The Doctoral Dissertation Award is awarded annually to recognize a recent doctoral candidate who has successfully defended and completed his or her Ph.D. dissertation in computer graphics and interactive techniques. This award recognizes young researchers who have already made a notable contribution very early during their doctoral study.
The 37th International Conference on Machine Learning is an annual event taking place virtually this week. Professor David Blei is the General Chair of the conference for the larger machine learning research community.
Professor Elias Bareinboim presented a tutorial entitled “Towards Causal Reinforcement Learning,” where he discussed a new approach for decision-making under uncertainty in sequential settings. The tutorial is based on his observation, in his own words, “Causal inference (CI) and reinforcement learning (RL) are two disciplines that have evolved independently and achieved great successes in the past decades, but, in reality, are much closer than one would expect. Many new learning problems emerge whenever we understand and formally acknowledge their connection. I believe this understanding will make them closer and more applicable to real-world settings.”
In particular, Bareinboim explained that CI provides a set of tools and principles that allows one to combine structural invariances about the environment with data to reason about questions of counterfactual nature — i.e., what would have happened had reality been different, even when no data about this imagined reality is available. On the other hand, RL is concerned with efficiently finding a policy that optimizes a specific function (e.g., reward, regret) in interactive environments under sampling constraints, i.e., regarding the agent’s number of interactions with the environment. These two disciplines have evolved with virtually no interaction between them. Bareinboim noticed that even though they operate under different aspects of reality (an “environment,” as usually said in RL jargon), they are two sides of the same coin, namely, counterfactual relations.
His group at Columbia, the Causal Artificial Intelligence Lab, has been investigating in the last years the implications of this observation for decision-making in partially observable environments. In the first part of his tutorial, Bareinboim introduced the basics of CI and RL, and then explained how they fit the larger picture through a CRL lens. In particular, he used a newly proved result (joint with collaborators at Stanford University), the Causal Hierarchy Theorem (CHT), to discuss the different types of “interactions” an agent could have with the environment it is deployed, namely, “seeing”, “doing”, and “imagining.” He then puts the literature of RL — on- and off-policy learning — as well as the CI type of learning — called do-calculus learning — under the same formal umbrella. After being able to formalize CI and RL in a shared notation, in the second part of the tutorial, he notices that CRL opens up a new family of learning problems that are both real and pervasive, but weren’t acknowledged before. He discusses many of these problems, including the combination of online & offline learning (called generalized policy learning), when and where the agent should intervene in a system, counterfactual decision-making, generalizability across environments, causal imitation learning, to cite a few.
Bareinboim’s program is to develop a principled framework for designing causal AI systems that integrate observational, experimental, counterfactual data, modes of reasoning, and knowledge, which he believes, will lead to “a natural treatment to human-like explainability and rational decision-making.” If you are interested in joining the effort, he is actively recruiting graduate students, postdoctoral scholars, and trying to find collaborators who believe in Causal AI. The tutorial’s material and further resources about CRL can be found here: https://crl.causalai.net.
Below are links to the accepted papers and brief research descriptions.
One of the central challenges in the data sciences is to compute the effect of a novel (never experience before) intervention from a combination of observational and experimental distributions, under the assumptions encoded in the form of a causal graph. Formally speaking, this problem appears under the rubric of causal effect identification and has been studied under various conditions in the theory of data-fusion (Survey: Bareinboim & Pearl, PNAS 2016; Video: Columbia Talk). Most of this literature, however, implicitly assumes that every variable modeled in the graph is measured throughout the datasets. This is a very stringent condition. In practice, the data collected in different studies are usually not consistent, i.e., each dataset measures a different set of variables.
For concreteness, consider a health care researcher who wants to estimate the effect of exercise (X) on cardiac stroke (Y) from two existing datasets. The first dataset is from an experimental study of the effect of exercise (X) on blood pressure (B) for different age groups (A). The second dataset is from an observational study that investigated the association between BMI (C), blood pressure (B), and stroke (Y). Currently, no algorithm can take these two datasets over {X, Y, A, B, C} and systematically combine them so as to identify the targeted causal effect — how exercise (X) affects cardiac stroke (Y).
In this paper, the researchers studied the causal effect identifiability problem when the available distributions encompass different sets of variables, which they refer to as causal effect identification under partial-observability (GID-PO). They derived properties of the factors that comprise a causal effect under various levels of abstraction (known as projections), and then characterized the relationship between them with respect to their status relative to the identification of a targeted intervention. They establish a sufficient graphical criterion for determining whether the effects are identifiable from partially-observed distributions. Finally, building on these graphical properties, they developed an algorithm that returns a formula for a causal effect in terms of the available distributions, whenever this effect is found identifiable.
