Graphics and HCI

Dingzeyu Li, Avinash S. Nair, Shree K. Nayar, and Changxi Zheng
AirCode: Unobtrusive Physical Tags for Digital Fabrication.
ACM User Interface Software and Technology (UIST), Oct. 2017
Paper(PDF) Project Page Abstract Video
AirCode: Unobtrusive Physical Tags for Digital Fabrication.
ACM User Interface Software and Technology (UIST), Oct. 2017
Paper(PDF) Project Page Abstract Video
We present AirCode, a technique that allows the user to tag physically fabricated objects with given information. An AirCode tag consists of a group of carefully designed air pockets placed beneath the object surface. These air pockets are easily produced during the fabrication process of the object, without any additional material or postprocessing. Meanwhile, the air pockets affect only the scattering light transport under the surface, and thus are hard to notice to our naked eyes. But, by using a computational imaging method, the tags become detectable. We present a tool that automates the design of air pockets for the user to encode information. AirCode system also allows the user to retrieve the information from captured images via a robust decoding algorithm. We demonstrate our tagging technique with applications for metadata embedding, robotic grasping, as well as conveying object affordances.

Yun (Raymond) Fei, Henrique Teles Maia, Christopher Batty, Changxi Zheng, and Eitan Grinspun
A Multi-Scale Model for Simulating Liquid-Hair Interactions.
ACM Transactions on Graphics (SIGGRAPH 2017), 36(4)
Paper(PDF) Project Page Abstract Bibtex Video
A Multi-Scale Model for Simulating Liquid-Hair Interactions.
ACM Transactions on Graphics (SIGGRAPH 2017), 36(4)
Paper(PDF) Project Page Abstract Bibtex Video
The diverse interactions between hair and liquid are complex and span multiple
length scales, yet are central to the appearance of humans and animals in
many situations. We therefore propose a novel multi-component simulation
framework that treats many of the key physical mechanisms governing the
dynamics of wet hair. The foundations of our approach are a discrete rod
model for hair and a particle-in-cell model for fluids. To treat the thin layer
of liquid that clings to the hair, we augment each hair strand with a height
field representation. Our contribution is to develop the necessary physical
and numerical models to evolve this new system and the interactions among
its components. We develop a new reduced-dimensional liquid model to
solve the motion of the liquid along the length of each hair, while accounting
for its moving reference frame and influence on the hair dynamics. We
derive a faithful model for surface tension-induced cohesion effects between
adjacent hairs, based on the geometry of the liquid bridges that connect
them. We adopt an empirically-validated drag model to treat the effects of
coarse-scale interactions between hair and surrounding fluid, and propose
new volume-conserving dripping and absorption strategies to transfer liquid
between the reduced and particle-in-cell liquid representations. The synthesis
of these techniques yields an effective wet hair simulator, which we use
to animate hair flipping, an animal shaking itself dry, a spinning car wash
roller brush dunked in liquid, and intricate hair coalescence effects, among
several additional scenarios.
@article{Fei:2017:liquidhair,
title={A Multi-Scale Model for Simulating Liquid-Hair Interactions},
author={Fei, Yun (Raymond) and Maia, Henrique Teles and Batty, Christopher and Zheng, Changxi
and Grinspun, Eitan},
journal={ACM Trans. Graph.},
volume={36},
number={4},
year={2017},
}
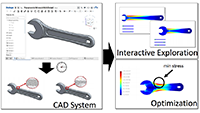
Adriana Schulz, Jie Xu, Bo Zhu, Changxi Zheng, Eitan Grispun, and Wojciech Matusik
Interactive Design Space Exploration and Optimization for CAD Models.
ACM Transactions on Graphics (SIGGRAPH 2017), 36(4)
Paper(PDF) Project Page Abstract Bibtex Video
Interactive Design Space Exploration and Optimization for CAD Models.
ACM Transactions on Graphics (SIGGRAPH 2017), 36(4)
Paper(PDF) Project Page Abstract Bibtex Video
Computer Aided Design (CAD) is a multi-billion dollar industry used by almost every mechanical engineer in the world to create practically every existing manufactured shape. CAD models are not only widely available but also extremely useful in the growing field of fabrication-oriented design because they are parametric by construction and capture the engineer’s design intent, including manufacturability. Harnessing this data, however, is challenging, because generating the geometry for a given parameter value requires time-consuming computations. Furthermore, the resulting meshes have different combinatorics, making the mesh data inherently dis- continuous with respect to parameter adjustments. In our work, we address these challenges and develop tools that allow interactive exploration and optimization of parametric CAD data. To achieve interactive rates, we use precomputation on an adaptively sampled grid and propose a novel scheme for interpolating in this domain where each sample is a mesh with different combinatorics. Specifically, we extract partial correspondences from CAD representations for local mesh morphing and propose a novel interpolation method for adaptive grids that is both continuous/smooth and local (i.e., the influence of each sample is constrained to the local regions where mesh morphing can be computed). We show examples of how our method can be used to interactively visualize and optimize objects with a variety of physical properties.
@article{Schulz:2017,
author = {Schulz, Adriana and Xu, Jie and Zhu, Bo and Zheng, Changxi
and Grinpun, Eitan and Matusik, Wojciech},
title = {Interactive Design Space Exploration and Optimization for CAD Models},
journal = {ACM Transactions on Graphics},
year = {July 2017},
volume = {36},
number = {4},
}

Shuang Zhao, Frédo Durand, and Changxi Zheng
Inverse Diffusion Curves using Shape Optimization.
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2017
Paper(PDF) Abstract Video
Inverse Diffusion Curves using Shape Optimization.
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2017
Paper(PDF) Abstract Video
The inverse diffusion curve problem focuses on automatic creation of diffusion curve images that resemble user provided color fields. This problem is challenging since the 1D curves have a nonlinear and global impact on resulting color fields via a partial differential equation (PDE). We introduce a new approach complementary to previous methods by optimizing curve geometry. In particular, we propose a novel iterative algorithm based on the theory of shape derivatives. The resulting diffusion curves are clean and well-shaped, and the final image closely approximates the input. Our method provides a user-controlled parameter to regularize curve complexity, and generalizes to handle input color fields represented in a variety of formats.
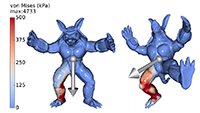
Xiang Chen, Changxi Zheng, and Kun Zhou
Example-Based Subspace Stress Analysis for Interactive Shape Design.
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2016
Paper(PDF) Abstract Bibtex Video
Example-Based Subspace Stress Analysis for Interactive Shape Design.
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2016
Paper(PDF) Abstract Bibtex Video
Stress analysis is a crucial tool for designing structurally sound shapes. However, the expensive computational cost has hampered its use in interactive shape editing tasks. We augment the existing example-based shape editing tools, and propose a fast subspace stress analysis method to enable stress-aware shape editing. In particular, we construct a reduced stress basis from a small set of shape exemplars and possible external forces. This stress basis is automatically adapted to the current user edited shape on the fly, and thereby offers reliable stress estimation. We then introduce a new finite element discretization scheme to use the reduced basis for fast stress analysis. Our method runs up to two orders of magnitude faster than the full-space finite element analysis, with average L2 estimation errors less than 2% and maximum L2 errors less than 6%. Furthermore, we build an interactive stress-aware shape editing tool to demonstrate its performance in practice.
@article{Chen:2016:stress,
title={Example-Based Subspace Stress Analysis for Interactive Shape Design},
author={Xiang Chen and Changxi Zheng and Kun Zhou},
publisher={IEEE Trans Vis Comput Graph. (TVCG)}
volume={PP},
number={99},
year={2016},
}

Gabriel Cirio, Dingzeyu Li, Eitan Grinspun, Miguel A. Otaduy, and Changxi Zheng
Crumpling Sound Synthesis.
ACM Transactions on Graphics (SIGGRAPH Asia 2016), 35(6)
Paper(PDF) Project Page Abstract Bibtex Video
Crumpling Sound Synthesis.
ACM Transactions on Graphics (SIGGRAPH Asia 2016), 35(6)
Paper(PDF) Project Page Abstract Bibtex Video
Crumpling a thin sheet produces a characteristic sound, comprised of distinct clicking sounds corresponding to buckling events. We propose a physically based algorithm that automatically synthesizes crumpling sounds for a given thin shell animation. The resulting sound is a superposition of individually synthesized clicking sounds corresponding to visually-significant and -insignificant buckling events. We identify visually significant buckling events on the dynamically evolving thin surface mesh, and instantiate visually insignificant buckling events via a stochastic model that seeks to mimic the power-law distribution of buckling energies observed in many materials.
In either case, the synthesis of a buckling sound employs linear modal analysis of the deformed thin shell. Because different buckling events in general occur at different deformed configurations, the question arises whether the calculation of linear modes can be reused. We amortize the cost of the linear modal analysis by dynamically partitioning the mesh into nearly rigid pieces: the modal analysis of a rigidly moving piece is retained over time, and the modal analysis of the assembly is obtained via Component Mode Synthesis (CMS). We illustrate our approach through a series of examples and a perceptual user study, demonstrating the utility of the sound synthesis method in producing realistic sounds at practical computation times.
In either case, the synthesis of a buckling sound employs linear modal analysis of the deformed thin shell. Because different buckling events in general occur at different deformed configurations, the question arises whether the calculation of linear modes can be reused. We amortize the cost of the linear modal analysis by dynamically partitioning the mesh into nearly rigid pieces: the modal analysis of a rigidly moving piece is retained over time, and the modal analysis of the assembly is obtained via Component Mode Synthesis (CMS). We illustrate our approach through a series of examples and a perceptual user study, demonstrating the utility of the sound synthesis method in producing realistic sounds at practical computation times.
@article{Cirio:2016:crumpling_sound_synthesis,
title={Crumpling Sound Synthesis},
author={Cirio, Gabriel and Li, Dingzeyu and Grinspun, Eitan and Otaduy, Miguel A.
and Zheng, Changxi},
journal={ACM Trans. Graph.},
volume={35},
number={6},
year={2016},
url = {http://www.cs.columbia.edu/cg/crumpling/}
}
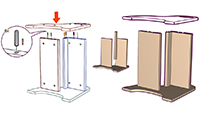
Tianjia Shao, Dongping Li, Yuliang Rong, Changxi Zheng, and Kun Zhou
Dynamic Furniture Modeling Through Assembly Instructions.
ACM Transactions on Graphics (SIGGRAPH Asia 2016), 35(6)
Paper(PDF) Abstract Bibtex Video
Dynamic Furniture Modeling Through Assembly Instructions.
ACM Transactions on Graphics (SIGGRAPH Asia 2016), 35(6)
Paper(PDF) Abstract Bibtex Video
We present a technique for parsing widely used furniture assembly instructions, and reconstructing the 3D models of furniture components and their dynamic assembly process. Our technique takes as input a multi-step assembly instruction in a vector graphic format and starts to group the vector graphic primitives into semantic elements representing individual furniture parts, mechanical connectors (e.g., screws, bolts and hinges), arrows, visual highlights, and numbers. To reconstruct the dynamic assembly process depicted over multiple steps, our system identifies previously built 3D furniture components when parsing a new step, and uses them to address the challenge of occlusions while generating new 3D components incrementally. With a wide range of examples covering a variety of furniture types, we demonstrate the use of our system to animate the 3D furniture assembly process and, beyond that, the semantic-aware furniture editing as well as the fabrication of personalized furnitures.
@article{Shao:2016:furnitures,
title={Dynamic Furniture Modeling Through Assembly Instructions},
author={Tianjia Shao and Dongping Li and Yuliang Rong and Changxi Zheng and Kun Zhou},
journal = {ACM Transactions on Graphics (SIGGRAPH Asia 2016)},
volume={35},
number={6},
year={2016}
}

Dingzeyu Li, David I.W. Levin, Wojciech Matusik, and Changxi Zheng
Acoustic Voxels: Computational Optimization of Modular Acoustic Filters.
ACM Transactions on Graphics (SIGGRAPH 2016), 35(4)
Paper(PDF) Project Page Abstract Bibtex Video
Acoustic Voxels: Computational Optimization of Modular Acoustic Filters.
ACM Transactions on Graphics (SIGGRAPH 2016), 35(4)
Paper(PDF) Project Page Abstract Bibtex Video
Acoustic filters have a wide range of applications, yet customizing them with desired properties is difficult. Motivated by recent progress in additive manufacturing that allows for fast prototyping of complex shapes, we present a computational approach that automates the design of acoustic filters with complex geometries. In our approach, we construct an acoustic filter comprised of a set of parameterized shape primitives, whose transmission matrices can be precomputed. Using an efficient method of simulating the transmission matrix of an assembly built from these underlying primitives, our method is able to optimize both the arrangement and the parameters of the acoustic shape primitives in order to satisfy target acoustic properties of the filter. We validate our results against industrial laboratory measurements and high-quality off-line simulations. We demonstrate that our method enables a wide range of applications including muffler design, musical wind instrument prototyping, and encoding imperceptible acoustic information into everyday objects.
@article{Li:2016:acoustic_voxels,
title={Acoustic Voxels: Computational Optimization of Modular Acoustic Filters},
author={Li, Dingzeyu and Levin, David I.W. and Matusik, Wojciech and Zheng, Changxi},
journal = {ACM Transactions on Graphics (SIGGRAPH 2016)},
volume={35},
number={4},
year={2016},
url = {http://www.cs.columbia.edu/cg/lego/}
}

Timothy R. Langlois, Changxi Zheng and Doug L. James
Toward Animating Water with Complex Acoustic Bubbles.
ACM Transactions on Graphics (SIGGRAPH 2016), 35(4)
Paper(PDF) Project Page Abstract Bibtex Video
Toward Animating Water with Complex Acoustic Bubbles.
ACM Transactions on Graphics (SIGGRAPH 2016), 35(4)
Paper(PDF) Project Page Abstract Bibtex Video
This paper explores methods for synthesizing physics-based bubble sounds directly from two-phase incompressible simulations of bubbly water flows. By tracking fluid-air interface geometry, we identify bubble geometry and topological changes due to splitting, merging and popping. A novel capacitance-based method is proposed that can estimate volume-mode bubble frequency changes due to bubble size, shape, and proximity to solid and air interfaces. Our acoustic transfer model is able to capture cavity resonance effects due to near-field geometry, and we also propose a fast precomputed bubble-plane model for cheap transfer evaluation. In addition, we consider a bubble forcing model that better accounts for bubble entrainment, splitting, and merging events, as well as a Helmholtz resonator model for bubble popping sounds. To overcome frequency bandwidth limitations associated with coarse resolution fluid grids, we simulate micro-bubbles in the audio domain using a power-law model of bubble populations. Finally, we present several detailed examples of audiovisual water simulations and physical experiments to validate our frequency model.
@article{Langlois:2016:Bubbles,
author = {Timothy R. Langlois and Changxi Zheng and Doug L. James},
title = {Toward Animating Water with Complex Acoustic Bubbles},
journal = {ACM Transactions on Graphics (SIGGRAPH 2016)},
year = {2016},
volume = {35},
number = {4},
month = Jul,
url = {http://www.cs.cornell.edu/projects/Sound/bubbles}
}
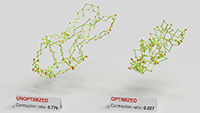
Changxi Zheng, Timothy Sun and Xiang Chen,
Deployable 3D Linkages with Collision Avoidance.
ACM SIGGRAPH/Eurographics Symposium on Computer Animation (SCA), July, 2016 (Best Paper Award)
Paper(PDF) Project Page Abstract Bibtex Video
Deployable 3D Linkages with Collision Avoidance.
ACM SIGGRAPH/Eurographics Symposium on Computer Animation (SCA), July, 2016 (Best Paper Award)
Paper(PDF) Project Page Abstract Bibtex Video
We present a pipeline that allows ordinary users to create deployable scissor linkages in arbitrary 3D shapes, whose mechanisms are inspired by Hoberman's Sphere. From an arbitrary 3D model and a few user inputs, our method can generate a fabricable scissor linkage resembling that shape that aims to save as much space as possible in its most contracted state. Self-collisions are the primary obstacle in this goal, and these are not addressed in prior work. One key component of our algorithm is a succinct parameterization of these types of linkages. The fast continuous collision detection that arises from this parameterization serves as the foundation for the discontinuous optimization procedure that automatically improves joint placement for avoiding collisions. While linkages are usually composed of straight bars, we consider curved bars as a means of improving the contractibility. To that end, we describe a continuous optimization algorithm for locally deforming the bars.
@inproceedings{Zheng16:Deployable,
author = {Changxi Zheng and Timothy Sun and Xiang Chen},
title = {Deployable 3D Linkages with Collision Avoidance},
booktitle = {Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation},
series = {SCA '16},
year = {2016},
month = Jul,
url = {http://www.cs.columbia.edu/cg/deployable}
}

Menglei Chai, Changxi Zheng and Kun Zhou
Adaptive Skinning for Interactive Hair-Solid Simulation.
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2016
Paper(PDF) Abstract Bibtex Video
Adaptive Skinning for Interactive Hair-Solid Simulation.
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2016
Paper(PDF) Abstract Bibtex Video
Reduced hair models have proven successful for interactively simulating a full head of hair strands, building upon a fundamental assumption that only a small set of guide hairs are needed for explicit simulation, and the rest of the hair move coherently and thus can be interpolated using guide hairs. Unfortunately, hair-solid interactions is a pathological case for traditional reduced hair models, as the motion coherence between hair strands can be arbitrarily broken by interacting with solids.
In this paper, we propose an adaptive hair skinning method for interactive hair simulation with hair-solid collisions. We precompute many eligible sets of guide hairs and the corresponding interpolation relationships that are represented using a compact strand-based hair skinning model. At runtime, we simulate only guide hairs; for interpolating every other hair, we adaptively choose its guide hairs, taking into account motion coherence and potential hair-solid collisions. Further, we introduce a two-way collision correction algorithm to allow sparsely sampled guide hairs to resolve collisions with solids that can have small geometric features. Our method enables interactive simulation of more than 150K hair strands interacting with complex solid objects, using 400 guide hairs. We demonstrate the efficiency and robustness of the method with various hairstyles and user-controlled arbitrary hair-solid interactions.
In this paper, we propose an adaptive hair skinning method for interactive hair simulation with hair-solid collisions. We precompute many eligible sets of guide hairs and the corresponding interpolation relationships that are represented using a compact strand-based hair skinning model. At runtime, we simulate only guide hairs; for interpolating every other hair, we adaptively choose its guide hairs, taking into account motion coherence and potential hair-solid collisions. Further, we introduce a two-way collision correction algorithm to allow sparsely sampled guide hairs to resolve collisions with solids that can have small geometric features. Our method enables interactive simulation of more than 150K hair strands interacting with complex solid objects, using 400 guide hairs. We demonstrate the efficiency and robustness of the method with various hairstyles and user-controlled arbitrary hair-solid interactions.
@article{chai2016adaptive,
title={Adaptive Skinning for Interactive Hair-Solid Simulation},
author={Chai, Menglei and Zheng, Changxi and Zhou, Kun},
year={2016},
publisher={IEEE Trans Vis Comput Graph. (TVCG)}
}

Gaurav Bharaj, David Levin, James Tompkin, Yun Fei, Hanspeter Pfister, Wojciech Matusik and Changxi Zheng
Computational Design of Metallophone Contact Sounds.
ACM Transactions on Graphics (SIGGRAPH Asia 2015), 34(6)
Paper(PDF) Project Page Abstract Bibtex Video Video 2
Computational Design of Metallophone Contact Sounds.
ACM Transactions on Graphics (SIGGRAPH Asia 2015), 34(6)
Paper(PDF) Project Page Abstract Bibtex Video Video 2
Metallophones such as glockenspiels produce sounds in response to contact. Building these instruments is a complicated process, limiting their shapes to well-understood designs such as bars. We automatically optimize the shape of arbitrary 2D and 3D objects through deformation and perforation to produce sounds when struck which match user-supplied frequency and amplitude spectra. This optimization requires navigating a complex energy landscape, for which we develop Latin Complement Sampling to both speed up finding minima and provide probabilistic bounds on landscape exploration. Our method produces instruments which perform similarly to those that have been professionally-manufactured, while also expanding the scope of shape and sound that can be realized, e.g., single object chords. Furthermore, we can optimize sound spectra to create overtones and to dampen specific frequencies. Thus our technique allows even novices to design metallophones with unique sound and appearance.
@article{Bharaj:2015:CDM,
author = {Bharaj, Gaurav and Levin, David I. W. and Tompkin, James and Fei, Yun and
Pfister, Hanspeter and Matusik, Wojciech and Zheng, Changxi},
title = {Computational Design of Metallophone Contact Sounds},
journal = {ACM Transactions on Graphics (SIGGRAPH Asia 2015)},
volume = {34},
number = {6},
year = {2015},
pages = {223:1--223:13},
publisher = {ACM},
address = {New York, NY, USA},
}

Yin Yang, Dingzeyu Li, Weiwei Xu, Yuan Tian and Changxi Zheng,
Expediting Precomputation for Reduced Deformable Simulation.
ACM Transactions on Graphics (SIGGRAPH Asia 2015), 34(6)
Paper(PDF) Project Page Abstract Bibtex Video
Expediting Precomputation for Reduced Deformable Simulation.
ACM Transactions on Graphics (SIGGRAPH Asia 2015), 34(6)
Paper(PDF) Project Page Abstract Bibtex Video
Model reduction has popularized itself for simulating elastic deformation for graphics applications. While these techniques enjoy orders-of-magnitude speedups at runtime simulation, the efficiency of precomputing reduced subspaces remains largely overlooked. We present a complete system of precomputation pipeline as a faster alternative to the classic linear and nonlinear modal analysis. We identify three bottlenecks in the traditional model reduction precomputation, namely modal matrix construction, cubature training, and training dataset generation, and accelerate each of them. Even with complex deformable models, our method has achieved orders-of-magnitude speedups over the traditional precomputation steps, while retaining comparable runtime simulation quality.
@article{Yang:2015:EPR,
author = {Yang, Yin and Li, Dingzeyu and Xu, Weiwei and Tian, Yuan and Zheng, Changxi},
title = {Expediting Precomputation for Reduced Deformable Simulation},
journal = {ACM Transactions on Graphics (SIGGRAPH Asia 2015)},
volume = {34},
number = {6},
month = oct,
year = {2015},
pages = {243:1--243:13},
publisher = {ACM},
address = {New York, NY, USA},
}

Dingzeyu Li, Yun Fei and Changxi Zheng,
Interactive Acoustic Transfer Approximation for Modal Sound.
ACM Transactions on Graphics, 35(1), 2015 (presented at SIGGRAPH 2016)
Paper(PDF) Project Page Abstract Bibtex Video
Interactive Acoustic Transfer Approximation for Modal Sound.
ACM Transactions on Graphics, 35(1), 2015 (presented at SIGGRAPH 2016)
Paper(PDF) Project Page Abstract Bibtex Video
Current linear modal sound models are tightly coupled with their frequency content. Both the modal vibration of object surfaces and the resulting sound radiation depend on the vibration frequency. Whenever the user tweaks modal parameters to adjust frequencies the modal sound model changes completely, necessitating expensive recomputation of modal vibration and sound radiation.
We propose a new method for interactive and continuous editing as well as exploration of modal sound parameters. We start by sampling a number of key points around a vibrating object, and then devise a compact, low-memory representation of frequency-varying acoustic transfer values at each key point using Prony series. We efficiently precompute these series using an adaptive frequency sweeping algorithm and volume-velocity-preserving mesh simplification. At runtime, we approximate acoustic transfer values using standard multipole expansions. Given user-specified modal frequencies, we solve a small least-squares system to estimate the expansion coefficients, and thereby quickly compute the resulting sound pressure value at arbitrary listening locations. We demonstrate the numerical accuracy, the runtime performance of our method on a set of comparisons and examples, and evaluate sound quality with user perception studies.
We propose a new method for interactive and continuous editing as well as exploration of modal sound parameters. We start by sampling a number of key points around a vibrating object, and then devise a compact, low-memory representation of frequency-varying acoustic transfer values at each key point using Prony series. We efficiently precompute these series using an adaptive frequency sweeping algorithm and volume-velocity-preserving mesh simplification. At runtime, we approximate acoustic transfer values using standard multipole expansions. Given user-specified modal frequencies, we solve a small least-squares system to estimate the expansion coefficients, and thereby quickly compute the resulting sound pressure value at arbitrary listening locations. We demonstrate the numerical accuracy, the runtime performance of our method on a set of comparisons and examples, and evaluate sound quality with user perception studies.
@article{Li:2015:IAT,
author = {Li, Dingzeyu and Fei, Yun and Zheng, Changxi},
title = {Interactive Acoustic Transfer Approximation for Modal Sound},
journal = {ACM Trans. Graph.},
volume = {35},
number = {1},
month = dec,
year = {2015},
pages = {2:1--2:16},
articleno = {2},
numpages = {16},
publisher = {ACM},
address = {New York, NY, USA},
}

Timothy Sun and Changxi Zheng,
Computational Design of Twisty Joints and Puzzles.
ACM Transactions on Graphics (SIGGRAPH 2015), 34(4)
Paper(PDF) Project Page Abstract Bibtex Video
Computational Design of Twisty Joints and Puzzles.
ACM Transactions on Graphics (SIGGRAPH 2015), 34(4)
Paper(PDF) Project Page Abstract Bibtex Video
We present the first computational method that allows ordinary users to create complex twisty joints and puzzles inspired by the Rubik's Cube mechanism. Given a user-supplied 3D model and a small subset of rotation axes, our method automatically adjusts those rotation axes and adds others to construct a "non-blocking" twisty joint in the shape of the 3D model. Our method outputs the shapes of pieces which can be directly 3D printed and assembled into an interlocking puzzle. We develop a group-theoretic approach to representing a wide class of twisty puzzles by establishing a connection between non-blocking twisty joints and the finite subgroups of the rotation group SO(3). The theoretical foundation enables us to build an efficient system for automatically completing the set of rotation axes and fast collision detection between pieces. We also generalize the Rubik's Cube mechanism to a large family of twisty puzzles.
@article{Sun15:TP,
author = {Timothy Sun and Changxi Zheng},
title = {Computational Design of Twisty Joints and Puzzles},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2015)},
year = {2015},
volume = {34},
number = {4},
month = Aug,
url = {http://www.cs.columbia.edu/cg/twisty}
}

Yizhong Zhang, Chunji Yin, Changxi Zheng and Kun Zhou,
Computational Hydrographic Printing.
ACM Transactions on Graphics (SIGGRAPH 2015), 34(4)
Paper(PDF) Project Page Abstract Bibtex Video
Computational Hydrographic Printing.
ACM Transactions on Graphics (SIGGRAPH 2015), 34(4)
Paper(PDF) Project Page Abstract Bibtex Video
Hydrographic printing is a well-known technique in industry for transferring color inks on a thin film to the surface of a manufactured 3D object. It enables high-quality coloring of object surfaces and works with a wide range of materials, but suffers from the inability to accurately register color texture to complex surface geometries. Thus, it is hardly usable by ordinary users with customized shapes and textures.
We present computational hydrographic printing, a new method that inherits the versatility of traditional hydrographic printing, while also enabling precise alignment of surface textures to possibly complex 3D surfaces. In particular, we propose the first computational model for simulating hydrographic printing pro- cess. This simulation enables us to compute a color image to feed into our hydrographic system for precise texture registration. We then build a physical hydrographic system upon off-the-shelf hardware, integrating virtual simulation, object calibration and controlled immersion. To overcome the difficulty of handling complex surfaces, we further extend our method to enable multiple immersions, each with a different object orientation, so the combined colors of individual immersions form a desired texture on the object surface. We validate the accuracy of our computational model through physical experiments, and demonstrate the efficacy and robustness of our system using a variety of objects with complex surface textures.
We present computational hydrographic printing, a new method that inherits the versatility of traditional hydrographic printing, while also enabling precise alignment of surface textures to possibly complex 3D surfaces. In particular, we propose the first computational model for simulating hydrographic printing pro- cess. This simulation enables us to compute a color image to feed into our hydrographic system for precise texture registration. We then build a physical hydrographic system upon off-the-shelf hardware, integrating virtual simulation, object calibration and controlled immersion. To overcome the difficulty of handling complex surfaces, we further extend our method to enable multiple immersions, each with a different object orientation, so the combined colors of individual immersions form a desired texture on the object surface. We validate the accuracy of our computational model through physical experiments, and demonstrate the efficacy and robustness of our system using a variety of objects with complex surface textures.
@article{Zhang15:CHP,
author = {Yizhong Zhang and Chunji Yin and Changxi Zheng and Kun Zhou},
title = {Computational Hydrographic Printing},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2015)},
year = {2015},
volume = {34},
number = {4},
month = Aug,
url = {http://www.cs.columbia.edu/cg/hydrographics}
}

Yonghao Yue, Breannan Smith, Christopher Batty, Changxi Zheng and Eitan Grinspun,
Continuum Foam: A Material Point Method for Shear-Dependent Flows.
ACM Transactions on Graphics, 2015 (presented at SIGGRAPH Asia 2015)
Paper(PDF) Project Page Abstract Bibtex Video
ACM Transactions on Graphics, 2015 (presented at SIGGRAPH Asia 2015)
Paper(PDF) Project Page Abstract Bibtex Video
We consider the simulation of dense foams composed of microscopic bubbles, such as shaving cream and whipped cream. We represent foam not as a collection of discrete bubbles, but instead as a continuum. We employ the Material Point Method (MPM) to discretize a hyperelastic constitutive relation augmented with the Herschel-Bulkley model of non-Newtonian plastic flow, which is known to closely approximate foam behavior. Since large shearing flows in foam can produce poor distributions of material points, a typical MPM implementation can produce non-physical internal holes in the continuum. To address these artifacts, we introduce a particle resampling method for MPM. In addition, we introduce an explicit tearing model to prevent regions from shearing into artificially-thin, honey-like threads. We evaluate our method's efficacy by simulating a number of dense foams, and we validate our method by comparing to real-world footage of foam.
@article{foam15,
author = {Yonghao Yue and Breannan Smith and Christopher Batty and
Changxi Zheng and Eitan Grinspun},
title = {Continuum Foam: A Material Point Method for Shear-Dependent Flows},
journal = {ACM Transactions on Graphics},
year = {2015},
volume = {34},
number = {5}
}

Zexiang Xu, Hsiang-Tao Wu, Lvdi Wang, Changxi Zheng, Xin Tong and Yue Qi,
Dynamic Hair Capture using Spacetime Optimization.
ACM Transactions on Graphics (SIGGRAPH Asia 2014), 33(6)
Paper(PDF) Project Page Abstract Bibtex Video
ACM Transactions on Graphics (SIGGRAPH Asia 2014), 33(6)
Paper(PDF) Project Page Abstract Bibtex Video
Dynamic hair strands have complex structures and experience intricate
collisions and occlusion, posing significant challenges for high-quality
reconstruction of their motions. We present a comprehensive dynamic hair
capture system for reconstructing realistic hair motions from multiple
synchronized video sequences. To recover hair strands' temporal
correspondence, we propose a motion-path analysis algorithm that can robustly
track local hair motions in input videos. To ensure the spatial and temporal
coherence of the dynamic capture, we formulate the global hair reconstruction
as a spacetime optimization problem solved iteratively. Demonstrated using a
range of real-world hairstyles driven by different wind conditions and head
motions, our approach is able to reconstruct complex hair dynamics matching
closely with video recordings both in terms of geometry and motion details.
@article{Xu14:HairCap,
author = {Zexiang Xu and Hsiang-Tao Wu and Lvdi Wang and Changxi Zheng and Xin Tong and Yue Qi},
title = {Dynamic Hair Capture using Spacetime Optimization},
journal = {ACM Transactions on Graphics (SIGGRAPH Asia 2014)},
year = {2014},
Month = Dec,
volume = {33},
number = {6},
}

Timothy Sun, Papoj Thamjaroenporn and Changxi Zheng,
Fast Multipole Representation of Diffusion Curves and Points.
ACM Transactions on Graphics (SIGGRAPH 2014), 33(4)
Paper(PDF) Project Page Abstract Bibtex Video
Fast Multipole Representation of Diffusion Curves and Points.
ACM Transactions on Graphics (SIGGRAPH 2014), 33(4)
Paper(PDF) Project Page Abstract Bibtex Video
We propose a new algorithm for random-access evaluation of diffusion
curve images (DCIs) using the fast multipole method. Unlike
all previous methods, our algorithm achieves real-time performance
for rasterization and texture-mapping DCIs of up to millions of
curves. After precomputation, computing the color at a single pixel
takes nearly constant time. We also incorporate Gaussian radial
basis functions into our fast multipole representation using the fast
Gauss transform. The fast multipole representation is not only a
data structure for fast color evaluation, but also a framework for
vector graphics analogues of bitmap editing operations. We exhibit
this capability by devising new tools for fast diffusion curve Poisson
cloning and composition with masks.
@article{Sun14:FMR,
author = {Timothy Sun and Papoj Thamjaroenporn and Changxi Zheng},
title = {Fast Multipole Representation of Diffusion Curves and Points},
journal = {ACM Transactions on Graphics (SIGGRAPH 2014)},
year = {2014},
volume = {33},
number = {4},
month = Aug,
url = {http://www.cs.columbia.edu/cg/fmr}
}

Menglei Chai, Changxi Zheng and Kun Zhou,
A Reduced Model for Interactive Hairs.
ACM Transactions on Graphics (SIGGRAPH 2014), 33(4)
Paper(PDF) Project Page Abstract Bibtex Video
A Reduced Model for Interactive Hairs.
ACM Transactions on Graphics (SIGGRAPH 2014), 33(4)
Paper(PDF) Project Page Abstract Bibtex Video
Realistic hair animation is a crucial component in depicting virtual
characters in interactive applications. While much progress has been
made in high-quality hair simulation, the overwhelming computation
cost hinders similar fidelity in realtime simulations. To bridge
this gap, we propose a data-driven solution. Building upon precomputed
simulation data, our approach constructs a reduced model to
optimally represent hair motion characteristics with a small number
of guide hairs and the corresponding interpolation relationships. At
runtime, utilizing such a reduced model, we only simulate guide
hairs that capture the general hair motion and interpolate all rest
strands. We further propose a hair correction method that corrects
the resulting hair motion with a position-based model to resolve
hair collisions and thus captures motion details. Our hair simulation
method enables a simulation of a full head of hairs with over 150K
strands in realtime. We demonstrate the efficacy and robustness of
our method with various hairstyles and driven motions (e.g., head
movement and wind force), and compared against full simulation
results that does not appear in the training data.
@article{Cai14:ARMI,
author = {Menglei Cai and Changxi Zheng and Kun Zhou},
title = {A Reduced Model for Interactive Hairs},
journal = {ACM Transactions on Graphics (SIGGRAPH 2014)},
year = {2014},
volume = {33},
number = {4},
month = Aug,
}

Xiang Chen, Changxi Zheng, Weiwei Xu and Kun Zhou,
An Asymptotic Numerical Method for Inverse Elastic Shape Design.
ACM Transactions on Graphics (SIGGRAPH 2014), 33(4)
Paper(PDF) Project Page Abstract Bibtex Video
An Asymptotic Numerical Method for Inverse Elastic Shape Design.
ACM Transactions on Graphics (SIGGRAPH 2014), 33(4)
Paper(PDF) Project Page Abstract Bibtex Video
Inverse shape design for elastic objects greatly eases the design efforts by
letting users focus on desired target shapes without thinking about elastic
deformations. Solving this problem using classic iterative methods (e.g.,
Newton-Raphson methods), however, often suffers from slow convergence toward a
desired solution. In this paper, we propose an asymptotic numerical method that
exploits the underlying mathematical structure of specific nonlinear material
models, and thus runs orders of magnitude faster than traditional Newton-type
methods. We apply this method to compute rest shapes for elastic fabrication,
where the rest shape of an elastic object is computed such that after physical
fabrication the real object deforms into a desired shape. We illustrate the
performance and robustness of our method through a series of elastic
fabrication experiments.
@article{Chen14:ANM,
author = {Xiang Chen and Changxi Zheng and Weiwei Xu and Kun Zhou},
title = {An Asymptotic Numerical Method for Inverse Elastic Shape Design},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2014)},
year = {2014},
volume = {33},
number = {4},
month = Aug,
}

Zherong Pan, Jin Huang, Yiying Tong, Changxi Zheng and Hujun Bao,
Interactive Localized Liquid Motion Editing.
ACM Transactions on Graphics (SIGGRAPH Asia 2013), 32(6)
Paper(PDF) Abstract Bibtex Video
ACM Transactions on Graphics (SIGGRAPH Asia 2013), 32(6)
Paper(PDF) Abstract Bibtex Video
Animation techniques for controlling liquid simulation are challenging: they
commonly require carefully setting initial and boundary conditions or
performing a costly numerical optimization scheme against user-provided
keyframes or animation sequences. Either way, the whole process is laborious
and computationally expensive.
We introduce a novel method to provide intuitive and interactive control of
liquid simulation. Our method enables a user to locally edit selected keyframes
and automatically propagates the editing in a nearby temporal region using
geometric deformation. We formulate our local editing techniques as a
small-scale nonlinear optimization problem which can be solved interactively.
With this uniformed formulation, we propose three editing metaphors, including
(i) sketching local fluid features using a few user strokes, (ii) dragging a
local fluid region, and (iii) controlling a local shape with
a small mesh patch. Finally, we use the edited liquid animation
to guide an of offline high-resolution simulation to recover more surface
details. We demonstrate the intuitiveness and efficacy of our method in
various practical scenarios.
@article{Pan:2013,
author = {Zherong Pan and Jin Huang and Yiying Tong and Changxi Zheng and Hujun Bao},
title = {Interactive Localized Liquid Motion Editing},
journal = {ACM Transactions on Graphics (SIGGRAPH Asia 2013)},
year = {2013},
month = Nov,
volume = {32},
number = {6},
}

Changxi Zheng,
One-to-Many: Example-Based Mesh Animation Synthesis.
ACM SIGGRAPH/Eurographics Symposium on Computer Animation (SCA), July, 2013
Paper(PDF) Project Page Abstract Bibtex
ACM SIGGRAPH/Eurographics Symposium on Computer Animation (SCA), July, 2013
Paper(PDF) Project Page Abstract Bibtex
We propose an example-based approach for synthesizing diverse mesh animations.
Provided a short clip of deformable mesh animation, our method
synthesizes a large number of different animations of arbitrary length.
Combining an automatically inferred linear blending skinning (LBS) model with a
PCA-based model reduction, our method identifies possible smooth transitions in the example
sequence. To create smooth transitions, we synthesize reduced
deformation parameters based on a set of characteristic key vertices on the
mesh. Furthermore, by analyzing cut nodes on a graph built upon the
LBS model, we are able to decompose the mesh into
independent components. Motions of these components are
synthesized individually and assembled together.
Our method has the complexity independent from mesh resolutions,
enabling efficient generation of arbitrarily long animations
without tedious parameter tuning and heavy computation.
We evaluate our method on various animation examples, and demonstrate that
numerous diverse animations can be generated from each single example.
@inproceedings{Zheng12:O2M,
author = {Changxi Zheng},
title = {One-to-Many: Example-Based Mesh Animation Synthesis},
booktitle = {Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation},
series = {SCA '13},
year = {2013},
month = Jul,
url = {http://www.cs.columbia.edu/~cxz/OneToMany}
}

Changxi Zheng and Doug L. James,
Energy-based Self-Collision Culling for Arbitrary Mesh Deformations.
ACM Transactions on Graphics (SIGGRAPH 2012), 31(4), August 2012
Paper(PDF) Project Page Abstract Bibtex
ACM Transactions on Graphics (SIGGRAPH 2012), 31(4), August 2012
Paper(PDF) Project Page Abstract Bibtex
In this paper, we accelerate self-collision detection (SCD) for a deforming triangle mesh
by exploiting the idea that a mesh cannot self collide unless it deforms enough. Unlike
prior work on subspace self-collision culling which is restricted to low-rank
deformation subspaces, our energy-based approach supports arbitrary mesh deformations
while still being fast. Given a bounding volume hierarchy (BVH) for a triangle mesh, we
precompute Energy-based Self-Collision Culling (ESCC) certificates on
bounding-volume-related sub-meshes which indicate the amount of deformation energy
required for it to self collide. After updating energy values at runtime, many
bounding-volume self-collision queries can be culled using the ESCC certificates. We
propose an affine-frame Laplacian-based energy definition which sports a highly
optimized certificate preprocess, and fast runtime energy evaluation. The latter is
performed hierarchically to amortize Laplacian energy and affine-frame estimation
computations. ESCC supports both discrete and continuous SCD, detailed and nonsmooth
geometry. We demonstrate significant culling on various examples, with SCD speed-ups up
to 26X.
@article{ZHENG12:ESCC,
author = {Changxi Zheng and Doug L. James},
title = {Energy-based Self-Collision Culling for Arbitrary Mesh Deformations},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2012)},
year = {2012},
volume = {31},
number = {4},
month = Aug,
url = {http://www.cs.cornell.edu/projects/escc}
}

Jeffrey N. Chadwick, Changxi Zheng and Doug L. James,
Precomputed Acceleration Noise for Improved Rigid-Body Sound.
ACM Transactions on Graphics (SIGGRAPH 2012), 31(4), August 2012
Paper(PDF) Project Page Abstract Bibtex
ACM Transactions on Graphics (SIGGRAPH 2012), 31(4), August 2012
Paper(PDF) Project Page Abstract Bibtex
We introduce an efficient method for synthesizing acceleration noise due to rigid-body collisions using standard data provided by rigid-body solvers. We accomplish this in two main steps. First, we estimate continuous contact force profiles from rigid-body impulses using a simple model based on Hertz contact theory. Next, we compute solutions to the acoustic wave equation due to short acceleration pulses in each rigid-body degree of freedom. We introduce an efficient representation for these solutions - Precomputed Acceleration Noise - which allows us to accurately estimate sound due to arbitrary rigid-body accelerations. We find that the addition of acceleration noise significantly complements the standard modal sound algorithm, especially for small objects.
@article{Chadwick12,
author = {Jeffrey N. Chadwick and Changxi Zheng and Doug L. James},
title = {Precomputed Acceleration Noise for Improved Rigid-Body Sound},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2012)},
year = {2012},
volume = {31},
number = {4},
month = Aug,
url = {http://www.cs.cornell.edu/projects/Sound/impact}
}

Jeffrey N. Chadwick, Changxi Zheng and Doug L. James,
Faster Acceleration Noise for Multibody Animations using Precomputed Soundbanks.
ACM/Eurographics Symposium on Computer Animation (SCA), July 2012
Paper(PDF) Project Page Abstract Bibtex
ACM/Eurographics Symposium on Computer Animation (SCA), July 2012
Paper(PDF) Project Page Abstract Bibtex
We introduce an efficient method for synthesizing rigid-body acceleration noise for complex multibody scenes. Existing acceleration noise synthesis methods for animation require object-specific precomputation, which is prohibitively expensive for scenes involving rigid-body fracture or other sources of small, procedurally generated debris. We avoid precomputation by introducing a proxy-based method for acceleration noise synthesis in which precomputed acceleration noise data is only generated for a small set of ellipsoidal proxies and stored in a proxy soundbank. Our proxy model is shown to be effective at approximating acceleration noise from scenes with lots of small debris (e.g., pieces produced by rigid-body fracture). This approach is not suitable for synthesizing acceleration noise from larger objects with complicated non-convex geometry; however, it has been shown in previous work that acceleration noise from objects such as these tends to be largely masked by modal vibration sound. We manage the cost of our proxy soundbank with a new wavelet-based compression scheme for acceleration noise and use our model to significantly improve sound synthesis results for several multibody animations.
@article{Chadwick12:SCA,
author = {Jeffrey N. Chadwick and Changxi Zheng and Doug L. James},
title = {Faster Acceleration Noise for Multibody Animations using
Precomputed Soundbanks},
journal = {ACM/Eurographics Symposium on Computer Animation},
year = {2012},
month = July,
url = {http://www.cs.cornell.edu/projects/Sound/proxy}
}

Changxi Zheng and Doug L. James,
Toward High-Quality Modal Contact Sound.
ACM Transactions on Graphics (SIGGRAPH 2011), 30(4), August 2011
Paper(PDF) Project Page Abstract Bibtex
ACM Transactions on Graphics (SIGGRAPH 2011), 30(4), August 2011
Paper(PDF) Project Page Abstract Bibtex
Contact sound models based on linear modal analysis are commonly
used with rigid body dynamics. Unfortunately, treating vibrating
objects as "rigid" during collision and contact processing
fundamentally limits the range of sounds that can be computed, and
contact solvers for rigid body animation can be ill-suited for modal
contact sound synthesis, producing various sound artifacts. In this
paper, we resolve modal vibrations in both collision and frictional
contact processing stages, thereby enabling non-rigid sound phenomena
such as micro-collisions, vibrational energy exchange, and
chattering. We propose a frictional multibody contact formulation
and modified Staggered Projections solver which is well-suited to
sound rendering and avoids noise artifacts associated with spatial
and temporal contact-force fluctuations which plague prior methods.
To enable practical animation and sound synthesis of numerous
bodies with many coupled modes, we propose a novel asynchronous
integrator with model-level adaptivity built into the frictional
contact solver. Vibrational contact damping is modeled to
approximate contact-dependent sound dissipation. Results are provided
that demonstrate high-quality contact resolution with sound.
@article{ZHENG11,
author = {Changxi Zheng and Doug L. James},
title = {Toward High-Quality Modal Contact Sound},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2011)},
year = {2011},
volume = {30},
number = {4},
month = Aug,
url = {http://www.cs.cornell.edu/projects/Sound/mc}
}

Changxi Zheng and Doug L. James,
Rigid-Body Fracture Sound with Precomputed Soundbanks.
ACM Transactions on Graphics (SIGGRAPH 2010), 29(3), July 2010
Paper(PDF) Project Page Abstract Bibtex
ACM Transactions on Graphics (SIGGRAPH 2010), 29(3), July 2010
Paper(PDF) Project Page Abstract Bibtex
We propose a physically based algorithm for synthesizing sounds synchronized
with brittle fracture animations. Motivated by laboratory experiments, we
approximate brittle fracture sounds using time-varying rigid-body sound models.
We extend methods for fracturing rigid materials by proposing a fast
quasistatic stress solver to resolve near-audio-rate fracture events,
energy-based fracture pattern modeling and estimation of "crack"-related
fracture impulses. Multipole radiation models provide scalable sound radiation
for complex debris and level of detail control. To reduce soundmodel generation
costs for complex fracture debris, we propose Precomputed Rigid-Body
Soundbanks comprised of precomputed ellipsoidal sound proxies. Examples and
experiments are presented that demonstrate plausible and affordable brittle
fracture sounds.
@article{ZHENG10,
author = {Changxi Zheng and Doug L. James},
title = {Rigid-Body Fracture Sound with Precomputed Soundbanks},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2010)},
year = {2010},
volume = {29},
number = {3},
month = jul,
url = {http://www.cs.cornell.edu/projects/fracturesound/}
}

Changxi Zheng and Doug L. James,
Harmonic Fluids.
ACM Transactions on Graphics (SIGGRAPH 2009), 28(3), August 2009
Paper(PDF) Project Page Abstract Bibtex
ACM Transactions on Graphics (SIGGRAPH 2009), 28(3), August 2009
Paper(PDF) Project Page Abstract Bibtex
Fluid sounds, such as splashing and pouring, are ubiquitous and familiar but we
lack physically based algorithms to synthesize them in computer animation or
interactive virtual environments. We propose a practical method for automatic
procedural synthesis of synchronized harmonic bubble-based sounds from 3D fluid
animations. To avoid audio-rate time-stepping of compressible fluids, we
acoustically augment existing incompressible fluid solvers with particle-based
models for bubble creation, vibration, advection, and radiation. Sound
radiation from harmonic fluid vibrations is modeled using a time-varying linear
superposition of bubble oscillators. We weight each oscillator by its
bubble-to-ear acoustic transfer function, which is modeled as a discrete
Green's function of the Helmholtz equation. To solve potentially millions of 3D
Helmholtz problems, we propose a fast dual-domain multipole boundary-integral
solver, with cost linear in the complexity of the fluid domain's boundary.
Enhancements are proposed for robust evaluation, noise elimination,
acceleration, and parallelization. Examples of harmonic fluid sounds are
provided for water drops, pouring, babbling, and splashing phenomena, often
with thousands of acoustic bubbles, and hundreds of thousands of transfer
function solves.
@article{ZHENG09,
author = {Changxi Zheng and Doug L. James},
title = {Harmonic Fluids},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2009)},
year = {2009},
volume = {28},
number = {3},
month = Aug,
url = {http://www.cs.cornell.edu/projects/HarmonicFluids/}
}
Wireless & Networking

Justin Chan, Changxi Zheng and Xia Zhou,
3D Printing Your Wireless Coverage.
ACM Workshop on Hot Topics in Wireless (HotWireless), 2015.
(Hot Paper Award)
Paper(PDF) Abstract Bibtex Video
3D Printing Your Wireless Coverage.
ACM Workshop on Hot Topics in Wireless (HotWireless), 2015.
(Hot Paper Award)
Paper(PDF) Abstract Bibtex Video
Directing wireless signals and customizing wireless coverage is of great importance in residential, commercial, and industrial environments. It can improve the wireless reception quality, reduce the energy consumption, and achieve better security and privacy. To this end, we propose WiPrint, a new computational approach to control wireless coverage by mounting signal reflectors in carefully optimized shapes on wireless routers. Leveraging 3D reconstruction, fast-wave simulations in acoustics, computational optimization, and 3D fabrication, our method is low-cost, adapts to different wireless routers and physical environments, and has a far-reaching impact by interweaving computational techniques to solve key problems in wireless communication.
@inproceedings{Chan2015,
author = {Chan, Justin and Zheng, Changxi and Zhou, Xia},
title = {3D Printing Your Wireless Coverage},
booktitle = {Proceedings of the 2nd International Workshop on Hot Topics in Wireless},
series = {HotWireless '15},
year = {2015},
pages = {1--5},
numpages = {5},
publisher = {ACM},
address = {New York, NY, USA}
}
Changxi Zheng, Lusheng Ji, Dan Pei, Jia Wang and Paul Francis,
A Light-Weight Distributed Scheme for Detecting IP Prefix Hijacks in Real-time.
Proc. of ACM SIGCOMM, Kyoto, Japan, August 2007
Paper(PDF) Abstract Bibtex
Proc. of ACM SIGCOMM, Kyoto, Japan, August 2007
Paper(PDF) Abstract Bibtex
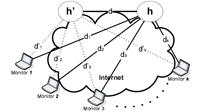
As more and more Internet IP prefix hijacking incidents are being reported, the value of hijacking detection services has become evident. Most of the current hijacking detection approaches monitor IP prefixes on the control plane and detect inconsistencies in route advertisements and route qualities. We propose a different approach that utilizes information collected mostly from the data plane. Our method is motivated by two key observations: when a prefix is not hijacked, 1) the hop count of the path from a source to this prefix is generally stable; and 2) the path from a source to this prefix is almost always a super-path of the path from the same source to a reference point along the previous path, as long as the reference point is topologically close to the prefix. By carefully selecting multiple vantage points and monitoring from these vantage points for any departure from these two observations, our method is able to detect prefix hijacking with high accuracy in a light-weight, distributed, and real-time fashion. Through simulations constructed based on real Internet measurement traces, we demonstrate that our scheme is accurate with both false positive and false negative ratios below 5%.
@inproceedings{Zheng:2007,
author = {Zheng, Changxi and Ji, Lusheng and Pei, Dan and Wang, Jia and Francis, Paul},
title = {A light-weight distributed scheme for detecting ip prefix hijacks in real-time},
booktitle = {Proceedings of the 2007 conference on Applications, technologies,
architectures, and protocols for computer communications},
series = {SIGCOMM '07},
year = {2007},
location = {Kyoto, Japan},
pages = {277--288},
numpages = {12},
publisher = {ACM},
address = {New York, NY, USA},
}
Applied Physics
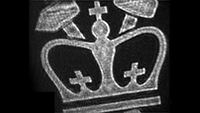
We report a high-efficiency dielectric metasurface with continuous and arbitrary control of both amplitude and phase. We experimentally demonstrated the advantages of complete wavefront control by comparing amplitude-phase modulation metasurface holograms to phase-only metasurface holograms.
Applied Math
Alexander Vladimirsky and Changxi Zheng,
A fast implicit method for time-dependent Hamilton-Jacobi PDEs.
Under review
Preprint Project Page Abstract Source Code
Under review
Preprint Project Page Abstract Source Code
We present a new efficient computational approach for time-dependent
first-order Hamilton-Jacobi-Bellman PDEs. Since our method is based on a
time-implicit Eulerian discretization, the numerical scheme is unconditionally
stable, but discretized equations for each time-slice are coupled and
non-linear. We show that the same system can be re-interpreted as a
discretization of a static Hamilton-Jacobi-Bellman PDE on the same physical
domain. The latter was shown to be "causal" in [Vladimirsky 2006], making fast
(non-iterative) methods applicable. The implicit discretization results in
higher computational cost per time slice compared to the explicit time
marching. However, the latter is subject to a CFL-stability condition, and the
implicit approach becomes significantly more efficient whenever the accuracy
demands on the time-step are less restrictive than the stability. We also
present a hybrid method, which aims to combine the advantages of both the
explicit and implicit discretizations. We demonstrate the efficiency of our
approach using several examples in optimal control of isotropic fixed-horizon
processes.
Robotics

Yun Jiang, Marcus Lim, Changxi Zheng, and Ashutosh Saxena,
Learning to Place New Objects in a Scene.
In International Journal of Robotics Research (IJRR), 2012
Paper(PDF) Project Page Abstract Bibtex
In International Journal of Robotics Research (IJRR), 2012
Paper(PDF) Project Page Abstract Bibtex
Placing is a necessary skill for a personal robot to have in order to perform tasks such as arranging objects in a disorganized room. The object placements should not only be stable but also be in their semantically preferred placing areas and orientations. This is challenging because an environment can have a large variety of objects and placing areas that may not have been seen by the robot before.
In this paper, we propose a learning approach for placing multiple objects in different placing areas in a scene. Given point-clouds of the objects and the scene, we design appropriate features and use a graphical model to encode various properties, such as the stacking of objects, stability, object-area relationship and common placing constraints. The inference in our model is an integer linear program, which we solve efficiently via an LP relaxation. We extensively evaluate our approach on 98 objects from 16 categories being placed into 40 areas. Our robotic experiments show a success rate of 98% in placing known objects and 82% in placing new objects stably. We use our method on our robots for performing tasks such as loading several dish-racks, a bookshelf and a fridge with multiple items.
In this paper, we propose a learning approach for placing multiple objects in different placing areas in a scene. Given point-clouds of the objects and the scene, we design appropriate features and use a graphical model to encode various properties, such as the stacking of objects, stability, object-area relationship and common placing constraints. The inference in our model is an integer linear program, which we solve efficiently via an LP relaxation. We extensively evaluate our approach on 98 objects from 16 categories being placed into 40 areas. Our robotic experiments show a success rate of 98% in placing known objects and 82% in placing new objects stably. We use our method on our robots for performing tasks such as loading several dish-racks, a bookshelf and a fridge with multiple items.
@article{jiang2012placingobjects,
title={Learning to Place New Objects in a Scene},
author={Yun Jiang and Marcus Lim and Changxi Zheng and Ashutosh Saxena},
year={2012},
volume={31},
number={9},
journal={IJRR}
}

Yun Jiang, Changxi Zheng, Marcus Lim, Ashutosh Saxena,
Learning to Place New Objects.
In International Conference on Robotics and Automation (ICRA), 2012. First appeared in RSS workshop on mobile manipulation, June 2011.
Paper(PDF) Project Page Abstract Bibtex
In International Conference on Robotics and Automation (ICRA), 2012. First appeared in RSS workshop on mobile manipulation, June 2011.
Paper(PDF) Project Page Abstract Bibtex
The ability to place objects in an environment is an important skill for a personal robot. An object should not only be placed stably, but should also be placed in its preferred location/orientation. For instance, a plate is preferred to be inserted vertically into the slot of a dish-rack as compared to be placed horizontally in it. Unstructured environments such as homes have a large variety of object types as well as of placing areas. Therefore our algorithms should be able to handle placing new object types and new placing areas. These reasons make placing a challenging manipulation task.
In this work, we propose a supervised learning algorithm for finding good placements given the point-clouds of the object and the placing area. It learns to combine the features that capture support, stability and preferred placements using a shared sparsity structure in the parameters. Even when neither the object nor the placing area is seen previously in the training set, our algorithm predicts good placements. In extensive experiments, our method enables the robot to stably place several new objects in several new placing areas with 98% success-rate; and it placed the objects in their preferred placements in 92% of the cases.
In this work, we propose a supervised learning algorithm for finding good placements given the point-clouds of the object and the placing area. It learns to combine the features that capture support, stability and preferred placements using a shared sparsity structure in the parameters. Even when neither the object nor the placing area is seen previously in the training set, our algorithm predicts good placements. In extensive experiments, our method enables the robot to stably place several new objects in several new placing areas with 98% success-rate; and it placed the objects in their preferred placements in 92% of the cases.
@inproceedings{jiang2011learningtoplace,
title={Learning to place new objects},
author={Jiang, Y. and Zheng, C. and Lim, M. and Saxena, A.},
booktitle={International Conference on Robotics and Automation (ICRA)},
year={2012},
}
Undergraduate Papers
Guobin Shen, Changxi Zheng, Wei Pu and Shipeng Li,
Distributed Segment Tree: A Unified Architecture to Support Range Query and Cover Query.
Technical Report MSR-TR-2007-30, 2007
Paper(PDF)
Technical Report MSR-TR-2007-30, 2007
Paper(PDF)
Changxi Zheng, Guobin Shen, Shipeng Li, and Scott Shenker,
Distributed Segment Tree: Support of Range Query and Cover Query over DHT.
The 5th International Workshop on Peer-to-Peer Systems (IPTPS) Santa Barbara, US, February 2006
Paper(PDF) Abstract Bibtex
The 5th International Workshop on Peer-to-Peer Systems (IPTPS) Santa Barbara, US, February 2006
Paper(PDF) Abstract Bibtex
Range query, which is defined as to find all the keys in a certain
range over the underlying P2P network, has received a lot of
research attentions recently. However, cover query, which is to
find all the ranges currently in the system that cover a given key,
is rarely touched. In this paper, we first identify that cover query
is a highly desired functionality by some popular P2P applications,
and then propose distributed segment tree (DST), a layered DHT
structure that incorporates the concept of segment tree. Due to
the intrinsic capability of segment tree in maintaining the sturcture
of ranges, DST is shown to be very efficient for supporting both
range query and cover query in a uniform way. It also possesses
excellent parallelizability in query operations and can achieve O(1)
complexity for moderate query ranges. To balance the load among
DHT nodes, we design a downward load stripping mechanism that
controls tradeoffs between load and performance. We implemented
DST on publicly available OpenDHT service and performed extensive
real experiments. All the results and comparisons demonstrate
the effectiveness of DST for several important metrics.
@inproceedings{Zheng06DST,
author = {Changxi Zheng and Guobin Shen and Shipeng Li and Scott Shenker},
title = {Distributed segment tree: Support of range query and cover query over dht},
booktitle = {In proceedings of the 5th International Workshop on
Peer-to-Peer Systems (IPTPS 06)},
year = {2006}
}
Ke Liang, Zaoyang Gong, Changxi Zheng, and Guobin Shen,
MOVIF: A Lower Power Consumption Live Video Multicasting Framework over Ad-hoc Networks with Terminal Collaboration.
International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Hong Kong, December 2005
Paper(PDF) Abstract
International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Hong Kong, December 2005
Paper(PDF) Abstract
Live video multicasting over wireless ad hoc networks is a tough
problem due to the restricted computational ability of the mobile
devices and non-predictive networks status. In this paper,
we propose MoViF, a lower power consumption multicasting framework
for live video multicasting over ad-hoc networks. The proposed
MoViF adopts distributed video coding (DVC) scheme and, as a
result, enjoys all the benefits of DVC such as lightweight encoder
and built-in error resilient capability. Moreover, MoViF manages
to apply an elegant strategy to minimize the overall power consumption
for all the receivers while improving their decoding quality by
dynamically assign the tasks of aid information extraction to
some intermediate powerful nodes in the multicast tree.
Simulation results demonstrate that the optimal strategy can lower down
the overall power consumption comparing to the random strategy.
Changxi Zheng, Guobin Shen, and Shipeng Li,
Distributed Prefetching Scheme for Random Seek Support in Peer-to-Peer Streaming Applications.
Workshop on Advances in Peer-to-Peer Multimedia Streaming, ACM Multimedia 2005, Singapore, November 2005
Paper(PDF) Abstract
Workshop on Advances in Peer-to-Peer Multimedia Streaming, ACM Multimedia 2005, Singapore, November 2005
Paper(PDF) Abstract
Through analysis of large volume of user behavior logs during
playing multimedia streaming, we extract a user viewing
pattern. The pattern indicates that random seek is a pervasive phenomenon,
contrary to the common assumptions that
users would watch a video session sequentially and passively
in most works on peer-to-peer streaming. We propose to use efficient
prefetching to facilitate the random seek functionality.
Because of the statistical nature of the user viewing
pattern and the ignorance of the users to the content, we
argue that the pattern should be used as a guidance to the
random seek. Based on the pattern, we set up an analogy
between the optimization problem of minimizing the seeking
distance and the optimal scalar quantization problem. We
then propose an optimal prefetching scheduling algorithm
based on the optimal scalar quantization theory. We further
propose a hierarchical prefetching scheme to carry out
the prefetching more effectively. Real user viewing logs are
used to drive the simulations which demonstrate that the
proposed prefetching scheduling algorithm and the hierarchical
prefetching scheme can improve the seeking performance significantly.
Changxi Zheng, Guobin Shen, and Shipeng Li,
Segment Tree Based Control Plane Protocol for Peer-to-Peer On-Demand Streaming Service Discovery.
Proc. of Visual Communication and Image Processing (VCIP), Beijing, China, July 2005
Paper(PDF) Abstract Bibtex
Proc. of Visual Communication and Image Processing (VCIP), Beijing, China, July 2005
Paper(PDF) Abstract Bibtex
As the intense academic interest in video streaming over peer-to-peer(P2P)
network, more and more streaming protocols have been proposed to address
different problems on this field, such as QoS, load balancing, transmission
reliability, bandwidth efficiency, etc. However, to the best of our knowledge, an
important component of any practical P2P streaming system, the streaming
service discovery, is rarely granted particular considerations, which is to
discover potential peers from which a newcomer could receive the requested
stream. In this paper, we are inspired from a special data structure, named
Segment Tree(ST), and propose a protocol to address this problem specifically.
Furthermore, we fully decouple the control plane and data plane on video
streaming, and hence provide more flexibilities in designing protocols on both
of them.
@inproceedings{Zheng05VCIP,
author = {Changxi Zheng and Guobin Shen and Shipeng Li},
title = {Segment Tree Based Control Plane Protocol for Peer-to-Peer
On-Demand Streaming Service Discovery},
booktitle = {In proceedings of Visual Communication and Image Processing (VCIP)},
year = {2006}
}
Changxi Zheng, Guobin Shen, Shipeng Li and Qianni Deng,
Joint Sender/Receiver Optimization Algorithm for Multi-Path Video Streaming Using High Rate Erasure Resilient Code.
Proc. of IEEE International Conference on Multimedia and Expo (ICME), Amsterdam, Netherlands, July 2005
Paper(PDF) Abstract Bibtex
Proc. of IEEE International Conference on Multimedia and Expo (ICME), Amsterdam, Netherlands, July 2005
Paper(PDF) Abstract Bibtex
In this paper we present a joint sender/receiver optimization algorithm and a
seamless rate adjustment protocol to reduce the total number of packets over
different paths in a streaming framework with a variety of constraints such as
target throughput, dynamic packet loss ratio, and available bandwidths. We
exploit the high rate erasure resilient code for the ease of packet loss
adaption and seamless rate adjustment. The proposed algorithm and adjustment
protocol can be applied at an arbitrary scale. Simulation results demonstrate
that the overall traffic is significantly reduced with the proposed algorithm
and protocol.
@inproceedings{Zheng05ICME,
author = {Changxi Zheng and Guobin Shen and Shipeng Li and Qianni Deng},
title = {Joint Sender/Receiver Optimization Algorithm for Multi-Path Video Streaming
Using High Rate Erasure Resilient Code},
booktitle = {IEEE International Conference on Multimedia and Expo (ICME)},
month = July,
year = {2005}
}
PhD Thesis

Changxi Zheng, Physics-Based Sound Rendering for Computer Animation.
Department of Computer Science, Cornell University, August 2012
(Cornell CS Best Dissertation Award)
Paper(PDF) Abstract
The real world is full of sounds: a babbling brook winding through a tranquil
forest, an agitated shopping cart plugging down a flight of stairs, or a
falling piggybank breaking on the ground. Unfortunately virtual worlds
simulated by current simulation algorithms are still inherently silent. Sounds
are added as afterthoughts, often using "canned sounds" which have little to
do with the animated geometry and physics. While recent decades have seen
dramatic success of 3D computer animation, our brain still expects a full
spectrum of sensations. The lack of realistic sound rendering methods will
continue to cripple our ability to enable highly interactive and realistic
virtual experiences as computers become faster.
This dissertation presents a family of algorithms for procedural sound synthesis for computer animation. These algorithms are built on physics-based simulation methods for computer graphics, simulating both the object vibrations for sound sources and sound propagation in virtual environments. These approaches make it feasible to automatically generate realistic sounds synchronized with animated dynamics.
Our first contribution is a physically based algorithm for synthesizing sounds synchronized with brittle fracture animations. Extending time-varying rigid-body sound models, this method first resolves near-audio-rate fracture events using a fast quasistatic elastic stress solver, and then estimates fracture patterns and resulting fracture impulses using an energy-based model. To make it practical for a large number of fracture debris, we exploit human perceptual ambiguity when synthesizing sounds from many objects, and propose to use pre-computed sound proxies for reduced cost of sound-model generation.
We then introduce a contact sound model for improved sound quality. This method captures very detailed non-rigid sound phenomena by resolving modal vibrations in both collision and frictional contact processing stages, thereby producing contact sounds with much richer audible details such as micro-collisions and chattering. This algorithm is practical, enabled by a novel asynchronous integrator with model-level adaptivity built into a frictional contact solver.
Our third contribution focuses on another major type of sound phenomena, fluid sounds. We propose a practical method for automatic synthesis of bubble-based fluid sounds from fluid animations. This method first acoustically augments existing incompressible fluid solvers with particle-based models for bubble creation, vibration, and advection. To model sound propagation in both fluid and air domain, we weight each single-bubble sound by its bubble-to-ear acoustic transfer function value, which is modeled as a discrete Green's function of the Helmholtz equation. A fast dual-domain multipole boundary-integral solver is introduced for hundreds of thousands of Helmholtz solves in a typical babbling fluid simulation.
Finally, we switch gear and present a fast self-collision detection method for deforming triangle meshes. This method can accelerate deformable simulations and lead to faster sound synthesis of deformable phenomena. Inspired by a simple idea that a mesh cannot self collide unless it deforms enough, this method supports arbitrary mesh deformations while still being fast. Given a bounding volume hierarchy (BVH) for a triangle mesh, we operate on bounding-volume-related submeshes, and precompute Energy-based Self-Collision Culling (ESCC) certificates, which indicate the amount of deformation energy required for the submesh to self collide. After updating energy values at runtime, many bounding-volume self-collision queries can be culled using the ESCC certificates. We propose an affine-frame Laplacian-based energy definition which sports a highly optimized certificate preprocess and fast runtime energy evaluation.
This dissertation presents a family of algorithms for procedural sound synthesis for computer animation. These algorithms are built on physics-based simulation methods for computer graphics, simulating both the object vibrations for sound sources and sound propagation in virtual environments. These approaches make it feasible to automatically generate realistic sounds synchronized with animated dynamics.
Our first contribution is a physically based algorithm for synthesizing sounds synchronized with brittle fracture animations. Extending time-varying rigid-body sound models, this method first resolves near-audio-rate fracture events using a fast quasistatic elastic stress solver, and then estimates fracture patterns and resulting fracture impulses using an energy-based model. To make it practical for a large number of fracture debris, we exploit human perceptual ambiguity when synthesizing sounds from many objects, and propose to use pre-computed sound proxies for reduced cost of sound-model generation.
We then introduce a contact sound model for improved sound quality. This method captures very detailed non-rigid sound phenomena by resolving modal vibrations in both collision and frictional contact processing stages, thereby producing contact sounds with much richer audible details such as micro-collisions and chattering. This algorithm is practical, enabled by a novel asynchronous integrator with model-level adaptivity built into a frictional contact solver.
Our third contribution focuses on another major type of sound phenomena, fluid sounds. We propose a practical method for automatic synthesis of bubble-based fluid sounds from fluid animations. This method first acoustically augments existing incompressible fluid solvers with particle-based models for bubble creation, vibration, and advection. To model sound propagation in both fluid and air domain, we weight each single-bubble sound by its bubble-to-ear acoustic transfer function value, which is modeled as a discrete Green's function of the Helmholtz equation. A fast dual-domain multipole boundary-integral solver is introduced for hundreds of thousands of Helmholtz solves in a typical babbling fluid simulation.
Finally, we switch gear and present a fast self-collision detection method for deforming triangle meshes. This method can accelerate deformable simulations and lead to faster sound synthesis of deformable phenomena. Inspired by a simple idea that a mesh cannot self collide unless it deforms enough, this method supports arbitrary mesh deformations while still being fast. Given a bounding volume hierarchy (BVH) for a triangle mesh, we operate on bounding-volume-related submeshes, and precompute Energy-based Self-Collision Culling (ESCC) certificates, which indicate the amount of deformation energy required for the submesh to self collide. After updating energy values at runtime, many bounding-volume self-collision queries can be culled using the ESCC certificates. We propose an affine-frame Laplacian-based energy definition which sports a highly optimized certificate preprocess and fast runtime energy evaluation.
Loading ......
COPYRIGHT 2012-2017. ALL RIGHTS RESERVED.