
Month: August 2019
11 Graduate Students Selected for Prestigious Fellowships
The diverse cohort come from the various groups within the department. They are a mix of those new to Columbia and students who have received fellowships for the year.
J.P. Morgan 2019 AI Research PhD Fellowship Awards
The inaugural award supports researchers who have the skills and imagination to potentially transform the way we live and work.

Ana-Andreaa Stoica
A third-year PhD student, Ana-Andreaa Stoica works with Augustin Chaintreau on social networks and algorithmic fairness. Her work focuses on mathematical models, data analysis, and policy implications for algorithm design in social networks. Stoica graduated from Princeton in 2016 with a bachelor’s degree in Mathematics and certificates in Computing and Applied Mathematics.
2019 Google PhD Fellowship in Algorithms, Optimizations, and Markets
The program recognizes outstanding graduate students doing exceptional work in computer science and related research areas.

Peilin Zhong
A member of the Theory Group, Peilin Zhong is a third-year PhD student who is particularly interested in parallel graph algorithms, generative models, and large-scale data computational models. His goal is to design new algorithms for large-scale computational models that have more impact in machine learning, data mining, and can be used in practice. Zhong was part of the Yao Class at Tsinghua University and graduated in 2016 with a bachelor’s degree in engineering.
National Defense Science and Engineering Graduate (NDSEG) Fellowship
The NDSEG is a highly competitive, portable fellowship that is awarded to U.S. citizens and nationals who intend to pursue a doctoral degree in one of fifteen supported disciplines.

Gabriel Ryan
Gabriel Ryan is a second-year PhD student whose current research involves using deep learning to construct logical formulas for program verification and synthesis. Prior to joining Columbia for graduate studies, he worked as a software engineer developing systems for data security, robotic 3D mapping and localization, and ballistic missile defense. Ryan graduated from Swarthmore College with a B.S. Engineering and B.A. Computer Science dual degree in 2013.
Ministry of Education of Taiwan – Government Scholarship to Study Abroad
The scholarship is awarded to Taiwanese students studying abroad with exceptional academic record and potential in their research areas.

Jen-Shuo Liu
Working in professor Steven Feiner’s Computer Graphics and User Interfaces Laboratory, third-year PhD student Jen-Shuo Liu’s research focus is user interface design for augmented reality and virtual reality. Liu has gained recognition for his work including an NYC Media Lab award for an augmented reality project. He graduated from National Taiwan University with an M.S. degree in Communication Engineering in 2016 .
The Belgian American Educational Foundation (BAEF)
The BAEF fosters the higher education of deserving Belgians and Americans through its exchange fellowship program.

Basile Van Hoorick
As an MS student, Basile Van Hoorick’s interests include computer vision, machine learning, and software engineering. While at Columbia, he hopes to work as a research and/or teaching assistant. Van Hoorick was a finalist in the Flemish Mathematics Olympiad (a national mathematics competition) in 2014 and studied electrical engineering at Ghent University in Belgium where he graduated summa cum laude in July 2019.
SEAS Fellowships
Columbia School of Engineering and Applied Sciences established the Presidential and SEAS fellowships to recruit outstanding students from around the world to pursue graduate studies at the school.

Xi Chen
As part of her research project, Xi Chen is trying to predict depression based on human mobility trajectory. Her interests lie in social networks and machine learning and she is a second-year PhD student working with Augustin Chaintreau. Chen graduated in 2018 with a degree in computer science and mathematics from Carleton College.

Shunhua Jiang
Shunhua Jiang is a first-year PhD student with the Theory Group, under the guidance of Omri Weinstein and Alex Andoni. Her research interests range from data structures, lower bounds, to algorithms. An alum of Tsinghua University, Jiang graduated in 2015 with a degree in computer science.

Eric Neyman
Eric Neyman is a first-year PhD student with the Theory Group under the supervision of professors Tim Roughgarden and Rocco Servedio. He looks forward to exploring the various disciplines of theoretical computer science. Neyman has earned three honorable mentions in the Putnam mathematical competition and graduated summa cum laude from Princeton University in 2019 with a degree in mathematics.

Chang Xiao
Chang Xiao is a fourth-year PhD student in computer science who works with professor Changxi Zheng. His research focuses on building human-computer interaction systems using computational methods. He has developed methods in a range of applications and his research has attracted public interest, including media coverage from CNN, IEEE Spectrum, etc. Chang received a BS degree in computer science from Zhejiang University in 2016 and is a recipient of the Snap Fellowship in 2019.

Hengjie Zhang
Hengjie Zhang’s research interests are graph theory, algorithms, and data structure. He will join the theory group as a first-year PhD student working with Alexandr Andoni and Omri Weinstein. He won a gold medal in the International Olympiad in Informatics and a Yao Award Recognition Prize from Tsinghua University where he graduated with a degree in engineering in 2019.

Joseph Zuckerman
With the system-level design group, Joseph Zuckerman will work on heterogeneous system-on-chip architectures. He is a first-year PhD student interested in application-specific architectures, the integration of accelerators, and hardware design methodologies. Zuckerman completed a B.S. in Electrical Engineering from Harvard University in 2019, with a focus on hardware architectures for machine learning applications.
An Interdisciplinary Approach to Artificial Intelligence

They could have been at the beach enjoying the summer. Instead, high school students gathered from across New York City and New Jersey for the AI4All program hosted by the Columbia community. The students came to learn about artificial intelligence (AI) but this program had a special twist – computer science (CS) and social work concepts were combined for a deeper, more meaningful look at AI.
“We created a space for young people to think critically about the social implications of artificial intelligence for the communities that they live in,” said Desmond Patton, the program co-director and associate professor of the School of Social Work. “We wanted them to understand how things like race, power, privilege and oppression can be baked into algorithms and their adverse effects on communities.”

The program participants, composed of 9th, 10th and 11th graders, are from racial and ethnic groups underrepresented in AI: Black, Hispanic, and Asian. Girls as well as youth from lower-income backgrounds were particularly encouraged to apply. For three weeks the students attended lectures, went on field trips to visit local companies (LinkedIn and Samsung) involved in the program, and visited other AI4All programs, like at Princeton University. Their work culminated in a final project which they presented to their classmates, mentors, and industry professionals.
“I believe that it is important to bring more ethics to AI,” said Augustin Chaintreau, the program co-director and a CS assistant professor. He sees ethics integrated into technical concepts and taught at the same time. Instead of learning about the social consequences and fixing it after, to solve an issue. Shared Chaintreau, “It shouldn’t be thought about just in passing but as a central part of why this is a tool and its implications.”
An interdisciplinary approach to AI was even part of how the classes were structured. Technical CS concepts, such as machine learning and Python, were taught in the morning by professors and student volunteers. While in the afternoon, guest speakers came to talk about their perspective to the day’s lesson. So, on the same day, students learned about supervised and unsupervised learning, and in the afternoon, someone who was formerly incarcerated described how the criminal policing that survey people on social media had a role in making a case against them.

“We were learning college courses meant to be taught in a month but for us it was just a couple of weeks and that was really impressive,” said Genesis Lopez, who is part of the robotics team at her school. Lopez loves robotics but works more on the mechanical side. She goes back to the team knowing how to use Python and is confident she can step up and code if needed. Continued Lopez, “I learned a lot but my favorite part was the people, we became a family.”
From Thesis Project to a Multi-Million Dollar Company
Text IQ started as co-founder Apoorv Agarwal’s (PhD ’14) Columbia thesis project titled “Social Network Extraction From Text.” The algorithm he built was able to read a novel, like Jane Austen’s “Emma,” for example, and understand the social hierarchy and interactions between characters.
Your Social Security Number Has Already Been Hacked. Why Do We Still Have Them?
CS Papers Accepted to ACL 2019
CS researchers will be at the 2019 Annual Meeting of the Association of Computational Linguistics in Florence, Italy. Numerous papers covering the computational approaches to natural language were accepted.
Accepted papers
- Pay “Attention” to Your Context when Classifying Abusive Language
Tuhin Chakrabarty Columbia University, Kilol Gupta Columbia University, and Smaranda Muresan Columbia University - Neural Network Alignment for Sentential Paraphrases
Jessica Ouyang Columbia University and Kathleen McKeown Columbia University - Rubric Reliability and Annotation of Content and Argument in Source-Based Argument Essays
Yanjun Gao Pennsylvania State University, Alex Driban Pennsylvania State University, Brennan Xavier McManus Columbia University, Elena Musi University of Liverpool, Patricia M. Davies Prince Mohammad Bin Fahd University, Smaranda Muresan Columbia University, and Rebecca J. Passonneau Pennsylvania State University - Unsupervised Morphological Segmentation for Low-Resource Polysynthetic Languages
Ramy Eskander Columbia University, Judith L. Klavans University of Maryland, Smaranda Muresan Columbia University
Summaries of the papers are below:
Pay “Attention” to Your Context when Classifying Abusive Language
Tuhin Chakrabarty Columbia University, Kilol Gupta Columbia University, and Smaranda Muresan Columbia University
The goal of any social media platform is to facilitate healthy and meaningful interactions among its users. But more often than not, it has been found that it becomes an avenue for wanton attacks.
In the paper the researchers propose an experimental study that has three aims: (1) to provide a deeper understanding of current datasets that focus on different types of abusive language, which are sometimes overlapping (racism, sexism, hate speech, offensive language and personal attacks); (2) to investigate what type of attention mechanism (contextual vs. self-attention) is better for abusive language detection using deep learning architectures; and (3) to investigate whether stacked architectures provide an advantage over simple architectures for this task.
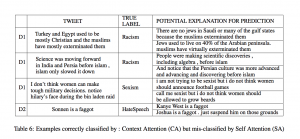
The work is about using context attention instead of self-attention for abuse detection which encapsulates the information by looking at examples globally through the training data, unlike self attention which only focuses on words for that particular tweet while trying to classify it.