One metaphor used throughout the paper is of a jigsaw puzzle, where the targeted effect is comprised of pieces and each dataset contains chunks, where each chunk is one or more pieces merged together. The task is to combine the chunks so as to solve the puzzle, even though not all puzzles are solvable. They infer that the identifiability problem under partial-observability is NP-complete.
“This conjecture is particularly surprising since many existing classes of identifiability problems have been entirely solved in polynomial time, the decision version of the problem, not an estimation,” said Sanghack Lee, an associate research scientist in the CausalAI Lab. “The class of time complexity of an identification problem may rely crucially on the lack of variables in the data sets, not the number of available data sets nor the size of a causal graph.”
Linear regression and its generalizations have been the go-to tool of a generation of data scientists trying to understand the relationships among variables in multivariate systems, and the workhorse behind countless breakthroughs in science. Modern statistics and machine learning techniques allow one to scale regression up to thousands of variables simultaneously. Despite the power entailed by this family of methods, it only explains the association (or correlation) between variables, while it remains silent with respect to causation. In practice, a health scientist may be interested in knowing the effect of a new treatment on the survival of its patients, while an economist may attempt to understand the unintended consequences of a new policy on a nation’s gross domestic product. If regression analysis doesn’t allow scientists to answer their more pressing questions, which technique or framework could legitimize such inferences?
The answer lies in the tools of causal inference, specifically in the methods developed to solve the problem of “identification”. In the context of linear systems, formally speaking, identification asks whether a specific causal coefficient can be uniquely computed from the observational covariance matrix and the causal model. There exists a rich literature on linear identification, which includes a general algebraic solution (based on Groebner bases) that is doubly-exponential. In practice, and given this hardness result, the most common approach in the field is known as the method of instrumental variables (IVs), which looks for a particular substructure within the covariance matrix.
The research develops a new polynomial-time algorithm for linear identification that generalizes IV and all known efficient methods. The machinery developed underlying this algorithm unifies several disparate methods developed in the literature for the last two decades. Perhaps surprisingly, it turns out that this new method is also able to subsume identification approaches based on conditioning, some of which have high identification power but undetermined computational complexity, with certain variants shown to be NP-Hard.
Finally, this paper also allows one to efficiently solve for total effects based on a new decomposition strategy of the covariance matrix. It is still an open problem whether there exists an algorithm capable of identifying all causal coefficients in polynomial time.
This paper investigates the problem of learning decision rules that dictate what action should be taken at each state given an evolving set of covariates (features) and actions, which is usually called Dynamic Treatment Regimes (DTRs). DTRs have been increasingly popular in decision-making settings in healthcare.
Consider the treatment of alcohol dependence. Based on the condition of alcohol-dependent patients (S1), the physician may prescribe medication or behavioral therapy (X1). Patients are then classified as responders or non-responders (S2) based on their level of heavy drinking within the next two months. The physician then must decide whether to continue the initial treatment or to switch to an augmented plan combining both medication and behavioral therapy (X2). The primary outcome Y is the percentage of abstinent days over a 12-month period. A DTR here is a sequence of decision rules x1 = f1(s1), x2 = f2(x1, s1, s2) that decides the treatment X so as to optimize the expected outcome Y.
In this paper, the researchers studied how to find the optimal DTR in the context of online reinforcement learning. It has been shown that finding the optimal DTR requires Ω(|X ⋃ S|) trials, where |X ⋃ S| is the size of the treatment and state variables. In many applications, the domains of X and S could be significantly large, which means that the time required to ensure appropriate learning may be unattainable. They develop a novel strategy that leverages the causal diagram of the underlying environment to improve this sample complexity, leading to online algorithms that require an exponentially smaller number of trials. They also introduce novel methods to derive bounds over the underlying system dynamics (i.e., the causal effects) from the combination of the causal diagram and the observational (nonexperimental) data (e.g., from the physicians’ prior decisions). The derived bounds are then incorporated into proposed online decision-making algorithms.
“This result is surprising since most of the existing methods would suggest discarding the observational data when it is plagued with the unobserved confounding, and the causal effect is not uniquely identifiable,” said Junzhe Zhang, a research assistant in the CausalAI lab. “We show that the performance of online learners could be consistently improved by leveraging abundant, yet biased observational data.”
Stochastic Flows and Geometric Optimization on the Orthogonal Group Krzysztof Choromanski Google Brain Robotics, Valerii Likhosherstov University of Cambridge, Jared Q Davis Google Research, David Cheikhi Columbia University, Achille Nazaret Columbia University, Xingyou Song Google Brain, Achraf Bahamou Columbia University, Jack Parker-Holder University of Oxford, Mrugank Akarte Columbia University, Yuan Gao Columbia University, Jacob Bergquist Columbia University, Aldo Pacchiano UC Berkeley, Vikas Sindhwani Google, Tamas Sarlos Google, Adrian Weller University of Cambridge, Alan Turing Institute
This paper presents a new class of stochastic, geometrically driven optimization algorithm for optimization problem defined on orthogonal group. The objective is to maximize a function F(x), where F takes arguments from matrix manifold. The paper solves this problem by computing and discretizing the on-manifold gradient flows and showed an intriguing connection between efficient stochastic optimization on the orthogonal group and graph theory.
