The researchers developed AwareDX – Analysing Women At Risk for Experiencing Drug toXicity – a machine learning algorithm that identifies and predicts differences in adverse drug effects between men and women by analyzing 50 years’ worth of reports in an FDA database. The algorithm automatically corrects for biases in these data that stem from an overrepresentation of male subjects in clinical research trials.
Though men and women can have different responses to medications – the sleep aid Ambien, for example, metabolizes more slowly in women, causing next-day grogginess – doctors may not know about these differences because most clinical trial data itself is biased toward men. This trickles down to impact prescribing guidelines, drug marketing, and ultimately, patients’ health. Unfortunately, pharmaceutical companies have a history of ignoring complex problems and clinical trials have singularly studied men, not even including women. As a result, there is a lot less information about how women respond to drugs compared to men. The research tries to bridge this information gap.
The Robot Operating System (ROS) is the most popular framework for robotics development. In this paper, the researchers conducted the first major empirical study of ROS, with the goal of understanding how developers collaborate across the many technical disciplines that coalesce in robotics.
Building a complete robot is a difficult task that involves bridging many technical disciplines. ROS aims to simplify development by providing reusable libraries, tools, and conventions for building a robot. Still, as building a robot requires domain expertise in software, mechanical, and electrical engineering, as well as artificial intelligence and robotics, ROS faces knowledge-based barriers to collaboration. The researchers wanted to understand how the necessity of domain-specific knowledge impacts the open-source collaboration model in ROS.
Virtually no one is an expert in every subdomain of robotics: experts who create computer vision packages likely need to rely on software designed by mechanical engineers to implement motor control. As a result, the researchers found that development in ROS is centered around a few unique subgroups each devoted to a different specialty in robotics (i.e. perception, motion). This is unlike other ecosystems, where competing implementations are the norm.
Performance has a major impact on the overall quality of a software project. Performance bugs—bugs that substantially decrease run-time—have long been studied in software engineering, and yet they remain incredibly difficult for developers to handle. In this project, the researchers leveraged contemporary methods in machine learning to create graph embeddings of Python code that can be used to automatically predict performance.
Using un-optimized programming language concepts can lead to performance bugs and the researchers hypothesized that statistical language embeddings could help reveal these patterns. By transforming code samples into graphs that captured the control and data flow of a program, the researchers studied how various unsupervised embeddings of these graphs could be used to predict performance.
Implementing “sort” by hand as opposed to using the built-in Python sort function is an example of a choice that typically slows down a program’s run-time. When the researchers embedded the AST and data flow of a code snippet in Euclidean space (using DeepWalk), patterns like this were captured in the embedding and allowed classifiers to learn which structures are correlated with various levels of performance.
“I was surprised by how often research changes directions,” said Sophia Kolak. In both projects, they started out with one set of questions but answered completely different ones by the end. “It showed me that, in addition to persistence, research requires open-mindedness.”
Yanda Chen Honorable Mention
Cross-language Sentence Selection Via Data Augmentation and Rationale Training Yanda Chen Columbia University, Chris Kedzie Columbia University, Suraj Nair University of Maryland, Petra Galuscakova University of Maryland, Rui Zhang Yale University, Douglas Oard University of Maryland, and Kathleen McKeown Columbia University
In this project, the researchers proposed a new approach to cross-language sentence selection, where they used models to predict sentence-level query relevance with English queries over sentences within document collections in low-resource languages such as Somali, Swahili, and Tagalog.
The system is used as part of cross-lingual information retrieval and query-focused summarization system. For example, if a user puts in a query word “business activity” and specifies Swahili as the language of source documents, then the system will automatically retrieve the Swahili documents that are related to “business activity” and produce short summaries that are then translated from Swahili to English.
A major challenge of the project was the lack of training data for low-resource languages. To tackle this problem, the researchers proposed to generate a relevance dataset of query-sentence pairs through data augmentation based on parallel corpora collected from the web. To mitigate the spurious correlations learned by the model, they proposed the idea of rationale training where they first trained a phrase-based statistical machine translation system and used the alignment information to provide additional supervision for the models.
The approach achieved state-of-the-art results on both text and speech across three languages – Somali, Swahili, and Tagalog.
Amaan Pirani (CC ’21) talks to CNBC about his start-up Gatherly, an online event platform designed to improve digital interactions, and how he balances school and his business.
The Universities Space Research Association (USRA) Distinguished Undergraduate Awards provide college scholarship awards to students who have shown a career interest in science or engineering with an emphasis on space research or space science education, and aeronautics-related sciences.
Differentially private computation and online learning over time have long been known to be much more difficult in a worst-case environment (with an adversary choosing the input) than in an average-case environment (with inputs drawn from an unknown probability distribution).
This work shows that in the “smoothed analysis” model, in which an adversarially chosen input is perturbed slightly by nature, private computation and online learning are almost as easy as in an average-case setting. This work also features a novel application of bracketing entropy to regret-minimization in online learning.
In safety-critical but computationally resource-constrained applications, deep learning faces two key challenges: lack of robustness against adversarial attacks and large neural network size (often millions of parameters). To overcome these two challenges jointly, the authors propose to make pruning techniques aware of the robust training objective and let the training objective guide the search for which connections to prune. They realize this insight by formulating the pruning objective as an empirical risk minimization problem which is solved efficiently using stochastic gradient descent. They further demonstrate the proposed approach, titled HYDRA, achieves compressed networks with state-of-the-art benign and robust accuracy simultaneously, on various vision tasks.
The authors show that it is crucial to make pruning techniques aware of the robust training objectives to obtain neural networks that are both compact and robust. They demonstrate the success of the proposed approach, HYDRA across three popular vision datasets with four state-of-the-art robust training techniques. Interestingly, they also show the existence of highly robust sub-networks within non-robust networks found by HYDRA.
Online algorithms for regret minimization play an important role in many applications where real-time sequential decision making is crucial. The paper studies the performance of the classic Hedge algorithm and its optimistic variant under the setting of repeated multiplayer games. The highlights are improved analyses on regrets that lead to faster convergence to (coarse) correlated equilibria.
This work studied a general class of problems in reinforcement learning. In particular, it proposed a planning algorithm for a deterministic system with general objective functions.
The algorithm is based on layering techniques in the sketching and streaming literature. This is the first time that the layering technique appears in sequential decision-making algorithms. Furthermore, it also proposed a new framework of dynamic programming approach for solving the deterministic system.
Ensuring Fairness Beyond the Training Data Debmalya Mandal Columbia University, Samuel Deng Columbia University, Suman Jana Columbia University, Jeannette Wing Columbia University, Daniel Hsu Columbia University
This paper initiates the study of fair classifiers that are robust to perturbations to the training distribution. Despite recent progress, the literature on fairness in machine learning has largely ignored the design of such fair and robust classifiers. Instead, fairness in these previous works was evaluated on sample datasets that may be unreliable due to sampling bias and missing attributes.
The authors of the present paper provide a new algorithm for training classifiers that are fair not only with respect to the training data, but also with respect to weight perturbations of the training data, which may account for discrepancies due to sampling bias and missing attributes. The approach is based on a min-max objective that is solved using a new iterative algorithm based on online learning. Experiments on standard machine learning fairness datasets suggest that, compared to the state-of-the-art fair classifiers, the robustly-fair classifiers retain fairness guarantees and test accuracy for a large class of perturbations on the test set.
One of the common ways children learn is by mimicking adults. If an agent is able to perfectly copy the behavior of a human expert, one may be tempted to surmise that the agent will perform equally well at the same type of task.
The paper “Causal Imitation Learning with Unobserved Confounders” shows that this notion is somewhat naive, and the agent would need to have exactly the same sensory inputs as the human for perfect imitation to translate into the same distribution of rewards. Perhaps surprisingly, if its inputs differ even slightly from the demonstrator’s, the agent’s performance can be arbitrarily low, even when it learns to copy the demonstrator’s actions perfectly.
This paper investigates imitation learning through a causal lens and reveals why the agent may fail to learn even when infinite demonstration’s trajectories are available. It then introduces a formal treatment to the problem, including clearly formulated conditions for when imitation learning can succeed. These criteria advance people’s understanding of how to identify situations/assumptions sufficient for imitation learning. Finally, it introduces a new algorithm for the agent to learn a strategy based on its own sensory capabilities, yet with performance identical to the expert.
Learning causal effects from data is a fundamental problem across the empirical sciences. Determining the identifiability of a target effect from a combination of the observational distribution and the causal graph underlying a phenomenon is well-understood in theory. However, in practice, it remains a challenge to apply the identification theory to estimate the identified causal functionals from finite samples. Although a plethora of practical estimators has been developed under the setting known as the back-door, also called conditional ignorability, there exists still no systematic way of estimating arbitrary causal functionals that are both computationally and statistically attractive.
This work aims to bridge this gap, from causal identification to causal estimation. The authors note that estimating functionals from limited samples based on the empirical risk minimization (ERM) principle has been pervasive in the machine learning literature, and these methods have been extended to causal inference under the back-door setting. In this paper, they introduce a learning framework that marries two families of methods, benefiting from the generality of the causal identification theory and the effectiveness of the estimators produced based on ERM’s principle. Specifically, they develop a sound and complete algorithm that generates causal functionals in the form of weighted distributions that are amenable to the ERM optimization. They then provide a practical procedure for learning causal effects from finite samples and a causal graph. Finally, experimental results support the effectiveness of our approach.
One fundamental problem in the empirical sciences is of reconstructing the causal structure that underlies a phenomenon of interest through observation and experimentation. While there exists a plethora of methods capable of learning the equivalence class of causal structures that are compatible with observations, it is less well-understood how to systematically combine observations and experiments to reconstruct the underlying structure.
This work investigates the task of structural learning from a combination of observational and experimental data when the interventional targets are unknown. The relaxation of not knowing the interventional targets is quite practical since in some fields, such as molecular biology, we are unable to identify the variables affected by interventions.
The topology of a causal structure imprints a set of non-parametric constraints over the generated distributions, one type of which are conditional independences. The proposed work derives a graphical characterization that allows one to test whether two causal structures are indistinguishable with respect to the set of constraints in the available data. As a result, an algorithm is developed that is capable of harnessing the collection of data to learn the equivalence class of the true causal structure. The algorithm is proven to be complete, in the sense that it is the most informative in the sample limit.
Intelligent agents are continuously faced with the challenge of optimizing a policy based on what they can observe (see) and which actions they can take (do) in the environment where they are deployed. Most policies can be parametrized in terms of these two dimensions, i.e., as a function of what can be seen and done given a certain situation, which we call a mixed policy.
This work investigates several properties of the mixed policies class and provides a characterization with respect to criteria such as optimality and non-redundancy. In particular, the authors introduce a graphical criterion to identify unnecessary contexts for a set of actions, leading to a natural characterization of the non-redundancy of mixed policies. Then derive sufficient conditions under which one strategy can dominate the other concerning their maximum achievable expected rewards or optimality. This characterization leads to a fundamental understanding of the space of mixed policies and possible refinement of the agent’s strategy to converge to the optimum faster and more robustly. One surprising result of the causal characterization is that the agent following a standard, non-causal approach — i.e., intervening on all intervenable variables and observing all available contexts — may be hurting itself, and may never be able to achieve an optimal performance regardless of the number of interactions performed.
The challenge of generalizing causal knowledge across different environments is pervasive in scientific explorations, including in artificial intelligence, machine learning, and data science. Scientists collect data and carry out experiments in a particular environment with the intent of, almost invariably, use them for applications deployed under different conditions. For instance, consider a rover trained in the California desert. After exhaustive months of training, NASA wants to deploy the vehicle on Mars, where the environment is not the same, yet somewhat similar to Earth. The expectation is that the rover will need minimal “experimentation” (i.e., trial-and-error) on Mars by leveraging the knowledge acquired here, operating more surgically and effectively there. In the causal inference literature, this task falls under the rubric of transportability (Bareinboim and Pearl, 2013).
Despite many advances in this area, there is not much work on transportability for interventions consisting of conditional plans or stochastic policies. These interventions, known as soft interventions, are common in many practical applications. For instance, it is critical in Reinforcement Learning, where the agents need to adapt to changing conditions in an unknown environment. This research extends transportability theory to encompass tasks where input data, as well as the target of the analysis, involve soft interventions.
The paper introduces the first sufficient and necessary graphical condition and algorithm to decide soft-transportability. That is, to determine if a query interest is inferable from a combination of available (soft-)experimental data from different domains, based on causal and domain knowledge in the form of a graph. Finally, the research proves the completeness of a set of inference rules, known as σ-calculus, for this task. In contrast to do-interventions commonly used in causal inference analysis, soft interventions model real-world decision making more closely. For this reason, authors expect these results will help data scientists apply formal transportability analysis in broader and more realistic scenarios.
Topological data analysis (TDA) is a new methodology for using geometric structures in data for inference and learning. A central theme in the area is the idea of persistence, which in its most basic form studies how measures of shape change as a scale parameter varies. In many applications, there are several different parameters one might wish to vary: for example, scale and density. One can compute persistent invariants in this setting as well – a key problem is then to transform the resulting multi-scale descriptors, which are very complicated, into tractable numerical extracts.
This paper introduces a new descriptor for multi-parameter persistence, which we call the multi-parameter persistence image. The resulting quantity is suitable for machine learning applications, is robust to perturbations in the data, has provably finer resolution than existing descriptors, and can be efficiently computed on data sets of realistic size.
No-Regret Learning and Mixed Nash Equilibria: They Do Not Mix Lampros Flokas Columbia University, Emmanouil-Vasileios Vlatakis-Gkaragkounis Columbia University, Thanasis Lianeas National Technical University of Athens, Panayotis Mertikopoulos Univ. Grenoble Alpes, Georgios Piliouras Singapore University of Technology and Design
One of the most fundamental ideas in game theory is that when it comes to economic interactions between multiple agents randomization is necessary to ensure economic stability. The canonical example here would be Rock-Paper-Scissors where it is necessary for both agents to pick a strategy uniformly at random so that neither of them has a profitable deviation.
This paper establishes that such randomized equilibria are at odds with algorithmic stability showing that even when primed to choose them optimization-driven dynamics will always fail to do so. Thus, this work reveals a novel discrepancy between economic stability and algorithmic stability with important implications both for game theory as well as computer science.
One of the most fundamental tasks in statistics is the computation of the median of an underlying distribution from a finite number of samples. Median is commonly preferable to other location estimation methods, like the mean or mode, due to its high break-down point.
Even in the task of determining the critical high-risk age groups during the ongoing COVID-19 pandemic, median estimator plays a significant role in balancing out some possible outliers. Despite its aggregating nature, median could give crucial information about the participants of a data set causing probably several social, political, and financial implications.