The first tweet belongs to the NONE class while the second tweet belongs to RACISM class. The word “islam” may appear in the realm of racism as well as in any normal conversation. The model successfully identified the two distinct contextual usages of the word “Islam” in the two tweets, as demonstrated by a much higher attention weight in the second case and a relatively smaller one in the first case.
Neural Network Alignment for Sentential Paraphrases
Jessica Ouyang Columbia University and Kathleen McKeown Columbia University
The researchers created a system that automatically aligns paraphrases between two input sentences — that is, it detects which parts of the two sentences are paraphrases of each other. Their aligner is unique in that it is able to align phrases of arbitrary length, including full sentences, as well as relatively loose paraphrases, where the two aligned phrases mean approximately, but not necessarily exactly, the same thing.
Paraphrase alignment is the task of detecting parts of two input sentences that mean the same thing. Previous work on this task has focused on a strict definition of paraphrase, which requires that the aligned phrases mean exactly the same thing; previous systems aligned only words that exactly matched, or were close synonyms, between the sentences. In addition, previous work on paraphrase alignment was practically limited to phrases of three or fewer words, due to running time constraints. However, most people’s intuition about what counts as a paraphrase is much less strict, and paraphrases can be much longer than three words.

The phrases in bold are examples of paraphrases that the system can align, but that previous work could not. The entire phrase, “I vaguely recalled him telling me” means the same thing as “I remembered a story” in the context of these two sentences, but there is no one-to-one mapping between the words in the two phrases (eg. “vaguely” in Sentence 1 has no corresponding word in Sentence 2), which would prevent previous systems from successfully aligning these phrases.
The designed system aligns these looser and longer paraphrases by first breaking the input sentences into grammatical chunks, such as noun or verb phrases. For each chunk, it calculates a single vector that represents the meaning of that chunk by combining the vectors representing the meanings of the words within it. Then, a neural network is used to align each chunk in one of the input sentences to the chunks in the other sentence. This method allows for the alignment of all of the words within a chunk at once, regardless of the length of the chunk, and small differences in meaning or in individual words are mitigated by the meanings of the other words in the chunk. The system is the first to use a neural network to perform the alignment task, and it is able to align longer and less exactly-matching sentences than previous systems could.
Rubric Reliability and Annotation of Content and Argument in Source-Based Argument Essays
Yanjun Gao Pennsylvania State University, Alex Driban Pennsylvania State University, Brennan Xavier McManus Columbia University, Elena Musi University of Liverpool, Patricia M. Davies Prince Mohammad Bin Fahd University, Smaranda Muresan Columbia University, and Rebecca J. Passonneau Pennsylvania State University
Students with STEM majors were prompted to write short argumentative essays on topics including cryptocurrencies, cybercrime, and self-driving cars. These essays were graded on a rubric, and the essays were analyzed for content.
The argumentative structure of these essays were analyzed, which involved breaking the essays down into units of argumentation and indicating whether one argument supports, attacks, or is necessary context for another, from the main claim of the essay down to individual pieces of evidence. The results of this annotation were compared to the results of applying the rubric for each of these essays, leading to a set of argumentative features associated with essays of particular scores.
One simple finding is that essays with the highest overall score (5) tended to have a higher ratio of argumentative sentences to non-argumentative sentences, while the essays in the next highest group (4) tended to be longer. The essays with the higher scores and lower scores often had similar numbers of claims, but the latter group would tend to fail to connect these claims to the main argument of their essay.
The goal of research in this area is to assess the eventual effectiveness and usability of automated grading assistants for argumentative essays, and to what extent a rubric can be applied to fairly analyze the content and argumentative structure of essays in a similar way in which automated grading scripts are used within the CS department here at Columbia.