
With Amazon Research Award, Eugene Wu will add interactivity and adversarial generation to entity matching
![]()

For his proposal “Interactive Matcher Debugging via Adversarial Generation,” Eugene Wu has been awarded an Amazon Research Award. This unrestricted gift, open to institutions of higher learning in North America and Europe, is intended to support one or two graduate students or post-doc researchers doing research under the guidance of the faculty member receiving the award.
An Assistant Professor of Computer Science at Columbia, Wu heads the WuLab research group and is a member of the Data Science Institute, where he co-chairs the Center for Data, Media and Society.
Wu will use the award to fund research that will extend existing techniques for entity matching, a data cleaning task that locates duplicate data entries referencing the same real-world entity (to learn, for example, that “M. S. Smith” and “Mike S. Smith” refer to the same person).
“Finding these duplicate records is crucial for integrating different data sources, and current methods rely on machine learning,” says Wu. “The problem is that machine learning is not perfect and it is hard to even anticipate where it is matching incorrectly. We are very pleased that Amazon has selected to fund this project where we will work toward two goals: help users identify cases likely to result in matching errors, and identify realistic data examples to use to improve the machine learning model.”
Online retailers and services collect their data from a huge number of different data sources that may use different spellings or naming conventions and provide different images or descriptions for the same item. Amazon might have hundreds of vendors listing and selling iPhones or iPhone-related products. If all of this data is uploaded to Amazon without being matched, customers might see 100 product pages for “iPhone,” “iPhone 6X Large,” “IPhONE 6 Best,” or even worse, a product search might come up empty if the search string doesn’t exactly match the product name as it is assigned by the vendor. Entity matching helps prevent these types of problems but entity matching is a deeply challenging problem.
Entity matching is a classification problem, with ensemble trees often used to label entity pairs as matching or non-matching. Errors in classification are a perennial problem, but if users understand why such errors occur, they can adjust the classification process to reduce errors.
Much of Wu’s research, and the focus of WuLab, has centered on creating interactive visualizations that make it easier for users to spot anomalous patterns and other problems while also providing explanations of why certain problems occur. Wu will do the same for entity matching by developing new algorithms and software components that, once inserted into existing entity-matching pipelines, will automatically generate high-level, easy-to-understand explanations so developers can readily understand what matching errors exist.
Once errors have been identified, the second direction of the research is to address the error. Wu will do so by generating training samples to feed back into the machine learning model and ultimately improve its accuracy. As with all classification tasks, entity matching requires huge amounts of training data, and it is often necessary to synthetically create additional data to train a classification model. One such data-generation technique is adversarial generation, which creates new data by taking a supplied, real-world string of values and changing one or two values to produce a new data string similar to real-world ones.
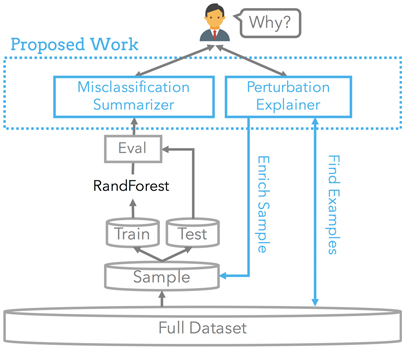
Widely used for images, adversarial generation has drawbacks for text since perturbing a single value often produces non-semantic text samples that wouldn’t actually occur in the real world; such data, inserted into the training set, could contribute to matching errors. Here, Wu proposes constraints that will consider the entire data record (not just individual string values) when perturbing transformations, thereby ensuring synthetic data is less arbitrary, more representative of real-world cases, and in the case of text, more semantically meaningful.
As part of the award, which totals $80K with an additional $20K in Amazon Web Services (AWS) Cloud Credits, Wu and his research group will meet and collaborate with Amazon research groups. The resulting paper will be published and the code written for the project will be made open source for other research groups.
Posted 02/01/2018
– Linda Crane