Droice’s drug prescription analyzer: From idea to hospital-wide rollout in less than 12 months
Three Columbia grad students—one in biomedical engineering, one in computer science, one in data science—met in January to brainstorm on what could be done in healthcare to assist doctors. There was no single inspired idea to productize, just an awareness that healthcare was a messy field more resistant than other fields to technology’s power to transform. Part of the problem is that healthcare data is dispersed and locked up in unstructured text, not the type of data artificial intelligence is designed to handle. But the three students knew that natural language processing, combined with new methods in machine learning, provided ways to extract meaningful data from text. They could get information from data, but what information did doctors actually need? For months, the three queried doctors, diving deep into the minutiae of a doctor’s daily workflow, learning step by step how to insert intelligence into a doctor’s daily routine. Less than 12 months later, a hospital-wide rollout to 300 doctors.
How does a doctor know what drugs and dosage to give to a patient?
Ideally a doctor refers to the most up-to-date research surrounding a drug’s efficacy, compares it to other drugs doing the same thing while taking into account the risks of adverse effects of a particular drug on a particular patient. Drug cost is also an issue.
There is an ocean of healthcare data to help support doctors in this decision, to the tune of one new scientific article every thirty seconds, not to mention vast amounts of existing literature. It’s too much for any single doctor to plow through. So in reality, doctors rely on what they learned in medical school, what they have seen work on their patients, and how colleagues have successfully treated patients. In essence doctors have to go through enormous amounts of data, both objective and subjective, to make an informed choice for their patients.
The ramifications are stark. Adverse drug events are the fourth leading cause of deaths in the US, costing an estimated $140B per year.
Technology solution for a healthcare problem
Mayur Saxena, Harshit Saxena (no relation to Mayur), and Aleksandr Makarov knew little of the particulars of the adverse drug problem in January when the three friends, all startup veterans, met to discuss ideas for a new venture. Healthcare was an obvious choice. Inefficient, expensive, and often deeply dissatisfying to patients and doctors alike, the field would seem ripe for innovation. And it is rich in the data that, once analyzed, can reveal new information capable of transforming the field. Many others were also noticing the possibilities; healthcare is awash in startups looking to “disrupt” present practices.
But healthcare is a thorny area. It’s highly regulated with strict privacy and security requirements that make getting private patient data difficult. Though there is also public healthcare data to work with, much of it is hardcore text, and thus inaccessible to standard data mining methods.
The three friends, however, had several advantages. M. Saxena as a PhD student in biomedical engineering had a good view of how healthcare worked, or rather didn’t work. Makarov was an MS student at the Data Science Institute with skills in big data analytics and machine learning; and H. Saxena, an MS student in computer science, specialized in the deep learning algorithms responsible for the recent, rapid progress in artificial intelligence. Crucially he was aware of how natural language processing can analyze massive amounts of text and categorize it by topic.
Says H. Saxena, “There is an ocean of data in health care—conference papers, clinical trial data, patient profiles, drug performance data, patient medical records—but it’s very hard for an individual doctor to navigate and find the exact data relevant to a specific case. By using natural language processing techniques, we could build a semantic-based search engine to aggregate all the relevant information a doctor would want but doesn’t have time to research.”
But what information to retrieve or for what purpose? Over weeks of discussions and learning more about adverse drug effects, they began thinking about a prescription drug analyzer that would compare all possible drug combinations for different medical conditions, extracting those features useful to a doctor when deciding the best drug to prescribe. An analyzer could evaluate several possible treatments and make a prediction on how well each would work for a particular patient while weighing the risks of adverse side effects.
The friends managed to get a public data set of about 40,000 patients, small but large enough to give them confidence the idea would work.
By February, they had written some software to evaluate diabetes drugs. Forming a team with the name Droice, they entered Cornell’s Data Science Hackathon, mostly as a way to solicit advice and reassurance their idea was a sound one. The team ended up winning the competition, and the $2K grand prize. A month later, they entered a Cornell-MIT Health Tech hackathon with a similar outcome. Obviously others, including some prominent people in healthcare who served as judges, thought a drug treatment analyzer had merit.
Adjustments for the workflow
The best drug treatment analyzer in the world won’t solve anything if doctors don’t use it. From the beginning, developing a drug analyzer was to be rigorous process driven by doctor feedback. Did doctors want or need this assistance? They would have to ask.
Of 200 doctors they interviewed (through personal connections, they contacted a number of doctors who enthusiastically referred them to still other doctors), the team learned much that would guide development.