The paper compares FLOPS needed for classification model on MISNT and CIFAR-10 dataset for our algorithm with state-of-the-art algorithms. The algorithm had substantial gains in time complexity as compared to other methods without much loss in accuracy. The paper also shows effectiveness of the algorithm for variety of continuous Reinforcement learning tasks like Humanoid from OpenAI gym.
Students from diverse, nontraditional backgrounds can now take a one-year transition before entering the MS program in computer science.
The CS@CU MS Bridge Program in Computer Science launched this summer with students from a variety of backgrounds ranging from the sciences to architecture, economics, finance, and management. The 22 students have one thing in common – a desire to learn computer science (CS) to jump-start a career in technology.
This program offers prospective applicants from non-computer science backgrounds, including those without programming experience, the opportunity to acquire the knowledge and skills necessary to prepare them for the CS master’s program. A year of rigorous “bridge” coursework is composed of introductory CS courses. This one-year transition prepares students for a seamless entrance into the MS program after the bridge year. The program is highly competitive with only 22 students accepted out of 88 applicants.
The virtual orientation of the first cohort.
The main inspiration for the program is Northeastern’s Align MS in Computer Science program. Columbia was one of a small number of schools which received seed funding from Facebook to help create bridge programs for students with diverse backgrounds at other universities.
“Unlike other similar programs, MS Bridge students start their program by taking the same core CS courses as our undergraduate students,” said Tony Dear, a Lecturer in Discipline and the CS@CU MS Bridge Program Director. The cohort has access to the same instruction, resources, and interactions with other students who are starting CS for the first time. In addition, MS Bridge students are afforded as much flexibility as they need, taking anywhere from one to three or four courses per semester until they are ready to move on to the MS portion of the program.
Another goal of the program is to advance diversity in the master’s program and this caught the attention of CS alum Janet Lustgarten (MS ‘85). “As a woman and an immigrant, I know how important it is to open up opportunities for different types of people,” said Lustgarten. After emigrating from Colombia at a young age, she found the universal language of mathematics a gateway to excel in school. She went on to become the first graduate with a degree in Computer Science and Mathematical Logic from Mount Holyoke and then received her MS degree from Columbia Engineering. She has led an exceptional career as co-founder & CEO of Kx Systems and President of Shakti Software, making numerous contributions to science, engineering, business, and beyond.
The Lustgarten-Whitney Family Fellowship was established specifically for the CS@CU MS Bridge Program. The generous gift provides fellowship support to three highly-qualified students from underrepresented and nontraditional backgrounds pursuing a career in computer science. Shared Lustgarten, “I hope that this gift from my family will play a vital role in launching the program, ensuring that the most qualified students are able to attend regardless of financial need, and inspiring a new generation of leaders in technology.”
Students convened virtually in May and most are now in the thick of summer classes. About half of the group is interested in pursuing the software systems and machine learning tracks for their master’s degree. Some have expressed interest in computational biology and natural language processing. A few already have plans to pursue a PhD afterward and they are interested in doing research and/or a thesis during the MS. Because there is flexibility when it comes to courses, this first cohort can explore and figure out the right path for their careers in technology.
Papers from the Speech and Natural Language Processing groups were accepted to the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020). The research developed systems that improve fact-checking, generate sarcasm, and detect deception and a neural network that extracts knowledge about products on Amazon.
A team led by Shih-Fu Chang, the Richard Dicker Professor and Senior Executive Vice Dean School of Engineering, won a Best Demonstration Paper award for GAIA: A Fine-grained Multimedia Knowledge Extraction System, the first comprehensive, open-source multimedia knowledge extraction system.
Kathleen McKeown, the Henry and Gertrude Rothschild Professor of Computer Science, also gave a keynote presentation – “Rewriting the Past: Assessing the Field through the Lens of Language Generation”.
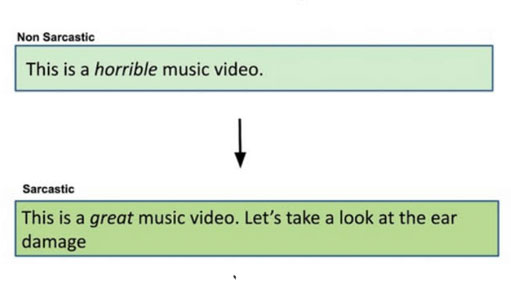
The paper proposes an unsupervised approach for sarcasm generation based on a non-sarcastic input sentence. This method employs a retrieve-and-edit framework to instantiate two major characteristics of sarcasm: reversal of valence and semantic incongruity with the context, which could include shared commonsense or world knowledge between the speaker and the listener.
While prior works on sarcasm generation predominantly focus on context incongruity, this research shows that combining valence reversal and semantic incongruity based on commonsense knowledge generates sarcastic messages of higher quality based on several criteria. Human evaluation shows that the system generates sarcasm better than human judges 34% of the time, and better than a reinforced hybrid baseline 90% of the time.
Humans are very poor lie detectors. Study after study has found that humans perform only slightly above chance at detecting lies. This paper aims to understand why people are so poor at detecting lies, and what factors affect human perception of deception. To conduct this research, a web-based lie detection game called LieCatcher was created. Players were presented with recordings of people telling lies and truths, and they had to guess which are truthful and which are deceptive. The game is entertaining for players and simultaneously provides labels of deception perception.
LieCatcher
Judgments from more than 400 players were collected. This perception data was used to identify linguistic and prosodic (intonation, tone, stress, and rhythm) characteristics of speech that lead listeners to believe what is true or to trust it.
The researchers studied how the characteristics of trusted speech align or misalign with indicators of deception, and they trained machine learning classifiers to automatically identify speech that is likely to be trusted or mistrusted. They found several intuitive indicators of mistrust, such as disfluencies (e.g. “um”, “uh”) and speaking slowly. An indicator of trust was a faster speaking rate — people tended to trust speech that was faster. They also observed a mismatch between features of trusted and truthful speech and the strategies used by the players to be ineffective.
What surprised the researchers is that prosodic indicators of deception, such as pitch and loudness changes, were the most difficult for humans to perceive and interpret correctly. In fact, many prosodic cues to deception were perceived by human raters as cues to the truth. For example, utterances with a higher pitch were perceived as more truthful, when in fact this is a cue to deception.
This work is useful for a number of applications, such as generating trustworthy speech for virtual assistants or dialogue systems.
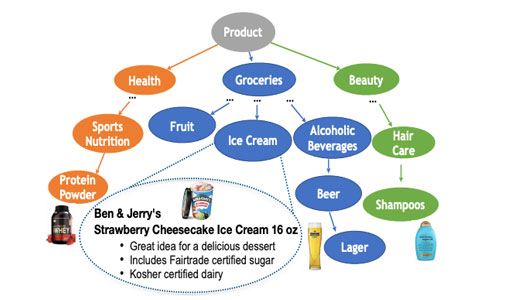
The paper presents TXtract, a neural network that extracts knowledge about products from Amazon’s taxonomy with thousands of product categories, ranging from groceries to health products and electronics.
For example, given an ice cream product at Amazon.com with text description “Ben & Jerry’s Strawberry Cheesecake Ice Cream 16 oz”, TXtract extracts text phrases as product attributes:
Values extracted through TXtract lead to a richer catalog with millions of products and their corresponding attributes, which is promising to improve the experience of customers searching for products at Amazon.com or asking product-specific questions through Amazon Alexa.
DeSePtion: Dual Sequence Prediction and Adversarial Examples for Improved Fact-Checking Christopher Hidey Columbia University, Tuhin Chakrabarty Columbia University, Tariq Alhindi Columbia University, Siddharth Varia Columbia University, Kriste Krstovski Columbia University, Mona Diab Facebook AI & George Washington University, and Smaranda Muresan Columbia University
The increased focus on misinformation has spurred the development of data and systems for detecting the veracity of a claim as well as retrieving authoritative evidence. The FactExtraction and VERification (FEVER) dataset provide such a resource for evaluating end-to-end fact-checking, requiring retrieval of evidence from Wikipedia to validate a veracity prediction.
This paper shows that current systems for FEVER are vulnerable to three categories of realistic challenges for fact-checking – multiple propositions, temporal reasoning, and ambiguity and lexical variation – and introduces a resource with these types of claims.
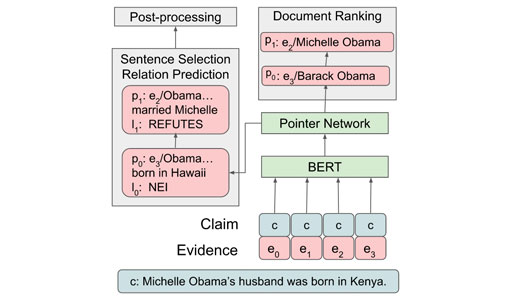
Fact checking where the fact needs to be verified with evidence from two different sources (Michelle Obama and Barrack Obama).
The researchers present a system designed to be resilient to these “attacks” using multiple pointer networks for document selection and jointly modeling a sequence of evidence sentences and veracity relation predictions. They found that in handling these attacks they obtained state-of-the-art results on FEVER, largely due to improved evidence retrieval.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor