even in some cases determining what website(s) a user is visiting. This type of attack, dubbed spy-in-the-sandbox, works by observing activity in the CPU cache on Intel microprocessors. It affects close to 80% of PCs, and it represents an escalation and scaling up of what’s possible with side-channel attacks, requiring no special software or close proximity to the victim. Fortunately the fix is easy and Web browser vendors, alerted to the problem, are updating their code bases to prevent such attacks. One other upside: the spy-in-the-sandbox attack may serve as a primitive for secure communications.
In a side-channel attack, an attacker is able to glean crucial information by analyzing physical emissions (power, radiation, heat, vibrations) produced during an otherwise secure computation. Side-channel attacks are not new; Cold-War examples abound, from aiming a laser beam at a window to pick up vibrations from conversations inside, or installing microphones in typewriters to identify letters being typed. On computers, side-channel-attacks often work by inferring information from how much time or battery power is required to process an input or execute an operation. Given precise side-channel measurements, an attacker can work backward to reconstruct the input.
Side channel attacks can be particularly insidious because they circumvent security mechanisms. Traditionally they are directed against targeted individuals and assume proximity and special software installed on the victim’s computer. However, those assumptions may have to be rethought after four computer scientists from Columbia University (Yossef Oren, Vasileios P. Kemerlis, Simha Sethumadhavan, and Angelos D. Keromytis) demonstrated for the first time that it is possible to launch a side channel attack from within a web browser. The method is detailed in their paper The Spy in the Sandbox — Practical Cache Attacks in JavaScript and Their Implications, which was presented this week (October 12) at the ACM Conference on Computer and Communications Security.
The attack, dubbed spy-in-the-sandbox by the researchers, does not steal passwords or extract encryption keys. Instead, it shows that the privacy of computer users can be compromised from code running inside the highly restricted (sandboxed) environment of a web browser. The researchers were able to tell for instance whether a user was sitting at the computer and hitting keys or moving the mouse; more worrisome from a privacy perspective, the researchers could determine with 80% accuracy whether the victim was visiting certain websites.
More may be possible. As Yossef Oren, a postdoctoral researcher who worked on the project (now an Assistant Professor at the Department of Information Systems Engineering in Ben-Gurion University) puts it, “Attacks always become worse.”
In one sense at least, spy-in-the-sandbox attacks are more dangerous than other side-channel attacks because they can scale up to attack 1,000, 10,000, or even a million users at once. Nor are only a few users vulnerable; the attack works against users running an HTML5-capable browser on a PC with an Intel CPU based on the Sandy Bridge, Ivy Bridge, Haswell, or Broadwell micro-architectures, which account for approximately 80% of PCs sold after 2011.
How it was done
Neither proximity or special software is required; the one assumption is that the victim can be lured to a website controlled by the attacker and leaves open the browser window.
What’s running in that open browser window is JavaScript code capable of viewing and recording the flow of data in and out of the computer’s cache, specifically the L3, or last-level, cache. (A cache is extra-fast memory close to the CPU to hold data currently in use; caching data saves the time it would take to fetch data from regular memory.)
That an attacker can launch a side-channel attack from a web browser is somewhat surprising. Websites running on a computer operate within a tightly contained environment (the sandbox) that restricts what the website’s JavaScript can do.
However, the sandbox does not prevent JavaScript running in an open browser window from observing activity in the L3 cache, where websites interact with other processes running on the computer, even those processes protected by higher-level security mechanisms like virtual memory, privilege rings, hypervisors, and sandboxing.
The attack is possible because memory location information leaks out by timing cache events. If a needed element is not in the cache (a cache miss event), for instance, it takes longer to retrieve the data element. This allows the researchers to know what data is currently being used by the computer. To add a new data element to the cache, the CPU will need to evict data elements to make room. The data element is evicted not only from the L3 cache but from lower-level caches as well. To check whether data residing at a certain physical address are present in the L3 cache as well, the CPU calculates which part of the cache (cache set) is responsible for the address, then only checks the certain lines within the cache that correspond to this set, allowing the researchers to associate cache lines with physical memory.
In timing events, researchers were able to infer which instruction sets are active and which are not, and what areas in memory are active when data is being fetched. “It’s remarkable that such a wealth of information about the system is available to an unprivileged webpage,” says Oren.
“While previous studies have been able to see some of the same behavior, they relied on specially written software that had to be installed on the victim’s machine. What’s remarkable here is that we see some of the same information using only a browser,” says Vasileios Kemerlis, a PhD student who worked on the project (now an Assistant Professor in the Computer Science Department at Brown University).
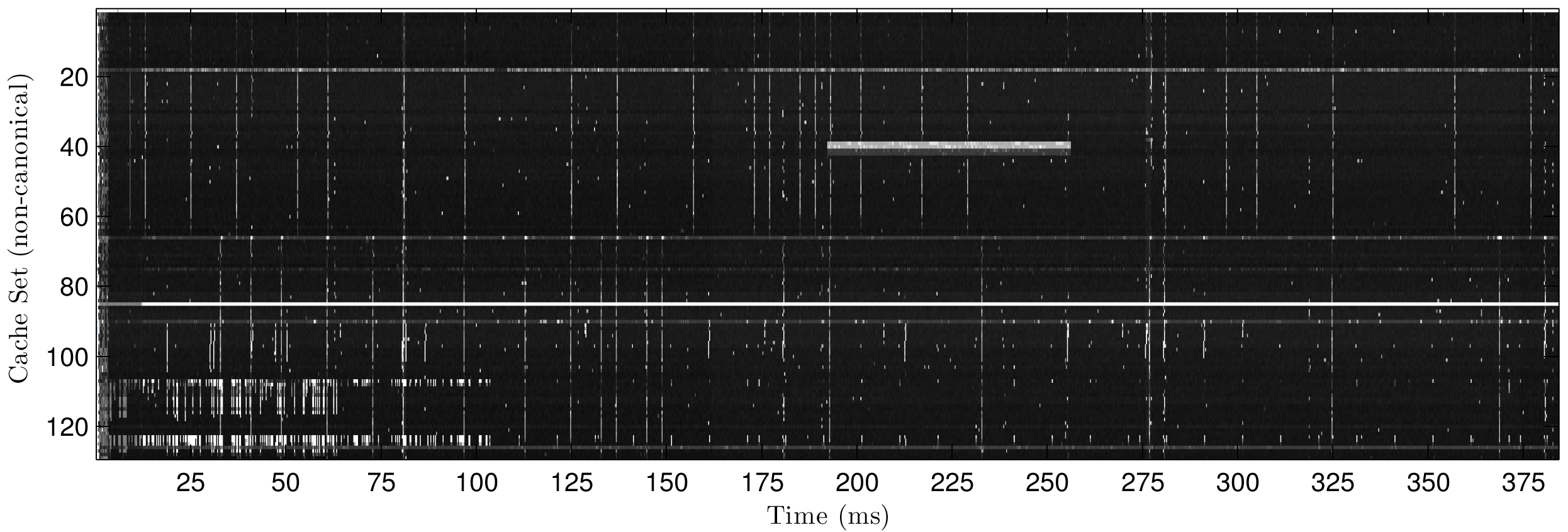
By selecting a group of cache sets and repeatedly measuring their access latencies over time, the researchers were able to construct a very detailed picture, or memorygram, of the real-time activity of the cache.
A memorygram of L3 cache activity: Vertical line segments indicate multiple adjacent cache sets are active during the same time period. Since consecutive cache sets (within the same page frame) correspond to consecutive addresses in physical memory, it may indicate the execution of a function call spanning more than 64 bytes of assembler instructions. The white horizontal line indicates a variable constantly being accessed during measurements, and probably belongs to the measurement code or to the underlying JavaScript runtime
.
Such a detailed picture is possible only because many web browsers recently upgraded the precision of their timers, making it possible to time events with microsecond precision. If memorygrams were fuzzier and less detailed, it would not be possible to capture such small events as a cache miss. (Different browsers implement this new feature with different precisions.) High-resolution timers have recently been added to browsers as a way to give developers, especially game developers, sufficient fine-grained detail to know what processes might be slowing performance. Of course, the more information developers have, the more information an attacker can access also.
Different processes have different memorygrams, and the same is true for different websites; their memorygrams will differ depending on the data the site is using, how the site is structured, how many images it contains and the size of those images. These various parts of the website end up in different locations in memory, and need to be called and cached, giving each website its own distinctive signature.
