
In IEEE Spectrum, Gil Zussman reports breakthrough on full-duplex chip
By sending and receiving simultaneously, a full-duplex chip could double phone-network data capacity.
By sending and receiving simultaneously, a full-duplex chip could double phone-network data capacity.
Researchers at Columbia University and Adobe Research have developed a new interactive image segmentation method that leverages both color and depth information in RGBD images to more cleanly and quickly separate target objects from the background. The method, described in Interactive Segmentation on RGBD Images via Cue Selection, a paper to be presented later this month at the Computer Vision and Pattern Recognition conference (June 26 — July 1), expands on previous RGB and RGBD segmentation methods in two ways: it derives normal vectors from depth information to serve as an additional cue, and it uses a single cue for each pixel, rather than a combination of all cues (color, depth, normal), to distinguish foreground objects from the background. The insight is that a single cue contains a preponderance of discriminative power in the local region, a power that may be diluted when combined with less predictive cues. The resulting cue map offers a new perspective into how each cue is used to produce segmentation. The approach is supported by experiments showing the single-cue method outperforms multiple-cue methods for both RGB and RGBD images, requiring fewer user inputs to achieve higher accuracy.
Separating objects from the background has many applications in image and video processing as well as image compression. It is also a well-known feature of popular consumer image editing programs like Photoshop, which offer a quick selection tool (magic wand) so users can indicate with clicks or brush strokes an object to isolate from the rest of the image. Image segmentation works generally by evaluating similarity or dissimilarity of neighboring pixels, usually on the basis of color, texture, and other such cues, and then establishing a border that encompasses similar pixels and excludes dissimilar ones.
Color or intensity, however, is often not enough to distinguish an object from the background. Foreground and background colors can overlap, colors might be affected by illumination, other objects may obfuscate an object’s borders. Users as a result often have to spend a lot of time finessing the selection process, zooming in to select first one pixel, then another until the selected object is fully separated.
Another, more promising cue is becoming available to make image segmentation more accurate. Depth information is increasingly being incorporated into images (RGBD format) courtesy of the Microsoft Kinect and similar depth-sensing devices (some new smart phones are already incorporating cameras that likewise perceive depth). Because depth measures the distance of each pixel from the camera and is not affected by illumination changes, it is often more accurate and reliable than color or other currently used cues at distinguishing foreground objects from the background.
A few segmentation methods are starting to take advantage of depth, using it as another channel of information that can be combined with color, texture, and other cues to more accurately isolate selected objects.
Rather than simply viewing depth as an additional cue to be linearly mixed with others, researchers from Columbia and Adobe looked more carefully at how depth information might be used in image segmentation, and also re-used. Besides using depth information to only establish relative distances of pixels from the background, researchers went one more step and computed normal vectors from an object’s surface orientation, making it possible to distinguish an object’s geometry and thus better draw the edges of an object.
Depth information, thus used twice, can distinguish two objects even when they are at the same depth.
Nor is depth—or any other cue—treated as simply an element of a combination. In experimenting with how best to combine depth and normal information with other cues, the researchers found that a single cue works better than a linear combination of many cues. Says Jie Feng, lead author of the paper. “Our insight was that among neighboring pixels, one cue is usually enough to explain why one pixel is foreground or why it is background. Combining many cues could dilute the predictive power of a strong signal within the local region.” A single cue has the added benefit of providing explanatory power, something lacking in a combination of multiple cues.
The single cue might be depth or it might be another cue; it all depends on what the user wants. Each time a user selects a pixel, the algorithm dynamically adapts a cue map, evaluating each pixel to determine the most predictive cue for that pixel (optimization was done using a modified version of Markov Random Field).

Different cues take effect in different areas of an image.
Top row: Clicking the dress once picks depth as best cue, isolating the entire dress.
Bottom row: Clicking the white part of the dress separates the dress into two parts with color as cue.
In extensive testing, the single-cue method, compared to other segmentation methods, required far fewer clicks to achieve the same accuracy, a result that holds for both RGB and RGBD images. Test results are demonstrated in the following video.

The general concept of using a single strong cue has application beyond segmenting images and may enhance performance of other tasks such as semantic or video segmentation, which also involve multiple features for single pixels. The researchers are also looking at extending their method to automatic image segmentation.
Posted: 6/15/2016
– Linda Crane
ICML is the premiere machine learning conference. This year, Columbia researchers were authors on 10 papers.

Theoretical computer scientists from Columbia University are presenting three papers at this year’s ACM Symposium on the Theory of Computing (STOC) conference, held June 19 – 21. STOC is one of two annual flagship conferences (the IEEE Symposium on Foundations of Computer Science being the other) across all of theoretical computer science. Two papers being presented by Columbia researchers prove new lower bounds, showing that certain problems, one from circuit complexity and one from proof complexity, can’t be efficiently solved. The third paper, however, reports positive results and opens the door to solving certain dynamic graph problems using a deterministic rather than a randomized approach.
A key method of the two lower-bounds papers is random projections, an extension of the classic random restriction method in circuit complexity. Random restrictions are a well-studied way of “simplifying” circuits by randomly fixing some input variables to constants; these simplifications are useful in lower bound proofs. Random projections go one step further by identifying certain sets of variables in a careful way and setting them all to the same value (i.e., “projecting” a set of distinct input variables to a common new variable). These variable identifications enable a level of “control” over the simplification process that makes it possible to obtain sharper quantitative bounds.
Xi Chen, Columbia University
Igor C. Oliveira, Charles University in Prague
Rocco Servedio, Columbia University
Li-Yang Tan, Toyota Technological Institute at Chicago
Given a graph, does it contain a path of k or fewer edges between vertex s and vertex t? This is the well-studied “distance-k-connectivity” problem. It is well known that efficient algorithms can solve this problem on a standard sequential computer, but what if we want to use a highly parallel computer that has many processing elements that can run simultaneously, but only for an extremely small number of parallel computational steps?
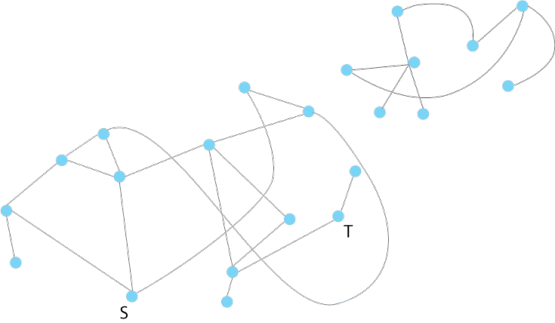
In Near-optimal small-depth lower bounds for small distance connectivity, the authors use the method of random projections to prove that any shallow circuit that solves the “small distance connectivity” problem must be very large. In the language of parallel computing, this translates into the following result: any highly parallel algorithm for this problem, running in very few parallel time steps, must use very many processors.
While previous results reached similar qualitative conclusions, this new paper gives significant quantitative improvements to those earlier lower bounds, providing a lower bound that almost matches known upper bounds.
Strengthening the paper’s lower bound to actually match the known upper bounds would imply a breakthrough in circuit complexity (since such a result would prove that the general undirected connectivity problem is not in the complexity class NC1).
Toniann Pitassi, University of Toronto
Rocco Servedio, Columbia University
Benjamin Rossman, National Institute of Informatics, Tokyo
Li-Yang Tan, Toyota Technological Institute at Chicago
How difficult is it to prove theorems in a specific formal logic system?
One way to measure this difficulty is to give a lower bound on the length of the shortest proof, or on the minimal number of steps in a proof. Just as circuit complexity establishes upper and lower bounds on the size of circuits computing particular functions, proof complexity aims to give bounds on the length of proofs in specific formal proof systems, often borrowing methods used to prove lower circuit bounds. The paper Poly-logarithmic Frege depth lower bounds via an expander switching lemma falls into this framework.
The paper studies the complexity of proofs of a specific logical statement, the so-called “Tseitin principle.” This principle formalizes the well-known “handshake lemma” which states that the total number of handshakes experienced in any group of interacting people must be even no matter who shakes hands with whom (this is true simply because each individual handshake is experienced by two people). The paper studies these “Tseitin principles” on 3-regular expander graphs and investigates the complexity of “small-depth Frege proofs” of these principles on these graphs. Frege proofs are a strong proof system; previous efforts were able to show only that short proofs cannot exist for Tseitin principles if each line in the proof is only allowed to be a Boolean formula of very small depth. Using a new switching lemma for a carefully designed random restriction process over these expanders, this paper proves that short proofs cannot exist for Tseitin principles even if each line in the proof is allowed to be a much deeper Boolean formula.
Aaron Bernstein, Columbia University
Shiri Chechik, Tel Aviv University
Given a large graph, what is the best way to recompute a shortest path when a single vertex or edge is removed? In an enormous graph, recomputing from scratch is no longer an option, and in the past 10-15 years computer scientists have found much faster ways to dynamically update graphs.
However, all such methods have been randomized (or incorporate randomization to some extent), where a small number of vertices and edges is sampled from an enormous graph to create a small, representative graph that can be more easily studied. Randomization helps ensure selected vertices or edges are representative of the whole graph; but it’s possible to get unlucky and randomly select vertices or edges that are not representative of the whole (just as a luckless pollster might randomly select all Democrats). It’s also possible—and especially problematic in graphs—that all selected edges or vertices are special in the same way (e.g., key servers in a network that handle large amounts of traffic). Such a lack of independence in the randomization could lead an adversary to delete exactly those vertices that were sampled.
With randomization seen as powerful but problematic, there has been a recent push to find a deterministic solution, with a couple of papers successfully incorporating deterministic aspects along with sampling.
In Deterministic Decremental Single Source Shortest Paths: Beyond the O(mn) Bound, Bernstein and Chechik describe the first wholly deterministic algorithm for computing a shortest path in the specific case when an edge is deleted and the path has to be reconstructed from a fixed source.
Rather than sampling, Bernstein and Chechik’s method stores information about every vertex and how it connects to its neighborhood. If an edge is removed, the stored information (which is not available to an adversary) is used to reconstruct what was there before.
This deterministic method is faster than recomputing from scratch, though it does not yet approach the speeds of randomized methods, which future work will address. More important for now, the method gives hope that other graph problems can be solved deterministically.
Posted 6/20/2016
Working backwards from queries indicating a user was diagnosed with pancreatic cancer, researchers looked for earlier searches of symptoms.
The research, done by Steven K. Feiner and Ajoy Fernandes, has application for consumer head-worn VR displays.

Martha Kim, associate professor of Computer Science at Columbia University and director of the ARCADE Lab, has been named a recipient of the annual Borg Early Career Award (BECA). Conferred by the Committee on the Status of Women in Computing Research (CRA-W), the award honors Anita Borg, the founder of the Borg Institute and an early CRA-W member committed to increasing the participation of women in computing research. The award is bestowed annually to one or two women in computer science or engineering, who like Kim, have made early-career research contributions and at the same time have committed themselves to encouraging young women to enter the computing field.
Kim’s research contributions are in the area of computer architecture, where creative solutions are needed if computing power is to keep pace with increasing demands, especially those posed by big data sets. Packing and operating more transistors on a single chip—the previous solution—no longer works due to the problem of heat buildup. Further computing advances require efficiency at every aspect of the chip, whether that means using new types of parallel processing, employing specialized circuits called accelerators, or introducing entirely new computer architectures. Kim’s research explores all of these solutions, each one highly complex in its own way.
She focuses particularly at the point where hardware and software meet, looking at how characteristics of one may be leveraged to improve operation of the other, thus realizing efficiencies not possible when each is examined in isolation. Accelerators she designed for database processing—specifically optimized for the row, column, table abstractions of database operations—resulted in 70x throughput improvements while saving three orders of magnitude in energy compared to traditional software database approaches. Her architectural designs include an intelligent data flow that optimizes resource usage by having processing units distributed across the chip perform calculations as their inputs are ready.
The quality of her research is reflected in the number of prestigious venues that have featured her work (including ISCA, ASPLOS, and HPCA). For three straight years (2013, 2014, 2015), papers she co-authored have been among the 10-12 selected each year by the IEEE to be “Top Picks in Computer Architecture.” Her research has also won her numerous awards, including the 2013 Rodriguez Family Award, the 2015 Edward and Carole Kim Faculty Involvement Award, and a 2013 NSF CAREER award. In July, she will serve as Program Co-Chair at the IEEE International Symposium on Workload Characterization.
Equally impressive to her research is Kim’s impact on advancing women in computing research. In making the award, CRA-W cited an expansive portfolio of outreach efforts: participating in high-school oriented conferences such as Code Like A Girl; reviewing and revising her high school’s approach to STEM education; acting as a faculty co-advisor for the Artemis Project, a summer school for rising 9th and 10th grade girls from local, underserved schools. Kim also devotes considerable time to performing service to the research community through program committees, journal reviewing, and conference organizing activities.
One tangible result of Kim’s outreach to women: her first two graduated PhD students are both women as are two-thirds of her current doctoral advisees.
Julia Hirschberg, chair of Columbia’s Computer Science Department, says the following of Kim. “Martha is an outstanding researcher recognized by her peers as being among the most innovative in her field. She is passionate about her research, and passionate also in her commitment to increasing the participation of women in computing. She is poised to become a leader in the field of computer systems.”
The camera’s photodiodes collect light and convert it to power, allowing the camera to operate without external power.
Update: Since being awarded the Presidential Award for Outstanding Teaching for Faculty, Adam Cannon has earned the additional honor of receiving the Great Teacher Award from the Society of Columbia Graduates. Since 1949, the award is given annually to two professors, one from Columbia College and one from Columbia Engineering, who demonstrate the ability to stimulate, challenge, and inspire students and relate positively to students beyond the classroom. This year Adam Cannon and Julie Crawford were named great teachers.

Adam Cannon and Jae Woo Lee, both lecturers in computer science, are to be recognized for excellence in teaching later this month. Cannon will receive the Presidential Award for Outstanding Teaching for Faculty, and Lee will receive the SEAS Alumni Association Distinguished Faculty Teaching Award.
Both Cannon and Lee are popular with students (each having earned a CULPA silver nugget) and respected for their teaching methods, their ability to inject humor and fun into what can be hard classes, their commitment to students inside and outside the classroom, and their efforts to continually explore ways to change computer science education.
Cannon, the Associate Chair for Undergraduate Education, teaches Introduction to Computer Science (1004) and Introduction to Computing for Engineers and Applied Scientists (1006), classes that number in the hundreds of students. But yet he is able to reach and excite students, making the often difficult concepts within computer science understandable to those just starting out. He often tells students that they might struggle for a bit but that it will eventually “click.” With Cannon as teacher, it almost always does.
 Cannon in front of his 1004 class. The number of undergraduates majoring in computer science is surging at Columbia, which saw a 30% increase this year over last year. (Photo credit: Tim Lee)
Cannon in front of his 1004 class. The number of undergraduates majoring in computer science is surging at Columbia, which saw a 30% increase this year over last year. (Photo credit: Tim Lee)
Making computer science accessible to all students is a particular focus of Cannon’s. His Emerging Scholars Program, made up of equal numbers of female and male undergraduates, de-emphasizes programming to concentrate more on the collaborative and problem-solving aspects of computer science. Last year, he introduced Computing in Context (1002), a rigorous computer science class aimed specifically at liberal arts students; in a first of its kind, the course combines lectures in basic computer science skills with lectures and projects from humanities professors who show how those skills apply within a specific liberal arts discipline. By engaging liberal arts students on their own ground, Cannon has introduced a whole new group of students to computer science.
For some of these students, the class has been life-changing. Many have opted to continue onto more advanced computer science classes; some have changed their majors.
It is for these and other efforts that Cannon was chosen as one of five faculty members from across the university to receive the Presidential Award for Outstanding Teaching, which will be bestowed during the commencement ceremony May 18.

“I think computer science is a subject that today’s students are very drawn to. Since many students get their first exposure to computing in my course, I get a lot of credit that really belongs to our entire faculty and to the discipline itself,” says Cannon, adding also, “I gladly accept it.”
Jae Woo Lee, who previously (in 2011) won the Presidential Award as a PhD student, is this year being awarded the SEAS Alumni Association Distinguished Faculty Teaching Award. His selection is based on student evaluations and recommendations of a selection committee made up of three students and two alumni.
Lee started teaching in 2008 as a graduate student, filling in on short notice to lead Advanced Programming (3157), then notorious for its difficulty. Drawing on his own academic struggles, Lee sought an overall vision for helping students master fundamental skills and concepts, one that relied less on lectures and more on hands-on coding. He completely redesigned the syllabus, winnowing the number of topics and using the extra time for actual programming projects. A series of assignments he devised would build on one after another towards a single capstone project, culminating in a tangible, real-world application: a fully functional web server. A mailing list he set up encouraged online collaboration so students could help one another. Today, Advanced Programming is one of the most popular courses offered within the department.

A highlight of Lee’s Advanced Programming class are two optional hackathons for students and class alumni, each billed as a night of hacking, good food, laughter, and friendship.
In 2012, Lee received his PhD in Computer Science and chose to remain at Columbia where today he teaches also Essential Data Structures (3136) and sometimes Operating Systems (4118). His stated goal is to turn students of programming into programmers; students’ enthusiastic comments recommending the class to others suggest Lee has been successful. Not content to rest, Lee is taking another look at the undergraduate computer science curriculum.
“Last year, in preparation for a panel on CS curriculum that I was set to moderate at our faculty retreat, I solicited comments from our students. The mailing list exploded with huge number of incredibly thoughtful comments and suggestions,” said Lee. “We haven’t forgotten them. It’s just that we’re a little busy dealing with quadrupled enrollments in our courses . . .” Lee is working on one of them though: a new course to cover some important topics that fall between Advanced Programming and Operating Systems.
The two awards won by Cannon and Lee represent something of a streak for the Computer Science department. It is the second time in the past four years a department faculty member has won the Presidential Award, the University’s highest award for teaching (Rocco Servedio received it in 2013); in eight of the past nine years, the SEAS Alumni Distinguished Faculty Teaching Award has been bestowed on someone from the department.
“We are incredibly proud to have two such wonderful people as Adam and Jae, teaching and mentoring our students,” says Julia Hirschberg, chair of the Computer Science Department. “It is due in great part to their contributions that the department has achieved such a high quality of teaching.”
Posted 5/5/2016
– Linda Crane
A former student of Steven Feiner, Gribetz studied both computer science and neuroscience at Columbia.
source{d} analyzed every Github repository, running its own version of git blame across 900 million commits to gain insight into the code published by over 6 million developers.
The paper, which will be published this fall in the Harvard Law Review, is entitled It’s Too Complicated: The Technological Implications of IP-based Communications on Content/Non-content Distinctions and the Third-Party Doctrine.
Augustin Chaintreau and Chris Riederer show that photos, text, and geotags from Instagram profiles can be used to determine age, race, and gender for census tracts in and around Manhattan.
Update: Since being awarded the Presidential Award for Outstanding Teaching for Faculty, Adam Cannon has earned the additional honor of receiving the Great Teacher Award from the Society of Columbia Graduates. Since 1949, the award is given annually to two professors, one from Columbia College and one from Columbia Engineering, who demonstrate the ability to stimulate, challenge, and inspire students and relate positively to students beyond the classroom. This year Adam Cannon and Julie Crawford were named great teachers.
Adam Cannon and Jae Woo Lee, both lecturers in computer science, are to be recognized for excellence in teaching later this month. Cannon will receive the Presidential Award for Outstanding Teaching for Faculty, and Lee will receive the SEAS Alumni Association Distinguished Faculty Teaching Award.
Both Cannon and Lee are popular with students (each having earned a CULPA silver nugget) and respected for their teaching methods, their ability to inject humor and fun into what can be hard classes, their commitment to students inside and outside the classroom, and their efforts to continually explore ways to change computer science education.
Cannon, the Associate Chair for Undergraduate Education, teaches Introduction to Computer Science (1004) and Introduction to Computing for Engineers and Applied Scientists (1006), classes that number in the hundreds of students. But yet he is able to reach and excite students, making the often difficult concepts within computer science understandable to those just starting out. He often tells students that they might struggle for a bit but that it will eventually “click.” With Cannon as teacher, it almost always does.
Making computer science accessible to all students is a particular focus of Cannon’s. His Emerging Scholars Program, made up of equal numbers of female and male undergraduates, de-emphasizes programming to concentrate more on the collaborative and problem-solving aspects of computer science. Last year, he introduced Computing in Context (1002), a rigorous computer science class aimed specifically at liberal arts students; in a first of its kind, the course combines lectures in basic computer science skills with lectures and projects from humanities professors who show how those skills apply within a specific liberal arts discipline. By engaging liberal arts students on their own ground, Cannon has introduced a whole new group of students to computer science.
For some of these students, the class has been life-changing. Many have opted to continue onto more advanced computer science classes; some have changed their majors.
It is for these and other efforts that Cannon was chosen as one of five faculty members from across the university to receive the Presidential Award for Outstanding Teaching, which will be bestowed during the commencement ceremony May 18.
“I think computer science is a subject that today’s students are very drawn to. Since many students get their first exposure to computing in my course, I get a lot of credit that really belongs to our entire faculty and to the discipline itself,” says Cannon, adding also, “I gladly accept it.”
Jae Woo Lee, who previously (in 2011) won the Presidential Award as a PhD student, is this year being awarded the SEAS Alumni Association Distinguished Faculty Teaching Award. His selection is based on student evaluations and recommendations of a selection committee made up of three students and two alumni.
Lee started teaching in 2008 as a graduate student, filling in on short notice to lead Advanced Programming (3157), then notorious for its difficulty. Drawing on his own academic struggles, Lee sought an overall vision for helping students master fundamental skills and concepts, one that relied less on lectures and more on hands-on coding. He completely redesigned the syllabus, winnowing the number of topics and using the extra time for actual programming projects. A series of assignments he devised would build on one after another towards a single capstone project, culminating in a tangible, real-world application: a fully functional web server. A mailing list he set up encouraged online collaboration so students could help one another. Today, Advanced Programming is one of the most popular courses offered within the department.
In 2012, Lee received his PhD in Computer Science and chose to remain at Columbia where today he teaches also Essential Data Structures (3136) and sometimes Operating Systems (4118). His stated goal is to turn students of programming into programmers; students’ enthusiastic comments recommending the class to others suggest Lee has been successful. Not content to rest, Lee is taking another look at the undergraduate computer science curriculum.
“Last year, in preparation for a panel on CS curriculum that I was set to moderate at our faculty retreat, I solicited comments from our students. The mailing list exploded with huge number of incredibly thoughtful comments and suggestions,” said Lee. “We haven’t forgotten them. It’s just that we’re a little busy dealing with quadrupled enrollments in our courses . . .” Lee is working on one of them though: a new course to cover some important topics that fall between Advanced Programming and Operating Systems.
The two awards won by Cannon and Lee represent something of a streak for the Computer Science department. It is the second time in the past four years a department faculty member has won the Presidential Award, the University’s highest award for teaching (Rocco Servedio received it in 2013); in eight of the past nine years, the SEAS Alumni Distinguished Faculty Teaching Award has been bestowed on someone from the department.
“We are incredibly proud to have two such wonderful people as Adam and Jae, teaching and mentoring our students,” says Julia Hirschberg, chair of the Computer Science Department. “It is due in great part to their contributions that the department has achieved such a high quality of teaching.”
Posted 5/5/2016
– Linda Crane