Maynard Marshall Ball has been selected to receive a two-year IBM PhD Fellowship for the 2018-19 and 2019-2020 academic years. Highly competitive (only 50 are awarded worldwide each year), IBM PhD fellowships recognize and support PhD students researching problems important to IBM and fundamental to innovation. Special attention this year was paid to AI, security, blockchain, and quantum computing.
A third-year PhD student, Ball is particularly interested in the foundations of cryptography and complexity, two fields deeply intertwined and whose connections Ball seeks to further understand. According to his advisor Tal Malkin, Ball has made fundamental scientific contributions in three separate areas:
Fine-grained cryptography, where Ball has modeled moderately-hard cryptographic systems and crafted provably-secure proofs-of-work, with applications to blockchain technologies and spam detection.
Non-malleable codes, where Ball has designed codes with new unconditional security guarantees to protect against tampering attacks.
Topology-hiding computation, where Ball has helped maintain network privacy by constructing efficient secure protocols for peer-to-peer networks.
IBM PhD fellowships, which are for two years, come with a stipend for living, travel, and conference expenses (in the US, the stipend amounts to $35,000 each academic year) as well as one-year education allowance. Fellows are matched with an IBM Mentor according to their disciplines and technical interests, and they are encouraged to participate in an onsite internship.
“I am honored and thrilled to be able to continue working on the foundations of cryptography and complexity. I am grateful to my advisor and the many other incredibly talented individuals with whom I have collaborated with thus far. I look forward to working with the outstanding cryptography group at IBM,” says Ball.
“Discriminative Training Methods for Hidden Markov Models: Theory and Experiments with Perceptron Algorithms” laid the foundation for how to use machine learning methods across a range of natural language processing tasks.
Award cites Yung’s innovative contributions to computer and network security. Yung (CS PhD ’88) is an adjunct and visiting faculty at Columbia and has advised several PhD students including Gödel Prize winner Matthew K. Franklin.
Unequal parts hackathon and learnathon—the emphasis is solidly on learning—the annual DevFest took place last month with 1300 participants attending. One of Columbia’s largest tech events and hosted annually by ADI (Application Development Initiative), DevFest is a week of classes, mini-lectures, workshops, and sponsor tech talks, topped off by an 18-hour hackathon—all interspersed with socializing, meetups, free food, and fun events.
Open to any student from Columbia College, Columbia Engineering, General Studies, and Barnard, DevFest had something for everyone.
Beginners, even those with zero coding experience, could take introductory classes in Python, HMTL, JavaScript. Those already coding had the opportunity to expand their programming knowledge through micro-lectures on iOS, data science, Civic Data and through workshops on geospatial visualization, UI/UX, web development, Chrome extensions, and more. DevFest sponsor Google gave tech talks on Tensorflow and Google Cloud Platform, with Google engineers onsite giving hands-on instruction and valuable advice.
Every evening, DevSpace offered self-paced, online tutorials to guide DevFest participants through the steps of building a fully functioning project. Four tracks were offered: Beginner Development (where participants set up a working website), Web Development, iOS Development, Data Science. On hand to provide more help were TAs, mentors, and peers.
This emphasis on learning within a supportive community made for a diverse group and not the usual hackathon mix: 60% were attending their first hackathon, 50% were women, and 25% identified as people of color.
DevFest events were kicked off on Monday, February 12, with talks by Computer Science professor Lydia Chilton (an HCI researcher) and Jenn Schiffer, a pixel design artist and tech satirist; events concluded with an 18-hour hackathon starting Saturday evening and continuing through Sunday.
Ends with a hackathon
Thirty teams competed in the DevFest hackathon. Limited to a few members only, teams either arrived ready-made or coalesced during a team-forming event where students pitched ideas to attract others with the needed skills.