This paper establishes an optimal and efficient mechanism for the computation of the median under differential privacy constraints to protect the individual or group privacy of the members of the sample.
When the Emerging Scholars Program (ESP) was established 12 years ago it was meant to introduce computer science (CS) topics to women interested in CS and to encourage them to pursue CS as a major. From four sections in 2008, it has expanded to eight and now it is open to everyone interested in CS and focused on making CS more inclusive for BIPOC students.
“The field of computer science is not programming, it is about solving problems computationally,” said Diana Abagyan, a senior from Columbia College who is a peer leader in the program. “The interactive nature of the class, in a low-stakes environment, equips students with the confidence that they can succeed in CS as much as anyone else.”
ESP aims to broaden how first and second-year students think about CS through its once-a-week, 75-minute workshop, and discussion section that can be taken in parallel with introductory CS classes. Each workshop is run by a peer leader who presents topics and problems from a specific field in CS.
The pass/fail class has no homework, no programming, and no other prerequisites except an interest in computer science. The goal of the program is to encourage more students to pursue computer science beyond the introductory level and into the major, by creating a program that encourages active participation and discussion of CS-related topics in a more positive, relaxed, and open environment.
“It was low-stakes CS work which I found incredibly helpful for my first semester,” said A.J. Cephus, a freshman from the School of General Studies who has decided to pursue CS as a major after taking the course. Like many ESP students, he does not have a computer science background. He found the course to be extremely helpful and made CS more approachable. Continued Cephus, “It was also inspiring to interact with undergraduate CS majors that are well versed in the topics.”
“We use problem-solving activities to help students wrap their heads around the concepts,” said Lindsey Wales, a peer leader who first encountered the program as a student in her freshman year. For example, in the natural language processing seminar, students have to read an unfamiliar language with English translations and try to use context clues to write and read sentences in that language. This helps them start to think about how machine translation works and which features are important to the structure of a language. They are able to work together to come up with a solution faster than they would alone, which is also a good introduction to team problem-solving.
“That teamwork is essential and shows students that not everything about CS is programming,” said Adam Cannon, a senior lecturer in discipline who is the program’s faculty advisor that started the program. The use of peer-led team learning has proven useful for both students and peer leaders in developing their skills. “Sometimes students don’t see this when their only early experiences are programming intensive introductory classes.”
The teaching style of ESP relies on small group interaction, discussion, and activities, rather than lectures. It has also been one of the department’s attempts to create a network of students who have a community to which to turn. ESP peer leaders also serve as points of contact within the major, and can provide important advice for classes, internships, and career paths.
“The best part of computer science is creative problem-solving and we try to show our students this from the beginning,” said Timothy Randolph, a third-year PhD student. He and Roland Maio are program coordinators who guide the program, support the peer leaders and workshop assistants, and keep everything running as smoothly as possible. Within the CS department, ESP has a unique opportunity and responsibility to make the major engaging to a wider variety of students and give them the skills and support network they need to succeed.
“It’s not always easy, but I like knowing that we can make Columbia CS stronger and improve the experience of our students,” said Randolph.
The Emerging Scholars Program team (left to right): Diana Abagyan, Jen Ozmen, Ajita Bala, Maria Teresa Tome, Pranjali Sharma, Walden Wang, Lindsey Wales, Roland Maio, Gala Kalevic, Tim Randolph
If you are interested in the Emerging Scholars Program, they are looking for students and workshop assistants for the Spring semester. Check out their website for details.
Alon Grinshpoon (MS ’18) kicks off the Ask Me Anything series of Columbia Engineering Entrepreneurship and talks about how he started his company, echoAR, by using the various resources at Columbia to develop his startup.
Yang Tang (PhD ’20) was awarded the Young Experts in Services Computing Student Paper award (YESC) from the IEEE Technical Committee on Services Computing (IEEE TCSVC).
Abstract: Literary tropes, from poetry to stories, are at the crux of human imagination and communication. Figurative language, such as a simile, goes beyond plain expressions to give readers new insights and inspirations. We tackle the problem of simile generation. Generating a simile requires proper understanding for effective mapping of properties between two concepts. To this end, we first propose a method to automatically construct a parallel corpus by transforming a large number of similes collected from Reddit to their literal counterpart using structured common sense knowledge. We then fine-tune a pre-trained sequence to sequence model, BART (Lewis et al., 2019), on the literal-simile pairs to generate novel similes given a literal sentence. Experiments show that our approach generates 88% novel similes that do not share properties with the training data. Human evaluation on an independent set of literal statements shows that our model generates similes better than two literary experts 37%1 of the times, and three baseline systems including a recent metaphor generation model 71%2 of the times when compared pairwise.3 We also show how replacing literal sentences with similes from our best model in machine-generated stories improves evocativeness and leads to better acceptance by human judges.
Content Planning for Neural Story Generation with Aristotelian Rescoring Seraphina Goldfarb-Tarrant University of Southern California and University of Edinburgh, Tuhin Chakrabarty Columbia University, Ralph Weischedel University of Southern California and Nanyun Peng University of Southern California and University of California, Los Angeles
Abstract: Long-form narrative text generated from large language models manages a fluent impersonation of human writing, but only at the local sentence level, and lacks structure or global cohesion. We posit that many of the problems of story generation can be addressed via high-quality content planning, and present a system that focuses on how to learn good plot structures to guide story generation. We utilize a plot-generation language model along with an ensemble of rescoring models that each implement an aspect of good story-writing as detailed in Aristotle’s Poetics. We find that stories written with our more principled plot structure are both more relevant to a given prompt and higher quality than baselines that do not content plan, or that plan in an unprincipled way.
Abstract: In this paper, we propose a neural architecture and a set of training methods for ordering events by predicting temporal relations. Our proposed models receive a pair of events within a span of text as input and they identify temporal relations (Before, After, Equal, Vague) between them. Given that a key challenge with this task is the scarcity of annotated data, our models rely on either pre-trained representations (i.e. RoBERTa, BERT or ELMo), transfer, and multi-task learning (by leveraging complementary datasets), and self-training techniques. Experiments on the MATRES dataset of English documents establish a new state-of-the-art on this task.
Abstract: We study the degree to which neural sequenceto-sequence models exhibit fine-grained controllability when performing natural language generation from a meaning representation. Using two task-oriented dialogue generation benchmarks, we systematically compare the effect of four input linearization strategies on controllability and faithfulness. Additionally, we evaluate how a phrase-based data augmentation method can improve performance. We find that properly aligning input sequences during training leads to highly controllable generation, both when training from scratch or when fine-tuning a larger pre-trained model. Data augmentation further improves control on difficult, randomly generated utterance plans.
Abstract: Stance detection is an important component of understanding hidden influences in everyday life. Since there are thousands of potential topics to take a stance on, most with little to no training data, we focus on zero-shot stance detection: classifying stance from no training examples. In this paper, we present a new dataset for zero-shot stance detection that captures a wider range of topics and lexical variation than in previous datasets. Additionally, we propose a new model for stance detection that implicitly captures relationships between topics using generalized topic representations and show that this model improves performance on a number of challenging linguistic phenomena.
Abstract: We describe a fully unsupervised cross-lingual transfer approach for part-of-speech (POS) tagging under a truly low resource scenario. We assume access to parallel translations between the target language and one or more source languages for which POS taggers are available. We use the Bible as parallel data in our experiments: small size, out-of-domain, and covering many diverse languages. Our approach innovates in three ways: 1) a robust approach of selecting training instances via cross-lingual annotation projection that exploits best practices of unsupervised type and token constraints, word-alignment confidence and density of projected POS, 2) a Bi-LSTM architecture that uses contextualized word embeddings, affix embeddings and hierarchical Brown clusters, and 3) an evaluation on 12 diverse languages in terms of language family and morphological typology. In spite of the use of limited and out-of-domain parallel data, our experiments demonstrate significant improvements in accuracy over previous work. In addition, we show that using multi-source information, either via projection or output combination, improves the performance for most target languages.
Although Sunday night for students is often spent alone, working on next week’s homework to make up for a weekend spent with friends, Matthew Wang, Columbia College junior and president of the Columbia eSports team, spends the night on Discord with more than 200 other members. At first glance, the server may seem quiet—nobody is constantly chatting or playing music when in fact, everyone is immersed in gaming as shown in their profiles: League of Legends and Overwatch scrimmages, or their nightly game of Minecraft or Hearthstone.
Edge-Weighted Online Bipartite Matching Matthew Fahrbach Google Research, Zhiyi Huang University of Hong Kong, Runzhou Tao Columbia University, Morteza Zadimoghaddam Google Research
The online bipartite matching problem introduced by Richard Karp, Umesh Vazirani, and Vijay Vazirani in 1990 is one of the most important problems in the field of online algorithms. In this problem, only one side of the bipartite graph (called “offline nodes”) is given. The other side of the graph (called “online nodes”) is given one by one. Each time an online node arrives, the algorithm must decide whether and how it should be matched. This decision is irrevocable. The online bipartite matching problem has a wide range of applications, e.g., online ad allocation, in which we can see advertisers as offline nodes and users as online nodes.
This paper gives a positive answer for this 30-year open problem by giving an 0.508-competitive algorithm for the edge-weighted bipartite online matching problem. The algorithm uses a new subroutine called Online Correlated Selection, which takes a sequence of pairs as input and selects one element from each pair. By negatively correlating the selections, one can produce a better online matching algorithm.
This new technique will have further applications in the field of online algorithms.
Consider the problem of maintaining a directed graph under edge addition/deletions, so that connectivity between any pair of vertices can be answered quickly. This basic problem has no efficient data structure, despite decades of research. In 2010, Patrascu proposed a communication problem (the “Multiphase Conjecture”), whose resolution would prove that problems like dynamic reachability indeed require slow (n^0.1) update or query time. We use information-theoretic tools to prove a weaker version of the Multiphase Conjecture, which implies a polynomial (~ \sqrt{n}) lower bound on “weakly-adaptive” dynamic data structures for the reachability problem. We also use this result to make progress on understanding the power of nonlinear gates in networks computing *linear* operators (x –> Ax).
This paper resolves an open question about the complexity of estimating the edit distance up to a constant factor. Edit distance is a fundamental problem, and its exact quadratic-time algorithm is one of the most classic dynamic programming problems.
It was shown that under the SETH conjecture, no exact algorithm can resolve it in sub-quadratic, so the open question remained what is the best approximation one can obtain. A breakthrough result from 2018 showed the first trust sub-quadratic algorithm for Constant factor, and the question remained if it can be done in near-linear time. This paper resolved this question positively.
Range-counting is one of the most omnipresent query spatial databases, computational geometry, and eCommerce (e.g. “Find all employees from countries X who have earned salary >X between years 2000-2018”). Fast data structures with linear space are known for various such problems, all of which use only additions and subtractions of pre-computed weighted sums (aka the “group model”). However, for general ranges (geometric shapes), no efficient data structures were known, yet proving > log(n)
Lower bounds in the group model remained a fundamental challenge since the early 1980s. The paper proves a *polynomial* (n^0.1) lower bound on the query time of linear-space data structures for an explicit range-counting problem of convex polygons in R^2.
Fundamental routing problems such as the Traveling Salesman Problem (TSP) and the Vehicle Routing Problem have been widely studied since the 1950s. Given a metric space, the goal is to find a minimum-weight collection of tours (only one for TSP) so as to meet a prescribed demand at some points of the metric space. Both problems have been the source of inspiration for many algorithmic breakthroughs and, quite frustratingly, remain good examples of the limits of the power of algorithmic methods.
The paper studies the geometry of weighted minor free graphs, which is a generalization of planar graphs, where the graph is somewhat topologically restricted. The framework is this of metric embeddings, where we create a “small-complexity” graph that approximately preserves distances between pairs of points in the original graph. We have two such structural results:
1. Light subset spanner: given a set K of terminals, we construct a subgraph of the original graph that preserves all distances between terminals up to 1+\eps factor and have total weight only slightly larger than the Steiner tree: the minimal weight subgraph connecting all terminals.
2. Stochastic metric embedding into low treewidth graphs: treewidth is a graph parameter measuring how much a graph is “treelike”. Many hard problems become tractable on bounded treewidth graphs. We create a distribution over mapping of the graph into a bounded treewidth graph, such that the distance between every pair of points increases only by a small additive constant (in expectation).
The structural results are then used to obtain an efficient polynomial approximation scheme (EPTAS) for subset TSP in minor-free graphs, and a quasi-polynomial approximation scheme (QPTAS) for the vehicle routing problem in minor-free graphs.
In an effort to reduce inequities in the PhD application process, a group of PhD students have created the Pre-Submission Application Review (PAR) Program to help applicants to the PhD program.
When Chris Kedzie and Katy Gero heard about Stanford University’s Student-Applicant Support Program they immediately thought, “this is something that we can do at Columbia.” Within hours they put together a rough plan on how to help applicants of the PhD program – by lending their expertise with reviewing a personal statement.
“Many times people who end up in PhD programs get there because of an invisible network of support, normally from other people who have attended a PhD program,” said Chris Kedzie, a seventh-year PhD student. When he was applying to graduate programs many of his friends who were in PhD programs helped and gave him invaluable feedback on his application, specifically his personal statement. “But for those who do not have access to that kind of network, it can put them at an unfair disadvantage.”
This review program attempts to fill the gap and help provide access to PhD students who can look over an applicant’s statement of purpose. “It is certainly not even close to addressing all of the systemic problems that some people face when applying to grad school,” said Katy Gero, a fourth-year PhD student. She, too, had friends in PhD programs who helped her with her application and she saw what a big difference getting feedback and guidance made. “We hope this is a small step in the right direction and it is something that we as grad students can implement ourselves.”
The initiative did not pop up out of the blue. Kedzie and Gero have been meeting with other students, faculty, and department staff since the #ShutDownSTEM strike for Black lives on June 10th. Over the summer, the group brainstormed ways that they can make the CS department more equitable. One of the points discussed was making the PhD program more accessible and so it was easy to get the group’s support for the PAR Program.
The initiative was put together quickly because of the support of fellow students, like Khalil Dozier and Tim Randolph, along with Associate Director for Academic Administration and Student Services Cindy Meekins, Professor Augustin Chaintreau, and CS Department Chair and Professor Rocco Servedio. The program was presented to the Dean’s office and officially launched in mid-October.
“The Computer Science Department is very happy to support our PhD students in this effort that they have led to improve the equity of our PhD program,” said Rocco Servedio, a professor and chair of the department. The department launched the CS@CU MS Bridge Program in computer science last year and is working on other programs with students and faculty. “We hope that this and other similar-in-spirit programs will bear fruit in broadening access to our department to a wide group of learners.”
Interested applicants have to apply to the PAR program and submit their personal statement and CV by November 7th at 11:59 pm EST. Because the program is student-run and dependent on volunteers, there is no guarantee that every applicant can be accommodated. For those who are accepted, they will be notified, then paired with a PhD student in the same research area who will review their materials and provide feedback to them by November 21st – well ahead of the December 15th deadline to apply to the PhD program.
“We have been really impressed by the support we have seen,” said Kedzie. “We hope that this is a step towards a lot of bigger changes to the department and the school, to make it a more equitable place for everyone.”
Payal Chandak (CC ’21) developed a machine learning model, AwareDX, that helps detect adverse drug effects specific to women patients. AwareDX mitigates sex biases in a drug safety dataset maintained by the FDA.
Below, Chandak talks about how her internship under the guidance of Nicholas Tatonetti, associate professor of biomedical informatics and a member of the Data Science Institute, inspired her to develop a machine learning tool to improve healthcare for women.
Payal Chandak
How did the project come about? I initiated this project during my internship at the Tatonetti Lab (T-lab) the summer after my first year. T-lab uses data science to study the side effects of drugs. I did some background research and learned that women face a two-fold greater risk of adverse events compared to men. While knowledge of sex differences in drug response is critical to drug prescription, there currently isn’t a comprehensive understanding of these differences. Dr. Tatonetti and I felt that we could use machine learning to tackle this problem and that’s how the project was born.
How many hours did you work on the project? How long did it last? The project lasted about two years. We refined our machine learning (ML) model, AwareDX, over many iterations to make it less susceptible to biases in the data. I probably spent a ridiculous number of hours developing it but the journey has been well worth it.
Were you prepared to work on it or did you learn as the project progressed? As a first-year student, I definitely didn’t know much when I started. Learning on the go became the norm. I understood some things by taking relevant CS classes and through reading Medium blogs and GitHub repositories –– this ability to learn independently might be one of the most valuable skills I have gained. I am very fortunate that Dr. Tatonetti guided me through this process and invested his time in developing my knowledge.
What were the things you already knew and what were the things you had to learn while working on the project? While I was familiar with biology and mathematics, computer science was totally new! In fact, T-Lab launched my journey to exploring computer science. This project exposed me to the great potential of artificial intelligence (AI) for revolutionizing healthcare, which in turn inspired me to explore the discipline academically. I went back and forth between taking classes relevant to my research and applying what I learned in class to my research. As I took increasingly technical classes like ML and probabilistic modelling, I was able to advance my abilities.
Looking back, what were the skills that you wished you had before the project? Having some experience with implementing real-world machine learning projects on giant datasets with millions of observations would have been very valuable.
Was this your first project to collaborate on? How was it? This was my first project and I worked under the guidance of Dr. Tatonetti. I thought it was a wonderful experience – not only has it been extremely rewarding to see my work come to fruition, but the journey itself has been so valuable. And Dr. Tatonetti has been the best mentor that I could have asked for!
Did working on this project make you change your research interests? I actually started off as pre-med. I was fascinated by the idea that “intelligent machines” could be used to improve medicine, and so I joined T-Lab. Over time, I’ve realized that recent advances in machine learning could redefine how doctors interact with their patients. These technologies have an incredible potential to assist with diagnosis, identify medical errors, and even recommend treatments. My perspective on how I could contribute to healthcare shifted completely, and I decided that bioinformatics has more potential to change the practice of medicine than a single doctor will ever have. This is why I’m now hoping to pursue a PhD in Biomedical Informatics.
Do you think your skills were enhanced by working on the project? Both my knowledge of ML and statistics and my ability to implement my ideas have grown immensely as a result of working on this project. Also, I failed about seven times over two years. We were designing the algorithm and it was an iterative process – the initial versions of the algorithm had many flaws and we started from scratch multiple times. The entire process required a lot of patience and persistence since it took over 2 years! So, I guess it has taught me immense patience and persistence.
Why did you decide to intern at the T-Lab? I was curious to learn more about the intersection of artificial intelligence and healthcare. I’m endlessly fascinated by the idea of improving the standards of healthcare by using machine learning models to assist doctors.
Would you recommend volunteering or seeking projects out to other students? Absolutely. I think everyone should explore research. We have incredible labs here at Columbia with the world’s best minds leading them. Research opens the doors to work closely with them. It creates an environment for students to learn about a niche discipline and to apply the knowledge they gain in class.
Professor Kathy McKeown talks with DeepLearning.AI’s Andrew Ng about how she started in artificial intelligence (AI), her research projects, how her understanding of AI has changed through the decades, and AI career advice for learners of NLP.
Fellows from the department were among the participants of the prestigious conference where laureates of mathematics and computer science meet the next generation of young researchers.
This year’s event, although virtual, still presented itself as an opportunity to learn new things and network for the fellows – alum Oded Stein (PhD ’20) and PhD students Ireti Akinola and Ana-Andreea Stoica. Below they share what they enjoyed most and how they look forward to attending the event in person after the pandemic.
I was excited to learn that Donald Knuth and Yoshua Bengio were among the Turing laureates that will be participating at this year’s conference. It was interesting to hear them talk about their careers. While they shared some thoughts on their specific paths, they were quick to point out that the world is a lot different now compared to when they started. What was evident with their talks was that they tried to work on problems that they found interesting.
In other sessions, speakers highly recommended multi-disciplinary collaborations to help advance impactful modern research. I also learned a bit more about health care and disease management, which is the main theme of the event. This was quite timely as the pandemic has made this time a defining moment in healthcare.
Science communication came up a lot throughout the course of the forum. As young researchers, speakers recommended writing as much as you can – writing ideas down, both in prose and equations, helps with clarity.
The Heidelberg forum was a good mix of learning from very accomplished academics and meeting other students. With all the difficulties that an online event presents, I appreciated that the organizers took many questions and feedback from participants, and the talks felt more like a lively discussion.
I liked hearing from prominent researchers like Karen Uhlenbeck and Don Knuth not only about their work, but also about their research process, interests, and a bit about their life story of how they got engaged with their field. Other than that, the forum presented several interesting discussions about current topics, such as using big data in healthcare, or the potential dangers of artificial intelligence, which connected some of the more theoretical foundations to application domains and ethical considerations.
The forum had a lively online platform that simulated real-life interaction and facilitated a poster session where people could mingle and learn from each other — which I think is really needed for any online event!
I learned about the forum from my advisor, Augustin Chaintreau, and was excited to see in the program many amazing researchers on fields related to mine. While I enjoyed the forum this year, I’m sure the in-person experience will be very different. I’m looking forward to participating (hopefully!) in person next year.
I really enjoyed attending the virtual forum. It was quite an experience to hear talks by some of the most esteemed people in mathematics and computer science. I was very inspired by hearing their stories and it was great that they answered many audience questions during the sessions.
There was also a virtual meeting room for a poster session, which provided social interactions between the attendees which I appreciated since we were all meeting virtually.
One specific thing I learned from the lab tours is that doing astronomy is very labor-intensive! The researchers hike far away to get to the telescopes, live in cramped living conditions to operate the machinery, and there is also the constant danger from forest fires.
I think it was a good experience, but it would have been even better if it was in-person. I’m looking forward to attending the event when the public health situation makes an in-person meeting possible.
On October 28, students, faculty, alumni, families, and friends—from across Columbia and around the world—come together to give back to Columbia Engineering on Giving Day. Together, we invest in the future of our department, our school, and our shared commitment to intellectual excellence and bringing this excellence to the service of humanity. This year on Giving Day you can give back directly to the Computer Science department!
P.S. For our students – be a part of the action by following our progress and amplifying the message via social media!
For the COVID-19 Hub, CRAC was asked to join a team along with CUIT and senior leadership across every campus to create a user-populated resource for COVID-related projects. The idea is that students and researchers alike can browse or search COVID-related projects and make connections with colleagues whose work and interest mirror their own.
Below, Mackenzie talks about volunteering and how it was working on the Project 8 COVID-19 Hub.
Matt Mackenzie
Why did you decide to volunteer? Being someone who is not fluent in anything biology, I didn’t think there was any way I could contribute to the fight against COVID. When I heard about a more IT-centric project, I thought I could be useful, and do my small part to help.
Were you actively looking for a project to work on or was your interest because the project was COVID-related? I was interested because of the COVID-related nature of the project. I had never worked on a research project before, and always wanted to, but being in the middle of the semester I was not actively looking for any more work!
How was it working on the project? What did you do? The project went from April to June. On average, I worked maybe 4 hours a week. But some days were very light, and some required many hours of work. The largest portion of my work was writing Python code to clean incoming data, which is something I was very comfortable with.
What were the things you already knew and what were the things you had to learn while working on the project? Python was our main tool for automation, and I have been using that for years. We were all responsible for knowing the structure of the data since sometimes we needed to populate missing fields or manually clean data, so learning the structure was also necessary. At one point we categorized some of the project data we were working with, and that required learning more about the projects themselves.
We used Qualtrics to collect survey data, knowing a little more about that would have been nice.
Was this your first project to collaborate on? How was it? This was my first project. I thought it was very interesting to see how rapidly things were accomplished, and how a vast network of individuals from all different backgrounds could work together so seamlessly.
While I was only a part of Project 8, the entire CRAC organization shared a Slack workspace, and watching the high level of intellectualism and professionalism in the conversations all across the organization was really inspiring to continue with research and education.
Do you think your skills were enhanced or improved by working on the project? Yes. While my Python skills maybe got a little bit of practice, I think my soft skills benefitted the most, as we had to work together and communicate electronically with each other.
I don’t see myself pursuing biology, but working on this project definitely has made me want to get involved with more research opportunities.
Would you recommend volunteering or seeking projects out to other students? Absolutely! The COVID-19 pandemic is obviously still on-going and will remain a problem for the foreseeable future. If you have the skills or passion to help in any way, I encourage everyone to do so. Not only is it a great learning experience, but you get to have a truly positive impact on society.
Assistant Professor Baishakhi Ray has won a VMware Early Career Faculty Award to develop machine learning tools that will improve software security. The grant program recognizes the next generation of exceptional faculty members. The gift is made to support early-career faculty’s research and promote excellence in teaching.
In today’s world, software controls almost every aspect of our lives. Unfortunately, most software tends to be buggy, often threatening even the most safety- and security-critical software. According to a recent report, 50% of software developers’ valuable time is wasted at finding and fixing bugs, costing the global economy around USD$1.1 trillion in 2016 alone.
“The goal of my research is to address this problem and figure out how to automatically detect and fix bugs to improve software robustness, for both traditional and machine learning-based software,” said Ray, who joined the department in 2018.
In particular, her research will address two main challenges of software robustness: (i) traditional software has numerous implicit and explicit specifications; it is often difficult to know all of them in advance. (ii) With the advent of machine learning-based systems (e.g., self-driving cars), explicitly providing such specifications involving natural inputs, like images and text, is very hard.
Ray’s plan is a two-pronged approach. First, she and her team will build novel machine learning models to learn implicit specifications/rules from traditional programs and leverage these rules to detect and fix bugs automatically. However, such techniques are not easily extendable to machine learning-based systems as they follow different software paradigms (e.g., finite state machine vs. neural network). To improve the robustness of such systems, they will also devise new analysis techniques to examine the internal states of the models for potential violations.
“A successful outcome of this project will produce new techniques to detect and remediate software errors and vulnerabilities with increased accuracy to make software more secure,” said Ray.
Womxn in Computer Science (WiCS) President Rediet Bekele (CC ’21) talks about the organization’s plans to help members and its new initiatives for the year. She takes a positive look at the move to virtual classes and online events and sees it as an opportunity to reach even more people and help members navigate this school year.
Rediet Bekele
Below, Bekele reflects on the changes this year and how WiCS will help build a sense of community for its members.
How do you see the year unfolding for WiCS? We are already in the works for Fall events that will allow our members to participate virtually. We started holding General Body meetings over the summer and it will continue virtually into the academic year. We are hoping that through these meetings we can instill the feeling of community that is currently much needed.
We plan to grow the number of members that join our club by onboarding early. WiCS’ community chairs are going to be working closely with incoming first-year students to create a channel with WiCS. They want students to use this channel to help navigate on-campus and virtual resources. Workshops on how to communicate with TAs and professors and lightning talks about research projects on campus are just some of the events we are organizing to help students understand course-related and research opportunities that are made available to them.
What do you hope to achieve this year as president? As an international student myself, I want to work on more initiatives that will help international students navigate the CS community at Columbia and use the resources available to them to succeed in the field. This will include organizing professional development opportunities, workshops on understanding work authorization, and making the most out of health and course-related resources on campus.
Within the club, I hope to make the transition to the coming academic year as smooth as possible on everyone on the board. We are anticipating the majority of our correspondence to be remote this coming year so I want to make sure that effective virtual communications still occur and that we are able to continue working with all of our members. It will definitely be a learning curve for all of us as the virtual format is truly a unique situation, but WICS’ amazing board members and general body are sure to make it an effortless transition.
How about the yearly events and activities that WiCs hosts, will any of those push through? Definitely! Just as we have done in previous years, we are sponsoring students attending the Grace Hopper Conference. This year, WiCS is a bronze level academic sponsor for the conference and we are incredibly excited to be sponsoring 30 women to attend the virtual conference in October!
DivHacks is also virtually taking place this fall from October 23 -25. Our diversity chairs have been working hard to make the fifth annual DivHacks hackathon the best one to date. The theme for this year’s hackathon is Encoding Justice. We encourage everyone to check out the DivHacks website and register for the event.
We also have numerous events coming up with our general body members such as virtual professor lunches, mock interview sessions to help our students during the recruitment season, and 1:1 coffee chats with engineers from our sponsor companies.
We can’t wait for students to take part in all of our events!
How can students reach out to WiCS and find out more about your programs? A great way to keep up with our events is to subscribe to our weekly newsletter. Students can subscribe through the link on our website. They can also reach out to us on our Facebook page and Instagram channel.
Is there anything else you think people should know? In light of current issues, from a pandemic that has closed the doors of our campus to heightened tension and protests against racial inequality, it is easy to feel overwhelmed, stressed, furious, and confused. We want to let everyone know that WiCS is here to serve not only the CS community but the entire Columbia and Barnard student community. We want to keep open lines of communications so that anyone can reach out to us and we would be happy to listen, provide resources, or support.
Graduate students from the department have been selected to receive scholarships. The diverse group is a mix of those new to Columbia and students who have received fellowships for the year.
J.P. Morgan 2019 AI Research PhD Fellowship Awards
The inaugural award supports researchers who have the skills and imagination to potentially transform the way we live and work.
Juan D. Correa Juan D. Correa‘s work focuses on the theoretical and logical foundations of causal inference. Correa is a second-year PhD student who works with associate professor Elias Bareinboim in the Causal Artificial Intelligence Lab.
In 2019, he received a Best Paper Award at the 35th Conference on Uncertainty in Artificial Intelligence and an Outstanding Paper Award Honorable Mention at the 32nd AAAI Conference on Artificial Intelligence (2018). He graduated in 2017 with an MSc in Computer Science from Purdue University and a bachelor’s degree in Computer Engineering from Universidad Autónoma de Manizales in Colombia in 2011.
NSF Graduate Research Fellowship Program (GRFP)
The GRFP is a five-year fellowship that recognizes and supports outstanding graduate students in NSF-supported STEM disciplines who are pursuing research-based master’s and doctoral degrees.
Emily Allaway EmilyAllaway is interested in implied semantics. In particular, she is interested in understanding stance and other types of meaning that are expressed but not explicitly stated in text. She is a third-year PhD student in the Natural Language Processing group under professor Kathy McKeown.
Allaway graduated from the University of Washington where she earned a BS in mathematics, a BS in computer science, and a minor in Ancient Greek.
Vivian Liu Vivian Liu’s research interests are in human-computer interaction (co-creating with AI), immersive technologies, and accessibility. She is a first-year PhD student set to work with assistant professor Lydia Chilton.
Liu graduated with general distinction from UC Berkeley in 2019 where she earned a B.A. in Computer Science, a B.A. in Cognitive Science, and a Certificate in New Media.
Sachit Menon Sachit Menon’s research interests lie in machine learning and computer vision. He is especially interested in allowing computers to learn with less human supervision, as well as enabling them to generalize past the specific data they’ve seen (for example, by reasoning about uncertainty or causality). Menon is a first-year PhD student who will be advised by assistant professor Carl Vondrick. His graduate studies are supported by the NSF Graduate Research Fellowship and the Columbia Presidential Fellowship.
This year he graduated from Duke University with a BS in Mathematics and Computer Science with Highest Distinction. Menon’s undergraduate studies were supported by an Angier B. Duke fellowship (Duke’s flagship merit scholarship) and a Goldwater Scholarship (the most prestigious undergraduate scholarship in scientific fields).
Shyamal Patel Shyamal Patel is a first-year PhD student interested in combinatorics and theoretical computer science. He will be joining the Theory group and will be supervised by associate professor Xi Chen and professor Clifford Stein.
Patel graduated from Georgia Tech in 2020 with a degree in computer science.
Abhishek Shah Abhishek Shah‘s research uses deep learning and optimization techniques to improve software security. He is a second-year PhD student co-advised by professor Simha Sethumadhavan and assistant professor Suman Jana.
Shah graduated in 2019 from Columbia University with a degree in computer science.
Qualcomm Innovation Fellowship (QInF)
The QInF is focused on recognizing, rewarding, and mentoring innovative PhD students across a broad range of technical research areas. The highly competitive program is open to PhD students in the Electrical Engineering and Computer Science departments from the top 24 US-based and Canadian schools. Only 13 two-member teams were awarded funding, out of 188 applications this year.
Evgeny Manzhosov Evgeny Manzhosov is a second-year PhD student who works with professor Simha Sethumadhavan to develop secure and reliable systems. Prior to Columbia, he worked as Physical Design Engineer at Intel (2011-13), Apple (2013-16), and Cisco (2016-17).
Evgeny has BSc in Electrical Engineering and BSc in Physics from Technion – Israel Institute of Technology (2015) and completed an MSc in Electrical Engineering at Columbia University with an Award of Excellence (2019).
Mohamed Tarek Mohamed Tarek’s research interests include systems security, microarchitecture design. and hardware support of security. He is a fourth-year PhD candidate under the guidance of professor Simha Sethumadhavan. His work on fine-grained memory safety, Califorms, is recognized with an IEEE Micro Top Picks Honorable Mention 2019.
Tarek received a B.Sc. and M.Sc. degrees in computer engineering at Ain Shams University, Egypt in 2014 and 2017, respectively. During his M.Sc. studies, he worked on using homomorphic encryption for secure data computations.
Cheung-Kong Innovation Doctoral Fellowship
The scholarship is set up to support doctoral studies at SEAS as part of the collaboration between Columbia Engineering (SEAS) and Cheung-Kong Graduate School of Business (CKGSB).
Keyon Vafa Fourth-year PhD student Keyon Vafa’s research focuses on probabilistic machine learning, where he works on applying probabilistic methods to deep learning with professor David Blei. He is especially excited by applications to text and the social sciences.
In 2016, Vafa was awarded an NSF GRFP fellowship and spent a year as a PhD student in the statistics department before transferring to the computer science department. He graduated from Harvard University magna cum laude with a bachelor’s in computer science and statistics in 2016.
Chang Xiao Chang Xiao is a fifth-year PhD student in the computer science department who works with associate professor Changxi Zheng. His research focuses on building human-computer interaction systems using computational methods and machine learning. He has developed methods in a range of applications and his research has attracted public interest, including media coverage from CNN, IEEE Spectrum, etc.
Chang received a BS degree in computer science from Zhejiang University in 2016 and is a recipient of the Snap Fellowship and a SEAS fellowship in 2019.
Dean’s Fellowship
The scholarship is a highly-selective fellowship offered to a small number of admitted students.
Kahlil Dozier Kahlil Dozier’s research focus is networked systems with a particular interest in systems building and formal analysis. He is a first-year PhD student who will work with professors Vishal Misra and Dan Rubenstein.
Dozier has two degrees from MIT – a BS Electrical Engineering (2012) and an M.Eng Electrical Engineering (2014). He also earned an MS in computer science from the University of Southern California (USC) in 2020.
Loqman Salamatian Loqman Salamatian is a first-year PhD student with the Networking group under the guidance of Ethan Katz-Bassett, Vishal Misra, and Dan Rubinstein. His main interests are in internet measurement, complex systems analysis, and information geometry. He will be working on finding new models to measure and understand the interactions between virtual and geographical space.
Salamatian is a mathematics graduate from Luxembourg University and has studied in France, Hong Kong, and Australia.
Rundi Wu Rundi Wu is a first-year PhD student advised by Prof. Changxi Zheng. His research interests lie in computer graphics, computer vision, and deep learning, with a special focus on learning-based 3D shape modeling.
He was part of the Turing class at Peking University and graduated in 2020 with a bachelor’s degree in computer science.
Greenwoods Fellowship
The Columbia School of Engineering and Applied Sciences recognizes and supports Ph.D. students reflecting their academic achievements and clear potential for future success.
Gaurav Jain A first-year PhD student, Gaurav Jain works with assistant professor Brian A. Smith on human-computer interaction and computer vision applications at the Computer-Enabled Abilities Laboratory (CEAL). His goal is to build interactive systems for people with disabilities (especially blind and visually impaired people) to better experience the world around them.
Gaurav received a bachelor’s degree in computer science from Delhi Technological University in 2020 and is a recipient of the Indian Academy of Sciences’ Summer Research Fellowship in 2019.
SEAS Fellowships
The Columbia School of Engineering and Applied Sciences established the Presidential and SEAS fellowships to recruit outstanding students from around the world to pursue graduate studies at the school.
Run Chen Run Chen is a first-year PhD student working with the Spoken Language Processing Group led by professor Julia Hirschberg. Her research interest lies in natural language processing and computational linguistics. She earned a silver medal from the International Linguistics Olympiad.
Chen graduated from MIT with a BS in computer science and linguistics in 2019, and an MEng in computer science in 2020.
Miranda Christ Miranda Christ is a first-year PhD student who is broadly interested in cryptography, complexity, and algorithms. She will join the theory group and will be co-advised by professors Tal Malkin and Mihalis Yannakakis.
Christ is also a Fulbright Scholar. She graduated magna cum laude from Brown University in 2020 with an Sc.B. in Mathematics-Computer Science.
Samir Gadre Samir Gadre‘s research interests include computer vision, robotics, interactive perception, lifelong learning, and machine learning. He is a first-year PhD student advised by assistant professor Shuran Song. While at Columbia his research will focus on object understanding, specifically on learning representations for everyday objects that are useful for downstream computer vision and robotics tasks.
Gadre graduated from Brown University with an Sc.B. Computer Science in 2018. For the past two years, he has worked as a Software Engineer at Microsoft HoloLens.
Melanie Subbiah Melanie Subbiah plans to explore the different areas of Natural Language Processing (NLP) for the first year of her PhD. Subbiah will work with professor Kathy McKeown and she is interested in long-form controllable text generation, self-supervised learning, and neural networks.
In 2017, she completed a Bachelor’s in Arts and Sciences in Computer Science from Williams College.
Computer science alumni share their experiences since graduating from Columbia and discuss emerging technologies, interview tips, finding meaningful work, and career trajectories in this weekly series.
CS researchers develop a new machine learning approach that shows promise in predicting necrotizing enterocolitis; could lead to improved medical decision-making in neonatal ICUs.
This summer seminar series highlights 14 computer science PhD students. The handpicked group of students hosted individual Zoom sessions to discuss their experiences and research projects.
The Doctoral Dissertation Award is awarded annually to recognize a recent doctoral candidate who has successfully defended and completed his or her Ph.D. dissertation in computer graphics and interactive techniques. This award recognizes young researchers who have already made a notable contribution very early during their doctoral study.
The 37th International Conference on Machine Learning is an annual event taking place virtually this week. Professor David Blei is the General Chair of the conference for the larger machine learning research community.
Professor Elias Bareinboim presented a tutorial entitled “Towards Causal Reinforcement Learning,” where he discussed a new approach for decision-making under uncertainty in sequential settings. The tutorial is based on his observation, in his own words, “Causal inference (CI) and reinforcement learning (RL) are two disciplines that have evolved independently and achieved great successes in the past decades, but, in reality, are much closer than one would expect. Many new learning problems emerge whenever we understand and formally acknowledge their connection. I believe this understanding will make them closer and more applicable to real-world settings.”
In particular, Bareinboim explained that CI provides a set of tools and principles that allows one to combine structural invariances about the environment with data to reason about questions of counterfactual nature — i.e., what would have happened had reality been different, even when no data about this imagined reality is available. On the other hand, RL is concerned with efficiently finding a policy that optimizes a specific function (e.g., reward, regret) in interactive environments under sampling constraints, i.e., regarding the agent’s number of interactions with the environment. These two disciplines have evolved with virtually no interaction between them. Bareinboim noticed that even though they operate under different aspects of reality (an “environment,” as usually said in RL jargon), they are two sides of the same coin, namely, counterfactual relations.
His group at Columbia, the Causal Artificial Intelligence Lab, has been investigating in the last years the implications of this observation for decision-making in partially observable environments. In the first part of his tutorial, Bareinboim introduced the basics of CI and RL, and then explained how they fit the larger picture through a CRL lens. In particular, he used a newly proved result (joint with collaborators at Stanford University), the Causal Hierarchy Theorem (CHT), to discuss the different types of “interactions” an agent could have with the environment it is deployed, namely, “seeing”, “doing”, and “imagining.” He then puts the literature of RL — on- and off-policy learning — as well as the CI type of learning — called do-calculus learning — under the same formal umbrella. After being able to formalize CI and RL in a shared notation, in the second part of the tutorial, he notices that CRL opens up a new family of learning problems that are both real and pervasive, but weren’t acknowledged before. He discusses many of these problems, including the combination of online & offline learning (called generalized policy learning), when and where the agent should intervene in a system, counterfactual decision-making, generalizability across environments, causal imitation learning, to cite a few.
Bareinboim’s program is to develop a principled framework for designing causal AI systems that integrate observational, experimental, counterfactual data, modes of reasoning, and knowledge, which he believes, will lead to “a natural treatment to human-like explainability and rational decision-making.” If you are interested in joining the effort, he is actively recruiting graduate students, postdoctoral scholars, and trying to find collaborators who believe in Causal AI. The tutorial’s material and further resources about CRL can be found here: https://crl.causalai.net.
Below are links to the accepted papers and brief research descriptions.
One of the central challenges in the data sciences is to compute the effect of a novel (never experience before) intervention from a combination of observational and experimental distributions, under the assumptions encoded in the form of a causal graph. Formally speaking, this problem appears under the rubric of causal effect identification and has been studied under various conditions in the theory of data-fusion (Survey: Bareinboim & Pearl, PNAS 2016; Video: Columbia Talk). Most of this literature, however, implicitly assumes that every variable modeled in the graph is measured throughout the datasets. This is a very stringent condition. In practice, the data collected in different studies are usually not consistent, i.e., each dataset measures a different set of variables.
For concreteness, consider a health care researcher who wants to estimate the effect of exercise (X) on cardiac stroke (Y) from two existing datasets. The first dataset is from an experimental study of the effect of exercise (X) on blood pressure (B) for different age groups (A). The second dataset is from an observational study that investigated the association between BMI (C), blood pressure (B), and stroke (Y). Currently, no algorithm can take these two datasets over {X, Y, A, B, C} and systematically combine them so as to identify the targeted causal effect — how exercise (X) affects cardiac stroke (Y).
In this paper, the researchers studied the causal effect identifiability problem when the available distributions encompass different sets of variables, which they refer to as causal effect identification under partial-observability (GID-PO). They derived properties of the factors that comprise a causal effect under various levels of abstraction (known as projections), and then characterized the relationship between them with respect to their status relative to the identification of a targeted intervention. They establish a sufficient graphical criterion for determining whether the effects are identifiable from partially-observed distributions. Finally, building on these graphical properties, they developed an algorithm that returns a formula for a causal effect in terms of the available distributions, whenever this effect is found identifiable.
One metaphor used throughout the paper is of a jigsaw puzzle, where the targeted effect is comprised of pieces and each dataset contains chunks, where each chunk is one or more pieces merged together. The task is to combine the chunks so as to solve the puzzle, even though not all puzzles are solvable. They infer that the identifiability problem under partial-observability is NP-complete.
“This conjecture is particularly surprising since many existing classes of identifiability problems have been entirely solved in polynomial time, the decision version of the problem, not an estimation,” said Sanghack Lee, an associate research scientist in the CausalAI Lab. “The class of time complexity of an identification problem may rely crucially on the lack of variables in the data sets, not the number of available data sets nor the size of a causal graph.”
Linear regression and its generalizations have been the go-to tool of a generation of data scientists trying to understand the relationships among variables in multivariate systems, and the workhorse behind countless breakthroughs in science. Modern statistics and machine learning techniques allow one to scale regression up to thousands of variables simultaneously. Despite the power entailed by this family of methods, it only explains the association (or correlation) between variables, while it remains silent with respect to causation. In practice, a health scientist may be interested in knowing the effect of a new treatment on the survival of its patients, while an economist may attempt to understand the unintended consequences of a new policy on a nation’s gross domestic product. If regression analysis doesn’t allow scientists to answer their more pressing questions, which technique or framework could legitimize such inferences?
The answer lies in the tools of causal inference, specifically in the methods developed to solve the problem of “identification”. In the context of linear systems, formally speaking, identification asks whether a specific causal coefficient can be uniquely computed from the observational covariance matrix and the causal model. There exists a rich literature on linear identification, which includes a general algebraic solution (based on Groebner bases) that is doubly-exponential. In practice, and given this hardness result, the most common approach in the field is known as the method of instrumental variables (IVs), which looks for a particular substructure within the covariance matrix.
The research develops a new polynomial-time algorithm for linear identification that generalizes IV and all known efficient methods. The machinery developed underlying this algorithm unifies several disparate methods developed in the literature for the last two decades. Perhaps surprisingly, it turns out that this new method is also able to subsume identification approaches based on conditioning, some of which have high identification power but undetermined computational complexity, with certain variants shown to be NP-Hard.
Finally, this paper also allows one to efficiently solve for total effects based on a new decomposition strategy of the covariance matrix. It is still an open problem whether there exists an algorithm capable of identifying all causal coefficients in polynomial time.
This paper investigates the problem of learning decision rules that dictate what action should be taken at each state given an evolving set of covariates (features) and actions, which is usually called Dynamic Treatment Regimes (DTRs). DTRs have been increasingly popular in decision-making settings in healthcare.
Consider the treatment of alcohol dependence. Based on the condition of alcohol-dependent patients (S1), the physician may prescribe medication or behavioral therapy (X1). Patients are then classified as responders or non-responders (S2) based on their level of heavy drinking within the next two months. The physician then must decide whether to continue the initial treatment or to switch to an augmented plan combining both medication and behavioral therapy (X2). The primary outcome Y is the percentage of abstinent days over a 12-month period. A DTR here is a sequence of decision rules x1 = f1(s1), x2 = f2(x1, s1, s2) that decides the treatment X so as to optimize the expected outcome Y.
In this paper, the researchers studied how to find the optimal DTR in the context of online reinforcement learning. It has been shown that finding the optimal DTR requires Ω(|X ⋃ S|) trials, where |X ⋃ S| is the size of the treatment and state variables. In many applications, the domains of X and S could be significantly large, which means that the time required to ensure appropriate learning may be unattainable. They develop a novel strategy that leverages the causal diagram of the underlying environment to improve this sample complexity, leading to online algorithms that require an exponentially smaller number of trials. They also introduce novel methods to derive bounds over the underlying system dynamics (i.e., the causal effects) from the combination of the causal diagram and the observational (nonexperimental) data (e.g., from the physicians’ prior decisions). The derived bounds are then incorporated into proposed online decision-making algorithms.
“This result is surprising since most of the existing methods would suggest discarding the observational data when it is plagued with the unobserved confounding, and the causal effect is not uniquely identifiable,” said Junzhe Zhang, a research assistant in the CausalAI lab. “We show that the performance of online learners could be consistently improved by leveraging abundant, yet biased observational data.”
Stochastic Flows and Geometric Optimization on the Orthogonal Group Krzysztof Choromanski Google Brain Robotics, Valerii Likhosherstov University of Cambridge, Jared Q Davis Google Research, David Cheikhi Columbia University, Achille Nazaret Columbia University, Xingyou Song Google Brain, Achraf Bahamou Columbia University, Jack Parker-Holder University of Oxford, Mrugank Akarte Columbia University, Yuan Gao Columbia University, Jacob Bergquist Columbia University, Aldo Pacchiano UC Berkeley, Vikas Sindhwani Google, Tamas Sarlos Google, Adrian Weller University of Cambridge, Alan Turing Institute
This paper presents a new class of stochastic, geometrically driven optimization algorithm for optimization problem defined on orthogonal group. The objective is to maximize a function F(x), where F takes arguments from matrix manifold. The paper solves this problem by computing and discretizing the on-manifold gradient flows and showed an intriguing connection between efficient stochastic optimization on the orthogonal group and graph theory.
The paper compares FLOPS needed for classification model on MISNT and CIFAR-10 dataset for our algorithm with state-of-the-art algorithms. The algorithm had substantial gains in time complexity as compared to other methods without much loss in accuracy. The paper also shows effectiveness of the algorithm for variety of continuous Reinforcement learning tasks like Humanoid from OpenAI gym.
Students from diverse, nontraditional backgrounds can now take a one-year transition before entering the MS program in computer science.
The CS@CU MS Bridge Program in Computer Science launched this summer with students from a variety of backgrounds ranging from the sciences to architecture, economics, finance, and management. The 22 students have one thing in common – a desire to learn computer science (CS) to jump-start a career in technology.
This program offers prospective applicants from non-computer science backgrounds, including those without programming experience, the opportunity to acquire the knowledge and skills necessary to prepare them for the CS master’s program. A year of rigorous “bridge” coursework is composed of introductory CS courses. This one-year transition prepares students for a seamless entrance into the MS program after the bridge year. The program is highly competitive with only 22 students accepted out of 88 applicants.
The virtual orientation of the first cohort.
The main inspiration for the program is Northeastern’s Align MS in Computer Science program. Columbia was one of a small number of schools which received seed funding from Facebook to help create bridge programs for students with diverse backgrounds at other universities.
“Unlike other similar programs, MS Bridge students start their program by taking the same core CS courses as our undergraduate students,” said Tony Dear, a Lecturer in Discipline and the CS@CU MS Bridge Program Director. The cohort has access to the same instruction, resources, and interactions with other students who are starting CS for the first time. In addition, MS Bridge students are afforded as much flexibility as they need, taking anywhere from one to three or four courses per semester until they are ready to move on to the MS portion of the program.
Another goal of the program is to advance diversity in the master’s program and this caught the attention of CS alum Janet Lustgarten (MS ‘85). “As a woman and an immigrant, I know how important it is to open up opportunities for different types of people,” said Lustgarten. After emigrating from Colombia at a young age, she found the universal language of mathematics a gateway to excel in school. She went on to become the first graduate with a degree in Computer Science and Mathematical Logic from Mount Holyoke and then received her MS degree from Columbia Engineering. She has led an exceptional career as co-founder & CEO of Kx Systems and President of Shakti Software, making numerous contributions to science, engineering, business, and beyond.
The Lustgarten-Whitney Family Fellowship was established specifically for the CS@CU MS Bridge Program. The generous gift provides fellowship support to three highly-qualified students from underrepresented and nontraditional backgrounds pursuing a career in computer science. Shared Lustgarten, “I hope that this gift from my family will play a vital role in launching the program, ensuring that the most qualified students are able to attend regardless of financial need, and inspiring a new generation of leaders in technology.”
Students convened virtually in May and most are now in the thick of summer classes. About half of the group is interested in pursuing the software systems and machine learning tracks for their master’s degree. Some have expressed interest in computational biology and natural language processing. A few already have plans to pursue a PhD afterward and they are interested in doing research and/or a thesis during the MS. Because there is flexibility when it comes to courses, this first cohort can explore and figure out the right path for their careers in technology.
Papers from the Speech and Natural Language Processing groups were accepted to the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020). The research developed systems that improve fact-checking, generate sarcasm, and detect deception and a neural network that extracts knowledge about products on Amazon.
A team led by Shih-Fu Chang, the Richard Dicker Professor and Senior Executive Vice Dean School of Engineering, won a Best Demonstration Paper award for GAIA: A Fine-grained Multimedia Knowledge Extraction System, the first comprehensive, open-source multimedia knowledge extraction system.
Kathleen McKeown, the Henry and Gertrude Rothschild Professor of Computer Science, also gave a keynote presentation – “Rewriting the Past: Assessing the Field through the Lens of Language Generation”.
The paper proposes an unsupervised approach for sarcasm generation based on a non-sarcastic input sentence. This method employs a retrieve-and-edit framework to instantiate two major characteristics of sarcasm: reversal of valence and semantic incongruity with the context, which could include shared commonsense or world knowledge between the speaker and the listener.
While prior works on sarcasm generation predominantly focus on context incongruity, this research shows that combining valence reversal and semantic incongruity based on commonsense knowledge generates sarcastic messages of higher quality based on several criteria. Human evaluation shows that the system generates sarcasm better than human judges 34% of the time, and better than a reinforced hybrid baseline 90% of the time.
Humans are very poor lie detectors. Study after study has found that humans perform only slightly above chance at detecting lies. This paper aims to understand why people are so poor at detecting lies, and what factors affect human perception of deception. To conduct this research, a web-based lie detection game called LieCatcher was created. Players were presented with recordings of people telling lies and truths, and they had to guess which are truthful and which are deceptive. The game is entertaining for players and simultaneously provides labels of deception perception.
LieCatcher
Judgments from more than 400 players were collected. This perception data was used to identify linguistic and prosodic (intonation, tone, stress, and rhythm) characteristics of speech that lead listeners to believe what is true or to trust it.
The researchers studied how the characteristics of trusted speech align or misalign with indicators of deception, and they trained machine learning classifiers to automatically identify speech that is likely to be trusted or mistrusted. They found several intuitive indicators of mistrust, such as disfluencies (e.g. “um”, “uh”) and speaking slowly. An indicator of trust was a faster speaking rate — people tended to trust speech that was faster. They also observed a mismatch between features of trusted and truthful speech and the strategies used by the players to be ineffective.
What surprised the researchers is that prosodic indicators of deception, such as pitch and loudness changes, were the most difficult for humans to perceive and interpret correctly. In fact, many prosodic cues to deception were perceived by human raters as cues to the truth. For example, utterances with a higher pitch were perceived as more truthful, when in fact this is a cue to deception.
This work is useful for a number of applications, such as generating trustworthy speech for virtual assistants or dialogue systems.
The paper presents TXtract, a neural network that extracts knowledge about products from Amazon’s taxonomy with thousands of product categories, ranging from groceries to health products and electronics.
For example, given an ice cream product at Amazon.com with text description “Ben & Jerry’s Strawberry Cheesecake Ice Cream 16 oz”, TXtract extracts text phrases as product attributes:
Values extracted through TXtract lead to a richer catalog with millions of products and their corresponding attributes, which is promising to improve the experience of customers searching for products at Amazon.com or asking product-specific questions through Amazon Alexa.
DeSePtion: Dual Sequence Prediction and Adversarial Examples for Improved Fact-Checking Christopher Hidey Columbia University, Tuhin Chakrabarty Columbia University, Tariq Alhindi Columbia University, Siddharth Varia Columbia University, Kriste Krstovski Columbia University, Mona Diab Facebook AI & George Washington University, and Smaranda Muresan Columbia University
The increased focus on misinformation has spurred the development of data and systems for detecting the veracity of a claim as well as retrieving authoritative evidence. The FactExtraction and VERification (FEVER) dataset provide such a resource for evaluating end-to-end fact-checking, requiring retrieval of evidence from Wikipedia to validate a veracity prediction.
This paper shows that current systems for FEVER are vulnerable to three categories of realistic challenges for fact-checking – multiple propositions, temporal reasoning, and ambiguity and lexical variation – and introduces a resource with these types of claims.
Fact checking where the fact needs to be verified with evidence from two different sources (Michelle Obama and Barrack Obama).
The researchers present a system designed to be resilient to these “attacks” using multiple pointer networks for document selection and jointly modeling a sequence of evidence sentences and veracity relation predictions. They found that in handling these attacks they obtained state-of-the-art results on FEVER, largely due to improved evidence retrieval.
In a story for the Simons Institute, Daniel Hsu writes about deep learning and how it has attracted new attention to several basic questions in statistical machine learning.
This paper considers the following setting: A data analysis algorithm is given access to noisy labeled data points (x,w.x + noise) where x is a high-dimensional vector, w.x is some linear function of x, and the true labels w.x are corrupted by noise. The goal is to determine whether the coefficient vector w=(w1,…,wn) is sparse (i.e. has almost all of its entries being zero) or is far from sparse (has many nonzero entries).
A long line of work in a field known as “compressed sensing” has addressed a related version of this problem in which the goal is to (approximately) discover the vector w assuming that it is sparse. It is known that algorithms for this “reconstruction” problem require a number of data points which grows with n. This work considers a potentially easier “decision” question, of just deciding whether or not the unknown vector w actually is sparse as described above…but is this problem actually easier, or not?
The main result of this paper gives a sharp characterization of the conditions under which the decision problem actually is easier than the reconstruction problem. It shows that for many distributions of data points, it is possible to solve the decision problem with no dependence on the dimension n, and explains why in the other cases a dependence on n is necessary.
“It was a bit of a surprise that we were able to come up with a sharp characterization of the problem variants for which there needs to be a dependence on the distribution,” said Rocco Servedio, a computer science professor who worked on the paper. “This characterization relied on some results from probability theory that were proved 80 years ago – we were lucky that the right tools for the job had already been prepared for us in the math literature.”
This paper is aimed at understanding the extent to which randomness can help computers solve problems more efficiently. A long line of research in this area aims at coming up with efficient deterministic (non-random) algorithms for various problems that are known to have efficient randomized algorithms; this research program is sometimes known as “derandomization,” as its goal is to show that randomness is not really necessary as a fundamental computational resource.
The most commonly pursued avenue of work along these lines is to design certain particular kinds of deterministic algorithms known as “pseudorandom generators”. Roughly speaking, a pseudorandom generator for a certain type of Boolean (0/1-valued) function gives an efficient deterministic way of estimating the fraction of inputs that make the function output 1 as opposed to 0. A natural way to estimate this fraction is just to do random sampling, but the key challenge is to do it without using randomness — i.e. to “derandomize” the natural random-sampling-based approach.
This particular paper develops new pseudorandom generators for a class of geometrically defined functions called “polynomial threshold functions”. A polynomial threshold function is defined by a multivariable polynomial, like p(x,y,z) = 3x^2 – 6 x^2 y^2 z^3 + 4xyz; the most important parameter of such a polynomial is its degree. (The degree of the example polynomial p(x,y,z) given above is 7, because of the x^2 y^2 z^3 term.) The higher the degree of a polynomial, the more complicated it is. The main result in this paper is a pseudorandom generator for polynomial threshold functions which can handle polynomials of exponentially higher degree than could be achieved in previous work.
The researchers designed a new parallel approximate undirected shortest path algorithm which has polylog(n) depth and near linear total work. This improved a long-standing upper bound obtained by Edith Cohen (STOC’94).
To further illustrate the efficiency of the algorithm, consider the case when the algorithm is run on a single processor, the running time is almost the same as the best known sequential shortest path algorithm, Dijkstra’s algorithm. If the algorithm is run on m processors, where m is the size of the graph, the algorithm only takes a polylog(n) number of rounds — this is also near optimal (many simple problems such as computing XOR of n bits need at least log(n) rounds).
The paper develops a new concept called low hop emulator to solve the parallel approximate shortest paths problem. It shows that for any graph G and any integer k>=1, there exists another graph G’ with size n^(1+2/k) such that 1. Any shortest path in G’ only uses log(k) number of edges, 2, the distance between each pair of vertices in G’ is a poly(k) approximation to their original distance in G.
“This result is surprising and I believe this is an important discovery in graph theory,” said Peilin Zhong, a fourth-year PhD student. “We also show that G’ can be constructed efficiently.”
Smoothed complexity of local Max-Cut and binary Max-CSP Emmanouil-Vasileios Vlatakis-Gkaragkounis Columbia University, Xi Chen Columbia University, Chenghao Guo IIIS, Tsinghua University, Mihalis Yannakakis Columbia University, Xinzhi Zhang IIIS, Tsinghua University
This work provides insights into the inner-workings of some of the most widely used local search methods.
Local search is one of the most prominent algorithm design paradigms for combinatorial optimization problems. A local search algorithm begins with an initial solution and then follows a path by iteratively moving to a better neighboring solution until a local optimum is reached. However, a recurring phenomenon in local search algorithms is that they are usually efficient in practice but the theory of worst-case analysis indicates the opposite — due to some delicate pathological instances that one may never encounter in practice, the algorithm would be characterized as an exponential running time method.
In order to bridge theory and practice, a smoothed complexity framework has been introduced, a hybrid complexity model between the pessimistic worst-case analysis and the optimistic average-case analysis.
This work analyzes the MaxCut problem, one of the famous 21-Karp NP-complete (”hard”) problems. Given a weighted undirected graph, the MaxCut problem seeks to partition the vertices of the graph into two sets such that the sum of the weights of the edges that join the two sets is maximized. Its applications come from diverse areas including the layout of electronic circuitry, social networks, and statistical physics.
The researchers improved the smoothed complexity of the local search methods for the Max-Cut problem. The result is based on an analysis of long sequences of local changes (flips), which shows that it is very unlikely for every flip in a long sequence to incur a positive but small improvement in the cut weight. They also extend the same upper bound on the smoothed complexity of FLIP to all binary Maximum Constraint Satisfaction Problems.
Alum Miral Kotb (CC ’01) talks to Newsweek about combining coding and dance to create Iluminate, wearable mini-computers that sync music, dance moves, and light.
Eugene Wu writes about his paper, “Compliant-driven Training Data Debugging” and examines how to debug complex workflows that combine traditional data analytics with machine learning predictions.
A team led by professor Christos Papadimitriou proposes a new computational system to expand the understanding of the brain at an intermediate level, between neurons and cognitive phenomena such as language.
Ryan Bubinski (CC ’11) founded the Application Development Initiative (ADI) while at Columbia. After graduation, he and Zach Sims started Codecademy to teach coding and programming in an engaging, effective way.
Five CS researchers received Test of Time awards for papers that have had a lasting impact on their fields. The influential papers were presented at their respective conferences in the past 25 years and have remained relevant to research and practice.
Moti Yung
IACR International Conference on Practice and Theory of Public-Key Cryptography (PKC2020) Test of Time award
Computer Engineering
Murshed Ahmed
Cansu Cabuk
Chun-Lin Chao
Ruikai Chen
Chengqi Dai
Rongcui Dong
Tvisha Gangwani
Ken Geng
Hanzhou Gu
Donglai Guo
Maoxin Hou
Yuanji Huang
Ruixin Huo
Xingchen Li
Kunjian Liao
Lu Liu
Tong Liu
Runda Lyu
Tushar Roy
Yu-Chun Shih
Ruilong Tang
Yiqian Wang
Shao-Fu Wu
Yiwen Xiao
Dajing Xu
Siyang Yin
Ruochen You
Xiren Zhou
Zhiyi Zhu
Computer Science
Ashna Aggarwal
Luv Aggarwal
Lin Ai
Syed Sarfaraz Akhtar
Amal Alabdulkarim
Anda An
Jonathan Armstrong
Neha Arora
Jaewan Bahk
Tony Butcher
Rebecca Calinsky
Andrew Calvano
Dhruv Chamania
Matthew Chan
Varun Chanddra
Chen Chen
Pengyu Chen
Yixin Chen
Zehan Chen
Zilin Chen
Tianchang Cheng
Shao-An Chien
Sai Srujan Chinta
Justin Cho
Justin Chou
Vaibhav Darbari
Pankil Daru
Aditya Das
Arjun DCunha
Saurav Dhakad
Yangruibo Ding
Eden Dolev
Can Dong
Pratik Dubal
Ethan Dunn
Daniel Echlin
Yousef Elsendiony
Steven Fantin
Leyu Fei
Yao Fu
Siddhant Gada
Chandana Priya Gandikota
Bicheng Gao
Feng Gao
Lingsong Gao
Rylie Gao
Connor Gatlin
Suwen Ge
Shivani Ghatge
Monish Godhia
Shivali Goel
Sonam Goenka
Jacob Gold
Ryan Goldenberg
Lingyu Gong
Zhicheng Gu
Jonas Guan
Jiakang Guo
Arjun Gupta
Aviral Gupta
Ege Gurmericliler
Kunyan Han
Mengyu Han
Xu Han
Danyang He
Doris He
Jiaheng He
Junyu He
Yangyang He
Yarne Hermann
Juwan Hong
Xin Hu
Yimin Hu
Joe Huang
Sin-Yi Huang
Wangyi Huang
James Hughes
Naman Jain
Tallis Jeng
Mengyu Ji
Ruolin Jia
Chongjiao Jiang
Shenghao Jiang
Cathy Jin
Chinmay Joshi
Prerna Kashyap
Sachin Kelkar
Ishan Khandelwal
Dainis Kiusals
Aleksandra Kolanko
Sharath Koorathota
Michael Kovalski
Patrick Kwok
Ombeline Lage
Sagar Lal
Alexandre Lamy
Victor Lecomte
Jake Lee
Yoongbok Lee
Jinhao Lei
Benjamin Lewinter
Xuheng Li
Yu Li
Zeshen Li
Zhihao Li
Terence Lim
Tia Lim
Yi Jun Lim
Adam Lin
Hsiao-Yuan Lin
Xi Lin
Yida Lin
Yuan-Fang Lin
Zikun Lin
Kangwei Ling
Bingchen Liu
Wei Liu
Yicun Liu
Yu Liu
Zefeng Liu
Zhihao Liu
Zizheng Liu
Bo Lu
Jing-Wei Lu
Kaiji Lu
Weiyi Lu
Yushi Lu
Timothy Luk
Wei Luo
Yue Luo
Hongyi Lyu
Mingyu Ma
Qiang Ma
Ashish Maheshwari
Andrew Mangeni
Arjun Mangla
Tianchen Min
Aashish Misraa
Yuchen Mo
Sachin Mysore Umashankar
Linyong Nan
Aditya Natarajan
Sagar Negi
Shilin Ni
Jingwen Nie
Ketakee Nimavat
Rudresh Panchal
Jangho Park
Jordan Park
Samrat Phatale
Prajesh Praveen Anchalia
Cong Qian
Jing Qian
Bohan Qu
Rakshita Raguraman
Kiran Ramesh
Claire Ren
Yixiong Ren
Zhuangyu Ren
Vasudha Rengarajan
Saurabh Runwal
Haris Sahovic
Pamela Sanchez
Sourav Sarkar
Mayank Saxena
Bruno Seiva Martins
Avijit Shah
Sahil Shah
Bhavya Shahi
Wufan Shangguan
Saurabh Sharma
Samuel Sharpe
Cheng Shen
Claudia Shi
Ritvik Shrivastava
Enoch Shum
Daniel Silva
Shubham Sinha
Samantha Siu
Harry Smith
Albert Song
Jian Song
Nicholas Sparks
Shruti Subramaniyam
Kang Sun
Wen Sun
Vatsala Swaroop
Pinxi Tai
Xin-Luan Tan
Xinyue Tan
Shulan Tang
Weijie Tang
Qing Teng
Darshan Thaker
Sukriti Tiwari
Shashwat Verma
Jia Wan
Ge Wang
Ruisi Wang
Shikun Wang
Tianwu Wang
Weiyu Wang
Wenqi Wang
Yueqi Wang
Ziao Wang
Zipeng Wang
Zizhao Wang
Bingqing Wei
Fan Wu
Junyue Wu
Alan Xu
Cheng Xu
Chengtian Xu
Ke Xu
Haoyu Yan
You Yan
Tianyang Yang
Xi Yang
Yifan Yang
M Najim Yaqubie
HyunBin Yoo
Lei You
Jianing Yu
Zihan Yu
Mengjie Yuan
Chi Zhang
Jiaxuan Zhang
Justin Zhang
Lixing Zhang
Ruxuan Zhang
Yipeng Zhang
Yuxuan Zhang
Zhen Zhang
Qianrui Zhao
Zian Zhao
Qian Zheng
Zhi Zheng
Liping Zhong
Jiao Zhou
Zhou Zhuang
Art Zuks
Computer Engineering
Shayel Benta
Fabio Ferra
Pushan Hinduja
Yusheng Hu
Jeffrey Jaquith
Justin Law
Chuyun Liu
Sami Malas
Peter Mansour
Doga Ozesmi
Fuming Qiu
Ignacio Ramirez, Sr.
Jarrett Ross
Luna Ruiz
William Stubbs
Arianna Tuwiner
Vladyslav Verba
Computer Science
Ryan Abbott
Ashley An
Sambhav Anand
Arsalaan Ansari
Shikhar Bakhda
Greyson Barrera
Sean Benton
Nicholas Bethune
Mahika Bhalla
Marcus Blake
Kevin Borup
Francesca Callejas
Eric Chase
Irene Chen
Yitao Chen
Jackson Chen
Jessica Cheng
Tahiya Chodhury
Olivia Chow
Lesley Cordero
Nicholas Cornejo
Robert Costales
Erek Cox
Meredith Cox
Eduardo Despradel
Kirit Dhillon
Nhu Doan
Malik Drabla
Isabel Ehrhardt
Dave Epstein
Hussein Fardous
Giorgia Fujita
Ria Garg
Connor Goggins
Yike Gong
Felipe Grabowsky
Martin Gracia
Hannah Gu
Andy Guo
Dennis Guzman
Xinyi Han
Emily Hao
Judith Haro
Lily He
Christine Hsu
Jiaheng Hu
Haoxuan Huang
Rose Huang
Jessica Huynh
Alyssa Hwang
Daniel Jeong
Sooyeon Jo
Vernon Johnson
Andrew Jones
Daniel Kang
Mikhail Karasev
Sam Kececi
Junghoo Kim
Nicholas Krasnoff
Pallavi Krishnamurthy
Vivek Kumar
Max Lascombe
Joshua Learn
Janill Lema
Gavaudan Leonardo
Kevin Li
Jiawen Li
Shaokai Lin
Jiaxin Lin
Amanda Liu
Benjamin Loewen
Anavi Lohia
Samantha Macilwaine
Michelle Mao
Jay Martin
Jr Martinez
Nicole Mbithe
Kevin Mejia
Alexander Milewski
Hana Mizuta
Juan Mojica
Aimee Morley
Suman Mulumudi
Morgan Navarro
Bryan Ontiveros
Julian Pantoja
Eunkyu Park
Ivan Perdomo
Phivian Phun
Madeline Placik
Brian Poor
Alexander Price
Biqing Qiu
Kanchana Raja
Sushanth Raman
Mauricio Rivera
Carlos Rosas
Kimberly Santiago
Michaella Schaszberger
Lucas Schuermann
Zijie Shen
Timothy Shertzer
Julia Sheth
Pranav Shrestha
Amita Shukla
Dhruv Singh
Joseph Skimmons
Dagmawi Sraj
Shaohua Tang
Dorrie Tang
Jonathan Timpanaro
Rosemary Torola
Logan Troy
Kanishk Vashisht
Gleb Vizitiv
Ning Wan
Zichuan Wang
Jingyuan Wang
Yifan Wang
Chenchen Wei
Denis Weng
Jack Winkler
Veronica Woldehanna
Tsun Wong
Victoria Yang
Brian Yang
Liuqing Yang
Spencer Yen
Mahlet Yifru
Kenneth Yuan
Nazli Yurdakul
Lillian Zha
Shenqi Zhai
Tong Zhang
Minghan Zhu
Justin Zwick
The department would like to honor all of our graduates and we look forward to when we can all come together and celebrate in person.
CS professors are extremely proud of all the hardworking and talented students they have worked with and they have a special message for you!
During Class Day, awards were given to students who excelled in academics, students with independent research projects, and to those with outstanding performance in teaching and services to the department. The list of awardees are in this year’s graduation handout.
At this year’s commencement, more than 600 students received a computer science degree. Click on the logos to see the CS graduates from each college.
Fall 2019
WiCS at Grace Hopper 2019
Fall CS Research Project Fair
CS researchers at EMNLP 2019 in Hong Kong
CS Team Wins the ICCV 2019 Learning-to-Drive Challenge
Facebook career talk
Welcome week
Holi 2019
CS Halloween party 2018
Uber career talk
Columbia One-Day Service @ New York Food Bank
Columbia Space Initiative High Altitude Balloon Team launching ROAREE 2, April 2018
CU Amateur Radio Club - Columbia Space Initiative collaboration making contact with International Space Station in Summer 2018
A new grant supports and expands Columbia’s proven track record for inclusivity.
There has been an explosion of interest from undergraduate women across Columbia and Barnard who are choosing to major in computer science (CS). In 2019, 39.5% of 1,268 CS declared majors were women (of 1,212 reporting gender across SEAS, Columbia College, General Studies, and Barnard). The CS major is the second largest at Columbia and still growing. This is the result of the centrality of computing to our lives today, as well as the Computer Science department’s initiatives over the past decade to encourage students to explore CS and to major or minor in CS.
In recognition of the high success rate in attracting and retaining women in Computer Science and the potential to do even more, Columbia is part of the first cohort to receive a grant from Northeastern University’sCenter for Inclusive Computing. The Center partners with “nonprofit colleges and universities with large computing programs (200 graduates or more per year) to implementevidence-based practices that support the recruitment, enrollment, and graduation of historically underrepresented groups majoring in computing.”
The grant will fund several new joint initiatives as well as expand existing ones that support Columbia Engineering’s and Barnard’s overarching objectives to attract and retain women in introductory CS classes, continuing to improve the climate for diversity across the University’s CS community with the goal of reaching gender parity.
“The department’s programs run by our faculty and students have helped keep women and underrepresented minorities in our introductory classes,” saidJulia Hirschberg, the Percy K. and Vida L. W. Hudson Professor of Computer Science. Hirschberg has been advocating for women in CS since she started at Bell Labs in the 1980s. “We are really delighted at how diverse our major has become.”
Columbia has come a long way to become one of the top schools in the US with a high percentage of women in CS. Ten years ago, the percentage of females majoring in computer science was just8% percent. Columbia and Barnard have worked closely together to make CS more accessible to students with little to no CS background, which disproportionately includes women and underrepresented minorities. The School has been able to retain women in its introductory classes with considerable success through the following initiatives:
The development of COMS 1004 Lab, in which students with little programming experience in the introductory CS course get help practicing coding
TheEmerging Scholars Program,in which students with little CS background attend weekly sessions to discuss CS as problem-solving
TheWomxn in Computer Sciencegroup, a network for women undergraduates, graduate students, postdocs, faculty, and staff; the group promotes interaction on academic, social, and professional issues
The development of COMS 1002 Computing in Context, in which students planning other majors can get basic CS training to use on interdisciplinary problems, this course has had an unanticipated effect—leading to an increased number of students with no CS background deciding to major in CS
“My introduction to CS was welcoming, especially for students like me who do not have a CS background,” said Desu Imudia, a second-year student from Columbia College. As an African American woman, she says there is little representation in the School and sees the value of the labs for students to learn in groups and build confidence. Imudia plans to declare CS as her major and to continue working as a teaching assistant. She added, “Even though I know a lot now, I am no expert, so I think more labs in addition to courses will be really helpful for students.”
Barnard has gone from just one graduating CS major in 2013 to 33 in 2019—CS is now one of Barnard’s 10 most popular majors. In 2019, Barnard hired its first CS faculty as part of a comprehensive plan to expand its focus on CS and fully meet students’ needs, as well as to bring computing education to Barnard students outside the CS major, potentially attracting more of them to major or minor in CS or newly developed joint programs.
Rebecca Wright, Druckenmiller Professor of Computer Science at Barnard College and director of the Vagelos Computational Science Center, said, “This is an extremely exciting time for CS at Barnard. In addition to continuing to collaborate with Columbia, we also have the opportunity to explore new models and new kinds of computing curriculum.”
As part of the project, Barnard will develop a Computing Fellows program. Led by the newVagelos Computational Science Centerat Barnard, the Computing Fellows program will support faculty to incorporate computational projects into their courses and provide ongoing support to faculty and students in those courses. Specifically, a number of undergraduates each year will be hired and trained as computing fellows to work with faculty in departments across Barnard and their students.
At Columbia Engineering, the COMS 1004 Lab, Emerging Scholars Program, and Computing in Context programs will continue under the grant, with additional teaching assistants and PhD students expected to be hired. Hirschberg will lead the project and manage the Computing in Context, the 1004 Lab, and the ESP initiatives in collaboration withAdam CannonandPaul Blaer, lecturers in discipline at Columbia Engineering.
At Barnard, Wright will spearhead the development and execution of the Computing Fellows program and will collaborate with the rest of the team across all of the initiatives.
“We are so grateful to Northeastern University’s Center for Inclusive Computing for helping us to expand the programs which have so far proven so successful in retaining a diverse group of CS majors,” said Hirschberg.
Georgia Essig (CC’20), a computer science major with a concentration in Russian language and culture, has been named valedictorian, the top academic honor for the Columbia College Class of 2020.
Katy Gero, a third-year PhD student, wins a Best Paper Award from the ACM Computer-Human Interaction (CHI 2020).
Mental Models of AI Agents in a Cooperative Game Setting Katy Ilonka Gero Columbia University, Zahra Ashktorab IBM Research AI , Casey Dugan IBM Research AI, Qian Pan IBM Research AI, James Johnson IBM Research AI, Werner Geyer IBM Research AI, Maria Ruiz IBM Watson, Sarah Miller IBM Watson, David R Millen IBM Watson, Murray Campbell IBM Research AI, Sadhana Kumaravel IBM Research AI, Wei Zhang IBM Research AI
As more and more forms of artificial intelligence (AI) become prevalent, it becomes increasingly important to understand how people develop mental models of these systems. In this work, the paper studies people’s mental models of AI in a cooperative word guessing game. The researchers wanted to know how people develop mental models of AI agents.
Mental models refer to how a person “thinks” a system works. For instance, someone’s mental model of driving a car is that when they push on the gas pedal, more gas is pumped into the engine which makes the car go faster. That may not be how a car “actually” works, it’s just one view a person may have as a non-car expert. (The actual way it works is the gas pedal lets more air into the engine; a series of sensors then adjust the amount of gas to match the amount of air.)
“Mental models are known to be incomplete, unstable, and often wrong,” said Katy Gero, a third year PhD student and the study’s lead author. “Though that doesn’t mean they’re not useful!”
To study the mental models of AI agents, the study’s participants played Passcode a word guessing game with an AI agent. The AI agent had a secret word, like “tomato”, and would give one word hints, like “salad” or “red”, to get the participant to guess the secret word. They learned that people’s mental models had three components:
– Global Behavior: How does the AI agent behave over time?
– Local Behavior: How does the AI agent decide on a single action?
– Knowledge Distribution: How much does the AI agent know about different parts of the world?
There was often a misunderstanding of local behavior. Sometimes the AI agent gave a hint that a participant didn’t understand. For instance, sometimes it gave the hint ‘hectic’ when the participant was meant to guess the word was ‘calm’. A participant might think that hint didn’t make any sense, like the AI agent made a mistake. In reality, the AI agent was giving an antonym hint. This is an example where a person had an incorrect mental model that they corrected over the course of several games.
The researchers conducted two studies – (1) a think-aloud study in which people play the game with an AI agent; through thematic analysis they identified features of the mental models developed by the participant and (2) a large-scale study where participants played the game with the AI agent online and used a post-game survey to probe their mental model
In the first study thematic analysis was used to develop a set of codes which describe the types of concerns participants had when playing with the AI agent. The most prevalent codes show what people think about most when playing with the AI agent: they worry about why it did something unexpected, they try to find patterns in its behavior, and they wonder what kinds of knowledge it has.
For the second study, they found that people who had the best understanding of how the AI agent behaved were able to play the game the best. However, as is expected with complex systems, no one had a perfect understanding of how the AI agent worked.
This work provides a new framework for modeling AI systems from a user-centered perspective: models should detail the global behavior, knowledge distribution, and local behavior of the AI agent. These studies also have implications for the design of AI systems that attempt to explain themselves to the user, especially AI agents that want to explain why they behave in certain ways.
For the third consecutive year, a team from the CS department has advanced to the International Collegiate Programming Contest (ICPC) World Finals. The ICPC is the premiere collegiate programming competition that brings together students from around the globe to solve real-world problems, fostering collaboration, creativity, innovation, and the ability to perform under pressure.
Peilin Zhong, Hengjie Zhang, Zhenjia Xu, Runzhou Tao, and Chengyu Lin at the Greater New York Regionals
The team composed of first-year PhD students Hengjie Zhang, Zhenjia Xu, and Runzhou Tao first qualified at the Greater New York regional last October. At the North America Championship held in February, the team competed without their third team member, Zhenjia Xu, who was in China because of visa issues due to the coronavirus pandemic shutdown.
“We were worried about competing with just the two of us,” said Hengjie Zhang. Luckily, he and Runzhou Tao are good friends and knew how to work well with one another. They worked with their coaches, Chengyu Lin and Peilin Zhong, to prepare for the North American Championship in Atlanta, Georgia. Continued Zhang, “It was hard but Runzhou is good at math and I am good at programming so we managed to win!”
Runzhou Tao and Hengjie Zhang at the North American Championship
Even with just two members, team Columbia-ūnus secured a win and is one of 19 teams from North America to compete in the World Finals. Because of the coronavirus pandemic, this year’s World Finals will be held in Moscow, Russia in June 2021.
Professor Salvatore Stolfo writes about phishing attacks and how it is important to stay vigilant against digital fraud even during the COVID-19 pandemic.
Ben Horowitz shares what makes for a great pitch, the qualities of successful entrepreneurs, and why you shouldn’t listen to your friends for career advice.
For this year’s Outstanding Undergraduate Researcher Award, three computer science students received honorable mentions – Lalita Devadas, Dave Epstein, and Jessy Xinyi Han. The Computing Research Association (CRA) recognized the undergraduates for their work in an area of computing research.
The researchers worked on using some recent advances in
garbling of arithmetic circuits for secure exponentiation mod N,
a vital operation in many cryptosystems, including in the RSA public-key
cryptosystem.
A garbled circuit is a cryptographic protocol which allows for
secure two-party computation, in which two parties, Alice and Bob, each with a
private input, want to compute some shared function of their inputs
without either party learning the other’s input.
Their novel approach implemented the Montgomery multiplication method, which uses clever arithmetic to avoid costly division by the modulus being multiplied in. The best method they found had each wire in a circuit representing one digit of a number in base p. They developed a system of base p arithmetic which is asymptotically more efficient in the given garbled circuit architecture than any existing protocols.
They measured performance for both approaches by counting
the ciphertexts communicated for a single multiplication (a typical
measure of efficiency for garbled circuit operations). They found that the
base p Montgomery multiplication implementation
vastly outperformed all other implementations for values
of N with bit length greater than 500 (i.e.,
all N used for applications like RSA encryption).
“Unfortunately, our best implementations showed only incremental improvement over existing non-Montgomery-based implementations for values of N used in practice,” said Lalita Devadas. “We are still looking into further optimizations using Montgomery multiplication.”
Secure multiparty computation has many applications outside of computer science. For example, suppose five friends want to know their cumulative net worth without anyone learning anyone else’s individual net worth. This is actually a secure computation problem, since the friends want to perform some computation of their inputs while keeping said inputs private from other parties.
The paper trains models to detect when human action is unintentional using self-supervised computer vision, an important step towards machines that can intelligently reason about the intentions behind complex human actions.
Despite enormous scientific progress over the last five to ten years, machines still struggle with tasks learned quickly and autonomously by young children, such as understanding human behavior or learning to speak a language. Epstein’s research tackles these types of problems by using self-supervised computer vision, a paradigm that predicts information naturally present in large amounts of input data such as images or videos. This stands in contrast with supervised learning, which relies on humans manually labelling data (e.g. “this is a picture of a dog”).
“I was surprised to learn that failure is an expected part of research and that it can take a long time to realize you’re failing,” said Dave Epstein. “Taking a failed idea, identifying the promising parts, and trying again leads to successful research.”
The paper explores the problem of social influence maximization
and how information is diffused in a social network.
For example, it might be about what kind of news people read on social media, how many people know about job opportunities or who hears about the latest loan options from a bank. So given a social network, classical algorithms are focused on picking the best k early-adopters based on how central they are in a network, say, based on their number of connections, to maximize outreach.
However, since social inequalities are reflected in
the uneven networks, classical algorithms which ignore demographics often
amplify such inequalities in information access.
“We were wondering if we can do better than an algorithm that ignores demographics,” said Jessy Xinyi Han. “‘Better’ here means more people in total and more people from the disadvantaged group can receive the information.”
Through a network model with unequal communities, they developed
new heuristics to take demographics into account, showing that
including sensitive features in the input of most natural seed selection
algorithms substantially improves diversity but also often leaves efficiency
untouched or even provides a small gain.
Such analytical condition turned out to be a closed-form
condition on the number of early adopters. They also validated this result on
the real CS co-authorship network from DBLP.
Almost 400,000 babies were born prematurely—before 37 weeks gestation—in 2018 in the United States. One of the leading causes of newborn deaths and long-term disabilities, preterm birth (PTB) is considered a public health problem with deep emotional and challenging financial consequences to families and society. If doctors were able to use data and artificial intelligence (AI) to predict which pregnant women might be at risk, many of these premature births might be avoided.
The Distinguished Lecture series brings computer scientists to Columbia to discuss current issues and research that are affecting their particular fields. This year, eight experts covered topics from machine learning, cryptography, privacy, algorithms, ethics, and computer vision.
Below are a couple of the lectures from prominent faculty from universities across the country.
The Data Science Institute (DSI) at Columbia University has awarded 2020 seed grants to research teams whose projects merge data science with traditional fields to solve pressing societal problems. DSI’s Seed Funds Program supports new collaborations to forge long-term relationships among faculty in different disciplines and use data science to transform all fields across Columbia.
Multidisciplinary collaborations across Columbia include work by CS professors – Peter Allen and Paul Blaer’s scans of French cathedrals and Steven Feiner’s augmented reality app of a 16th-century manuscript.
Nine papers from CS researchers were accepted to the ACM-SIAM Symposium on Discrete Algorithms (SODA20), held in Salt Lake City, Utah. The conference focuses on algorithm design and discrete mathematics.
A common type of problem studied in machine learning is learning an unknown classification rule from labeled data. In this problem paradigm, the learner receives a collection of data points, some of which are labeled “positive” and some of which are labeled “negative”, and the goal is to come up with a rule which will have high accuracy in classifying future data points as either “positive” or “negative”.
In a SODA 2015 paper, De, Diakonikolas, and Servedio studied the possibilities and limitations of efficient machine learning algorithms when the learner is only given access to one type of data point, namely points that are labeled “positive”. (These are also known as “satisfying assignments” of the unknown classification rule.) They showed that certain types of classification rules can be learned efficiently in this setting while others cannot. However, all of the settings considered in that earlier work were ones in which the data points themselves were defined in terms of “categorical” features also known as binary yes-no features (such as “hairy/hairless” “mammal/non-mammal” “aquatic/non-aquatic” and so on). In many natural settings, though, data points are defined in terms of continuous numerical features (such as “eight inches tall” “weighs seventeen pounds” “six years old” and so on).
This paper extended the earlier SODA 2015 paper’s results to handle classification rules defined in terms of continuous features as well. It shows that certain types of classification rules over continuous data are efficiently learnable from positive examples only while others are not.
“Most learning algorithms in the literature crucially use both positive and negative examples,” said Rocco Servedio. “So at first I thought that it is somewhat surprising that learning is possible at all in this kind of setting where you only have positive examples as opposed to both positive and negative examples.”
But learning from positive examples only is actually pretty similar to what humans do when they learn — teachers rarely show students approaches that fail to solve a problem, rarely have them carry out experiments that don’t work, etc. Continued Servedio, “So maybe we should have expected this type of learning to be possible all along.”
The researchers were interested in algorithms which are given access to a large undirected graph G on n vertices and estimate the number of edges of the graph up to a small multiplicative error. In other words, for a very small ϵ > 0 (think of this as 0.01) and a graph with m edges, they wanted to output a number m’ satisfying (1-ε) m ≤ m’ ≤ (1+ε) m with probability at least 2/3, and the goal is to perform this task without having to read the whole graph.
For a simple example, suppose that the access to a graph allowed to check whether two vertices are connected by an edge. Then, an algorithm for counting the number of edges exactly would need to ask whether all pairs of vertices are connected, resulting in an (n choose 2)-query algorithm since these are all possible pairs of vertices. However, sampling Θ((n choose 2) / (m ε2)) random pairs of vertices one can estimate the edges up to (1± ε)-error with probability 2/3, which would result in a significantly faster algorithm!
The question here is: how do different types of access to the graph result in algorithms with different complexities? Recent work by Beame, Har-Peled, Ramamoorthy, Rashtchian, and Sinha studied certain “independent set queries” and “bipartite independent set queries”: in the first (most relevant to our work), an algorithm is allowed to ask whether a set of vertices of the graph forms an independent set, and in the second, the algorithm is allowed to ask whether two sets form a bipartite independent set. The researchers give nearly matching upper and lower bounds for estimating edges with an independent set queries.
The researchers imagined situations in which the graph is extremely large and wanted to determine whether or not the graph has cycles in a computationally efficient manner (by looking at as few of the nodes in the graph as possible). As yet, there’s no known solution to this problem that does significantly better than looking at a constant fraction of the nodes, but they proved a new lower bound – that is, they found a new limit on how efficiently the problem can be solved. In particular, their proof of the lower bound uses a new technique to capture the best possible behavior of any algorithm for this problem.
Suppose there is a large directed graph that describes the connections between neurons in a portion of the brain, and the number of neurons is very large, say, several billion. If the graph has many cycles, this might indicate that the portion of the brain contains recurrences and feedback loops, while if it has no cycles, this might indicate information flows through the graph in a linear manner. Knowing this fact might help deduce the function of this part of the brain. The paper’s result is negative – it provides a lower bound on the number of neurons needed to determine this fact. (This might sound a little discouraging, but this research isn’t really targeted at specific applications – rather, it takes a step toward better understanding the types of approaches we need to use to efficiently determine the properties of large directed graphs.)
This is part of a subfield of theoretical computer science that has to do with finding things out about enormous data objects by asking just a few questions (relatively speaking). Said Tim Randolph, “Problems like these become increasingly important as we generate huge volumes of data, because without knowing how to solve them we can’t take advantage of what we know.”
The paper studies the problem of privacy-preserving (approximate) similarity search, which is the backbone of many industry-scale applications and machine learning algorithms. It obtains a quadratic improvement over the highest *unconditional* lower bound for oblivious (secure) near-neighbor search in dynamic settings. This shows that dynamic similarity search has a logarithmic price if one wishes to perform it in an (information theoretic) secure manner.
In this paper the researcher studied the case where there is a set K of terminals, and the goal is to embed only the terminals into `1 with low distortion.
Given two metric spaces $(X,d_X),(Y,d_Y)$, an embedding is a function $f:X\to Y$. We say that an embedding $f$ has distortion $t$ if for every two points $u,v\in X$, it holds that $d_X(u,v)\le d_Y(f(u),f(v))\le t\cdot d_X(u,v)$. “Given a hard problem in a space $X$, it is often useful to embed it into a simpler space $Y$, solve the problem there, and then pull the solution back to the original space $X$,” said Arnold Filtser, a postdoctoral fellow. “The quality of the received solution will usually depend on the quality of the embedding (distortion), and the simplicity of the host space. Metric embeddings have a fundamental place in the algorithmic toolbox.”
In $\ell_1$ distance, a.k.a. Manhattan distance, given two vectors $\vec{x},\vec{y}\in\mathbb{R}^d$ the distance defined as $\Vert \vec{x}-\vec{y}\Vert_1=\sum_i |x_i-y_i|$. A planar graph $G=(V,E,w)$, is a graph that can be drawn in the plane in such a way that its edges $E$ intersect only at their endpoints. This paper studies metric embeddings of planar graphs into $\ell_1$.
It was conjectured by Gupta et al. that every planar graph can be embedded into $\ell_1$ with constant distortion. However, given an $n$-vertex weighted planar graph, the best upper bound on the distortion is only $O(\sqrt{\log n})$, by Rao. The only known lower bound is $2$’ and the fundamental question of the right bound is quite eluding.
The paper studies the case where there is a set $K$ of terminals, and the goal is to embed only the terminals into $\ell_1$ with low distortion and it’s contribution is a further improvement on the upper bound to $O(\sqrt{\log\gamma})$. Since every planar graph has at most $O(n)$ faces, any further improvement on this result, will be a major breakthrough, directly improving upon Rao’s long standing upper bound.
It is well known that the flow-cut gap equals to the distortion of the best embedding into $\ell_1$. Therefore, our result provides a polynomial time $O(\sqrt{\log \gamma})$-approximation to the sparsest cut problem on planar graphs, for the case where all the demand pairs can be covered by $\gamma$ faces.
A Boolean function f : {0,1}n → {0,1} is monotone if for every two points x, y ∈ {0,1}n where xi ≤ yi for every i∈[n], f(x) ≤ f(y). There has been a long and very fruitful line of research, starting with the work of Goldreich, Goldwasser, Lehman, Ron, and Samorodnitsky, exploring algorithms which can test whether a Boolean function is monotone.
The core question studied in the first paper was: suppose a function f is ϵ-far from monotone, i.e., any monotone function must differ with f on at least an ϵ-fraction of the points, how many pairs of points x, y ∈ {0,1}n which differ in only one bit i∈[n] (an edge of the hypercube) must satisfy f(x) = 1 but f(y) = 0 but x ≤ y (a violation of monotonicity)?
The paper focuses on the question of efficient algorithms which can estimate the distance to monotonicity of a function, i.e., the smallest possible ϵ where f is ϵ-far from monotone. It gives a non-adaptive algorithm making poly(n) queries which estimates ϵ up to a factor of Õ(√n). “The above approximation is not good since it degrades very badly as the number of variables of the function increases,” said Erik Waingarten. “However, the surprising thing is that substantially better approximations require exponentially many non-adaptive queries.”
The Complexity of Contracts Paul Duetting London School of Economics, Tim Roughgarden Columbia University, Inbal Talgam-Cohen Technion, Israel Institute of Technology
Contract theory is a major topic in economics (e.g., the 2016 Nobel Prize in Economics was awarded to Oliver Hart and Bengt Holmström for their work on the topic). A canonical problem in the area is how to structure compensation to employees (e.g. as a function of sales), when the effort exerted by employees is not directly observable.
This paper provides both positive and negative results about when optimal or approximately optimal contracts can be computed efficiently by an algorithm. The researchers design such an efficient algorithm for settings with very large outcome spaces (such as all subsets of a set of products) and small agent action spaces (such as exerting low, medium, or high effort).
How to Store a Random Walk Emanuele Viola Northeastern University, Omri Weinstein Columbia University, Huacheng Yu Harvard University
Motivated by storage applications, the researchers studied the problem of “locally-decodable” data compression. For example, suppose an encoder wishes to store a collection of n *correlated* files using as little space as possible, such that each individual X_i can be recovered quickly with few (ideally constant) memory accesses.
A natural example is a collection of similar images or DNA strands on a large sever, say, Dropbox. The researchers show that for file collections with “time-decaying” correlations (i.e., Markov chains), one can get the best of both worlds. This surprising result is achieved by proving that a random walk on any graph can be stored very close to its entropy, while still enabling *constant* time decoding on a word-RAM. The data structures generalize to dynamic (online) setting.
The paper investigates for which metric spaces the performance of distance labeling and of `∞- embeddings differ, and how significant can this difference be.
A distance labeling is a distributed representation of distances in a metric space $(X,d)$, where each point $x\in X$ is assigned a succinct label, such that the distance between any two points $x,y \in X$ can be approximated given only their labels.
A highly structured special case is an embedding into $\ell_\infty$, where each point $x\in X$ is assigned a vector $f(x)$ such that $\|f(x)-f(y)\|_\infty$ is approximately $d(x,y)$. The performance of a distance labeling, or an $\ell_\infty$-embedding, is measured by its distortion and its label-size/dimension. “As $\ell_\infty$ is a norm space, it posses a natural structure that can be exploited by various algorithms,” said Arnold Filtser. “Thus it is more desirable to obtain embeddings rather than general labeling schemes.”
The researchers also studied the analogous question for the prioritized versions of these two measures. Here, a priority order $\pi=(x_1,\dots,x_n)$ of the point set $X$ is given, and higher-priority points should have shorter labels. Formally, a distance labeling has prioritized label-size $\alpha(.)$ if every $x_j$ has label size at most $\alpha(j)$. Similarly, an embedding $f: X \to \ell_\infty$ has prioritized dimension $\alpha(\cdot)$ if $f(x_j)$ is non-zero only in the first $\alpha(j)$ coordinates. In addition, they compare these prioritized measures to their classical (worst-case) versions.
They answer these questions in several scenarios, uncovering a surprisingly diverse range of behaviors. First, in some cases labelings and embeddings have very similar worst-case performance, but in other cases there is a huge disparity. However in the prioritized setting, they found a strict separation between the performance of labelings and embeddings. And finally, when comparing the classical and prioritized settings, they found that the worst-case bound for label size often “translates” to a prioritized one, but also a surprising exception to this rule.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor

 Payal Chandak
Payal Chandak Sophia Kolak
Sophia Kolak Yanda Chen
Yanda Chen


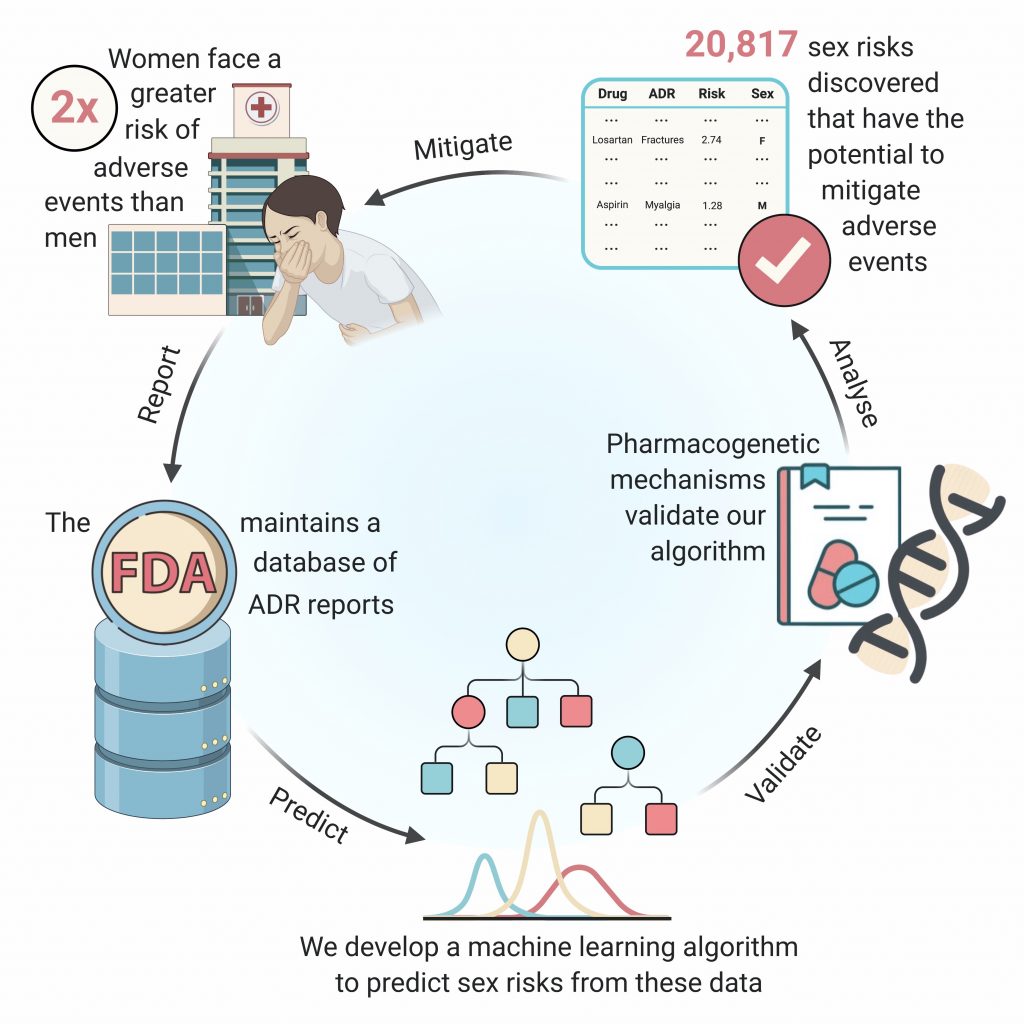
 I was excited to learn that
I was excited to learn that  The Heidelberg forum was a good mix of learning from very accomplished academics and meeting other students. With all the difficulties that an online event presents, I appreciated that the organizers took many questions and feedback from participants, and the talks felt more like a lively discussion.
The Heidelberg forum was a good mix of learning from very accomplished academics and meeting other students. With all the difficulties that an online event presents, I appreciated that the organizers took many questions and feedback from participants, and the talks felt more like a lively discussion. I really enjoyed attending the virtual forum. It was quite an experience to hear talks by some of the most esteemed people in mathematics and computer science. I was very inspired by hearing their stories and it was great that they answered many audience questions during the sessions.
I really enjoyed attending the virtual forum. It was quite an experience to hear talks by some of the most esteemed people in mathematics and computer science. I was very inspired by hearing their stories and it was great that they answered many audience questions during the sessions. On October 28, students, faculty, alumni, families, and friends—from across Columbia and around the world—come together to give back to Columbia Engineering on
On October 28, students, faculty, alumni, families, and friends—from across Columbia and around the world—come together to give back to Columbia Engineering on 

 Juan D. Correa
Juan D. Correa Emily Allaway
Emily Allaway Vivian Liu
Vivian Liu Sachit Menon
Sachit Menon Shyamal Patel
Shyamal Patel Abhishek Shah
Abhishek Shah Evgeny Manzhosov
Evgeny Manzhosov
 Keyon Vafa
Keyon Vafa Chang Xiao
Chang Xiao Kahlil Dozier
Kahlil Dozier Loqman Salamatian
Loqman Salamatian Rundi Wu
Rundi Wu Gaurav Jain
Gaurav Jain Run Chen
Run Chen Miranda Christ
Miranda Christ Samir Gadre
Samir Gadre Melanie Subbiah
Melanie Subbiah