The analyzer software would have to embed in the software doctors use to view and update patients’ electronic health records (EHRs). No one could expect doctors—in the small window of time they see a patient—to open (or learn) another software program. Says M. Saxena, “One glance; if doctors don’t get value, they won’t glance at it again. That’s how tricky the space is.” For three months, the team would work to seamlessly embed their software into the programs doctors were already using.
Doctors did not want black box software. “If you give doctors a prediction, no matter how good that prediction is, they want to know why. That’s their training. Once we wrote the software to return the scientific papers or clinical trial relevant to a particular analysis, that’s when doctors started paying attention.”
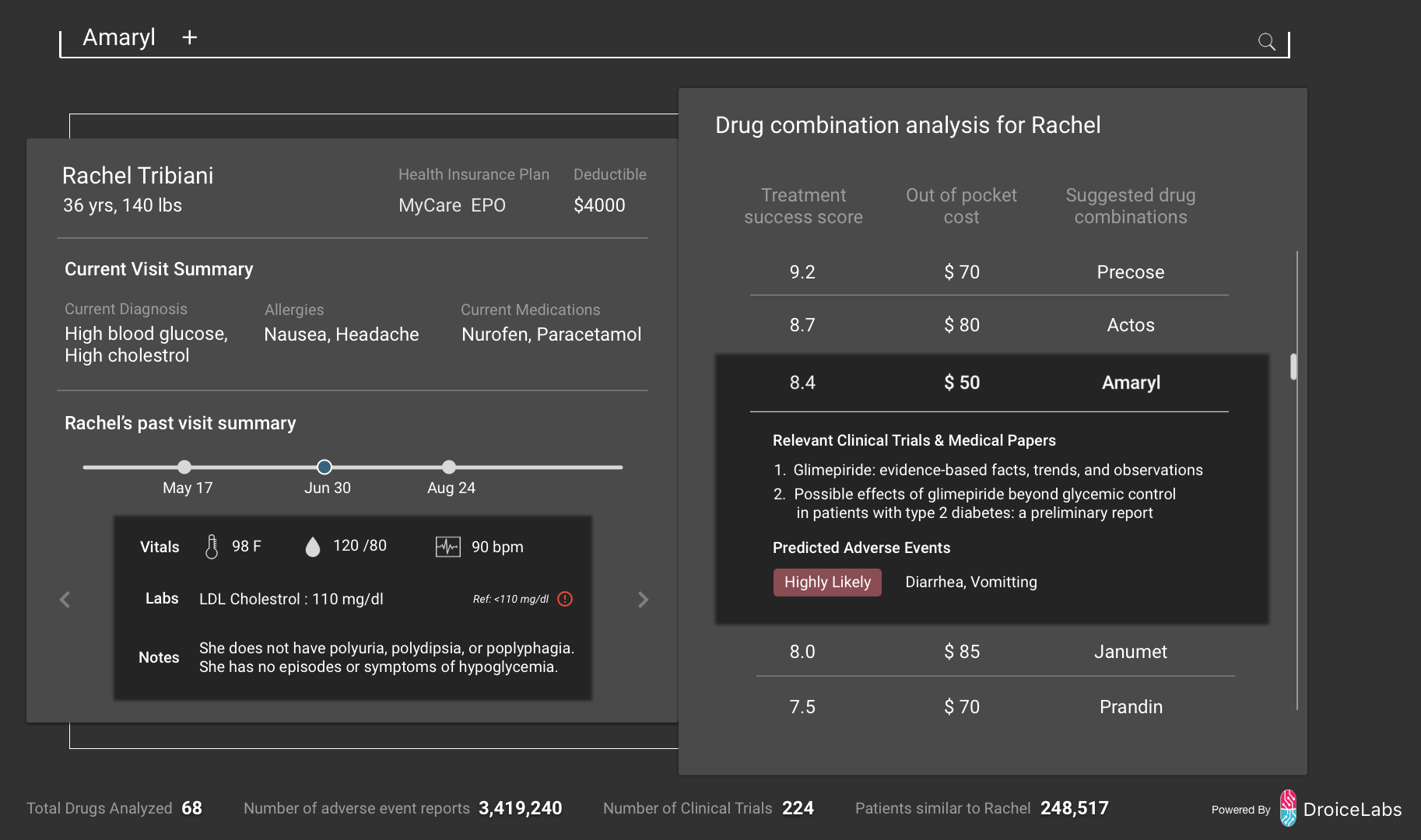
Droice drug analysis is embedded in a patient’s electronic health record as shown in this fictitious example. From scientific papers, drug performance data, a patient’s health profile, and other data, Droice predicts which drug treatments can be most effective for a particular patient and their likely adverse drug effects. The actual display will appear different in different health record systems.
They learned also that Amsterdam—highly regulated and maintaining the highest standards—was the best place to test their software; meeting criteria set by Amsterdam hospitals would go far in making the software acceptable to almost any hospital in the world, including those in the US. By September, the team would have a small pilot project at an Amsterdam hospital.
In addition, software would have to be compliant with HIPAA and other regulations in effect in US and Europe. Hacking was such a huge concern, Droice over the summer hired an expert in cybersecurity to ensure its software was built with cybersecurity from the start.
Developing a marketing strategy
In April, the Droice team entered the Columbia Venture Competition. Sponsored by Columbia’s Engineering School, the competition helps student entrepreneurs find teammates and get practical advice. The team won the technology category and $25K; almost more valuable were connections with alumni, who freely offered suggestions; for the first time, investors approached them.
With a product idea solidified and with plans to expand beyond diabetes, Droice was beginning to look like a company. A board of advisors was now working with the team as it started drawing up a marketing strategy and looking for hospitals to approach to test the analyzer. One thing the team did not want to do was give away its product and services in a bid to get into hospitals. While hospitals were more than willing to let a subset of doctors tests Droice, only a hospital-wide rollout would provide enough detailed information to fully understand how the software would work in a realistic hospital setting. Nor would a series of small trials in a bunch of different places (each requiring labor-intensive customization) produce solid, publishable results for a paper the team is already planning for mid 2017.
It was a strategic decision to send Makarov across Europe to look for a hospital that would agree to roll out the software to all doctors. Expense was one thing; moving Makarov off development for three months was a difficult decision but one that ultimately paid off. Makarov found two hospitals, both in Russia, that agreed to the hospital-wide provision in exchange for lower pricing.
December rollout
The rollout at the first hospital, in St. Petersburg with 300 hundred doctors, was underway by December 1; in January, a second St. Petersburg hospital with 400 doctors will begin using Droice.
By any measure, the speed at which the Droice software, complex artificial intelligence software, was developed and deployed qualifies as fast. For a healthcare product, it is blindingly fast.
The team credits in part the support given to entrepreneurs by Columbia. Says M. Saxena, “If we were not at Columbia, it would have been much, much more difficult. We met through hackathons and other events held at Columbia, and we received help and guidance from alumni who stay connected to the university. Many of our advisors came to us through Columbia connections.”
But in the end, it’s the idea and the willingness to modify that idea that will ultimately decide their success. The software they have now looks very different than at the beginning of the process, shaped by what doctors asked for, by the counsel of advisors, and by healthcare standards. They expect further changes.
What hasn’t changed is the desire to assist doctors and to change healthcare so it works better for both patients and doctors. Droice team members will know by April how successful the program has been, but they are already looking beyond the drug treatment analyzer to new ways to use aggregated healthcare data. To that end, the company hired this summer a machine learning expert with close ties to others in the field to help decide the company’s next new directions.
Dean Boyce's statement on amicus brief filed by President Bollinger
President Bollinger announced that Columbia University along with many other academic institutions (sixteen, including all Ivy League universities) filed an amicus brief in the U.S. District Court for the Eastern District of New York challenging the Executive Order regarding immigrants from seven designated countries and refugees. Among other things, the brief asserts that “safety and security concerns can be addressed in a manner that is consistent with the values America has always stood for, including the free flow of ideas and people across borders and the welcoming of immigrants to our universities.”
This recent action provides a moment for us to collectively reflect on our community within Columbia Engineering and the importance of our commitment to maintaining an open and welcoming community for all students, faculty, researchers and administrative staff. As a School of Engineering and Applied Science, we are fortunate to attract students and faculty from diverse backgrounds, from across the country, and from around the world. It is a great benefit to be able to gather engineers and scientists of so many different perspectives and talents – all with a commitment to learning, a focus on pushing the frontiers of knowledge and discovery, and with a passion for translating our work to impact humanity.
I am proud of our community, and wish to take this opportunity to reinforce our collective commitment to maintaining an open and collegial environment. We are fortunate to have the privilege to learn from one another, and to study, work, and live together in such a dynamic and vibrant place as Columbia.
Sincerely,
Mary C. Boyce
Dean of Engineering
Morris A. and Alma Schapiro Professor