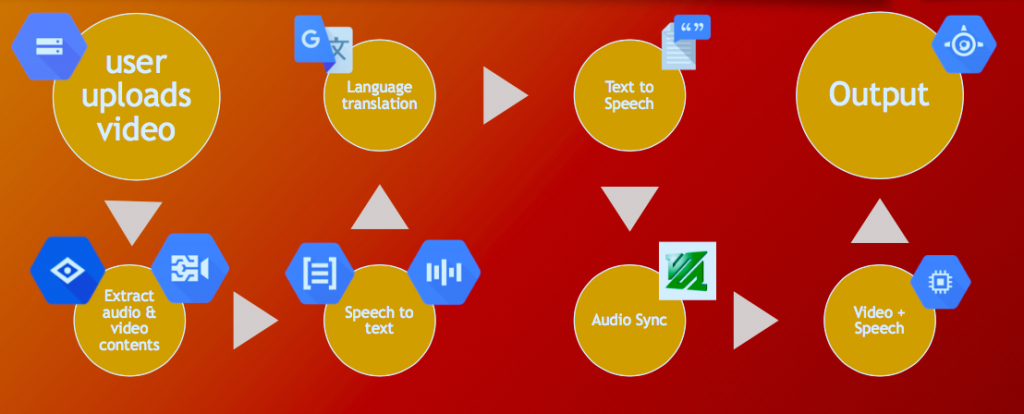
The $1500 first place went to Eyes and Ears, a video service aimed at making information within video more widely accessible, both by translating it for those who don’t speak the language in a video, and by providing audio descriptions of a scene’s content for people with visual impairments. The aim was to erase barriers preventing people from accessing the increasing amounts of information resources available in video. Someone using the service simply chooses a video, selects a language, and then waits for an email delivering the translated video complete with audio scene descriptions.
Eyes and Ears is the project of four computer science MS students—Siddhant Somani, Ishan Jain, Shubham Singhal, Amit Bhat—who came to DevFest with the intent to compete as a team in the hackathon. The idea for a project came after they attended Google’s Cloud workshop, learning there about an array of Google APIs. The question then became finding a way to combine APIs to create something with an impact for good.
The initial idea was to “simply” translate a video from any language to any other language supported by Google Translate (roughly 80% of the world’s languages). However, having built a translation pipeline, the team realized the pipeline could be extended to include audio descriptions of a video’s visual scenes, both when a scene changes or per a user’s request.
That such a service is even possible—let alone buildable in 18 hours—is due to the power of APIs to perform complex technology tasks.
Eyes and Ears: An end-to-end pipeline to make information in video more accessible through translations and audio scene descriptions.
It’s in the spaces between the many APIs and the sequential order of those APIs that required engineering effort. The team had to shepherd the output of one API to the output of another, sync pauses to the audio (which required an algorithm for detecting the start and stop of speech), sync the pace of one language to the pace of the other language (taking into account a differing number of words). Because Google Video Intelligence API, which is designed for indexing video only, outputs sparse single words (mostly nouns like “car” or “dog”), the team had to construct full, semantically correct sentences. All in 18 hours.
The project earned praise from Google engineers for its imaginative and ambitious use of APIs. In addition to its first place prize, Eyes and Ears was named best use of Google Cloud API.
The team will look to continue work on Eyes and Ears in future hackathons.
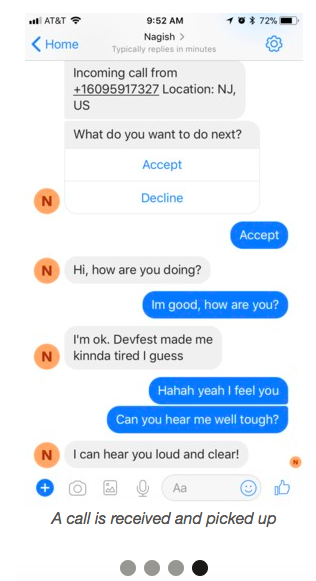
The $1000 second-place prize went to Nagish (Hebrew for “accessible”), a platform that makes it simple for people with hearing or speaking difficulties to make and receive phone calls using their smart phone. For incoming and outgoing calls, Nagish converts text to speech and speech to text in real time so voice phone calls can be read or generated via Facebook Messenger. All conversions are done in real-time for seamless and natural phone conversations.
The Nagish team— computer science majors Ori Aboodi, Roy Prigat, Ben Arbib, Tomer Aharoni, Alon Ezer—are five veterans who were motivated to help fellow veterans as well as others with hearing and speech impairments.
To do so required a fairly complex environment made up of several APIs (Google’s text-to-speech and speech-to-text as well as a Twilio API for generating phone numbers for each user and retrieving the mp3 files of the calls), all made to “talk” to one another over custom Python programs. Additionally, the team created a chatbot to connect Nagish to the Facebook platform.
For providing a needed service to those with hearing and speech impairments, the team won the Best Hack for Social Good.
Of course, potential users don’t have to be hearing- or speech-impaired to appreciate how Nagish makes it possible to unobtrusively take an important, or not so important, phone call during a meeting or perhaps even during class.
With Nagish uploaded to a smart phone, Facebook Messenger becomes a platform for making and receiving silent phone calls via speech-text conversion.