The researchers visited 10 sites and recorded multiple memorygrams in each case to build a classifier that could, with 80% accuracy, determine if a website open on a victim’s machine matched one of the 10 pre-selected sites. (The same website viewed on different browsers will exhibit slight differences; it’s this noise that prevents 100% accuracy when matching memorygrams.)
Future work
As pernicious as is the side-channel attack, especially considering how practical, scalable, and low-cost it is, avoiding it is surprisingly easy: run only a single web browser window at a time. An across-the-board fix to prevent the attacks is easy also; have browsers return to using less precise timers (or alert users of the high-precision timers that there exist possible security vulnerabilities).
And in this story of data privacy at least there is a happy ending. In March 2015, the researchers shared their research with all major browser vendors; by September 2015, Apple, Google, and Mozilla had released updated versions of their browsers to close the identified security hole.
The researchers are not yet done examining the potential of web-based side-channel attacks. They will continue looking at the problem (on old versions of browsers) to test the attack at larger scale. They are also considering a more interesting question; can memorygrams be used for good purposes?
A pre-set memorygrams might be placed in memory to be viewed by a trusted party to convey information. One memorygram might represent a 1 bit, another a 0 bit. The process of communicating in this fashion would be slow, but it would be extremely difficult for an attacker to even figure out that explicit communication is occurring between two parties. Memorygrams might thus serve as a primitive in securely conveying information, and what was once a threat to security may serve to enhance it.
About the researchers
Yossi Oren, currently Senior Lecturer (Assistant Professor) at Ben Gurion University’s Cyber Security Research Center, had previously worked as a postdoc at Columbia University within the Network Security Lab of Angelos D. Keromytis and as a Senior Innovation Research Engineer at Samsung Research Israel. Oren holds a PhD in Electrical Engineering from Tel-Aviv University and an M.Sc. in Computer Science from the Weizmann Institute of Science. His main research interests are hardware and architectural security (low-resource cryptographic constructions, power analysis and other hardware attacks and countermeasures) and Network Security (cyber-physical system security, consumer and voter privacy, web application security).Vasileios (Vasilis) Kemerlis is an Assistant Professor of Computer Science at Brown University. His research interests are in the areas of systems and network security, with a focus on automated software hardening and information-flow tracking. Currently, he works on operating systems security, and specifically on kernel exploitation and defense. Kemerlis graduated in the summer of 2015 from Columbia University with a PhD in Computer Science, working under the supervision of Angelos Keromytis. In addition, he holds a M.Phil (2013) and MS (2010) in Computer Science from Columbia University, and a BS (2006) in Computer Science from Athens University of Economics and Business.
Simha Sethumadhavan is an Associate Professor of Computer Science at Columbia Engineering. He is the founding director of the Computer Architecture and Security Technologies Lab (CASTL) at Columbia University. Sethumadhavan’s research interests are in hardware security, hardware support for security and privacy and energy-efficient computing. He has been recognized with an NSF CAREER award (2011), a top paper award (2004) and a teaching award (2006). He obtained his PhD from University of Texas, Austin in 2007.
Angelos D. Keromytis is an associate professor in the Computer Science department at Columbia University, where he directs the Network Security Lab. His general research interests are in systems and network security, and applied cryptography. In the past, he was an active participant in the IETF (Internet Engineering Task Force), and in particular the IPsec and IPSP Working Groups. He was the primary author of the IPsec stack and the OpenBSD Cryptographic Framework (OCF), which was later ported to FreeBSD and NetBSD. He has co-founded two technology startups, published over 250 refereed technical papers, and is a co-inventor in 33 issued US patents.
With little fanfare, zero congressional review or debate, and barely any public awareness, the FBI is requesting a rule change to gain broad powers to remotely search multiple computers, no matter location, on a single warrant. The implications are far-reaching and apt to affect not only suspected criminals but the innocent as well, including victims of hackers and botnets. Setting aside the Fourth Amendment, privacy concerns, and potential diplomatic consequences, there are technical reasons to oppose the rule change as proposed. Remote searches require the installation of software, or malware, which often causes unintended computer problems. What provisions prevent damage to files or programs? How will computer owners be notified? These and other technical questions are contained in a comments document by Steven M. Bellovin, Matt Blaze (University of Pennsylvania), and Susan Landau (Worcester Polytechnic Institute) and summarized here.
Today when the FBI wants to search a computer, it first obtains a search warrant from a judge within the district where the computer is located. If a second computer is to be searched and is located in a different district than the first, the FBI must go to a judge in that district for a search warrant.
Once the FBI has a seized computer in its possession, the gold standard for forensic procedures is to create a perfect image copy and search the copy, not the original. This prevents evidence from being altered—viewing files changes time-stamp information, for example—and compromising the prosecution’s case.
The one problem in all this is that the location of the computer can’t always be known. Criminals use Tor and other anonymizing software to deliberately disguise their IP addresses and locations. Another problem is investigating botnets where large numbers of computers are spread over multiple districts, making it inconvenient to obtain search warrants from judges in each district.
For this reason, the FBI is proposing a change to Rule 41(b) of the Federal Rules of Criminal Procedure—the terms under which the FBI is allowed to conduct searches—that will allow the FBI in cases when an IP address is being disguised to go to any judge in any district to get a single warrant that would allow it to remotely search one or more computers in or outside that district.
The proposed rule change is being sought from the relatively unknown Advisory Committee on Criminal Rules, an administrative office of the courts. This committee is currently considering comments on the proposed rule change until February 17, 2015.
Before getting into the technical issues raised in Comments on Proposed Remote Search Rules, it’s important to point out that the proposed rule change will affect not only suspected criminals. The comments document points out that innocent people, too, act to disguise their locations and IP addresses. Dissidents, human rights activists, whistleblowers, and journalists often deliberately disguise their identities and locations, especially in countries where their safety is at risk. The intent is to hide but the motive is to maintain personal safety not to harm others.
Users of VPNs (virtual private networks) would also fall into the category of those disguising their IP addresses. But here again the motive is not criminal. People use VPNs for a variety of innocent reasons, including accessing a work LAN (local area network) or protecting data or communications when connecting to untrusted public networks (hotels are notorious for not securing their networks).
Victims of botnets and other hacking schemes would also be potential targets of the FBI’s expanded computer searches since their computers might contain evidence of a crime or pointers that lead back to the botnet’s command-and-control node. The comments document points out that a single warrant to cover all nodes in a botnet will sweep up large numbers of innocent people, potentially hundreds of thousands and even millions. Thus the technical issues associated with remote searches extend potentially to the innocent as well.
Software installation carries risks
Remote computer searches require the installation of surveillance software. In that this software will perform actions unwanted or unknown to the computer owner, the comments document notes the FBI’s surveillance software meets at least some definitions of malware.
Install new software, especially third-party software written to run on multiple platforms, and there’s a strong possibility something will break. Almost everyone has experienced such a problem: the cardiologist whose image-reading program stops working after a new browser version is uploaded, or the writer whose Office files refuse to open after an upgrade to a new version of Windows.
It’s the nature of software. Every computer is different, and everyone is running a different version or patch of an operating system, browser, or program. The network environment, again different for everyone, adds another layer of complexity. There is no lab in the world that can test for every case. Even Apple with its vast resources and its reputation for quality is not immune. The company’s iOS 8.0.1 release last year, presumably after much testing, broke the ability of some iPhones to make phone calls.
The comments document lists two other famous cases to illustrate the point. The Stuxnet virus, surreptitiously installed on computers in the Iranian Natanz nuclear plant in 2009, worked as planned to cause the centrifuges to spin out of control. Unplanned was a bug that caused some computers to arbitrarily reboot. Plant engineers, noticing the strange reboot behavior not the centrifuge problem, sent a computer off to a Belarusian security firm for testing. Only then was the attack software found.
In 2005, hackers installed unauthorized software on a mobile phone switch operated by Vodaphone Greece. This software allowed the hackers to essentially hijack the intercept mechanism (meant for lawful enforcement purposes) to secretly wiretap 100 prominent people, including the prime minister of Greece. The problem was discovered only when the hackers upgraded the planted software and in the process inadvertently interfered with the forwarding of texts. It is not at all surprising to the technical community that software related to one part of the system (the intercept mechanism) broke an unrelated feature (text forwarding).
Remote search software is even worse at causing problems because it runs as a “root” or administrator program to override file protections. Installing software won’t cause problems on all computers, but installed on enough computers, someone somewhere is going to have problems.
From the perspective of the user whose computer stops working correctly, it may make little difference whether the responsible software was installed by the FBI or the cybercriminal down the block.
The problem of notification
Given that remote searches can cause damage, it seems only right that the FBI notify computer owners of a remote search. After all, the comments document points out that traditional search warrants generally require notice to the target, including a receipt for items seized. The innocent, whose computers are searched only for evidence of a crime done by another, should be extended the same courtesy. But how?
The comments document notes four possible notification methods: a file installed on the computer, a pop-up notification window, email, and a physical letter. Each is problematic. Few people will notice a new file. Pop-up notifications and emails might be disregarded by users who may naturally assume they are the work of hackers. (The FBI in the past has warned of malicious spam email purporting to be from the FBI.) Physical letters are time-consuming and require the cooperation of ISPs to match the IP address to a physical one. It’s not hard to imagine that ISPs might find such requests burdensome, especially when they number in the hundreds of thousands.
The proposed rule change acknowledges the difficulty of notification, requiring only that the “executing officer make reasonable efforts to provide notice,” conceding “the officer may be unable to provide notice of the warrant” when it’s not possible to reasonably determine the owner’s whereabouts.
Most owners, it seems likely, may never be notified.
A general warrant for the computer age?
Underlying the whole issue is the lack of explicit statutory authority for computer searches, and a lack of guidance on what restrictions apply.
Physical searches are limited in scope by the Fourth Amendment’s specificity requirement, which provides explicit guidance as to what can and cannot be searched. A search warrant for a particular house applies only to that house, not to adjacent buildings or to an offsite storage unit rented by the homeowner. Evidence seized in a search not covered by a warrant is often inadmissible in court under the exclusionary rule.
No explicit decision has ever been made on what specificity means in a computer context. Today a warrant to search a computer is often treated as carte blanche to search everywhere on the computer, with the “plain view” exception used to justify opening and looking through all files. Someone accused of a drug offense, whose searched computer also gives up child pornography, may be charged with this second crime. While it is hard to sympathize for a suspected criminal accused of two crimes and not one, scale makes a difference, and technology is all about scale.
Imagine a warrant to search for evidence of a 100,000-member botnet. In an instant, with no effective way to notify computer owners presumed to be innocent victims, the FBI releases surveillance software onto 100,000 computers. While the initial goal is only to find botnet evidence, what happens when such searches yield evidence of tax evasion, purchases of Class A drugs, multiple prescriptions for opioids, or threatening emails? The proposed rule change does not address this issue.
In its one-size-fits-all approach with no explicit limits to what can be searched and targeting both the presumed guilty and the presumed innocent, a remote computer search begins to resemble a general warrant, the very thing the Fourth Amendment was intended to prevent.
Hidden methods
Technology makes the difficult easy, but technology is not infallible. Bugs in the surveillance software or the examination process can affect results or make it easy to imperceptibly exceed the original scope of a warrant. Human mistakes—mistyped IP numbers, misspelled names—creep in.
Protecting the innocent from such errors becomes harder because it can’t be easily ascertained as to how the evidence was collected. The FBI keeps its methods tightly under wraps, even their existence or general notions of how they work. A defendant believing evidence to be in error needs detailed technical information about how a search was conducted in order to determine the source of the error and analyze the scope of the intrusion.
Other law enforcement techniques are transparent while remaining effective. Everybody knows the police look at fingerprints and DNA, but this doesn’t stop such evidence from being useful. Because the science is well understood and known to be reliable, juries and others trust these methods, when followed correctly, to decide guilt or innocence. When procedures are not followed correctly, the reliability of the evidence can be called into question, allowing defense attorneys an opportunity to cast doubt in the minds of juries.
This is the adversarial process guaranteed by the constitution, but it breaks down when the methods to procure evidence remain hidden. Prosecutors should be just as concerned as those charged with a crime. Evidence gathered through unknown means may make prosecutions more difficult. As well it should when it’s not clear what software is being used, whether it has been adequately tested for reliability or veracity, or whether a forensic lab is using it correctly.
A need for discussion
The comments document understands that law enforcement not surprisingly views remote computer searches as a boon to crime-fighting. For less effort than it takes to search the image copy of a seized computer, it’s possible to search millions to collect more evidence more quickly, and in a less noticeable way.
But just because technology makes remote searches easy and unobtrusive, should we allow such searches? To do so means to casually disregard constitutional protections and legal processes that have been in place for generations. National sovereignty also begins to lose meaning and force when searches of computers easily extend beyond national borders. While individual computer owners may have little recourse or few options, there may be serious consequences to ignoring national borders. We risks alienating allies, and we give other countries a pretext to retaliate in kind.
There are choices. While technology may make it easy to circumvent legal and constitutional procedures, it can also be used to bolster those protections, providing solutions for gathering evidence that are less intrusive and destructive than remote searches. In the case of botnets, honeypot machines—programmed to act like normal computers for the express purpose of becoming infected—have been shown to work effectively in monitoring and locating botnets. Engaging the technical community may well result in other technologies that aid law enforcement in less intrusive and riskier ways more in line with the legal process than remote computer searches.
The authors of Comments on Proposed Remote Search Rules do not oppose remote computer searches in principle, acknowledging that such methods are sometimes necessary to locate those who actively hide their locations to disguise criminal activity that affects us all. They question, however, is whether the extraordinary step of multi-district, single-warrant, remote searches—with all the risks such searches carry—should be applied as a matter of course even when searching bystanders’ computers.
Maybe the answer in the end is “yes” or more likely “yes in certain cases.” But the question needs to be posed in the first place, in stark and honest terms, so that the public debate produces the final answer. The authors suggest, and have made the argument at greater length elsewhere, that a legislative fix would be best given the intrusiveness of remote computer searches.
Those wanting to also comment on the proposed changes (found here, starting on page 155) can do so by following the instructions given here. The deadline for comments is February 17, 2015. The comments document written by Bellovin, Landau, and Blaze is found here.
Steven M. Bellovin is a researcher on computer networking and security, and why the two don’t get along. He is a Professor in the Computer Science department at Columbia University. Prior to joining the faculty at Columbia in 2005, he worked for many years at Bell Labs and AT&T Labs where he earned distinction as an AT&T Fellow.
He has long been interested in public policy. Beginning in 2012, Bellovin began serving as Chief Technologist of the Federal Trade Commission. He is a member of the National Academy of Engineering, and he serves on the Computer Science and Telecommunications Board of the National Academies, the Department of Homeland Security’s Science and Technology Advisory Committee, and the Election Assistance Commission’s Technical Guidelines Development Committee.
In 2007, Bellovin received the NIST/NSA National Computer Systems Security Award. He holds numerous other awards and distinctions. Along with Tom Truscott and Jim Ellis, he was awarded The Usenix Lifetime Achievement Award, The Flame for his efforts in creating USENET. He’s been actively involved with the Internet Engineering Task Force (IETF), most notably in areas pertaining to security. He also served on the Internet Architecture Board from 1996-2002, and as Security Area co-Director with the Internet Engineering Steering Group (IESG) from 2002-2004.
In addition to holding a number of patents on cryptographic and network protocols, Bellovin is the co-author of Firewalls and Internet Security: Repelling the Wily Hacker. He has been a member of numerous National Research Council Study committees during his professional career.
Matt Blaze
Matt Blaze is a cryptology expert and a computer science professor at University of Pennsylvania where he directs the Distributed Systems Lab. His research focuses on the architecture and design of secure systems based on cryptographic techniques, analysis of secure systems against practical attack models, and on finding new cryptographic primitives and techniques. He was a designer of swIPe, a predecessor of the now standard IPSEC protocol for protecting Internet traffic. Another project, CFS, investigated and demonstrated the feasibility of including encryption as file system service.
He is a member of Institute for Medicine and Engineering, and the author of numerous papers, many dealing with public policy issues especially those that concern security technology and surveillance. He often contributes articles to Wired magazine.
Susan Landau
Susan Landau is a professor in the Department of Social Science and Policy Studies at Worcester Polytechnic Institute, where she works in cybersecurity, privacy, and public policy.
She previously served as Senior Staff Privacy Analyst at Google. She was a Guggenheim Fellow and a Visiting Scholar at the Computer Science Department, Harvard University in 2012.
In 2010-2011, she was a Fellow at the Radcliffe Institute for Advanced Study at Harvard, where she investigated issues involving security of government systems, and their privacy and policy implications.
A 2012 Guggenheim fellow, Landau is the recipient of the 2008 Women of Vision Social Impact Award, and is also a fellow of the American Association for the Advancement of Science and the Association for Computing Machinery.
Eugene Wu, Assistant Professor of Computer Science
For exploring complex data sets, nothing matches the power of interactive visualizations that let people directly manipulate data and arrange it in new ways. Unfortunately, that level of interactivity is not yet possible for massive data sets.
“Computing power has grown, data sets have grown, what hasn’t kept pace is the ability to visualize and interact with all this data in a way that’s easy and intuitive for people to understand,” says Eugene Wu, who recently received his PhD from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), where he was a member of the database group.
Speed is one important component for visualizing data, but there are others, such as the ease with which interactive visualizations can be created and the ability to help understand what the results actually say. For his PhD thesis, Wu tackled the latter problem by developing a visualization tool that automatically generates explanations for anomalies in a user’s visualization. This is important because while visualizations are very good at showing what’s happening in the data, they are not good at explaining why. A visualization might show that company expenses shot up 400% in a single month, and an analyst would naturally want to understand what types of expenditures are responsible.
However, the monthly statistic is often computed from thousands or millions of input data points, and identifying a simple description of the exact subset causing the spike (e.g., California shops overspent their budgets) requires laborious, error-prone effort.
Now starting at Columbia, Wu is broadening the scope of his research and is among the first looking at the challenging problems in the overlap between databases and how people want to interact with and visualize the data in those databases. Visualization systems currently being built must take an all-or-nothing approach. “You either get performance for small data sets using a small set of fixed interactions, or you get full expressiveness with SQL and queries but you have to wait and give up interactivity.”
Part of the problem is that the database and the visualization communities have traditionally been separate, with the database side focusing on efficient query processing and accuracy, and the visualization community focusing on usability and interactions. Says Wu, “If you look at visualizations from a database perspective, a lot of it looks like database operations. In both cases, you’re computing sums, you’re computing common aggregates. We can remove many of the perceived differences between databases and visualization systems.” Wu wants to bridge the two sides to operate more closely together so both consider first the expectations and requirements of the human in the loop.
For instance, what does database accuracy mean when a human analyst can’t differentiate 3.4 from 3.45 in a scatterplot? A slight relaxation of accuracy requirements—unnoticeable to users—would conserve resources while speeding up query operations. In understanding the boundary between what a human can perceive and what amounts to wasted computations, Wu hopes to develop models of human perception that are both faithful to studies in the Human Computer Interaction and Psychology literatures, and applicable to database and visualization system performance.
On the visualization side, less attention has been paid to the programming languages (like JavaScript) used to construct the visualizations; consequently, visualizations are hard to write, to debug, and even harder to scale. A similar situation once prevailed in the database world, where application developers wrote complex and brittle code to fetch data from their databases; but the invention of SQL, a high-level, declarative language, made it easier for developers to express relationships within the data without having to worry about the underlying data representations, paving the way towards today’s ubiquitous use of data.
For Wu, the natural progression is to extend the declarative approach to interactive visualizations. With colleagues at Berkeley and University of Washington, Wu is designing a declarative visualization language to provide a set of logical operations and mappings that would free programmers from implementation details so they can logically state what they want while letting the database figure out the best way to do it.
A declarative language for visualization would have additional positive benefits. “Once you have a high-level language capable of expressing analyses, all of these analysis tools such as the explanatory analysis from my thesis is in a sense baked into whatever you build; it comes for free. There will be less need for individuals to write their own ad hoc analysis programs.”
As interactions become portable and sharable, they can be copied and pasted from one interactive visualization to another for someone else to modify. And it becomes easier to build tools, which fits with Wu’s focus in making data accessible and understandable to all users.
“When a diverse group of people look at the same data, the questions you get are more interesting than if just other computer scientists or business people are asking questions.” One of the attractions for Wu in coming to Columbia is the chance to work within the Data Science Institute and collaborate with researchers from across the university, all sharing ideas on new ways to investigate data. “Columbia has a huge range of leaders in nearly every discipline from Journalism, to Bioinformatics to Government studies. Our use of data is ultimately driven by the applications built on top, and I’m excited about working on research that can help improve and benefit from the depth and breath of research at the university.”
B.S., Electrical Engineering and Computer Science, UC Berkeley, 2007; M.S. and Ph.D., Electrical Engineering and Computer Science, Massachusetts Institute of Technology, 2011 and 2014 respectively
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor

 , currently Senior Lecturer (Assistant Professor) at Ben Gurion University’s Cyber Security Research Center, had previously worked as a postdoc at Columbia University within the Network Security Lab of Angelos D. Keromytis and as a Senior Innovation Research Engineer at Samsung Research Israel. Oren holds a PhD in Electrical Engineering from Tel-Aviv University and an M.Sc. in Computer Science from the Weizmann Institute of Science. His main research interests are hardware and architectural security (low-resource cryptographic constructions, power analysis and other hardware attacks and countermeasures) and Network Security (cyber-physical system security, consumer and voter privacy, web application security).Vasileios (Vasilis) Kemerlis is an Assistant Professor of Computer Science at Brown Un
, currently Senior Lecturer (Assistant Professor) at Ben Gurion University’s Cyber Security Research Center, had previously worked as a postdoc at Columbia University within the Network Security Lab of Angelos D. Keromytis and as a Senior Innovation Research Engineer at Samsung Research Israel. Oren holds a PhD in Electrical Engineering from Tel-Aviv University and an M.Sc. in Computer Science from the Weizmann Institute of Science. His main research interests are hardware and architectural security (low-resource cryptographic constructions, power analysis and other hardware attacks and countermeasures) and Network Security (cyber-physical system security, consumer and voter privacy, web application security).Vasileios (Vasilis) Kemerlis is an Assistant Professor of Computer Science at Brown Un iversity. His research interests are in the areas of systems and network security, with a focus on automated software hardening and information-flow tracking. Currently, he works on operating systems security, and specifically on kernel exploitation and defense. Kemerlis graduated in the summer of 2015 from Columbia University with a PhD in Computer Science, working under the supervision of Angelos Keromytis. In addition, he holds a M.Phil (2013) and MS (2010) in Computer Science from Columbia University, and a BS (2006) in Computer Science from Athens University of Economics and Business.
iversity. His research interests are in the areas of systems and network security, with a focus on automated software hardening and information-flow tracking. Currently, he works on operating systems security, and specifically on kernel exploitation and defense. Kemerlis graduated in the summer of 2015 from Columbia University with a PhD in Computer Science, working under the supervision of Angelos Keromytis. In addition, he holds a M.Phil (2013) and MS (2010) in Computer Science from Columbia University, and a BS (2006) in Computer Science from Athens University of Economics and Business.
 is an Associate Professor of Computer Science at Columbia Engineering. He is the founding director of the Computer Architecture and Security Technologies Lab (CASTL) at Columbia University. Sethumadhavan’s research interests are in hardware security, hardware support for security and privacy and energy-efficient computing. He has been recognized with an NSF CAREER award (2011), a top paper award (2004) and a teaching award (2006). He obtained his PhD from University of Texas, Austin in 2007.
is an Associate Professor of Computer Science at Columbia Engineering. He is the founding director of the Computer Architecture and Security Technologies Lab (CASTL) at Columbia University. Sethumadhavan’s research interests are in hardware security, hardware support for security and privacy and energy-efficient computing. He has been recognized with an NSF CAREER award (2011), a top paper award (2004) and a teaching award (2006). He obtained his PhD from University of Texas, Austin in 2007. is an associate professor in the Computer Science department at Columbia University, where he directs the Network Security Lab. His general research interests are in systems and network security, and applied cryptography. In the past, he was an active participant in the IETF (Internet Engineering Task Force), and in particular the IPsec and IPSP Working Groups. He was the primary author of the IPsec stack and the OpenBSD Cryptographic Framework (OCF), which was later ported to FreeBSD and NetBSD. He has co-founded two technology startups, published over 250 refereed technical papers, and is a co-inventor in 33 issued US patents.
is an associate professor in the Computer Science department at Columbia University, where he directs the Network Security Lab. His general research interests are in systems and network security, and applied cryptography. In the past, he was an active participant in the IETF (Internet Engineering Task Force), and in particular the IPsec and IPSP Working Groups. He was the primary author of the IPsec stack and the OpenBSD Cryptographic Framework (OCF), which was later ported to FreeBSD and NetBSD. He has co-founded two technology startups, published over 250 refereed technical papers, and is a co-inventor in 33 issued US patents.


