
Month: December 2016
IEEE Micro magazine selects “Evaluation of an Analog Accelerator for Linear Algebra” as a top pick
Coauthored by students Yipeng Huang and Ning Guo, paper will be featured in May/June 2017 issue as one of “Top Picks from Computer Architecture Conferences.”
Undergrads Terra Blevins, Ruoxin (Amy) Jiang, and Jun Ho Yoon recognized for research
Three undergraduate computer science majors have been recognized by the Computing Research Association (CRA) for showing outstanding research potential in computing research.

For her work on natural language processing, Terra Blevins (CS’17) was named a finalist for the Outstanding Undergraduate Researchers award. Since her sophomore year she has been doing research in the lab of Kathy McKeown, working on a number of projects including automatic language generation, a task that relies on constructing templates that identify slots where nouns or other entities should go; a typical template might be “[number] people were killed in the [event] in [city]” with each slot updated for new events. Generating language using templates is manually intensive, and the language created in this fashion is often generic and repetitious, lacking the natural variation of human-generated language. The project for which Blevins is being recognized tackles both problems: automating the creation of templates while employing paraphrasing to insert more variation for more naturalness. Rather than gathering paraphrases from pairs of similar, or aligned, corpuses—where sentences from one text map to corresponding sentences in the second (as in two different translations of a French novel to English)—Blevins worked with her colleagues to automatically generate paraphrases from the unaligned corpus of Wikipedia articles. Sentences that corresponded with one another were identified using clustering techniques that analyzed semantic similarity. Blevins is coauthor of the paper describing the method. A second project on which she works aims to predict gang violence by automatically analyzing the language contained in tweets circulating among gang-involved youth.
Blevins hopes to continue her work in natural language processing and is currently applying to graduate schools.

The research for which Ruoxin (Amy) Jiang, BS’17, received honorable mention revolves around the complex issue of computer security, specifically on exploring ways to streamline the API libraries (SSL) used by developers to make their applications secure. The sheer number of API functions contained in these libraries and the complexity of some can overwhelm and confuse developers, leading security vulnerabilities that result from incorrectly selecting and using the functions. Under the guidance of Suman Jana, Jiang has been measuring how much of the SSL API space is actually used by existing applications, and what part goes mostly unused. The ultimate goal is to identify common API usage patterns across different applications, and reduce the unused API space. Specifically, Jiang analyzed the usage of OpenSSL API in 32 popular open source programs, applying several techniques (k-means clustering, hierarchical clustering, frequent itemset mining) to identify common patterns. In promising results, she found that the applications studied used only 24% of all OpenSSL API functions, demonstrating that the OpenSSL API can be significantly simplified without compromising application functionality.
After graduation, Jiang will continue on at Columbia to finish her Master’s in computer science.

Jun Ho Yoon (CS’17) received an Honorable Mention for the CRA Outstanding Undergraduate Male Researchers Award for his work on machine learning and computational genomics. Working in Itsik Pe’er’s computational biology lab, Yoon helped develop a hierarchical Bayesian nonparametric model for variation of gene expression, a computationally challenging problem due to operating in the genome-wide space, and one not easily handled by classical machine learning techniques. To scale the work for the large number of variables to be inferred, Yoon helped develop a GPU implementation of the algorithm, first learning the GPU programming language CUDA to do so. He applied the model to real data, revealing new regulatory structures.
Prior to joining Pe’er’s lab, Yoon took two PhD-level courses about Bayesian frameworks for machine learning and furthered his understanding through research projects about topic models under the guidance of David Blei. After graduation, Yoon hopes to continue researching machine learning as a PhD student.
Posted 12/22/16
Women and computer science at Columbia
![]()
Part 2 of Making computer science accessible to Columbia’s wider student population.

![]()
Update: This article was originally posted December 2016. Since then, with students having declared their majors in Spring 2017, the percentage of female computer science majors again increased. Women now make up 45% of Columbia’s computer science majors.
At Columbia University, women make up 37% of computer science majors. With the national average slightly below 20%, Columbia’s relatively high percentage ranks it among the top universities in attracting women to computer science. It wasn’t always so. In 2008, the percentage of women majoring in computer science at Columbia was 8%, mirroring a nation-wide, generation-long decline that began in 1984 when women nationally made up 37% of computer science majors. Columbia’s success in reversing the trend is due to efforts by the Computer Science Department to directly address the gender imbalance, both by dispelling popular stereotypes and misconceptions about who is good at computer science, and by exposing students sooner to the wide range of problems that can be solved computationally.
![]()
Why do so few women major in computer science?
Cultural stereotypes may have a lot to do with it. The popular image of a computer programmer—a male sitting alone in front of a computer screen for hours on end either coding or gaming while consuming fast food in situ with Star Wars posters on the wall—isn’t attractive to many people. It’s not just women; many men don’t see themselves in this picture either.
It’s an unfortunate stereotype and an untrue one. Much more than programming, computer science is an approach to problem solving, entailing critical, abstract, and creative thinking that has application across disciplines, from biology and medicine, the social and natural sciences, to music, art, and the liberal arts.
Nor is programming solitary. In the real world, programming and software development are collaborative activities, with people working to build something together.
The whole notion of purposeful creation is lacking from the popular stereotype, which equates programming with computer science. It is a high school concept of computer science, and it’s in high school that the stereotype takes hold for many students, perhaps in part because the original AP exam—introduced in 1984, the beginning of the decline of women in computer science—requires students to know details of programming syntax. (Changes are in place with the introduction this fall of a new AP exam, Computer Science Principles, which focuses on algorithms, variables, and other general computing concepts.)
The jumpstart in programming that male students get in high school carries over to the college level, leading to what Julia Hirschberg, chair of Columbia’s Computer Science Department, sees as a confidence gap. “Because men typically enter college with more computer programming than female classmates, men often have higher confidence levels about computing and are more eager to speak up in class. For students just starting out, not yet fluent in the vocabulary or syntax of computer science, it’s easy to feel far behind. It can be discouraging.”
Unfortunately, introductory computer science classes, necessarily focused on teaching basic programming and computational skills, often do little initially to dispel the popular thinking. And the packed, auditorium-sized lecture classes may make it harder for students to become acquainted with peers and form study groups to help one another.
![]()
Much more than programming
In 2008, the year the number of women computer science majors hit rock bottom at Columbia, Adam Cannon, Chris Murphy, and Kristen Parton introduced the Emerging Scholars Program (ESP) to directly address the gender imbalance. ESP takes its name and model from workshops started in the 1970s by Uri Treisman at the University of California, Berkeley to improve the performance of underrepresented minority students in math classes by encouraging students to form small study groups.
With seed funding from the National Center for Women and Information Technology, Cannon, Murphy, and Parton adapted the ESP model for a computer science setting. Combining ESP with the Peer-Led Team Learning (following the example of Susan Rodger), they created a one-point, once-a-week seminar to expose students to the non-programming and collaborative aspects of computer science that typically are not a big part of introductory classes.
There is no coding and no grading or homework in ESP; the focus is entirely on high-level concepts in computer science, particularly on algorithmic thinking, the logical, step-by-step decomposing of a problem into component parts that can be solved by computer; it’s a type of critical thinking with application beyond computer science. In ESP, students learn algorithmic thinking by discussing together algorithmic solutions to a set of problems taken from natural language processing, artificial intelligence, cryptography, and social networking.
When it’s easy for a beginner to get stuck on trivial things—for loops, syntax—Emerging Scholars serves as a sort of preview of the interesting problems students will encounter in later classes.
The approach has proven successful. Students taking ESP are much more likely (as much as three times more likely) to major in computer science than the students who don’t take ESP. Over the first four years of ESP being offered (2008-2012), women went from 9% to 23% of Columbia computer science majors.
![]()
What the women are doing about it
Women themselves have not been sitting around waiting for others to fix the problem. In 1998, when women made up 10% of computer science majors (but fully half of the top 10% of students), a number of undergraduate women approached Kathy McKeown, then chair of the Computer Science Department, about forming a woman’s support group that would provide an informal, friendly environment for women in the department to connect with one another, get help on problems and projects, and share their experiences in a heavily male-dominated field. Women in Computer Science (WiCS) has grown over the years and broadened its charter to organizing networking events and arranging site visits to employers in the city.
Though funded by the department and some corporate sponsors, WiCS works outside the department to make computer science more inclusive to women. But Cherie Luo, president of WiCS, see signs that the department itself is becoming more responsive to the increasing diversity of students who want to develop computational skills. “I think a way to make computer science more appealing to women and those who yet not exposed to it is to show how computer science can apply and relate to students in all fields of study. Computing in Context does that in an approachable, interdisciplinary setting outside the ‘hyper-competitive’ intro classes.”
“Little things can help a lot. Example problems sets shouldn’t always use just men; include women also or use the plural to include everyone.”
“Role models are important. It would be nice to see more women professors and more women TAs.”
“It’s always inspiring to talk to women who have gone through the academic channel and what’s it’s been like for them.”
![]()
Changes in course curriculum
Started by Cannon in Spring 2015 to teach computing to liberal arts students, Computing in Context is a rigorous introductory computer science course that is half computer science and half applications of computer science. The course is taught by a team of professors; a computer science professor lectures to all students on basic computer and programming skills, and professors in the humanities, social sciences, and other departments show through projects and lectures (some live, some recorded) how those skills and methods apply to a specific liberal arts discipline.
Computing in Context thus engages students on their own ground, teaching computer science not as a separate field of study but as a way for students to better understand their own fields. In doing so, Computing in Context is the rare case of an introductory computer science class that naturally achieves gender balance.
The course is a unique collaboration between the Computer Science Department and other departments across campus that want to give their students the computational skills increasingly necessary in all fields and disciplines. Currently, Computing in Context has tracks for digital humanities, social science, economics and finance, and international and public affairs, with plans to add computational biology starting next year.
As new tracks are added, more students are exposed to computer science, including many students who would not otherwise take a computer science class or who still harbor misconceptions about what computer science entails. Often students coming to Computing in Context to learn how to better study their own fields surprise themselves by becoming passionate about computer science, even switching their major. It might not be the most direct route to a computer science major but it is a route nonetheless, and one that may be more inviting to many women.
By shifting the emphasis from coding to the tremendous potential of computer science to solve problems in the real world—and doing so in a context that makes sense to students—both ESP and Computing in Context more fully define the field of computer science, erasing for once and all the simplistic stereotypes that students might once have held. And this may be key to making computer science accessible not just to women but to all students, especially those who don’t see themselves as stereotypical programmers.
Posted: 12/20/2016. Update added September 20, 2017.
– Linda Crane
Droice’s drug prescription analyzer: From idea to hospital-wide rollout in less than 12 months
![]()

![]()
![]()
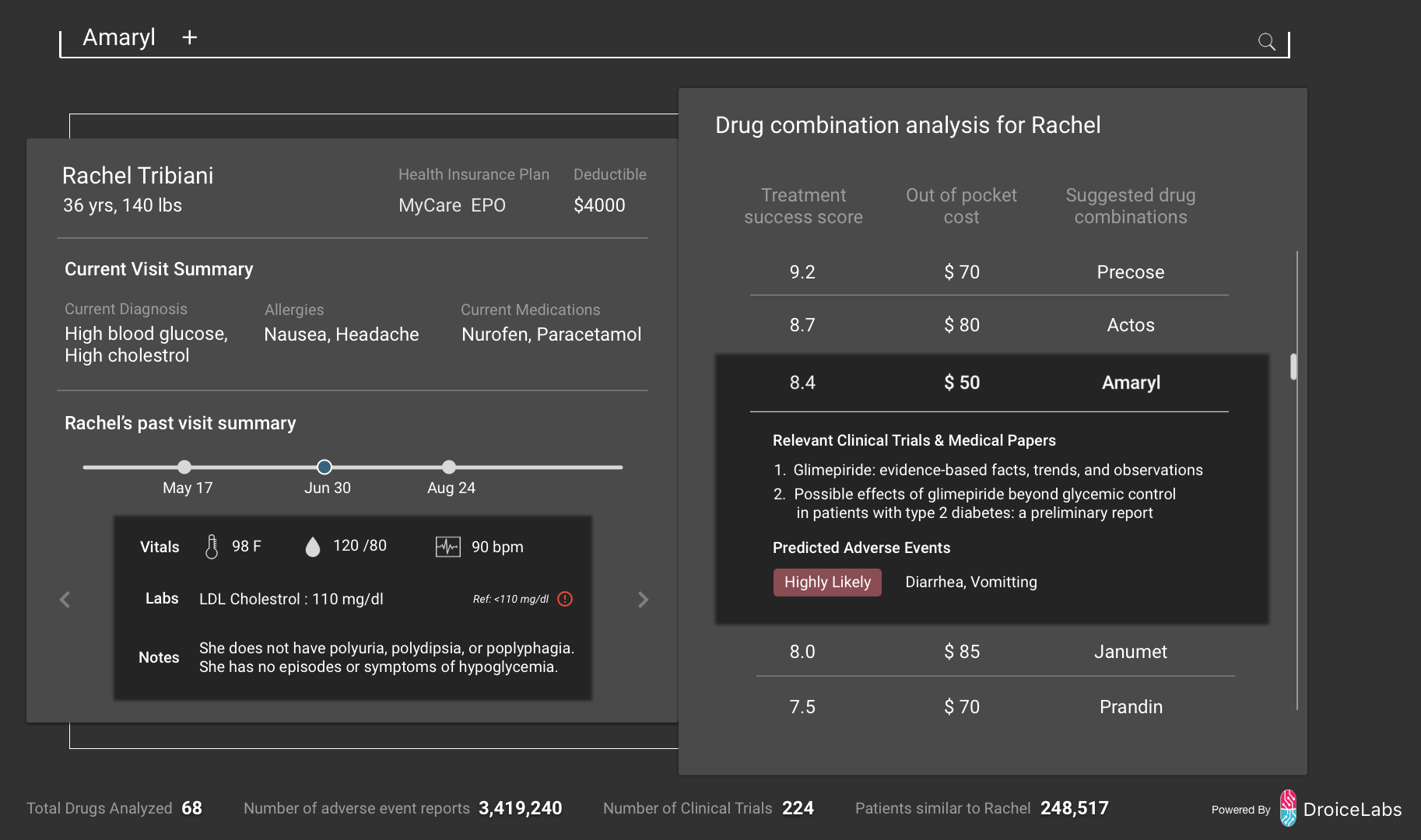
Three Columbia grad students—one in biomedical engineering, one in computer science, one in data science—met in January to brainstorm on what could be done in healthcare to assist doctors. There was no single inspired idea to productize, just an awareness that healthcare was a messy field more resistant than other fields to technology’s power to transform. Part of the problem is that healthcare data is dispersed and locked up in unstructured text, not the type of data artificial intelligence is designed to handle. But the three students knew that natural language processing, combined with new methods in machine learning, provided ways to extract meaningful data from text. They could get information from data, but what information did doctors actually need? For months, the three queried doctors, diving deep into the minutiae of a doctor’s daily workflow, learning step by step how to insert intelligence into a doctor’s daily routine. Less than 12 months later, a hospital-wide rollout to 300 doctors.

How does a doctor know what drugs and dosage to give to a patient?
Ideally a doctor refers to the most up-to-date research surrounding a drug’s efficacy, compares it to other drugs doing the same thing while taking into account the risks of adverse effects of a particular drug on a particular patient. Drug cost is also an issue.
There is an ocean of healthcare data to help support doctors in this decision, to the tune of one new scientific article every thirty seconds, not to mention vast amounts of existing literature. It’s too much for any single doctor to plow through. So in reality, doctors rely on what they learned in medical school, what they have seen work on their patients, and how colleagues have successfully treated patients. In essence doctors have to go through enormous amounts of data, both objective and subjective, to make an informed choice for their patients.
The ramifications are stark. Adverse drug events are the fourth leading cause of deaths in the US, costing an estimated $140B per year.
Technology solution for a healthcare problem
Mayur Saxena, Harshit Saxena (no relation to Mayur), and Aleksandr Makarov knew little of the particulars of the adverse drug problem in January when the three friends, all startup veterans, met to discuss ideas for a new venture. Healthcare was an obvious choice. Inefficient, expensive, and often deeply dissatisfying to patients and doctors alike, the field would seem ripe for innovation. And it is rich in the data that, once analyzed, can reveal new information capable of transforming the field. Many others were also noticing the possibilities; healthcare is awash in startups looking to “disrupt” present practices.
But healthcare is a thorny area. It’s highly regulated with strict privacy and security requirements that make getting private patient data difficult. Though there is also public healthcare data to work with, much of it is hardcore text, and thus inaccessible to standard data mining methods.
The three friends, however, had several advantages. M. Saxena as a PhD student in biomedical engineering had a good view of how healthcare worked, or rather didn’t work. Makarov was an MS student at the Data Science Institute with skills in big data analytics and machine learning; and H. Saxena, an MS student in computer science, specialized in the deep learning algorithms responsible for the recent, rapid progress in artificial intelligence. Crucially he was aware of how natural language processing can analyze massive amounts of text and categorize it by topic.
Says H. Saxena, “There is an ocean of data in health care—conference papers, clinical trial data, patient profiles, drug performance data, patient medical records—but it’s very hard for an individual doctor to navigate and find the exact data relevant to a specific case. By using natural language processing techniques, we could build a semantic-based search engine to aggregate all the relevant information a doctor would want but doesn’t have time to research.”
But what information to retrieve or for what purpose? Over weeks of discussions and learning more about adverse drug effects, they began thinking about a prescription drug analyzer that would compare all possible drug combinations for different medical conditions, extracting those features useful to a doctor when deciding the best drug to prescribe. An analyzer could evaluate several possible treatments and make a prediction on how well each would work for a particular patient while weighing the risks of adverse side effects.
The friends managed to get a public data set of about 40,000 patients, small but large enough to give them confidence the idea would work.
By February, they had written some software to evaluate diabetes drugs. Forming a team with the name Droice, they entered Cornell’s Data Science Hackathon, mostly as a way to solicit advice and reassurance their idea was a sound one. The team ended up winning the competition, and the $2K grand prize. A month later, they entered a Cornell-MIT Health Tech hackathon with a similar outcome. Obviously others, including some prominent people in healthcare who served as judges, thought a drug treatment analyzer had merit.
Adjustments for the workflow
The best drug treatment analyzer in the world won’t solve anything if doctors don’t use it. From the beginning, developing a drug analyzer was to be rigorous process driven by doctor feedback. Did doctors want or need this assistance? They would have to ask.
Of 200 doctors they interviewed (through personal connections, they contacted a number of doctors who enthusiastically referred them to still other doctors), the team learned much that would guide development.
The analyzer software would have to embed in the software doctors use to view and update patients’ electronic health records (EHRs). No one could expect doctors—in the small window of time they see a patient—to open (or learn) another software program. Says M. Saxena, “One glance; if doctors don’t get value, they won’t glance at it again. That’s how tricky the space is.” For three months, the team would work to seamlessly embed their software into the programs doctors were already using.
Doctors did not want black box software. “If you give doctors a prediction, no matter how good that prediction is, they want to know why. That’s their training. Once we wrote the software to return the scientific papers or clinical trial relevant to a particular analysis, that’s when doctors started paying attention.”
They learned also that Amsterdam—highly regulated and maintaining the highest standards—was the best place to test their software; meeting criteria set by Amsterdam hospitals would go far in making the software acceptable to almost any hospital in the world, including those in the US. By September, the team would have a small pilot project at an Amsterdam hospital.
In addition, software would have to be compliant with HIPAA and other regulations in effect in US and Europe. Hacking was such a huge concern, Droice over the summer hired an expert in cybersecurity to ensure its software was built with cybersecurity from the start.
Developing a marketing strategy
In April, the Droice team entered the Columbia Venture Competition. Sponsored by Columbia’s Engineering School, the competition helps student entrepreneurs find teammates and get practical advice. The team won the technology category and $25K; almost more valuable were connections with alumni, who freely offered suggestions; for the first time, investors approached them.
With a product idea solidified and with plans to expand beyond diabetes, Droice was beginning to look like a company. A board of advisors was now working with the team as it started drawing up a marketing strategy and looking for hospitals to approach to test the analyzer. One thing the team did not want to do was give away its product and services in a bid to get into hospitals. While hospitals were more than willing to let a subset of doctors tests Droice, only a hospital-wide rollout would provide enough detailed information to fully understand how the software would work in a realistic hospital setting. Nor would a series of small trials in a bunch of different places (each requiring labor-intensive customization) produce solid, publishable results for a paper the team is already planning for mid 2017.
It was a strategic decision to send Makarov across Europe to look for a hospital that would agree to roll out the software to all doctors. Expense was one thing; moving Makarov off development for three months was a difficult decision but one that ultimately paid off. Makarov found two hospitals, both in Russia, that agreed to the hospital-wide provision in exchange for lower pricing.
December rollout
The rollout at the first hospital, in St. Petersburg with 300 hundred doctors, was underway by December 1; in January, a second St. Petersburg hospital with 400 doctors will begin using Droice.
By any measure, the speed at which the Droice software, complex artificial intelligence software, was developed and deployed qualifies as fast. For a healthcare product, it is blindingly fast.
The team credits in part the support given to entrepreneurs by Columbia. Says M. Saxena, “If we were not at Columbia, it would have been much, much more difficult. We met through hackathons and other events held at Columbia, and we received help and guidance from alumni who stay connected to the university. Many of our advisors came to us through Columbia connections.”
But in the end, it’s the idea and the willingness to modify that idea that will ultimately decide their success. The software they have now looks very different than at the beginning of the process, shaped by what doctors asked for, by the counsel of advisors, and by healthcare standards. They expect further changes.
What hasn’t changed is the desire to assist doctors and to change healthcare so it works better for both patients and doctors. Droice team members will know by April how successful the program has been, but they are already looking beyond the drug treatment analyzer to new ways to use aggregated healthcare data. To that end, the company hired this summer a machine learning expert with close ties to others in the field to help decide the company’s next new directions.
For more information about Droice Labs:
Droice Labs website
A Tool to Customize Drug Recommendations for Patients
Posted 12/14/2016
– Linda Crane
Eran Tromer, a visiting research scientist at Columbia, is featured in Spectrum article
An expert in side-channel attacks, Tromer is a co-inventor of the cryptographic protocol of the Zcash privacy-preserving digital currency.
Interview with Bjarne Stroustrup, inventor of C++ and visiting Columbia professor
Stroustrup talks about his career path, his role in creating and continuing to improve C++, and technological changes across industries, particularly in financial services.
Creative, extreme engineering
Eitan Grinspun talks to former NASA astronaut Professor Michael Massimino about research done in the Computer Graphics lab.
Solution to JIT-ROP cyber attacks: Scramble code quickly
Allison Bishop delivers TEDx talk
In a retelling of Alice in Wonderland, Bishop illustrates the fundamentals and power of cryptography while warning how human error undermines that power.
Vladimir Vapnik awarded the IEEE John von Neumann Medal

“For the development of statistical learning theory, the theoretical foundations for machine learning, and support vector machines,” Vladimir Vapnik has been awarded this year’s IEEE John von Neumann Medal. Named in honor of the mathematician John von Neumann, the medal was established by the IEEE in 1990 to recognize individuals who have contributed outstanding achievements in computer-related science and technology.
For four decades, Vapnik has worked on learning theory related problems and in the field of theoretical and applied statistics, publishing six monographs and over a hundred research papers. He is probably best known as the co-inventor of support vector machines, which are widely used for analyzing text, images, and other content. He is also one of the main developers of the Vapnik–Chervonenkis theory of statistical learning, which measures the capacity of a learning machine.
As of November 2016, Vapnik’s publications have been cited 175,602 times and his h-index stands at 112.
A professor of Computer Science at Columbia since 2003, Vapnik previously worked at the Institute of Control Sciences, Moscow (1961 to 1990), where he became Head of the Computer Science Research Department. After moving to the US in 1990, he went to work at AT&T Bell Labs; it was at AT&T that he and his colleagues developed the theory of support vector machines. In 1995 he was appointed Professor of Computer Science and Statistics at Royal Holloway. After leaving AT&T in 2002, he also worked at NEC Laboratories in Princeton, New Jersey, working in the Machine Learning group.
In 2006 Vapnik was elected to the National Academy of Engineering (NAE) for “insights into the fundamental complexities of learning and for inventing practical and widely applied machine-learning algorithms.” Other awards accorded Vapnik: the 2005 Gabor Award, the 2008 Paris Kanellakis Award, the 2010 Neural Networks Pioneer Award, the 2012 IEEE Frank Rosenblatt Award, the 2012 Benjamin Franklin Medal in Computer and Cognitive Science from the Franklin Institute, and the 2014 Kampé de Fériet Award.
For Vapnik’s 75th birthday anniversary, the Max Planck Institute for Intelligent Systems organized in December 2011 the Empirical Inference Symposium.
Vapnik continues to research new topics and in November 2014 joined Facebook AI Research where he will collaborate with research scientists there to develop some of his ideas.
Posted 12/1/2016