The first-year PhD student is developing tools that help people create engaging images and videos.
After growing up in Jiangsu, China, Sitong Wang studied electrical engineering at Chongqing University and the University of Cincinnati. During her co-op at the Hong Kong University of Science and Technology (HKUST), she was introduced to Human-Computer Interaction (HCI). This research area understands and enhances the interaction between humans and computers. She became interested in the field and then took her master’s at Columbia CS. Wang was intrigued by how computation can power the creative process when she worked on a design challenge that blends pop culture references with products or services and helped a group of students promote their beverage start-up.
Sitong Wang
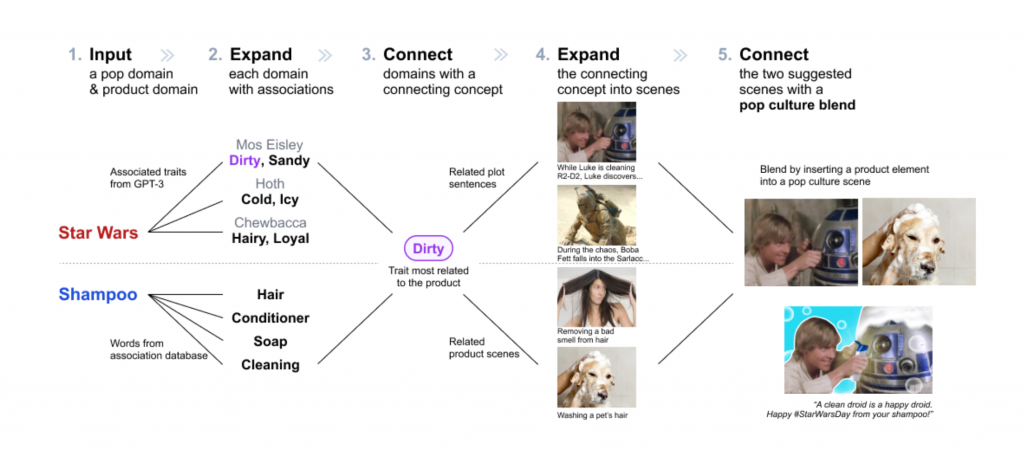
Encouraged by the creative work she could do, Wang joined the Computational Design Lab as a PhD student to continue to work with Assistant Professor Lydia Chilton and explore ways to design AI-powered creativity support tools. She recently published her first first-author research paper at the Conference on Human Factors in Computing Systems (CHI 2023). She and colleagues designed PopBlends, a system that automatically suggests conceptual blends by connecting a user’s topic with a pop culture domain. Their user study shows that people found twice as many blend suggestions as they did without the system and with half the mental demand.
We caught up with Wang to discuss her research, her work on generative AI tools, and what it is like to be a graduate student at Columbia.
Pop culture blends for Star Wars Day collected on Twitter from McDonald’s, Volkswagon, and the Girl Scouts.
Q: What is PopBlends and why did you choose to focus on the design process?
In the paper, we tackled the creative challenge of designing pop culture blends—images that use pop culture references to promote a product or service. We designed PopBlends, an automated pipeline consisting of three complementary strategies to find creative connections between a product and a pop culture domain.
Our work explores how large language models (LLMs) can provide associative knowledge and commonsense reasoning for creative tasks. We also discuss how to combine the power of traditional knowledge bases and LLMs to support creators in their divergent and convergent thinking.
It can help people, especially those without a design background, create pop culture blends more easily to advertise their brands. We want to make the design process more enjoyable and less cognitively demanding for everyone. We hope to enhance people’s creativity and productivity by scaffolding the creative process and using the power of computation to help people explore the design space more efficiently.
Q: Why did you create a tool incorporating pop culture into product ads?
Pop culture is important in everyday communication. Pop culture blends are helpful for online campaigns because they capture attention and connect the product to something people already know and like. However, creating these images is a challenging conceptual blending task and requires finding connections between two very different domains.
So we built an automated computational pipeline that can effectively support divergent and convergent thinking in finding such creative connections. We explored how to apply generative AI to creative workflows to assist people better—generative AI is powerful, but it is not perfect—thus, it is valuable to use different strategies that combine a knowledge base (which is accurate) and LLM (which has a vast amount of data) to support creative tasks.
Q: How were large language models (LLMs) helpful in your research?
Conceptual blending is complex—the design space is vast and valuable connections are rare—to tackle this challenge, we need to scaffold the ideation process and combine the intelligence of humans and machines. When we started this project, GPT-3 was not yet available; we tried traditional NLP techniques to find attribute associations (e.g., Chewbacca is fluffy) but faced challenges. Then, by chance, we tried GPT-3, which worked well with the necessary prompt engineering.
I was surprised by the associative reasoning capability of LLMs—which is technically a model that predicts the most probable next word. It easily listed related concepts for different domains and could suggest possible creative connections. I was also surprised by the hallucinations the LLMs made through our experiments, and the models could say things that were not true with great confidence.
As an emerging technology, LLMs are powerful in many ways and open up new opportunities for the computational design field. However, LLMs currently have a lot of limitations; it is essential to explore how to build system architectures around them to produce valuable results for people.
Wang presenting PopBlends at CHI’23
Q: How was it like presenting your work at CHI?
I was both nervous and excited because it had been a long time since I had presented in front of a crowd (since we did everything online during COVID). It was also my first time presenting at a computing conference, and the “Large Language Models” session I attended was very popular.
I am grateful to my labmate Vivian Liu, who provided valuable advice, helped me rehearse, and took pictures of me. The presentation went well, and I am glad we had the opportunity to present our work to a large audience of researchers. I would also like to express my gratitude to the researchers I met during the conference, as they provided encouragement and helpful tips that greatly contributed to my experience.
Q: What are you working on now?
I am working on a tool to help journalists transform their print articles into reels using generative AI by assisting them in the creative stages of producing scripts, character boards, and storyboards. In this work, in addition to LLMs, we incorporate text-to-image models and try to combine the power of both to support creators.
During the summer, I will work as a research intern at Adobe, where I will be focusing on AI and video authoring. Our work will revolve around facilitating the future of podcast video creation.
Q: Can you talk about your background and why you pursued a PhD?
My undergraduate program offered great co-op opportunities that allowed me to explore different paths, including roles as an engineer, UI designer, and research intern across Chongqing, Charlottesville, and Hong Kong. During my final co-op, I had the opportunity to work in the HCI lab at the Hong Kong University of Science and Technology (HKUST). This experience ignited my passion for HCI research and marked the beginning of my research journey in this field.
I enjoy exploring unanswered questions, particularly those that reside at the intersection of multiple disciplines. A PhD program provides an excellent opportunity to work on the problems that interest me the most. In addition, I think the training provided at the PhD level can enhance essential skills such as leadership, collaboration, critical thinking, and effective communication.
Q: What are your research interests?
My research interest lies in the creativity support in the HCI field. I am particularly interested in exploring the role of multimodal generative AI in creativity support tools. I enjoy developing co-creative interactive systems to support everyone in their everyday creative tasks.
Q: What research questions or issues do you hope to answer now?
I want to explore the role of generative AI models in future creativity support tools and build co-creative intelligent systems that support multimodal creativity, especially in the dimensions of audio and videos, as they are how we interact with the world. I also want to explore some theoretical questions, such as the overtrust/overreliance in AI, and see how we might understand and resolve them.
Sitong Wang
Q: Why did you choose to apply to Columbia CS? What attracted you to the program?
I love the vibrant environment of Columbia and NYC and how Columbia is strong in diverse disciplines, such as journalism, business, and law. It is an ideal place to do multi-disciplinary collaborative research.
Also, I got to know Professor Chilton well during my masters at Columbia. She is incredibly supportive and wonderful, and we share many common interests. That is why I chose to continue to work with her for my PhD journey.
Q: What has been the highlight of your time at Columbia?
The highlight would be when I witnessed the success of the students I mentored. It was such a rewarding process to guide and help undergraduate students interested in HCI research begin their journey.
Q: What is your advice to students on how to navigate their time at Columbia? If they want to do research, what should they know or do to prepare?
Enjoy your time in NYC! Please don’t burn yourself out; learn how to manage your time efficiently. Don’t be afraid to try new things—start with manageable tasks, but also step out of your comfort zone. You will have fun!
If you want to do research, find research questions that genuinely interest you and be prepared to face challenges. Most importantly, preserve and trust yourself and your collaborators. Your efforts will eventually pay off!
For robots to be generally useful, they must be able to find arbitrary objects described by people (i.e., be language-driven) even without expensive navigation training on in-domain data (i.e., perform zero-shot inference). We explore these capabilities in a unified setting: language-driven zero-shot object navigation (L-ZSON). Inspired by the recent success of open-vocabulary models for image classification, we investigate a straightforward framework, CLIP on Wheels (CoW), to adapt open-vocabulary models to this task without fine-tuning. To better evaluate L-ZSON, we introduce the Pasture benchmark, which considers finding uncommon objects, objects described by spatial and appearance attributes, and hidden objects described relative to visible objects. We conduct an in-depth empirical study by directly deploying 21 CoW baselines across Habitat, RoboTHOR, and Pasture. In total, we evaluate over 90k navigation episodes and find that (1) CoW baselines often struggle to leverage language descriptions, but are proficient at finding uncommon objects. (2) A simple CoW, with CLIP-based object localization and classical exploration — and no additional training — matches the navigation efficiency of a state-of-the-art ZSON method trained for 500M steps on Habitat MP3D data. This same CoW provides a 15.6 percentage point improvement in success over a state-of-the-art RoboTHOR ZSON model.
Multi-channel video-language retrieval require models to understand information from different channels (e.g. video+question, video+speech) to correctly link a video with a textual response or query. Fortunately, contrastive multimodal models are shown to be highly effective at aligning entities in images/videos and text, e.g., CLIP; text contrastive models are extensively studied recently for their strong ability of producing discriminative sentence embeddings, e.g., SimCSE. However, there is not a clear way to quickly adapt these two lines to multi-channel video-language retrieval with limited data and resources. In this paper, we identify a principled model design space with two axes: how to represent videos and how to fuse video and text information. Based on categorization of recent methods, we investigate the options of representing videos using continuous feature vectors or discrete text tokens; for the fusion method, we explore the use of a multimodal transformer or a pretrained contrastive text model. We extensively evaluate the four combinations on five video-language datasets. We surprisingly find that discrete text tokens coupled with a pretrained contrastive text model yields the best performance, which can even outperform state-of-the-art on the iVQA and How2QA datasets without additional training on millions of video-text data. Further analysis shows that this is because representing videos as text tokens captures the key visual information and text tokens are naturally aligned with text models that are strong retrievers after the contrastive pretraining process. All the empirical analysis establishes a solid foundation for future research on affordable and upgradable multimodal intelligence.
Generalized few-shot object detection aims to achieve precise detection on both base classes with abundant annotations and novel classes with limited training data. Existing approaches enhance few-shot generalization with the sacrifice of base-class performance, or maintain high precision in base-class detection with limited improvement in novel-class adaptation. In this paper, we point out the reason is insufficient Discriminative feature learning for all of the classes. As such, we propose a new training framework, DiGeo, to learn Geometry-aware features of inter-class separation and intra-class compactness. To guide the separation of feature clusters, we derive an offline simplex equiangular tight frame (ETF) classifier whose weights serve as class centers and are maximally and equally separated. To tighten the cluster for each class, we include adaptive class-specific margins into the classification loss and encourage the features close to the class centers. Experimental studies on two few-shot benchmark datasets (VOC, COCO) and one long-tail dataset (LVIS) demonstrate that, with a single model, our method can effectively improve generalization on novel classes without hurting the detection of base classes.
Vision Transformers (ViTs) emerge to achieve impressive performance on many data-abundant computer vision tasks by capturing long-range dependencies among local features. However, under few-shot learning (FSL) settings on small datasets with only a few labeled data, ViT tends to overfit and suffers from severe performance degradation due to its absence of CNN-alike inductive bias. Previous works in FSL avoid such problem either through the help of self-supervised auxiliary losses, or through the dextile uses of label information under supervised settings. But the gap between self-supervised and supervised few-shot Transformers is still unfilled. Inspired by recent advances in self-supervised knowledge distillation and masked image modeling (MIM), we propose a novel Supervised Masked Knowledge Distillation model (SMKD) for few-shot Transformers which incorporates label information into self-distillation frameworks. Compared with previous self-supervised methods, we allow intra-class knowledge distillation on both class and patch tokens, and introduce the challenging task of masked patch tokens reconstruction across intra-class images. Experimental results on four few-shot classification benchmark datasets show that our method with simple design outperforms previous methods by a large margin and achieves a new start-of-the-art. Detailed ablation studies confirm the effectiveness of each component of our model. Code for this paper is available here: this https URL.
Synthesizing 3D human avatars interacting realistically with a scene is an important problem with applications in AR/VR, video games and robotics. Towards this goal, we address the task of generating a virtual human — hands and full body — grasping everyday objects. Existing methods approach this problem by collecting a 3D dataset of humans interacting with objects and training on this data. However, 1) these methods do not generalize to different object positions and orientations, or to the presence of furniture in the scene, and 2) the diversity of their generated full-body poses is very limited. In this work, we address all the above challenges to generate realistic, diverse full-body grasps in everyday scenes without requiring any 3D full-body grasping data. Our key insight is to leverage the existence of both full-body pose and hand grasping priors, composing them using 3D geometrical constraints to obtain full-body grasps. We empirically validate that these constraints can generate a variety of feasible human grasps that are superior to baselines both quantitatively and qualitatively. See our webpage for more details: this https URL.