Taking the $750 third-place prize was Three a Day, a platform that matches restaurants or individuals wanting to donate food with those in need of food donations. The goal is making sure every individual gets three meals a day. The two-person team (computer science majors Kanishk Vashisht and Sambhav Anand) built Three a Day using Firebase as the database and React as the front end, with the back-end computing supplied primarily through Google Cloud functions. A Digital Ocean server runs Cron jobs to schedule the matching of restaurants and charities. The team also won for the best use of Digital Ocean products.
PhD student Brian A. Smith developed the RAD—racing auditory display—to enable people who are visually impaired to play the same racing games sighted players play, with the same level of speed, control, and excitement.
Peter Allen and Eugene Wu of Columbia’s Computer Science Department are each recipients of a Google Faculty Research Award. This highly competitive award (15% acceptance rate) recognizes and financially supports university faculty working on research in fields of interest to Google. The award amount, given as an unrestricted gift, is designed to support the cost of one graduate student for one year. The intent is for projects funded through this award to be made openly available to the research community.
Peter Allen: Visual-Tactile Integration for Reinforcement Learning of Robotic Grasping
Peter Allen
To incorporate a visual-tactile learning component into a robotic grasping and manipulation system, Peter Allen will receive $71K. A Professor of Computer Science at Columbia, Allen heads the Columbia University Robotics Group.
In grasping objects, robots for the most part rely on visual feedback to locate an object and guide the grasping movements. But visual information by itself is not sufficient to achieve a stable grasp: it cannot measure how much force or pressure to apply and is of limited value when an object is partially occluded or hidden at the bottom of a gym bag. Humans rely as much or more on touch, easily grasping objects sight unseen and feeling an object to deduce its shape, apply the right amount of pressure and force, and detect when it begins to slip from grasp.
With funding provided by Google, Allen will add simulated rich tactile sensor data (both capacitive and piezoelectric) to robotic hand simulators, capturing and transforming low-level sensor data into high-level information useful for grasping and manipulation. This high-level information can then be used to build reinforcement learning (RL) algorithms that enable an agent to find stable grasps of complex objects using multi-fingered hands. The RL system can learn a grasping control policy and an ability to reason about 3D geometry from both raw depth and tactile sensory observations.
This project builds on previous work by Allen’s group on shape completion—also with a Google research grant—where an occluded object’s complete 3D shape is inferred by comparing it to hundreds of thousands of models contained within a data set. The shape completion work used machine learning with a convolutional neural network (CNN), with simulated 3D vision data on models of hundreds of thousands of views of everyday objects. This allowed the CNN to generalize a full 3D model from a single limited view. With this project, the CNN will now be trained on both visual and tactile information to produce more realistic simulation environments that can be used by Google and others (the project code and datasets will be open source) for more accurate robot grasping.
Eugene Wu: NeuroFlash: System to Inspect, Check, and Monitor Deep Neural Networks
Deep neural networks, consisting of many layers of interacting neurons, are famously difficult to debug. Unlike traditional software programs, which are structured into modular functions that can be separately interpreted and debugged, deep neural networks are more akin to a single, massive block of code, often described as a black box, where logic is smeared throughout the behavior of thousands of neurons with no clear way of disentangling interactions among neurons. Without an ability to reason about how neural networks make decisions, it is not possible to understand if and how they can fail, for example, when used for self-driving cars or managing critical infrastructure.
To bring modularity to deep neural networks, NeuroFlash aims to identify functional logic components within the network. Using a method similar to MRI in medical diagnosis, which looks for brain neuron activations when humans perform specific tasks, NeuroFlash observes the behavior of neural network neurons to identify which ones are mimicking a user-provided high-level function (e.g., identify sentiment, detect vertical line, parse verb). To verify that the neurons are indeed following the function’s behavior and not spurious, NeuroFlash alters the neural network in systematic ways to examine and compare its behavior with the function.
The ability to attribute high-level logic to portions of a deep neural network forms the basis for being able to introduce “modules” into neural networks; test and debug these modules in isolation in order to ensure they work when deployed; and develop monitoring tools for machine learning pipelines.
Work on the project is driven by Thibault Sellam, Kevin Lin, Ian Huang, and Carl Vondrick and complements recent work from Google on model attribution, where neuron output is attributed to specific input features. With a focus on scalability, NeuroFlash generalizes this idea by attributing logical functions.
Wu will make all code and data open source, hosting it on Github for other researchers to access.
A study published in Science describes how researchers created, from 86M genealogy profiles, population-scale family trees to reassess longevity and marriage and migration patterns. Yaniv Erlich is the study’s senior author.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor