Machine Learning For The Power Gride
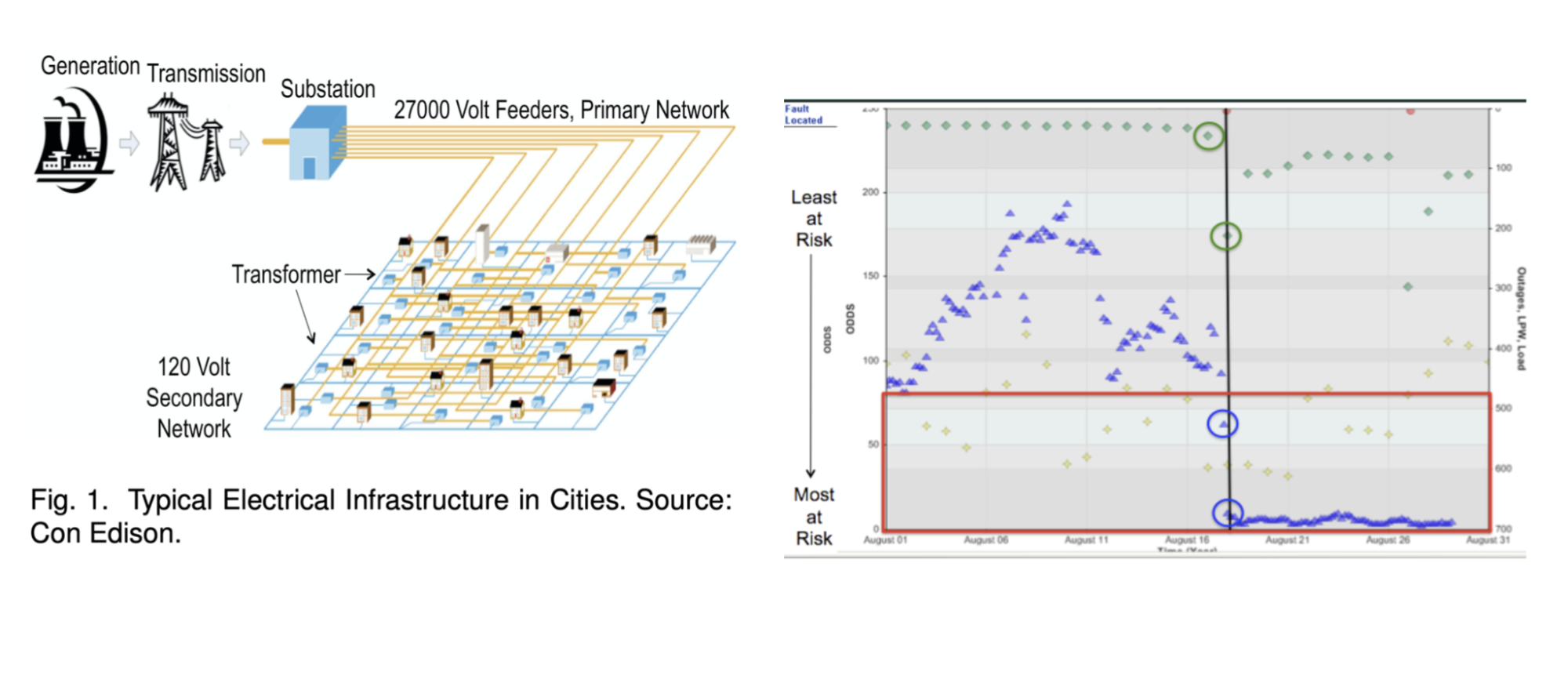
We proposed machine learning models and algorithms to rank the underground primary feeders and transformers of New York City's electrical grid according to their susceptibility to outages. Funding for this work is provided by a contract between Columbia University and the Consolidated Edison Company of New York.
Machine learning for power grid
RN Anderson, A Boulanger, C Rudin, D Waltz, A Salleb-Aouissi, M Chow, ...US Patent 8,751,421
Machine learning for the New York City power grid
C Rudin, D Waltz, RN Anderson, A Boulanger, A Salleb-Aouissi, M Chow, ...IEEE transactions on pattern analysis and machine intelligence 34 (2), 328-345
Ranking electrical feeders of the New York power grid
P Gross, A Salleb-Aouissi, H Dutta, A Boulanger. 2009 International Conference on Machine Learning and Applications, 359-365
Evaluating machine learning for improving power grid reliability
LL Wu, GE Kaiser, C Rudin, DL Waltz, RN Anderson, AG Boulanger, Ansaf Salleb-Aouissi, Haimonti Dutta, Manoj Pooleery. ICML 2011 Workshop on Machine Learning for Global Challenges, Bellevue, WA, USA, 2011.
Estimating the time between failures of electrical feeders in the new york power grid
H Dutta, D Waltz, A Moschitti, D Pighin, P Gross, C Monteleoni, ... Next Generation Data Mining Summit, NGDM
Alive on Back-feed Culprit Identification via Machine Learning
B Huang, A Salleb-Aouissi, P Gross. 2009 International Conference on Machine Learning and Applications, 725-730
Rule Learning
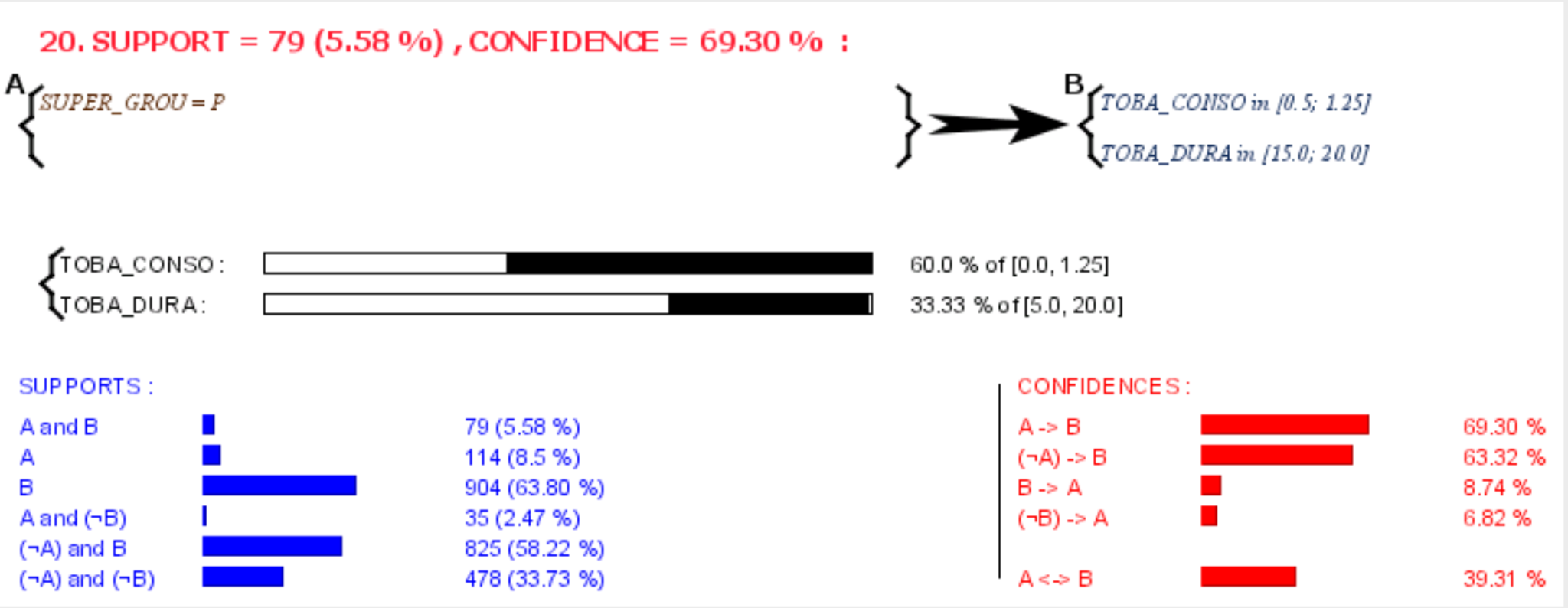
We explored mining frequent patterns indatabases. This expensive step is common to several data mining tasks. Westudied, in particular, the mining of association and characterization rules,both relying on mining frequent patterns.
On the one hand, we have studied mining frequent patterns in theso-called 'transaction databases'. A transaction database is a finite multi-setof transactions, each one composed of a set of items, called an itemset.We propose a boolean based approach for mining frequent itemsets. The ideais to represent a transaction database by a function taking as inputs boolean variables andgiving integer output values. The undertaken study shows theeffectiveness and efficiency of the approach to represent and to load densetransaction databases in memory, but also the interest of theuse of this condensed format for mining maximal frequent itemsets.
On the other hand, mining frequent patterns in databases storing objects and theirrelationships, such as relational and geographic databases, is not straightforward, becauseof a large and complex search space. We propose an original framework for mining characteristic rules. A frequent pattern inthis case is a rule characterizing concisely a target set of objects according to the objects linked to themdirectly or indirectly. This framework relies on new concepts such as theconcept of quantified path defined on the objects related to the target set of objects and the propertiesdescribing these objects.
QuantMiner: A Genetic Algorithm for Mining Quantitative Association Rules.
A Salleb-Aouissi, C Vrain, C Nortet. IJCAI 7, 1035-1040
Quantminer for mining quantitative association rules
A Salleb-Aouissi, C Vrain, C Nortet, X Kong, V Rathod, D Cassard. The Journal of Machine Learning Research 14 (1), 3153-3157
On the discovery of exception rules: A survey
B Duval, A Salleb, C Vrain. Quality Measures in Data Mining, 77-98
Mining maximal frequent itemsets by a boolean based approach
A Salleb, Z Maazouzi, C Vrain. Proc. 15th Eur. Conf. Artif. Intell, 385-389
Building actions from classification rules
R Trépos, A Salleb-Aouissi, MO Cordier, V Masson, C Gascuel-Odoux. Knowledge and information systems 34 (2), 267-298
A distance-based approach for action recommendation
R Trepos, A Salleb, MO Cordier, V Masson, C Gascuel. European conference on machine learning, 425-436
Discovering characterization rules from rankings
A Salleb-Aouissi, B Huang, D Waltz2009. International Conference on Machine Learning and Applications, 154-161
Sequential event prediction with association rules
C Rudin, B Letham, A Salleb-Aouissi, E Kogan, D Madigan. Proceedings of the 24th annual conference on learning theory, 615-634
Mining Quantitative Association Rules in a Atherosclerosis Dataset
A Salleb, T Turmeaux, C Vrain, C Nortet - 2004
A framework for supervised learning with association rules
C Rudin, B Letham, A Salleb-Aouissi, E Kogan, D Madigan. Proceedings of the 24th Annual Conference on Learning Theory (COLT)
Mining quantitative association rules in a atherosclerosis dataset
C Nortet, A Salleb, T Turmeaux, C Vrain. PKDD Discovery Challenge 2004 (co-located with the 6th European Conference on Principles and Practice of Knowledge Discovery in Databases)
Knowledge Discovery in Geographic Data
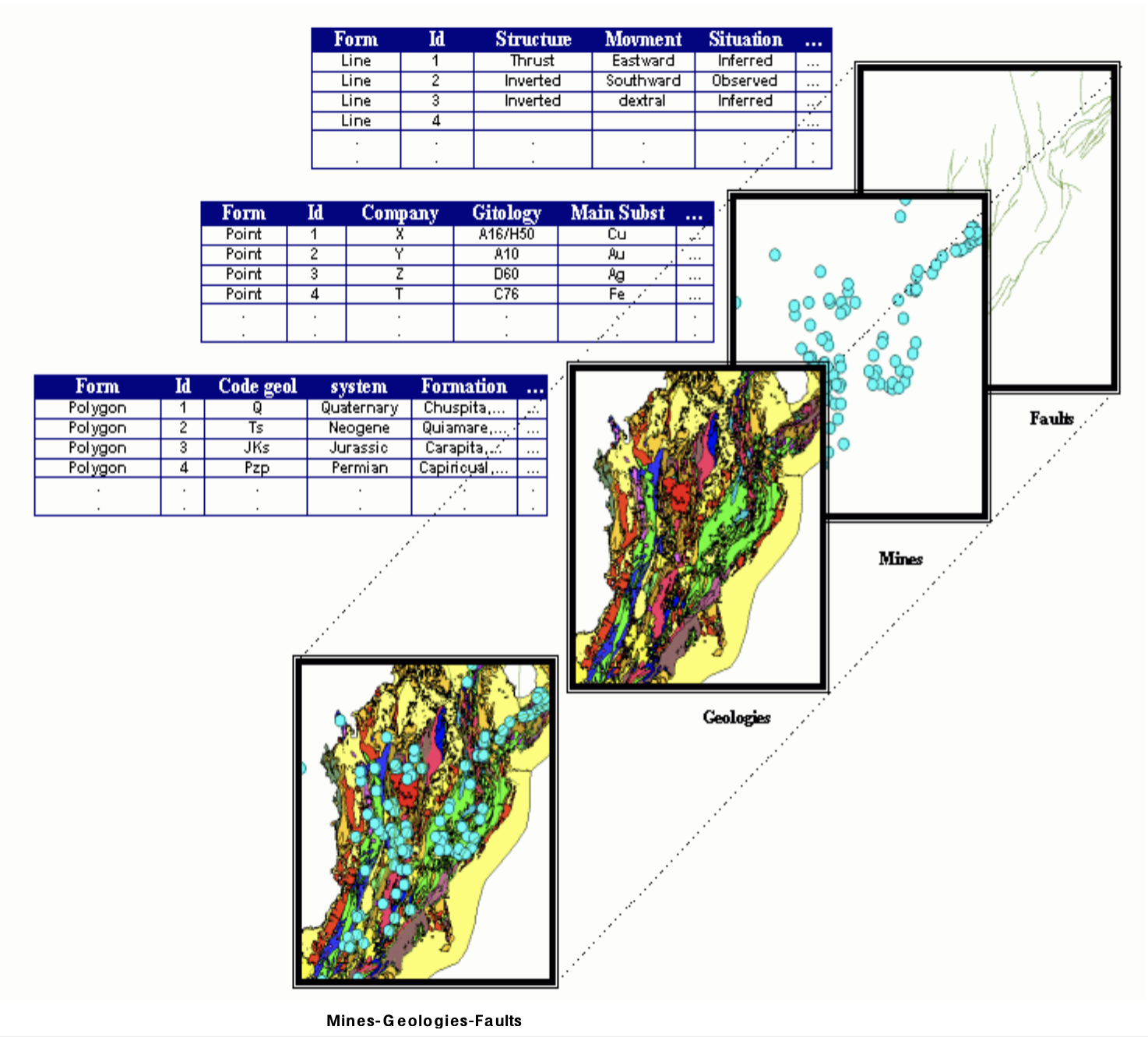
We propose approaches for knowledge discovery in geographic information systems, from the field of mineral exploration, developed by the BRGM: French Geological Survey. We addressed two tasks: mining association and characterization rules, and thus tested our approaches to real databases.
Learning Characteristic Rules in Geographic Information Systems
A Salleb-Aouissi, C Vrain, D Cassard. International Symposium on Rules and Rule Markup Languages for the Semantic Web
Learning characteristic rules relying on quantified paths
T Turmeaux, A Salleb, C Vrain, D Cassard. European Conference on Principles of Data Mining and Knowledge Discovery
An application of association rules discovery to geographic information systems.
Ansaf Salleb and Christel Vrain. European Conference on Principles of Data Mining and Knowledge Discovery 2000
Quantitative assessments of a continent-scale metallogenic GIS by data-driven and knowledge-driven approaches to construct decision-aid documents
ALW Lips, D Cassard, V Bouchot, M Billa, A Salleb, M Gonzalez, ...GIS in Geology Int. Conference, Vernadsky SGM RAS, 74-76
Crowd Labeling
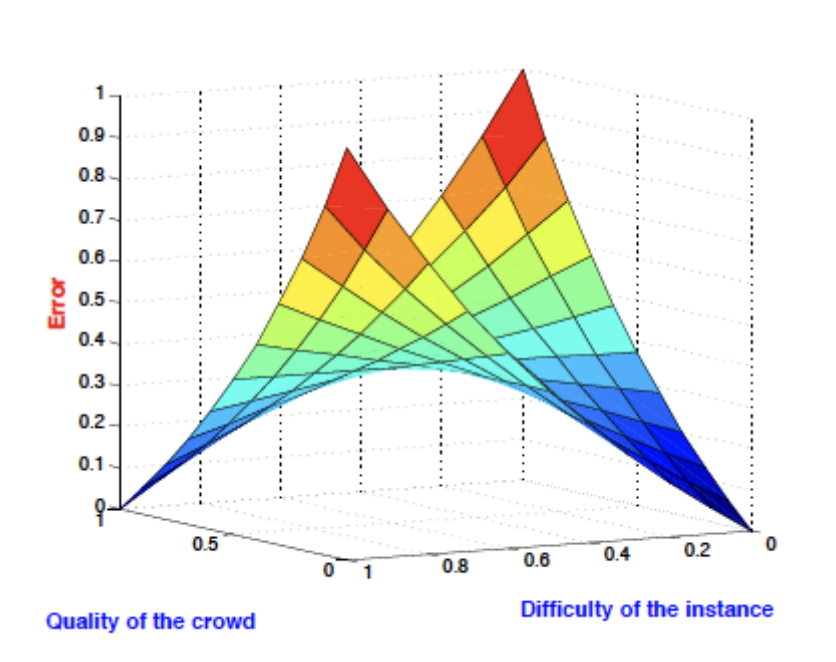
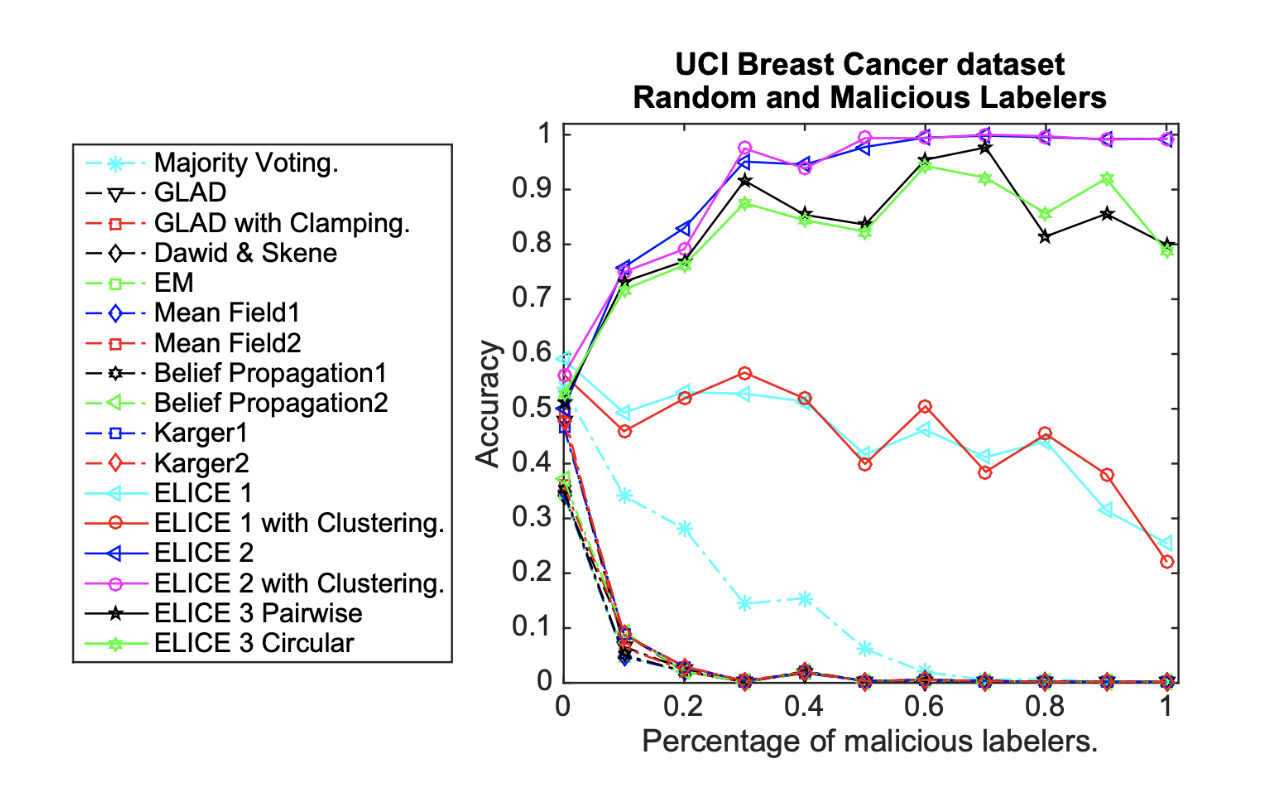
Crowd Labeling emerged from the need to label large-scale and complex data, a tedious, expensive and time-consuming task. Each object to label is generally annotated by multiple crowd labelers, and the collected labels are combined to infer one final estimated label. One open problem is the quality and integration of different labels, especially when the labelers participating in the task are of unknown expertise. In order to address this challenge, we propose a new framework that automatically combines and boosts bulk crowd labels with a limited number of ground truth labels from experts. We show through extensive experiments that, unlike other state-of-the-art approaches, our method is robust to estimate true labels even with the presence of a large proportion of not-so-good labelers in the crowd.
Improving crowd labeling through expert evaluation
FK Khattak, A Salleb-Aouissi. 2012 AAAI Spring Symposium Series
Robust crowd labeling using little expertise
FK Khattak, A Salleb-Aouissi. International Conference on Discovery Science, 94-109
Quality control of crowd labeling through expert evaluation
FK Khattak, A Salleb-Aouissi. Proceedings of the NIPS 2nd Workshop on Computational Social Science and the Wisdom of Crowds
Anveshan: a framework for analysis of multiple annotators’ labeling behavior
V Bhardwaj, RJ Passonneau, A Salleb-Aouissi, N Ide. Proceedings of the Fourth Linguistic Annotation Workshop, 47-55
Word sense annotation of polysemous words by multiple annotators
RJ Passonneau, A Salleb-Aouissi, V Bhardwaj, N Ide. Proceedings of the Seventh International Conference on Language Resources and Evaluation
Multiplicity and word sense: evaluating and learning from multiply labeled word sense annotations
RJ Passonneau, V Bhardwaj, A Salleb-Aouissi, N Ide. Language Resources and Evaluation 46 (2), 219-252