The relatively hot temperature of the human body causes people to turn into long-wave infrared light sources. Since this emitted light has a larger wavelength than visible light, many surfaces in typical scenes act as infrared mirrors with strong specular reflections. We exploit the thermal reflections of a person onto objects in order to locate their position and reconstruct their pose, even if they are not visible to a normal camera. We propose an analysis-by-synthesis framework that jointly models the objects, people, and their thermal reflections, which combines generative models with differentiable rendering of reflections. Quantitative and qualitative experiments show our approach works in highly challenging cases, such as with curved mirrors or when the person is completely unseen by a normal camera.
Tracking Through Containers and Occluders in the Wild Basile Van Hoorick Columbia University, Pavel Tokmakov Toyota Research Institute, Simon Stent Woven Planet, Jie Li Toyota Research Institute, Carl Vondrick Columbia University
Tracking objects with persistence in cluttered and dynamic environments remains a difficult challenge for computer vision systems. In this paper, we introduce TCOW, a new benchmark and model for visual tracking through heavy occlusion and containment. We set up a task where the goal is to, given a video sequence, segment both the projected extent of the target object, as well as the surrounding container or occluder whenever one exists. To study this task, we create a mixture of synthetic and annotated real datasets to support both supervised learning and structured evaluation of model performance under various forms of task variation, such as moving or nested containment. We evaluate two recent transformer-based video models and find that while they can be surprisingly capable of tracking targets under certain settings of task variation, there remains a considerable performance gap before we can claim a tracking model to have acquired a true notion of object permanence.
Doubly Right Object Recognition: A Why Prompt for Visual Rationales Chengzhi Mao Columbia University, Revant Teotia Columbia University, Amrutha Sundar Columbia University, Sachit Menon Columbia University, Junfeng Yang Columbia University, Xin Wang Microsoft Research, Carl Vondrick Columbia University
Many visual recognition models are evaluated only on their classification accuracy, a metric for which they obtain strong performance. In this paper, we investigate whether computer vision models can also provide correct rationales for their predictions. We propose a “doubly right” object recognition benchmark, where the metric requires the model to simultaneously produce both the right labels as well as the right rationales. We find that state-of-the-art visual models, such as CLIP, often provide incorrect rationales for their categorical predictions. However, by transferring the rationales from language models into visual representations through a tailored dataset, we show that we can learn a “why prompt,” which adapts large visual representations to produce correct rationales. Visualizations and empirical experiments show that our prompts significantly improve performance on doubly right object recognition, in addition to zero-shot transfer to unseen tasks and datasets.
What You Can Reconstruct From a Shadow Ruoshi Liu Columbia University, Sachit Menon Columbia University, Chengzhi Mao Columbia University, Dennis Park Toyota Research Institute, Simon Stent Woven Planet, Carl Vondrick Columbia University
3D reconstruction is a fundamental problem in computer vision, and the task is especially challenging when the object to reconstruct is partially or fully occluded. We introduce a method that uses the shadows cast by an unobserved object in order to infer the possible 3D volumes under occlusion. We create a differentiable image formation model that allows us to jointly infer the 3D shape of an object, its pose, and the position of a light source. Since the approach is end-to-end differentiable, we are able to integrate learned priors of object geometry in order to generate realistic 3D shapes of different object categories. Experiments and visualizations show that the method is able to generate multiple possible solutions that are consistent with the observation of the shadow. Our approach works even when the position of the light source and object pose are both unknown. Our approach is also robust to real-world images where ground-truth shadow mask is unknown.
Recent works have demonstrated that natural language can be used to generate and edit 3D shapes. However, these methods generate shapes with limited fidelity and diversity. We introduce CLIP-Sculptor, a method to address these constraints by producing high-fidelity and diverse 3D shapes without the need for (text, shape) pairs during training. CLIP-Sculptor achieves this in a multi-resolution approach that first generates in a low-dimensional latent space and then upscales to a higher resolution for improved shape fidelity. For improved shape diversity, we use a discrete latent space which is modeled using a transformer conditioned on CLIP’s image-text embedding space. We also present a novel variant of classifier-free guidance, which improves the accuracy-diversity trade-off. Finally, we perform extensive experiments demonstrating that CLIP-Sculptor outperforms state-of-the-art baselines.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor